我用官方 skill-creator,做出了一個勝率 75% 的更強 skill-creator
整理版優先睇
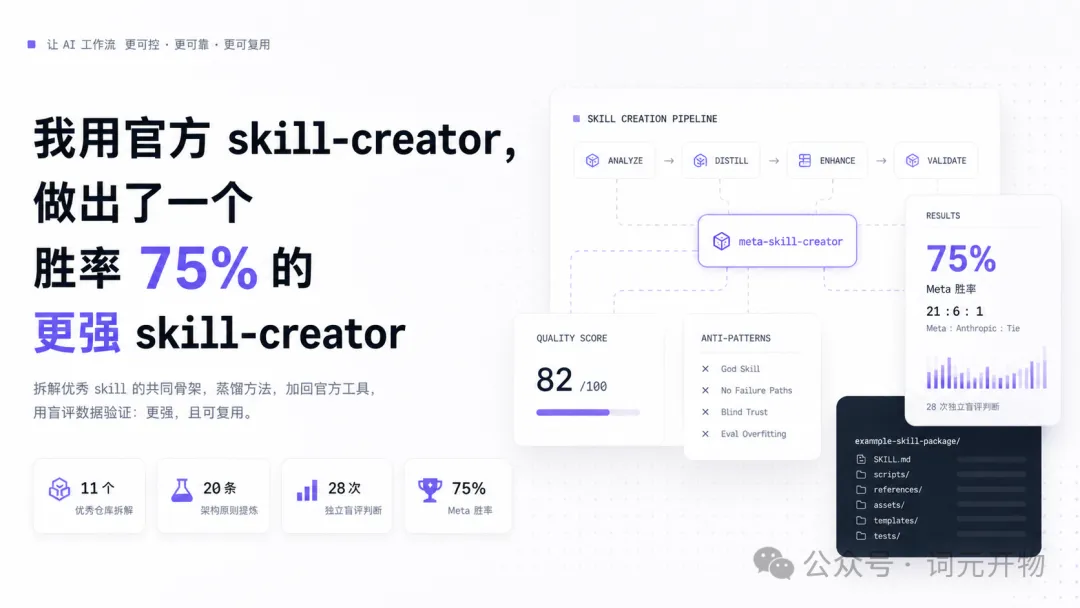
作者透過逆向工程優秀 skill 倉庫,提煉20條原則並疊加到 Anthropic 官方 skill-creator,製作出勝率75%嘅 meta-skill-creator,將 skill 寫作從手藝活轉為工程流程。
呢篇文章係作者分享佢點樣用 Anthropic 官方 skill-creator 做出一個更強嘅 meta-skill-creator。作者一開始諗住好簡單:用官方工具做一個更強嘅 skill-creator。但真正有意思嘅地方係喺「點樣判斷一個 AI skill 寫得好唔好」呢個問題上。
作者唔想淨係睇文檔靚唔靚或者模型話檢查過就算數。佢想要嘅係可分類、可診斷、可驗證、可比較、更架構化同系統化嘅答案。於是佢開始逆向工程,拆開市面上11個優秀嘅 skill 倉庫,按照注入邏輯、驗證迴路、精準控制、理論基礎同架構權衡五個維度分析。
最後提煉出20條 skill 架構原則,再疊加到 Anthropic 官方嘅 skill-creator 上面,保留對方嘅寫作能力同時加入工程能力。經過14個測試案例、28次盲評判斷,最終 meta-skill-creator 以21:6勝出,總勝率75%。作者強調呢個結果唔係全面碾壓,而係喺複雜、可維護、團隊級嘅 skill 工程上更強。
- 結論:meta-skill-creator 喺複雜 skill 工程上勝率75%,但 Anthropic 喺解釋性同新手友好度仍然優勝。
- 方法:透過拆解11個優秀倉庫,按5個維度分析,提煉20條原則,再疊加到官方工具,唔係完全取代。
- 差異:新方法將 skill 寫作從「手藝活」變成「工程流程」,加入8種原型、質量診斷同反模式掃描。
- 啟發:AI 能力提升正從「更會說話」轉向「更會受控地做事」,個人靈感用 prompt,長期複用做 skill。
- 可行動點:讀者可以自己嘗試蒸餾:揾5-10個優秀樣本,拆結構,揾共同點,寫成檢查表,再用盲評驗證。
內容片段
1. 注入邏輯:它怎麼被觸發、加載、調用?2. 驗證迴路:有沒有 plan -> execute -> verify -> learn?3. 精準控制:怎麼限制邊界、錯誤和跳步驟?4. 理論基礎:它借用了哪些軟件工程或系統設計思想?5. 架構權衡:它強在哪裏,又犧牲了什麼?點解要做一個更強嘅 skill-creator?
呢篇文章係作者分享佢點樣用 Anthropic 官方 skill-creator 做出一個更強嘅 meta-skill-creator。佢一開始諗住好簡單,但真正嘅問題係:點樣判斷一個 AI skill 寫得好唔好?唔係睇 Markdown 靚唔靚,而係要 可分類、可診斷、可驗證、可比較、更架構化同系統化。
作者定義咗 skill 係一包可複用嘅 AI 工作說明,通常包含 SKILL.md,有時帶腳本同模板。好多時人寫 skill 其實係寫一段更長嘅 prompt,但咁樣唔穩定,因為一個真正可複用嘅 skill 要回答觸發條件、輸入來源、輸出格式、完成標準同失敗處理等問題。
meta-skill-creator 做嘅係「將寫 skill 從手藝活變成一套工程流程」
點樣蒸餾同驗證?
作者拆咗11個優秀嘅 Claude Code / Agent skill 倉庫,涵蓋官方參考、方法論框架、平台化系統、企業工作流、專業技能庫同設計類 skill。佢唔係淨係睇寫得好唔好,而係按 注入邏輯、驗證迴路、精準控制、理論基礎、架構權衡 五個維度分析。
提煉出20條原則之後,作者做咗兩層交叉驗證。第一層係來源交叉驗證:同一原則必須喺多個獨立倉庫出現至算穩定解。第二層係結果交叉驗證:將改良後嘅 meta-skill-creator 同原版用同一批任務盲評,由 Claude 同 GPT 獨立評審。
- 1 Suite 1: 從零生成新 SKILL.md,8個案例,16次判斷
- 2 Suite 2: 修復有缺陷嘅 skill,3個案例,6次判斷
- 3 Suite 3: 生成多文件 skill 包,3個案例,6次判斷
- 4 總計14個測試案例,28次盲評判斷
新工具加咗啲咩功能?
作者冇替換 Anthropic 嘅 skill-creator,而係保留佢嘅寫作能力,再疊加工程能力。第一層係 8種 skill 原型,包括 Standalone Utility、Quality Checker、Coordinator、Orchestrator、Methodology / Process、Knowledge / Reference、Creative / Generative、Meta-Skill。先分清楚類型,再對症下藥。
第二層係 100分質量診斷,拆成8個維度:Structural Completeness、Constraint Density、Output Consumability、DoD Verifiability、Input Resolution、Recovery Design、Context Economy、Behavioral Guardrails。第三層係 反模式掃描,常見壞味道包括 God Skill、No Failure Paths、Blind Trust of Agent Output、Eval Overfitting、Benchmark Cherry-Picking。
- God Skill: 一個 skill 乜都想管
- No Failure Paths: 只寫成功路徑,唔寫失敗點算
- Blind Trust of Agent Output: 工人話做完就信
測試結果同對你有咩用?
盲評結果顯示:Meta 21 : 6 Anthropic + 1 tie,總勝率75%。但分佈好重要:Meta 喺創建可複用 skill 工件嘅場景更強,Anthropic 喺解釋性、教學性、對新手更友好嘅場景仍然好強。
作者提醒,AI 能力提升正從「更會說話」轉向「更會受控地做事」。如果你只係偶然寫一個小 prompt,唔需要呢套工具。但如果你係做重複工作沉澱、維護 skill 倉庫、改進誤觸發 skill、做質量審查、生成多文件 skill 包,或者想比較新舊版本,咁就好有用。
最後,作者鼓勵讀者自己試下蒸餾:揾5-10個優秀樣本,拆結構,揾共同點,寫成檢查表,再用盲評驗證。真正有用嘅蒸餾係將好結果背後嘅結構拆出來,再放返自己工作流度測試。
聽落好似繞口令。實際做落嚟,佢係一次逆向工程:首先拆開市面上優秀 skill 嘅共同骨架,再將呢啲方法加返入 Anthropic 嘅官方 skill-creator 度,最後用盲評數據睇嚇佢係咪真係勁咗。
我一開始想做嘅嘢好簡單:
用 Anthropic 嘅官方 skill-creator,做一個更勁嘅 skill-creator。
呢句嘢有啲「自己整自己」嘅味道。但真正有趣嘅地方唔係遞歸,而係另一個問題:
如果 AI 已經可以幫我哋寫 skill,咁點判斷佢寫出嚟嘅 skill 真係好?
唔係「睇落好完整」。唔係「Markdown 好靚」。亦都唔係「模型話佢已經檢查過」。
我要嘅係另一種答案:可以分類、可以診斷、可以驗證、可以比較、更加結構化同系統化。
這就是 meta-skill-creator:一個專門用嚟生產、修復、評估其他 skill 嘅 meta skill。
先講人話:佢解決咩問題
先把詞講清楚:呢度講嘅 skill,唔係「技能證書」,而係一包可以重用嘅 AI 工作說明。佢通常包含 SKILL.md,有時仲會帶腳本、參考資料同模板。
好多人寫 skill,其實係寫一段長啲嘅提示詞。
比如:
「以後遇到代碼審查,就跟呢個流程嚟做。」
呢種寫法用得,但唔穩定。因為一個真正可以重用嘅 skill,至少要回答呢啲問題:
所以 meta-skill-creator 做嘅唔係「幫你寫得更似文檔」。
佢做嘅係:將寫 skill 從手藝活,變成一 set 工程流程。
 |  |
左邊係一次性 prompt。右邊係可以重用、可以維護、可以測試嘅 skill 包。
分別唔在於字數。分別在於有冇結構。
唔係憑空發明:佢係點樣「蒸餾」出嚟
meta-skill-creator 唔係拍拍個頭就寫出嚟。
佢背後有一輪好重嘅分析:我拆咗 11 個優秀嘅 Claude Code / Agent skill 倉庫。
呢啲倉庫嚟自唔同路線:
分析時唔係淨係睇「佢哋寫得好唔好」。而係按 5 個維度拆:
1. 注入邏輯:它怎麼被觸發、加載、調用?
2. 驗證迴路:有沒有 plan -> execute -> verify -> learn?
3. 精準控制:怎麼限制邊界、錯誤和跳步驟?
4. 理論基礎:它借用了哪些軟件工程或系統設計思想?
5. 架構權衡:它強在哪裏,又犧牲了什麼?
拆完之後,再做橫向對比。
如果一個模式只喺一個倉庫出現,可能只係作者嘅偏好。
如果多個獨立倉庫都用類似方法,咁就更加似「穩定解」。
最後提煉出咗 20 條 skill 架構原則。例如:
呢一步就係「蒸餾」。
唔係將人哋嘅句子拼埋一齊,而係將唔同優秀 skill 背後嘅共同結構抽返出嚟。
點樣做交叉驗證
淨係提煉仲唔夠。
因為「我從 11 個倉庫總結出 20 條原則」,聽起嚟好似自說自話。真正重要嘅係:呢啲原則放返入 skill-creator 之後,可唔可以令產物變好?
所以做咗兩層交叉驗證。
第一層係來源交叉驗證。
同一條原則,一定要喺唔同路線嘅倉庫度揾到影子。例如「漸進式披露」唔係某一個作者嘅偏好,Anthropic、gstack、jeffallan-skills 都用緊類似思路:入口文件保持輕,詳細資料按需加載。再例如「驗證唔可以省」,superpowers、gstack、autoresearch 都將完成後嘅檢查當成關鍵步驟。
第二層係結果交叉驗證。
將改造後嘅 meta-skill-creator 同 Anthropic skill-creator 放喺同一批任務,用兩個唔同模型做盲評:
同一個任務
-> Anthropic skill-creator 生成一個結果
-> meta-skill-creator 生成一個結果
-> 打亂成 A / B
-> Claude 和 GPT 分別評審
-> 統計誰贏、哪裏贏、哪裏輸
呢一步嘅重點唔係揾一個「永遠正確」嘅裁判。
重點係減少偏見:唔俾評審知道邊個係 Meta,邊個係 Anthropic;亦都唔只信一個模型嘅口味。
跟住點樣做加法
呢度有一個關鍵選擇:唔好取代 Anthropic 嘅 skill-creator。
早期版本試過取代。結果好尷尬:結構強咗,但讀起嚟更加似規格書。佢可以話俾 Agent 知「一定要做啲咩」,但少咗 Anthropic 官方版本入面嗰種解釋「點解要咁做」嘅自然感覺。
所以後嚟嘅策略變咗:
保留 Anthropic 嘅寫作能力,再喺上面疊加工程能力。
具體加咗幾層。
第一層:8 種 skill 原型
唔係所有 skill 都應該係同一個樣。
meta-skill-creator 會先問:呢個 skill 到底係邊一類?
白話講:先睇病種,再開藥。
一個 commit message 工具,唔需要複雜嘅多 Agent 失敗恢復。
一個發佈協調 skill,如果冇前置檢查、失敗路徑同回滾邊界,咁就好危險。
第二層:100 分質量診斷
佢唔係靠「感覺唔錯」嚟評估 skill,而係拆成 8 個維度打分。
呢度嘅重點唔係「總分越高越好」。
更加重要嘅係揾弱點。例如一個 skill 總分 82,但冇明確邊界,咁都係硬傷。
因為有啲問題唔係扣幾分嘅問題,而係阻斷器。
比如:
description 冇講清楚幾時觸發 冇寫「唔做啲咩」 需要結構化輸出,但淨係畀一段散文 高風險流程冇失敗路徑 完成標準冇辦法驗證 盲目信 worker 或 Agent 嘅口頭結果
呢啲問題唔解決,分數再高都唔可靠。
第三層:反模式掃描
meta-skill-creator 仲將常見壞味道整理成反模式。
有啲名好直接:
呢一步好似代碼審查入面嘅 checklist。
唔係因為作者唔認真,而係因為人同模型都會漏咗熟悉嘅陷阱。
測試結果:到底勁咗幾多
跟住講數據。
評測唔係畀自己睇自己。佢用咗兩個獨立評審:
Claude Opus 4.7 GPT-5.4 Codex
方法係盲評。即係將兩個輸出標成 A / B,唔話俾評審知邊個嚟自 Anthropic,邊個嚟自 Meta。評審淨係睇質量,唔睇名。
一共做咗 3 套測試:
總結果:
Suite 1(創建) Meta 10 : 5 Anthropic + 1 tie
Suite 2(改進) Meta 6 : 0 Anthropic
Suite 3(複雜) Meta 5 : 1 Anthropic
總計 Meta 21 : 6 Anthropic + 1 tie
Meta 勝率 75.0%
呢組數據入面,最重要嘅唔係總勝率,而係分佈。
Suite 1:從零創建 skill
8 個案例覆蓋 8 種原型。
呢樣說明 Meta 唔係喺所有場景都碾壓。
佢喺「要產出可重用 skill 工件」嘅場景更強。
Anthropic 喺「解釋性、教學性、對新手更友好」嘅場景仍然好強。
呢點好重要。如果唔係就會變咗營銷稿。
Suite 2:修復壞 skill
呢一組最能夠說明問題。
測試輸入唔係從零寫,而係畀一個有缺陷嘅 skill,再畀用戶反饋,睇邊個可以修得更系統。
Anthropic 喺呢一組冇贏。
原因都好直接:修復壞 skill 嗰陣,真正難嘅唔係「將句子寫順」,而係揾出結構缺陷。
例如誤報嚴重嘅安全檢查器,唔可以淨係寫「注意減少誤報」。佢需要檢測規則、置信度規則、證據要求、輸出格式一齊改。
呢樣正正係 meta-skill-creator 擅長嘅地方。
Suite 3:複雜多文件 skill
呢一組最接近真實工程。
唔係淨係生成一個 SKILL.md,而係同時涉及:
scripts/references/assets/多文件之間嘅一致性
呢一組 Meta 嘅結果係 5 : 1。佢贏喺三個位:
呢度可以睇到 meta-skill-creator 嘅核心優勢:佢更擅長將一個 skill 當成「完整包」嚟設計,而唔係淨係寫一個靚嘅入口文件。
複雜 AI 工作流嘅提升,好多時唔係靠更長嘅 prompt,而係靠更好嘅系統邊界。
但佢都唔係萬能
呢度一定要講清楚。
meta-skill-creator 並唔係所有維度都贏。
Anthropic 仍然更強嘅地方包括:
解釋性文字更自然 對新手更友好 喺某啲知識型 skill 裏便,領域講解更細膩 喺安全審查呢類場景裏便,有時對誤報更敏感
評測本身都有邊界:
所以更準確嘅講法唔係:
meta-skill-creator 全面超過 Anthropic。
更準確嘅講法係:
如果你要做團隊級、可維護、可審查、複雜度較高嘅 skill,meta-skill-creator 更強。
對普通用戶有咩用
如果你唔寫 skill,只係平時用 AI,呢件事都有啓發。
因為佢講咗一個趨勢:
AI 能力嘅提升,正喺度從「更會講嘢」轉向「更會受控地做嘢」。
以前我哋優化 prompt,重點係令模型明白我哋。
而家我哋優化 skill,重點係令模型喺邊界內穩定行動。
呢個就好似從「請你幫我煮飯」變成:
菜譜係咩 食材從邊度嚟 咩情況唔可以繼續做 做完點驗收 下次點樣重用
睇落麻煩,但呢個係由傾偈走向工作嘅必經之路。
適合邊個用
如果你只係間中寫一個小 prompt,咁就唔需要。
但如果你正喺度做呢啲嘢,咁就好有用:
將重複工作沉澱成 skill 維護一個 skill 倉庫 改進經常誤觸發嘅 skill 俾 skill 做質量審查 生成帶腳本、參考資料、資產嘅 skill 包 令多個 Agent 協作,但又唔想盲信佢哋嘅口頭彙報 想比較新舊版本,而唔係憑感覺話「好似好咗」
一句講曬:
個人靈感用 prompt,長期重用做 skill。
簡單 skill 睇文筆,複雜 skill 睇工程。
你自己都可以試嚇蒸餾
呢件事唔單止適用於 skill-creator。
如果你平時有一類重複工作,都可以用同樣嘅方法,蒸餾出自己嘅 skill。
步驟唔複雜:
揾 5 到 10 個優秀樣本。可以係人哋嘅 skill、你自己嘅高質量提示詞,或者團隊成日用嘅 SOP。 唔好一開始就抄內容,先拆結構。睇嚇佢哋點觸發、點定義邊界、點處理失敗、點輸出結果。 揾共同點。得一個樣本有嘅,暫時當係個別例子;多個樣本獨立出現嘅,優先提煉成原則。 將原則寫成檢查表。例如「係咪清楚講明唔做啲咩」「係咪有可驗證嘅完成標準」「係咪有失敗處理」。 用同一批任務對比舊方法同新 skill。唔好淨係睇一個成功案例,至少睇創建、改進、複雜情況三類。 俾人哋或者另一個模型盲評。唔好話佢知邊個係新版,先睇結果,再睇原因。
真正有用嘅蒸餾,唔係將好句子抽返出嚟。
而係將好結果背後嘅結構拆出嚟,再放返入自己嘅工作流度測試。
最後
meta-skill-creator 最有價值嘅地方,唔係「佢識得寫 skill」。
Anthropic 嘅 skill-creator 都識得寫。
佢真正有價值嘅地方係:佢將「點樣寫一個好 skill」呢件事拆開咗。
拆成分類、邊界、結構、評分、反模式、驗證、評測。
呢個聽落冇「AI 自動創造 AI」咁刺激。
但對真正想將 AI 用入工作流嘅人嚟講,呢個先係更加重要嘅部分。
因為最後決定一個 skill 可唔可以長期用嘅,唔係佢第一次生成時有幾驚豔。
而係三個月後,你仲敢唔敢俾佢繼續行。
一頁總結
聽起來像繞口令。實際做下來,它是一次逆向工程:先拆開市面上優秀 skill 的共同骨架,再把這些方法加回 Anthropic 的官方 skill-creator 裏,最後用盲評數據看它到底有沒有變強。
我一開始想做的事很簡單:
用 Anthropic 的官方 skill-creator,做一個更強的 skill-creator。
這句話有點“自己製造自己”的味道。可真正有意思的地方不在遞歸,而在另一個問題:
如果 AI 已經能幫我們寫 skill,那怎麼判斷它寫出來的 skill 真的好?
不是“看起來挺完整”。不是“Markdown 很漂亮”。也不是“模型說它已經檢查過”。
我要的是另一種答案:可分類、可診斷、可驗證、可比較、更架構化和系統化。
這就是 meta-skill-creator:一個專門用來生產、修復、評估其他 skill 的 meta skill。
先說人話:它解決什麼問題
先把詞說清楚:這裏的 skill,不是“技能證書”,而是一包可複用的 AI 工作說明。它通常包含 SKILL.md,有時還會帶腳本、參考資料和模板。
很多人寫 skill,其實是在寫一段更長的提示詞。
比如:
“以後遇到代碼審查,就按這個流程來。”
這種寫法能用,但不穩。因為一個真正可複用的 skill,至少要回答這些問題:
所以 meta-skill-creator 做的不是“幫你寫得更像文檔”。
它做的是:把寫 skill 從手藝活,變成一套工程流程。
| |
左邊是一次性 prompt。右邊是可以複用、可以維護、可以測試的 skill 包。
差別不在字數。差別在有沒有結構。
不是憑空發明:它是怎麼“蒸餾”出來的
meta-skill-creator 不是拍腦袋寫出來的。
它背後有一輪很重的分析:我拆了 11 個優秀的 Claude Code / Agent skill 倉庫。
這些倉庫來自不同路線:
分析時沒有隻看“它們寫得好不好”。而是按 5 個維度拆:
1. 注入邏輯:它怎麼被觸發、加載、調用?
2. 驗證迴路:有沒有 plan -> execute -> verify -> learn?
3. 精準控制:怎麼限制邊界、錯誤和跳步驟?
4. 理論基礎:它借用了哪些軟件工程或系統設計思想?
5. 架構權衡:它強在哪裏,又犧牲了什麼?
拆完之後,再做橫向對比。
如果一個模式只在一個倉庫裏出現,可能只是作者偏好。
如果多個獨立倉庫都用類似方法,那就更像“穩定解”。
最後提煉出了 20 條 skill 架構原則。比如:
這一步就是“蒸餾”。
不是把別人的句子拼在一起,而是把不同優秀 skill 背後的共同結構抽出來。
怎麼做交叉驗證
只提煉還不夠。
因為“我從 11 個倉庫裏總結出 20 條原則”,聽起來很像自說自話。真正要緊的是:這些原則放回 skill-creator 以後,能不能讓產物變好?
所以做了兩層交叉驗證。
第一層是來源交叉驗證。
同一個原則,必須能在不同路線的倉庫裏找到影子。比如“漸進式披露”不是某一個作者的偏好,Anthropic、gstack、jeffallan-skills 都在用類似思路:入口文件保持輕,詳細資料按需加載。再比如“驗證不能省”,superpowers、gstack、autoresearch 都把完成後的檢查當成關鍵步驟。
第二層是結果交叉驗證。
把改造後的 meta-skill-creator 和 Anthropic skill-creator 放到同一批任務裏,用兩個不同模型做盲評:
同一個任務
-> Anthropic skill-creator 生成一個結果
-> meta-skill-creator 生成一個結果
-> 打亂成 A / B
-> Claude 和 GPT 分別評審
-> 統計誰贏、哪裏贏、哪裏輸
這一步的重點不是找一個“永遠正確”的裁判。
重點是減少偏見:不讓評審知道哪個是 Meta,哪個是 Anthropic;也不只相信一個模型的口味。
然後怎麼做加法
這裏有個關鍵選擇:不要替換 Anthropic 的 skill-creator。
早期版本試過替換。結果很尷尬:結構更強了,讀起來卻更像規格書。它能告訴 Agent “必須做什麼”,但少了 Anthropic 官方版本里那種解釋“為什麼要這麼做”的自然感。
所以後來的策略變了:
保留 Anthropic 的寫作能力,再往上疊加工程能力。
具體加了幾層。
第一層:8 種 skill 原型
不是所有 skill 都該長一個樣。
meta-skill-creator 會先問:這個 skill 到底是哪類?
白話說:先看病種,再開藥。
一個 commit message 工具,不需要複雜的多 Agent 失敗恢復。
一個發佈協調 skill,如果沒有前置檢查、失敗路徑和回滾邊界,就很危險。
第二層:100 分質量診斷
它不是靠“感覺不錯”評估 skill,而是拆成 8 個維度打分。
這裏的重點不是“總分越高越好”。
更重要的是找弱點。比如一個 skill 總分 82,但沒有明確邊界,那仍然是硬傷。
因為有些問題不是扣幾分的問題,而是阻斷器。
比如:
description 沒說清楚何時觸發 沒有寫“不做什麼” 需要結構化輸出,卻只給一段散文 高風險流程沒有失敗路徑 完成標準無法驗證 盲目信任 worker 或 Agent 的口頭結果
這些問題不解決,分數再高也不可靠。
第三層:反模式掃描
meta-skill-creator 還把常見壞味道整理成反模式。
有些名字很直白:
這一步很像代碼審查裏的 checklist。
不是因為作者不認真,而是因為人和模型都會漏掉熟悉的坑。
測試結果:到底強了多少
接下來講數據。
評測不是讓自己看自己。它用了兩個獨立評審:
Claude Opus 4.7 GPT-5.4 Codex
方法是盲評。也就是把兩個輸出標成 A / B,不告訴評審哪個來自 Anthropic,哪個來自 Meta。評審只看質量,不看名字。
一共做了 3 套測試:
總結果:
Suite 1(創建) Meta 10 : 5 Anthropic + 1 tie
Suite 2(改進) Meta 6 : 0 Anthropic
Suite 3(複雜) Meta 5 : 1 Anthropic
總計 Meta 21 : 6 Anthropic + 1 tie
Meta 勝率 75.0%
這組數據裏,最重要的不是總勝率,而是分佈。
Suite 1:從零創建 skill
8 個案例覆蓋 8 種原型。
這說明 Meta 不是在所有場景碾壓。
它在“要產出可複用 skill 工件”的場景更強。
Anthropic 在“解釋性、教學性、對新手更友好”的場景仍然很強。
這點很重要。否則就變成營銷稿了。
Suite 2:修復壞 skill
這一組最能說明問題。
測試輸入不是從零寫,而是給一個有缺陷的 skill,再給用戶反饋,看誰能修得更系統。
Anthropic 在這一組沒有贏。
原因也很直接:修復壞 skill 時,真正難的不是“把句子寫順”,而是找出結構缺陷。
比如誤報嚴重的安全檢查器,不能只寫“注意減少誤報”。它需要檢測規則、置信度規則、證據要求、輸出格式一起改。
這正是 meta-skill-creator 擅長的地方。
Suite 3:複雜多文件 skill
這一組最接近真實工程。
不是隻生成一個 SKILL.md,而是同時涉及:
scripts/references/assets/多文件之間的一致性
這一組 Meta 的結果是 5 : 1。它贏在三個點:
這裏能看出 meta-skill-creator 的核心優勢:它更擅長把一個 skill 當成“完整包”來設計,而不是隻寫一個好看的入口文件。
複雜 AI 工作流的提升,往往不是靠更長 prompt,而是靠更好的系統邊界。
但它也不是萬能的
這裏必須講清楚。
meta-skill-creator 並不是所有維度都贏。
Anthropic 仍然更強的地方包括:
解釋性文字更自然 對新手更友好 在某些知識型 skill 裏,領域講解更細膩 在安全審查這類場景裏,有時對誤報更敏感
評測本身也有邊界:
所以更準確的說法不是:
meta-skill-creator 全面超過 Anthropic。
更準確的說法是:
如果你要做團隊級、可維護、可審查、複雜度較高的 skill,meta-skill-creator 更強。
對普通用戶有什麼用
如果你不寫 skill,只是平時用 AI,這件事也有啓發。
因為它說透了一個趨勢:
AI 能力的提升,正在從“更會說話”轉向“更會受控地做事”。
以前我們優化 prompt,重點是讓模型理解我們。
現在我們優化 skill,重點是讓模型在邊界內穩定行動。
這就像從“請你幫我做飯”變成:
菜譜是什麼 食材從哪裏來 什麼情況不能繼續做 做完怎麼驗收 下次怎麼複用
看起來麻煩,但這是從聊天走向工作的必經路。
適合誰用
如果你只是偶爾寫一個小 prompt,不需要它。
但如果你正在做這些事,它就很有用:
把重複工作沉澱成 skill 維護一個 skill 倉庫 改進經常誤觸發的 skill 給 skill 做質量審查 生成帶腳本、參考資料、資產的 skill 包 讓多個 Agent 協作,但又不想盲信它們的口頭彙報 想比較新舊版本,而不是憑感覺說“好像更好了”
一句話:
個人靈感用 prompt,長期複用做 skill。
簡單 skill 看文筆,複雜 skill 看工程。
你也可以自己試着蒸餾
這件事不只適用於 skill-creator。
如果你平時有一類重複工作,也可以用同樣的方法,蒸餾出自己的 skill。
步驟不復雜:
找 5 到 10 個優秀樣本。可以是別人的 skill、你自己的高質量提示詞,也可以是團隊裏反覆使用的 SOP。 不要先抄內容,先拆結構。看它們怎麼觸發、怎麼定義邊界、怎麼處理失敗、怎麼輸出結果。 找共同點。只在一個樣本里出現的,先當作個例;多個樣本獨立出現的,優先提煉成原則。 把原則寫成檢查表。比如“是否有明確不做什麼”“是否有可驗證完成標準”“是否有失敗處理”。 用同一批任務對比舊方法和新 skill。不要只看一個成功案例,至少看創建、改進、複雜情況三類。 讓別人或另一個模型盲評。不要告訴它哪個是新版本,先看結果,再看原因。
真正有用的蒸餾,不是把好句子摘出來。
而是把好結果背後的結構拆出來,再放回自己的工作流裏測試。
最後
meta-skill-creator 最有價值的地方,不是“它能寫 skill”。
Anthropic 的 skill-creator 也能寫。
它真正有價值的地方是:它把“怎麼寫一個好 skill”這件事拆開了。
拆成分類、邊界、結構、評分、反模式、驗證、評測。
這聽起來沒有“AI 自動創造 AI”那麼刺激。
但對真正想把 AI 用進工作流的人來說,這才是更重要的部分。
因為最後決定一個 skill 能不能長期用的,不是它第一次生成時有多驚豔。
而是三個月後,你還敢不敢讓它繼續跑。