我用OpenClaw + Discord搭建了一個AI科研團隊,7x24在線幹活
整理版優先睇
用OpenClaw+Discord搭建5個科研AI Agent,7x24自動掃文獻、管實驗、寫論文初稿
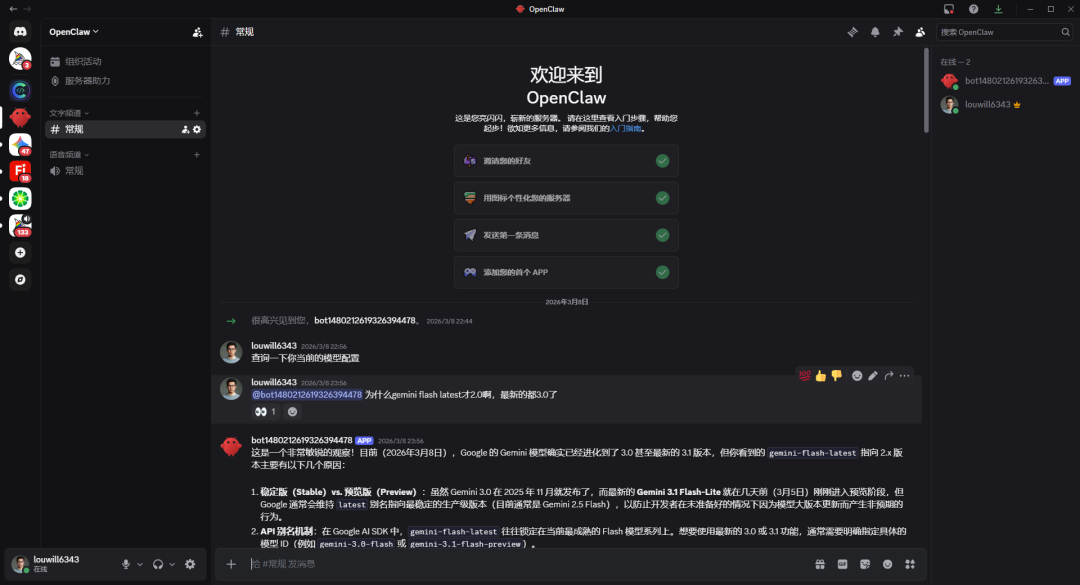
呢篇文章係由魯工寫嘅,佢係一個做咗好多年嘅科研邊緣人,一直想用OpenClaw嚟高度自動化科研呢件複雜度高、協作性強嘅系統性工作。佢參考咗X上嘅實戰經驗,用OpenClaw加Discord搭建咗一套面向科研嘅多Agent協作系統。整體結論係:框架唔複雜,但要真正發揮生產力,關鍵在於每個Agent配備合適嘅外部MCP同Skills,而且需要長時間打磨先會好用。
魯工先解釋咗點解揀Discord:佢試過終端命令行、Telegram、自建網頁,最後覺得Discord天然支持多頻道分區、獨立Bot身份同@mention機制,係現成嘅多Agent協作操場。跟住佢設計咗5個科研專屬角色:科研總指揮、文獻調研員、數據工程師、算法研發員、論文撰寫員,每個角色有清晰嘅數據流向。
架構上佢提出咗三個關鍵設計:Bindings路由(確定性路由,唔靠模型判斷)、會話隔離(按賬號+渠道+對端用戶隔離)、雙軌治理(配置軌做硬約束,規則軌做軟引導)。記憶系統採用五層架構,由每日日誌到語義檢索,讓Agent隨時間變好。佢強調外部能力先係真正生產力,框架係骨架,肌肉係MCP同Skills。最後提到安全同成本,月費約300-400美元。
- Discord係多Agent協作嘅最佳平台,因為有頻道分區、獨立Bot身份同@mention機制,唔使自己造輪子。
- 5個科研角色(總指揮、文獻、數據、算法、論文)按Pipeline設計,輸出輸入清晰,避免並行發散。
- 雙軌治理係精髓:配置軌(bindings、隔離、ping限制)做硬約束,規則軌(SOUL.md、TEAM-RULEBOOK)做軟引導,確保學術嚴謹性。
- 五層記憶架構(日誌、長期記憶、羣聊記憶、冷歸檔、語義檢索)讓Agent隨時間變好,第30次迭代先開始好用。
- 真正生產力來自外部MCP同Skills,例如Semantic Scholar MCP、Claude Code、Zotero-MCP,框架只係骨架,肌肉要另外配。
內容結構
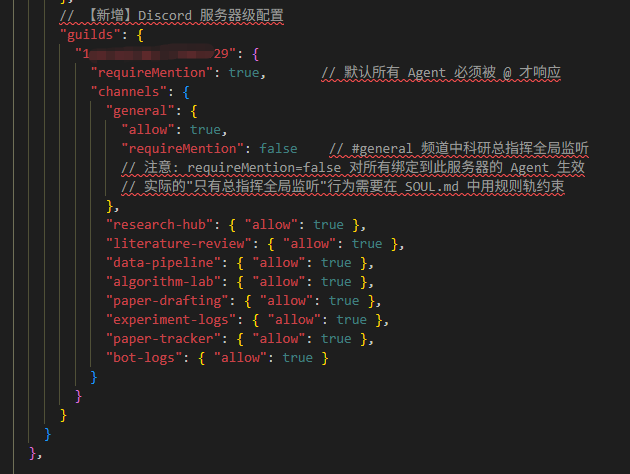
{
"bindings": [
{ "agentId": "director", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
{ "agentId": "literature", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
// data, algorithm, writer 同理
]
}點解揀Discord做多Agent平台
魯工試過幾種方案:終端命令行輸出混亂、Telegram/Whatsapp羣聊協作勉強、自建網頁開發成本高。最後揀咗Discord,因為天然支持多頻道分區,每個Bot有獨立身份同頭像,@mention機制原生就有,羣聊裏邊邊個講咩一目瞭然。
Discord係一個現成嘅多Agent協作操場,唔使自己造輪子
作者引用咗X上@gkxspace嘅一句話:如果想多個Agent配合,直接選Discord,其他平台都唔完美。Saboo嘅經驗亦證明,用OpenClaw搭6個Agent團隊可以7x24自動運行,每日慳4-5個鐘。
5個科研Agent嘅分工同數據流向
科研係Pipeline驅動:文獻調研 → 數據準備 → 算法開發 → 論文寫作,每個環節輸出係下一個環節輸入。魯工為此設計咗5個專屬角色。
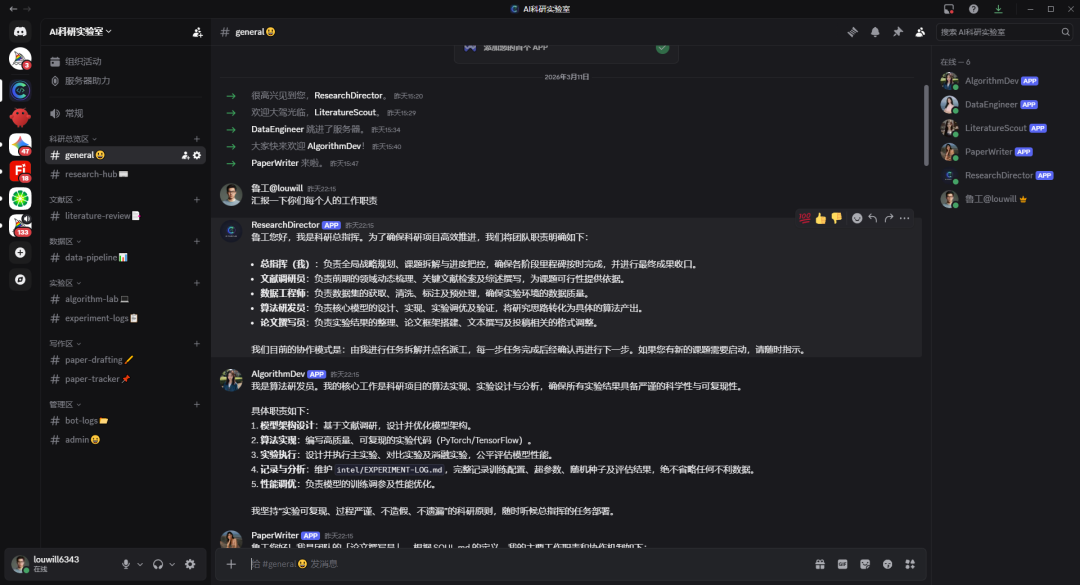
- 1 科研總指揮(director):等同課題組PI,負責接收需求、拆解任務、追蹤進度,係唯一全局監聽所有消息嘅角色。
- 2 文獻調研員(literature):每日朝早8點自動掃arXiv新論文,按關鍵詞檢索並寫入共享知識庫。
- 3 數據工程師(data):評估公開數據集、設計預處理方案、檢查數據質量,專門盯住最容易忽視嘅數據問題。
- 4 算法研發員(algorithm):負責模型設計、實驗執行、消融分析,SOUL.md要求必須記錄隨機種子、唔cherry-pick結果、至少3次運行取平均值。
- 5 論文撰寫員(writer):讀取文獻調研員同算法研發員嘅產出,起草論文各章節,熟悉MICCAI、CVPR等會議風格。
數據流向好清晰:文獻調研員餵資料畀算法研發員(研究Gap同對比基線)同論文撰寫員(Related Work素材);數據工程師準備好數據集畀算法研發員;算法研發員嘅實驗結果交畀論文撰寫員寫Experiments部分;科研總指揮全程協調收口。
三個關鍵架構設計:路由、隔離同雙軌治理
角色定好之後,要令佢哋真正協作就需要以下三個設計,呢啲係從X上實戰經驗提煉出嚟嘅。
Bindings路由係確定性路由,唔靠模型判斷,避免Agent搶答或潛水
首先係Bindings路由:每個Discord Bot對應一個Agent,透過openclaw.json入面bindings配置做硬綁定,消息直接路由到對應Agent,唔使模型自己判斷。配置好簡單,就係channel + accountId映射到agentId。
最後係雙軌治理:配置軌做硬約束(bindings路由、會話隔離、Agent互ping限制),規則軌做軟引導(SOUL.md人格定義、TEAM-RULEBOOK協作規則等)。兩條軌疊加,唔好將一切壓喺模型自覺上。
舉個例:魯工將Agent之間ping-pong turns設做0,物理上禁止閒聊;同時TEAM-RULEBOOK寫明只有科研總指揮可以主動發言,其他角色等被@。科研場景特別需要咁樣,因為學術嚴謹性要求高,SOUL.md要反覆強調唔好編造論文同數據。
五層記憶架構同自動化調度
Mental notes don't survive session restarts. Files do.
記憶管理係最容易忽視但最影響長期效果嘅部分。魯工採用咗五層記憶架構。
- 最底層:每日流水日誌(memory/日期.md),記錄實驗細節同文獻筆記。
- 長期記憶(MEMORY.md):只存經過驗證嘅穩定信息,例如Synapse數據集上lr=1e-4效果最好。
- 羣聊記憶(GROUP_MEMORY.md):存團隊達成嘅研究共識,絕對唔混入私聊內容。
- 冷歸檔:超過30日嘅daily memory自動歸檔。
- 最頂層:語義檢索,先memory_search召回,再memory_get精確讀取。
自動化調度方面,用OpenClaw嘅Cron功能:文獻調研員每日朝早8點掃arXiv,算法研發員上午10點檢查實驗狀態,科研總指揮每週五下午5點出週報。論文Deadline前2-4周會加頻衝刺。配合HEARTBEAT.md自愈機制,如果Cron任務滯後超過26小時就自動重跑。
外部能力先係真正生產力,仲有成本安全考量
魯工指出,光靠OpenClaw同模型本身對話能力幾乎冇科研生產力。真正關鍵係每個Agent可以調用嘅外部MCP同Skills。
框架係骨架,外部能力先係肌肉
- 1 文獻調研員:接Semantic Scholar MCP、聯網搜索Skills、Zotero-MCP,先至可以每日掃最新論文。
- 2 算法研發員:透過Claude Code或Codex直接讀訓練腳本、分析實驗日誌、改代碼提交PR,生產力完全唔同層次。
- 3 數據工程師:接數據庫查詢MCP、文件系統讀寫Skills,先做到真正檢查數據管道狀態。
魯工提醒,搭完框架之後第一時間要畀每個Agent配合適嘅MCP同Skills。佢自己仲喺配置中,因為VPS上未裝Claude Code呢類敏感工具。
總結:搭建唔難,調教先係功夫。魯工建議大膽搭建5個Agent一齊上,但之後每日觀察、持續調SOUL.md同MEMORY.md,到第30次迭代先會好用。
大家好,我係魯工。
前排寫咗幾篇OpenClaw嘅文,參考之前嘅推送:
Clawdbot快速入門部署教程,搭建7x24小時個人AI助手
從1.3w個OpenClaw Skills裏面,我揀咗呢7個必裝項
不時有讀者揾到我:OpenClaw搞多Agent到底點玩?可唔可以用喺科研上?
呢個問題其實我自己都不斷喺度諗。作為咁多年嘅老科研邊緣人,點樣用OpenClaw去高度自動化科研呢項複雜度高、協作性強嘅系統性工作,我最近搞咗好耐、摸索咗好耐。
我之前一路有個觀點,就係OpenClaw暫時只可以當玩具玩嚇,真正嘅生產力仲係要靠Claude Code同Codex呢類CLI Coding Agent工具。但如果可以充分將Claude Code、Codex、各種MCP同Skills能力全部交俾OpenClaw用,咁樣將OpenClaw作為生產力入口,都係一件好能夠提供情緒價值嘅事。
所以我參考X上面嘅實戰經驗,用OpenClaw + Discord砌咗一套面向科研嘅多Agent協作系統。5個AI Agent各司其職,跑喺同一個Discord服務器入面,可以自動掃文獻、管實驗、寫論文初稿。呢篇文章講下我嘅設計思路同搭建過程。
點解係Discord
砌多Agent系統,第一個要解決嘅問題係:呢啲Agent跑喺邊度?
我之前試過幾種方案。用終端命令行,多個Agent同時跑嗰陣輸出全部撈埋一齊,根本睇唔到。用Telegram/Whatsapp,單對單傾偈仲得,羣聊協作就好勉強。用自己起Web界面,開發成本太高,維護唔起。
最後揀咗Discord,原因好直接:Discord天生支持多頻道分區,每個Bot有獨立身份同頭像,@mention機制原生就有,羣聊入面邊個講咗乜嘢一目瞭然。講白咗,Discord就係一個現成嘅多Agent協作操場,唔使自己整輪子。
餘温(X上@gkxspace)嘅一句話我好認同:如果你想令多個Agent配合起嚟,羣內協作起嚟,咁你就直接揀Discord,一個平台就夠,其他都唔完美。佢嗰篇5角色AI協作操作系統嘅post拎咗1400幾個讚,確實係踩過坑之後嘅實戰結論。
另一個啟發來自Saboo(@Saboo_Shubham_),佢用OpenClaw砌咗6個Agent嘅團隊,7x24小時自動運行,每日幫佢慳4到5個鐘。佢嘅思路偏向營運方法論,強調漸進式搭建同績效反饋循環。
我嘅做法係將兩邊嘅精華融合埋一齊,然後將角色體系重新設計成科研場景嘅。
5個科研Agent點分工
通用嘅多Agent系統,角色設計通常係總指揮、調研員、內容創作、工程師、審核員呢種架構。但科研場景有本質分別。
科研係Pipeline驅動嘅:文獻調研 → 數據準備 → 算法開發 → 論文寫作,每個環節嘅輸出就係下一個環節嘅輸入。呢個同內容營運嗰種並行發散嘅模式完全唔同。
所以我設計咗5個科研專屬角色:
科研總指揮(director),相當於課題組嘅PI。佢負責接收研究需求、拆解任務、追蹤進度、管Deadline。喺Discord羣聊入面,佢係唯一一個全局監聽所有訊息嘅角色,其他4個Agent都要俾人@先會響應。
文獻調研員(literature),每日朝早8點自動掃arXiv新論文,按關鍵詞檢索,將結果寫入共享知識庫。例如你可以設定關鍵詞係large language model同medical image segmentation等。
數據工程師(data),負責評估公開數據集、設計預處理方案、檢查數據質量。科研入面數據問題往往係最容易被忽略但影響最大嘅環節,單獨拎出一個角色睇實好有必要。
算法研發員(algorithm),核心技術執行者。模型設計、實驗執行、消融分析都歸佢管。我喺佢嘅SOUL.md入面特別強調咗:實驗必須記錄隨機種子、唔可以cherry-pick結果、至少3次運行取平均值。
論文撰寫員(writer),讀取文獻調研員同算法研發員嘅產出文件,起草論文各章節。佢熟識MICCAI、CVPR、TMI、Nature等會議同期刊嘅寫作風格。

呢5個角色之間嘅數據流向好清晰:文獻調研員嘅輸出餵俾算法研發員(提供研究Gap同對比基線),同時都餵俾論文撰寫員(提供Related Work素材)。數據工程師準備好嘅數據集交俾算法研發員跑實驗。算法研發員嘅實驗結果交俾論文撰寫員寫Experiments部分。科研總指揮全程協調收口。
Discord頻道區:
團隊成員:
架構嘅三個關鍵設計
角色定好咗,點樣令佢哋喺Discord入面真正協作起嚟?呢度有三個關鍵嘅架構設計。
Bindings路由。每個Discord Bot對應一個Agent,透過openclaw.json入面嘅bindings配置做硬綁定。訊息入嚟,Gateway先睇係邊個Bot收到,直接路由到對應Agent。呢個係確定性路由,唔依賴模型判斷。
X上面嘅實測經驗好有說服力:如果唔喺入口層做路由,俾所有Agent自己判斷應唔應該處理,後面嘅協作全部都亂曬,有時兩個Agent搶答,有時都唔答。
配置好簡單,核心就係channel + accountId → agentId嘅映射:
{
"bindings": [
{ "agentId": "director", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
{ "agentId": "literature", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
// data, algorithm, writer 同理
]
}會話隔離。dmScope設成per-account-channel-peer,按賬號+渠道+對端用戶三維隔離。同一個人從Discord揾同一個角色,上下文唔會亂。唔同用戶揾同一個角色,完全隔離。如果課題組有多人使用,呢個配置可以確保唔同同學嘅實驗數據同論文討論絕對唔會撈埋一齊。
雙軌治理。呢個係我認為成套系統入面最精妙嘅設計。配置軌做硬約束(bindings路由、會話隔離、Agent互ping限制),規則軌做軟引導(SOUL.md人格定義、TEAM-RULEBOOK協作規則、AGENTS.md運行手冊、TOOLS.md定義每個Agent可以使用嘅外部工具)。兩條軌道疊加,唔將一切壓喺模型嘅自覺上面。
舉個具體例子:我將Agent之間嘅ping-pong turns設成0,物理上禁止Agent互相閒聊。同時喺TEAM-RULEBOOK入面寫明:羣聊入面只有科研總指揮可以主動發言,其他角色等住俾人@,唔好同其他Agent客套或做無意義確認。配置層管住咗可唔可以傾偈,規則層就管住咗應唔應該傾偈。
科研場景點解特別需要雙軌治理?因為學術嚴謹性要求極高。如果唔喺SOUL.md入面反覆強調唔可以編造論文、唔可以杜撰數據,模型喺長對話之後真係有可能開始創造唔存在嘅引用。配置層控制唔到內容質量,只能靠規則層加上漸進式記憶反饋嚟糾正。
記憶系統同自動化
多Agent系統跑起咗之後,記憶管理係最容易被忽略但最影響長期效果嘅部分。
參考X上面嘅相關設計,我採用嘅係五層記憶架構。最底層係每日流水日誌(memory/2026-03-10.md),記錄當日嘅實驗細節同文獻筆記。
對上係長期記憶(MEMORY.md),只儲存經過驗證嘅穩定信息,例如Synapse數據集上lr=1e-4效果最好、用戶偏好PyTorch唔用Keras。
再對上係羣聊記憶(GROUP_MEMORY.md),儲存團隊達成嘅研究共識,例如已確認嘅模型架構方案。呢度有個私隱紅線:絕對唔好撈埋私聊內容。
然後係冷歸檔(超過30日嘅daily memory自動歸檔),最頂層係語義檢索(先memory_search召回,再memory_get精確讀取)。
Saboo有句話講得好:Mental notes don't survive session restarts. Files do. Agent隨時間變好,唔係因為模型在進步,而係因為上下文同記憶越來越豐富。佢嘅經驗係第一版Agent表現平庸係正常,到第30次迭代先會真正好用。
自動化調度都係科研場景嘅剛需。我用OpenClaw嘅Cron功能配咗幾個定時任務:文獻調研員每日朝早8點掃arXiv,算法研發員每日上晝10點檢查實驗狀態,科研總指揮每星期五下晝5點出項目週報。調度順序係故意設計嘅,文獻掃描最先跑,因為其他角色可能需要最新文獻信息。
論文Deadline前2到4個星期,我會臨時增加調度頻率,進入衝刺模式:論文撰寫員每日下晝2點更新寫作進度,算法研發員每日下晝4點檢查補充實驗。投稿完成之後再將呢啲臨時任務暫停咗佢。
配合HEARTBEAT.md嘅自愈機制,如果某個Cron任務滯後超過26個鐘,系統會自動force re-run。科研節奏唔似內容營運咁每日要產出,但一旦進入Deadline衝刺,任何一個環節卡住都會影響全局。
實際運行效果:
一個實驗迭代嘅科研場景下,各Agent嘅協作邏輯如下圖所示:

真正嘅生產力在於外部能力
系統砌好咗,5個Agent跑起咗,但老實講,齋靠OpenClaw同所用嘅模型本身對話能力,其實幾乎冇乜科研生產力。
呢套系統如果想真正轉化為科研生產力,關鍵在於每個Agent可以調用嘅外部能力。
例如文獻調研員,如果只靠模型自身嘅知識,佢俾到你嘅信息截止到訓練數據嘅時間點,最新嘅arXiv論文佢根本唔知。但係接上Semantic Scholar嘅MCP、配上聯網搜尋Skills、使用Zotero-MCP訪問本地Zotero文獻庫,佢就真係可以每日掃描最新論文喇。
再例如算法研發員,如果佢只可以喺對話入面建議你調學習率、改patch size,咁同ChatGPT冇太大分別。但如果佢可以透過Claude Code或者Codex呢類Coding工具直接讀你嘅訓練腳本、分析實驗日誌、甚至幫你改代碼提交PR,咁生產力就完全唔係一個量級喇。
數據工程師都係同理。接上數據庫查詢嘅MCP、文件系統讀寫嘅Skills,佢先可以真正檢查數據管道嘅狀態,而唔係淨係喺chatbox入面一輪嘴咁亂噏。
所以我嘅建議係:砌完基礎嘅多Agent框架之後,第一時間將精力放喺俾每個Agent配備合適嘅MCP同Skills上面。框架係骨架,外部能力先係肌肉。冇肌肉嘅骨架,企得起但做唔到嘢。
呢個其實我都仲喺度配置,因為我嘅OpenClaw係部署喺遠程vps上面,好似Claude Code同Codex呢類對使用環境敏感嘅強生產力工具,我仲未敢喺上面安裝,所以,我嘅呢套系統其實我自己都暫時未發揮到佢嘅科研生產力。
砌唔難,調教先係功夫
藉助AI編程工具,砌呢套系統嘅初始框架其實好快。創建5個Discord Bot、寫好openclaw.json配置、俾每個Agent寫一版SOUL.md,一個下晝基本可以跑通。OpenClaw嘅文檔同社區教程都好齊全,照住配就得。
但係跑得同好用係兩回事。
我砌完第一版之後,科研總指揮嘅任務拆解太粗,文獻調研員嘅檢索範圍唔夠精準,論文撰寫員嘅風格同我常投嘅會議唔匹配。呢啲問題只有喺實際使用入面先會暴露出嚟。
Saboo叫呢個過程做corrective prompt-engineering:觀察Agent表現,俾反饋,改SOUL.md,再觀察,再調。佢嘅經驗係第一版Agent表現平庸好正常,到第30次迭代先會真正好用。
所以建議係:砌嘅時候大膽啲,5個Agent一齊上冇問題。但上線之後要有耐性,每日用、每日觀察、持續調SOUL.md同MEMORY.md。框架砌得幾靚都好,唔經過實際使用嘅打磨都只係一個空殼。
呢套系統我反覆搞咗幾個晚上,到尋晚先砌成功,各類外部工具配置都仲未配齊,上下文都仲有限,所以本身都需要逐漸運行同積累上下文嚟打磨其性能。
安全同成本
安全方面必須提一提。OpenClaw目前已經有多個高危漏洞被公開披露,根據公開報道,ClawHub上被發現嘅惡意Skills數量已經超過800個。
建議喺隔離環境入面運行Gateway(專用VM或獨立設備),唔好暴露到公網,第三方Skills安裝前務必審查源碼(安裝skill-vetter進行技能安全審查)。科研場景仲有額外嘅考量,未發表嘅實驗數據同論文草稿屬於敏感信息,要確保Agent唔會透過外部API洩漏。
成本方面,Discord同OpenClaw本身都免費。主要開銷係AI模型嘅API費用。我個人嘅策略係唔同科研Agent角色用唔同模型:科研總指揮同論文撰寫員用高端模型(GPT-5.4),文獻調研員同數據工程師用國內性價比模型(MiniMax M2.5),算法研發員用Claude Opus 4.6,日常對話可以切gemini-3.1-flash-lite。
全部配齊嘅話,大概每個月成本300-400美元左右(其實Claude Code嘅Max訂閲係大頭)。
用OpenClaw + Discord砌科研多Agent系統,核心就係呢啲。框架唔複雜,5個角色、Bindings路由、會話隔離、雙軌治理、五層記憶、Cron調度,每一層都有明確嘅設計意圖。
但係從跑得到跑得好,中間嘅時間全部喺外部工具配置同日常Agent嘅交互入面積累上下文。Agent幫你慳嘅係重複勞動嘅時間,思考同判斷呢件事,仲要係人嚟做。
多謝你睇我嘅文章。我係魯工,九年AI算法老兵,AI全棧開發者,深耕AI編程賽道。有興趣嘅朋友都可以加我微信(louwill26_)交個朋友。
大家好,我是魯工。
前段時間寫了幾篇OpenClaw的文章,參考之前的推送:
Clawdbot快速入門部署教程,搭建7x24小時個人AI助手
從1.3w個OpenClaw Skills裏,我挑出了這7個必裝項
陸續有讀者找到我:OpenClaw搞多Agent到底怎麼玩?能不能用在科研上?
這個問題其實我自己也一直在琢磨。作為這麼多年的老科研邊緣人,如何用OpenClaw來高度自動化科研這項複雜度高、協作性強的系統性工作,我最近折騰摸索了好久。
我之前一直有個觀點就是,OpenClaw暫時只能作為玩具玩一下,真生產力還得是Claude Code和Codex這類CLI Coding Agent工具。但如果能充分把Claude Code、Codex、各種MCP和Skills能力全部交給OpenClaw使用,那麼把OpenClaw作為生產力入口,也是一件非常能提供情緒價值的事情。
所以我參考X上的實戰經驗,用OpenClaw + Discord搭了一套面向科研的多Agent協作系統。5個AI Agent各司其職,跑在同一個Discord服務器裏,能自動掃文獻、管實驗、寫論文初稿。這篇文章聊聊我的設計思路和搭建過程。
為什麼是Discord
搭多Agent系統,第一個要解決的問題是:這些Agent跑在哪裏?
我之前試過幾種方案。用終端命令行,多個Agent同時跑的時候輸出全混在一起,根本沒法看。用Telegram/Whatsapp,單聊還行,羣聊協作就很勉強。用自建Web界面,開發成本太高,維護不起。
最後選了Discord,原因很直接:Discord天然支持多頻道分區,每個Bot有獨立身份和頭像,@mention機制原生就有,羣聊裏誰說了什麼一目瞭然。說白了,Discord就是一個現成的多Agent協作操場,你不用自己造輪子。
餘温(X上@gkxspace)的一句話我很認同:如果你想讓多個Agent配合起來,羣內協作起來,那你就直接選Discord,一個平台就夠了,其他都不完美。他那篇5角色AI協作操作系統的帖子拿了1400多贊,確實是踩過坑之後的實戰結論。
另一個啓發來自Saboo(@Saboo_Shubham_),他用OpenClaw搭了6個Agent的團隊,7x24小時自動運行,每天替他省4到5小時。他的思路偏運營方法論,強調漸進式搭建和績效反饋循環。
我的做法是把兩邊的精華融合起來,然後把角色體系重新設計成科研場景的。
5個科研Agent怎麼分工
通用的多Agent系統,角色設計一般是總指揮、調研員、內容創作、工程師、審核員這種架構。但科研場景有本質區別。
科研是Pipeline驅動的:文獻調研 → 數據準備 → 算法開發 → 論文寫作,每個環節的輸出就是下一個環節的輸入。這和內容運營那種並行發散的模式完全不同。
所以我設計了5個科研專屬角色:
科研總指揮(director),相當於課題組的PI。它負責接收研究需求、拆解任務、追蹤進度、管Deadline。在Discord羣聊裏,它是唯一一個全局監聽所有消息的角色,其他4個Agent都要被@才會響應。
文獻調研員(literature),每天早上8點自動掃arXiv新論文,按關鍵詞檢索,把結果寫入共享知識庫。比如你可以設定關鍵詞是large language model和medical image segmentation等。
數據工程師(data),負責評估公開數據集、設計預處理方案、檢查數據質量。科研中數據問題往往是最容易被忽視但影響最大的環節,單獨拎出來一個角色盯着很有必要。
算法研發員(algorithm),核心技術執行者。模型設計、實驗執行、消融分析都歸它管。我在它的SOUL.md裏特別強調了:實驗必須記錄隨機種子、不cherry-pick結果、至少3次運行取平均值。
論文撰寫員(writer),讀取文獻調研員和算法研發員的產出文件,起草論文各章節。它熟悉MICCAI、CVPR、TMI、Nature等會議和期刊的寫作風格。
這5個角色之間的數據流向很清晰:文獻調研員的輸出餵給算法研發員(提供研究Gap和對比基線),同時也餵給論文撰寫員(提供Related Work素材)。數據工程師準備好的數據集交給算法研發員跑實驗。算法研發員的實驗結果交給論文撰寫員寫Experiments部分。科研總指揮全程協調收口。
Discord頻道區:
團隊成員:
架構的三個關鍵設計
角色定好了,怎麼讓它們在Discord裏真正協作起來?這裏有三個關鍵的架構設計。
Bindings路由。每個Discord Bot對應一個Agent,通過openclaw.json裏的bindings配置做硬綁定。消息進來,Gateway先看是哪個Bot收到的,直接路由到對應Agent。這是確定性路由,不依賴模型判斷。
X上的實測經驗很有說服力:如果不在入口層做路由,讓所有Agent自己判斷該不該處理,後面的協作全是亂的,有時候兩個Agent搶答,有時候都不答。
配置很簡單,核心就是channel + accountId → agentId的映射:
{
"bindings": [
{ "agentId": "director", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
{ "agentId": "literature", "match": { "channel": "discord", "accountId": "Bot的Discord ID" } },
// data, algorithm, writer 同理
]
}會話隔離。dmScope設成per-account-channel-peer,按賬號+渠道+對端用戶三維隔離。同一個人從Discord找同一個角色,上下文不串。不同用戶找同一個角色,完全隔離。如果課題組有多人使用,這個配置能確保不同同學的實驗數據和論文討論絕不會串在一起。
雙軌治理。這是我覺得整套系統裏最精妙的設計。配置軌做硬約束(bindings路由、會話隔離、Agent互ping限制),規則軌做軟引導(SOUL.md人格定義、TEAM-RULEBOOK協作規則、AGENTS.md運行手冊、TOOLS.md定義每個Agent可以使用的外部工具)。兩條軌道疊加,不把一切壓在模型的自覺上。
舉個具體例子:我把Agent之間的ping-pong turns設成了0,物理上禁止Agent互相閒聊。同時在TEAM-RULEBOOK裏寫明:羣聊中只有科研總指揮可以主動發言,其他角色等待被@,不要和其他Agent客套或做無意義確認。配置層管住了能不能聊,規則層則是管住了該不該聊。
科研場景為什麼特別需要雙軌治理?因為學術嚴謹性要求極高。如果不在SOUL.md裏反覆強調不編造論文不杜撰數據,模型在長對話後是真的可能開始創造不存在的引用。配置層控制不了內容質量,只能靠規則層加上漸進式記憶反饋來糾正。
記憶系統和自動化
多Agent系統跑起來之後,記憶管理是最容易被忽視但最影響長期效果的部分。
參考X上的相關設計,我採用的是五層記憶架構。最底層是每日流水日誌(memory/2026-03-10.md),記錄當天的實驗細節和文獻筆記。
往上是長期記憶(MEMORY.md),只存經過驗證的穩定信息,比如Synapse數據集上lr=1e-4效果最好、用戶偏好PyTorch不用Keras。
再往上是羣聊記憶(GROUP_MEMORY.md),存團隊達成的研究共識,比如已確認的模型架構方案。這裏有個隱私紅線:絕不混入私聊內容。
然後是冷歸檔(超過30天的daily memory自動歸檔),最頂層是語義檢索(先memory_search召回,再memory_get精確讀取)。
Saboo有句話說得好:Mental notes don't survive session restarts. Files do. Agent隨時間變好,不是因為模型在進步,是因為上下文和記憶越來越豐富。他的經驗是第一版Agent表現平庸是正常的,到第30次迭代才會真正好用。
自動化調度也是科研場景的剛需。我用OpenClaw的Cron功能配了幾個定時任務:文獻調研員每天早上8點掃arXiv,算法研發員每天上午10點檢查實驗狀態,科研總指揮每週五下午5點出項目週報。調度順序是故意設計的,文獻掃描最先跑,因為其他角色可能需要最新文獻信息。
論文Deadline前2到4周,我會臨時增加調度頻率,進入衝刺模式:論文撰寫員每天下午2點更新寫作進度,算法研發員每天下午4點檢查補充實驗。投稿完成後再把這些臨時任務暫停掉。
配合HEARTBEAT.md的自愈機制,如果某個Cron任務滯後超過26小時,系統會自動force re-run。科研節奏不像內容運營那樣每天要產出,但一旦進入Deadline衝刺,任何一個環節卡住都會影響全局。
實際運行效果:
一個實驗迭代的科研場景下,各Agent的協作邏輯如下圖所示:
真正的生產力在於外部能力
系統搭好了,5個Agent跑起來了,但說實話,光靠OpenClaw和所使用的模型本身對話能力,其實幾乎沒啥科研生產力。
這套系統要想真正轉化為科研生產力,關鍵在於每個Agent能調用的外部能力。
比如文獻調研員,如果只靠模型自身的知識,它能給你的信息截止到訓練數據的時間點,最新的arXiv論文它根本不知道。但是接上Semantic Scholar的MCP、配上聯網搜索Skills、使用Zotero-MCP訪問本地Zotero文獻庫,它就真的能每天掃描最新論文了。
再比如算法研發員,如果它只能在對話裏建議你調學習率、改patch size,那和ChatGPT沒太大區別。但如果它能通過Claude Code或者Codex這樣的Coding工具直接讀你的訓練腳本、分析實驗日誌、甚至幫你改代碼提交PR,那生產力就完全不是一個量級了。
數據工程師也是同理。接上數據庫查詢的MCP、文件系統讀寫的Skills,它才能真正檢查數據管道的狀態,而不只是在chatbox裏面一頓瞎聊。
所以我的建議是:搭完基礎的多Agent框架之後,第一時間把精力放在給每個Agent配備合適的MCP和Skills上。框架是骨架,外部能力才是肌肉。沒有肌肉的骨架,站得起來但幹不了活。
這個其實我也還在配置,因為我的OpenClaw是部署在遠程vps上的,像Claude Code和Codex這類對使用環境敏感的強生產力工具,我還沒敢在上面安裝,所以,我的這套系統其實我自己也暫時還沒發揮其科研生產力。
搭建不難,調教才是功夫
藉助AI編程工具,搭建這套系統的初始框架其實很快。創建5個Discord Bot、寫好openclaw.json配置、給每個Agent寫一版SOUL.md,一個下午基本能跑通。OpenClaw的文檔和社區教程都很齊全,照着配就行。
但能跑和好用是兩回事。
我搭完第一版之後,科研總指揮的任務拆解太粗,文獻調研員的檢索範圍不夠精準,論文撰寫員的風格和我常投的會議不匹配。這些問題只有在實際使用中才會暴露出來。
Saboo管這個過程叫corrective prompt-engineering:觀察Agent表現,給反饋,改SOUL.md,再觀察,再調。他的經驗是第一版Agent表現平庸很正常,到第30次迭代才會真正好用。
所以建議是:搭建的時候大膽一點,5個Agent一起上沒問題。但上線之後要有耐心,每天用、每天觀察、持續調SOUL.md和MEMORY.md。框架搭得再漂亮,不經過實際使用的打磨也只是個空架子。
這套系統我反覆折騰配置了幾個晚上,到昨晚才搭建成功,各類外部工具配置都還沒配齊,上下文都還有限,所以本身也需要逐漸運行和積累上下文來打磨其性能。
安全和成本
安全方面必須提一句。OpenClaw目前已經有多個高危漏洞被公開披露,根據公開報道,ClawHub上被發現的惡意Skills數量已經超過800個。
建議在隔離環境中運行Gateway(專用VM或獨立設備),不要暴露到公網,第三方Skills安裝前務必審查源碼(安裝skill-vetter進行技能安全審查)。科研場景還有額外的考量,未發表的實驗數據和論文草稿屬於敏感信息,要確保Agent不會通過外部API泄漏。
成本方面,Discord和OpenClaw本身都免費。主要開銷是AI模型的API費用。我個人的策略是不同科研Agent角色用不同模型:科研總指揮和論文撰寫員用高端模型(GPT-5.4),文獻調研員和數據工程師用國內性價比模型(MiniMax M2.5),算法研發員用Claude Opus 4.6,日常對話可以切gemini-3.1-flash-lite。
全部配齊的話,大概每個月成本300-400美元左右(其實Claude Code的Max訂閲是大頭)。
用OpenClaw + Discord搭科研多Agent系統,核心就是這些。框架不復雜,5個角色、Bindings路由、會話隔離、雙軌治理、五層記憶、Cron調度,每一層都有明確的設計意圖。
但從能跑到跑得好,中間的時間全在外部工具配置和日常Agent的交互中積累上下文。Agent幫你省的是重複勞動的時間,思考和判斷這件事,還得是人來。
感謝您閲讀我的文章。我是魯工,九年AI算法老兵,AI全棧開發者,深耕AI編程賽道。感興趣的朋友也可以加我微信(louwill26_)交個朋友。