用Superpowers自動調試:讓AI自己找bug、自己修、自己驗證
整理版優先睇
用systematic-debugging同verification-before-completion兩個Skill,將AI修bug從猜謎變成系統定位-修復-驗證閉環
呢篇文章係講Superpowers嘅調試體系,重點介紹兩個Skill:systematic-debugging(系統調試)同verification-before-completion(完成前驗證)。作者指出AI修bug成日有三個壞習慣:一係見到錯誤就估住改,唔追根因;二係一次改多個地方,搞到唔知邊個改錯;三係冇驗證就話搞掂咗。呢啲習慣令到修bug變成猜謎遊戲,愈修愈多新bug。
為咗解決呢個問題,Superpowers提出咗一套系統化嘅調試方法。systematic-debugging將調試分成四個階段:根因調查、模式分析、假設驗證、實施修復,每個階段都要完成先可以進入下一個。而verification-before-completion就係一個五步門禁,要求一定要跑完驗證命令、睇過輸出,先可以話搞掂。兩個Skill配合,形成定位→修復→驗證嘅完整閉環。
整體結論係:用呢套系統調試方法,可以將首次修復率從40%提升到95%,引入新bug嘅概率接近零。即使喺時間好急嘅情況下,都應該用系統調試,因為估嘅代價更大。文章仲提供咗兩個真實案例,一個係React白屏,另一個係Node.js工具鏈嘅路徑問題,示範點樣逐步揾根因、修復同驗證。最後講咗三個輔助技術:根因追蹤、縱深防禦、條件等待,幫手應付複雜場景。
- 結論:系統調試比估住改效率高得多,首次修復率升到95%,新bug接近零。
- 方法:systematic-debugging必須跟足四個階段——根因調查、模式分析、假設驗證、實施修復,唔準跳步。
- 差異:verification-before-completion要求一定要跑完整命令先可以話搞掂,用證據代替「應該冇問題」。
- 啟發:修復完之後要加縱深防禦,喺數據流每一層都加校驗,防止同類bug再出現。
- 可行動點:遇到bug時,要逼AI行曬四個階段同五步門禁,唔好畀佢估住改。
內容片段
TypeError: Cannot read properties of undefined (reading 'map') at OrderList (src/components/OrderList.tsx:23:
18) at renderWithHooks (react-dom.js:16175:
18) at mountIndeterminateComponent (react-dom.js:20919:18)AI修bug嘅三大壞習慣同Superpowers嘅鐵律
你畀AI修bug,好大機會係咁:貼個錯誤,AI話「試嚇改呢度」,改完仲係錯;再貼,AI話「試嚇改嗰度」,改完出新錯誤。來回幾輪,bug未修好,反而多咗幾個新bug。
呢個唔係AI能力問題,係AI冇調試紀律。
- 估住改,唔揾根因:見到錯誤關鍵字就直接畀方案,結果治標唔治本,根因繼續存在。
- 一次改多個地方:順便「優化」其他位,改完唔知邊個改啱邊個改錯,引入新bug。
- 冇驗證就話搞掂:AI改完話「應該冇問題」,但冇跑測試,部署上去先發現bug仲喺度。
系統調試15-30分鐘搞掂嘅問題,估-改-估-改要2-3小時;首次修復率從40%升到95%。
systematic-debugging:四個階段,唔準跳步
systematic-debugging將調試拆成四個階段,每個階段一定要完成先可以進入下一個。
注意階段3同階段4嘅分別:階段3係驗證假設,階段4先係正式修復。
- 1 階段1:根因調查 - 讀錯誤、復現、查變更、多組件收集證據、追蹤數據流。成功標準:理解「咩壞咗」同「點解壞」。
- 2 階段2:模式分析 - 揾正常代碼、對比參考實現、對比差異、理解依賴。成功標準:揾到正常同異常嘅差異。
- 3 階段3:假設驗證 - 提出一個假設,做最小改動驗證,確認後進入階段4,推翻就重新假設。成功標準:假設被確認或推翻。
- 4 階段4:實施修復 - 寫失敗測試、修根因、驗證通過;如果失敗就重新分析或質疑架構。成功標準:bug修復、測試通過。
重要原則:唔確定就承認。Skill原文講明「Say 'I don't understand X'」——唔肯定嘅時候要去問人、研究,唔好裝知然後亂估。
咩時候最需要用systematic-debugging?唔係閒嗰陣,係最急嗰陣。原文話「Use this ESPECIALLY when under time pressure.」因為愈急愈想估,但估嘅代價最大。
系統調試15-30分鐘搞掂嘅問題,估-改-估-改要2-3小時;首次修復率從40%升到95%。
verification-before-completion同閉環配合
systematic-debugging修完bug之後,點確認真係修好?靠verification-before-completion。呢個Skill嘅鐵律係:未跑過驗證命令,唔準聲稱完成;「啱先跑過」唔算,因為可能改咗代碼;「應該冇問題」唔算,一定要有命令輸出做證據。
鐵律重點:命令必須新鮮、完整,唔可以用上次結果。
- 1 IDENTIFY:咩命令可以證明呢個聲明?
- 2 RUN:執行完整命令(要新鮮嘅、完整嘅)。
- 3 READ:睇完整輸出,檢查退出碼,數失敗數。
- 4 VERIFY:輸出係咪確認咗聲明?如果冇,用證據講實際狀態;如果確認咗,聲明要附帶證據。
- 5 ONLY THEN:先可以作聲明。
常見錯誤聲明例如「應該冇問題」、「測試應該能通過」,正確做法係附上命令輸出。
代理報告唔可信,必須自己獨立驗證。
三個輔助技術:根因追蹤、縱深防禦、條件等待
根因追蹤:從報錯位置逐層向上追,唔好只修報錯位置,要修源頭。如果追唔通,可以加棧追蹤(new Error().stack)打印完整調用鏈。
縱深防禦:修完bug後,喺數據流經過嘅每一層都加校驗,形成四層模型:入口校驗、業務邏輯校驗、環境守衞、調試日誌。四層一齊,同類bug極難再發生。
條件等待:用「等條件滿足」代替「等固定時間」,例如用waitFor(() => getResult() !== undefined)取代setTimeout。要留意輪詢頻率同超時設定。
三個輔助技術分別對應唔同場景:根因追蹤對付深層錯誤,縱深防禦防止重複,條件等待解決時靈時不靈測試。
systematic-debugging迫AI先揾根因先至改bug,verification-before-completion要求AI要執行完命令先可以話「搞掂曬」。兩個Skill配合,由「估-改-估-改」變成「定位-修復-驗證」三步閉環
寫喺前面
你用AI改bug,多數都係咁:
報咗個錯,將錯誤信息貼畀AI,AI話「試下改呢度」,改咗,又係錯。再貼,AI話「咁試下改嗰度」,改咗,出咗新錯誤。來回幾輪,bug未整好,反而多咗3個新bug。
呢個唔係AI能力唔得,而係AI欠缺調試紀律。
冇紀律嘅調試就係靠估。估一次兩次可能撞啱,但係估嘅效率遠低過系統排查——根據實際使用經驗:系統調試15-30分鐘搞掂嘅問題,估-改-估-改要2-3個鐘;首次修復率由40%提升到95%;系統調試引入新bug嘅機率接近零,估-改-估-改引入新bug係家常便飯。
呢篇文章講Superpowers嘅調試體系:systematic-debugging(系統調試)同verification-before-completion(完成前驗證)點樣配合,將「AI估bug」變成「AI定位bug→修bug→驗證修復」嘅閉環。我會用兩個真實場景行一次完整流程,每一步嘅輸入輸出都寫出嚟。
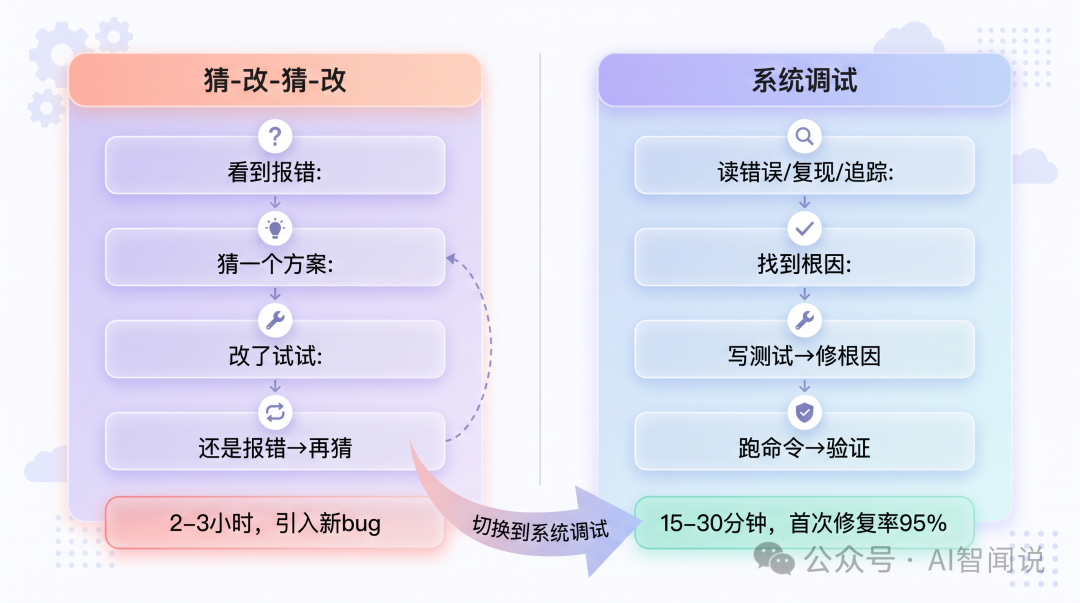
一、點解AI修bug容易越修越爛
AI修bug有3個天生嘅壞習慣:
1. 估住嚟改,唔揾根因
你貼咗一行報錯,AI就直接畀方案。佢冇先讀曬完整嘅錯誤信息、冇重現、冇追蹤數據流,就係見到報錯關鍵字就畀修改建議。
結果:只係整咗病徵,根因仲喺度。換個場景,同一個bug會用另一種方式走返出嚟。
2. 一次改多個地方
AI覺得「既然要改,順便將呢幾個相關嘅都優化埋」。一次改3個地方,有一個改啱咗,另外兩個引入咗新bug。但係你唔知邊個改啱、邊個改錯,因為改咗太多。
結果:舊bug未整好,新bug就嚟咗。
3. 冇驗證就宣佈整好
AI改完code,話「應該冇問題㗎喇」。「應該」兩個字係關鍵——佢冇跑測試,冇確認報錯消失,只係覺得code邏輯上冇問題。
結果:你部署咗上去,發現bug仲喺度。
Superpowers嘅systematic-debugging同verification-before-completion兩個Skill就係針對呢3個壞習慣。三條鐵律:
二、systematic-debugging:4個階段,唔可以跳步
systematic-debugging將調試拆成4個階段,每個階段一定要完成咗先可以進入下一個:
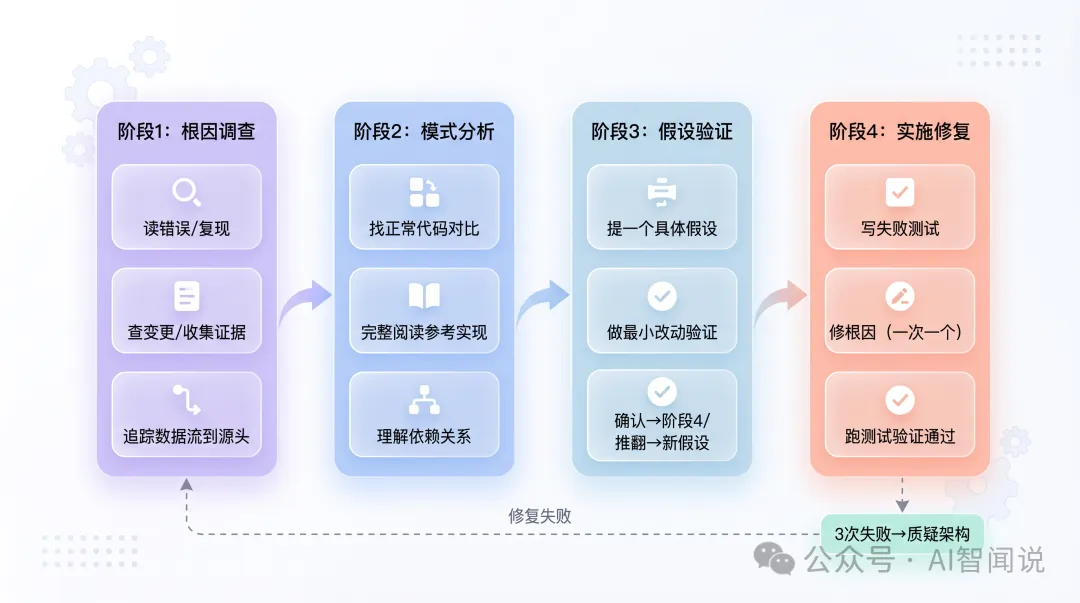
留意階段3同階段4嘅分別:階段3係驗證假設(改完睇效果),階段4係正式修復(寫測試、改code、跑驗證)。
階段3驗證之後有兩條路:
仲有一條原則好多人忽略:唔知就認。Skill原文明確講「Say 'I don't understand X'」——唔確定嘅時候,去問人、去研究,唔好扮識然後亂估。
幾時最應該用systematic-debugging?
唔係得閒嘅時候,係最急嘅時候。Skill原文寫得好清楚:「Use this ESPECIALLY when under time pressure.」(有時間壓力嘅時候尤其要用呢個Skill。)
緊急嘅時候,靠估嘅誘惑最大。但係靠估嘅代價都最大——估一次5分鐘,估錯一次5分鐘加回滾10分鐘,3次估錯就已經1個鐘。系統排查15-30分鐘搞掂,慳返嘅時間遠超「試咗先」慳到嘅時間。
三、調試流程速查
入實戰之前,先畀一個完整嘅流程概覽,方便之後對照:
發現bug嘅時候:
宣稱整好嘅時候:
修復失敗嘅時候:
揾唔到根因嘅時候:
系統性調查之後的確可能會遇到環境因素、時序依賴或者外部原因導致嘅bug。呢個時候應該:記錄調查過程、實現防禦性處理(例如重試機制、超時兜底、友善嘅錯誤提示)、加監控日誌等陣好查。但要留意:絕大多數「揾唔到根因」其實係調查得唔夠徹底。
四、實戰1:報錯位置同根因好近
場景:React + TypeScript項目,用戶反映「提交表單之後頁面白屏」
階段1:根因調查
1.1 完整讀錯誤信息
AI嘅第一反應唔係畀方案,而係先讀錯誤:
TypeError: Cannot read properties of undefined (reading 'map')
at OrderList (src/components/OrderList.tsx:23:18)
at renderWithHooks (react-dom.js:16175:18)
at mountIndeterminateComponent (react-dom.js:20919:18)
錯誤在 OrderList.tsx 第23行,對 undefined 調用了 .map()。呢個表示某個array變數係 undefined,唔係空array。
1.2 穩定重現
AI嘗試重現:
重現條件確認:只有提交新訂單之後先會白屏,刷新之後恢復。
1.3 檢查最近變更
git diff HEAD~3 -- src/components/OrderList.tsx
發現最近一次提交將訂單接口嘅返回類型由 Order[] 改成了 { orders: Order[]; total: number },但 OrderList 組件仲係直接對成個響應做 .map()。
1.4 多組件系統收集證據
呢個bug涉及前端同BFF兩層。AI喺組件邊界加診斷日誌:
// 在API調用處
console.error('DEBUG fetchOrders:', { url, params, response: data });
// 在Hook處
console.error('DEBUG useOrders:', { rawData: data, extractedOrders: data?.orders });
// 在組件處
console.error('DEBUG OrderList:', { orders, type: typeof orders, isArray: Array.isArray(orders) });
跑一次,收集到嘅證據:
DEBUG fetchOrders: { url: '/api/orders', params: {page: 1}, response: {orders: [...], total: 42} }
DEBUG useOrders: { rawData: {orders: [...], total: 42}, extractedOrders: undefined }
DEBUG OrderList: { orders: {orders: [...], total: 42}, type: 'object', isArray: false }
證據顯示:API返回格式正確,但useOrders冇從返回值提取 .orders,直接將成個對象傳畀組件。
1.5 追蹤數據流
AI追蹤數據由接口到組件嘅完整路徑:
api/orders.ts 的 fetchOrders() 返回 { orders: Order[], total: number } ✓hooks/useOrders.ts 的 useOrders() 將返回值直接存到 state ✗(應該提取 .orders)OrderList.tsx 從 useOrders() 拿到 state,直接對 state 做 .map() ✗問題喺第2步同第3步:Hook冇提取 .orders,組件對成個對象做 .map()。
根因揾到咗:接口返回格式變咗,Hook同組件冇同步更新。
到呢一步,AI仲未改任何code。
階段2:模式分析
2.1 揾正常運作嘅類似code
AI搜索項目中其他使用 fetchOrders 嘅地方:
grep -rn "fetchOrders" src/
發現 Dashboard.tsx 都有呼叫 fetchOrders,但佢喺渲染時用咗 data.orders.map(),冇白屏。
2.2 對比參考實現
AI完整閲讀 Dashboard.tsx 中調用 fetchOrders 嘅部分,確認佢正確咁由返回值提取咗 .orders。呢個參考實現就係「正常運作嘅code」。
2.3 對比差異
差異確認:Dashboard 正確咁由返回值拎咗 .orders,OrderList 沒有。
2.4 理解依賴
AI檢查咗 useOrders Hook嘅依賴:佢依賴 fetchOrders 嘅返回格式。當 fetchOrders 嘅返回格式變更時,所有呼叫方都要同步更新。Dashboard 更新咗,OrderList 漏了。
階段3:假設驗證
AI提出假設:「OrderList組件需要由useOrders返回值拎 .orders 屬性」。
做最小改動驗證:
// 修改前
const orders = useOrders();
// 最小改動
const { orders } = useOrders();
淨係改咗呢一行,其他唔鬱。提交表單測試:白屏消失,訂單正常顯示。
假設確認。(呢個case比較簡單,階段3嘅驗證改動同階段4嘅正式修復剛好一樣。喺複雜場景中,階段3可能係臨時加一行日誌或者hardcode一個值嚟驗證假設,確認之後階段4先寫正式嘅修復code同測試。)
階段4:實施修復
systematic-debugging要求先寫失敗測試,再改code。
4.1 寫失敗測試
test('fetchOrders返回新格式時,OrderList正確渲染訂單列表', () => {
// 模擬新格式的API返回
mockFetchOrders.mockResolvedValue({
orders: [{ id: 1, name: '測試訂單' }],
total: 1,
});
render(<OrderList />);
// 驗證組件能正確從 { orders, total } 中提取 orders 並渲染
expect(screen.getByText('測試訂單')).toBeInTheDocument();
});
運行測試:失敗。因為組件仲係對成個返回值做 .map()。
4.2 修復根因
// 修改前
const orders = useOrders();
// 修復後
const { orders } = useOrders();
運行測試:通過。
4.3 驗證冇其他測試被破壞
npm test
全部通過。
到呢度,呢個bug整好咗。但係呢個例子太簡單——睇報錯信息基本上就估到根因。下面睇一個報錯位置同根因遠離嘅場景,呢個先係systematic-debugging真正發揮價值嘅地方。
五、實戰2:報錯位置同根因隔咗4層
場景:一個Node.js工具鏈項目,測試環境跑CI時,git init 喺源碼目錄執行咗,而唔係喺臨時目錄。呢個令到 .git 文件夾出現喺 packages/core/ 入面,污染咗源碼倉庫。
報錯信息指向嘅係 git init 命令本身,但係根因喺4層調用之外。
階段1:根因調查
讀錯誤信息: git init 在 /Users/jesse/project/packages/core 執行咗,而唔係喺臨時目錄。
復現: 每次跑測試都會喺 packages/core/ 下生成 .git 目錄。
檢查最近變更: 最近改咗 Session.create() 嘅初始化邏輯。
追蹤數據流(5層):
git init 在 process.cwd() 執行 ← 空嘅 cwd 參數WorktreeManager.createSessionWorktree(projectDir, sessionId) ← projectDir 係空字串Session.initializeWorkspace() ← 傳咗空字串Session.create() ← 傳咗空字串beforeEach 之前就訪問咗 context.tempDir ← setupCoreTest() 返回 { tempDir: '' }根因揾到咗:唔係 git init 本身有問題,係測試code喺初始化之前就訪問咗臨時目錄變數,拎到空字串,一路傳到落尾,git init 拎到空字串作為工作目錄,解析做 process.cwd()(源碼目錄)。
報錯位置同根因隔咗4層調用。如果淨係睇報錯位置嚟修——畀 git init 加個目錄檢查——可以整到呢一個場景,但係下次其他命令拎到空路徑,同樣問題一樣會出現。修根因(令到 tempDir 喺被提前訪問時拋錯)先可以一勞永逸。
階段2:模式分析
AI揾到項目中其他地方使用 tempDir 嘅code,發現所有正常使用嘅地方都係喺 beforeEach 之後先訪問。得呢個測試喺 beforeEach 之前訪問咗。
階段3:假設驗證
假設:「將 tempDir 改成 getter,喺 beforeEach 之前訪問就拋錯」。
最小改動:將 tempDir: '' 改成 get tempDir() { if (!this._tempDir) throw new Error('...'); return this._tempDir; }。
跑測試:.git 唔再出現喺源碼目錄。假設確認。
階段4:實施修復
寫失敗測試:訪問 context.tempDir 在 beforeEach 之前,斷言拋錯。
修復根因:實現 getter。
跑測試:通過。
但systematic-debugging仲要求一步:縱深防禦。修完根因之後,喺數據流經過嘅每一層都加校驗,令到同類bug喺結構上冇可能再發生:
Project.create() 校驗 workingDirectory 唔可以為空、一定要存在、一定要係目錄WorkspaceManager 校驗 projectDir 唔可以為空git init 拒絕喺臨時目錄之外執行git init 之前記錄目錄、cwd、調用棧點解要4層而唔係1層?唔同嘅code路徑可能會繞過某一層。入口校驗可以攔到大多數情況,但mock同測試可能繞過;業務邏輯校驗可以攔到邊緣情況,但跨平台差異可能繞過;環境守衞可以攔到特定上下文。4層一齊,同類bug極難再發生。
如果手動追蹤行唔通點算?
上面嘅例子係手動逐層追蹤揾到根因。但係有啲調用鏈好深,手動追蹤會斷。呢個時候有兩個技術可以用:
加棧追蹤: 喺問題操作之前打印完整調用鏈:
async function gitInit(directory: string) {
const stack = new Error().stack;
console.error('DEBUG git init:', {
directory,
cwd: process.cwd(),
stack,
});
await execFileAsync('git', ['init'], { cwd: directory });
}
用 console.error 而唔係 logger(logger喺測試中可能被靜默)。跑測試之後搜索 DEBUG git init 就可以睇到完整調用鏈。
二分查找污染源: 如果某個測試污染咗全局狀態導致其他測試失敗,但唔知係邊個測試,可以用二分法:逐個跑測試,揾到第一個污染源。Superpowers提供咗一個腳本 find-polluter.sh 嚟做呢件事。
六、verification-before-completion:未跑命令,唔可以話「搞掂曬」
systematic-debugging改完bug之後,點樣確認真係整好咗?靠verification-before-completion。
呢個Skill嘅鐵律:
佢定義咗一個5步門禁函數:
常見嘅錯誤聲明同正確聲明對比:
「頭先跑過」點解唔得? 因為你可能喺兩次運行之間又改咗code。上一次嘅測試結果唔可以證明當前code冇問題。verification-before-completion要求嘅係「新鮮嘅證據」。
容易踩嘅信號
Skill原文列舉咗幾個典型嘅「就快違反鐵律」嘅信號,見到呢啲信號就應該停低:
Skill原文記錄咗多次違反驗證鐵律嘅失敗案例,包括:代理報告「成功」但實際有未定義函數、功能唔完整就聲稱完成、信任代理報告導致浪費時間返工。呢啲案例嘅共同點:冇跑命令就聲稱完成,結果部署之後出問題。
七、兩個Skill點樣配合
systematic-debugging同verification-before-completion唔係孤立嘅兩個Skill,佢哋組成一個閉環:
少咗第3步同第4步,改bug就少咗閉環。你可能整好咗A但破壞咗B,自己都唔知。
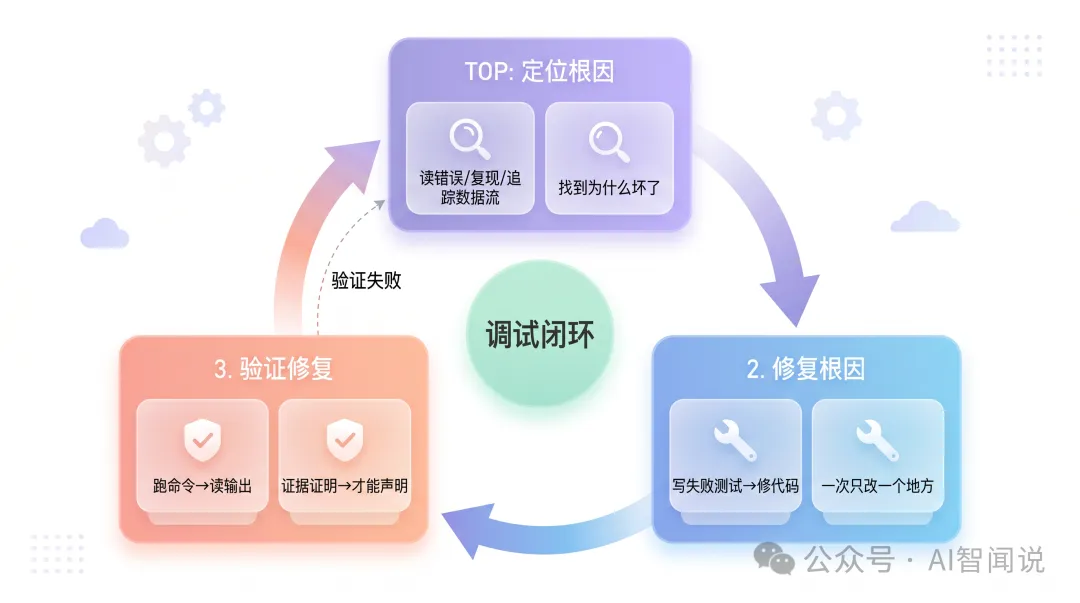
一個完整嘅調試閉環示例:
你:提交表單後頁面白屏,幫我修一下
AI(進入systematic-debugging階段1):
讀錯誤信息:TypeError: Cannot read properties ofundefined (reading 'map')
復現條件:提交新訂單後白屏,刷新後恢復
檢查變更:最近提交改了接口返回格式
多組件收集證據:在API、Hook、組件邊界加日誌,確認數據在Hook層丟失
追蹤數據流:接口返回{orders, total},Hook沒有提取.orders
AI(進入階段2):
找正常代碼:Dashboard.tsx用了data.orders.map(),沒問題
對比參考實現:完整閲讀Dashboard的調用方式
對比差異:OrderList沒有取.orders屬性
理解依賴:useOrders依賴fetchOrders的返回格式
AI(進入階段3):
假設:OrderList需要從返回值取.orders屬性
最小改動:const { orders } = useOrders()
驗證:白屏消失
假設確認 → 進入階段4
AI(進入階段4):
寫失敗測試:模擬新格式API返回,斷言組件正確渲染
運行測試:失敗(確認測試能捕獲bug)
修復根因:改解構賦值
運行測試:通過
AI(進入verification-before-completion):
IDENTIFY:什麼命令能證明bug修好了?
RUN:npm test
READ:34/34通過,0個失敗
VERIFY:全部通過,確認修復
聲明:運行npm test,34個測試全部通過,0個失敗。OrderList白屏bug已修復。
你:確認,提交代碼
留意最後一個聲明。AI唔係話「修好咗」,而係話「執行npm test,34個測試全部通過,0個失敗」。前者係主觀判斷,後者係客觀證據。
八、3個輔助技術
systematic-debugging帶咗3個輔助技術,佢哋唔止係「特定場景先用」嘅可選工具——根因追蹤係階段1嘅核心技術,縱深防禦係修復之後嘅必要步驟,條件等待係整時靈時唔靈bug嘅唯一可靠方法。
8.1 根因追蹤(root-cause-tracing)
適用於:錯誤發生喺調用棧深處,你唔清楚數據係由邊度開始錯。
方法:由報錯位置開始,逐層向上追蹤,揾到數據嘅源頭。如果手動追蹤行唔通,加棧追蹤(new Error().stack)打印完整調用鏈。如果係測試污染問題,用二分法逐個跑測試揾到污染源。
核心原則:永遠唔好淨係修報錯位置,要修源頭。 報錯位置係病徵,源頭係根因。修病徵,同一個根因會換個方式走返出嚟。
8.2 縱深防禦(defense-in-depth)
適用於:修完一個bug之後,想防止同類bug再出現。
方法:喺數據流經過嘅每一層都加校驗。4層模型:入口校驗、業務邏輯校驗、環境守衞、調試日誌。
點解需要4層而唔係1層?唔同嘅code路徑可能會繞過某一層。入口校驗可以攔到大多數情況,但mock同測試可能繞過;業務邏輯校驗可以攔到邊緣情況,但跨平台差異可能繞過;環境守衞可以攔到特定上下文,但正常使用唔會觸發。4層一齊,同類bug極難再發生。
8.3 條件等待(condition-based-waiting)
適用於:測試中有 setTimeout、sleep 等硬編碼等待,令到測試時得時唔得。
方法:用「等條件滿足」代替「等固定時間」。
// 錯誤:猜時間
await new Promise(r => setTimeout(r, 50));
const result = getResult();
// 正確:等條件
await waitFor(() => getResult() !== undefined);
const result = getResult();
3個常見錯誤:
setTimeout(check, 1) 浪費CPU,應該10ms輪詢一次幾時唔應該用條件等待:測試實際嘅時序行為(debounce、throttle間隔)時,應該用固定等待,但一定要加註釋說明點解需要固定等待。
根據實際使用反映:一批時得時唔得嘅測試改成條件等待之後,通過率可以由60%左右提升到接近100%,執行時間都明顯縮短。
九、AI修bug嘅藉口,同Superpowers點樣堵
systematic-debugging嘅藉口:
verification-before-completion嘅藉口:
第4條藉口「我試咗2次都未整好」特別值得留意。3次規則唔係「試3次就放棄」,而係:
寫喺最後
調試嘅本質唔係「改code令到報錯消失」,而係「揾到根因,修咗根因,驗證修復」。systematic-debugging迫AI行曬「定位-修復-驗證」嘅完整閉環,verification-before-completion迫AI用命令輸出講嘢而唔係用「應該冇問題」嚟敷衍。兩個Skill配合,將改bug由猜謎遊戲變成工程流程。
改bug嘅紀律比寫code嘅能力更容易被忽略,但大部分開發時間唔係喺寫新code,係喺修緊舊bug。令到AI改bug改得可靠,比令佢寫code寫得快更有價值。
systematic-debugging逼AI先找根因再修bug,verification-before-completion要求AI跑完命令才能說"搞定了"。兩個Skill配合,從"猜-改-猜-改"變成"定位-修復-驗證"三步閉環
寫在前面
你用AI修bug,大概率是這樣的:
報了個錯,把錯誤信息貼給AI,AI說"試試改這個",改了,還是報錯。再貼,AI說"那試試改那個",改了,新錯誤出現了。來回幾輪,bug沒修好,倒是多出來3個新bug。
這不是AI能力不行,是AI缺少調試紀律。
沒有紀律的調試就是猜。猜一次兩次可能蒙對,但猜的效率遠低於系統排查——根據實際使用經驗:系統調試15-30分鐘搞定的問題,猜-改-猜-改要2-3小時;首次修復率從40%提升到95%;系統調試引入新bug的概率接近零,猜-改-猜-改引入新bug是常事。
這篇文章講Superpowers的調試體系:systematic-debugging(系統調試)和verification-before-completion(完成前驗證)怎麼配合,把"AI猜bug"變成"AI定位bug→修bug→驗證修復"的閉環。我會用兩個真實場景走一遍完整流程,每一步的輸入輸出都寫出來。
一、為什麼AI修bug容易越修越爛
AI修bug有3個天生的壞習慣:
1. 猜着改,不找根因
你貼了一行報錯,AI直接給方案。它沒有先讀完整的錯誤信息、沒有復現、沒有追蹤數據流,就是看到報錯關鍵詞就給修改建議。
結果:修了症狀,根因還在。換個場景,同一個bug換個方式冒出來。
2. 一次改多個地方
AI覺得"既然在改,順便把這幾個相關的也優化一下"。一次改3個地方,有一個改對了,另外兩個引入了新bug。但你不知道哪個改對了、哪個改錯了,因為改了太多。
結果:舊bug沒修好,新bug來了。
3. 沒驗證就宣佈修好了
AI改完代碼,說"應該沒問題了"。"應該"兩個字是關鍵——它沒跑測試,沒確認報錯消失,只是覺得代碼邏輯上沒問題。
結果:你部署上去,發現bug還在。
Superpowers的systematic-debugging和verification-before-completion兩個Skill就是針對這3個壞習慣的。三條鐵律:
二、systematic-debugging:4個階段,不能跳步
systematic-debugging把調試拆成4個階段,每個階段必須完成後才能進入下一個:
注意階段3和階段4的區別:階段3是驗證假設(改了看效果),階段4是正式修復(寫測試、改代碼、跑驗證)。
階段3驗證後有兩條路:
還有一條原則很多人忽略:不知道就承認。Skill原文明確說"Say 'I don't understand X'"——不確定的時候,去問人、去研究,不要假裝知道然後瞎猜。
什麼時候最該用systematic-debugging?
不是閒的時候,是最急的時候。Skill原文寫得很明確:"Use this ESPECIALLY when under time pressure."(在時間壓力下尤其要使用這個Skill。)
緊急的時候,猜的誘惑最大。但猜的代價也最大——猜一次5分鐘,猜錯一次5分鐘加回滾10分鐘,3次猜錯就1小時了。系統排查15-30分鐘搞定,省下來的時間遠超"先試試"省下的時間。
三、調試流程速查
在進入實戰之前,先給一個完整的流程概覽,方便後續對照:
發現bug時:
聲稱修好時:
修復失敗時:
找不到根因時:
系統性調查後確實可能遇到環境因素、時序依賴或外部原因導致的bug。此時應該:記錄調查過程、實現防禦性處理(如重試機制、超時兜底、友好的錯誤提示)、加監控日誌以備後續排查。但要注意:絕大多數"找不到根因"其實是調查不充分。
四、實戰1:報錯位置和根因很近
場景:React + TypeScript項目,用戶反饋"提交表單後頁面白屏"。
階段1:根因調查
1.1 完整讀錯誤信息
AI的第一反應不是給方案,而是先讀錯誤:
TypeError: Cannot read properties of undefined (reading 'map')
at OrderList (src/components/OrderList.tsx:23:18)
at renderWithHooks (react-dom.js:16175:18)
at mountIndeterminateComponent (react-dom.js:20919:18)
錯誤在 OrderList.tsx 第23行,對 undefined 調用了 .map()。這說明某個數組變量是 undefined,不是空數組。
1.2 穩定復現
AI嘗試復現:
復現條件確認:只有提交新訂單後才會白屏,刷新後恢復。
1.3 檢查最近變更
git diff HEAD~3 -- src/components/OrderList.tsx
發現最近一次提交把訂單接口的返回類型從 Order[] 改成了 { orders: Order[]; total: number },但 OrderList 組件還在直接對整個響應做 .map()。
1.4 多組件系統收集證據
這個bug涉及前端和BFF兩層。AI在組件邊界加診斷日誌:
// 在API調用處
console.error('DEBUG fetchOrders:', { url, params, response: data });
// 在Hook處
console.error('DEBUG useOrders:', { rawData: data, extractedOrders: data?.orders });
// 在組件處
console.error('DEBUG OrderList:', { orders, type: typeof orders, isArray: Array.isArray(orders) });
跑一次,收集到的證據:
DEBUG fetchOrders: { url: '/api/orders', params: {page: 1}, response: {orders: [...], total: 42} }
DEBUG useOrders: { rawData: {orders: [...], total: 42}, extractedOrders: undefined }
DEBUG OrderList: { orders: {orders: [...], total: 42}, type: 'object', isArray: false }
證據顯示:API返回格式正確,但useOrders沒有從返回值中提取 .orders,直接把整個對象傳給了組件。
1.5 追蹤數據流
AI追蹤數據從接口到組件的完整路徑:
api/orders.ts 的 fetchOrders() 返回 { orders: Order[], total: number } ✓hooks/useOrders.ts 的 useOrders() 把返回值直接存到 state ✗(應該提取 .orders)OrderList.tsx 從 useOrders() 拿到 state,直接對 state 做 .map() ✗問題在第2步和第3步:Hook沒有提取 .orders,組件對整個對象做 .map()。
根因找到了:接口返回格式變了,Hook和組件沒有同步更新。
到這一步,AI還沒有改任何代碼。
階段2:模式分析
2.1 找正常工作的類似代碼
AI搜索項目中其他使用了 fetchOrders 的地方:
grep -rn "fetchOrders" src/
發現 Dashboard.tsx 也調用了 fetchOrders,但它在渲染時用了 data.orders.map(),沒有白屏。
2.2 對比參考實現
AI完整閲讀了 Dashboard.tsx 中調用 fetchOrders 的部分,確認它正確地從返回值中提取了 .orders。這個參考實現就是"正常工作的代碼"。
2.3 對比差異
差異確認:Dashboard 正確地從返回值中取了 .orders,OrderList 沒有。
2.4 理解依賴
AI檢查了 useOrders Hook的依賴:它依賴 fetchOrders 的返回格式。當 fetchOrders 的返回格式變更時,所有調用方都需要同步更新。Dashboard 更新了,OrderList 漏了。
階段3:假設驗證
AI提出假設:"OrderList組件需要從useOrders返回值中取 .orders 屬性"。
做最小改動驗證:
// 修改前
const orders = useOrders();
// 最小改動
const { orders } = useOrders();
只改了這一行,其他都不動。提交表單測試:白屏消失,訂單正常顯示。
假設確認。(這個case比較簡單,階段3的驗證改動和階段4的正式修復恰好一樣。在複雜場景中,階段3可能是臨時加一行日誌或hardcode一個值來驗證假設,確認後階段4才寫正式的修復代碼和測試。)
階段4:實施修復
systematic-debugging要求先寫失敗測試,再修代碼。
4.1 寫失敗測試
test('fetchOrders返回新格式時,OrderList正確渲染訂單列表', () => {
// 模擬新格式的API返回
mockFetchOrders.mockResolvedValue({
orders: [{ id: 1, name: '測試訂單' }],
total: 1,
});
render(<OrderList />);
// 驗證組件能正確從 { orders, total } 中提取 orders 並渲染
expect(screen.getByText('測試訂單')).toBeInTheDocument();
});
運行測試:失敗。因為組件還在對整個返回值做 .map()。
4.2 修復根因
// 修改前
const orders = useOrders();
// 修復後
const { orders } = useOrders();
運行測試:通過。
4.3 驗證沒有其他測試被破壞
npm test
全部通過。
到這裏,這個bug修好了。但這個例子太簡單了——看報錯信息基本就能猜到根因。下面看一個報錯位置和根因遠離的場景,這才是systematic-debugging真正發揮價值的地方。
五、實戰2:報錯位置和根因隔了4層
場景:一個Node.js工具鏈項目,測試環境跑CI時,git init 在源碼目錄執行了,而不是在臨時目錄。這導致 .git 文件夾出現在了 packages/core/ 裏,污染了源碼倉庫。
報錯信息指向的是 git init 命令本身,但根因在4層調用之外。
階段1:根因調查
讀錯誤信息: git init 在 /Users/jesse/project/packages/core 執行了,而不是在臨時目錄。
復現: 每次跑測試都會在 packages/core/ 下生成 .git 目錄。
檢查最近變更: 最近改了 Session.create() 的初始化邏輯。
追蹤數據流(5層):
git init 在 process.cwd() 執行 ← 空的 cwd 參數WorktreeManager.createSessionWorktree(projectDir, sessionId) ← projectDir 是空字符串Session.initializeWorkspace() ← 傳了空字符串Session.create() ← 傳了空字符串beforeEach 之前就訪問了 context.tempDir ← setupCoreTest() 返回 { tempDir: '' }根因找到了:不是 git init 本身有問題,是測試代碼在初始化之前就訪問了臨時目錄變量,拿到空字符串,一路傳到底,git init 拿到空字符串作為工作目錄,解析為 process.cwd()(源碼目錄)。
報錯位置和根因隔了4層調用。如果只看報錯位置修——給 git init 加個目錄檢查——能修掉這一個場景,但下次其他命令拿到空路徑,同樣的問題還會出現。修根因(讓 tempDir 在被提前訪問時拋錯)才能一勞永逸。
階段2:模式分析
AI找到項目中其他地方使用 tempDir 的代碼,發現所有正常使用的地方都在 beforeEach 之後訪問。只有這一個測試在 beforeEach 之前訪問了。
階段3:假設驗證
假設:"把 tempDir 改成 getter,在 beforeEach 之前訪問就拋錯"。
最小改動:把 tempDir: '' 改成 get tempDir() { if (!this._tempDir) throw new Error('...'); return this._tempDir; }。
跑測試:.git 不再出現在源碼目錄。假設確認。
階段4:實施修復
寫失敗測試:訪問 context.tempDir 在 beforeEach 之前,斷言拋錯。
修復根因:實現 getter。
跑測試:通過。
但systematic-debugging還要求一步:縱深防禦。修完根因後,在數據流經過的每一層都加校驗,讓同類bug在結構上不可能發生:
Project.create() 校驗 workingDirectory 不能為空、必須存在、必須是目錄WorkspaceManager 校驗 projectDir 不能為空git init 拒絕在臨時目錄之外執行git init 前記錄目錄、cwd、調用棧為什麼4層而不是1層?不同的代碼路徑可能繞過某一層。入口校驗能攔住大多數情況,但mock和測試可能繞過;業務邏輯校驗能攔住邊緣情況,但跨平台差異可能繞過;環境守衞能攔住特定上下文。4層一起,同類bug極難再發生。
如果手動追蹤走不通怎麼辦?
上面的例子是手動逐層追蹤找到的根因。但有些調用鏈很深,手動追蹤會斷。這時候有兩個技術可以用:
加棧追蹤: 在問題操作前打印完整調用鏈:
async function gitInit(directory: string) {
const stack = new Error().stack;
console.error('DEBUG git init:', {
directory,
cwd: process.cwd(),
stack,
});
await execFileAsync('git', ['init'], { cwd: directory });
}
用 console.error 而不是 logger(logger在測試中可能被靜默)。跑測試後搜索 DEBUG git init 就能看到完整調用鏈。
二分查找污染源: 如果某個測試污染了全局狀態導致其他測試失敗,但不知道是哪個測試,可以用二分法:逐個跑測試,找到第一個污染源。Superpowers提供了一個腳本 find-polluter.sh 來做這件事。
六、verification-before-completion:沒跑命令,不能說"搞定了"
systematic-debugging修完bug後,怎麼確認真的修好了?靠verification-before-completion。
這個Skill的鐵律:
它定義了一個5步門禁函數:
常見的錯誤聲明和正確聲明對比:
"剛才跑過了"為什麼不行? 因為你可能在兩次運行之間又改了代碼。上一次的測試結果不能證明當前代碼沒問題。verification-before-completion要求的是"新鮮的證據"。
容易踩的信號
Skill原文列舉了幾個典型的"快要違反鐵律"的信號,看到這些信號就該停下來了:
Skill原文記錄了多次違反驗證鐵律的失敗案例,包括:代理報告"成功"但實際有未定義函數、功能不完整就聲稱完成、信任代理報告導致浪費時間返工。這些案例的共同點:沒跑命令就聲稱完成,結果部署後出問題。
七、兩個Skill怎麼配合
systematic-debugging和verification-before-completion不是孤立的兩個Skill,它們組成一個閉環:
少了第3步和第4步,修bug就少了閉環。你可能修了A但破壞了B,自己還不知道。
一個完整的調試閉環示例:
你:提交表單後頁面白屏,幫我修一下
AI(進入systematic-debugging階段1):
讀錯誤信息:TypeError: Cannot read properties ofundefined (reading 'map')
復現條件:提交新訂單後白屏,刷新後恢復
檢查變更:最近提交改了接口返回格式
多組件收集證據:在API、Hook、組件邊界加日誌,確認數據在Hook層丟失
追蹤數據流:接口返回{orders, total},Hook沒有提取.orders
AI(進入階段2):
找正常代碼:Dashboard.tsx用了data.orders.map(),沒問題
對比參考實現:完整閲讀Dashboard的調用方式
對比差異:OrderList沒有取.orders屬性
理解依賴:useOrders依賴fetchOrders的返回格式
AI(進入階段3):
假設:OrderList需要從返回值取.orders屬性
最小改動:const { orders } = useOrders()
驗證:白屏消失
假設確認 → 進入階段4
AI(進入階段4):
寫失敗測試:模擬新格式API返回,斷言組件正確渲染
運行測試:失敗(確認測試能捕獲bug)
修復根因:改解構賦值
運行測試:通過
AI(進入verification-before-completion):
IDENTIFY:什麼命令能證明bug修好了?
RUN:npm test
READ:34/34通過,0個失敗
VERIFY:全部通過,確認修復
聲明:運行npm test,34個測試全部通過,0個失敗。OrderList白屏bug已修復。
你:確認,提交代碼
注意最後一個聲明。AI不是說"修好了",而是說"運行npm test,34個測試全部通過,0個失敗"。前者是主觀判斷,後者是客觀證據。
八、3個輔助技術
systematic-debugging帶了3個輔助技術,它們不只是"特定場景才用"的可選工具——根因追蹤是階段1的核心技術,縱深防禦是修復後的必要步驟,條件等待是修時靈時不靈bug的唯一可靠方法。
8.1 根因追蹤(root-cause-tracing)
適用於:錯誤發生在調用棧深處,你不清楚數據是從哪裏開始錯的。
方法:從報錯位置開始,逐層向上追蹤,找到數據的源頭。如果手動追蹤走不通,加棧追蹤(new Error().stack)打印完整調用鏈。如果是測試污染問題,用二分法逐個跑測試找到污染源。
核心原則:永遠不要只修報錯位置,要修源頭。 報錯位置是症狀,源頭是根因。修症狀,同一個根因會換個方式冒出來。
8.2 縱深防禦(defense-in-depth)
適用於:修完一個bug後,想防止同類bug再次出現。
方法:在數據流經過的每一層都加校驗。4層模型:入口校驗、業務邏輯校驗、環境守衞、調試日誌。
為什麼需要4層而不是1層?不同的代碼路徑可能繞過某一層。入口校驗能攔住大多數情況,但mock和測試可能繞過;業務邏輯校驗能攔住邊緣情況,但跨平台差異可能繞過;環境守衞能攔住特定上下文,但正常使用不會觸發。4層一起,同類bug極難再發生。
8.3 條件等待(condition-based-waiting)
適用於:測試中有 setTimeout、sleep 等硬編碼等待,導致測試時靈時不靈。
方法:用"等待條件滿足"替代"等待固定時間"。
// 錯誤:猜時間
await new Promise(r => setTimeout(r, 50));
const result = getResult();
// 正確:等條件
await waitFor(() => getResult() !== undefined);
const result = getResult();
3個常見錯誤:
setTimeout(check, 1) 浪費CPU,應該10ms輪詢一次什麼時候不該用條件等待:測試實際的時序行為(debounce、throttle間隔)時,應該用固定等待,但必須註釋說明為什麼需要固定等待。
根據實際使用反饋:一批時靈時不靈的測試改成條件等待後,通過率可以從60%左右提升到接近100%,執行時間也明顯縮短。
九、AI修bug的藉口,和Superpowers怎麼堵
systematic-debugging的藉口:
verification-before-completion的藉口:
第4條藉口"我試了2次都沒修好"特別值得注意。3次規則不是"試3次就放棄",而是:
寫在最後
調試的本質不是"改代碼讓報錯消失",而是"找到根因,修掉根因,驗證修復"。systematic-debugging逼AI走完"定位-修復-驗證"的完整閉環,verification-before-completion逼AI用命令輸出說話而不是用"應該沒問題"糊弄。兩個Skill配合,把修bug從猜謎遊戲變成工程流程。
修bug的紀律比寫代碼的能力更容易被忽視,但大部分開發時間不是在寫新代碼,是在修舊bug。讓AI修bug修得靠譜,比讓它寫代碼寫得快更有價值。