第007篇| Claude + Obsidian如何真正用好你的第二大腦
整理版優先睇
Claude + Obsidian 將 Obsidian 倉庫變成自動整合知識嘅 Wiki 系統,透過 /save、/autoresearch、/canvas 三個命令同持續導入習慣,令知識像複利咁累積。
呢篇文章係一篇技術指南,介紹 claude-obsidian 呢個 Claude Code 技能,由社羣開發,目標係解決兩個常見問題:AI 對話完就失憶,同埋 Obsidian 筆記寫完就無人再睇。作者提出一個整合方案,將 Obsidian 倉庫變成一個可持續積累同生長嘅 Wiki 知識系統。
整體結論係:只要準備好 Obsidian、Node.js 同 Claude Code,安裝技能後初始化,再養成習慣將任何資料放入 .raw/.raw/ 並執行 ingest,Claude 就會自動抽取概念、建立 wikilink、標記矛盾點,將新資料整合入既有知識網絡。系統使用熱緩存(hot.md)同索引(index.md),只加載相關頁面,所以即使倉庫擴展到幾千頁,token 成本都唔會失控。
日常使用只需三個命令:/save 將對話保存為 wiki 頁面,/autoresearch 針對主題做多輪研究並生成結構化頁面,/canvas 生成可視化知識圖譜。一個多月後,Obsidian 嘅 graph view 會顯示按顏色分層嘅知識地圖,主題形成簇狀結構,矛盾點被標記,真正實現「第二大腦」嘅願景。
- 結論:claude-obsidian 能夠將 Obsidian 轉化為自動成長嘅知識網絡,解決 AI 失憶同筆記孤立問題。
- 方法:只需三步:準備 Obsidian、Node.js、Claude Code;安裝技能;初始化 vault。
- 差異:同一般 AI 搜索工具唔同,呢套系統會自動抽取概念、建立 wikilink、標記矛盾點,唔需要手動維護。
- 啟發:三個核心命令(/save、/autoresearch、/canvas)令到知識管理自動化,特別係 /autoresearch 會做多輪研究。
- 可行動點:養成習慣將任何資料放入 .raw/.raw/ 並執行 ingest,系統會自動整合成結構化 wiki 頁面。
背景:AI 失憶同筆記孤立嘅雙重問題
你嘅 AI,關掉聊天窗口嗰一刻就開始失憶。你嘅 Obsidian 倉庫堆滿筆記,但幾乎冇人回頭睇,連你自己都一樣。呢兩個問題放埋一齊,會唔會互相抵消?呢正正係 claude-obsidian 要做嘅事。
claude-obsidian 係一個為 Claude Code 設計嘅技能,能將 Obsidian 倉庫變成可持續積累嘅 Wiki 知識系統
claude-obsidian 唔同於一般 AI 搜索工具,佢遵循 Karpathy 提出嘅 LLM Wiki 思路。
LLM Wiki 思路:你只要將 PDF、URL、字幕、網頁等原始材料丟入去,Claude 就會自動完成結構化工作
具體來講,佢會抽取概念、創建帶 frontmatter 嘅結構化頁面、自動加 wikilink、標記矛盾點,並歸檔到合適位置。
每增加一份新資料,增強嘅係整個知識網絡,而唔係再多一篇孤立筆記
搭建:三個準備、三步安裝
開始之前,你需要準備三樣嘢:Obsidian(免費)、Node.js 18 或以上、Claude Code 桌面端配套環境。
- 1 下載 Obsidian,新建一個 vault,本質上就係一個 Markdown 文件夾。
- 2 確保 Node.js 版本 v18 或以上,否則下載 LTS 版本。
- 3 安裝 Claude Code,即 Claude 嘅命令行版本,可直接讀寫電腦文件。
然後打開 Claude,進入 vault 目錄,粘貼安裝命令。插件會自動將全部 10 個技能複製入 vault,唔需要手動下載。
執行安裝命令後,技能會自動複製,唔需要手動下載
第一次啟動時輸入初始化命令,Claude 會自動搭建完整 vault 結構:包括 wiki 目錄、hot cache、index 及其他基礎文件。佢會先展示要創建嘅內容俾你確認,然後先真正執行。
初始化命令會自動搭建 wiki 目錄、hot cache、index
核心命令與日常習慣:三個命令一個習慣
日常最核心嘅命令只有三個,只要你經常用,系統就會越長越完整。
- /save:每次同 Claude 討論出有價值嘅內容,輸入 /save 佢會讀取對話,提取觀點,自動生成格式規範嘅 wiki 頁面,補好 frontmatter 同 wikilink,並更新索引。
- /autoresearch:想圍繞一個主題深入研究,輸入 /autoresearch,Claude 會進行 3-5 輪搜索,最終整理成結構化 wiki 頁面,並同既有概念交叉引用。
- /canvas:想「睇見」知識關係,用 /canvas 生成 Obsidian Canvas(無限畫布),自動排列知識節點,可製作流程圖、知識圖譜、時間線等。
/save、/autoresearch、/canvas 三個命令
wiki-ingest agent 會自動檢查新資料同既有知識嘅衝突,如果發現矛盾,會用 [!contradiction] 標記。
自動標記矛盾點
日常最關鍵嘅習慣係持續導入。只要遇到值得保留嘅內容——文章、PDF、視頻字幕、會議紀要——就放入 .raw/.raw/ 文件夾,然後告訴 Claude 去 ingest。
ingest 後會生成 8-15 個關聯頁面,平均十幾個 wikilink
成本控制與成果:熱緩存令 token 成本唔失控
你可能擔心倉庫變大後 token 成本好高。但呢套系統只會按順序加載三類文件:hot.md(約500 tokens)、index.md(每頁一行)、同埋真正相關嘅頁面。所以即使 vault 有幾千頁,成本都唔會失控。
系統只加載 hot.md、index.md 同相關頁面,即使幾千頁成本都唔會失控
用幾星期後,打開 Obsidian 嘅 graph view,你會見到一張按顏色分層嘅知識地圖:讀過嘅內容、想過嘅問題、形成嘅概念、積累嘅來源都自動連成網絡。深入研究嘅主題自然形成簇狀結構,矛盾點亦被標記。
graph view 顯示按顏色分層嘅知識地圖,主題形成簇狀結構
矛盾點亦被標記
你嘅 AI,喺你熄咗對話視窗嗰一刻就開始失憶。
你嘅 Obsidian 倉庫裡面塞滿咗筆記,但幾乎冇人會返睇,連你自己都係一樣。咁如果將呢兩個問題擺埋一齊,會唔會剛好互相抵消?
這正是 claude-obsidian 做緊嘅嘢。佢係一個為 Claude Code 設計嘅技能,可以將你嘅 Obsidian 倉庫變成一個可持續積累、可持續生長嘅 Wiki 知識系統。

你後來加入嘅每一份資料,都會被整合曬入成個知識網絡;你之後提出嘅每一個問題,亦都會由已經讀過嘅內容裡面揾答案。
知識會好似複利咁累積。Claude 之所以唔會忘記你之前做緊乜,唔係因為佢「記憶力突然變強」,而係因為系統喺每次會話都會加載一份熱緩存。
呢篇文章就係完整嘅搭建說明。你只要一步一步跟住做,最後會得到一個真係用得嘅系統,而且佢會隨住你嘅使用變得越來越聰明。
喺執行任何命令之前,先講清楚呢套嘢到底解決咗乜問題。
大多數所謂嘅 Obsidian + AI 工具,本質上只係「俾 AI 同你啲筆記傾嚇計」,最多算係一個好睇啲嘅 AI 搜尋界面。筆記仲係你寫,連結仲係你建,維護工作都係你自己做。
但 claude-obsidian 唔同。佢跟嘅係 Karpathy 提出嘅 LLM Wiki 思路:你只要將 PDF、URL、字幕、網頁、筆記呢啲原始材料掉入去,Claude 就會幫你完成後續大部份嘅結構化工作。
佢會抽取概念、建立帶 frontmatter 嘅結構化頁面、自動加 wikilink、標記同現有知識矛盾嘅地方,並將內容歸檔到合適嘅位置。
每加一份新資料,強化嘅係成個知識網絡,而唔係又多一篇孤立筆記。
下面開始正式搭建。
第一步:開始之前,你需要準備啲乜
總共準備三樣嘢,順序咁嚟。第一樣係 Obsidian。
先下載佢。Obsidian 係免費嘅。安裝之後新建一個 vault,本質上佢就係你電腦上嘅一個 Markdown 資料夾,名你自己改。
然後你需要 Node.js。
Claude Code 需要 Node.js 18 或以上版本先用到,所以先 check 嚇你嘅版本符唔符要求。
如果你見到 v18 或以上,就可以直接繼續;如果唔係,就去下載安裝 LTS 版本。
Claude Code
Claude Code 係 Claude 嘅命令行版本,佢可以直接讀寫你電腦上嘅檔案。呢度我哋安裝桌面端配套環境就得。

第二步:安裝 claude-obsidian
打開 Claude,入去你啱啱建立嘅 Obsidian 倉庫目錄,然後將安裝命令貼上去。
跟住將後面兩條命令順次序執行:第一條、第二條。
執行完成之後,插件會自動將全部 10 個技能複製入你嘅 vault,唔使你手動下載檔案,亦唔使自己另外寫腳本。
第三步:第一次啟動
仍然喺 Claude Code 裏面,輸入初始化命令。
Claude 會自動幫你搭好完整嘅 vault 結構:包括 wiki 目錄、hot cache、index 以及其他基本檔案。更重要嘅係,佢會先將要建立嘅內容 show 俾你確認,然後先真正執行。
你最後會見到一個類似下面嘅結果。
呢個時候,你嘅「第二大腦」就已經初始化完成,可以開始做嘢。
第四步:你真正要記住嘅 3 個指令
呢套系統,日常最核心嘅其實得 3 個指令。只要你成日用,佢就會自己越嚟越完整。
/save
每次你同 Claude 討論出啲有價值嘅嘢,例如一個決策、一個概念、一份項目方案,完咗之後輸入:
/save
Claude 會讀曬成段對話,抽出關鍵觀點,自動生成格式規範嘅 wiki 頁面,補好 frontmatter 同 wikilink,並將佢哋放入正確目錄,同時更新 index。
咁樣一來,好嘅對話就唔會再隨住會話結束而消失,而係會被歸檔落嚟。
/autoresearch
如果你想圍繞一個主題深入研究,就輸入:
/autoresearch
Claude 會先做一輪比較廣泛嘅網絡搜尋,再補齊缺口,再沿住最關鍵嘅來源繼續追蹤,通常會進行 3 到 5 輪研究。
最後佢會將結論整理成結構化 wiki 頁面,並且同你倉庫裏面已有嘅相關概念做交叉引用。
如果你有特定偏好嘅資訊來源,可以編輯下面呢個檔案嚟自訂研究策略:
skills/autoresearch/references/program.md
例如醫學研究者可以寫「優先 PubMed」,創業者可以寫「優先 founder blog 同案例」。如果冇特別需求,預設配置已經夠好用。
/canvas
如果你唔只想「讀」知識,而係想「見到」知識之間嘅關係,就用:
/canvas
Claude 會直接生成一個 Obsidian Canvas,即係一個無限畫布,然後將同你主題相關嘅知識節點自動排入去。
你可以叫佢生成流程圖、知識圖譜、時間線,甚至演示用嘅視覺佈局。
而且你仲可以直接喺 Obsidian 裏面將圖片、PDF、影片、GIF 拖入畫布。Canvas 最終會儲存為 .canvas 檔案,Obsidian 原生支援打開。
第五步:日常最關鍵嘅習慣 —— 持續匯入
呢個其實先係成個系統真正嘅核心習慣。只要你遇到值得保留嘅內容——文章、PDF、影片字幕、會議紀錄——都可以跟住呢個流程加入系統。
先將佢放入 .raw/
.raw/ 資料夾就係你嘅原始資料檔案庫。你可以拉檔案入去、貼網址、存字幕,放咗入去之後就唔好再改佢。呢度保存嘅係你最原始嘅記錄。
然後同 Claude 講去 ingest 佢。
Claude 會呼叫 wiki-ingest agent。對於一份普通嘅 20 頁文件,佢通常會生成 8 到 15 個互相關聯嘅 wiki 頁面,而且每頁平均會有十幾個 wikilink。
實體會有自己嘅頁面,概念會有自己嘅頁面;如果佢發現新資料同現有知識有衝突,仲會用 [!contradiction] callout 標記出嚟。
成個處理過程仲會記錄落 wiki/log.md。
你自己幾乎唔需要手動維護目錄、標籤或連結,呢啲都由系統搞掂。
跟住,你就可以開始問問題。
Claude 會先讀 hot cache,再 scan index,識別相關 wiki 頁面,然後基於你自己倉庫入面嘅內容俾答案,並標註引用頁面。
即係話,佢引用嘅唔再只係訓練數據,而係你已經整理好、屬於你自己嘅知識資產。
點解倉庫越大,成本都唔會失控?
好多人會擔心:如果將來倉庫有幾千頁內容,會唔會 token 成本越來越高?答案係:不會。
呢套系統只會順序加載 3 類檔案:
hot.md:大約 500 字嘅近期上下文(約 500 tokens)index.md:每頁一行,Claude 通過佢快速判斷邊啲內容相關
相關頁面本身:只加載同當前問題真正有關嘅檔案
所以即使你嘅 vault 擴展到幾千頁,token 成本變化都唔會太大,因為佢從來唔會一次過將所有嘢塞入上下文。
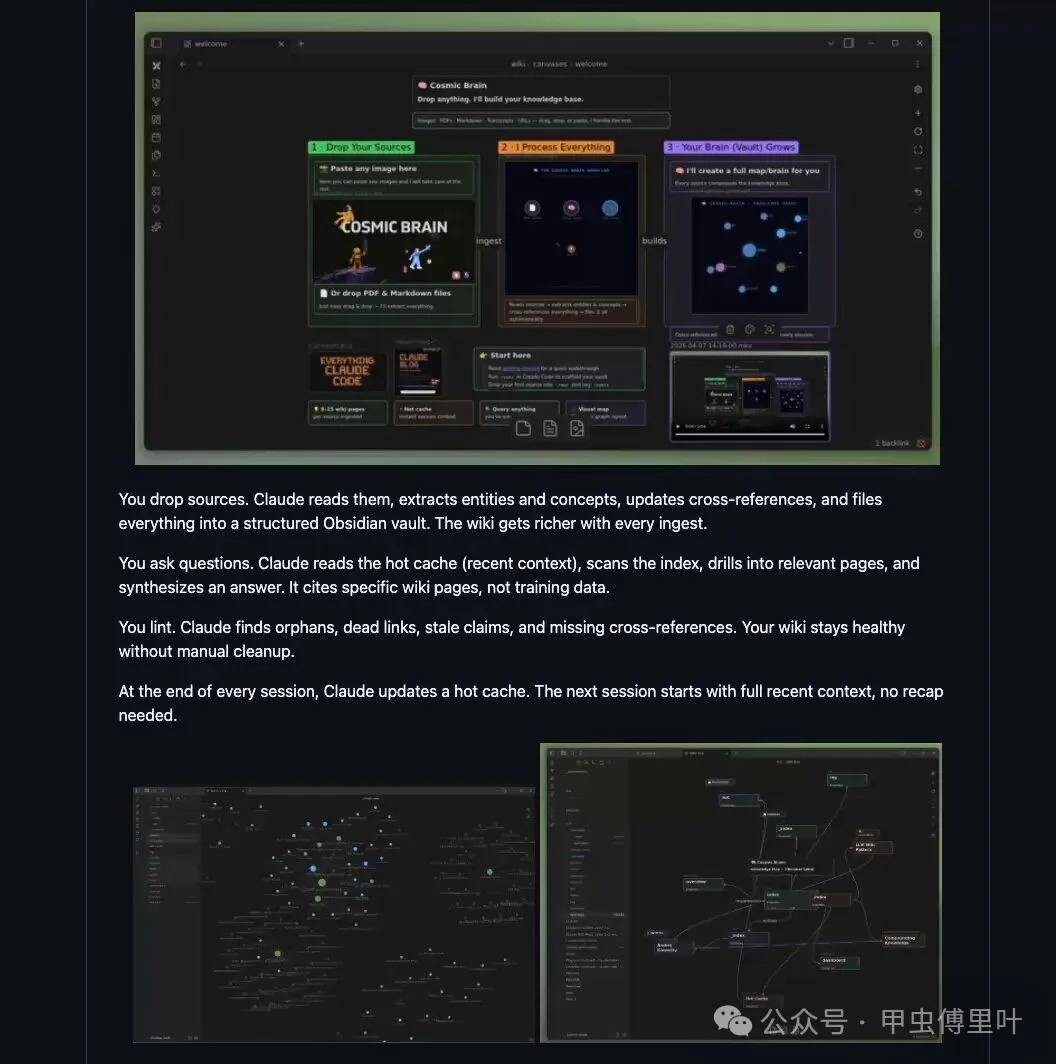
一個多月之後,佢會變成點樣?
連續用幾星期之後,你再打開 Obsidian 嘅 graph view,就會見到一張按顏色分層嘅知識地圖:你讀過嘅內容、諗過嘅問題、形成嘅概念、積累嘅來源、重要實體,都會自動連成網絡。
深入研究嘅主題會自然形成簇狀結構,相近概念之間會自動建立聯繫,矛盾嘅地方亦會被標記出嚟。
呢個先係 Obsidian 當初應承俾你嘅「好似大腦咁」嘅知識圖譜。
以上,就係呢套系統嘅核心諗法。
如果你希望將 AI 由「臨時聊天助手」升級成「可持續工作嘅知識接口」,咁 Claude + Obsidian 呢套組合,的確值得認真搭建起嚟。
你的 AI,在你關掉聊天窗口的那一刻就開始失憶。
你的 Obsidian 倉庫裏堆滿了筆記,但幾乎沒人回頭看,連你自己也一樣。那如果把這兩個問題放在一起,會不會剛好互相抵消?
這正是 claude-obsidian 在做的事。它是一個為 Claude Code 設計的技能,能把你的 Obsidian 倉庫變成一個可持續積累、可持續生長的 Wiki 知識系統。
你後來加入的每一份資料,都會被整合進整個知識網絡;你之後提出的每一個問題,也都會從已經讀過的內容裏調用答案。
知識會像複利一樣累積。Claude 之所以不會忘記你之前在做什麼,不是因為它“記憶力突然變強”,而是因為系統會在每次會話裏都加載一份熱緩存。
這篇文章就是完整的搭建說明。你只要一步一步照着做,最後會得到一個真正可用的系統,而且它會隨着你的使用越來越聰明。
在運行任何命令之前,先說清楚這套東西到底解決了什麼問題。
大多數所謂的 Obsidian + AI 工具,本質上只是“讓 AI 跟你的筆記聊聊天”,最多算是一個更好看的 AI 搜索界面。筆記還是你寫,連結還是你建,維護工作還是你自己做。
但 claude-obsidian 不一樣。它遵循的是 Karpathy 提出的 LLM Wiki 思路:你只要把 PDF、URL、字幕、網頁、筆記這些原始材料丟進去,Claude 會替你完成後續的大部分結構化工作。
它會抽取概念、創建帶 frontmatter 的結構化頁面、自動加 wikilink、標記與既有知識的矛盾點,並把內容歸檔到合適的位置。
每增加一份新資料,增強的是整個知識網絡,而不是再多堆出一篇孤立筆記。
下面開始正式搭建。
第一步:開始之前,你需要準備什麼
一共準備三樣東西,按順序來。第一樣是 Obsidian。
先下載它。Obsidian 是免費的。安裝後新建一個 vault,本質上它就是你電腦上的一個 Markdown 文件夾,名字隨你取。
然後你還需要 Node.js。
Claude Code 依賴 Node.js 18 及以上版本運行,所以先檢查一下你的版本是否滿足要求。
如果你看到的是 v18 或以上,就可以直接繼續;如果不是,就去下載安裝 LTS 版本。
Claude Code
Claude Code 是 Claude 的命令行版本,它可以直接讀寫你電腦上的文件。這裏我們安裝桌面端配套環境即可。
第二步:安裝 claude-obsidian
打開 Claude,進入你剛剛創建的 Obsidian 倉庫目錄,然後把安裝命令粘貼進去。
接着把後面的兩條命令依次執行:第一條、第二條。
執行完成後,插件會自動把全部 10 個技能複製進你的 vault,不需要你手動下載文件,也不需要自己額外寫腳本。
第三步:第一次啓動
仍然在 Claude Code 裏,輸入初始化命令。
Claude 會自動幫你搭好完整的 vault 結構:包括 wiki 目錄、hot cache、index,以及其他基礎文件。更重要的是,它會先把要創建的內容展示給你確認,然後再真正執行。
你最後會看到一個類似下面的結果。
這時候,你的“第二大腦”就已經初始化完成,可以開始工作了。
第四步:你真正要記住的 3 個命令
這整套系統,日常最核心的其實就 3 個命令。只要你經常用,它就會自己越長越完整。
/save
每次你和 Claude 討論出一些有價值的東西,比如一個決策、一個概念、一份項目方案,結束後輸入:
/save
Claude 會讀取整段對話,提取關鍵觀點,自動生成格式規範的 wiki 頁面,補好 frontmatter 和 wikilink,並把它們放進正確目錄,同時更新索引。
這樣一來,好的對話就不會再隨着會話結束而消失,而是會被歸檔下來。
/autoresearch
如果你想圍繞一個主題深入研究,就輸入:
/autoresearch
Claude 會先做一輪較廣的網絡搜索,再補齊缺口,再沿着最關鍵的來源繼續追蹤,通常會進行 3 到 5 輪研究。
最後它會把結論整理成結構化 wiki 頁面,並且和你倉庫裏已有的相關概念做交叉引用。
如果你有特定偏好的信息來源,還可以編輯下面這個文件來自定義研究策略:
skills/autoresearch/references/program.md
比如醫學研究者可以寫“優先 PubMed”,創業者可以寫“優先 founder blog 和案例”。如果沒有特別需求,默認配置已經足夠好用。
/canvas
如果你不只想“讀”知識,而是想“看見”知識之間的關係,那就用:
/canvas
Claude 會直接生成一個 Obsidian Canvas,也就是一個無限畫布,然後把與你主題相關的知識節點自動排進去。
你可以讓它生成流程圖、知識圖譜、時間線,甚至演示用的視覺佈局。
而且你還能直接在 Obsidian 裏把圖片、PDF、視頻、GIF 拖到畫布裏。Canvas 最終保存為 .canvas 文件,Obsidian 原生支持打開。
第五步:日常最關鍵的習慣 —— 持續導入
這其實才是整套系統真正的核心習慣。只要你遇到值得保留的內容——文章、PDF、視頻字幕、會議紀要——都可以按這個流程加入系統。
先把它放進 .raw/
.raw/ 文件夾就是你的原始資料檔案庫。你可以往裏面拖文件、貼網址、存字幕,放進去之後就不要再改它。這裏保存的是你最原始的記錄。
然後告訴 Claude 去 ingest 它。
Claude 會調用 wiki-ingest agent。對於一份普通的 20 頁文檔,它通常能生成 8 到 15 個彼此關聯的 wiki 頁面,而且每頁平均會有十幾個 wikilink。
實體會有自己的頁面,概念會有自己的頁面;如果它發現新資料和既有知識存在衝突,還會用 [!contradiction] callout 標記出來。
整個處理過程還會被記錄進 wiki/log.md。
你自己幾乎不需要手動維護目錄、標籤或連結,這些都由系統完成。
接下來,你就可以開始提問了。
Claude 會先讀 hot cache,再掃描 index,識別相關 wiki 頁面,然後基於你自己倉庫裏的內容給出答案,並標註引用頁面。
也就是說,它引用的不再只是訓練數據,而是你已經整理好的、屬於你自己的知識資產。
為什麼倉庫越大,成本也不會失控?
很多人會擔心:如果以後倉庫裏有幾千頁內容,會不會 token 成本越來越高?答案是:不會。
這套系統只會按順序加載 3 類文件:
hot.md:大約 500 詞的近期上下文(約 500 tokens)index.md:每頁一行,Claude 通過它快速判斷哪些內容相關
相關頁面本身:只加載和當前問題真正有關的那些文件
所以即使你的 vault 擴展到幾千頁,token 成本變化也不會太大,因為它從來不會一次性把所有東西都塞進上下文。
一個多月之後,它會長成什麼樣?
連續用幾周之後,你再打開 Obsidian 的 graph view,就會看到一張按顏色分層的知識地圖:你讀過的內容、想過的問題、形成的概念、積累的來源、重要實體,都會自動連成網絡。
深入研究的主題會自然形成簇狀結構,鄰近概念之間會自動建立聯繫,矛盾點也會被標記出來。
這才是 Obsidian 當初承諾給你的那種“像大腦一樣”的知識圖譜。
以上,就是這套系統的核心思路。
如果你希望把 AI 從“臨時聊天助手”升級成“可持續工作的知識接口”,那 Claude + Obsidian 這套組合,確實值得認真搭起來。