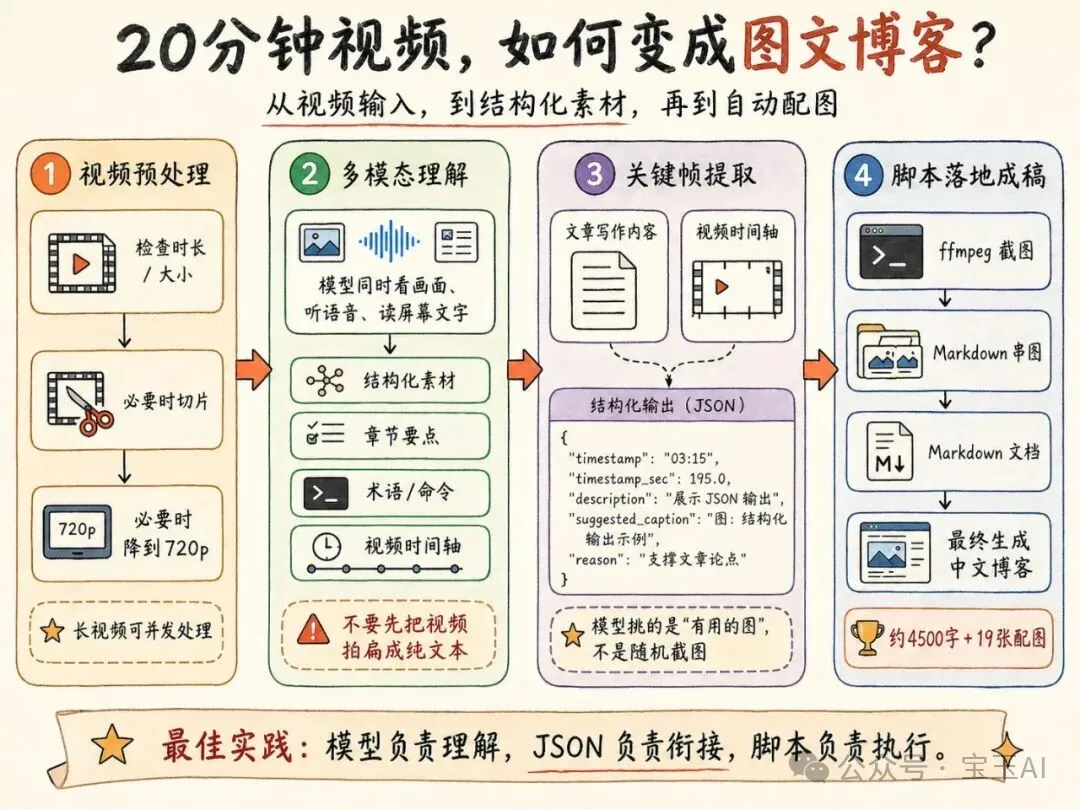
把視頻變成圖文博客:Agent + 豆包 Seed2.0 lite 重做 Karpathy 兩年前的工作流
整理版優先睇
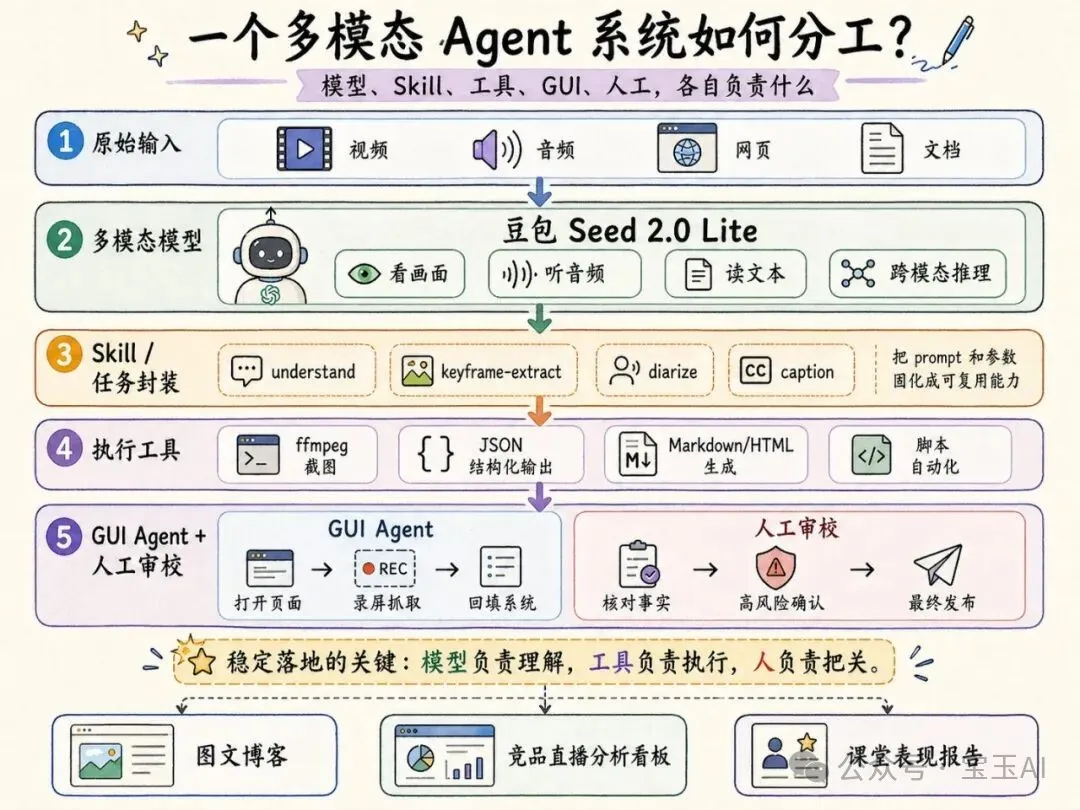
用多模態Agent工作流,將技術演講視頻自動轉成圖文並茂嘅博客,效率大幅提升
作者兩年前跟過Andrej Karpathy嘅推文,想將技術演講視頻自動轉成博客,但當時傳統ASR+LLM流水線效果唔穩定,因為每一步都丟失信息:ASR只剩文字,LLM睇唔到畫面,配圖又要另揾模型。最近作者受邀測試豆包Seed 2.0 Lite,呢款輕量全模態模型可以同時理解視頻、圖片、語音同文本,並做聯合推理。
作者重新嘗試同一任務,發現可以將工作流拆成四步:1) 長視頻切片但保留多模態;2) 先生成結構化素材,唔直接寫終稿;3) 根據文章反查視頻,自動挑選關鍵幀;4) 用ffmpeg截圖插入Markdown。呢個方法嘅核心係將視頻當成完整知識對象,模型負責理解判斷,工具負責確定性執行。
最終生成嘅博客圖文並茂,讀者可以搜索、掃讀、收藏。作者認為多模態理解已經從研究流水線變成可工程化複用嘅Agent工作流,適合課程視頻、會議錄屏、直播回放等場景。
- 多模態模型比傳統ASR+LLM流水線更適合技術視頻轉文章,因為能同時睇畫面、聽聲音、讀文字,唔會丟失關鍵信息。
- 將工作流拆成四步:切片保留多模態、生成結構化素材、反查視頻挑關鍵幀、用腳本截圖插入Markdown。
- 傳統流水線先將視頻壓縮成文本,新方法保留視頻、圖片、語音、文本於同一理解空間,效果更穩定。
- 多模態能力可以封裝成原子化Skill(如doubao-multimodal),自由組合,適用於競品分析、課堂報告、遊戲覆盤等場景。
- 如果你有課程視頻、會議錄屏、直播回放,可以試用豆包Seed 2.0 Lite,並採用四步流程同作者提供嘅Skill。
doubao-multimodal-skill
Bun + TypeScript CLI,封裝豆包Seed多模態chat completion endpoint,支援下載、切片、併發調用、結果合併、token統計,提供asr、caption、keyframe-extract等原子化task。
生成結構化素材嘅Prompt模板
「請基於呢段技術演講視頻,輸出一份用於撰寫中文技術博客嘅結構化素材。請同時利用畫面、語音同屏幕文字,唔好只總結語音。請至少包含:- 視頻主題同一句話摘要;- 按時間順序拆分嘅章節;- 每一章嘅講解重點;- 畫面中出現嘅關鍵證據,例如代碼、架構圖、命令、UI狀態;- 需要原樣保留嘅英文術語、命令、文件名、API名稱;- 唔確定或需要人工複核嘅點。」
內容片段
請不要直接一次性生成終稿。請按四個階段完成:
1. 先檢查視頻大小、時長和分辨率,必要時切片,但不要把視頻退化成純文本;
2. 先輸出結構化寫作素材,包括主題、段落、畫面證據、關鍵術語和不確定點;
3. 基於文章內容反查視頻,挑選適合作為配圖的關鍵幀,並解釋每張圖服務於哪個論點;
4. 用 ffmpeg 等確定性工具截圖,把圖片按順序插入 Markdown,最後檢查路徑和標題。從Karpathy嘅舊點子到新工具
兩年前,Andrej Karpathy想將自己2小時13分鐘嘅tokenizer教學視頻自動轉成一本書嘅章節或者一篇博客。作者當時都試過,但傳統流水線效果唔穩定。最近作者受邀提前測試Doubao-Seed-2.0-lite,第一時間攞返呢個任務出嚟試。
呢款輕量全模態模型可以同時理解視頻、圖片、語音同文本,並做聯合推理
傳統流水線嘅瓶頸
傳統做法係先用Whisper轉寫,再切成「圖像+文本」對齊嘅小段,然後用LLM改寫。但問題係效果唔穩定,因為每一步都喺度丟信息。
- 1 ASR只留低「講者講咗咩」,丟咗語氣、停頓、背景音同現場節奏。
- 2 LLM只讀到轉錄稿,睇唔到屏幕嘅代碼、圖表、PPT同UI。
- 3 配圖係另一個獨立任務,要人工挑幀或再引入視覺模型,最後仲要重新對齊文字、時間戳同截圖。
每個人都只拎到一部分上下文,出錯好正常
多模態Agent工作流:四步最佳實踐
作者將整個任務拆成四步,等模型負責理解判斷,工具負責確定性執行。以下係具體步驟:
- 1 長視頻切片但保留多模態:用ffmpeg自動切片,必要時降到720p,每個切片仍然保留視頻、畫面同音頻信息。
- 2 先輸出結構化寫作素材:要求模型輸出主題、章節、畫面證據、術語等,唔好直接憋終稿。
- 3 根據文章反查視頻,自動挑選關鍵幀:模型要解釋每張圖服務於邊個論點,輸出timestamp、description同reason。
- 4 用ffmpeg截圖,將圖片按順序插入Markdown:唔使模型諗點樣截圖,全部由確定性工具處理。
切片保留多模態信息,將問題變成多個可控嘅小任務
從博客到更多場景
呢套模式可以遷移到好多場景:多模態模型負責理解,Agent負責拆解任務,Coding能力負責生成頁面或報告。以下係三個例子:
- 競品直播追蹤:GUI Agent定時錄屏,多模態模型分析商品、價格、話術,Coding Agent生成HTML看板。
- 在線課堂報告:將課堂錄屏、學生語音、互動UI一齊分析,評估學生專注度同老師引導質素。
- 遊戲賽後覆盤:分析錄屏嘅槍聲、腳步聲、隊友語音、站位選擇,生成教練式覆盤報告。
如果模型可以同時睇畫面、聽聲音、讀文字,並且能將結果交畀Agent自動執行下一步,呢個工作流值得重新做一遍
侷限與總結
今次測試體驗幾好,但都有啲限制要講清楚。
- 1 輸入長度同大小仍然有限制:要切片同降解像度犧牲優雅換穩定。
- 2 長輸出穩定性要特別設計:拆階段,每步結構化輸出,避免一次性生成。
- 3 時間戳唔係幀級精確:如果要高清畫面,最好前後多截幾張候選幀做二次篩選。
- 4 技術文章最終需要人工審稿:尤其係英文轉中文時,術語翻譯同上文補充容易影響理解。
- 5 呢類能力適合異步深度理解,唔等於實時流式助手。
豆包Seed 2.0 Lite將視頻、圖片、語音、文本放埋同一個理解框架,又夠輕量適合封裝成Skill接入真實開發流程。對開發者嚟講,好多以前「諗得通但做好煩」嘅音視頻任務,可以重新做一遍。
兩年前,Andrej Karpathy 發過一條很有意思的推文。他想把自己 2 小時 13 分鐘的 tokenizer 教學視頻,自動轉換成一本書的章節,或者一篇關於 tokenizer 的博客。
這件事當時我也關注過,還動手嘗試過。那時候比較自然的實現流程大概是這樣:
1. 用 Whisper 給視頻轉寫; 2. 把視頻切成“圖像 + 文本”對齊的小段; 3. 用 LLM 一段段改寫成文章; 4. 導出成頁面,並給原視頻片段加引用連結。
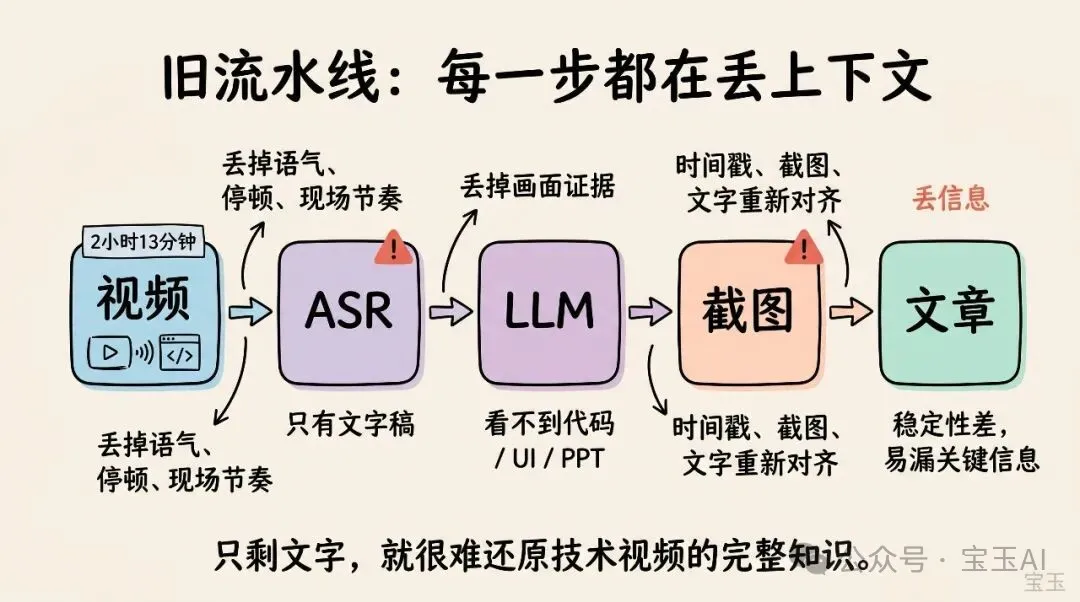
這個方案聽起來很合理,也確實能做。但問題是:效果往往不夠穩定,因為整條流水線的每一步都在丟信息。
ASR(自動語音識別),只留下了“說話的人說了什麼”,但丟掉了語氣、停頓、背景音和現場節奏;LLM 只能讀轉錄稿,看不到屏幕上的代碼、圖表、PPT 和 UI;配圖又是另一個獨立任務,要麼人工挑幀,要麼再引入視覺模型做畫面理解。最後還要把文字、時間戳、截圖重新對齊。
這就像請一個人只聽課堂錄音寫筆記,再讓另一個人只看 PPT 截圖挑插圖,最後讓第三個人把兩份結果拼起來。每個人都只拿到了一部分上下文,出錯很正常。
這件事當時雖然沒完全做成,但給我留下了很深的印象。因為它代表了一類很常見的需求:我們希望有一種把視頻重新整理成可閲讀、可搜索、可複用知識的方式。
最近受邀提前測試了 Doubao-Seed-2.0-lite,我第一時間又把這件事拿出來試了一遍。
Doubao-Seed-2.0-lite 是一款輕量級全模態理解模型。這裏的“全模態”是指模型能夠同時輸入並理解視頻、圖片、語音和文本,並在這些信號之間做聯合推理。換句話說,它不只是“看圖”“聽音頻”“讀文字”三個能力的簡單相加,更可以處理那些必須音畫結合才能判斷的問題。
Doubao-Seed-2.0-lite 模型的更多信息可以看官方的這篇文章:《Doubao-Seed-2.0-lite 升級,支持全模態理解》:
全模態理解:不止看懂圖文,更能聽懂世界
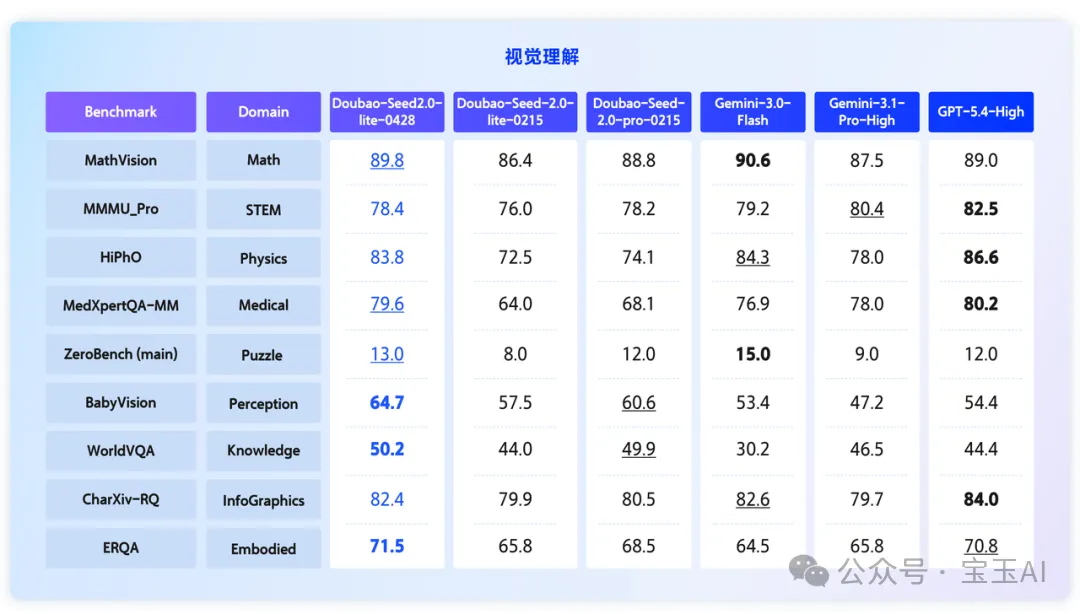
新版本的 Doubao-Seed-2.0-lite 繼續在視覺理解能力上大幅提升,在物理(HiPhO)、醫療(MedXpertQA)等高階學科推理上,表現大幅超越 2 月發佈的 Doubao-Seed-2.0-pro。在細粒度感知(BabyVision、WorldVQA)與具身理解(ERQA)等關鍵領域達到 SOTA 水平,更適合企業在高價值場景規模化部署。
視頻轉博客,正好就是這樣一個問題。
你看一場技術演講時,不會只聽聲音。你會看講者切到了哪一頁 slide,會看代碼裏哪幾行被高亮,會注意 demo 頁面有沒有真的跑起來,也會根據講者的語氣判斷他是在介紹背景、強調風險,還是現場調試失敗。一個真正好用的視頻轉博客系統,也應該儘量接近這種理解方式。
所以這次我做的不是“先轉文字,再讓 LLM 改寫”。我更想試的是:如果讓 Agent 擁有多模態理解能力,它能不能像一個認真看完視頻的技術編輯一樣,把視頻整理成一篇圖文並茂的博客?
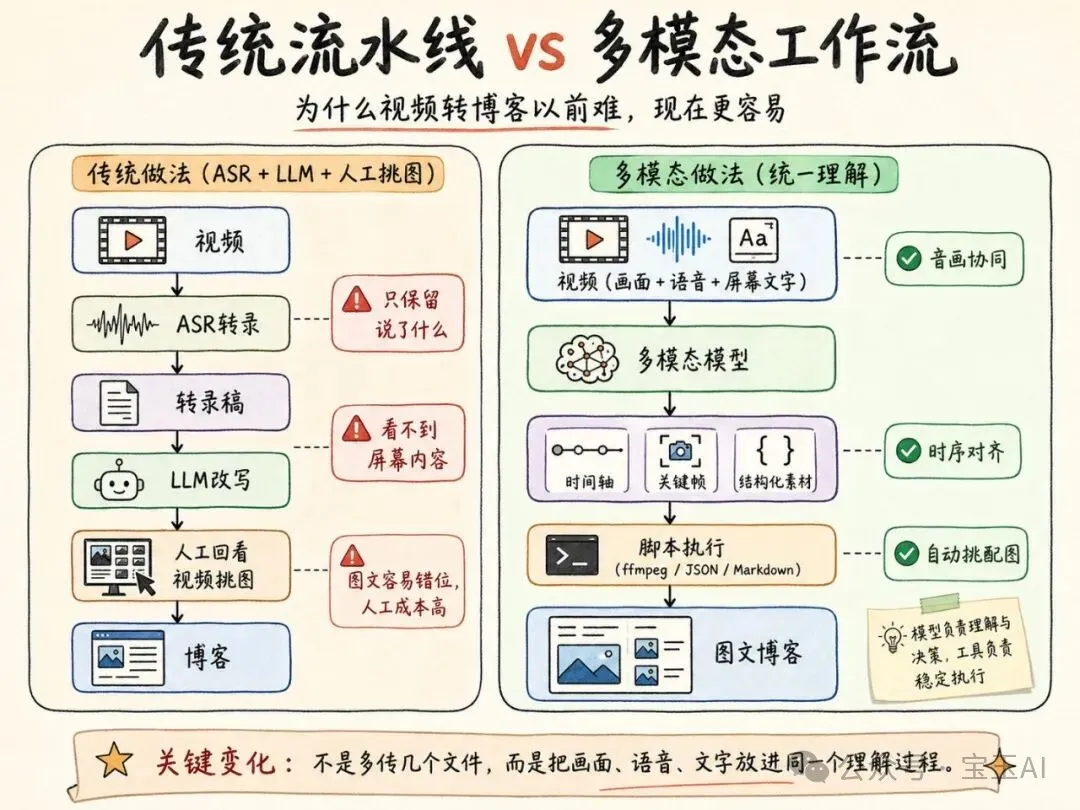
傳統的 ASR(自動語音識別)+ LLM 流水線,本質上是先把視頻壓縮成文本,再讓模型基於文本寫文章。這對純訪談、播客、會議紀要已經很有用,但對技術視頻會遇到天然瓶頸。
技術視頻裏的大量關鍵信息並不在語音裏,而在畫面裏:
• slide 上的架構圖; • 終端裏剛跑出的命令; • IDE 裏被修改的那幾行代碼; • GitHub issue、PR、Action runner 的狀態變化; • demo 頁面裏一個按鈕、表單、報錯、加載狀態的變化。
這些信息如果在第一步就沒有進入模型上下文,後面再怎麼 prompt engineering,都只能補救,很難真正還原。
多模態模型的價值,是把“音頻”“畫面”“屏幕文字”“上下文文本”放到同一個理解空間裏。它可以同時回答三類問題:
• 講者剛才說了什麼? • 畫面上現在出現了什麼? • 這兩件事合在一起,真正表達的技術含義是什麼?
這也是我這次測試 Doubao-Seed-2.0-lite 時最明顯的體感:它不僅能把視頻轉成一段文字,還可以把視頻當成一個完整的知識對象來處理。
先給 Agent 裝一個多模態 Skill
這兩年大模型領域除了多模態能力的提升,另一個重要變化是 Agent 能力也進步了很多。
以前做這類工作流,需要自己寫一堆膠水代碼:下載視頻、轉碼、切片、上傳、調用模型、解析 JSON、截圖、插圖、保存文件,還要人工檢查哪裏失敗了。現在更自然的方式,是把這些能力封裝成一個 Skill,讓 Agent 在需要的時候自己調用。
有人可能會問:Agent 自身不是也可以有多模態能力嗎?
這取決於 Agent 背後的模型。有些 Agent 底層模型主要擅長文本和代碼,不一定能直接理解視頻;有些模型支持圖像,但不一定支持長視頻和音頻;也有一些模型支持得很完整,但成本可能不適合高頻、批量任務。
把多模態能力做成 Skill 的好處是:
• 如果 Agent 自身沒有視頻理解能力,它可以藉助 Skill 獲得這項能力; • 如果 Agent 自身有多模態能力,也可以把輕量模型作為更便宜的批處理工具; • 如果你經常做類似任務,可以把穩定下來的流程沉澱成 Skill,而不是每次從零寫 prompt。
我寫了一個 Skill,叫 doubao-multimodal(https://github.com/JimLiu/doubao-multimodal-skill)。它裏面是一個 Bun + TypeScript 寫的 CLI,封裝 Doubao-Seed 的多模態 chat completion endpoint。它接收本地文件或遠程 URL,自動處理下載、本地文件上傳到雲端、視頻切片、併發調用、結果合併、token 統計等工程細節。
我把常用能力拆成了幾類 task:
asr | ||
asr-timestamp | ||
multispeaker-asr | ||
diarize | ||
caption | ||
video-timeline | ||
keyframe-extract | ||
understand |
注意,這裏我沒有做一個專門的“視頻轉博客”Skill,而是把能力拆成一組原子化 task。好處是:這些 task 可以自由組合,不只服務於博客寫作——換一套 prompt 和輸出格式,同一個 Skill 就可以用在轉寫報告、競品分析、課堂記錄、遊戲覆盤等完全不同的場景裏。
有了這些原子化能力,Agent 不需要每次都重新發明輪子。它只要知道“現在要做的是轉寫、打軸、整體理解,還是關鍵幀抽取”,就可以選擇合適的 task 和 prompt。
這套四步流程,是和 Agent 一起跑出來的最佳實踐
回到“視頻轉博客”這個場景。現在我只需要給 Agent 一個很短的指令:
/doubao-multimodal 幫我基於 <~/downloads/xxx.mp4> 這個視頻寫一篇中文技術博客,內容翔實,要圖文並茂,保存到 out 下,新建一個目錄,包括 markdown 和 imgs。如果 Agent 背後的模型足夠聰明,它有時候會自己摸索出一條不錯的流程,甚至一步到位完成:分析視頻、寫文章、挑截圖、保存文件。
但在實際工作裏,我更建議把這件事明確拆成四步。因為這四步是我和 Agent 反覆實踐後得到的穩定做法:讓模型負責理解和判斷,讓工具負責確定性執行;先生成可檢查的中間結果,再生成最終文章。
如果你只是偶爾寫一篇,可以在提示詞裏直接引導 Agent:
請不要直接一次性生成終稿。請按四個階段完成:
1. 先檢查視頻大小、時長和分辨率,必要時切片,但不要把視頻退化成純文本;
2. 先輸出結構化寫作素材,包括主題、段落、畫面證據、關鍵術語和不確定點;
3. 基於文章內容反查視頻,挑選適合作為配圖的關鍵幀,並解釋每張圖服務於哪個論點;
4. 用 ffmpeg 等確定性工具截圖,把圖片按順序插入 Markdown,最後檢查路徑和標題。如果你經常要做視頻轉文章,那就不應該每次都把這段 prompt 重新打一遍,而應該把它沉澱成 Skill:固定 task、固定輸出 schema、固定重試邏輯、固定文件結構。這樣 Agent 每次做的時候就不會“自由發揮”,而會調用一套可複用的工作流。
下面展開講這四步。
第一步:長視頻切片,但不把視頻“拍扁”成純文本
模型單次輸入通常會有時長和大小限制,所以 Skill 會先檢查視頻。如果視頻超過 20 分鐘或 50 MB,就用 ffmpeg 自動切片;如果分辨率高於 720p,就下采樣到 720p;切片後併發調用模型,再按時間順序合併結果。
這裏有一個關鍵點:切片不是轉寫。
切片只是為了讓輸入更穩定、更容易被模型處理,但每個切片仍然保留視頻、畫面和音頻信息。也就是說,模型在處理每一段時,仍然可以看到 slide、代碼、UI 和聽到講者聲音,而不是隻能讀一段 ASR 文本。
這一步看起來像工程細節,但它直接決定了後面的穩定性。長視頻硬塞給模型,容易遇到輸入限制;把長視頻先壓成文字,又會丟掉畫面。切片保留了多模態信息,同時把問題變成多個可控的小任務。
第二步:先讓模型生成“文章素材”,而不是直接憋終稿
很多人第一次用模型寫文章時,會直接說:“請根據這個視頻寫一篇漂亮的博客。”
短視頻可能還行,但長視頻不建議這麼做。更穩定的方式,是先讓模型輸出結構化素材:主題是什麼、視頻分成哪幾段、每段畫面出現了什麼、講解重點是什麼、哪些命令和術語應該保留、哪些結論只是推論,不能過度發揮。
這個 prompt 的核心是要先把事實邊界整理清楚:
請基於這段技術演講視頻,輸出一份用於撰寫中文技術博客的結構化素材。
請同時利用畫面、語音和屏幕文字,不要只總結語音。
請至少包含:
- 視頻主題和一句話摘要;
- 按時間順序拆分的章節;
- 每一章的講解重點;
- 畫面中出現的關鍵證據,例如代碼、架構圖、命令、UI 狀態;
- 需要原樣保留的英文術語、命令、文件名、API 名稱;
- 不確定或需要人工複核的點。這一步相當於讓模型先當“研究助理”,而不是直接當“作者”。
對長視頻來說,這非常重要。因為一個好的技術博客是要重新組織知識而不是僅僅把視頻逐句翻譯:該合併的地方合併,該補上下文的地方補上下文,該保留命令和術語的地方不要漏,該提醒不確定性的地方不要瞎編。
拿到結構化素材後,Agent 再進入寫作階段,把素材改寫成中文博客初稿。這樣寫出來的文章通常比一步到位更穩定,也更容易檢查。
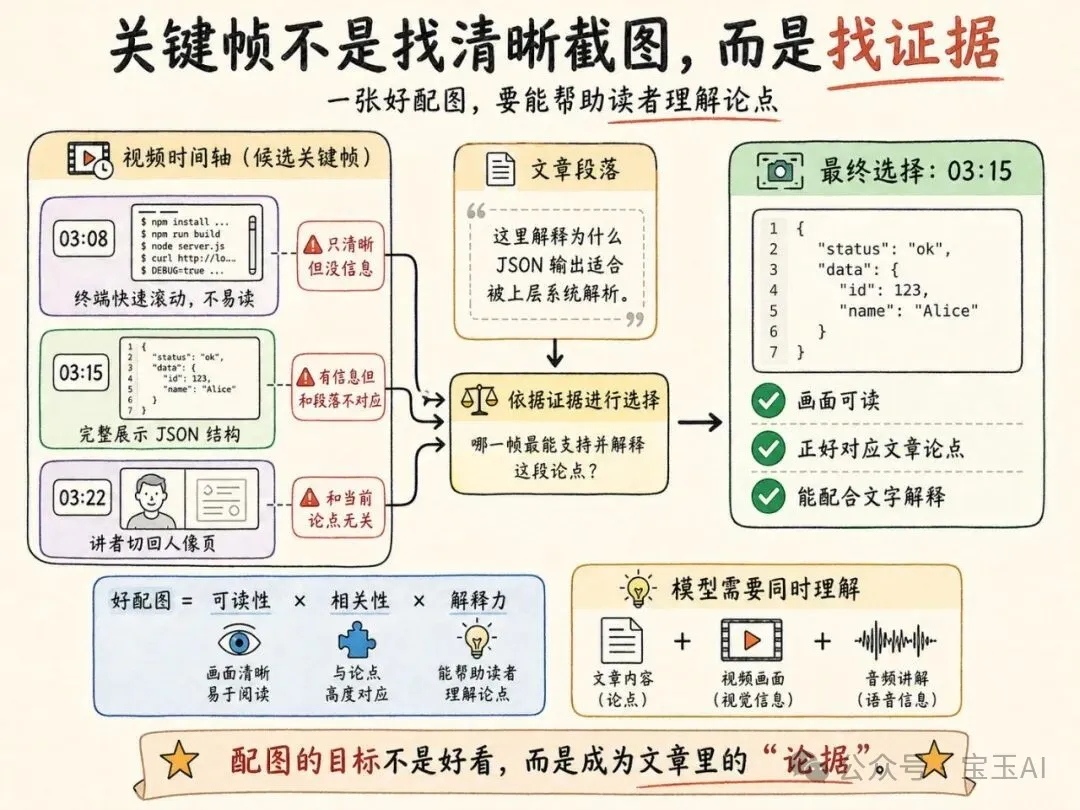
第三步:根據文章反查視頻,自動挑關鍵幀
文章初稿出來後,下一步是讓 Agent 把“文章內容”和“原視頻”一起交給同一個多模態模型,讓它為博客挑配圖。
這一步的輸出的是結構化 JSON:
{
"keyframes": [
{
"timestamp": "03:15",
"timestamp_sec": 195.0,
"description": "VS Code 中出現完整命令行輸出,展示 JSON 結構",
"suggested_caption": "圖:結構化輸出示例",
"reason": "對應文章中關於 JSON / stream-json 可被上層系統解析的論點"
}
]
}這裏最重要的字段是 reason。
description 只是告訴你“畫面裏有什麼”;reason 則要求模型解釋“為什麼這一幀應該放進文章”。換句話說,模型必須同時回答三件事:
• 文章這一段在講什麼? • 視頻這個時刻畫面裏有什麼? • 這張圖能不能幫助讀者理解這個論點?
這正是傳統 ASR + LLM 流水線很難做好的地方。
比如生成結果裏的第一張圖,是視頻開頭的標題頁:

它適合作為第一張圖,因為它第一次完整呈現了演講主題,是後文所有內容的視覺錨點。
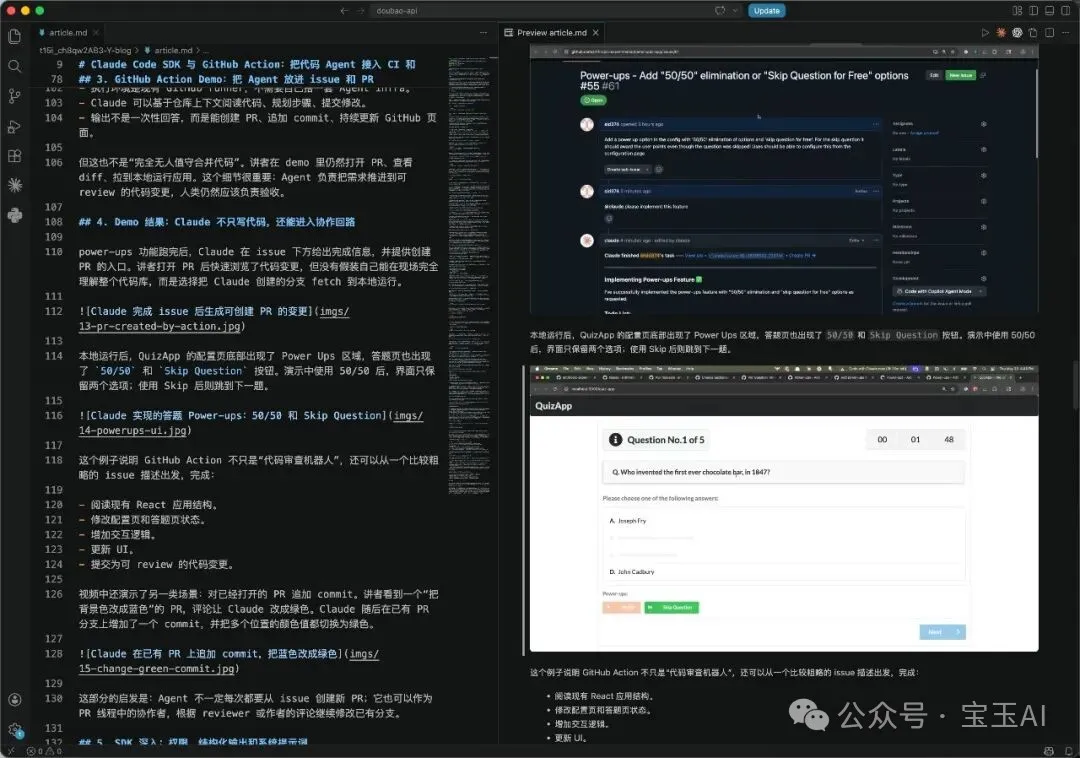
再比如 GitHub Action demo 部分,模型挑到了 issue 觸發、Action run、todo list 這類畫面:
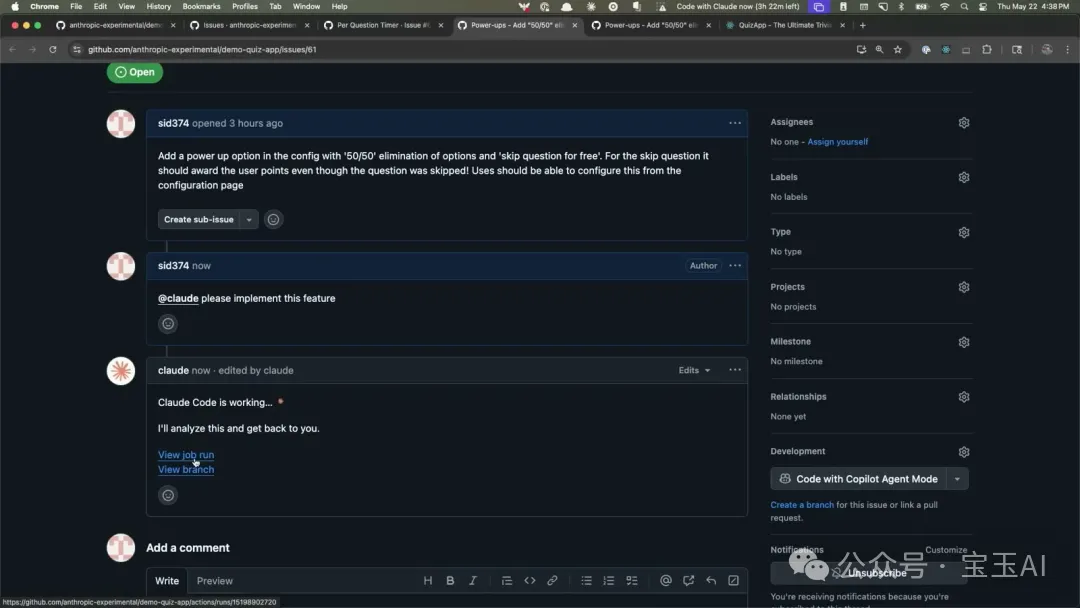
這些圖能幫助讀者理解:Agent 會真的進入 GitHub issue、PR、runner 這套工程協作流程裏,把需求推進成可 review 的代碼變更。
這一步也是多模態模型最有價值的地方:它會讀過文章、理解過視頻,再反過來選擇最能支撐論點的畫面。
第四步:用 ffmpeg 截圖,把圖片插回 Markdown
拿到關鍵幀 JSON 後,剩下的就是機械活:用 timestamp_sec 調 ffmpeg 截圖,然後把圖片按順序插進 Markdown。
這裏不需要再讓模型“想辦法截圖”。截圖、命名、保存、插入路徑,都應該交給確定性工具。
mkdir -p imgs
i=0
jq -r '
(.segments[0].text | fromjson | .keyframes[]) |
[.timestamp_sec, .suggested_caption] | @tsv
' out/keyframe-extract.json |
while IFS=$'\t' read -r ts caption; do
i=$((i + 1))
file=$(printf "%02d.jpg" "$i")
ffmpeg -hide_banner -loglevel error \
-ss "$ts" -i talk.mp4 \
-frames:v 1 -q:v 2 "imgs/$file"
printf "%s[%s](imgs/%s)\n\n" "!" "$caption" "$file" >> frames.md
done如果視頻被切成了多段,還需要注意一個小細節:模型返回的 timestamp_sec 可能是分段內的局部時間戳。穩妥做法是讓 Skill 在合併結果時把 segment.start_sec 加回去,統一轉換成原視頻的全局時間戳。
這一步沒有什麼“AI 魔法”,但非常重要:一個好用的多模態 Agent 工作流,不應該把所有事情都塞給模型。模型負責理解和決策,腳本負責穩定執行。
最終博客長什麼樣?
這次測試的視頻是一段 20 分鐘左右的英文技術演講,主題是 Building headless automation with Claude Code[1]。生成出來的文章標題是:
Claude Code SDK 與 GitHub Action:把代碼 Agent 接入 CI 和 GitHub 協作流
開頭幾段大概是這樣:
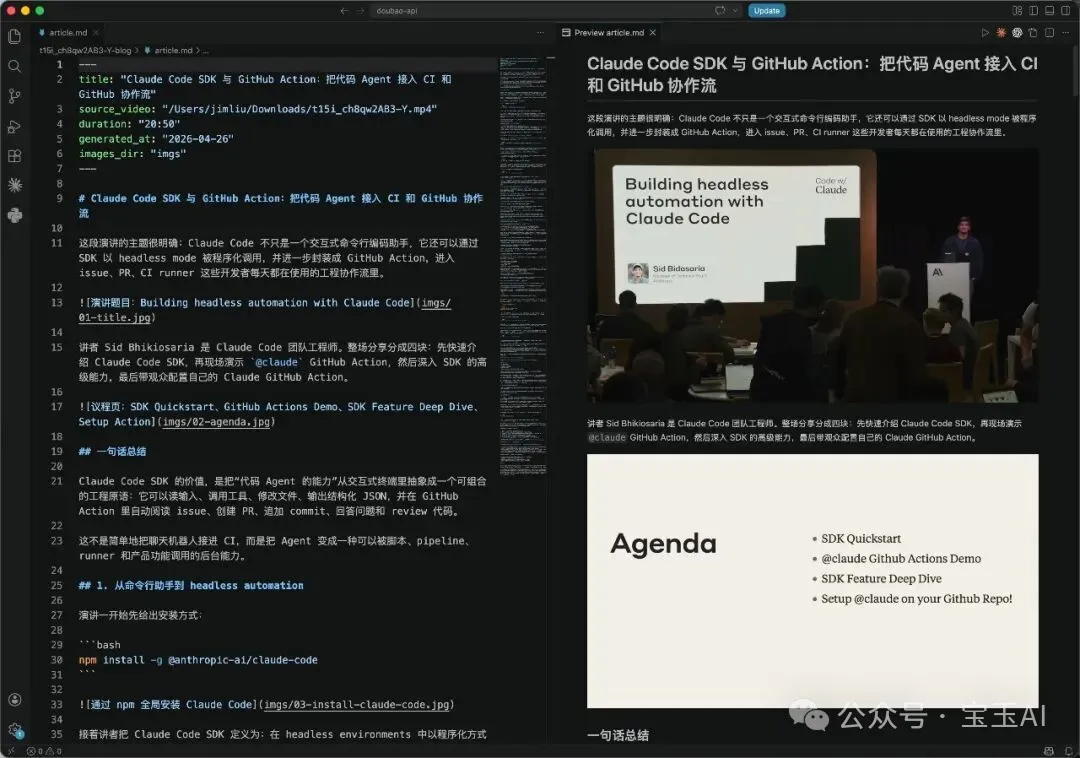
文章中間會穿插對應截圖。例如講到 Power-ups 功能時,配圖是能直接看到 `50/50` 和 `Skip Question` 按鈕的最終效果:
講到 Action 架構時,配圖則是三層結構:Claude Code SDK、Base Action、PR Action。
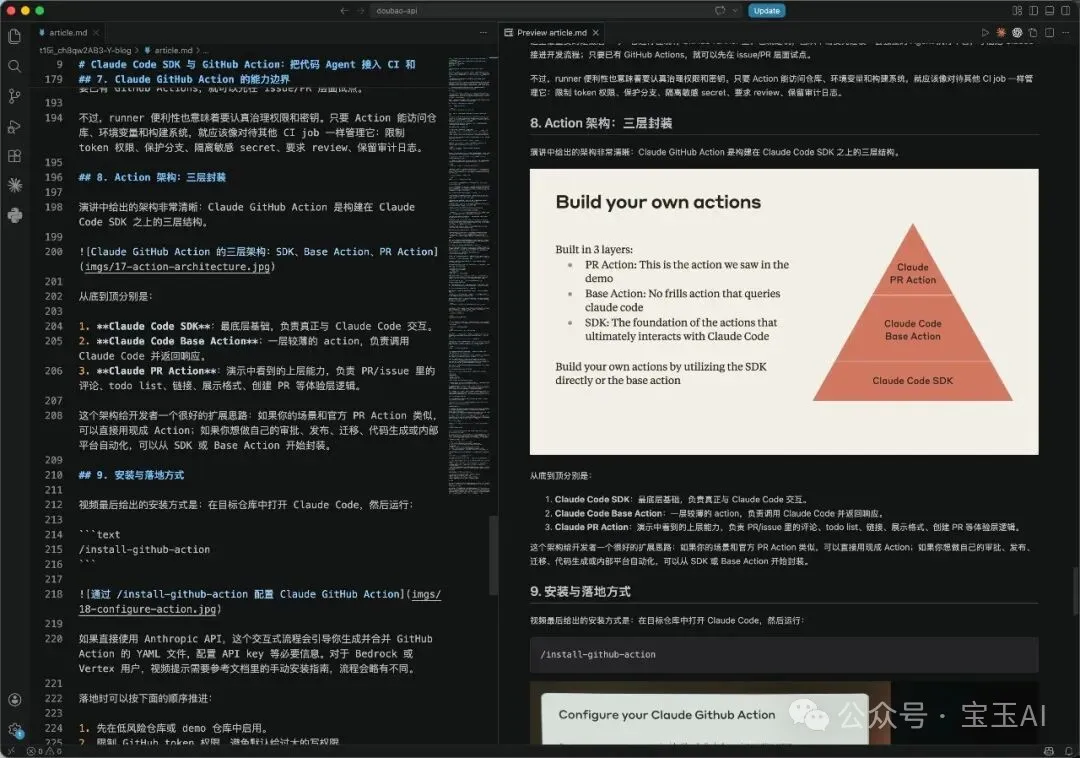
這類圖片對讀者很有價值。因為技術博客不僅僅是把視頻“翻譯成文字”,還要幫讀者節省時間:該看的圖直接放出來,該解釋的概念重新組織,該保留的命令和術語不要漏。
從讀者角度看,最終得到的是一篇可以搜索、可以收藏、可以快速掃讀的文章;從作者角度看,原來需要人工看視頻、暫停、截圖、整理大綱、改寫的過程,被壓縮成了一套 Agent 可以執行的工作流。
這套方法的侷限
這次 Doubao-Seed-2.0-lite 的多模態測試體驗給我感覺非常不錯,但也有一些侷限需要說清楚。多模態模型是把很多過去做不了、或者成本很高的事情,變成了可以工程化處理的事情。
* 第一,輸入長度和大小仍然有限制。 長視頻、高清錄屏、大體積文件不適合直接一次性塞給模型。我的做法是先切片、必要時降到 720p,再併發處理,最後把結果按時間線合併。這樣犧牲了一點端到端的“優雅”,但換來了穩定性。
* 第二,多模態輸出的形式可以很豐富,但長輸出的穩定性仍然要特別設計。 讓模型一次性輸出一篇很長的文章、幾十張圖、複雜 JSON 和完整文件結構,失敗概率會變高。更穩的做法是拆階段:先素材,再文章,再關鍵幀 JSON,再由腳本落盤。每一步輸出都儘量結構化、可解析、可重試。
* 第三,時間戳不是永遠幀級精確。 模型能定位“大概哪個時刻適合截圖”,但如果你對畫面清晰度要求很高,最好在 `timestamp_sec` 前後再取幾張候選幀,讓 Agent 或腳本做二次篩選。
* 第四,技術文章最終仍然需要人工審稿。 模型能幫你理解視頻、整理結構、保留術語、挑圖,但涉及具體 API、版本、命令、事實判斷時,發佈前最好人工過一遍。尤其是英文技術視頻轉中文文章,術語翻譯和上下文補充很容易影響讀者理解。
* 最後,這類能力更適合異步深度理解,不等同於實時流式音視頻助手。 像“錄完一節課後生成報告”“看完一場直播後出分析”“處理完一段演講後寫博客”這樣的場景很適合;如果要邊看邊實時反饋,就還需要另外的實時系統設計。
不只視頻博客:還可以怎麼用?
“視頻轉圖文博客”只是一個比較直觀、也比較適合開發者理解的精品 Demo。真正有意思的是,這套模式可以遷移到很多場景:多模態模型負責理解,Agent 負責拆解任務,GUI / Browser Use 負責採集和操作,Coding 能力負責把結果生成頁面、看板或報告。
1. 競品直播追蹤:GUI 採集 + 多模態理解 + 看板生成
比如海外電商團隊想分析競品直播。過去這件事很依賴人工:運營要定時進入直播間,記錄商品、價格、促銷話術、逼單節奏,再整理成表格。
放到 ArkClaw 或 Hermes Agent 這樣的框架裏,流程可以變成:
1. GUI Agent 定時打開直播平台,搜索指定競品賬號,進入直播間並錄屏; 2. Agent 抓取商品列表、價格、優惠信息,同時保存直播視頻; 3. Doubao Seed 2.0 Lite 對錄屏做多模態理解:看畫面上的商品、聽主播話術、識別價格變化和促銷節點; 4. Coding Agent 把分析結果生成 HTML 看板,展示不同場次的商品節奏、轉化話術、價格策略和高光片段; 5. Agent 把報告連結發到飛書或 Slack。
這裏如果只有 ASR,就只能得到主播說了什麼;如果只有截圖,就不知道主播當時在強調什麼。必須把畫面、音頻和時間線結合起來,才能分析“這個商品為什麼在這個時刻被重點推”。
2. 在線課堂報告:學生表現不是隻看答對沒答對
在線教育裏也有類似需求。比如一節英語直播課結束後,家長想知道孩子這節課表現如何。傳統系統可以統計答題正確率,但很難判斷孩子是否專注、回答是否流暢、發音是否猶豫、老師是否及時引導。
多模態 Agent 可以把課堂錄屏、學生語音、老師語音和互動 UI 放在一起分析:
• 學生回答了什麼,是否聽懂問題; • 回答是否流暢,是否有長時間停頓; • 發音、語調和情緒是否穩定; • 畫面裏是否頻繁走神、低頭、離開屏幕; • 老師有沒有及時反饋和追問。
最後由 Coding Agent 生成一份家長能看懂的課後報告:本節課知識點、孩子高光時刻、需要複習的內容、老師建議。對教研團隊,也可以生成另一份老師表現反饋。
這個場景的關鍵同樣不僅要“把課堂錄音轉成文字”,還要把聲音、畫面、互動狀態一起理解。
3. 遊戲賽後覆盤:錄屏、隊友語音和事件時間線一起看
遊戲覆盤也是很適合三模態理解的場景。以 CS2 這類遊戲為例,一場比賽裏有槍聲、腳步聲、隊友報點、經濟系統、道具使用、站位選擇、擊殺時機。只看錄像會漏掉語音,只聽語音又看不到站位和畫面。
Agent 可以在賽後處理整場錄屏:先切成多個 round,再分析每一局的經濟選擇、道具使用、準星位置、隊友溝通、關鍵失誤和高光操作。最後生成一份像教練寫的覆盤報告,告訴玩家:哪一局該保槍,哪一次道具丟早了,哪一次聽到了腳步但沒有及時反應。
這種任務對實時性要求不一定高,但對長程視頻理解、多模態線索追蹤和結構化輸出要求很高,正是輕量全模態模型適合進入生產的地方。
最後
回頭看 Karpathy 兩年前那條推文,他說這個想法“feels tractable but non-trivial”。
兩年後,我的感受是:它仍然不是一個“丟進去就完事”的玩具任務,但已經從一個複雜的研究型流水線,變成了一個可以工程化複用的 Agent 工作流。
變化的核心,不只是模型更強了,而且多模態理解開始變成一種可組合的工程原語。
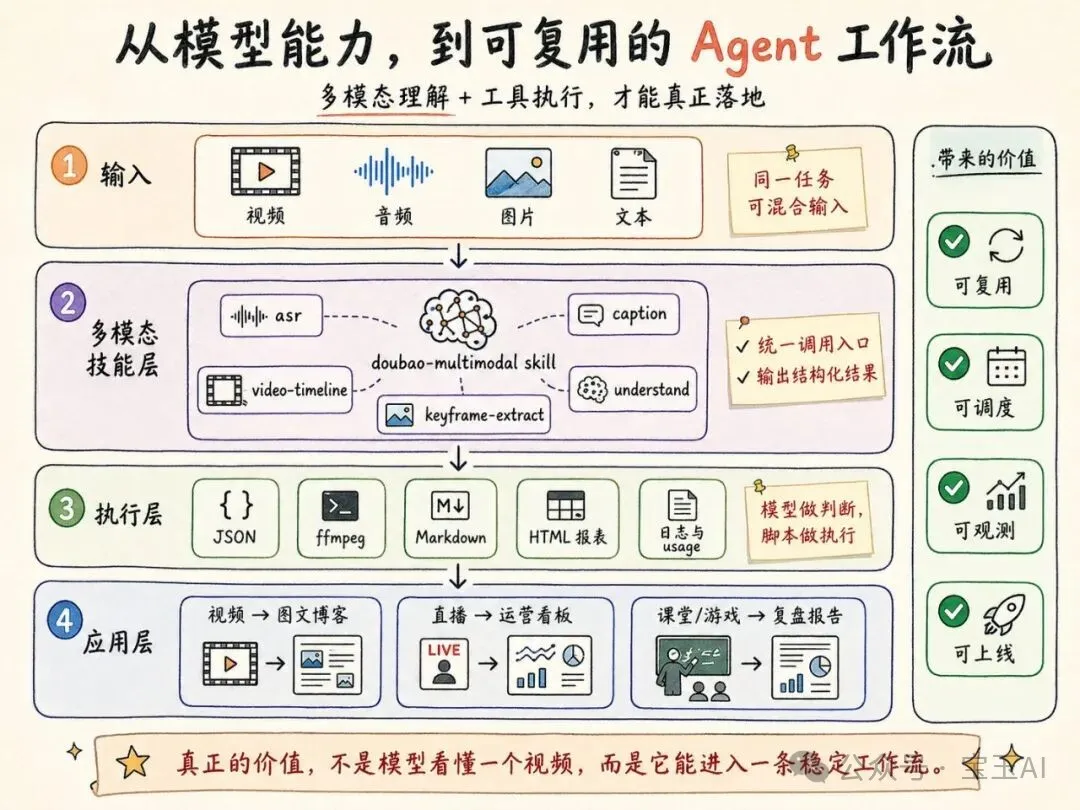
以前我們會把視頻拆成音頻、文字、截圖,再讓不同模型分別處理;現在更自然的方式是讓模型直接理解同一個事件的多個模態,再把結果以結構化形式交給 Agent 和工具鏈繼續處理。
豆包 Seed 2.0 Lite 0415 讓我印象最深的地方也在這裏:它不僅只在某個單點能力上更進一步,還把視頻、圖片、語音、文本放進同一個理解框架裏,同時又足夠輕量,適合被封裝成 Skill,接入 Agent、Coding、GUI 這些真實開發流程。
對開發者來說,這意味着很多過去“能想明白,但實現很麻煩”的音視頻任務,開始值得重新做一遍。
你手裏如果有課程視頻、會議錄屏、直播回放、產品演示、遊戲錄像、客服質檢視頻,不妨問自己一個問題:
如果模型能同時看畫面、聽聲音、讀文字,並且能把結果交給 Agent 自動執行下一步,這個工作流還能不能重做一遍?
這可能才是多模態模型真正進入生產的開始。
引用連結
[1] Building headless automation with Claude Code: https://www.youtube.com/watch?v=dRsjO-88nBs