省 Token,我給 Agent 做了個網頁快照生成器
整理版優先睇
為 AI Agent 慳 Token,作者自建 Pug 格式網頁快照生成器
呢篇文章係作者分享佢為自己嘅 AI Web Agent「Tapero」開發網頁快照生成器嘅過程。背景係:AI Agent 要做網頁自動化,但直接將完整 HTML 掉畀 AI 會消耗大量 Token,而且 HTML 入面好多無關嘅 div、style、script 對 AI 係噪音。作者想揾一個方法,將網頁壓縮成結構化嘅描述,只保留自動化真正需要嘅資訊。
作者調研咗業界做法,例如 Playwright MCP 同 Agent Browser 係用瀏覽器嘅 Accessibility Tree 生成快照,好處係語義清晰、噪音少,但缺點係資訊被過度抽象,層級同屬性細節會流失。作者因為執行環境拎唔到 Accessibility Tree,加上唔滿意資訊損失,決定自己用另一條路:基於 DOM 嚟生成快照。
經過三次迭代,作者揀咗 Pug 子集做快照格式,保留標籤、屬性同埋狀態(例如 inviewport),結構一目瞭然。佢測試咗幾個典型頁面,壓縮率可以做到 2% 至 4%,而且保留到足夠資訊畀 AI 做定位。作者認為網頁快照係 AI Web Agent 嘅地圖,唔可以太複雜(慳 Token),又唔可以太簡單(唔漏關鍵資訊)。
- 網頁快照係 AI Web Agent 嘅地圖,用嚟壓縮 HTML 並保留關鍵結構,慳 Token 同時提升穩定性。
- 作者選擇基於 DOM 生成快照,而非業界常用嘅 Accessibility Tree,因為 DOM 保留更多層級同屬性資訊。
- 快照格式用 Pug 子集,有縮進表示層級,能夠擴展狀態屬性如 inviewport,對 AI 友善。
- 實測壓縮率約 2% 至 4%,例如 Amazon 商品頁由 3509 節點壓縮到 649 節點,耗時 36ms。
- 主要挑戰包括偽交互元素判斷、超大列表修剪、嵌套 iframe 處理、Shadow DOM 展開等,需要做平衡同取捨。
AI Agent 慳 Token 嘅現實問題
作者最近為佢嘅 AI Web Agent「Tapero」整咗個網頁快照生成器。動機好簡單:網頁太大,直接將整個 HTML 掉畀 AI 等於燒錢。一個複雜頁面有成千上萬行代碼,夾雜無關 div、style、script,對 AI 係噪音,對 Token 係成本。
AI Agent 想做網頁自動化,但每步都要喂一坨嘢,唔單止貴,仲唔穩定。
所以網頁快照變得好關鍵:畀頁面做一層壓縮同結構化描述,只保留對自動化有用嘅資訊。AI 唔睇原始 HTML,而係睇呢份精簡版快照。
業界做法 vs 作者選擇:DOM 快照
業界主流係用瀏覽器嘅 Accessibility Tree 生成快照,例如 Playwright MCP 同 Agent Browser。Accessibility Tree 將元素轉成「角色+文本+狀態」,語義清晰、噪音少,但資訊被過度抽象,層級同屬性細節會流失。
作者執行環境拎唔到 Accessibility Tree,加上唔滿意資訊損失,決定直接基於 DOM 生成快照。佢遍歷 DOM 樹,過濾無關節點(script、style、div 等),提取關鍵屬性同文本,壓縮成結構化文本表示。
Pug 子集格式:結構清晰、資訊豐富
經過三次迭代,作者揀咗 Pug 子集做快照格式。縮進表示層級,保留標籤、屬性同文本,仲擴展咗狀態屬性(如 inviewport、disabled、hidden)。
page(ref="n1" title="Demo" lang="en" url="https://example.com")
form#feedback(ref="n2" inviewport)
input(ref="n3" type="email" name="email" placeholder="Email" required)
button(ref="n4" type="submit" inviewport) Continue- 結構一眼睇得明:縮進就係層級
- 資訊保留完整:標籤+屬性+文本
- 狀態屬性擴展:inviewport, disabled, hidden 等
- 對 AI 友善:比 HTML 乾淨好多
作者願意犧牲一點點 Token,換取更準確嘅 AI 識別。
呢套實現嘅優勢係保留更多原始資訊,AI 定位更穩;唔依賴瀏覽器底層,通用性極強;可控性高,可以自己擴展字段。
踩坑與取捨:平衡體積與資訊
作者面對幾個主要挑戰:偽交互元素需要自己推斷(例如用 div 實現嘅按鈕),執行效率要控制在 150ms 內,仲有隱藏元素、超大列表、嵌套 iframe、Shadow DOM 等問題。
- 1 隱藏元素:下拉菜單默認 hidden,保留會增大體積,唔保留會影響 AI 下一步推斷。
- 2 超大數據列表:無限滾動列表全保留體積爆炸,需要做抽樣或推斷。
- 3 嵌套 iframe:唔處理會漏資訊,處理又怕性能問題同跨域限制,尤其係廣告 iframe。
- 4 In Viewport 判定:只保留可視區域可壓縮體積,但關鍵元素可能喺首屏外,作者將 In Viewport 做成狀態畀 AI 判斷。
- 5 Shadow DOM:現代組件往往喺裏面,唔展開就「睇唔見」,展開又複雜,有啲 closed 節點仲唔畀睇。
- 6 節點修剪策略:點樣從 1000+ 節點篩到 200-300 個,需要先分類再模式分層控制。
實測成績:壓縮率 2-4%,AI 友好
作者用幾個典型頁面測試,結果如下:
- X 個人主頁:耗時 18ms,989 節點保留 207,壓縮率 ~2%
- Amazon 商品詳情頁:耗時 36ms,3509 節點保留 649,壓縮率 ~4%
- Google 搜索結果頁:耗時 24ms,1633 節點保留 280,壓縮率 ~2%
Amazon 頁面嘅結果超出期望,極大壓縮咗網頁體積。
作者總結:網頁快照係 AI Web Agent 嘅地圖,唔可以太複雜(Token 有限),又唔可以太簡單(漏關鍵資訊)。佢會繼續公開做呢個 AI Web Agent,記錄技術選型、踩坑同取捨。
最近,我喺做一件幾有趣嘅事,今日嚟同大家分享下:
我為 Tapero 整咗一個網頁快照生成器。
一開始嘅動機其實好簡單 —— 網頁實在太大啦!
如果你直接將成個頁面嘅 HTML 掉俾 AI,叫佢去理解、定位、操作,基本上等於燒錢。
一個複雜少少嘅頁面,隨時幾千幾萬行 code,入面仲夾雜住各種無關嘅 div、style、script,對 AI 嚟講全部係噪音,但對 Token 嚟講全部係成本呀。
咁就變成一個好現實嘅問題:
AI Agent 想做網頁自動化,但每一步都要餵咁大嚿嘢入去,唔單止貴,仲唔穩定(AI 都會誤判)。
所以,網頁快照呢樣嘢就變得好關鍵。你可以理解為 —— 將頁面做一層壓縮兼結構化嘅描述,淨係保留對自動化有用嘅資訊。AI 唔再睇原始 HTML,而係睇呢份精簡版嘅快照。
業界係點做㗎?
其實呢個方向已經有人喺度做,例如 Playwright MCP(鼻祖),同埋後嚟 Agent Browser 嘅實現。
佢哋大多數係基於瀏覽器嘅 Accessibility Tree 嚟生成快照。
簡單講,Accessibility Tree 係瀏覽器為咗無障礙訪問(例如屏幕閲讀器)而生成嘅一棵語義樹。佢會將頁面入面嘅元素轉成「角色 + 文本 + 狀態」咁嘅結構,例如按鈕、輸入框、標題之類。
呢種方式有個好大嘅優點:語義清晰,噪音好少。
佢哋生成嘅快照大約係咁樣(簡化示意):
- heading "Welcome to Amazon"
- textbox "Search"
- button "Search"
- link "Today's Deals"
或者更結構化啲:
role=button name="Submit" focused=true
role=textbox name="Email" required=true
我呢度有一張 Agent Browser 實際生成快照嘅截圖,我哋睇下:
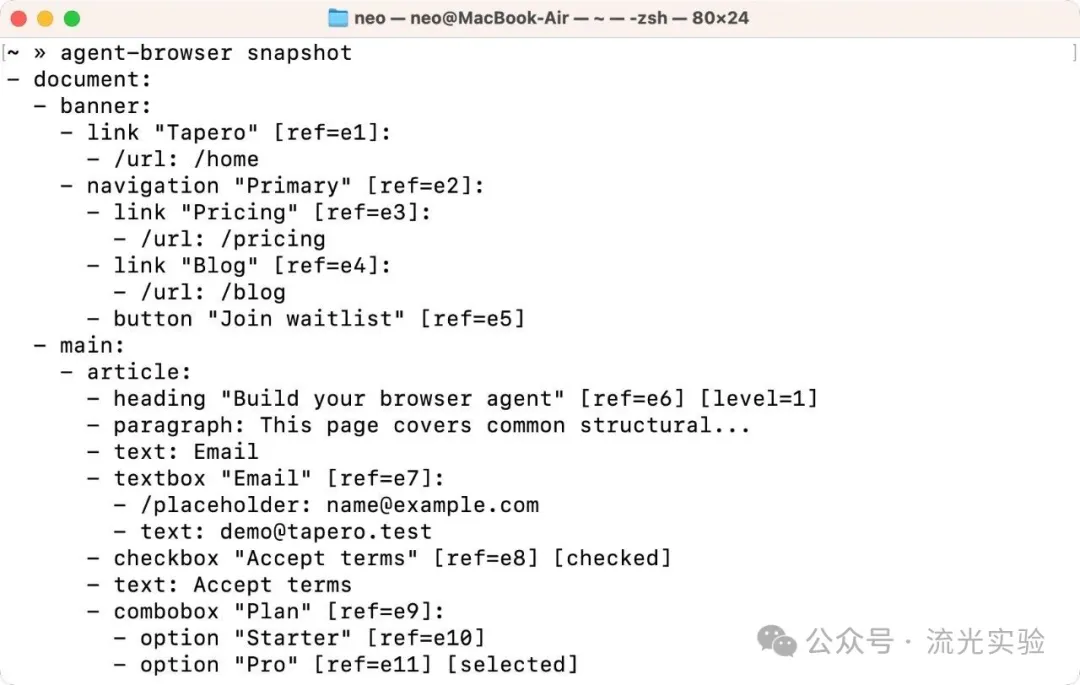
嗯,睇落好乾淨,啱唔啱?對 AI 都好友好。
但佢都有一個問題:資訊被過度抽象化咗。好多原始 HTML 裏面嘅結構資訊,例如層級關係、屬性細節,有時就冇咗。咁可能會造成誤判,例如頁面有兩個一樣嘅按鈕,AI 唔知應該㩒邊個?
我嘅實現:基於 DOM 嘅快照
好,調查一輪之後,終於輪到我鬱手,現實就俾咗我一拳。
我而家嘅執行環境,拎唔到 Accessibility Tree —— 佢需要更高嘅權限(我唔想申請呢個權限),或者直接喺瀏覽器內核層做。
加上,我其實都唔係好滿意 Accessibility Tree 嘅資訊損失,佢太偏語義。但做自動化嘅時候,有啲原始資訊反而好重要,例如:
明確嘅層級結構、佈局結構 元素嘅屬性(id、name、type 等) 一啲唔喺語義樹裏面嘅元素(好多非標準網頁冇標明語義)
所以我行咗另一條路:直接基於 DOM 嚟生成快照。
思路好簡單:
遍歷 DOM 樹 過濾掉無關嘅節點(script、style、div 等) 提取元素嘅關鍵屬性 + 文本 壓縮成一個結構化嘅文本表示層
經過 3 次迭代之後,我最終揀咗 Pug 子集嚟做快照嘅格式,睇起嚟係咁:
page(ref="n1" title="Demo" lang="en" url="https://example.com")
form#feedback(ref="n2" inviewport)
input(ref="n3" type="email" name="email" placeholder="Email" required)
button(ref="n4" type="submit" inviewport) Continue
我都對同一個網頁生成咗快照,同 Agent Browser 對比下:
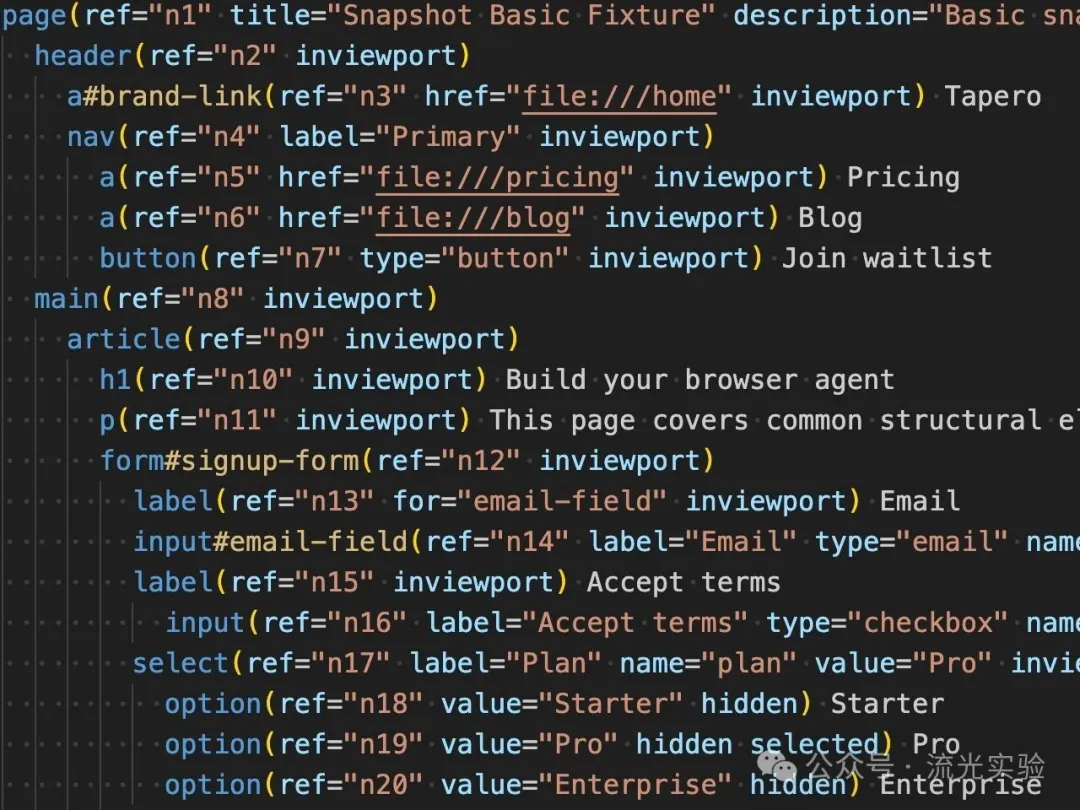
可以見到,資訊更加豐富,但一啲都唔亂。當然,我都提供咗選項可以輸出極簡快照。但我更願意資訊豐富啲,犧牲少少 Token,等 AI 識別得更準確!
呢個格式有幾個我自己幾鍾意嘅點:
結構一眼就睇得明(縮排就係層級) 資訊保留得比較完整(標籤 + 屬性 + 文本) 擴展咗狀態屬性(例如 inviewport, disabled, hidden 等) 對 AI 都好友好(比 HTML 乾淨好多)
呢套實現嘅優勢
保留咗更多原始資訊,AI 做定位更穩定 唔依賴瀏覽器底層能力,通用性極強 可控性高,想加咩字段都可以自己擴展
面臨嘅挑戰
偽交互元素需要自己推斷
例如一個用普通 div 實現嘅按鈕,語義上佢唔係 button,但行為上係,呢類判斷需要額外邏輯去補。
執行效率需要控制在 150ms 內
頁面越大、機器性能越差,遍歷同裁剪嘅成本就越高,呢度其實好考工程優化。
我踩過嘅一啲坑
隱藏元素應唔應該保留?
有啲下拉菜單默認係 hidden,但撳咗之後會出現,保留就會增加體積,唔保留又會影響 AI 嘅下一步推斷。
超大數據列表要唔要修剪?
例如無限滾動嘅列表,如果全部保留,體積會直接爆,但修剪又可能會丟失關鍵數據。呢個就需要做個平衡,加多啲邏輯去推斷,係全部保留定係抽樣保留。
嵌套 iframe 要唔要遞歸處理?
唔處理會丟失資訊,處理又可能帶嚟性能問題同跨域限制。仲有網頁入面有大量廣告(基本都係透過 iframe 注入)嘅情況,會嚴重拖慢快照嘅生成。
In Viewport 判定策略
淨係保留可視區域可以大幅壓縮體積,但有時候關鍵元素喺首屏之外。所以,我將佢整成狀態,等 AI 知道邊啲元素喺視口入面?咁就可以做出更好嘅推斷。
Shadow DOM 嘅處理策略
好多現代組件都收埋喺入面,唔展開就「睇唔到」,展開又會令結構變複雜。仲有啲節點係 closed 嘅,唔俾睇。好彩最後都揾到合適嘅處理方案。
節點修剪策略
點樣由 1000+ 個節點篩到 200~300 個,係個好微妙嘅平衡。需要先將所有節點分類,再透過模式分層控制,決定輸出邊啲節點。
實測效果
講咗咁多,嚟啲實際嘅。我拎幾個典型頁面跑咗下,下面我哋睇下測試結果。
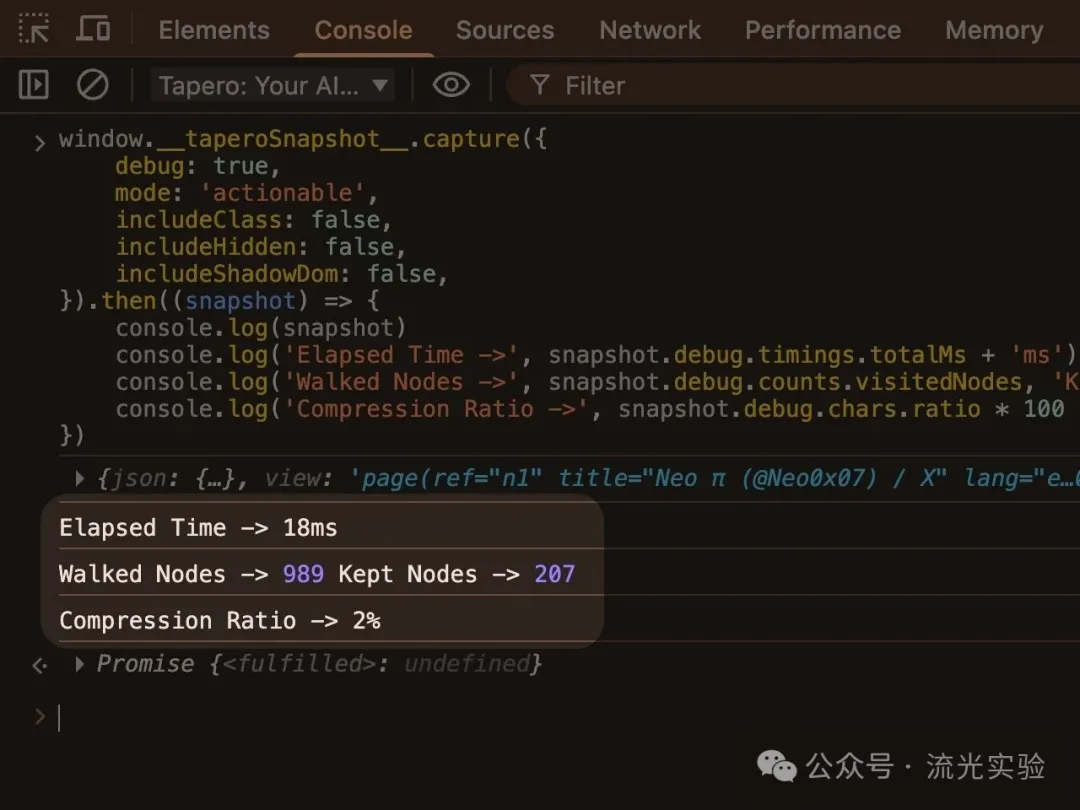
1. X 嘅個人主頁
頁面結構高度嵌套 隨住向下滾動,節點數量會越來越多
以下係跑出嚟嘅結果:
耗時:18ms 遍歷節點:989 保留節點:207 壓縮率:≈ 2%
對於呢個結果,我其實幾滿意,基本上將網頁資訊壓到一個 AI 可以接受嘅範圍。
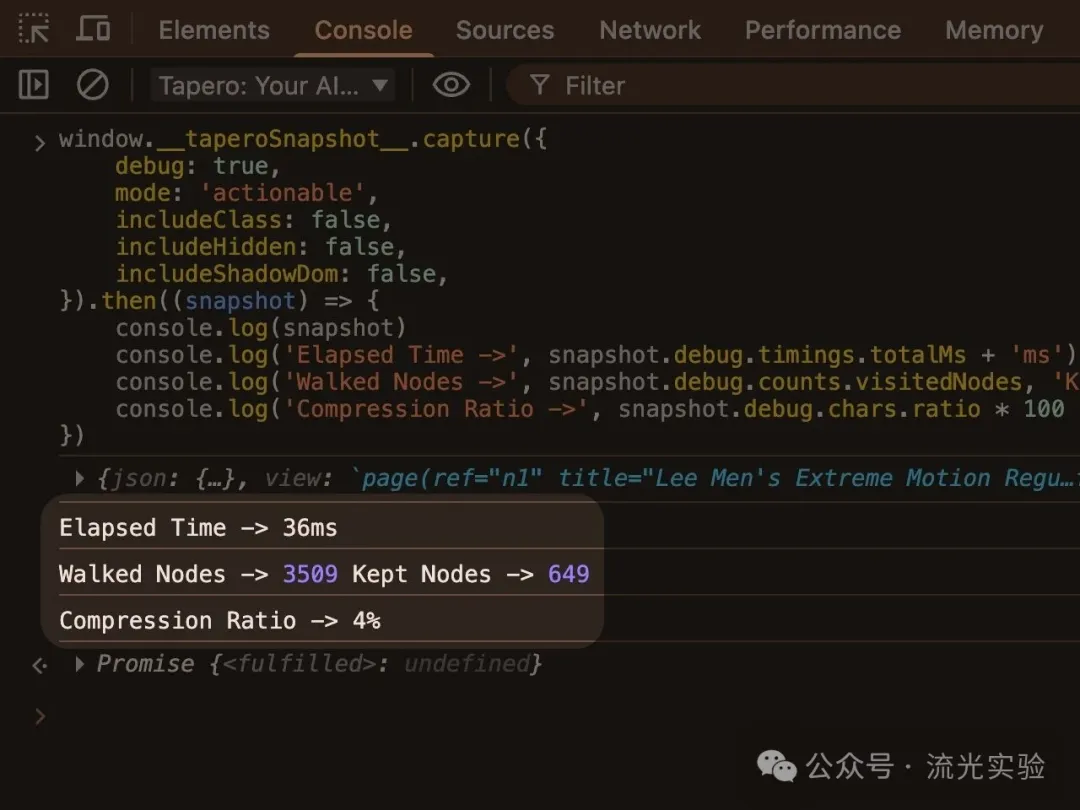
2. Amazon 商品詳情頁
頁面結構非常複雜,節點爆炸 需要重點保留:標題、價格、圖片、購買按鈕等資訊
以下係跑出嚟嘅結果:
耗時:36ms 遍歷節點:3509 保留節點:649 壓縮率:≈ 4%
呢個效果已經遠遠超出我嘅預期,極大咁壓縮咗網頁嘅體積。
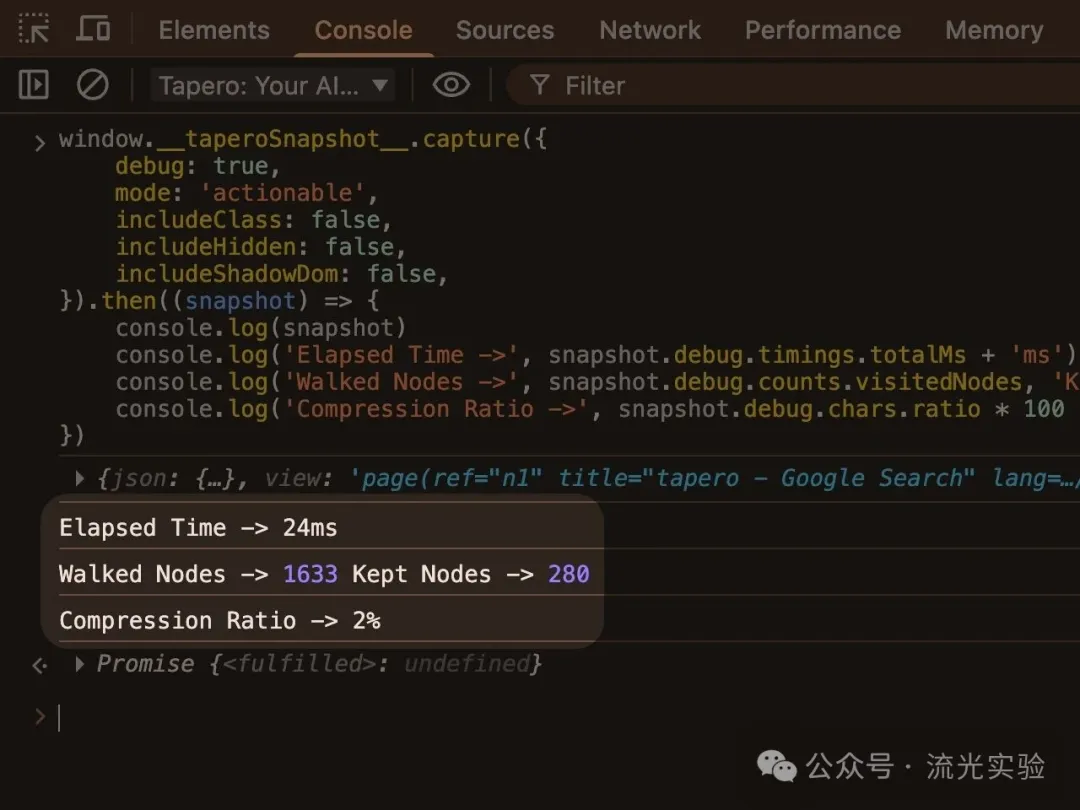
3. Google 搜尋結果頁
結構相對規整,但資訊密度高 重點係結果列表 + 標題 + 連結
以下係跑出嚟嘅結果:
耗時:24ms 遍歷節點:1633 保留節點:280 壓縮率:≈ 2%
快照出咗之後,基本上可以直接用嚟做「抓取搜尋結果」嘅自動化任務。

最後
呢一輪做落嚟,我對網頁快照有新嘅感受:
佢係 AI Web Agent 嘅地圖,有咗佢 AI 先可以規劃出行動路線。
佢唔可以太複雜,體積唔可以太大,AI 嘅上下文有限,而且 Token 都唔平。
佢亦唔可以太簡單,遺漏關鍵資訊,等於俾 AI 一份錯誤嘅地圖,佢再聰明都好難做啱嘢。
好喇,今日就講到呢度!多謝有 Codex 同我結對編程,先可以將呢個快照生成引擎做出嚟!
我而家公開做一個 AI Web Agent,我會將佢由 0 到 1 嘅成個過程都記錄低。包括技術選型、踩坑、各種取捨,都會慢慢寫出嚟。
如果你都係做緊類似嘅嘢,或者對呢個方向有興趣,歡迎嚟傾下。
最近,我在做一件挺有意思的事,今天來給大家分享了:
我為 Tapero 擼了一個網頁快照生成器。
一開始的動機其實很簡單 —— 網頁實在太大了!
你如果直接把一整個頁面的 HTML 丟給 AI,讓它去理解、定位、操作,基本等於在燒錢。
一個稍微複雜一點的頁面,動不動就幾千上萬行代碼,裏面還夾雜着各種無關的 div、style、script,對 AI 來說全是噪音,但對 Token 來說全是成本呀。
這就變成了一個很現實的問題:
AI Agent 想做網頁自動化,但每走一步都要喂這麼一坨東西進去,不僅貴,還不穩定(AI 也會誤判)。
所以,網頁快照這個東西就變得很關鍵了。你可以把它理解成 —— 給頁面做一層壓縮且結構化的描述,只保留對自動化真正有用的信息。AI 不再看原始 HTML,而是看這份精簡版的快照。
業界是怎麼做的?
其實這個方向已經有人在做了,比如 Playwright MCP(鼻祖),還有後來 Agent Browser 的實現。
它們大多是基於瀏覽器的 Accessibility Tree 來生成快照。
簡單說,Accessibility Tree 是瀏覽器為了無障礙訪問(比如屏幕閲讀器)生成的一棵語義樹。它會把頁面裏的元素轉成“角色 + 文本 + 狀態”這樣的結構,比如按鈕、輸入框、標題之類的。
這種方式有個很大的優點:語義清晰,噪音很少。
它們生成的快照大概長這樣(簡化示意):
- heading "Welcome to Amazon"
- textbox "Search"
- button "Search"
- link "Today's Deals"
或者更結構化一點:
role=button name="Submit" focused=true
role=textbox name="Email" required=true
我這裏有一張 Agent Browser 實際生成快照的截圖,咱們來看看:
嗯,看起來很乾淨,對吧?對 AI 也很友好。
但它也有一個問題:信息被過度抽象了。很多原始 HTML 裏的結構信息,比如層級關係、屬性細節,有時候就丟了。這就可能造成誤判,比如頁面有兩個一樣的按鈕,AI 不知道應該點哪個?
我的實現:基於 DOM 的快照
好,一番調研後,終於輪到我動手了,現實卻給了我一拳。
我當前的執行環境,拿不到 Accessibility Tree —— 它需要更高的權限(我不想申請這個權限),或者直接在瀏覽器內核層做。
再加上,我其實也不太滿意 Accessibility Tree 的信息損失,它太偏語義了。但在做自動化的時候,有些原始信息卻很重要,比如:
明確的層級結構、佈局結構 元素的屬性(id、name、type 等) 一些不在語義樹裏的元素(很多非標網頁沒有註明語義)
所以我走了另一條路:直接基於 DOM 來生成快照。
思路很簡單:
遍歷 DOM 樹 過濾掉無關節點(script、style、div 等) 提取元素的關鍵屬性 + 文本 壓縮成一個結構化的文本表示層
經過 3 次迭代後,我最後選擇 Pug 子集來作為快照的格式,看起來長這樣:
page(ref="n1" title="Demo" lang="en" url="https://example.com")
form#feedback(ref="n2" inviewport)
input(ref="n3" type="email" name="email" placeholder="Email" required)
button(ref="n4" type="submit" inviewport) Continue
我也對同一個網頁生成了快照,來和 Agent Browser 對比一下:
可以看到,信息更加豐富了,但一點都不亂。當然了,我也提供了選項來輸出極簡快照。但我更願意信息豐富一點,犧牲一點點 Token,讓 AI 識別起來更準些!
這個格式有幾個我自己挺喜歡的點:
結構一眼能看懂(縮進就是層級) 信息保留得比較完整(標籤 + 屬性 + 文本) 擴展了狀態屬性(如 inviewport, disabled, hidden 等) 對 AI 也很友好(比 HTML 乾淨太多)
這套實現的優勢
保留了更多原始信息,AI 做定位更穩 不依賴瀏覽器底層能力,通用性極強 可控性高,想加什麼字段都可以自己擴展
面臨的挑戰
偽交互元素需要自己推斷
比如一個用普通 div 實現的按鈕,語義上它不是 button,但行為上是,這類判斷需要額外邏輯去補。
執行效率需要控制在 150ms 內
頁面越大、機器性能越差,遍歷和裁剪的成本就越高,這裏其實挺考驗工程優化的。
我踩過的一些坑
隱藏元素要不要保留?
有些下拉菜單默認是 hidden,但點擊後會出現,保留則多增加體積,不保留則會影響 AI 的下一步推斷。
超大數據列表要不要修剪?
比如無限滾動的列表,如果全保留,體積直接爆炸,但裁剪又可能丟關鍵數據。這就需要做個平衡,增加額外的邏輯來推斷,是全保留,還是抽樣保留。
嵌套 iframe 要不要遞歸處理?
不處理會丟信息,處理又可能帶來性能問題和跨域限制。還有網頁中有大量廣告(基本都是通過 iframe 注入的)的情況,會嚴重拖慢快照的生成。
In Viewport 判定策略
只保留可視區域可以大幅壓縮體積,但有時候關鍵元素在首屏外。所以,我把它做成狀態,讓 AI 知道哪些元素在視口中?這樣可以做出更好的推斷。
Shadow DOM 的處理策略
很多現代組件都藏在裏面,不展開就“看不見”,展開又會讓結構變複雜。還有一些節點是 closed 的,不讓看。好在最終都找到了合適的處理方案。
節點修剪策略
怎麼從 1000+ 節點裏篩到 200~300 個,是個很微妙的平衡。需要先對所有節點分類,再通過模式分層控制,決定輸出哪些節點。
實測效果
說了這麼多,來點實際的。我拿幾個典型頁面跑了一下,下面我們來看看測結果。
1. X 的個人主頁
頁面結構高度嵌套 隨着往下滾動,節點數量會越來越多
以下是跑出來的結果:
耗時:18ms 遍歷節點:989 保留節點:207 壓縮率:≈ 2%
對於這個結果,我其實挺滿意的,基本把網頁信息壓到了一個 AI 可以接受的範圍。
2. Amazon 商品詳情頁
頁面結構非常複雜,節點爆炸 需要重點保留:標題、價格、圖片、購買按鈕等信息
以下是跑出來的結果:
耗時:36ms 遍歷節點:3509 保留節點:649 壓縮率:≈ 4%
這個效果已經遠遠超出我的期望了,極大的壓縮了網頁的體積。
3. Google 搜索結果頁
結構相對規整,但信息密度高 重點是結果列表 + 標題 + 連結
以下是跑出來的結果:
耗時:24ms 遍歷節點:1633 保留節點:280 壓縮率:≈ 2%
快照出來之後,基本可以直接用於“抓取搜索結果”的自動化任務。
最後
這一輪做下來,我對網頁快照有了新感受:
它是 AI Web Agent 的地圖,有了它 AI 才能規劃出執行路線。
它不能太複雜,體積不能太大,AI 的上下文有限,且 Token 也不便宜。
它也不能太簡單,遺漏關鍵信息,相當於給 AI 一版錯誤的地圖,它再聰明也很難做出正確的事。
好了,今天就到這!感謝有 Codex 和我結對編程,才能把這個快照生成引擎做出來!
我現正在公開做一個 AI Web Agent,我會把它從 0 到 1 的整個過程都記錄下來。包括技術選型、踩坑、各種取捨,都會慢慢寫出來。
如果你也在做類似的事,或者對這個方向感興趣,歡迎來聊聊。