用一隻騎自行車的鵜鶘,看懂AI這半年
整理版優先睇
AI模型半年迭代五次,用「鵜鶘測試」睇真功夫:冇萬能模型,只有適合嘅模型
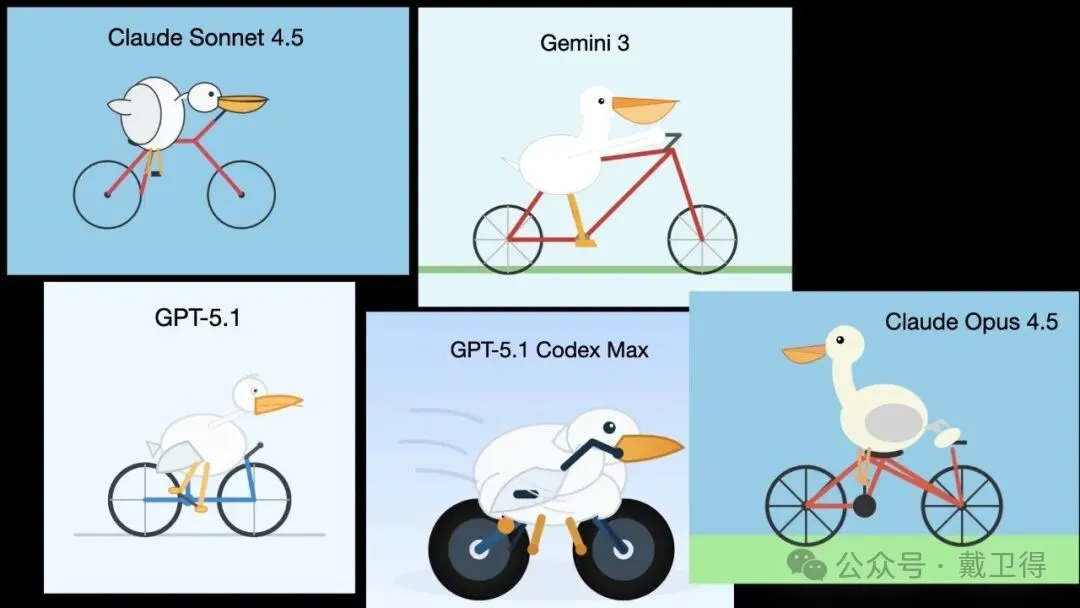
呢篇文章出自Django聯合創始人Simon Willison,佢用「畫一隻騎自行車嘅鵜鶘」呢個標準prompt測試新AI模型,因為呢個測試同時考空間推理、細節還原同代碼生成,而且冇得刷題,係真正能力嘅指標。過去半年,OpenAI、Anthropic、Google三家嘅旗艦模型輪流坐莊,王座換咗5次主人,節奏前所未有咁密集。
作者梳理咗由2025年11月到2026年4月嘅時間線,指出唔同模型喺唔同任務上各有所長:寫代碼用Claude,做研究用Gemini,通用場景用GPT。而家「最好嘅模型」呢個概念已經模糊化,更加重要嘅係三項根本轉變:思考型模型成為標配、自主Agent落地、本地模型終於好用。呢啲改變令AI從「能聊天」進化到「能幹活」。
整體結論係:冇萬能模型,只有適合你嘅模型。讀者應該按需求揀,而唔係盲目追「最好」。作者建議寫代碼上Claude,做研究上Gemini,日常聊天用GPT,想慳錢就跑本地模型。
- 「畫一隻騎自行車嘅鵜鶘」係Simon Willison用嚟測試模型真本事嘅標準prompt,因為佢同時考空間推理、細節還原同代碼生成,而且冇得刷題。
- 過去半年「最好模型」王座換咗5次主人,OpenAI、Anthropic、Google三家交替領先,但唔同模型各有專長,冇一個萬能。
- Anthropic嘅Claude偏精確,OpenAI嘅GPT偏豐富,Google嘅Gemini偏大膽,三種風格冇高下,只有各有所長。
- 三項根本轉變:思考型模型成標配、自主Agent落地、本地模型終於好用,呢啲改變令AI從對話變成行動。
- 實用建議:按任務選模型,寫代碼用Claude,做研究用Gemini,日常用GPT,想慳錢跑本地模型。
點解一隻鵜鶘測到模型嘅真本事
Simon Willison成日話,「畫一隻騎自行車嘅鵜鶘」係佢最鍾意嘅測試,因為呢個prompt同時考驗三樣嘢:空間推理、細節還原同代碼生成。模型要諗到一隻鳥點樣坐到座椅上,腳點踩踏板,翅膀放邊度;自行車要有輪輻同鏈條,鵜鶘嘅長嘴唔可以畫成鴨嘴;最後仲要用SVG代碼畫出嚟。
畫一隻騎自行車的鵜鶘- 空間推理:理解鵜鶘同自行車嘅物理關係,例如腳踏踏板、翅膀位置。
- 細節還原:自行車要有輪輻、鏈條,鵜鶘嘅長嘴要正確。
- 代碼生成:輸出可執行嘅SVG代碼,考驗模型對座標、路徑嘅掌握。
半年換位5次,發生咗咩
由2025年11月到2026年4月,「最好模型」呢個位換咗5次主人。節奏非常密集:2025年11月11日內,GPT-5.1、Gemini 3 Pro、Claude Opus 4.5輪流出場。之後每個月都有新版本。
- 2025.11 – Gemini 3 Pro (Google):宣稱智能新紀元
- 2025.11 – Claude Opus 4.5 (Anthropic):多模態+推理融合
- 2026.02 – Claude Opus 4.6 (Anthropic):當時最強
- 2026.03 – GPT-5.4 Pro (OpenAI):榜單改變者
- 2026.04 – Claude Opus 4.7 (Anthropic):知識截止到2026年1月
- 2026.04 – GPT-5.5 (OpenAI):最強自主Agent模型
「最好嘅模型」呢個概念本身變得模糊,因為唔同模型喺唔同任務上各有所長。寫代碼用Claude,做研究用Gemini,通用場景用GPT,已經成為2026年嘅行業共識。
三隻鵜鶘,三個方向
如果讓三家最新模型各畫一隻鵜鶘,會見到三種完全唔同嘅風格,呢啲係技術路線差異嘅縮影。
- Anthropic嘅鵜鶘偏精確:結構嚴謹,細節到位,先求準確再求創意。Claude喺編程任務上嘅統治力就係呢個路線嘅產物。
- OpenAI嘅鵜鶘偏豐富:可能帶背景、配色、故事感。GPT系列走通用性路線,擅長接近人類嘅表達。
- Google嘅鵜鶘偏大膽:Gemini 3 Deep Think畫嘅鵜鶘有雲、太陽、戴帽,社區公認最好。Google推推理深度,長上下文同Deep Think模式為複雜推理設計。
呢半年真正改變咗咩
回顧過去6個月,有三件事比任何單一模型都重要:
- 1 思考型模型成為標配:模型回答之前先花時間諗,唔再係單純文字接龍。呢個轉變係根本性嘅。
- 2 自主Agent落地:GPT-5.5係「最強自主Agent模型」,從你問一句佢答一句,變成你講個目標佢自己跑流程。
- 3 本地模型終於好用:唔使雲端API,唔使每月200美金,自己機上就能跑夠用嘅模型,改變咗AI嘅可及性。
如果你係普通用戶,最實用嘅建議好簡單:別追「最好嘅模型」,追「最適合你嘅模型」。寫代碼上Claude,做研究上Gemini,日常聊天用GPT,想慳錢跑本地模型。