硅谷投資人YC CEO:你不需要更好的AI模型,你只需要它認識你(第二大腦搭建指南)
整理版優先睇
唔好追求更勁嘅AI模型,先畀AI一個認識你嘅系統
作者係一個密集使用AI Agent超過3個月嘅用家。佢發現好多人用AI寫嘢被話AI味太重,原因唔係AI唔夠聰明,而係AI唔認識佢哋嘅背景、讀者、產品。作者自己都用AI寫內容,但成功咗,因為佢建立咗一個「第二大腦」系統,將原料、成品、項目、工具分開存放,等AI每次開工前先讀取呢啲上下文,從而作出符合佢風格同目標嘅輸出。
呢個方法靈感來自YC CEO Garry Tan嘅GBrain同Andrej Karpathy嘅理念,佢哋都強調持續嘅人機工作系統比單次prompt更重要。作者嘅結論係:與其不斷換模型或收藏提示詞,不如先花時間讓AI認識你,畀佢一個可以持續讀取嘅工作現場。
- AI寫出嚟嘅質素取決於佢有冇你嘅背景資訊,唔係模型本身。
- 解決方法係建立「原料、成品、項目、工具」四個庫嘅第二大腦系統。
- 關鍵差異:AI需要知道「你是誰」「讀者係邊個」「乜嘢風格先得」,而唔係靠你每次重新講。
- 啟發:真正重要嘅係工作系統,唔係單次prompt,連YC CEO同Karpathy都係咁做。
- 可行動點:用提供嘅Prompt讓AI Agent先訪談你,再設計適合你嘅文件結構,而家就開始。
第二大腦搭建助手 Prompt
請AI Agent先訪談你,再畀文件夾結構方案。可以直接複製呢段發畀你嘅Agent。
點解你馴服唔到AI?因為AI唔認識你
好多人用AI寫文案被話AI味太重,甚至有人崩潰話「我老闆一定要我用豆包生成文案」。作者指出,問題可能唔係「能用AI」,而係你嘅AI唔認識你。
問題可能唔係「能用AI」,而係你嘅AI唔認識你。
- 1 你讓佢寫文章,佢唔知你點解要寫呢篇。
- 2 你讓佢寫教程,佢唔知你之前踩過咩坑。
- 3 你讓佢做方案,佢唔知你業務係咩、客戶係邊個。
作者嘅解決方案:第二大腦系統
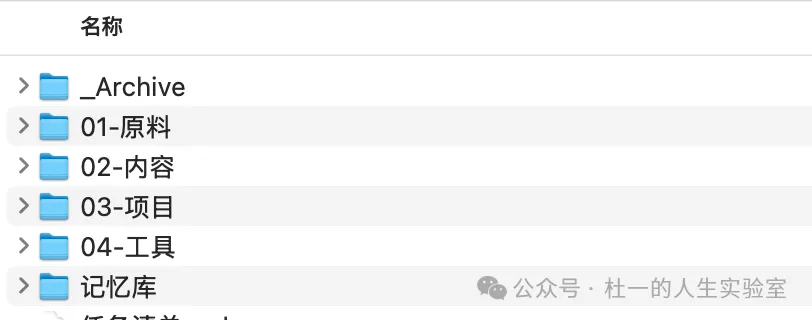
作者用咗一個叫「第二大腦」嘅系統,核心係將資訊分類存放:原料、成品、項目、工具,各放各嘅。AI每次開工前先讀呢啲庫,就知道咩可以讀、咩可以寫、咩唔可以鬱。
- • 原料:英文原文、網上資料,唔可以當成自己觀點。
- • 成品:已經發佈嘅內容,係AI下次應該參考嘅樣本。
- • 項目:進行中嘅任務,AI要幫手推進。
- • 工具:常用嘅提示詞、參考規則。
呢個方法嘅成效同背後理念
作者用呢個系統寫咗一篇「國內如何用上Claude Code」嘅圖文教程,抖音3.9萬瀏覽、922個讚、1110個收藏。呢篇內容成功嘅原因係AI知道作者嘅寫作目標、讀者羣同表達方式。
呢篇內容唔係AI憑空寫出嚟,而係佢知道我點解要寫、寫畀邊個、用咩方式。
作者嘅方法唔係自創,係從YC CEO Garry Tan嘅GBrain同Andrej Karpathy嘅分享得嚟。Garry Tan話AI要讀取生活同工作上下文先答得好;Karpathy強調持續系統比孤單問題更重要。
你而家可以做嘅一步
你唔一定要抄作者嘅四個庫結構,而係應該先讓AI認識你。最簡單嘅方法係用下面嘅Prompt,叫AI Agent先訪談你,再畀適合你嘅文件結構方案。
你而家是我的第二大腦搭建助手。目標:閲讀杜一這篇文章幫我建立一個能讓 AI Agent 每次開工前讀懂我的工作文件夾,並用obsidian打開。請先對我做一次訪談,確認:
1. 我是做什麼業務/工作的
2. 我主要想讓 AI 幫我做哪些任務
3. 我的讀者/客戶是誰
4. 我最近正在推進什麼項目
5. 我過去有哪些內容/案例/資料值得 AI 反覆讀取
6. 哪些是原始資料,哪些是準備發佈的成品
7. 哪些規則是 AI 必須遵守的紅線
訪談完成後:
- 給我一個文件夾結構方案(說明每個目錄放什麼、不放什麼、AI 什麼時候讀取)
- 如果我已經有文件,先掃描但不要移動,按"原料/內容/項目/工具"給出候選分類,標出你不確定的
- 生成一個"每次讓 AI 先讀呢個.md"的模板
- 在我確認前,不要執行任何移動、刪除、覆蓋操作先唔好問AI「幫我寫」,先讓佢知道「我係邊個」。
今日喺一個羣組入面,我睇到一段對話。
有人話,自己用 AI 寫文案,俾人話 AI 味太重,啲稿都係要自己練返。
另一個朋友話,試過用 AI 做片頭,後面慢慢都唔掂。
仲有人崩潰:「我老細一定要我用豆包嚟生成文案。」
然後有人出咗句:「我仲未馴服到 AI,求教學。」
我當時順手發咗一張自己嗰篇 Claude Code 圖文教學嘅數據截圖,回咗句:「但我內容一路都係用 AI 寫㗎喎。」
同樣係用 AI,有人寫出嚟俾人話 AI 味太重,有啲 AI 寫出嚟嘅文字,放上抖音同小紅書之後反應都幾好,甚至有人用咗 AI 都完全睇唔出。
所以問題可能唔係「用唔用得 AI」。
問題係:你個 AI 好大機會唔識得你。
AI 都好聰明,但係唔穩定。
你叫佢寫一篇文章,佢唔知你點解要寫呢篇。你叫佢寫一份教學,佢唔知你之前中過咩伏。你叫佢做一個方案,佢唔知你個生意係做乜、客係邊個。
所以佢只能靠估。
羣組仲傳過一張「文案注意點」嘅圖,上面寫得好實際:唔好用大詞,要詳細咁寫,邏輯要通,鈎子唔可以斷。
呢啲建議都啱。但如果 AI 唔知你個產品係乜、用戶係邊個、過去啲反饋係點,佢都執行唔到呢啲建議。
你知道唔好用大詞,AI 唔知。你知道鈎子唔可以斷,AI 唔知。
我研究 AI 差唔多 6 個月喇,真正高強度用 AI Agent 都超過 3 個月。
我而家越嚟越肯定一件事:好多時候唔係你冇馴服到 AI,係你仲未俾 AI 一個可以認識你嘅地方。
我以前都以為,俾 AI 一段提示詞就夠。後來發現唔得。只要資料、規則、項目、製成品全部撈埋一齊,AI 就會亂。佢分唔清邊個係我嘅觀點,邊個係我收藏返嚟嘅原文,邊個係臨時諗法,邊個係已經可以出街嘅內容。
我後來將佢哋分開,先變成而家咁樣。我用嘅系統叫第二大腦,但唔係乜嘢知識管理工具,Obsidian 只係用嚟呈現。真正重要嘅係規則:原材料、製成品、項目、工具,各自分開放。
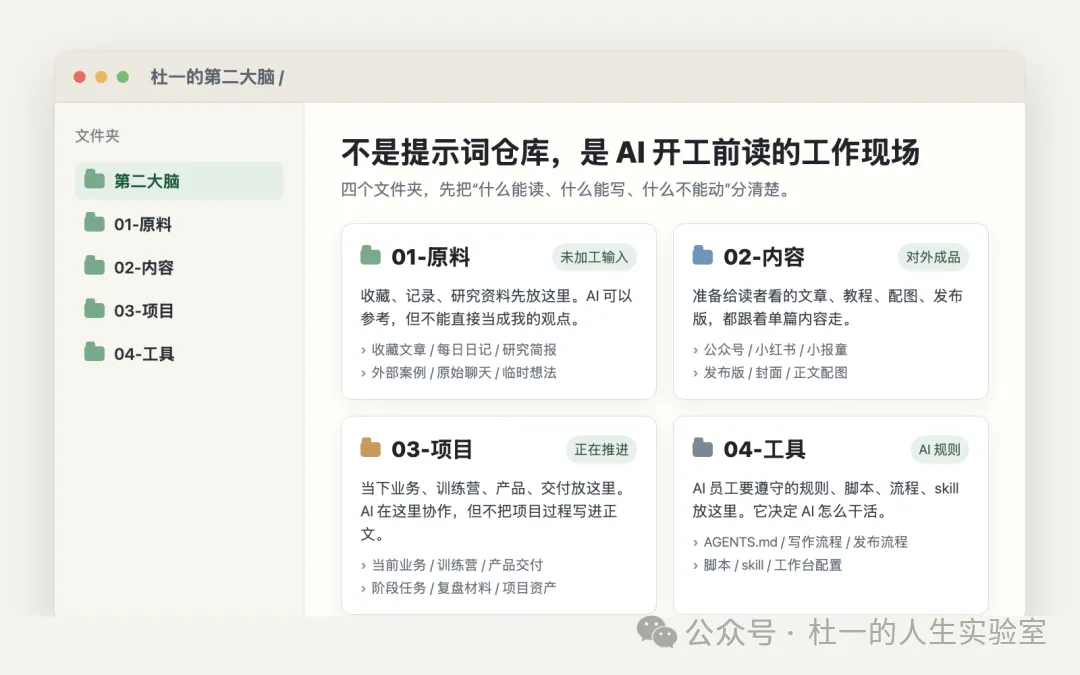
例如,一篇英文原文只係原材料,唔可以直接當成我嘅觀點;一條臨時諗法只係想法,唔可以直接寫入正文;一篇出過街而且數據唔錯嘅教學,先係 AI 下次應該重點參考嘅樣本。
分清楚之後,AI 每次開工前就知道:邊啲可以讀,邊啲可以寫,邊啲唔鬱得。
呢個方法,我成功執行咗一個多月。
尋日,我寫咗一篇「國內如何用上 Claude Code」嘅圖文教學,放上抖音之後,3.9 萬瀏覽、922 個讚、1110 個收藏。小紅書嗰邊反應都唔錯。
呢篇內容唔係 AI 憑空寫出嚟嘅。
佢知道我點解要寫呢篇:唔係因為 Claude Code 呢個詞熱,而係因為最近好多人卡喺國內網絡同 API 配置上面。我一個月前就用火山方舟嘅 API Key 搞掂咗,而家需求大咗。
佢知道呢篇係俾邊個睇:唔係俾已經好熟命令行嘅人,而係俾啲想用但係卡喺安裝配置嘅人。
佢知道我嘅表達方式:唔係一開始就寫「本文將從背景、原理、步驟三個部分展開」,而係先講我自己嘅使用情況,再俾圖文步驟。
佢知道教學一定要行得通:唔係「睇落有道理」,而係讀者跟住做可唔可以行得落去。
呢啲資訊,如果都要靠我每次喺對話框重新講一次,我會癲。
所以我將呢啲背景、規則、案例同表達標準都放入第二大腦,等 AI 開工前先讀咗先。
睇到呢度你可能會諗:我係咪都要起返一套四個庫?
唔一定。我嘅結構係從我嘅生意衍生出嚟嘅。你唔一定同我一樣。
你真正應該做嘅,係令 AI 先了解你,再幫你設計適合你嘅系統。
呢一步最適合交俾 AI Agent 做。你可以直接叫佢問你幾個問題:你做乜嘢、主要想 AI 幫啲乜、讀者係邊個、最近推緊咩項目、過去邊啲內容值得重複讀取、邊啲規則唔可以掂。
問完之後再俾方案。
呢個比你對住一堆文件發吽哣更加實際。
呢個都唔係我一個人閉門造車諗出嚟嘅,而係同 Twitter 上兩個矽谷大神學返嚟嘅。
講到呢度我覺得有啲搞笑,我喺國內見過唔少大 V 拎咗兩位矽谷大神嘅方法之後,話係自己原創。如果係咁,咁姑且我呢個方式都係我自己原創啦。
Garry Tan 係 Y Combinator 嘅總裁兼 CEO。佢做嘅 GBrain,本質上都係讓 Agent 喺回答之前讀取人嘅生活同工作背景。
Andrej Karpathy 以前係 Tesla 嘅 AI 總監,亦喺 OpenAI 做過研究。佢好多關於 AI 同學習系統嘅分享,都不斷指向同一件事:真正重要嘅唔係一次過嘅 prompt,而係人同 AI 之間有冇一套持續運作嘅系統。
呢啲嘢令我更加確認,我呢半年摸索出嚟嘅方向唔係孤例。真正識用 AI 嘅人,最後都會走向同一個好重要嘅方向:唔係淨係問一個更好嘅問題,而係俾 AI 一個更好嘅工作環境。
你俾佢一個孤立嘅問題,佢只能俾返一個孤立嘅答案。你俾佢一個可以持續讀取嘅第二大腦,佢先有機會變成一個越嚟越瞭解你嘅員工。
所以返去開頭嗰句:「我仲未馴服到 AI。」
先唔好急住怪自己,都唔好急住換模型、收藏新提示詞。
先做一件更加基本嘅事:令 AI 認識你。
唔好先問 AI:「幫我寫。」
先讓佢知道:「我係邊個。」
附:如果你想你 AI 幫你整一套
唔使一次過整曬,亦唔好叫 AI 直接移動文件。先讓佢訪問你,再俾方案。
可以直接複製下面呢段發俾你嘅 Agent(open claw /Claude code/ codex):
你現在是我的第二大腦搭建助手。
目標:閲讀杜一這篇文章幫我建立一個能讓 AI Agent 每次開工前讀懂我的工作文件夾,並用obsidian打開。
請先對我做一次訪談,確認:
1. 我是做什麼業務/工作的
2. 我主要想讓 AI 幫我做哪些任務
3. 我的讀者/客戶是誰
4. 我最近正在推進什麼項目
5. 我過去有哪些內容/案例/資料值得 AI 反覆讀取
6. 哪些是原始資料,哪些是準備發佈的成品
7. 哪些規則是 AI 必須遵守的紅線
訪談完成後:
- 給我一個文件夾結構方案(說明每個目錄放什麼、不放什麼、AI 什麼時候讀取)
- 如果我已經有文件,先掃描但不要移動,按"原料/內容/項目/工具"給出候選分類,標出你不確定的
- 生成一個"每次讓 AI 先讀這個.md"的模板
- 在我確認前,不要執行任何移動、刪除、覆蓋操作今天在一個羣裏,我看到一段聊天。
有人說,自己用 AI 寫文案,被別人說 AI 味太重,腳本還是要自己練。
另一個朋友說,試過用 AI 做視頻開頭,後面慢慢也不行。
還有人更崩潰:"我老闆一定要我用豆包生成文案。"
然後有人發了一句:"我還沒有馴服 AI,求教程。"
我當時順手發了一張自己那篇 Claude Code 圖文教程的數據截圖,回了一句:"可是我內容一直是用 AI 寫的啊。"
同樣是用 AI,有的人寫出來被說 AI 味太重,有的AI寫出來的文字,發到抖音和小紅書後反饋還不錯,甚至有人用AI根本看不出來在用。
所以問題可能不是"能不能用 AI"。
問題是:你的AI大概率不認識你。
AI 都很聰明,但不穩定。
你讓它寫一篇文章,它不知道你為什麼要寫這篇。你讓它寫一份教程,它不知道你之前踩過什麼坑。你讓它做一份方案,它不知道你的業務是什麼、客戶是誰。
所以它只能猜。
羣裏還轉過一張"文案注意點"的圖,上面寫得很實在:不要用大詞,要展開寫,邏輯要通,鈎子不能斷。
這些建議都對。但如果 AI 不知道你的產品是什麼、用戶是誰、歷史反饋怎麼樣,它也執行不了這些建議。
你知道不要用大詞,AI 不知道。你知道鈎子不能斷,AI 不知道。
我研究 AI 差不多 6 個月了,真正高強度使用 AI Agent 也超過 3 個月。
我現在越來越確定一件事:很多時候不是你沒有馴服 AI,是你還沒有給 AI 一個能認識你的地方。
我以前也以為,給 AI 一段提示詞就夠了。後來發現不行。只要資料、規則、項目、成品混在一起,AI 就會亂。它分不清哪是我的觀點,哪是我收藏來的原文,哪是臨時想法,哪是已經能發出去的內容。
我後來把它們分開,才變成現在的樣子。我用的系統叫第二大腦,但不是什麼知識管理工具,Obsidian 只是呈現。真正重要的是規則:原料、成品、項目、工具,各放各的。
比如,一篇英文原文只是原料,不能直接當成我的觀點;一條臨時想法只是想法,不能直接寫進正文;一篇發過的數據不錯的教程,才是 AI 下次應該重點參考的樣本。
分清楚之後,AI 每次開工前就知道:什麼能讀,什麼能寫,什麼不能動。
這個方法,我跑通了1個多月。
昨天,我寫了一篇"國內如何用上 Claude Code"的圖文教程,發到抖音後,3.9 萬瀏覽、922 個點贊、1110 個收藏。小紅書那邊反饋也不錯。
這篇內容不是 AI 憑空寫出來的。
它知道我為什麼要寫這篇:不是因為 Claude Code 這個詞熱,而是因為最近很多人卡在國內網絡和 API 配置上。我一個月前就用火山方舟的 API Key 跑通了,現在需求變強了。
它知道這篇給誰看:不是給已經很懂命令行的人,而是給那些想用但卡在安裝配置的人。
它知道我的表達方式:不是上來寫"本文將從背景、原理、步驟三個部分展開",而是先講我自己的使用現場,再給圖文步驟。
它知道教程必須能跑:不是"看起來有道理",而是讀者照着做能不能走下去。
這些信息,如果都靠我每次在聊天框裏重新說一遍,我會瘋。
所以我把這些背景、規則、案例和表達標準都放進第二大腦,讓 AI 開工前先讀。
看到這裏你可能會想:我是不是也要建一套四個庫?
不一定。我的結構是從我的業務長出來的。你不一定和我一樣。
你真正應該做的,是讓 AI 先理解你,再幫你設計適合你的系統。
這一步最適合交給 AI Agent 做。你可以直接讓它問你幾個問題:你是做什麼的、主要想讓 AI 幫什麼、讀者是誰、最近推進什麼項目、過去哪些內容值得反覆讀取、哪些規則不能碰。
問完再給方案。
這比你自己對着一堆文件發呆要現實得多。
這也不是我一個人關起門來想出來的,而是和推特上的兩個硅谷大神學來的。
說到這兒我覺得有點搞笑,我在國內見過不少大v拿兩位硅谷大神的方法後,說為自創。如果是,那姑且我這個方式也是我自創吧。
Garry Tan 是 Y Combinator 的總裁兼 CEO。他做的 GBrain,本質上也是讓 Agent 在回答前讀取人的生活和工作上下文。
Andrej Karpathy 以前是特斯拉 AI 總監,也在 OpenAI 做過研究。他很多關於 AI 和學習系統的分享,也在反覆指向一件事:真正重要的不是單次 prompt,而是人和 AI 之間有沒有一套持續工作的系統。
這些東西讓我更確認,我這半年踩出來的方向不是孤例。真正會用 AI 的人,最後都會走向同一個很重要的方向:不是隻問一個更好的問題,而是給 AI 一個更好的工作現場。
你給它一個孤零零的問題,它只能給你一個孤零零的答案。你給它一個能持續讀取的第二大腦,它才有機會變成一個越來越懂你的員工。
所以回到開頭那句話:"我還沒有馴服 AI。"
先別急着怪自己,也別急着換模型、收藏新提示詞。
先做一件更基礎的事:讓 AI 認識你。
不要先問 AI:"幫我寫。"
先讓它知道:"我是誰。"
附:如果你想讓 AI 幫你搭一套
不用一次搭完,也不要讓 AI 直接移動文件。先讓它訪談你,在給方案。
可以直接複製下面這段發給你的 Agent(open claw /Claude code/ codex):
你現在是我的第二大腦搭建助手。
目標:閲讀杜一這篇文章幫我建立一個能讓 AI Agent 每次開工前讀懂我的工作文件夾,並用obsidian打開。
請先對我做一次訪談,確認:
1. 我是做什麼業務/工作的
2. 我主要想讓 AI 幫我做哪些任務
3. 我的讀者/客戶是誰
4. 我最近正在推進什麼項目
5. 我過去有哪些內容/案例/資料值得 AI 反覆讀取
6. 哪些是原始資料,哪些是準備發佈的成品
7. 哪些規則是 AI 必須遵守的紅線
訪談完成後:
- 給我一個文件夾結構方案(說明每個目錄放什麼、不放什麼、AI 什麼時候讀取)
- 如果我已經有文件,先掃描但不要移動,按"原料/內容/項目/工具"給出候選分類,標出你不確定的
- 生成一個"每次讓 AI 先讀這個.md"的模板
- 在我確認前,不要執行任何移動、刪除、覆蓋操作