拆完370個GPT-Image-2爆款案例,我精煉了一個skill
整理版優先睇
從370個案例提煉結構化提示詞協議,解決GPT-Image-2出圖唔穩定嘅問題,封裝成Skill自動化生成
呢篇文章嘅作者拆解咗370幾個GPT-Image-2爆款案例,發現出圖唔穩定嘅源頭唔係模型本身,而係提示詞冇結構。佢逆向提煉出16類場景嘅「必填槽位」,再封裝成一個WorkBuddy Skill——GPT-Image-2 Prompt Forge。
作者指出兩個最常見嘅翻車位:第一係信息流失——散文式描述成日漏咗材質、光線、構圖呢啲關鍵,模型要自由發揮,結果次次風格唔同。第二係中文文字渲染——唔顯式聲明字體同語言,出嚟啲字亂碼或者變繁體。佢嘅Forge透過場景路由、槽位填充同Pitfall Lint檢查,自動補齊默認值同提醒缺失,確保每次輸出穩定。
整體結論係:提示詞唔係寫作文,而係寫協議。你要好似填表咁逐項確認,模型先至唔會亂估。作者嘅Skill輸出英文提示詞、JSON格式同備選方案,用家只需一句話描述需求,Forge就自動編譯出可用嘅prompt。
- 結論:出圖唔穩定嘅主因係提示詞冇結構,唔係模型廢。
- 方法:拆解370+案例提煉16類場景嘅必填槽位,將提示詞從散文變成協議。
- 差異:結構化提示詞穩定輸出,散文式每次風格飄忽。
- 啟發:提示詞要好似填表咁逐項確認,缺槽位會導致模型自由發揮。
- 可行動點:用Skill自動生成英文提示詞,直接貼上zenmux.ai出圖。
開源項目:awesome-gpt-image-2
370+個GPT-Image-2爆款案例,按場景逆向拆解,提煉出16類場景嘅必填槽位。
免費出圖平台:zenmux.ai
支援GPT-Image-2模型,註冊有免費額度。
Skill下載:GPT-Image-2 Prompt Forge
WorkBuddy用嘅Skill,作者練好咗,直接導入就用。
出圖唔穩定嘅真正原因
作者指出,GPT-Image-2出圖最大嘅問題唔係模型唔夠勁,而係提示詞冇結構。同樣嘅需求,散文式描述每次出圖風格都飄,人哋用結構化協議就一次到位、批次穩定。差距唔在「寫得好唔好」,而係「寫得啱唔啱」。
- 1 信息流失:你講「高級感電商主圖,貓糧,突出凍乾」,但缺咗材質關鍵詞(磨砂塑料?亮面?)、光線關鍵詞(柔光箱?輪廓光?)、構圖角度(3/4俯視?平視?),模型會自由發揮,次次補出嚟嘅結果都唔同。
- 2 中文文字渲染:370個案例入面最多人中招嘅坑。唔顯式鎖定字體同語言,出嚟啲字亂碼、變繁體或者被日文漢字取代。加句「所有畫面文字用簡體中文渲染」就搞掂,但好多人唔知要咁寫。
從散文到協議嘅三步轉換
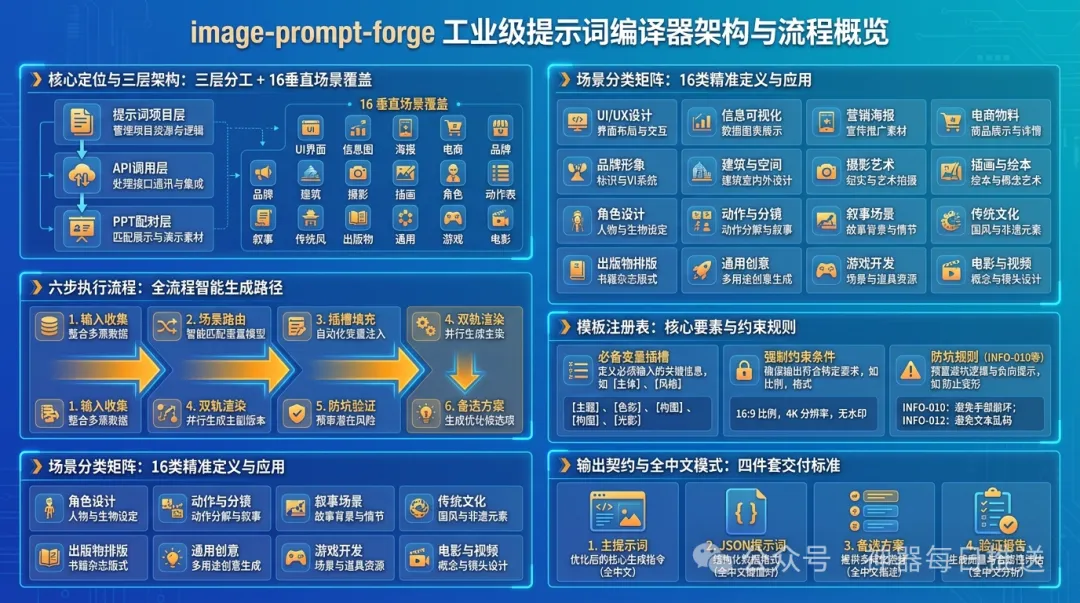
作者透過拆解370個案例,提煉出16類場景各自嘅必填槽位,然後封裝成一個自動化流程。Forge會幫你做曬三步:
- 1 場景路由:16種場景各走各嘅模板——海報、電商主圖、UI截圖、品牌視覺、攝影、插畫、角色設定、敍事場景、歷史東方、建築渲染、信息圖、社論排版,加上運動海報、蘋果風格自然海報、角色動作表、通用兜底。你描述需求,Forge自己判斷該行邊條路。
- 2 槽位填充:每個場景有必填項,好似填表咁逐項確認。電商主圖一定要填材質+光線,缺咗就係貼圖質感或者白底摳圖;海報要將標題同副標題逐字寫入提示詞,唔寫模型會自己編文案。Forge會自動補默認值,或者提醒你填。
- 3 Pitfall Lint檢查:輸出前跑一次規則,逐條報PASS或WARN。電商圖缺材質?[WARN] ECOM-004。海報冇硬編碼標題?[WARN] POSTER-002。話畀你知邊度有問題,點樣補。
Skill實戰:一句話出圖
裝好Skill之後,喺WorkBuddy對話框講你嘅需求就得。例如:「幫我設計一張微信公眾號16:9封面。」Forge會自動激活,場景路由、槽位推斷、Lint檢查一條龍走完,輸出完整英文提示詞。你唔使背規則,唔使記場景,亦唔使手寫TYPOGRAPHY LOCK。
每次輸出三份嘢:一份可以直接用嘅英文提示詞,一份JSON格式(方便接自動化),同一份風格唔同嘅備選方案。
如果生成嘅圖像規格唔滿意,你可以切換到圖像編輯模式下擴展,或者叫佢直接生成HTML信息圖。注意:呢個Skill係用嚟生成GPT-Image-2文生圖描述詞,唔係用嚟設計HTML。
完整出圖流程
- 1 描述需求:喺WorkBuddy對話框講你嘅要求。
- 2 Forge編譯:場景路由、槽位填充、Pitfall Lint自動執行,輸出Primary Prompt。
- 3 粘貼出圖:打開zenmux.ai,選GPT-Image-2模型,粘貼Prompt,直接出圖。
資源與連結
- 開源項目:github.com/freestylefly/awesome-gpt-image-2 — 370+個案例同16類場景槽位。
- 免費出圖:zenmux.ai — 支援GPT-Image-2,註冊有免費額度。
- Skill下載:pan.quark.cn/s/f37b6600e247 — 作者練好咗嘅WorkBuddy Skill。

GPT-Image-2 出圖最大嘅問題唔係模型唔得,係提示詞冇結構。
同一個需求,你寫嘅散文式描述每次出圖風格都飄;人哋用結構化協議,一次到位,批次穩定。差距唔在於「寫得好唔好」,在於「寫得啱唔啱」。
GitHub 上有個項目 awesome-gpt-image-2,做嘅嘢好直接:370+ 個 GPT-Image-2 爆款案例,按場景逆向拆解,提煉出 16 類場景各自嘅「必填槽位」——缺咗邊個槽,就出邊類廢圖。
呢套規律我封裝咗做 WorkBuddy 裏面嘅一個 Skill:GPT-Image-2 Prompt Forge。
出圖唔穩定,責任喺提示詞唔係模型
兩個高頻翻車點。
信息流失。你話「做一張高級感嘅電商主圖,貓糧,突出凍乾」,三個信息點。但係缺咗材質關鍵詞(磨砂膠?光面?)、光線關鍵詞(柔光箱?輪廓光?)、構圖角度(3/4 俯視?平視?),模型會自由發揮補齊空白,每次補出嚟嘅結果都唔同。

中文文字渲染。370 個案例裏面翻車頻率最高嘅窿。GPT-Image-2 唔自動鎖定字體同文字語言,你唔顯式聲明,出嚟嘅字一係亂碼,一係繁體,一係俾日文漢字取代。提示詞裏面加一句「所有畫面文字用簡體中文渲染」就搞得掂,但係大部分人唔知要寫呢句。
將提示詞由散文變成協議
三步。
場景路由。16 種場景各走各嘅模板——海報、電商主圖、UI 截圖、品牌視覺、攝影、插畫、角色設定、敍事場景、歷史東方、建築渲染、信息圖、社論排版,加上運動海報、蘋果風格自然海報、角色動作表、通用兜底。你描述需求,Forge 自己判斷應該行邊條路。
槽位填充。每個場景有必填項,好似填表咁逐項確認。電商主圖一定要填材質+光線,缺咗就係貼圖質感或者白底摳圖;海報一定要將標題同副標題逐字寫入提示詞,唔寫嘅話,模型會自己編文案。缺咗邊個槽,Forge 會自動補默認值,或者提你填。
Pitfall Lint 檢查。輸出前跑一次規則,逐條報 PASS 或者 WARN。電商圖缺材質?[WARN] ECOM-004。海報冇硬編碼標題?[WARN] POSTER-002。話俾你知邊度有問題,點樣補。
每次輸出三份嘢:一份可以直接用嘅英文提示詞,一份 JSON 格式(方便接自動化),仲有一份風格唔同嘅備選方案。
裝好 Skill,講一句話就可以出圖
裝好呢個 Skill(技能名:gpt-image-2-prompt-forge-en)之後,直接用就得。
觸發。喺 WorkBuddy 對話框裏面講你嘅需求:
根據文章內容,幫我設計一張微信公眾號16:9封面

如果生成嘅圖像規格唔滿意,你可以轉去圖像編輯模式擴展:

或者可以叫佢直接生成 html 信息圖,注意:佢嘅用途係用嚟生成 gpt-image-2 文生圖描述詞,唔係用嚟設計 html。
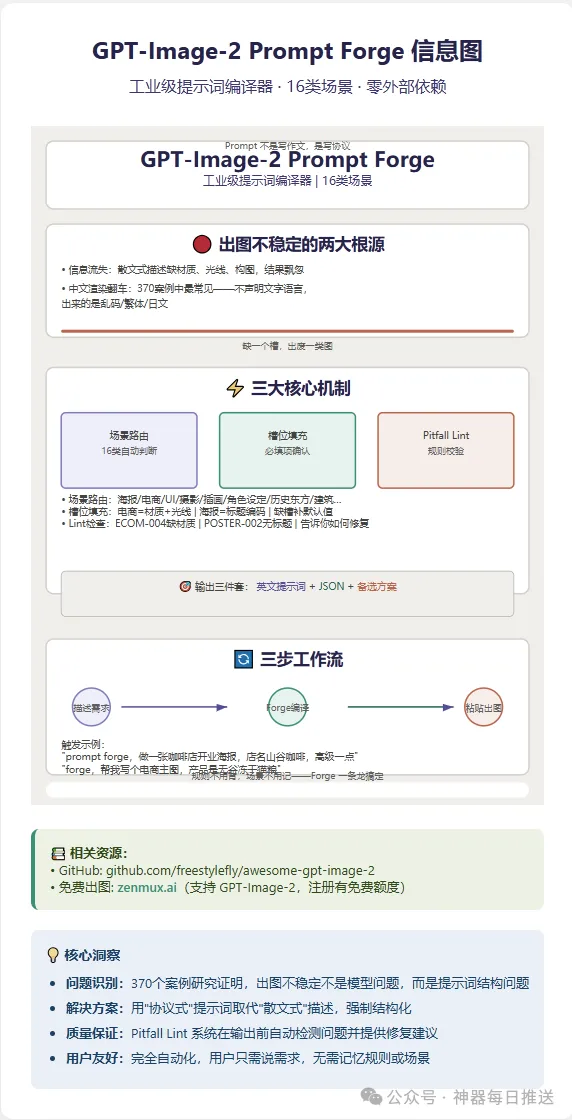
以下係 banana 生成嘅信息圖:
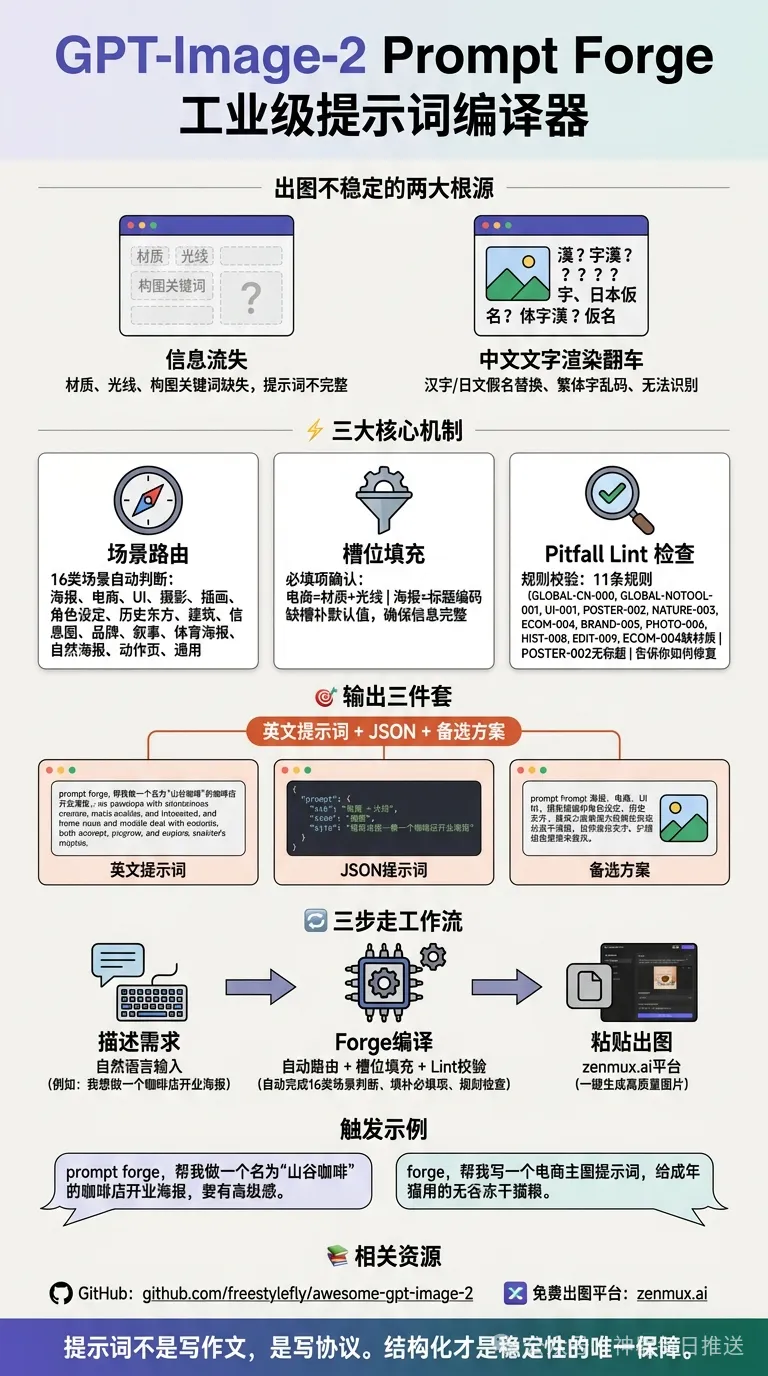
其他 gpt-image-2 出圖效果:
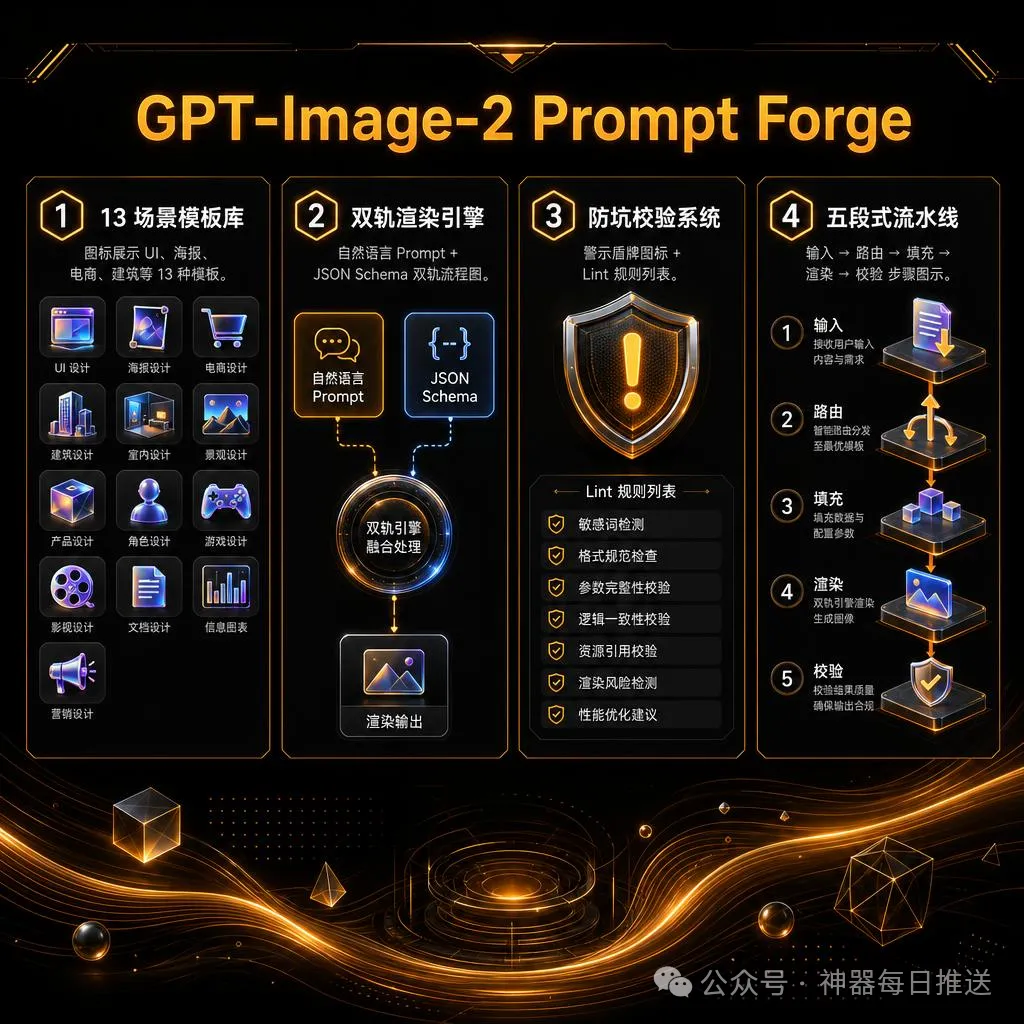
以下係簡版效果
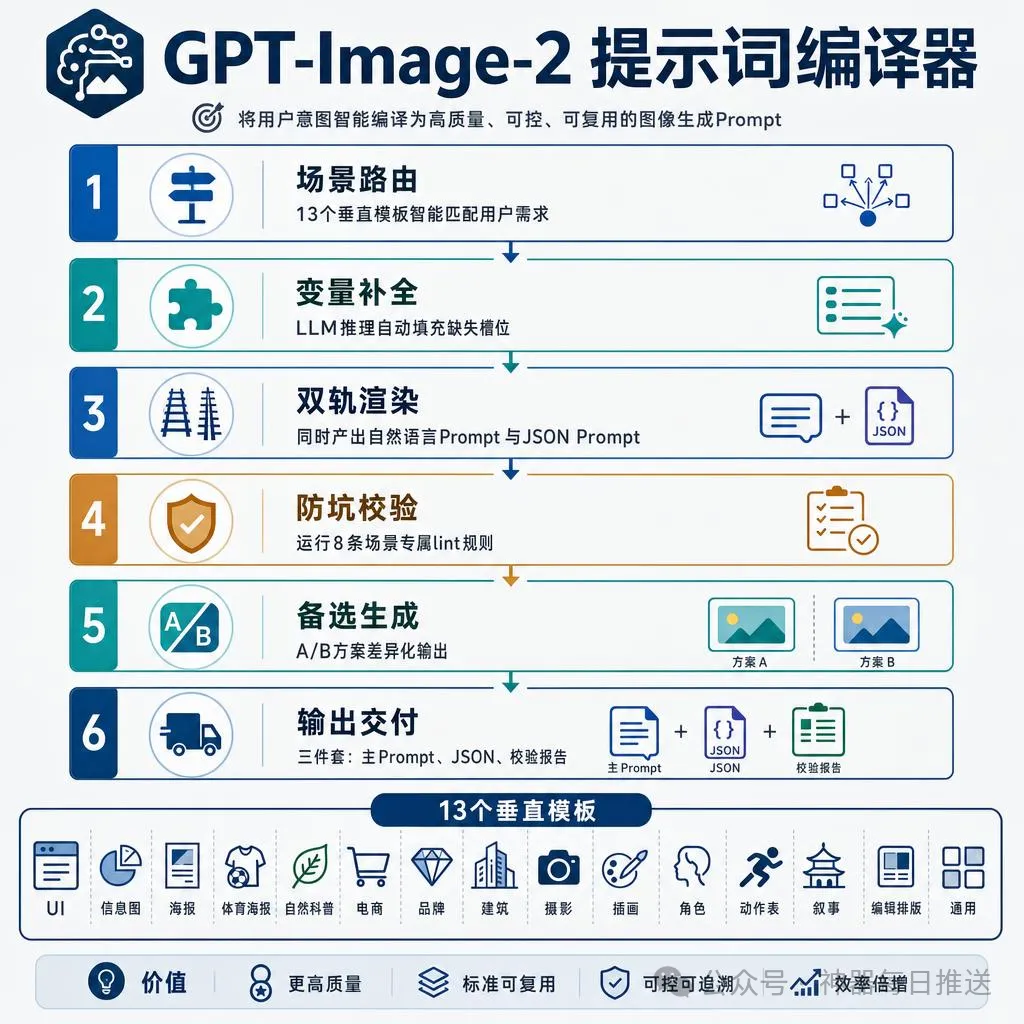

仲有啲實測圖

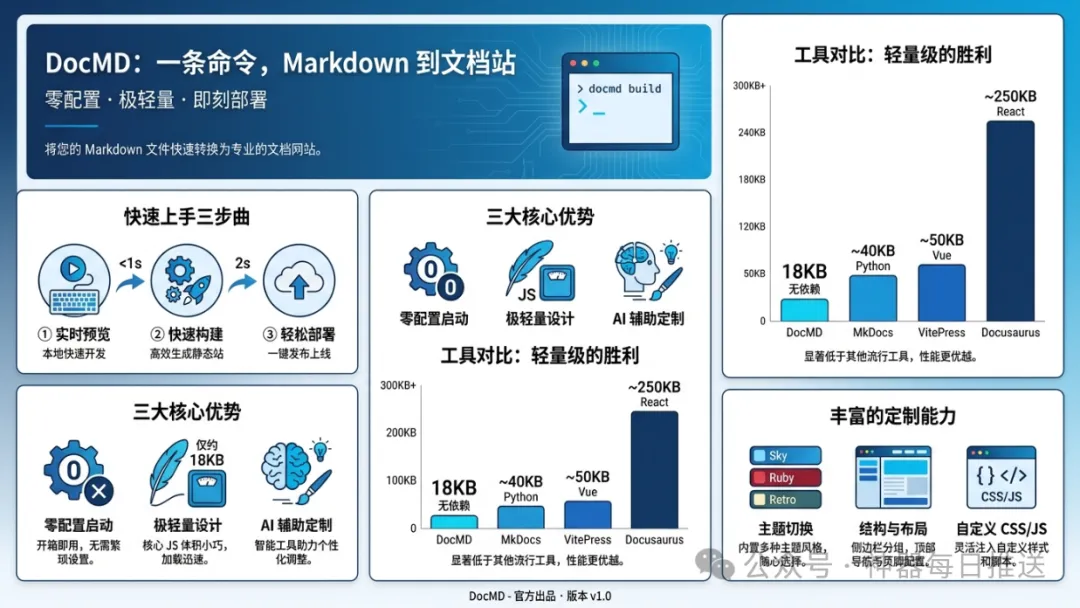
Forge 會自動激活,場景路由、槽位推斷、Lint 檢查一條龍行曬,輸出完整英文提示詞。規則唔使背,場景唔使記,TYPOGRAPHY LOCK 唔使手寫。
出圖。拎住英文提示詞,打開 zenmux.ai,註冊有免費額度,揀 GPT-Image-2 模型,將 Forge 輸出嘅 Primary Prompt 貼上去,直接出圖。
三步搞掂:描述需求 → Forge 編譯 → 貼上出圖。
項目開源:
github.com/freestylefly/awesome-gpt-image-2
免費出圖:
zenmux.ai,支援 GPT-Image-2,註冊有免費額度
提示詞唔係寫作文,係寫協議。
我練好嘅 skill:
https://pan.quark.cn/s/f37b6600e247
GPT-Image-2 出圖最大的問題不是模型不行,是提示詞沒結構。
同一個需求,你寫的散文式描述每次出圖風格都飄;別人用結構化協議,一次到位,批次穩定。差距不在"寫得好不好",在"寫得對不對"。
GitHub 上有個項目 awesome-gpt-image-2,做的事很直接:370+ 個 GPT-Image-2 爆款案例,按場景逆向拆解,提煉出 16 類場景各自的"必填槽位"——缺哪個槽,就出哪類廢圖。
這套規律我封裝成了 WorkBuddy 裏的一個 Skill:GPT-Image-2 Prompt Forge。
出圖不穩定,鍋在提示詞不在模型
兩個高頻翻車點。
信息流失。你說"做一張高級感的電商主圖,貓糧,突出凍幹",三個信息點。但缺了材質關鍵詞(磨砂塑料?亮面?)、光線關鍵詞(柔光箱?輪廓光?)、構圖角度(3/4 俯視?平視?),模型會自由發揮補全空白,每次補出來的結果都不一樣。
中文文字渲染。370 個案例裏翻車頻率最高的坑。GPT-Image-2 不自動鎖定字體和文字語言,你不顯式聲明,出來的字要麼亂碼,要麼繁體,要麼被日文漢字替換。提示詞里加一句"所有畫面文字用簡體中文渲染"就能解決,但大部分人不知道要寫這句。
把提示詞從散文變成協議
三步。
場景路由。16 種場景各走各的模板——海報、電商主圖、UI 截圖、品牌視覺、攝影、插畫、角色設定、敍事場景、歷史東方、建築渲染、信息圖、社論排版,加上運動海報、蘋果風格自然海報、角色動作表、通用兜底。你描述需求,Forge 自己判斷該走哪條路。
槽位填充。每個場景有必填項,像填表一樣逐項確認。電商主圖必須填材質+光線,缺了就是貼圖質感或白底摳圖;海報必須把標題和副標題逐字寫進提示詞,不寫,模型會自己編文案。缺什麼槽,Forge 會自動補默認值,或者提醒你填。
Pitfall Lint 檢查。輸出前跑一遍規則,逐條報 PASS 或 WARN。電商圖缺材質?[WARN] ECOM-004。海報沒硬編碼標題?[WARN] POSTER-002。告訴你哪裏有問題,怎麼補。
每次輸出三份東西:一份可以直接用的英文提示詞,一份 JSON 格式(方便接自動化),還有一份風格不同的備選方案。
裝好Skill,說一句話就能出圖
裝好這個 Skill(技能名:gpt-image-2-prompt-forge-en)之後,直接用就行。
觸發。在 WorkBuddy 對話框裏說你的需求:
根據文章內容,幫我設計一張微信公眾號16:9封面
如果生成的圖像規格不滿意,你可以切換到圖像編輯模式下擴展:
或者可以讓它直接生成html信息圖,注意:它的用途是用來生成gpt-image-2文生圖描述詞,不是用於設計html。
以下是banana生成的信息圖:
其它gpt-image-2出圖效果:
以下是簡版效果
還有一些實測圖
Forge 會自動激活,場景路由、槽位推斷、Lint 檢查一條龍走完,輸出完整英文提示詞。規則不用背,場景不用記,TYPOGRAPHY LOCK 不用手寫。
出圖。拿着英文提示詞,打開 zenmux.ai,註冊有免費額度,選 GPT-Image-2 模型,把 Forge 輸出的 Primary Prompt 粘貼進去,直接出圖。
三步走完:描述需求 → Forge 編譯 → 粘貼出圖。
項目開源:
github.com/freestylefly/awesome-gpt-image-2
免費出圖:
zenmux.ai,支持 GPT-Image-2,註冊有免費額度
提示詞不是寫作文,是寫協議。
我練好的skill:
https://pan.quark.cn/s/f37b6600e247