看懂這 20 個概念,你就會用市面上所有AI產品
整理版優先睇
掌握呢20個AI核心概念,由神經網絡到擴散模型,一次搞懂所有AI產品嘅底層邏輯。
呢篇文章係由Rahul喺Twitter上整理嘅,佢將現代AI產品背後嘅20個核心概念一次過解釋清楚。作者嘅目標係幫讀者由基礎開始,逐步理解神經網絡、Transformer呢啲技術點樣構成今日嘅AI產品,並帶出「搞懂呢啲概念,你就會用市面上所有AI產品」嘅結論。
文章分為四大部分,由AI嘅基本運作原理(神經網絡、分詞、向量、注意力、Transformer),到聊天背後嘅機制(LLM、上下文窗口、温度、幻覺、提示詞工程),再到模型進階訓練(遷移學習、微調、RLHF、LoRA、量化),最後係真實產品搭建(RAG、向量數據庫、AI Agent、思維鏈、擴散模型)。每部分都解釋咗一個關鍵概念,仲附有簡單例子,令讀者容易理解。
整體嚟講,呢篇文章係一份好實用嘅AI入門指南,尤其適合想深入瞭解AI點樣運作嘅人。文中冇過多嘅技術細節,但用生活化例子同直接嘅講法,將複雜概念變得易明。
- 結論:AI產品底層都係由呢20個概念支撐,理解佢哋就能掌握所有AI產品嘅運作邏輯。
- 方法:透過分詞、向量、注意力機制,AI能夠有效率咁處理人類語言。
- 差異:提示詞工程只係臨時指令,微調先係直接改變模型性格嘅方法,兩者用途唔同。
- 啟發:AI嘅「幻覺」源於佢只係玩接龍,唔識分辨真假,所以要搭RAG補足。
- 可行動點:日常使用AI時,可以調整温度、善用提示詞工程、同埋結合RAG同向量數據庫提升準確度。
AI嘅基礎運作原理
神經網絡係AI嘅「大腦」,由一層層小開關組成,每個開關掛住一個叫「權重」嘅數字。訓練就係畀佢睇幾億個例子,等佢自己反覆試錯,調整呢啲權重。GPT-4有1.8萬億個權重,所以訓一次要燒幾百萬美元。
分詞(Tokenization)係將句子拆成碎片,例如「你好」變成「你」「好」「,」。呢啲碎片叫token,係AI能識別嘅最小單位。英文都一樣,'playing'會切做'play'加'ing'。
每個字入到模型都會被翻譯成一串數字,叫向量(Embedding),代表佢嘅「含義座標」。醫生同護士喺呢個坐標繫好近,醫生同披薩就好遠。一個經典例子:國王減男人加女人約等於女王。
Transformer係GPT、Claude、Gemini等大模型嘅共同架構,出自2017年論文《Attention Is All You Need》。工作流程:文本切token→token轉embedding→喂入多層注意力→最後輸出。淺層管語法,中層管詞關係,深層管推理。
同AI傾偈時,佢腦入面發生嘅事
LLM(大語言模型)由頭到尾只學咗一件事:預測下一個字。灌入幾萬億個token之後,模型自己「湧現」出語法、推理、寫code、翻譯等能力。ChatGPT、Claude、Gemini都係咁樣燒出嚟嘅。
上下文窗口(Context Window)係AI嘅腦容量上限。GPT-4有12.8萬token,Claude 3.5有20萬,Gemini 1.5 Pro直接100萬。但就算窗口夠大,模型只記得開頭同結尾,中間會Lost in the Middle。
- 温度(Temperature)係控制創意嘅旋鈕:0最保守,1開始調皮,2以上亂噏。寫code、查事實要調低;寫文、腦暴就拉高。
- 幻覺(Hallucination)係模型玩接龍唔睇真假,會作啲唔存在嘅嘢出嚟。所以涉及事實最好用RAG兜底。
- 提示詞工程(Prompt Engineering)係點樣問問題嘅學問:交代背景、設角色、俾例子、講輸出格式、拆步驟,就係溝通基本功。
温度等於0時模型最保守,結果最穩定;等於1時開始有啲創意;拉到2以上基本係胡言亂語。
點樣令模型越練越聰明
遷移學習(Transfer Learning)令獨立開發者都可以搞出AI應用,因為唔使由零開始訓。拎住預訓練好嘅半成品,加啲自己嘅數據再行一公里就搞掂。
微調(Fine-Tuning)係用自己嘅數據繼續訓練模型,等佢由通才變專才。例如將GPT微調成自家客服版本,或者令Llama專寫SQL。提示詞係臨時指令,微調係直接改性格。
- 1 RLHF(基於人類反饋嘅強化學習):人類標註員幫模型回答打分,訓練出獎勵模型,再用強化學習將主模型推向人類喜好。冇RLHF就冇今日嘅ChatGPT同Claude。
- 2 LoRA(低秩適配):主模型唔鬱,外掛細細個補丁矩陣,只調補丁,參數量少過1%,效果接近全量微調。一張4090就搞得掂。
- 3 量化(Quantization):將權重由32位壓縮到16、8甚至4位,體積大減,速度提升,效果只損失少少。一個70B嘅Llama量化到4位後,35GB就夠,Mac Mini都跑到。
真實AI產品係點樣搭建
向量數據庫(Vector Databases)存嘅係embedding,查嘅係「含義相近」嘅向量,唔係關鍵詞匹配。Pinecone、Weaviate、Qdrant呢啲工具係RAG系統嘅地基,係大模型時代新嘅硬碟。
AI Agent(智能體)係可以自己規劃、調用工具、採取行動、觀察結果、再決定下一步嘅「打工機器」。Cursor可以自己改code,Devin可以自己跑項目,2024年AI公司都喺度卷呢個方向。
- 思維鏈(Chain of Thought):叫AI「一步一步想」先畀答案,正確率即刻提升。OpenAI o系列、Claude擴展思考、DeepSeek R1都用緊進化版。
- 擴散模型(Diffusion Models):先教AI點樣毀掉一張圖(加噪音),再反過來學還原。Stable Diffusion、Midjourney、DALL-E、Sora都係呢條路線。
作者:Rahul
來源:https://x.com/sairahul1/status/2057740928908161461?s=20

你每日都用AI,但係你真心知唔知佢點樣運作㗎?
佢點解成日唔記得你講過嘅嘢?點解夠膽作啲根本唔存在嘅論文出嚟?ai編程憑咩可以自己改你嘅代碼?
呢啲問題背後,係20個你避唔開嘅概念。
睇完呢篇文章,你就會明曬所有AI產品嘅底層邏輯!
第一部分:AI到底係點樣運作㗎
1. 神經網絡(Neural Networks)
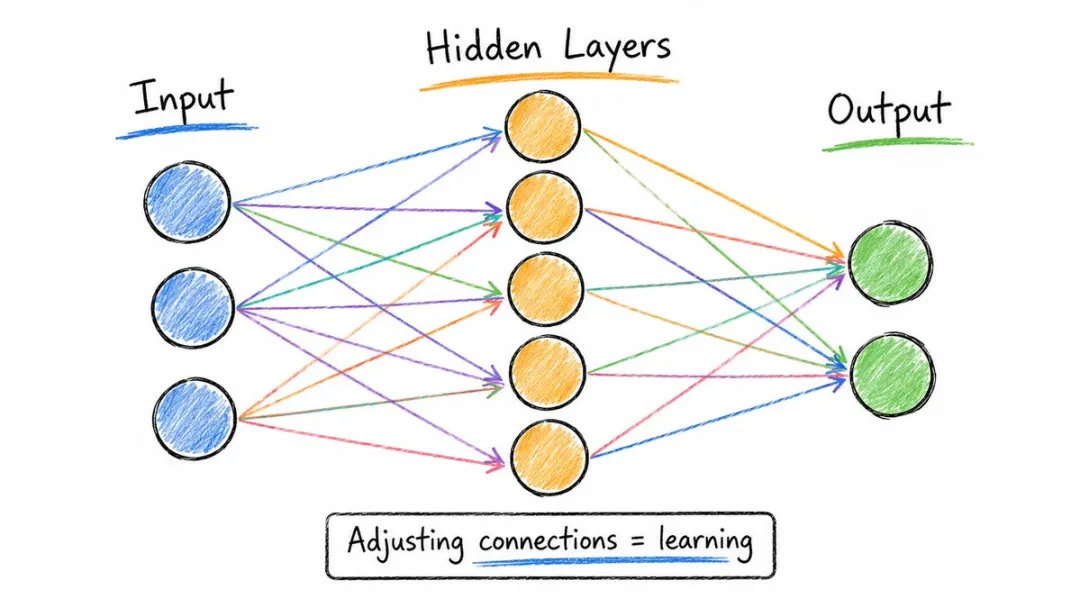
憑咩一部機器可以好似一個人咁同你傾偈?講到尾,靠嘅係佢嘅「大腦」,亦即係神經網絡。
但係呢個腦同你諗嘅完全唔一樣,佢係一層一層疊起嚟嘅細開關,每個開關上邊掛住一個叫「權重」嘅數字。
你俾佢一句話,訊號就沿住開關一路串落嚟,最後吐出一個回答。
所謂訓練,就係俾佢睇幾億個例子,叫佢自己反覆試錯,將呢幾十億個數字慢慢調到可以猜啱為止。
GPT-4 嘅腦入面掛住1.8萬億個咁嘅細數字,呢個亦都係點解訓練一次佢就要燒掉幾百萬美金。
2. 分詞(Tokenization)
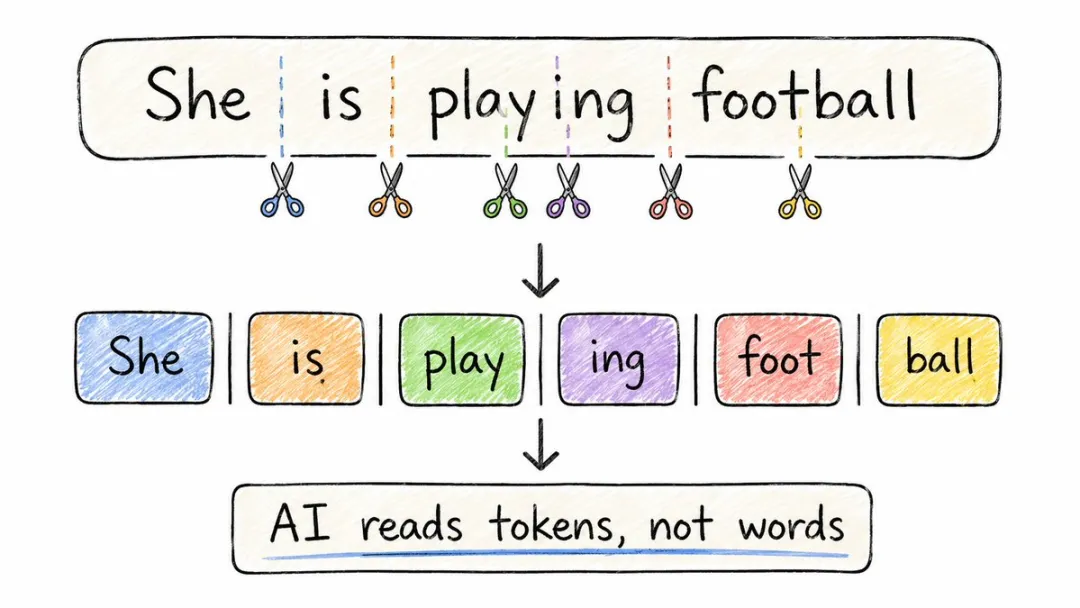
你以為 ChatGPT 收到嘅係「你好,今日天氣點樣呀?」
其實唔係。
佢見到嘅係一堆碎片:「你」「好」「,」「今日」「天氣」「點樣」。
每一片都叫一個 token,係 AI 可以識別嘅最細單位。
英文都一樣會被切開,playing會俾人切成play加ing,ChatGPT會俾人切成Chat加G加PT,
得dog呢啲短詞先會保持原樣。
點解唔直接按成個詞嚟?
因為人類語言本身就好亂,新詞出得快,錯別字一大堆,仲有中英混住用,要列一張可以裝得曬所有詞嘅詞典,根本唔現實。
改用碎片之後,就算模型從來未見過某個新詞,都可以拆成熟悉嘅細塊湊出意思。
換算公式瞭解下就得:1000個token大約等於750個英文詞。
下次再見到 API 按 token 報價,個心就唔會矇查查。
3. 向量(Embeddings)
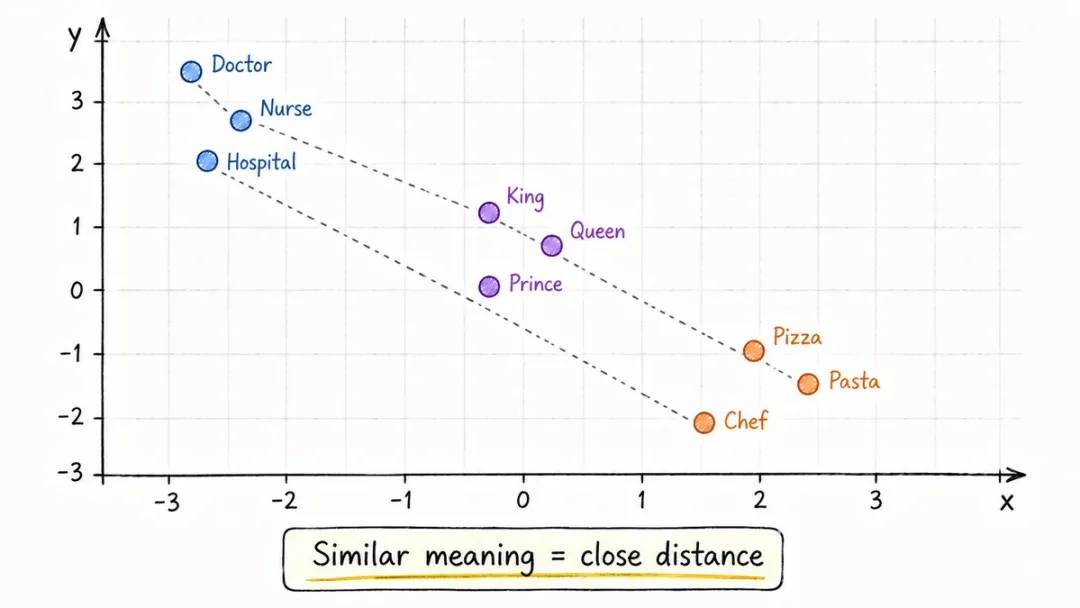
AI 憑咩可以分辨「醫生」同「護士」係同一類嘢,而「醫生」同「pizza」就完全冇關係?
因為每個字入咗模型,都會俾人翻譯成一串數字。
這串數字就係佢嘅「含義座標」,技術上叫 embedding。
你可以將所有詞想像成俾人釘喺一張超高維度嘅地圖上面。
醫生同護士黐得好近,醫生同pizza就隔咗十萬八千里。
仲有一個好神奇嘅現象,將「國王」嘅座標減走「男人」再加上「女人」,得到嘅位置竟然大約等於「女王」。
模型並唔似你咁讀明一個詞,佢讀嘅係詞與詞之間嘅距離同方向。
所有睇落好似「明你意圖」嘅產品,無論係語義搜索、商品推薦定係AI客服,底層行嘅都係呢一套向量。
4. 注意力(Attention)
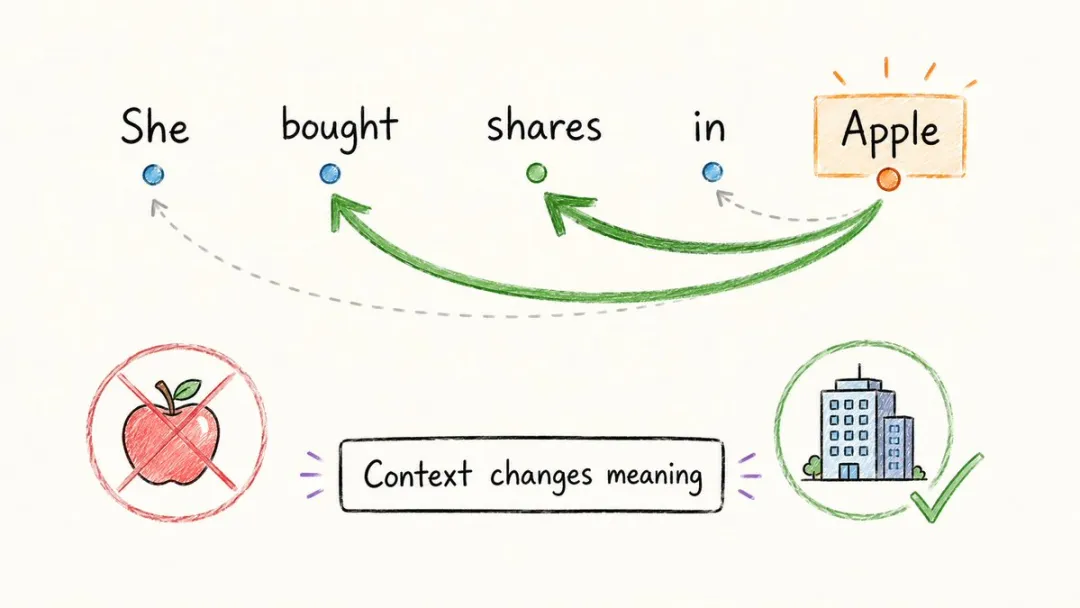
同一個「蘋果」,意思可能完全唔一樣,AI 憑咩可以分清楚你講緊嘅係生果定係公司?
「我食咗一個蘋果」入面佢係生果,「我買咗蘋果嘅股票」入面佢係公司。
淨係靠 embedding 係分唔到㗎,要叫「注意力」出馬。
注意力嘅作用,係令句子入面嘅每個詞都回頭睇一睇其他詞,再判斷邊啲同自己最相關。
喺「佢買咗蘋果嘅股票」入面,「蘋果」會將注意力集中喺「買」同「股票」上面,模型即刻就明:呢個係公司,唔係生果。
注意力出現之前,AI 只能一個字一個字咁往後讀,又慢又蠢。
有咗佢之後,模型一口氣就可以將成句話睇曬。
就係呢一個想法,撐起咗今日成個AI時代。
5. Transformer
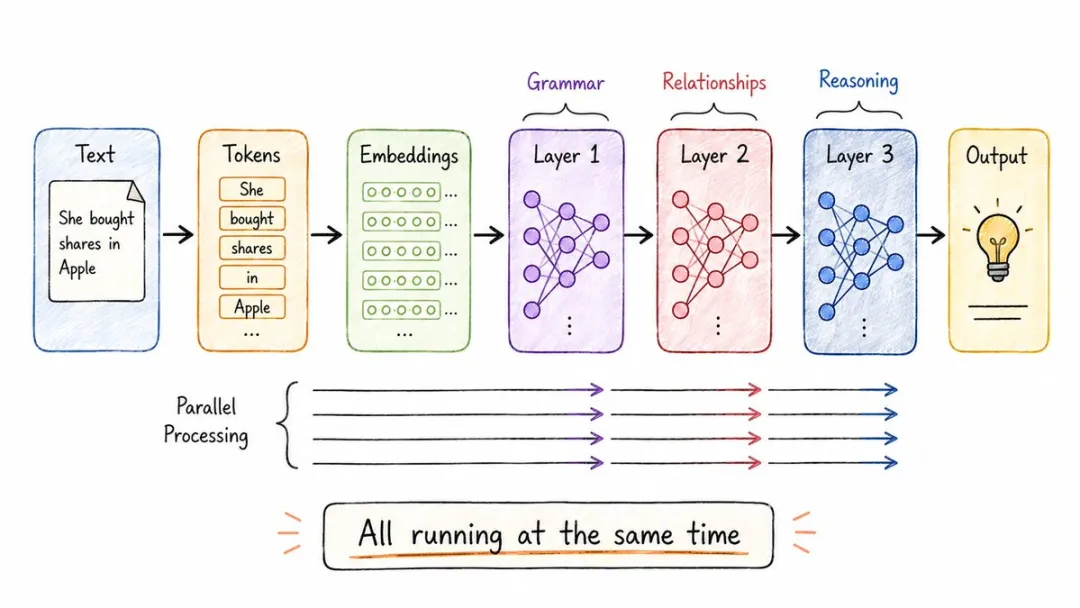
GPT、Claude、Gemini、Llama、Mistral,只要你叫得出名嘅大模型,背後用嘅其實都係同一套架構,叫 Transformer。
佢出自2017年嗰篇俾人引用到癲嘅論文《Attention Is All You Need》,核心思路就係我哋上面提到嘅內容:
唔好再一個字一個字咁讀,用注意力一口氣並行處理整段文本。
呢個就係AI嘅工作流程,講起嚟好簡單,文本先切成token,token翻譯成embedding,再餵入一層層疊起嚟嘅注意力,最後吐出輸出。
每一層負責嘅嘢都唔一樣,淺層管語法,中層管詞與詞嘅關係,深層就開始做推理呢種重功夫。
搞掂呢一個架構,現代AI你就明咗一大半。
第二部分:你同AI傾偈嗰時,佢個腦入面喺度做咩
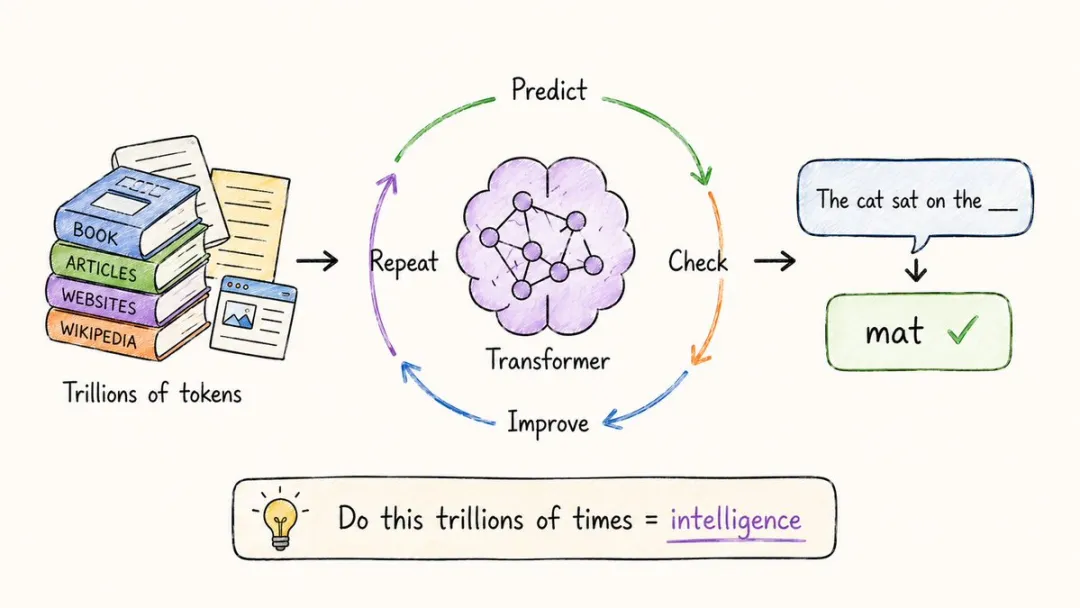
6. LLM(大語言模型)
冇人單獨教過 ChatGPT 點樣傾偈,但佢會傾;冇人教過佢寫代碼,但佢會寫;冇人教過佢做翻譯,但佢識翻。
呢個係點樣一回事?
講出嚟你可能唔信,佢由頭到尾只係學咗一件事,就係預測下一個字。
向一個 Transformer 度灌幾萬億個 token,書、網頁、代碼、維基百科、Reddit 全部塞曬入去,叫佢一路玩「猜下一個字」。
等訓練規模大到某個程度,神奇嘅事情就發生咗,模型自己悟出咗語法、推理、寫代碼、做翻譯、解數學題。
呢種「冇人教過但自己識咗」嘅現象,有個專門嘅名,叫「湧現」。
ChatGPT、Claude、Gemini,全部都係呢條路行出嚟嘅。
幾千億參數起步,幾百萬美金打底,佢哋都係真係燒出嚟㗎。
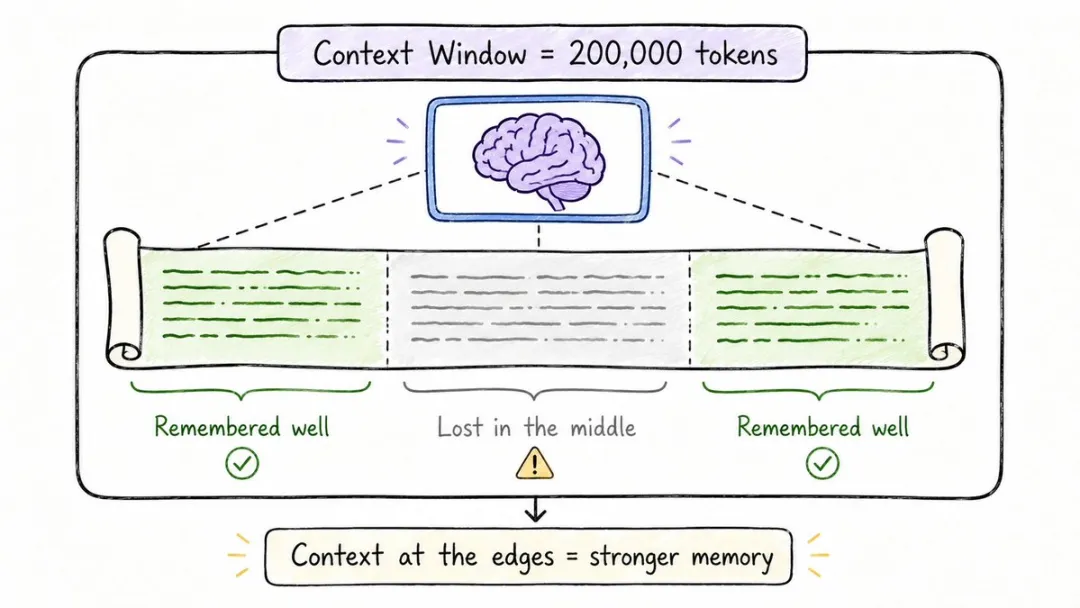
7. 上下文窗口(Context Window)
點解 ChatGPT 成日唔記得你之前講過嘅嘢?
因為佢有個叫「上下文窗口」嘅腦容量上限。
你同佢傾得太長,前面嗰段就會俾人擠出窗口外,直接失憶。
GPT-4 嘅窗口可以裝到12.8萬個token,大約等於一本中篇小說;
Claude 3.5 去到20萬;Gemini 1.5 Pro 直接去到100萬,可以塞得落七本《三體》。
但更加狗血嘅係,就算窗口夠大,模型都只係記得開頭同結尾,中間嗰段會俾人自動遺忘。
呢個現象有個名,叫 Lost in the Middle。
窗口大,並唔等於記性好,模型都係凡人。
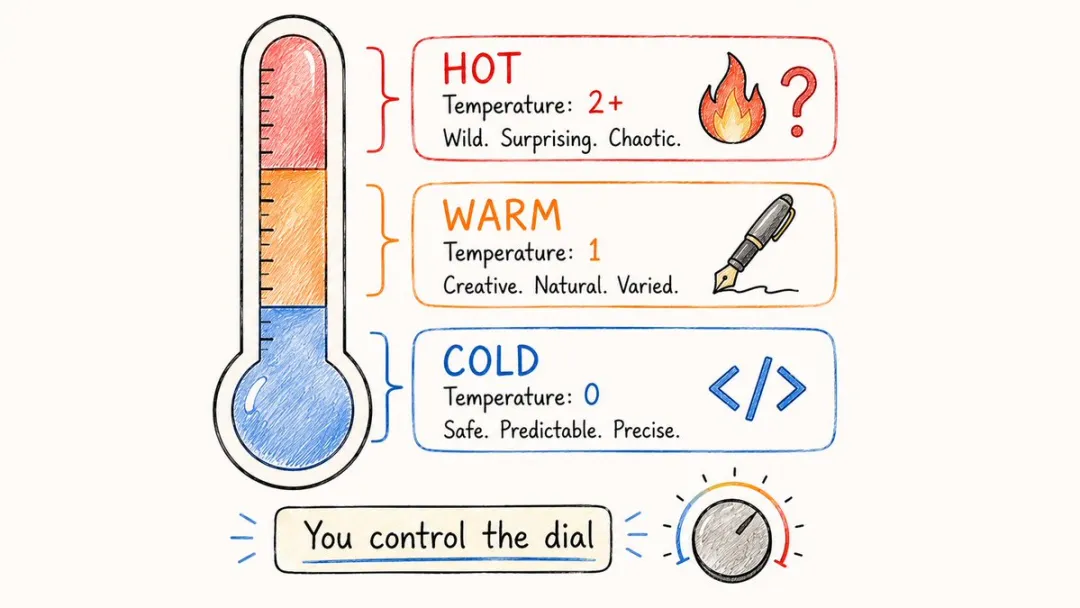
8. 温度(Temperature)
點解同一個問題,AI 有時一本正經,有時又開始放飛自我?
因為模型背後收埋咗一個用嚟調創意嘅旋鈕,叫温度。
温度等於0時佢最保守,結果最穩陣;等於1時開始有少少皮;拉到2以上基本上就係亂噏廿四。
寫代碼、查事實,將温度調低;頭腦風暴、寫文案,就將温度向上拉。
9. 幻覺(Hallucination)
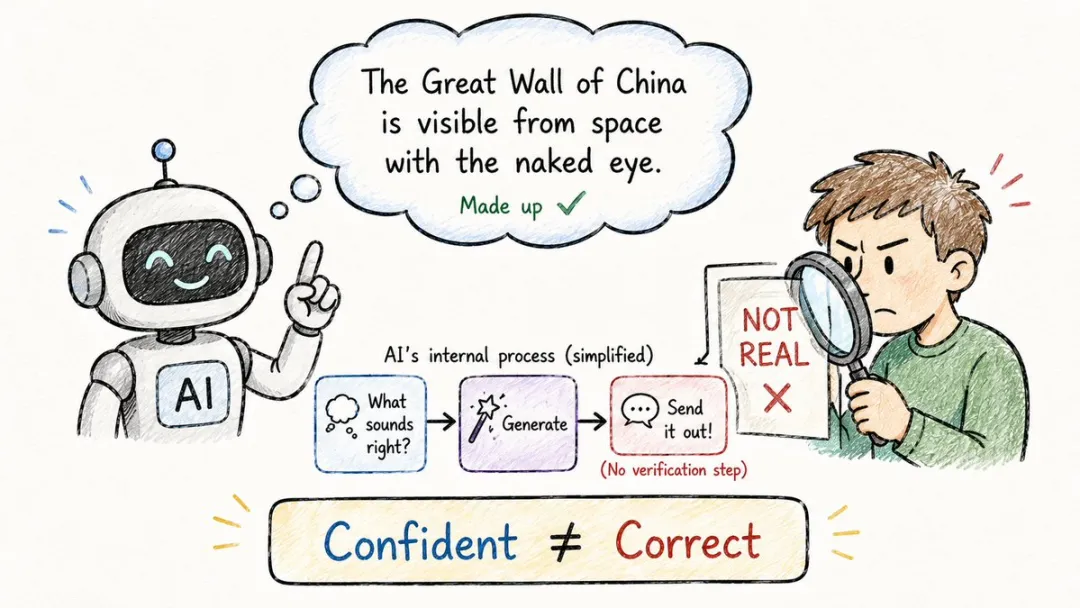
你叫 ChatGPT 俾你列三篇相關論文,佢就同你作咗三篇根本唔存在嘅,名、作者、年份仲要齊全。
點解佢夠膽咁做?
因為佢根本唔認識「真假」呢兩個字。
佢喺度玩接龍,唔係喺度查證據,只係理下一個字接落嚟順唔順口,唔理啱唔啱。
所以涉及事實嘅內容唔好全信佢,最好再搭一套RAG俾佢兜底(呢樣嘢係乜,向下睇)。
10. 提示詞工程(Prompt Engineering)
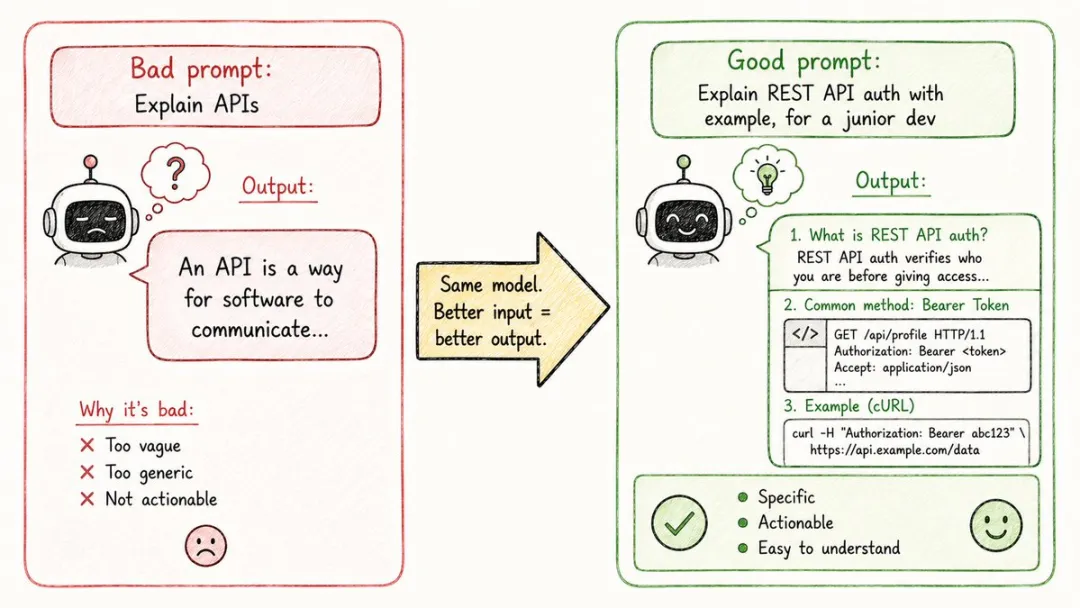
點解有人問 ChatGPT 出嚟嘅答案似廢話,有人問出嚟嘅就係乾貨?
講到尾,你點樣問,就決定咗佢點樣答。
好嘅提示詞通常會做呢幾件事:交代清楚背景,設定一個角色,舉幾個例子,說明輸出格式,將任務拆成步驟。
講穿咗就係一件事,點樣將說話講清楚。
呢個唔係AI玄學,係溝通嘅基本功。
第三部分:模型係點樣越練越聰明㗎
接下來呢五個概念,係用嚟幫模型加 buff 嘅。
11. 遷移學習(Transfer Learning)
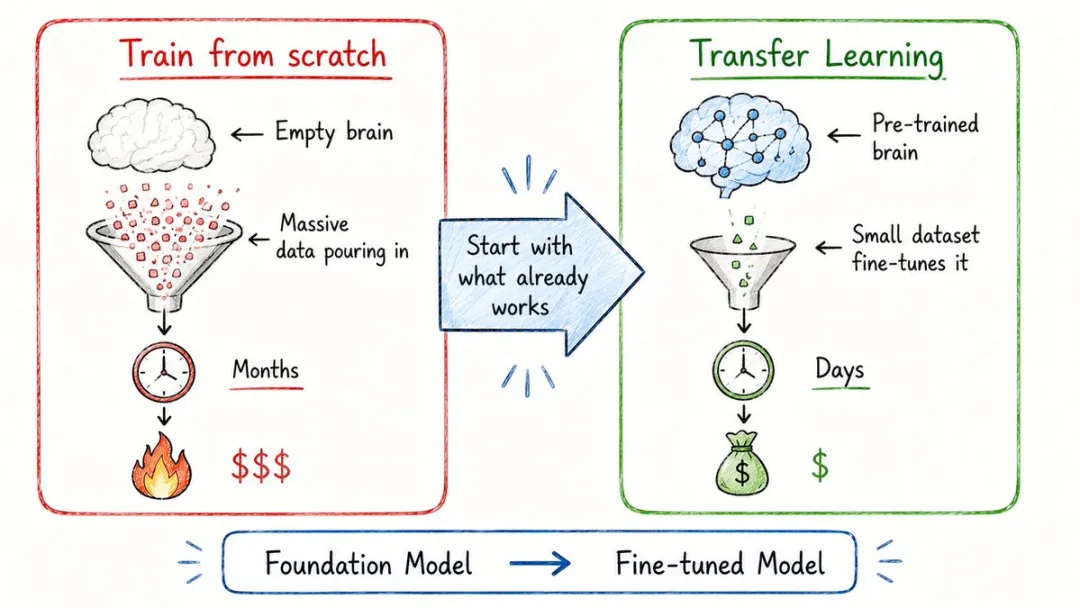
點解今日一個獨立開發者都可以整到用得嘅AI應用?因為佢根本唔使由零開始訓練。
由零開始訓練一個大模型,動輒要燒幾百萬美金、行上幾個禮拜;
但係拎一個已經訓練好嘅半成品再改造,可能幾個鐘就夠。
這就是遷移學習,人哋付出天價將通用能力訓練出嚟,你只要接手行埋最後一公里。
ImageNet上訓練出嚟嘅圖像模型,加幾張醫學影像就可以識別病灶;
BERT喺維基百科上面學到嘅語言能力,加幾千條客服對話就可以做到意圖識別。
今日Hugging Face上面幾十萬個模型,絕大多數都係企喺人哋膊頭上嘅遷移版本。
12. 微調(Fine-Tuning)
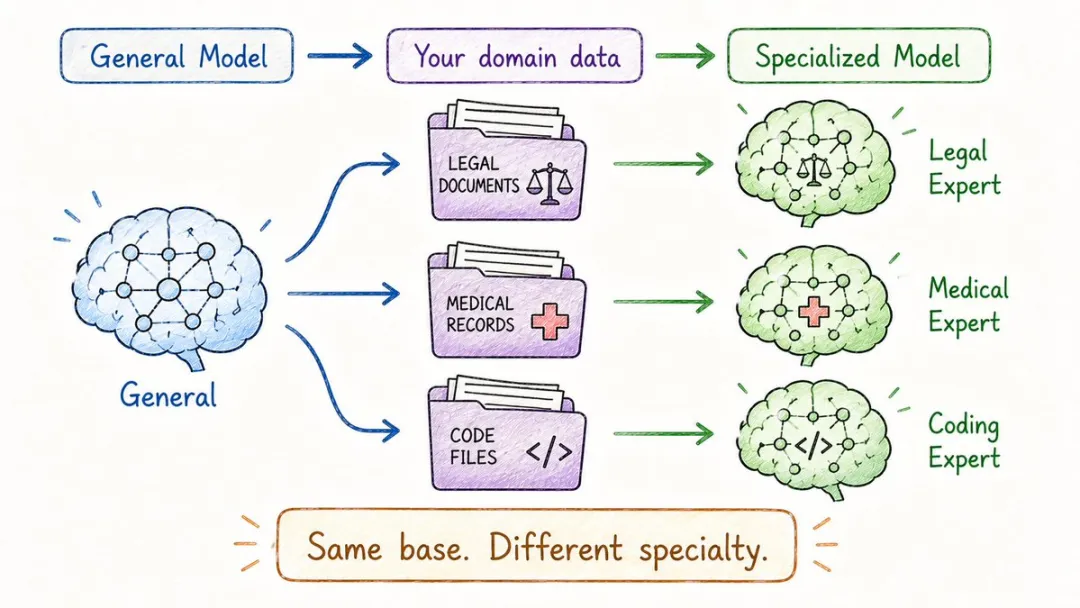
點樣令一個通用AI學識你公司嘅術語?
一個通用LLM冇讀過你公司嘅產品文檔,唔熟悉你嘅語氣,亦都答唔到你行業嘅專有名詞,呢個時候就要靠微調。
攞一個預訓練模型,再用你自己嘅數據繼續訓練一陣,令佢由通才變成專才。
例如將GPT微調成自己客服嘅專屬版本,將Llama微調成專門寫SQL嘅助手,或者叫模型只用某個作者嘅腔調講嘢。
提示詞工程只係臨時俾指令,微調就係直接改佢嘅性格,前者輕便,後者可靠。
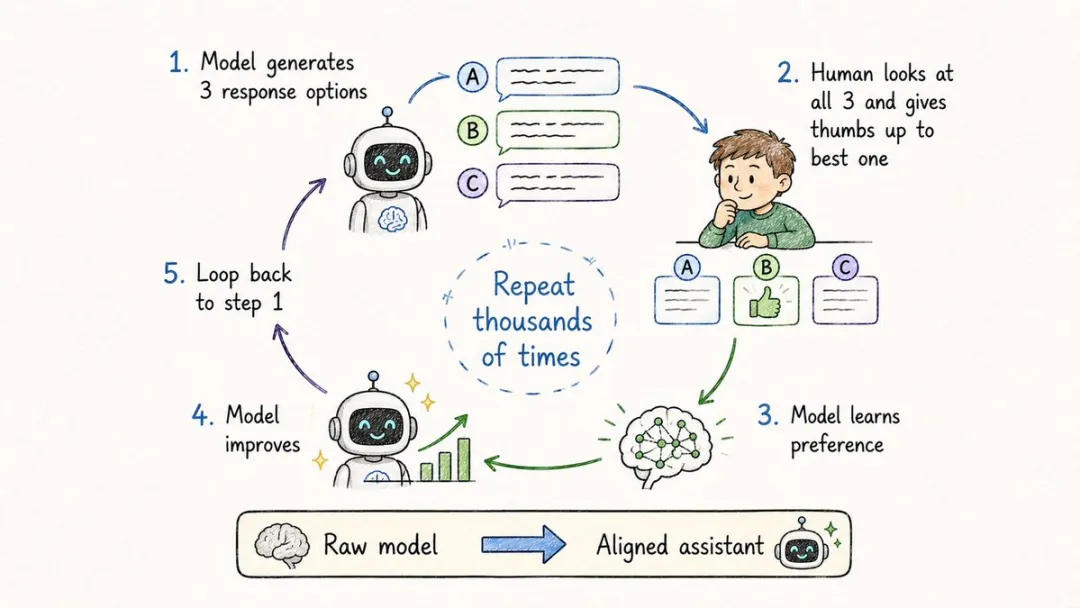
13. RLHF(基於人類反饋的強化學習)
點解ChatGPT睇起上嚟咁有禮貌、會拒絕越界請求、講嘢仲好似個人?
因為佢俾一種叫 RLHF 嘅方法狠狠調教過。
一個淨係識預測下一個token嘅原始大模型,本質上就係個嘴碎嘅復讀機,並唔知道點樣嘅回答更加有用、更加安全。
RLHF做嘅事,係叫一班人類標註員去幫模型嘅回答打分,再訓練出一個「獎勵模型」代替人類繼續打分,
最後用強化學習不停推住主模型向人類鍾意嘅方向調整。
冇RLHF,就冇今日嘅ChatGPT同Claude。
某種意義上嚟講,係RLHF將統計模型變成咗可以打工嘅助手。
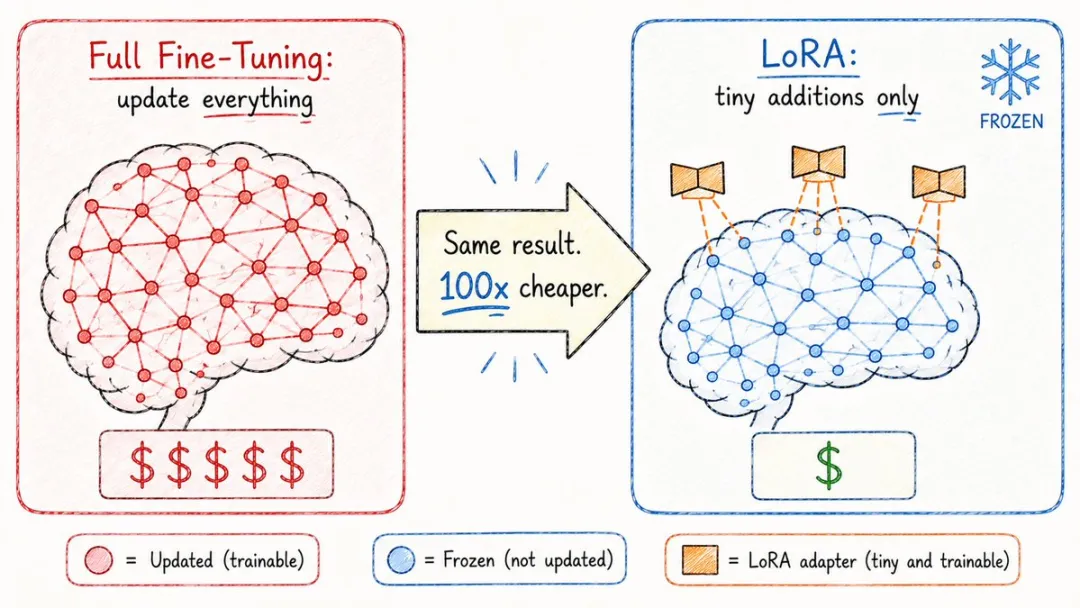
14. LoRA(低秩適配)
點解而家一張消費級顯示卡,甚至一部Mac Mini都可以玩微調?
因為有個叫 LoRA 嘅技術,思路好聰明。
主模型一動不動,只係喺外面掛幾個細細嘅「補丁矩陣」,訓練時只調整呢啲補丁。
參數量可能得原模型嘅唔夠1%,效果就接近全量微調。
結果就係,原本需要成個H100集羣先做到嘅嘢,而家一張4090就搞得掂。
你喺網上面見到嘅各種「人物Lora」「畫風Lora」「中文Lora」,背後全部係呢個技術。
佢第一次令微調呢件事,走進咗普通人嘅桌面。
15. 量化(Quantization)
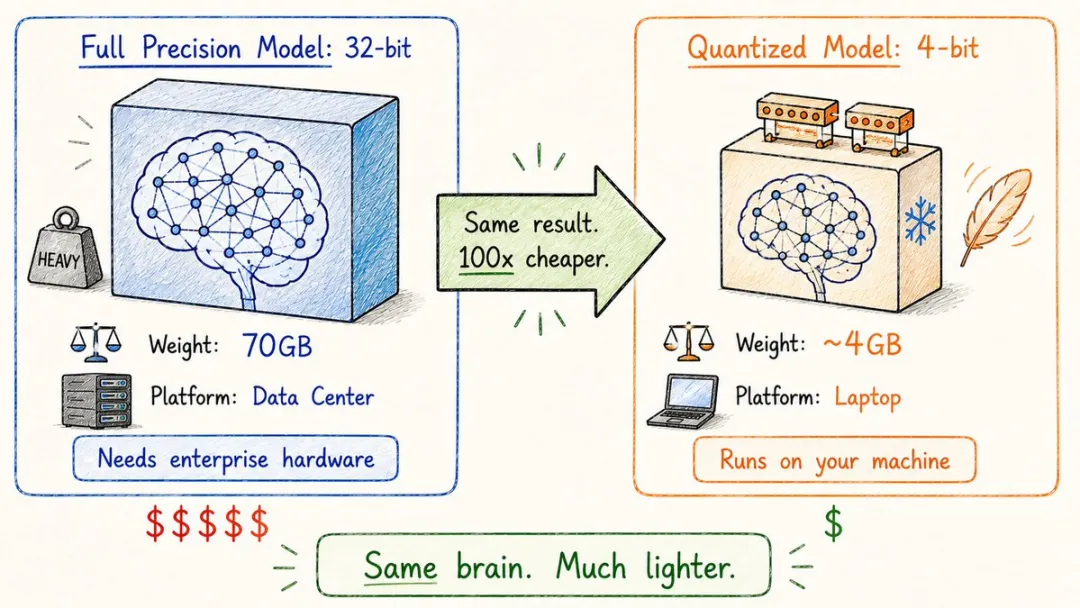
啲權重默認用32位浮點數儲存,精度高但係好佔位。
幾百億參數嘅大模型,係點樣塞入你手機同筆記本電腦度㗎?
靠嘅係量化。
模型裏面啲權重默認用32位浮點數儲存,精度高但係好佔位。
量化就係將佢哋由32位壓成16位、8位甚至4位,體積大幅縮水,推理速度仲可以順便提升一截,效果只係損失少少。
一個70B參數嘅Llama,原版要140GB顯存先跑到;量化到4位之後,35GB就夠,一部Mac Mini都行得到。
呢個就係點解本地大模型呢兩年開始普及。
係量化,將AI真正由雲端拉到咗你枱面上。
呢個就係點解手機上面、筆記本上面可以塞到越來越似樣嘅本地模型,量化先係真正令大模型走出雲端嘅嗰隻手。
第四部分:真實嘅AI產品係點樣搭建出嚟㗎
16. RAG(檢索增強生成)
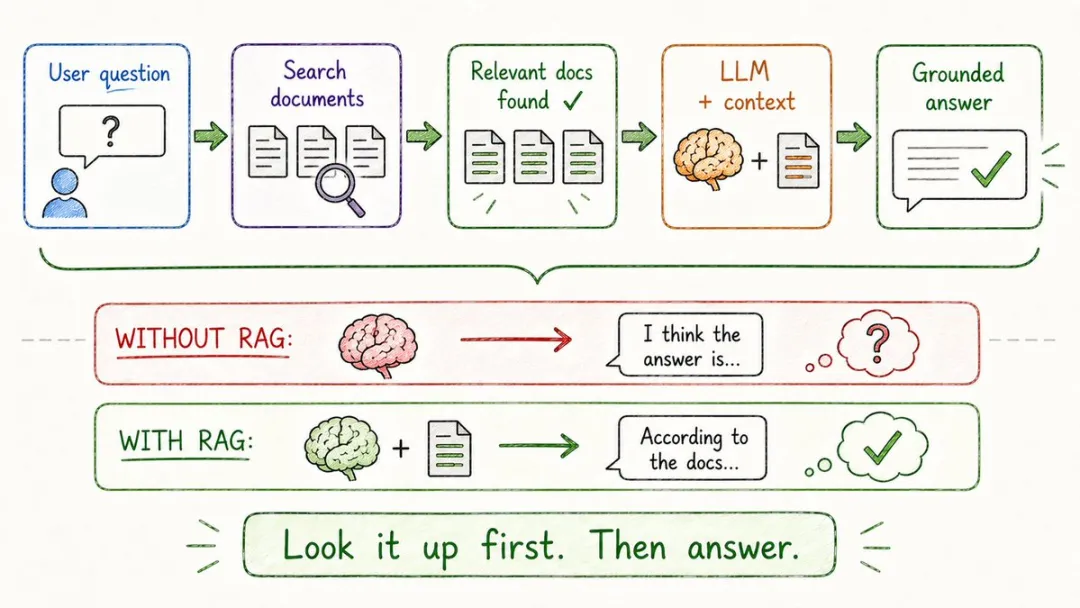
ChatGPT嘅訓練數據停喺某個截止日期,咁佢點樣可以答到你公司琴日發出嘅內部公告,或者今日嘅實時新聞?
靠嘅係RAG。
喺叫模型回答之前,先去你俾佢嘅資料庫度揾一圈相關文檔,將揾到嘅內容塞入上下文,再叫佢基於呢啲揾到嘅證據作答。
你日常用嘅每一個「上傳PDF俾我提問」「同公司文檔對話」「企業知識庫問答」,幾乎都係RAG。
佢最大嘅好處在於,模型唔使重新訓練,資料庫可以隨時更新,多一份文檔就等於多一份知識。
靠呢一招,AI先真正由嘴炮變成咗可以查資料嘅助手。
17. 向量數據庫(Vector Databases)
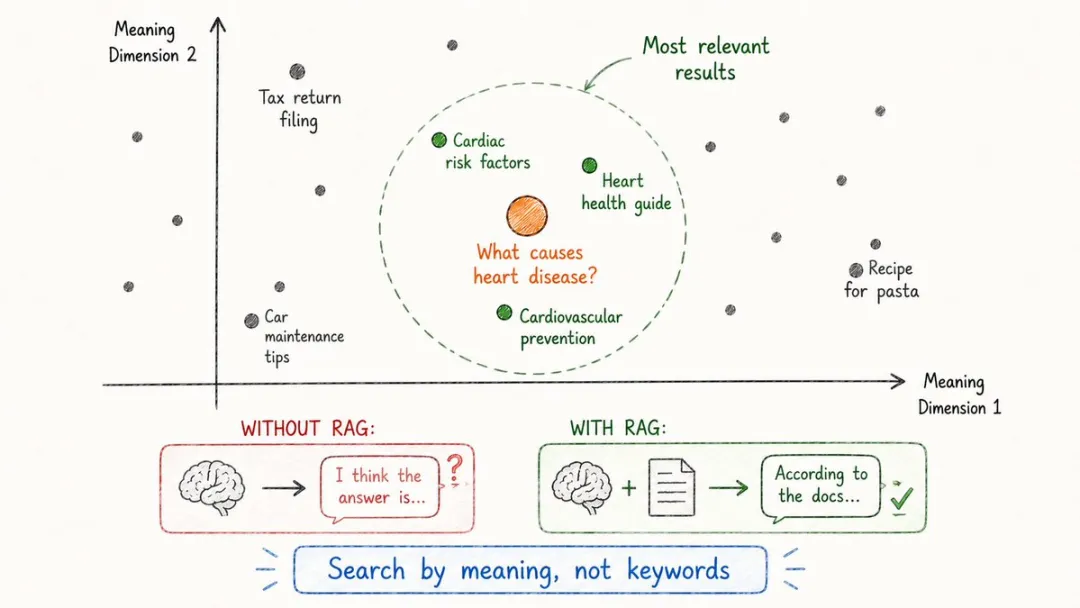
你掉俾AI三千份PDF叫佢回答一個問題,佢幾毫秒就將最相關嗰一段揪出嚟,呢個係點樣做到㗎?
傳統數據庫按「關鍵詞完全匹配」嚟查,但AI想要嘅唔係匹配字符,而係匹配含義。
例如「貓糧」同「寵物食品」明明係同一回事,關鍵詞搜索卻點樣都對唔上。
向量數據庫就係為呢個場景而生嘅:佢存嘅唔係文字,係embedding;佢查嘅唔係字符串,係「含義相近」嘅向量。
Pinecone、Weaviate、Qdrant、Chroma呢啲工具,本質上都係RAG系統嘅地基。
可以話,向量數據庫係大模型時代新嘅硬碟。
18. AI Agent(智能體)
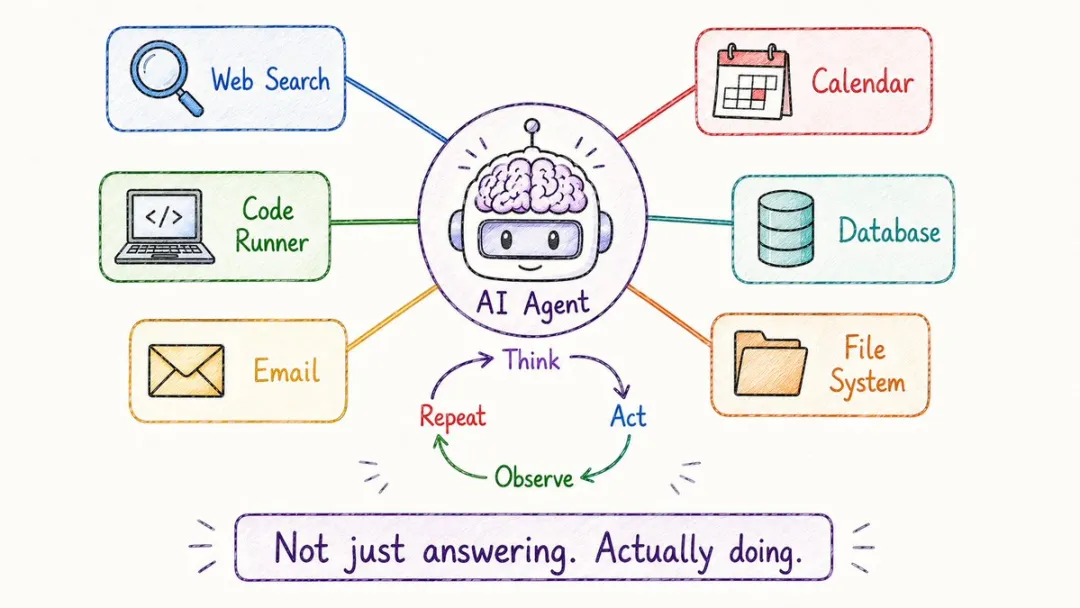
點解Cursor可以自己改你嘅代碼?點解Devin可以自己跑完一整個項目?
因為佢哋唔係普通嘅LLM,而係Agent。
普通LLM係問一句答一句嘅「對話機器」,Agent係可以自己規劃、調用工具、採取行動、觀察結果、再決定下一步嘅「打工機器」。
佢嘅內部循環大致係:諗 → 做 → 睇 → 再諗,一遍一遍直到將任務搞掂。
你掉俾佢一句「幫我整理上季度銷售數據並生成報表」,佢會自己拆任務、讀數據庫、寫SQL、行代碼、將結果彙總成文檔。
2024年開始,所有AI公司都喺度內卷呢個方向。
19. 思維鏈(Chain of Thought)
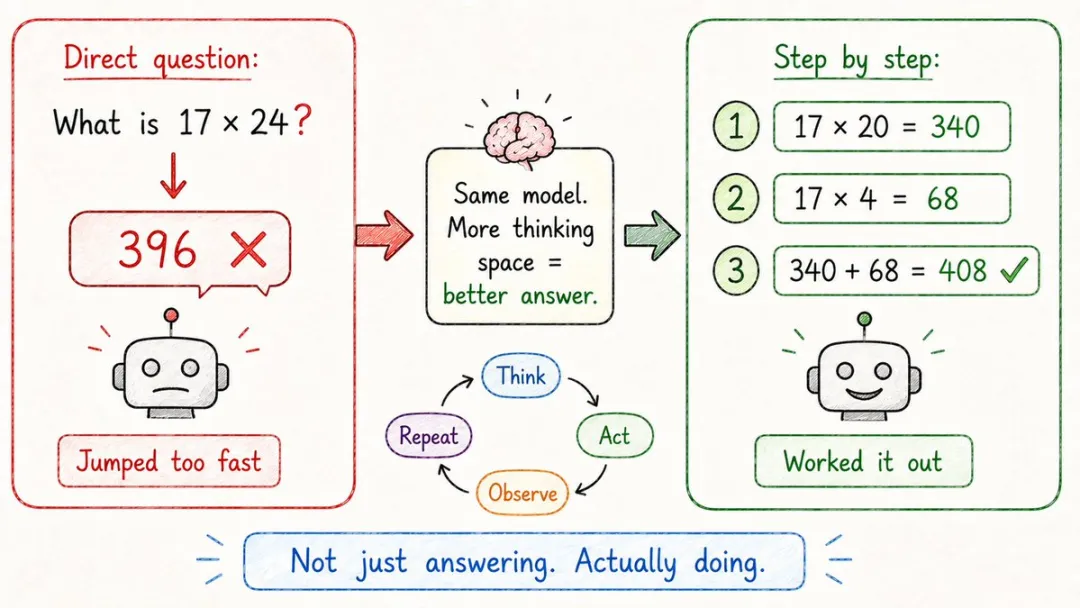
同樣一道複雜題,叫AI直接俾答案,佢成日答錯;
但你只要加一句「一步一步諗,再俾最終答案」,正確率即刻就可以跳一級。
點解咁神奇?
呢個魔法叫思維鏈,英文縮寫CoT,本質係俾模型喺「答案空間」入面多留幾步推理嘅餘地。
模型本身係逐token生成嘅,叫佢先將推理過程寫出嚟,相當於俾自己搭咗腳手架。
今日OpenAI嘅o系列、Claude嘅擴展思考、DeepSeek R1呢啲推理模型,玩嘅就係CoT嘅進化版,將思考呢件事都變成了訓練嘅一部分。
20. 擴散模型(Diffusion Models)
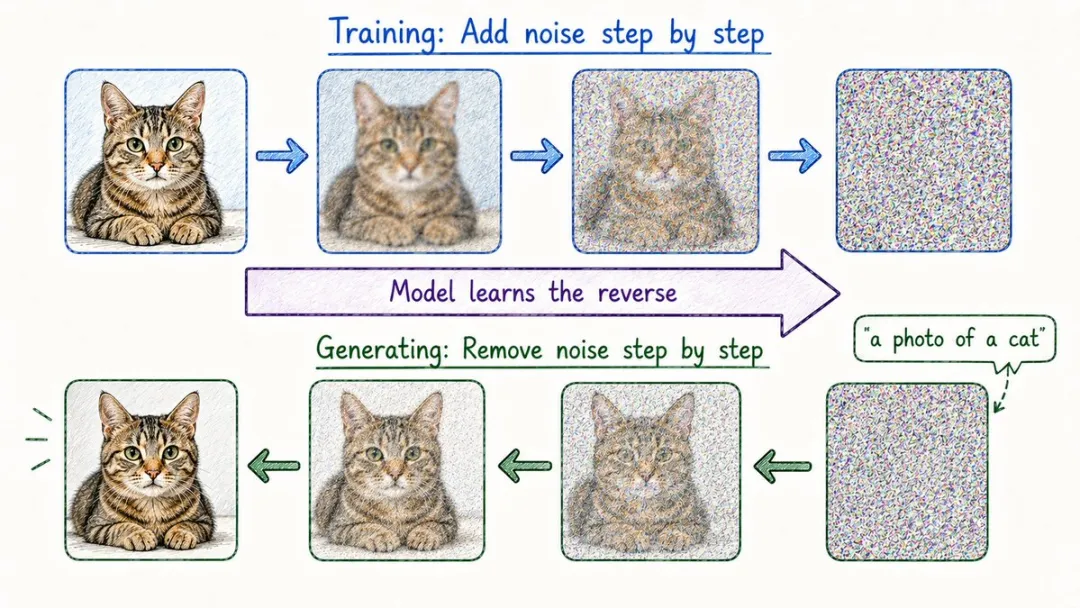
Midjourney憑咩可以畫出幾乎以假亂真嘅圖?Sora憑咩可以憑空生成一段視頻?
答案有啲反直覺:訓練嘅時候,先教AI點樣毀咗一張圖。
具體過程係咁:將一張清晰圖片一步步加噪聲,加到睇起嚟就係一片雪花。
然後叫模型反過來學,喺文字提示嘅引導下,將呢堆雪花一步步還原成一張完整嘅圖。
Stable Diffusion、Midjourney、DALL-E、Sora,背後都係呢一套思路,只係由圖像擴展到咗視頻、音頻同3D。
AI生成圖像喺過去三年由鬼畫符飛躍到真假難辨,靠嘅就係呢條路線。
以上就係2026年你避唔開嘅20個AI概念。
下次再聽到呢啲詞俾人拋出嚟,你個心就有譜啦,佢哋背後到底係點樣一回事,已經唔再係黑箱。
建議收藏呢一篇,遲啲你仲會翻返出嚟睇多次。
作者:Rahul
來源:https://x.com/sairahul1/status/2057740928908161461?s=20
你每天用AI,但你真的知道它是怎麼工作的嗎?
它為什麼老是忘記你說過的話?為什麼敢編出根本不存在的論文?ai編程憑啥能自己改你的代碼?
這些問題背後,是 20 個你繞不開的概念。
看完這篇文章,你就理解了所有AI產品的底層邏輯!
第一部分:AI 到底是怎麼轉的
1. 神經網絡(Neural Networks)
憑什麼一台機器能像個人一樣跟你聊天?說到底,靠的是它的「大腦」,也就是神經網絡。
但這個腦子跟你想的完全不一樣,它是一層一層堆起來的小開關,每個開關上掛着一個叫「權重」的數字。
你給它一句話,信號順着開關一路串下來,最後吐出一個回答。
所謂訓練,就是給它看幾億個例子,讓它自己反覆試錯,把這幾十億個數字慢慢調到能猜對為止。
GPT-4 的腦子裏掛着 1.8 萬億個這樣的小數字,這也是為啥訓一次它要燒掉幾百萬美元。
2. 分詞(Tokenization)
你以為 ChatGPT 收到的是「你好,今天天氣怎麼樣?」
其實並不是。
它看到的是一堆碎片:「你」「好」「,」「今天」「天氣」「怎麼樣」。
每一片都叫一個 token,是 AI 能識別的最小單位。
英文也一樣會被切開,playing會被切成play加ing,ChatGPT會被切成Chat加G加PT,
只有dog這種短詞才會保持原樣。
為啥不直接按整詞來?
因為人類語言本來就亂,新詞冒得快,錯別字一堆,還有中英混着用,要列一張能裝下所有詞的詞典,根本不現實。
改用碎片之後,哪怕模型從沒見過某個新詞,也能拆成熟悉的小塊湊出意思。
換算公式瞭解下就行:1000 個 token 大約 750 個英文詞。
下次再看到 API 按 token 報價,心裏就不會發懵。
3. 向量(Embeddings)
AI 憑什麼能分辨「醫生」和「護士」是同一類東西,而「醫生」和「披薩」八竿子打不着?
因為每個字進了模型,都會被翻譯成一串數字。
這串數字就是它的「含義座標」,技術上叫 embedding。
你可以把所有詞想象成被釘在一張超高維的地圖上。
醫生和護士捱得很近,醫生和披薩隔着十萬八千里。
還有一個特別神奇的現象,把「國王」的座標減掉「男人」再加上「女人」,得到的位置竟然約等於「女王」。
模型並不像你那樣讀懂一個詞,它讀的是詞與詞之間的距離和方向。
所有看起來「懂你意圖」的產品,不管是語義搜索、商品推薦還是 AI 客服,底下跑的都是這一套向量。
4. 注意力(Attention)
同一個「蘋果」,意思可能完全不一樣,AI 憑什麼能分清你說的是水果還是公司?
「我吃了一個蘋果」裏它是水果,「我買了蘋果的股票」裏它是公司。
光靠 embedding 是區分不了的,得讓「注意力」出馬。
注意力的作用,是讓句子裏的每個詞都回頭掃一眼別的詞,再判斷哪些跟自己最相關。
在「她買了蘋果的股票」裏,「蘋果」會把注意力集中到「買」和「股票」上,模型立刻就明白:這是公司,不是水果。
注意力出現之前,AI 只能一個字一個字往後讀,又慢又笨。
有了它之後,模型一口氣就能把整句話看完。
就這一個想法,撐起了今天整個 AI 時代。
5. Transformer
GPT、Claude、Gemini、Llama、Mistral,凡是你叫得上名的大模型,背後用的其實都是同一套架構,叫 Transformer。
它出自 2017 年那篇被引瘋了的論文《Attention Is All You Need》,核心思路就是我們上面提到的內容:
別再一個字一個字讀,用注意力一口氣並行處理整段文本。
這就是AI的工作流程,說起來很簡單,文本先切成 token,token 翻譯成 embedding,再喂進一層層堆起來的注意力,最後吐出輸出。
每一層負責的事都不一樣,淺層管語法,中層管詞與詞的關係,深層開始幹推理這種重活。
搞懂這一個架構,現代 AI 你就懂了一大半。
第二部分:你跟 AI 聊天時,它腦子裏在幹什麼
6. LLM(大語言模型)
沒人單獨教過 ChatGPT 怎麼聊天,但它會聊;沒人教過它寫代碼,但它會寫;沒人教過它做翻譯,但它能翻。
這是怎麼回事?
說出來你可能不信,它從頭到尾只學了一件事,就是預測下一個字。
往一個 Transformer 裏灌幾萬億個 token,書、網頁、代碼、維基百科、Reddit 全往裏塞,讓它一直玩「猜下一個字」。
等訓練規模大到一定程度,神奇的事情就發生了,模型自己悟出了語法、推理、寫代碼、做翻譯、解數學題。
這種「沒人教過但自己會了」的現象,有個專門的名字,叫「湧現」。
ChatGPT、Claude、Gemini,全是這條路上走出來的。
幾千億參數起步,幾百萬美元打底,它們也是真燒出來的。
7. 上下文窗口(Context Window)
為什麼 ChatGPT 老是忘記你前面說過的話?
因為它有個叫「上下文窗口」的腦容量上限。
你跟它聊得太長,前面那段就會被擠出窗口外,直接失憶。
GPT-4 的窗口能裝下 12.8 萬個 token,差不多一本中篇小說;
Claude 3.5 翻到 20 萬;Gemini 1.5 Pro 直接幹到 100 萬,能塞下七本《三體》。
但更狗血的是,就算窗口夠大,模型也只記得開頭和結尾,中間那段會被自動遺忘。
這個現象有個名字,叫 Lost in the Middle。
窗口大,並不等於記性好,模型也是凡人。
8. 温度(Temperature)
為什麼同樣一個問題,AI 有時一本正經,有時又開始放飛?
因為模型背後藏着一個用來調創意的旋鈕,叫温度。
温度等於 0 時它最保守,結果最穩;等於 1 時開始有點皮;拉到 2 以上基本就是胡言亂語。
寫代碼、查事實,把温度調低;頭腦風暴、寫文案,就把温度往上拉。
9. 幻覺(Hallucination)
你讓 ChatGPT 給你列三篇相關論文,它給你編了三篇根本不存在的,名字、作者、年份還都齊全。
為什麼它敢這麼幹?
因為它根本不認識「真假」這兩個字。
它在玩接龍,不是在查證據,只管下一個字接起來順不順嘴,不管對不對。
所以涉及事實的內容別全信它,最好再搭一套 RAG 給它兜底(這玩意是啥,往下看)。
10. 提示詞工程(Prompt Engineering)
為什麼有人問 ChatGPT 出來的答案像廢話,有人問出來的就是乾貨?
說到底,你怎麼問,決定了它怎麼答。
好提示詞通常會做這幾件事:交代清楚背景,設定一個角色,舉幾個例子,說明輸出格式,把任務拆成步驟。
說穿了就一件事,怎麼把話講清楚。
這不是 AI 玄學,是溝通的基本功。
第三部分:模型是怎麼越練越聰明的
接下來這五個概念,是給模型加 buff用的。
11. 遷移學習(Transfer Learning)
為什麼今天一個獨立開發者都能搞出能用的 AI 應用?因為他根本不用從零開始訓。
從零訓一個大模型,動輒要燒幾百萬美元、跑上幾周;
但拿一個已經訓好的半成品接着改造,可能幾個小時就夠了。
這就是遷移學習,別人花了天價把通用能力訓出來,你只要接過來走完最後一公里。
ImageNet 上訓出來的圖像模型,加幾張醫學影像就能識別病灶;
BERT 在維基百科上學到的語言能力,加幾千條客服對話就能做意圖識別。
今天 Hugging Face 上幾十萬個模型,絕大多數都是站在別人肩膀上的遷移版本。
12. 微調(Fine-Tuning)
怎麼讓一個通用 AI 學會你公司的黑話?
一個通用 LLM 沒讀過你公司的產品文檔,不熟悉你的語氣,也答不出你行業的專有名詞,這時候就得靠微調。
拿一個預訓練模型,再用你自己的數據接着訓一陣,讓它從通才變成專才。
比如把 GPT 微調成自家客服的專屬版本,把 Llama 微調成專門寫 SQL 的助手,或者讓模型只用某個作者的腔調說話。
提示詞工程只是臨時給指令,微調則是直接改它的性格,前者輕便,後者牢靠。
13. RLHF(基於人類反饋的強化學習)
為什麼 ChatGPT 看起來這麼有禮貌、會拒絕越界請求、說話還像個人?
因為它被一種叫 RLHF 的方法狠狠調教過。
一個只會預測下一個 token 的原始大模型,本質上就是個嘴碎的復讀機,並不知道什麼樣的回答更有用、更安全。
RLHF 乾的事,是讓一羣人類標註員去給模型的回答打分,再訓出一個「獎勵模型」代替人類繼續打分,
最後用強化學習不停推着主模型往人類喜歡的方向調。
沒有 RLHF,就沒有今天的 ChatGPT 和 Claude。
某種意義上說,是 RLHF 把統計模型變成了能打工的助手。
14. LoRA(低秩適配)
為啥現在一張消費級顯卡,甚至一台 Mac Mini 都能玩微調?
因為有個叫 LoRA 的技術,思路特別聰明。
主模型一動不動,只在外面掛幾個小小的「補丁矩陣」,訓練時只調這些補丁。
參數量可能只有原模型的不到 1%,效果卻接近全量微調。
結果就是,原本需要整整一個 H100 集羣才能乾的活,現在一張 4090 就能搞定。
你在網上看到的各種「人物 Lora」「畫風 Lora」「中文 Lora」,背後全是這個技術。
它第一次讓微調這件事,走進了普通人的桌面。
15. 量化(Quantization)
那些權重默認用 32 位浮點數存,精度高但佔地方。
幾百億參數的大模型,是怎麼塞進你手機和筆記本里的?
靠的是量化。
模型裏那些權重默認用 32 位浮點數存,精度高但佔地方。
量化就是把它們從 32 位壓成 16 位、8 位甚至 4 位,體積大幅縮水,推理速度還能順帶提一截,效果只損失一點點。
一個 70B 參數的 Llama,原版要 140GB 顯存才能跑起來;量化到 4 位之後,35GB 就夠了,一台 Mac Mini 都能跑得動。
這就是為啥本地大模型這兩年開始普及。
是量化,把 AI 真正從雲端拉到了你桌面上。
這就是為啥手機上、筆記本上能塞下越來越像樣的本地模型,量化才是真正讓大模型走出雲端的那隻手。
第四部分:真實的 AI 產品是怎麼搭出來的
16. RAG(檢索增強生成)
ChatGPT 的訓練數據停在某個截止日期,那它怎麼能答出你公司昨天發的內部公告,或者今天的實時新聞?
靠的是 RAG。
在讓模型回答之前,先去你給它的資料庫裏搜一圈相關文檔,把搜到的內容塞進上下文,再讓它基於這些找到的證據作答。
你日常用的每一個「上傳 PDF 給我提問」「跟公司文檔對話」「企業知識庫問答」,幾乎都是 RAG。
它最大的好處在於,模型不用重訓,資料庫可以隨時更新,多一份文檔就等於多一份知識。
靠這一招,AI 才真正從嘴炮變成了能查資料的助手。
17. 向量數據庫(Vector Databases)
你扔給 AI 三千份 PDF 讓它回答一個問題,它幾毫秒就把最相關的那一段揪出來,這是怎麼做到的?
傳統數據庫按「關鍵詞完全匹配」來查,但 AI 要的不是匹配字符,而是匹配含義。
比如「貓糧」和「寵物食品」明明是一回事,關鍵詞搜索卻怎麼也對不上。
向量數據庫就是為這個場景生的:它存的不是文字,是 embedding;它查的不是字符串,是“含義相近”的向量。
Pinecone、Weaviate、Qdrant、Chroma 這些工具,本質上都是 RAG 系統的地基。
可以說,向量數據庫是大模型時代新的硬盤。
18. AI Agent(智能體)
為什麼 Cursor 可以自己改你的代碼?為什麼 Devin 能自己跑完一整個項目?
因為它們不是普通的 LLM,而是 Agent。
普通 LLM 是問一句答一句的“對話機器”,Agent 是能自己規劃、調用工具、採取行動、觀察結果、再決定下一步的“打工機器”。
它的內部循環大致是:想 → 做 → 看 → 再想,一遍一遍直到把任務搞定。
你扔給它一句「幫我整理上季度銷售數據並生成報表」,它會自己拆任務、讀數據庫、寫 SQL、跑代碼、把結果彙總成文檔。
2024 年開始,所有 AI 公司都在卷這個方向。
19. 思維鏈(Chain of Thought)
同樣一道複雜題,讓 AI 直接給答案,它經常答錯;
但你只要加一句「一步一步想,再給最終答案」,正確率立刻就能跳一檔。
為啥這麼神奇?
這個魔法叫思維鏈,英文縮寫 CoT,本質是給模型在「答案空間」裏多留幾步推理的餘地。
模型本來就是逐 token 生成的,讓它先把推理過程寫出來,相當於給自己搭了腳手架。
今天 OpenAI 的 o 系列、Claude 的擴展思考、DeepSeek R1 這些推理模型,玩的就是 CoT 的進化版,把思考這件事也變成了訓練的一部分。
20. 擴散模型(Diffusion Models)
Midjourney 憑什麼能畫出幾乎以假亂真的圖?Sora 憑什麼能憑空生成一段視頻?
答案有點反直覺:訓練的時候,先教 AI 怎麼毀掉一張圖。
具體過程是這樣:把一張清晰圖片一步步加噪聲,加到看起來就是一片雪花。
然後讓模型反過來學會,在文字提示的引導下,把這堆雪花一步步還原成一張完整的圖。
Stable Diffusion、Midjourney、DALL-E、Sora,背後都是這一套思路,只是從圖像擴展到了視頻、音頻和 3D。
AI 生成圖像在過去三年裏從鬼畫符飛躍到真假難辨,靠的就是這條路線。
以上就是 2026 年你繞不開的 20 個 AI 概念。
下次再聽到這些詞被甩出來,你心裏就有譜了,它們背後到底是怎麼回事,已經不再是黑箱。
建議收藏這一篇,回頭你還會反覆翻。