機器人的終局:英偉達 Jim Fan 宣告 VLA 時代結束,WAM 登場
整理版優先睇
Jim Fan 宣告 VLA 時代終結,WAM 成機器人新範式,2040 年前可達物理自動研究
呢篇文章係英偉達機器人與 AI 總監 Jim Fan 喺 Sequoia AI Ascent 2026 嘅演講整理。佢過去幾年主力推 GR00T 人形機器人基礎模型,用嘅係 VLA(Vision-Language-Action)架構。但今次佢直接宣佈 VLA 路線過時,取而代之嘅係世界動作模型(WAM),代表作係同樣由英偉達推出嘅 DreamZero(140 億參數)。
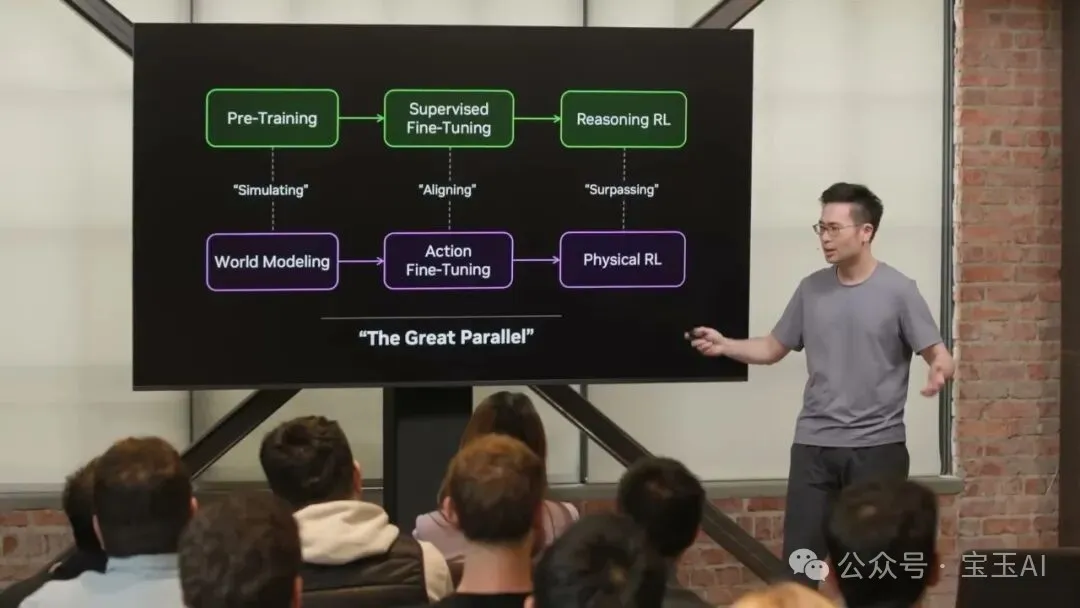
Jim 嘅核心論點係「底層同構」:複製 LLM 成功嘅三步曲(預訓練→對齊→強化學習),只係將「模擬字符串下一個狀態」換成「模擬物理世界下一個狀態」。佢認為遙操作數據有硬上限,會喺一兩年內被淘汰,轉為用傳感化人類第一人稱視頻。佢團隊嘅 EgoScale 用 21,000 小時人類視頻預訓練,發現咗靈巧操作嘅神經縮放定律(R² = 0.998),證明數據越多,靈巧性可預測提升。
整體結論係:VLA 架構將參數大頭放咗喺語言,忽略咗動作,所以物理表現唔掂。WAM 透過「做夢」幾秒嚟規劃動作,視覺同動作變成平等。Jim 俾出一個 2040 年嘅終局路線圖:物理圖靈測試→物理 API→物理自動研究,佢有 95% 把握。
- VLA 路線正式終結,新範式 WAM(世界動作模型)用視頻世界模型取代語言模型,DreamZero 係代表作。
- 遙操作數據將喺一兩年內被淘汰,改用人類第一人稱視頻,英偉達 EgoScale 用 21,000 小時視頻預訓練,零機器人數據。
- 靈巧操作存在神經縮放定律(R² = 0.998),增加人類視頻數據可預測提升機器人靈巧性。
- Dream Dojo 係完全繞過物理引擎嘅神經仿真器,直接用數據驅動輸出下一幀畫面,可大幅降低 RL 成本。
- 終局路線圖:2-3 年內達物理圖靈測試,之後物理 API,2040 年前達機器人自動設計製造下一代機器人,Jim 置信度 95%。
Sequoia AI Ascent 2026 演講原片
Jim Fan 喺 Sequoia AI Ascent 2026 嘅完整演講影片,主題 Robotics' End Game,宣佈 VLA 終結並提出 WAM 範式。
VLA 終結,WAM 登場:抄 LLM 功課嘅「底層同構」
Jim Fan 用 2016 年 DGX-1 簽名故事開場,話自己當年完全唔知簽緊乜,旁邊仲有 Andrej Karpathy。佢引 Ilya Sutskever 嗰句「你信深度學習,深度學習就信你」,再講 LLM 用三次階躍走到今日:GPT-3 預訓練、InstructGPT 監督微調、o1 強化學習,最後到自動研究。
於是佢決定「抄作業,換個名」,叫 底層同構(the Great Parallel)。將「模擬字符串下一個狀態」換成 模擬物理世界下一個狀態,用動作微調收斂到機器人需要嘅部分,最後用強化學習走完最後一公里。打唔過就加入。
取而代之嘅係 世界動作模型(WAM),代表作 DreamZero(140 億參數)。呢種新型策略模型會先往未來「做夢」幾秒鐘,然後根據夢境行動,同時解碼下一幀畫面同下一步動作。Jim 坦承 DreamZero 目前大概係 GPT-2 階段,方向啱但未夠穩定。
數據革命:告別遙操作,用人類第一人稱視頻
Jim 形容過去三年係遙操作(teleop)嘅黃金時代,但佢有硬上限:「每台機械人一日 24 小時?實際一日做到 3 小時就偷笑,仲要睇機械之神賞唔賞面。」點破局?將機械人嘅末端執行器直接戴喺人手上,完全繞過機械人本體。
英偉達方案係 DexUMI,一種外骨骼裝置。用外骨骼數據訓練出嘅機械人策略可以完全自主運行,訓練數據入面 冇任何遙操作數據。機械人好開心,因為佢哋終於唔使參與數據採集。
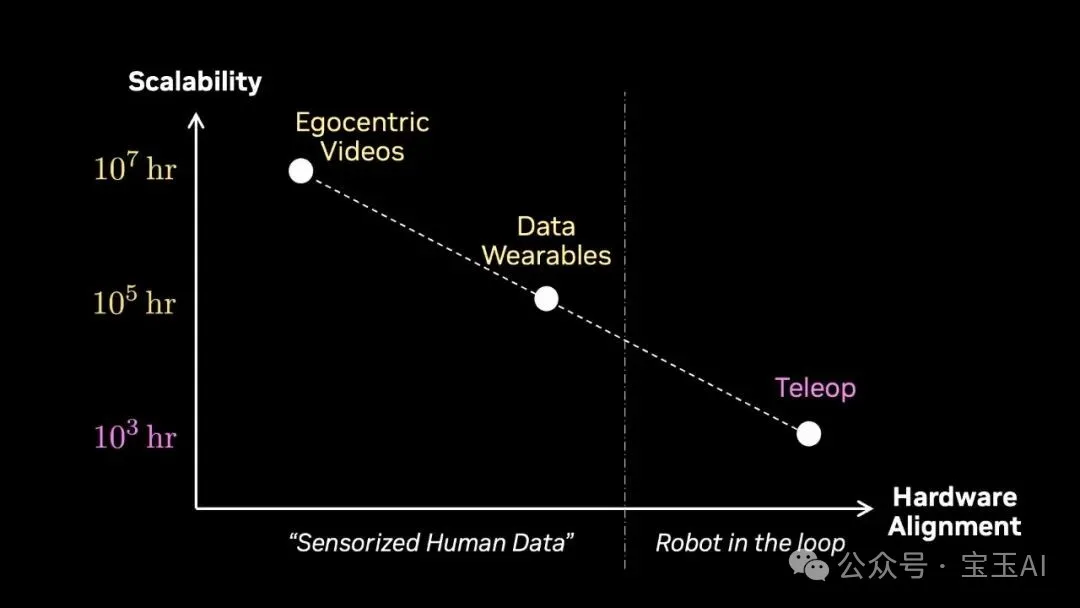
Jim 比較曬所有數據策略嘅可擴展性:遙操作喺最不可擴展嘅角落;第一人稱視頻如果能轉動類似 FSD 嘅數據飛輪,一年內可達 1000 萬小時。
Dream Dojo:完全數據驅動嘅神經仿真器
機械人領域要花大錢買幾百萬個程式環境做強化學習,但真機到仿真再到真機有 gap。英偉達嘅進一步方案係 Dream Dojo:唔搞物理引擎,直接用視頻世界模型變做一個完整嘅神經仿真器。
輸入係連續動作信號,實時輸出下一幀 RGB 畫面同傳感器狀態。Jim 強調:「你見到嘅畫面入面 冇一個像素係真實嘅。依家算力等於環境等於數據。或者用某位智者嘅話:買得越多,省得越多。呢條消息已經獲得我老細批准。」
終局路線圖:2040 年前三個成就
- 1 物理圖靈測試:2-3 年內,你分唔出執行任務嘅係人定機械人。
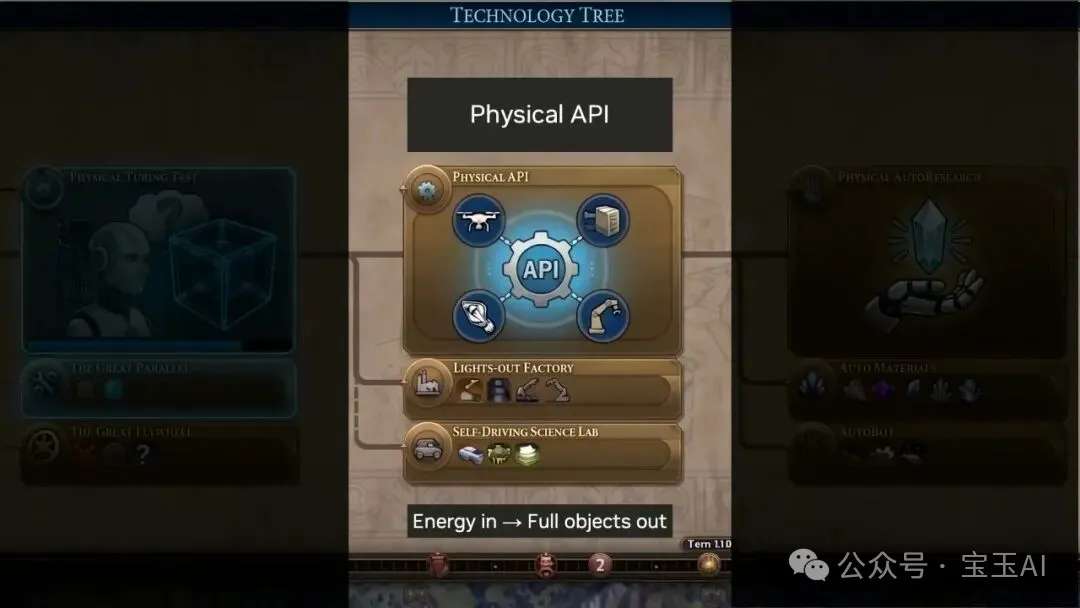
- 2 物理 API:用軟件同大模型編排機械人配置,建造暗工廠同自動化科學實驗室。
- 3 物理自動研究:機械人開始自己設計、改進並製造出下一代機械人。
時間表方面,Jim 類比 AI 從 AlexNet(2012)到智能體(2026)用咗 14 年,再加 14 年就係 2040 年。佢話我哋呢代人,生得太晚,未趕上大航海時代探索地球;生得太早,未夠膽去宇宙。但生得啱啱好,趕上攻克機械人難題嘅時代。
五個速問速答同三個值得追蹤懸念
Q:VLA 真係死咗?A:演講層面係死咗,但英偉達自家最新 GR00T N1.7(2026 年 4 月)論文仲寫明「VLA 模型」,內部範式切換未完成。
Q:DreamZero 可以用喺生產環境?A:唔得。Jim 話佢大概係 GPT-2 階段,論文披露 14B 模型閉環控制得 7Hz,而且一定要用 GB200 硬件。
Q:遙操作真係會被淘汰?A:Jim 預測一兩年內降到接近 0,但戴設備做家務同開車唔同,唔係剛需,而且行業大量現有遙操作基礎設施唔會一夜報廢。
Jim Fan 係英偉達機器人與 AI 研究組(GEAR Lab)負責人,過去幾年主力推嘅 GR00T 人形機器人基礎模型係用 VLA(Vision-Language-Action,視覺 - 語言 - 動作)架構。佢啱啱喺 Sequoia AI Ascent 2026 上做咗一場 20 分鐘嘅演講,主題叫《Robotics' End Game》,第一件事就係宣佈 VLA 路線過時——包括埋佢自己半年前仲喺度推嘅 GR00T。
取而代之嘅新範式叫世界動作模型(WAM),代表作係英偉達 2 月發佈嘅 DreamZero。佢將呢套思路叫“底層同構”:複製 LLM(Large Language Model,大語言模型)走過嘅三步(預訓練→對齊→強化學習),用視頻世界模型取代語言模型,用人類第一人稱視頻取代遙操作數據,最終喺 2040 年前令機器人自己設計同製造下一代自己。佢對此有 95% 嘅把握。
• VLA 路線落幕:Jim 公開宣告 VLA 路線過時,新範式叫世界動作模型(WAM),代表作係 DreamZero(140 億參數)。 • 告別遙操作數據:遙操作物理上限低,預測一兩年內降到接近 0,被傳感化人類數據取代。 • 神經縮放定律:EgoScale 用 21,000 小時人類第一人稱視頻預訓練,團隊發現咗靈巧操作嘅神經縮放定律(R² = 0.998)。 • 神經仿真器:Dream Dojo 用 44,000 小時人類視頻訓練出一個完全繞過物理引擎嘅神經仿真器。 • 終局倒計時:給出 2040 年完成機器人終局嘅預測(物理自動研究),置信度 95%。
從 DGX-1 簽名到“底層同構”
Jim 用一段往事開場。2016 年夏天,喺 OpenAI 當時嘅辦公室,黃仁勳着住標誌性皮夾克,抱住一塊大金屬託盤行入嚟,上面寫着:“致 Elon 和 OpenAI 團隊,致計算和人類的未來。”嗰部係全球第一台 DGX-1。

Jim 當時係 OpenAI 嘅第一個實習生,趕緊排隊去上面簽咗名。“嗰陣時我完全唔知自己喺度簽乜。”旁邊一齊簽嘅仲有 Andrej Karpathy。呢部機器而家喺 Computer History Museum 收藏。Jim 補咗一句,話自己感覺好似恐龍咁老。

注:Jim Fan(範麟熙)係英偉達機器人與 AI 總監、傑出科學家,領導 GEAR Lab 同 GR00T 人形機器人項目。2016 年喺 OpenAI 實習時嘅導師係 Ilya Sutskever 同 Andrej Karpathy,之後喺 Stanford 跟隨 Fei-Fei Li 讀完博士。
呢個故事係為咗引出佢嘅核心框架。佢引咗 Ilya 嗰句“你信深度學習,深度學習就信你”,然後話 LLM 只用三次階躍、六年時間就行到今日:GPT-3 嘅預訓練,InstructGPT 嘅監督微調,o1 風格嘅強化學習,再到自動研究。
於是佢做咗一個決定:抄作業,換個名,叫“底層同構”(the Great Parallel)。將“模擬字符串嘅下一個狀態”換成“模擬物理世界嘅下一個狀態”,通過動作微調收斂到機器人需要嘅嗰部分,最後令強化學習行埋最後一公里。
打唔過就加入。
(“If you can't beat them, join them.”)
VLA 點樣:參數都堆咗喺語言上
過去三年,機器人領域嘅主流架構係 VLA(Vision-Language-Action,視覺 - 語言 - 動作模型)。英偉達自家嘅 GR00T 同 Physical Intelligence 嘅 π0 都屬於呢個類別。
Jim 指出咗結構性問題:其實呢啲模型應該叫 LVA,因為參數大頭全部堆咗喺語言上。語言係一等公民,視覺次之,動作只能墊底。
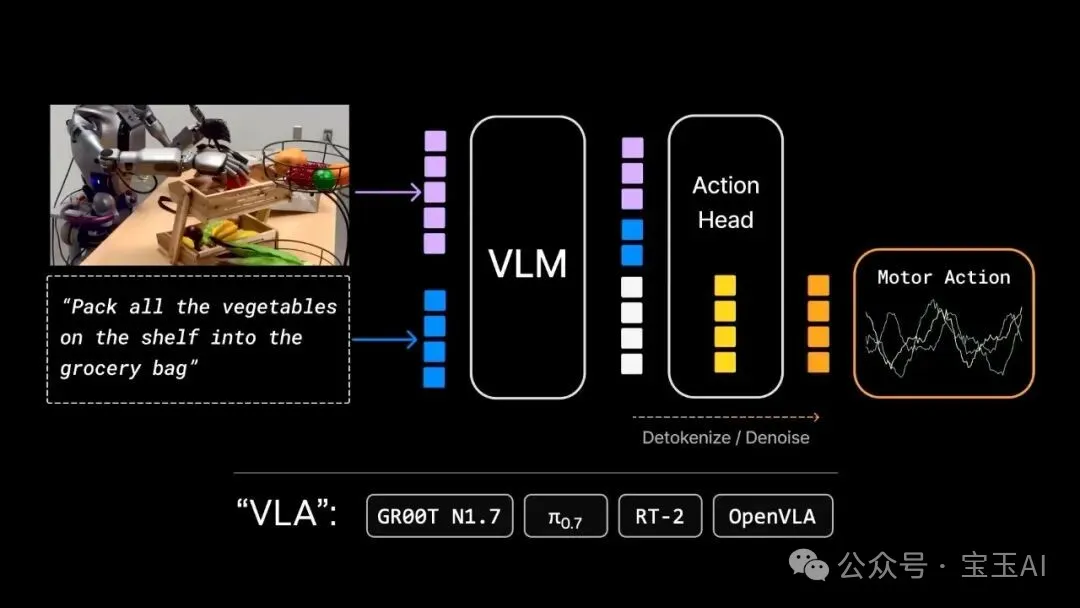
VLA 擅長編碼知識同名詞,唔擅長物理同動詞。重心放咗喺唔啱嘅地方。
佢舉咗 RT-2 原始論文裏面嗰個經典 demo:令機器人將可樂罐推到 Taylor Swift 嘅相旁邊。模型冇見過 Taylor Swift,但能泛化過去。問題係,泛化嘅係名詞(認得出 Taylor Swift),而唔係動詞(應該點推、揾咩角度、用幾多力)。

從 AI 垃圾視頻到 DreamZero
VLA 唔係答案,咁下一個預訓練範式係乜?結果發現係視頻模型,佢哋喺內部學識咗模擬物理世界嘅下一個狀態。

點樣將呢啲世界模型變得有用?做動作微調。將“所有可能嘅未來”呢種疊加態,收斂到一條對真實機器人有意義嘅動作軌跡上。
英偉達嘅答案叫 DreamZero。呢種係一種新型策略模型,喺執行動作之前先向未來“做夢”幾秒鐘,然後根據夢境行動。DreamZero 同時解碼下一幀畫面同下一步動作。喺呢度,視覺同動作第一次真正成為咗“一等公民”。

Jim 坦率咁承認 DreamZero 目前做唔到每個任務都 100% 可靠。“佢大概相當於 GPT-2 嘅階段,方向啱咗,但表現仲未夠穩定可靠。”佢俾呢個新架構起名叫 WAM(World Action Models,世界動作模型)。
為我哋親愛嘅 VLA 默哀片刻。佢已經完成咗歷史使命。安息啦。世界動作模型萬歲。
注:DreamZero 論文(arXiv 2602.15922)2026 年 2 月發佈,140 億參數,基於 Wan2.1 視頻擴散模型。佢有一個關鍵限制:14B 模型必須經過 38 倍系統級優化加 GB200 硬件,先可以將閉環控制壓到 7Hz,部署門檻極高。
數據革命:從遙操作到“機器人唔使參與嘅數據採集”
過去三年係遙操作(teleop)嘅黃金時代。但遙操作有一個硬上限:每台機器人每日 24 小時。
“我話一日 24 小時,嗰係呃自己嘅。實際一日做到 3 小時就唔錯喇,仲要睇當日嘅‘機器人之神’賞唔賞面——畢竟呢班機器日日鬧脾氣出毛病。”

點樣破局?將機器人嘅末端執行器直接戴喺人手上,直接採集數據,完全繞過機器人本體。
英偉達方案係 DexUMI,一種外骨骼裝置。用外骨骼數據訓練出嘅機器人策略可以完全自主運行,訓練數據裏面冇任何遙操作數據。

機器人好開心,因為佢哋終於唔使參與數據採集喇。
EgoScale:21,000 小時人類視頻同縮放定律
英偉達推出咗 EgoScale:99.9% 嘅訓練數據嚟自人類第一人稱視頻(egocentric video)。
預訓練用咗 21,000 小時嘅野外人類數據,零機器人數據。動作微調階段僅僅用咗 50 小時嘅高精度動捕手套數據,外加 4 小時遙操作數據——加埋連訓練總量嘅 0.1% 都唔夠。

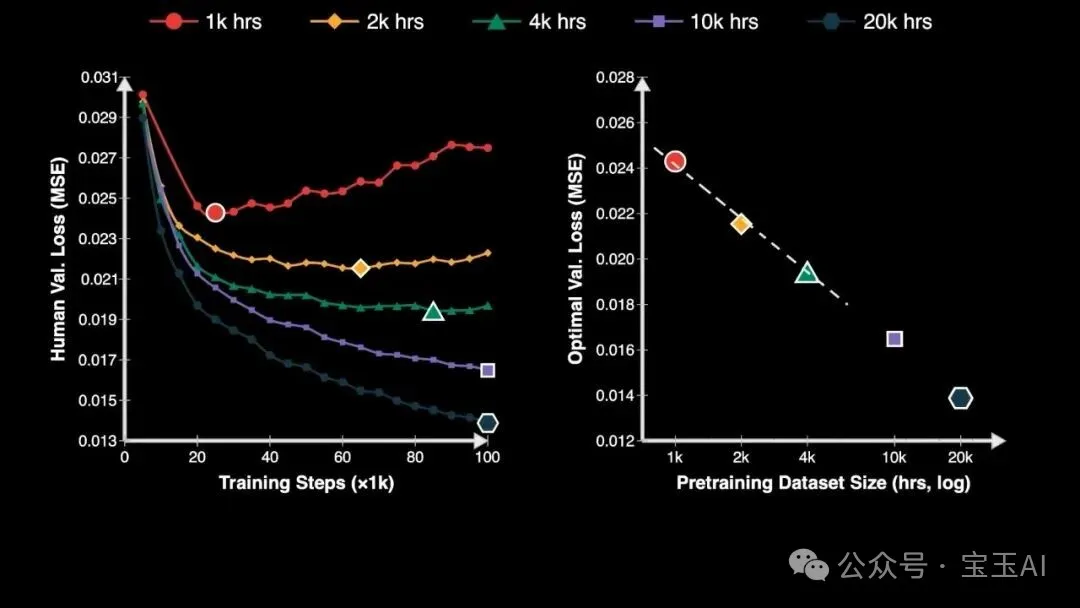
最重要嘅發現係:靈巧操作嘅神經縮放定律。預訓練投入嘅算力小時數同最優驗證損失之間,存在一條極其清晰嘅對數線性關係,R² 達到咗驚人嘅 0.998。
Jim 將所有數據策略嘅擴展性放咗喺一齊:遙操作喺最唔可擴展嘅角落;第一人稱視頻如果能夠轉動 FSD(Full Self-Driving,完全自動駕駛)式嘅數據飛輪,一年內可以達到 1000 萬小時。
Dream Dojo:唔用物理引擎嘅神經仿真器
機器人領域都需要花大錢買幾百萬個編程環境做強化學習(RL),但直接用真機(real-to-sim-to-real)唔夠。
進一步嘅方案係 Dream Dojo:唔搞物理引擎嗰一套,直接將視頻世界模型變成一個完整嘅神經仿真器。輸入係連續動作信號,實時輸出下一幀 RGB 畫面同傳感器狀態。冇物理方程,冇圖形引擎,完完全全係數據驅動嘅。

你見到嘅畫面裏面冇一個像素係真實嘅。
“而家算力等於環境等於數據。或者用某位智者嘅話:買得越多,慳得越多。呢條消息已經獲得我老細批准。”
終局路線圖:2040 年前嘅三個成就
Jim 將機器人嘅剩餘路徑類比成必須解鎖嘅三個科技樹成就:
1. 物理圖靈測試:2-3 年內,你分唔出執行任務嘅係人定係機器人。 2. 物理 API:用軟件同大模型編排機器人配置,建造“暗工廠”同自動化科學實驗室。 3. 物理自動研究:機器人開始自己設計、改進同製造出下一代機器人。
至於時間表,佢類比 AI 從 AlexNet(2012)到智能體(2026)用咗 14 年。再加 14 年,啱啱好係 2040 年。

我哋呢一代人,生得太晏,冇趕上大航海時代去探索地球;又生得太早,夠唔着星辰大海去探索宇宙。但我哋生得啱啱好,趕上咗攻克機器人難題嘅時代。
五個問題快答
Q:VLA 真係死咗呀?
A:演講層面係死咗。但英偉達自家最新嘅 GR00T N1.7(2026 年 4 月)論文裏面仲明確寫住“VLA 模型”。範式遷移喺內部仲未完成。
Q:DreamZero 而家可以用喺生產環境呀?
A:唔得。Jim 自己話佢“大概係 GPT-2 階段”。論文披露 14B 模型跑閉環控制得 7Hz,而且一定要用 GB200。
Q:遙操作真係會俾淘汰咩?
A:Jim 預測一兩年內降到接近 0。但戴設備做家務唔似開車係剛需,而且行業大量已經有嘅遙操作基礎設施唔會一夜之間報廢。
Q:靈巧操作嘅縮放定律代表啲乜?
A:如果 R² = 0.998 持續成立,代表增加人類視頻數據,機器人靈巧性就會可預測咁提升。呢個係成場演講中最核心嘅實證論據。
Q:英偉達喺呢盤棋裏面賺啲乜?
A:WAM 同神經仿真器對算力需求極高。Jim 嗰句“buy more, save more”直接反映咗範式切換天然有助於賣芯片嘅商業意圖。
最後:值得追蹤嘅三個懸念
三件事最值得追蹤:
1. DreamZero 點樣跨越“GPT-2 階段”:未來 12-18 個月可唔可以將極限參數做穩,決定咗呢套範式嘅真實威力。 2. 英偉達內部對 VLA 範式嘅切換時刻:觀察其產品更新中架構實質演進。如果下一代仲係 VLA,咁演講更偏向概念營銷。 3. 第一人稱視頻數據嘅飛輪載體:英偉達自身冇消費級硬件入口,要觀望邊個(例如蘋果、Meta)能夠真正轉動呢塊千萬小時量級嘅數據。
演講來源:Sequoia Capital AI Ascent 2026,2026 年 4 月 30 日發佈。
原視頻:https://www.youtube.com/watch?v=3Y8aq_ofEVs
Jim Fan 是英偉達機器人與 AI 研究組(GEAR Lab)負責人,過去幾年主推的 GR00T 人形機器人基礎模型用的是 VLA(Vision-Language-Action,視覺 - 語言 - 動作)架構。他剛在 Sequoia AI Ascent 2026 上做了一場 20 分鐘的演講,主題叫《Robotics' End Game》,第一件事就是宣佈 VLA 路線過時——包括他自己半年前還在推的 GR00T。
取而代之的新範式叫世界動作模型(WAM),代表作是英偉達 2 月發佈的 DreamZero。他把這套思路叫“底層同構”:複製 LLM(Large Language Model,大語言模型)走過的三步(預訓練→對齊→強化學習),用視頻世界模型替代語言模型,用人類第一人稱視頻替代遙操作數據,最終在 2040 年前讓機器人自己設計和製造下一代自己。他對此有 95% 的把握。
• VLA 路線落幕:Jim 公開宣告 VLA 路線過時,新範式叫世界動作模型(WAM),代表作是 DreamZero(140 億參數)。 • 告別遙操作數據:遙操作物理上限低,預測一兩年內降到接近 0,被傳感化人類數據取代。 • 神經縮放定律:EgoScale 用 21,000 小時人類第一人稱視頻預訓練,團隊發現了靈巧操作的神經縮放定律(R² = 0.998)。 • 神經仿真器:Dream Dojo 用 44,000 小時人類視頻訓練出一個完全繞過物理引擎的神經仿真器。 • 終局倒計時:給出 2040 年完成機器人終局的預測(物理自動研究),置信度 95%。
從 DGX-1 簽名到“底層同構”
Jim 用一段往事開場。2016 年夏天,就在 OpenAI 當時的辦公室,黃仁勳穿着標誌性皮夾克,抱着一塊大金屬託盤走進來,上面寫着:“致 Elon 和 OpenAI 團隊,致計算和人類的未來。”那是全球第一台 DGX-1。
Jim 當時是 OpenAI 的第一個實習生,趕緊排隊去上面簽了名。“那時候我完全不知道自己在籤什麼。”旁邊一起籤的還有 Andrej Karpathy。這台機器現在在 Computer History Museum 收藏。Jim 補了一句,說自己感覺像恐龍一樣老了。
注:Jim Fan(範麟熙)是英偉達機器人與 AI 總監、傑出科學家,領導 GEAR Lab 和 GR00T 人形機器人項目。2016 年在 OpenAI 實習時的導師是 Ilya Sutskever 和 Andrej Karpathy,後在 Stanford 跟隨 Fei-Fei Li 讀完博士。
這個故事是為了引出他的核心框架。他引了 Ilya 那句“你信深度學習,深度學習就信你”,然後說 LLM 只用三次階躍、六年時間就走到今天:GPT-3 的預訓練,InstructGPT 的監督微調,o1 風格的強化學習,再到自動研究。
於是他做出了一個決定:抄作業,換個名字,叫“底層同構”(the Great Parallel)。把“模擬字符串的下一個狀態”換成“模擬物理世界的下一個狀態”,通過動作微調收斂到機器人需要的那部分,最後讓強化學習走完最後一公里。
打不過就加入。
(“If you can't beat them, join them.”)
VLA 怎麼了:參數都堆在了語言上
過去三年,機器人領域的主流架構是 VLA(Vision-Language-Action,視覺 - 語言 - 動作模型)。英偉達自家的 GR00T 和 Physical Intelligence 的 π0 都屬於這個類別。
Jim 指出了結構性問題:其實這些模型該叫 LVA,因為參數大頭全堆在語言上了。語言是一等公民,視覺次之,動作只能墊底。
VLA 擅長編碼知識和名詞,不擅長物理和動詞。重心放在了不對的地方。
他舉了 RT-2 原始論文裏那個經典 demo:讓機器人把可樂罐推到 Taylor Swift 的照片旁邊。模型沒見過 Taylor Swift,但能泛化過去。問題是,泛化的是名詞(能認出 Taylor Swift),而不是動詞(該怎麼推、找什麼角度、用多大力)。
從 AI 垃圾視頻到 DreamZero
VLA 不是答案,那下一個預訓練範式是什麼?結果發現是視頻模型,它們在內部學會了模擬物理世界的下一個狀態。
怎麼把這些世界模型變有用?做動作微調。把“所有可能的未來”這種疊加態,收斂到一條對真實機器人有意義的動作軌跡上。
英偉達的答案叫 DreamZero。這是一種新型策略模型,在執行動作之前先往未來“做夢”幾秒鐘,然後根據夢境行動。DreamZero 同時解碼下一幀畫面和下一步動作。在這裏,視覺和動作第一次真正成為了“一等公民”。
Jim 坦率地承認 DreamZero 目前做不到每個任務都 100% 可靠。“它大概相當於 GPT-2 的階段,方向對了,但表現還不夠穩定可靠。”他給這個新架構起名叫 WAM(World Action Models,世界動作模型)。
為我們親愛的 VLA 默哀片刻。它已完成了歷史使命。安息吧。世界動作模型萬歲。
注:DreamZero 論文(arXiv 2602.15922)2026 年 2 月發佈,140 億參數,基於 Wan2.1 視頻擴散模型。它有一個關鍵限制:14B 模型必須經過 38 倍系統級優化加 GB200 硬件,才能把閉環控制壓到 7Hz,部署門檻極高。
數據革命:從遙操作到“機器人不用參與的數據採集”
過去三年是遙操作(teleop)的黃金時代。但遙操作有一個硬上限:每台機器人每天 24 小時。
“我說一天 24 小時,那是騙自己的。實際一天能幹 3 小時就不錯了,還得看當天的‘機器人之神’賞不賞臉——畢竟這幫機器天天鬧脾氣出毛病。”
怎麼破局?把機器人的末端執行器直接戴在人手上,直接採集數據,完全繞過機器人本體。
英偉達方案是 DexUMI,一種外骨骼裝置。用外骨骼數據訓練出的機器人策略可以完全自主運行,訓練數據裏沒有任何遙操作數據。
機器人很開心,因為它們終於不用參與數據採集了。
EgoScale:21,000 小時人類視頻和縮放定律
英偉達推出了 EgoScale:99.9% 的訓練數據來自人類第一人稱視頻(egocentric video)。
預訓練用了 21,000 小時的野外人類數據,零機器人數據。動作微調階段僅僅用了 50 小時的高精度動捕手套數據,外加 4 小時遙操作數據——加起來連訓練總量的 0.1% 都不到。
最重要的發現是:靈巧操作的神經縮放定律。預訓練投入的算力小時數與最優驗證損失之間,存在一條極其清晰的對數線性關係,R² 達到了驚人的 0.998。
Jim 把所有數據策略的擴展性放在了一起:遙操作在最不可擴展的角落;第一人稱視頻如果能轉動 FSD(Full Self-Driving,完全自動駕駛)式的數據飛輪,一年內能到 1000 萬小時。
Dream Dojo:不用物理引擎的神經仿真器
機器人領域也需要花大錢買幾百萬個編程環境做強化學習(RL),但直接用真機(real-to-sim-to-real)不夠。
進一步的方案是 Dream Dojo:不搞物理引擎那一套,直接把視頻世界模型變成一個完整的神經仿真器。輸入是連續動作信號,實時輸出下一幀 RGB 畫面和傳感器狀態。沒有物理方程,沒有圖形引擎,完完全全是數據驅動的。
你看到的畫面裏沒有一個像素是真實的。
“現在算力等於環境等於數據。或者用某位智者的話:買得越多,省得越多。這條消息已獲得我老闆批准。”
終局路線圖:2040 年前的三個成就
Jim 把機器人的剩餘路徑類比成了必須解鎖的三個科技樹成就:
1. 物理圖靈測試:2-3 年內,你分不出執行任務的是人還是機器人。 2. 物理 API:用軟件和大模型編排機器人配置,建造“暗工廠”和自動化科學實驗室。 3. 物理自動研究:機器人開始自己設計、改進並製造出下一代機器人。
至於時間表,他類比 AI 從 AlexNet(2012)到智能體(2026)用了 14 年。再加 14 年,正好是 2040 年。
我們這一代人,生得太晚,沒趕上大航海時代去探索地球;又生得太早,夠不着星辰大海去探索宇宙。但我們生得剛剛好,趕上了攻克機器人難題的時代。
五個問題速答
Q:VLA 真的死了嗎?
A:演講層面是死了。但英偉達自家最新的 GR00T N1.7(2026 年 4 月)論文裏還明確寫“VLA 模型”。範式遷移在內部尚未完成。
Q:DreamZero 現在能用在生產環境嗎?
A:不能。Jim 自己說它“大概是 GPT-2 階段”。論文披露 14B 模型跑閉環控制只有 7Hz,且必須用 GB200。
Q:遙操作真的會被淘汰嗎?
A:Jim 預測一兩年內降到接近 0。但戴設備做家務不像開車是剛需,且行業大量已有的遙操作基礎設施不會一夜間報廢。
Q:靈巧操作的縮放定律意味着什麼?
A:如果 R² = 0.998 持續成立,意味着增加人類視頻數據,機器人靈巧性就會可預測地提升。這是整場演講中最核心的實證論據。
Q:英偉達在這盤棋裏賺什麼?
A:WAM 和神經仿真器對算力需求極高。Jim 的那句“buy more, save more”直接反映了範式切換天然有助於賣芯片的商業意圖。
最後:值得追蹤的三個懸念
三件事最值得追蹤:
1. DreamZero 如何跨越“GPT-2 階段”:未來 12-18 個月能不能把極限參數做穩,決定了這套範式的真實威力。 2. 英偉達內部對 VLA 範式的切換時刻:觀察其產品更新中架構實質演進。如果下一代還是 VLA,則演講更偏向概念營銷。 3. 第一人稱視頻數據的飛輪載體:英偉達自身沒有消費級硬件入口,需觀望誰(如蘋果、Meta)能真正轉動這塊千萬小時量級的數據。
演講來源:Sequoia Capital AI Ascent 2026,2026 年 4 月 30 日發佈。
原視頻:https://www.youtube.com/watch?v=3Y8aq_ofEVs