看完Claude Code泄露代碼,明白了Agent為什麼需要做夢
整理版優先睇
Claude Code 嘅分級記憶系統:先控制成本,再談長期記憶
呢篇文章係基於 Claude Code 泄露嘅 harness 代碼分析,作者係一位關注 AI Agent 工程實現嘅觀察者。佢想探討嘅核心問題係:代碼 Agent 喺長對話過程中點樣防止上下文膨脹同遺忘。整體結論係 Claude Code 並唔係追求「記住一切」,而係設計咗一套從便宜到昂貴、從前台到後台嘅分級防遺忘機制,優先確保會話持續運行,唔係追求完美記憶。
呢套系統包含 7 層結構,前三層負責用低成本方式阻隔噪音,例如將大結果落盤、微壓縮清理舊工具結果、持續維持結構化筆記。第四層係真正嘅大壓縮,只有當前面方法都唔夠用嗰陣先會觸發,fork 一個專門嘅 summarizer agent 生成摘要嚟續命。最後三層先進入長期記憶範疇,包括自動提取跨會話知識、後台 dreaming 整合、同埋跨 Agent 通訊。
作者提醒,最值得學習嘅唔係 Dreaming 呢個花俏名詞,而係整套系統嘅成本順序:能落盤就唔入上下文,能微清理就唔做摘要,能用現成筆記就唔新開 summarizer,能後台做就唔好阻住前台。對 Agent 開發者嚟講,呢種工程優先級往往比大道理更重要。
- Claude Code 嘅記憶設計係一套分級防線,優先使用低成本方法避免上下文膨脹,唔係追求記住所有嘢。
- 前三層(Tool Result Storage、Microcompaction、Session Memory)用落盤、清理、筆記等方式低成本阻隔噪音,係最值得抄嘅工程細節。
- 第四層 Full Compaction 先係真正大壓縮,fork summarizer agent 生成摘要續命,並有失敗保護機制(連續 3 次失敗就停止)。
- 後三層(Auto Memory Extraction、Dreaming、Cross-Agent Communication)實現跨會話知識沉澱,邊界清晰:唔儲存可從代碼推導嘅資訊,只留影響決策嘅用戶偏好。
- 對開發者啟示:Agent 系統嘅瓶頸多數係做到一半失憶,而唔係思考能力唔夠;應優先建立「防遺忘機制」,再考慮「記憶強度」。
問題解剖與設計哲學
Claude Code 泄露嘅 harness 最值得睇嘅係點樣防止 Agent 喺長代碼任務中失憶。佢冇將記憶理解成豪華數據庫,而係拆成多層分級系統,每步都問:有冇更平嘅辦法先?
呢套系統寫得非常工程化
前三層:低成本防噪
第一層 Tool Result Storage 將大結果落盤,正文只留預覽同 <persisted-output> 標記,直接攔住最容易失控嘅輸入。
能落盤就唔入上下文
第二層 Microcompaction 每輪清理舊工具結果,最靚係 cache_edits:本地消息唔改,但舊結果已被剔出,唔會打碎 prompt cache。
真正貴嘅係刪完會唔會打碎 prompt cache
第三層 Session Memory 持續維護結構化筆記,記錄任務狀態、關鍵文件、踩坑等,必要時直接塞返入上下文。
邊做邊記工作日誌,笨但有效
第四層:續命式壓縮
當前面方法都唔夠,Claude Code 觸發 Full Compaction,fork 一個 summarizer agent 按固定結構生成摘要,再將關鍵上下文注返入主會話。連續 3 次失敗就停止壓縮,避免無限放大錯誤。
Compaction 係明確嘅續命操作
後三層與整體啟示
第五層 Auto Memory Extraction 抽取跨會話可用知識,排除可從代碼推導嘅資訊,只留影響決策嘅用戶偏好。第六層 Dreaming 用四個階段(Orient、Gather、Consolidate、Prune)喺後台整合記憶,有完善嘅保護機制。第七層 Cross-Agent Communication 實現狀態隔離但緩存共享。
真正值得留嘅係用戶更在意集成測試,而唔係項目有 utils.ts
後台值夜班嗰套流程
狀態隔離但緩存共享
作者將呢套系統對應記憶理論:情境記憶(對話記錄)、語義記憶(session memory 同 auto extraction)、程序化記憶(feedback)。Claude Code 對正負回饋都保留,唔似其他系統只記錯誤。
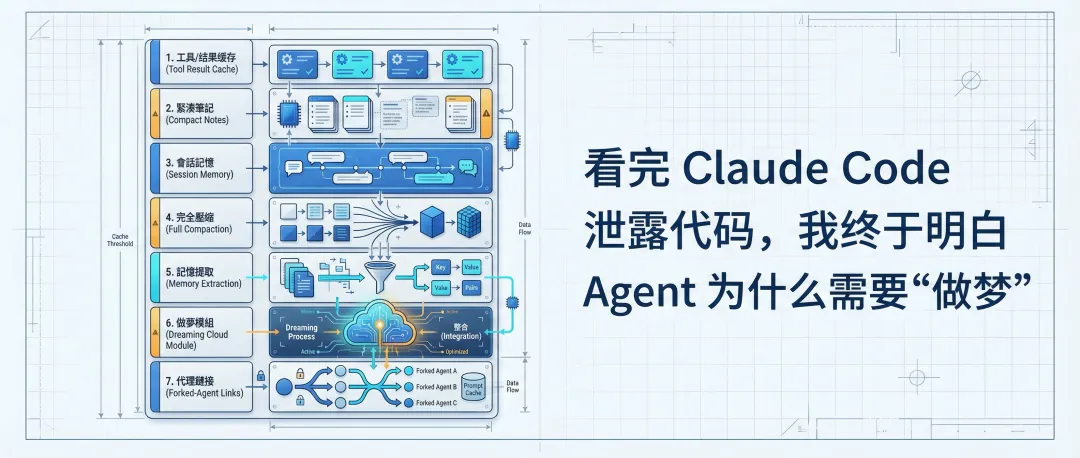
真正令到 Agent 表現有分別嘅,通常係佢會唔會唔記得。模型梗係重要,但係做 code 任務時間一長,文件越睇越多,grep 結果越揭越厚,幾十輪對話之後,模型好容易將真正重要嘅上下文同一大堆臨時噪音撈埋一齊。Claude Code 今次洩露出嚟嘅 harness,最值得睇嘅就係呢部分:佢冇將「記憶」當成一個豪華數據庫,而係拆成咗一套由平到貴、由前台到後台嘅分級系統。
我睇曬成個實現之後第一個感覺好直接:呢套嘢寫得好工程化。佢唔追求「記住一切」嘅浪漫講法,而係喺每一步都問同一個問題:今次有冇更平嘅方法,唔好搞到成本升咗先。於是你會見到一個好有層次嘅設計,前幾層負責減肥同止血,後幾層先負責整理、沉澱同長期鞏固。dreaming 呢個名聽落好玄,其實就係後台版嘅記憶整固。
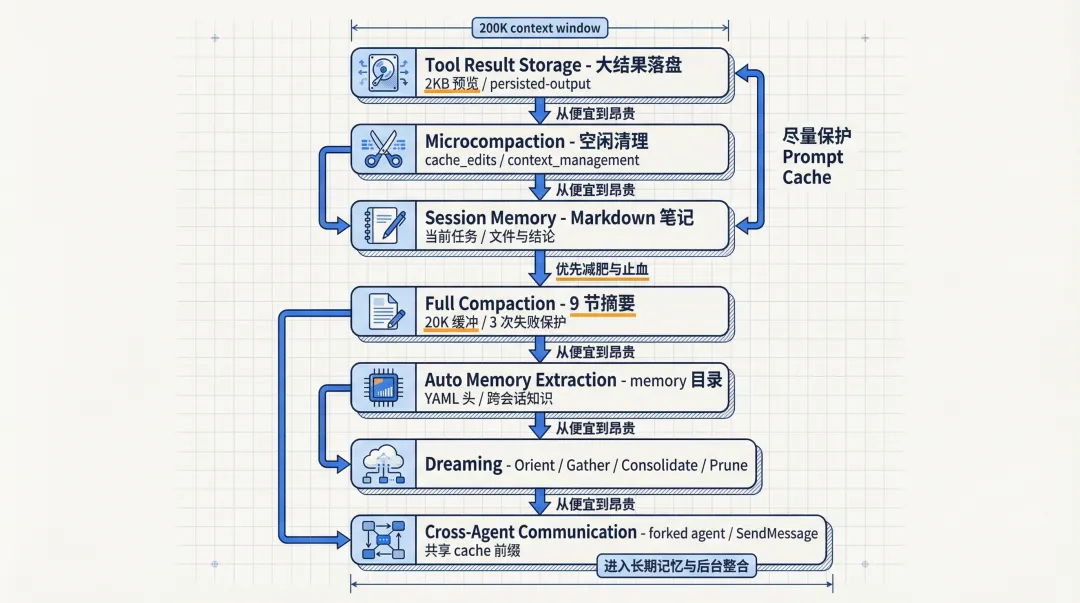
Claude Code 通常係 200K token 窗口入面做嘢,就算帶埋更大嘅上下文,問題都唔會消失。因為寫 code 唔係靜態閲讀,而係不斷讀文件、行 command、試錯、回滾、再試一次。一個大 repo 隨手一次 grep,返回結果隨時幾十 KB;一次大文件讀取,即刻又要食一大截預算。上下文膨脹得好快,更麻煩嘅係,呢啲內容多數幾分鐘之後就冇咁重要。
所以 Claude Code 嘅思路唔係單純「擴容」,而係先將上下文當作一個會不斷變壞嘅工作現場去管理。佢先精確估算 token,用 API 返嘅精確計數加埋後續消息嘅啟發式估算,再專門留低 20K token 做 compaction 輸出緩衝。呢個細節好關鍵,因為系統默認承認一件事:你總有需要壓縮嘅時候,唔可以將窗口用到一滴不剩。
呢 7 層體系,核心唔係多,而係順序要啱
如果將成套機制攤開嚟睇,會發現佢唔係七個排平嘅功能點,而係一道瀑布式防線。平嘅層先擋,擋唔住先輪到貴嘅層。
第 1 層到第 3 層,先將噪音擋喺外面
第一層係 Tool Result Storage。大結果唔直接塞滿上下文,而係即刻落盤,正文入面只留大約 2KB 預覽同一個 <persisted-output> 標記。之後真係要睇全文,先用 Read 呢啲工具按需攞返。呢個設計睇落簡單,但殺傷力好大,因為佢直接攔住咗最容易失控嗰部分輸入。
第二層係 Microcompaction。佢唔做總結,只做清理。Claude Code 會喺每一輪調用前掃一次舊工具結果,判斷邊啲嘢已經過時,可以從緩存側刪走或者從上下文清空。最靚嘅地方係 cache_edits:本地消息唔改,服務器緩存前綴照樣命中,但舊工具結果已經被剔除咗。寫呢塊嘅人顯然好清楚,真正貴嘅唔係「刪唔刪」,而係「刪完會唔會打散 prompt cache」。
第三層係 Session Memory。系統會持續維護一份結構化 Markdown 筆記,將當前任務狀態、關鍵文件、踩過嘅坑同已經得出嘅結論慢慢寫入去。咁樣當上下文真係去到 threshold 嘅時候,佢唔使臨時開一個貴嘅總結流程,直接將現成筆記塞返去就得。講白啲,呢種係邊做嘢邊寫工作日誌嘅做法,蠢,但好有效。
去到第 4 層,先輪到真正嘅「大壓縮」
只有前面嘅平價方法都唔夠用,Claude Code 先會觸發 Full Compaction。呢度佢會 fork 一個專門嘅 summarizer agent,按固定結構生成摘要,再將最近文件、技能、計劃呢啲關鍵上下文重新注入主會話。連失敗保護都做得好實在:連續 3 次失敗,就停止自動壓縮,避免將同一個錯誤無限放大。
呢一層令我印象最深刻嘅,唔係摘要寫得有幾靚,而係佢一直喺度保護系統繼續做嘢。Compaction 喺呢度唔係「整理筆記」咁文藝,而係一次明確嘅續命操作。只要會話仲可以繼續行,摘要就算完成咗任務。
第 5 層到第 7 層,先算真正進入「記憶系統」
第五層 Auto Memory Extraction,開始將一次會話入面嘅有效結論抽出來,儲存成跨會話可用嘅知識。佢明確排除咗啲可以從 code 本身推導出嚟嘅嘢,避免將 memory 目錄變成另一份 repo 副本。呢個邊界劃得好啱。真正值得留低嘅,唔係「個 project 入面有個 utils.ts」,而係「呢個用戶更關心集成測試,唔信 mock」呢啲以後會持續影響決策嘅資訊。
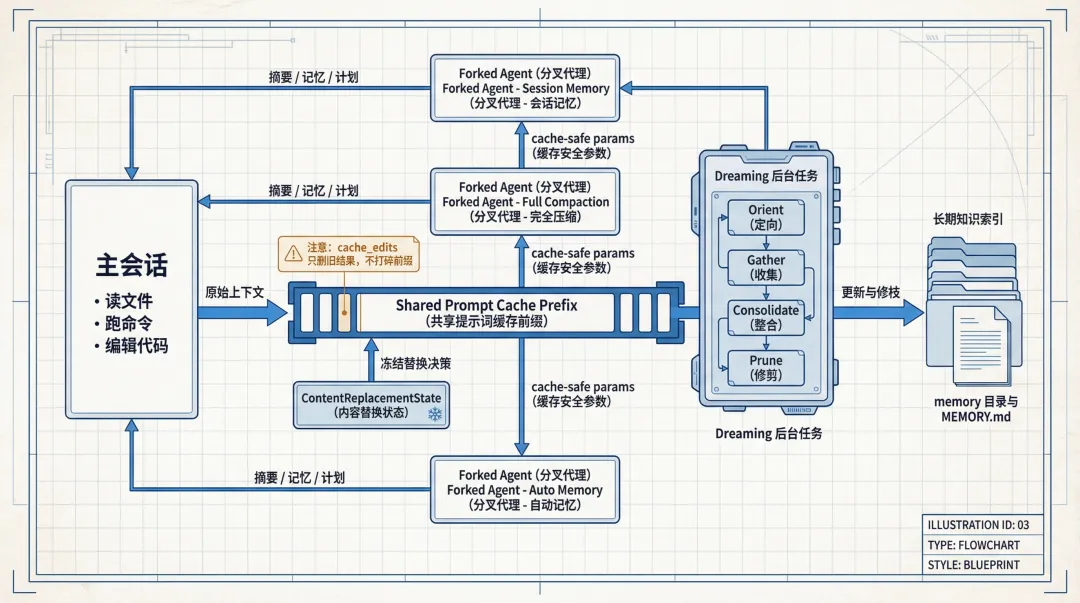
第六層 Dreaming 更加有趣。佢會喺後台用四個階段做記憶整合:Orient、Gather、Consolidate、Prune。先睇現有記憶,再攞最近信號,再合併修正,最後修枝同更新索引。呢個名改得好花巧,但實現其實相當剋制。只讀工具限制、鎖文件、崩潰恢復、超時回收,一樣都冇少。講白啲,佢就係後台夜晚當值嗰套流程。
第七層 Cross-Agent Communication 就將成件事閉環咗。無論係 session memory、full compaction,定係 dreaming,本質上都係靠 forked agent 去做。子 Agent 拎到隔離嘅可變狀態,避免搞污糟主線程;同時又盡量共享 prompt cache 前綴,避免每次開一個子任務就要重新畀一次上下文成本。呢種「狀態隔離,但緩存共享」嘅平衡感,係成個系統最老練嘅地方。
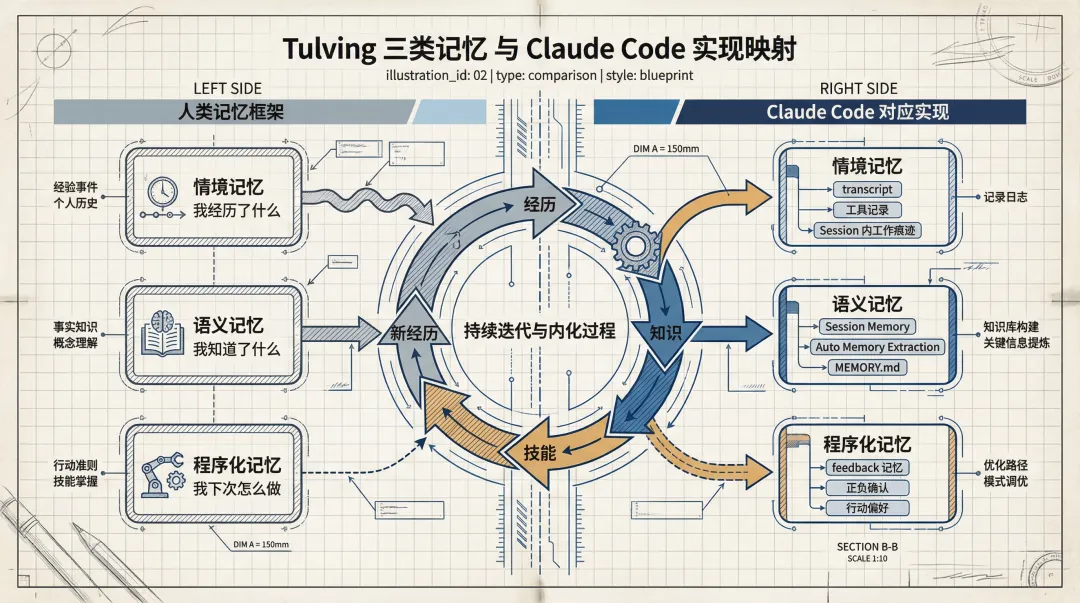
如果借用記憶理論嚟睇,呢套設計就更加清楚
Tulving 當年將記憶分成情境記憶、語義記憶同程序化記憶。呢個框架放喺 Claude Code 身上,幾乎係一一對應嘅。
對話 transcript、工具調用記錄、session 入面嘅工作痕跡,都係情境記憶。佢哋記錄嘅係「發生過啲乜」。Session Memory 同 Auto Memory Extraction 更加似語義記憶,佢哋將零散經歷蒸餾成可以重複用嘅規律,記錄嘅係「我知道咗啲乜」。而 feedback 呢類帶有正負校正意思嘅長期記憶,就明顯接近程序化記憶,記錄嘅係「下次應該點做、唔好點做」。
好多記憶框架淨係肯保存負反饋,怕 Agent 再犯錯。Claude Code 呢點反而做得更加似真實團隊合作:用戶明確肯定過嘅方法,一樣值得沉澱。因為一個系統如果淨係記得啲乜唔做得,最後往往會越嚟越保守;佢仲要知邊啲做法係被驗證過嘅,先可以真正將經驗變成動作。
佢當然都唔完美,而且弱點唔難揾
如果攞佢同 EverMemOS、MemOS、Zep、Mem0 呢啲長期記憶框架正面硬碰,Claude Code 並唔佔優。佢冇強語義召回,memory 文件數量都有硬上限,遺忘同整合策略都相對粗。好多記憶仍然係「文件嘅集合」,仲未做到成熟嘅關聯網絡。
但呢啲正正暴露咗 Anthropic 嘅取捨。佢冇將 Claude Code 推向「全量記憶操作系統」嗰條路,而係堅持將佢做成一個執行型 Agent。對呢類產品嚟講,睇清曬成個世界唔係第一優先,持續做到手頭上嘅任務先係。內存管理、緩存命中、會話唔中斷,呢啲工程細節比「記住一切」更加值錢。
OpenClaw 嘅路線啱啱好用嚟做對比。佢更加關心「記憶幾時應該被拉返入嚟」,所以會刻意將記憶分層收斂;Claude Code 就更似一個喺現場排障嘅工程師,一邊睇,一邊改,一邊行,再根據結果修正下一步。佢需要嘅唔係百科全書式大腦,而係一套唔好喺關鍵時刻失憶嘅機制。
最值得學嘅,其實唔係 Dreaming,而係嗰種成本順序
好多人見到 Claude Code 嘅 dreaming,會本能咁將注意力放喺「長期記憶鞏固」呢幾個字。但我覺得真正值得抄作業嘅,係佢嗰套極度樸素嘅優先級:能落盤就唔好入上下文,能微清理就唔好做摘要,能用現成 session memory 就唔好開新 summarizer,能後台做嘅嘢就唔好塞住前台。
呢個亦係點解我睇完之後,反而不太想將佢誇成一個「記憶好強」嘅系統。我更願意將佢睇成一套成熟嘅防遺忘機制。對 code Agent 嚟講,呢樣嘢往往比識得講幾多大道理更加重要。多數真實任務輸嘅唔係思考能力唔夠,而係做到一半,將前面已經諗明咗嘅嘢唔見咗。
真正拉開 Agent 差距的,往往是它會不會忘。模型當然重要,但代碼任務一旦拉長,文件越讀越多,grep 結果越翻越厚,幾十輪對話以後,模型很容易把真正重要的上下文和一堆臨時噪音混在一起。Claude Code 這次泄露出來的 harness,最值得看的恰恰是這部分: 它沒把“記憶”理解成一個豪華數據庫,而是拆成了一套從便宜到昂貴、從前台到後台的分級系統。
我看完整體實現後的第一感受很直接: 這套東西寫得非常工程化。它不追求“記住一切”的浪漫敍事,而是在每一步都問同一個問題: 這次有沒有更便宜的辦法,先別把成本抬上去。於是你會看到一個很有層次感的設計,前幾層負責減肥和止血,後幾層才負責整理、沉澱和長期鞏固。dreaming 這個名字聽着玄乎,其實就是後台版的記憶整固。
Claude Code 通常工作在 200K token 窗口裏,哪怕帶上更大的上下文,問題也不會消失。因為寫代碼不是靜態閲讀,而是不斷讀文件、跑命令、試錯、回滾、再試一次。一個大倉庫裏隨手一次 grep,返回結果就可能是幾十 KB;一次大文件讀取,馬上又要吃掉一大截預算。上下文膨脹得很快,更麻煩的是,這些內容大多幾分鐘後就沒那麼重要了。
所以 Claude Code 的思路不是單純“擴容”,而是先把上下文當作一個會不斷腐敗的工作現場來管理。它先精確估算 token,用 API 返回的精確計數加上後續消息的啓發式估算,再專門預留 20K token 作為 compaction 輸出緩衝。這個細節很關鍵,因為系統默認承認一件事: 你總有需要壓縮的時候,不能把窗口花到一滴不剩。
這 7 層體系,核心不是多,而是順序對了
如果把整套機制攤開看,會發現它不是七個平鋪的功能點,而是一道瀑布式防線。便宜的層先擋,擋不住才輪到更貴的層。
第 1 層到第 3 層,先把噪音擋在外面
第一層是 Tool Result Storage。大結果不直接塞滿上下文,而是立即落盤,正文裏只保留大約 2KB 預覽和一個 <persisted-output> 標記。後面真要看全文,再用 Read 之類的工具按需取回。這個設計看起來樸素,殺傷力卻很大,因為它直接攔住了最容易失控的那部分輸入。
第二層是 Microcompaction。它不做總結,只做清理。Claude Code 會在每輪調用前掃一遍舊工具結果,判斷哪些東西已經過時,可以從緩存側刪掉或從上下文裏清空。最漂亮的地方是 cache_edits: 本地消息不改,服務器緩存前綴照樣命中,但舊工具結果已經被剔出去了。寫這塊的人顯然非常清楚,真正貴的不是“刪不刪”,而是“刪完會不會把 prompt cache 打碎”。
第三層是 Session Memory。系統會持續維護一份結構化 Markdown 筆記,把當前任務狀態、關鍵文件、踩過的坑和已經得出的結論慢慢寫進去。這樣當上下文真的逼近閾值時,它不必臨時開一個高成本總結流程,直接把現成筆記塞回去就行。說白了,這是一種邊幹活邊記工作日誌的做法,笨,但非常有效。
到了第 4 層,才輪到真正的“大壓縮”
只有前面的便宜辦法都不夠了,Claude Code 才會觸發 Full Compaction。這裏它會 fork 一個專門的 summarizer agent,按固定結構生成摘要,再把最近文件、技能、計劃這些關鍵上下文重新注回主會話。連失敗保護都做得很實在: 連續 3 次失敗,就停止自動壓縮,避免把同一個錯誤無限放大。
這一層讓我印象最深的,不是摘要寫得多漂亮,而是它始終在保護系統繼續工作。Compaction 在這裏不是“整理筆記”那麼文藝,而是一次明確的續命操作。只要會話還能繼續跑,摘要就算完成了任務。
第 5 層到第 7 層,才算真正進入“記憶系統”
第五層 Auto Memory Extraction,開始把一次會話裏的有效結論抽出來,存成跨會話可用的知識。它明確排除那些能從代碼本身推導出的東西,避免把 memory 目錄寫成另一份倉庫副本。這個邊界劃得很對。真正值得留下的,不是“項目裏有個 utils.ts”,而是“這個用戶更在意集成測試,不信任 mock”這種以後會持續影響決策的信息。
第六層 Dreaming 更有意思。它會在後台用四個階段做記憶整合: Orient、Gather、Consolidate、Prune。先看現有記憶,再抓最近信號,再合併修正,最後修枝和更新索引。這個名字取得很花哨,但實現其實相當剋制。只讀工具限制、鎖文件、崩潰恢復、超時回收,一個沒少。說白了,它就是後台值夜班那套流程。
第七層 Cross-Agent Communication 則把整件事閉環了。無論是 session memory、full compaction,還是 dreaming,本質上都靠 forked agent 去做。子 Agent 拿到隔離的可變狀態,避免把主線程弄髒;同時又儘量共享 prompt cache 前綴,避免每開一個子任務就重新付一遍上下文成本。這種“狀態隔離,但緩存共享”的平衡感,是整套系統最老練的地方。
如果借用記憶理論來看,這套設計就更清楚了
Tulving 當年把記憶分成情境記憶、語義記憶和程序化記憶。這個框架放到 Claude Code 身上,幾乎是一一對應的。
對話 transcript、工具調用記錄、session 內的工作痕跡,都是情境記憶。它們記錄的是“發生過什麼”。Session Memory 和 Auto Memory Extraction 更像語義記憶,它們把零散經歷蒸餾成可以複用的規律,記錄的是“我知道了什麼”。而 feedback 這類帶有正負校正意味的長期記憶,則明顯接近程序化記憶,記錄的是“下次該怎麼做、不要怎麼做”。
很多記憶框架只願意保存負反饋,生怕 Agent 再犯錯。Claude Code 這點反而做得更像真實團隊協作: 用戶明確肯定過的方法,同樣值得沉澱。因為一個系統如果只記得什麼不能做,最後往往會越來越保守;它還得知道哪些做法是被驗證過的,才能真正把經驗變成動作。
它當然也不完美,而且弱點並不難找
如果拿它去和 EverMemOS、MemOS、Zep、Mem0 這類長期記憶框架正面硬碰,Claude Code 並不佔優。它沒有強語義召回,memory 文件數量也有硬上限,遺忘和整合策略也相對粗。很多記憶仍然是“文件的集合”,還談不上成熟的關聯網絡。
但這恰恰暴露了 Anthropic 的取捨。它沒有把 Claude Code 往“全量記憶操作系統”那條路推,而是堅持把它做成一個執行型 Agent。對這種產品來說,看清全部世界並不是第一優先級,持續把手頭任務做下去才是。內存管理、緩存命中、會話不中斷,這些工程細節比“記住一切”更值錢。
OpenClaw 的路線剛好能拿來做對照。它更關心“記憶什麼時候該被拉進來”,所以會刻意把記憶分層收斂;Claude Code 則更像一個正在現場排障的工程師,一邊看,一邊改,一邊跑,再根據結果修正下一步。它需要的不是百科全書式大腦,而是一套別在關鍵時刻失憶的機制。
最值得學的,其實不是 Dreaming,而是那種成本順序
很多人看到 Claude Code 的 dreaming,會本能地把注意力放在“長期記憶鞏固”這幾個字上。但我覺得真正值得抄作業的,是它那套極度樸素的優先級: 能落盤就別進上下文,能微清理就別做摘要,能用現成 session memory 就別新開 summarizer,能後台乾的事就別堵住前台。
這也是為什麼我看完以後,反而不太想把它誇成一個“記憶很強”的系統。我更願意把它看成一套成熟的防遺忘機制。對代碼 Agent 來說,這往往比會講多少大道理更重要。多數真實任務輸的不是思考能力不夠,而是做到一半,把前面已經想明白的東西弄丟了。