用了這個 GPT-5.5,Codex 額度一下午就燒完了
整理版優先睇
GPT-5.5 實測:性能登頂但額度消耗驚人,Agent 能力進化至「自動驗收」新階段。
呢篇文章係作者竇竇第一時間用 Codex 實測 OpenAI 新推出嘅 GPT-5.5 之後嘅深度反思。作者作為一個重度 AI 使用者,想解決嘅問題係:新模型係咪真係值得轉會?喺真實嘅前端開發任務入面,GPT-5.5 展現咗極強嘅自主性,甚至識得喺寫完 code 之後自己開 browser 做驗收,呢種 Agent 級別嘅表現確實令人驚喜。
不過,作者亦都帶出咗一個好現實嘅痛點:強大嘅代價係燒錢燒得好快。GPT-5.5 嘅 API 輸出價格比上一代翻咗一倍,連 ChatGPT Plus 嘅額度都頂唔到一個下晝。整體結論係,雖然 GPT-5.5 喺綜合跑分攞到第一,但喺純寫 code 穩定性上仲係輸畀 Claude Opus 4.7 少少,建議大家要學識「混合路由」去平衡成本同效率。
- 性能表現:GPT-5.5 喺公開模型入面綜合實力最強,攞到 14 項 Benchmark 第一,但喺專業寫 code 領域(SWE-bench Pro)仲係輸畀 Claude Opus 4.7。
- Agent 進化:模型唔單止寫 code 快咗,仲識得「自己檢查自己」,喺無指令下自動開瀏覽器測試頁面,自主驗收能力大幅提升。
- 成本警示:API 輸出價格升到 $30/1M tokens,比 5.4 版本貴咗一倍,Plus 用戶嘅 5 小時額度窗口好容易喺一個 session 入面用曬。
- 省錢技巧:建議精簡 Prompt 同 AGENTS.md 文件,關閉唔用嘅 MCP server,並將日常簡單任務分流畀 GPT-5.4-mini 處理。
- 選型建議:如果係以寫 code 為主,Opus 4.7 依然係更穩嘅選擇;如果係跑複雜嘅 Agent 工作流或知識型任務,GPT-5.5 就係目前首選。
Codex 額度管理建議
1. Prompt 要精準,避免無關上下文;2. 縮減 AGENTS.md 文件體積;3. 關閉閒置 MCP server;4. 唔趕時間就唔好開 Fast mode。
跑分登頂,但寫 Code 仲有天花板?
GPT-5.5 喺 Artificial Analysis 綜合榜攞到 89 分,正式超越 Opus 4.7 同 Gemini 3.1 Pro。不過,如果你係專業 Developer 就要留意,喺 SWE-bench Pro 呢類硬核寫 code 測試入面,GPT-5.5 只有 58.6%,比起 Opus 4.7 嘅 64.3% 仲係差咗一截。
體感實測:識得「自己驗收」嘅 AI 助手
用 Codex 跑前端任務嗰陣,最驚艷嘅唔係速度,而係佢嘅 Agent 能力。佢寫完 code 之後,竟然會自動打開瀏覽器去 check 下個網頁行唔行得通,成個過程完全唔使人手幹預。
GPT-5.5 唔單止係識寫代碼,佢仲進化到識得幫你做埋 QA 驗收。
好用但肉痛:額度燒得快過火箭
OpenAI 依家嘅策略好明顯:模型更強,但算力更貴。GPT-5.5 嘅 API 輸出價格直接翻倍去到 $30/1M tokens。雖然佢用嘅 token 數比舊版少,但整體成本依然係上升咗。
總結:唔好二選一,要識得「混合路由」
面對越嚟越貴嘅旗艦模型,最聰明嘅做法係根據任務性質去揀模型。寫 code 為主就用 Opus 4.7,跑複雜 Agent 流程就用 GPT-5.5。免費午餐已經結束,識得判斷邊條路值得行,先係 AI 時代最值錢嘅能力。

尋日 OpenAI 出咗 GPT-5.5。
我第一時間攞 Codex 嚟跑咗幾個真實任務。
講真,模型確實係勁咗。但係額度消耗嘅速度,亦都令我睇到頭皮發麻。
先睇跑分:OpenAI 終於追上嚟喇
今次唔係小升級,係真係追到上嚟。
GPT-5.5 喺 Artificial Analysis 綜合榜攞到 89 分,Opus 4.7 係 86 分,Gemini 3.1 Pro 就再低少少。喺公開可以用嘅模型入面,GPT-5.5 攞咗 14 個 benchmark 第一。
但你先唔好咁急落結論住。
Anthropic 嗰個未完全放晒出嚟嘅 Mythos Preview,喺 SWE-bench Pro 上面打到 77.8%,GPT-5.5 先得 58.6%。Humanity's Last Exam 亦都係 Mythos 領先,56.8% 對 41.4%。
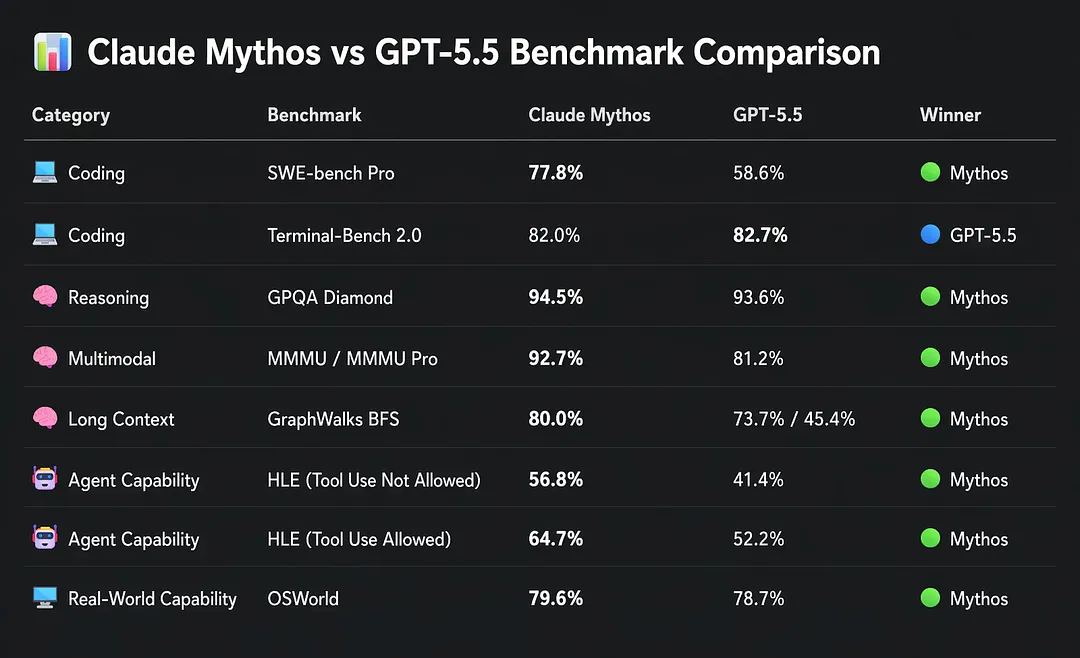
講白啲就係:公開模型入面 GPT-5.5 最勁,但 Mythos 依然係天花板。
輕微吐槽一下:天花板再高都好,普通用戶用唔到都係冇用,我快要由 Claude Max 用戶轉做 ChatGPT Pro 用戶喇。
Opus 4.7 亦都冇被甩開。寫 code 呢方面,SWE-bench Pro 上面 Opus 4.7 攞到 64.3%,比 GPT-5.5 高咗差唔多 6 個點。如果你係主力做 coding,Opus 4.7 依然係更穩陣嘅選擇。
實際體驗:快咗,而且更「聰明」咗
跑分係一回事,手感又係另一回事。
我用 Codex 掛 GPT-5.5 High 跑咗一個前端任務,係比較複雜嗰種。
第一感覺:快。係肉眼可以感知到嘅快。OpenAI 官方講法係「同 GPT-5.4 延遲持平,但智能水平高一檔」,實際體驗確實係咁。
更令我驚訝嘅係佢做完嘢之後嘅操作。
佢自己開咗瀏覽器,去測試生成咗嘅網頁。我明明冇叫佢咁做。
呢種「自己檢查自己」嘅行為,喺之前嘅模型好少見。講白啲就係 agent 能力又進步咗——唔單止係寫 code,仲識得驗收。
仲有一個細節:同樣嘅任務,GPT-5.5 用嘅 token 數明顯比 5.4 少。OpenAI 自己都講咗,「用更少 token 達到同等甚至更好嘅結果」。呢點對控制成本好關鍵。
問題嚟喇:額度燒得太快
體驗完嗰個前端任務,又做咗幾輪 code review 同 bug fix。
跟住就見到呢句:
You've hit your usage limit.
我係 ChatGPT Plus 用戶。5 個鐘嘅額度窗口,一個完整嘅 coding session 就用晒。
Plus 以前係夠用嘅。而家明顯唔夠喇。
你可能會話,咁升 Pro 囉。Pro 嘅額度係 Plus 嘅 5 到 10 倍,但按我呢種用法,重度開發一日落嚟都好掹掗。
OpenAI 而家嘅策略係:超咗可以額外買 credits 續命。但咁樣就代表月費唔再係固定㗎喇。
API 定價:貴咗一倍
查咗一下 GPT-5.5 嘅 API 價錢:
輸入:$5 / 1M tokens 輸出:$30 / 1M tokens
對比 GPT-5.4,輸出價錢直接翻倍。
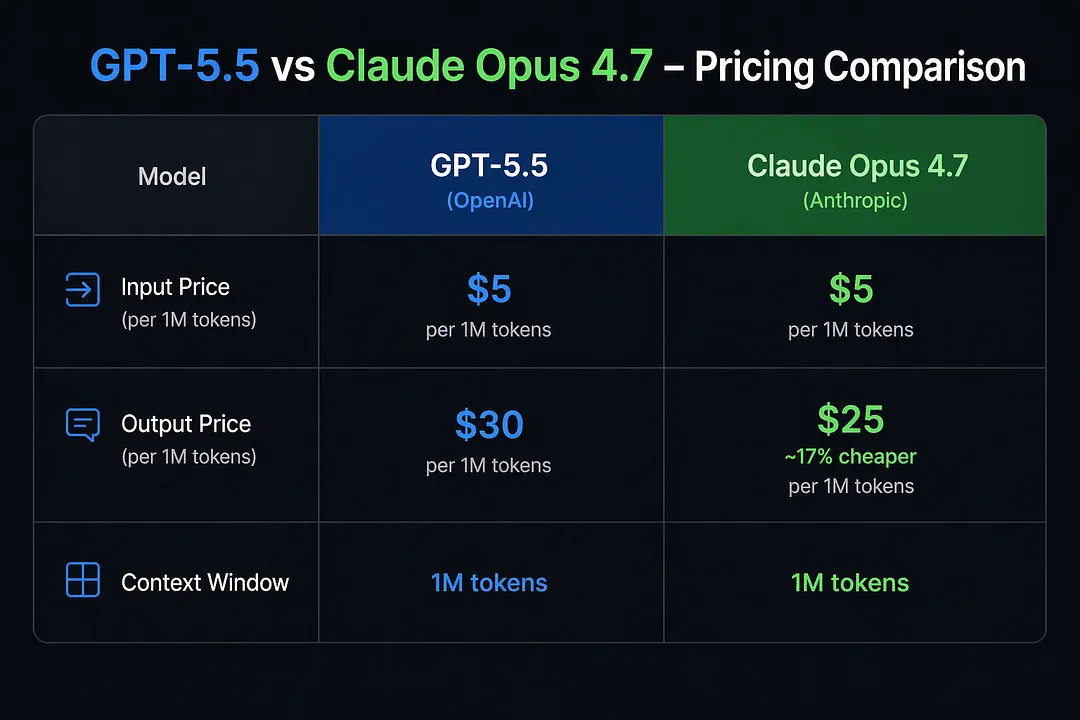
再對比 Claude Opus 4.7:輸入 25。
OpenAI 嘅旗艦模型,而家貴過 Anthropic 嗰個。
不過有一點要講返句公道話:GPT-5.5 做同一個任務用嘅 token 係少啲。所以實際開支未必係簡單嘅「翻倍」,要睇返你具體嘅 workload。
批量處理同 Flex 模式可以打五折,呢個對要跑大量任務嘅人嚟講係個好消息。
踩過嘅坑
1. API 未開放
留意返,GPT-5.5 目前只係喺 ChatGPT 同 Codex 入面用到。API 仲未放寬,OpenAI 話「需要唔同嘅安全防護措施」,具體時間未講。
如果你想喺自己產品入面 call GPT-5.5,而家仲未得。
2. Codex 額度管理技巧
根據 OpenAI 官方建議,想慳額度可以咁樣做:
prompt 寫精準啲,唔好堆無關嘅上下文 AGENTS.md 檔案唔好太大 唔用嘅 MCP server 熄咗佢,每掛多一個都會食 token 日常任務轉用 GPT-5.4 或者 5.4-mini,唔好乜都用旗艦
3. 速度模式會加速燒額度
Codex 嘅 Fast mode 消耗速度更快。如果你唔趕時間,就唔好開 Fast。
應該點樣揀?一張表睇晒
| 64.3% | ||
| 82.7% | ||
| 更強 | ||
我嘅建議:唔好只係揀一個,兩個都用晒佢。
寫 Code 為主嘅話 → Opus 4.7 會穩陣啲。跑 agent 任務、做知識型工作 → GPT-5.5 就更強。混合路由(Hybrid Routing)先係最優解。
最後講多兩句
GPT-5.5 確實係一個好大嘅升級。唔係嗰種「跑分高咗但體感冇變」嘅升級,而係你真係會感受得到。
但同時都要留意到:好嘅模型係越嚟越貴。
GPT-5.5 輸出價錢翻咗倍,Codex 額度用得仲快,Plus 用戶一個下晝就可以燒晒。
呢個唔單止係 OpenAI 嘅問題。成個行業都係往呢個方向行——模型更強,但算力更緊,價錢更高。
「免費午餐」嘅時代,確實係快將結束。
想試嘅話,Plus 或以上就用得。但建議你先諗清楚:你最需要處理邊類任務?揀啱模型,比起揀貴模型更加重要。
完。
識得搵出 code 入面嘅伏位、識得判斷邊條路行得通、識得將技術變做用到嘅嘢——呢 啲先至係 AI 時代真正值錢嘅能力。
「AI Native 實戰」訂閱說明
啱邊啲人:
想持續了解 AI 工具、Claude / Codex / Agent 實戰更新嘅人
你可以得到:
1. 每星期幫你篩一次值得睇嘅 AI 工具同更新
2. 遇到部署、揀選、使用問題可以直接問我
3. 幫你少行冤枉路,慳返自己搵資料同試錯嘅時間
價錢:
體驗價 19.9 蚊 / 年
訂閱方式:
加我微信 kbhero21 / 直接私訊我
備註:AI Native

我更鍾意分享一啲我自己親手試過、踩過坑,最後覺得真係有用嘅嘢。
關注我,一齊將複雜嘅 AI,變成普通人都用得到嘅日常。
祝各位讀者週末愉快😁,出街玩啦!
昨天 OpenAI 發了 GPT-5.5。
我第一時間拿 Codex 跑了幾個真實任務。
說實話,模型確實變強了。但額度消耗速度,也讓我頭皮發麻。
先看跑分:OpenAI 終於追上來了
這次不是小升級,是真的追上來了。
GPT-5.5 在 Artificial Analysis 綜合榜拿到 89 分,Opus 4.7 是 86 分,Gemini 3.1 Pro 更低一點。在公開可用的模型裏,GPT-5.5 拿下了 14 個 benchmark 第一。
但你別急着下結論。
Anthropic 那個沒完全放出來的 Mythos Preview,在 SWE-bench Pro 上打到 77.8%,GPT-5.5 才 58.6%。Humanity's Last Exam 也是 Mythos 領先,56.8% 對 41.4%。
說白了就是:公開模型裏 GPT-5.5 最強,但 Mythos 還是天花板。
輕微吐槽一下:天花板再高,普通用戶用不上,也白搭,我快要從Claude Max用戶到chat GPT pro用戶。
Opus 4.7 也沒被甩開。寫代碼這塊,SWE-bench Pro 上 Opus 4.7 打 64.3%,比 GPT-5.5 高了快 6 個點。你要是主力幹 coding,Opus 4.7 依然是更穩的選擇。
實際體驗:快了,而且更"聰明"了
跑分是一回事,手感是另一回事。
我用 Codex 掛 GPT-5.5 High 跑了一個前端任務,比較複雜的那種。
第一感覺:快。肉眼可感知的快。OpenAI 官方說法是"和 GPT-5.4 延遲持平,但智能水平高一檔",實際體驗確實如此。
更讓我驚訝的是它幹完活之後的操作。
它自己打開了瀏覽器,去測試生成的頁面。我沒讓它這麼做。
這種"自己檢查自己"的行為,在之前的模型上很少見。說白了就是 agent 能力又進了一步——不只是寫代碼,還會驗收。
還有一個細節:同樣的任務,GPT-5.5 用的 token 數明顯比 5.4 少。OpenAI 自己也說了,"用更少 token 達到同等甚至更好的結果"。這個對成本控制很關鍵。
問題來了:額度燒得太快
體驗完那個前端任務,又做了幾輪 code review 和 bug fix。
然後就看到了這個:
You've hit your usage limit.
我是 ChatGPT Plus 用戶。5 小時的額度窗口,一個完整的 coding session 就幹完了。
Plus 以前夠用的。現在明顯不夠了。
你可能會說,那升 Pro 唄。Pro 的額度是 Plus 的 5-10 倍,但按我這個用法,重度開發一天下來也夠嗆。
OpenAI 現在的策略是:超了可以額外買 credits 續命。但這就意味着月費不再是固定的了。
API 定價:翻倍了
查了一下 GPT-5.5 的 API 價格:
輸入:$5 / 1M tokens 輸出:$30 / 1M tokens
對比 GPT-5.4,輸出價格直接翻倍。
再對比 Claude Opus 4.7:輸入 25。
OpenAI 的旗艦模型,現在比 Anthropic 的還貴。
不過有一點要說公道話:GPT-5.5 同樣任務用的 token 更少。所以實際花費不一定就是簡單的"翻倍"。得看你的具體 workload。
批量處理和 Flex 模式可以打五折,這對跑大量任務的人是個好消息。
踩過的坑
1. API 還沒開放
注意了,GPT-5.5 目前只在 ChatGPT 和 Codex 裏可用。API 還沒放出來,OpenAI 說"需要不同的安全防護措施",具體時間沒說。
你要是想在自己的產品裏調用 GPT-5.5,現在還不行。
2. Codex 額度管理技巧
根據 OpenAI 官方建議,想省額度可以這麼做:
prompt 寫精準一點,別堆無關上下文 AGENTS.md 文件別太大 不用的 MCP server 關掉,每多掛一個都會吃 token 日常任務切到 GPT-5.4 或 5.4-mini,別啥都用旗艦
3. 速度模式會加速燒額度
Codex 的 Fast mode 消耗速度更快。如果你不趕時間,別開 Fast。
該怎麼選?一張表說清楚
| 64.3% | ||
| 82.7% | ||
| 更強 | ||
我的建議:別選一個,兩個都用。
寫代碼為主 → Opus 4.7 更穩。跑 agent 任務、做知識工作 → GPT-5.5 更強。混合路由是最優解。
最後說兩句
GPT-5.5 確實是一個實質性的升級。不是那種"跑分高了但體感沒變"的升級,是你能真實感受到的。
但同時也要看到:好模型越來越貴了。
GPT-5.5 輸出價格翻倍,Codex 額度消耗更快,Plus 用戶一下午就能燒完。
這不只是 OpenAI 的問題。整個行業都在往這個方向走——模型更強,但算力更緊,價格更高。
免費午餐的時代,確實在快速結束。
想試的話,Plus 及以上就能用。但建議你先想好:你最需要的是哪類任務?選對模型,比選貴的模型更重要。
end.
能識別代碼裏的坑、能判斷哪條路值得走、能把技術變成可用的東西—這 些才是 AI 時代真正值錢的能力。
「AI Native 實戰」訂閲說明
適合誰:
想持續瞭解 AI 工具、Claude / Codex / Agent 實戰更新的人
你能得到:
1. 每週篩一遍值得看的 AI 工具和更新
2. 遇到部署、選型、使用問題可直接問我
3. 幫你少踩坑,節省自己找資料和試錯時間
價格:
體驗價 19.9 元 /年
訂閲方式:
加我微信kbhero21 / 直接私信我
備註:AI Native
更喜歡分享 我自己試過、踩過坑、最後覺得真有用的東西
關注我,一起把複雜的 AI,過成普通人也能用上的日常。
祝每位讀者週末愉快😁,出門玩去啦!