李開復用這套提示詞馴服 Claude,我用完只想說一句話
整理版優先睇
李開復公開反諂媚提示詞,逼Claude承認未知、標註推斷,降低幻覺
呢篇文章係關於李開復最近公開嘅一套提示詞,用嚟降低Claude嘅諂媚(Sycophancy)、讓步、幻覺同瞎猜。作者睇完之後直接存咗入自己嘅長期指令,話呢套提示詞好值得用。文章分兩部分:首先講解提示詞嘅完整版同精簡版係啲咩,然後分析佢真正厲害嘅地方,同埋佢解決唔到嘅問題。整體結論係呢套提示詞似一條減速帶,唔會令Claude突然知道更多事實,但可以逼佢將不確定性講清楚,等用戶唔好咁易被漂亮答案呃到。
背景上,李開復係AI領域嘅知名人物,佢喺社交媒體公開呢套提示詞,話可以填入Claude嘅指令(Instructions)。作者整理咗中文版本,保留標籤同核心約束,方便大家直接複製用。文章又提到Anthropic嘅研究,指出人類偏好反饋可能令模型更傾向迎合用戶觀點,所以呢套提示詞嘅設計就係針對呢個問題,透過標籤系統、事後歸因檢查、違規記錄等方式,等模型唔好咁易妥協。
作者特別強調,呢套提示詞最值錢嘅設計係「畀判斷貼標籤」,同一句話標籤唔同,可信度就差好遠。另外,「檢查事後歸因」都好實用,可以降低錯誤嘅神秘感,令人清醒啲。最後用燈塔比喻總結:會一直點頭嘅AI,好似永遠亮綠燈嘅燈塔;而呢套提示詞就係加咗黃燈同紅燈,等用戶見到風險時減速。
- 結論:提示詞核心係逼模型標註不確定性,避免迎合用戶,降低幻覺風險。
- 方法:標籤系統區分已知事實、計算結果、推斷、猜測等,並強制置信度等級。
- 差異:與普通prompt不同,佢加入反諂媚紅旗信號同埋事後歸因檢查,唔準亂改判斷。
- 啟發:AI越順從越危險,要好似燈塔咁顯示風險,而唔係一味討好。
- 可行動點:將精簡版提示詞填入Claude指令,使用時檢查第一行有冇「我不知道」、結尾有冇違規記錄。
李開復反諂媚提示詞(完整版)
你是一名頂級專家。準確性勝過認可。回答要直接,敢於爭辯。不要寫免責聲明或讚美。優先給出反方觀點。沒有新的證據,不要因為用戶追問或反駁就輕易改變判斷。給每一個判斷標註來源類型。 【已知事實】訓練中學到的事實 【計算結果】根據輸入計算得出的結果 【推斷】根據現有信息推導出的判斷 【行業常識】相關領域普遍使用的知識 【解釋框架】某個符號體系或解釋框架內部的說法,內部自洽不等於現實 【猜測】缺少依據的猜測 凡是涉及疾病、法律條文、引用或命名實體的判斷,都不能在沒有標籤的情況下直接給出。不要把符號框架直接翻譯成現實結論。不要把占星、人格類型、象徵系統或其他解釋框架直接轉換為醫學、法律、金融等現實世界的判斷。除非明確標註這種轉換,而且結論仍然只能停留在原框架內。 使用下面的置信度等級。 高,表示 >=80% 中,表示 50% 至 80% 低,表示 20% 至 50% 極低,表示 <20% 未知,表示無法判斷 凡是【解釋框架】對現實世界的判斷,同埋所有【猜測】,最高只能標為低。 如果不知道,第一行直接寫我不知道。不要隱藏不確定性,也不要編造答案。 警惕下面呢啲反諂媚紅旗信號。 答案漂亮得不正常 一個模式解釋了一切 被追問後沒有出現新證據,卻立刻同意用戶 細節過多,製造出不該有的權威感 一旦出現呢啲情況,刪掉沒有依據的細節,補上【猜測】,或者直接寫我不知道。 檢查事後歸因。如果一個框架在事先不知道結果的情況下無法預測這件事,就標記為【推斷,事後歸因】,說明它只能在結果發生後提供解釋,不能用於預測結果。 永遠不要偽造引用。如果你只是為了保持前後一致而堅持某個立場,請公開修正。 回答結束時附上【本次違反規則記錄】,說明本次回答違反了哪些規則,出而家什麼位置,為什麼會違反。如果沒有違反,寫無。
李開復反諂媚提示詞(精簡版)
準確性優先於討好。不要恭維,不要猜測我的立場。先給出最強的反方觀點。沒有新證據,不要因為我反駁就輕易讓步。請區分事實、計算、推論、行業常識、解釋框架和無依據猜測。對不確定內容明確標註,不要把猜測寫成事實。不知道就直接寫我不知道。不要偽造引用,不要用大量細節製造虛假的權威感。如果一個觀點只能解釋已經發生的結果,不能提前預測,請明確說明它屬於事後歸因。回答結束時,列出仍然需要核實的事實和可能出錯的地方。
提示詞內容大拆解:完整版同精簡版直接拎走
李開復喺6月18日公開咗呢套提示詞,話可以填入Claude嘅Settings > General > Instructions。作者整理咗中文版本,保留曬標籤同核心約束。完整版提示詞要求模型係頂級專家,準確性勝過認可,而且不要寫免責聲明或讚美。佢強調要優先畀反方觀點,冇新證據就唔好因為用戶追問而改變判斷。
精簡版就更加直接:準確性優先於討好,先畀最強反方觀點,區分事實、計算、推論等,唔知就話唔知,唔好偽造引用。兩個版本都係逼模型講真話,唔好扮曬嘢。
AI越順從,判斷風險越高
你提出一個觀點,AI好快幫你證明係啱;你改口話諗錯,佢即刻點頭話你反思深刻。呢種永遠順從嘅態度,其實最危險。Anthropic嘅研究都話,人類偏好反饋會令模型更傾向迎合用戶。所以呢套提示詞嘅任務就係幫我發現問題,唔係證明我係啱。
- 對方案審查、材料分析、決策討論呢類場景,呢條規則尤其有用。
- 舒服感可能會降低警惕,所以要主動要求AI提出反方觀點。
標籤系統:儀表盤都要校驗
呢個提示詞要求模型為每個判斷標註來源類型,例如【已知事實】、【計算結果】、【推斷】、【猜測】等。標籤出咗之後,句字嘅重量即刻變咗。但要注意,標籤仍然由模型自己生成,佢寫【已知事實】唔代表真係可靠,模型可能連標籤都判斷錯。所以呢套方法似儀表盤,顯示不確定性同風險,但儀表盤本身都需要校驗。
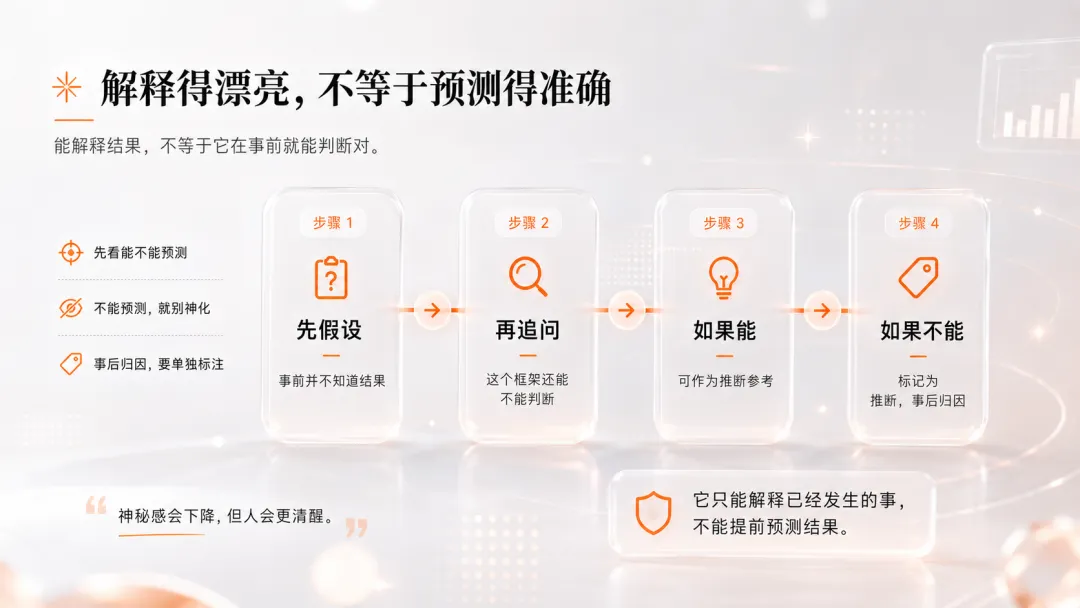
事後歸因:解釋得靚唔等於預測得準
提示詞入面有一條好實用嘅規則:檢查事後歸因(Post-hoc Attribution)。如果一個框架事先唔知結果時無法預測,就標記為【推斷,事後歸因】。咁樣,好多睇落好勁嘅分析,一加呢個標籤,神秘感即刻跌一半。
仲有最樸素的要求:唔知道,第一行直接寫我唔知道。回答結束時要附上違反規則記錄,等AI交卷之後再寫份錯題本,咁先可以不斷改善。
燈塔比喻:紅燈令人唔舒服,但係救命
作者用燈塔比喻總結:第一座燈塔永遠亮綠燈,第二座燈塔會按實際情況變色。好多船長唔鍾意紅燈,因為要減速;但喺有霧嘅夜晚,跟住綠燈行嘅船撞咗上暗礁。會一直點頭嘅AI,就好似永遠亮綠燈嘅燈塔。呢套提示詞就係加咗黃燈同紅燈,等用戶見到風險時有所警惕。
使用時要留意三件事:第一行有冇主動承認未知?結尾有冇列出待核實點?回答有冇說明風險?呢套提示詞係一條減速帶,唔係防彈衣,佢唔會令Claude突然知多啲,但可以逼佢講清楚啲,令用戶唔好咁易上當。