我的-AI博客每日精選技能是如何煉成的!
整理版優先睇
ai-digest-suite 係一條自動化 AI 技術日報流水線,從 RSS 抓取、AI 評分摘要到郵件發送,全部包辦,仲有強大容錯機制。
呢篇文章係作者分享佢嘅 ai-digest-suite 技能點樣實現,佢想解決嘅問題係:好多人每日想睇 AI、技術等高質內容,但 RSS 源太多篩唔切,仲要整理、翻譯、排版,最後先發得出郵件。所以佢整咗一條完整流水線,將成個過程自動化。整體結論係:呢套技能唔係一個簡單腳本,而係一個分層清楚、自帶全家桶嘅系統,仲有好多防翻車設計。
作者自己用呢套技能每日生成日報,過程中遇到好多實際問題,例如模型返回髒 JSON、部分 RSS 源失效、時區唔統一等等,佢逐一解決咗。文章詳細拆解咗每個環節嘅設計思路同工程細節,強調容錯優先同現實導向,令呢個技能可以長期穩定運行。作者嘅經驗係:先讓系統完整跑通,再做美化;Markdown 做中間產物,HTML 做投遞產物;包裝層同核心邏輯分離;容錯優先。呢啲設計思想值得借鑑。
- ai-digest-suite 係一條完整嘅自動化日報流水線,覆蓋 RSS 抓取、AI 評分摘要、Markdown 生成到 HTML 郵件發送。
- 系統分為三個核心腳本:digest.ts(日報內容生產)、send_mail.py(郵件發送)、ai_digest_suite.py(總調度),並支援 generate、preview、send、generate-and-send 四種模式。
- 同其他技能唔同,呢個技能自帶全家桶,核心能力收喺自己目錄,唔依賴外部目錄;Markdown 做中間產物,HTML 做投遞產物,兼顧可讀性同可加工性。
- 容錯設計係關鍵——抓源失敗繼續、評分失敗有默認分、摘要失敗有逐條重試、JSON 解析有多層修復,先確保唔崩再求優雅。
- 可以基於呢個技能包自訂 RSS 源、調整評分維度、改 HTML 模板,或者抽成公共函數統一日期時區,進一步提升靈活性。
核心文件清單
技能說明 SKILL.md、總調度入口 ai_digest_suite.py、日報生成主邏輯 digest.ts、SMTP 發信邏輯 send_mail.py、使用說明 README.md
問題背景同技能定位
呢篇文章係作者詳細拆解 ai-digest-suite 呢個技能嘅實現,佢背後嘅問題好現實:每日要睇大量技術博客,但 RSS 源太多、好文章夾雜雜音,仲要自己整理、翻譯、寫摘要,最後排版成郵件,好多人都做唔到。
ai-digest-suite 係一條自動化日報流水線
作者想解決嘅就係呢條鏈路:批量抓 RSS、篩選時間範圍、AI 打分揀 Top N、生成中文標題摘要同推薦理由、彙總成 Markdown 日報、再轉成 HTML 郵件、最後透過 SMTP 發出。成個流程一體化。
核心設計同工作模式
技能主要由三個腳本組成,各自負責唔同層面:digest.ts 做內容生產,send_mail.py 做郵件發送,ai_digest_suite.py 做總調度。總調度將能力拆成四種模式,方便靈活使用。
- 1 generate:只生成日報唔發送,適合先睇效果
- 2 preview:預覽已生成嘅 Markdown 文件前幾行,快速檢查
- 3 send:發送一個已存在嘅日報,遇到 .md 會自動轉成 HTML 再發
- 4 generate-and-send:一條龍,先生成再發郵件,重用 generate 同 send 嘅邏輯
配置方面,技能根目錄支援自己嘅 .env 檔
配置分為日報生成相關(DIGEST_PROVIDER、MODEL、API_KEY等)同郵件相關(EMAIL_FROM_ADDR、PASSWORD等),搬去新機器只要帶走 .env 就得。另外,腳本路徑預設用自帶嘅,但高級用戶可以用環境變量覆蓋。
默認自洽,但冇寫死
RSS 抓取同 AI 評分邏輯
digest.ts 負責抓文章。佢內置咗大約 90 個技術博客 RSS 源,嚟自 Karpathy 推薦嘅集合。抓取時用併發控制,每次最多 10 個源並行,每個源超時 15 秒,用 Promise.allSettled 確保部分失敗唔會影響整體。
併發抓取、容錯處理
文章抓返嚟之後,先按 --hours 參數計算 cutoffTime,分成 recentArticles 同 olderArticles。如果 recentArticles 唔夠 topN,會用 olderArticles 補齊,確保日報穩定輸出夠數。
Top N 唔夠自動補齊
呢度有個好重要嘅設計:模型成日俾髒 JSON,所以技能內置咗多層修復函數 parseJsonResponse,會嘗試直接 parse、去 code fence、抽 JSON 塊、清洗常見問題(中文引號、多餘逗號、裸換行等),多輪嘗試,盡量救返可用數據。
多層 JSON 修復機制
摘要生成同郵件發送
評分揀出 Top N 之後,AI 要為每篇文章生成中文標題、4-6 句摘要同推薦理由。如果批次失敗,會逐條重試;單條都失敗就用 fallback(原始標題、截斷描述)。今日看點係另外調一次 AI,根據當日 Top 10 總結趨勢同導語。
摘要批次失敗後逐條重試
最終 Markdown 日報結構完整:標題、導語、今日看點、今日必讀(Top 3)、數據概覽表、Mermaid 圖表、按分類分組嘅文章卡片。但 Markdown 直接發郵件會暴露 Mermaid 代碼、<details> 等,所以技能專門做咗「郵件友好渲染鏈路」。
Markdown 做中間產物,HTML 做投遞產物
ai_digest_suite.py 負責將 Markdown 轉成 HTML:先 extract_sections() 拆章節,再清洗 Mermaid、details、分隔線等內容,然後將數據概覽抽成統計卡片(2x2 佈局),文章變成圓角卡片。分類標題保留 emoji 但去掉 ##,確保唔會重複表格。最後組裝成美觀郵件。
郵件發送由 send_mail.py 完成,支援 QQ、163、Gmail、Outlook 等常見 SMTP,可以自動從郵箱地址猜 provider。仲支援自訂主題(預設從日報第一行標題取)、發件人名、線程控制(用 In-Reply-To 串起同一組日報)。
日期統一用 Asia/Shanghai
作者特別強調時區問題:最初用 UTC 搞到日期錯一日,後來全部改為北京時間。呢個教訓對做日報、定時報表好重要。
這篇文章,專門把
ai-digest-suite這個技能到底是怎麼實現的,掰開揉碎講清楚。不講虛的,不講大詞,直接從“這個技能要解決什麼問題”開始,一路講到“它怎麼抓 RSS、怎麼篩文章、怎麼讓 AI 打分、怎麼生成摘要、怎麼排版成好看的 HTML 郵件、怎麼發出去、怎麼兜底、怎麼避免翻車”。
而且我會盡量用口語化、小白也能聽懂的方式講,但每一個關鍵實現細節都不會漏。
先別整沒用的,先上效果:
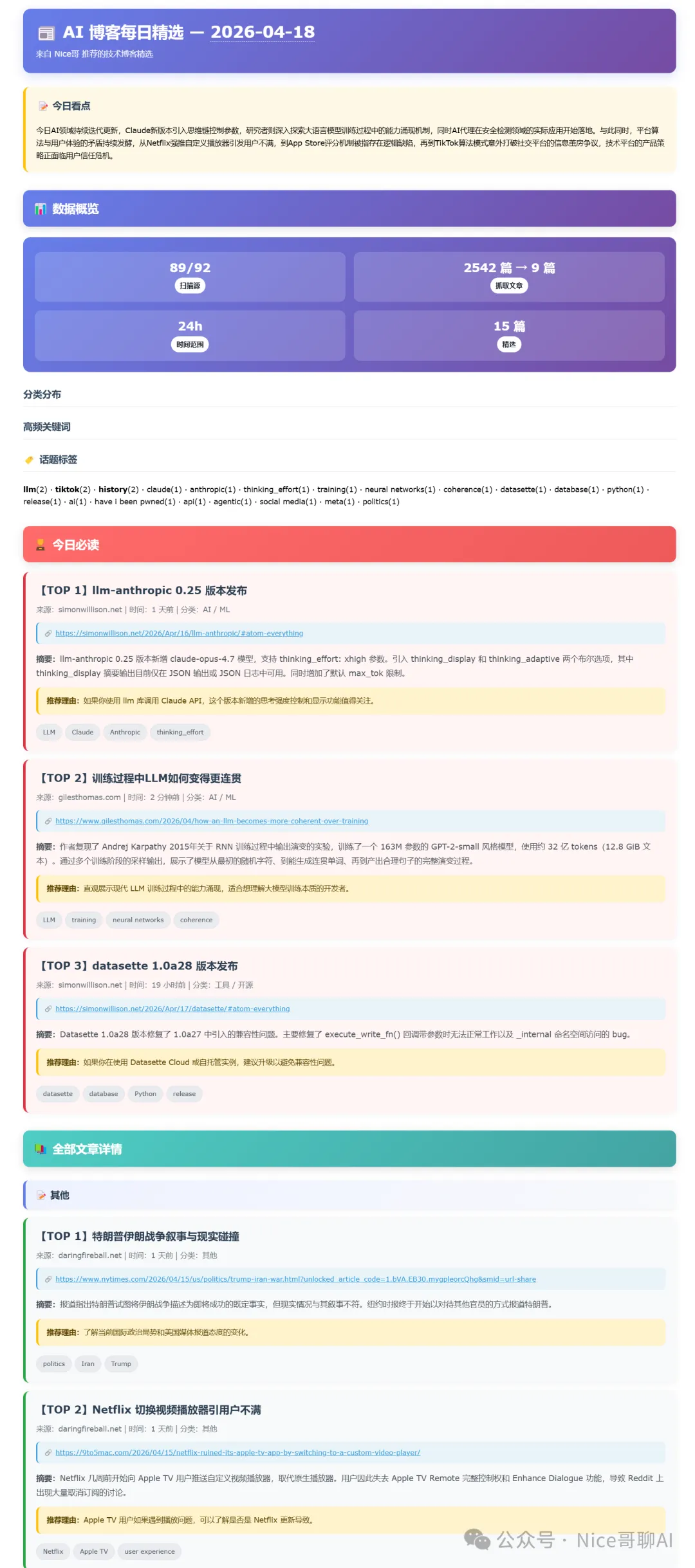
一、先說結論:這個技能到底是幹嘛的?
ai-digest-suite,本質上是一個自動生成 AI / 技術博客日報,並通過 HTML 郵件發送出去的獨立技能包。
它解決的是一個很實際的問題:
很多人每天都想看 AI、技術、工程、安全、開源這些方向的高質量內容,但問題是:
• RSS 源太多,自己刷不過來 • 好文章很多,但雜音也很多 • 即使篩出來了,也還得整理、翻譯、寫摘要、寫推薦理由 • 最後還得排版成一封能看的郵件
所以,這個技能就把整條鏈路給包了:
1. 批量抓 RSS 2. 按時間範圍篩選文章 3. 讓 AI 給文章打分 4. 選出 Top N 5. 讓 AI 生成中文標題、摘要、推薦理由 6. 自動彙總成 Markdown 日報 7. 再把 Markdown 轉成郵件友好的 HTML 8. 最後通過 SMTP 發到郵箱
一句話總結:
它不是一個“只會發郵件”的小腳本,而是一條完整的“內容抓取 → 評分 → 摘要 → 排版 → 投遞”的自動化日報流水線。
二、這個技能為什麼特別?——因為它是“自帶全家桶”的
很多技能有個毛病:
表面上看是一個技能,實際上要依賴一堆外部目錄、別的腳本、別的配置,搬家就炸。
而 ai-digest-suite 這次做的一個核心設計,就是:
它儘量把核心能力都收進自己目錄裏
技能目錄裏內置了 3 個核心腳本:
• scripts/digest.ts• scripts/send_mail.py• scripts/ai_digest_suite.py
它們各自負責不同工作:
1)digest.ts
它負責“日報內容生產”。
也就是:
• 抓 RSS • 過濾時間範圍 • 讓 AI 打分 • 選出 Top N • 生成摘要 • 生成今日看點 • 輸出 Markdown 報告
2)send_mail.py
它負責“發郵件”。
也就是:
• 讀取文本 / Markdown / HTML 內容 • 組裝郵件頭 • 連接 SMTP • 登錄郵箱 • 發出去
3)ai_digest_suite.py
它是“總調度器”。
也就是:
• 統一命令入口 • 負責 generate / preview / send / generate-and-send 四種模式 • 負責讀配置 • 負責把 provider 配置橋接給 digest.ts• 負責在發郵件前,把 .md自動轉換成郵件友好版 HTML
所以這個技能不是“一個腳本”,而是一個分層清楚的小系統。
三、這個技能支持哪幾種工作模式?
ai_digest_suite.py 裏把能力拆成了 4 種模式:
1)generate
只生成日報,不發送。
適合你想先看看效果的時候。
例如:
python3 scripts/ai_digest_suite.py generate --hours 24 --top-n 15 --lang zh2)preview
預覽已經生成好的 Markdown 文件前若干行。
適合快速檢查。
例如:
python3 scripts/ai_digest_suite.py preview --file ./output/digest-20260418.md3)send
發送一個已經存在的日報文件。
重點來了:
如果你傳進去的是
.md文件,它不會傻乎乎把 Markdown 原文直接塞進郵件,而是會先轉成更適合郵件閲讀的 HTML,再發送。
例如:
python3 scripts/ai_digest_suite.py send --file ./output/digest-20260418.md4)generate-and-send
一條龍:先生成,再發郵件。
例如:
python3 scripts/ai_digest_suite.py generate-and-send --hours 24 --top-n 15 --lang zh這個模式其實就是:
• 先內部調用 cmd_generate• 再構造參數調用 cmd_send
所以它不是額外寫了一套重複邏輯,而是重用已有能力。
這點很重要,因為這樣更穩、更容易維護。
四、配置是怎麼設計的?
這套技能在配置設計上,只有一個目標:
使用簡單
讀本地 .env
技能根目錄支持自己的 .env 文件:
skills/ai-digest-suite/.env這裏可以配置:
日報生成相關
• DIGEST_PROVIDER• DIGEST_MODEL• DIGEST_API_KEY• DIGEST_TIME_RANGE• DIGEST_TOP_N• DIGEST_LANGUAGE
郵件相關
• EMAIL_FROM_ADDR• EMAIL_PASSWORD• EMAIL_TO_ADDR• EMAIL_PROVIDER
這樣一來,這個技能搬去別的機器時,只要把技能目錄和 .env 帶走,基本就能跑。
五、它是怎麼找到自己要調用的腳本的?
這塊很多人會忽略,但它其實很關鍵。
ai_digest_suite.py 裏並不是把路徑寫死成“某個別的技能目錄”,而是先做一層“資源解析”。
它有幾個函數:
• resolve_digest_ts()• resolve_mailer_py()• resolve_digest_to_email_py()
默認會優先找:
• skills/ai-digest-suite/scripts/digest.ts• skills/ai-digest-suite/scripts/send_mail.py
如果你真想覆蓋,也支持環境變量:
• AI_DIGEST_TS• AI_DIGEST_MAILER• AI_DIGEST_TO_EMAIL
這意味着什麼?
意味着這個技能默認是自洽的
但又沒把自己寫死。
說白了就是:
默認你用我自帶的,最省心;
如果你是高級用戶,想換別的腳本,也給你口子。
六、RSS 抓取這塊,具體怎麼幹的?
真正抓文章的邏輯在 digest.ts 裏。
1)先內置了一大批 RSS 源
這個文件裏直接維護了一個 RSS 列表 RSS_FEEDS。
這些源來自:
Hacker News Popularity Contest 2025(Karpathy 推薦的高質量技術博客集合)
它裏面塞了大約 90 多個技術博客源,比如:
• simonwillison.net • troyhunt.com • krebsonsecurity.com • daringfireball.net • overreacted.io • gwern • 等等
每一項都帶:
• 名稱 name• RSS 地址 xmlUrl• 網站主頁 htmlUrl
所以這套技能一啓動,不需要你再手工一個個配訂閲源。
2)抓 RSS 時做了併發控制
抓源不是一個一個慢吞吞抓,而是分批併發抓。
它用了這些常量:
• FEED_FETCH_TIMEOUT_MS = 15000• FEED_CONCURRENCY = 10
意思就是:
• 單個源超時 15 秒 • 每次併發抓 10 個源
這樣做的好處很明顯:
• 比串行快很多 • 又不會一口氣把對方站點或本機打爆
3)抓失敗也不會整鍋端
每一批抓源時,用的是:
Promise.allSettled(...)這意味着:
• 某幾個源 403 了,沒關係 • 某幾個源 timeout 了,也沒關係 • 剩下成功的繼續收
最後只會打印日誌,比如:
• 哪些源超時了 • 哪些源返回 403 • 一共成功多少個源、失敗多少個源
這就很適合真實世界,因為 RSS 世界從來就不乾淨。
4)同時兼容 RSS 和 Atom
這個實現不是隻會一種 XML 格式。
它在 parseRSSItems() 裏會先判斷:
• 是 RSS <item>• 還是 Atom <entry>
然後分別解析:
RSS 常見字段
• title• link• pubDate• description• content:encoded
Atom 常見字段
• title• link href• published• updated• summary• content
為了更通用,它還做了這些輔助處理:
• stripHtml():去 HTML 標籤• extractCDATA():處理 CDATA• getTagContent():取 XML 標籤內容• getAttrValue():取標籤屬性• parseDate():解析日期
這就是為什麼它面對各種風格的技術博客訂閲源時,兼容性還不錯。
七、它怎麼決定“哪些文章算今天的”?
抓回來只是“原材料”,接下來要篩時間範圍。
1)先計算 cutoffTime
代碼裏會根據參數 --hours 算一個截止時間:
const cutoffTime = new Date(Date.now() - hours * 60 * 60 * 1000);比如 --hours 24,那就是“最近 24 小時”。
2)分成 recent 和 older 兩組
它不是簡單隻保留 recent,而是分成:
• recentArticles:最近 N 小時內的文章• olderArticles:更早的文章
這塊後來專門做過一次升級,因為之前出現過一個實際問題:
想發 Top 15,但最近 24 小時內只有 14 條。
於是後來改成了:
當前策略
• 如果 recentArticles 已經 ≥ topN • 就只用 recentArticles • 如果 recentArticles < topN • 就用 recentArticles + olderArticles • 按發佈時間倒序補足候選池 • 再從裏面選 Top N
也就是說:
現在的
top-n=15,不再只是“上限 15”,而是“儘量湊滿 15”。
這個策略對“日報穩定輸出”非常關鍵。
八、文章抓回來之後,AI 是怎麼給它打分的?
這裏是整套系統的第一層智能篩選。
1)評分維度有 3 個
每篇文章會讓 AI 從 3 個維度評分,分值 1-10:
relevance(相關性)
看這篇文章對技術/AI/互聯網從業者有沒有價值。
quality(質量)
看文章本身是否有深度、有信息量、有原創洞見。
timeliness(時效性)
看它是不是最近值得看、是不是熱點、是不是剛發佈的重要內容。
最後總分其實就是這 3 項相加。
2)還要順便給分類和關鍵詞
除了打分,AI 還得給每篇文章補兩個結構化信息:
分類 category
必須從這幾個裏選一個:
• ai-ml• security• engineering• tools• opinion• other
系統內部再映射成更好看的展示標籤:
• 🤖 AI / ML• 🔒 安全• ⚙️ 工程• 🛠 工具 / 開源• 💡 觀點 / 雜談• 📝 其他
關鍵詞 keywords
每篇文章提取 2-4 個英文關鍵詞。
這些關鍵詞後面會被用來做:
• 高頻關鍵詞圖 • 標籤雲 • 文章卡片裏的關鍵詞 tag
3)評分不是一篇一篇單獨調模型,而是批量調
代碼裏用了:
• GEMINI_BATCH_SIZE = 10• MAX_CONCURRENT_GEMINI = 2
意思是:
• 每批 10 篇文章一起送給模型 • 併發跑 2 批
這樣可以兼顧:
• 速度 • 成本 • 穩定性
而不是傻乎乎每篇文章都單獨請求一次。
4)評分結果會被兜底
如果某批評分失敗,不會讓整條鏈路崩掉。
它會給這一批文章套一個默認分:
• relevance: 5 • quality: 5 • timeliness: 5 • category: other • keywords: []
這就叫“先活着再說”。
在自動化系統裏,這種兜底非常重要。
九、為什麼這套技能不容易被模型的髒 JSON 搞死?
這個是整個系統裏非常關鍵、也非常工程化的一塊。
因為大模型有個老毛病:
你讓它返回 JSON,它經常給你:
• 包一層 ```json 代碼塊 • 前後夾雜說明文字 • 字符串裏直接帶裸換行 • 中文引號亂入 • 末尾多一個逗號
以前這種情況一多,整個摘要批次就廢了。
所以這次專門強化了 parseJsonResponse()。
它具體做了什麼?
1)先嚐試直接 JSON.parse
如果運氣好,直接過。
2)去代碼圍欄
比如把:
{ ... }外面那層去掉。
3)從雜亂文本里抽出“平衡的 JSON 塊”
也就是從一堆廢話裏儘量找到真正的 {...} 或 [...]。
4)清理常見髒問題
比如:
• 去 BOM • 把中文引號替換成英文引號 • 去掉對象或數組結尾前多餘的逗號 • 把字符串裏的裸換行、回車、tab 轉義掉
5)多輪嘗試解析
它會準備很多 candidate:
• 原始文本 • 去圍欄文本 • 抽出的 JSON • 清洗後的 JSON • 清洗後的抽取 JSON
一輪輪試。
如果最後還不行,才拋錯。
這塊的價值很大,因為它直接決定:
批量 AI 輸出是不是一出錯就全線報廢。
十、摘要生成是怎麼做的?
評分只是“選文章”,摘要才是讀者真正要看的內容。
每篇文章最終要補 3 樣東西
在摘要階段,系統會要求 AI 為每篇文章輸出:
1)中文標題 titleZh
如果原文標題是英文,就翻成自然中文。
2)摘要 summary
一般要求 4-6 句話,讓讀者不點原文也知道重點。
3)推薦理由 reason
也就是“為什麼這篇值得看”。
這個字段非常適合郵件場景,因為它能幫助讀者快速決定要不要點進去。
中文標題還做了額外收緊
這套實現不是“模型給啥就用啥”,而是額外做了中文標題歸一化。
原因很簡單:
大模型生成的中文標題,有時會:
• 太長 • 太繞 • 太像機翻
所以這塊做了進一步修整,讓標題更適合日報展示。
批量失敗時,還會逐條重試
這是這次升級裏非常值錢的一點。
以前如果一批文章摘要返回髒 JSON,可能整批都丟。
現在不是。
當前機制是:
• 先按批次摘要 • 如果批次解析失敗 • 再把這一批裏的文章一條條單獨重試 • 如果單條還失敗 • 再走 fallback
這個策略很工程,也很實用。
因為真實模型調用裏,常見情況其實是:
10 條裏有 1 條特別怪,把整批 JSON 搞壞了。
逐條重試之後,往往能救回來大部分。
最後的 fallback 是什麼?
如果連單條重試都失敗,那系統會給它一個降級摘要。
一般會用:
• 原始標題 • description 截斷內容 • 空的或簡化的推薦理由
這樣至少不會讓日報徹底缺塊。
十一、“今日看點”是怎麼生成的?
日報開頭那一段“今日看點”,不是手寫的,也不是簡單拼接前 3 條。
它是專門調了一次 AI,讓它根據當天前 10 條精選文章,總結出:
• 今天的 2-3 個主要趨勢 • 一個更像新聞導語的整體概覽
要求是:
• 不逐篇羅列 • 做宏觀歸納 • 語氣簡潔有力
這個設計非常好,因為它讓日報不只是“文章列表”,而是有一個總覽入口。
你可以把它理解成:
給讀者先上一段“今天科技圈發生了什麼”的電梯摘要。
十二、最終 Markdown 日報長什麼樣?
日報的內容組織結構在 generateDigestReport() 裏。
這個函數會把前面所有步驟產出的結果,組裝成一篇完整 Markdown。
它的結構是:
1)標題
例如:
# 📰 AI 博客每日精選 — 2026-04-18現在這裏的日期已經固定按:
• Asia/Shanghai• 也就是北京時間
不是按服務器 UTC。
2)一句話導語
例如:
> 來自 Karpathy 推薦的 92 個頂級技術博客,AI 精選 Top 15這一段主要是交代來源和數量。
3)今日看點
也就是剛才說的那段 AI 總結。
4)今日必讀
會先展示 Top 3,作為最值得優先看的內容。
每條包含:
• 【TOP N】標題• 來源 • 時間 • 分類 • 連結 • 摘要 • 推薦理由 • 關鍵詞
5)數據概覽
這裏會生成一張表:
• 掃描源 • 抓取文章 • 時間範圍 • 精選數量
例如:
| 掃描源 | 抓取文章 | 時間範圍 | 精選 |
|:---:|:---:|:---:|:---:|
| 89/92 | 2542 篇 → 15 篇 | 24h | 15 篇 |6)圖表和標籤
這裏還會自動生成幾類信息可視化:
分類分佈
Mermaid 餅圖。
高頻關鍵詞
Mermaid 柱狀圖。
終端友好 ASCII 條形圖
塞在 <details> 裏。
標籤雲
按出現頻率列關鍵詞。
7)按分類分組的全文詳情
這塊是讀者真正深入閲讀的主戰場。
會按分類輸出:
• ## 📝 其他• ## 🤖 AI / ML• ## ⚙️ 工程• ## 🛠 工具 / 開源• ## 🔒 安全• ## 💡 觀點 / 雜談
然後把文章一篇篇塞進去。
每條結構也是統一卡片內容:
• 標題 • 來源 / 時間 / 分類 • 連結 • 摘要 • 推薦理由 • 關鍵詞
8)尾部 footer
Markdown 原始日報裏還會帶上:
• 生成時間 • 掃描統計 • RSS 來源說明 • 製作說明
不過後來在 HTML 郵件版裏,這部分做了專門裁剪和美化,不會原樣照抄。
十三、為什麼郵件版不是直接發 Markdown?
因為直接發 Markdown 到郵箱,一般會遇到幾個很噁心的問題:
• Mermaid 代碼塊會原樣露出來 • <details>會變成髒 HTML 或純文本• ##標題看起來很生硬• 整體像程序員日誌,不像可讀郵件
所以這個技能後來專門補了一條“郵件友好渲染鏈路”。
也就是說:
生成產物還是 Markdown,但發送到郵箱時,會優先轉成美觀的 HTML。
這是一個非常合理的設計:
• Markdown 方便保存、diff、再加工 • HTML 方便投遞和閲讀
兩邊都照顧到了。
十四、Markdown 是怎麼轉成 HTML 郵件的?
這部分主要在 ai_digest_suite.py 裏做。
整體流程是:
第一步:拆章節 extract_sections()
先把 Markdown 按邏輯拆成幾個部分:
• 標題 title• 今日看點 highlights• 數據概覽 stats• 今日必讀 must_read• 全部文章正文 articles• 尾部 tail
這一步非常關鍵,因為只有先把結構拆出來,後面 HTML 才能真正做成“模塊化排版”。
第二步:清洗郵件裏不該出現的內容
郵件裏不適合原樣顯示的內容,會先被過濾掉:
• Mermaid 代碼塊 • <details>/<summary>• 原始 Markdown 分隔線 • 某些尾註
比如:
• *生成於 ...*• *基於 Hacker News Popularity Contest ...*• 某些作者署名行
這些東西在 Markdown 裏可能還行,但在美化郵件裏看起來很髒,所以都做了處理。
第三步:把數據概覽抽成統計卡片
原始 Markdown 裏,數據概覽是一張表。
到了 HTML 郵件裏,不再只是硬表格,而是會抽出 4 個核心字段做成 stats cards:
• 掃描源 • 抓取文章 • 時間範圍 • 精選
而且後來還專門改過幾版,把這個區塊一點點打磨到了現在的狀態:
• 標籤從白字改成了黑色加粗 • 加了白底圓角 chip 樣式 • 精選這張卡不再顯示成原始 Markdown 的**15 篇**,而是直接顯示正常的15 篇• 統計數字字號做了收縮,避免像 2542 篇 → 15 篇這種內容在卡片裏擠得太難看• 最終佈局改成了 2×2 卡片佈局,不再是一行 4 列,這樣每張卡更寬,長數字更容易保持單行顯示
這個調整看起來像樣式小事,但其實很關鍵。因為日報郵件不是給人“研究 DOM 結構”的,而是讓人一眼掃懂核心數據的。
第四步:保留卡片,刪除重複表格
原始 Markdown 裏的數據概覽,本來是“表格 + 後續圖表”的結構。
如果 HTML 郵件裏既顯示統計卡片,又把原表格原樣再渲染一遍,就會出現一個很明顯的問題:
• 上面卡片已經顯示了一遍 • 下面又重複出現一張一模一樣的數據表
讀者會覺得囉嗦,而且視覺上很擠。
所以最終版做了一個明確取捨:
• 保留統計卡片 • 刪除卡片下方重複的數據表格 • 保留後面的分類圖、關鍵詞圖、標籤雲等補充信息
也就是說,現在 HTML 郵件裏的“數據概覽”區,不再是“卡片 + 重複表格”,而是“卡片 + 圖表/標籤”,層次更清楚。
第五步:把文章塊渲染成卡片
每篇文章在 HTML 裏會被轉成一個 news-item 卡片。
卡片裏有:
• 標題 news-title• 元信息 news-meta• 連結 link-box• 摘要 news-desc• 推薦理由 reason-box• 關鍵詞 tag-row
這樣一來,讀者掃郵件時就是“看卡片”,而不是“看原始文檔”。
第六步:保留分類,但去掉 Markdown 痕跡
這部分是後來專門修過坑的。
最開始分類標題顯示有兩個問題:
1. ## 🤖 AI / ML這種 Markdown 標記直接露出來,不好看2. 某些分類標題出來了,但下面沒有正文
後來做了兩步修復:
修復 1:保留分類,但去掉 ##Markdown標識
也就是:
• 保留 🤖 AI / ML• 保留 🛠 工具 / 開源• 保留 💡 觀點 / 雜談
但不顯示 ##。
修復 2:按 section 解析分類
之前的 bug 是:
• 看到分類標題就 continue• 結果把同分類下面的文章也誤跳過了
後來改成:
• 先識別一個分類標題 • 截出它到下一個分類標題之間的正文 • 再單獨渲染這個 section 裏的文章
這才徹底修掉了:
• 🛠 工具 / 開源有標題沒正文• 🔒 安全有標題沒正文• 💡 觀點 / 雜談有標題沒正文
的問題。
第六步:刪除新聞中不該出現的 ---符號,影響美觀
這個坑也挺典型。
Markdown 裏文章之間用 --- 分隔,本來沒問題。
但在 HTML 卡片解析過程中,如果不額外過濾,這些 --- 會被當成正文殘留塞進卡片裏。
於是後來專門加了規則:
• 如果某一行是純分隔線 ---• 直接忽略,不渲染
這樣新聞卡片裏就不會出現奇怪的 --- 了。
第七步:最終 HTML 主題風格怎麼設計的?
這次 HTML 郵件的美化風格,借鑑了 mazda-daily-report 的視覺設計思路。
最後做出來的郵件結構大概是這樣:
1)頂部 Hero 區
• 漸變背景 • 大標題 • 副標題
副標題後來還改成了:
來自 Nice哥 推薦的技術博客精選不再是原先那種帶 Karpathy 和“HTML 郵件增強版”的說明。
2)今日看點高亮塊
黃色高亮,視覺上更抓眼。
3)數據概覽區
漸變橫幅 + 統計卡片。
4)今日必讀區
紅色風格橫幅。
5)全部文章詳情區
青綠色風格橫幅。
6)分類橫幅
淺色漸變條,突出不同分類。
7)文章卡片
圓角、陰影、標籤、推薦理由提示框。
8)頁腳
最後保留成一句更乾淨的話:
由「Nice哥聊AI」製作,歡迎關注同名微信公眾號獲取更多 AI 實用技巧 💡而不是把生成時間、來源說明、技術尾註全都堆在頁腳裏。
十五、郵件到底是怎麼發出去的?
這部分由 send_mail.py 完成。
1)支持的服務商
它內置了幾種常見 SMTP 配置:
• QQ • 163 • Gmail • Outlook
每種服務商有對應的:
• SMTP 服務器地址 • 端口 • SSL / TLS 策略
2)可以從郵箱地址自動猜 provider
比如:
• xxx@qq.com→qq• xxx@gmail.com→gmail
當然也可以手工傳 --provider。
3)發信時組裝 MIME 郵件
發郵件不是簡單 socket 發文本,而是標準 MIME 郵件。
如果發 HTML:
• MIMEText(..., 'html', 'utf-8')
如果發純文本:
• MIMEText(..., 'plain', 'utf-8')
外面再套一層:
• MIMEMultipart('alternative')
這樣客戶端兼容性更好。
4)支持主題、發件人名、線程控制
除了普通發信,它還支持:
• --subject• --from-name• --thread-key• --no-thread
其中 threading 相關設計很實用:
• 默認每封信有獨立 Message-ID • 如果給了 thread-key• 就會帶 In-Reply-To• 帶 References• 讓客戶端把它們串成一組
所以它不只是“能發”,還考慮了“郵箱客戶端怎麼顯示”。
十六、郵件主題現在是怎麼決定的?
這塊也是這次專門改過的。
之前默認主題是寫死的:
📰 AI 博客每日精選後來改成了更自然的規則:
如果你沒手動傳 --subject
就自動從日報文件第一行標題裏取主題。
例如 Markdown 第一行是:
# 📰 AI 博客每日精選 — 2026-04-18那郵件主題就自動變成:
📰 AI 博客每日精選 — 2026-04-18如果實在讀不到標題,就 fallback 成:
📰 AI 博客每日精選 — 北京時間當天日期這個改動非常實用,因為它讓:
• 郵件標題 • 日報標題 • 輸出文件日期
三者統一了。
十七、日期到底跟誰走?北京時間還是服務器時間?
這也是這次重點修過的一塊。
最開始代碼裏用的是:
new Date().toISOString()這會返回 UTC 時間。
於是就出現了一個很真實的問題:
• 服務器還是 4 月 17 日 UTC • 但中國已經是 4 月 18 日凌晨 • 最終郵件標題還寫着 2026-04-17
後來專門改成了:
全部按 Asia/Shanghai
在 digest.ts 裏新增了 formatShanghaiDateTime():
• 標題日期按北京時間 • footer 生成時間按北京時間 • 默認輸出文件名按北京時間
同時在 Python 包裝層裏:
• 默認輸出路徑 default_output_path()改成北京時間• fallback 郵件主題日期也按北京時間
所以現在這套系統在日期上是統一的。
這裏最大的教訓就是:
做日報、郵件、定時報表時,時區絕對不能靠“服務器默認行為”。
必須寫死時區。
十八、這套技能還做了哪些“防翻車設計”?
這一塊很值得單獨拎出來講,因為真正能用的自動化系統,拼的就是這些細節。
1)抓源失敗不崩
部分 RSS 源掛了,繼續跑。
2)評分失敗有默認分
不會因為某批 AI 評分失敗導致整份日報沒法產出。
3)摘要失敗先批量重試、再逐條重試
最大限度搶救結果。
4)JSON 解析做多層修復
儘量從髒響應裏摳出可用 JSON。
5)Markdown 發信默認轉 HTML
避免直接發原始 Markdown 造成閲讀災難。
6)HTML 渲染中專門過濾髒塊
比如:
• Mermaid • details • raw markdown heading • 分隔線 • 尾註元信息
7)Top N 不夠時自動補齊
避免“明明要 Top 15,結果只出 14 條”。
8)日期統一北京時間
避免晚八小時錯一天。
這些點加在一起,才讓它從一個“能跑的 demo”,慢慢變成一個“能長期發日報的工具”。
十九、整個技能完整執行流程,按順序捋一遍
如果你想徹底理解它,可以把整個鏈路記成下面這 14 步:
第 1 步:讀取配置
優先 .env,沒有再讀舊 JSON。
第 2 步:確定模式
是 generate、preview、send,還是 generate-and-send。
第 3 步:解析 provider 配置
把不同供應商映射成 digest.ts 真正能吃的環境變量。
第 4 步:抓 90+ RSS 源
併發、超時、容錯。
第 5 步:解析 RSS / Atom 內容
提取標題、連結、時間、簡介。
第 6 步:按時間範圍篩選
得到 recentArticles,必要時再補 olderArticles。
第 7 步:讓 AI 給候選文章打分
輸出相關性、質量、時效性、分類、關鍵詞。
第 8 步:排序,取 Top N
按總分降序取前 N 條。
第 9 步:讓 AI 生成摘要內容
輸出中文標題、摘要、推薦理由。
第 10 步:生成“今日看點”
總結當天的整體趨勢。
第 11 步:拼接成 Markdown 日報
帶標題、Top3、數據概覽、圖表、分類詳情。
第 12 步:如果要發郵件
對 Markdown 進行 HTML 友好渲染。
第 13 步:組裝 SMTP 郵件併發送
帶主題、HTML 正文、MIME 頭。
第 14 步:輸出日誌與結果路徑
告訴你生成了什麼、發到了哪。
這 14 步,就是這個技能的完整生命線。
二十、這套實現最值得借鑑的地方是什麼?
如果你不是單純想用它,而是想學它,我覺得最值得借鑑的是這幾個設計思想。
1)先讓系統完整跑通,再做美化
它不是一上來就搞 UI,而是先打通抓取、篩選、摘要、發送主鏈路。
2)Markdown 作為中間產物,HTML 作為投遞產物
這是一種非常實用的“雙格式設計”。
3)包裝層和核心邏輯分離
Python 做 orchestrator,TypeScript 做內容生產,職責很清楚。
4)容錯優先
很多代碼都不是在追求“最優雅”,而是在追求“不要崩”。
5)現實導向
比如:
• 支持舊配置回退 • 支持 SMTP 常見服務商 • 支持自動主題 • 解決時區問題 • 解決模型 JSON 髒輸出
這些都不是 PPT 功能,而是實際會天天遇到的問題。
二十一、最後做個大白話總結
如果讓我用一句最通俗的話,向完全不懂技術的人解釋這個技能,我會這麼說:
ai-digest-suite就像一個每天替你刷幾十上百個技術博客、幫你挑重點、寫中文摘要、整理成日報、再漂漂亮亮發到你郵箱裏的“AI 內容助理”。
但如果讓我用一句更偏工程的話總結它,我會說:
它是一條把 RSS 聚合、LLM 策展、結構化摘要、Markdown 報告生成、郵件友好 HTML 渲染、SMTP 投遞 串起來的獨立日報流水線。
這兩句話,其實說的是同一個東西。
一個偏用戶視角,一個偏實現視角。
而 ai-digest-suite 真正做得好的地方就在於:
它把一件原本很碎、很容易翻車、很容易越改越亂的事,儘量收斂成了一套可遷移、可維護、可持續優化的技能包。
二十二、附:這個技能的核心文件清單
如果你想繼續深挖代碼,重點看這幾個文件就夠了:
1)技能說明
skills/ai-digest-suite/SKILL.md2)總調度入口
skills/ai-digest-suite/scripts/ai_digest_suite.py3)日報生成主邏輯
skills/ai-digest-suite/scripts/digest.ts4)SMTP 發信邏輯
skills/ai-digest-suite/scripts/send_mail.py5)使用說明
skills/ai-digest-suite/README.md二十三、給想自己改這套技能的人幾個建議
如果你後面還想繼續進化這套技能,我建議優先做下面幾個方向:
1)把副標題、頁腳品牌文案做成配置項
現在還是寫死的,未來可以抽到 .env 裏。
2)把 HTML 模板再獨立成單文件模板
現在是在 Python 裏拼字符串,夠用,但後面會越來越難維護。
3)給摘要失敗項做更精細的回填提示
比如在正文裏標記“該條為降級摘要”。
4)給 Top N 補齊策略加可配置開關
有些人想嚴格只看最近 24 小時,有些人想穩定湊滿 15 條。
5)把日報發佈時間、日期標題、郵件主題統一抽成一個公共函數
雖然現在已經基本統一了,但還可以進一步收斂。
結尾
如果你看到這裏,其實已經不是“會不會用這個技能”的問題了,而是你已經徹底理解了:
• 它為什麼這樣設計 • 每一層分別做什麼 • 哪些地方最容易踩坑 • 哪些升級是這次真正補上的
這才是最值錢的部分。
因為代碼能複製,
但“為什麼這麼寫”這件事,往往比代碼本身更重要。
歡迎各位小夥伴在評論區談談自己的看法。如果有需要這個技能的,歡迎在評論區留言,我會根據情況開源這個技能!