編程、寫作、AI 短劇,Opus 4.8 的 effort 怎麼選
整理版優先睇
用 Claude 唔係愈高 effort 愈好,按場景配檔先係慳錢又有效嘅關鍵。
我一直以嚟用 Claude 都習慣將推理檔位拉到最高嘅 max,覺得咁樣模型最強。由 3.7 用到 4.6 都冇問題,但去到 4.7 用嚟寫作嘅時候,發現文筆好差,乾、僵、冇靈氣。最初以為係模型退化,後尾先發現原來係自己一直用錯檔位——max 根本唔係為文筆設計,而係為強對齊、強校驗、強邏輯。叫一個專門「較真」嘅檔去做需要鬆弛同靈氣嘅創作,梗係出事。
推理檔位其實係調同一模型嘅「投入度」,即係佢肯為件事花幾多力氣去諗、去查、去主動做嘢。低檔唔係閹割,係有啲活根本唔需要咁認真。Anthropic 最新嘅 Opus 4.8 將檔位重新校準過,默認由 max 變咗 high,medium 比以前多諗咗,xhigh 明顯多咗。呢個改變令我認真研究每個檔位嘅用途。
最後得出結論:高檔唔係更聰明,係更捨得花力氣。失敗代價高、上下文長、需要反覆驗證嘅任務(例如跨文件 debug、AI 短劇規劃)先用 high 或以上;相反,短而明確、需要鬆弛靈氣嘅任務(例如寫小說、初稿發散)就用 medium 或 low。作者仲提醒,創作上温度參數 temperature 先係控制發散嘅,但而家已經要用提示詞代替。總結一句:按場景配檔,唔好一個 max 開到黑。
- 結論:推理檔位調整投入度,唔係模型強弱,要根據任務性質選擇。
- 方法:判斷標準係失敗代價、上下文長度、需要反覆驗證嘅程度;代碼用 high/xhigh,寫作用 medium,AI 短劇規劃用 high/max。
- 差異:寫作同 AI 短劇雖然都係創作,但寫作要靈氣(低檔),短劇要一致性(高檔),所以檔位選擇相反。
- 啟發:作者反思自己一直開 max 係用錯地方,喺寫作上反而幫倒忙,提醒唔好盲目信最高檔。
- 可行動點:整理一個按場景嘅檔位對照表,實踐按場景配檔,節省 tokens。
從 max 開到黑,到按場景配檔
我一直以嚟用 Claude 都習慣將推理檔位拉到最高嘅 max,覺得咁樣模型最強。由 3.7 用到 4.6 都冇問題,但去到 4.7 用嚟寫作嘅時候,發現文筆好差,乾、僵、冇靈氣。
最初以為係模型退化,後尾先發現原來係自己一直用錯檔位——max 根本唔係為文筆設計,而係為強對齊、強校驗、強邏輯。叫一個專門「較真」嘅檔去做需要鬆弛同靈氣嘅創作,梗係出事。
max 根本唔係為文筆設計
強對齊、強校驗、強邏輯
推理檔位其實係調投入度,唔係模型強弱
寫 code 要較真,高檔先肯動手
寫代碼時,小修小補、改明確嘅小函數、解釋報錯,用 medium 就夠,圖快。日常開發、寫普通功能、局部重構,我用 high,呢個都係 4.8 嘅默認檔,質量、速度、成本最平衡。
真係要往上走,係碰到跨文件 bug、測試一直掛、接口遷移呢類活,我會上 xhigh。官方建議都係咁,寫代碼同高自主任務直接從 xhigh 起步。xhigh 有用,關鍵唔係想得更深,係肯唔肯動手——檔位低時傾向少調工具、少跑命令,高檔先肯去翻文件、跑測試、比較實現、查邊界情況。
關鍵唔係想得更深,係肯唔肯動手
質量成日就藏喺呢個來回裏:讀一遍、跑一下、睇結果、改假設、再跑一遍
- medium:小修小補、明確函數、解釋報錯
- high:日常開發、普通功能、局部重構(4.8默認)
- xhigh:跨文件bug、測試一直掛、接口遷移
- max:最後複核,極難bug或影響大嘅改動
- ultracode:全倉遷移、整個代碼庫審計,開agent並行
寫作要靈氣,短劇要一致——同一創作,兩種檔位
寫作方面,我食過最大嘅虧就係全程開 max。結果文字過度規整、過度安全,冇鮮活感。你要嘅意外同口語毛刺,高檔會幫你抹平。所以而家初稿同發散用 medium,等佢唔好咁端着。
文字會變得過度規整、過度安全
真正決定文字好壞嘅唔係檔位,係你餵畀佢嘅提示詞
但 AI 短劇/漫劇規劃就啱啱相反。分鏡要連貫、服化道提示詞要精確,命門係一致性同精確,唔係靈氣。呢啲恰恰係高檔擅長嘅強對齊、強校驗。所以我做短劇規劃反而願意開 high 甚至 max,等佢幫我對齊幾十個鏡頭嘅設定、摳提示詞、挑前後矛盾。
命門係一致性同精確,唔係靈氣
強對齊、強校驗、前後一致
一句話決定用邊檔,同埋最終反思
總括嚟講,我而家嘅判斷標準好簡單:一件事,失敗代價越高、要讀嘅上下文越長、需要反覆驗證嘅地方越多、越要靠佢主動去查去跑,就越往 high、xhigh、max 呢邊走;反過來,越短、越明確、越係批量重複、越要鬆弛同靈氣,就越往 medium、low 呢邊走。
失敗代價越高、上下文越長、需要反覆驗證嘅地方越多,就越要高檔
我一直默認 max 唔算錯,係用錯地方。喺代碼複核、AI 短劇規劃呢啲要較真嘅活上,max 仲係我最信任嘅檔;但喺寫小說、推文呢啲要活氣嘅活上,佢一直幫倒忙,我卻怪模型文筆差。呢次 4.8,我打算認真按場景去配檔,而唔係一個 max 開到黑。
按場景配檔,唔好一個 max 開到黑
用咗 Claude 呢一年幾,我淨係得一個習慣,推理可以推到幾高就推到幾高。自從有咗 max 呢個檔之後,更加係雷打唔鬱,一路開住。
邏輯好簡單,推理能力校到最高,個模型咪最強囉。所以無論寫 code、寫小說,定係幫 AI 做分鏡,我都將個檔校到最盡,而且深信唔疑。呢個信念由 3.7 嗰陣一路用到 4.6,差唔多冇出過錯。
直到 4.7。
嗰排用佢寫嘢,成日覺得文筆好差,乾、硬、冇靈氣。我第一反應係模型退化咗。後來先慢慢醒覺,可能唔關模型事,係我一直冇搞清一件事,max 呢個檔,根本唔係為文筆而設計嘅。
佢係為咗強對齊、強校驗、強檢查、強邏輯而設計嘅。
我叫一個專門負責「認真」嘅檔,去做一件需要放鬆同靈氣嘅嘢,佢梗係唔順啦。呢個唔怪佢,係我用錯咗。
真正令我將呢件事徹底搞清楚嘅,係今日凌晨 Opus 4.8 發佈、我上手測試嗰陣。
Anthropic 將 4.8 講成而家最強嘅正式模型,主打長時間嘅 agentic 編程、更穩定嘅長上下文、仲有應該用工具嘅時候唔好漏咗。我嘅第一反應仲係老習慣,隻手就向 max 伸。但今次我多咗停一停,認真去睇佢嘅推理檔位到底點樣分,由低到高排落來係呢幾級。
呢張圖你睇一眼就記得啦,low、medium、high、xhigh,再加最高嘅 max。但佢淨係話俾你知有呢幾檔,冇話俾你知每一檔到底調緊啲乜,更加冇話俾你知手上呢個 job 應該揀邊一檔。呢個先係真正令人頭痛嘅地方,亦都係我呢篇想幫你搞清楚嘅。
推理檔調嘅唔係模型,係「投入度」
佢調嘅唔係模型,係同一個模型上面,你叫佢為呢件事花幾多力氣。力氣花喺三個地方,諗得有幾深、查得有幾嚴、同埋佢有幾願意主動鬱手,例如自己去揾資料、行工具、反覆驗證。檔位越高,呢三樣俾得越足。
我以前最大嘅誤會,係將低檔當成縮水版。一路覺得低檔就係為咗慳錢,開到高嘅點解要開低嘅。呢個想法係錯嘅。低檔唔係閹割,係有啲 job 根本唔需要咁認真,你逼佢認真,佢反而將簡單嘢諗複雜,兜遠路,又慢又貴。我兜咗好耐先諗通一句話,高檔唔係更聰明,係更肯花力氣;job 如果唔需要呢份力氣,硬係校高反而幫倒忙。
呢度仲要順便分清楚三樣成日俾人搞亂嘅嘢。由 low 到 max 呢幾檔,係同一個模型嘅投入度,max 係其中最高嗰檔,一個回合入面將一件事諗到最透。
仲有一個叫 ultracode 嘅,成日俾人當成比 max 仲要高嘅檔,其實佢根本唔係推理檔,係 Claude Code 入面嘅一個會話模式,底層用緊 xhigh,額外叫 Claude 自己去編排一批 agent 並行做嘢,嗰個係另一個維度嘅事,等陣再單獨講。
另一個要知道嘅變化,4.8 將呢幾檔重新校準過咗。官方嘅講法係,medium 比以前諗得更多,high 稍微少咗啲,xhigh 明顯更多。意思係如果你由 4.6、4.7 一路用過來,靠舊感覺揀檔,而家多數唔啱喇。仲有個細節令我當時呆咗一呆,4.8 預設掛嘅係 high,唔係 max。我自己一路預設 max,原來連官方都冇將 max 當成預設。
寫 code 同做產品:唔好喺應該認真嘅地方慳
先講 code 呢塊,亦都係我而家分得最清楚嘅地方。
小修小補,改個明確嘅小 function、解釋一個 error,medium 就夠,貪快。日常開發、寫個普通功能、做啲局部重構,我用 high,呢個都係 4.8 嘅預設檔,質量、速度、成本最平衡嘅一檔。真係要再上,係遇到跨 file 嘅 bug、測試一直 fail、或者接口遷移呢種 job,我會上 xhigh。官方建議都係咁,寫 code 同嗰啲高自主嘅任務,直接由 xhigh 開始,唔好由 high 開始。
xhigh 對呢種 job 有用,關鍵唔係佢諗得更深,係佢願唔願意鬱手。檔位低嘅時候,佢傾向少啲 call 工具、少啲行指令,你一問佢就直接答。檔位高咗,佢先肯去將相關文件睇一次,將測試行一次,將幾種實現比較一下,將邊界情況查一查。寫 code 呢行,質量好多時就藏係呢個來回入面,讀一次、行一次、睇結果、改假設、再行一次。你將檔校低,佢就懶得行呢個來回,睇落答得好快,坑全部埋咗係你冇叫佢檢查嘅地方。
做產品都係同一個道理。我寫 code 之前習慣先將 PRD 諗清楚,要咩功能、交互點樣行、邊界喺邊,都諗明先鬱手。呢種將你容易漏咗嘅地方幫你諗齊嘅 job,本身就要 high 或以上,佢先會主動幫你補返啲你諗唔到嘅嘢。
max 喺 code 入面,我而家只係拎佢嚟做最後一道複核。極難嘅 bug,或者一個改動牽連好大、錯咗代價好高,我會叫 max 專門再睇一次揀邏輯漏洞。但佢真係唔適合做日常檔,官方自己都提醒,max 容易諗太多、兜遠路,收益仲遞減。4.8 喺呢點有個我幾在意嘅改進,佢比以前少咗將自己寫嘅、其實有問題嘅 code 當成搞掂咗矇混過去,更願意主動講呢 part 我冇把握。檔位開得高,等於俾咗佢更多空間去做呢種自我檢查。
至於全倉遷移、整個 codebase audit、幾百個 file 一齊改呢種,先輪到 ultracode 出場。佢唔係將一個問題答得更認真,係直接開一批 agent 並行去做,分頭理解、修改、驗證,再互相檢查、彙總,規模可以去到幾十上百個。呢個係將一個人嘅 job 拆成一個臨時小組嘅 job,代價係更慢、更燒 token,日常小修小補用佢純粹浪費。
文章/劇本創作:我食過最大嘅虧
寫作就完全係另一回事,亦都係我開頭講嗰個坑嘅正主。
劇本、小說、公眾號推文,我以前係全程 max 嘅,結果就係越寫越覺得文字硬。諗明之後先知道,文章/劇本創作恰恰係少數幾個推理唔係越高越好嘅場景。檔位校高,佢會特別想將結構、邏輯、受眾、每一處伏筆都論證到位,呢個對嚴謹係好事,對文采係災難。文字會變得過度規整、過度安全,邊度都揀唔出錯,就係唔生動。你想要嗰啲意外,嗰啲口語入面嘅毛刺,佢喺高檔下反而會一點一點幫你磨平。
所以而家要靈氣嘅 job,初稿同發散我用 medium,等佢唔好咁拘謹。講到尾,真正決定文字好壞嘅唔係檔位,係你餵俾佢嘅嘢。俾佢風格 sample、俾佢節奏、俾佢口吻、話佢知咩唔準寫,比你把檔位校到最高有用得多。仲要講清楚一個成日誤會嘅點。真正管文字發散程度嗰個參數叫 temperature,佢一路都係得 call API 嗰陣先可以 set,平時你喺 client 入面用根本掂唔到呢個掣;由 4.7 開始,連 API 都唔收佢嘅非默認值喇,4.8 都一樣,官方直接叫你用 prompt 嚟控制。所以喺創作上,推理檔從來就唔係嗰個調發散嘅掣,唔好指望校高佢,文字就會生猛。
文章/劇本創作入面都唔係冇應該用高檔嘅地方。長篇嘅前後一致、人物動機唔崩、幾萬字入面埋嘅伏筆唔斷線,呢種偏結構嘅 job,high 甚至 xhigh 係有用嘅。我而家大約係咁分,寫得放、要靈氣嘅時候用低檔,梳結構、查一致性、揀邏輯硬傷嘅時候轉高檔。同一篇嘢,唔同階段用唔同檔,呢個係我以前完全冇諗過嘅用法。
AI 短劇/漫劇規劃:同寫作剛好相反
同文章/劇本創作剛好相反嘅,係我做 AI 短劇/漫劇規劃嘅時候。
做 AI 短劇/漫劇,我要規劃分鏡、寫 prompt、仲要管服化道呢啲嘅 prompt。呢啲 job 表面睇都係創作,但佢嘅命門係一致性同精確,唔係靈氣。分鏡要連貫,呢個鏡到下個鏡要接得住。服化道嘅 prompt,同一個角色由頭到尾嘅髮型、衫、質感唔可以飄。每一條 prompt 嘅措辭都要精確,差一個詞,出嚟嘅畫面就會走樣。
呢個恰恰係高檔擅長嘅,強對齊、強校驗、前後一致。同樣係創作,文章/劇本創作我避開 max,AI 短劇/漫劇規劃我反而願意校高啲,等佢幫我將幾十個鏡頭嘅設定對齊,將每條 prompt 摳精確,將我自己冇發現嘅前後矛盾揀出嚟。
呢兩塊擺埋一齊,我先算真正諗明開頭嗰件事。檔位揀得啱唔啱,本身就已經係一個變數,同模型強唔強係兩回事。我一直信嗰句校到最盡就最強,錯就錯在將一個變數當成常數。
錢同速度,都要計埋入去
除咗做唔做得好,推理檔仲順便改幾樣嘢,簡單講下。
最直接嘅係錢同速度。檔越高,佢諗得越多、行得越多,思考同輸出嘅 token 全部升,錢跟住升,速度亦都慢落嚟。低檔快,仲更慳你嘅調用額度。批量嘅、重複嘅、簡單嘅 job 掛住高檔,基本上就係白燒錢。輸出嘅詳略都跟住變,高檔鍾意寫得長、寫得周全、周圍俾你加提醒,低檔乾脆利落。你淨係要個標題、要段摘要,俾佢 max,佢可以交一篇小作文返嚟。
一句話判斷標準,同一張速查表
兜咗咁大個圈,我自己嘅判斷標準,其實縮成咗一句話。一件事,失敗嘅代價越高、要讀嘅上下文越長、需要反覆驗證嘅地方越多、越要靠佢主動去查去行,就越向 high、xhigh、max 呢邊行;反過來,越短、越明確、越是批量重複、越要鬆弛同靈氣,就越向 medium、low 呢邊行。
我一直預設嘅 max 唔算錯,係用錯咗地方。佢喺 code 複核、喺 AI 短劇/漫劇規劃呢種要認真嘅 job 上面,到今日仲係我最信任嘅檔。但係喺寫小說、寫推文呢種要生氣嘅 job 上面,佢一路喺度幫倒忙,我卻怪咗模型咁耐,話佢文筆差。
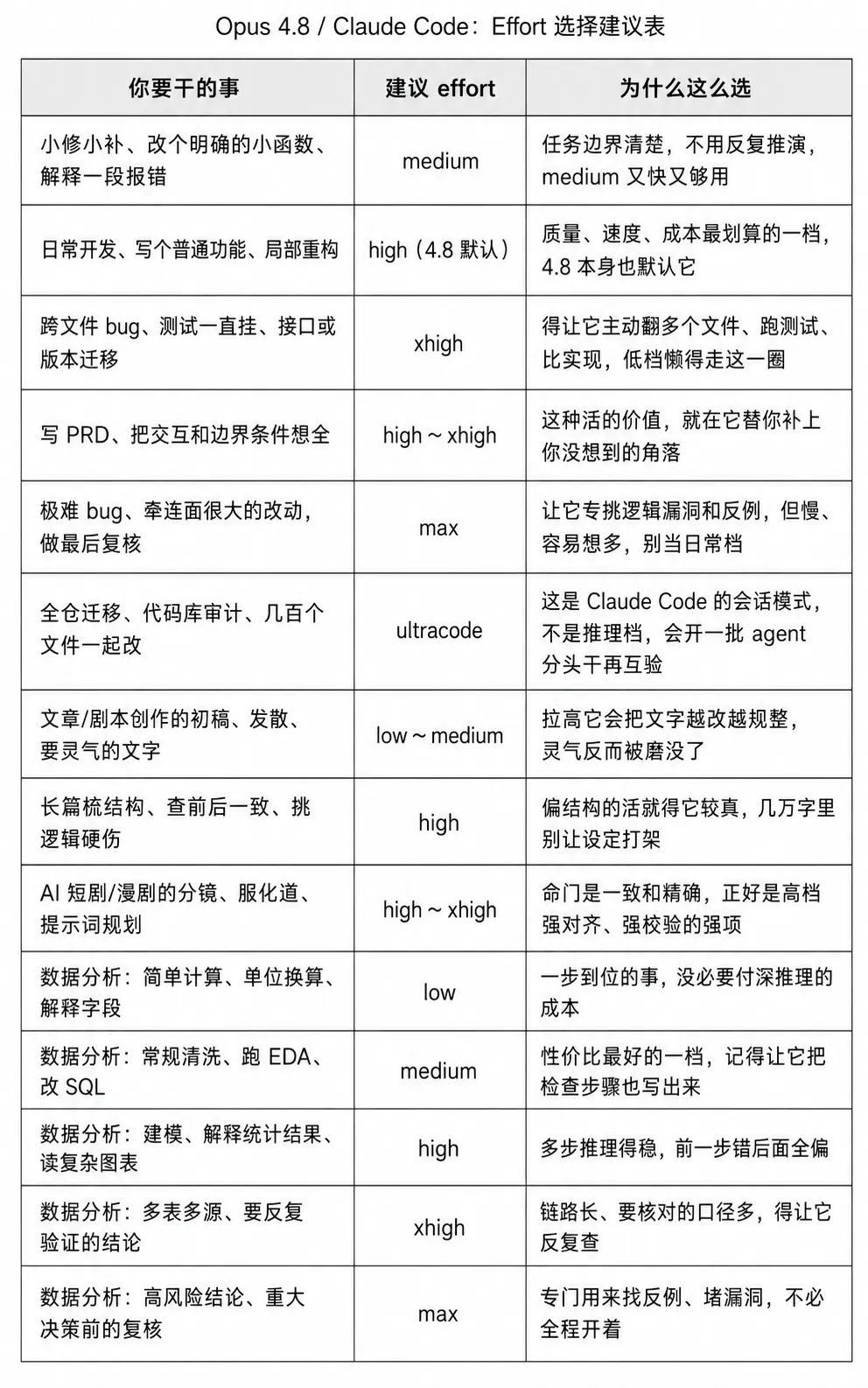
呢次 4.8,我打算第一次認真咁按場景去配檔,而唔係一個 max 用到盡。下面呢張表係我自己整理嘅一份對照。可能仲有確認嘅空間,但係整體框架都仲可以參考。
開 max 開到而家,我總算學識咗,希望之後可以慳返啲 token。
用 Claude 這一年多,我只有一個習慣,推理能拉多高就拉多高。打從有了 max 這檔起,更是雷打不動,一直開着。
邏輯特別簡單,推理能力調到最高,模型不就最強嗎。所以不管寫代碼、寫小說,還是給 AI 做分鏡,我都把檔位頂到頭,而且深信不疑。這個信仰從 3.7 那會兒一路用到 4.6,幾乎沒出過錯。
直到 4.7。
那陣子拿它寫東西,總覺得文筆很拉,幹、僵、沒靈氣。我第一反應是模型退化了。後來才慢慢回過味來,可能不怪模型,是我一直沒搞明白一件事,max 這個檔,根本就不是為文筆設計的。
它是為強對齊、強校驗、強檢查、強邏輯設計的。
我讓一個專門負責“較真”的檔,去幹一件需要鬆弛和靈氣的活,它當然彆扭。這不怪它,是我用錯了。
真正讓我把這件事徹底捋清楚的,是今天凌晨 Opus 4.8 發佈、我上手測試那會兒。
Anthropic 把 4.8 說成現在最強的正式模型,主打長時間的 agentic 編程、更穩的長上下文、還有該調工具的時候別漏掉。我的第一反應還是老習慣,手就往 max 上伸。但這次我多停了一下,認真去看它的推理檔位到底怎麼分,從低到高排下來是這麼幾級。
這張圖你掃一眼就記住了,low、medium、high、xhigh,再加最高的 max。可它只告訴你有這麼幾檔,不告訴你每一檔到底在調什麼,更不告訴你手上這個活兒該挑哪一檔。這才是真正讓人犯難的地方,也是我這篇想替你捋清楚的。
推理檔調的不是模型,是“投入度”
它調的不是模型,是同一個模型上,你讓它為這件事花多少力氣。力氣花在三個地方,想得有多深,查得有多嚴,還有它有多願意主動動手,比如自己去翻資料、跑工具、反覆驗證。檔位越高,這三樣給得越足。
我以前最大的誤會,是把低檔當成了縮水版。一直覺得低檔就是為了省錢,能開高的幹嘛開低的。這個想法是錯的。低檔不是閹割,是有些活兒根本不需要那麼較真,你非讓它較真,它反而把簡單事想複雜,繞遠路,又慢又貴。我繞了好久才想通一句話,高檔不是更聰明,是更捨得花力氣;活兒要是不需要這份力氣,硬拉高反而幫倒忙。
這裏還得順手分清楚三樣老被搞混的東西。從 low 到 max 這幾檔,是同一個模型的投入度,max 是其中最高那檔,一個回合裏把一件事想到最透。
還有一個叫 ultracode 的,經常被當成比 max 還高的檔,其實它壓根不是推理檔,是 Claude Code 裏的一個會話模式,底層用的是 xhigh,額外讓 Claude 自己去編排一批 agent 並行幹活,那是另一個維度的事,待會兒單說。
另一個得知道的變化,4.8 把這幾檔重新校準過了。官方的說法是,medium 比以前想得更多,high 略微少一點,xhigh 明顯更多。意思是你要是從 4.6、4.7 一路用過來,憑老感覺選檔,現在多半不準了。還有個細節讓我當時愣了一下,4.8 默認掛的是 high,不是 max。我自己一直默認 max,原來連官方都沒把 max 當默認。
寫代碼和做產品:別在該較真的地方省
先說代碼這塊,也是我現在分得最清楚的地方。
小修小補,改個明確的小函數、解釋個報錯,medium 就夠了,圖快。日常開發、寫個普通功能、做點局部重構,我用 high,這也是 4.8 的默認檔,質量、速度、成本最平衡的一檔。真要往上走,是碰到跨文件的 bug、測試一直掛、或者接口遷移這種活兒,我會上 xhigh。官方建議也是這樣,寫代碼和那種高自主的任務,直接從 xhigh 起步,別從 high 起。
xhigh 對這種活兒有用,關鍵不在它想得更深,在它願不願意動手。檔位低的時候,它傾向於少調工具、少跑命令,你一問它就直接答了。檔位高了,它才肯去把相關文件翻一遍,把測試跑一跑,把幾種實現比一比,把邊界情況查一查。寫代碼這行,質量經常就藏在這個來回裏,讀一遍、跑一下、看結果、改假設、再跑一遍。你把檔壓低,它就懶得走這個來回,看着答得飛快,坑全埋在你沒讓它檢查的地方。
做產品也是一個道理。我寫代碼之前習慣先把 PRD 想清楚,要什麼功能、交互怎麼走、邊界在哪,都想明白再動手。這種把你容易漏掉的地方替你想全的活兒,本身就得 high 往上,它才會主動幫你補上那些你沒想到的。
max 在代碼裏,我現在只拿它當最後一道複核。極難的 bug,或者一個改動牽連面特別大、錯了代價很高,我會讓 max 專門再過一遍挑邏輯漏洞。但它真不適合做日常檔,官方自己都提醒,max 容易想太多、繞遠路,收益還遞減。4.8 在這點上有個我挺在意的改進,它比前代更少把自己寫的、其實有毛病的代碼當成搞定了矇混過去,更願意主動說這塊我沒把握。檔位開得高,等於給了它更多空間去做這種自我檢查。
至於全倉遷移、整個代碼庫審計、幾百個文件一起改這種,才輪到 ultracode 出場。它不是把一個問題答得更認真,是直接開一批 agent 並行去幹,分頭理解、修改、驗證,再互相檢查、彙總,體量能到幾十上百個。這是把一個人的活拆成一個臨時小組的活,代價是更慢、更燒 token,日常小修小補用它純屬浪費。
文章/劇本創作:我吃過的最大的虧
寫作就完全是另一回事了,也是我開頭說那個坑的正主。
劇本、小說、公眾號推文,我以前是全程 max 的,結果就是越寫越覺得文字僵。想明白之後才知道,文章/劇本創作恰恰是少數幾個推理不是越高越好的場景。檔位拉高,它會特別想把結構、邏輯、受眾、每一處伏筆都論證到位,這對嚴謹是好事,對文采是災難。文字會變得過度規整、過度安全,哪兒都挑不出錯,就是不鮮活。你要的那點意外,那點口語裏的毛刺,它在高檔下反而會一點點幫你抹平。
所以現在要靈氣的活,初稿和發散我用 medium,讓它別那麼端着。說到底,真正決定文字好壞的不是檔位,是你餵給它的東西。給它風格樣例、給它節奏、給它口吻、告訴它什麼不許寫,比你把檔位拉滿管用得多。還得說清一個常被誤會的點。真正管文字發散程度的那個參數叫 temperature,它一直只能在調 API 的時候設,平時你在客戶端裏用根本碰不到這個旋鈕;從 4.7 起,連 API 都不收它的非默認值了,4.8 也一樣,官方直接讓你用提示詞來控制。所以在創作上,推理檔從來就不是那個調發散的鈕,別指望把它擰高,文字就能活。
文章/劇本創作裏也不是沒有該用高檔的地方。長篇的前後一致、人物動機不崩、幾萬字裏埋的伏筆不掉線,這種偏結構的活,high 甚至 xhigh 是有用的。我現在大概是這麼分的,寫得野、要靈氣的時候用低檔,梳結構、查一致性、挑邏輯硬傷的時候換高檔。同一篇東西,不同階段用不同檔,這是我以前壓根沒想過的用法。
AI 短劇/漫劇規劃:跟寫作正好反過來
跟文章/劇本創作正好反過來的,是我做 AI 短劇/漫劇規劃的時候。
做 AI 短劇/漫劇,我要規劃分鏡、寫提示詞、還要管服化道這些的提示詞。這些活兒表面看也是創作,可它的命門是一致性和精確,不是靈氣。分鏡得連貫,這一鏡到下一鏡得接得住。服化道的提示詞,同一個角色從頭到尾的髮型、衣服、質感不能飄。每一條提示詞的措辭都得精確,差一個詞,出來的畫面就跑偏。
這恰恰是高檔擅長的,強對齊、強校驗、前後一致。同樣是創作,文章/劇本創作我躲着 max,AI 短劇/漫劇規劃我反而願意往高了開,讓它幫我把幾十個鏡頭的設定對齊,把每條提示詞摳精確,把我自己沒發現的前後矛盾挑出來。
這兩塊擺在一起,我才算真正想明白開頭那件事。檔位選得對不對,本身就是一個變量,跟模型強不強是兩碼事。我一直信的那句拉滿就最強,錯就錯在把一個變量當成了常量。
錢和速度,也得算進去
除了幹不幹得好,推理檔還順帶改幾樣東西,簡單說一下。
最直接的是錢和速度。檔越高,它想得越多、跑得越多,思考和輸出的 token 全漲,錢跟着漲,速度也慢下來。低檔快,還更省你的調用額度。批量的、重複的、簡單的活兒掛着高檔,基本就是白燒錢。輸出的詳略也跟着變,高檔愛寫得長、寫得周全、處處給你加提醒,低檔乾脆利落。你就要個標題、要段摘要,給它 max,它能給你交一篇小作文回來。
一句話判斷標準,和一張速查表
繞了這麼大一圈,我自己的判斷標準,其實縮成了一句話。一件事,失敗的代價越高、要讀的上下文越長、需要反覆驗證的地方越多、越得靠它主動去查去跑,就越往 high、xhigh、max 這邊走;反過來,越短、越明確、越是批量重複、越要鬆弛和靈氣,就越往 medium、low 這邊走。
我一直默認的 max 不算錯,是用錯了地方。它在代碼複核、在 AI 短劇/漫劇規劃這種要較真的活兒上,到今天還是我最信任的檔。可在寫小說、寫推文這種要活氣的活兒上,它一直在幫倒忙,我卻怪了模型這麼久,說它文筆差。
這回 4.8,我打算第一次認真地按場景去配檔,而不是一個 max 開到黑。下面這張表是我自己理的一份對照。可能還有確認的空間,但是整體框架還是可以參考的。
開 max 開到現在,我總算學會了,希望之後可以節省點 Tokens。