我讓 Claude Code 當裁判,橫評 DeepSeek V4 和 GLM-5.1
整理版優先睇
Claude Code 做裁判:GLM 5.1 同 DeepSeek V4 Pro 嘅 coding 能力橫評
呢篇文章係一個自媒體經營者,佢平時常用 Claude Code、Codex 等工具,想親身比較兩個國產開源模型——GLM 5.1 同 DeepSeek V4 Pro——喺實際編程任務上嘅表現。作者覺得其他人嘅評測未必信得過,索性用自己慣用嘅懶人方法:叫 Claude Code 自己出題、自己做裁判,自動化咁跑四個 case。整體結論係:GLM 5.1 喺代碼可靠性同執行速度上明顯佔優,四個 case 入面三個贏得清脆;DeepSeek V4 Pro 嘅分析深度同架構設計則有亮點,但執行層面會出小問題,速度亦慢好多。
測試方法係喺 Claude Code 入面切換模型後端,作者先配置好 settings 檔同 alias,然後叫 Claude Code 自己設計測試方案、寫 prompt、分別用兩個模型跑相同任務,最後由 Claude Code 評判結果。四個 case 分別係:併發 bug 修復、從零寫 rate limiter、流量數據分析、互動儀表盤生成。整個過程幾乎零手動,反映作者追求效率嘅風格。
作者強調呢個只係四個 case 嘅小測試,唔係全面 benchmark,而且裁判 Claude Code 自身都有侷限。但佢認為結果同社區體感一致:GLM 5.1 喺非頂級模型入面 coding 能力排得幾前,DeepSeek V4 Pro 實力強勁但需要時間優化速度同穩定性。最後佢公開曬所有測試數據,鼓勵大家自己跑…
- 測試方法:Claude Code 自行設計四個 case(bug 修復、生成代碼、數據分析、儀表盤),自動切換模型後端,完全隔離執行並評分。
- 結果:GLM 5.1 喺三個 case 中勝出(bug 修復打平但修復更乾淨、代碼生成 100% 測試通過且快 8 倍、數據分析維度更多),DeepSeek V4 Pro 靠分析深度同建議可操作性喺數據分析 case 略遜但仍有亮點。
- 主要差異:GLM 傾向穩陣執行、速度快;DeepSeek 傾向深入分析、架構設計更成熟,但執行時有瑕疵(測試失敗、速度慢)。
- 啟發:實際使用可按任務特性揀模型——追求可靠性同效率揀 GLM,需要深入分析同建議揀 DeepSeek;兩者都仲有進步空間,期待國產模型追上閉源。
- 可行動點:你可以用作者開源嘅測試資料(GitHub repo)自己跑更多 case,或者直接 PR 加入新測試,豐富呢個小型 benchmark。
測試原始數據及對比報告
每個 case 嘅輸入代碼、prompt、兩個模型完整輸出同 Claude Code 嘅對比報告,全部開源。
測試背景同方法:懶人嘅自動化橫評
作者係 AGI Hunt 公眾號營運者,平時成日試唔同模型嘅 coding 能力。佢覺得其他人嘅實測唔完全信得過,所以決定自己動手。佢嘅做法係:叫 Claude Code 做裁判,由 Claude Code 自己設計測試方案、寫 prompt、分別用兩個模型跑相同任務,最後自己評判結果。成個過程幾乎零手動,主要係語音輸入要求,然後坐喺度睇佢自己跑。
測試用嘅係 Claude Code 嘅 --settings 參數切換後端,DeepSeek 同智譜都支援 anthropic 協議。作者喺 shell 配咗 alias 方便切換:cc 用預設模型,ccg 用 GLM 5.1。佢仲特登為 DeepSeek 充咗 200 蚊,話「V4 發佈值得致敬」。
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的API key",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic"
}
}alias cc="claude --dangerously-skip-permissions"
alias ccg="claude --dangerously-skip-permissions --settings /path/to/settings_glm.json --model glm-5.1"四個 case 覆蓋咗 bug 修復、代碼生成、數據分析、可視化 四個維度,每個 case 兩個模型拎到完全相同嘅 prompt,喺完全隔離嘅工作目錄各自完成。Claude Code 仲自己創建隔離目錄、寫好 buggy code、轉換數據格式,然後同時啟動 4 個子 agent 並行跑測試,效率好高。
Case 1:併發 Bug 修復——分析定修復更緊要?
第一個測試係一段大約 150 行嘅異步 HTTP 連接池代碼,有 semaphore 泄漏、TOCTOU 競態、未加鎖計數器 等真實併發 bug。問題描述係「50+ 併發請求時偶發 connection pool exhausted 錯誤」。
- GLM 5.1 找到 5 個問題,根因分析正確,特別係 semaphore 泄漏嘅正反饋循環——「每次 acquire 失敗後 semaphore 永久丟失一個 slot,導致池子容量持續縮小」。修復後 50 個 worker 全部通過,連接數精確等於 max_connections。
- DeepSeek V4 Pro 都找到 5 個問題,前 3 個同 GLM 一致。第 4 個係 UnboundLocalError 隱患:acquire() 喺第一次重試失敗時,conn 未定義就入 finally 塊。呢個 GLM 冇提。DeepSeek 仲畀每個 bug 標咗嚴重等級,分析文檔比 GLM 長約 40%。
Case 2:從零寫 Rate Limiter——速度快過你想像
第二個測試係從零實現一個生產級嘅滑動窗口 rate limiter,要求 內存同 Redis 雙後端、多規則組合(100 次/分鐘且 1000 次/小時)、線程安全、異步兼容、帶完整 pytest 測試。
- GLM 5.1:2 分鐘完成,56 個測試全部通過。代碼 316 行,簡潔夠用。測試覆蓋基本限流、多規則、窗口滑動、併發安全等。小瑕疵係 README 嘅 API 示例同實際代碼對唔上(寫 is_allowed() 但實際係 acquire())。
- DeepSeek V4 Pro:17 分鐘完成,63/65 個測試通過。代碼 543 行,架構設計更成熟:有命名規則、定時清理、deque 做 O(1) 剪枝、條件化 Redis 導入。但有 2 個測試失敗:一個係 frozen dataclass 寫法錯誤,另一個係清理定時器競態。
Case 3 & 4:數據分析同儀表盤——各有千秋
第三個測試係用作者公眾號 AGI Hunt 近兩個月嘅流量數據,分析渠道分佈同文章表現。第四個測試係用同一份數據生成可交互 HTML 儀表盤。
GLM 5.1 嘅分析報告 287 行,亮點包括:標題關鍵詞頻率表(統計關鍵詞出現頻次同對應平均閲讀量)、推薦渠道增長時間線(由 25.8% 到 48.4% 再到 65%),仲將 54 日流量拆成「起步期→爆發期→穩定期」三個階段,易讀清晰。DeepSeek V4 Pro 嘅報告 372 行,獨到分析有:前後 25% 文章分位數對比,發現社交分享渠道喺爆文中佔 18.3%,普通文章得 6.6%,從而得出「決定文章爆發係社交分享,推薦算法只係放大器」;仲注意到 4 月 19 號爆文後冇追發,錯過流量窗口;建議更量化可落地,例如「文章過 5 萬時 24 小時內追發」「內容配比 50/30/20」。
- Claude Code 判定數據分析 GLM 略勝:分析維度更多樣,對數據結構理解更準確。DeepSeek 建議可操作性更強,但整體唔夠紮實。
- 儀表盤方面:GLM 用 ECharts 做深色科技風,6 個統計卡片+6 個圖表,內容豐富;DeepSeek 用 Chart.js 做微信綠配色,4 個圖表,散點圖帶 R² 迴歸值,但 Top 10 文章只顯示序號冇標題(其實 hover 可看,係裁判偏頗)。Claude Code 判定各有勝負。
GLM 分析維度更多,DeepSeek 建議更可操作
速度差異同最終結論:GLM 暫時領先,DeepSeek 潛力大
速度係重要差異:Case 2 入面 GLM 用 2 分鐘,DeepSeek 用 17 分鐘,其他 case 都有類似差距。模型跑得快意味住工具調用嘅反饋循環更短,整體效率更高。GLM 喺 SWE-Bench Pro 排第一,可能同「快速試錯、快速修正」能力有關。DeepSeek V4 Pro 目前推理速度受限於算力,華為昇騰 950 超級節點下半年上線後有改善。
作者強調呢次只係小測試,唔係全面 benchmark,而且裁判 Claude Code 都有侷限。佢公開咗所有原始數據(GitHub: https://github.com/Johnixr/cc-model-bench),鼓勵大家自己跑過對比。最後佢希望國產模型卷得更猛,2026 年內卷番國外兩家閉源模型。
DeepSeek V4 發布嗰陣,喺技術報告入邊寫得非常真誠:喺推理能力上,「落後前沿閉源模型大約 3 到 6 個月」。
而最近兩日,我嘅各個編程交流羣組入邊就開始對 V4 同各家模型做好多比較同討論。當中討論到嘅國產模型,最多嘅一個我睇落就係智譜嘅 GLM 喇:
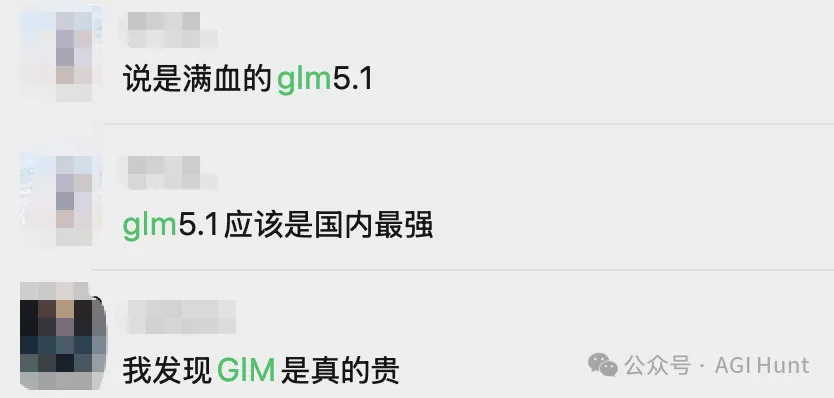

兩個國產開源模型,一個俾人覺得更似 Opus,另一個就主動認差距……
而喺月頭 GLM 5.1 發布(GLM-5.1 上線,同 Opus 只差 2.6 分)之後,我都搞咗個佢嘅 Coding Plan 嚟用(當然我用得最多嘅仲係 Claude Code 同 Codex,目前就用呢三個),咁要唔要轉去 DeepSeek Coding Plan 呢?

老實講,其他人嘅實測我都唔係咁信,我始終想自己動手感受下。雖然我測都唔一定全面……
咁就不如用返我嘅老方法,使出我慣用嘅懶人招數:等 Claude Code 自己出題自己做裁判,畀兩個模型做一次自動化嘅橫向比較。
01測試方法
當然唔可以直接 call API 嚟測,我揀咗喺 Claude Code 入邊進行測試對比。
我一直有智譜嘅 GLM Coding Plan,所以就唔使再充值。而為咗今次測試我都係畀 DeepSeek 細細充值咗 200 蚊,我完全唔肉赤,DeepSeek V4 嘅發布,至少值得我課啲錢致敬一下。
而我哋知道,Claude Code 係支持透過 --settings 參數切換唔同嘅模型後端,設定檔係咁樣:
●●●
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的API key",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic"
}
}└
為咗方便我哋喺 Claude Code 入邊用,DeepSeek 同智譜都支援 anthropic 嘅協議,而且推出咗對應嘅端點,所以換個 base URL 同模型名就可以直接用。
因為日常成日切換同懶,我喺 shell 入邊整咗一堆 alias:
●●●
alias cc="claude --dangerously-skip-permissions"
alias ccg="claude --dangerously-skip-permissions --settings /path/to/settings_glm.json --model glm-5.1"└
平時就 cc 和 ccg 兩個指令來回切(當然仲有個 cx = codex),我唔會用 CC Switch 之類嘅花巧方案。如果你之前未用過 alias,可以揾個 AI 學下,用過就會覺得……好正。
而成個測試,我全部都係叫 Claude Code(Opus 4.7)自己完成:等佢自己設計測試方案,自己寫 prompt,分別用 GLM 5.1 同 DeepSeek V4 Pro 行同樣嘅任務,最後自己評判結果。
成個過程我幾乎零插手,主要係花咗 3 分鐘用語音輸入要求,然後就坐喺旁邊睇佢自己行。
(我而家好多測試、好多工作都係咁做……主打一個零人工介入。效果點樣另計,但一定要係省事的 )
)
以下係 Claude Code 準備測試材料嘅過程:
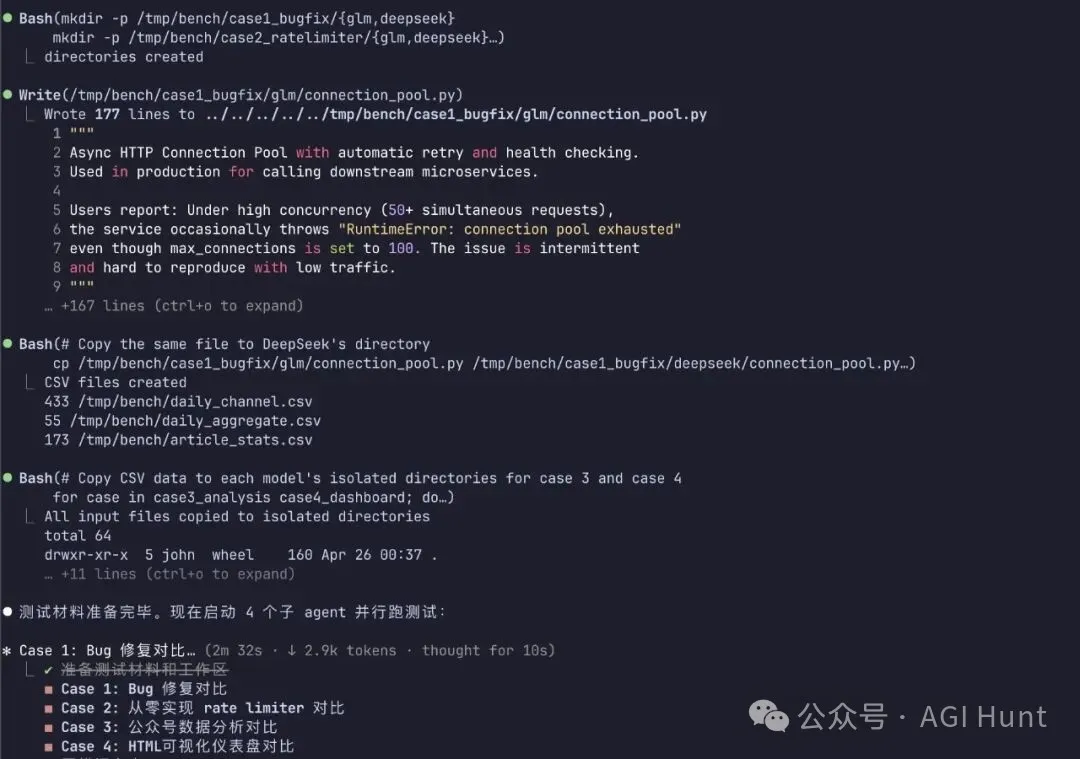
佢自己建立咗隔離目錄、寫好咗 buggy code、轉換咗數據格式,然後同時啟動咗 4 個子 agent 並行跑測試。
多樣性方面,Claude Code 一共設定咗 4 個 case,涵蓋 bug 修正、程式碼生成、數據分析、可視化四個維度。
每個 case 兩個模型拎到完全一樣嘅 prompt,喺完全隔離嘅工作目錄入邊各自完成任務。
公平競爭。
02Case 1:併發 Bug
第一個測試,係叫模型定位同修正一段有併發問題嘅 Python 連接池程式碼,大約 150 行。
呢段程式碼模擬咗一個生產環境入邊常見嘅場景:異步 HTTP 連接池,有自動重試同健康檢查。問題描述係「50+ 併發請求時偶發 connection pool exhausted 錯誤」。

當然,問題程式碼都係 Claude 裁判生成嘅。
入面埋咗幾個真係嘅併發 bug:semaphore 泄漏、TOCTOU 競態、未加鎖嘅計數器等。
GLM 5.1 揾到咗 5 個問題。
根因分析正確。特別係 semaphore 泄漏嘅根因分析,GLM 5.1 直接指出咗「每次 acquire 失敗之後 semaphore 永久唔見一個 slot,令到池容量持續縮細」嘅正反饋循環。
GLM 5.1 喺修正之後自己行咗一次測試,50 個併發 worker 全部通過,連接數精確等於 max_connections。
DeepSeek V4 Pro 都揾到咗 5 個問題。
前 3 個同 GLM 完全一樣。唔同嘅係第 4 個:DeepSeek 發現咗一個 UnboundLocalError 嘅隱患,當 acquire() 喺第一次重試時失敗,conn 變數可能未定義就入咗 finally 塊。呢個問題 GLM 冇提過。
DeepSeek 仲畀每個 bug 標咗嚴重等級(CRITICAL / HIGH / MEDIUM / LOW),分析文件比 GLM 長咗約 40%。
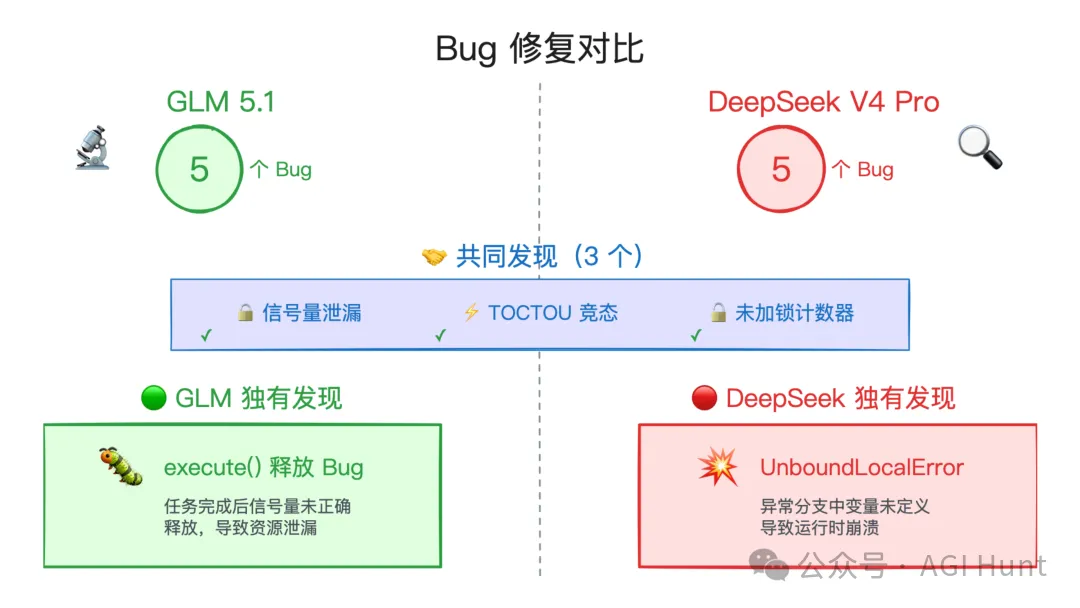
Claude Code 判定:呢輪基本上打和。
GLM 嘅修正更加乾淨利落,DeepSeek 嘅分析更加仔細。如果係交畀團隊做 code review,兩份報告都用得。
03Case 2:由零寫程式碼
第二個測試:由零實現一個生產級嘅滑動窗口 rate limiter。
Claude 畀出嘅要求係:支援記憶體同 Redis 雙後端、多規則組合(例如 100 次/分鐘兼且 1000 次/小時)、線程安全、異步兼容、有完整 pytest 測試。
GLM 5.1:2 分鐘完成,56 個測試全部通過。
程式碼共 316 行,簡潔得嚟夠用。測試涵蓋咗基本限流、多規則、窗口滑動、併發安全等場景。不過有一個小瑕疵:README 入邊嘅 API 示例同實際程式碼對唔上(文件寫嘅係 is_allowed(),實際上係 acquire())。
DeepSeek V4 Pro:17 分鐘完成,63/65 個測試通過。
程式碼共 543 行,架構設計更加成熟,有命名規則、定時清理、deque 做 O(1) 剪枝、條件化 Redis 導入等。
README 同程式碼一致。但有 2 個測試失敗:一個係 frozen dataclass 嘅測試寫法有錯,另一個係清理定時器嘅競態。

Claude Code 判定:呢輪 GLM 贏,贏在可靠性。
100% 測試通過 vs 96.9%,速度比 DeepSeek 快咗 8 倍。DeepSeek 嘅架構想法更多,但……「想太多」有時反而引入咗新問題。
04Case 3:數據分析
第三個測試,Claude Code 揾到咗一個之前我叫佢做過嘅工作,於是出題完全轉咗個唔同嘅方向。
佢將我自己公眾號 AGI Hunt 近兩個月嘅流量數據(日均閲讀、渠道分佈、文章級別統計)掟咗畀兩個模型,等佢哋各自寫一份數據分析報告。
GLM 5.1 嘅報告 287 行,亮點有三個地方。
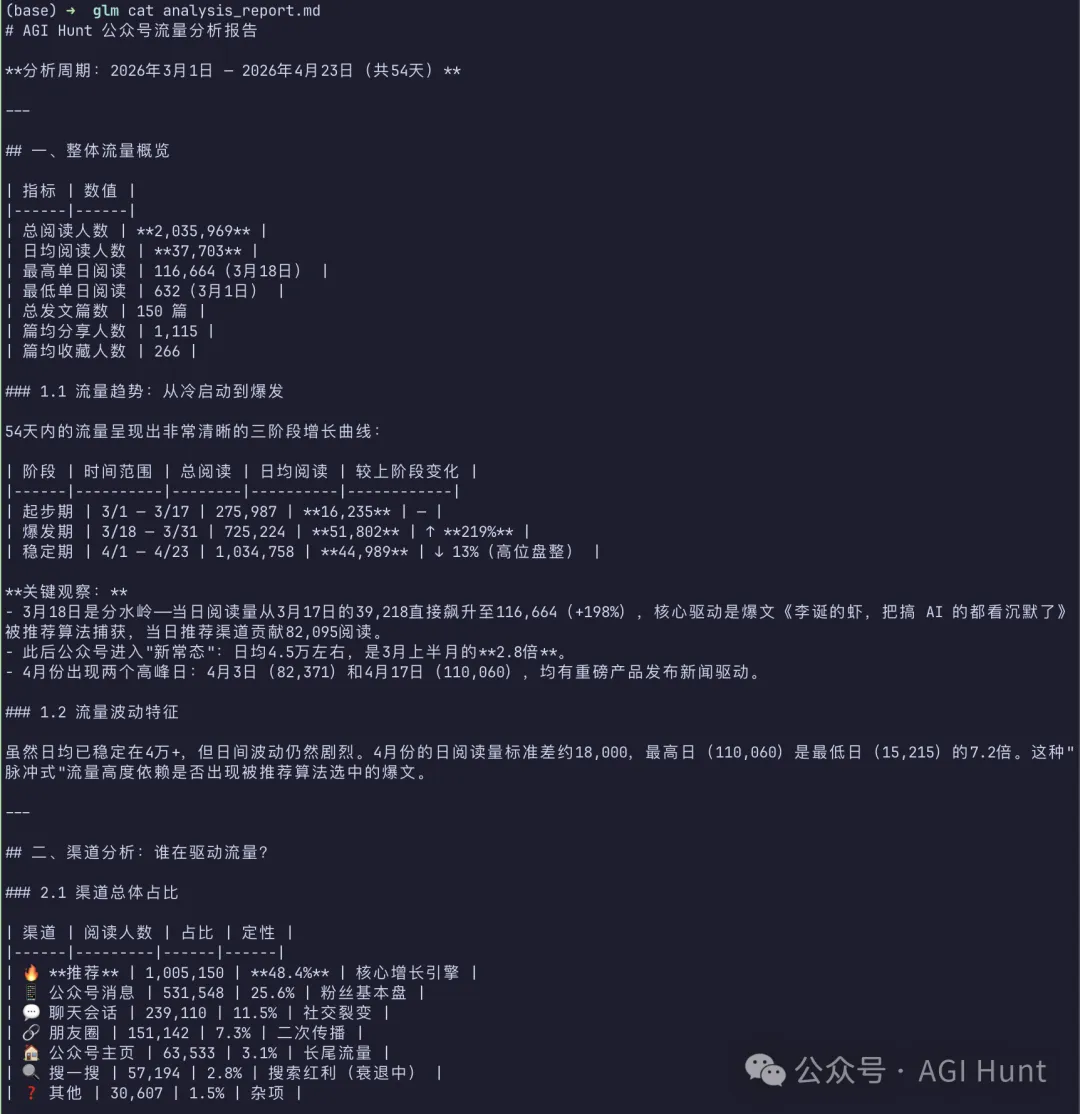
佢做咗一個標題關鍵詞頻率表,統計關鍵詞嘅出現次數同對應平均閲讀量……呢樣對於搞自媒體嘅人嚟講,都幾實用。
推薦渠道嘅增長時間線都有好細緻嘅追蹤:由 3 月上旬嘅 25.8% 到之後嘅 48.4%,再到高峯期接近 65%。
另外,佢將 54 日嘅流量拆咗做「起步期→爆發期→穩定期」三個階段,易明易讀,清晰準確。
DeepSeek V4 Pro 嘅報告 372 行,篇幅更長,有啲獨到嘅分析。

佢做咗一個前後 25% 文章嘅分位數對比,發現社交分享渠道(聊天會話 + 朋友圈)喺爆文中佔 18.3%,喺普通文章中只有 6.6%。
由呢度得出一個結論:決定文章能否爆發嘅,其實係社交分享,推薦算法只係放大器。
佢仲留意到 4 月 19 號有一篇文章突破咗 11 萬閲讀,但第二日冇追發新內容,錯過咗流量窗口(確實係我唔識嘅技巧……)。

建議方面,都比 GLM 更加具體同可執行,而且帶有量化嘅閾值:「文章過 5 萬時 24 小時內追發」「內容配比 50/30/20」之類,真係比我專業太多……
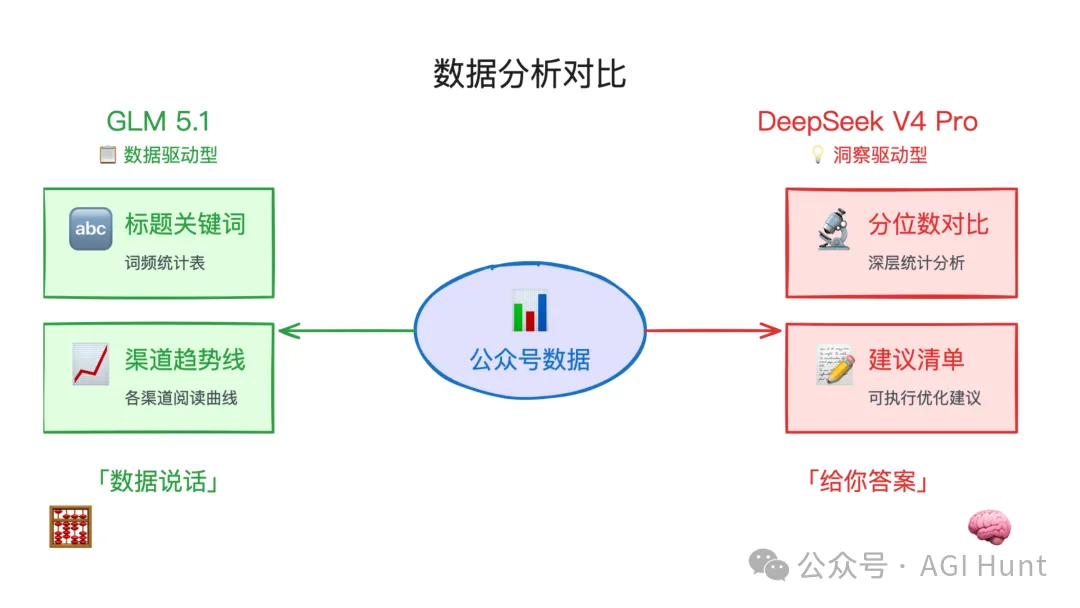
Claude Code 判定:呢輪 GLM 略勝。
分析維度更加多樣,對數據結構嘅理解亦更準確。DeepSeek 喺建議嘅可操作性上更強,但整體唔及 GLM 紮實。
(但我其實,更加傾向 DeepSeek 少少……,可能真係 GLM 更 Opus 啦,偏心咗 )
)
Case 4:儀錶板
最後一個測試:用同一份數據,生成一個可互動嘅 HTML 可視化儀錶板。
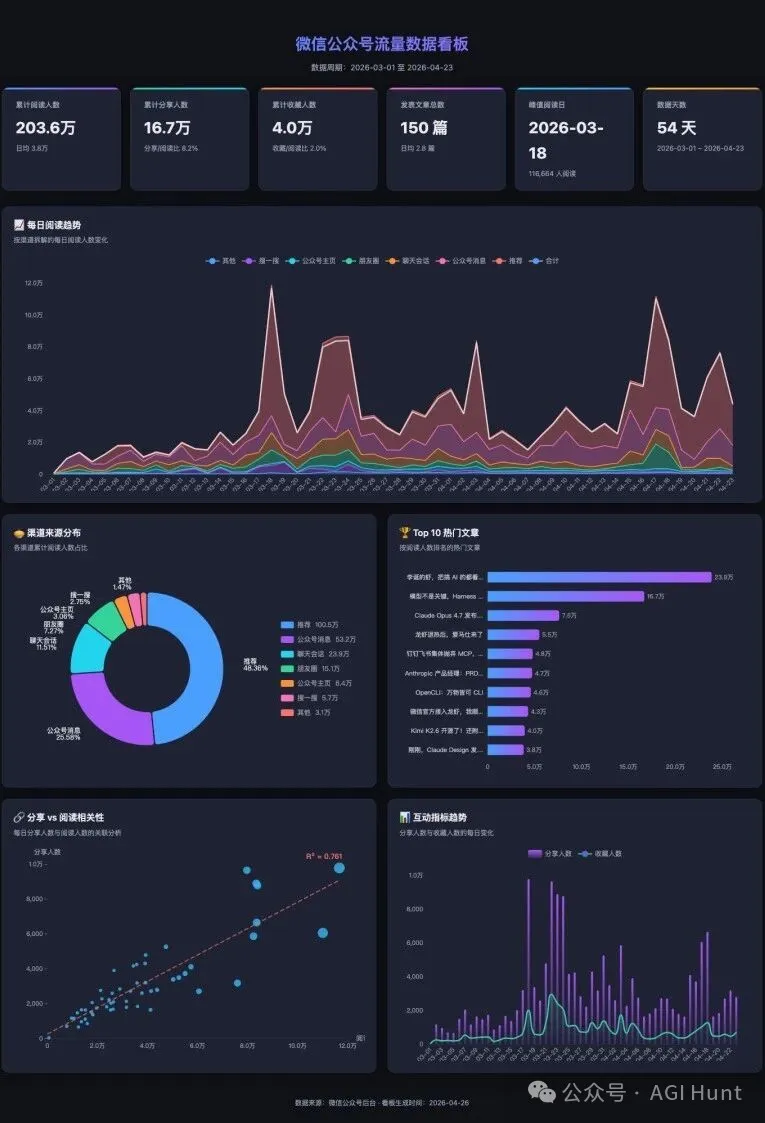
GLM 5.1 用 ECharts 做咗一個深色科技風格嘅儀錶板:6 個統計卡片、6 個圖表(堆疊面積趨勢圖、環形圓餅圖、橫向 Top 10 文章、散點回歸圖、互動指標趨勢圖)。圖表數量同資訊密度都比要求嘅更多更細緻。
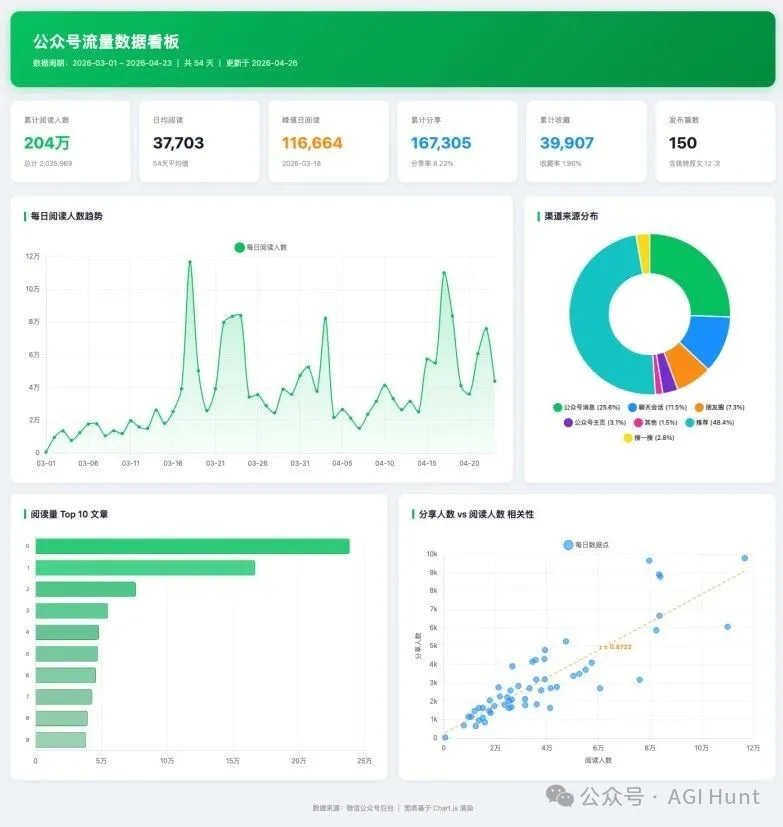
DeepSeek V4 Pro 就用 Chart.js 做咗一個淺色主題嘅儀錶板:微信綠配色,4 個圖表,整體更加簡潔更有微信味道。
甚至散點圖入邊仲有 R² 迴歸值。不過 Top 10 文章嘅條形圖只顯示咗序號,冇文章標題,算係一個小缺失(其實呢度有失偏頗,係 Claude Code 呢個裁判冇發現 hover 係睇到標題嘅……)。
Claude Code 判定:呢輪各有勝負。
GLM 嘅內容更豐富,6 個圖表涵蓋咗更多分析維度。DeepSeek 嘅 UI 配色更加貼合微信嘅視覺體系,望落更專業。
06速度差異
另外仲有一個好重要嘅差異:速度。
喺 Case 2 入邊,GLM 5.1 用咗 2 分鐘,DeepSeek V4 Pro 用咗 17 分鐘。其他幾個 case 都有類似嘅差距。
要知道,模型跑得快意味住工具調用嘅反饋循環更短,整體效率更高。GLM 喺 SWE-Bench Pro 上嘅第一名,可能同呢種「快速試錯、快速修正」嘅能力有關係。
當然,DeepSeek V4 Pro 目前嘅推理速度受限於算力,而且可能因為啱啱推出而過於火爆。喺 V4 嘅技術報告入邊都有提到,等華為昇騰 950 超級節點下半年大規模上線之後,Pro 嘅速度同價格都會有明顯改善。
07總成績
| 100% 測試通過,2 分鐘 | ||
| 分析維度更多 | ||
由呢 4 個 case 嚟睇,GLM 5.1 喺程式碼嘅可靠性同行效率上確實有優勢。DeepSeek V4 Pro 喺架構設計同分析深度上亦有自己嘅長處,但執行層面會出小問題。
呢個同社區嘅體感基本一致:喺非頂級模型(Claude、GPT 之外)嘅 coding 能力排名入邊,GLM 5.1 依然比較打得,排名靠前。而 DeepSeek 因為啱啱推出,雖然實力已經好強勁,但喺速度同模型優化方面仲需要繼續磨煉一下。
GLM 5.1 啱啱推出嗰陣,都俾人話速度太慢。而家明顯就快咗好多,希望/相信 DeepSeek 好快都可以追到上嚟。
08侷限
需要聲明嘅係,呢個只係 4 個 case 嘅測試,稱唔上全面嘅 benchmark。
Bug 修正只用咗一段程式碼,程式碼生成只測咗一種類型,數據分析同可視化亦只用咗一份數據。真正嘅全面評測需要成百上千個 case,呢個工作量唔係呢篇文章入邊嘅幾個 case 就可以全面覆蓋到。
以及裁判 Claude Code 本身,都有其侷限性。
另外,DeepSeek V4 喺多模態上目前確實仲有待補齊,呢個都係佢即將發力嘅方向。而 GLM 5.1 喺綜合能力上更加全面啲,尤其係喺實際工程任務入邊嘅表現。
不過呢兩間都在快速迭代,希望國產模型們,都可以卷得更勁啲,甚至喺 26 年內可以卷贏國外嘅兩間閉源模型。09
最後
另外,為咗公平公開,我仲叫 cc 將今次測試所有原始數據都開源咗:
每個 case 嘅輸入程式碼、prompt、兩個模型嘅完整輸出、對比報告,全部放曬喺 GitHub 上:
https://github.com/Johnixr/cc-model-bench
你可以用嚟對唔同模型自己行、自己比較、自己判斷。
當然,如果你有更好嘅測試 case,都歡迎直接 PR 嚟豐富呢個小 benchmark。◇ ◆ ◇
相關連結:
• GLM 5.1:https://huggingface.co/zai-org/GLM-5.1
• DeepSeek V4:https://huggingface.co/collections/deepseek-ai/deepseek-v4
• GLM Coding Plan:https://docs.z.ai/guides/llm/glm-5.1
• DeepSeek API:https://api-docs.deepseek.com
• 開源測試數據:https://github.com/Johnixr/cc-model-bench
DeepSeek V4 發佈時,在技術報告裏寫的非常真誠:在推理能力上,「落後前沿閉源模型大約 3 到 6 個月」。
而最近兩天,我的各個編程交流羣裏就開始了對 V4 和各家模型進行大量比較、討論。其中討論到的國產模型,最多的一個我看下來就是智譜的 GLM 了:
兩個國產開源模型,一個自己被認為更 Opus,一個主動承認差距……
而在月初的 GLM 5.1 發佈(GLM-5.1 上線,與 Opus 僅差,2.6 分)後,我也搞了個它的 Coding Plan 在用(當然我用的最多的還是 Claude Code 和 Codex,目前就用這三),那要不要切到 DeepSeek Coding Plan 呢?
說實話,其他人的實測我也不大會信,我還是希望自己動手感受。雖然我測也不一定全面……
索性,我就老辦法,使出我的慣用懶人招式:讓 Claude Code 自己出題自己當裁判,給兩個模型做了一次自動化的橫評對比。
01測試方法
當然不能直接調 API 來測,我選擇的是在 Claude Code 中來進行測試對比。
我一直有智譜的 GLM Coding Plan,就不用再充錢了。而為了這次測試我也是給 DeepSeek 小充了 200 塊錢,我完全不心疼,DeepSeek V4 的發佈,至少值得我充點錢致敬一下。
而我們知道,Claude Code 是支持通過 --settings 參數切換不同的模型後端,配置文件長這樣:
●●●
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的API key",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic"
}
}└
為了便於我們在 Claude Code 中使用,DeepSeek 和 智譜也都支持 anthropic 的協議並推出了對應的端點,所以換個 base URL 和模型名就可以直接使用了。
因為日常經常切換及懶,我在 shell 裏配了一堆 alias:
●●●
alias cc="claude --dangerously-skip-permissions"
alias ccg="claude --dangerously-skip-permissions --settings /path/to/settings_glm.json --model glm-5.1"└
平時就 cc 和 ccg 兩個命令來回切(當然還有個 cx = codex),我不用什麼 CC Switch 之類的花哨方案。如果你之前沒用過 alias,可以找個 AI 學一下,用過就會覺得……很香。
而整個測試,我全都是讓 Claude Code(Opus 4.7)自己完成的:讓它自己設計測試方案,自己寫 prompt,分別使用 GLM 5.1 和 DeepSeek V4 Pro 跑同樣的任務,最後自己評判結果。
整個過程我幾乎零動手,主要是花了 3 分鐘動嘴語音輸入要求,然後就是坐在旁邊看它自己跑。
(我現在很多測試、很多工作都是這麼做的……主打一個 0 人工介入。效果好不好另說,但一定得是省事的)
下面是 Claude Code 在準備測試材料的過程:
它自己創建了隔離目錄、寫好了 buggy code、轉換了數據格式,然後同時啓動了 4 個子 agent 並行跑測試。
多樣性方面,Claude Code 一共設置了 4 個 case,覆蓋 bug 修復、代碼生成、數據分析、可視化四個維度。
每個 case 兩個模型拿到完全相同的 prompt,在完全隔離的工作目錄裏各自完成任務。
公平競爭。
02Case 1:併發 Bug
第一個測試,是讓模型定位並修復一段有併發問題的 Python 連接池代碼,大約 150 行。
這段代碼模擬了一個生產環境裏常見的場景:異步 HTTP 連接池,帶自動重試和健康檢查。問題描述是「50+ 併發請求時偶發 connection pool exhausted 錯誤」。
當然,問題代碼也是 Claude 裁判給生成的。
裏面埋了幾個真實的併發 bug:semaphore 泄漏、TOCTOU 競態、未加鎖的計數器等。
GLM 5.1 找到了 5 個問題。
根因分析正確。特別是 semaphore 泄漏的根因分析,GLM 5.1 直接指出了「每次 acquire 失敗後 semaphore 永久丟失一個 slot,導致池子容量持續縮小」的正反饋循環。
GLM 5.1 在修復後自己跑了一遍測試,50 個併發 worker 全部通過,連接數精確等於 max_connections。
DeepSeek V4 Pro 也找到了 5 個問題。
前 3 個和 GLM 完全一致。不同的是第 4 個:DeepSeek 發現了一個 UnboundLocalError 的隱患,當 acquire() 在第一次重試時失敗,conn 變量可能還沒定義就進了 finally 塊。這個問題 GLM 沒有提到。
DeepSeek 還給每個 bug 標了嚴重等級(CRITICAL / HIGH / MEDIUM / LOW),分析文檔比 GLM 長了約 40%。
Claude Code 判定:這輪基本打平。
GLM 的修復更乾淨利落,DeepSeek 的分析更細緻。如果是交給團隊做 code review,兩份報告都能用。
03Case 2:從零寫代碼
第二個測試:從零實現一個生產級的滑動窗口 rate limiter。
Claude 給出的要求是:支持內存和 Redis 雙後端、多規則組合(比如 100 次/分鐘且 1000 次/小時)、線程安全、異步兼容、帶完整 pytest 測試。
GLM 5.1:2 分鐘完成,56 個測試全部通過。
代碼共 316 行,簡潔且夠用。測試覆蓋了基本限流、多規則、窗口滑動、併發安全等場景。不過有一個小瑕疵:README 裏的 API 示例和實際代碼對不上(文檔寫的是 is_allowed(),實際是 acquire())。
DeepSeek V4 Pro:17 分鐘完成,63/65 個測試通過。
代碼共 543 行,架構設計更成熟,有命名規則、定時清理、deque 做 O(1) 剪枝、條件化 Redis 導入等。
README 和代碼一致。但有 2 個測試失敗:一個是 frozen dataclass 的測試寫法有誤,另一個是清理定時器的競態。
Claude Code 判定:這輪 GLM 贏,贏在可靠性。
100% 測試通過 vs 96.9%,速度比 DeepSeek 快了 8 倍。DeepSeek 的架構想法更多,但……「想太多」有時候反而引入了新問題。
04Case 3:數據分析
第三個測試,Claude Code 找到了一個之前我讓它做過的工作,於是出的題完全換了個不同的方向。
它把我自己公眾號 AGI Hunt 近兩個月的流量數據(日均閲讀、渠道分佈、文章級別統計)扔給了兩個模型,讓它們各自寫一份數據分析報告。
GLM 5.1 的報告 287 行,亮點在三個地方。
它做了一個標題關鍵詞頻率表,統計關鍵詞的出現頻次和對應平均閲讀量……這對搞自媒體的人來說,還是挺實用的。
推薦渠道的增長時間線也有很細緻的追蹤:從 3 月上旬的 25.8% 到後來的 48.4%,再到高峯期接近 65%。
另外,它把 54 天的流量拆成了「起步期→爆發期→穩定期」三個階段,易讀易懂,清晰準確。
DeepSeek V4 Pro 的報告 372 行,篇幅更長,有一些獨到的分析。
它做了一個前後 25% 文章的分位數對比,發現社交分享渠道(聊天會話 + 朋友圈)在爆文中佔 18.3%,在普通文章中只有 6.6%。
從這裏得出了一個結論:決定文章能否爆發的,其實是社交分享,推薦算法只是放大器。
它還注意到 4 月 19 號一篇文章突破了 11 萬閲讀,但第二天沒有追發新內容,錯過了流量窗口(確實是我不會的技巧……)。
建議方面,也比 GLM 要更具體和可落地,而且帶有量化的閾值:「文章過 5 萬時 24 小時內追發」「內容配比 50/30/20」之類,真的比我專業太多了……
Claude Code 判定:這輪 GLM 略勝。
分析維度更多樣,對數據結構的理解也更準確。DeepSeek 在建議的可操作性上更強,但整體不如 GLM 紮實。
(但我其實,更傾向於 DeepSeek 一些……,可能確實 GLM 更 Opus 吧,偏心了)
Case 4:儀表盤
最後一個測試:用同一份數據,生成一個可交互的 HTML 可視化儀表盤。
GLM 5.1 用 ECharts 做了一個深色科技風的儀表盤:6 個統計卡片、6 個圖表(堆疊面積趨勢圖、環形餅圖、橫向 Top 10 文章、散點回歸圖、互動指標趨勢圖)。圖表數量和信息密度都比要求的更多更細緻。
DeepSeek V4 Pro 則用 Chart.js 做了一個淺色主題的儀表盤:微信綠配色,4 個圖表,整體更簡潔更有微信味道。
甚至散點圖裏還帶了 R² 迴歸值。不過 Top 10 文章的條形圖只顯示了序號,沒有文章標題,算是個小缺陷(其實這裏有失偏頗,是 Claude Code 這個裁判沒發現 hover 是能看到標題的……)。
Claude Code 判定:這輪各有勝負。
GLM 的內容更豐富,6 個圖表覆蓋了更多分析維度。DeepSeek 的 UI 配色更貼合微信的視覺體系,看着更專業。
06速度差異
另外還有一個很重要的差異:速度。
在 Case 2 中,GLM 5.1 用了 2 分鐘,DeepSeek V4 Pro 用了 17 分鐘。其他幾個 case 也有類似的差距。
要知道,模型跑得快意味着工具調用的反饋循環更短,整體效率更高。GLM 在 SWE-Bench Pro 上的第一名,可能和這種「快速試錯、快速修正」的能力有關係。
當然,DeepSeek V4 Pro 目前的推理速度受限於算力,且可能由於剛推出而過於火爆。在 V4 的技術報告裏也有提到,等華為昇騰 950 超級節點下半年大規模上線後,Pro 的速度和價格都會有明顯改善。
07總成績
| 100% 測試通過,2 分鐘 | ||
| 分析維度更多 | ||
從這 4 個 case 來看,GLM 5.1 在代碼的可靠性和執行效率上確實有優勢。DeepSeek V4 Pro 在架構設計和分析深度上也有自己的長處,但執行層面會出小問題。
這和社區的體感基本一致:在非頂級模型(Claude、GPT 之外)的 coding 能力排名裏,GLM 5.1 還是比較能打,排名靠前。而 DeepSeek 由於剛推出,雖然實力已然非常強勁,但在速度和模型優化方面還需要繼續打磨一下。
GLM 5.1 剛推出來時,也有被詬病速度太慢。現在顯然就快了巨多,希望/相信 DeepSeek 很快也能追上來。
08侷限
需要聲明的是,這只是 4 個 case 的測試,算不上全面的 benchmark。
Bug 修復只用了一段代碼,代碼生成只測了一種類型,數據分析和可視化也只用了一份數據。真正的全面評測需要成百上千個 case,這個工作量不是這一篇文章裏的幾個 case 就能全面覆蓋的。
以及裁判 Claude Code 自身,也有其侷限性。
另外,DeepSeek V4 在多模態上目前確實還有待補齊,這也是它即將發力的方向。而 GLM 5.1 在綜合能力上更全面一些,尤其是在實際工程任務中的表現。
不過這兩家都在快速迭代,希望國產模型們,都能卷得更猛一些,甚至能在 26 年內能卷番國外的兩家閉源模型。09
最後
另外,為了公平公開,我還讓 cc 把這次測試的所有原始數據都開源了:
每個 case 的輸入代碼、prompt、兩個模型的完整輸出、對比報告,全部放在 GitHub 上:
https://github.com/Johnixr/cc-model-bench
你可以用來對不同模型自己跑、自己對比、自己判斷。
當然,如果你有更好的測試 case,也歡迎直接 PR 來豐富這個小 benchmark。◇ ◆ ◇
相關連結:
• GLM 5.1:https://huggingface.co/zai-org/GLM-5.1
• DeepSeek V4:https://huggingface.co/collections/deepseek-ai/deepseek-v4
• GLM Coding Plan:https://docs.z.ai/guides/llm/glm-5.1
• DeepSeek API:https://api-docs.deepseek.com
• 開源測試數據:https://github.com/Johnixr/cc-model-bench