每天早上 7 點,自動把英文 AI 圈的新選題送到 Obsidian
整理版優先睇
用工作流自動掃英文 AI 信號源並反查中文站,每日生成選題清單到 Obsidian
呢篇文章係一個 AI 內容創作者分享佢點樣用自動化工作流解決選題難題。佢發現英文 AI 圈嘅內容比中文圈快 3 至 7 日,手動追太嘥時間,而且容易漏高質來源。佢想做到「每日穩定揾到中文圈未寫爛嘅選題」,而唔係純粹追熱點。
佢嘅方法係先用 Claude Code + XCrawl Search 掃英文 AI 信號源,再用 Map 驗證可爬性,大站一定要加 filter 只取內容頁。然後用 n8n 每日定時掃瞄 10 個英文站,抽標題摘要,再反查中文站有冇人寫過,0 命中就標 🔥 放最前,最後生成 Markdown 日報入 Obsidian。工作流仲有狀態記憶、每日 cap、串行 batching 等設計,確保穩定又慳 credits。
成個流程大概燒咗 100 credits,穩定後每日 5 條深抓仲可以跑 19 日。關鍵係要跟住「Search→Map→Scrape」順序、用 .seen.json 防止重複、大站加 filter、讓 code 節點兜底 LLM 輸出。最終目標係每日打開 Obsidian 就見到已篩好嘅選題,慳返半個鐘以上。
- 用 Search+Map 取代直覺列源,補返漏咗嘅高質獨立站如 Import AI
- 大站一定要加 filter 只爬內容頁,否則變導航頁白跑
- n8n 流程包含反查中文站、狀態記憶、每日 cap,慳 credit 又穩定
- 中間踩坑:容器網絡、文件讀寫、LLM 唔跟 schema,要靠 code 節點兜底
- 核心價值係將揾選題時間由一個鐘縮到 5 分鐘,唔係代你寫文
點解要搞自動化選題?
AI 圈內容越嚟越難寫,唔係因為冇嘢寫,而係個個都喺同一池度撈。新模型、新工具、新論文、新爭議每日都湧現,中文圈反應已經好快,但英文圈通常係早一步:先評測、先討論、先吵起嚟。中間呢 3 至 7 天,就係內容創作者 最值錢嘅縫隙。
真正嘅問題唔係「要唔要追熱點」,而係:點樣每日穩定揾到仲未俾中文圈寫爛嘅選題。作者提出一個實用方法:用 Claude Code + XCrawl + n8n 組成工作流,每日自動掃英文 AI 信號源,再去中文站反查,最後整理成日報落到 Obsidian。
第一步:揾信號源,唔好靠直覺
好多人做選題第一步就錯:憑印象列幾個站,然後每日手動刷。咁樣好容易漏,尤其英文 AI 圈有啲源唔係日日出圈但質量好高,例如 獨立 newsletter、研究者博客、公司官方 blog、論文摘要頁。更佳做法係先叫 Claude Code 用 XCrawl Search 跑幾組搜索,揾出反覆出現嘅獨立域名。
- 真正嘅信號源,例如 The Rundown AI、Superhuman AI、TLDR AI
- 列名單文章,例如「Top AI Newsletters」,文章本身唔重要,裏面提到嘅站名先重要
- 噪音,例如社區討論、視頻、轉載頁
最值錢嘅唔係「搜到幾個站」,而係將自己腦入面漏咗嘅源補返,好似 Import AI 呢類由 Anthropic 聯創 Jack Clark 寫嘅 newsletter,如果只靠中文圈轉述好可能遲好多先發現。
第二步:驗證可爬性,大站記得加 filter
有咗候選池仲唔可以直接 Scrape,先用 XCrawl Map 驗證一轉。Map 好簡單:畀個域名,返回呢個站點可以發現嘅 URL 列表,又平又適合做第一輪篩選。
anthropic.com:只要 /news/.*
huggingface.co/papers:只要 /papers/.*
blog.google:只要 /innovation-and-ai/.*最後可以收斂出 10 個英文信號源,再配 4 箇中文反查站:量子位、機器之心、36kr、少數派。英文站負責發現新嘢,中文站只答一個問題:呢題中文圈寫過未?
第三步:用 n8n 整成每日雷達
目標好清楚:每日早上 7 點掃 10 個英文站,揾新文章,抽標題同摘要,再拎話題去中文站反查。中文站 0 命中嘅就標 🔥,排喺最前,最後生成 Markdown 日報寫入 Obsidian vault。
- 1 一定要有 狀態記憶,喺 vault 隔籬放一個 .seen.json 記錄已掃 URL,否則每日重複消費。
- 2 每日要設 cap,例如最多深抓 5 條新 URL。
- 3 外部 API 要用 串行 batching,batchSize=1、batchInterval=1500ms 就夠穩定。
慳 credits 同避坑心得
呢類工作流最煩嘅唔係思路複雜,而係小坑好多。例如 n8n 容器打唔到外網,可以切 --network host;Code 節點默認唔可以讀寫文件,要加 NODE_FUNCTION_ALLOW_BUILTIN=fs,path;XCrawl 嘅 LLM 有時唔跟自定義 schema,就唔好同佢硬碰,退一步叫佢出固定格式,再用 Code 節點兜底。
「1 credit 嘅真實測試,比半小時腦補有用」
總結八條原則,幫你慳錢又穩定:
AI 圈嘅內容越嚟越難寫,唔係因為冇嘢寫,而係所有人喺同一個池度撈嘢。
新模型、新工具、新論文、新爭議,日日都湧出嚟。中文圈反應已經算快,但英文圈通常都會快一步:先評測、先討論、先炒起。中間呢 3 到 7 日,就係內容創作者最值錢嘅空隙。
真正嘅問題唔係「應唔應該追熱點」,而係:點樣每日穩定揾到仲未俾中文圈寫爛嘅題目。
一個比較實用嘅方法,係將揾題目呢件事做成工作流:用 Claude Code + XCrawl + n8n,每日自動掃一次英文 AI 信號源,再去中文站反查有冇人寫過,最後將候選題整理成日報,放落 Obsidian 度。
打開筆記,就係嗰日嘅題目清單。
第一步:唔好靠直覺列信息源
好多人做選題,第一步就錯咗:憑印象列幾個網站,然後每日手動刷。
咁樣好容易漏。尤其英文 AI 圈入面,有啲源唔一定日日出圈,但係質素好高,例如獨立 newsletter、研究者博客、公司官方 blog、論文摘要頁。
更好嘅做法係先叫 Claude Code 用 XCrawl Search 行幾組搜索:
揾英文 AI 內容站、AI newsletter、AI tools daily news,刪走 Reddit、YouTube、LinkedIn、Medium 呢啲聚合社區,只保留成日出現嘅獨立域名。
跑完之後,結果通常會分做三類:
• 真正嘅信號源,例如 The Rundown AI、Superhuman AI、TLDR AI • 列名單文章,例如「Top AI Newsletters」呢類,文章本身唔重要,但入面提到嘅網站名好重要 • 噪音,例如社區討論、影片、轉載頁
呢度最有價值嘅唔係「揾到幾個站」,而係將自己個腦漏咗嘅源補返。例如 Import AI 呢類 Anthropic 聯創 Jack Clark 寫嘅 newsletter,如果淨係靠中文圈轉述,可能好遲先留意到。
第二步:名氣大,唔代表適合爬
有咗候選池,仲未可以直接用 Scrape。先用 XCrawl Map 驗證一次。
Map 嘅作用好簡單:俾一個域名,佢會返呢個站點入面揾到嘅 URL 列表。佢夠平,亦適合做第一輪篩選。
呢一輪主要睇三樣嘢:
• 個站仲生唔生,拎唔拎到最近文章 • URL 結構乾唔乾淨,篩唔篩得到真正嘅內容頁 • 有冇 robots.txt 或者反爬限制
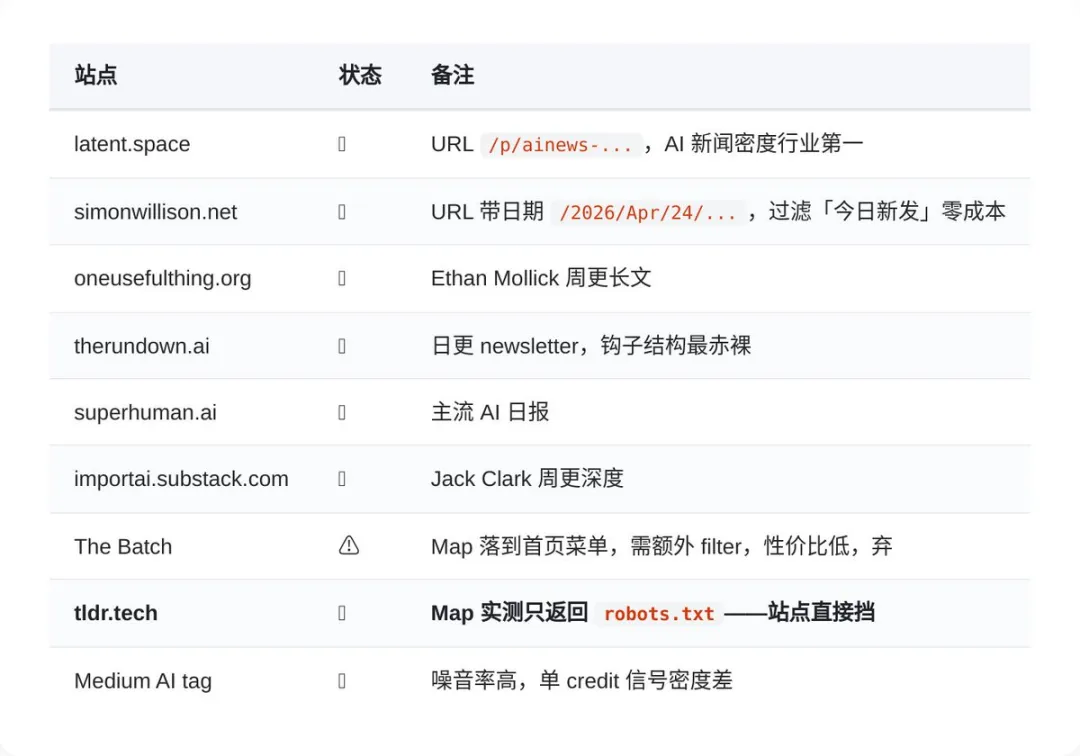
呢度會遇到一個好現實嘅情況:有啲站好出名,但未必爬得到。例如 tldr.tech,Map 過去只係返 robots.txt,即係話佢明確拒絕抓取。
呢種情況唔好硬來。工作流要長期行到,前提係要尊重邊界。爬得就爬,擋咗就跳,唔好為咗一個源搞到成套流程唔穩定。
第三步:大站一定要加 filter
官方 blog 同大公司網站係高價值信號源,但同時最易出現「睇落爬得,實際冇用」。
例如直接 Map anthropic.com,拎到嘅可能係一堆導航頁:careers、about、產品介紹、模型頁面。你想要嘅係 news,唔係站點菜單。
解決方法係加 filter。
先睇真實文章 URL 係點樣,再寫一個正則,只保留目標路徑:
• anthropic.com:只要 /news/.*• huggingface.co/papers:只要 /papers/.*• blog.google:只要 /innovation-and-ai/.*
咁樣 Map 出嚟嘅先係內容頁,而唔係導航結構。
入口決定由邊度開始行,filter 決定留低啲乜。 呢句好關鍵。大站唔加 filter,基本上等於白做。
最後可以收窄到 10 個英文信號源,再加 4 個中文反查站:量子位、機器之心、36kr、少數派。
英文站負責發現新嘢,中文站只答一個問題:呢題中文圈寫過未?

第四步:用 n8n 將佢接成每日雷達
信號源有咗,下一步就係自動化。
目標好清楚:每日早上 7 點掃 10 個英文站,揾新文章,抽標題同摘要,再拎話題去中文站反查。中文站 0 命中嘅,標一個 🔥,排喺前面。最後生成 Markdown 日報,寫入 Obsidian vault。
呢件事用 n8n 好適合。
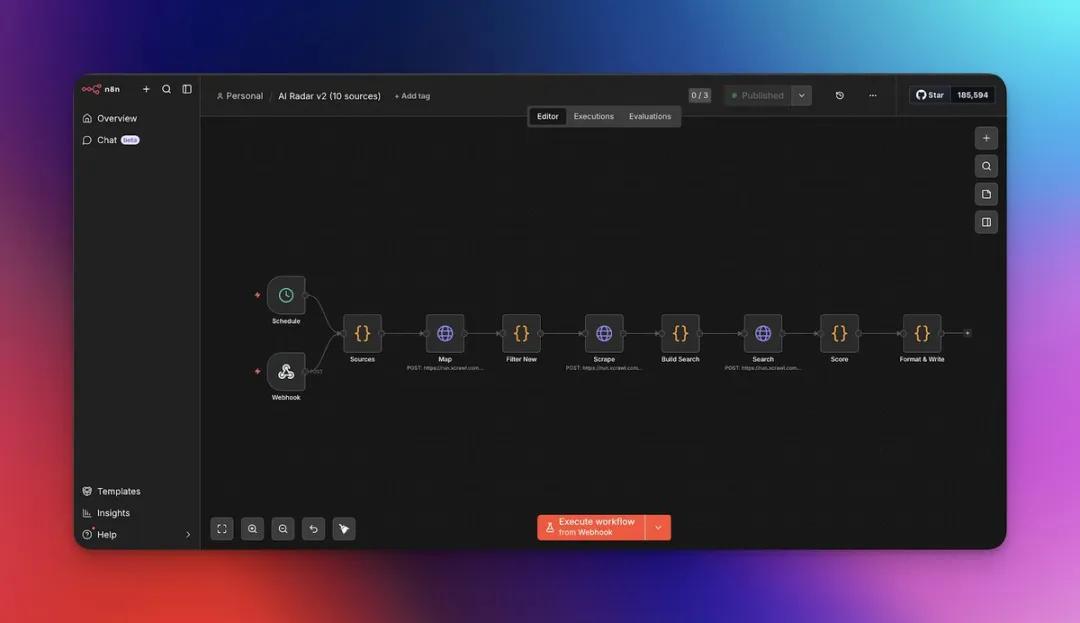
流程大概係:
• Schedule 每日定時觸發,亦保留 Webhook 手動觸發 • Sources 輸出 10 個站點設定 • Map 節點逐個取 URL • Code 節點去重、過濾、讀寫狀態 • Scrape 節點抓正文並做摘要 • Search 節點去中文站反查 • Score 節點排序 • 最後寫成 Markdown 檔案
呢度有幾個設計點好實用。
第一,狀態記憶一定要有。喺 vault 隔籬放一個 .seen.json,記錄已經掃過嘅 URL。如果唔係,每日都會重複消費同一批連結,credit 嘥得好冤枉。
第二,每日要設 cap。例如每日最多深抓 5 條新 URL。英文圈一日可以冒出幾十條內容,真係全部跑一次,賬單同注意力都會爆。
第三,外部 API 唔好並發猛打。n8n 嘅 HTTP 節點可以 set batching,例如 batchSize=1、batchInterval=1500ms,慢啲但穩定好多。
中間會遇到嘅坑,基本上都好具體
呢類工作流最煩嘅地方,唔係思路複雜,而係小坑好多。
例如 n8n 容器打唔到外網,可能係 docker bridge 網絡問題,直接轉 --network host 更簡單。
Code 節點默認唔可以讀寫檔案,就加:
NODE_FUNCTION_ALLOW_BUILTIN=fs,path容器睇唔到 Obsidian vault,就喺容器內建輸出目錄,再喺 vault 度做符號連結。
XCrawl 嘅 LLM 有時唔係好跟自訂 schema 返,就唔好同佢拗,退一步:叫佢返固定 summary format,再用 Code 節點自己整理。
仲有啲反直覺嘅小 bug,例如搜中文站時 location: "CN" 反而失敗,set 做 US 先得。呢啲嘢文檔唔一定會寫,只能靠真實調用先發現。
跑起之後,價值就好直接
日報係咁樣:

最有用的係排序。
如果 DeepSeek V4、Shopify 呢啲題目中文圈已經有 10 個命中,就會自動放後。0 命中嘅,標 🔥,直接出現喺 TOP 區。
每日打開 Obsidian,只需要睇最前面幾條:
• 邊條英文圈啱啱熱起 • 中文圈有冇寫過 • 值唔值得今日搶先寫
原本可能要刷一個幾鐘嘅英文站,而家 5 分鐘就定到題。
呢個先係呢套工作流嘅核心:唔係幫你寫文章,而係幫你將「今日應該寫乜」先篩出嚟。
Credit 賬本都要計清楚
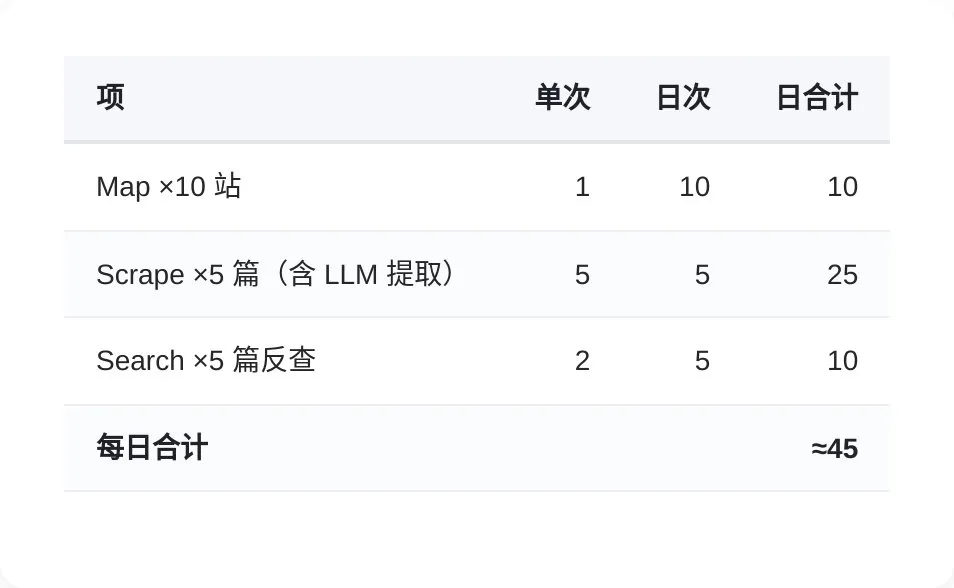
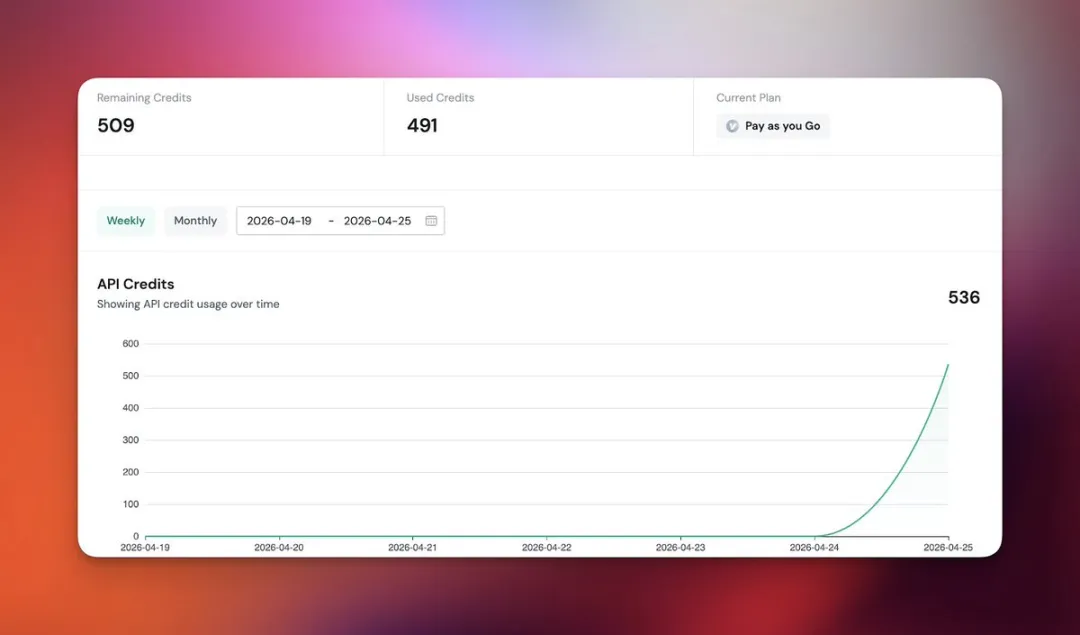
選源、驗證、搭工作流、多次測試,成套流程行完,大概燒咗 100 幾個 credits。

穩定運行之後,如果每日限制 5 條深抓,剩返嘅 880 credits 大概仲可以行 19 日。
呢個已經夠儲一星期甚至更耐嘅選題池。真正要慳錢,關鍵仲係兩點:
• 先 Search / Map,唔好一嚟就 Scrape • 用 .seen.json防止重複掃舊連結
最後記住呢幾點
第一,憑直覺列信息源,一定會漏。叫工具幫你掃一輪,可以補到好多平時睇唔到嘅源。
第二,出名嘅站唔一定適合爬。爬得到、URL 乾淨、更新穩定,先係好源。
第三,大站一定要加 filter。如果唔係,抓到嘅多數係導航頁。
第四,Search → Map → Scrape 呢個次序最慳。先發現候選,再驗證可爬,最後先抓正文。
第五,工作流要有狀態記憶。冇 .seen.json,就係每日重複使錢。
第六,rate limit 用串行 batching,唔好並發衝。
第七,LLM 輸出唔穩定嗰陣,唔好迷信 schema。可以叫 code 節點兜底,就俾 code 節點兜底。
第八,好多坑只有確實行過先知。1 credit 嘅真實測試,好過半個鐘齋諗。
對於做 AI 內容嘅人嚟講,信息差唔會消失,只會變得更加短。英文圈同中文圈之間嘅幾日窗口,手動刷好攰,但用工作流可以穩定處理。
最好嘅狀態係:每日早上打開 Obsidian,最新選題已經排好隊。你要做嘅唔係揾方向,而係揀一個值得寫嘅方向,然後寫好佢。
AI 圈的內容越來越難寫,不是因為沒東西,而是所有人都在同一個池子裏撈東西。
新模型、新工具、新論文、新爭議,每天都在冒出來。中文圈反應已經很快了,但英文圈通常還是會早一步:先評測、先討論、先吵起來。中間這 3 到 7 天,就是內容創作者最值錢的縫隙。
真正的問題不是“要不要追熱點”,而是:怎麼每天穩定找到還沒被中文圈寫爛的選題。
一個比較實用的辦法,是把找選題這件事做成工作流:用 Claude Code + XCrawl + n8n,每天自動掃一遍英文 AI 信號源,再去中文站反查有沒有人寫過,最後把候選題整理成日報,落到 Obsidian 裏。
打開筆記,就是當天的選題清單。
第一步:別靠直覺列信息源
很多人做選題,第一步就錯了:憑印象列幾個站,然後每天手動刷。
這很容易漏。尤其英文 AI 圈裏,有些源不一定天天出圈,但質量很高,比如獨立 newsletter、研究者博客、公司官方 blog、論文摘要頁。
更好的做法是先讓 Claude Code 用 XCrawl Search 跑幾組搜索:
找英文 AI 內容站、AI newsletter、AI tools daily news,去掉 Reddit、YouTube、LinkedIn、Medium 這種聚合社區,只保留反覆出現的獨立域名。
跑完之後,結果通常會分成三類:
• 真正的信號源,比如 The Rundown AI、Superhuman AI、TLDR AI • 列名單文章,比如 “Top AI Newsletters” 這類,文章本身不重要,裏面提到的站名很重要 • 噪音,比如社區討論、視頻、轉載頁
這裏最有價值的不是“搜到了幾個站”,而是把自己腦子裏漏掉的源補回來。比如 Import AI 這種 Anthropic 聯創 Jack Clark 寫的 newsletter,如果只靠中文圈轉述,很可能很晚才注意到。
第二步:名氣大,不代表適合爬
有了候選池,還不能直接上 Scrape。先用 XCrawl Map 驗證一遍。
Map 的作用很簡單:給一個域名,返回這個站點裏能發現的 URL 列表。它便宜,也適合做第一輪篩選。
這一輪主要看三件事:
• 站點還活不活,能不能拿到最近文章 • URL 結構乾不乾淨,能不能篩出真正的內容頁 • 有沒有 robots.txt 或反爬限制
這裏會遇到一個很現實的情況:有些站很有名,但不一定能爬。比如 tldr.tech,Map 過去只返回 robots.txt,這就說明對方明確拒絕抓取。
這種情況不要硬上。工作流能長期跑,前提是尊重邊界。能爬就爬,擋了就跳,別為了一個源把整套流程搞得不穩定。
第三步:大站一定要加 filter
官方 blog 和大公司站點是高價值信號源,但也最容易“看起來能爬,實際沒用”。
比如直接 Map anthropic.com,拿到的可能是一堆導航頁:careers、about、產品介紹、模型頁面。你要的是 news,不是站點菜單。
解決辦法是加 filter。
先看真實文章 URL 長什麼樣,再寫一個正則,只保留目標路徑:
• anthropic.com:只要 /news/.*• huggingface.co/papers:只要 /papers/.*• blog.google:只要 /innovation-and-ai/.*
這樣 Map 出來的才是內容頁,而不是導航骨架。
入口決定從哪開始走,filter 決定留下什麼。 這句話很關鍵。大站不加 filter,基本等於白跑。
最後可以收斂出 10 個英文信號源,再配 4 箇中文反查站:量子位、機器之心、36kr、少數派。
英文站負責發現新東西,中文站只回答一個問題:這題中文圈寫過了嗎?
第四步:用 n8n 把它接成每日雷達
信號源有了,接下來就是自動化。
目標很清楚:每天早上 7 點掃 10 個英文站,找新文章,抽標題和摘要,再拿話題去中文站反查。中文站 0 命中的,標一個 🔥,排在前面。最後生成 Markdown 日報,寫進 Obsidian vault。
這件事用 n8n 很合適。
流程大概是:
• Schedule 每天定時觸發,也保留 Webhook 手動觸發 • Sources 輸出 10 個站點配置 • Map 節點逐個取 URL • Code 節點去重、過濾、讀寫狀態 • Scrape 節點抓正文並做摘要 • Search 節點去中文站反查 • Score 節點排序 • 最後寫成 Markdown 文件
這裏有幾個設計點很實用。
第一,狀態記憶必須有。在 vault 旁邊放一個 .seen.json,記錄已經掃過的 URL。否則每天都會重複消費同一批連結,credit 燒得很冤。
第二,每天要設 cap。比如每天最多深抓 5 條新 URL。英文圈一天能冒出幾十條內容,真全跑一遍,賬單和注意力都會爆。
第三,外部 API 不要併發猛懟。n8n 的 HTTP 節點可以設置 batching,比如 batchSize=1、batchInterval=1500ms,慢一點,但穩定很多。
中間會踩的坑,基本都很具體
這類工作流最煩的地方,不是思路複雜,而是小坑很多。
比如 n8n 容器打不到外網,可能是 docker bridge 網絡問題,直接切 --network host 更省事。
Code 節點默認不能讀寫文件,就加:
NODE_FUNCTION_ALLOW_BUILTIN=fs,path容器看不到 Obsidian vault,就在容器內建輸出目錄,再在 vault 裏做符號連結。
XCrawl 的 LLM 有時不嚴格按自定義 schema 回,就別跟它較勁,退一步:讓它返回固定 summary format,再用 Code 節點自己整理。
還有一些反直覺的小 bug,比如搜中文站時 location: "CN" 反而失敗,設成 US 才能跑。這種東西文檔裏不一定寫,只能靠真實調用發現。
跑起來之後,價值就很直接
日報長這樣:
最有用的是排序。
如果 DeepSeek V4、Shopify 這種題中文圈已經 10 個命中,就自動往後放。0 命中的,標 🔥,直接出現在 TOP 區。
每天打開 Obsidian,只需要看最前面幾條:
• 哪條英文圈剛熱起來 • 中文圈有沒有寫過 • 值不值得今天搶先寫
原來可能要刷一個多小時的英文站,現在 5 分鐘就能定題。
這才是這套工作流的核心:不是替你寫文章,而是替你把“今天該寫什麼”先篩出來。
Credit 賬本也要算清楚
選源、驗證、搭工作流、多次測試,整套流程跑下來,大概燒掉 100 多 credits。
穩定運行後,如果每天限制 5 條深抓,剩餘 880 credits 大概還能跑 19 天。
這已經夠攢一週甚至更久的選題池。真正要省錢,關鍵還是兩點:
• 先 Search / Map,別一上來就 Scrape • 用 .seen.json防止重複掃舊連結
最後記住這幾條
第一,憑直覺列信息源,一定會漏。讓工具幫你掃一輪,能補到很多平時看不到的源。
第二,名氣大的站不一定適合爬。能爬、URL 乾淨、更新穩定,才是好源。
第三,大站必須加 filter。否則抓到的多半是導航頁。
第四,Search → Map → Scrape 這個順序最省。先發現候選,再驗證可爬,最後才抓正文。
第五,工作流要有狀態記憶。沒有 .seen.json,就是每天重複花錢。
第六,rate limit 用串行 batching,別併發衝。
第七,LLM 輸出不穩定時,不要迷信 schema。能讓代碼節點兜底,就讓代碼節點兜底。
第八,很多坑只有真跑才知道。1 credit 的真實測試,比半小時腦補有用。
對做 AI 內容的人來說,信息差不會消失,只會變得更短。英文圈和中文圈之間那幾天窗口,手動刷很累,但用工作流可以穩住。
最好的狀態是:每天早上打開 Obsidian,最新選題已經排好隊。你要做的不是找方向,而是挑一個值得寫的方向,把它寫好。