我用Obsidian 給 Coding Agent裝了一塊硬盤!它終於不再失憶了
整理版優先睇
用 Obsidian 做 Coding Agent 嘅長期記憶,解決跨會話失憶問題
呢篇文章係作者分享佢用 Obsidian 同 Coding Agent(如 Claude Code、Codex)一齊用嘅實戰方法。佢發現 Agent 每次開新對話都要重新交代背景,因為上下文窗口一清就乜都唔記得,造成重複勞動同浪費時間。作者想解決嘅問題係:點樣俾 Agent 一個持久化嘅長期記憶庫,等佢唔會失憶。
作者參考人類記憶模型(工作記憶 vs 長期記憶),將上下文窗口當作工作記憶,用 Obsidian 做長期記憶庫。佢提出三層記憶架構:AGENTS.md/CLAUDE.md 做入口指示,Obsidian 項目筆記儲存決策、錯誤同待辦,session 日誌記錄每次會話完成嘅內容。具體實施要用 Obsidian CLI 俾 Agent 直接操控筆記。
整體結論係:呢套方案可以大幅降低開新對話嘅心智成本,Agent 讀完記憶後自己總結嘅狀態比作者自己描述仲要清晰。作者強調呢個係最小化結構,用家可以按自己需要調整。
- 跨會話失憶係所有 Coding Agent 嘅共同問題,分三層:跨會話失憶、上下文壓縮失真、重複勞動成本。
- 解決方法:用 Obsidian 做長期記憶庫,配合 AGENTS.md/CLAUDE.md 做入口,三層架構(入口、筆記、日誌)缺一不可。
- 具體實施:用 Obsidian CLI 俾 Agent 直接控制筆記,文件結構包括 overview.md、decisions.md、errors.md、todo.md 同 sessions/YYYY-MM-DD.md。
- 可封裝成 Claude Code 自定義命令:/init-memory 讀取記憶,/save-memory 寫入會話總結,每條命令自動完成整套工作流。
- 使用時要 Agent 先讀記憶再報告現狀,工作期間自動更新筆記,結束時生成五點 session 總結(尤其係「邊啲模塊唔好重複修改」)。
CLAUDE.md(Claude Code 用)
放喺項目根目錄,指示 Claude Code 讀取 Obsidian 記憶庫嘅文件,包括 overview.md、decisions.md、errors.md、todo.md,同埋行為要求(開始編碼前輸出理解、唔好重做已完成模塊、追加錯誤同決策、更新 todo、寫 session 摘要)。
AGENTS.md(Codex 等用)
類似 CLAUDE.md,但更簡潔,包括 Memory Protocol:編碼前讀記憶、編碼中唔好重複已完成工作、編碼後更新 todo 同寫 session 總結。
Claude Code 自定義命令
.claude/commands/ 下嘅 /init-memory 命令:讀 CLAUDE.md 同 Obsidian 記憶文件,產出項目狀態摘要;/save-memory 命令:寫 session 總結到 sessions/YYYY-MM-DD.md,包括完成內容、改嘅文件、決定、錯誤、下一步同唔好再改嘅模塊。
Coding Agent 失憶嘅煩惱
每日用 Coding Agent 寫 code 嘅場景大家都好熟:早上開 Claude Code 重構一個 Go 後端,花 40 分鐘交代背景——項目結構、用咩數據庫、技術決策、踩過嘅坑。點知第二日 /compact 一下或者開新對話,所有 context 就冇曬,又要重新交代。
上下文窗口就係 Agent 嘅全部記憶,窗口一清,佢就失憶成陌生人。
呢個唔係特定模型嘅 bug,而係所有 Coding Agent 嘅共同問題。問題本質分三層:跨會話失憶、上下文壓縮失真、重複勞動成本。
三層記憶架構:Obsidian 做長期記憶
參考人類記憶模型,上下文窗口係工作記憶,容量有限;我哋需要幫 Agent 建立長期記憶庫。作者揀咗 Obsidian,因為佢係純文字 markdown,易俾 Agent 讀寫,而且可以用 CLI 控制。
- 1 第一層:AGENTS.md / CLAUDE.md —— 工作手冊嘅目錄頁
- 2 第二層:Obsidian 項目筆記(overview.md、decisions.md、errors.md、todo.md)—— 工作手冊正文
- 3 第三層:sessions/YYYY-MM-DD.md —— 會話工作日誌
具體點樣搭?用 Obsidian CLI 自動化
用 Obsidian CLI 可以令 Agent 直接從終端控制 Obsidian,唔使手動開 app。
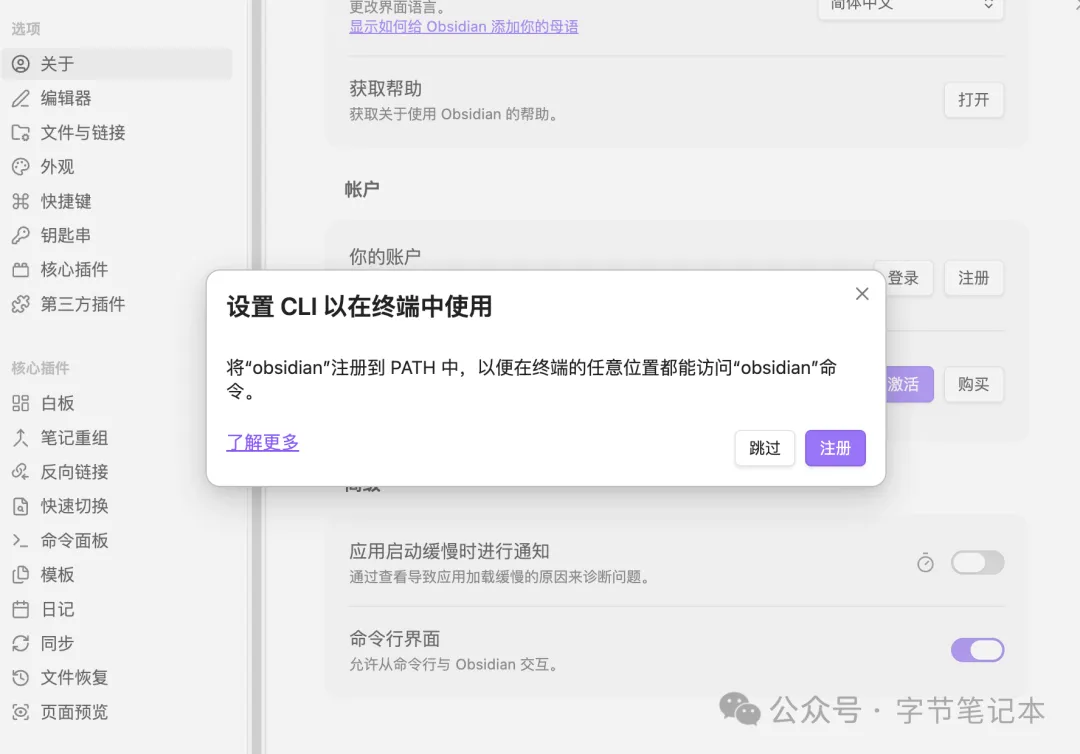
先喺 Obsidian 啟用 Command line interface 並註冊 CLI 工具。然後建立記憶目錄,以 Demo Todo App 為例:
decisions.md ── 已確定嘅技術決策
errors.md ── 踩過嘅坑,每次追加
todo.md ── 下一步要做嘅任務
overview.md ── 項目當前狀態
sessions/YYYY-MM-DD.md ── 每日會話總結跟住喺項目根目錄放 CLAUDE.md 同 AGENTS.md,內容見 resources。最後封裝 Claude Code 自定義命令,例如 /init-memory 同 /save-memory。
/init-memory 命令:讀 CLAUDE.md 同 Obsidian 記憶文件,產出項目狀態摘要
/save-memory 命令:寫 session 總結,包括完成咩、改咗咩、決定、錯誤、下一步、唔好再改嘅模塊
日常使用工作流
搭好之後,每次開新對話就俾 Agent 呢啲指示:先讀 CLAUDE.md,再讀 Obsidian 記憶文件,輸出佢理解嘅當前狀態同修改計劃。
讓 Agent 先報告現狀,係確認佢真係讀到記憶,而唔係直接開幹。
工作期間遵守三條規則:發現新坑追加到 errors.md;做咗設計決策追加到 decisions.md;完成一個模塊更新 todo.md。結束時生成 session 總結,尤其係「邊啲模塊唔好重複修改」。
- 完成咗咩?
- 修改咗邊啲文件?
- 仍然有咩問題?
- 下次繼續應從邊度開始?
- 邊啲模塊唔好重複修改?(呢條最關鍵)
「邊啲模塊唔好重複修改」呢條冇紀錄,Agent 下次好可能將你已打磨好嘅 code 重構掉。
用後感:心智成本大減
作者用咗呢套方案一段時間,最直接感受係開新對話嘅心唔再咁重。以前怕交代麻煩,成日將一個對話拖到好長,結果上下文膨脹 compact 失真。
而家開新對話,兩句話叫 Agent 讀記憶,佢自己總結嘅狀態比作者自己描述仲清晰。
作者認為呢個先係 Coding Agent 應有嘅工作節奏:上下文窗口只係工作記憶,Obsidian 做長期記憶。每日用 Obsidian CLI 整理項目 markdown 已經變成習慣,幾分鐘嘅功夫,收益長期。
我哋每日用Coding Agent寫code嘅情形大概係咁:
朝早打開Codex/Claude Code重構一個Go後端。
花咗40分鐘同佢交代背景,項目結構係點、用咗邊個數據庫、有邊啲已經定好嘅技術決策、有邊啲坑踩過唔好再踩。
呢段時間,無論係國產模型定係官方訂閲,佢哋都做得幾好。
第二日,/compact 一下,或者開個新會話,上下文本信息全部冇曬或者壓縮到冇咗。
又要花20分鐘重新交代過。
第三日,同樣嘅事再做一次。
其實呢個唔係Claude Code嘅bug,亦都唔係Codex嘅缺陷,而係而家所有Coding Agent共同嘅問題:
上下文視窗就係佢嘅全部記憶,視窗一清,佢就失憶變成陌生人。
點樣解決呢?
先搞清楚問題嘅本質
Agent到底喺邊個層面唔記得呢?
其實包含咗三層:
第一層,跨會話失憶。
今日嘅對話同尋日嘅對話之間冇連接,Agent唔知尋日發生咗乜嘢。
第二層,上下文壓縮失真。
當對話變長,/compact 會將早期內容壓縮成摘要,細節會丟失,但細節往往藏咗魔鬼。
第三層,重複勞動成本。
Agent會重新做已經做過嘅事,因為佢唔知嗰件事已經做完。
基於以上幾點,我哋好有必要喺Agent工作記憶之外,幫佢建立一個持久化嘅長期記憶庫。
認知科學入面有一個經典模型,人類記憶分工作記憶同長期記憶。工作記憶容量有限,處理當前任務;長期記憶容量大,儲存經驗同知識。
兩者協作,先至令人可以應付複雜問題。
上下文視窗就係Agent嘅工作記憶。而Obsidian就係我哋要幫佢建立嘅長期記憶。
而家嘅問題係,點樣組織同使用Obsidian嚟建立長期記憶,可以按下面嘅架構同方式進行?
三層記憶架構
我將成個系統分成咗三層,每層職責唔同:
第一層:AGENTS.md / CLAUDE.md
話畀Agent知去邊度讀記憶,遵守乜嘢規則。佢係工作手冊嘅目錄頁。
第二層:Obsidian 項目筆記
用嚟保存長期狀態、技術決策、踩坑記錄、下一步任務,係成個工作手冊嘅正文。
第三層:sessions/YYYY-MM-DD.md
記錄每次Agent完成咗乜嘢工作,防止第二日重複,相當於你嘅會話工作日誌。
三層缺一不可。
得第一層,Agent知道規則但冇記憶。
得第二層,Agent冇入口讀到記憶。
冇第三層,今日做咗乜嘢聽日又要點樣重新交代。
AGENTS.md係啟動式,Obsidian係長期記憶庫,Coding Agent係執行工人。
具體點樣搭建?
呢度建議用Obsidian CLI,而唔係靠手動去維護。
透過官方Obsidian CLI,我哋可以令Coding Agent直接由終端控制Obsidian,實現腳本、自動化、插件開發、搜索、打開/建立筆記。
開啟方法好簡單,下載或者更新Obsidian之後,啟用Command line interface並註冊CLI工具。
我呢度用一個真實項目嚟示範成個工作流程點樣用。
假設項目叫Demo Todo App,擺喺 ~/development/demo-todoapp,
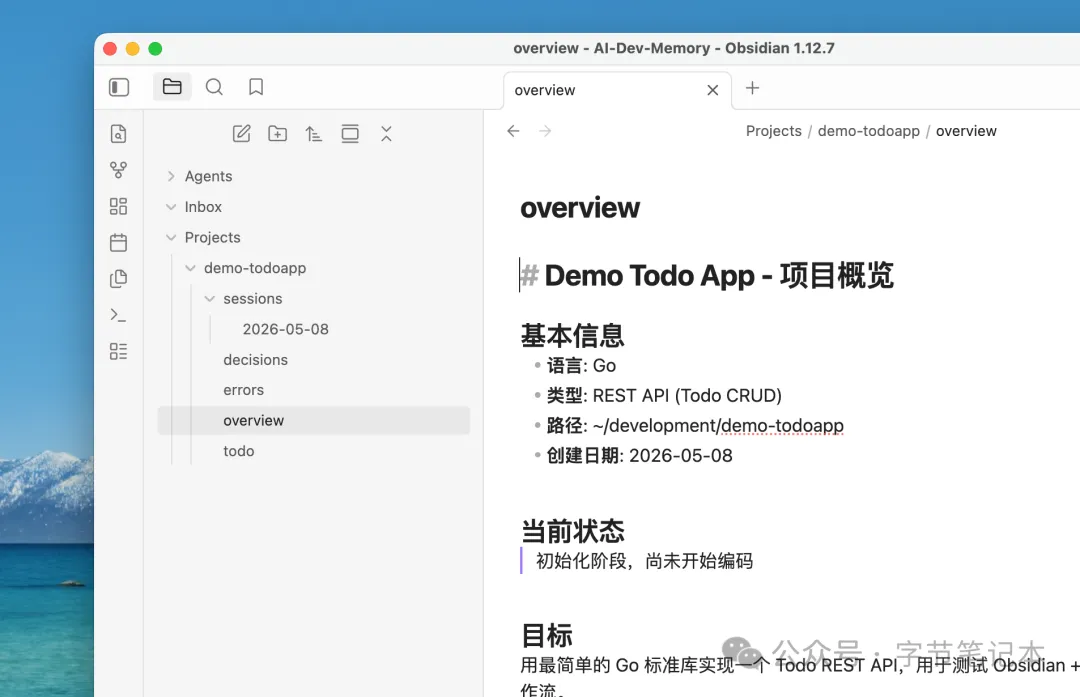
一個非常簡單嘅任務,用Go標準庫 net/http + SQLite實現一個Todo REST API,唔用框架,唔用ORM。
項目本身夠曬精簡,集中睇記憶工作流程點樣運作。
第一步:建立Obsidian記憶目錄
Obsidian Vault 最終嘅文件結構如下:
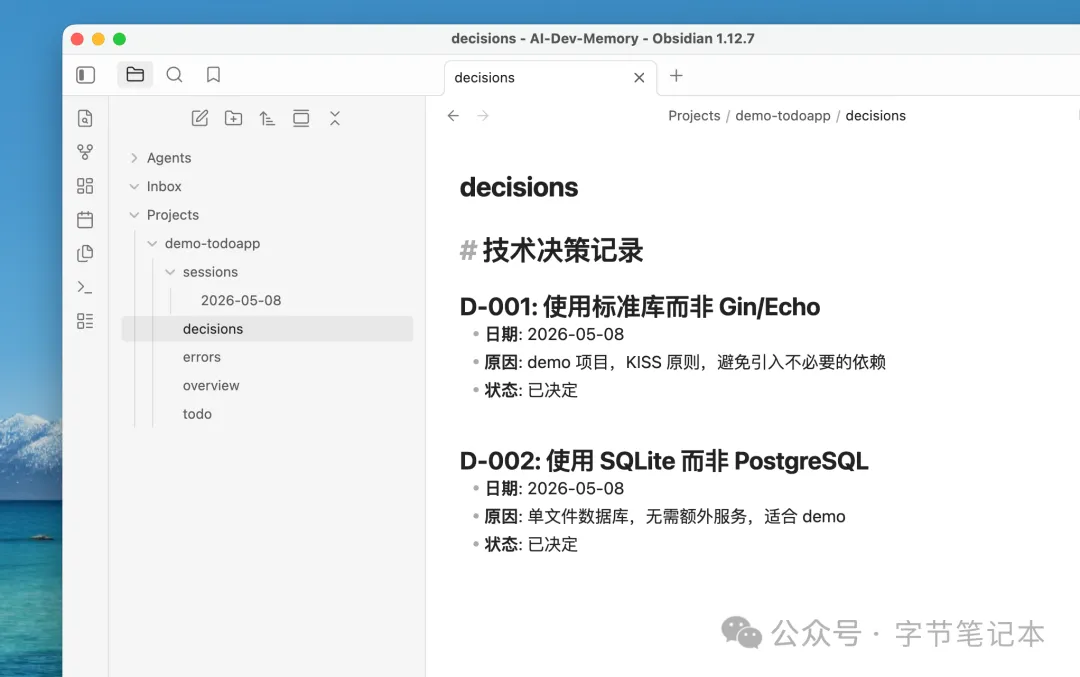
decisions.md 寫已經定好嘅技術決策。呢個係最關鍵嘅文件,防止Agent不斷質疑已經做完嘅選擇:
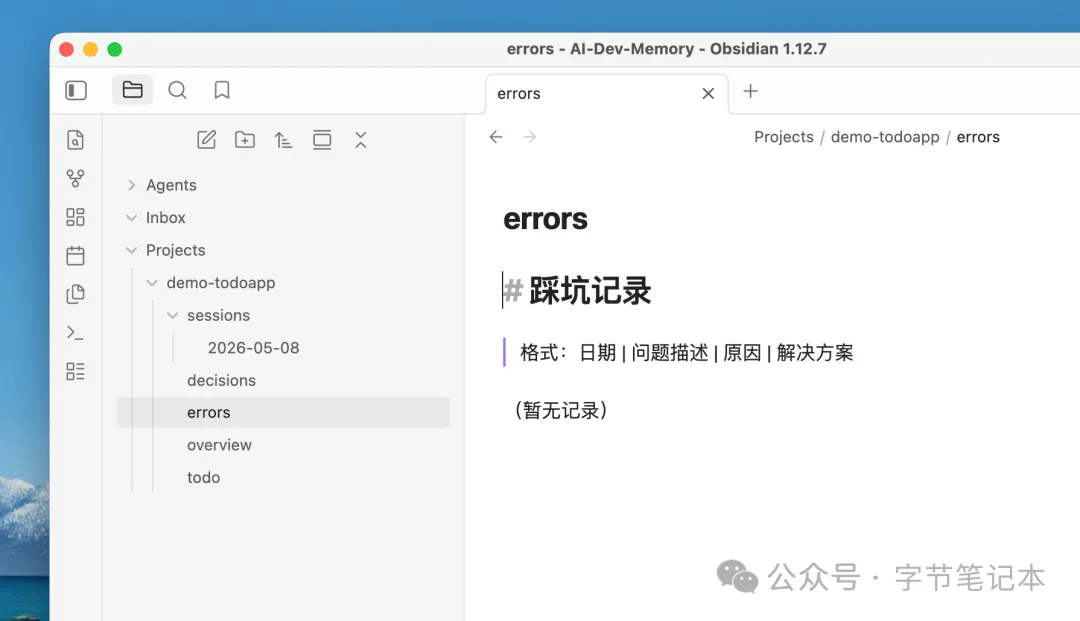
errors.md 寫踩過嘅坑。每次踩坑就加落去,等Agent下次唔好重蹈覆轍。
todo.md 寫下一步要做乜嘢。每次任務完成之後更新:
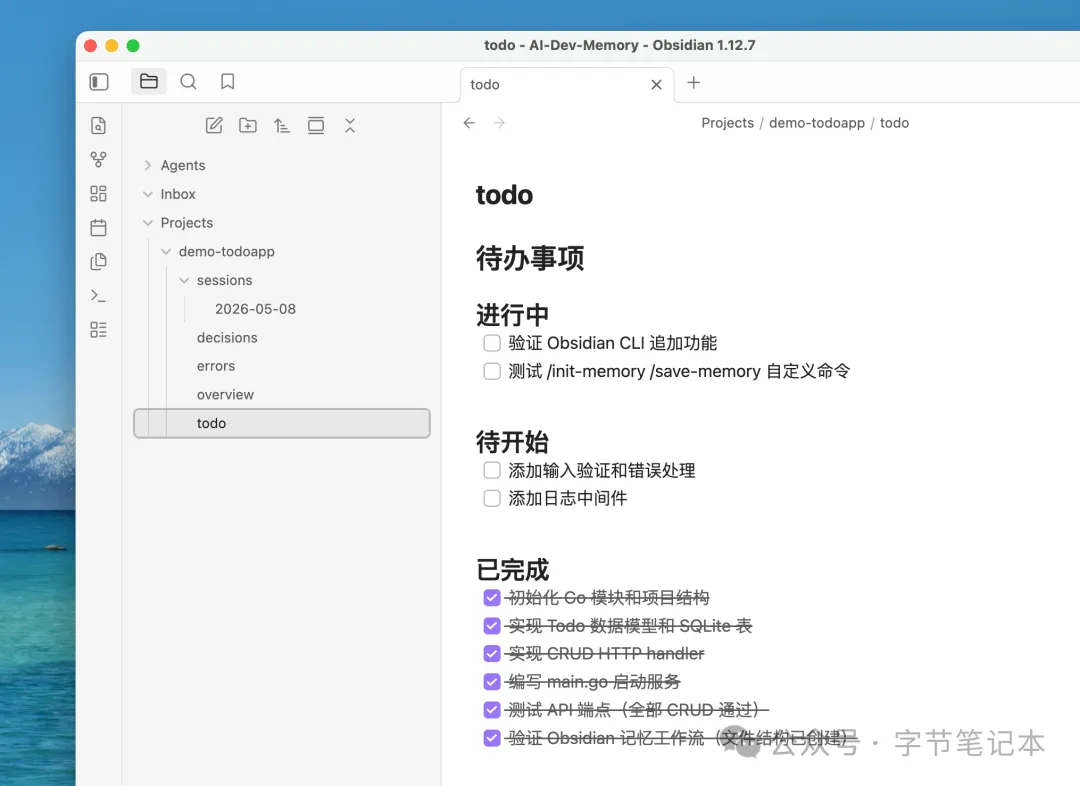
第二步:喺項目根目錄放CLAUDE.md同AGENTS.md
呢兩個文件係Agent嘅入口,話畀佢知開始工作前要讀記憶,佢係透過Obsidian CLI嚟自動更新流程嘅關鍵,上面文件結構嘅內容就係靠佢嚟自動維護建立嘅。
CLAUDE.md,畀Claude Code用:
# CLAUDE.md
## 長期記憶
本項目使用 Obsidian 作為長期記憶庫。
記憶路徑:~/Obsidian/AI-Dev-Memory/Projects/demo-todoapp/
開始重要工作前,必須先讀取:
1. overview.md - 瞭解項目當前狀態
2. decisions.md - 瞭解已確定的技術決策
3. errors.md - 瞭解踩過的坑,避免重複
4. todo.md - 瞭解下一步任務
## 行為要求
- 開始編碼前,先輸出你對當前項目狀態的理解。
- 不要重做已完成的模塊,除非被明確要求。
- 發現重複出現的 bug,追加到 errors.md。
- 做了架構選擇,追加到 decisions.md。
- 完成一個模塊,更新 todo.md。
- 每次會話結束後,寫 session 摘要到 sessions/YYYY-MM-DD.md。
AGENTS.md,畀Codex或者其他Agent用:
# AGENTS.md
## Memory Protocol
Before coding:
- Read ~/Obsidian/AI-Dev-Memory/Projects/demo-todoapp/
- Check overview.md, decisions.md, errors.md, todo.md
During coding:
- Do not repeat completed work
- Keep changes minimal
- Run tests after modifications
After coding:
- Update todo.md
- Append session summary to sessions/YYYY-MM-DD.md
第三步:封裝成Claude Code自定義命令
如果用Claude Code,可以將常用操作整成/命令,擺喺項目的.claude/commands/目錄下。
/init-memory 命令:
Read CLAUDE.md and AGENTS.md first.
Then read these Obsidian memory files:
- overview.md
- decisions.md
- errors.md
- todo.md
Before writing any code, summarize:
1. Current project status
2. Key constraints and decisions
3. Known pitfalls to avoid
4. What should NOT be modified again
/save-memory 命令:
Append a session summary to sessions/YYYY-MM-DD.md.
Include:
- What was completed
- Files changed
- Decisions made
- Bugs encountered
- Next steps
- Modules that should not be refactored again
咁樣每次開始工作輸入/init-memory,結束時輸入/save-memory,兩條命令,成個記憶工作流程就會自動同完整咁運轉。
Coding Agent使用時嘅工作流程
搭好之後,我哋就可以咁樣開始使用。
進入項目之後,畀Agent呢個提示詞:
先讀取 CLAUDE.md,然後讀取 Obsidian 項目記憶目錄裏的
overview.md、decisions.md、errors.md、todo.md。
不要急着改代碼,先輸出你理解的當前項目狀態和本次修改計劃。
叫Agent先報告現狀,係確認佢真係讀到記憶、理解咗上下文,而唔係直接開工。
工作過程中,叫佢遵守三條規則:
- 發現新坑,加落errors.md。
- 做咗設計決策,加落decisions.md。
- 完成一個模組,更新todo.md。
結束任務之後,叫佢生成session總結:
請把本次工作寫入 Obsidian 項目記憶:
1. 完成了什麼
2. 修改了哪些文件
3. 仍然存在什麼問題
4. 下次繼續時應該從哪裏開始
5. 哪些模塊不要重複修改
呢五條都係精髓,尤其係第五條,邊啲模組唔好重複修改,呢條信息如果冇明確記錄,Agent下次好可能將你花咗時間打磨好嘅代碼重構咗。
當然,呢個係我個人畀出嘅最小化結構版本,用幾日,你自然會知道邊度需要補充,邊度需要擴展,完全可以根據你自己嘅業務同使用習慣嚟改造。
我用呢套方案跑咗一段時間,最直接嘅感受係:開啟會話嘅心智成本降低咗。
以前每次開新對話,我都要諗又要重新交代一次,有時覺得麻煩就乾脆唔開新對話,將一個會話拉到好長,結果上下文膨脹compact失真。
而家唔同啦。
開新會話,兩句說話叫Agent讀記憶,佢自己總結出嚟嘅狀態仲清晰過我自己描述。
我覺得呢個先係Coding Agent應該有嘅工作節奏:上下文視窗只係工作記憶,Obsidian作為長期記憶。
每日結合Obsidian CLI或者手動整理項目嘅markdown文件都成為咗我每日嘅必做項目。
Coding Agent外掛硬碟之後,終於有咗記性,再唔使擔心會話嘅丟失,無論係上下文信息嘅管理、項目總結定係模組嘅遷移都大有裨益。
幾分鐘嘅事,收益係長期嘅。
更多AI編程嘅高級技巧可以關注我嘅專欄合集:AI編程高效開發指南
我們每天使用Coding Agent寫代碼的場景大抵如此:
早上打開Codex/Claude Code重構一個 Go 後端。
花了 40 分鐘給它交代背景,項目結構是什麼、用的什麼數據庫、有哪些已經定下來的技術決策、有哪些坑踩過了不要再踩。
這段時間不管是國產模型還是官方訂閲,它們乾得很好。
第二天,/compact 一下,或者新開一個會話,上下文本信息全部丟失或者壓縮沒了。
又是花了20分鐘重新交代。
第三天,同樣的事情再來一遍。
其實這也不是 Claude Code 的 bug,也不是 Codex 的缺陷,這是當前所有Coding Agent共同的問題:
上下文窗口就是它的全部記憶,窗口一清,它就失憶成陌生人。
怎麼解決呢?
先搞清楚問題的本質
Agent 到底在什麼層面不記得呢?
其實包含了三層:
第一層,跨會話失憶。
今天的對話和昨天的對話之間沒有連接,Agent 不知道昨天發生了什麼。
第二層,上下文壓縮失真。
當對話變長,/compact 會把早期內容壓縮成摘要,細節丟失,但往往細節裏藏着魔鬼。
第三層,重複勞動成本。
Agent 會重新做已經做過的事,因為它不知道那件事已經做完了。
基於以上幾點,我們非常有必要在 Agent 工作記憶之外,給它建一個持久化的長期記憶庫。
認知科學裏有一個經典模型,人類記憶分工作記憶和長期記憶。工作記憶容量有限,處理當前任務;長期記憶容量大,存儲經驗和知識。
兩者協作,才讓人能應對複雜問題。
上下文窗口就是 Agent 的工作記憶。而Obsidian 就是我們要幫它建的長期記憶。
現在的問題是,如何組織和使用Obsidian來建立長期記憶可以按下面的架構和方式來?
三層記憶架構
我把這個整套系統分成了三層,每層職責不同:
第一層:AGENTS.md / CLAUDE.md
告訴 Agent 去哪裏讀記憶,遵守什麼規則。它是工作手冊的目錄頁。
第二層:Obsidian 項目筆記
用來保存長期狀態、技術決策、踩坑記錄、下一步任務,是整個工作手冊的正文。
第三層:sessions/YYYY-MM-DD.md
記錄每次 Agent 工作完成了什麼,防止第二天重複,相當於你的會話工作日誌。
三層缺一不可。
只有第一層,Agent 知道規則但沒有記憶。
只有第二層,Agent 沒有入口讀到記憶。
沒有第三層,今天做了什麼明天又要重新交代。
AGENTS.md 是啓動式,Obsidian 是長期記憶庫,Coding Agent 是執行工人。
具體怎麼搭?
這裏要推薦使用Obsidian CLI,而不是純靠手動去維護。
藉助官方Obsidian CLI,我們可以讓Coding Agent直接從終端直接控制 Obsidian,實現腳本、自動化、插件開發、搜索、打開/創建筆記。
開啓方法很簡單,下載或者更新Obsidian後,啓用 Command line interface 並註冊 CLI工具。
我這裏用一個真實項目來演示整套工作流怎麼用。
假設項目叫 Demo Todo App,放在 ~/development/demo-todoapp,
一個非常簡單的任務,用 Go 標準庫 net/http + SQLite 實現一個 Todo REST API,不用框架,不用 ORM。
項目本身足夠精簡,專注看記憶工作流是怎麼運轉的。
第一步:建 Obsidian 記憶目錄
Obsidian Vault 最終的文件結構如下:
decisions.md 寫已經定下來的技術決策。這是最關鍵的文件,它防止 Agent 反覆質疑已經做完的選擇:
errors.md 寫踩過的坑。每次踩坑就追加,讓 Agent 下次不要重蹈覆轍。
todo.md 寫下一步要做什麼。每次任務完成後更新:
第二步:在項目根目錄放 CLAUDE.md 和 AGENTS.md
這兩個文件是 Agent 的入口,告訴它開始工作前先讀記憶,它是通過Obsidian CLI來自動更新流的關鍵所在,上面的文件結構裏面的內容就是通過它來自動維護創建的。
CLAUDE.md,給 Claude Code 用:
# CLAUDE.md
## 長期記憶
本項目使用 Obsidian 作為長期記憶庫。
記憶路徑:~/Obsidian/AI-Dev-Memory/Projects/demo-todoapp/
開始重要工作前,必須先讀取:
1. overview.md - 瞭解項目當前狀態
2. decisions.md - 瞭解已確定的技術決策
3. errors.md - 瞭解踩過的坑,避免重複
4. todo.md - 瞭解下一步任務
## 行為要求
- 開始編碼前,先輸出你對當前項目狀態的理解。
- 不要重做已完成的模塊,除非被明確要求。
- 發現重複出現的 bug,追加到 errors.md。
- 做了架構選擇,追加到 decisions.md。
- 完成一個模塊,更新 todo.md。
- 每次會話結束後,寫 session 摘要到 sessions/YYYY-MM-DD.md。
AGENTS.md,給 Codex 或其他 Agent 用:
# AGENTS.md
## Memory Protocol
Before coding:
- Read ~/Obsidian/AI-Dev-Memory/Projects/demo-todoapp/
- Check overview.md, decisions.md, errors.md, todo.md
During coding:
- Do not repeat completed work
- Keep changes minimal
- Run tests after modifications
After coding:
- Update todo.md
- Append session summary to sessions/YYYY-MM-DD.md
第三步:封裝成 Claude Code 自定義命令
如果用 Claude Code,可以把常用操作做成 /命令,放在項目的 .claude/commands/目錄下。
/init-memory 命令:
Read CLAUDE.md and AGENTS.md first.
Then read these Obsidian memory files:
- overview.md
- decisions.md
- errors.md
- todo.md
Before writing any code, summarize:
1. Current project status
2. Key constraints and decisions
3. Known pitfalls to avoid
4. What should NOT be modified again
/save-memory 命令:
Append a session summary to sessions/YYYY-MM-DD.md.
Include:
- What was completed
- Files changed
- Decisions made
- Bugs encountered
- Next steps
- Modules that should not be refactored again
這樣每次開始工作輸入/init-memory,結束時輸入/save-memory,兩條命令,整套的記憶工作流就會自動並完整地運轉。
Coding Agent使用時的工作流
搭好之後,我們就可以這樣開始使用。
進入項目之後,給 Agent 這樣的提示詞:
先讀取 CLAUDE.md,然後讀取 Obsidian 項目記憶目錄裏的
overview.md、decisions.md、errors.md、todo.md。
不要急着改代碼,先輸出你理解的當前項目狀態和本次修改計劃。
讓 Agent 先報告現狀,是確認它真的讀到了記憶、理解了上下文,而不是直接開幹。
工作過程中,讓它遵守三條規則:
- 發現新坑,追加到 errors.md。
- 做了設計決策,追加到 decisions.md。
- 完成一個模塊,更新 todo.md。
結束任務後,讓它生成 session 總結:
請把本次工作寫入 Obsidian 項目記憶:
1. 完成了什麼
2. 修改了哪些文件
3. 仍然存在什麼問題
4. 下次繼續時應該從哪裏開始
5. 哪些模塊不要重複修改
這五條都是精華,尤其是第五條,哪些模塊不要重複修改,這條信息如果沒有顯式記錄,Agent 下次很可能把你已經花時間打磨好的代碼重構掉。
當然,這是我個人給出的最小化結構的版本,用幾天,你自然會知道哪裏需要補充,哪裏需要拓展,完全可以根據你自己的業務和使用習慣來改造。
我用這套方案跑了一段時間,最直觀的感受是:開會話的心智成本降低了。
以前每次開新對話,我都要想又要重新交代一遍,有時候嫌麻煩就乾脆不開新對話,把一個會話拉得很長,結果上下文膨脹compact 失真。
現在不一樣了。
開新會話,兩句話讓 Agent 讀記憶,它自己總結出來的狀態比我自己描述的還要清晰。
我覺得這才是 Coding Agent 應該有的工作節奏:上下文窗口只是工作記憶,Obsidian 作為長期記憶。
每天結合Obsidian CLI或者手工整理項目的markdown文件也成為了我每天的必做項目。
Coding Agent外掛硬盤之後,終於有了記性,再也不用擔心會話的丟失,不管是上下文信息的管理,項目總結或者是模塊的遷移都大有裨益。
幾分鐘的事,收益卻是長期的。
更多AI編程的高級技巧可以關注我的專欄合集:AI編程高效開發指南