神仙打架!Anthropic 和 OpenAI 同一天亮劍,開發者到底該站哪邊?
整理版優先睇
Anthropic同OpenAI同日發布旗艦模型,開發者應按場景活用兩者。
呢篇文章出自Leo哥之手,講述2026年2月5日傍晚,Anthropic同OpenAI相隔20分鐘先後發布Claude Opus 4.6同GPT-5.3-Codex。呢個唔係巧合,而係首次正面對決,作者用意係幫讀者睇清楚門道,唔係單純搬運新聞。
Claude Opus 4.6主打廣度,提供百萬token上下文、Agent Teams多智能體協作、自適應思維,仲有辦公集成,目標係做全能型AI平台。GPT-5.3-Codex則專注深度,編程能力登頂Terminal-Bench 77.3%,仲首次實現「參與自我構建」,但亦引起安全擔憂。OpenAI更因為網絡安全風險而延遲API訪問。
作者建議日常寫Code用GPT-5.3-Codex,處理大型項目或長文檔就用Claude Opus 4.6,多任務並行嘅時候用Agent Teams。總之,2026年仲綁死喺單一AI工具係最唔明智嘅做法。呢場軍備競賽嘅真正贏家係我哋開發者,因為競爭令價格下降、性能提升、生態擴展。
- 兩者無絕對優劣,應根據場景切換使用。
- Claude Opus 4.6以百萬token、Agent Teams、自適應思維實現廣度。
- GPT-5.3-Codex憑Terminal-Bench 77.3%及自我構建成為編程王者。
- 「自我構建」標誌AI邁向自我迭代,同時引發安全警號。
- 可行動點:日常用GPT,大型項目用Claude,並行用Agent Teams。
神仙打架:同日發佈嘅背後邏輯
2026年2月5日傍晚,Anthropic同OpenAI相隔20分鐘先後發布旗艦模型,呢個唔係巧合,而係首次正面對決。
「中門對狙」
作者話呢種場景喺AI發展史上係第一次,對開發者嚟講,呢種競爭帶嚟嘅係純粹嘅利好。
Claude Opus 4.6:廣度之王
Anthropic嘅策略係做最全面嘅AI,Opus 4.6定位為全能型AI平台。
- 百萬token上下文:由200K飛躍至1M,可以處理5本技術書或整個中型項目代碼庫。
- Agent Teams:多智能體並行協作,將大任務拆細,效率翻倍。
- 自適應思維:根據任務複雜度動態調整推理深度,有4級強度,既省錢又唔會掉鏈子。
百萬token
Agent Teams
自適應思維
Context Compaction
其他亮點包括自動壓縮舊對話、集成PowerPoint同Excel,同埋上線Vertex AI、GitHub Copilot等平台。
GPT-5.3-Codex:深度之王
OpenAI就走另一條路,將所有資源砸向編程能力,目標係做最強編程AI。
Terminal-Bench 77.3%
自我構建
SWE-Bench Pro 56.8%
- 編程能力碾壓:Terminal-Bench 2.0 77.3%,比Claude Opus 4.6高12個百分點。
- 自我迭代:早期版本參與自身訓練調試、部署管理同評估診斷。
- 全端覆蓋:Codex App、CLI、IDE插件、Web四大渠道。
- 速度比上代快25%,適合快速開發。
OSWorld-Verified得分64.7%,進一步證明其系統操作能力。
開發者選型指南:應該點樣揀?
冇絕對好壞,只有適合場景,作者建議「兩個都用」。
「兩個都用」
- 1 日常編程(寫代碼/debug/重構):推薦GPT-5.3-Codex,因為Terminal-Bench 77.3%編程最強。
- 2 大型項目理解與重構:推薦Claude Opus 4.6,因為百萬token + Agent Teams。
- 3 長文檔分析:推薦Claude Opus 4.6,1M上下文優勢。
- 4 多任務並行處理:推薦Claude Opus 4.6,Agent Teams獨家。
- 5 快速原型開發:推薦GPT-5.3-Codex,速度快25%。
- 6 預算敏感型:推薦Claude Opus 4.6,價格透明$25 per M tokens。
按場景靈活切換
總結:AI軍備競賽令開發者得益,我哋係真正贏家。
神仙打架!Anthropic 同 OpenAI 同一日出招,開發者到底應該企喺邊邊?
前言
大家好,我係Leo哥。2026年2月5日,傍晚6點40分,Anthropic正式宣佈 Claude Opus 4.6。
20分鐘後,7點正,OpenAI 即刻跟住推出 GPT-5.3-Codex。
20分鐘。得20分鐘咋。
呢個唔係巧合,呢個係 「中門對射」。
如果你係FPS玩家,你一定明嗰種兩邊同時出門、狙鏡對到正嘅窒息感——冇試探、冇兜圈,直接正面硬撼。AI發展史上,兩大巨頭第一次喺同一日、同一段時間,同時曬自己嘅旗艦模型,呢場神仙打架嘅激烈程度,恐怕以後要寫入AI編年史。
呢篇文章唔係新聞搬字過紙。我要做嘅係幫你**「睇清楚個門路」**——兩款模型到底勁喺邊?有咩本質分別?作為開發者你應該企喺邊一邊?
坐穩喇,我哋開始。
2月5日究竟發生咗啲咩?
以前兩間公司發佈模型,中間至少隔幾個星期甚至幾個月,你來我往慢慢過招。今次唔同,「20分鐘嘅時間差」,幾乎就係講:你出咩牌我早就知,我嘅底牌都準備好曬。
Claude Opus 4.6:廣度之王
Anthropic 今次嘅策略好明確——「我要做最全面嘅AI」。
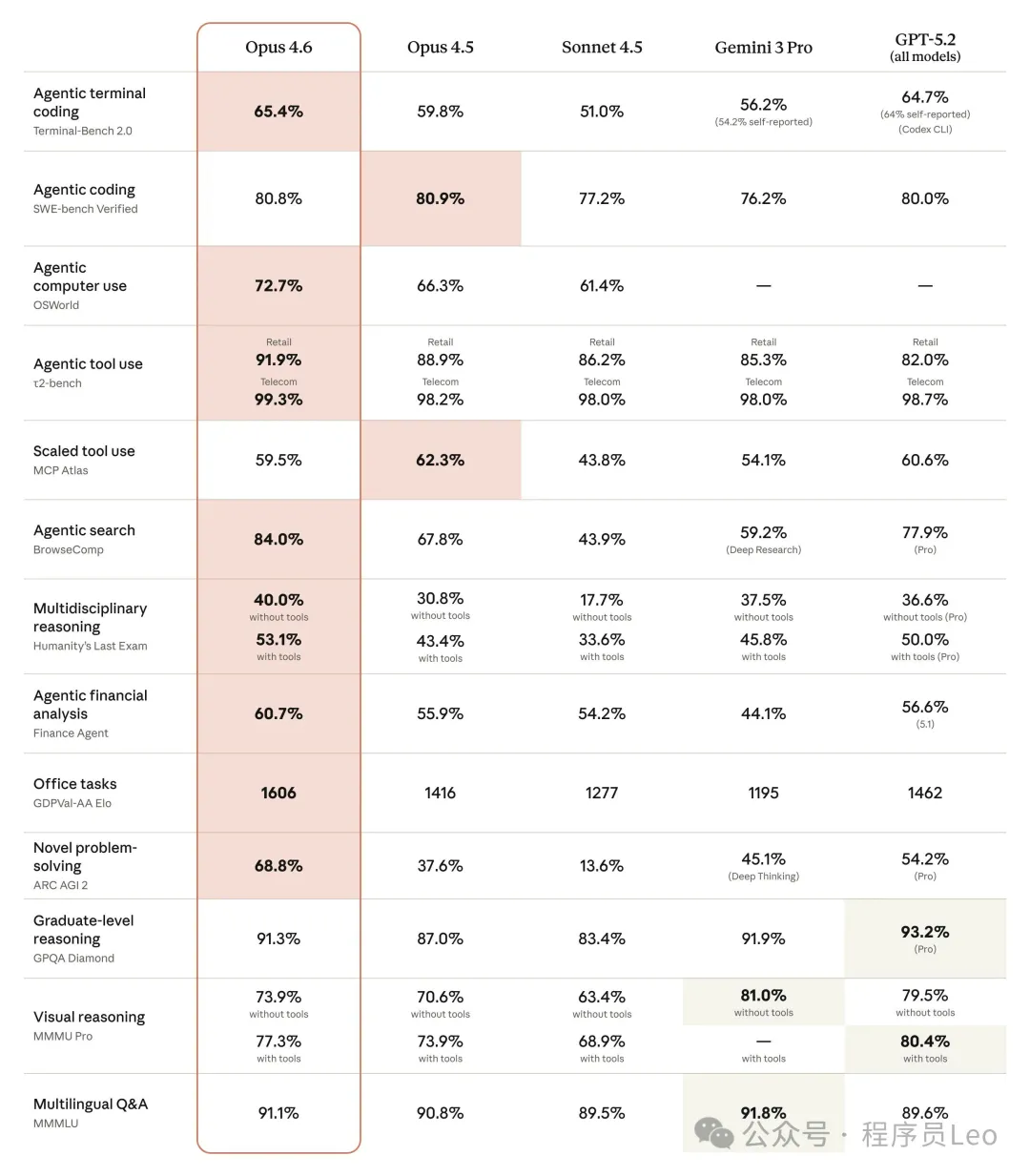
呢個跑分我睇完都覺得好犀利。
百萬token上下文:從200K到1M嘅飛躍
先講最爆嘅數字。Opus 4.5 嘅上下文窗口係 200K token,已經好大㗎啦,係咪?Opus 4.6 直接推上**「1M token」,整整「5倍提升」**。
呢個係咩概念?打個比喻:
• 200K token ≈ 一本中等厚度嘅技術書 • 1M token ≈ 「5本技術書同時塞入去」,或者一個中型項目嘅完整程式碼庫
呢個意味住咩?意味住你可以將成個項目嘅程式碼掟畀佢,等佢理解曬整體架構之後再幫你改bug。以前你要一個檔案一個檔案咁餵,而家可以直接「全部要曬」。
配合**「MRCR v2(長上下文評測)76%」**嘅成績,呢個百萬token唔係得個樣。作為對比,Sonnet 4.5 喺同一個評測得 18.5%,差距係碾壓級別。
Agent Teams:多智能體並行協作
第二個大招係**「Agent Teams」**。
以前嘅AI助手係「一個人做曬所有事」,而家 Opus 4.6 可以將一個大任務拆做多個子任務,「由多個Agent各自負責、同時執行」。
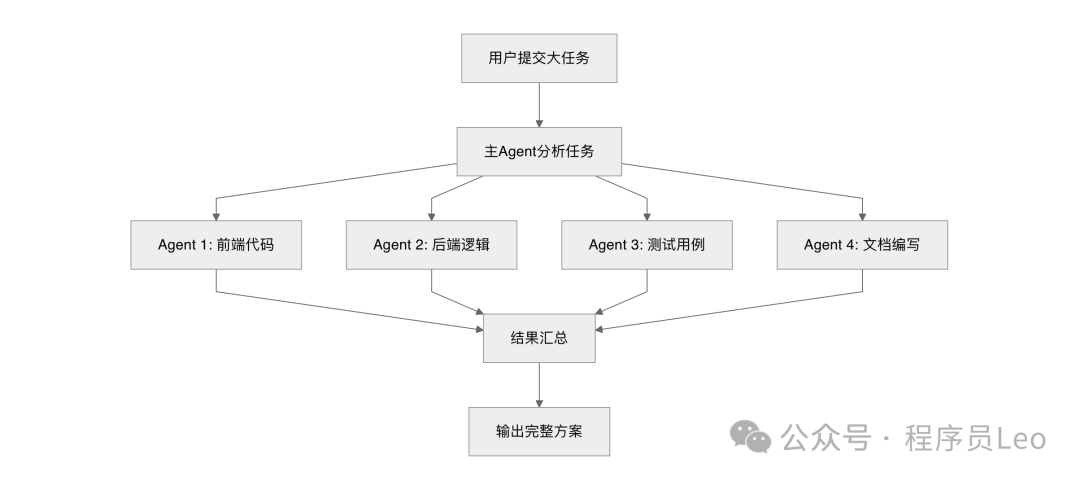
講白啲就係由「單兵作戰」進化到「小隊協作」。你叫佢重構一個項目,佢可以同時安排一個Agent分析架構、一個Agent寫程式碼、一個Agent跑測試,效率直接翻倍。
以我個人體驗嚟講,呢個能力喺處理大型程式碼庫重構、多檔案聯動修改呢類場景特別好用。
Adaptive Thinking:聰明咁分配腦力
第三個亮點係 「自適應思維(Adaptive Thinking)」,根據任務複雜度動態調整推理深度,提供 「4個可選強度級別」。
簡單問題?快速回答,唔浪費算力。
複雜問題?深度思考,該用嘅token一點都唔慳。
呢個設計好聰明。以前唔理你問「1+1等於幾」定「幫我設計一個分佈式系統」,模型都用同樣嘅推理深度。而家佢會自己判斷要用幾成功力,「又慳錢又唔會失準」。
其他亮點快睇
GPT-5.3-Codex:深度之王
OpenAI呢邊行另一條路——「我要做最勁嘅編程AI」。
點講呢,Codex除咗慢,其他方面都算唔錯,模型能力冇問題,不過成日一個任務搞半個鐘都係家常便飯。
相比claude code嗰幾次烏龍事件,openai呢邊奧特曼就親自落場監督。

「首個參與自我構建嘅AI模型」
呢句話第一次見到嗰陣,我呆咗大概三秒鐘。
咩叫「參與自我構建」?即係 GPT-5.3-Codex 嘅早期版本 「參與咗自身嘅訓練調試、部署管理同評估診斷」。唔係人類由頭到尾手把手訓練出嚟,而係AI自己幫手將自己「造」出嚟。
呢件事點評價好呢?技術上確係勁,佢標誌住AI開始具備一定程度嘅**「自我疊代能力」**。但同時亦令好多人背脊一涼——呢個距離科幻片裏面AI自我進化嘅場景,係咪太近喇?
編程能力:真·王者級別
用數據講嘢。Terminal-Bench 2.0 得分**「77.3%」**,而 Claude Opus 4.6 係 65.4%。
差唔多**「12個百分點嘅差距」**,喺編程能力呢個單項上,GPT-5.3-Codex 係實實在在嘅碾壓。
唔單止咁:
再加上比 GPT-5.2-Codex **「快25%」**嘅運行速度,喺「寫程式碼」呢件事上,暫時市面上冇對手。
呢個對於以編程為主要使用場景嘅開發者嚟講,係一個非常強烈嘅信號。
覆蓋全端,無處不在
GPT-5.3-Codex 嘅分發策略亦都好激進——面向所有付費 ChatGPT 用戶,覆蓋**「Codex App、CLI、IDE 插件、Web」**四大渠道。簡單講就係:無論你喺邊度寫程式碼,我都可以揾到你。
正面對決:Benchmark 擂台賽
好喇,兩邊嘅底牌都曬曬,係時候上擂台。
全維度數據對比
點睇呢張表?
呢張表嘅信息量好大,核心結論有三個:
1. 編程能力,GPT-5.3 贏咗,而且贏得好明顯。 Terminal-Bench 12個百分點嘅差距唔係細數字。如果你嘅核心要求就係「幫我寫程式碼」,GPT-5.3-Codex 暫時係更強嘅選擇。
2. 綜合能力同生態廣度,Opus 4.6 更全面。 百萬token上下文、Agent Teams、自適應思維、辦公集成……Anthropic做嘅唔係一個「編程助手」,而係一個**「全能型AI平台」**。
3. 兩家各有千秋,唔存在「邊個碾壓邊個」。 呢個亦係呢場對決最有意思嘅地方——唔係一面倒,而係真正嘅神仙打架。
兩種AI哲學:廣度 vs 深度
呢場對決最值得諗清楚嘅,唔係邊個Benchmark高啲低啲,而係兩間公司背後完全唔同嘅**「產品哲學」**。

Anthropic:做AI世界嘅「瑞士軍刀」
Anthropic 嘅策略可以用一個詞概括:「廣度」。
百萬token令你可以處理超長文件同成個程式碼庫。Agent Teams令你可以同時處理多個複雜任務。集成 PowerPoint 同 Excel 令AI走入辦公室。上線 Vertex AI、GitHub Copilot、Microsoft Foundry 令你喺邊度都用得。
佢嘅邏輯係:「AI唔應該淨係一個編程工具,佢應該係一個咩都可以幫你搞掂嘅智能夥伴」。
呢條路線配合 Claude Code 年化收入達到**「3500億」**,呢個數字喺兩年前簡直唔敢諗。
OpenAI:做編程領域嘅「六邊形戰士」
OpenAI 嘅策略亦都一個詞:「深度」。
Terminal-Bench 77.3%,SWE-Bench Pro 56.8%,運行速度快25%。所有資源都掟曬喺一個方向——「將編程能力做到最盡」。
仲勁嘅係「自我構建」呢個概念。呢個唔單止係一個產品特性,而係一個技術路線嘅宣言:「AI應該可以自我進化」。
邊條路線好啲?呢個問題冇標準答案。就好似揀工具一樣——你需要嘅係一把瑞士軍刀,定係一把專業廚刀?取決於你嘅場景。
安全警鐘:當AI開始「自我構建」
OK,呢一節我想認真傾下安全問題。
GPT-5.3-Codex 係首個喺 OpenAI 準備框架中被標記為**「網絡安全「高能力」」**嘅模型。呢個標籤意味住咩?意味住OpenAI內部評估認為,呢個模型喺網絡安全領域具有「顯著嘅攻防能力」**。
因為呢個原因,OpenAI做咗一個罕有嘅決定——「延遲完全API訪問」。Sam Altman 本人甚至親自出帖文講安全擔憂。
「自我構建」呢件事,好嗰方面講係「AI效率飛躍」,往壞嗰方面諗係「AI自我進化嘅起點」。當一個AI能夠參與自己嘅訓練同調試,咁下一步係咪就係自己決定訓練方向?再下一步呢?
以我個人角度嚟講,我覺得OpenAI今次喺安全透明度上做得幾好——至少佢哋主動公開咗安全評估結果,冇收收埋埋。但係「高能力」呢個標籤的確令人多咗一層擔憂。
開發者選型指南:應該企邊隊?
講咗咁多,返到最實際嘅問題——「我到底應該用邊個?」
先講結論:「唔存在絕對嘅邊個好邊個差,只有適唔適合你嘅場景」。
場景化推薦
我嘅個人建議
如果你問我點揀,我嘅建議係:「兩個都用」。
冇講笑。2026年喇,將自己綁死喺單一AI工具係最唔明智嘅做法。就好似你寫程式碼唔會淨係用一個IDE咁,AI工具都應該根據場景靈活切換。
• 寫程式碼嗰陣開 GPT-5.3-Codex • 需要理解大型項目或者處理長文件嗰陣就轉 Claude Opus 4.6 • 需要多任務並行嗰陣用 Opus 嘅 Agent Teams
寫喺最後
回過頭嚟睇2月5日嘅呢場「中門對射」,我最大嘅感受係:「AI軍備競賽嘅真正贏家,係我哋呢班開發者」。
兩年前你用嘅AI助手,寫個冒泡排序都會出bug。而家呢?一個食得落百萬token理解你成個項目,另一個Terminal-Bench 77.3%編程能力登頂。兩間公司為咗爭你呢個用戶,將價格打落嚟、將性能推上去、將生態鋪開曬。
呢種級數嘅競爭,對用戶嚟講係純粹嘅好消息。
如果呢篇文章對你有幫助,麻煩幫手點讚、轉發,我哋下篇文章再見~
神仙打架!Anthropic 和 OpenAI 同一天亮劍,開發者到底該站哪邊?
前言
大家好,我是Leo哥。2026年2月5日,傍晚6點40分,Anthropic官宣 Claude Opus 4.6。
20分鐘後,7點整,OpenAI緊跟着甩出 GPT-5.3-Codex。
20分鐘。就20分鐘。
這不是巧合,這是 「中門對狙」。
如果你是個FPS玩家,你一定懂那種兩邊同時出門、狙鏡對上的窒息感——沒有試探,沒有迂迴,直接正面剛。AI發展史上,兩大巨頭第一次在同一天、同一個時段、同時亮出自己的旗艦模型,這場神仙打架的激烈程度,怕是以後要寫進AI編年史的。
這篇文章不是新聞搬運。我要做的是幫你**「看懂門道」**——兩款模型到底強在哪?有什麼本質區別?作為開發者你該站哪邊?
坐穩了,咱們開始。
2月5日到底發生了什麼?
以前兩家發佈模型,中間至少隔幾周甚至幾個月,你來我往慢慢過招。這次不一樣,「20分鐘的時間差」,幾乎就是在說:你出什麼牌我早就知道了,我的底牌也準備好了。
Claude Opus 4.6:廣度之王
Anthropic這次的策略很明確——「我要做最全面的AI」。
這個跑分看着我都感覺以及很牛逼了。
百萬token上下文:從200K到1M的飛躍
先說最炸裂的數字。Opus 4.5 的上下文窗口是 200K token,已經很大了對不對?Opus 4.6 直接拉到**「1M token」,整整「5倍提升」**。
這是什麼概念?打個比方:
• 200K token ≈ 一本中等厚度的技術書 • 1M token ≈ 「5本技術書同時塞進去」,或者一整個中型項目的代碼庫
這意味着什麼?意味着你可以把一整個項目的代碼扔給它,讓它理解全局架構之後再幫你改bug。以前你得一個文件一個文件地喂,現在直接"全都要"。
配合**「MRCR v2(長上下文評測)76%」**的成績,這個百萬token不是擺設。作為對比,Sonnet 4.5 在同一評測上只有 18.5%,差距是碾壓級的。
Agent Teams:多智能體並行協作
第二個大招是**「Agent Teams」**。
以前的AI助手是"一個人幹所有事",現在 Opus 4.6 可以把一個大任務拆分成多個子任務,「讓多個Agent各自負責、並行執行」。
說白了就是從"單兵作戰"進化到了"小隊協作"。你讓它重構一個項目,它可以同時安排一個Agent分析架構、一個Agent寫代碼、一個Agent跑測試,效率直接翻倍。
從我個人體驗來看,這個能力在處理大型代碼庫重構、多文件聯動修改這類場景下特別香。
Adaptive Thinking:聰明地分配腦力
第三個亮點是 「自適應思維(Adaptive Thinking)」,根據任務複雜度動態調整推理深度,提供 「4個可選強度級別」。
簡單問題?快速回答,不浪費算力。
複雜問題?深度思考,該燒的token一點不省。
這個設計很聰明。以前不管你問"1+1等於幾"還是"幫我設計一個分佈式系統",模型都是同樣的推理深度。現在它會自己判斷該用幾成功力,「既省錢又不掉鏈子」。
其他亮點速覽
GPT-5.3-Codex:深度之王
OpenAI這邊走的是另一條路——「我要做最強的編程AI」。
怎麼說呢,Codex除了慢,其他方面也還算不錯,模型能力也沒問題,不過經常一個任務半小時也都是家常便飯。
相比於claude code的幾次烏龍事件,openai這裏奧特曼則是親自下次監督。
"首個參與自我構建的AI模型"
這句話第一次看到的時候,我愣了大概三秒鐘。
什麼叫"參與自我構建"?意思是 GPT-5.3-Codex 的早期版本 「參與了自身的訓練調試、部署管理和評估診斷」。不是人類從頭到尾手把手訓出來的,是AI自己幫着把自己"造"出來的。
這個事兒怎麼評價呢?技術上確實牛,它標誌着AI開始具備一定程度的**「自我迭代能力」**。但同時也讓不少人後脊樑發涼——這離科幻電影裏AI自我進化的場景,是不是太近了?
編程能力:真·王者段位
數據說話。Terminal-Bench 2.0 得分**「77.3%」**,而 Claude Opus 4.6 是 65.4%。
將近**「12個百分點的差距」**,在編程能力這個單項上,GPT-5.3-Codex 是實打實的碾壓。
不僅如此:
再加上比 GPT-5.2-Codex **「快25%」**的運行速度,在"寫代碼"這件事上,目前市面上沒有對手。
這對於以編程為主要使用場景的開發者來說,是一個非常強的信號。
覆蓋全端,無處不在
GPT-5.3-Codex 的分發策略也很激進——面向所有付費 ChatGPT 用戶,覆蓋**「Codex App、CLI、IDE 插件、Web」**四大渠道。簡單說就是:不管你在哪裏寫代碼,我都能找到你。
正面對決:Benchmark 擂台賽
好了,兩邊的底牌都亮完了,該上擂台了。
全維度數據對比
怎麼看這張表?
這張表的信息量非常大,核心結論有三個:
1. 編程能力,GPT-5.3 贏了,而且贏得很明顯。 Terminal-Bench 12個百分點的差距不是小數字。如果你的核心訴求就是"幫我寫代碼",GPT-5.3-Codex 目前確實是更強的選擇。
2. 綜合能力和生態廣度,Opus 4.6 更全面。 百萬token上下文、Agent Teams、自適應思維、辦公集成……Anthropic做的不是一個"編程助手",而是一個**「全能型AI平台」**。
3. 兩家各有勝場,不存在"誰碾壓誰"。 這也是這場對決最有意思的地方——不是一邊倒,而是真正的神仙打架。
兩種AI哲學:廣度 vs 深度
這場對決最值得琢磨的,不是哪個Benchmark誰高誰低,而是兩家公司背後截然不同的**「產品哲學」**。
Anthropic:做AI世界的"瑞士軍刀"
Anthropic 的策略可以用一個詞概括:「廣度」。
百萬token讓你能處理超長文檔和整個代碼庫。Agent Teams讓你能並行處理多個複雜任務。集成 PowerPoint 和 Excel 讓AI走進辦公室。上線 Vertex AI、GitHub Copilot、Microsoft Foundry 讓你在哪都能用。
它的邏輯是:「AI不應該只是一個編程工具,它應該是一個什麼都能幫你乾的智能夥伴」。
這個路線配合 Claude Code 年化收入達**「3500億」**,這個數字放在兩年前簡直不敢想。
OpenAI:做編程領域的"六邊形戰士"
OpenAI 的策略同樣一個詞:「深度」。
Terminal-Bench 77.3%,SWE-Bench Pro 56.8%,運行速度快25%。所有的資源都砸在一個方向上——「把編程能力做到極致」。
更狠的是"自我構建"這個概念。這不只是一個產品特性,這是一個技術路線的宣言:「AI應該能夠自我進化」。
哪個路線更好?這個問題沒有標準答案。就像選工具一樣——你是需要一把瑞士軍刀,還是一把專業廚刀?取決於你的場景。
安全警鐘:當AI開始"自我構建"
OK,這一節我想認真聊一下安全問題。
GPT-5.3-Codex 是首個在 OpenAI 準備框架中被標記為**「網絡安全"高能力"」的模型。這個標籤意味着什麼?意味着OpenAI內部評估認為,這個模型在網絡安全領域具有「顯著的攻防能力」**。
因為這個原因,OpenAI做了一個罕見的決定——「延遲完全API訪問」。Sam Altman 本人甚至親自發帖談安全擔憂。
"自我構建"這件事情,往好了說是"AI效率飛躍",往壞了想是"AI自我進化的起點"。當一個AI能夠參與自己的訓練和調試,那下一步是不是就是自己決定訓練方向?再下一步呢?
從我個人角度來說,我覺得OpenAI這次在安全透明度上做得還不錯——至少他們主動公開了安全評估結果,沒有藏着掖着。但"高能力"這個標籤確實讓人多了一層擔憂。
開發者選型指南:該站隊誰?
說了這麼多,回到最實際的問題——「我到底該用哪個?」
先說結論:「不存在絕對的誰好誰壞,只有適不適合你的場景」。
場景化推薦
我的個人建議
如果你問我怎麼選,我的建議是:「兩個都用」。
沒有開玩笑。2026年了,把自己綁定在單一AI工具上是最不明智的做法。就像你寫代碼不會只用一個IDE一樣,AI工具也應該根據場景靈活切換。
• 寫代碼的時候開 GPT-5.3-Codex • 需要理解大型項目或處理長文檔的時候切 Claude Opus 4.6 • 需要多任務並行的時候用 Opus 的 Agent Teams
寫在最後
回過頭來看2月5日的這場"中門對狙",我最大的感受是:「AI軍備競賽的真正贏家,是我們這些開發者」。
兩年前你用的AI助手,寫個冒泡排序還會出bug。現在呢?一個能吃下百萬token理解你的整個項目,另一個Terminal-Bench 77.3%編程能力登頂。兩家為了爭你這個用戶,把價格打下來、把性能拉上去、把生態鋪開來。
這種級別的競爭,對用戶來說是純粹的利好。
如果這篇文章對你有幫助,還請幫忙點贊、轉發,咱們下篇文章見~