用AI 48小時速通梅花易數之後,我想通了「學習」的最終解
整理版優先睇
AI時代的學習公式:AI做80%低效環節,人做20%不可替代環節——用48小時速通梅花易數的實戰框架
呢篇文章嘅作者本身係一個「幹中學」嘅信徒,從來冇系統學過理論,信實戰倒逼認知。AI出現之後,佢興奮咗,因為幹中學呢條路被放大咗100倍。但佢同時諗咗一個大半年嘅問題:如果AI乜嘢都能夠做,我自己仲要學啲乜?
為咗揾答案,佢用48小時由零入門梅花易數——一門古人要拜師三年嘅學問,結果週一就能夠斷卦。佢從呢個過程提煉出一套完整嘅學習框架:學習 = AI負責80%低效環節(選型、內容生產、出題、重複練習、知識檢索)+ 人負責20%不可替代環節(理解、判斷、經驗注入、驗證糾錯)。具體分六步:選型決策、認知概覽、定製課程、多模態輸入、實戰陪練、驗證糾錯。
佢最終嘅哲學結論係:AI令到知識獲取成本趨近於零,但「驗證知識」同「應用知識」嘅能力反而變得前所未有咁值錢。學習嘅新目標唔係「學識知識」,而係「學到能夠發現AI邊度錯咗」,然後將人生經驗注入,形成AI畀唔到嘅判斷。呢個先係AI時代學習嘅最終解。
- 結論:學習 = AI負責80%(選型、內容生產、出題、重複練習、知識檢索)+ 人負責20%(理解、判斷、經驗注入、驗證糾錯)
- 方法:六步學習鏈路——選型決策(結構化約束條件畀AI)、認知概覽(低負荷播客建立地圖)、定製課程、多模態輸入(讀睇練糾四種通道)、實戰陪練(Agent主動出題+陪練+覆盤)、驗證糾錯(雙AI交叉)
- 差異:傳統學習從精讀開始,AI時代應先建認知地圖再逐點攻破;練習形式要匹配知識類型(記憶型用閃卡,推理型用矩陣)
- 啟發:學習目標從「學知識」變為「學到能發現AI錯誤嘅程度」;驗證能力比知識本身更值錢,人生經驗注入先係人不可替代嘅部分
- 可行動點:用決策矩陣讓AI做選型;配一個7×24嘅Agent陪練(主動出題+實戰+覆盤);為精確符號系統(卦象、分子式等)用代碼取代AI圖像生成
AI選型決策提示詞模板
將學習目標嘅約束條件結構化,讓AI輸出多維度決策矩陣。參考模板:我的背景是[X],核心需求場景是[Y],時間約束是[Z],候選方案有[A/B/C/D],請輸出決策矩陣,對比維度包含:學習成本、實用場景覆蓋度、與我現有技能的遷移性、短期投入產出比。給出明確推薦和理由。
核心公式:學習點樣分工先至高效?
作者認為,AI負責嗰80%做得快你100倍,唔會累、唔會煩,亦唔會因為你問第八次同一個問題就翻白眼。而人負責嗰20%先至係「學到了」嘅本質。
- 選型決策:將約束條件結構化,畀AI做多維度匹配,輸出決策矩陣
- 認知概覽:用低負荷方式(播客、概念圖)先建立全局地圖
- 定製課程:由AI根據你嘅需求設計每日學習計劃
- 多模態輸入:同一知識點用閲讀、觀看、練習、糾錯四種通道同時編碼
- 實戰陪練:配一個Agent,主動出題、陪你實戰、幫你覆盤
- 驗證糾錯:用雙AI交叉驗證,確保準確性
六步走通:由零到實戰嘅完整鏈路
大多數人學新嘢第一步係去B站搜教程、去知乎睇推薦,呢個起手式就錯咗。你收到嘅係別人嘅推薦,唔係基於你嘅情況做嘅決策。
第一步應該係讓AI幫你做選型決策
作者將四個約束條件一次性丟畀Claude Opus:需求場景(創業決策、識人)、個人背景(十年數據分析)、時間約束(要快)、實用性要求(能結合數學推理)。Claude輸出一份決策矩陣,結論係「梅花易數為主、六爻為輔」,理由係梅花底層係確定性算法,同數據分析思維同構。
- 1 選型決策:用結構化約束條件畀AI,輸出決策矩陣,30秒定方向
- 2 認知概覽:低負荷播客建立地圖,通勤時聽完,唔佔額外時間
- 3 定製課程:Claude設計30天學習安排,每日內容針對知識類型
- 4 多模態輸入:同一知識點,用文檔閲讀、影片觀看、練習操作、糾錯回饋四種通道同步編碼
- 5 實戰陪練:OpenClaw上配一個Agent(梅花先生),可個性化出題、實戰排盤、即時覆盤
- 6 驗證糾錯:用雙AI交叉核對,確保斷卦準確
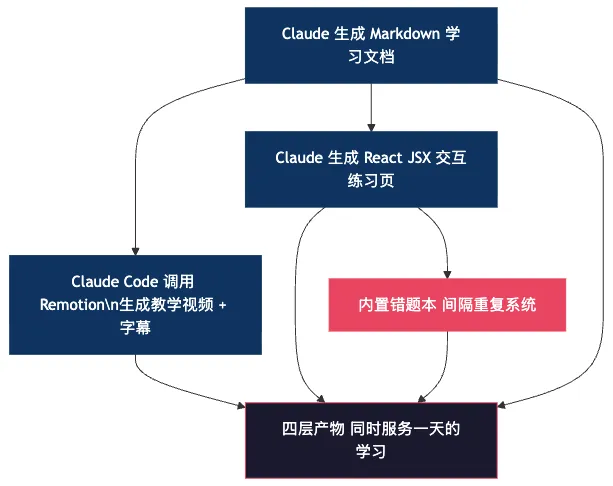
四層產物:同一知識點用四種方式入腦
作者設計咗一套「四層產物模型」——同一個知識點,AI同時生產閲讀材料、影片教學、互動練習、糾錯反饋。呢啲對應四種認知通道,記憶留存率由純閲讀嘅10%拉到75%。
每日練習模式要匹配知識類型
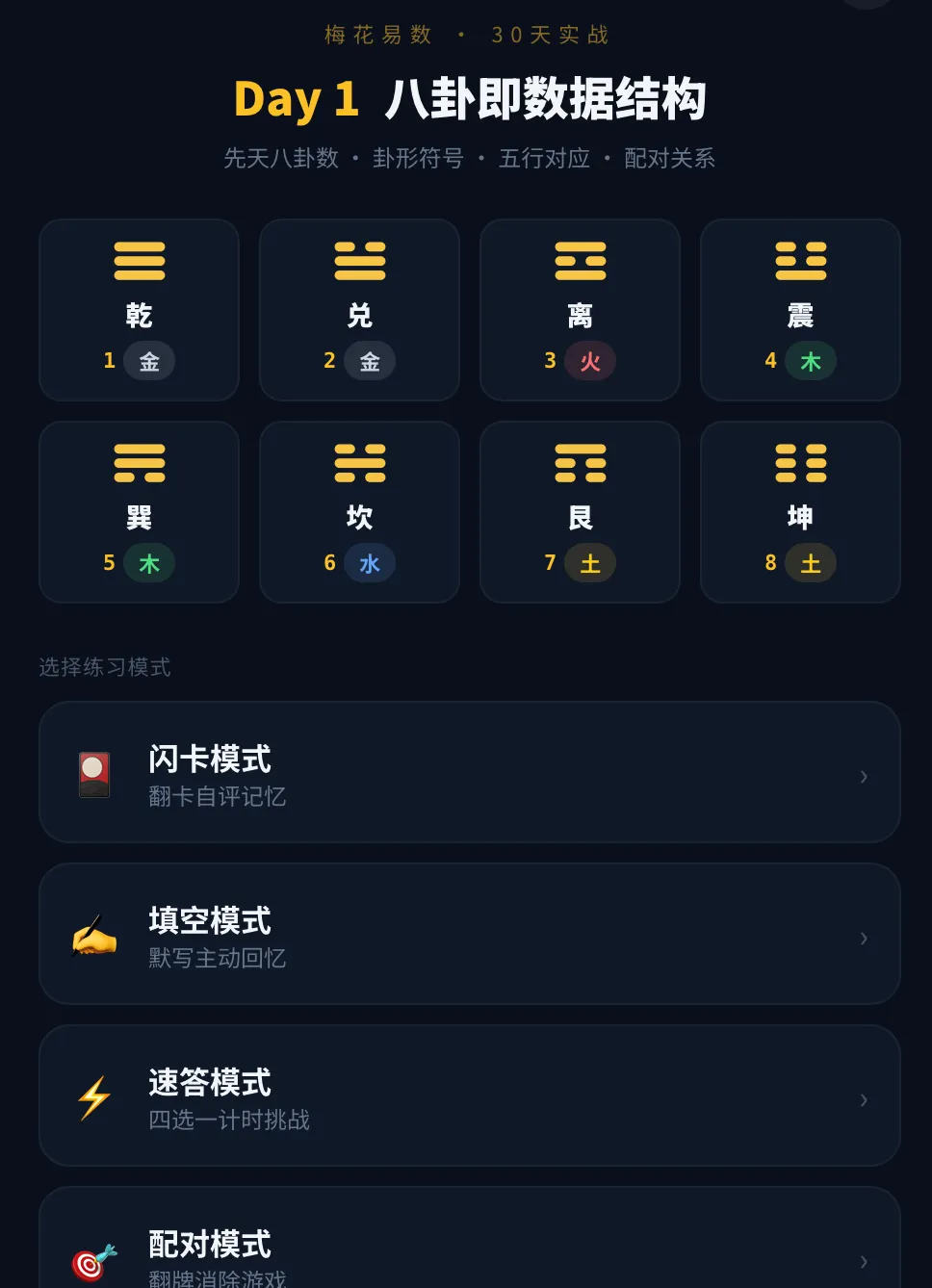
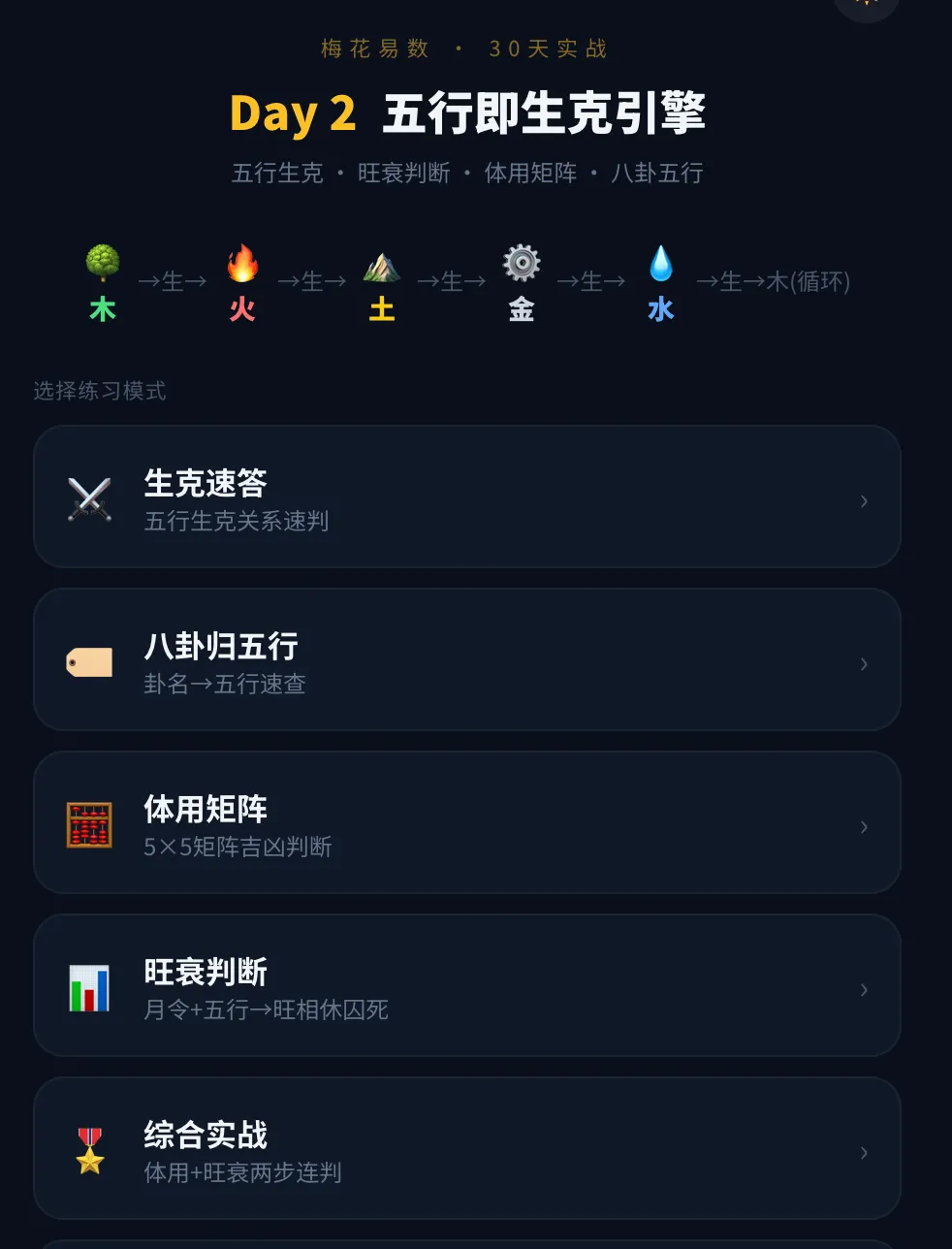
Day 1學八卦(記憶型),用閃卡+選擇題+連線題;Day 2學五行生剋(推理型),用速答+判斷矩陣+對戰。練習形式由AI自動匹配,唔係千篇一律。
作者甚至用React JSX做咗一個網站
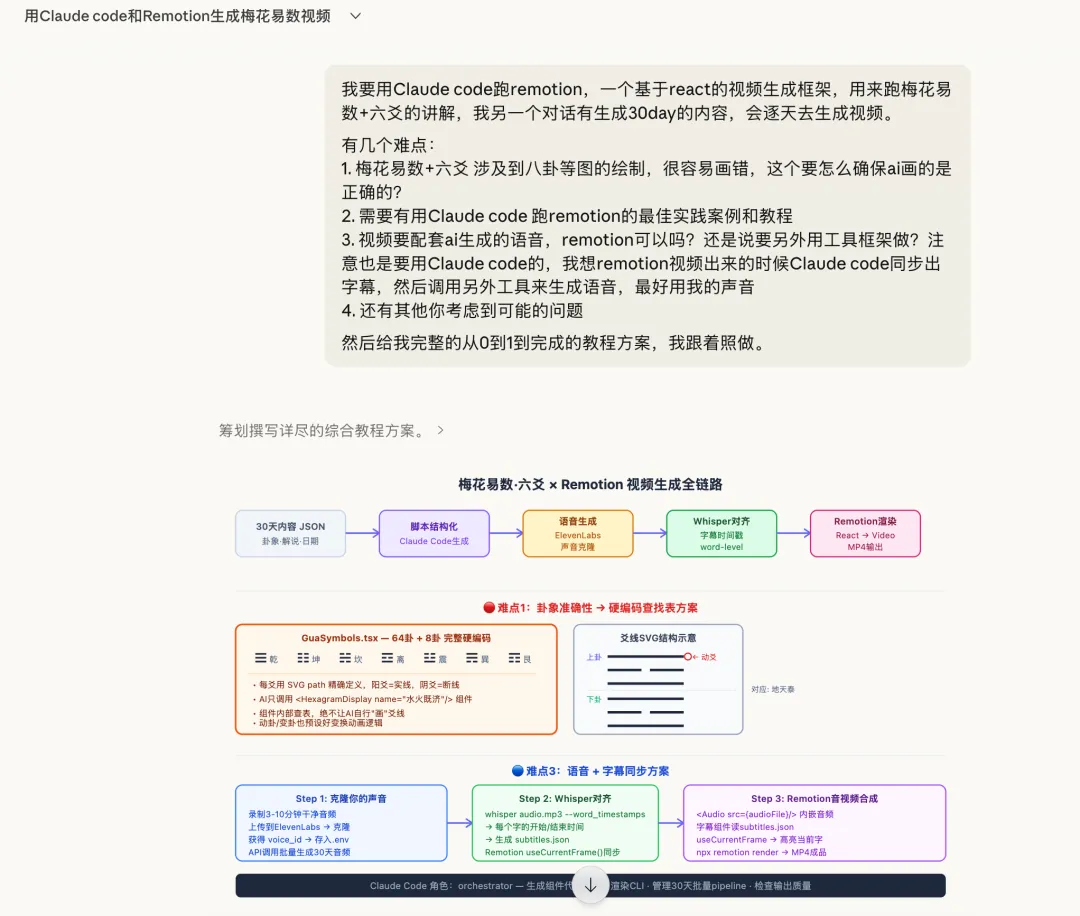
將學習內容、影片、練習放埋一齊,每日睇一次。影片用Claude Code + Remotion生成,保證卦象準確——因為用SVG代碼渲染,[1,1,1] = 乾☰,[0,0,0] = 坤☷,數據驅動,100%準確。
- 閲讀:AI生成圖文說明,解釋核心概念
- 觀看:AI生成簡短教學影片,展示動態過程
- 練習:針對知識類型設計互動題目(閃卡、矩陣、對戰)
- 糾錯:Agent即時反饋,解釋點解錯,並調整後續出題重點
實戰踩出來嘅三條鐵律
作者話每一條都交過學費。第一條:AI生成嘅視覺內容,凡涉及精確符號,一律用代碼替代。
AI圖像生成對精確符號系統不可靠
例如卦象,作者一開始讓AI畫PPT,結果全部錯曬。改用SVG代碼渲染後,100%準確。化學分子式、樂譜、電路圖、數學公式嘅圖形表示都係咁,唔好信AI圖像生成,用代碼。
第三條:Agent嘅準確率取決於你畀佢嘅約束模板,唔取決於模型有幾強。作者梅花先生起初互卦成日錯,後來加咗強制約束:每次排盤必須逐步寫出六爻數組,唔準心算跳步,準確率由70%拉到100%。
好的約束唔係限制AI,係幫AI穩定釋放能力
AI時代學習嘅終極哲學
傳統學習目標係「我要學識呢個知識」,將知識裝入腦,用嘅時候掏出來用。AI時代呢個目標變咗——知識獲取成本趨近於零,但「睇落專業」同「真係對」之間有一道巨大鴻溝。
新目標:學識驗證AI畀嘅嘢係咪啱
然後將人生經驗注入,形成AI畀唔到嘅判斷。例如AI知道「巽為風」解作飄移、流動、不定,但結合「呢隻係遺失咗嘅貓」嘅具體語境,人能解讀出「佢唔喺固定位置,有活動性但唔易直接遇上,可能係遊蕩中」。呢啲對生活場景嘅理解、對貓行為習性嘅常識、對求卦人心態嘅體察,AI畀唔到。
我在ChatGPT來之前就是一個學習上癮的人。
自學西班牙語,沒學利索就飛哥倫比亞、墨西哥參展,用蹩腳西語跟本地老外硬聊,居然也談成了幾單。
自學數據分析,從0給前公司搭了數據庫、BI、自動化報表,一整套數據中心。
我從來沒有系統學過任何理論。我信幹中學——先上手,遇到問題再補課,用實戰倒逼認知。
AI來了之後,我沒焦慮,我興奮了。因為幹中學這條路,突然被放大了100倍。
但人跟AI到底要怎麼分工?AI幫我學,我自己要學到什麼程度?
這個問題我想了大半年。
尤其是OpenClaw出來之後,AI Agent能自己拆任務、自己執行、自己覆盤了,這個問題變得更加尖鋭——如果AI什麼都能幹,我還需要學嗎?
過去兩天的週末,我用48小時從零入門了梅花易數。一門古人要拜師三年的學問,週一我就能斷卦了。
這個過程給了我答案。
不是一個模糊的感覺,是一套我反覆打磨、親身跑通、AI時代下「學習」的完整框架。
今天把它拆開講。
如果你正好也想學習某門學科,就不妨來參考一下我的解法。
01 先說結論:AI時代的學習公式
學習 = AI負責80%的低效環節 + 人負責20%的不可替代環節
那80%是什麼?
選型、內容生產、出題、重複練習、知識檢索。這些事AI做得比你快100倍,而且不累、不煩、不會因為你問了第八遍同一個問題而翻白眼。
那20%是什麼?
理解、判斷、經驗注入、驗證糾錯。這些事AI做不了,做了也不算數,因為這些才是「學到了」的本質。
我在過去48小時跑的完整鏈路,拆成六步:
1. 選型決策 - Claude Opus 2. 認知概覽 - Gemini NotebookLM,出對話播客,讓小白有個整體的認知 3. 定製課程 - Claude Opus,跑了30天的學習安排 4. 多模態輸入(文檔➡️視頻➡️練習) - Claude Code + Remotion + JSX 5. 實戰陪練 - Openclaw 作為7×24陪練的Agent 6. 驗證糾錯 - 雙AI交叉
接下來,看下我每一步在幹嘛。
02 第一步:讓AI做選型決策
大多數人學新東西的第一步是去B站搜教程、去知乎看推薦、問朋友學哪個好。
這個起手式就錯了。
你收到的是別人的推薦,不是基於你的情況做的決策。別人推薦的好課,可能完全不匹配你的背景、你的時間、你的應用場景。
第一步應該是讓AI幫你做選型決策。
我怎麼做的——把四個約束條件一次性丟給Claude Opus:
- 需求場景:創業決策、識人、商業合作判斷
- 個人背景:十年數據分析,有代碼能力,偏邏輯推理型思維
- 時間約束:要快,學習曲線要平,不能佔用大量業務時間
- 實用性要求:能跟數學結合,能推理算數,不是純靠靈感

Claude給我輸出了一份決策矩陣——梅花易數、六爻、奇門遁甲、大六壬,四套體系在五個維度上的完整對比。
結論:梅花易數為主、六爻為輔。
理由不是感覺,是推理——梅花的底層是取數、除法取餘、對應卦象,整套過程是確定性算法。五行生剋是一套完整的邏輯推演鏈,跟數據分析的思維方式同構,遷移成本最低。而奇門遁甲和大六壬體系龐大,入門至少半年密集投入,跟我當前的業務節奏衝突。
30秒,方向就定了。
學任何新東西之前,先把你的約束條件結構化,讓AI做多維度匹配。你給AI的不是「幫我找XXX的教程」,而是一個決策問題。
參考提示詞:
我的背景是[X],核心需求場景是[Y],時間約束是[Z],
候選方案有[A/B/C/D],
請輸出決策矩陣,對比維度包含:學習成本、實用場景覆蓋度、
與我現有技能的遷移性、短期投入產出比。
給出明確推薦和理由。03 第二步:先建認知地圖,再逐點攻破
選型定了之後,我沒有直接開始精學。
我用Google Gemini的NotebookLM,把梅花易數的核心資料丟進去,生成了一期AI對話播客。
兩個AI主持人用聊天的方式,把八卦、五行、起卦、斷卦的核心概念過了一遍。大概20分鐘。
不需要記住任何東西。只需要聽完之後,腦子裏有一張粗略的地圖。
這一步的底層原理叫「預暴露效應」——先給大腦一個低分辨率的全局框架,後續精學每個知識點的時候,它不再是一個完全陌生的概念,你已經「見過一面」了。認知負荷直接減半。
學習材料的認知負荷是有層級的:
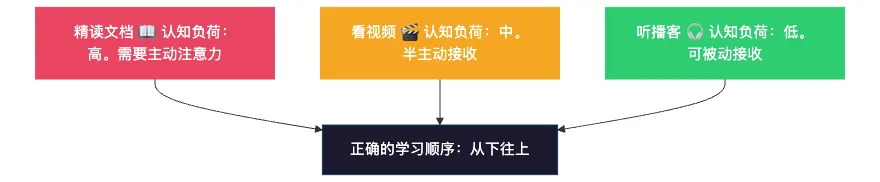
大多數人的學習順序是從上往下——先啃書、啃不動就看視頻、看不懂就放棄。
正確的順序是從下往上——先用最低負荷的方式過一遍全貌(播客),再用中等負荷強化(視頻),最後精讀攻堅。
這20分鐘的投入,能讓後面每一小時的精學效率提升一倍。我是通勤的時候聽完的,不佔任何額外時間。
不管學什麼,第一步永遠不是精讀。先讓AI把核心內容轉成你能被動接收的形態——播客、摘要、概念圖——花20分鐘建立全局認知,再進入逐章精學。
同步,還讓Claude根據我需求去設計30天的課程

04 第三步:四層產物模型——我在這一步上設計最久
這是整個框架裏我打磨時間最長的部分。
不是讓AI隨便生成一份學習資料就完了。我設計了一套「同一個知識點,四種認知模態同時編碼」的內容生產體系。
每天的學習,AI同時生產四層產物:

四層不是重複。是同一套知識在四種認知通道里走了一遍。
認知科學裏叫「多模態編碼」——同一個知識點通過閲讀、觀看、動手操作、糾錯四個通道進入大腦,記憶留存率從純閲讀的10%拉到75%
每天的內容生產鏈路:
一個關鍵細節:每天的練習模式完全不同。
不是千篇一律的選擇題。
Day 1是八卦閃卡+選擇題+連線題,因為核心任務是「記住八個卦的名字、數字、五行屬性」,純記憶型知識用閃卡最高效。
Day 2是五行生剋速答+旺衰判斷矩陣+體用關係對戰,因為核心任務是「掌握五行之間的生克推理鏈」,推理型知識用矩陣訓練最高效。
練習形式要匹配知識類型。這個匹配本身就是AI幫你做的——你告訴它今天要學什麼類型的知識,它自動選擇最合適的練習形式。
不管學什麼,都要把「讀」「看」「練」「糾」四個動作拆開,用AI幫你針對每個動作生產對應的內容。一份學習資料只激活一種認知通道,四份同時激活四種,效果天差地別。
我甚至還做了個網站把學習內容、視頻、練習放一起,每天看一次。
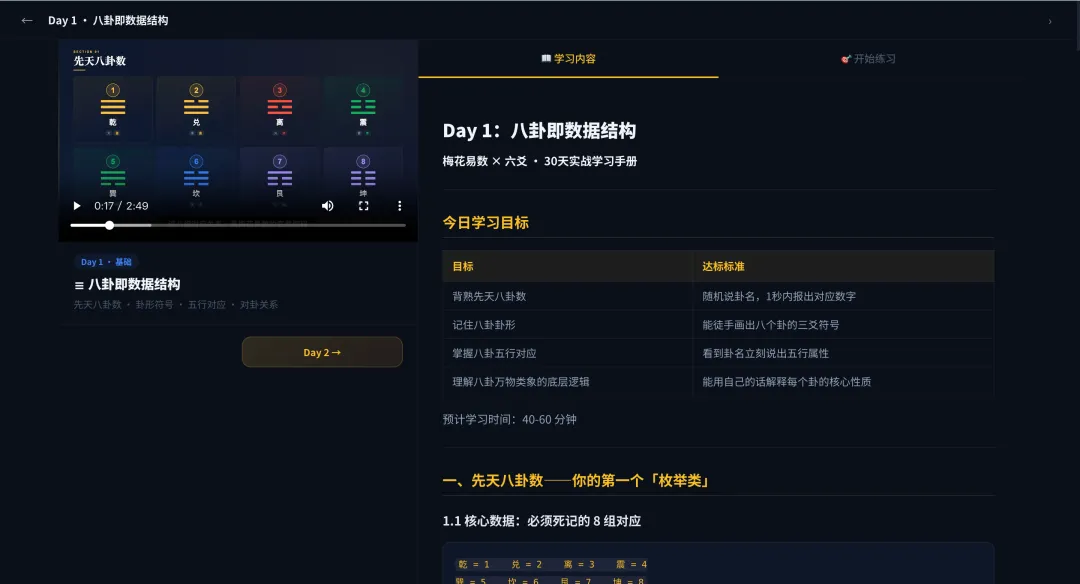
視頻效果真不錯,且都是對的:
對於做視頻的方案參考:
05 第四步:AI不是老師,是7×24小時陪練
這一步是整個體系的閉環。
我在OpenClaw上配了一個Agent,叫梅花先生。
它不是一個你問它答的問答機器人。它在學習場景裏做到了三件傳統學習根本做不到的事。

第一,個性化出題。 根據我的錯題記錄動態調整出題權重。Day 2五行生剋老是搞混木和土的關係,下次出題這個方向的比例自動拉高。不是均勻出題,是盯着你的薄弱點打。
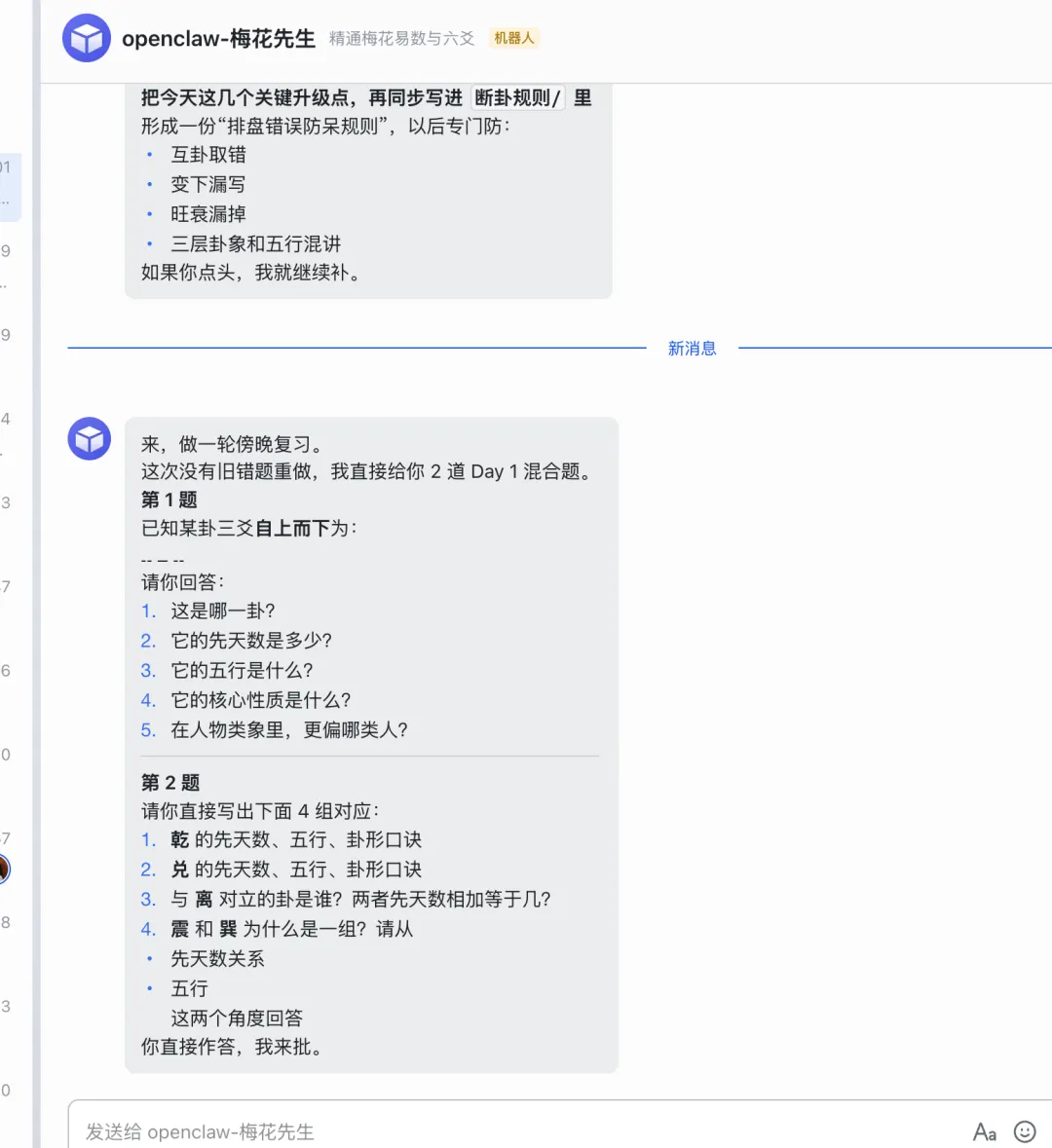
第二,實戰即學習。 每次我有需要占卜的場景,它按標準排盤模板走完整流程,並給我講解。每一次實戰都是一次完整的知識應用,比做100道練習題都管用。
第三,即時覆盤。 斷完卦馬上分析,哪裏斷對了,哪裏偏了,為什麼偏了。這個反饋循環是準確率提升最快的路徑。
傳統學習裏,學、練、用、覆盤四步是割裂的。上課學,回家練,工作中用,有空才覆盤——大多數人到第三步就斷了,覆盤更是幾乎沒有人做。
AI Agent把這四步壓縮到了同一個對話窗口裏:

一個晚上就能跑完一個完整循環。以前要一個月的事,現在一個晚上。
學任何東西,都要儘早配一個AI Agent做陪練。不是配一個問答機器人,是配一個能「主動出題 + 陪你實戰 + 幫你覆盤」的閉環搭檔。OpenClaw就能做,關鍵是你要把學習的SOP寫進Agent的配置裏。
06 踩出來的三條鐵律
每一條都交了學費。
鐵律一:AI生成的視覺內容,凡涉及精確符號,一律用代碼替代
梅花易數的卦象其實不復雜,但我一開始讓AI生成PPT來畫。
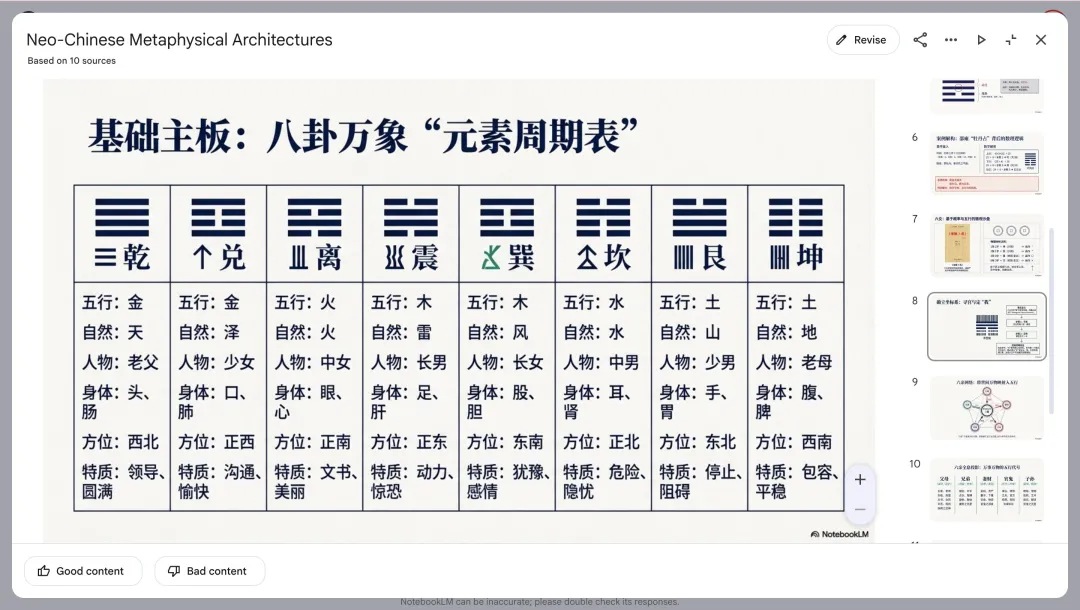
結果,全是錯的。
AI圖像生成對這種需要嚴格精確的符號系統,目前根本不可靠。不是模型不行,是圖像生成這個範式本身就不適合處理離散精確符號。
我的解法:全部用SVG代碼渲染。
[1,1,1] = 乾 ☰ 三條陽爻(完整橫線)
[0,0,0] = 坤 ☷ 三條陰爻(斷開橫線)
[1,0,1] = 離 ☲ 陽陰陽數據驅動,程序畫圖,100%準確。不存在畫錯的可能。
這也是為什麼我的練習頁面選了React JSX而不是普通HTML——卦象需要根據數據動態渲染,組件化的方式更乾淨,而且能保證每一個卦在任何場景下都準確無誤。
化學分子式、樂譜、電路圖、數學公式的圖形表示、棋譜——只要是精確符號系統,都別信AI的圖像生成,用代碼。
鐵律二:你必須學到能發現AI哪裏錯了的程度
「AI時代還需不需要學習」這個問題,我的答案很明確:需要。但學的目標變了——不是學知識本身,是學到能發現AI哪裏給錯了的程度。
這個「能發現錯誤的判斷力」,才是AI時代個人最值錢的能力。
鐵律三:Agent的準確率取決於你給它的約束模板,不取決於模型有多強
梅花先生在幫我算卦的時候,互卦經常出錯。
這不是模型能力的問題。Claude Opus足夠強了。問題出在我沒有給它一個不可跳步的計算模板。
我加了一個強制約束:每次排盤必須先把六爻數組完整寫出來——
六爻(從下到上):
初爻=0 二爻=1 三爻=0 四爻=0 五爻=0 上爻=0然後逐位標號取值,不允許心算跳步。
加上這個約束之後,準確率從大概70%直接拉到了100%。
讓AI做任何有精確步驟的事情,都要給一個「逐步展示中間過程」的模板。不是因為它不會算,是因為它在心算的時候會跳步,跳步就容易出錯。模型能力是天花板,約束模板決定它能穩定發揮幾成。
好的約束不是限制AI的能力,是幫AI把能力穩定地釋放出來。
07 AI時代學習的哲學
最後講講我想了大半年的那個問題。
傳統時代學習的目標是「我要學會這個知識」。你把知識裝進腦子裏,能用的時候掏出來用。
AI時代,這個目標變了。
知識獲取的成本已經趨近於零了。你問AI任何問題,它都能給你一個看起來很專業的回答。但「看起來專業」和「真的對」之間,有一道巨大的鴻溝。
新的目標是:我要學會驗證AI給我的東西對不對,然後把我的人生經驗注入進去,形成AI給不了的判斷。
拿梅花易數來說。AI能幫我起卦、排盤、算五行生剋,算得比我快、比我準(在有約束模板的前提下)。
但斷卦的最後一步——象的解讀——只有人能做。
同樣一個「巽為風」的變卦,AI只會告訴你:飄移、流動、不定。但結合「這是一隻丟失的貓」這個具體語境,我能解讀出:它不在一個固定位置,有活動性但不容易直接碰上,不是被人收留的狀態,更可能在遊蕩。
這個解讀需要對生活場景的理解、對貓的行為習性的常識、對求卦人心態的體察。這些東西AI給不了,也不應該指望AI給。
所以AI時代學習的分工,我最終的結論是這張圖:
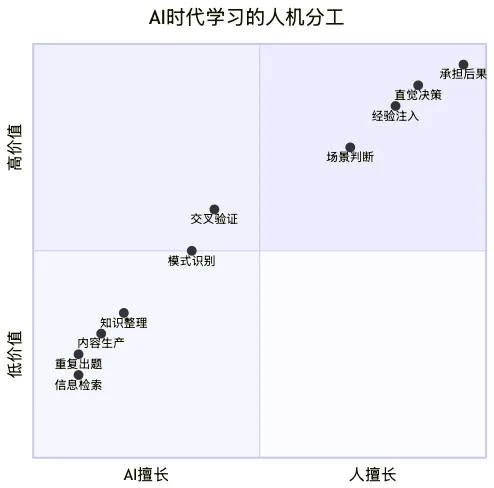
越往右上角,越是人不可替代的部分,也越值錢。
AI讓獲取知識的成本趨近於零,但驗證知識和應用知識的能力,反而變得前所未有地值錢。
學習這件事,從來沒有捷徑。
但確實有了更聰明的路徑分工。