我用AI復活了散落 10 年的筆記:Karpathy 方法實測
整理版優先睇
從RAG到LLM Wiki:用Karpathy方法將十年散落筆記編譯成知識網絡
作者噪點用咗十年,筆記散落喺飛書、印象筆記、備忘錄等平台,一路都係各自為政。上個月睇到Karpathy提出嘅LLM Wiki範式,覺得呢個概念好有啟發性,於是花咗一星期時間,結合Obsidian同Claude,將啲散落內容重新整合成一個本地知識庫。
Karpathy認為,而家主流嘅RAG做法係每次問問題先臨時拼湊答案,浪費咗AI嘅持續學習能力。佢提出嘅LLM Wiki係要AI一次過將原始資料編譯成持久嘅Markdown頁面,以後直接讀編譯好嘅結果就得。作者實測後發現,呢個方法真係令啲筆記由檔案夾嘅孤島變成一個可以查、可以問、不斷進化嘅活網絡。
- LLM Wiki將AI從臨時問答工具升級為持續編譯知識嘅長期合夥人,核心喺編譯成持久Markdown頁面,取代每次拼湊嘅RAG。
- 範式分三層:raw(原始資料)、wiki(AI編譯頁面)、CLAUDE.md(規則文件),配合ingest/query/lint/index四個操作。
- 實踐三步:先搭骨架(raw、wiki、index、log、CLAUDE.md),再用一篇文章跑通完整鏈路,最後分批導入並迭代CLAUDE.md規則。
- 關鍵喺CLAUDE.md規則文件,決定AI點樣組織知識庫,需要喺實踐中不斷迭代。
- 呢個方法令知識真正複利,沉澱個人獨特上下文資產,越用越清晰,任何工具都比唔上呢個價值。
Karpathy LLM Wiki Gist
Karpathy提出嘅LLM Wiki範式核心概念同骨架,包括raw/wiki/CLAUDE.md等結構。
LLM Wiki範式:從臨時工到全職員工
我哋平時用嘅知識庫工具,無論係Claude、ChatGPT上傳檔案問答,定係NotebookLM、各種RAG產品,本質都係臨時工——每次提問AI就現場翻資料拼一個答案出嚟,答完就散,下次問又要重頭嚟過。
而LLM Wiki嘅邏輯就唔同,佢要AI將讀過嘅內容編譯成持久嘅Markdown頁面,下次問問題直接讀已經編譯好嘅頁面就得,唔使再翻原始資料。簡單講就係RAG係臨時工,LLM Wiki係全職員工,越做越熟練。
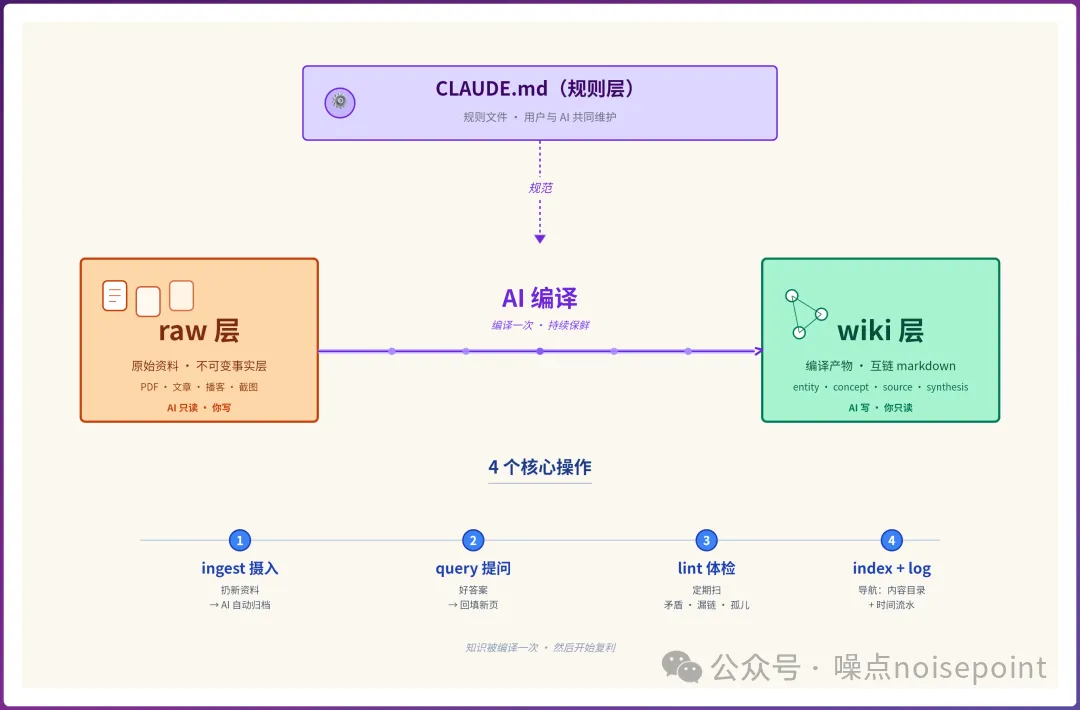
整個範式由三層架構成:raw層係原始資料(文章、播客稿、截圖、PDF等),AI只讀唔寫;wiki層係AI編譯出嘅Markdown頁面(實體頁、概念頁、來源摘要、綜合分析),只有AI寫;CLAUDE.md層係規則文件,話畀AI知個wiki點組織、點樣寫頁面、點樣接入新資料。
- 1 ingest:攝入新資料,AI自動寫摘要、更新相關頁面、追加Log。
- 2 query:日常提問,遇到好答案可以叫Claude保存成新頁面,令探索沉澱落嚟。
- 3 lint:定期體檢,揾出知識網絡入面嘅矛盾、孤兒頁、漏鏈。
- 4 index & log:index係內容目錄,log係時間流水,方便導航。
三步實踐:由骨架到完整鏈路
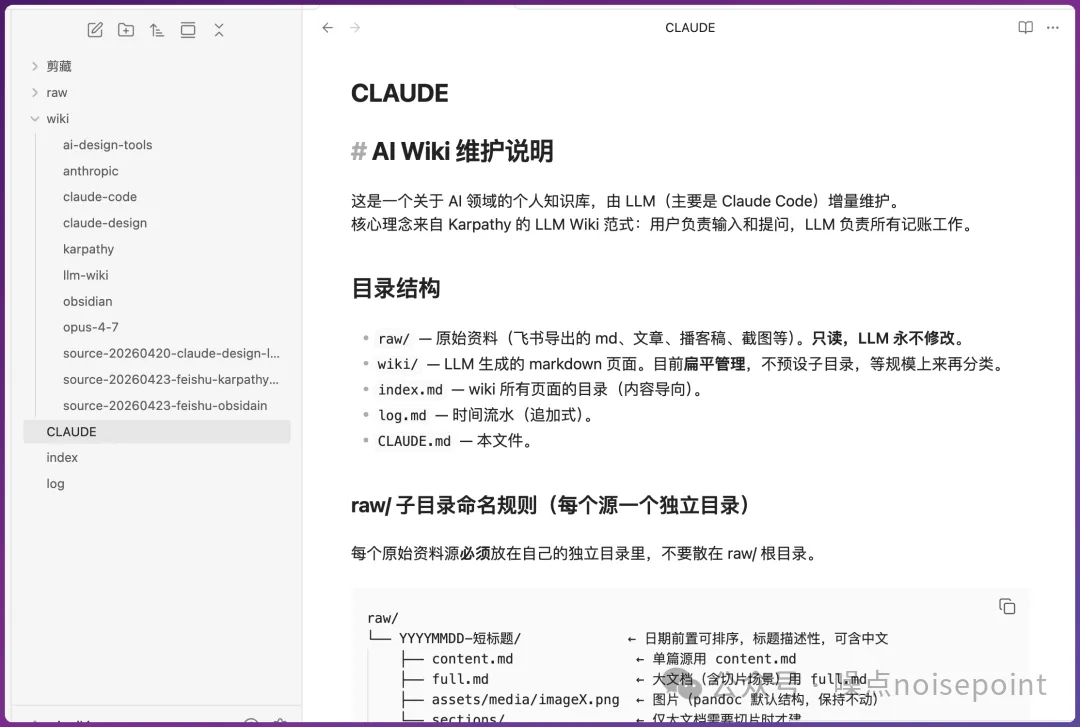
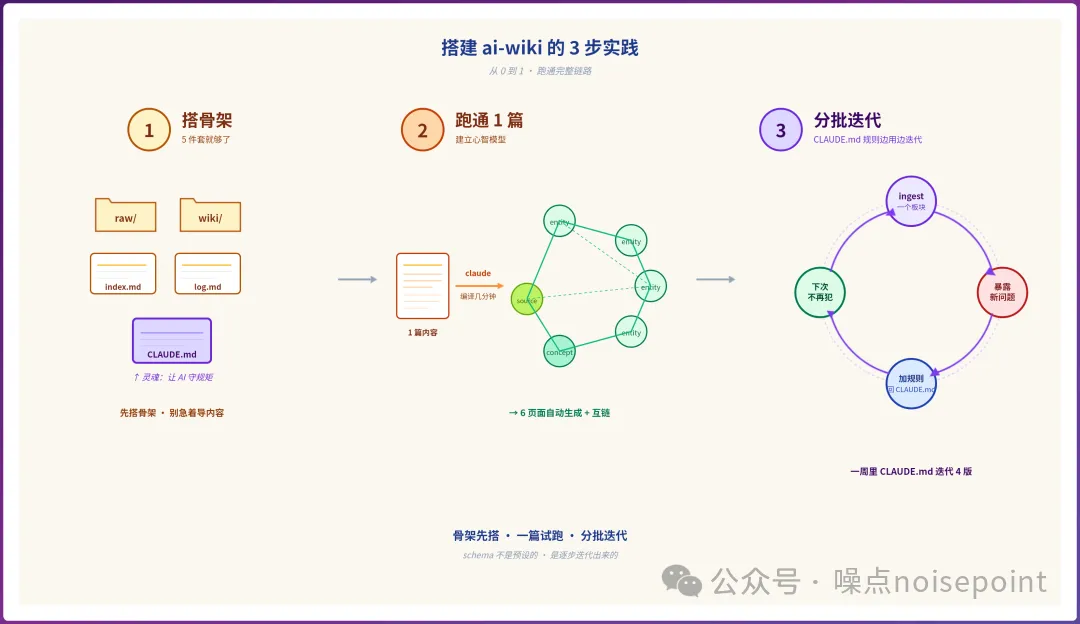
第一步係搭骨架。直接將Karpathy個Gist發畀Claude,叫佢根據個範式建立知識庫骨架。核心骨架包括:raw文件夾放原始資料、wiki文件夾放AI寫嘅頁面、index.md目錄、log.md流水、CLAUDE.md規則文件。呢度嘅靈魂係CLAUDE.md,要清楚寫明頁面類型(entity/concept/source/synthesis)、命名規則、ingest流程、query步驟。
第二步係用一篇文章跑通完整鏈路。揀一篇最熟悉、最細嘅文章,將原始文檔放入raw,叫Claude完整讀一次。佢會自動識別出需要建立嘅實體同概念,自動創建交叉雙鏈,最後更新index同log。作者用自己一篇公眾號測試,一篇文章搞掂,6個頁面自動創建、互相連結,成個過程幾分鐘搞掂。
第三步係分批導入 + 邊用邊調整CLAUDE.md。絕對唔好一次過導入曬啲內容,要按板塊切片,每次只ingest一個主題。因為一次過塞太多,Claude上下文唔夠,wiki結構會失控;而且每次ingest都會暴露新問題,例如圖片處理方式、檔案命名規則、wiki同CLAUDE.md嘅邊界等。作者嘅CLAUDE.md一星期內迭代咗4版,每次都係之前ingest嘅規則沉澱。
知識複利:越用越清晰嘅活網絡
之前啲散落四處嘅知識碎片,終於第一次以網絡嘅形式連咗埋一齊,唔再係檔案夾入面嘅孤島,而係一張可以查、可以問答、可以不斷進化更新嘅活嘅知識網絡。
以前普通筆記越記越多、越多越亂、越多越揾唔到,每次更新交叉引用、保持同步、標註矛盾點呢啲嘢,如果靠人力去做,做兩次就心累,所以大多數人記記嚇就放棄。但交畀AI佢唔會攰,所以呢個wiki好難半途而廢。
大家好,我係噪點
最近一個禮拜,我做咗件超爽嘅事。
將記咗十幾年,散落喺唔同平台嘅幾十萬字筆記,好似飛書文檔、印象筆記、備忘錄呢啲,第一次以「知識網絡」嘅形式連埋一齊。
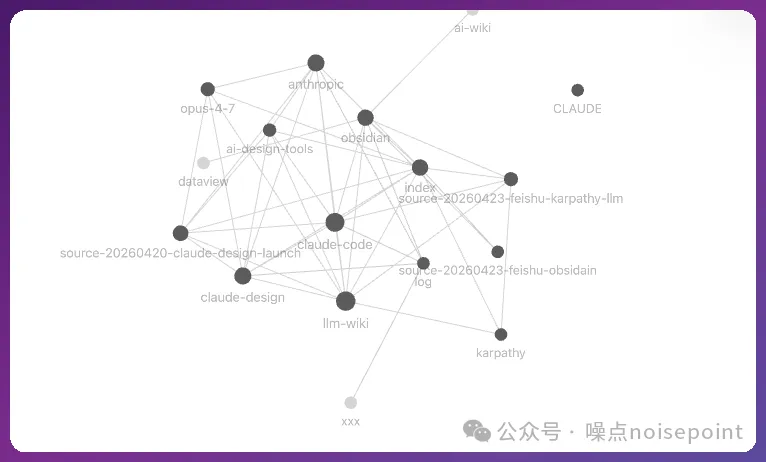
起因係上個月睇到 Karpathy(OpenAI 早期成員、特斯拉前 AI 總監)嘅一個分享,佢提出咗知識庫新範式叫 LLM Wiki,核心思想係「知識被編譯一次之後就可以 keep 住新鮮」,嗰陣時好 hit。
佢認為,而家所有將資料掉俾 AI 要佢即刻砌答案嘅 RAG 做法係錯嘅,知識應該由 AI 一次過編譯成持久嘅頁面,唔係每次問答都從頭砌過;呢個諗法直接令我發現新大陸。
我用咗一個禮拜嚟研究、結合 obsidian 實踐呢個範式,將我散落各地嘅內容搭咗個本地知識庫。
而家已經行通咗 0-1 流程,初步沉澱咗十幾個互相連結嘅 wiki 頁面,中間包括 4 次 CLAUDE.md schema 架構迭代;之後只要將新文章掟入去,相關嘅十幾個頁面就會自動更新、互相補充。
成個搭建過程好有趣,呢篇就同大家分享下完整路徑。照舊習慣,先講框架,再分享具體步驟;會由 LLM Wiki 範式係咩、具體實踐、我嘅體會 3 部分講起。
簡單講,就係將 LLM 由「一次性問答工具」升級做「持續幫你編譯知識嘅長期合夥人」。
我哋日常用嘅知識庫工具,無論係普通 claude、chatgpt 上傳文件問答,定係 notebooklm、各種 RAG 產品,本質上都係臨時砌出嚟。你每次問嘢,AI 即刻翻你啲資料,砌個答案俾你;答完之後知識就散咗,下次問同一條問題又要再翻過。
LLM Wiki 嘅邏輯就唔同,佢叫 AI 將讀過嘅內容編譯成持久嘅 markdown 頁面,我哋下次問問題,AI 直接讀已經編譯好嘅頁面就得,唔使從頭砌過。
簡單理解就係 RAG 係臨時工,做完就走;LLM Wiki 係全職員工,愈做愈熟練。
成個範式由 3 層架構組成。
raw 層係我哋掟入去嘅原始資料(例如文章、播客稿、截圖、PDF 等),AI 只讀唔寫,係原始事實。
wiki 層係 AI 根據 raw 層原始資料編譯產出嘅 markdown 頁面(包括實體頁、概念頁、來源摘要、綜合分析),只有 AI 寫,我哋只讀。
CLAUDE.md(schema 層)係規則文件,話俾 AI 知呢個 wiki 點樣組織、點樣寫頁面、點樣 ingest 接入新資料。呢一層好關鍵,佢決定 AI 點樣處理我哋上傳嘅知識庫。
日常對應 4 個核心操作。
ingest 係攝入新資料,掟一份入嚟,AI 自動寫摘要、更新已有相關頁、加 log 日誌條目。
query 係日常提問,如果覺得答案好,可以叫 claude 保存做新頁面入 wiki,令探索本身都沉澱落嚟。
lint 係定期體檢,叫 AI 揾知識網絡連結入面嘅矛盾、孤兒頁、漏鏈等。
最後係 index 同 log 兩個特殊文件,一個係內容目錄,一個係時間流水,方便日常導航。
第一步:先搭骨架
可以直接將 karpathy 呢個項目 send 俾 claude,叫 AI 根據呢個搭知識庫骨架。
地址:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
核心骨架 5 部分:raw 文件夾放原始資料、wiki 文件夾放 AI 寫嘅頁面、index.md 係內容目錄、log.md 係時間流水、CLAUDE.md 係俾 AI 睇嘅規則文件。
呢入面嘅靈魂係 CLAUDE.md。要寫清楚幾件事:頁面類型有邊啲(entity / concept / source / synthesis)、命名規則係咩、ingest 時行咩流程、query 時按咩步驟回答。
初頭我都搞唔清楚應該點寫,第一版得幾十行,或者直接由範式介紹度整理出嚟照抄都得。
重點係要首先建立呢個文件,令 AI 入到嚟就知道自己嘅核心職責係 wiki 維護,唔係聊天助手。
然後開 obsidian 入去啱啱建立嘅文件倉庫,就可以見到 claude 搭建嘅文件骨架喇。
第二步:用一篇文章行通完整鏈路
骨架搭好之後,唔好急住批量導入內容,先揀一篇最熟悉、最細嘅內容行一次完整鏈路,睇下效果,建立整體心智。
我揀咗自己之前寫嘅一篇公眾號(claude design 上線嗰篇),將 docx 文檔導入 claude 之後,叫佢轉做 markdown 放入 raw,然後完整讀一次,claude 自動識別出 6 個需要建立嘅實體同概念,自動建立咗交叉雙鏈,最後更新咗 index 同 log。
成個過程只係用咗幾分鐘。
輸入一篇文章,6 個頁面自動創建、互相連結,的確有種「知識正在被編譯」嘅感覺。
第三步:分批導入 + claude.md 規則邊用邊調
行通一篇之後就可以加量喇,但千祈唔好一次過全導入,建議分批切片,每次只 ingest 一個板塊或者一個主題。
我嘅做法係,先將成個文檔下載轉做 markdown,例如我嗰 30 幾萬字嘅飛書雲文檔,再叫 claude 按板塊切分,一次只塞一個板塊入去。
因為一次過全導入會有 2 個明顯問題:
第一係塞太多 claude 上下文唔夠,wiki 會結構失控、分類混亂、互相引用亂曬。
第二係 claude.md 嘅架構規則係每次實操踩坑之後不斷演化出嚟嘅。
例如每次 ingest 完都可能暴露新問題,可能係圖片處理方式、可能係文件命名規則、可能係 wiki 同 CLAUDE.md 嘅邊界等等。
呢啲問題暴露之後,都需要我哋返去 CLAUDE.md 度加新規則,下次 ingest 先唔會再犯。我嘅 CLAUDE.md 就係一個禮拜入面迭代咗 4 版,每一版都係上一次 ingest 嘅規則沉澱。
這樣,我哋就將成個 0-1 嘅流程行通咗,剩下嘅就係日常 send 內容俾 claude,叫佢放入 raw 文件夾,然後編譯做 wiki,不斷積累更新;如果有需要就根據實際情況調整 claude.md。
呢套 llm wiki 方法整體體驗落嚟,我最直接嘅感受就係:
之前嗰啲散落喺唔同地方嘅知識碎片,終於第一次以「網絡」嘅形式連埋一齊,佢哋唔再係文件夾入面嘅孤島,而係一張可以查、可以問答、而且可以不斷進化、更新嘅、活嘅知識網絡。
好似以前,普通筆記會愈記愈多、愈多愈亂、愈多愈揾唔到,每次更新交叉引用、保持修改同步、標註矛盾點等,如果純靠人手去維護,基本上做兩次就心累,所以大多數人記記嚇就放棄咗。
但交俾 AI 佢唔會攰,所以呢個 wiki 其實好難半途而廢。而且每嚟一篇新內容,相關嘅幾十上百個頁面會被自動更新、互相連結,愈用愈清晰。
更關鍵嘅係,佢沉澱嘅唔只係網上可以揾到嘅內容。我哋每次同 AI 嘅對話、每次對比分析、靈感思路等都可以被回填成新嘅頁面,長遠落嚟,呢個 wiki 裝嘅就係我哋自己獨特嘅上下文資產,呢啲係任何工具都俾唔到嘅。
呢個先係 llm wiki 真正嘅價值:令知識真正開始複利。
如果你覺得呢篇分享對你有幫助,歡迎一鍵三連,方便更多朋友睇到~
對AI工具、AI乾貨技巧、vibe coding 有興趣,可以俾『噪點』加個星標 ⭐️,第一時間收到推送!亦都歡迎交個朋友~
大家好,我是噪點
最近一週,我做了件超爽的事兒。
把記了十多年,散落在各平台上的幾十萬字筆記,像飛書文檔、印象筆記、備忘錄這些,第一次以"知識網絡"的形式連了起來。
緣起是上個月刷到 Karpathy (OpenAI 早期成員、特斯拉前 AI 總監)的一個分享,他提出了個知識庫新範式叫 LLM Wiki,核心思想是"知識被編譯一次後就可以持續保鮮",當時非常火。
他認為,現在所有把資料丟給 AI 讓它現場拼答案的 RAG 做法是錯的,知識應該被 AI 一次編譯成持久的頁面,而不是現在每次問答都從零拼湊;這個想法直接讓我發現了新大陸。
我花了一週時間來研究、結合 obsidian 實踐了這個範式,把我散落各地的內容搭建了個本地知識庫。
目前已經跑通了 0-1 流程,初步沉澱了十幾個互相連結的 wiki 頁面、中間包括 4 次 CLAUDE.md schema 架構迭代;後面只需將新文章扔進去,相關十幾個頁面就會自動更新、互相補充。
整個搭建過程很有意思,本篇就和大家分享下完整路徑。還是按照老習慣,先從框架講起,再分享具體步驟;會從 LLM Wiki 範式是什麼、具體實踐、我的體會 3 部分展開。
大白話解釋下,就是把 LLM 從"一次性問答工具"升級成"持續幫你編譯知識的長期合夥人"。
我們日常用的知識庫工具,不管是常規 claude、chatgpt 上傳文件問答,還是 notebooklm、各種 RAG 產品,本質都是臨時拼湊。你每次提問,AI 現場翻你的資料,拼一個回答給你;這次回答完知識就散了,下次問同樣的問題還得重翻一遍。
LLM Wiki 的邏輯則不同,它讓 AI 把讀過的內容編譯成持久的 markdown 頁面,我們下次問問題,AI 直接讀已經編譯好的頁面就行,不用從頭拼湊。
簡單理解就是 RAG 是臨時工,幹完就走人;LLM Wiki 是全職員工,越幹越熟練。
整個範式由 3 層架構組成。
raw 層是我們扔進去的原始資料(比如文章、播客稿、截圖、PDF 等),AI 只讀不寫,是原始事實。
wiki 層是 AI 根據 raw 層原始資料編譯產出的 markdown 頁面(包括實體頁、概念頁、來源摘要、綜合分析),只有 AI 寫,我們只讀。
CLAUDE.md(schema 層)是規則文件,告訴 AI 這個 wiki 怎麼組織、怎麼寫頁面、怎麼 ingest 接入新資料。這一層非常關鍵,它決定 AI 如何去處理我們上傳的知識庫。
日常對應 4 個核心操作。
ingest 是攝入新資料,扔一份進來,AI 自動寫摘要、更新已有相關頁、追加 log 日誌條目。
query 是日常提問,如果是覺得好的答案可以讓 claude 保存為新頁面到 wiki 裏,讓探索本身也沉澱下來。
lint 是定期體檢,讓 AI 找知識網絡連接裏的矛盾、孤兒頁、漏鏈等。
最後是 index 和 log 兩個特殊文件,一個是內容目錄、一個是時間流水,方便日常導航。
第一步:先搭骨架
可以直接把 karpathy 這個項目發給 claude,讓ai根據這個搭知識庫骨架。
地址:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
核心骨架 5 部分:raw 文件夾放原始資料、wiki 文件夾放 AI 寫的頁面、index.md 是內容目錄、log.md 是時間流水、CLAUDE.md 是給 AI 看的規則文件。
這裏面的靈魂是 CLAUDE.md。要寫清楚幾件事:頁面類型有哪些(entity / concept / source / synthesis)、命名規則是什麼、ingest 時走什麼流程、query 時按什麼步驟回答。
剛開始我也搞不清楚該怎麼寫,第一版就幾十行,或者從範式介紹裏整理出來直接抄都行。
重點是先把這個文件建起來,讓 AI 進來就知道自己的核心職責是 wiki 維護,不是聊天助手。
然後打開obsidian進入剛剛創建的文件倉庫就能看到claude搭建的文件骨架了。
第二步:用一篇文章跑通完整鏈路
骨架搭好後別急着批量導入內容,先挑一篇最熟悉、最小的內容跑一遍完整鏈路,看看效果、建立起整體心智。
我選了自己之前寫的一篇公眾號(claude design 上線那篇),把 docx 文檔導入 claude 後,讓它轉成 markdown 放進 raw,然後完整讀一遍,claude 自動識別出 6 個需要建的實體和概念,自動建立了交叉雙鏈,最後更新了 index 和 log。
整個過程只用了幾分鐘。
輸入一篇文章,6 個頁面自動創建、互相連結,確實有種"知識在被編譯"的感覺。
第三步:分批導入 + claude.md 規則邊用邊調
跑通一篇後就可以上量了,但絕對不要一次全導入,建議分批切片,每次只 ingest 一個板塊或一個主題。
我的做法是,先把整個文檔下載轉 markdown,比如我的 30 多萬字的飛書雲文檔,再讓 claude 按板塊切分,一次只塞一個板塊進去。
因為一次全導入會有 2 個明顯問題:
一是塞太多 claude 上下文不夠,wiki 會結構失控、分類混亂、互相引用亂掉。
二是 claude.md 的架構規則是在每次實操踩坑後不斷演化出來的。
比如每次 ingest 完可能都會暴露新問題,可能是圖片處理方式、可能是文件命名規則、可能是 wiki 和 CLAUDE.md 的邊界等等。
這些問題暴露後,都需要我們回到 CLAUDE.md 里加新規則,下次 ingest 才不會再犯。我的 CLAUDE.md 就是一週裏迭代了 4 版,每一版都是上一次 ingest 的規則沉澱。
這樣,我們就把整個 0-1 的流程跑通了,剩下的就是日常給 claude 發內容,讓它放到 raw 文件夾,然後編譯成 wiki,不斷積累更新;如果有需要就根據實際情況調整 claude.md。
這套 llm wiki 方法整體體驗下來,我最直觀的感受就是:
之前那些散落在各處的知識碎片,終於第一次以"網絡"的形式連了起來,它們不再是文件夾裏的孤島,而是一張能查、能問答、並且能不斷進化、更新的、活的知識網絡。
像以前,普通筆記會越記越多、越多越亂、越多越找不到,每次更新交叉引用、保持修改同步、標註矛盾點等,如果純靠人力去維護,基本幹 2 次就心累了,所以大多數人記着記着就放棄了。
但交給 AI它不會累,所以這個 wiki 其實很難半途夭折。並且每來一篇新內容,相關的幾十上百個頁面會被自動更新、互相連結,越用越清晰。
更關鍵的是,它沉澱的不只是網上能搜到的內容。我們每次和 AI 的對話、每次對比分析、靈感思路等都可以被回填成新的頁面,長期下來,這個 wiki 裝的就是我們自己獨特的上下文資產,這是任何工具都給不了的。
這才是 llm wiki 真正的價值:讓知識真正開始複利。
如果覺得本篇分享對你有幫助,歡迎一鍵三連,方便更多朋友看到~
對AI工具、AI乾貨技巧、vibe coding感興趣,可以給『噪點』加個星標 ⭐️,第一時間獲取推送!也歡迎交個朋友~