用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)
整理版優先睇
你攢了200篇筆記,寫文章時還是打開空白文檔從零開始。這篇文章教你把知識庫變成寫作彈藥庫,從找素材到出初稿,幫你一條鏈路全部打通寫在前面上一篇我們搭好了知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你的筆記現在有摘要、有標籤、有連結,整整齊齊。但問題來了:筆記整理得再好,寫文章時你還是從空白文檔開始。打開編輯器,盯着光標閃了5分鐘,然後切到Obsidian翻筆記,複製一段,切回來粘貼,再切過去翻另一篇……寫一篇文章要在Obsidian和編輯器之間反覆切換。最後寫出來的東西,和你知識庫裏的筆記幾乎沒關係——你攢的那些筆記、摘要、連結,全成了擺設。這不是你的問題。大多數人的知識庫和寫作是脱節的:收集是一套流程,寫作是另一套流程,兩者之間沒有橋樑。這篇文章要做的事就是搭這座橋。我會教你用Obsidian + Claude Code把知識庫變成寫作彈藥庫:找素材:用Dataview和Claude Code從知識庫中快速挖出相關筆記,不用一篇篇翻搭骨架:讓Claude Code基於你的筆記生成寫作大綱,不是讓AI憑空編,是讓它組織你已有的內容出初稿:基於大綱和素材筆記,讓Claude Code生成初稿,你來做精修自動化:週報、月總結、讀書筆記綜述,這些重複性寫作讓知識庫自動驅動前置閲讀: 本文是《用Claude Code給Obsidian裝上AI大腦》的續篇。如果你還沒有搭好知識庫(倉庫結構、CLAUDE.md、Dataview),建議先看上一篇。一、問題出在哪——存了不用,等於沒存先說一個常見的場景。你要寫一篇關於"刻意練習"的文章。你的知識庫裏明明有8篇相關筆記——3篇讀書筆記、2篇課程筆記、3篇自己的想法記錄。但你寫文章時怎麼做?打開Obsidian,搜索"刻意練習",看到8個結果,逐個點開看,覺得這篇有用複製一段,那篇有用複製一段,最後切到編輯器拼成一篇文章。這個過程有三個問題:1搜索太粗:Obsidian搜索只能按關鍵詞匹配,搜"刻意練習"只能找到標題或正文包含這四個字的筆記。如果你的筆記標題是"《原子習慣》讀書筆記"、正文裏提到了刻意練習但沒出現這四個字,你就搜不到2閲讀太慢:8篇筆記逐個打開閲讀,判斷哪些內容可以用,耗時不少3組織太難:把不同筆記的片段拼在一起,邏輯容易散,銜接容易生硬根本原因是你把知識庫當倉庫用——存了就不管,而不是為了寫文章去調用。 知識庫驅動創作的核心思路是:不讓AI從零寫文章,而是讓AI從你的筆記中組織內容。這裏有一個關鍵區別:讓AI從零寫文章:AI編造內容,質量不可控,和你無關讓AI基於你的筆記組織內容:AI整理你的想法和素材,內容有根基,和你有關第二種方式才是知識庫驅動創作的正確姿勢。注意: 如果你剛搭好知識庫,筆記還不多(比如不到10篇),知識庫驅動寫作的效果有限——素材不夠,大綱和初稿都會很單薄。建議先把精力放在積累筆記上,等某個主題積累了5篇以上筆記後再嘗試。二、寫作前的準備——讓知識庫能"回答"寫作需求在開始寫作之前,需要做兩件事:更新CLAUDE.md加入寫作規則,創建寫作專用的Dataview查詢。更新CLAUDE.md——加入寫作規則上一篇的CLAUDE.md只定義了整理規則。現在要加入寫作相關的規則,讓Claude Code知道你希望它怎麼幫你寫。在倉庫根目錄的CLAUDE.md末尾追加以下內容:## 寫作規則### 角色當我說"寫文章"、"生成大綱"、"生成初稿"時,你切換到寫作助手角色。### 大綱生成規則1. 大綱基於我指定的筆記內容生成,不要憑空編造2. 大綱結構:標題 + 每個小節的要點(2-3條)+ 每個小節引用哪些筆記3. 大綱中標註信息來源,用 [[筆記名]] 標註每個觀點來自哪篇筆記4. 大綱生成後先給我審閲,我確認後再生成初稿### 初稿生成規則1. 初稿基於大綱和我指定的筆記內容生成2. 不要添加筆記中沒有的內容,如果需要補充信息,先標註【待補充】讓我決定3. 正文中引用具體觀點時,用括號標註來源筆記4. 保持簡潔直接的寫作風格,不用華麗辭藻5. 初稿生成後,我來做精修,你只需要搭好框架和填充素材### 素材查找規則1. 當我說"找關於XX的素材"時,搜索整個倉庫中和XX相關的筆記2. 搜索範圍不只是標題和標籤,也包括正文內容和摘要3. 返回結果時,列出每篇筆記的標題、摘要、和XX的關聯度(高/中/低)4. 如果結果超過10篇,只返回關聯度最高的10篇這段配置的核心思想是:AI是組織者,不是創作者。 它負責從你的筆記中提取、組織、排列信息,但不負責編造內容。這個邊界很重要——越過了這個邊界,AI寫出來的東西就和你無關了。注意:CLAUDE.md的總長度不要超過200行。 如果你之前已經寫了很多整理規則,追加寫作規則時注意精簡。加上本篇的寫作規則後,總長度大約90行,還有餘量。太長的CLAUDE.md會導致Claude Code對後面的規則響應變弱。所以追加前先檢查一下現有長度,必要時精簡已有規則。創建寫作素材查詢頁在Obsidian根目錄創建一篇筆記,命名為 寫作素材庫.md:---title: "寫作素材庫"date: 2026-05-21tags: [寫作, 素材庫]summary: "按主題聚合筆記,為寫作提供素材"---## 最近更新的筆記```dataviewTABLE date AS "日期", tags AS "標籤", summary AS "摘要"FROM "notes"SORT date DESCLIMIT 20```## 讀書筆記```dataviewTABLE date AS "日期", category AS "分類", rating AS "評分", summary AS "摘要"FROM "notes/reading"SORT date DESC```## 項目筆記```dataviewTABLE date AS "日期", status AS "狀態", summary AS "摘要"FROM "projects"SORT date DESC```## 未整理的素材```dataviewLISTFROM "inbox"```這篇筆記就是一個寫作素材的"總入口"。每次要寫文章時,先打開這篇筆記,用Dataview查詢快速瀏覽最近有什麼素材可用。Dataview查詢語句的含義:TABLE 表示以表格形式展示,FROM 指定查詢的文件夾,SORT date DESC 表示按日期倒序排列,LIMIT 20 表示最多顯示20條。如果你想按條件過濾,可以在 FROM 和 SORT 之間添加 WHERE 子句(比如 WHERE contains(tags, "知識管理"))來篩選特定筆記。前提: 這些查詢依賴frontmatter中的tags字段是YAML數組格式(如 tags: [知識管理, 筆記方法])。如果你用的是上一篇文章的模板,格式是正確的。但如果你的筆記用的是 #標籤 行內語法而不是frontmatter標籤,需要改用 contains(file.tags, "知識管理") 來查詢。創建寫作模板在 templates/ 文件夾中創建 寫作模板.md:---title: "<% tp.file.cursor(1) %>"date: <% tp.date.now("YYYY-MM-DD") %>tags: [寫作]status: "草稿"sources: []summary: ""---## 大綱## 初稿## 精修稿## 引用筆記-其中 <% tp.file.cursor(1) %> 是 Templater 插件的光標定位語法——創建筆記後,光標會自動跳到 title 字段等你輸入標題,不需要手動定位。sources 字段用來記錄這篇文章引用了哪些筆記,方便以後回溯。status 字段追蹤寫作進度:草稿 → 精修 → 定稿。創建新文章時,在Obsidian中按 Ctrl/Cmd + P 打開命令面板,搜索"Templater: Create new note from template",選擇"寫作模板",輸入文章標題即可創建一篇帶有frontmatter和章節結構的草稿筆記。注意: 這個模板只在Obsidian中手動創建寫作筆記時生效。當你通過Claude Code生成初稿時,Claude Code會直接寫入frontmatter內容(如 title: "如何建立知識管理體系"),不會觸發Templater模板。模板的作用是:你在Obsidian中手動新建寫作筆記時,自動填好格式,你只需要填內容。三、找素材——從知識庫挖出你要的內容準備工作做好了,現在進入實戰。假設你要寫一篇關於"如何建立知識管理體系"的文章。方法一:用Dataview按主題聚合打開 寫作素材庫.md,在Dataview查詢區域添加一個主題查詢:TABLE date AS "日期", tags AS "標籤", summary AS "摘要"FROM "notes"WHERE contains(tags, "知識管理") OR contains(tags, "筆記方法") OR contains(tags, "obsidian")SORT date DESC這會列出所有標籤中包含"知識管理"、"筆記方法"或"obsidian"的筆記。如果你在frontmatter中打了準確的標籤,這個查詢很有效。但Dataview有一個侷限:它只能匹配標籤和frontmatter字段,不能理解筆記內容。 如果一篇筆記的標籤是"閲讀"但正文大量提到知識管理,Dataview搜不到它。方法二:問Claude Code——語義搜索在Obsidian右側欄點擊Claudian圖標打開對話窗口,輸入:我要寫一篇關於"如何建立知識管理體系"的文章。請搜索整個倉庫,找出所有和知識管理相關的筆記,包括:1)標籤或標題中包含"知識管理"、"筆記方法"、"obsidian"的筆記;2)正文中提到知識管理、筆記整理、信息組織等概念的筆記。對每篇筆記,給出標題、摘要、和主題的關聯度(高/中/低),按關聯度排序。Claude Code會做兩件事Dataview做不到的:1理解語義:即使筆記裏沒有"知識管理"這四個字,只要內容相關,它也能找到。比如一篇標題為"《卡片筆記寫作法》讀書筆記"的筆記,Dataview搜不到(標籤是"閲讀"不是"知識管理"),但Claude Code能判斷它和知識管理高度相關2評估關聯度:不只告訴你"有關/無關",還告訴你"多有關",幫你判斷哪些筆記值得重點參考Claude Code的"語義搜索"和真正的語義搜索引擎(如Obsidian的Smart Connections插件,基於向量嵌入)不同。它的工作方式是讀取倉庫中的文件內容,用語言模型理解語義來判斷相關性。這意味着它不需要預先建立索引,即搜即用,但也受限於上下文窗口——如果你的倉庫筆記數量多且單篇篇幅長(比如超過200篇、每篇超過1000字),總內容可能接近單次對話的上下文上限,導致分析不完整。Claude Code返回的結果大概長這樣:找到8篇和"知識管理"相關的筆記:【高關聯】1. 《卡片筆記寫作法》讀書筆記 — 系統介紹卡片筆記法,核心理念是"寫下來而不是記下來"2. Obsidian知識庫搭建實錄 — 用Claude Code搭建知識庫的完整流程3. 雙向連結的真正用法 — 詳解雙向連結如何建立知識網絡【中關聯】4. 《原子習慣》讀書筆記 — 習慣養成方法,可引用"讓好習慣顯而易見"的部分5. 信息過載的應對方法 — 提到了知識管理的幾個常見誤區6. PARA方法實踐記錄 — 另一種知識組織方法,可作為對比【低關聯】7. 每週覆盤模板 — 覆盤流程中涉及知識整理8. 工具切換記錄 — 記錄了從Notion切換到Obsidian的原因這個輸出的質量取決於你知識庫的整理程度。 如果你的筆記都按照上一篇的規範添加了frontmatter(title、tags、summary),Claude Code能快速提取結構化信息,輸出會很整齊。如果筆記沒有統一格式,Claude Code需要從正文中提取信息,輸出可能不夠精確。這也是上一篇強調"每篇筆記必須有frontmatter"的原因——整理得越好,寫作時搜索和引用越準確。注意: 筆記越多,Claude Code讀取和分析的時間越長。筆記量大時(超過50篇),建議先用Dataview或MOC縮小範圍,再讓Claude Code在篩選結果中做深度分析。另外,搜索大量文件會消耗較多Token,注意API費用。方法三:用MOC當寫作索引如果你按上一篇的方法建了MOC,寫作時MOC就是現成的素材目錄。打開 notes/MOC - 知識管理.md,裏面已經列出了所有知識管理相關的筆記和簡短描述。MOC的好處是人工篩選過的——你建MOC時已經判斷過哪些筆記值得索引。Dataview和Claude Code是"廣撒網",MOC是"精篩選"。三種方法各有適用場景,不需要每次都走完三步:場景推薦方法原因主題明確,標籤規範先看MOCMOC已經人工篩選過,最精準不確定有哪些筆記Dataview查漏 + Claude Code語義搜索標籤可能遺漏,需要內容層面的搜索筆記少於20篇直接用Claude Code量少時語義搜索最快筆記超過50篇Dataview先縮小範圍,再Claude Code精準搜索避免Claude Code讀取過多文件寫重複性文章(週報等)只用Dataview素材來源固定,Dataview查詢即可四、搭骨架——讓Claude Code基於素材生成大綱找到素材後,下一步是搭大綱。這一步的關鍵原則是:大綱必須基於你的筆記內容,不是AI憑空編的。怎麼給Claude Code下指令在Claudian中輸入:我要寫一篇關於"如何建立知識管理體系"的文章。以下是我的相關筆記:1. 《卡片筆記寫作法》讀書筆記 — notes/reading/卡片筆記寫作法.md2. Obsidian知識庫搭建實錄 — notes/obsidian知識庫搭建.md3. 雙向連結的真正用法 — notes/雙向連結的真正用法.md4. 《原子習慣》讀書筆記 — notes/reading/原子習慣.md5. 信息過載的應對方法 — notes/信息過載的應對.md請閲讀這些筆記,然後生成一個文章大綱。要求:1. 大綱基於這些筆記的實際內容,不要添加筆記中沒有的觀點2. 每個小節標註信息來源,用 [[筆記名]] 格式3. 先給我大綱,我確認後再寫初稿在Claudian中,你可以直接在對話中引用文件路徑,Claude Code會自動讀取對應文件的內容。你也可以選中筆記中的文字後發送指令,Claude Code會把選中的文字作為上下文。兩種方式都能讓Claude Code獲取筆記內容,區別在於:引用文件路徑會讀取完整筆記,選中文字只處理你選中的部分。注意: 如果你的筆記很長或數量很多,Claude Code可能無法一次性讀取全部內容。建議單次指定不超過5篇筆記。如果素材超過5篇,先讓Claude Code為每篇筆記生成摘要,再基於摘要生成大綱。Claude Code會先讀取這些筆記,理解內容,然後生成大綱:# 如何建立知識管理體系## 引言:為什麼你的筆記總是找不到- 大多數人的筆記工具只管"存"不管"用" [[信息過載的應對方法]]- 知識管理的核心不是分類,是連接 [[卡片筆記寫作法]]## 一、從文件夾到知識網絡- 文件夾分類的問題:一篇筆記只能在一個位置 [[Obsidian知識庫搭建實錄]]- 雙向連結:讓筆記之間產生關聯 [[雙向連結的真正用法]]- 標籤和連結的配合:標籤管分類,連結管關聯 [[Obsidian知識庫搭建實錄]]## 二、讓整理變自動- 手動整理不可持續,需要自動化 [[Obsidian知識庫搭建實錄]]- 用AI輔助整理:打標籤、建連結、寫摘要 [[Obsidian知識庫搭建實錄]]- 每週15分鐘整理流程 [[Obsidian知識庫搭建實錄]]## 三、從收集到輸出- 知識管理的終極目標是輸出,不是存儲 [[卡片筆記寫作法]]- 讓好習慣顯而易見:降低整理和寫作的門檻 [[原子習慣]]- 知識庫驅動創作:用已有筆記作為寫作素材 [[卡片筆記寫作法]]## 總結- 知識管理不是整理,是建立連接和驅動輸出- 工具和方法缺一不可審閲和調整大綱大綱生成後,一定要審閲再繼續。 AI生成的大綱可能有這些問題:1遺漏了你認為重要的點:AI可能沒注意到某篇筆記中的關鍵觀點,你可以要求補充2結構不合理:比如三個小節權重不均,你可以要求調整3引用不準確:AI可能把觀點歸到了錯誤的筆記上,你需要核實審閲後,在Claudian中繼續對話調整:大綱整體不錯,但需要調整:1."引言"部分太短,加一段關於"筆記越多越難找"的具體場景2."從收集到輸出"這一節,加上從信息過載筆記中引用的"三個常見誤區"3. 總結部分太籠統,改為具體的行動建議Claude Code會根據你的反饋調整大綱。你可能需要來回調整2-3輪,這是正常的——大綱是文章的骨架,骨架歪了,初稿怎麼改都不對。審閲大綱花的時間不多,但能大幅減少後面改初稿的時間。五、從大綱到初稿——知識庫驅動的寫作流程大綱審閲調整完畢,確認結構沒問題後,就可以進入下一步了。讓Claude Code基於大綱和素材筆記生成初稿:大綱已確認,請基於大綱和之前列出的5篇筆記生成初稿。要求:1. 每個觀點都要有筆記中的原文或轉述作為支撐2. 不要添加筆記中沒有的內容,如果需要補充,標註【待補充】3. 保持簡潔直接的寫作風格,不用華麗辭藻4. 正文中引用觀點時,用括號標註來源筆記5. 保存到 projects/如何建立知識管理體系.mdClaude Code會生成一篇完整的初稿,保存到 projects/ 文件夾下。這篇初稿的特點是:每個觀點都來自你的筆記,不是AI憑空編的。 你可以驗證——如果某個觀點你不確定是不是自己寫的,看括號裏的來源筆記就知道。初稿大概長這樣:## 引言:為什麼你的筆記總是找不到大多數人使用筆記工具的方式是"存了就走",從不回顧。結果筆記越積越多,找到需要的那篇越來越難。(《信息過載的應對方法》)知識管理的核心問題不是"怎麼分類",而是"怎麼讓筆記之間產生連接"。(《卡片筆記寫作法》)## 一、從文件夾到知識網絡傳統文件夾分類有一個根本問題:一篇筆記只能存在於一個位置。比如"用Python做數據分析"這篇筆記,放到"編程"還是"數據分析"?這種糾結本身就說明文件夾分類不夠用。(《Obsidian知識庫搭建實錄》)雙向連結解決了這個問題——筆記不需要"放在"某個位置,而是通過連結建立關聯。(《雙向連結的真正用法》)【待補充:這裏可以加入你從文件夾切換到雙向連結的具體經歷】## 二、讓整理變自動手動給每篇筆記打標籤、建連結,一兩週還能堅持,時間一長必然鬆懈。(《Obsidian知識庫搭建實錄》)解決方法是用AI輔助整理:自動打標籤、自動建連結、自動生成摘要,把每週的整理時間壓縮到15分鐘以內。(《Obsidian知識庫搭建實錄》)## 三、從收集到輸出知識管理的終極目標不是把筆記存好,而是在需要時能調用出來產生新內容。(《卡片筆記寫作法》)"讓好習慣顯而易見"——降低整理和寫作的門檻,讓輸出變得像記筆記一樣簡單。(《原子習慣》)## 總結- 從文件夾分類切換到雙向連結,建立知識網絡- 用AI自動化整理流程,降低維護成本- 以輸出為導向使用知識庫,而不是隻管收集註意初稿的特點:每個觀點都有筆記來源標註,需要補充的地方用【待補充】標記。這篇初稿不能直接用,但骨架已經有了——你的素材被組織成了有邏輯的文章,你只需要精修。精修——最重要的環節初稿是半成品,不是成品。最重要的一步是核實引用。 AI可能把觀點歸到錯誤的筆記上,或者"編造"看似合理但筆記中不存在的論據。這不是AI故意犯錯,而是它理解內容時可能產生偏差。每一條標註了來源的觀點,都要打開原筆記確認。具體精修步驟:1核實引用:在Obsidian中打開初稿,對每個帶來源標註的觀點,點擊連結跳轉到原筆記,確認原文確實是那個意思。比如初稿寫"知識管理的核心是連接而非分類",你打開《卡片筆記寫作法》筆記一看,原文說的是"知識工作的核心不是分類存儲,而是產生連接"——措辭不同,意思一致,這個引用是準確的。如果發現AI誤讀了原文,直接修改初稿2補充【待補充】:AI標註了【待補充】的地方,要麼自己補充內容後刪除標記,要麼刪除整段(如果該觀點不重要)3調整語言:直接在Obsidian編輯器中修改措辭。如果你平時寫作風格偏口語,把AI的書面化表達改成你的說話方式。也可以選中段落,讓Claude Code"用更口語化的方式改寫"4補充個人觀點:在大綱和初稿覆蓋不到的地方,加入你自己的想法和經歷。這是AI做不到的部分——它只能組織你已有的筆記,不能替你思考5刪減冗餘:AI可能把多個筆記中相似的觀點都列出來了,需要合併重複內容,精簡到每個觀點只出現一次精修完成後,更新筆記的 status 字段從"草稿"改為"精修",在 sources 字段中列出引用的筆記:---title:"如何建立知識管理體系"date:2026-05-21tags: [寫作, 知識管理]status:"精修"sources: [卡片筆記寫作法, Obsidian知識庫搭建實錄, 雙向連結的真正用法, 原子習慣, 信息過載的應對方法]summary:"從文件夾分類到知識網絡,從手動整理到AI輔助,從收集存儲到驅動輸出——知識管理體系的完整搭建方法"---完整的寫作流程把上面的步驟串起來,知識庫驅動的寫作流程是這樣的:1確定主題 — 你要寫什麼2找素材 — 根據場景選擇合適的方法(MOC精篩、Dataview查漏、Claude Code語義搜索)3搭大綱 — 讓Claude Code基於素材筆記生成大綱,你審閲調整4出初稿 — 讓Claude Code基於大綱和筆記生成初稿5精修 — 核實引用、補充內容、調整語言、刪減冗餘6定稿 — 更新status字段,記錄引用來源和傳統寫作流程的區別在於:傳統流程中找素材和搭大綱是最耗時的部分,知識庫驅動後這兩步快了很多——素材已經在知識庫裏了,你不需要重新搜索和閲讀;大綱由AI基於你的筆記生成,你只需要審閲和調整。省下來的時間可以花在精修上——這才是決定文章質量的關鍵環節。實戰案例:用5篇讀書筆記寫一篇對比文章假設你過去半年讀了5本關於習慣養成的書,每本都做了讀書筆記存在 notes/reading/ 裏。現在你想寫一篇"習慣養成的5本書對比"文章。用上面介紹的流程,核心步驟和主流程一樣,但對比文章有一些特別之處:搭大綱時,指定對比維度:我要寫一篇"習慣養成的5本書對比"文章。請閲讀以下5篇讀書筆記:- notes/reading/原子習慣.md- notes/reading/掌控習慣.md- notes/reading/微習慣.md- notes/reading/習慣的力量.md- notes/reading/刻意練習.md生成一個對比文章的大綱,要求:1. 先概述5本書各自的核心觀點2. 然後從3-4個維度對比(比如:習慣形成原理、實操方法、適用場景、閲讀門檻)3. 最後給出推薦:不同需求的人適合讀哪本4. 每個觀點標註來源筆記對比文章的大綱結構和普通文章不同:它需要先分別介紹每本書,再橫向對比。這個結構需要你在prompt中明確指定,否則AI可能生成一篇普通的綜述而不是對比文章。精修時,重點核實每本書的核心觀點是否準確。 對比文章的引用密度比普通文章高——每個對比維度下要引用多本書的觀點,任何一處引用錯誤都會影響整篇文章的可信度。六、自動化寫作——週報、月總結、讀書綜述有些寫作是重複性的:每週的週報、每月的總結、讀完一系列書後的綜述。這些內容有固定格式,素材來源也是確定的(當週的筆記、當月的筆記、同一主題的讀書筆記),很適合用知識庫自動化。週報自動化每週五下午,讓Claude Code幫你生成周報:請生成本週的週報。步驟:1. 讀取 daily/ 文件夾下本週一到週五的每日筆記(文件名格式為 YYYY-MM-DD.md)2. 用命令查找本週修改過的筆記:find notes projects -name "*.md" -mtime -73. 讀取步驟2找到的筆記4. 從以上筆記中提取:本週完成的事項、遇到的問題、下週計劃5. 按以下格式生成周報: - 本週完成:(列出事項,標註來源筆記) - 遇到的問題:(列出問題和解決情況) - 下週計劃:(從筆記中提取待辦事項)6. 保存到 projects/週報/2026-W21.mdClaude Code會讀取你的每日筆記和項目筆記,提取關鍵信息,生成結構化的週報。生成的週報大概長這樣:# 週報 2026-W21## 本週完成- 完成Obsidian知識庫搭建,配置了CLAUDE.md和五層組織體系 (來源:projects/知識庫搭建.md)- 讀完《卡片筆記寫作法》,整理了3條核心觀點 (來源:notes/reading/卡片筆記寫作法.md)- 修復了項目中的登錄問題,原因是token過期未刷新 (來源:projects/用戶系統.md)## 遇到的問題- 知識庫批量整理時標籤不一致,部分筆記標籤用了中文,部分用了英文 已通過更新CLAUDE.md規範解決- Dataview查詢無法按正文內容過濾,部分相關筆記被遺漏 已記錄,計劃下週補充標籤## 下週計劃- 測試知識庫驅動創作流程,寫一篇實踐文章- 繼續閲讀《原子習慣》,整理讀書筆記注意週報中的【待補充】部分需要你手動補充。AI只能從已有筆記中提取信息,你腦子裏想但沒寫下來的事情,它不知道。注意:每日筆記是週報的主要素材來源。 如果你平時沒有寫每日筆記的習慣,週報的素材會不夠。建議每天花2分鐘在 daily/ 下記錄當天做了什麼,這樣週五生成周報時就有足夠的內容。月度總結自動化類似週報,但時間範圍更大:請生成本月的月度總結。步驟:1. 讀取 daily/ 文件夾下本月所有每日筆記2. 用命令查找本月新增的筆記:find notes -name "*.md" -mtime -303. 讀取步驟2找到的筆記4. 統計:本月新增筆記數量、各主題筆記分佈5. 提取:本月學到的最重要的3個知識點、本月完成的項目進展、下月重點6. 保存到 projects/月度總結/2026-05.md月度總結的價值不只是回顧——它讓你看到自己一個月到底學了什麼、做了什麼,而不是憑感覺回憶。讀書綜述自動化讀完一個主題的多本書後,讓Claude Code生成綜述:請閲讀 notes/reading/ 下和"認知科學"相關的讀書筆記(如果超過10篇,只選擇關聯度最高的10篇),生成一篇讀書綜述。要求:1. 概述每本書的核心觀點2. 找出這些書之間的共識和分歧3. 提煉出3-5個該主題的核心問題4. 給出進一步閲讀建議5. 每個觀點標註來源筆記6. 保存到 notes/reading/認知科學讀書綜述.md自動化寫作的邊界: 週報和月總結因為格式固定、信息來源確定,AI生成的質量通常較高,稍作修改就能用。但讀書綜述涉及"找共識、找分歧、提問題"這類分析工作,AI生成的結果可能流於表面——它能發現明顯的共同點和不同點,但容易遺漏隱含的深層聯繫。建議把AI生成的綜述當作起點,你在此基礎上加入自己的深度思考。你做到了什麼讀完這篇文章,你給知識庫加上了"輸出"能力:更新了CLAUDE.md的寫作規則,創建了寫作素材庫和模板,學會了用MOC、Dataview、Claude Code三種方式找素材,跑通了從找素材到精修的完整寫作流程,還實現了週報和月總結的自動化生成。上一篇搭好了知識庫的骨架,這篇讓知識庫能產出內容。但還有一個問題:你的知識庫是封閉的——所有信息都要你手動輸入。下一篇,我們用MCP讓知識庫聯網,自動抓取網頁、連接外部工具,讓信息自動流入你的知識庫。掃碼關注「AI智聞說」,每天3分鐘掌握AI新知識
你攢了200篇筆記,寫文章時還是打開空白文檔從零開始。這篇文章教你把知識庫變成寫作彈藥庫,從找素材到出初稿,幫你一條鏈路全部打通寫在前面上一篇我們搭好了知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你的筆記而家有摘要、有標籤、有連結,整整齊齊。但問題來了:筆記整理得再好,寫文章時你還是從空白文檔開始。
打開編輯器,盯着光標閃了5分鐘,然後切到Obsidian翻筆記,複製一段,切回來粘貼,再切過去翻另一篇……寫一篇文章要在Obsidian和編輯器之間反覆切換。最後寫出來的東西,和你知識庫裏的筆記幾乎沒關係——你攢的嗰啲筆記、摘要、連結,全成了擺設。這不是你的問題。大多數人的知識庫和寫作是脱節的:收集是一套流程,寫作是另一套流程,兩者之間沒有橋樑。
這篇文章要做的事就是搭這座橋。我會教你用Obsidian + Claude Code把知識庫變成寫作彈藥庫:找素材:用Dataview和Claude Code從知識庫中快速挖出相關筆記,不用一篇篇翻搭骨架:讓Claude Code基於你的筆記生成寫作大綱,不是讓AI憑空編,是讓它組織你已有的內容出初稿:基於大綱和素材筆記,讓Claude Code生成初稿,你來做精修自動化:週報、月總結、讀書筆記綜述,呢啲重複性寫作讓知識庫自動驅動前置閲讀: 本文是《用Claude Code給Obsidian裝上AI大腦》的續篇。如果你還沒有搭好知識庫(倉庫結構、CLA…
- 用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)
- 用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)|重點…
- 用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)|重點…
- 用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)|重點…
- 用知識庫"喂"出你的文章——Obsidian驅動創作實戰(二)|重點…
可記低 Prompt
你攢了200篇筆記,寫文章時還是打開空白文檔從零開始。這篇文章教你把知識庫變成寫作彈藥庫,從找素材到出初稿,幫你一條鏈路全部打通寫在前面上一篇我們搭好了知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你的筆記現在有摘要…
結構示例
## 寫作規則### 角色當我說"寫文章"、"生成大綱"、"生成初稿"時,你切換到寫作助手角色。### 大綱生成規則1. 大綱基於我指定的筆記內容生成,不要憑空編造2. 大綱結構:標題 + 每個小節的要點(2-3條)+ 每個小節引用哪些筆記3. 大綱中標註信息來源,用 [[筆記名]] 標註每個觀點來自哪篇筆記4. 大綱生成後先給我審閲,我確認後再生成初稿### 初稿生成規則1. 初稿基於大綱和我指定的筆記內容生成2. 不要添加筆記中沒有的內容,如果需要補充信息,先標註【待補充】讓我決定3. 正文中引用具體觀點時,用括號標註來源筆記4. 保持簡潔直接的寫作風格,不用華麗辭藻5. 初稿生成後,我來做精修,你只需要搭好框架和填充素材### 素材查找規則1. 當我說"找關於XX的素材"時,搜索整個倉庫中和XX相關的筆記2. 搜索範圍不只是標題和標籤,也包括正文內容和摘要3. 返回結果時,列出每篇筆記的標題、摘要、和XX的關聯度(高/中/低)4. 如果結果超過10篇,只返回關聯度最高的10篇整理版
你攢了200篇筆記,寫文章時還是打開空白文檔從零開始。這篇文章教你把知識庫變成寫作彈藥庫,從找素材到出初稿,幫你一條鏈路全部打通寫在前面上一篇我們搭好了知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你的筆記而家有摘要、有標籤、有連結,整整齊齊。但問題來了:筆記整理得再好,寫文章時你還是從空白文檔開始。打開編輯器,盯着光標閃了5分鐘,然後切到Obsidian翻筆記,複製一段,切回來粘貼,再切過去翻另一篇……寫一篇文章要在Obsidian和編輯器之間反覆切換。最後寫出來的東西,和你知識庫裏的筆記幾乎沒關係——你攢的嗰啲筆記、摘要、連結,全成了擺設。這不是你的問題。大多數人的知識庫和寫作是脱節的:收集是一套流程,寫作是另一套流程,兩者之間沒有橋樑。這篇文章要做的事就是搭這座橋。我會教你用Obsidian + Claude Code把知識庫變成寫作彈藥庫:找素材:用Dataview和Claude Code從知識庫中快速挖出相關筆記,不用一篇篇翻搭骨架:讓Claude Code基於你的筆記生成寫作大綱,不是讓AI憑空編,是讓它組織你已有的內容出初稿:基於大綱和素材筆記,讓Claude Code生成初稿,你來做精修自動化:週報、月總結、讀書筆記綜述,呢啲重複性寫作讓知識庫自動驅動前置閲讀: 本文是《用Claude Code給Obsidian裝上AI大腦》的續篇。如果你還沒有搭好知識庫(倉庫結構、CLAUDE.md、Dataview),建議先看上一篇。一、問題出在哪——存了不用,等於沒存先說一個常見的場景。你要寫一篇關於"刻意練習"的文章。你的知識庫裏明明有8篇相關筆記——3篇讀書筆記、2篇課程筆記、3篇自己的想法記錄。但你寫文章時怎麼做?打開Obsidian,搜索"刻意練習",看到8個結果,逐個點開看,覺得這篇有用複製一段,那篇有用複製一段,最後切到編輯器拼成一篇文章。呢個過程有三個問題:1搜索太粗:Obsidian搜索只能按關鍵詞匹配,搜"刻意練習"只能找到標題或正文包含這四個字的筆記。如果你的筆記標題是"《原子習慣》讀書筆記"、正文裏提到了刻意練習但沒出現這四個字,你就搜不到2閲讀太慢:8篇筆記逐個打開閲讀,判斷哪些內容可以用,耗時不少3組織太難:把不同筆記的片段拼在一起,邏輯容易散,銜接容易生硬根本原因是你把知識庫當倉庫用——存了就不管,而不是為了寫文章去調用。 知識庫驅動創作的核心思路是:不讓AI從零寫文章,而是讓AI從你的筆記中組織內容。這裏有一個關鍵區別:讓AI從零寫文章:AI編造內容,質量不可控,和你無關讓AI基於你的筆記組織內容:AI整理你的想法和素材,內容有根基,和你有關第二種方式才是知識庫驅動創作的正確姿勢。注意: 如果你剛搭好知識庫,筆記還不多(比如不到10篇),知識庫驅動寫作的效果有限——素材不夠,大綱和初稿都會很單薄。建議先把精力放在積累筆記上,等某個主題積累了5篇以上筆記後再嘗試。二、寫作前的準備——讓知識庫能"回答"寫作需求在開始寫作之前,需要做兩件事:更新CLAUDE.md加入寫作規則,創建寫作專用的Dataview查詢。更新CLAUDE.md——加入寫作規則上一篇的CLAUDE.md只定義了整理規則。而家要加入寫作相關的規則,讓Claude Code知道你希望它怎麼幫你寫。在倉庫根目錄的CLAUDE.md末尾追加以下內容:## 寫作規則### 角色當我說"寫文章"、"生成大綱"、"生成初稿"時,你切換到寫作助手角色。### 大綱生成規則1. 大綱基於我指定的筆記內容生成,不要憑空編造2. 大綱結構:標題 + 每個小節的要點(2-3條)+ 每個小節引用哪些筆記3. 大綱中標註信息來源,用 [[筆記名]] 標註每個觀點來自哪篇筆記4. 大綱生成後先給我審閲,我確認後再生成初稿### 初稿生成規則1. 初稿基於大綱和我指定的筆記內容生成2. 不要添加筆記中沒有的內容,如果需要補充信息,先標註【待補充】讓我決定3. 正文中引用具體觀點時,用括號標註來源筆記4. 保持簡潔直接的寫作風格,不用華麗辭藻5. 初稿生成後,我來做精修,你只需要搭好框架和填充素材### 素材查找規則1. 當我說"找關於XX的素材"時,搜索整個倉庫中和XX相關的筆記2. 搜索範圍不只是標題和標籤,也包括正文內容和摘要3. 返回結果時,列出每篇筆記的標題、摘要、和XX的關聯度(高/中/低)4. 如果結果超過10篇,只返回關聯度最高的10篇這段配置的核心思想是:AI是組織者,不是創作者。 它負責從你的筆記中提取、組織、排列信息,但不負責編造內容。呢個邊界很重要——越過了呢個邊界,AI寫出來的東西就和你無關了。注意:CLAUDE.md的總長度不要超過200行。 如果你之前已經寫了很多整理規則,追加寫作規則時注意精簡。加上本篇的寫作規則後,總長度大約90行,還有餘量。太長的CLAUDE.md會導致Claude Code對後面的規則響應變弱。所以追加前先檢查一下現有長度,必要時精簡已有規則。創建寫作素材查詢頁在Obsidian根目錄創建一篇筆記,命名為 寫作素材庫.md:---title: "寫作素材庫"date: 2026-05-21tags: [寫作, 素材庫]summary: "按主題聚合筆記,為寫作提供素材"---## 最近更新的筆記```dataviewTABLE date AS "日期", tags AS "標籤", summary AS "摘要"FROM "notes"SORT date DESCLIMIT 20```## 讀書筆記```dataviewTABLE date AS "日期", category AS "分類", rating AS "評分", summary AS "摘要"FROM "notes/reading"SORT date DESC```## 項目筆記```dataviewTABLE date AS "日期", status AS "狀態", summary AS "摘要"FROM "projects"SORT date DESC```## 未整理的素材```dataviewLISTFROM "inbox"```這篇筆記就是一個寫作素材的"總入口"。每次要寫文章時,先打開這篇筆記,用Dataview查詢快速瀏覽最近有什麼素材可用。Dataview查詢語句的含義:TABLE 表示以表格形式展示,FROM 指定查詢的文件夾,SORT date DESC 表示按日期倒序排列,LIMIT 20 表示最多顯示20條。如果你想按條件過濾,可以在 FROM 和 SORT 之間添加 WHERE 子句(比如 WHERE contains(tags, "知識管理"))來篩選特定筆記。前提: 呢啲查詢依賴frontmatter中的tags字段是YAML數組格式(如 tags: [知識管理, 筆記方法])。如果你用的是上一篇文章的模板,格式是正確的。但如果你的筆記用的是 #標籤 行內語法而不是frontmatter標籤,需要改用 contains(file.tags, "知識管理") 來查詢。創建寫作模板在 templates/ 文件夾中創建 寫作模板.md:---title: "<% tp.file.cursor(1) %>"date: <% tp.date.now("YYYY-MM-DD") %>tags: [寫作]status: "草稿"sources: []summary: ""---## 大綱## 初稿## 精修稿## 引用筆記-其中 <% tp.file.cursor(1) %> 是 Templater 插件的光標定位語法——創建筆記後,光標會自動跳到 title 字段等你輸入標題,不需要手動定位。sources 字段用來記錄這篇文章引用了哪些筆記,方便以後回溯。status 字段追蹤寫作進度:草稿 → 精修 → 定稿。創建新文章時,在Obsidian中按 Ctrl/Cmd + P 打開命令面板,搜索"Templater: Create new note from template",選擇"寫作模板",輸入文章標題即可創建一篇帶有frontmatter和章節結構的草稿筆記。注意: 呢個模板只在Obsidian中手動創建寫作筆記時生效。當你通過Claude Code生成初稿時,Claude Code會直接寫入frontmatter內容(如 title: "如何建立知識管理體系"),不會觸發Templater模板。模板的作用是:你在Obsidian中手動新建寫作筆記時,自動填好格式,你只需要填內容。三、找素材——從知識庫挖出你要的內容準備工作做好了,而家進入實戰。假設你要寫一篇關於"如何建立知識管理體系"的文章。方法一:用Dataview按主題聚合打開 寫作素材庫.md,在Dataview查詢區域添加一個主題查詢:TABLE date AS "日期", tags AS "標籤", summary AS "摘要"FROM "notes"WHERE contains(tags, "知識管理") OR contains(tags, "筆記方法") OR contains(tags, "obsidian")SORT date DESC這會列出所有標籤中包含"知識管理"、"筆記方法"或"obsidian"的筆記。如果你在frontmatter中打了準確的標籤,呢個查詢很有效。但Dataview有一個侷限:它只能匹配標籤和frontmatter字段,不能理解筆記內容。 如果一篇筆記的標籤是"閲讀"但正文大量提到知識管理,Dataview搜不到它。方法二:問Claude Code——語義搜索在Obsidian右側欄點擊Claudian圖標打開對話窗口,輸入:我要寫一篇關於"如何建立知識管理體系"的文章。請搜索整個倉庫,找出所有和知識管理相關的筆記,包括:1)標籤或標題中包含"知識管理"、"筆記方法"、"obsidian"的筆記;2)正文中提到知識管理、筆記整理、信息組織等概念的筆記。對每篇筆記,給出標題、摘要、和主題的關聯度(高/中/低),按關聯度排序。Claude Code會做兩件事Dataview做不到的:1理解語義:即使筆記裏沒有"知識管理"這四個字,只要內容相關,它也能找到。比如一篇標題為"《卡片筆記寫作法》讀書筆記"的筆記,Dataview搜不到(標籤是"閲讀"不是"知識管理"),但Claude Code能判斷它和知識管理高度相關2評估關聯度:不只告訴你"有關/無關",還告訴你"多有關",幫你判斷哪些筆記值得重點參考Claude Code的"語義搜索"和真正的語義搜索引擎(如Obsidian的Smart Connections插件,基於向量嵌入)不同。它的工作方式是讀取倉庫中的文件內容,用語言模型理解語義來判斷相關性。這意味着它不需要預先建立索引,即搜即用,但也受限於上下文窗口——如果你的倉庫筆記數量多且單篇篇幅長(比如超過200篇、每篇超過1000字),總內容可能接近單次對話的上下文上限,導致分析不完整。Claude Code返回的結果大概長咁樣:找到8篇和"知識管理"相關的筆記:【高關聯】1. 《卡片筆記寫作法》讀書筆記 — 系統介紹卡片筆記法,核心理念是"寫下來而不是記下來"2. Obsidian知識庫搭建實錄 — 用Claude Code搭建知識庫的完整流程3. 雙向連結的真正用法 — 詳解雙向連結如何建立知識網絡【中關聯】4. 《原子習慣》讀書筆記 — 習慣養成方法,可引用"讓好習慣顯而易見"的部分5. 信息過載的應對方法 — 提到了知識管理的幾個常見誤區6. PARA方法實踐記錄 — 另一種知識組織方法,可作為對比【低關聯】7. 每週覆盤模板 — 覆盤流程中涉及知識整理8. 工具切換記錄 — 記錄了從Notion切換到Obsidian的原因呢個輸出的質量取決於你知識庫的整理程度。 如果你的筆記都按照上一篇的規範添加了frontmatter(title、tags、summary),Claude Code能快速提取結構化信息,輸出會很整齊。如果筆記沒有統一格式,Claude Code需要從正文中提取信息,輸出可能不夠精確。這也是上一篇強調"每篇筆記必須有frontmatter"的原因——整理得越好,寫作時搜索和引用越準確。注意: 筆記越多,Claude Code讀取和分析的時間越長。筆記量大時(超過50篇),建議先用Dataview或MOC縮小範圍,再讓Claude Code在篩選結果中做深度分析。另外,搜索大量文件會消耗較多Token,注意API費用。方法三:用MOC當寫作索引如果你按上一篇的方法建了MOC,寫作時MOC就是現成的素材目錄。打開 notes/MOC - 知識管理.md,裏面已經列出了所有知識管理相關的筆記和簡短描述。MOC的好處是人工篩選過的——你建MOC時已經判斷過哪些筆記值得索引。Dataview和Claude Code是"廣撒網",MOC是"精篩選"。三種方法各有適用場景,不需要每次都走完三步:場景推薦方法原因主題明確,標籤規範先看MOCMOC已經人工篩選過,最精準不確定有哪些筆記Dataview查漏 + Claude Code語義搜索標籤可能遺漏,需要內容層面的搜索筆記少於20篇直接用Claude Code量少時語義搜索最快筆記超過50篇Dataview先縮小範圍,再Claude Code精準搜索避免Claude Code讀取過多文件寫重複性文章(週報等)只用Dataview素材來源固定,Dataview查詢即可四、搭骨架——讓Claude Code基於素材生成大綱找到素材後,下一步是搭大綱。這一步的關鍵原則是:大綱必須基於你的筆記內容,不是AI憑空編的。怎麼給Claude Code下指令在Claudian中輸入:我要寫一篇關於"如何建立知識管理體系"的文章。以下是我的相關筆記:1. 《卡片筆記寫作法》讀書筆記 — notes/reading/卡片筆記寫作法.md2. Obsidian知識庫搭建實錄 — notes/obsidian知識庫搭建.md3. 雙向連結的真正用法 — notes/雙向連結的真正用法.md4. 《原子習慣》讀書筆記 — notes/reading/原子習慣.md5. 信息過載的應對方法 — notes/信息過載的應對.md請閲讀呢啲筆記,然後生成一個文章大綱。要求:1. 大綱基於呢啲筆記的實際內容,不要添加筆記中沒有的觀點2. 每個小節標註信息來源,用 [[筆記名]] 格式3. 先給我大綱,我確認後再寫初稿在Claudian中,你可以直接在對話中引用文件路徑,Claude Code會自動讀取對應文件的內容。你也可以選中筆記中的文字後發送指令,Claude Code會把選中的文字作為上下文。兩種方式都能讓Claude Code獲取筆記內容,區別在於:引用文件路徑會讀取完整筆記,選中文字只處理你選中的部分。注意: 如果你的筆記很長或數量很多,Claude Code可能無法一次性讀取全部內容。建議單次指定不超過5篇筆記。如果素材超過5篇,先讓Claude Code為每篇筆記生成摘要,再基於摘要生成大綱。Claude Code會先讀取呢啲筆記,理解內容,然後生成大綱:# 如何建立知識管理體系## 引言:為什麼你的筆記總是找不到- 大多數人的筆記工具只管"存"不管"用" [[信息過載的應對方法]]- 知識管理的核心不是分類,是連接 [[卡片筆記寫作法]]## 一、從文件夾到知識網絡- 文件夾分類的問題:一篇筆記只能在一個位置 [[Obsidian知識庫搭建實錄]]- 雙向連結:讓筆記之間產生關聯 [[雙向連結的真正用法]]- 標籤和連結的配合:標籤管分類,連結管關聯 [[Obsidian知識庫搭建實錄]]## 二、讓整理變自動- 手動整理不可持續,需要自動化 [[Obsidian知識庫搭建實錄]]- 用AI輔助整理:打標籤、建連結、寫摘要 [[Obsidian知識庫搭建實錄]]- 每週15分鐘整理流程 [[Obsidian知識庫搭建實錄]]## 三、從收集到輸出- 知識管理的終極目標是輸出,不是存儲 [[卡片筆記寫作法]]- 讓好習慣顯而易見:降低整理和寫作的門檻 [[原子習慣]]- 知識庫驅動創作:用已有筆記作為寫作素材 [[卡片筆記寫作法]]## 總結- 知識管理不是整理,是建立連接和驅動輸出- 工具和方法缺一不可審閲和調整大綱大綱生成後,一定要審閲再繼續。 AI生成的大綱可能有呢啲問題:1遺漏了你認為重要的點:AI可能沒注意到某篇筆記中的關鍵觀點,你可以要求補充2結構不合理:比如三個小節權重不均,你可以要求調整3引用不準確:AI可能把觀點歸到了錯誤的筆記上,你需要核實審閲後,在Claudian中繼續對話調整:大綱整體不錯,但需要調整:1."引言"部分太短,加一段關於"筆記越多越難找"的具體場景2."從收集到輸出"這一節,加上從信息過載筆記中引用的"三個常見誤區"3. 總結部分太籠統,改為具體的行動建議Claude Code會根據你的反饋調整大綱。你可能需要來回調整2-3輪,這是正常的——大綱是文章的骨架,骨架歪了,初稿怎麼改都不對。審閲大綱花的時間不多,但能大幅減少後面改初稿的時間。五、從大綱到初稿——知識庫驅動的寫作流程大綱審閲調整完畢,確認結構沒問題後,就可以進入下一步了。讓Claude Code基於大綱和素材筆記生成初稿:大綱已確認,請基於大綱和之前列出的5篇筆記生成初稿。要求:1. 每個觀點都要有筆記中的原文或轉述作為支撐2. 不要添加筆記中沒有的內容,如果需要補充,標註【待補充】3. 保持簡潔直接的寫作風格,不用華麗辭藻4. 正文中引用觀點時,用括號標註來源筆記5. 保存到 projects/如何建立知識管理體系.mdClaude Code會生成一篇完整的初稿,保存到 projects/ 文件夾下。這篇初稿的特點是:每個觀點都來自你的筆記,不是AI憑空編的。 你可以驗證——如果某個觀點你不確定是不是自己寫的,看括號裏的來源筆記就知道。初稿大概長咁樣:## 引言:為什麼你的筆記總是找不到大多數人使用筆記工具的方式是"存了就走",從不回顧。結果筆記越積越多,找到需要的那篇越來越難。(《信息過載的應對方法》)知識管理的核心問題不是"怎麼分類",而是"怎麼讓筆記之間產生連接"。(《卡片筆記寫作法》)## 一、從文件夾到知識網絡傳統文件夾分類有一個根本問題:一篇筆記只能存在於一個位置。比如"用Python做數據分析"這篇筆記,放到"編程"還是"數據分析"?這種糾結本身就說明文件夾分類不夠用。(《Obsidian知識庫搭建實錄》)雙向連結解決了呢個問題——筆記不需要"放在"某個位置,而是通過連結建立關聯。(《雙向連結的真正用法》)【待補充:這裏可以加入你從文件夾切換到雙向連結的具體經歷】## 二、讓整理變自動手動給每篇筆記打標籤、建連結,一兩週還能堅持,時間一長必然鬆懈。(《Obsidian知識庫搭建實錄》)解決方法是用AI輔助整理:自動打標籤、自動建連結、自動生成摘要,把每週的整理時間壓縮到15分鐘以內。(《Obsidian知識庫搭建實錄》)## 三、從收集到輸出知識管理的終極目標不是把筆記存好,而是在需要時能調用出來產生新內容。(《卡片筆記寫作法》)"讓好習慣顯而易見"——降低整理和寫作的門檻,讓輸出變得像記筆記一樣簡單。(《原子習慣》)## 總結- 從文件夾分類切換到雙向連結,建立知識網絡- 用AI自動化整理流程,降低維護成本- 以輸出為導向使用知識庫,而不是隻管收集註意初稿的特點:每個觀點都有筆記來源標註,需要補充的地方用【待補充】標記。這篇初稿不能直接用,但骨架已經有了——你的素材被組織成了有邏輯的文章,你只需要精修。精修——最重要的環節初稿是半成品,不是成品。最重要的一步是核實引用。 AI可能把觀點歸到錯誤的筆記上,或者"編造"看似合理但筆記中不存在的論據。這不是AI故意犯錯,而是它理解內容時可能產生偏差。每一條標註了來源的觀點,都要打開原筆記確認。具體精修步驟:1核實引用:在Obsidian中打開初稿,對每個帶來源標註的觀點,點擊連結跳轉到原筆記,確認原文確實是嗰個意思。比如初稿寫"知識管理的核心是連接而非分類",你打開《卡片筆記寫作法》筆記一看,原文說的是"知識工作的核心不是分類存儲,而是產生連接"——措辭不同,意思一致,呢個引用是準確的。如果發現AI誤讀了原文,直接修改初稿2補充【待補充】:AI標註了【待補充】的地方,要麼自己補充內容後刪除標記,要麼刪除整段(如果該觀點不重要)3調整語言:直接在Obsidian編輯器中修改措辭。如果你平時寫作風格偏口語,把AI的書面化表達改成你的說話方式。也可以選中段落,讓Claude Code"用更口語化的方式改寫"4補充個人觀點:在大綱和初稿覆蓋不到的地方,加入你自己的想法和經歷。這是AI做不到的部分——它只能組織你已有的筆記,不能替你思考5刪減冗餘:AI可能把多個筆記中相似的觀點都列出來了,需要合併重複內容,精簡到每個觀點只出現一次精修完成後,更新筆記的 status 字段從"草稿"改為"精修",在 sources 字段中列出引用的筆記:---title:"如何建立知識管理體系"date:2026-05-21tags: [寫作, 知識管理]status:"精修"sources: [卡片筆記寫作法, Obsidian知識庫搭建實錄, 雙向連結的真正用法, 原子習慣, 信息過載的應對方法]summary:"從文件夾分類到知識網絡,從手動整理到AI輔助,從收集存儲到驅動輸出——知識管理體系的完整搭建方法"---完整的寫作流程把上面的步驟串起來,知識庫驅動的寫作流程是咁樣的:1確定主題 — 你要寫什麼2找素材 — 根據場景選擇合適的方法(MOC精篩、Dataview查漏、Claude Code語義搜索)3搭大綱 — 讓Claude Code基於素材筆記生成大綱,你審閲調整4出初稿 — 讓Claude Code基於大綱和筆記生成初稿5精修 — 核實引用、補充內容、調整語言、刪減冗餘6定稿 — 更新status字段,記錄引用來源和傳統寫作流程的區別在於:傳統流程中找素材和搭大綱是最耗時的部分,知識庫驅動後這兩步快了很多——素材已經在知識庫裏了,你不需要重新搜索和閲讀;大綱由AI基於你的筆記生成,你只需要審閲和調整。省下來的時間可以花在精修上——這才是決定文章質量的關鍵環節。實戰案例:用5篇讀書筆記寫一篇對比文章假設你過去半年讀了5本關於習慣養成的書,每本都做了讀書筆記存在 notes/reading/ 裏。而家你想寫一篇"習慣養成的5本書對比"文章。用上面介紹的流程,核心步驟和主流程一樣,但對比文章有一些特別之處:搭大綱時,指定對比維度:我要寫一篇"習慣養成的5本書對比"文章。請閲讀以下5篇讀書筆記:- notes/reading/原子習慣.md- notes/reading/掌控習慣.md- notes/reading/微習慣.md- notes/reading/習慣的力量.md- notes/reading/刻意練習.md生成一個對比文章的大綱,要求:1. 先概述5本書各自的核心觀點2. 然後從3-4個維度對比(比如:習慣形成原理、實操方法、適用場景、閲讀門檻)3. 最後給出推薦:不同需求的人適合讀哪本4. 每個觀點標註來源筆記對比文章的大綱結構和普通文章不同:它需要先分別介紹每本書,再橫向對比。呢個結構需要你在prompt中明確指定,否則AI可能生成一篇普通的綜述而不是對比文章。精修時,重點核實每本書的核心觀點是否準確。 對比文章的引用密度比普通文章高——每個對比維度下要引用多本書的觀點,任何一處引用錯誤都會影響整篇文章的可信度。六、自動化寫作——週報、月總結、讀書綜述有些寫作是重複性的:每週的週報、每月的總結、讀完一系列書後的綜述。呢啲內容有固定格式,素材來源也是確定的(當週的筆記、當月的筆記、同一主題的讀書筆記),很適合用知識庫自動化。週報自動化每週五下午,讓Claude Code幫你生成周報:請生成本週的週報。步驟:1. 讀取 daily/ 文件夾下本週一到週五的每日筆記(文件名格式為 YYYY-MM-DD.md)2. 用命令查找本週修改過的筆記:find notes projects -name "*.md" -mtime -73. 讀取步驟2找到的筆記4. 從以上筆記中提取:本週完成的事項、遇到的問題、下週計劃5. 按以下格式生成周報: - 本週完成:(列出事項,標註來源筆記) - 遇到的問題:(列出問題和解決情況) - 下週計劃:(從筆記中提取待辦事項)6. 保存到 projects/週報/2026-W21.mdClaude Code會讀取你的每日筆記和項目筆記,提取關鍵信息,生成結構化的週報。生成的週報大概長咁樣:# 週報 2026-W21## 本週完成- 完成Obsidian知識庫搭建,配置了CLAUDE.md和五層組織體系 (來源:projects/知識庫搭建.md)- 讀完《卡片筆記寫作法》,整理了3條核心觀點 (來源:notes/reading/卡片筆記寫作法.md)- 修復了項目中的登錄問題,原因是token過期未刷新 (來源:projects/用戶系統.md)## 遇到的問題- 知識庫批量整理時標籤不一致,部分筆記標籤用了中文,部分用了英文 已通過更新CLAUDE.md規範解決- Dataview查詢無法按正文內容過濾,部分相關筆記被遺漏 已記錄,計劃下週補充標籤## 下週計劃- 測試知識庫驅動創作流程,寫一篇實踐文章- 繼續閲讀《原子習慣》,整理讀書筆記注意週報中的【待補充】部分需要你手動補充。AI只能從已有筆記中提取信息,你腦子裏想但沒寫下來的事情,它不知道。注意:每日筆記是週報的主要素材來源。 如果你平時沒有寫每日筆記的習慣,週報的素材會不夠。建議每天花2分鐘在 daily/ 下記錄當天做了什麼,咁樣週五生成周報時就有足夠的內容。月度總結自動化類似週報,但時間範圍更大:請生成本月的月度總結。步驟:1. 讀取 daily/ 文件夾下本月所有每日筆記2. 用命令查找本月新增的筆記:find notes -name "*.md" -mtime -303. 讀取步驟2找到的筆記4. 統計:本月新增筆記數量、各主題筆記分佈5. 提取:本月學到的最重要的3個知識點、本月完成的項目進展、下月重點6. 保存到 projects/月度總結/2026-05.md月度總結的價值不只是回顧——它讓你看到自己一個月到底學了什麼、做了什麼,而不是憑感覺回憶。讀書綜述自動化讀完一個主題的多本書後,讓Claude Code生成綜述:請閲讀 notes/reading/ 下和"認知科學"相關的讀書筆記(如果超過10篇,只選擇關聯度最高的10篇),生成一篇讀書綜述。要求:1. 概述每本書的核心觀點2. 找出呢啲書之間的共識和分歧3. 提煉出3-5個該主題的核心問題4. 給出進一步閲讀建議5. 每個觀點標註來源筆記6. 保存到 notes/reading/認知科學讀書綜述.md自動化寫作的邊界: 週報和月總結因為格式固定、信息來源確定,AI生成的質量通常較高,稍作修改就能用。但讀書綜述涉及"找共識、找分歧、提問題"這類分析工作,AI生成的結果可能流於表面——它能發現明顯的共同點和不同點,但容易遺漏隱含的深層聯繫。建議把AI生成的綜述當作起點,你在此基礎上加入自己的深度思考。你做到了什麼讀完這篇文章,你給知識庫加上了"輸出"能力:更新了CLAUDE.md的寫作規則,創建了寫作素材庫和模板,學會了用MOC、Dataview、Claude Code三種方式找素材,跑通了從找素材到精修的完整寫作流程,還實現了週報和月總結的自動化生成。上一篇搭好了知識庫的骨架,這篇讓知識庫能產出內容。但還有一個問題:你的知識庫是封閉的——所有信息都要你手動輸入。下一篇,我們用MCP讓知識庫聯網,自動抓取網頁、連接外部工具,讓信息自動流入你的知識庫。掃碼關注「AI智聞說」,每天3分鐘掌握AI新知識
你儲咗200篇筆記,寫文章嗰陣都係開個空白文檔由零開始。呢篇文章教你將知識庫變成寫作彈藥庫,由揾素材到出初稿,幫你一條龍搞掂。
寫喺前面
上一篇我哋砌好咗知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你啲筆記而家有摘要、有標籤、有連結,整整齊齊。
但問題嚟喇:筆記整理得幾好都好,寫文章嗰陣你仍然係由空白文檔開始。
打開編輯器,望住個光標閃咗5分鐘,然後 switch 去 Obsidian 揾筆記,複製一段, switch 返嚟貼上,再 switch 過去揾另一篇……寫一篇文章要喺 Obsidian 同編輯器之間不停切換。最後寫出嚟嘅嘢,同你知識庫裏面嘅筆記幾乎冇關係——你儲埋嗰啲筆記、摘要、連結,全部變咗裝飾。
呢個唔係你嘅問題。大多數人嘅知識庫同寫作係脱節嘅:收集係一套流程,寫作係另一套流程,兩者之間冇橋樑。
呢篇文章要做嘅就係起呢座橋。我會教你用 Obsidian + Claude Code 將知識庫變成寫作彈藥庫:
前置閲讀: 本文係《用Claude Code俾Obsidian裝上AI大腦》嘅續篇。如果你仲未砌好知識庫(倉庫結構、CLAUDE.md、Dataview),建議睇咗上一篇先。
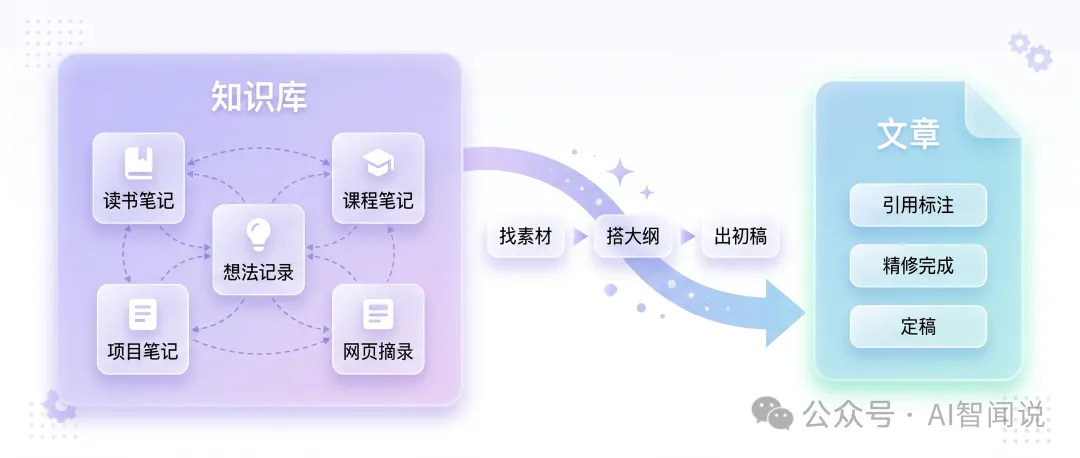
一、問題喺邊——儲咗唔用,等於冇儲
先講一個常見嘅場景。
你要寫一篇關於「刻意練習」嘅文章。你嘅知識庫裏面明明有8篇相關筆記——3篇讀書筆記、2篇課程筆記、3篇自己嘅想法記錄。但你寫文章嗰陣點做?打開 Obsidian,搜尋「刻意練習」,見到8個結果,逐個撳開嚟睇,覺得呢篇有用複製一段,嗰篇有用複製一段,最後 switch 去編輯器拼成一篇文。
呢個過程有三個問題:
根本原因係你將知識庫當倉庫用——儲咗就唔理,而唔係為咗寫文章去叫出嚟用。 知識庫驅動創作嘅核心思路係:唔俾 AI 由零寫文章,而係叫 AI 從你啲筆記中組織內容。
呢度有一個關鍵區別:
第二種方式先係知識庫驅動創作嘅正確姿勢。
注意: 如果你啱啱砌好知識庫,筆記仲唔多(例如唔夠10篇),知識庫驅動寫作嘅效果有限——素材唔夠,大綱同初稿都會好單薄。建議將精力先放喺累積筆記上面,等某個主題累積咗5篇以上筆記之後再試。
二、寫作前嘅準備——令知識庫可以「回答」寫作需求
喺開始寫作之前,要做兩件事:更新 CLAUDE.md 加入寫作規則,創建寫作專用嘅 Dataview 查詢。
更新 CLAUDE.md——加入寫作規則
上一篇嘅 CLAUDE.md 只係定義咗整理規則。而家要加入寫作相關嘅規則,令 Claude Code 知道你希望佢點樣幫你寫。
喺倉庫根目錄嘅 CLAUDE.md 最尾追加以下內容:
## 寫作規則
### 角色
當我說"寫文章"、"生成大綱"、"生成初稿"時,你切換到寫作助手角色。
### 大綱生成規則
1. 大綱基於我指定的筆記內容生成,不要憑空編造
2. 大綱結構:標題 + 每個小節的要點(2-3條)+ 每個小節引用哪些筆記
3. 大綱中標註信息來源,用 [[筆記名]] 標註每個觀點來自哪篇筆記
4. 大綱生成後先給我審閲,我確認後再生成初稿
### 初稿生成規則
1. 初稿基於大綱和我指定的筆記內容生成
2. 不要添加筆記中沒有的內容,如果需要補充信息,先標註【待補充】讓我決定
3. 正文中引用具體觀點時,用括號標註來源筆記
4. 保持簡潔直接的寫作風格,不用華麗辭藻
5. 初稿生成後,我來做精修,你只需要搭好框架和填充素材
### 素材查找規則
1. 當我說"找關於XX的素材"時,搜索整個倉庫中和XX相關的筆記
2. 搜索範圍不只是標題和標籤,也包括正文內容和摘要
3. 返回結果時,列出每篇筆記的標題、摘要、和XX的關聯度(高/中/低)
4. 如果結果超過10篇,只返回關聯度最高的10篇
呢段配置嘅核心思想係:AI 係組織者,唔係創作者。 佢負責從你嘅筆記中提取、組織、排列資訊,但唔負責作嘢。呢個邊界好重要——越過咗呢個邊界,AI 寫出嚟嘅嘢就同你無關喇。
注意:CLAUDE.md 嘅總長度唔好超過200行。 如果你之前已經寫咗好多整理規則,追加寫作規則嗰陣注意精簡。加上本篇嘅寫作規則之後,總長度大約90行,仲有空間。太長嘅 CLAUDE.md 會令 Claude Code 對後面嘅規則反應變弱。所以追加前先 check 嚇現有長度,必要時精簡已有規則。
創建寫作素材查詢頁
喺 Obsidian 根目錄創建一篇筆記,命名為 寫作素材庫.md:
---
title: "寫作素材庫"
date: 2026-05-21
tags: [寫作, 素材庫]
summary: "按主題聚合筆記,為寫作提供素材"
---
## 最近更新的筆記
```dataview
TABLE date AS "日期", tags AS "標籤", summary AS "摘要"
FROM "notes"
SORT date DESC
LIMIT 20
```
## 讀書筆記
```dataview
TABLE date AS "日期", category AS "分類", rating AS "評分", summary AS "摘要"
FROM "notes/reading"
SORT date DESC
```
## 項目筆記
```dataview
TABLE date AS "日期", status AS "狀態", summary AS "摘要"
FROM "projects"
SORT date DESC
```
## 未整理的素材
```dataview
LIST
FROM "inbox"
```
呢篇筆記就係一個寫作素材嘅「總入口」。每次要寫文章嗰陣,先打開呢篇筆記,用 Dataview 查詢快速睇嚇最近有啲乜嘢素材用得。
Dataview 查詢語句嘅含義:TABLE 表示以表格形式展示,FROM 指定查詢嘅文件夾,SORT date DESC 表示按日期倒序排列,LIMIT 20 表示最多顯示20條。如果你想按條件過濾,可以喺 FROM 和 SORT 之間添加 WHERE 子句(例如 WHERE contains(tags, "知識管理"))嚟篩選特定筆記。
前提: 呢啲查詢依賴 frontmatter 中嘅 tags 字段係 YAML 數組格式(例如 tags: [知識管理, 筆記方法])。如果你用嘅係上一篇文章嘅模板,格式係正確嘅。但如果你啲筆記用嘅係 #標籤 行內語法而唔係 frontmatter 標籤,就需要改用 contains(file.tags, "知識管理") 嚟查詢。
創建寫作模板
在 templates/ 文件夾入面創建 寫作模板.md:
---
title: "<% tp.file.cursor(1) %>"
date: <% tp.date.now("YYYY-MM-DD") %>
tags: [寫作]
status: "草稿"
sources: []
summary: ""
---
## 大綱
## 初稿
## 精修稿
## 引用筆記
-
其中 <% tp.file.cursor(1) %> 係 Templater 插件嘅光標定位語法——創建筆記之後,光標會自動跳到 title 字段等你輸入標題,唔需要手動定位。
sources 字段用嚟記錄呢篇文章引用咗邊啲筆記,方便之後回溯。status 字段追蹤寫作進度:草稿 → 精修 → 定稿。
創建新文章嗰陣,喺 Obsidian 中按 Ctrl/Cmd + P 打開命令面板,搜尋「Templater: Create new note from template」,揀「寫作模板」,輸入文章標題就可以創建一篇帶有 frontmatter 同章節結構嘅草稿筆記。
注意: 呢個模板只係喺 Obsidian 中手動創建寫作筆記嗰陣生效。當你經 Claude Code 生成初稿嗰陣,Claude Code 會直接寫入 frontmatter 內容(例如 title: "如何建立知識管理體系"),唔會觸發 Templater 模板。模板嘅作用係:你喺 Obsidian 中手動新建寫作筆記嗰陣,自動填好格式,你只需要填內容。
三、揾素材——從知識庫挖出你要嘅內容
準備功夫做好咗,而家進入實戰。假設你要寫一篇關於「點樣建立知識管理體系」嘅文章。
方法一:用 Dataview 按主題聚合
打開 寫作素材庫.md,喺 Dataview 查詢區域添加一個主題查詢:
TABLE date AS "日期", tags AS "標籤", summary AS "摘要"
FROM "notes"
WHERE contains(tags, "知識管理") OR contains(tags, "筆記方法") OR contains(tags, "obsidian")
SORT date DESC
呢個會列出所有標籤中包含「知識管理」、「筆記方法」或「obsidian」嘅筆記。如果你喺 frontmatter 打咗準確嘅標籤,呢個查詢好有效。
但 Dataview 有一個侷限:佢只能匹配標籤同 frontmatter 字段,唔能夠理解筆記內容。 如果一篇筆記嘅標籤係「閲讀」但正文大量提到知識管理,Dataview 揾唔到佢。
方法二:問 Claude Code——語義搜索
喺 Obsidian 右側欄㩒 Claudian 圖標打開對話窗口,輸入:
我要寫一篇關於"如何建立知識管理體系"的文章。請搜索整個倉庫,找出所有和知識管理相關的筆記,包括:1)標籤或標題中包含"知識管理"、"筆記方法"、"obsidian"的筆記;2)正文中提到知識管理、筆記整理、信息組織等概念的筆記。對每篇筆記,給出標題、摘要、和主題的關聯度(高/中/低),按關聯度排序。
Claude Code 會做兩件 Dataview 做唔到嘅嘢:
Claude Code 嘅「語義搜索」同真正嘅語義搜索引擎(例如 Obsidian 嘅 Smart Connections 插件,基於向量嵌入)唔同。佢嘅工作方式係讀取倉庫中嘅檔案內容,用語言模型理解語義嚟判斷相關性。呢個意味住佢唔需要預先建立索引,即搜即用,但亦受限於上下文窗口——如果你嘅倉庫筆記數量多而且單篇篇幅長(例如超過200篇、每篇超過1000字),總內容可能接近單次對話嘅上下文上限,導致分析唔完整。
Claude Code 返回嘅結果大概係咁:
找到8篇和"知識管理"相關的筆記:
【高關聯】
1. 《卡片筆記寫作法》讀書筆記 — 系統介紹卡片筆記法,核心理念是"寫下來而不是記下來"
2. Obsidian知識庫搭建實錄 — 用Claude Code搭建知識庫的完整流程
3. 雙向連結的真正用法 — 詳解雙向連結如何建立知識網絡
【中關聯】
4. 《原子習慣》讀書筆記 — 習慣養成方法,可引用"讓好習慣顯而易見"的部分
5. 信息過載的應對方法 — 提到了知識管理的幾個常見誤區
6. PARA方法實踐記錄 — 另一種知識組織方法,可作為對比
【低關聯】
7. 每週覆盤模板 — 覆盤流程中涉及知識整理
8. 工具切換記錄 — 記錄了從Notion切換到Obsidian的原因
呢個輸出嘅質量取決於你知識庫嘅整理程度。 如果你啲筆記都按照上一篇嘅規範添加咗 frontmatter(title、tags、summary),Claude Code 可以快速提取結構化資訊,輸出會好整齊。如果筆記冇統一格式,Claude Code 需要從正文中提取資訊,輸出可能唔夠精確。呢個亦係上一篇強調「每篇筆記必須有 frontmatter」嘅原因——整理得越好,寫作時搜尋同引用越準確。
注意: 筆記越多,Claude Code 讀取同分析嘅時間越長。筆記量大嗰陣(超過50篇),建議先用 Dataview 或 MOC 縮窄範圍,再叫 Claude Code 喺篩選結果入面做深度分析。另外,搜尋大量檔案會消耗較多 Token,留意 API 費用。
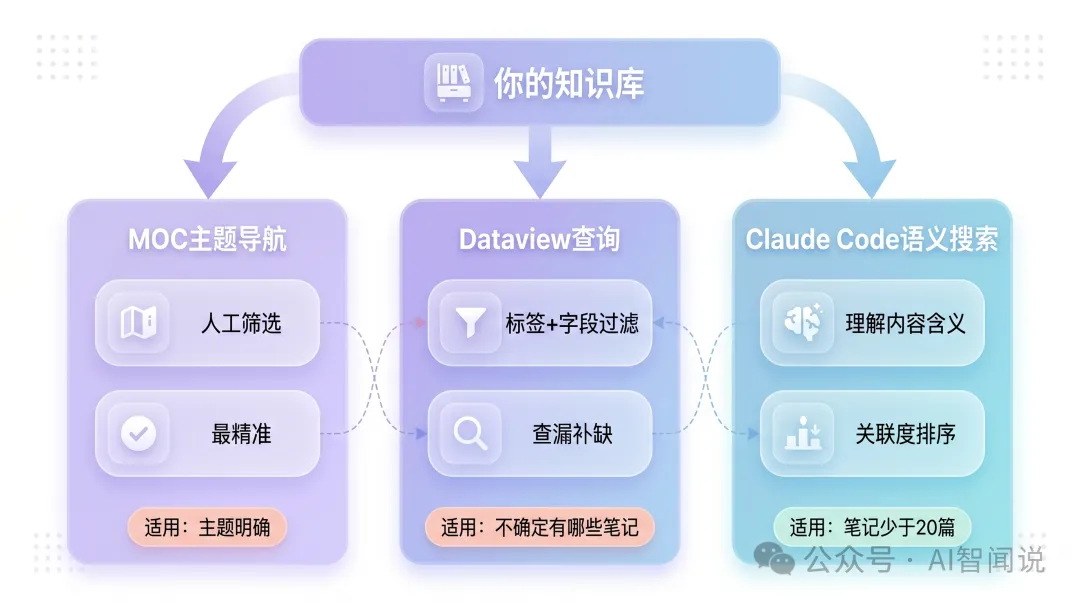
方法三:用 MOC 當寫作索引
如果你按上一篇嘅方法建立咗 MOC,寫作時 MOC 就係現成嘅素材目錄。打開 notes/MOC - 知識管理.md,裏面已經列出曬所有知識管理相關嘅筆記同簡短描述。
MOC 嘅好處係人手篩選過嘅——你建立 MOC 時已經判斷過邊啲筆記值得索引。Dataview 同 Claude Code 係「撒大網」,MOC 係「精篩選」。
三種方法各有適用場景,唔需要每次都行曬三步:
四、砌骨架——叫 Claude Code 根據素材生成大綱
揾到素材之後,下一步係砌大綱。呢一步嘅關鍵原則係:大綱必須根據你嘅筆記內容,唔係 AI 憑空作出嚟嘅。
點樣俾 Claude Code 落指令
喺 Claudian 入面輸入:
我要寫一篇關於"如何建立知識管理體系"的文章。以下是我的相關筆記:
1. 《卡片筆記寫作法》讀書筆記 — notes/reading/卡片筆記寫作法.md
2. Obsidian知識庫搭建實錄 — notes/obsidian知識庫搭建.md
3. 雙向連結的真正用法 — notes/雙向連結的真正用法.md
4. 《原子習慣》讀書筆記 — notes/reading/原子習慣.md
5. 信息過載的應對方法 — notes/信息過載的應對.md
請閲讀這些筆記,然後生成一個文章大綱。要求:
1. 大綱基於這些筆記的實際內容,不要添加筆記中沒有的觀點
2. 每個小節標註信息來源,用 [[筆記名]] 格式
3. 先給我大綱,我確認後再寫初稿
喺 Claudian 入面,你可以直接喺對話中引用檔案路徑,Claude Code 會自動讀取對應檔案嘅內容。你亦可以揀中筆記中嘅文字之後傳送指令,Claude Code 會將揀中嘅文字作為上下文。兩種方式都可以令 Claude Code 攞到筆記內容,分別在於:引用檔案路徑會讀取完整筆記,揀中文字只係處理你揀中嘅部分。
注意: 如果你啲筆記好長或者數量好多,Claude Code 可能冇辦法一次過讀取全部內容。建議單次指定唔好超過5篇筆記。如果素材超過5篇,先叫 Claude Code 為每篇筆記生成摘要,再根據摘要生成大綱。
Claude Code 會先讀取呢啲筆記,理解內容,然後生成大綱:
# 如何建立知識管理體系
## 引言:為什麼你的筆記總是找不到
- 大多數人的筆記工具只管"存"不管"用" [[信息過載的應對方法]]
- 知識管理的核心不是分類,是連接 [[卡片筆記寫作法]]
## 一、從文件夾到知識網絡
- 文件夾分類的問題:一篇筆記只能在一個位置 [[Obsidian知識庫搭建實錄]]
- 雙向連結:讓筆記之間產生關聯 [[雙向連結的真正用法]]
- 標籤和連結的配合:標籤管分類,連結管關聯 [[Obsidian知識庫搭建實錄]]
## 二、讓整理變自動
- 手動整理不可持續,需要自動化 [[Obsidian知識庫搭建實錄]]
- 用AI輔助整理:打標籤、建連結、寫摘要 [[Obsidian知識庫搭建實錄]]
- 每週15分鐘整理流程 [[Obsidian知識庫搭建實錄]]
## 三、從收集到輸出
- 知識管理的終極目標是輸出,不是存儲 [[卡片筆記寫作法]]
- 讓好習慣顯而易見:降低整理和寫作的門檻 [[原子習慣]]
- 知識庫驅動創作:用已有筆記作為寫作素材 [[卡片筆記寫作法]]
## 總結
- 知識管理不是整理,是建立連接和驅動輸出
- 工具和方法缺一不可
審閲同調整大綱
大綱生成之後,一定要審閲先好繼續。 AI 生成嘅大綱可能有呢啲問題:
審閲之後,喺 Claudian 入面繼續對話調整:
大綱整體不錯,但需要調整:
1."引言"部分太短,加一段關於"筆記越多越難找"的具體場景
2."從收集到輸出"這一節,加上從信息過載筆記中引用的"三個常見誤區"
3. 總結部分太籠統,改為具體的行動建議
Claude Code 會根據你嘅反饋調整大綱。你可能需要來回調整2-3輪,呢個係正常嘅——大綱係文章嘅骨架,骨架歪咗,初稿點改都唔啱。審閲大綱花嘅時間唔多,但可以大幅減少之後改初稿嘅時間。
五、從大綱到初稿——知識庫驅動嘅寫作流程
大綱審閲調整完畢,確認結構冇問題之後,就可以進入下一步喇。
叫 Claude Code 根據大綱同素材筆記生成初稿:
大綱已確認,請基於大綱和之前列出的5篇筆記生成初稿。要求:
1. 每個觀點都要有筆記中的原文或轉述作為支撐
2. 不要添加筆記中沒有的內容,如果需要補充,標註【待補充】
3. 保持簡潔直接的寫作風格,不用華麗辭藻
4. 正文中引用觀點時,用括號標註來源筆記
5. 保存到 projects/如何建立知識管理體系.md
Claude Code 會生成一篇完整嘅初稿,保存到 projects/ 文件夾下面。呢篇初稿嘅特點係:每個觀點都來自你嘅筆記,唔係 AI 憑空作出嚟嘅。 你可以驗證——如果某個觀點你唔肯定係咪自己寫嘅,睇括號入面嘅來源筆記就知。
初稿大概係咁:
## 引言:為什麼你的筆記總是找不到
大多數人使用筆記工具的方式是"存了就走",從不回顧。結果筆記越積越多,
找到需要的那篇越來越難。(《信息過載的應對方法》)知識管理的核心問題
不是"怎麼分類",而是"怎麼讓筆記之間產生連接"。(《卡片筆記寫作法》)
## 一、從文件夾到知識網絡
傳統文件夾分類有一個根本問題:一篇筆記只能存在於一個位置。比如"用
Python做數據分析"這篇筆記,放到"編程"還是"數據分析"?這種糾結本身
就說明文件夾分類不夠用。(《Obsidian知識庫搭建實錄》)
雙向連結解決了這個問題——筆記不需要"放在"某個位置,而是通過連結建立
關聯。(《雙向連結的真正用法》)
【待補充:這裏可以加入你從文件夾切換到雙向連結的具體經歷】
## 二、讓整理變自動
手動給每篇筆記打標籤、建連結,一兩週還能堅持,時間一長必然鬆懈。
(《Obsidian知識庫搭建實錄》)解決方法是用AI輔助整理:自動打標籤、
自動建連結、自動生成摘要,把每週的整理時間壓縮到15分鐘以內。
(《Obsidian知識庫搭建實錄》)
## 三、從收集到輸出
知識管理的終極目標不是把筆記存好,而是在需要時能調用出來產生新內容。
(《卡片筆記寫作法》)"讓好習慣顯而易見"——降低整理和寫作的門檻,
讓輸出變得像記筆記一樣簡單。(《原子習慣》)
## 總結
- 從文件夾分類切換到雙向連結,建立知識網絡
- 用AI自動化整理流程,降低維護成本
- 以輸出為導向使用知識庫,而不是隻管收集
留意初稿嘅特點:每個觀點都有筆記來源標註,需要補充嘅地方用【待補充】標記。呢篇初稿唔可以直接用,但骨架已經有咗——你嘅素材被組織成有邏輯嘅文章,你只需要精修。
精修——最重要嘅環節
初稿係半成品,唔係成品。最重要嘅一步係核實引用。 AI 可能將觀點歸到錯嘅筆記上面,或者「作」出嚟啲睇落合理但筆記中唔存在嘅論據。呢個唔係 AI 故意犯錯,而係佢理解內容時可能出現偏差。每一條標註咗來源嘅觀點,都要打開原筆記確認。
具體精修步驟:
精修完成之後,更新筆記嘅 status 字段由「草稿」改為「精修」,喺 sources 字段中列出引用嘅筆記:
---
title:"如何建立知識管理體系"
date:2026-05-21
tags: [寫作, 知識管理]
status:"精修"
sources: [卡片筆記寫作法, Obsidian知識庫搭建實錄, 雙向連結的真正用法, 原子習慣, 信息過載的應對方法]
summary:"從文件夾分類到知識網絡,從手動整理到AI輔助,從收集存儲到驅動輸出——知識管理體系的完整搭建方法"
---
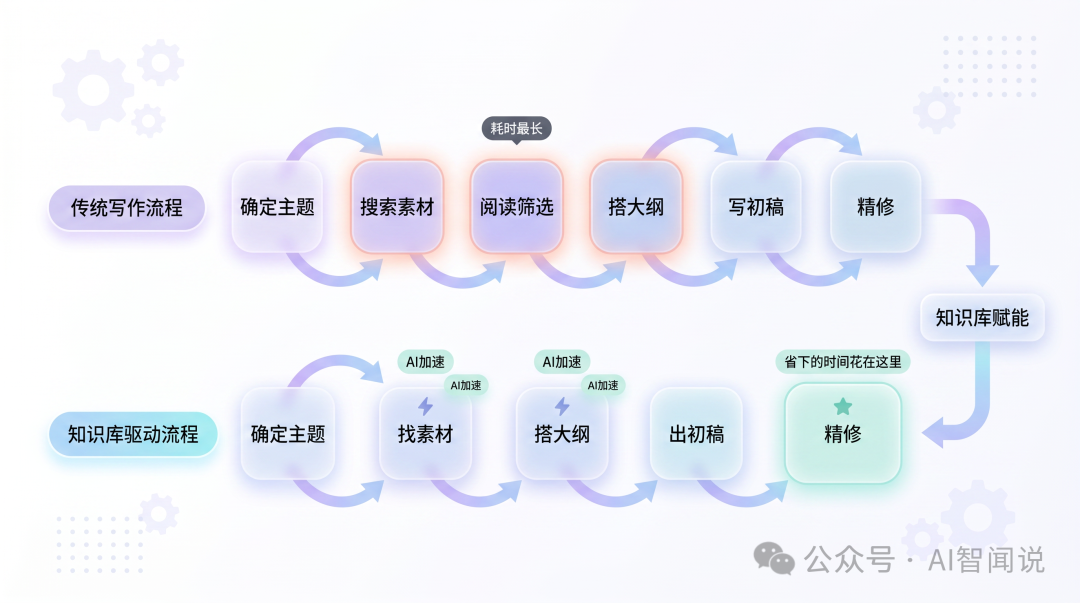
完整嘅寫作流程
將上面嘅步驟串埋一齊,知識庫驅動嘅寫作流程係咁嘅:
同傳統寫作流程嘅分別在於:傳統流程中揾素材同砌大綱係最花時間嘅部分,知識庫驅動之後呢兩步快咗好多——素材已經喺知識庫裏面,你唔需要重新搜尋同閲讀;大綱由 AI 根據你嘅筆記生成,你只需要審閲同調整。慳返嘅時間可以花喺精修上面——呢個先係決定文章質量嘅關鍵環節。
實戰案例:用5篇讀書筆記寫一篇對比文章
假設你過去半年讀咗5本關於習慣養成嘅書,每本都做咗讀書筆記存在 notes/reading/ 裏面。而家你想寫一篇「習慣養成嘅5本書對比」文章。
用上面介紹嘅流程,核心步驟同主流程一樣,但對比文章有啲特別嘅地方:
砌大綱嗰陣,指定對比維度:
我要寫一篇"習慣養成的5本書對比"文章。請閲讀以下5篇讀書筆記:
- notes/reading/原子習慣.md
- notes/reading/掌控習慣.md
- notes/reading/微習慣.md
- notes/reading/習慣的力量.md
- notes/reading/刻意練習.md
生成一個對比文章的大綱,要求:
1. 先概述5本書各自的核心觀點
2. 然後從3-4個維度對比(比如:習慣形成原理、實操方法、適用場景、閲讀門檻)
3. 最後給出推薦:不同需求的人適合讀哪本
4. 每個觀點標註來源筆記
對比文章嘅大綱結構同普通文章唔同:佢需要先分別介紹每本書,再橫向對比。呢個結構需要你喺 prompt 入面明確指定,否則 AI 可能會生成一篇普通嘅綜述而唔係對比文章。
精修嗰陣,重點核實每本書嘅核心觀點係咪準確。 對比文章嘅引用密度比普通文章高——每個對比維度下面要引用多本書嘅觀點,任何一處引用錯誤都會影響整篇文章嘅可信度。
六、自動化寫作——週報、月總結、讀書綜述
有啲寫作係重複性嘅:每週嘅週報、每月嘅總結、讀完一系列書之後嘅綜述。呢啲內容有固定格式,素材來源都係確定嘅(當週嘅筆記、當月嘅筆記、同一主題嘅讀書筆記),好適合用知識庫自動化。
週報自動化
每週五下晝,叫 Claude Code 幫你生成週報:
請生成本週的週報。步驟:
1. 讀取 daily/ 文件夾下本週一到週五的每日筆記(文件名格式為 YYYY-MM-DD.md)
2. 用命令查找本週修改過的筆記:find notes projects -name "*.md" -mtime -7
3. 讀取步驟2找到的筆記
4. 從以上筆記中提取:本週完成的事項、遇到的問題、下週計劃
5. 按以下格式生成周報:
- 本週完成:(列出事項,標註來源筆記)
- 遇到的問題:(列出問題和解決情況)
- 下週計劃:(從筆記中提取待辦事項)
6. 保存到 projects/週報/2026-W21.md
Claude Code 會讀取你嘅每日筆記同項目筆記,提取關鍵資訊,生成結構化嘅週報。生成嘅週報大概係咁:
# 週報 2026-W21
## 本週完成
- 完成Obsidian知識庫搭建,配置了CLAUDE.md和五層組織體系
(來源:projects/知識庫搭建.md)
- 讀完《卡片筆記寫作法》,整理了3條核心觀點
(來源:notes/reading/卡片筆記寫作法.md)
- 修復了項目中的登錄問題,原因是token過期未刷新
(來源:projects/用戶系統.md)
## 遇到的問題
- 知識庫批量整理時標籤不一致,部分筆記標籤用了中文,部分用了英文
已通過更新CLAUDE.md規範解決
- Dataview查詢無法按正文內容過濾,部分相關筆記被遺漏
已記錄,計劃下週補充標籤
## 下週計劃
- 測試知識庫驅動創作流程,寫一篇實踐文章
- 繼續閲讀《原子習慣》,整理讀書筆記
留意週報中嘅【待補充】部分需要你手動補充。AI 只能從已有筆記中提取資訊,你腦諗到但冇寫低嘅嘢,佢唔知道。
留意:每日筆記係週報嘅主要素材來源。 如果你平時冇寫每日筆記嘅習慣,週報嘅素材會唔夠。建議每日花2分鐘喺 daily/ 下面記錄當日做咗啲乜,咁樣週五生成週報嗰陣就有足夠嘅內容。
月度總結自動化
類似週報,但時間範圍更大:
請生成本月的月度總結。步驟:
1. 讀取 daily/ 文件夾下本月所有每日筆記
2. 用命令查找本月新增的筆記:find notes -name "*.md" -mtime -30
3. 讀取步驟2找到的筆記
4. 統計:本月新增筆記數量、各主題筆記分佈
5. 提取:本月學到的最重要的3個知識點、本月完成的項目進展、下月重點
6. 保存到 projects/月度總結/2026-05.md
月度總結嘅價值唔單止係回顧——佢令你見到自己一個月到底學咗啲乜、做咗啲乜,而唔係靠感覺回憶。
讀書綜述自動化
讀完一個主題嘅多本書之後,叫 Claude Code 生成綜述:
請閲讀 notes/reading/ 下和"認知科學"相關的讀書筆記(如果超過10篇,只選擇關聯度最高的10篇),生成一篇讀書綜述。要求:
1. 概述每本書的核心觀點
2. 找出這些書之間的共識和分歧
3. 提煉出3-5個該主題的核心問題
4. 給出進一步閲讀建議
5. 每個觀點標註來源筆記
6. 保存到 notes/reading/認知科學讀書綜述.md
自動化寫作嘅邊界: 週報同月總結因為格式固定、資訊來源確定,AI 生成嘅質量通常較高,稍為修改就可以用。但讀書綜述涉及「揾共識、揾分歧、提出問題」呢類分析工作,AI 生成嘅結果可能流於表面——佢可以發現明顯嘅共同點同不同點,但容易遺漏隱含嘅深層聯繫。建議將 AI 生成嘅綜述當作起點,你喺呢個基礎上加入自己嘅深度思考。
你做咗啲乜
讀完呢篇文章,你幫知識庫加咗「輸出」能力:更新咗 CLAUDE.md 嘅寫作規則,創建咗寫作素材庫同模板,學識咗用 MOC、Dataview、Claude Code 三種方式揾素材,行順咗由揾素材到精修嘅完整寫作流程,仲實現咗週報同月總結嘅自動化生成。
上一篇砌好咗知識庫嘅骨架,呢篇令知識庫可以產出內容。但仲有一個問題:你嘅知識庫係封閉嘅——所有資訊都要你手動輸入。下一篇,我哋用 MCP 令知識庫連網,自動抓取網頁、連接外部工具,令資訊自動流入你嘅知識庫。
掃碼關注「AI智聞說」,每日3分鐘掌握AI新知識

你攢了200篇筆記,寫文章時還是打開空白文檔從零開始。這篇文章教你把知識庫變成寫作彈藥庫,從找素材到出初稿,幫你一條鏈路全部打通
寫在前面
上一篇我們搭好了知識庫:五層組織體系、Claude Code自動整理、MOC主題導航。你的筆記現在有摘要、有標籤、有連結,整整齊齊。
但問題來了:筆記整理得再好,寫文章時你還是從空白文檔開始。
打開編輯器,盯着光標閃了5分鐘,然後切到Obsidian翻筆記,複製一段,切回來粘貼,再切過去翻另一篇……寫一篇文章要在Obsidian和編輯器之間反覆切換。最後寫出來的東西,和你知識庫裏的筆記幾乎沒關係——你攢的那些筆記、摘要、連結,全成了擺設。
這不是你的問題。大多數人的知識庫和寫作是脱節的:收集是一套流程,寫作是另一套流程,兩者之間沒有橋樑。
這篇文章要做的事就是搭這座橋。我會教你用Obsidian + Claude Code把知識庫變成寫作彈藥庫:
前置閲讀: 本文是《用Claude Code給Obsidian裝上AI大腦》的續篇。如果你還沒有搭好知識庫(倉庫結構、CLAUDE.md、Dataview),建議先看上一篇。
一、問題出在哪——存了不用,等於沒存
先說一個常見的場景。
你要寫一篇關於"刻意練習"的文章。你的知識庫裏明明有8篇相關筆記——3篇讀書筆記、2篇課程筆記、3篇自己的想法記錄。但你寫文章時怎麼做?打開Obsidian,搜索"刻意練習",看到8個結果,逐個點開看,覺得這篇有用複製一段,那篇有用複製一段,最後切到編輯器拼成一篇文章。
這個過程有三個問題:
根本原因是你把知識庫當倉庫用——存了就不管,而不是為了寫文章去調用。 知識庫驅動創作的核心思路是:不讓AI從零寫文章,而是讓AI從你的筆記中組織內容。
這裏有一個關鍵區別:
第二種方式才是知識庫驅動創作的正確姿勢。
注意: 如果你剛搭好知識庫,筆記還不多(比如不到10篇),知識庫驅動寫作的效果有限——素材不夠,大綱和初稿都會很單薄。建議先把精力放在積累筆記上,等某個主題積累了5篇以上筆記後再嘗試。
二、寫作前的準備——讓知識庫能"回答"寫作需求
在開始寫作之前,需要做兩件事:更新CLAUDE.md加入寫作規則,創建寫作專用的Dataview查詢。
更新CLAUDE.md——加入寫作規則
上一篇的CLAUDE.md只定義了整理規則。現在要加入寫作相關的規則,讓Claude Code知道你希望它怎麼幫你寫。
在倉庫根目錄的CLAUDE.md末尾追加以下內容:
## 寫作規則
### 角色
當我說"寫文章"、"生成大綱"、"生成初稿"時,你切換到寫作助手角色。
### 大綱生成規則
1. 大綱基於我指定的筆記內容生成,不要憑空編造
2. 大綱結構:標題 + 每個小節的要點(2-3條)+ 每個小節引用哪些筆記
3. 大綱中標註信息來源,用 [[筆記名]] 標註每個觀點來自哪篇筆記
4. 大綱生成後先給我審閲,我確認後再生成初稿
### 初稿生成規則
1. 初稿基於大綱和我指定的筆記內容生成
2. 不要添加筆記中沒有的內容,如果需要補充信息,先標註【待補充】讓我決定
3. 正文中引用具體觀點時,用括號標註來源筆記
4. 保持簡潔直接的寫作風格,不用華麗辭藻
5. 初稿生成後,我來做精修,你只需要搭好框架和填充素材
### 素材查找規則
1. 當我說"找關於XX的素材"時,搜索整個倉庫中和XX相關的筆記
2. 搜索範圍不只是標題和標籤,也包括正文內容和摘要
3. 返回結果時,列出每篇筆記的標題、摘要、和XX的關聯度(高/中/低)
4. 如果結果超過10篇,只返回關聯度最高的10篇
這段配置的核心思想是:AI是組織者,不是創作者。 它負責從你的筆記中提取、組織、排列信息,但不負責編造內容。這個邊界很重要——越過了這個邊界,AI寫出來的東西就和你無關了。
注意:CLAUDE.md的總長度不要超過200行。 如果你之前已經寫了很多整理規則,追加寫作規則時注意精簡。加上本篇的寫作規則後,總長度大約90行,還有餘量。太長的CLAUDE.md會導致Claude Code對後面的規則響應變弱。所以追加前先檢查一下現有長度,必要時精簡已有規則。
創建寫作素材查詢頁
在Obsidian根目錄創建一篇筆記,命名為 寫作素材庫.md:
---
title: "寫作素材庫"
date: 2026-05-21
tags: [寫作, 素材庫]
summary: "按主題聚合筆記,為寫作提供素材"
---
## 最近更新的筆記
```dataview
TABLE date AS "日期", tags AS "標籤", summary AS "摘要"
FROM "notes"
SORT date DESC
LIMIT 20
```
## 讀書筆記
```dataview
TABLE date AS "日期", category AS "分類", rating AS "評分", summary AS "摘要"
FROM "notes/reading"
SORT date DESC
```
## 項目筆記
```dataview
TABLE date AS "日期", status AS "狀態", summary AS "摘要"
FROM "projects"
SORT date DESC
```
## 未整理的素材
```dataview
LIST
FROM "inbox"
```
這篇筆記就是一個寫作素材的"總入口"。每次要寫文章時,先打開這篇筆記,用Dataview查詢快速瀏覽最近有什麼素材可用。
Dataview查詢語句的含義:TABLE 表示以表格形式展示,FROM 指定查詢的文件夾,SORT date DESC 表示按日期倒序排列,LIMIT 20 表示最多顯示20條。如果你想按條件過濾,可以在 FROM 和 SORT 之間添加 WHERE 子句(比如 WHERE contains(tags, "知識管理"))來篩選特定筆記。
前提: 這些查詢依賴frontmatter中的tags字段是YAML數組格式(如 tags: [知識管理, 筆記方法])。如果你用的是上一篇文章的模板,格式是正確的。但如果你的筆記用的是 #標籤 行內語法而不是frontmatter標籤,需要改用 contains(file.tags, "知識管理") 來查詢。
創建寫作模板
在 templates/ 文件夾中創建 寫作模板.md:
---
title: "<% tp.file.cursor(1) %>"
date: <% tp.date.now("YYYY-MM-DD") %>
tags: [寫作]
status: "草稿"
sources: []
summary: ""
---
## 大綱
## 初稿
## 精修稿
## 引用筆記
-
其中 <% tp.file.cursor(1) %> 是 Templater 插件的光標定位語法——創建筆記後,光標會自動跳到 title 字段等你輸入標題,不需要手動定位。
sources 字段用來記錄這篇文章引用了哪些筆記,方便以後回溯。status 字段追蹤寫作進度:草稿 → 精修 → 定稿。
創建新文章時,在Obsidian中按 Ctrl/Cmd + P 打開命令面板,搜索"Templater: Create new note from template",選擇"寫作模板",輸入文章標題即可創建一篇帶有frontmatter和章節結構的草稿筆記。
注意: 這個模板只在Obsidian中手動創建寫作筆記時生效。當你通過Claude Code生成初稿時,Claude Code會直接寫入frontmatter內容(如 title: "如何建立知識管理體系"),不會觸發Templater模板。模板的作用是:你在Obsidian中手動新建寫作筆記時,自動填好格式,你只需要填內容。
三、找素材——從知識庫挖出你要的內容
準備工作做好了,現在進入實戰。假設你要寫一篇關於"如何建立知識管理體系"的文章。
方法一:用Dataview按主題聚合
打開 寫作素材庫.md,在Dataview查詢區域添加一個主題查詢:
TABLE date AS "日期", tags AS "標籤", summary AS "摘要"
FROM "notes"
WHERE contains(tags, "知識管理") OR contains(tags, "筆記方法") OR contains(tags, "obsidian")
SORT date DESC
這會列出所有標籤中包含"知識管理"、"筆記方法"或"obsidian"的筆記。如果你在frontmatter中打了準確的標籤,這個查詢很有效。
但Dataview有一個侷限:它只能匹配標籤和frontmatter字段,不能理解筆記內容。 如果一篇筆記的標籤是"閲讀"但正文大量提到知識管理,Dataview搜不到它。
方法二:問Claude Code——語義搜索
在Obsidian右側欄點擊Claudian圖標打開對話窗口,輸入:
我要寫一篇關於"如何建立知識管理體系"的文章。請搜索整個倉庫,找出所有和知識管理相關的筆記,包括:1)標籤或標題中包含"知識管理"、"筆記方法"、"obsidian"的筆記;2)正文中提到知識管理、筆記整理、信息組織等概念的筆記。對每篇筆記,給出標題、摘要、和主題的關聯度(高/中/低),按關聯度排序。
Claude Code會做兩件事Dataview做不到的:
Claude Code的"語義搜索"和真正的語義搜索引擎(如Obsidian的Smart Connections插件,基於向量嵌入)不同。它的工作方式是讀取倉庫中的文件內容,用語言模型理解語義來判斷相關性。這意味着它不需要預先建立索引,即搜即用,但也受限於上下文窗口——如果你的倉庫筆記數量多且單篇篇幅長(比如超過200篇、每篇超過1000字),總內容可能接近單次對話的上下文上限,導致分析不完整。
Claude Code返回的結果大概長這樣:
找到8篇和"知識管理"相關的筆記:
【高關聯】
1. 《卡片筆記寫作法》讀書筆記 — 系統介紹卡片筆記法,核心理念是"寫下來而不是記下來"
2. Obsidian知識庫搭建實錄 — 用Claude Code搭建知識庫的完整流程
3. 雙向連結的真正用法 — 詳解雙向連結如何建立知識網絡
【中關聯】
4. 《原子習慣》讀書筆記 — 習慣養成方法,可引用"讓好習慣顯而易見"的部分
5. 信息過載的應對方法 — 提到了知識管理的幾個常見誤區
6. PARA方法實踐記錄 — 另一種知識組織方法,可作為對比
【低關聯】
7. 每週覆盤模板 — 覆盤流程中涉及知識整理
8. 工具切換記錄 — 記錄了從Notion切換到Obsidian的原因
這個輸出的質量取決於你知識庫的整理程度。 如果你的筆記都按照上一篇的規範添加了frontmatter(title、tags、summary),Claude Code能快速提取結構化信息,輸出會很整齊。如果筆記沒有統一格式,Claude Code需要從正文中提取信息,輸出可能不夠精確。這也是上一篇強調"每篇筆記必須有frontmatter"的原因——整理得越好,寫作時搜索和引用越準確。
注意: 筆記越多,Claude Code讀取和分析的時間越長。筆記量大時(超過50篇),建議先用Dataview或MOC縮小範圍,再讓Claude Code在篩選結果中做深度分析。另外,搜索大量文件會消耗較多Token,注意API費用。
方法三:用MOC當寫作索引
如果你按上一篇的方法建了MOC,寫作時MOC就是現成的素材目錄。打開 notes/MOC - 知識管理.md,裏面已經列出了所有知識管理相關的筆記和簡短描述。
MOC的好處是人工篩選過的——你建MOC時已經判斷過哪些筆記值得索引。Dataview和Claude Code是"廣撒網",MOC是"精篩選"。
三種方法各有適用場景,不需要每次都走完三步:
四、搭骨架——讓Claude Code基於素材生成大綱
找到素材後,下一步是搭大綱。這一步的關鍵原則是:大綱必須基於你的筆記內容,不是AI憑空編的。
怎麼給Claude Code下指令
在Claudian中輸入:
我要寫一篇關於"如何建立知識管理體系"的文章。以下是我的相關筆記:
1. 《卡片筆記寫作法》讀書筆記 — notes/reading/卡片筆記寫作法.md
2. Obsidian知識庫搭建實錄 — notes/obsidian知識庫搭建.md
3. 雙向連結的真正用法 — notes/雙向連結的真正用法.md
4. 《原子習慣》讀書筆記 — notes/reading/原子習慣.md
5. 信息過載的應對方法 — notes/信息過載的應對.md
請閲讀這些筆記,然後生成一個文章大綱。要求:
1. 大綱基於這些筆記的實際內容,不要添加筆記中沒有的觀點
2. 每個小節標註信息來源,用 [[筆記名]] 格式
3. 先給我大綱,我確認後再寫初稿
在Claudian中,你可以直接在對話中引用文件路徑,Claude Code會自動讀取對應文件的內容。你也可以選中筆記中的文字後發送指令,Claude Code會把選中的文字作為上下文。兩種方式都能讓Claude Code獲取筆記內容,區別在於:引用文件路徑會讀取完整筆記,選中文字只處理你選中的部分。
注意: 如果你的筆記很長或數量很多,Claude Code可能無法一次性讀取全部內容。建議單次指定不超過5篇筆記。如果素材超過5篇,先讓Claude Code為每篇筆記生成摘要,再基於摘要生成大綱。
Claude Code會先讀取這些筆記,理解內容,然後生成大綱:
# 如何建立知識管理體系
## 引言:為什麼你的筆記總是找不到
- 大多數人的筆記工具只管"存"不管"用" [[信息過載的應對方法]]
- 知識管理的核心不是分類,是連接 [[卡片筆記寫作法]]
## 一、從文件夾到知識網絡
- 文件夾分類的問題:一篇筆記只能在一個位置 [[Obsidian知識庫搭建實錄]]
- 雙向連結:讓筆記之間產生關聯 [[雙向連結的真正用法]]
- 標籤和連結的配合:標籤管分類,連結管關聯 [[Obsidian知識庫搭建實錄]]
## 二、讓整理變自動
- 手動整理不可持續,需要自動化 [[Obsidian知識庫搭建實錄]]
- 用AI輔助整理:打標籤、建連結、寫摘要 [[Obsidian知識庫搭建實錄]]
- 每週15分鐘整理流程 [[Obsidian知識庫搭建實錄]]
## 三、從收集到輸出
- 知識管理的終極目標是輸出,不是存儲 [[卡片筆記寫作法]]
- 讓好習慣顯而易見:降低整理和寫作的門檻 [[原子習慣]]
- 知識庫驅動創作:用已有筆記作為寫作素材 [[卡片筆記寫作法]]
## 總結
- 知識管理不是整理,是建立連接和驅動輸出
- 工具和方法缺一不可
審閲和調整大綱
大綱生成後,一定要審閲再繼續。 AI生成的大綱可能有這些問題:
審閲後,在Claudian中繼續對話調整:
大綱整體不錯,但需要調整:
1."引言"部分太短,加一段關於"筆記越多越難找"的具體場景
2."從收集到輸出"這一節,加上從信息過載筆記中引用的"三個常見誤區"
3. 總結部分太籠統,改為具體的行動建議
Claude Code會根據你的反饋調整大綱。你可能需要來回調整2-3輪,這是正常的——大綱是文章的骨架,骨架歪了,初稿怎麼改都不對。審閲大綱花的時間不多,但能大幅減少後面改初稿的時間。
五、從大綱到初稿——知識庫驅動的寫作流程
大綱審閲調整完畢,確認結構沒問題後,就可以進入下一步了。
讓Claude Code基於大綱和素材筆記生成初稿:
大綱已確認,請基於大綱和之前列出的5篇筆記生成初稿。要求:
1. 每個觀點都要有筆記中的原文或轉述作為支撐
2. 不要添加筆記中沒有的內容,如果需要補充,標註【待補充】
3. 保持簡潔直接的寫作風格,不用華麗辭藻
4. 正文中引用觀點時,用括號標註來源筆記
5. 保存到 projects/如何建立知識管理體系.md
Claude Code會生成一篇完整的初稿,保存到 projects/ 文件夾下。這篇初稿的特點是:每個觀點都來自你的筆記,不是AI憑空編的。 你可以驗證——如果某個觀點你不確定是不是自己寫的,看括號裏的來源筆記就知道。
初稿大概長這樣:
## 引言:為什麼你的筆記總是找不到
大多數人使用筆記工具的方式是"存了就走",從不回顧。結果筆記越積越多,
找到需要的那篇越來越難。(《信息過載的應對方法》)知識管理的核心問題
不是"怎麼分類",而是"怎麼讓筆記之間產生連接"。(《卡片筆記寫作法》)
## 一、從文件夾到知識網絡
傳統文件夾分類有一個根本問題:一篇筆記只能存在於一個位置。比如"用
Python做數據分析"這篇筆記,放到"編程"還是"數據分析"?這種糾結本身
就說明文件夾分類不夠用。(《Obsidian知識庫搭建實錄》)
雙向連結解決了這個問題——筆記不需要"放在"某個位置,而是通過連結建立
關聯。(《雙向連結的真正用法》)
【待補充:這裏可以加入你從文件夾切換到雙向連結的具體經歷】
## 二、讓整理變自動
手動給每篇筆記打標籤、建連結,一兩週還能堅持,時間一長必然鬆懈。
(《Obsidian知識庫搭建實錄》)解決方法是用AI輔助整理:自動打標籤、
自動建連結、自動生成摘要,把每週的整理時間壓縮到15分鐘以內。
(《Obsidian知識庫搭建實錄》)
## 三、從收集到輸出
知識管理的終極目標不是把筆記存好,而是在需要時能調用出來產生新內容。
(《卡片筆記寫作法》)"讓好習慣顯而易見"——降低整理和寫作的門檻,
讓輸出變得像記筆記一樣簡單。(《原子習慣》)
## 總結
- 從文件夾分類切換到雙向連結,建立知識網絡
- 用AI自動化整理流程,降低維護成本
- 以輸出為導向使用知識庫,而不是隻管收集
注意初稿的特點:每個觀點都有筆記來源標註,需要補充的地方用【待補充】標記。這篇初稿不能直接用,但骨架已經有了——你的素材被組織成了有邏輯的文章,你只需要精修。
精修——最重要的環節
初稿是半成品,不是成品。最重要的一步是核實引用。 AI可能把觀點歸到錯誤的筆記上,或者"編造"看似合理但筆記中不存在的論據。這不是AI故意犯錯,而是它理解內容時可能產生偏差。每一條標註了來源的觀點,都要打開原筆記確認。
具體精修步驟:
精修完成後,更新筆記的 status 字段從"草稿"改為"精修",在 sources 字段中列出引用的筆記:
---
title:"如何建立知識管理體系"
date:2026-05-21
tags: [寫作, 知識管理]
status:"精修"
sources: [卡片筆記寫作法, Obsidian知識庫搭建實錄, 雙向連結的真正用法, 原子習慣, 信息過載的應對方法]
summary:"從文件夾分類到知識網絡,從手動整理到AI輔助,從收集存儲到驅動輸出——知識管理體系的完整搭建方法"
---
完整的寫作流程
把上面的步驟串起來,知識庫驅動的寫作流程是這樣的:
和傳統寫作流程的區別在於:傳統流程中找素材和搭大綱是最耗時的部分,知識庫驅動後這兩步快了很多——素材已經在知識庫裏了,你不需要重新搜索和閲讀;大綱由AI基於你的筆記生成,你只需要審閲和調整。省下來的時間可以花在精修上——這才是決定文章質量的關鍵環節。
實戰案例:用5篇讀書筆記寫一篇對比文章
假設你過去半年讀了5本關於習慣養成的書,每本都做了讀書筆記存在 notes/reading/ 裏。現在你想寫一篇"習慣養成的5本書對比"文章。
用上面介紹的流程,核心步驟和主流程一樣,但對比文章有一些特別之處:
搭大綱時,指定對比維度:
我要寫一篇"習慣養成的5本書對比"文章。請閲讀以下5篇讀書筆記:
- notes/reading/原子習慣.md
- notes/reading/掌控習慣.md
- notes/reading/微習慣.md
- notes/reading/習慣的力量.md
- notes/reading/刻意練習.md
生成一個對比文章的大綱,要求:
1. 先概述5本書各自的核心觀點
2. 然後從3-4個維度對比(比如:習慣形成原理、實操方法、適用場景、閲讀門檻)
3. 最後給出推薦:不同需求的人適合讀哪本
4. 每個觀點標註來源筆記
對比文章的大綱結構和普通文章不同:它需要先分別介紹每本書,再橫向對比。這個結構需要你在prompt中明確指定,否則AI可能生成一篇普通的綜述而不是對比文章。
精修時,重點核實每本書的核心觀點是否準確。 對比文章的引用密度比普通文章高——每個對比維度下要引用多本書的觀點,任何一處引用錯誤都會影響整篇文章的可信度。
六、自動化寫作——週報、月總結、讀書綜述
有些寫作是重複性的:每週的週報、每月的總結、讀完一系列書後的綜述。這些內容有固定格式,素材來源也是確定的(當週的筆記、當月的筆記、同一主題的讀書筆記),很適合用知識庫自動化。
週報自動化
每週五下午,讓Claude Code幫你生成周報:
請生成本週的週報。步驟:
1. 讀取 daily/ 文件夾下本週一到週五的每日筆記(文件名格式為 YYYY-MM-DD.md)
2. 用命令查找本週修改過的筆記:find notes projects -name "*.md" -mtime -7
3. 讀取步驟2找到的筆記
4. 從以上筆記中提取:本週完成的事項、遇到的問題、下週計劃
5. 按以下格式生成周報:
- 本週完成:(列出事項,標註來源筆記)
- 遇到的問題:(列出問題和解決情況)
- 下週計劃:(從筆記中提取待辦事項)
6. 保存到 projects/週報/2026-W21.md
Claude Code會讀取你的每日筆記和項目筆記,提取關鍵信息,生成結構化的週報。生成的週報大概長這樣:
# 週報 2026-W21
## 本週完成
- 完成Obsidian知識庫搭建,配置了CLAUDE.md和五層組織體系
(來源:projects/知識庫搭建.md)
- 讀完《卡片筆記寫作法》,整理了3條核心觀點
(來源:notes/reading/卡片筆記寫作法.md)
- 修復了項目中的登錄問題,原因是token過期未刷新
(來源:projects/用戶系統.md)
## 遇到的問題
- 知識庫批量整理時標籤不一致,部分筆記標籤用了中文,部分用了英文
已通過更新CLAUDE.md規範解決
- Dataview查詢無法按正文內容過濾,部分相關筆記被遺漏
已記錄,計劃下週補充標籤
## 下週計劃
- 測試知識庫驅動創作流程,寫一篇實踐文章
- 繼續閲讀《原子習慣》,整理讀書筆記
注意週報中的【待補充】部分需要你手動補充。AI只能從已有筆記中提取信息,你腦子裏想但沒寫下來的事情,它不知道。
注意:每日筆記是週報的主要素材來源。 如果你平時沒有寫每日筆記的習慣,週報的素材會不夠。建議每天花2分鐘在 daily/ 下記錄當天做了什麼,這樣週五生成周報時就有足夠的內容。
月度總結自動化
類似週報,但時間範圍更大:
請生成本月的月度總結。步驟:
1. 讀取 daily/ 文件夾下本月所有每日筆記
2. 用命令查找本月新增的筆記:find notes -name "*.md" -mtime -30
3. 讀取步驟2找到的筆記
4. 統計:本月新增筆記數量、各主題筆記分佈
5. 提取:本月學到的最重要的3個知識點、本月完成的項目進展、下月重點
6. 保存到 projects/月度總結/2026-05.md
月度總結的價值不只是回顧——它讓你看到自己一個月到底學了什麼、做了什麼,而不是憑感覺回憶。
讀書綜述自動化
讀完一個主題的多本書後,讓Claude Code生成綜述:
請閲讀 notes/reading/ 下和"認知科學"相關的讀書筆記(如果超過10篇,只選擇關聯度最高的10篇),生成一篇讀書綜述。要求:
1. 概述每本書的核心觀點
2. 找出這些書之間的共識和分歧
3. 提煉出3-5個該主題的核心問題
4. 給出進一步閲讀建議
5. 每個觀點標註來源筆記
6. 保存到 notes/reading/認知科學讀書綜述.md
自動化寫作的邊界: 週報和月總結因為格式固定、信息來源確定,AI生成的質量通常較高,稍作修改就能用。但讀書綜述涉及"找共識、找分歧、提問題"這類分析工作,AI生成的結果可能流於表面——它能發現明顯的共同點和不同點,但容易遺漏隱含的深層聯繫。建議把AI生成的綜述當作起點,你在此基礎上加入自己的深度思考。
你做到了什麼
讀完這篇文章,你給知識庫加上了"輸出"能力:更新了CLAUDE.md的寫作規則,創建了寫作素材庫和模板,學會了用MOC、Dataview、Claude Code三種方式找素材,跑通了從找素材到精修的完整寫作流程,還實現了週報和月總結的自動化生成。
上一篇搭好了知識庫的骨架,這篇讓知識庫能產出內容。但還有一個問題:你的知識庫是封閉的——所有信息都要你手動輸入。下一篇,我們用MCP讓知識庫聯網,自動抓取網頁、連接外部工具,讓信息自動流入你的知識庫。
掃碼關注「AI智聞說」,每天3分鐘掌握AI新知識