給 Agent 寫 Skill,禁令可能比不寫還糟:Superpowers 6.0 的 writing-skills 怎麼把規則寫對
整理版優先睇
寫 Agent 規則要按失敗類型選形態:禁令唔係萬能,配方可能更有效
呢篇文章係術哥根據 Superpowers 6.0 嘅 writing-skills 源碼同文檔整理出嚟。Superpowers 係一個開源嘅 agent skill 庫,佢哋喺實際測試中發現一個反直覺嘅結果:喺某啲場景下,寫禁令(例如「唔好做 X」)比唔寫任何指導仲差。作者想幫我哋理解點解會咁,同埋提供一套叫「Match the Form to the Failure」嘅方法,去決定點樣寫規則先至有效。
呢套方法嘅核心係:寫規則之前,要先用無指導對照組測試,揾出基線失敗嘅類型。失敗分為四大類:壓力下違反規則(明知故犯)、輸出形狀唔啱(例如寫成散文)、漏咗必需元素、行為要根據條件而定。每類失敗都有對應嘅正確形態同錯誤形態。例如形狀類失敗,正確形態係正面配方(具體講輸出應該係點),錯誤形態係禁令清單。禁令喺形狀類問題上會反噬,因為佢俾咗 agent 談判空間,而配方就冇。
除咗形態選擇,文章仲提到 micro-test 方法去驗證措辭、description 字段嘅陷阱(唔好寫工作流摘要,否則 agent 會跳過正文),同埋兩條鐵律:唔好加細微差別條款,例外條款無法限定作用域。最後強調要誠實面對方法論嘅邊界——呢啲係工程經驗,學術研究只係側面支撐。總括嚟講,寫 agent 規則要 testing、iteration、承認直覺會錯。
- 寫規則前要先分類失敗:明知故犯用禁令,形狀問題用配方,漏元素用結構模板,條件行為用條件句;選錯形態會反噬。
- 禁令唔係默認選項:喺形狀類問題上,禁令可能比無指導仲差;配方唔留談判空間,係核心優勢。
- 唔好喺有效配方加 nuance,否則一致會變嘈雜;例外條款亦無法限定作用域。
- description 只寫觸發條件,唔好摘要工作流,否則 agent 會跳過正文。
- 用 micro-test 驗證措辭:5次重複,方差係指標;冇基線失敗就唔好寫規則。
Superpowers 開源項目
GitHub 倉庫,包含 writing-skills 等技能源碼
Jang et al. (2022) - 否定句逆縮放定律
研究發現模型越大,否定句任務表現越差
Truong et al. (2023) - LLM 對否定詞不敏感
LLM 無法喺否定下正常推理
結構示例
## Output Format### Spec Compliance- ✅ Spec compliant | ❌ Issues found: [what's missing/extra/misunderstood, with file:line references]- ⚠️ Cannot verify from diff: [...]### Strengths[What's well done? Be specific.]### Issues#### Critical (Must Fix)#### Important (Should Fix)#### Minor (Nice to Have)### Assessment**Task quality:** [Approved | Needs fixes]**Reasoning:** [1-2 sentence technical assessment]禁令可能比唔寫仲差?
寫規則嘅本能係落禁令,但 Superpowers 做咗個措辭對照測試,結果嚇親人:禁令組比配方組產生更多唔想要嘅內容,分佈完全分離,甚至比完全冇指導嘅對照組仲有變差嘅趨勢。
呢個結論有特定條件——係喺「讓 prompt 自包含」嘅競爭性激勵下。但源碼明確建議:永遠唔好默認伸手攞禁令,而係要先 micro-test 自己嘅場景。
配方唔留談判空間,輸出要麼符合聲明形狀,要麼唔符合
禁令俾咗 agent 喺多重目標下談判嘅餘地
先分類失敗,再揀形態
方法論核心係喺寫規則之前,先分類基線失敗嘅類型。源碼提供咗一張映射表,將失敗分為四類,每類有對應嘅正確形態同錯誤形態。
- 壓力下違反規則(明知故犯):正確形態係禁令 + 合理化表 + 紅旗列表;錯誤形態係軟指導(prefer、consider)。
- 輸出形狀唔啱(臃腫、埋沒結論):正確形態係正面配方,按順序列出輸出組成部分;錯誤形態係禁令清單。
- 漏咗必需元素:正確形態係結構性模板(如 REQUIRED 字段);錯誤形態係模板附近嘅散文式提醒。
- 行為應依條件而定:正確形態係基於可觀察謂詞嘅條件句;錯誤形態係無條件規則加例外條款。
例如 TDD skill 要防明知故犯,用全套禁令工具包(MUST、Never、紅旗列表)係正確嘅;而 task-reviewer 要防形狀唔啱,就用 Output Format 配方模板。
禁令喺形狀類問題上會可測量地反噬
形狀類失敗要用正面配方,唔係唔準做咩,而係清楚講應該做咩
點解配方比禁令更硬?
源碼解釋得好精煉:配方唔留談判空間——輸出要符合聲明形狀,要麼就唔符合。禁令係負面約束,但冇話俾 agent 知應該點做,結果 agent 自己平衡目標,往往唔係你想要嘅。
禁令喺競爭性激勵下打開談判空間
舉個具體對比:想 reviewer 報告結構清晰,禁令會寫「唔好寫成長篇大論、唔好複述 spec」,但 agent 可能會「總結一下」;配方直接定義輸出骨架:Spec Compliance、Strengths、Issues、Assessment,每個部分填咩寫清楚,agent 冇得走盞。
例外條款無法限定作用域,本質係幹擾
有效嘅配方加一個「除非」就破壞咗約束力
Description 字段同 Micro-Test
Description 係 agent 決定睇唔睇正文嘅關鍵。Superpowers 發現,如果 description 寫咗工作流摘要,agent 會跟住 description 做,跳過 skill 正文。正確做法係只寫觸發條件,唔好寫步驟。
摘要工作流嘅 description 創造咗一條 agent 會走嘅捷徑
例如 workflow description 寫「Use for TDD - write test first」,agent 可能直接跟着做,冇讀入面嘅詳細流程。改為「Use when executing implementation plans with independent tasks」先正確。
- 1 每次調用一個全新上下文樣本,用原始 API 或單次 subagent。
- 2 system prompt 放規則將要生存嘅真實 context,user message 放誘使失敗嘅任務。
- 3 必須包含無指導對照組——如果對照組都唔失敗,就冇嘢要修。
- 4 每個變體做5次以上重複,單樣本會呃人。
- 5 方差係指標:收斂代表規則有效,發散代表要收緊形態。
冇基線失敗,就唔好寫規則
微測試驗證措辭,唔可以代替紀律類嘅壓力場景測試
方法論嘅邊界同工程態度
呢套方法唔係孤立發明,agentskills.io 都有類似「Match specificity to fragility」嘅建議。學術研究如 Jang et al. (2022) 同 Truong et al. (2023) 從側面支持 LLM 對否定詞處理弱於對肯定指令,但層面唔同,形態選擇有效性嘅直接研究仍然係空白。
形態選擇有效性嘅直接研究目前係空白
說服心理學研究(Cialdini;Meincke 2025)為紀律類 skill 用權威語言提供依據,但只適用於紀律類,唔係萬能。總括嚟講,Match the Form to the Failure 教嘅係一種工程態度:寫規則同寫 code 一樣,需要測試、迭代、承認直覺會錯。
先問自己:我要防嘅失敗係邊一類?
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 147 篇,AI 編程最佳實戰「2026」系列第 44 篇
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。

封面:四類失敗對應四種正確形態,反直覺結論——禁令可能最差
說明:本文內容係基於 Superpowers 開源項目源碼(github.com/obra/superpowers)同相關官方文檔分析整理,文入面嘅方法論結論嚟自項目
skills/writing-skills/目錄嘅源碼同配套文檔。文中嘅實驗數據同測試結論都保留官方原文嘅限定條件(特定場景下嘅測試,唔係普適定律),方法同建議僅供參考,實際效果請以你自己嘅 agent 環境同場景測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
畀 AI agent 寫規則,多數人嘅本能反應係寫禁令:唔好做 X、禁止 Y、絕對唔 Z。呢個好符合直覺——你唔想要嘅結果,就明確話唔。
但開源 skill 庫 Superpowers 嘅源碼入面記住一條反直覺嘅實驗結論:喺佢哋做嘅措辭對照測試中,禁令組比配方組產生咗更多唔受歡迎嘅內容,分佈完全分離,甚至比完全唔寫指導嘅對照組仲有變差嘅趨勢。
換句話講,某啲場景下,你辛辛苦苦寫咗一大堆唔好,效果仲不如乜都唔寫。
呢個背後嘅方法論叫 Match the Form to the Failure(讓指導嘅形態匹配失敗嘅形態),係 Superpowers 6.0 版本沉澱嘅一套工程化規則設計方法。佢回答嘅問題好具體:畀 AI agent 寫 skill、prompt、system instruction 時,乜嘢嘅指導形態先至真正有效,乜嘢嘅會適得其反。
翻咗一次呢套方法嘅源碼同配套文檔,我覺得佢對寫過 agent 規則嘅人嘅啟發,遠不止於 Superpowers 本身——呢套係可以遷移到任何 agent prompt 設計嘅方法。下面將關鍵發現整理出嚟。
1. 先分類失敗,再伸手拎形態
呢套方法嘅核心主張:喺寫指導之前,先分類基線失敗(baseline failure)嘅類型。 因為能夠防住一種失敗嘅寫法,喺另一種失敗上會可測量地反噬(measurably backfires)。
源碼(writing-skills/SKILL.md:463-468)俾咗一張映射表,將失敗分成四類,每類對應一種正確形態同一種錯誤形態:
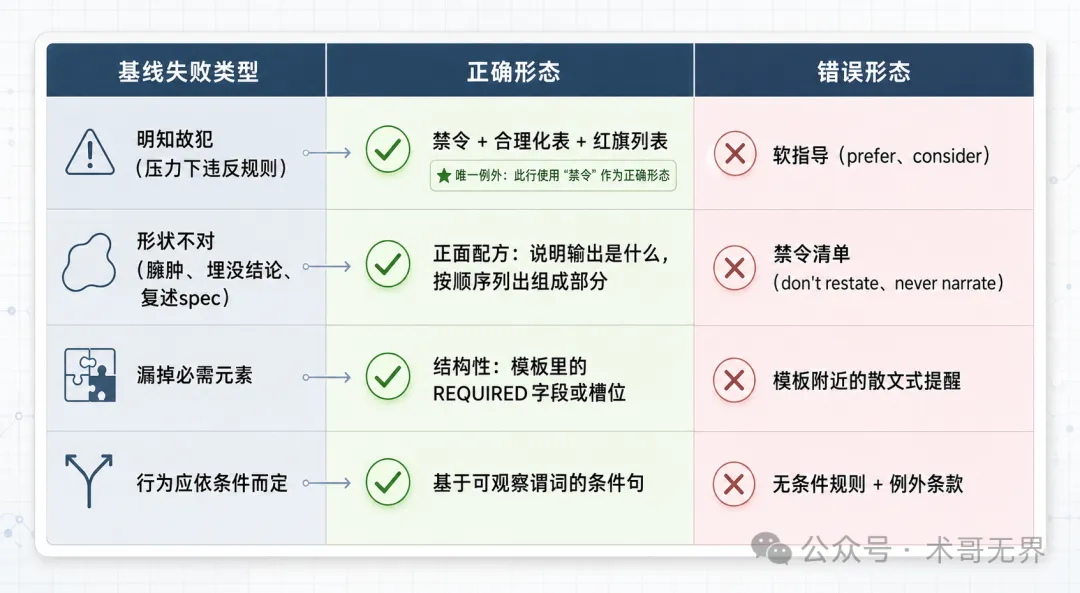
圖 1:四類失敗基型嘅形態映射——左列失敗類型,中列正確形態(綠),右列錯誤形態(粉),禁令只喺明知故犯嗰行係正確選擇
呢張表嘅關鍵唔喺四類失敗本身,而係喺錯誤形態嗰一列。你會留意到一個規律:每一行嘅錯誤形態,恰好係好多人寫規則時嘅默認選擇。
形狀類失敗,錯誤形態係禁令清單;條件類失敗,錯誤形態係無條件規則加例外條款——呢個咪就係我哋平時最順手嗰種寫法囉?
然後係嗰個反直覺結論(SKILL.md:470)。源碼原文:
under a competing incentive ('make the prompt self-contained'), agents negotiate with 'don't X'. In head-to-head wording tests on dispatch-prompt guidance, the prohibition arm produced clearly more of the unwanted content than the recipe arm (fully separated distributions), and trended worse than even the no-guidance control.
翻譯過來:喺 dispatch-prompt 指導嘅對照測試入面,禁令組比配方組產生咗明顯更多嘅唔要內容(分佈完全分離),而且比唔寫任何指導嘅對照組仲有變差嘅趨勢。
呢度有個限定條件必須講清楚——呢個係喺特定場景(dispatch-prompt guidance 加上令 prompt 自包含嘅競爭性激勵)之下做嘅,唔係普適定律。源碼嘅建議係:micro-test 你自己嘅場景,唔好假設,但永遠唔好默認伸手拎禁令(never reach for the prohibition by default)。
源碼仲俾咗兩條對所有形態都適用嘅鐵律(SKILL.md:472-474):
唔好加細微差別條款(nuance clause)。Don't X unless it matters 呢種寫法會重新打開談判空間——畀一個有效嘅配方加一個除非,喺同樣嘅測試入面令佢從一致(consistent)退化到嘈雜(noisy)。
例外條款無法限定作用域(exemption clauses don't scope)。呢條限制唔適用於代碼塊呢種話,實際上仍然會抑制代碼塊。如果輸出嘅一部分必須豁免,應該重新組織結構,令規則掂唔到佢。
呢兩條鐵律嘅本質係同一個意思:一旦你寫咗規則,agent 就會按字面執行,包括你寫嘅例外——例外本身都係一種幹擾。
2. 配方點解比禁令更硬
咁點解禁令喺形狀類問題上會反噬?
源碼(SKILL.md:470)俾咗一句好精煉嘅解釋:
A recipe leaves nothing to negotiate: the output matches the stated shape or it doesn't.
配方唔留談判空間——輸出要麼符合聲明嘅形狀,要麼唔符合。而禁令(don't X)俾咗 agent 喺競爭性激勵下談判嘅餘地。
呢度嘅談判唔係擬人化。佢指嘅係:當 agent 同時面對多個目標時(例如令 prompt 自包含 同 唔好複述 spec),禁令係一個負面約束,佢話畀 agent 唔可以做乜,但冇話畀 agent 應該做乜。於是 agent 會自己決定點平衡呢兩個目標——而呢個平衡往往唔係你想要嘅。
配方啱啱相反。佢係一個正面契約:你嘅輸出必須包含呢幾個部分,按呢個順序。agent 冇自由發揮嘅空間,只能照住填。
舉個具體嘅對比。假設你想令 reviewer 嘅報告結構清晰,唔好寫成散文。
禁令形態會寫成:
不要寫成長篇大論。
不要複述 spec。
不要在開頭鋪墊太多。
配方形態會寫成(呢個係 Superpowers 入面 task-reviewer-prompt 嘅真實模板,task-reviewer-prompt.md:139-166):
## Output Format
### Spec Compliance
- ✅ Spec compliant | ❌ Issues found: [what's missing/extra/misunderstood, with file:line references]
- ⚠️ Cannot verify from diff: [...]
### Strengths
[What's well done? Be specific.]
### Issues
#### Critical (Must Fix)
#### Important (Should Fix)
#### Minor (Nice to Have)
### Assessment
**Task quality:** [Approved | Needs fixes]
**Reasoning:** [1-2 sentence technical assessment]
前者俾咗 agent 一大堆唔好,但冇話報告應該係點。agent 可能會諗:唔複述 spec,咁我總結一下總得掛?然後寫出一堆你以為佢唔會寫嘅嘢。
後者直接定義咗報告嘅骨架:四個部分,每個部分填乜。reviewer 嘅輸出要麼符合呢個形狀,要麼唔符合——一目瞭然,冇灰色地帶。
呢個就係 Match the Form to the Failure 入面形狀類失敗要用正面配方嘅實際效果。配方唔留談判空間,唔係一句口號,而係結構上嘅必然。
3. 兩份真實 skill 代碼嘅形態對照
光講理論唔夠直觀,嚟睇下 Superpowers 自己嘅 skill 係點揀形態嘅。
先睇紀律類嘅典型:test-driven-development/SKILL.md。呢個 skill 要防嘅失敗係 agent 喺壓力下違反 TDD 規則(例如已經寫咗 200 行代碼,先諗起冇寫測試)。佢嘅形態選擇係全套禁令工具包:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST
Write code before test? Delete it. Start over.
配套嘅仲有一句基礎原則(SKILL.md:14):違反規則嘅字面,就係違反規則嘅精神。 然後係一張合理化表(rationalization table,第 258-271 行),列出 11 個常見藉口同對應嘅現實,例如:
藉口:This case is different because... 現實:[顯式反駁]
再往後係 13 條紅旗信號(red flags,第 272-288 行),話畀 agent 幾時應該即刻停低重嚟。
呢度大量使用 MUST、Never、No exceptions 呢種權威語言。呢個同禁令喺形狀類問題上反噬並唔矛盾——因為 TDD 要防嘅係明知故犯,屬於紀律類失敗,禁令形態喺呢度係正確嘅。

圖 2:兩份真實 skill 嘅形態對照——左為 TDD 嘅禁令工具包(禁令+合理化表+紅旗),右為 task-reviewer 嘅配方骨架(四段式 Output Format),形態選擇決定 skill 整體結構
再睇形狀類嘅典型:前面提到嘅 task-reviewer-prompt.md。呢個 skill 要防嘅失敗係 reviewer 嘅輸出形狀唔啱——可能寫成散文、可能埋沒結論、可能結構混亂。
佢嘅主形態係嗰個 Output Format 配方模板,冇用 don't write essays、never bury the verdict 呢種禁令清單。
有意思嘅係,佢喺第 118-121 行確實用咗一句禁止式:
Your final message is the report itself: begin directly with the spec-compliance verdict. Every line is a verdict, a finding with file:line, or a check you ran — no preamble, no process narration, no closing summary.
呢度嘅 no preamble 睇落似禁令,但佢服務嘅係配方嘅收尾約束,唔係主形態。整個 skill 嘅骨架仍然係報告係點,而唔係唔好寫成點。
呢兩份代碼對照住睇,形態選擇就唔係一個抽象原則喇——佢實實在在地決定咗 skill 嘅整體結構係點。
順帶提一個相關嘅紀律類禁令。subagent-driven-development/SKILL.md 第 381-383 行禁止喺派發 reviewer 時預判結論:
Tell a reviewer what not to flag, or pre-rate a finding's severity in the dispatch prompt ('treat it as Minor at most') — the plan's example code is a starting point, not evidence that its weaknesses were chosen
呢個都係一個唔好做 X 嘅禁令,但佢針對嘅係 reviewer 喺壓力下傾向於減輕嚴重程度嘅紀律類失敗,所以禁令形態係啱嘅。
如果你都喺度畀 agent 寫規則,不妨對照一下:你寫嗰條規則,防嘅係明知故犯,定係形狀唔啱?呢兩種情況用嘅形態應該完全唔同。你喺項目入面寫過類似嘅 agent 規則嗎?歡迎喺評論區傾下你踩過嘅形態選擇嘅坑。
4. description 字段嘅隱蔽陷阱
形態選擇仲有一個容易被忽略嘅地方:skill 嘅 description 字段。
Superpowers 嘅源碼(writing-skills/SKILL.md:154-158)記錄咗一個實驗發現:當 description 寫咗工作流摘要時,agent 可能會跟住 description 做,跳過 skill 正文。
具體例子好說明問題。有個 skill 嘅流程圖明明定義咗兩階段 review(先 spec 合規,再代碼質量),但 description 寫成咗 code review between tasks(任務之間做代碼審查)。結果 agent 淨係做咗一次 review——佢讀咗 description,覺得自己已經知道要做乜,就冇去讀正文入面嘅流程圖。
當 description 改成淨係寫觸發條件(Use when executing implementation plans with independent tasks,唔寫工作流摘要),agent 先正確讀咗流程圖並執行咗兩階段審查。
源碼嘅總結(SKILL.md:158):
Descriptions that summarize workflow create a shortcut agents will take. The skill body becomes documentation agents skip.
摘要工作流嘅 description 創造咗一條 agent 會行嘅捷徑,skill 正文變成咗 agent 會跳過嘅文檔。
正確嘅寫法係 description 淨係描述觸發條件,唔摘要工作流(SKILL.md:160-172):
# ❌ 摘要工作流:agent 可能跟着這個做,而不是讀 skill
description:Usewhenexecutingplans-dispatchessubagentpertaskwithcodereviewbetweentasks
# ❌ 太多流程細節
description:UseforTDD-writetestfirst,watchitfail,writeminimalcode,refactor
# ✅ 只寫觸發條件,不寫工作流摘要
description:Usewhenexecutingimplementationplanswithindependenttasksinthecurrentsession
呢個陷阱嘅本質係:description 係 agent 決定要唔要讀正文嘅依據。如果 description 入面已經包含咗點做,agent 就冇動機去讀正文入面嘅詳細流程。Superpowers 將呢個問題單獨抽出來,叫 SDO(Skill Discovery Optimization,技能發現優化)陷阱。
5. 用 Micro-Test 驗證措辭
講咗咁多應該點揀形態,但實際寫規則時,你點知道自己揀嘅措辭有效?
Superpowers 嘅答案係:唔好靠直覺,要 micro-test(writing-skills/SKILL.md:579-583)。完整嘅壓力場景測試(pressure scenario)係最終關卡,但每次迭代都好慢。micro-test 係喺跑昂貴測試前,用最低成本驗證措辭本身。
五步方法論:
每次調用一個全新上下文樣本。用原始 API 調用,或單次 subagent。system prompt 放指導將要生存嘅真實上下文(完整嘅 skill 或 prompt 模板),user message 放一個誘使失敗嘅任務。
必須包含無指導對照組。如果對照組都唔表現出失敗,說明冇要修嘅嘢——停低,唔好編寫指導。呢條好重要:冇基線失敗,就唔好寫規則。
每個變體 5 次以上重複。單樣本會呃人(Single samples lie)。
手動讀每個標記嘅匹配。可以用程序評分,但模板回聲同引用反例會偽裝成命中;自動化計數會同時高估失敗同成功。
方差係指標。當指導生效時,重複會收斂到同一種形狀。5 次重複出現 5 種唔同嘅解釋,意味住措辭冇約束力——先收緊形態,再加詞。
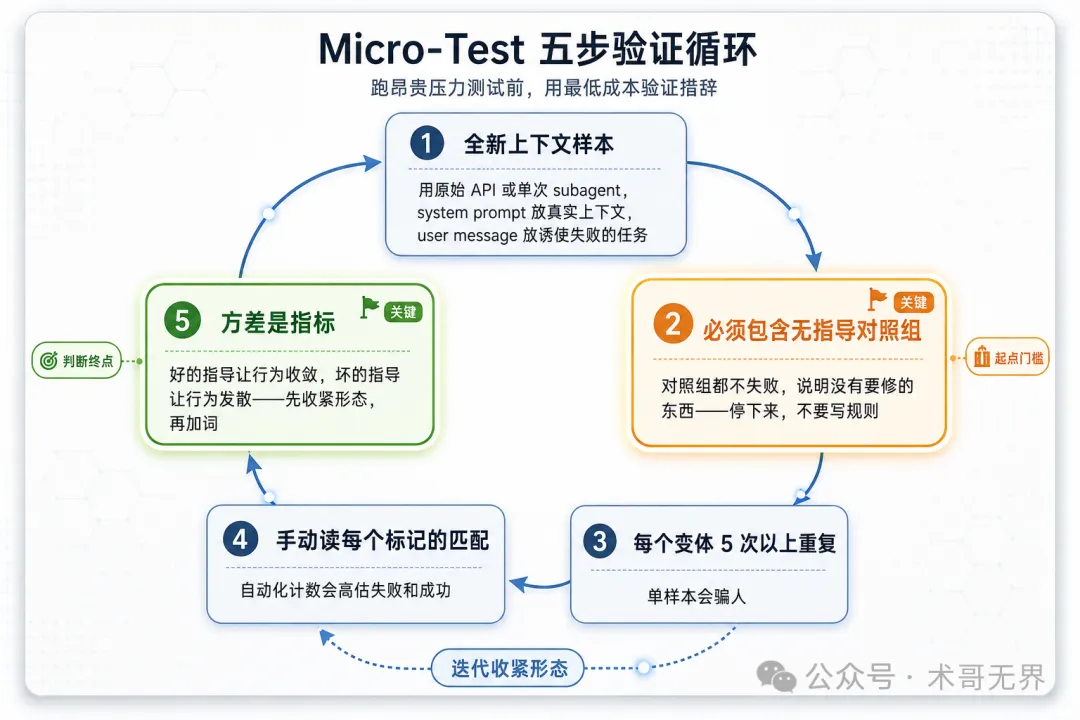
圖 3:Micro-Test 五步驗證循環——無指導對照組係起點門檻(冇基線失敗就唔寫規則),方差係判斷終點(發散即收緊形態)
第 5 步值得講多兩句。方差係指標呢個講法,初讀容易滑過去。佢嘅意思係:好嘅指導會令 agent 嘅行為收斂,壞嘅指導會令 agent 嘅行為發散。
如果你寫咗條規則,跑 5 次,agent 畀你 5 種唔同嘅理解——唔係 agent 嘅問題,係你嘅措辭冇約束力。呢個時候你唔應該加更多解釋(嗰往往會令事情更差),而應該收緊形態,令輸出形狀更確定。
呢個思路對任何寫 agent prompt 嘅人都適用:與其糾結措辭夠唔夠清晰,不如睇下重複測試嘅方差。方差大,說明形態冇揀啱。
最後,micro-test 有佢嘅邊界(SKILL.md:585):
Micro-tests verify wording; they do not replace pressure scenarios for discipline skills.
micro-test 驗證嘅係措辭,佢唔可以替代紀律類 skill 嘅壓力場景測試。形狀類問題用 micro-test 就夠,紀律類問題仲要靠完整嘅壓力測試——因為紀律類失敗只有喺多重壓力下先會暴露。
6. 呢套方法論嘅邊界同誠實
Superpowers 嘅呢套方法論唔係孤立發明。
agentskills.io 嘅官方實踐指南入面有一節標題就叫 Match specificity to fragility(令指令嘅具體程度匹配任務嘅脆弱程度),原文話:唔係 skill 嘅每個部分都需要同樣嘅指令強度,令具體程度匹配脆弱程度。
呢個幾乎就係 Match the Form to the Failure 嘅官方同義表述。兩者共享同一個洞察:指令唔應該全部用同一種強度,而應該根據搞錯咗會點樣嚟差異化配置。
官方對 description 字段嘅建議都體現 micro-test 精神:應該說明 skill 做乜 + 幾時用 + 包含幫助 agent 識別相關任務嘅具體關鍵詞。
學術研究提供側面支撐,但要誠實標註邊界。兩篇 cs.CL 論文值得提:
Jang 等(2022) 發現咗否定句嘅逆縮放定律:模型越大,喺否定句任務上表現反而越差,覆蓋 125M–175B 參數(論文:https://arxiv.org/abs/2209.12711)。 Truong 等(2023) 發現 LLM 對否定詞唔敏感,無法喺否定下正常推理(論文:https://arxiv.org/abs/2306.08189)。
呢兩篇支持一個底層洞察:LLM 對避免乜嘅處理,弱於對做乜嘅處理。 呢個同 Superpowers 配方優先、禁令慎用嘅方向一致。
但必須說明邊界:呢啲研究針對嘅係語言學否定(not、no、never),而 Superpowers 討論嘅係指令形態選擇(清單、流程圖、配方、條件句)。兩者層面唔同。目前冇直接研究指令形態選擇有效性嘅學術論文——呢個係一個真實嘅研究空白。
Superpowers 嘅方法論,以及 agentskills.io 嘅建議,本質都係實踐先行、理論滯後嘅工程經驗總結。佢嘅價值在於經過咗大量 skill 嘅實測驗證,而唔係因為有乜學術理論背書。
說服心理學呢塊都有研究支撐(persuasion-principles.md)。Cialdini 嘅經典研究(2021)提出七大說服原則;Meincke 等(2025)喺 28000 次 LLM 對話測試中發現,說服技術將合規率從 33% 提升到 72%,其中權威、承諾、稀缺三個原則最有效。呢個為紀律類 skill 使用權威語言提供咗依據——但要記住,呢個係紀律類嘅依據,唔係形狀類嘅。唔同失敗類型,用唔同嘅說服策略,呢個本身就係 Match the Form to the Failure 嘅延伸。
總結
將呢套方法論濃縮成幾條可以帶走嘅判斷:
寫規則前先分類失敗。明知故犯用禁令,形狀唔啱用配方,漏元素用結構模板,條件行為用基於謂詞嘅條件句。揀錯形態會反噬。
禁令唔係默認選項。喺形狀類問題上,禁令可能比無指導仲差。配方唔留談判空間,呢個係佢嘅核心優勢。
唔好畀有效配方加 nuance。除非會令一致嘅配方退化成交差。例外條款都無法限定作用域。
description 淨係寫觸發條件。摘要工作流嘅 description 會令 agent 跳過正文。
用 micro-test 驗證措辭。5 次重複,方差係指標。冇基線失敗,就唔好寫規則。
誠實面對邊界。呢套方法嘅實證基礎係工程經驗,學術研究只提供側面支撐,形態選擇有效性嘅直接研究目前仲係空白。
講到底,Match the Form to the Failure 教嘅唔係某種具體寫法,而係一種工程態度:畀 agent 寫規則,同寫代碼一樣,需要測試、需要迭代、需要承認直覺會出錯。
如果你都喺度寫 agent 嘅 skill 或 system prompt,下次動手前可以先問自己一句:我要防嘅失敗,係邊一類? 呢個問題答啱咗,後面嘅事會順利好多。
如果你身邊有同事喺度搞 agent prompt,轉發畀佢睇下——形態選擇呢樣嘢,踩坑嘅人唔少。
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發畀需要嘅朋友,我哋下一期再見!敬請期待!
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 147 篇,AI 編程最佳實戰「2026」系列第 44 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
封面:四類失敗對應四種正確形態,反直覺結論——禁令可能最差
說明:本文內容基於 Superpowers 開源項目源碼(github.com/obra/superpowers)和相關官方文檔分析整理,文中的方法論結論來自項目
skills/writing-skills/目錄的源碼與配套文檔。文中的實驗數據和測試結論均保留官方原文的限定條件(特定場景下的測試,非普適定律),方法和建議僅供參考,實際效果請以你自己的 agent 環境和場景測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
給 AI agent 寫規則,多數人的本能反應是寫禁令:不要做 X、禁止 Y、絕不 Z。這很符合直覺——你不想要的結果,就明確說不。
但開源 skill 庫 Superpowers 的源碼裏記着一條反直覺的實驗結論:在他們做的措辭對照測試中,禁令組比配方組產生了更多不受歡迎的內容,分佈完全分離,甚至比完全不寫指導的對照組還有變差的趨勢。
換句話說,某些場景下,你辛辛苦苦寫了一堆不要,效果還不如什麼都不寫。
這背後的方法論叫 Match the Form to the Failure(讓指導的形態匹配失敗的形態),是 Superpowers 6.0 版本沉澱的一套工程化規則設計方法。它回答的問題很具體:給 AI agent 寫 skill、prompt、system instruction 時,什麼樣的指導形態才真正有效,什麼樣的會適得其反。
翻了一遍這套方法的源碼和配套文檔,我覺得它對寫過 agent 規則的人的啓發,遠不止於 Superpowers 本身——這是一套可以遷移到任何 agent prompt 設計的方法。下面把關鍵發現整理出來。
1. 先分類失敗,再伸手拿形態
這套方法的核心主張:在寫指導之前,先分類基線失敗(baseline failure)的類型。 因為能防住一種失敗的寫法,在另一種失敗上會可測量地反噬(measurably backfires)。
源碼(writing-skills/SKILL.md:463-468)給了一張映射表,把失敗分成四類,每類對應一種正確形態和一種錯誤形態:
圖 1:四類失敗基型的形態映射——左列失敗類型,中列正確形態(綠),右列錯誤形態(粉),禁令只在明知故犯那行是正確選擇
這張表的關鍵不在四類失敗本身,而在錯誤形態那一列。你會注意到一個規律:每一行的錯誤形態,恰好是很多人寫規則時的默認選擇。
形狀類失敗,錯誤形態是禁令清單;條件類失敗,錯誤形態是無條件規則加例外條款——這不就是我們平時最順手的那種寫法嗎?
然後是那個反直覺結論(SKILL.md:470)。源碼原文:
under a competing incentive ('make the prompt self-contained'), agents negotiate with 'don't X'. In head-to-head wording tests on dispatch-prompt guidance, the prohibition arm produced clearly more of the unwanted content than the recipe arm (fully separated distributions), and trended worse than even the no-guidance control.
翻譯過來:在 dispatch-prompt 指導的對照測試裏,禁令組比配方組產生了明顯更多的不想要內容(分佈完全分離),而且比不寫任何指導的對照組還有變差的趨勢。
這裏有個限定條件必須說清楚——這是在特定場景(dispatch-prompt guidance 加上讓 prompt 自包含的競爭性激勵)下做的,不是普適定律。源碼的建議是:micro-test 你自己的場景,別假設,但永遠不要默認伸手拿禁令(never reach for the prohibition by default)。
源碼還給了兩條對所有形態都適用的鐵律(SKILL.md:472-474):
不要加細微差別條款(nuance clause)。Don't X unless it matters 這種寫法會重新打開談判空間——給一個有效的配方加一個除非,在同樣的測試裏讓它從一致(consistent)退化到嘈雜(noisy)。
例外條款無法限定作用域(exemption clauses don't scope)。這條限制不適用於代碼塊這種話,實際上仍然會抑制代碼塊。如果輸出的一部分必須豁免,應該重新組織結構,讓規則夠不到它。
這兩條鐵律的本質是同一個意思:一旦你寫了規則,agent 就會按字面執行,包括你寫的例外——例外本身也是一種干擾。
2. 配方為什麼比禁令更硬
那為什麼禁令在形狀類問題上會反噬?
源碼(SKILL.md:470)給了一句很精煉的解釋:
A recipe leaves nothing to negotiate: the output matches the stated shape or it doesn't.
配方不留談判空間——輸出要麼符合聲明的形狀,要麼不符合。而禁令(don't X)給了 agent 在競爭性激勵下談判的餘地。
這裏的談判不是擬人化。它指的是:當 agent 同時面對多個目標時(比如讓 prompt 自包含 和 不要複述 spec),禁令是一個負面約束,它告訴 agent 不能做什麼,但沒有告訴 agent 應該做什麼。於是 agent 會自己決定怎麼平衡這兩個目標——而這個平衡往往不是你想要的。
配方正好相反。它是一個正面契約:你的輸出必須包含這幾個部分,按這個順序。agent 沒有自由發揮的空間,只能照着填。
舉個具體的對比。假設你想讓 reviewer 的報告結構清晰,不要寫成散文。
禁令形態會寫成:
不要寫成長篇大論。
不要複述 spec。
不要在開頭鋪墊太多。
配方形態會寫成(這是 Superpowers 裏 task-reviewer-prompt 的真實模板,task-reviewer-prompt.md:139-166):
## Output Format
### Spec Compliance
- ✅ Spec compliant | ❌ Issues found: [what's missing/extra/misunderstood, with file:line references]
- ⚠️ Cannot verify from diff: [...]
### Strengths
[What's well done? Be specific.]
### Issues
#### Critical (Must Fix)
#### Important (Should Fix)
#### Minor (Nice to Have)
### Assessment
**Task quality:** [Approved | Needs fixes]
**Reasoning:** [1-2 sentence technical assessment]
前者給了 agent 一堆不要,但沒說報告應該長什麼樣。agent 可能會想:不復述 spec,那我總結一下總行吧?然後寫出一堆你以為它不會寫的東西。
後者直接定義了報告的骨架:四個部分,每個部分填什麼。reviewer 的輸出要麼符合這個形狀,要麼不符合——一目瞭然,沒有灰色地帶。
這就是 Match the Form to the Failure 裏形狀類失敗要用正面配方的實際效果。配方不留談判空間,不是一句口號,而是結構上的必然。
3. 兩份真實 skill 代碼的形態對照
光說理論不夠直觀,來看看 Superpowers 自己的 skill 是怎麼選形態的。
先看紀律類的典型:test-driven-development/SKILL.md。這個 skill 要防的失敗是 agent 在壓力下違反 TDD 規則(比如已經寫了 200 行代碼,才想起來沒寫測試)。它的形態選擇是全套禁令工具包:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST
Write code before test? Delete it. Start over.
配套的還有一句基礎原則(SKILL.md:14):違反規則的字面,就是違反規則的精神。 然後是一張合理化表(rationalization table,第 258-271 行),列出 11 個常見藉口和對應的現實,比如:
藉口:This case is different because... 現實:[顯式反駁]
再往後是 13 條紅旗信號(red flags,第 272-288 行),告訴 agent 什麼時候該立即停下重來。
這裏大量使用 MUST、Never、No exceptions 這種權威語言。這和禁令在形狀類問題上反噬並不矛盾——因為 TDD 要防的是明知故犯,屬於紀律類失敗,禁令形態在這裏是正確的。
圖 2:兩份真實 skill 的形態對照——左為 TDD 的禁令工具包(禁令+合理化表+紅旗),右為 task-reviewer 的配方骨架(四段式 Output Format),形態選擇決定 skill 整體結構
再看形狀類的典型:前面提到的 task-reviewer-prompt.md。這個 skill 要防的失敗是 reviewer 的輸出形狀不對——可能寫成散文、可能埋沒結論、可能結構混亂。
它的主形態是那個 Output Format 配方模板,沒有用 don't write essays、never bury the verdict 這種禁令清單。
有意思的是,它在第 118-121 行確實用了一句禁止式:
Your final message is the report itself: begin directly with the spec-compliance verdict. Every line is a verdict, a finding with file:line, or a check you ran — no preamble, no process narration, no closing summary.
這裏的 no preamble 看起來像禁令,但它服務的是配方的收尾約束,不是主形態。整個 skill 的骨架仍然是報告長什麼樣,而不是不要寫成什麼樣。
這兩份代碼對照着看,形態選擇就不是一個抽象原則了——它實實在在地決定了 skill 的整體結構長什麼樣。
順帶提一個相關的紀律類禁令。subagent-driven-development/SKILL.md 第 381-383 行禁止在派發 reviewer 時預判結論:
Tell a reviewer what not to flag, or pre-rate a finding's severity in the dispatch prompt ('treat it as Minor at most') — the plan's example code is a starting point, not evidence that its weaknesses were chosen
這也是一個不要做 X 的禁令,但它針對的是 reviewer 在壓力下傾向於減輕嚴重程度的紀律類失敗,所以禁令形態是對的。
如果你也在給 agent 寫規則,不妨對照一下:你寫的那條規則,防的是明知故犯,還是形狀不對?這兩種情況用的形態應該完全不同。你在項目裏寫過類似的 agent 規則嗎?歡迎在評論區聊聊你踩過的形態選擇的坑。
4. description 字段的隱蔽陷阱
形態選擇還有一個容易被忽略的地方:skill 的 description 字段。
Superpowers 的源碼(writing-skills/SKILL.md:154-158)記錄了一個實驗發現:當 description 寫了工作流摘要時,agent 可能會跟着 description 做,跳過 skill 正文。
具體例子很說明問題。有個 skill 的流程圖明明定義了兩階段 review(先 spec 合規,再代碼質量),但 description 寫成了 code review between tasks(任務之間做代碼審查)。結果 agent 只做了一次 review——它讀了 description,覺得自己已經知道該幹什麼了,就沒去讀正文裏的流程圖。
當 description 改成只寫觸發條件(Use when executing implementation plans with independent tasks,不寫工作流摘要),agent 才正確讀了流程圖並執行了兩階段審查。
源碼的總結(SKILL.md:158):
Descriptions that summarize workflow create a shortcut agents will take. The skill body becomes documentation agents skip.
摘要工作流的 description 創造了一條 agent 會走的捷徑,skill 正文變成了 agent 會跳過的文檔。
正確的寫法是 description 只描述觸發條件,不摘要工作流(SKILL.md:160-172):
# ❌ 摘要工作流:agent 可能跟着這個做,而不是讀 skill
description:Usewhenexecutingplans-dispatchessubagentpertaskwithcodereviewbetweentasks
# ❌ 太多流程細節
description:UseforTDD-writetestfirst,watchitfail,writeminimalcode,refactor
# ✅ 只寫觸發條件,不寫工作流摘要
description:Usewhenexecutingimplementationplanswithindependenttasksinthecurrentsession
這個陷阱的本質是:description 是 agent 決定要不要讀正文的依據。如果 description 裏已經包含了怎麼做,agent 就沒有動機去讀正文裏的詳細流程。Superpowers 把這個問題單獨拎出來,叫 SDO(Skill Discovery Optimization,技能發現優化)陷阱。
5. 用 Micro-Test 驗證措辭
說了這麼多該怎麼選形態,但實際寫規則時,你怎麼知道自己選的措辭有效?
Superpowers 的答案是:不要靠直覺,要 micro-test(writing-skills/SKILL.md:579-583)。完整的壓力場景測試(pressure scenario)是最終關卡,但每次迭代都很慢。micro-test 是在跑昂貴測試前,用最低成本驗證措辭本身。
五步方法論:
每次調用一個全新上下文樣本。用原始 API 調用,或單次 subagent。system prompt 放指導將要生存的真實上下文(完整的 skill 或 prompt 模板),user message 放一個誘使失敗的任務。
必須包含無指導對照組。如果對照組都不表現出失敗,說明沒有要修的東西——停下來,不要編寫指導。這條很重要:沒有基線失敗,就不要寫規則。
每個變體 5 次以上重複。單樣本會騙人(Single samples lie)。
手動讀每個標記的匹配。可以用程序評分,但模板回聲和引用反例會偽裝成命中;自動化計數會同時高估失敗和成功。
方差是指標。當指導生效時,重複會收斂到同一種形狀。5 次重複出現 5 種不同的解釋,意味着措辭沒有約束力——先收緊形態,再加詞。
圖 3:Micro-Test 五步驗證循環——無指導對照組是起點門檻(沒有基線失敗就不寫規則),方差是判斷終點(發散即收緊形態)
第 5 步值得多說兩句。方差是指標這個說法,初讀容易滑過去。它的意思是:好的指導會讓 agent 的行為收斂,壞的指導會讓 agent 的行為發散。
如果你寫了條規則,跑 5 次,agent 給你 5 種不同的理解——那不是 agent 的問題,是你的措辭沒有約束力。這時候你不應該加更多解釋(那往往會讓事情更糟),而應該收緊形態,讓輸出形狀更確定。
這個思路對任何寫 agent prompt 的人都適用:與其糾結措辭夠不夠清晰,不如看看重複測試的方差。方差大,說明形態沒選對。
最後,micro-test 有它的邊界(SKILL.md:585):
Micro-tests verify wording; they do not replace pressure scenarios for discipline skills.
micro-test 驗證的是措辭,它不能替代紀律類 skill 的壓力場景測試。形狀類問題用 micro-test 就夠,紀律類問題還得靠完整的壓力測試——因為紀律類失敗只有在多重壓力下才會暴露。
6. 這套方法論的邊界與誠實
Superpowers 的這套方法論不是孤立發明。
agentskills.io 的官方實踐指南里有一節標題就叫 Match specificity to fragility(讓指令的具體程度匹配任務的脆弱程度),原文說:不是 skill 的每個部分都需要同樣的指令強度,讓具體程度匹配脆弱程度。
這幾乎就是 Match the Form to the Failure 的官方同義表述。兩者共享同一個洞察:指令不應該全用同一種強度,而應該根據搞錯了會怎樣來差異化配置。
官方對 description 字段的建議也體現 micro-test 精神:應該說明 skill 做什麼 + 什麼時候用 + 包含幫助 agent 識別相關任務的具體關鍵詞。
學術研究提供側面支撐,但要誠實標註邊界。兩篇 cs.CL 論文值得提:
Jang 等(2022) 發現了否定句的逆縮放定律:模型越大,在否定句任務上表現反而越差,覆蓋 125M–175B 參數(論文:https://arxiv.org/abs/2209.12711)。 Truong 等(2023) 發現 LLM 對否定詞不敏感,無法在否定下正常推理(論文:https://arxiv.org/abs/2306.08189)。
這兩篇支持一個底層洞察:LLM 對避免什麼的處理,弱於對做什麼的處理。 這和 Superpowers 配方優先、禁令慎用的方向一致。
但必須說明邊界:這些研究針對的是語言學否定(not、no、never),而 Superpowers 討論的是指令形態選擇(清單、流程圖、配方、條件句)。兩者層面不同。目前沒有找到直接研究指令形態選擇有效性的學術論文——這是一個真實的研究空白。
Superpowers 的方法論,以及 agentskills.io 的建議,本質都是實踐先行、理論滯後的工程經驗總結。它的價值在於經過了大量 skill 的實測驗證,而不是因為有什麼學術理論背書。
說服心理學這塊也有研究支撐(persuasion-principles.md)。Cialdini 的經典研究(2021)提出七大說服原則;Meincke 等(2025)在 28000 次 LLM 對話測試中發現,說服技術把合規率從 33% 提升到 72%,其中權威、承諾、稀缺三個原則最有效。這為紀律類 skill 使用權威語言提供了依據——但要記住,這是紀律類的依據,不是形狀類的。不同失敗類型,用不同的說服策略,這本身就是 Match the Form to the Failure 的延伸。
總結
把這套方法論濃縮成幾條可帶走的判斷:
寫規則前先分類失敗。明知故犯用禁令,形狀不對用配方,漏元素用結構模板,條件行為用基於謂詞的條件句。選錯形態會反噬。
禁令不是默認選項。在形狀類問題上,禁令可能比無指導還差。配方不留談判空間,這是它的核心優勢。
不要給有效配方加 nuance。除非會讓一致的配方退化成嘈雜。例外條款也無法限定作用域。
description 只寫觸發條件。摘要工作流的 description 會讓 agent 跳過正文。
用 micro-test 驗證措辭。5 次重複,方差是指標。沒有基線失敗,就不要寫規則。
誠實面對邊界。這套方法的實證基礎是工程經驗,學術研究只提供側面支撐,形態選擇有效性的直接研究目前還是空白。
說到底,Match the Form to the Failure 教的不是某種具體寫法,而是一種工程態度:給 agent 寫規則,和寫代碼一樣,需要測試、需要迭代、需要承認直覺會出錯。
如果你也在寫 agent 的 skill 或 system prompt,下次動手前可以先問自己一句:我要防的失敗,是哪一類? 這個問題答對了,後面的事會順利很多。
如果你身邊有同事在折騰 agent prompt,轉發給他看看——形態選擇這事兒,踩坑的人不少。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!