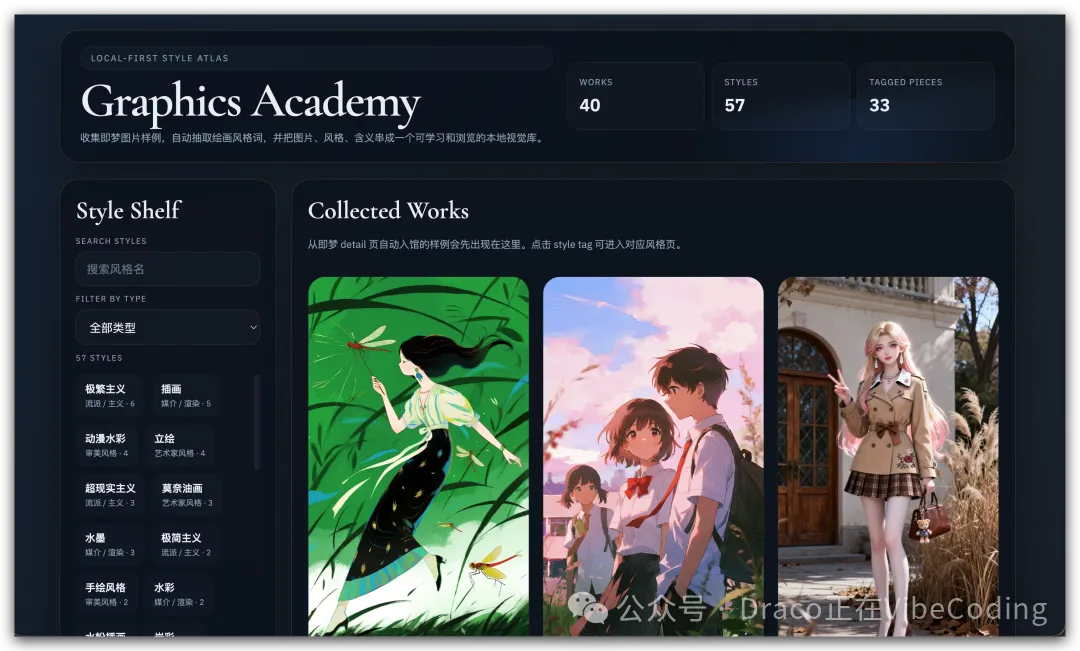
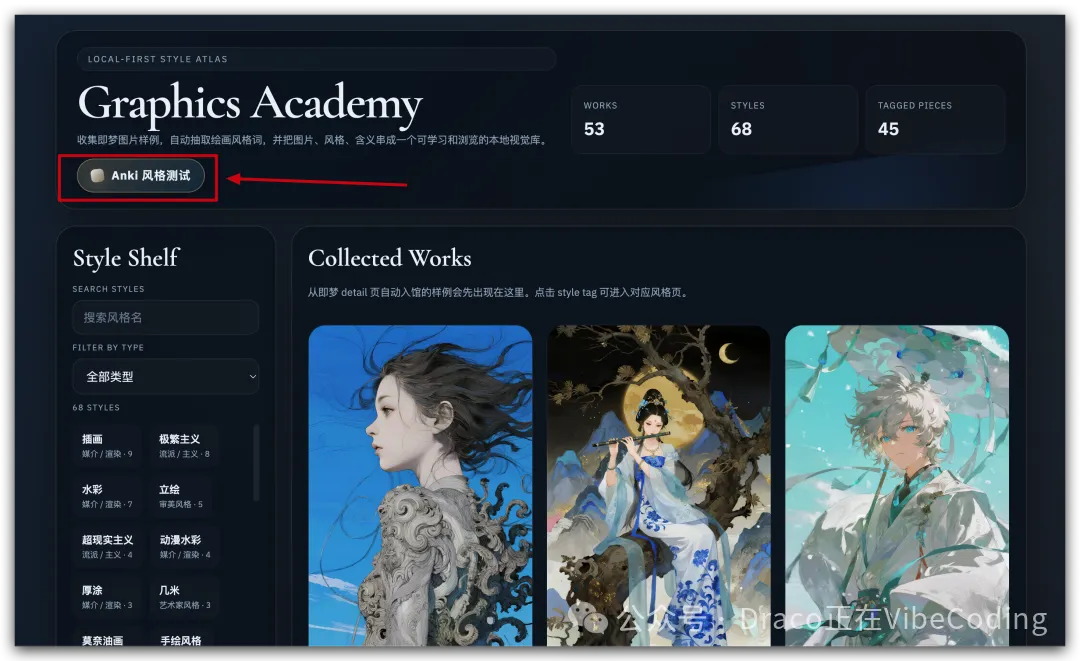
來,立刻擁有你的私人AI圖片風格影像館
整理版優先睇
利用半自動收藏工具訓練自己辨識AI圖片風格嘅能力,將視覺消費轉化為創作力。
作者Draco Hu指出,隨住AI圖像生成普及,視覺辨識能力變得越來越重要,尤其係要能夠用自然語言講出圖片嘅風格關鍵詞。佢認為,如果唔掌握呢種能力,就只能消費而無法創作,而創作先係價值嘅源泉。為咗幫自己同其他非科班出身嘅人練習,佢整咗一個叫「Graphics Academy」嘅開源項目(即係t2i_museum)。
呢個工具嘅核心係半自動收集AI圖片嘅風格關鍵詞,用戶可以喺即夢等平台睇到圖片時,透過Chrome插件一鍵提取Prompt,然後由大模型解析出風格關鍵詞(包括審美風格、媒介、藝術家風格等),之後用戶必須手動審核、增刪改,最後先入館。作者特別強調,呢個「手動審核」嘅步驟係刻意練習嘅關鍵,避免跌入「收集者謬誤」——收藏咗就以為自己擁有,其實腦海冇留低任何痕跡。
整體結論係:收藏唔等於學習,入館前改一次關鍵詞,遠比入咗100張圖但冇睇過更有價值。作者鼓勵大家立即部署呢個開源項目,開始練習,從而掌握視覺風格辨識呢項未來必備嘅技能。
- 結論:視覺辨識能力係創作嘅基礎,要透過刻意練習去掌握風格關鍵詞。
- 方法:利用半自動收藏工具(t2i_museum)收集AI圖像,手動審核風格關鍵詞以強化記憶。
- 差異:避免「收集者謬誤」,強調每次入館前修改關鍵詞先算真正學到嘢。
- 啟發:大模型解析唔會100%正確,人機協作先係最有效學習路徑。
- 可行動點:即日起部署項目、安裝Chrome插件、開始練習風格辨識。
t2i_museum GitHub Repo
開源項目,用於收集AI圖片風格關鍵詞並進行刻意練習。包含後端、前端同Chrome插件,支援本地或雲端部署。
點解視覺辨識咁重要?
作者認為,AI時代嘅視覺能力唔再係「識睇」就得,而係要能夠用自然語言精準描述一幅畫嘅風格、一條片嘅分鏡。呢個係由消費者轉變為創作者嘅必經之路。
視覺會變得更重要!重要到你要即刻講出幅畫嘅風格。
呢套工具點幫你刻意練習?
整套系統包括一個GitHub倉庫同一個Chrome插件。部署之後,你去即夢睇圖片,右邊會多咗個「COLLECT」按鈕,一㩒就自動提取Prompt,然後用DeepSeek-V4-Flash解析出風格關鍵詞。
解析完會彈出一個分類彈窗,涵蓋審美風格、媒介、藝術家風格、流派主義、質量修飾、題材內容同情緒氛圍。
- 1 如果分類唔合理,你可以叫Coding Agent幫手調整。
- 2 大模型解析未必準確,你要手動增刪改關鍵詞,確保正確。
- 3 編輯完之後㩒「確認入館」,張圖就會存入本地數據庫,喺主頁可以瀏覽。
入館後仲可以重新編輯或刪除,管理好自己嘅風格資料庫。
點解要做半自動,唔全自動?
作者刻意設計成半自動,因為全自動只會令你「無腦」確認,學唔到嘢。佢引用一個概念叫「Collector's Fallacy」,意思係收藏咗就覺得擁有了,其實大部份內容都喺度食灰。
視覺衝擊力再強嘅圖,都係人哋嘅能力,唔會自動變做你嘅。
點樣擴展到其他網站?
如果覺得只支持即夢唔夠,而且你有一定動手能力,可以同Coding Agent講你想支持邊個網站。最方便係用CDP直連瀏覽器,讀取該網站圖片詳情頁嘅DOM結構,好快就可以擴展。
畀個網址俾Coding Agent,佢就可以幫你分析DOM,支援更多平台。
而家就行動!
作者仲整咗個Anki閃卡風格測試,幫你鞏固所學。立即去GitHub下載代碼,用Coding Agent部署,安裝插件,開始收集第一張圖啦!
倉庫喺:https://github.com/dracohu2025-cloud/t2i_museum,歡迎俾Star!
git clone https://github.com/dracohu2025-cloud/t2i_museum.git
cd t2i_museum
# 使用Coding Agent(例如Claude Code)部署
# 前置條件:OpenRouter API Key、可選騰訊雲COS
# 啟動localhost: http://127.0.0.1:4317/museum先睇幾張圖片,你講唔講得出佢哋嘅Prompt入面帶咗咩風格關鍵詞?



答案分別係:
1. 穆夏風格 2. Moebius風格 3. 幾米繪本風格
如果你大致答啱曬,恭喜你,你係呢個時代嘅天選之人!
如果一個都估唔中,都唔使擔心,我畀你一個用嚟做「刻意練習」嘅工具。
在之前嘅文章入面我曾經咁樣寫:
視覺唔係唔重要;相反,視覺會變得更加重要!
重要到,當畀你睇一幅畫時,你要即刻講得出呢幅畫嘅風格,用自然語言對呢幅畫進行精準嘅描述(人腦反推);畀你睇一條片時,你要即刻講得出呢條片嘅分鏡設計!係呀,就係要達到呢個程度~
否則,你就幾乎只能消費,而唔能夠創作。而創作係價值嘅泉源!
而呢個,就係我下個階段探索嘅方向!(我而家正喺度整一個叫 Graphics Academy 嘅網站/應用,嚟幫你(我自己)呢啲非科班出身嘅人掌握上面↑描述嘅呢種能力)~ 敬請期待!
今日嚟填返呢個坑:Graphics Academy V1.0 版!
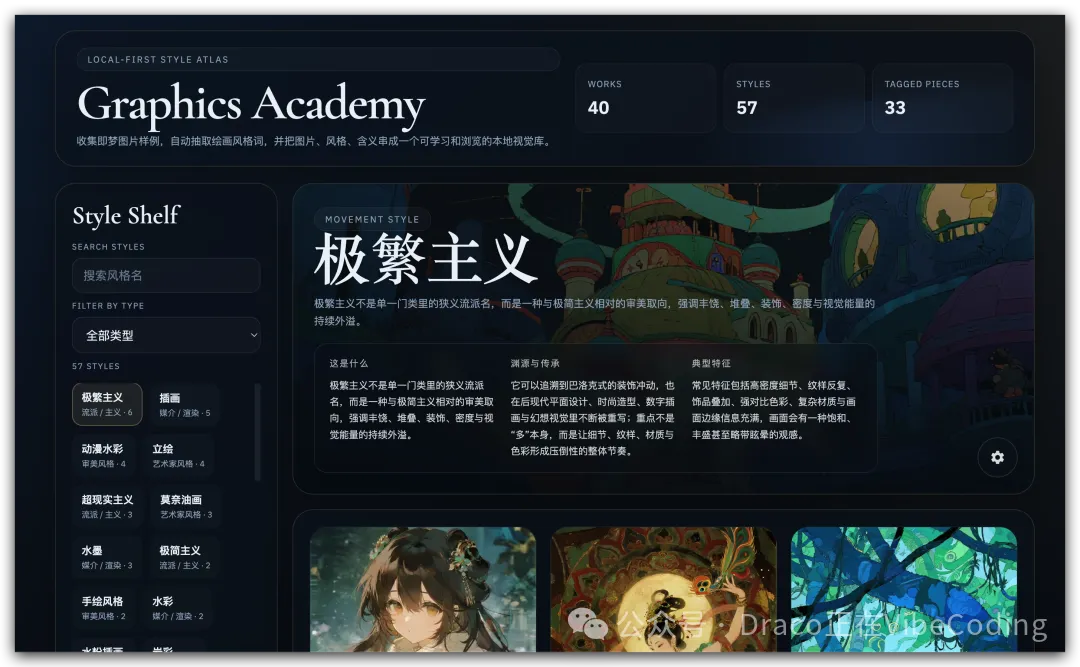
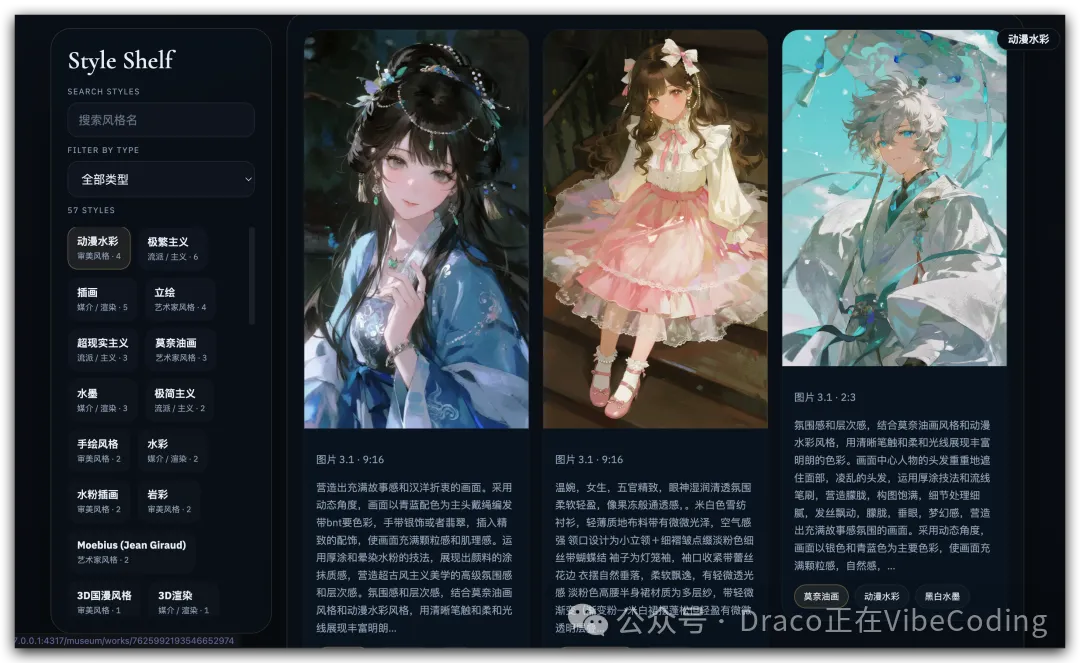
所有 code 都喺 Github 倉庫:https://github.com/dracohu2025-cloud/t2i_museum
你可以將 code 下載到本地,然後叫 Coding Agent(例如 Claude Code/Codex/OpenCode 等等)喺本地進行部署(當然都可以部署喺雲端)。項目入面有啲前置條件:
喺本地部署並啟動 localhost(默認係運行喺:http://127.0.0.1:4317/museum)之後,需要將呢個項目自帶嘅 Chrome 插件裝上(插件名係 t2i_museum Collector),位置喺:
/t2i_museum/apps/extension/dist
裝好之後,隨便開一個即夢圖片嘅詳情頁,就會見到喺圖片右邊多咗一個 COLLECT 掣:
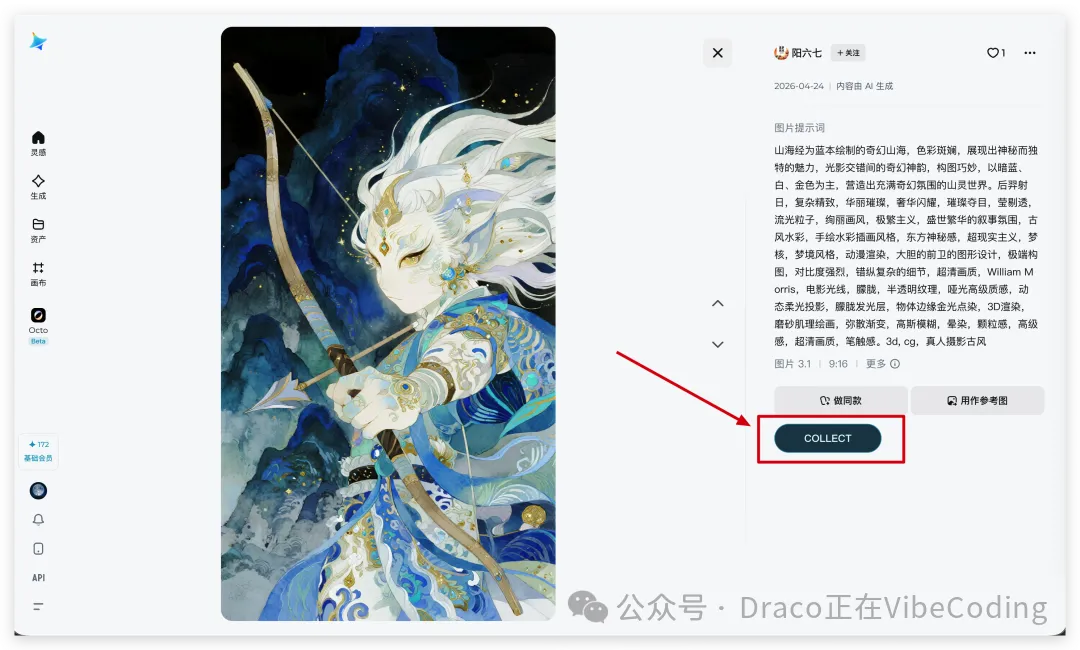
如果遇到冇呢個掣嘅情況,請 refresh 一下個頁面就得;如果仍然冇,就係 P0 bug 啦,叫 Coding Agent 嚟 fix;
幾秒之後,插件會將目前頁面嘅 Prompt 回傳到本地,經過大模型解析之後,會彈出一個呢張圖片所涉及嘅「風格關鍵詞」彈窗。
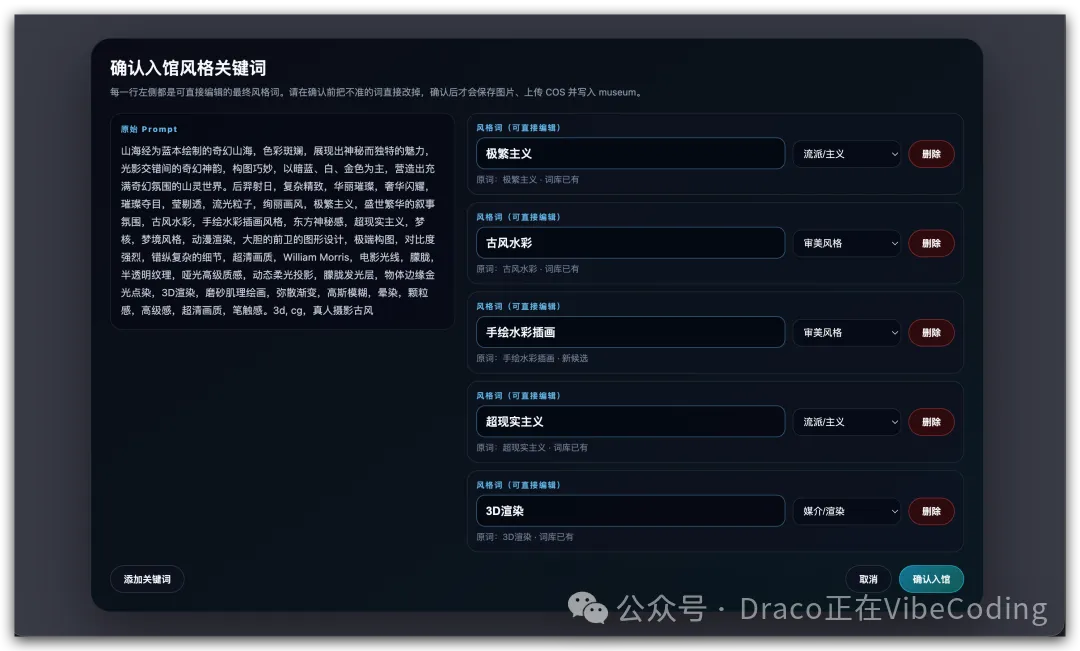
風格關鍵詞包括幾種類型:
審美風格、媒介/渲染、藝術家風格、流派主義、質量修飾、題材內容、情緒氛圍
如果你認為以上分類唔合理,可以叫你嘅 Agent 嚟調整呢啲分類
當然,大模型解析完嘅結果可能準,亦可能唔準,呢個時候你應該對「風格關鍵詞」進行加、刪、改嘅操作。
如果大模型返回嘅風格關鍵詞入面缺少某個類別,就撳左下角嘅「添加關鍵詞」手動添加:
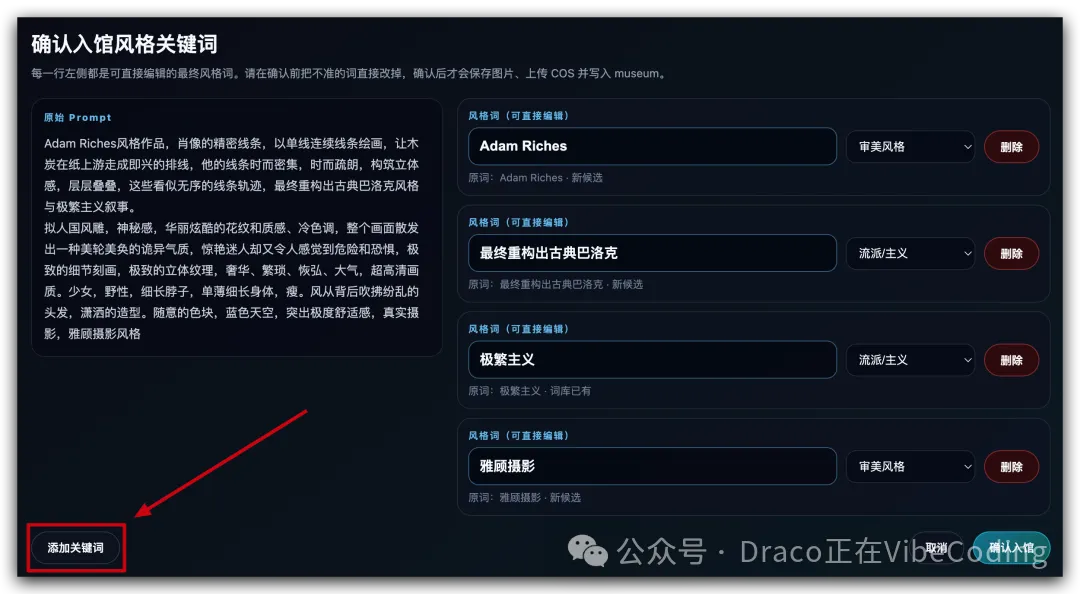
添加關鍵詞時,系統會自動判斷呢個詞係新加嘅,定係已經喺數據庫入面出現過;如果已經出現過,提交之後會自動合併:
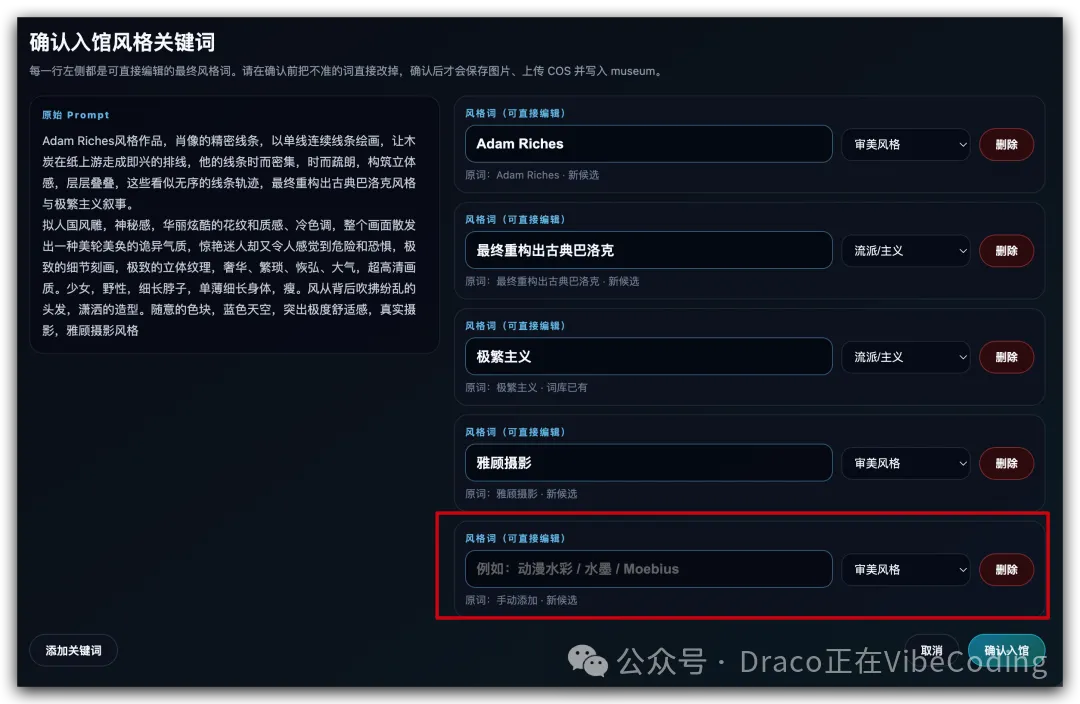
當風格關鍵詞編輯完成之後,撳「確認入館」:
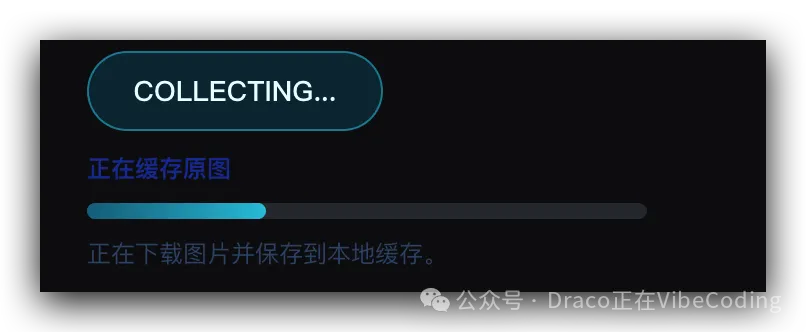
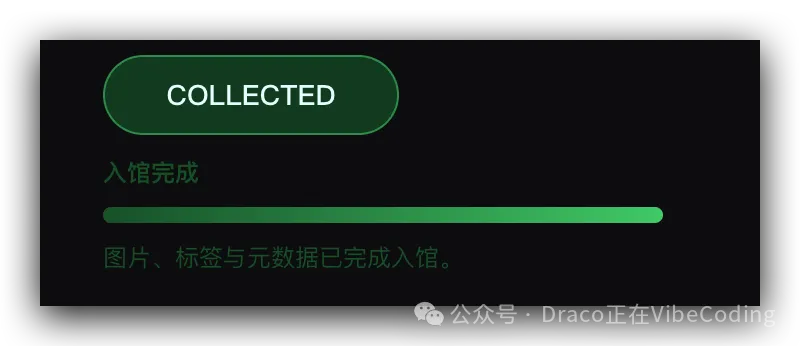
一陣之後,入館成功:
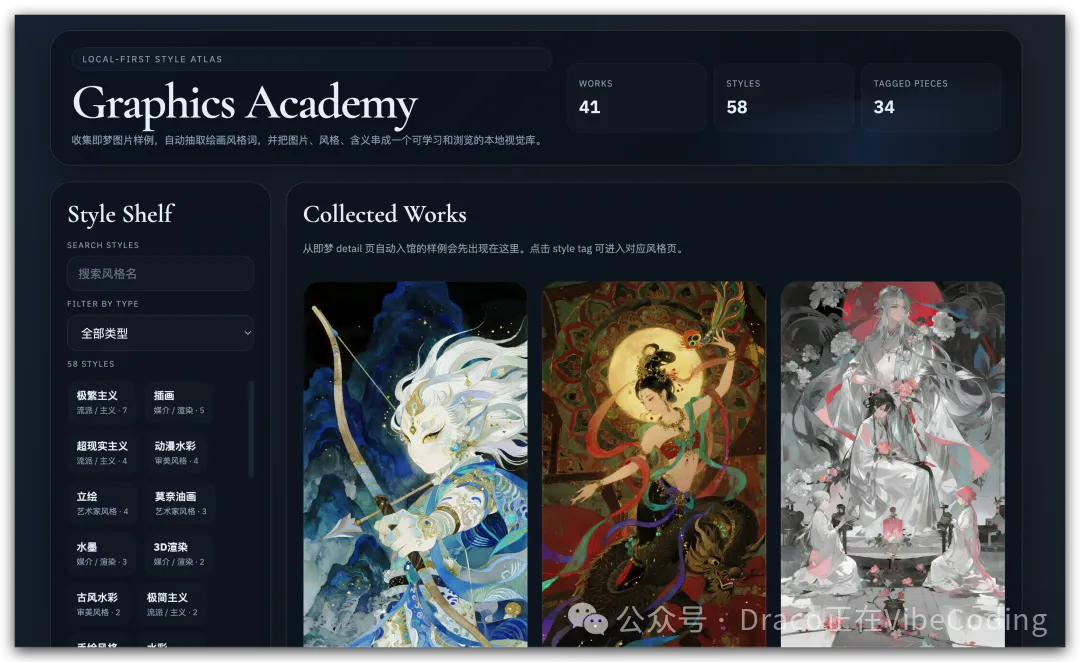
呢個時候,返去 Graphics Academy 首頁,就可以見到啱先新入館嗰張圖喇:
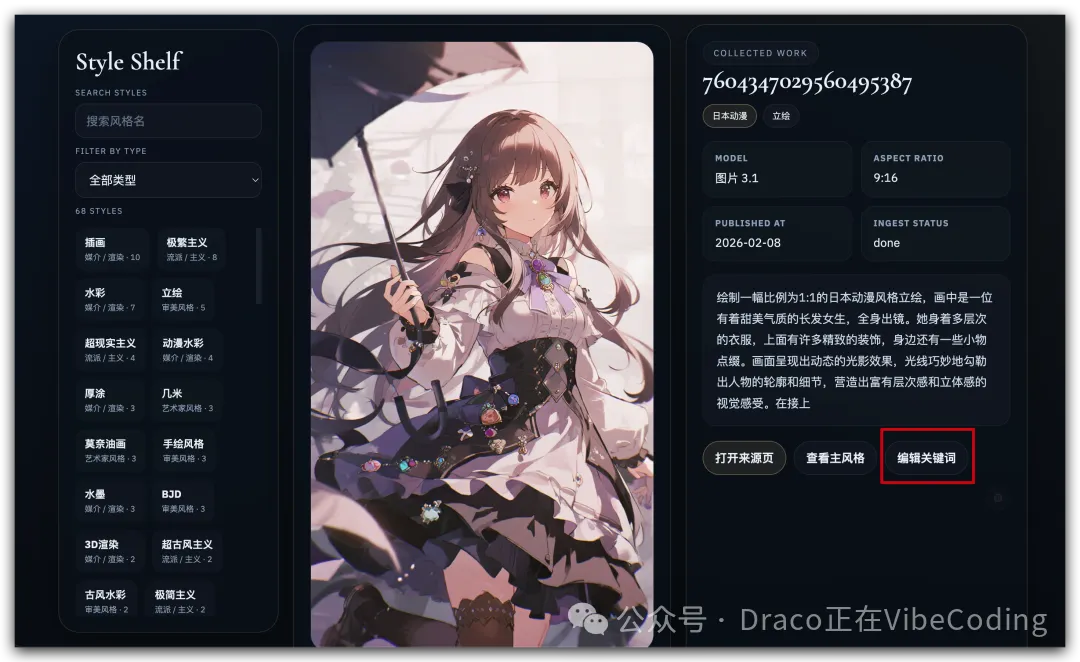
當然,如果入館時填錯咗,都可以喺詳情頁重新編輯:
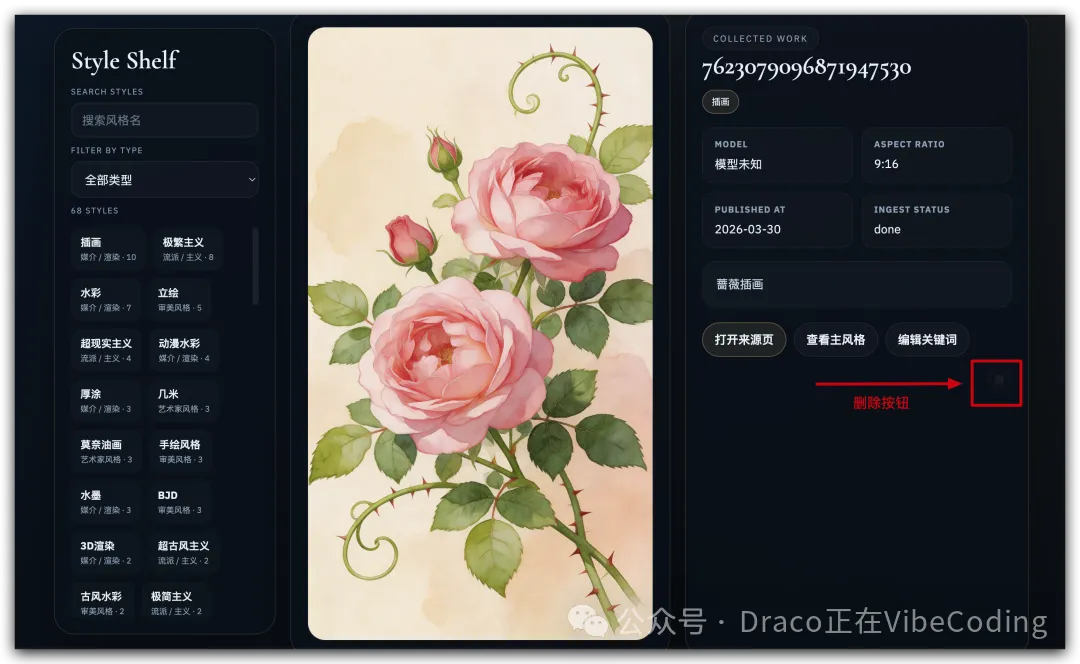
如果唔想收藏某張圖,都可以喺呢個隱蔽嘅角落揾到刪除掣,從數據庫度刪除:
點解要做成半自動而唔係全自動入館?
因為:
1. 首先,大模型嘅解析唔會100%正確; 2. 更重要嘅係,即使後續嘅迭代可以將大模型嘅正確率調到無限接近100%,都唔建議你每次都只係「無腦」撳「確認入館」(有個概念叫「Collector's Fallacy-收集者謬誤」,意思係收藏咗就覺得擁有咗,其實絕大多數情況下被收藏嘅內容都喺度食塵,喺腦入面留唔低一絲痕跡),而係每次入館前都要眼同腦配合,過一過風格關鍵詞啱唔啱,如果缺咗,要手動補上,呢個係一種「刻意練習」嘅過程;畢竟,視覺衝擊力再強嘅圖,都係人哋嘅能力,唔係你嘅。
如果你覺得只係支援即夢唔夠,而且自己有一定嘅動手能力,咁,成功部署呢個項目之後,可以同你嘅 Coding Agent 講你想支援邊啲其他網站,並且將網址話畀 Coding Agent 知,最方便係叫佢用 CDP 直接連你個瀏覽器嚟讀取嗰個網站圖片詳情頁嘅 DOM 結構等資訊,咁樣,應該可以好快支援更多你心儀嘅帶 Prompt 詳細資訊嘅 AIGC 生圖網站。
同時,我仲做咗個 Anki 閃卡風格測試:
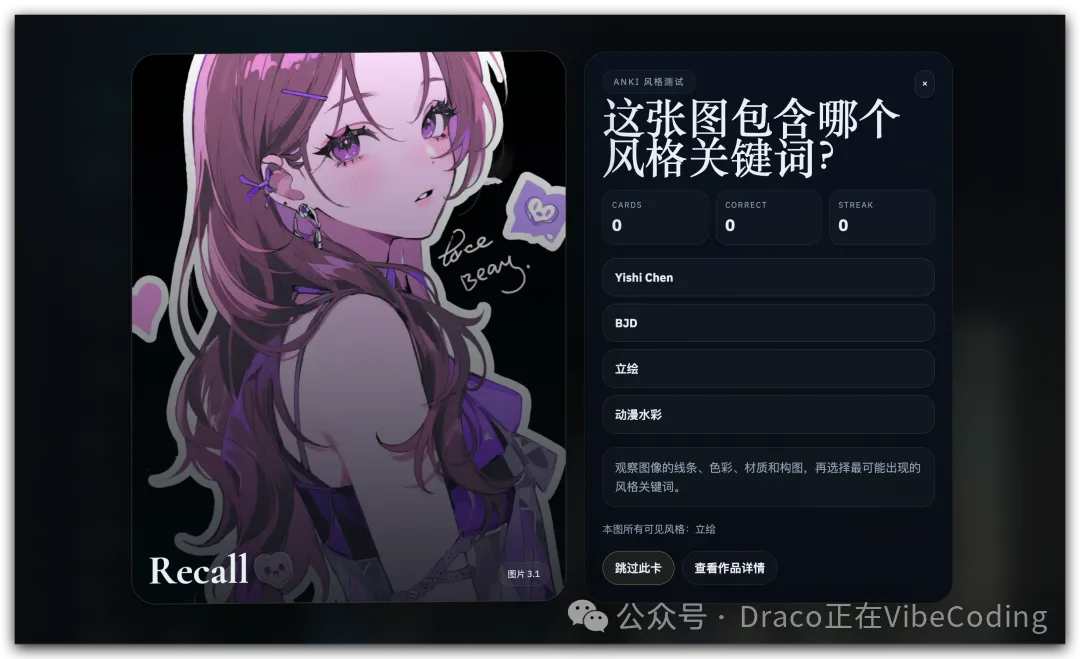
仲等咩嘢,快啲用啦~
倉庫喺:https://github.com/dracohu2025-cloud/t2i_museum
歡迎畀個 Star~
先來看幾張圖片,你是否能說出它們的Prompt中攜帶的風格關鍵詞:
答案分別是:
1. 穆夏風格 2. Moebius風格 3. 幾米繪本風格
如果你基本都答對了,恭喜你,你是這個時代的天選之人!
如果一個沒猜對,也不用擔心,我來給你一個用來做“刻意練習”的工具。
在之前的文章中,我曾這樣寫:
視覺不是不重要;相反,視覺會變得更重要!
重要到,當給你看一幅畫時,你需要馬上說出這幅畫的風格,用自然語言對這幅畫進行精準的描述(人腦反推);給你看一條視頻時,你需要馬上講出這條視頻的分鏡設計!對,就是需要達到這個程度~
否則,你就幾乎只能消費,而無法創作。而創作是價值的源泉!
而這,就是我下個階段探索的方向!(正在搭建一個名為Graphics Academy的網站/應用,來幫助你(我自己)這些非科班出身的人來掌握上面👆描述的這種能力)~ 敬請期待!
今天來填上這個坑:Graphics Academy V1.0版!
所有代碼都在Github倉庫:https://github.com/dracohu2025-cloud/t2i_museum
你可以把代碼下載到本地,然後讓Coding Agent(比如Claude Code/Codex/OpenCode/etc.)在本地進行部署(當然也可以部署在雲端)。項目中有一些前置條件:
在本地部署並啓動localhost(默認是運行在:http://127.0.0.1:4317/museum) 之後,需要將該項目自帶的Chrome插件裝上(插件名字是t2i_museum Collector),位置在:
/t2i_museum/apps/extension/dist
安裝好之後,隨便打開一個即夢圖片的詳情頁,就能看到在圖片右側會多出一個COLLECT按鈕:
如果遇到沒有該按鈕的情況,請刷新一下頁面即可;如果依然沒有,那就是P0 bug了,讓Coding Agent來fix;
幾秒後,插件會將當前頁面中的Prompt回傳到本地,經大模型解析後,會彈出一個本張圖片所涉及的【風格關鍵詞】彈窗。
風格關鍵詞包括幾種類型:
審美風格、媒介/渲染、藝術家風格、流派主義、質量修飾、題材內容、情緒氛圍
如果你認為以上分類不合理,可以讓你的Agent來調整這些分類
當然,大模型解析後的結果可能準,也可能不準,這時候你應該對【風格關鍵詞】進行增、刪、改的操作。
如果大模型返回的風格關鍵詞裏缺少某個類別,則點擊左下角的【添加關鍵詞】手動添加:
添加關鍵詞時,系統會自動判斷這個詞是新加的,還是已經在數據庫中存在過;如果已經存在過,則提交後會自動合併:
當風格關鍵詞編輯完成之後,點擊“確認入館”:
片刻之後,入館成功:
這時,回到Graphics Academy首頁,就可以看到剛才新入館的那張圖了:
當然,如果入館時填錯了,也可以在詳情頁重新編輯:
如果不想收藏某張圖了,也可以在這個隱蔽的角落找到刪除按鈕,從數據庫中刪除:
為什麼要做成半自動而不是全自動入館?
因為:
1. 首先,大模型的解析不會100%正確; 2. 更重要的是,即便後續的迭代能把大模型的正確率調優到無限接近100%,也不建議你每次只是“無腦”點擊“確認入館”(有個概念叫“Collector's Fallacy-收集者謬誤”,意思是收藏了就覺得擁有了,其實絕大多數情況下被收藏的內容都在吃灰,在腦子裏留不下一絲痕跡),而是每次入館前都要眼睛和腦子配合,過一下風格關鍵詞對不對,如果缺失了,要手動補上,這是一種“刻意練習”的過程;畢竟,視覺衝擊力再強的圖,那也是別人的能力,不是你的。
如果你覺得只支持即夢不夠,並且自己有一定的動手能力,那麼,在成功部署該項目後,可以和你的Coding Agent說你希望支持哪些其他網站,並且將網址告訴Coding Agent,最方便是讓它用CDP直連你的瀏覽器來讀取該網站圖片詳情頁面的DOM結構等信息,如此,應該可以很快支持更多你心儀的帶Prompt詳細信息的AIGC生圖網站。
同時,我還做了個Anki閃卡風格測試:
還等啥,趕緊用起來啊~
倉庫在:https://github.com/dracohu2025-cloud/t2i_museum
歡迎給Star~