效果炸裂?試了一下最近很火的GPT-Image2【分鏡說明書】,10min出高質量短片
整理版優先睇
用GPT生成「分鏡說明書」,10分鐘快速產出高質量短片
張張係一位AI視頻創作者,佢發現好多人整AI視頻嘅時候卡喺分鏡同角色一致性呢啲問題上。佢自己測試咗GPT生成分鏡說明書嘅方法,結論係:雖然唔完美,但夠用,可以大幅降低門檻。
具體做法係先整主體角色圖,再用GPT生成一張包含藝術指導、角色多角度、環境設計、俯視動線圖、8個分鏡等模塊嘅分鏡說明書,然後用Gemini或Claude反推提示詞,最後用Seedance 2.0生成15秒短片。
呢個流程嘅價值在於令到唔識分鏡嘅人都可以快速開始。雖然仲要手動調整,但已經令更多人能夠動手創作。工具嘅真正意義係服務普通人,而唔係最頂尖嘅人。
- 結論:GPT生成嘅分鏡說明書可以有效整合角色、場景、運鏡等變量,降低AI視頻創作門檻。
- 方法:先做主體角色圖,再生成分鏡說明書(包含多模塊),反推提示詞後用視頻生成器產出短片。
- 差異:對比分鏡說明書方法與傳統逐個生成畫面,前者更系統、更省事。
- 啟發:工具價值在於服務普通人,令更多人可以開始嘗試。
- 可行動點:建議親自跑一遍流程,體驗從分鏡到成片嘅完整過程。
AI視頻分鏡說明書生成提示詞
創建一個極具動感的AI視頻分鏡說明書電影製作板 / 視覺規劃表,比例16:9,展示一支具有強烈電影感、適合短視頻傳播的完整視頻概念。佈局簡潔,結構清晰,信息密度高,像專業導演的拍攝指南。內容需要包含有:藝術指導(頂部欄)、角色與風格參考部分、環境和場景設計部分、故事板部分(8個分鏡)、燈光/情緒/風格備註、情緒和關鍵詞塊、音頻/音調部分、鏡頭類型部分。整個版面必須保持高度連貫、專業、清晰。
分鏡說明書嘅價值:將多個變量壓入一張圖
最近GPT生成嘅分鏡說明書好流行,一張圖包含多種資訊:
角色三視圖
鏡頭編號
運鏡路線
燈光氛圍
音頻情緒
作者實測後發現效果唔錯,雖然唔係完美,但夠用。
四步流程:從主體到短片
- 第一步:生成主體角色初始圖,呢步好關鍵,後面鏡頭一致性要靠呢個設定。
- 第二步:用GPT生成「分鏡說明書」,要明確話俾模型知係電影製作板,而唔係普通分鏡圖。
- 第三步:將生成嘅分鏡說明書丟俾Gemini或Claude呢類圖像理解模型,叫佢反推中文提示詞。
- 第四步:將分鏡圖連同反推嘅提示詞一齊放入視頻生成器,作者用Seedance 2.0,時長拉到15秒。
呢個流程係
由零散抽卡變成系統性創作
視頻生成後可能效果唔完美,部分鏡頭需要抽卡或剪輯,但整體流程已經夠用。第二步嘅關鍵係要明確話俾模型知係
電影製作板
第三步用Gemini或Claude反推提示詞,呢步好重要。
反推提示詞
第四步用
Seedance 2.0
15秒視頻
降低門檻,先做起來更重要
作者反思呢個方法嘅價值在於
降低門檻
令普通人可以開始做AI視頻
以前好多人卡喺
唔識分鏡
而家有模型幫手組織
雖然仍然需要人手調整,但已經令更多本來做唔到嘅人可以開始嘗試。建議讀者親自跑一遍,體驗一下。
大家好,我係張張。
唔知最近大家有冇見過類似下面呢種GPT新模型出嘅圖。

一張圖入面,角色三視圖、鏡頭編號、運鏡路線、燈光氛圍,甚至連音頻情緒都塞曬入去。關鍵係可以直接拎去跑視頻。
初頭我對呢種圖直接俾SD2.0跑視頻嘅效果係有啲懷疑,所以我自己都親手跑咗一次。
跑完之後,我嘅態度真係有啲變。當然佢仲未係一步到位嘅傻瓜神器。但如果只係想快啲做出一個睇得嘅短片,或者更低成本試一個視頻方向,呢個玩法,值得一試。

呢個係我測試做嘅一個產品短片,就幾分鐘嘅事。主要係操作比較傻瓜式,唔需要諗太多。
好多人第一次見到呢條片同參考圖,好容易被「睇起嚟好專業」而吸引。我覺得佢有價值,唔係話真係有幾高級,主要係省事。
以前做 AI 視頻,最麻煩嘅通常係生成之前嗰堆雜務。角色統一、場景統一、分鏡拆解、運鏡...
呢啲問題,逐個睇唔算大。但係一旦真係開始做,就會發現佢哋會一齊需要逐個解決。有時係唔識寫提示詞,有時係場景圖有瑕疵,有時係運鏡效果唔理想。我哋同時要管嘅變量太多喇。
「分鏡說明書」呢個玩法,就係先幫我哋將呢啲變量,全部壓入同一張圖入面。某程度上我哋唔使再完全靠腦補去銜接。
步驟1:生成主體角色初始圖

第一步:先做主體,我自己嘅習慣,係先快速生成一個主體對象。呢一步好關鍵。後面好多鏡頭嘅一致性,最後都要返到呢個主體設定上。
第二步:做「分鏡說明書」
主體有咗之後,再新建一個 image2 嘅圖片生成器。然後重點嚟喇。唔好就咁同模型講一句「幫我做個分鏡圖」。咁樣太虛。要明確話畀佢知:
呢係一張電影製作板 / 視覺規劃表。
呢句話好重要。因為由呢度開始,你畀佢嘅唔係單一畫面需求,而係一整套拍攝組織邏輯。
我今次實測時,會強制佢喺一張圖入麪包含呢啲模塊:
頂部嘅藝術指導資訊
主體嘅多角度參考
環境同場景設計
俯視路線圖
編號分鏡
每個鏡頭嘅景別、運鏡同動作描述
燈光同氛圍說明
音頻情緒指引
鏡頭風格備註
你可以咁理解:以前我哋係用提示詞去「求」一個畫面。而家係先畀模型一套更完整嘅創作邊界,等佢喺呢個邊界入面幫你組織資訊。呢個時候出嚟嘅嘢,就算仲未完美,都會比零散抽卡穩定啲。

提示詞參考:
創建一個極具動感嘅AI視頻分鏡說明書電影製作板 / 視覺規劃表,比例16:9,展示一支具有強烈電影感、適合短視頻傳播嘅完整視頻概念。佈局簡潔,結構清晰,資訊密度高,似專業導演嘅拍攝指南。
內容需要包含:
藝術指導(頂部欄):概述項目內容,例如鏡頭數量、統一色卡、影片環境、整體視覺風格。
角色與風格參考部分:展示主體角色/主體對象嘅多個角度(正面、背面、側面、特寫、放鬆姿態),附帶服裝、材質、細節、風格參考。嚴格保持主體一致性。
環境同場景設計部分:展示核心場景設定,以及俯視示意圖,標明角色/主體喺空間入面嘅移動路徑。包括攝像機位置、機位變化、沿路線標註嘅拍攝類型。
故事板部分:以16:9尺寸展示8個詳細編號分鏡,完整呈現拍攝進程。每個分鏡都要清楚體現動作、構圖、景別、視角同節奏。如果畫面涉及速度感、衝擊感或情緒推進,必須加入運動模糊與動態張力。
每個分鏡包括:攝像機類型 / 鏡頭感覺/鏡頭大小(廣角、中景、特寫、微距)/運動方式(靜態、跟蹤、手持、推進、環繞等)/動作同情緒進展嘅簡要描述
燈光 / 情緒 / 風格備註:提供燈光氛圍、畫面質感、色温、材質、風格關鍵詞嘅視覺示例同簡短說明。
情緒同關鍵詞塊:概括整條片嘅情緒、基調、主題、敍事氣質。
音頻 / 音調部分:配樂風格、環境音、特效音效同整體聲音氛圍嘅指導。
鏡頭類型部分:體現鏡頭語言、運動風格、剪輯節奏同後期處理嘅視覺哲學。
整個版面必須保持高度連貫、專業、清晰,似一張資訊塞滿一頁嘅影視級分鏡說明書,既有設計感,又能真正作為導演同AI視頻生成嘅執行參考。
第三步:將呢張圖拎去反推提示詞
直接將呢張「分鏡說明書」掟畀 Gemini /Claude 呢類理解圖像能力比較強嘅模型,等佢幫你反推出可以直接用嘅中文提示詞。
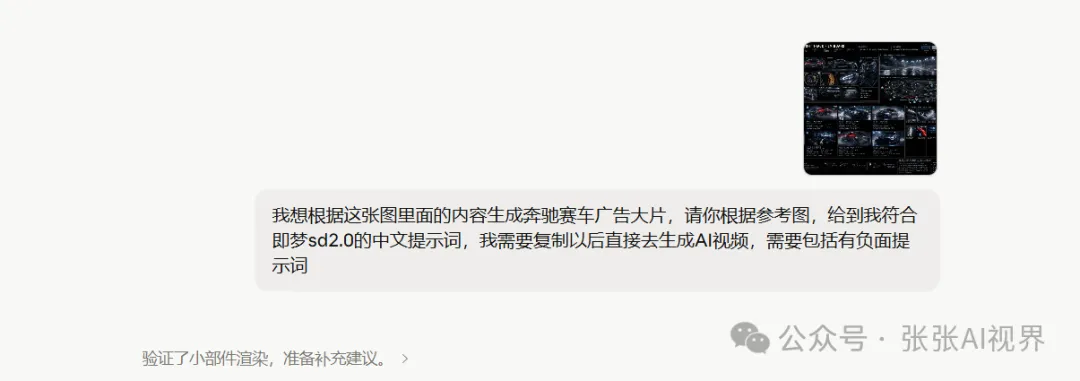
第四步:視頻生成
接下來就簡單喇。將生成好嘅圖,連同上一步反推出嚟嘅提示詞,一齊掟入視頻生成器。我今次用嘅係 Seedance 2.0,時長直接拉到 15 秒。
SD2.0 喺直接生成15秒嘅視頻時多少會抽下風,所以可能部分鏡頭效果唔會太好。適當嘅需要抽卡或者剪走。
呢啲都係正常嘅。但呢個唔影響整體流程。最後出嚟嘅嘢,對唔少實際需求嚟講,夠用喇。
當然,如果你做嘅係要求好高嘅品牌片、鏡頭控制好精細嘅高級項目,或者你對每一秒動作都要嚴格設計,咁呢套方法仲係唔太夠。
呢個流程,將創作嘅門檻又推低咗少少。以前好多人係卡喺「唔識分鏡」呢一步。
唔係冇想法。係個腦知道自己想要一個咩感覺,但冇能力將呢個感覺拆成鏡頭語言、運鏡邏輯、場景結構,再一條條餵畀模型。
呢中間嘅翻譯成本,其實好高。而而家,至少多咗一種辦法。我哋可以先用模型幫你將呢套嘢整理出嚟。就算唔完美,就算仲要人工修,就算最後要剪輯補救。
佢都已經令更多本來做唔到嘅人,先開始做。我覺得呢件事本身就已經好重要。因為真正有價值嘅工具,好多時候唔係服務最頂尖嘅人。而係令更多普通人,都可以開始動手。
如果你最近都喺度搞 AI 視頻,都諗緊點樣更省心做出一個睇得嘅嘢,咁呢個思路,我覺得你真係可以親自跑一次。好多嘢,只有自己抽過幾輪卡,自己拼過幾次素材,先會知道佢到底係咪你杯茶。
以上係今日嘅分享,如果對你有幫助嘅話,歡迎按讚【Like】、【收藏】同【讚好】,幫助更多人瞭解~


大家好,我是張張。
不知道最近大家有沒有刷到過類似下面這種GPT新模型出的圖。
一張圖裏,角色三視圖、鏡頭編號、運鏡路線、燈光氛圍、甚至連音頻情緒都給你塞進去了。關鍵是可以直接拿去跑視頻。
剛開始我對這種圖直接給SD2.0跑視頻的效果是存疑的,所以我自己也上手跑了一遍。
跑完之後,我的態度還真變了點。當然它還不是那種一步到位的傻瓜神器。但如果只是想更快地做出一個能看的短片,或者更低成本地試一個視頻方向,這個玩法,值得一試。
這個是我測試做的一個產品短片,就幾分鐘的事情。主要是操作比較傻瓜式,不需要動天多腦筋。
很多人第一次看到這視頻和參考圖,很容易被“看起來很專業”而吸引。我覺得它有價值,倒不是說真的有多麼高級,主要還是省事。
以前做 AI 視頻,最麻煩的往往是生成之前那一堆雜事。角色統一、場景統一、分鏡拆解、運鏡....
這些問題,單看每一個都不算大。可一旦真開始做,就會發現它們會一起需要被逐個解決。有時候是不會寫提示詞,有時候是場景圖有瑕疵,有時候是運鏡效果不理想。我們同時要管的變量太多了。
“分鏡說明書”這個玩法,就是先幫我們把這些變量,都壓進同一張圖裏。一定程度上我們不用再完全靠腦補去銜接了。
步驟1:生成主體角色初始圖
第一步:先做主體,我自己的習慣,是先快速生成一個主體對象。這一步很關鍵。後面很多鏡頭的一致性,最後都要回到這個主體設定上。
第二步:做“分鏡說明書”、
主體有了之後,再新建一個 image2 的圖片生成器。然後重點來了。不要只是跟模型說一句“幫我做個分鏡圖”。這樣太空了。得明確告訴它:
這是一張電影製作板 / 視覺規劃表。
這句話很重要。因為從這裏開始,你給它的就不是單一畫面需求,而是一整套拍攝組織邏輯。
我這次實測時,會強制它在一張圖裏包含這些模塊:
頂部的藝術指導信息
主體的多角度參考
環境和場景設計
俯視動線圖
編號分鏡
每個鏡頭的景別、運鏡和動作描述
燈光和氛圍說明
音頻情緒指引
鏡頭風格備註
你可以把它理解成:以前我們是拿提示詞去“求”一個畫面。現在是先給模型一套更完整的創作邊界,讓它在這個邊界裏替你組織信息。這時候出來的東西,哪怕還不完美,也會比那種零散抽卡更穩一點。
提示詞參考:
創建一個極具動感的AI視頻分鏡說明書電影製作板 / 視覺規劃表,比例16:9,展示一支具有強烈電影感、適合短視頻傳播的完整視頻概念。佈局簡潔,結構清晰,信息密度高,像專業導演的拍攝指南。
內容需要包含有:
藝術指導(頂部欄):概述項目內容,如鏡頭數量、統一色卡、影片環境、整體視覺風格。
角色與風格參考部分:展示主體角色/主體對象的多個角度(正面、背面、側面、特寫、放鬆姿態),附帶服裝、材質、細節、風格參考。嚴格保持主體一致性。
環境和場景設計部分:展示核心場景設定,以及俯視示意圖,標明角色/主體在空間中的移動路徑。包括攝像機位置、機位變化、沿路線標註的拍攝類型。
故事板部分:以16:9尺寸展示8個詳細編號分鏡,完整呈現拍攝進程。每個分鏡都要清楚體現動作、構圖、景別、視角和節奏。如果畫面涉及速度感、衝擊感或情緒推進,必須加入運動模糊與動態張力。
每個分鏡包括:攝像機類型 / 鏡頭感覺/鏡頭大小(廣角、中景、特寫、微距)/運動方式(靜態、跟蹤、手持、推進、環繞等)/動作和情緒進展的簡要描述
燈光 / 情緒 / 風格備註:提供燈光氛圍、畫面質感、色温、材質、風格關鍵詞的視覺示例和簡短說明。
情緒和關鍵詞塊:概括整支片子的情緒、基調、主題、敍事氣質。
音頻 / 音調部分:配樂風格、環境音、特效音效和整體聲音氛圍的指導。
鏡頭類型部分:體現鏡頭語言、運動風格、剪輯節奏和後期處理的視覺哲學。
整個版面必須保持高度連貫、專業、清晰,像一張信息塞滿一頁的影視級分鏡說明書,既有設計感,又能真正作為導演和AI視頻生成的執行參考。
第三步:把這張圖拿去反推提示詞
直接把這張“分鏡說明書”丟給 Gemini /Claude這類理解圖像能力比較強的模型,讓它幫你反推出可直接使用的中文提示詞。
第四步:視頻生成
接下來就簡單了。把生成好的圖,連同上一步反推出來的提示詞,一起丟進視頻生成器。我這次用的是 Seedance 2.0,時長直接拉到 15 秒。
SD2.0在直接生成15s的視頻時多少會抽點風,所以可能部分鏡頭效果並不會很好。適當的需要抽卡或者剪切。
這些都是正常的。但這不影響整體流程。最後出來的東西,對不少實際需求來說,夠用了。
當然,如果你做的是要求特別高的品牌片、鏡頭控制非常精細的高級項目,或者你對每一秒動作都要嚴格設計,那這套方法還是不太夠。
這個流程,把創作的門檻又往下推了一點。以前很多人是卡在“不會分鏡”這一步。
不是沒想法。是腦子裏知道自己想要一個什麼感覺,但沒有能力把這個感覺拆成鏡頭語言、運鏡邏輯、場景結構,再一條條餵給模型。
這中間的翻譯成本,其實很高。而現在,至少多了一種辦法。我們可以先讓模型幫你把這套東西攏出來。哪怕不完美,哪怕還是要人工修,哪怕最後還得剪輯補救。
它也已經讓更多本來做不了的人,先做起來了。我覺得這件事本身就很重要。因為真正有價值的工具,很多時候不是服務最頂尖的人。而是讓更多普通人,也能開始動手。
如果你最近也在折騰 AI 視頻,也在想怎麼更省心地做出一個能看的東西,那這個思路,我覺得你真可以親自跑一遍。很多東西,只有自己抽過幾輪卡,自己拼過幾次素材,才會知道它到底是不是你的菜。
以上是今天的分享,如果對你有幫助的話,歡迎點亮【在看】,【收藏】和【點贊】,幫助更多人瞭解~