深度拆解 Hermes Agent 的記憶系統:它如何修正 OpenClaw 的誤區
整理版優先睇
Hermes Agent 用四層記憶系統解決 OpenClaw 嘅「流水賬」問題,核心係保持提示詞穩定嚟慳成本
作者 Manthan Gupta 一直研究 AI Agent 嘅記憶系統,之前分析過 ChatGPT、Claude 同 Clawdbot。今次佢直接睇開源項目 Hermes Agent 嘅代碼,發現呢個系統唔靠盲測,而係透過實際 code path 理解佢點樣構建提示詞狀態、持久化會話、清理記憶同查詢歷史。
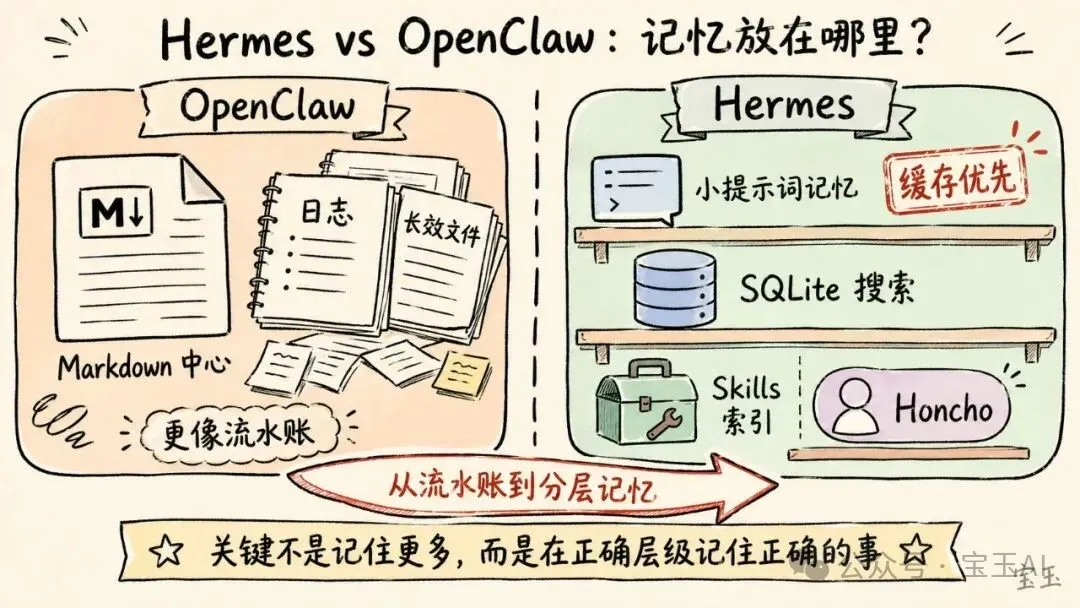
Hermes 擁有四套記憶系統:固化嘅 MEMORY.md/USER.md、可搜索嘅 SQLite 歷史會話、技能管理同可選嘅 Honcho 用戶建模。整體設計邏輯好簡單:保持提示詞穩定以利用大模型供應商嘅提示詞緩存機制,其他繁雜信息就靠工具按需檢索。結論係:真正的訣竅唔係記住更多,而係喺正確嘅層級、以正確嘅成本,記住正確嘅事。
- Hermes 採用四層記憶系統:固化提示詞記憶(MEMORY.md/USER.md)、SQLite 歷史搜索、技能管理、可選 Honcho 用戶建模。
- 提示詞結構被優化以最大化緩存命中率,穩定前綴保持不變,大量信息改為按需檢索。
- 與 OpenClaw 關鍵差異:Hermes 嚴格限制提示詞記憶容量,只保存用戶偏好、環境事實、反覆錯誤修正,唔保存任務進度或臨時待辦。
- 壓縮長對話前進行「記憶沖刷」,讓模型將值得記住嘅嘢寫入永久記憶,避免摘要有損。
- 技能管理作為程序記憶,只放索引,具體內容按需加載,提升效率。
Hermes 嘅上下文結構同緩存策略
Hermes 嘅系統提示詞係按特定順序組裝嘅,目的係令穩定嘅前綴部分盡可能長時間保持不變,咁樣就可以充分利用大模型供應商嘅提示詞緩存(Prompt Caching)機制。呢個決定解釋咗大部分記憶架構:如果信息每一輪都要用,就縮到好細注入;如果係歷史舊賬或者偶爾有用,就踢出提示詞,改用按需檢索。
- 1 默認智能體身份
- 2 工具使用行為指南
- 3 Honcho 集成模塊(可選)
- 4 可選系統消息
- 5 固化嘅 MEMORY.md 快照
- 6 固化嘅 USER.md 快照
- 7 技能索引
- 8 上下文文件(AGENTS.md、SOUL.md 等規則文件)
第一層:固化提示詞記憶——精選狀態,唔係日記
Hermes 將持久記憶儲存在 <code>~/.hermes/memories/</code> 嘅兩個檔案:MEMORY.md(智能體筆記,上限 2,200 字符)同 USER.md(用戶畫像,上限 1,375 字符)。加埋大約 1,300 個 Token,容量好細,但係刻意為之。
會話開始時,Hermes 加載呢兩個檔案,渲染成提示詞區塊,然後成個會話期間固化呢個快照。中途寫入嘅記憶會立即存硬碟,但唔會改變已生成嘅系統提示詞,只會喺新會話或觸發壓縮重建時生效。
══════════════════════════════════════════════
MEMORY (你的個人筆記) [67% — 1,474/2,200 字符]
══════════════════════════════════════════════
用戶的項目是一個位於 ~/code/myapi 的 Rust Web 服務,使用 Axum + SQLx§
這台機器運行 Ubuntu 22.04,安裝了 Docker 和 Podman§
用戶喜歡簡潔的回覆,討厭冗長的解釋- 用字符限制而非 Token 限制,令記憶邏輯與模型無關。
- 簡單嘅分隔符檔案格式:條目之間用 § 分隔。
- 刻意保持極小嘅系統提示詞空間,只留最有價值嘅事實。
- 記憶係「精選狀態」,唔係「日記」:只保存用戶偏好、環境事實、反覆錯誤修正、穩定規範,唔保存任務進度、會話結果或臨時待辦。
第二、三層:歷史回溯同壓縮記憶沖刷
session_search 係 Hermes 嘅「長尾回溯系統」。所有過去會話儲存喺 SQLite 數據庫,支援全文搜索。當模型需要回想以前內容,佢會先搜索數據庫,按會話分組結果,再用一個平嘅輔助模型做摘要,最後將精煉後嘅回顧內容畀主模型。
- 1 喺過去嘅消息中進行全文搜索。
- 2 按會話分組結果。
- 3 加載匹配度最高嘅會話。
- 4 用便宜嘅輔助模型對呢啲會話做摘要總結。
- 5 將精煉回顧內容返回畀主模型。
處理長對話時,Hermes 會進行壓縮(Compression)。但摘要係有損嘅,所以壓縮前會先做一次記憶沖刷(Memory Flush):發送指令叫模型保存任何值得記住嘅嘢,例如用戶偏好、修正建議同重複模式,然後只開 memory 工具,等模型寫入 MEMORY.md。
第四、五層:技能記憶同 Honcho 深層建模
Hermes 唔止記事實,仲記技能(Skills)。技能儲存喺 <code>~/.hermes/skills/</code>,當佢發現複雜流程、修復棘手問題或學到更好方法時,可以保存做技能。為咗效率,提示詞只放技能索引,具體內容按需加載。
可選嘅Honcho 層係更複雜嘅用戶模型,支援跨設備、跨平台記憶連續性。集成方式好巧妙:第一輪將 Honcho 上下文織入系統提示詞,之後嘅對話就將回溯內容附加喺用戶提問後面,咁樣唔破壞提示詞緩存。
- 技能作為程序記憶,提升智能體「點樣做」嘅能力。
- Honcho 提供深層用戶建模,但要保持提示詞穩定。
與 OpenClaw 嘅關鍵差異同總結
OpenClaw 嘅記憶偏向「以 Markdown 為中心嘅儲存」,日誌同長效檔案係主要事實來源;而 Hermes 就嚴格限制提示詞記憶,歷史記錄放 SQLite,只有需要時先搜索。Hermes 更關注緩存效率,認為唔係所有嘢都配住喺「系統提示詞」呢個黃金地段。
作者:Manthan Gupta
原文:I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong[1]
如果你有睇過我之前關於 ChatGPT、Claude 同 Clawdbot 記憶系統嘅文章,你就會知道我一路喺度研究同一個問題:呢啲 AI 智能體(AI Agent)到底係點樣記嘢㗎?
Hermes Agent 對我嚟講特別有趣,因為今次我唔需要淨係靠觀察佢嘅行為嚟做「逆向工程」。Hermes 係開源嘅,佢嘅代碼庫同文檔都係公開嘅。所以,我冇透過提示詞(Prompt)去盲測呢個黑盒,而係直接睇咗佢嘅代碼路徑——由佢點樣構建提示詞狀態、持久化會話,到點樣清理記憶同查詢歷史對話。
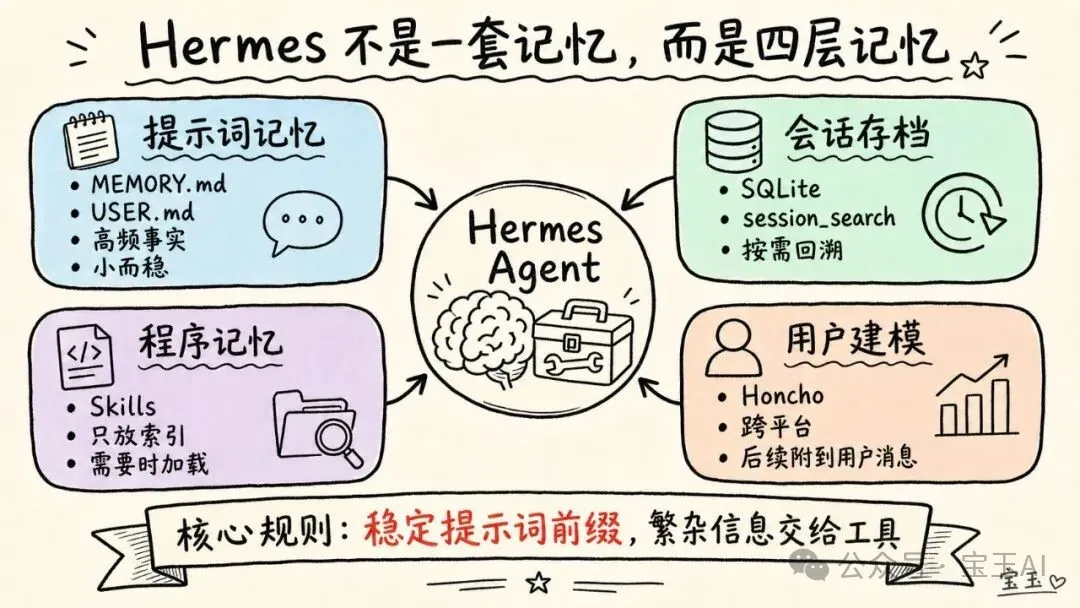
簡單講:Hermes 擁有嘅唔係一套記憶系統,而係四套。
1. 儲存喺 MEMORY.md和USER.md入面、經過高度濃縮嘅提示詞記憶。2. 透過 session_search調用的 SQLite 歷史會話存檔(可以搜尋)。3. 好似程序記憶(Procedural Memory)咁運作嘅智能體技能管理。 4. 可選嘅 Honcho 層,用嚟做更深層嘅用戶建模(User Modeling)。
將呢啲設計連繫埋一齊嘅核心邏輯好簡單:保持提示詞穩定,以便利用緩存(Caching),其他所有繁雜資訊都交俾工具。
等我哋深入講下。
Hermes 嘅上下文結構
瞭解記憶之前,我哋先睇下 Hermes 到底傳咗啲乜嘢俾模型。
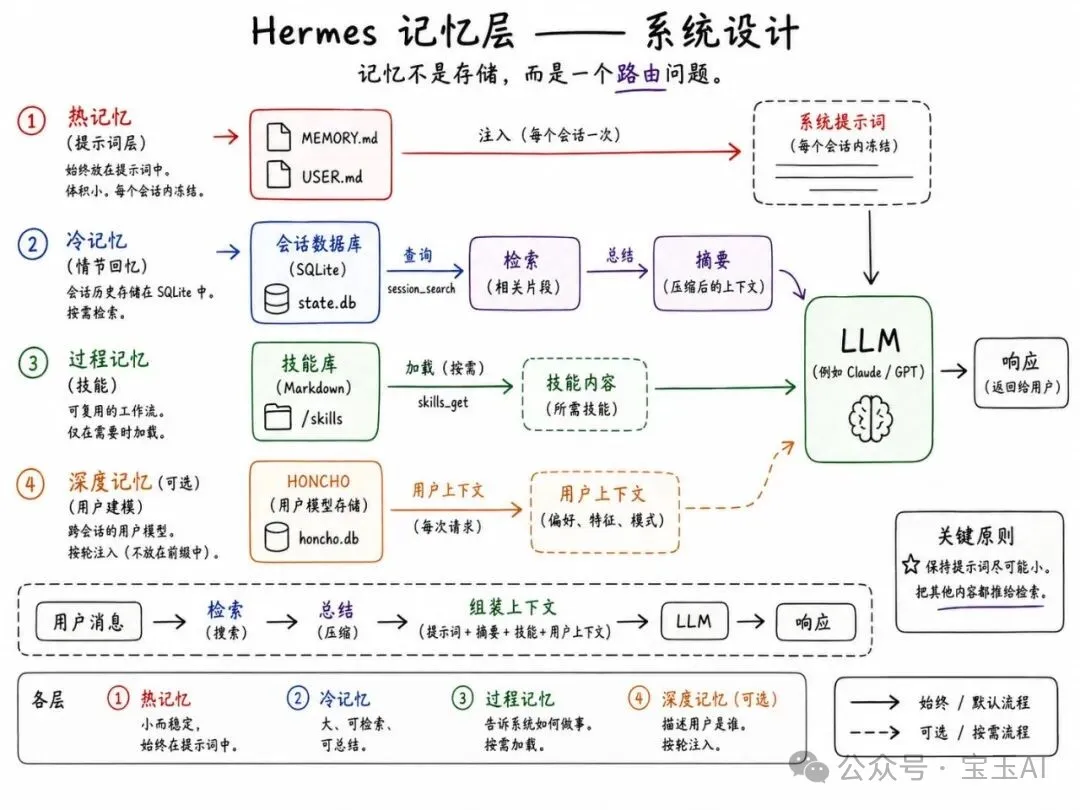
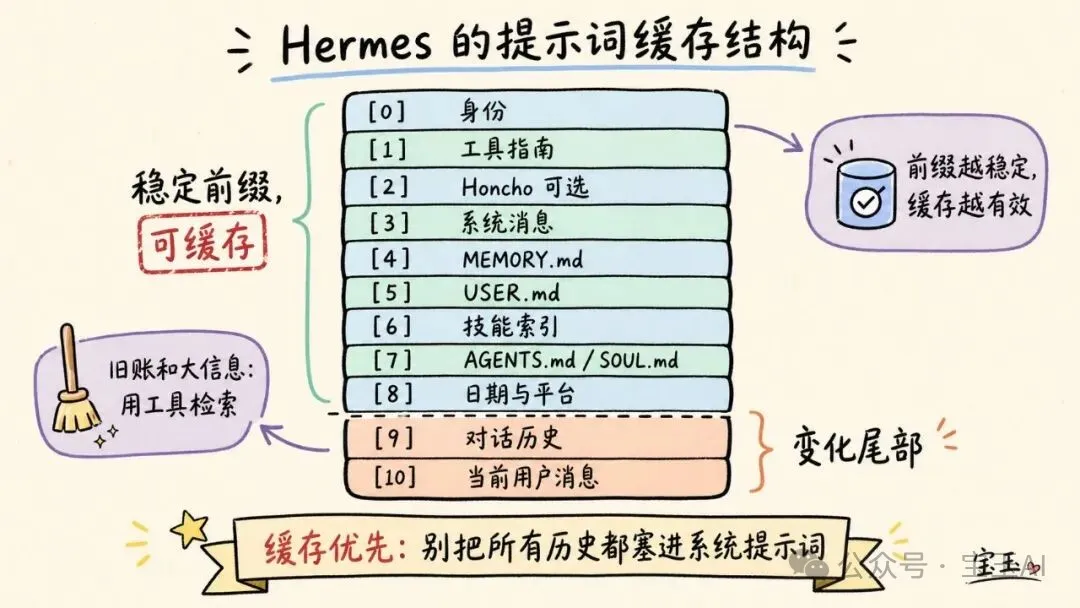
系統提示詞(System Prompt)大致係跟以下順序組裝嘅:
[0] 默認智能體身份
[1] 工具使用行為指南
[2] Honcho 集成模塊(可選)
[3] 可選系統消息
[4] 固化的 MEMORY.md 快照
[5] 固化的 USER.md 快照
[6] 技能索引
[7] 上下文文件(AGENTS.md, SOUL.md 等規則文件)
[8] 日期/時間 + 平台信息
[9] 對話歷史
[10] 當前用戶消息呢點好關鍵,因為 Hermes 正係針對大模型供應商嘅提示詞緩存(Prompt Caching)機制嚟做優化。代碼顯示,提示詞構建器嘅目標好明確:令穩定嘅前綴部分可以盡可能長時間保持不變。
就係呢個決定解釋咗 Hermes 大部份嘅記憶架構。
如果某條資訊每一輪對話都要用到,Hermes 會盡量將佢縮到好細並注入落去;如果資訊量好大、屬於歷史舊數或者間中先用得着,Hermes 就會將佢踢出提示詞,改用「按需檢索」嘅方式。
第一層:固化嘅提示詞記憶
佢內置嘅記憶系統細到令人驚訝。
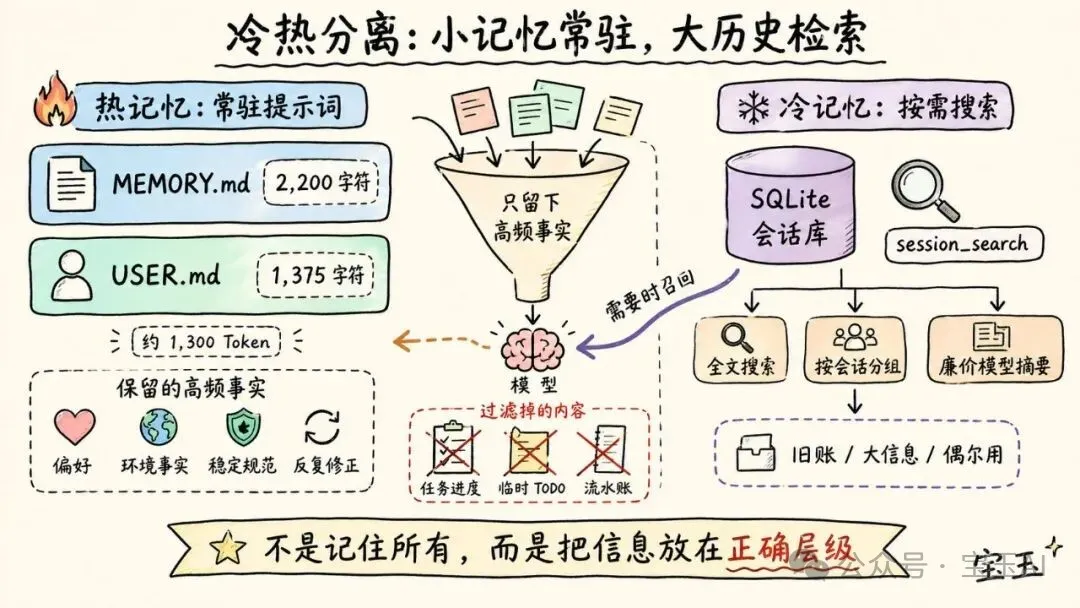
Hermes 將持久記憶儲存喺 ~/.hermes/memories/ 下面嘅兩個檔案入面:
MEMORY.md | ||
USER.md |
容量真係唔大。加埋大約得 1,300 個 Token(模型理解文字嘅最小單位)。
而呢個係刻意為之。
喺會話開始嗰陣,Hermes 加載呢兩個檔案,將佢哋渲染入提示詞區塊,然後喺成個會話期間固化呢個快照。會話中途寫入嘅記憶會即刻存入硬碟,但唔會改變已經生成嘅系統提示詞。呢啲改動要等到開新會話,或者觸發咗「壓縮(Compression)」導致嘅提示詞重建嗰陣先會生效。
渲染之後嘅格式如下:
══════════════════════════════════════════════
MEMORY (你的個人筆記) [67% — 1,474/2,200 字符]
══════════════════════════════════════════════
用戶的項目是一個位於 ~/code/myapi 的 Rust Web 服務,使用 Axum + SQLx
§
這台機器運行 Ubuntu 22.04,安裝了 Docker 和 Podman
§
用戶喜歡簡潔的回覆,討厭冗長的解釋以下有幾個我好欣賞嘅細節設計:
1. 用字符限制而唔係 Token 限制:咁樣可以令記憶邏輯同模型無關。Hermes 唔需要叫特定模型嘅計算工具就能判斷記憶係咪寫滿咗。 2. 簡單嘅分隔符檔案格式:條目之間用 §分隔。冇複雜嘅向量數據庫(Vector DB),冇自定義二進制儲存,就係純文字。3. 刻意保持極細嘅系統提示詞空間:呢個係成個設計嘅重中之重。Hermes 唔想將所有歷史都塞入提示詞,佢只要最有價值嘅事實。 4. 記憶係「精選狀態」,而唔係「日記」:呢個係 Hermes 同 OpenClaw 最大嘅分別。
OpenClaw 嘅日誌比較似「流水賬」。而 Hermes 就相反。佢嘅工具架構同測試邏輯強調:
• 保存用戶偏好。 • 保存環境事實。 • 保存反覆出現嘅錯誤修正。 • 保存穩定嘅規範。 • 不保存任務進度。 • 不保存會話結果。 • 不保存臨時嘅待辦事項(TODO)。
真相係:Hermes 希望 MEMORY.md 和 USER.md 保持精簡、高頻同對緩存友好。
memory 工具
Hermes 透過一個擁有三種操作 memory 嘅工具嚟管理呢啲檔案:add(添加)、replace(替換)、remove(移除)。
一個好用嘅細節係:replace 和 remove 使用子字符串匹配。你唔需要記住條目嘅內部 ID,只要傳入現有條目入面一段獨特嘅文字就得。
另外,系統會拒絕完全重複嘅內容,並攔截危險資訊。源代碼會掃描記憶條目,防止提示詞注入(Prompt Injection,即係透過輸入惡意指令誤導 AI)、憑證洩漏或者隱藏嘅 Unicode 字符。
第二層:用嚟做情景回溯嘅 session_search
如果說 MEMORY.md 係 Hermes 嘅「短期熱記憶」,咁 session_search 就係佢嘅「長尾回溯系統」。
所有過去嘅會話都儲存喺 SQLite 數據庫入面,有完整嘅索引同搜尋功能。當模型需要諗起以前傾過嘅內容時,佢唔會去翻 MEMORY.md,而係搜尋呢個會話數據庫。
佢嘅工作流程係:
1. 喺過去嘅訊息入面做全文搜尋。 2. 按會話分組結果。 3. 加載匹配度最高嘅會話。 4. 用一個平價嘅輔助模型對呢啲會話做摘要總結。 5. 將精煉咗嘅回顧內容返回俾主模型。
呢個係一個好務實嘅設計。佢比盲目咁將長篇大論嘅歷史塞入每一個提示詞要平同高效得多。
第三層:壓縮同記憶沖刷(Memory Flush)
Hermes 另一個聰明嘅地方係佢處理長對話「壓縮」嘅方式。
當會話變得太長,Hermes 會壓縮對話中間嘅部分嚟節省空間。但係摘要有損,重要事實可能會丟失。
於是,Hermes 會先做一次「記憶沖刷」。
喺壓縮之前,佢會傳一條指令俾模型話:
「會話就嚟壓縮,請保存任何值得記住嘅嘢。優先保存用戶偏好、修正建議同重複模式,而唔係具體嘅任務細節。」
然後佢會運行一次額外嘅模型調用,淨係開 memory 工具。如果模型覺得有啲嘢應該留低,就會喺對話被「洗走」之前將佢寫入 MEMORY.md。
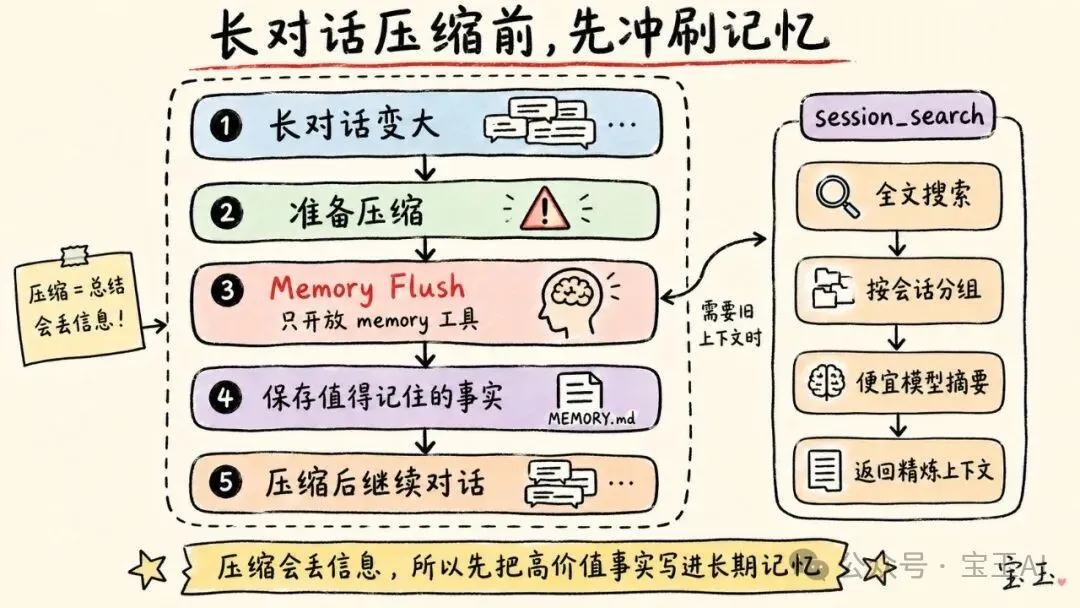
第四層:作為程序記憶嘅技能(Skills)
Hermes 唔單止可以記住事實,仲可以記住技能。
技能(Skills)儲存喺 ~/.hermes/skills/ 下面。當 Hermes 發現咗一個複雜嘅流程、修復咗一個棘手嘅問題或者學識咗更好嘅方法時,佢可以將佢保存為「技能」。
大多數記憶系統淨係關注「語義回溯」(名、偏好、事實),但智能體仲需要記住點樣做嘢。
為咗效率,Hermes 唔會將所有技能都塞入提示詞,而係淨係放一個技能索引,只有喺需要嗰陣先加載具體嘅技能內容。
第五層:用嚟做深層建模嘅 Honcho
最後係可選嘅 Honcho 層。如果話本地記憶係 Hermes 嘅筆記簿,Honcho 就係佢嘗試構建嘅複雜用戶模型。佢可以做到跨裝置、跨平台嘅記憶連續性。
最妙嘅係佢點樣喺唔破壞提示詞緩存嘅前提下做到集成:
• 喺會話嘅第一輪,Honcho 嘅上下文會織入系統提示詞。 • 喺之後嘅對話入面,為咗保持提示詞穩定,Honcho 嘅回溯內容會附加喺當前用戶嘅提問後面,而唔係修改系統提示詞。
咁樣確保咗緩存依然有效,同時 AI 依然可以讀到最新嘅背景資訊。
Hermes 同 OpenClaw 嘅分別
• OpenClaw:記憶比較似「以 Markdown 為中心嘅儲存」,日誌同長效檔案係主要事實來源。 • Hermes:提示詞記憶被嚴格限制,歷史記錄存在 SQLite 入面,只有需要嗰陣先搜尋。
Hermes 更加關注緩存效率。 佢認為:唔係所有嘢都配住喺「系統提示詞」呢個黃金地段。
總結:Hermes 做啱咗啲乜?
1. 冷熱分離:細規模嘅提示詞記憶負責長駐資訊,搜尋負責間中用嘅資訊。 2. 緩存優先:佢意識到成日改提示詞會導致延遲增加同成本上升。 3. 記憶多樣性:佢承認記憶係分層嘅——包括個人畫像、情景回溯、操作技能同深層建模。
Hermes 嘅核心設計原理最令我折服:記憶應該令智能體變得更好用,而唔係透過摧毀提示詞嘅穩定性嚟換取博聞強記。
真正嘅秘訣唔係記住更多,而係喺正確嘅層級、用正確嘅成本,記住正確嘅嘢。
引用連結
[1] I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong: https://x.com/manthanguptaa/status/2034849672985288957
作者:Manthan Gupta
原文:I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong[1]
如果你讀過我之前關於 ChatGPT、Claude 以及 Clawdbot 記憶系統的文章,你就會知道我一直在鑽研同一個問題:這些 AI 智能體(AI Agent)到底是怎麼記事的?
Hermes Agent 對我來說格外有趣,因為這次我不需要只靠觀察它的行為來搞“逆向工程”。Hermes 是開源的,它的代碼庫和文檔都是公開的。所以,我沒有通過提示詞(Prompt)去盲測這個黑盒,而是直接翻看了它的代碼路徑——從它如何構建提示詞狀態、持久化會話,到如何清理記憶和查詢歷史對話。
簡而言之:Hermes 擁有的不是一套記憶系統,而是四套。
1. 存儲在 MEMORY.md和USER.md中、經過高度濃縮的提示詞記憶。2. 通過 session_search調用的 SQLite 歷史會話存檔(可搜索)。3. 像程序記憶(Procedural Memory)一樣運作的智能體技能管理。 4. 可選的 Honcho 層,用於更深層的用戶建模(User Modeling)。
把這些設計聯繫在一起的核心邏輯非常簡單:保持提示詞穩定以便利用緩存(Caching),其他一切繁雜信息都交給工具。
讓我們深入聊聊。
Hermes 的上下文結構
在理解記憶之前,我們先看看 Hermes 到底給模型發送了什麼。
系統提示詞(System Prompt)大致是按以下順序組裝的:
[0] 默認智能體身份
[1] 工具使用行為指南
[2] Honcho 集成模塊(可選)
[3] 可選系統消息
[4] 固化的 MEMORY.md 快照
[5] 固化的 USER.md 快照
[6] 技能索引
[7] 上下文文件(AGENTS.md, SOUL.md 等規則文件)
[8] 日期/時間 + 平台信息
[9] 對話歷史
[10] 當前用戶消息這非常關鍵,因為 Hermes 正在針對大模型供應商的提示詞緩存(Prompt Caching)機制進行優化。代碼顯示,提示詞構建器的目標非常明確:讓穩定的前綴部分儘可能長時間地保持不變。
這一個決定就解釋了 Hermes 大部分的記憶架構。
如果某條信息每一輪對話都要用到,Hermes 會盡量把它縮得很小並注入進去;如果信息量很大、屬於歷史舊賬或者偶爾才有用,Hermes 就會把它踢出提示詞,改用“按需檢索”的方式。
第一層:固化的提示詞記憶
其內置的記憶系統小得令人驚訝。
Hermes 將持久記憶存儲在 ~/.hermes/memories/ 下的兩個文件中:
MEMORY.md | ||
USER.md |
這容量真不大。加起來大約只有 1,300 個 Token(模型理解文本的最小單位)。
而這正是刻意為之。
在會話開始時,Hermes 加載這兩個文件,把它們渲染進提示詞區塊,然後在整個會話期間固化這個快照。會話中途寫入的記憶會立即存入硬盤,但不會改變已經生成的系統提示詞。這些改動只有在開啓新會話,或者觸發了“壓縮(Compression)”導致的提示詞重建時才會生效。
渲染後的格式如下:
══════════════════════════════════════════════
MEMORY (你的個人筆記) [67% — 1,474/2,200 字符]
══════════════════════════════════════════════
用戶的項目是一個位於 ~/code/myapi 的 Rust Web 服務,使用 Axum + SQLx
§
這台機器運行 Ubuntu 22.04,安裝了 Docker 和 Podman
§
用戶喜歡簡潔的回覆,討厭冗長的解釋這裏有幾個我非常欣賞的細節設計:
1. 使用字符限制而非 Token 限制:這讓記憶邏輯與模型無關。Hermes 不需要調用特定模型的計算工具就能判斷記憶是否存滿。 2. 簡單的分隔符文件格式:條目之間用 §分隔。沒有複雜的向量數據庫(Vector DB),沒有自定義二進制存儲,就是純文本。3. 刻意保持極小的系統提示詞空間:這是整個設計的重中之重。Hermes 不想把所有歷史都塞進提示詞,它只想要最有價值的事實。 4. 記憶是“精選狀態”,而不是“日記”:這是 Hermes 與 OpenClaw 最大的區別。
OpenClaw 的日誌更像是“流水賬”。而 Hermes 則反其道而行。它的工具架構和測試邏輯強調:
• 保存用戶偏好。 • 保存環境事實。 • 保存反覆出現的錯誤修正。 • 保存穩定的規範。 • 不保存任務進度。 • 不保存會話結果。 • 不保存臨時的待辦事項(TODO)。
真相是:Hermes 希望 MEMORY.md 和 USER.md 保持精簡、高頻且對緩存友好。
memory 工具
Hermes 通過一個擁有三種操作的 memory 工具來管理這些文件:add(添加)、replace(替換)、remove(移除)。
一個好用的細節是:replace 和 remove 使用子字符串匹配。你不需要記住條目的內部 ID,只需要傳入現有條目中一段唯一的文字即可。
此外,系統會拒絕完全重複的內容,並攔截危險信息。源代碼會掃描記憶條目,防止提示詞注入(Prompt Injection,即通過輸入惡意指令誤導 AI)、憑證泄露或隱藏的 Unicode 字符。
第二層:用於情景回溯的 session_search
如果說 MEMORY.md 是 Hermes 的“短期熱記憶”,那麼 session_search 就是它的“長尾回溯系統”。
所有過去的會話都存儲在 SQLite 數據庫中,擁有完整的索引和搜索功能。當模型需要想起以前聊過的內容時,它不去翻 MEMORY.md,而是搜索這個會話數據庫。
其工作流程是:
1. 在過去的消息中進行全文搜索。 2. 按會話分組結果。 3. 加載匹配度最高的會話。 4. 使用一個便宜的輔助模型對這些會話進行摘要總結。 5. 將精煉後的回顧內容返回給主模型。
這是一種非常務實的設計。它比盲目地把長篇累牘的歷史塞進每一個提示詞要便宜且高效得多。
第三層:壓縮與記憶沖刷(Memory Flush)
Hermes 另一個聰明之處在於它處理長對話“壓縮”的方式。
當會話變得太長,Hermes 會壓縮對話中間的部分以節省空間。但摘要是有損的,重要事實可能會丟失。
於是,Hermes 會先進行一次“記憶沖刷”。
在壓縮之前,它會發送一條指令告訴模型:
“會話即將壓縮,請保存任何值得記住的東西。優先保存用戶偏好、修正建議和重複模式,而非具體的任務細節。”
然後它運行一次額外的模型調用,只開啓 memory 工具。如果模型覺得有什麼東西該留下來,就會在對話被“洗掉”之前把它寫入 MEMORY.md。
第四層:作為程序記憶的技能(Skills)
Hermes 不僅能記住事實,還能記住技能。
技能(Skills)存儲在 ~/.hermes/skills/ 下。當 Hermes 發現了一個複雜的流程、修復了一個棘手的問題或學會了更好的方法時,它可以將其保存為“技能”。
大多數記憶系統只關注“語義回溯”(名字、偏好、事實),但智能體還需要記住如何做事。
為了效率,Hermes 不會把所有技能都塞進提示詞,而是隻放一個技能索引,只有在需要時才加載具體的技能內容。
第五層:用於深層建模的 Honcho
最後是可選的 Honcho 層。如果說本地記憶是 Hermes 的筆記本,Honcho 就是它嘗試構建的複雜用戶模型。它能實現跨設備、跨平台的記憶連續性。
最精妙的是它如何在不破壞提示詞緩存的前提下實現集成:
• 在會話的第一輪,Honcho 的上下文會被織入系統提示詞。 • 在之後的對話中,為了保持提示詞穩定,Honcho 的回溯內容會附加在當前用戶的提問後面,而不是修改系統提示詞。
這確保了緩存依然有效,同時 AI 依然能讀到最新的背景信息。
Hermes 與 OpenClaw 的區別
• OpenClaw:記憶更接近“以 Markdown 為中心的存儲”,日誌和長效文件是主要事實來源。 • Hermes:提示詞記憶被嚴格限制,歷史記錄存在 SQLite 裏,只有需要時才搜索。
Hermes 更加關注緩存效率。 它認為:不是所有東西都配住在“系統提示詞”這個黃金地段。
總結:Hermes 做對了什麼?
1. 冷熱分離:小規模提示詞記憶負責常駐信息,搜索負責偶爾用到的信息。 2. 緩存優先:它意識到頻繁改動提示詞會導致延遲增加和成本上升。 3. 記憶的多樣性:它承認記憶是分層的——包括個人畫像、情景回溯、操作技能和深層建模。
Hermes 的核心設計原則最令我折服:記憶應該讓智能體變得更好用,而不是通過摧毀提示詞的穩定性來換取博聞強識。
真正的訣竅不是記住更多,而是在正確的層級、以正確的成本,記住正確的事情。
引用連結
[1] I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong: https://x.com/manthanguptaa/status/2034849672985288957