第 013 篇|實現一個自己的 發票管理Skill:把重複瑣事變成兩條命令
整理版優先睇
每月兩小時發票庶務,變兩條命令:用 AI Skill 徹底移除重複勞動
呢篇文章係實踐哥 MinLi 分享佢點樣用 AI 將每月兩小時嘅發票整理工作,變成兩條命令嘅經驗。佢本身每個月要面對一堆「您的電子發票」郵件,手動下載 PDF、OFD、連結,再核對發票號、剔除個人抬頭、分類彙總。佢嘅出發點好簡單:呢啲重複勞動,點解唔交俾 AI?
佢用咗大約半小時,叫 Claude Code 幫佢自動化咗呢個流程。跑咗三個月之後,成果係:363 封郵件、62 封候選、44 張唯一發票、總金額 ¥8,861.69。原來每個月要花兩小時嘅嘢,而家變成兩條命令就搞掂。
呢篇文章嘅核心價值唔係教你點寫代碼,而係講清楚背後嘅方法:普通人點樣將一個重複任務,變成自己嘅 Skill。重點包括:Skill 本質係一個文件夾;你唔使寫代碼,而係做產品經理定義問題;先同 AI 傾清楚需求,包括目標、數據來源、未來變化同邊界條件;留意授權管理同安全;同埋結構化任務可以用輕量模型。呢套方法可以套用到報銷、週報、工時填報等好多週期性瑣事。
- 結論:重複、規則固定嘅任務最適合用 AI 自動化;唔需要編程,講清楚需求就得。
- 方法:Skill 本質係一個文件夾,包含說明書同工具;三步:建文件夾、寫說明書、放工具。
- 差異:用戶角色係產品經理,負責定義問題同邊界,唔係寫代碼。
- 啟發:先問「未來會變什麼」設計解耦架構;真實世界有 PDF/OFD 覆蓋、搜索 bug 等陷阱。
- 可行動點:用三問判斷任務值唔值得自動化:係咪反覆出現?規則固定?重複判斷?係就做成 Skill。
實踐哥 MinLi 的 X 狀態
原始發文,包含更多討論
原文 X Article
《實現一個自己的skill,一篇文章就夠了》
每月兩小時嘅發票庶務,點樣變成兩條命令
實踐哥 MinLi 每個月都要花兩小時,面對一堆「您的電子發票」郵件,手動下載各種格式,再核對發票號、剔除個人抬頭、分類彙總。佢問咗自己一句:呢啲重複勞動,點解唔交俾 AI?
呢啲重複勞動,點解唔交俾 AI?
佢用咗大約半小時,叫 Claude Code 幫佢自動化咗呢個流程。跑咗三個月之後,成果係:363 封郵件、62 封候選、44 張唯一發票、總金額 ¥8,861.69。原來每個月要花兩小時嘅嘢,而家變成兩條命令就搞掂。
兩條命令
Skill 唔係神秘能力,本質就係一個文件夾
Skill 本質上就係一個文件夾,入面通常有說明書、幹活嘅小工具同部署注意事項。以「發票整理」Skill為例,佢包含咗說明書、抓郵件工具、處理連結工具同部署備忘。
Skill 本質就係一個文件夾
- 建一個文件夾
- 寫清楚說明書
- 將真正幹活嘅工具放進去
你唔需要先學會編程,你先要學會將需求講清楚。喺呢個工作流入面,你嘅角色係產品經理,負責用人話提需求。
你嘅角色係產品經理
第一步唔好急住寫 code,先同 AI 傾清楚需求
作者喺開始之前,先問咗幾個關鍵問題:你最終想要咩結果?數據從邊度來?未來邊度可能變化?有咩邊界條件要留意?
你最終想要咩結果?
未來邊度可能變化?
特別係「未來會變咩」呢一問,決定咗點樣拆 Skill。作者建議將能力拆成兩個 Skill:一個負責拉發票,一個負責整理 Excel,咁樣日後改郵箱或改模板就唔使推倒重來。
真實世界有好多陷阱,例如個人抬頭不能報、一張發票可能同時有 PDF 同 OFD、平台有時發連結唔係 PDF。呢啲邊界條件要一早講明。
個人抬頭不能報
AI 寫、AI 跑,你負責用人話報錯
作者分享咗兩個典型嘅坑:QQ 郵箱搜索因為括號問題返咗 9740 封郵件;PDF 同 OFD 因為用同一個發票號做唯一標識而互相覆蓋。呢啲問題說明,一個能長期複用嘅 Skill 係喺真實數據裏面跑出來、改出來。
9740 封郵件
PDF 同 OFD 互相覆蓋
安全方面,核心係用授權碼代替主密碼,將授權碼放喺 .env 並加入 .gitignore。唔好將敏感資料傳出去。
用授權碼代替主密碼
模型選型方面,作者最後用咗 Ling-2.6-flash 輕量模型,因為任務結構化、步驟固定。實測 44 張發票字段全對,耗時 1 分 50 秒,成本 $0。關鍵唔係用最貴模型,而係揀最適合任務複雜度嘅模型。
用最適合任務複雜度嘅模型
呢套方法可以遷移到報銷、週報、工時填報等週期性瑣事。判斷一個任務值唔值得自動化,可以問三個問題:係咪反覆出現?規則係咪固定?係咪每次重複同樣判斷動作?如果都係,就做成 Skill。

好多人以為,AI 嘅價值在於「幫你寫啲嘢」。
但真正有價值嘅,往往唔係多寫一段文字,而係將嗰啲每個月固定出現、又唔值得你親自投入注意力嘅重複勞動,完全從工作流程入面拎走。
實踐哥 MinLi 喺原文入面舉咗一個超典型嘅例子:整理發票。
呢件事佢已經做咗三年。每個月要花兩個鐘,面對一堆「你的電子發票」郵件,手動下載 PDF、OFD、12306 連結、滴滴連結、京東 XML,再肉眼核對發票號、剔除個人抬頭、最後打落 Excel 分類匯總。
後來佢做咗一件好樸素、亦都好關鍵嘅事:唔再問「我點樣更快整理發票」,而係直接問「呢啲唔係 AI 應該做嘅嘢咩?」
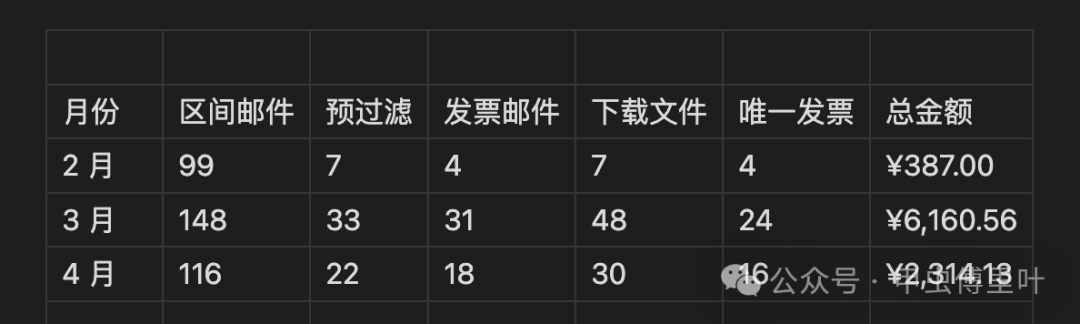
於是,佢用咗大約半個鐘,叫 Claude Code 幫自己將呢件事自動化咗。行咗三個月之後,得到嘅數據係:
• 363 封郵件 • 62 封候選郵件 • 44 張唯一發票 • 總金額 ¥8,861.69
原來每月兩個鐘嘅瑣碎事,變咗做兩條命令。
呢篇文章,唔係程式碼教學,而係將呢件事背後嘅方法講清楚:普通人點樣將一個重複任務,變成自己嘅 skill。
一、咩係 Skill:唔係神秘能力,本質就係一個資料夾
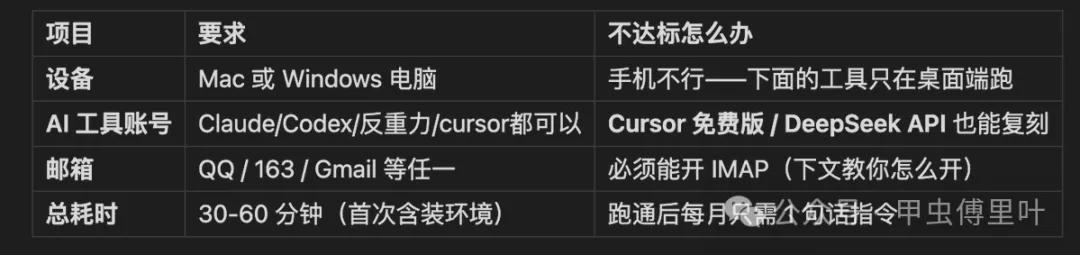
首先將一個容易講到好複雜嘅概念講簡單啲。
根據原文嘅解釋,skill 本質上就係一個資料夾。
呢個資料夾裏面通常會放幾類嘢:
• 一份說明書:話俾 AI 知呢個能力係做咩 • 幾個真正做嘢嘅小工具:腳本、配置、處理邏輯 • 一啲部署同注意事項:例如環境變數、授權方式、使用方法
原文中呢個「發票整理」 skill,就包含咗:
• 說明書 • 抓郵件工具 • 處理連結工具 • 部署備忘
當 AI 啟動時,佢會掃描呢啲 skill 資料夾,將說明書讀入去。之後你再講一句「拉一下 4 月發票」,佢就知道應該調用邊套工具、跟咩步驟執行。
所以,「實現一個自己嘅 skill」拆開嚟睇,其實得三步:
1. 開一個資料夾 2. 寫清楚說明書 3. 將真正做嘢嘅工具放落去
呢個亦係點解原文一直強調:你唔需要先學識編程,你要先學識將需求講清楚。
二、你唔使寫程式,你似產品經理多啲
呢點係原文入面我好認同嘅。
好多人一聽到「自動化」「腳本」「AI Agent」,第一個反應係:我唔識寫程式,呢啲嘢同我冇關係。
但係如果你將角色轉一轉,會發現唔係咁樣。
喺呢類工作流程入面,普通用戶最重要嘅工作,唔係寫實作,而係定義問題:
• 我到底想要咩結果? • 數據從邊度嚟? • 邊啲情況算異常? • 邊啲規則將來可能會變? • 邊啲邊界條件絕對唔可以錯?
原文將呢個角色歸納得好準確:你係產品經理。
你負責用人話提出需求:
• 我想要啲咩 • 我唔想要啲咩 • 出錯之後應該點處理 • 邊啲規則係硬約束 • 邊啲情況將來會變化
如果程式碼洗版睇唔明,都冇問題,直接問 AI:「呢段係做緊咩?」
真正決定一個 skill 好唔好用嘅,唔係程式碼靚唔靚,而係需求有冇講清楚。尤其係公司規矩、報銷模板、郵件習慣、去重邏輯,呢啲都係通用模型唔知、但你自己最清楚嘅嘢。
三、第一步唔好急住叫 AI 開工,先將需求傾透
原文入面最有價值嘅部分,唔係「叫 AI 寫咗啲咩」,而係「開工前先討論咗啲咩」。
喺開始寫之前,作者先將幾個關鍵問題講清楚。
1)你最終想要咩結果
呢度唔係求其話「幫我整理發票」,而係具體到產出物:
• 每月尾生成一份 Excel • 按類別匯總金額
即係話,目標唔係「捉到郵件」,而係「形成可交付嘅報銷結果」。
2)數據從邊度嚟
原文嘅輸入來源係:
• QQ 郵箱 • 搜尋關鍵詞「發票」
呢一步睇落簡單,實際上係界定系統邊界。否則 AI 可能會誤以為你要掃描本地資料夾、網盤附件,甚至 OCR 截圖。
3)未來邊度可能會變
呢點係原文特別強調嘅,亦係方法論上最值得記住嘅一點:
「未來會變啲咩」,決定咗 AI 點樣拆 skill。
比如:
• 將來可能會轉郵箱 • 可能會轉報銷模板 • 可能分類規則會調整 • 可能附件格式繼續變化
如果呢啲變化一開始唔講,AI 好容易將系統寫成一個一次性嘅腳本;一旦環境變動,成 set 嘢就好難維護。
作者因此建議,將能力拆成兩個 skill:
• 一個負責拉發票 • 一個負責整理 Excel
呢個背後其實係做緊解耦:輸入獲取同結果整理分開,之後改郵箱或者改模板嗰陣,就唔使推倒重來。
4)有邊啲必須警惕嘅邊界條件
原文入面提到幾個好真實嘅陷阱:
• 個人抬頭唔可以報銷 • 一張發票可能同時有 PDF 同 OFD 兩份 • 12306、滴滴、京東有時發嘅係連結,唔係 PDF
呢類條件,正正係自動化最容易「表面行得通、結果錯曬」嘅地方。
所以第一步最重要嘅,唔係叫 AI 快啲寫程式碼,而係先要佢充分理解你嘅業務規則。
四、AI 寫、AI 行,你負責用人話報錯
原文對呢段嘅描述好貼地:AI 寫、AI 行,你負責報錯。
呢句話聽落輕鬆,其實係好實用嘅協作方式。
你唔使自己調每一行程式碼,但你要識得觀察結果,話俾 AI 知:
• 邊度唔啱 • 現象係咩 • 你原本期望啲咩 • 邊啲數據明顯異常
原文畀咗兩個好典型嘅陷阱。
陷阱一:QQ 郵箱搜尋結果嚴重異常
作者本來只想拎 4 月嘅百幾封相關郵件,點知程式回傳咗 9740 封。
後來定位到嘅原因係:
• 搜尋語句外面加咗括號 • 搞到截止日期條件被吞咗
呢類問題就好典型:唔係「程式碼完全行唔到」,而係「睇落行到,但結果離曬譜」。如果你唔睇實數據,就會將錯誤結果一路傳到後面嘅 Excel。
陷阱二:PDF 同 OFD 互相覆蓋
最初為咗去重,程式用咗「發票號」做唯一標識。
但現實入面,同一張發票可能同時有 PDF 同 OFD 兩個版本。結果就係:後來嘅 OFD 將前面嘅 PDF 頂走咗。
呢類問題說明,真實世界嘅數據永遠比第一版規則更複雜。
所以一個可以長期複用嘅 skill,唔係一次寫啱,而係喺真實數據入面行出嚟、改出嚟、磨出嚟嘅。
呢度有一個好重要嘅心態轉變:
你唔需要自己改程式碼,但你一定要對結果負責。
即係話,AI 可以幫你實現,但唔可以幫你判斷業務上「呢個係咪啱嘅」。
五、第一次配置最重要嘅,唔係程式碼,而係授權
原文將郵箱授權呢一步專門拎出嚟講,我覺得好有需要。
因為好多自動化任務,卡嘅位唔係邏輯,而係訪問權限。
以郵箱為例,作者嘅做法係:
1. 喺電腦瀏覽器入郵箱設定 2. 開啓 IMAP/SMTP 3. 通過短訊驗證 4. 獲取一個 16 位授權碼 5. 將授權碼貼俾 AI,或者寫入 .env6. 叫 AI 寫入 .env,並加入.gitignore7. 然後測試登入
原文都提到,163、Gmail、Outlook 嘅流程類似。
呢度要注意一件事:呢個授權碼唔係主密碼,而係專門俾程式用嘅替身密碼。佢嘅好處係可以獨立撤銷,安全邊界更清晰。
好多人第一次做自動化,會將注意力全部放喺「模型識唔識寫程式碼」,但真正決定你敢唔敢長期用嘅,係憑證管理係咪規範。
六、安全紅線唔可以交俾模型幫你記
原文對安全嘅提醒好短,但非常重要。
核心得三條:
1. 用授權碼,唔用主密碼 2. 授權碼放喺敏感設定檔入面,唔好分享,唔好上公網 3. 確認 .gitignore生效
呢部分睇落似常識,但現實入面最容易出事嘅,亦正係呢啲「以為自己唔會犯」嘅小動作。
比如:
• 把 .env一齊傳入公開倉庫• 截圖嗰陣將敏感設定帶出去 • 將授權碼直接貼入聊天記錄同筆記 • 以為「只係本地試下」,就唔做隔離
真正有價值嘅,唔係叫 AI 幫你駁多幾個系統,而係每一次「駁系統」嗰陣,先將權限邊界劃清楚。
如果呢一步唔穩,自動化做得越多,風險只會越大。
七、輕量模型都可以做嘢,關鍵係睇任務係咪結構化
原文最後一部分,講嘅係模型選擇,呢度都好有啟發。
作者後來將流程轉到 Ling-2.6-flash,原因好簡單:
呢個任務本質上係:
• 抽固定欄位 • 行固定流程 • 唔需要複雜推理
於是,輕量模型就夠曬數。
原文畀出嘅實測結果係:
• 44 張發票欄位全部啱 • 旗艦模型需時 3 分 20 秒 • Ling 需時 1 分 50 秒 • 賬單 ¥0
呢個結論好值得記低:
唔係所有自動化都值得用最貴嘅模型。
如果任務係高度結構化、邊界明確、步驟固定嘅流水線,咁模型能力過剩,唔一定帶嚟更高收益,反而可能增加延遲同成本。
模型選擇要同任務複雜度匹配。
八、呢件事真正可以複用嘅,唔係「發票 skill」,而係拆問題嘅方法
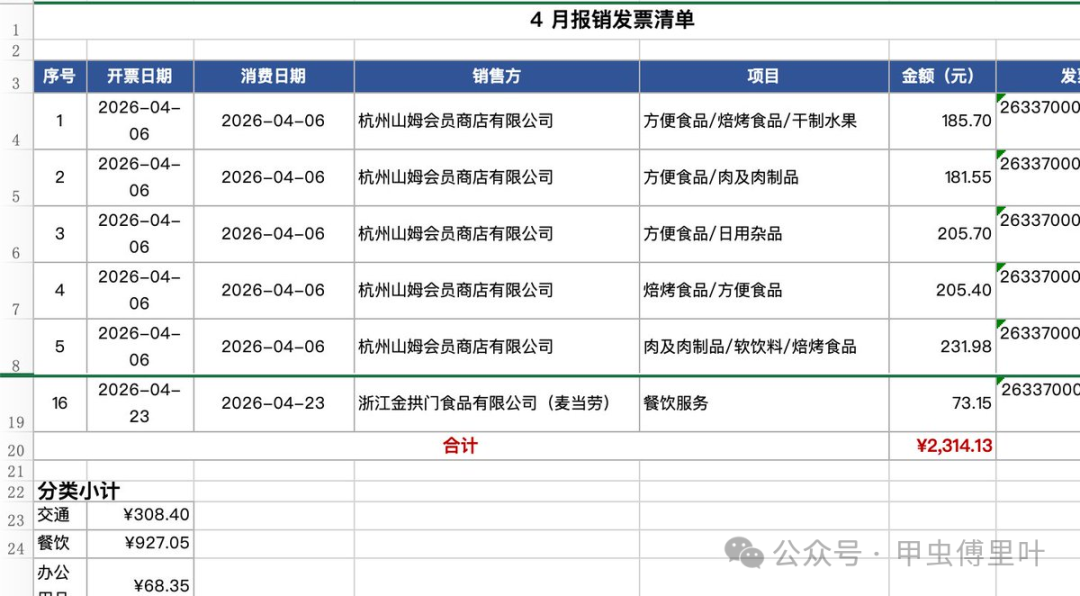
如果只係將原文理解成「教你整一個發票自動化」,其實有啲可惜。
佢真正有價值嘅,係提供咗一套可以搬過去嘅方法。
你可以將同樣嘅思路搬去好多月尾煩人嘅事情上,例如原文最後提到嘅:
• 報銷發票 • 週報月報 • 工時填報 • 信用卡還款賬單整理 • 打新日曆維護
呢啲事情有幾個共通點:
• 週期固定 • 步驟重複 • 規則相對穩定 • 人做起上嚟好悶 • 出錯成本唔算低
呢類任務,正正係最適合被做成 skill 嘅。
判斷一個任務值唔值得自動化,可以先問自己三個問題:
1. 呢件事係咪會重複出現? 2. 規則係咪大致固定? 3. 我係咪每次都要重複同樣嘅判斷動作?
如果三個答案都係「係」,咁佢大概率就唔係「應唔應該自己再努力啲」,而係「應唔應該交俾 AI」。
對老九工作流有咩借鑒意義
如果將呢篇原文放入老九嘅工作流入面,我覺得至少有幾個直接借鑒。
第一,唔好將 skill 理解成「大工程」,先將佢理解成「可以穩定複用嘅一套小能力」。
好多時候,阻礙我哋動手嘅唔係任務本身太難,而係一開頭就想做到平台、做到產品、做到完整系統。原文呢個案例提醒我哋,先將一個具體重複動作搞掂,收益往往即刻見到。
第二,寫 skill 嘅關鍵唔係程式碼,而係將邊界條件講透。
尤其係「未來會變啲咩」呢一問,值得變成所有自動化需求嘅固定模板。因為真正拖垮複用性嘅,往往唔係第一版行唔行到,而係第二個月規則一變就全部斷纜。
第三,結構化任務唔好迷信最貴嘅模型。
只要流程拆得清楚,好多工作完全可以交俾輕量模型去行。咁樣做嘅意義唔止係慳錢,更重要係令自動化真係可以長期掛住行,唔係每次一計成本又退回手動。
講到底,真正有價值嘅,唔係你擁有一個 skill,而係你開始習慣將重複勞動識別出嚟、拆開、描述清楚,再交俾 AI 接手。
呢種係工作方式嘅升級。
信息來源與說明
嚟自原文嘅內容
以下內容直接基於實踐哥 MinLi 嘅 X Article《實現一個自己的skill,一篇文章就夠了》整理改寫:
• 「整理發票」作為自動化案例嘅背景同痛點 • 「約半個鐘搭建、三個月實測」嘅敍述 • 數據結果:363 封郵件、62 封候選、44 張唯一發票、¥8,861.69 總額 • skill 嘅基本定義與組成 • 「你唔使寫程式,你係產品經理」嘅協作方式 • 需求梳理中嘅關鍵點:目標結果、數據來源、未來變化、邊界條件 • QQ 郵箱搜尋 bug 同 PDF/OFD 覆蓋問題 • IMAP/SMTP、授權碼、 .env、.gitignore相關配置同安全提醒• 使用輕量模型替代旗艦模型嘅判斷邏輯同實測結果 • 原文結尾提出嘅可遷移場景示例
整理提煉嘅內容
以下內容為基於原文所做嘅結構化整理,冇新增原文之外嘅事實判斷:
• 微信公眾號版本嘅標題、段落組織同小節劃分 • 對「點解要先傾需求、點解要拆成兩個 skill、點解輕量模型就夠」嘅方法論總結 • 「判斷一個任務是否值得自動化」嘅三問框架 • 「對老九工作流有咩借鑒意義」一節
原始來源
• X 狀態連結:https://x.com/MinLiBuilds/status/2048054481733169337 • X Article 連結:https://x.com/i/article/2048048703941095424 • 原作者:實踐哥 MinLi(@MinLiBuilds)
如果你最近都有一件「每個月都要做、每次都好煩、但規則其實差唔多」嘅事,不妨先唔好問「AI 係咪可以更快幫我做」,而係問一句:
呢件事,係咪已經適合做成一個自己嘅 skill 喇?
很多人以為,AI 的價值在於“幫你寫點東西”。
但真正有價值的,往往不是多寫一段文字,而是把那些每個月固定出現、又不值得你親自投入注意力的重複勞動,徹底從工作流裏拿掉。
實踐哥 MinLi 在原文裏舉了一個特別典型的例子:整理發票。
這件事他已經做了三年。每個月要花兩小時,面對一堆“您的電子發票”郵件,手動下載 PDF、OFD、12306 連結、滴滴連結、京東 XML,再肉眼核對發票號、剔除個人抬頭、最後敲進 Excel 分類彙總。
後來他做了一件很樸素、也很關鍵的事:不再問“我怎麼更快整理發票”,而是直接問“這不就是 AI 該乾的活嗎?”
於是,他用大約半小時,讓 Claude Code 幫自己把這件事自動化了。跑了三個月後,得到的數據是:
• 363 封郵件 • 62 封候選郵件 • 44 張唯一發票 • 總金額 ¥8,861.69
原來每月兩小時的瑣事,變成了兩條命令。
這篇文章,不是代碼教程,而是把這件事背後的方法講清楚:普通人怎麼把一個重複任務,變成自己的 skill。
一、什麼是 Skill:不是神秘能力,本質就是一個文件夾
先把一個容易被說複雜的概念說簡單。
按原文的解釋,skill 本質上就是一個文件夾。
這個文件夾裏通常會放幾類東西:
• 一份說明書:告訴 AI 這個能力是幹什麼的 • 幾個真正幹活的小工具:腳本、配置、處理邏輯 • 一些部署和注意事項:比如環境變量、授權方式、使用方法
原文中這個“發票整理” skill,就包含了:
• 說明書 • 抓郵件工具 • 處理連結工具 • 部署備忘
當 AI 啓動時,它會掃描這些 skill 文件夾,把說明書讀進去。之後你再說一句“拉一下 4 月發票”,它就知道該調用哪套工具、按什麼步驟執行。
所以,“實現一個自己的 skill”拆開看,其實只有三步:
1. 建一個文件夾 2. 寫清楚說明書 3. 把真正幹活的工具放進去
這也是為什麼,原文一直在強調:你不需要先學會編程,你先要學會把需求講清楚。
二、你不用寫代碼,你更像產品經理
這是原文裏我很認同的一點。
很多人一聽到“自動化”“腳本”“AI Agent”,第一反應是:我不會寫代碼,這事和我沒關係。
但如果你把角色切換一下,會發現不是這麼回事。
在這類工作流裏,普通用戶最重要的工作,不是寫實現,而是定義問題:
• 我到底想要什麼結果? • 數據從哪裏來? • 哪些情況算異常? • 哪些規則以後可能會變? • 哪些邊界條件絕對不能錯?
原文把這個角色概括得很準確:你是產品經理。
你負責用人話提需求:
• 我想要什麼 • 我不想要什麼 • 出錯了以後應該怎麼處理 • 哪些規則是硬約束 • 哪些情況未來會變化
如果代碼刷屏看不懂,也沒關係,直接問 AI:“這段是在幹嘛?”
真正決定一個 skill 好不好用的,不是代碼炫不炫,而是需求有沒有說清楚。尤其是公司規則、報銷模板、郵件習慣、去重邏輯,這些都是通用模型不知道、但你自己最清楚的東西。
三、第一步不要急着讓 AI 動手,先把需求聊透
原文裏最有價值的部分,不是“讓 AI 寫了什麼”,而是“動手前先討論了什麼”。
在開始寫之前,作者先把幾個關鍵問題講清楚了。
1)你最終想要什麼結果
這裏不是泛泛地說“幫我整理發票”,而是具體到產出物:
• 每月底生成一份 Excel • 按類別彙總金額
也就是說,目標不是“抓到郵件”,而是“形成可交付的報銷結果”。
2)數據從哪裏來
原文的輸入源是:
• QQ 郵箱 • 搜索關鍵詞“發票”
這一步看似簡單,實際上是在界定系統邊界。否則 AI 可能會誤以為你要掃描本地文件夾、網盤附件,甚至 OCR 截圖。
3)未來哪裏可能變化
這是原文特別強調的一點,也是方法論上最值得記住的一點:
“未來會變什麼”,決定了 AI 怎麼拆 skill。
比如:
• 以後可能換郵箱 • 可能換報銷模板 • 可能分類規則調整 • 可能附件格式繼續變化
如果這些變化一開始不說,AI 很容易把系統寫成一個一次性的腳本;一旦環境變動,整套東西就很難維護。
作者因此建議,把能力拆成兩個 skill:
• 一個負責拉發票 • 一個負責整理 Excel
這背後其實是在做解耦:輸入獲取和結果整理分開,後續改郵箱或改模板時,就不用推倒重來。
4)有哪些必須警惕的邊界條件
原文裏提到幾個非常真實的坑:
• 個人抬頭不能報 • 一張發票可能同時有 PDF 和 OFD 兩份 • 12306、滴滴、京東有時發的是連結,不是 PDF
這類條件,恰恰是自動化最容易“表面跑通、結果錯掉”的地方。
所以第一步最重要的,不是讓 AI 趕緊寫代碼,而是先讓它充分理解你的業務規則。
四、AI 寫、AI 跑,你負責用人話報錯
原文對這一段的描述非常接地氣:AI 寫、AI 跑,你負責報錯。
這句話聽起來輕鬆,其實是很實用的協作方式。
你不用自己調每一行代碼,但你要會觀察結果,告訴 AI:
• 哪裏不對 • 現象是什麼 • 你原本期望什麼 • 哪些數據明顯異常
原文給了兩個非常典型的坑。
坑一:QQ 郵箱搜索結果嚴重異常
作者原本只想拿 4 月的一百多封相關郵件,結果程序返回了 9740 封。
後來定位到的原因是:
• 搜索語句外層帶了括號 • 導致截止日期條件被吞掉
這類問題就很典型:不是“代碼完全不會跑”,而是“看起來跑了,但結果離譜”。如果你不盯數據,就會把錯誤結果一路傳到後面的 Excel。
坑二:PDF 和 OFD 互相覆蓋
最初為了去重,程序用了“發票號”作為唯一標識。
但現實裏,同一張發票可能同時有 PDF 和 OFD 兩個版本。結果就是:後來的 OFD 把前面的 PDF 頂掉了。
這類問題說明,真實世界的數據永遠比我們第一版規則更復雜。
所以一個能長期複用的 skill,不是一次寫對,而是在真實數據裏跑出來、改出來、磨出來的。
這裏有一個很重要的心態轉變:
你不需要自己修代碼,但你必須對結果負責。
也就是說,AI 可以替你實現,但不能替你判斷業務上“這是不是對的”。
五、第一次配置最關鍵的,不是代碼,而是授權
原文把郵箱授權這一步專門拎出來講,我覺得非常有必要。
因為很多自動化任務,卡的不是邏輯,而是訪問權限。
以郵箱為例,作者的做法是:
1. 在電腦端瀏覽器進入郵箱設置 2. 開啓 IMAP/SMTP 3. 通過短信驗證 4. 獲取一個 16 位授權碼 5. 把授權碼粘給 AI,或者寫進 .env6. 讓 AI 寫入 .env,並加入.gitignore7. 然後測試登錄
原文也提到,163、Gmail、Outlook 的流程類似。
這裏要注意一件事:這個授權碼不是主密碼,而是專門給程序使用的替身密碼。它的好處是可以單獨撤銷,安全邊界更清晰。
很多人第一次做自動化,會把注意力全部放在“模型能不能寫代碼”,但真正決定你敢不敢長期使用的,是憑據管理是否規範。
六、安全紅線不能交給模型替你記
原文對安全的提醒很短,但非常重要。
核心就三條:
1. 用授權碼,不用主密碼 2. 授權碼放在敏感配置文件裏,不要分享,不要上公網 3. 確認 .gitignore生效
這部分看起來像常識,但現實裏最容易出事的,也正是這些“以為自己不會犯”的小動作。
比如:
• 把 .env一起傳進公開倉庫• 截圖時把敏感配置帶出去 • 把授權碼直接貼進聊天記錄和筆記 • 以為“只是本地試一下”,就不做隔離
真正有價值的,不是讓 AI 替你多接幾個系統,而是在每一次“接系統”的時候,先把權限邊界劃清楚。
如果這一步不穩,自動化做得越多,風險只會越大。
七、輕量模型也能幹活,關鍵看任務是不是結構化
原文最後一部分,講的是模型選型,這裏也很有啓發。
作者後來把流程切到 Ling-2.6-flash,原因很簡單:
這個任務本質上是:
• 抽固定字段 • 走固定流程 • 不需要複雜推理
於是,輕量模型就足夠了。
原文給出的實測結果是:
• 44 張發票字段全對 • 旗艦模型耗時 3 分 20 秒 • Ling 耗時 1 分 50 秒 • 賬單 ¥0
這個結論非常值得記下來:
不是所有自動化都值得上最貴模型。
如果任務是高度結構化、邊界明確、步驟固定的流水線,那麼模型能力過剩,不一定帶來更高收益,反而可能增加延遲和成本。
模型選型要和任務複雜度匹配。
八、這件事真正可複用的,不是“發票 skill”,而是拆問題的方法
如果只把原文理解成“教你做一個發票自動化”,其實有點可惜。
它真正有價值的,是提供了一套可遷移的方法。
你可以把同樣的思路遷移到很多月底煩人的事情上,比如原文最後提到的:
• 報銷發票 • 週報月報 • 工時填報 • 信用卡還款賬單整理 • 打新日曆維護
這些事情有幾個共性:
• 週期固定 • 步驟重複 • 規則相對穩定 • 人做起來枯燥 • 出錯成本不算低
這類任務,正是最適合被做成 skill 的。
判斷一個任務值不值得自動化,可以先問自己三個問題:
1. 這件事是不是會反覆出現? 2. 規則是不是大體固定? 3. 我是不是每次都在重複同樣的判斷動作?
如果三個答案都是“是”,那它大概率就不是“該不該自己更努力”,而是“該不該交給 AI”。
對老九工作流有什麼借鑑意義
如果把這篇原文放進老九的工作流裏,我覺得至少有三個直接借鑑。
第一,不要把 skill 理解成“大工程”,先把它理解成“能穩定複用的一套小能力”。
很多時候,阻礙我們動手的不是任務本身太難,而是一上來就想做成平台、做成產品、做成完整系統。原文這個案例提醒我們,先把一個具體重複動作拿下,收益往往立刻可見。
第二,寫 skill 的關鍵不是代碼,而是把邊界條件說透。
尤其是“未來會變什麼”這一問,值得變成所有自動化需求的固定模板。因為真正拖垮複用性的,往往不是第一版能不能跑,而是第二個月規則一變就全斷掉。
第三,結構化任務不必迷信最貴模型。
只要流程拆得清楚,很多工作完全可以交給輕量模型去跑。這樣做的意義不只是省錢,更重要的是讓自動化真正能長期掛着跑,而不是每次一算成本又退回手工。
說到底,真正有價值的,不是你擁有一個 skill,而是你開始習慣於把重複勞動識別出來、拆開、描述清楚,再交給 AI 接手。
這是一種工作方式的升級。
信息來源與說明
來自原文的內容
以下內容直接基於實踐哥 MinLi 的 X Article《實現一個自己的skill,一篇文章就夠了》整理改寫:
• “整理發票”作為自動化案例的背景與痛點 • “約半小時搭建、三個月實測”的敍述 • 數據結果:363 封郵件、62 封候選、44 張唯一發票、¥8,861.69 總額 • skill 的基本定義與組成 • “你不用寫代碼,你是產品經理”的協作方式 • 需求梳理中的關鍵點:目標結果、數據來源、未來變化、邊界條件 • QQ 郵箱搜索 bug 與 PDF/OFD 覆蓋問題 • IMAP/SMTP、授權碼、 .env、.gitignore相關配置與安全提醒• 使用輕量模型替代旗艦模型的判斷邏輯與實測結果 • 原文結尾提出的可遷移場景示例
整理提煉的內容
以下內容為基於原文所做的結構化整理,不新增原文之外的事實判斷:
• 微信公眾號版本的標題、段落組織與小節劃分 • 對“為什麼先聊需求、為什麼要拆成兩個 skill、為什麼輕量模型足夠”的方法論總結 • “判斷一個任務是否值得自動化”的三問框架 • “對老九工作流有什麼借鑑意義”一節
原始來源
• X 狀態連結:https://x.com/MinLiBuilds/status/2048054481733169337 • X Article 連結:https://x.com/i/article/2048048703941095424 • 原作者:實踐哥 MinLi(@MinLiBuilds)
如果你最近也有一件“每個月都要做、每次都很煩、但規則其實差不多”的事,不妨先別問“AI 能不能更快幫我做”,而是問一句:
這件事,是不是已經適合做成一個自己的 skill 了?