編程智能體的核心組件【譯】
整理版優先睇
編程智能體的核心在於外圍 Harness,六大組件決定實際表現
呢篇文章出自 Sebastian Raschka 博士,佢寫過《從零構建大語言模型》同《從零構建推理模型》。佢成日收到讀者問關於智能體嘅問題,所以整理咗呢篇參考指南,專門講編程智能體嘅核心組件。
作者首先釐清三個成日撈亂嘅概念:大語言模型(LLM)係核心,推理模型係強化過嘅 LLM,識得做中間推理步驟,而智能體就係包住模型嘅一層「控制循環」,負責決定點樣用工具、管理上下文同狀態。佢強調,編程智能體之所以比普通聊天界面勁咁多,關鍵唔係模型本身,而係外圍嘅 Coding harness。呢個 harness 會幫你管理代碼倉庫上下文、快取提示詞、安全調用工具、壓縮上下文、保存記憶,仲可以委派子任務。
整體嚟講,呢篇文章嘅結論係:而家頂級 LLM 嘅能力已經好接近,真正分出高下嘅係 Harness。作者用自己整嘅 Mini Coding Agent 做例子,拆解出六個核心組件:即時代碼倉庫上下文、提示詞形態與快取複用、工具接入與調用、上下文瘦身、結構化會話記憶,同埋任務委派。呢啲組件夾埋,就係點解 Claude Code 或者 Codex 用起嚟咁順手嘅原因。
- 編程智能體嘅核心係 Coding harness,而唔係模型本身;頂級 LLM 能力接近,Harness 先係決勝關鍵。
- 六大組件包括:即時代碼倉庫上下文、提示詞快取、工具調用、上下文壓縮、結構化記憶、子任務委派。
- 成功嘅 Harness 會將提示詞分為穩定前綴(系統指令、工具說明、工作區摘要)同頻繁更新部分(對話記錄、最新需求),並利用 prompt caching 慳成本。
- 工具調用必須經過安檢:驗證工具名、參數、權限、路徑,確保模型唔會亂行高危命令。
- 上下文壓縮係最被低估嘅環節:透過裁剪、去重、對話總結,保持提示詞質量,避免 token 爆炸。
Mini Coding Agent 源碼
作者用純 Python 從頭編寫嘅極簡編程智能體,示範六大核心組件嘅具體實作。
從零構建推理模型(Build A Reasoning Model From Scratch)
作者新書,涵蓋推理模型評估、推理時算力擴展、自我反思、強化學習、模型蒸餾等內容。
內容結構
################################## 六大智能體組件 ###################################
1) 實時代碼倉庫上下文 -> WorkspaceContext#
2) 提示詞形態與緩存複用 -> build_prefix, memory_text, prompt#
3) 結構化工具、驗證與權限 -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*#
4) 上下文瘦身與輸出管理 -> clip, history_text#
5) 完整對話記錄、記憶與恢復 -> SessionStore, record, note_tool, ask, reset#
6) 任務委派與受限子智能體 -> tool_delegate釐清核心概念:LLM、推理模型與智能體
作者指出,成日有人將「模型本身」、「推理行為」同「智能體產品」撈亂。佢用一個好嘅比喻:LLM 係普通引擎;推理模型係爆改引擎,馬力更強但更嘥錢;而 Agent harness 就係成架車嘅系統,幫你更好地駕馭引擎。
- 大語言模型 (LLM):基礎模型,不斷預測下一個詞。
- 推理模型 (Reasoning model):經過特殊訓練或提示,犧牲更多計算力做中間推理同自我驗證。
- 智能體 (Agent):圍繞模型嘅控制循環,包含工具調用、記憶、環境反饋。
- Agent harness:軟件腳手架,管理上下文、工具、提示詞、狀態。
- Coding harness:專注軟件工程嘅 harness,管理代碼上下文、開發工具、代碼執行同迭代。
六大核心組件:令模型變身編程高手
作者用自己嘅 Mini Coding Agent 做例子,逐一拆解六個組件。佢強調呢啲組件係互相交織,唔係獨立運作。
- 1 即時代碼倉庫上下文:智能體一開始會收集 Git 分支、檔案結構、AGENTS.md 等情報,製作工作區摘要,避免每次盲摸摸。
- 2 提示詞形態與快取複用:將穩定嘅部分(系統指令、工具說明、工作區摘要)組成「穩定前綴」並快取,每次只更新對話記錄同最新需求,大幅節省成本。
- 3 工具接入與調用:模型只能從預先定義嘅白名單工具箱入面揀工具,仲要經過參數驗證、權限審批、路徑限制先至執行得。
- 4 上下文瘦身:透過裁剪(Clipping)超長輸出同對話精簡(將遠期歷史壓縮,近期保留較多細節),防止 token 爆棚。
- 5 結構化會話記憶:硬碟上分為完整記錄(所有歷史)同工作記憶(提純後嘅核心狀態),工作記憶用嚟保持任務連貫性。
- 6 任務委派與受限子智能體:主智能體可以派子任務畀子智能體,但要限制佢哋嘅權限(例如唯讀)同執行深度,防止混亂。
呢六大組件入面,上下文瘦身係最被低估嘅環節
Coding Harness 嘅真正價值:唔係模型,而係系統
作者認為,而家頂級 LLM 嘅基礎能力已經好接近,真正令某個模型「好用」嘅關鍵反而係外圍 Harness。佢大膽猜測:將最新開源模型塞入同一個好嘅 Harness,表現唔會輸畀 Claude Code 或 Codex。
後訓練(Post-training)專門為 Harness 做最佳化仍然有幫助
佢用 OpenClaw 做對比,指出 OpenClaw 係通用智能體平台,重心係同時養住多個長存智能體;而 Coding harness 係專為軟件開發極致優化,集中處理檔案檢查、修改代碼、本地工具執行。
原文:Components of A Coding Agent https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
作者:Sebastian Raschka, 博士
編程智能體點樣喺實踐中用工具、記憶同代碼倉庫上下文,令到大語言模型發揮更大威力
呢篇文章裏面,我想同大家傾嚇編程智能體(Coding Agent)同 Agent harness(智能體 Harness)嘅整體設計。佢哋究竟係乜嘢?點樣運作?喺實際應用入面,各部件又係點樣一齊配合?因為成日有讀者問我關於智能體嘅問題(佢哋大多睇過我寫嘅《由零開始構建大語言模型》同《由零開始構建推理模型》),所以我決定寫呢篇參考指南,方便第時直接分享畀大家。
宏觀嚟講,智能體而家咁流行,係因為近排實用化大語言模型(LLM)嘅進步,唔單止靠模型本身變強,更在於我哋怎麼用佢哋。喺好多真實落地場景入面,模型外圍嘅配套系統——好似工具調用、上下文管理同記憶功能——發揮嘅作用一啲都唔比模型本身細。呢個就解釋咗,點解好似 Claude Code 或 Codex 呢類系統,用起上嚟感覺比喺普通聊天界面直接同佢哋背後嘅模型對話要勁好多。
跟住落嚟,我會為大家梳理編程智能體嘅六大核心模塊。
Claude Code、Codex CLI 同其他編程智能體
大家可能對 Claude Code 或 Codex CLI(CLI 即係命令行界面,一種畀用戶喺終端通過打字輸入指令嚟操作電腦嘅工具)已經好熟。簡單定個調:佢哋本質上都係智能體化嘅編程工具。佢哋將大語言模型包裝喺一個應用層(即係我哋講嘅 Agent harness)入面,從而在處理編程任務時更順手,表現亦更好。
WECHATIMGPH_1
圖 1:Claude Code CLI、Codex CLI,同我自己寫嘅極簡版編程智能體。
編程智能體係專為軟件開發而設。喺呢度,重點唔單止係你揀咗邊個模型,更在於外圍嘅配套系統——包括代碼倉庫嘅上下文(Repo Context)、工具嘅設計、提示詞緩存嘅穩定性、記憶能力,同埋能夠應付長時間連續工作嘅連貫性。
搞清楚呢個分別好重要。因為當我哋講起「大語言模型嘅編程能力」時,大家往往會將「模型本身」、「模型嘅推理行為」同「智能體產品」撈亂。所以喺深入探討編程智能體細節之前,等我花啲時間,簡單梳理嚇大語言模型、推理模型同智能體呢三個廣泛概念之間嘅分別。
釐清關係:大語言模型、推理模型同智能體
大語言模型(LLM) 係核心,本質上佢就係一個不斷預測「下一個詞」嘅模型。推理模型(Reasoning Model) 其實都係 LLM,只不過佢受過特殊訓練或提示詞引導,會喺生成答案時投入更多計算力(即係增加推理時間嘅算力消耗,呢個叫做 test-time compute),用嚟做中間步驟嘅推理、自我驗證,或者喺多個候選答案入面搜索最佳結果。
智能體(Agent) 係冚喺模型上面嘅一層,你可以理解佢係一個圍住模型運轉嘅「控制循環」。通常情況係咁:你畀一個目標,智能體層(或者叫 Harness)就會替模型決定:下一步要檢查啲乜?應該調用邊個工具?點樣更新當前狀態?幾時算係搞掂可以停落嚟?
打個唔係好恰當但好直觀嘅比喻:LLM 就好似一部普通嘅引擎;推理模型係一部經過爆改、馬力更勁嘅引擎(當然,亦更浪費錢);而 Agent harness,就係幫我哋更好咁駕馭呢部引擎嘅整車系統。雖然我哋都可以直接喺聊天界面或 Python 代碼入面單用 LLM 同推理模型,但我希望呢個比喻可以講得清楚佢哋嘅關係。
WECHATIMGPH_2
圖 2:常規大語言模型、推理大語言模型(或推理模型)同包喺 Agent harness 入面嘅大語言模型之間嘅關係。
換句話講,智能體就係一個喺特定環境入面不斷循環調用模型嘅系統。
總結嚇:
• 大語言模型 (LLM): 最原始嘅基礎模型。 • 推理模型 (Reasoning model): 優化過嘅 LLM,專門為咗輸出中間推理過程(即係我哋成日講嘅思維鏈 Chain of Thought)同增強自我驗證能力。 • 智能體 (Agent): 一個包含咗「模型 + 工具 + 記憶 + 環境反饋」嘅循環系統。 • Agent harness (智能體運行框架): 圍住智能體搭建嘅軟件腳手架,負責管理上下文、工具調用、提示詞、狀態同控制流。 • Coding harness (編程運行框架): Agent harness 嘅「特化版」,專門針對軟件工程量身訂做,負責管理代碼上下文、開發工具、代碼執行同迭代反饋。
好似上面列出咗,係討論智能體同編程工具時,我哋成日會碰到呢兩個詞:Agent harness(智能體運行框架) 和 Coding harness(編程運行框架)。Coding harness 係幫模型高效編寫同修改代碼嘅軟件腳手架。而 Agent harness 嘅適用面更廣,唔止限於編程(例如 OpenClaw)。Codex 同 Claude Code 都算係 Coding harness。
總括嚟講:更好嘅 LLM 能夠為推理模型打落更堅實嘅基礎(當然仲需要額外訓練),而優秀嘅 Harness 就能夠將推理模型嘅潛力壓榨到極致。
當然,LLM 同推理模型靠自己(唔用任何 Harness)都可以解決一啲編程問題。但係,真實嘅寫代碼唔淨係「預測下一個詞」。開發工作有好多精力嘥咗喺瀏覽代碼倉庫、搜尋文檔、揾函數、應用代碼差異(Diff)、跑測試、排查報錯,同埋喺個腦入面將所有呢啲資訊串連埋一齊。(程序員朋友肯定深有體會,呢個絕對係極其耗費心神嘅腦力活,呢個亦解釋咗點解大家專注寫代碼時最討厭畀人打斷 :))。
WECHATIMGPH_3
圖 3:一個 Coding harness 融合咗三層結構:模型家族、智能體循環同運行時支撐。模型提供咗「引擎」,智能體循環驅動迭代式嘅解題過程,而運行時支撐就提供咗必要嘅基礎管道。喺呢個循環入面,「觀察」負責由環境收集情報,「審查」負責分析呢啲情報,「選擇」決定下一步點樣行,「執行」就負責落地行動。
呢度嘅核心要點係:一個優秀嘅 Coding harness,能夠令模型(無論係咪推理模型)用起上嚟覺得比喺簡陋嘅聊天框入面強大無數倍,因為佢幫你將上下文管理等污糟嘢全部搞掂曬。
Coding harness:模型嘅超級外掛
好似啱啱提到咁,當我哋講「Harness(運行框架)」時,通常係指包喺模型外面嘅一層軟件。佢簡直係個全能管家,負責拼接提示詞、提供工具、追蹤檔案狀態、修改代碼、執行指令、管理權限、緩存啲唔變嘅提示詞前綴,仲要負責儲存記憶等等。
而家,當你用大模型時,你嘅絕大部分體驗,都係由呢一層 Harness 決定。呢個同直接去提示(Prompt)模型,或者用普通嘅網頁聊天界面(嗰種似係「上載個檔案然後同佢尬聊」)有天淵之別。
我認為,而家嘅原味基礎版大模型(例如 GPT-5.4、Opus 4.6 同 GLM-5 嘅基礎版),佢哋嘅能力其實已經好接近。喺呢個階段,真正拉開差距、令某個模型顯得更實用嘅決定性因素,往往就係呢個外圍 Harness。
呢度我大膽估嚇:如果我哋將最新、最強嘅開源模型(例如 GLM-5)塞入一個同樣優秀嘅 Harness 入面,佢嘅表現好可能同 Codex 裏面嘅 GPT-5.4 或者 Claude Code 入面嘅 Claude Opus 4.6 不相伯仲。話雖如此,專門為咗配合 Harness 做一啲後訓練(Post-training)肯定仲有好處。例如,OpenAI 以前會專門維護 GPT-5.3 同專門寫代碼嘅 GPT-5.3-Codex 兩個唔同版本。
喺下一節,我會用我手搓嘅一個開源項目「迷你編程智能體(Mini Coding Agent)」做例子,帶大家深入瞭解 Coding harness 嘅具體細節同核心組件。項目網址:https://github.com/rasbt/mini-coding-agent。
WECHATIMGPH_4
圖 4:將會喺後續章節探討嘅編程智能體/Coding harness 嘅核心功能模塊。
順便提一句,為咗閲讀流暢,本文入面我會交替使用「編程智能體」同「Coding harness」呢兩個詞。(嚴格嚟講,智能體係由模型驅動嘅決策循環,而 Harness 係提供上下文、工具同執行環境嘅外圍軟件腳手架。)
WECHATIMGPH_5
圖 5:極簡但五臟俱全、純手工打造嘅 Mini Coding Agent(純 Python 實現)。
廢話少講,下面就係編程智能體嘅六大核心組件。如果你想睇具體嘅代碼實現,可以過去睇我用純 Python 由頭寫嘅 Mini Coding Agent[1]。代碼入面亦用註釋標咗呢六大組件:
##############################
#### 六大智能體組件 ####
##############################
# 1) 實時代碼倉庫上下文 -> WorkspaceContext
# 2) 提示詞形態與緩存複用 -> build_prefix, memory_text, prompt
# 3) 結構化工具、驗證與權限 -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
# 4) 上下文瘦身與輸出管理 -> clip, history_text
# 5) 完整對話記錄、記憶與恢復 -> SessionStore, record, note_tool, ask, reset
# 6) 任務委派與受限子智能體 -> tool_delegate1. 實時代碼倉庫上下文 (Live Repo Context)
呢個可能係最顯而易見嘅一個組件,但都絕對係最關鍵之一。
當用戶下達命令「將測試代碼改返好」或者「實現 xyz 功能」時,模型唔可以兩眼一抹黑。佢要知道自己係咪喺一個 Git 代碼庫入面、而家喺邊個分支、項目嘅邊啲文檔可能藏住開發規範等等。
點解呢?因為呢啲細節直接決定咗模型應該採取咩行動。「改測試」呢句話本身資訊量係唔夠嘅。如果智能體睇到 AGENTS.md 或者項目嘅 README 檔案,佢就能夠學到應該行邊條具體嘅測試指令。如果佢瞭解代碼庫嘅根目錄同檔案結構,佢就可以有目標咁去啱嘅地方揾代碼,而唔係亂估。
另外,Git 嘅分支、狀態同提交記錄(Commits)都能夠提供豐富嘅背景資訊,話畀模型知道而家做緊啲咩修改、重點應該擺喺邊度。
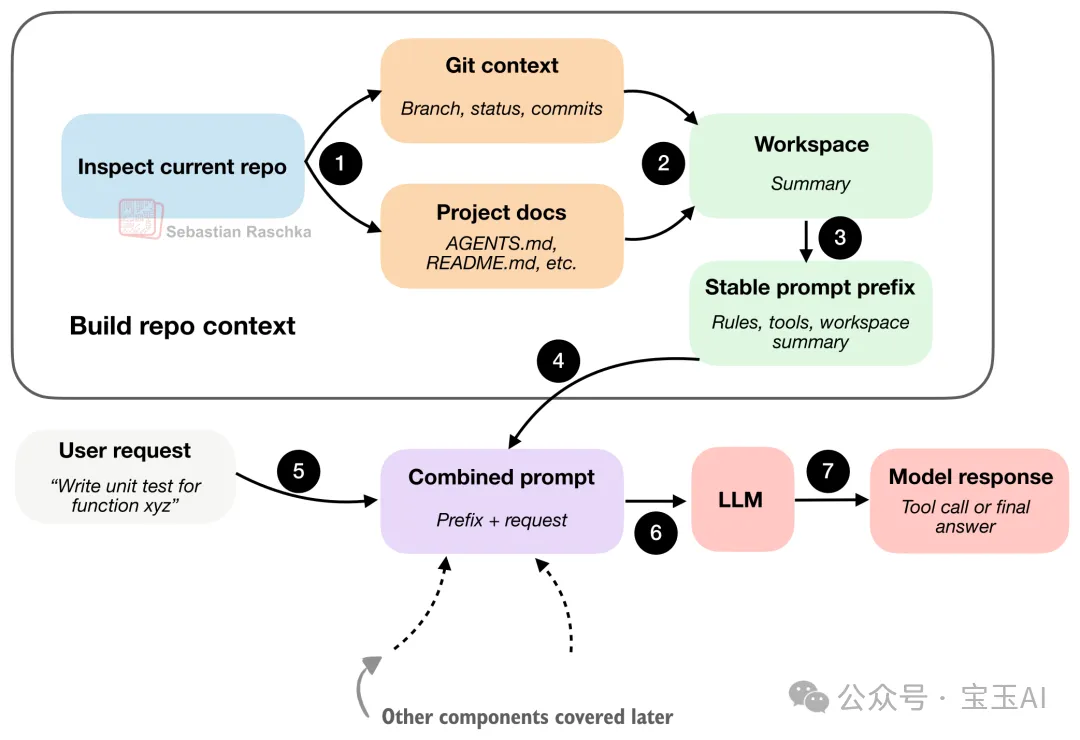
圖 6:Coding harness 首先會生成一份簡短嘅工作區摘要,並將佢同用戶嘅請求合併,從而為模型提供更多嘅項目上下文。
所以呢度嘅精髓在於:喺動手幹活之前,編程智能體會先去收集情報(將呢啲「穩定嘅事實」打包成一份工作區摘要)。咁樣一嚟,喺面對你每一次嘅提示時,佢都唔係喺冇任何上下文嘅「零基礎」狀態下盲目啟動。
2. 提示詞形態與緩存複用 (Prompt Shape And Cache Reuse)
智能體摸清咗代碼庫嘅底細之後,下一個問題就嚟:點樣將呢啲資訊餵畀模型?上一節嘅示意圖畀咗一個極之簡化嘅講法(「合併提示詞:前綴 + 請求」)。但係喺實作中,如果每一次用戶提問,都要將一大疊工作區摘要重新拼湊、叫模型重新睇一次,咁絕對係巨大嘅算力浪費。
寫代碼係一個反反覆覆嘅過程。喺呢個過程中,智能體嘅行為準則通常係唔變嘅,工具嘅說明書係唔變嘅,甚至連工作區摘要喺大部分時間都係基本唔變。真正成日變嘅係乜?係你最新發出嘅指令、啱啱產生嘅對話記錄,同一啲短期記憶。
一個「聰明」嘅 Harness,絕對唔會喺每一輪對話時,都將所有嘢揉成一團巨大嘅提示詞重新掟畀模型。呢個就如下圖所示:
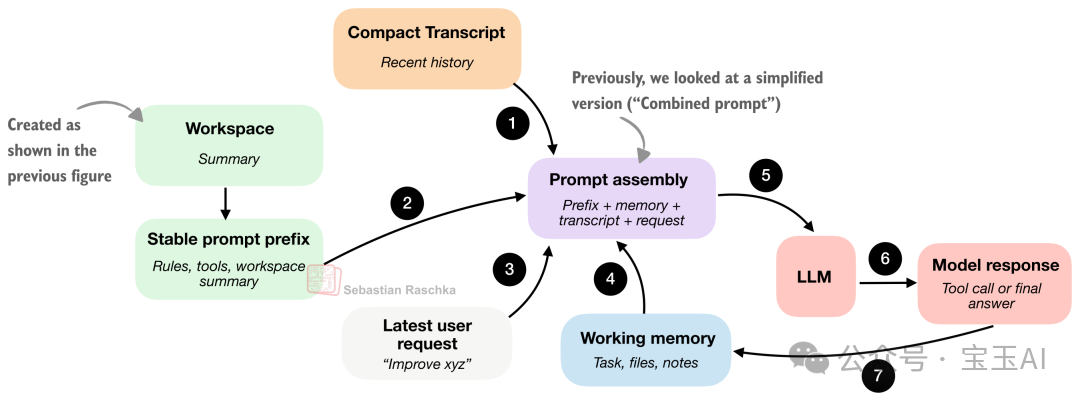
圖 7:Coding harness 會構建一個穩定嘅提示詞前綴,拼上不斷變化嘅會話狀態,然後將呢份合併咗嘅提示詞餵畀模型。
同第 1 節唔同:第 1 節講嘅係點樣收集代碼庫嘅情報;而呢一節關注嘅係,點樣將呢啲情報高效咁打包同緩存起嚟,方便模型喺無數次調用中反覆使用。
所謂嘅「穩定嘅提示詞前綴」,意思係呢度嘅資訊變動極細。佢通常包含咗通用嘅系統指令、工具嘅說明同工作區摘要。只要冇發生傷筋動骨嘅變化,我哋就唔會浪費算力去每次由頭重建呢部分內容(而家主流水嘅大模型 API 都支援咗 Prompt Cache,即係提示詞緩存機制,可以大幅慳錢同提升回應速度)。
)那些需要成日更新嘅組件(通常每輪對話都要變),就包括短期記憶、近期嘅對話記錄,同用戶最新嘅需求。
簡而言之,聰明嘅 Harness 會盡可能將「穩定嘅提示詞前綴」緩存起嚟重複利用。
3. 工具嘅接入與調用 (Tool Access and Use)
一旦去到工具嘅接入同調用,呢個就開始脱離「單純傾偈」嘅範疇,真正有咗「智能體」嘅味道。
普通模型只能用文字大大段咁建議你「應該點樣做」;但係裝喺 Coding harness 入面嘅 LLM,動作要精準、實用得多。佢能夠實實在在咁去執行指令,並自己將運行結果攞返嚟分析(唔使我哋手動複製指令去終端跑,然後再將報錯資訊貼返入聊天框)。
不過,Harness 唔會任由模型放飛自我亂寫一通。通常,Harness 會提供一份預先定義好嘅「白名單工具箱」,每個工具都有名、明確嘅輸入要求同嚴格嘅邊界。(當然,你都可以將類似 Python 嘅 subprocess.call 塞入工具箱,咁樣智能體就能夠執行極之廣泛嘅終端指令。)
工具調用嘅完整流程如下:
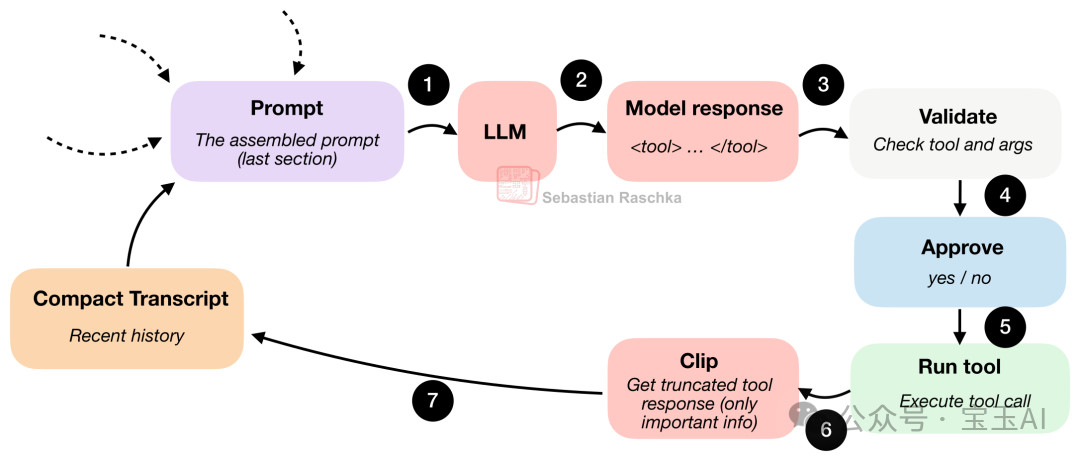
圖 8:模型輸出一個結構化嘅動作,Harness 對佢進行驗證(有需要嘅話仲會請求人工批准),然後執行該動作,最後將受控嘅執行結果傳返畀循環系統。
為咗更直觀,我用我嘅 Mini Coding Agent 行咗個例子畀大家睇。喺用戶視角下,佢係咁樣嘅。(介面雖然冇 Claude Code 或 Codex 咁靚,畢竟佢係用純 Python 寫嘅極簡版本,冇任何外部依賴。)
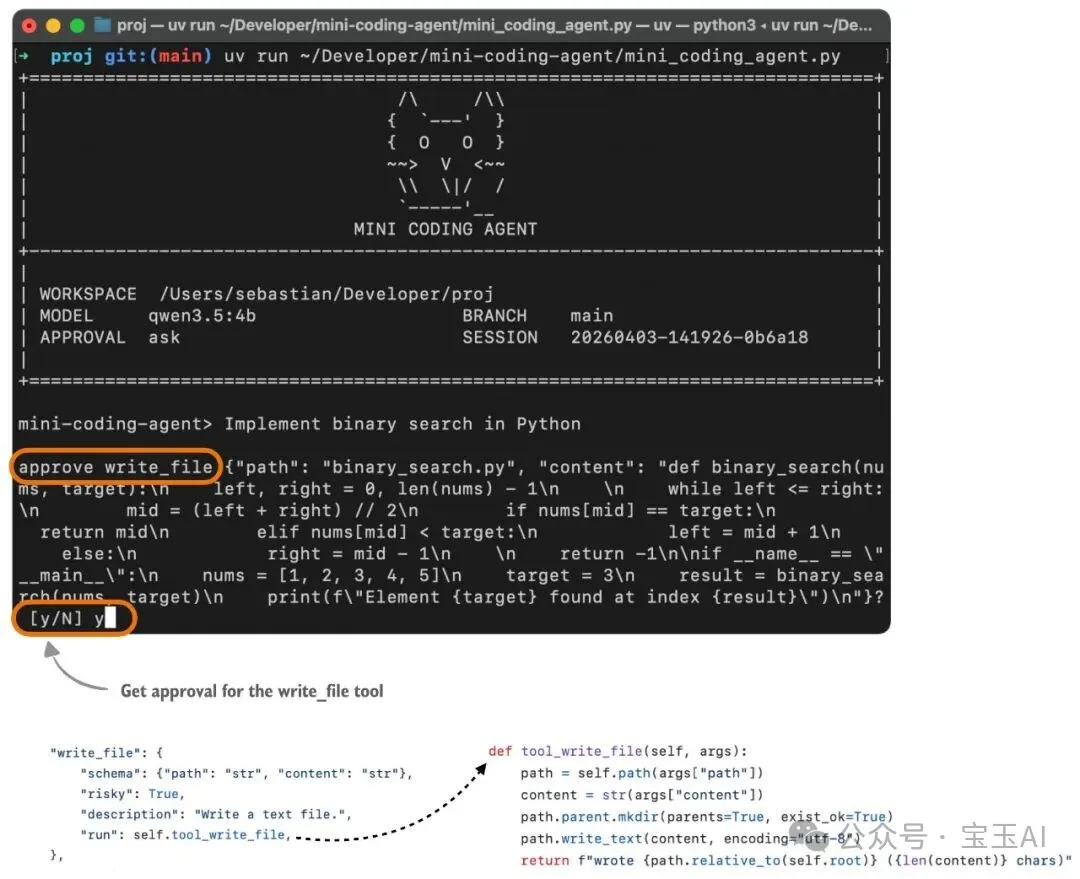
圖 9:Mini Coding Agent 彈出工具調用審批請求嘅介面示例。
喺呢個環節,模型必須由 Harness 認識嘅動作入面揀一個,例如:列出目錄檔案、讀取檔案、全局搜尋、執行 Shell 指令、寫入檔案等。同時,佢提供參數嘅格式都要規規矩矩,方便 Harness 進行攔截校驗。
所以,每當模型嘗試動手做啲嘢時,運行環境就可以即刻按暫停,並通過代碼進行「安檢」:
• 「呢個係一個已知嘅工具嗎?」 • 「參數合法嗎?」 • 「呢個高危操作需要用戶手動批准嗎?」 • 「你要訪問嘅檔案路徑,超出咗當前代碼倉庫嘅範圍嗎?」
只有呢啲安檢全部綠燈,指令先會真正被執行。雖說讓智能體自己行代碼肯定有風險,但正正因為有咗 Harness 嘅重重把關,確保模型唔會亂行高危指令,成個系統嘅可靠性先得以大幅提升。
另外,除咗攔截格式錯誤嘅動作同引入人工審批,Harness 仲可以通過卡死檔案路徑,將模型嘅操作死死限制喺代碼倉庫嘅範圍內。從某種意義上講,Harness 的確剝奪咗模型嘅一部分「自由」,但咁樣亦換嚟咗極大嘅安全性同實用性。
4. 幫上下文減肥,防止爆煲 (Minimizing Context Bloat)
「上下文膨脹(Context Bloat)」唔係編程智能體獨有嘅煩惱,佢係所有大模型共同嘅痛點。的確,而家嘅 LLM 支援嘅上下文越來越長(我最近先寫過一篇關於注意力機制變體點樣降低計算成本嘅文),但係長上下文依然好嘥錢,而且如果入面混咗大量無關資訊,仲會畀模型帶嚟嚴重嘅噪音幹擾。
喺多輪對話中,編程智能體比普通嘅 LLM 聊天更容易「食滯」。因為佢哋會成日讀取檔案,而工具輸出同日誌資訊往往又長又臭。
如果 Harness 老老實實咁將所有細節一字不漏咁保存落嚟,可用嘅 Token 額度瞬間就會被榨乾。因此,一個優秀嘅 Coding harness,喺處理上下文減肥呢方面通常好硬核,絕對唔係好似普通聊天軟件咁簡單粗暴咁裁剪或總結一下就搞掂。
概念上,編程智能體嘅上下文壓縮機制可以總結為下圖。簡單嚟講,呢個係對上一節圖 8 中「裁剪(clip,步驟 6)」環節嘅放大特寫。
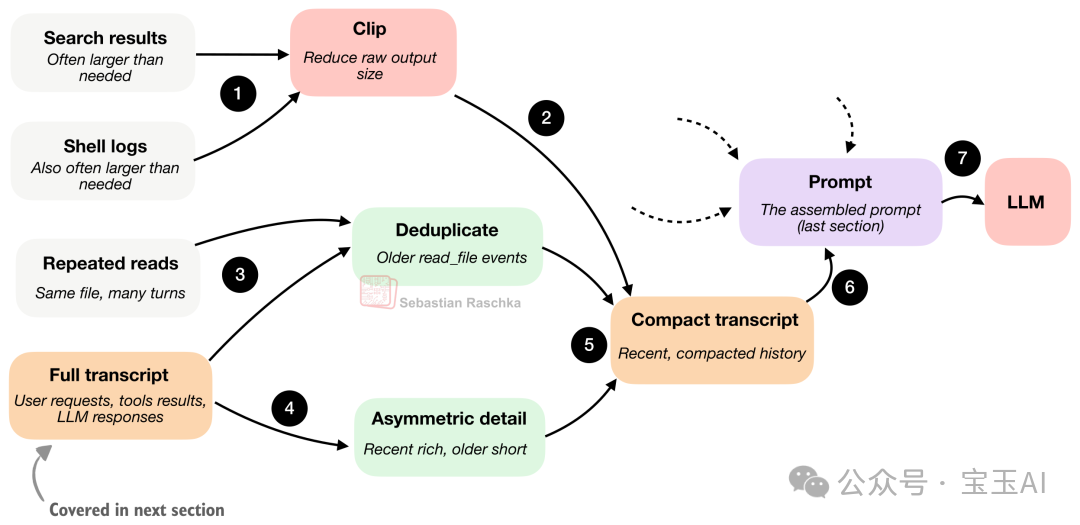
圖 10:超長嘅輸出會被暴力裁剪,早期讀取嘅重複檔案會被剔除,而完整嘅對話記錄喺重新塞入提示詞之前會被大幅壓縮。
一個合格嘅極簡 Harness,至少會用兩招嚟對付呢個問題。
第一招係裁剪(Clipping)。面對長篇大論嘅文檔片段、海量嘅工具輸出日誌、備忘錄同長對話,佢會唔客氣咁截斷。換句話講,絕對唔可以畀某段廢話因為「碰巧比較長」,就霸佔咗成個提示詞嘅預算。
第二招係對話記錄精簡或總結(Transcript reduction/summarization)。佢會將完整嘅歷史記錄(下一節會詳細講)提煉成一份輕量級嘅、方便放入提示詞嘅摘要。
呢度嘅核心秘訣係:越近期嘅事,保留嘅細節越多,因為佢哋往往對當刻嘅決策最關鍵;越耐之前嘅事,壓縮得越犀利,因為佢哋嘅參考價值已經冇咁大。
此外,我哋仲要對早期讀取嘅檔案做去重處理。唔可以因為智能體喺幾輪對話前反覆睇過某個檔案,就令到模型一遍又一遍咁喺上下文入面睇到同樣嘅檔案內容。
總括嚟講,我認為呢部分係優秀嘅編程智能體設計中,最被低估、亦最枯燥嘅環節。我哋平時讚嘅所謂「呢個模型真聰明」,好大程度上其實歸功於「呢個系統餵畀佢嘅上下文質量真高」。
5. 結構化嘅會話記憶 (Structured Session Memory)
喺實作中,本文提到嘅呢 6 個核心概念係緊密交織喺一齊嘅,唔同章節同配圖只係側重點同放大倍數唔同。喺上一節,我哋探討咗喺「構建提示詞時」點樣利用歷史記錄,同埋點樣打造精簡版對話。嗰一節嘅核心問題係:喺下一輪對話中,應該將幾多歷史包袱塞返畀模型?所以重點在於壓縮、裁剪、去重同近期優先。
而而家呢一節「結構化嘅會話記憶」,講嘅係喺「硬盤儲存時」歷史記錄應該係點樣。呢度嘅核心問題變咗:智能體應該長期保存邊啲數據作為永久檔案?呢度嘅重點係:運行環境唔單止要保存一份鉅細無遺嘅「完整對話記錄」作為持久狀態,仲要維護一個更輕量級嘅「記憶層」。呢個記憶層好細,而且佢係不斷被修改同提煉嘅,而唔係好似流水賬咁一味只增不減。
總結嚇,編程智能體會將狀態(至少)分為兩層:
• 工作記憶(Working memory): 細細粒但純粹,係智能體刻意分開維護嘅核心狀態。 • 完整記錄(Full transcript): 涵蓋咗用戶嘅所有請求、所有工具嘅輸出日誌,同 LLM 嘅每一次回答。
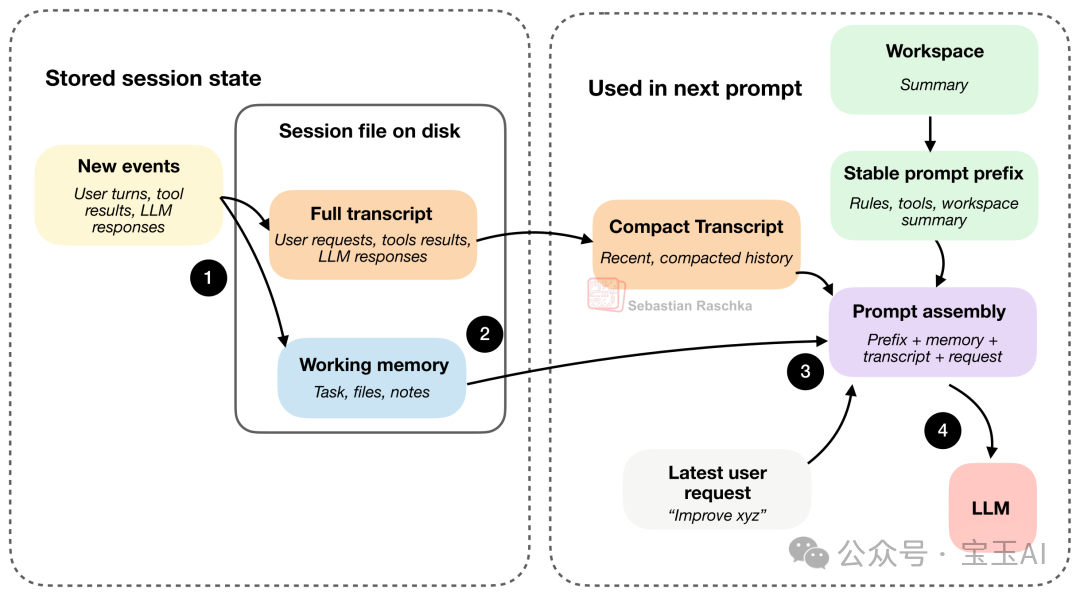
圖 11:產生嘅新事件會被追加到完整記錄中,同時其核心資訊會被總結入工作記憶入面。硬盤上保存嘅會話檔案通常係 JSON 格式。
上圖展示咗呢兩個主要嘅會話檔案,佢哋通常以 JSON 格式擺喺你嘅硬盤入面。如前所述,完整記錄保存咗事無大小嘅所有歷史,就算你熄咗智能體,下次開返依然能夠無縫恢復。而工作記憶就係提純後嘅精華,只留當下最重要嘅資訊(呢個同前面提到嘅「精簡版對話」有啲似)。
但係,「精簡版對話」同「工作記憶」分工仲有微妙嘅分別。精簡版對話係為咗重組提示詞服務,佢嘅任務係畀模型一個近期歷史嘅壓縮包,令佢唔使睇曬整部《資治通鑑》都繼續傾得落去。而工作記憶係為咗保持任務連貫性服務。佢嘅任務係喺多輪對話中,手動維護一個包含核心關鍵點嘅小備忘錄——例如而家首要任務係乜、邊啲檔案最重要、啱啱做過嘅關鍵筆記等。
順住上圖嘅第 4 步睇落去,最新嘅用戶請求、LLM 嘅回覆同工具嘅輸出,會喺下一回合作為「新事件」同時記錄到完整記錄同工作記憶中(為咗唔畀張圖顯得太亂,呢一步喺圖入面省略咗)。
6. 任務委派與受限子智能體 (Delegation With (Bounded) Subagents)
當智能體裝備咗工具,又有咗記憶狀態,接下來最順理成章嘅高階能力就係:搖人(任務委派)。
點解需要呢個?因為佢可以將某啲污糟嘢拆成子任務,分畀「細佬(子智能體)」去並行處理,從而大幅加快主線任務嘅進度。舉個例,主智能體正做緊大嘢,突然需要查個資料:呢個變數係喺邊個檔案入面定義?設定檔入面寫咗乜?或者呢個測試點解會死?呢個時候,將呢啲偏離主線嘅疑問抽離出嚟,交畀一個有明確邊界嘅子任務去查,一定比逼住主智能體一個腦同時處理所有線索要高效得多。
(喺我嘅 Mini Coding Agent 入面,實現方式比較簡陋,細佬仲係同步串行做嘢,但背後嘅核心思想係一脈相承嘅。)
不過,要令子智能體做出成績,就要畀佢繼承足夠嘅上下文。但麻煩在於,如果唔加以限制,你好快就會見到一羣智能體喺入面無序繁殖:佢哋重複做同一件事、爭住改同一個檔案,甚至子智能體又生出孫子智能體,直接亂曬龍。
所以,呢度最考驗設計嘅難點,唔單止係點樣「生」出一個子智能體,更加在於點樣畀佢套上「緊箍咒」 :)。
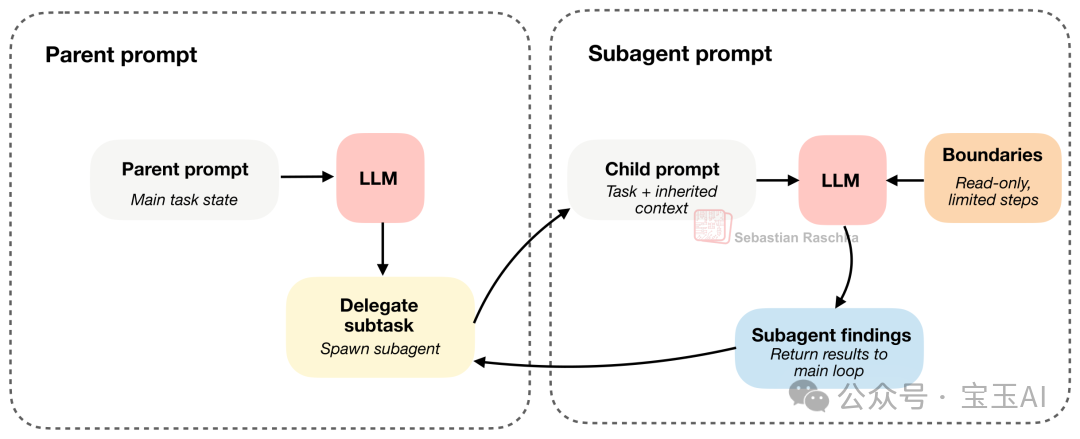
圖 12:子智能體繼承咗足以幹活嘅上下文,但佢嘅運行邊界比主智能體要嚴格得多。
呢度嘅精妙之處在於:子智能體既要繼承足夠嘅上下文以便幹活,又必須受到嚴格嘅約束(例如:唯讀可以訪問檔案,絕對唔準亂改代碼;同埋限制佢再嗌人嘅深度,防止無限遞歸)。
Claude Code 好早就支援子智能體,Codex 最近都補返呢個功能。有趣嘅係,Codex 通常唔會一刀切咁強迫子智能體進入「唯讀模式」。相反,佢哋一般會繼承主智能體嘅沙箱環境同審批權限。所以,Codex 畀細佬畫嘅圈,更多係限制喺任務範圍、上下文大小同執行深度上。
組件總結
上面嘅內容盡量涵蓋咗編程智能體嘅所有核心組件。好似之前講咁,喺真實嘅代碼實現入面,佢哋其實係盤根錯節、深度交織嘅。不過,我都希望透過呢種抽絲剝繭嘅拆解,能夠幫你建立起一個全面嘅心智模型:深刻理解 Coding harness 到底係點樣運作,同埋點解有咗佢,大語言模型會比以前嗰個乾巴巴嘅多輪聊天機械人好用無數倍。
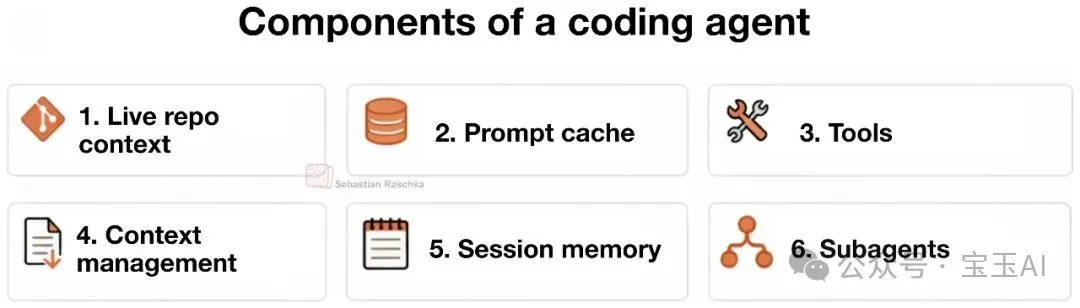
圖 13:前面各節討論嘅 Coding harness 嘅六大核心功能。
如果你手痕想睇用極之乾淨、極簡嘅 Python 代碼係點樣實現呢啲概念,強烈建議去睇嚇我嘅 Mini Coding Agent[2]。
佢同 OpenClaw 比有咩分別?
用 OpenClaw 嚟做對比幾有趣,但佢哋其實唔係同一類型嘅系統。
OpenClaw 更加似一個本地運行嘅通用智能體平台(只係啱啱好佢都能夠寫代碼),而唔係一個好似我哋喺終端入面專用嘅純血編程助手。
當然,佢同我哋討論嘅 Coding harness 仲有唔少重合點:
• 佢都會利用工作區入面嘅提示詞同指令檔案,例如 AGENTS.md、SOUL.md和TOOLS.md。• 佢都用 JSONL 格式保存會話檔案,同樣支援對話記錄壓縮同會話管理。 • 佢都能夠叫細佬(建立助手會話同子智能體)。 • 諸如此類。
但係,如前所述,兩者嘅重心截然不同。編程智能體係專為伏喺代碼庫入面做嘢嘅人而極致優化,佢唯一嘅追求就係高效咁幫你檢查檔案、修改代碼、喺本地行工具。而 OpenClaw 優化嘅方向係:喺多個聊天框、頻道同工作區入面,同一時間養住一羣長期生存嘅本地智能體——對 OpenClaw 嚟講,寫代碼只係呢羣智能體嘅眾多日常打卡工作之一。
順便同大家分享一個好消息:我嘅新書《由零開始構建推理模型》(Build A Reasoning Model (From Scratch))終於寫完啦!所有章節目前都開放咗搶先體驗(Early access)。出版社正努力排版,預計今年夏天就會正式上市。
呢本可能係我至今為止野心最大嘅一本書。我足足熬咗 1.5 年,喺入面塞咗無數嘅實驗。無論係投入嘅時間、精力定係打磨嘅程度,呢個都係我傾注最多心血嘅作品,真心希望大家會鍾意。
喺 Manning 同亞馬遜可以揾到《由零開始構建推理模型》。
本書嘅核心乾貨包括:
• 評估推理模型 • 推理時算力擴展(Inference-time scaling) • 自我反思與優化(Self-refinement) • 強化學習(Reinforcement learning) • 模型蒸餾(Distillation)
而家成個圈都熱炒 LLM 嘅「推理(Reasoning)」能力。而我認為,要真正搞明 LLM 語境下嘅「推理」究竟係乜,最硬核、最透徹嘅方法就係——由零開始,親手寫代碼搓一個出嚟!
• Amazon 亞馬遜[3] (可預購) • Manning 出版社[4] (搶先體驗版已包含完整內容,排版正在收尾,共 528 頁)
來源:https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
引用連結
[1] Mini Coding Agent: https://github.com/rasbt/mini-coding-agent/blob/main/mini_coding_agent.py[2] Mini Coding Agent: https://github.com/rasbt/mini-coding-agent[3] Amazon 亞馬遜: https://amzn.to/4aAKiFY[4] Manning 出版社: https://mng.bz/Nwr7
原文:Components of A Coding Agent https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
作者:Sebastian Raschka, 博士
編程智能體如何在實踐中利用工具、記憶和代碼倉庫上下文,讓大語言模型發揮更大威力
在這篇文章裏,我想和大家聊聊編程智能體(Coding Agent)和 Agent harness(智能體 Harness)的整體設計。它們到底是什麼?怎麼工作的?在實際應用中,各個部件又是如何協同配合的?因為經常有讀者問我關於智能體的問題(他們大多讀過我寫的《從零構建大語言模型》和《從零構建推理模型》),所以我決定寫這篇參考指南,方便以後直接分享給大家。
往大了說,智能體現在之所以這麼火,是因為最近實用化大語言模型(LLM)的進步,不僅僅靠模型本身變強,更在於我們怎麼用它們。在很多真實的落地場景裏,模型外圍的配套系統——比如工具調用、上下文管理和記憶功能——發揮的作用一點都不比模型本身小。這就解釋了,為什麼像 Claude Code 或 Codex 這樣的系統,用起來感覺比你在普通聊天界面裏直接跟它們背後的模型對話要強得多。
接下來,我將為大家梳理編程智能體的六大核心模塊。
Claude Code、Codex CLI 與其他編程智能體
大家可能對 Claude Code 或 Codex CLI(CLI 即命令行界面,一種讓用戶在終端中通過敲代碼輸入指令來操作計算機的工具)已經很熟悉了。簡單定個基調:它們本質上都是智能體化的編程工具。它們把大語言模型包裹在一個應用層(也就是我們說的 Agent harness)裏,從而在處理編程任務時更加順手,表現也更好。
WECHATIMGPH_1
圖 1:Claude Code CLI、Codex CLI,以及我自己寫的極簡版編程智能體。
編程智能體是專門為軟件開發打造的。在這裏,重頭戲可不僅僅是你選了哪個模型,更在於外圍的配套系統——包括代碼倉庫的上下文(Repo Context)、工具的設計、提示詞緩存的穩定性、記憶能力,以及能夠應對長時間連續工作的連貫性。
弄清楚這個區別很重要。因為當我們聊起“大語言模型的編程能力”時,大家往往會把“模型本身”、“模型的推理行為”和“智能體產品”混為一談。所以在深入探討編程智能體細節之前,讓我先花點時間,簡單梳理一下大語言模型、推理模型和智能體這三個寬泛概念之間的區別。
釐清關係:大語言模型、推理模型與智能體
大語言模型(LLM) 是核心,本質上它就是一個不斷預測“下一個詞”的模型。推理模型(Reasoning Model) 其實也是 LLM,只不過它經過了特殊的訓練或提示詞引導,會在生成答案時投入更多的計算力(即增加推理時間的算力消耗,這被稱為 test-time compute),用來做中間步驟的推理、自我驗證,或者在多個候選答案中搜索最佳結果。
智能體(Agent) 則是蓋在模型上面的一層,你可以把它理解為一個圍繞模型運轉的“控制循環”。通常情況是這樣的:你給出一個目標,智能體層(或者說 Harness)就會替模型做決定:接下來要檢查什麼?該調用哪個工具?怎麼更新當前的狀態?什麼時候算是大功告成可以停下來?
打個不太恰當但很直觀的比方:LLM 就像是一台普通的發動機;推理模型是一台經過爆改、馬力更強勁的發動機(當然,也更費錢);而 Agent harness,則是幫助我們更好地駕馭這台發動機的整車系統。雖然我們也可以直接在聊天界面或 Python 代碼裏單拎出 LLM 和推理模型來用,但我希望這個比喻能把它們的關係說明白。
WECHATIMGPH_2
圖 2:常規大語言模型、推理大語言模型(或推理模型)與包裹在 Agent harness 中的大語言模型之間的關係。
換句話說,智能體就是一個在特定環境裏不斷循環調用模型的系統。
總結一下:
• 大語言模型 (LLM): 最原始的基礎模型。 • 推理模型 (Reasoning model): 優化過的 LLM,專門為了輸出中間推理過程(也就是我們常說的思維鏈 Chain of Thought)和增強自我驗證能力。 • 智能體 (Agent): 一個包含了“模型 + 工具 + 記憶 + 環境反饋”的循環系統。 • Agent harness (智能體運行框架): 圍繞智能體搭建的軟件腳手架,負責管理上下文、工具調用、提示詞、狀態和控制流。 • Coding harness (編程運行框架): Agent harness 的“特化版”,專門針對軟件工程量身定製,負責管理代碼上下文、開發工具、代碼執行和迭代反饋。
就像上面列出的,在討論智能體和編程工具時,我們常會碰到這兩個詞:Agent harness(智能體運行框架) 和 Coding harness(編程運行框架)。Coding harness 是幫助模型高效編寫和修改代碼的軟件腳手架。而 Agent harness 的適用面更廣,不僅限於編程(比如 OpenClaw)。Codex 和 Claude Code 都可以算作 Coding harness。
總而言之:更好的 LLM 能為推理模型打下更堅實的基礎(當然還需要額外的訓練),而優秀的 Harness 則能把推理模型的潛力壓榨到極致。
當然,LLM 和推理模型光靠自己(不用任何 Harness)也能解決一些編程問題。但是,真實的寫代碼可不僅僅是“預測下一個詞”。開發工作中有很大一部分精力耗費在瀏覽代碼倉庫、搜索文檔、查找函數、應用代碼差異(Diff)、跑測試、排查報錯,以及在腦子裏把所有這些信息串聯起來。(程序員朋友們肯定深有體會,這絕對是個極其耗費心神的腦力活,這也是為什麼大家在專注敲代碼時最討厭被打斷 :))。
WECHATIMGPH_3
圖 3:一個 Coding harness 融合了三層結構:模型家族、智能體循環以及運行時支撐。模型提供了“發動機”,智能體循環驅動迭代式的解題過程,而運行時支撐則提供了必要的基礎管道。在這個循環裏,“觀察”負責從環境收集情報,“審查”負責分析這些情報,“選擇”決定下一步該怎麼走,“執行”則負責落地行動。
這裏的核心要點是:一個優秀的 Coding harness,能讓模型(無論是不是推理模型)用起來感覺比在簡陋的聊天框裏強大無數倍,因為它幫你把上下文管理等髒活累活全乾了。
Coding harness:模型的超級外掛
就像剛才提到的,當我們說“Harness(運行框架)”時,通常指的是包裹在模型外面的那一層軟件。它簡直是個全能管家,負責拼接提示詞、提供工具、追蹤文件狀態、修改代碼、執行命令、管理權限、緩存那些不變的提示詞前綴,還要負責存儲記憶等等。
今天,當你使用大模型時,你的絕大部分體驗,都是由這一層 Harness 決定的。這跟直接去提示(Prompt)模型,或者用普通的網頁聊天界面(那種更像是“上傳個文件然後跟它尬聊”)有着天壤之別。
在我看來,現在的原味基礎版大模型(比如 GPT-5.4、Opus 4.6 和 GLM-5 的基礎版),它們的能力其實已經非常接近了。在這個階段,真正拉開差距、讓某個模型顯得更好用的決定性因素,往往就是這個外圍 Harness。
這裏我大膽猜測一下:如果我們把最新、最強的開源模型(比如 GLM-5)塞進一個同樣優秀的 Harness 裏,它的表現很可能跟 Codex 裏的 GPT-5.4 或者 Claude Code 裏的 Claude Opus 4.6 不相上下。話雖如此,專門為了適配 Harness 做一些後訓練(Post-training)肯定還是有好處的。比如,OpenAI 過去就會專門維護 GPT-5.3 和專門寫代碼的 GPT-5.3-Codex 兩個不同的版本。
在下一節,我將用我手搓的一個開源項目“迷你編程智能體(Mini Coding Agent)”為例,帶大家深入瞭解 Coding harness 的具體細節和核心組件。項目地址:https://github.com/rasbt/mini-coding-agent。
WECHATIMGPH_4
圖 4:將在後續章節中探討的編程智能體/Coding harness 的核心功能模塊。
順便提一句,為了閲讀流暢,本文中我會交替使用“編程智能體”和“Coding harness”這兩個詞。(嚴格來說,智能體是由模型驅動的決策循環,而 Harness 是提供上下文、工具和執行環境的外圍軟件腳手架。)
WECHATIMGPH_5
圖 5:極簡但五臟俱全、純手工打造的 Mini Coding Agent(純 Python 實現)。
廢話不多說,下面就是編程智能體的六大核心組件。如果你想看具體的代碼實現,可以去翻翻我用純 Python 從頭編寫的 Mini Coding Agent[1]。代碼裏也用註釋標出了這六大組件:
##############################
#### 六大智能體組件 ####
##############################
# 1) 實時代碼倉庫上下文 -> WorkspaceContext
# 2) 提示詞形態與緩存複用 -> build_prefix, memory_text, prompt
# 3) 結構化工具、驗證與權限 -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
# 4) 上下文瘦身與輸出管理 -> clip, history_text
# 5) 完整對話記錄、記憶與恢復 -> SessionStore, record, note_tool, ask, reset
# 6) 任務委派與受限子智能體 -> tool_delegate1. 實時代碼倉庫上下文 (Live Repo Context)
這可能是最顯而易見的一個組件,但也絕對是最關鍵的之一。
當用戶下達命令“把測試代碼修一下”或者“實現 xyz 功能”時,模型不能兩眼一抹黑。它得知道自己是不是在一個 Git 代碼庫裏、當前在哪個分支上、項目的哪些文檔裏可能藏着開發規範等等。
為什麼呢?因為這些細節直接決定了模型該採取什麼行動。“修測試”這句話本身信息量是不夠的。如果智能體能看到 AGENTS.md 或者項目的 README 文件,它就能學到該運行哪條具體的測試命令。如果它瞭解代碼庫的根目錄和文件結構,它就能有的放矢地去對的地方找代碼,而不是瞎猜。
另外,Git 的分支、狀態和提交記錄(Commits)也能提供豐富的背景信息,告訴模型當前正在做哪些修改、重點應該放在哪裏。
圖 6:Coding harness 首先會生成一份簡短的工作區摘要,並將其與用戶的請求合併,從而為模型提供更多的項目上下文。
所以這裏的精髓在於:在動手幹活之前,編程智能體會先去收集情報(把這些“穩定的事實”打包成一份工作區摘要)。這樣一來,在面對你的每一次提示時,它都不是在沒有任何上下文的“零基礎”狀態下盲目啓動。
2. 提示詞形態與緩存複用 (Prompt Shape And Cache Reuse)
智能體摸清了代碼庫的底細後,下一個問題來了:怎麼把這些信息餵給模型?上一節的示意圖給了一個極其簡化的說法(“合併提示詞:前綴 + 請求”)。但在實操中,如果每一次用戶提問,都要把一大坨工作區摘要重新拼湊、讓模型重新閲讀一遍,那絕對是巨大的算力浪費。
寫代碼是一個反覆拉扯的過程。在這個過程中,智能體的行為準則通常是不變的,工具的說明書是不變的,甚至連工作區摘要在大部分時間裏也是基本不變的。真正頻繁變動的是什麼?是你最新發出的指令、剛剛產生的對話記錄,以及一些短期記憶。
一個“聰明”的 Harness,絕對不會在每一輪對話時,都把所有東西揉成一團巨大的提示詞重新扔給模型。這就如下圖所示:
圖 7:Coding harness 會構建一個穩定的提示詞前綴,拼上不斷變化的會話狀態,然後把這份合併後的提示詞餵給模型。
和第 1 節不同:第 1 節講的是如何收集代碼庫的情報;而這一節關注的是,如何把這些情報高效地打包和緩存起來,方便模型在無數次調用中反覆使用。
所謂的“穩定的提示詞前綴”,意思是這裏面的信息變動極小。它通常包含了通用的系統指令、工具的說明以及工作區摘要。只要沒有發生傷筋動骨的變化,我們就絕不浪費算力去每次從頭重建這部分內容(現在主流的大模型 API 都支持了 Prompt Cache,即提示詞緩存機制,可以大幅省錢和提升響應速度)。
那些需要頻繁更新的組件(通常每輪對話都要變),則包括短期記憶、近期的對話記錄,以及用戶最新的需求。
簡而言之,聰明的 Harness 會盡可能地把“穩定的提示詞前綴”緩存起來重複利用。
3. 工具的接入與調用 (Tool Access and Use)
一旦涉及到工具的接入和調用,這就開始脱離“單純聊天”的範疇,真正有了“智能體”的內味兒了。
普通模型只能用文字大段大段地建議你“應該怎麼做”;但裝在 Coding harness 裏的 LLM,動作要精準、實用得多。它能夠實打實地去執行命令,並自己把運行結果取回來分析(再也不用我們手動複製命令去終端跑,然後再把報錯信息粘貼回聊天框了)。
不過,Harness 可不會任由模型放飛自我地亂寫一通。通常,Harness 會提供一份預先定義好的“白名單工具箱”,每個工具都有名字、明確的輸入要求和嚴格的邊界。(當然,你也可以把類似 Python 的 subprocess.call 塞進工具箱,這樣智能體就能執行極其廣泛的終端命令了。)
工具調用的完整流程如下:
圖 8:模型輸出一個結構化的動作,Harness 對其進行驗證(需要的話還會請求人工批准),然後執行該動作,最後把受控的執行結果傳回給循環系統。
為了更直觀,我用我的 Mini Coding Agent 跑了個例子給大家看。在用戶視角下,它是長這樣的。(界面雖然沒有 Claude Code 或 Codex 那麼炫酷,畢竟它是用純 Python 寫的極簡版本,沒有任何外部依賴。)
圖 9:Mini Coding Agent 彈出工具調用審批請求的界面示例。
在這個環節,模型必須從 Harness 認識的動作裏挑一個,比如:列出目錄文件、讀取文件、全局搜索、運行 Shell 命令、寫入文件等。同時,它提供參數的格式也必須規規矩矩,方便 Harness 進行攔截校驗。
所以,每當模型試圖動手乾點什麼時,運行環境就能立刻按暫停,並通過代碼進行“安檢”:
• “這是一個已知的工具嗎?” • “參數合法嗎?” • “這個高危操作需要用戶手動批准嗎?” • “你要訪問的文件路徑,超出當前代碼倉庫的範圍了嗎?”
只有這些安檢全部綠燈,命令才會被真正執行。雖說讓智能體自己跑代碼肯定有風險,但正是有了 Harness 的重重把關,確保模型不會瞎跑高危命令,整個系統的可靠性才得以大幅提升。
另外,除了攔截格式錯誤的動作和引入人工審批,Harness 還能通過卡死文件路徑,把模型的操作死死限制在代碼倉庫的範圍內。從某種意義上說,Harness 確實剝奪了模型的一部分“自由”,但這也換來了極大的安全性和實用性。
4. 給上下文瘦身,防止撐爆 (Minimizing Context Bloat)
“上下文膨脹(Context Bloat)”並不是編程智能體獨有的煩惱,它是所有大模型共同的痛點。確實,現在的 LLM 支持的上下文越來越長(我最近剛寫過一篇關於注意力機制變體如何降低計算成本的文章),但是長上下文依然很費錢,而且如果裏面混入了大量無關信息,還會給模型帶來嚴重的噪音干擾。
在多輪對話中,編程智能體比普通的 LLM 聊天更容易“吃撐”。因為它們會頻繁地讀取文件,而工具輸出和日誌信息往往又臭又長。
如果 Harness 老老實實地把所有細節一字不落地存下來,可用的 Token 額度瞬間就會被榨乾。因此,一個優秀的 Coding harness,在處理上下文瘦身這方面通常非常硬核,絕對不是像普通聊天軟件那樣簡單粗暴地裁剪或總結一下就完事了。
概念上,編程智能體的上下文壓縮機制可以總結為下圖。簡單來說,這是對上一節圖 8 中“裁剪(clip,步驟 6)”環節的放大特寫。
圖 10:超長的輸出會被暴力裁剪,早期讀取的重複文件會被剔除,而完整的對話記錄在重新塞入提示詞之前會被大幅壓縮。
一個及格的極簡 Harness,至少會用兩招來對付這個問題。
第一招是裁剪(Clipping)。面對長篇大論的文檔片段、海量的工具輸出日誌、備忘錄以及長對話,它會毫不留情地截斷。換句話說,絕不能讓某一段廢話因為“碰巧比較長”,就擠佔了整個提示詞的預算。
第二招是對話記錄精簡或總結(Transcript reduction/summarization)。它會把完整的歷史記錄(下一節會詳細講)提煉成一份輕量級的、方便放入提示詞的摘要。
這裏的核心秘訣是:越近的事情,保留的細節越多,因為它們往往對當下的決策最關鍵;越久遠的事情,壓縮得越狠,因為它們的參考價值已經沒那麼大了。
此外,我們還要對早期讀取的文件做去重處理。不能因為智能體在幾輪對話前反覆查看了某個文件,就讓模型一遍遍地在上下文裏看到同樣的文件內容。
總的來說,我認為這部分是優秀的編程智能體設計中,最被低估、也最枯燥的環節。我們平時誇讚的所謂“這個模型真聰明”,很大程度上其實歸功於“這個系統餵給它的上下文質量真高”。
5. 結構化的會話記憶 (Structured Session Memory)
在實操中,本文提到的這 6 個核心概念是緊密交織在一起的,不同的章節和配圖只是側重點和放大倍數不同。在上一節中,我們探討了在“構建提示詞時”如何利用歷史記錄,以及如何打造精簡版對話。那一節的核心問題是:在下一輪對話中,應該把多少歷史包袱塞回給模型?所以重點在於壓縮、裁剪、去重和近期優先。
而現在這一節“結構化的會話記憶”,講的是在“硬盤存儲時”歷史記錄該長什麼樣。這裏的核心問題變成了:智能體該長期保存哪些數據作為永久檔案?這裏的重點是:運行環境不僅要保存一份鉅細無靡的“完整對話記錄”作為持久狀態,還要維護一個更輕量級的“記憶層”。這個記憶層很小,並且它是被不斷修改和提煉的,而不是像流水賬那樣一味地只增不減。
總結一下,編程智能體會把狀態(至少)分為兩層:
• 工作記憶(Working memory): 小巧而純粹,是智能體刻意單獨維護的核心狀態。 • 完整記錄(Full transcript): 涵蓋了用戶的所有請求、所有工具的輸出日誌,以及 LLM 的每一次回答。
圖 11:產生的新事件會被追加到完整記錄中,同時其核心信息會被總結進工作記憶裏。硬盤上保存的會話文件通常是 JSON 格式。
上圖展示了這兩個主要的會話文件,它們通常以 JSON 格式躺在你的硬盤裏。如前所述,完整記錄保存了事無鉅細的所有歷史,就算你把智能體關了,下次打開依然能無縫恢復。而工作記憶則是提純後的精華,只留當下最要緊的信息(這跟前面提到的“精簡版對話”有點像)。
但是,“精簡版對話”和“工作記憶”分工還是有微妙區別的。精簡版對話是為了重組提示詞服務的,它的使命是給模型一個近期歷史的壓縮包,讓它不用看完整部《資治通鑑》也能接着往下聊。而工作記憶是為了保持任務連貫性服務的。它的使命是在多輪對話中,手動維護一個包含了核心關鍵點的小備忘錄——比如現在的首要任務是什麼、哪些文件最核心、剛剛做過的關鍵筆記等。
順着上圖的第 4 步往下看,最新的用戶請求、LLM 的回覆以及工具的輸出,會在下一回合作為“新事件”同時記錄到完整記錄和工作記憶中(為了不讓圖片顯得太亂,這一步在圖裏省略了)。
6. 任務委派與受限子智能體 (Delegation With (Bounded) Subagents)
當智能體裝備了工具,又有了記憶狀態,接下來最順理成章的高階能力就是:搖人(任務委派)。
為什麼需要這個?因為它能把某些髒活累活拆成子任務,分給“小弟(子智能體)”去並行處理,從而大幅加快主線任務的進度。舉個例子,主智能體正幹着大活,突然需要查個資料:這個變量是在哪個文件裏定義的?配置文件裏寫了啥?或者這個測試為啥掛了?這時候,把這些岔開的疑問剝離出來,交給一個有明確邊界的子任務去查,絕對比逼着主智能體一個腦子同時處理所有線索要高效得多。
(在我的 Mini Coding Agent 裏,實現方式比較簡陋,小弟還是同步串行工作的,但背後的核心思想是一脈相承的。)
不過,要想讓子智能體幹出點成績,就得給它傳承足夠的上下文。但麻煩在於,如果不加以限制,你很快就會看到一羣智能體在裏面無序繁殖:它們重複做同一件事、搶着修改同一個文件,甚至子智能體又生出孫子智能體,直接亂套。
所以,這裏最考驗設計的難點,不僅僅是怎麼“生”出一個子智能體,更在於怎麼給它套上“緊箍咒” :)。
圖 12:子智能體繼承了足以幹活的上下文,但它的運行邊界比主智能體要嚴格得多。
這裏的精妙之處在於:子智能體既要繼承足夠的上下文以便幹活,又必須受到嚴格的約束(比如:只能只讀訪問文件,絕不允許亂改代碼;並且限制它再往下搖人的深度,防止無限遞歸)。
Claude Code 很早之前就支持子智能體了,Codex 最近也補上了這個功能。有意思的是,Codex 通常不會一刀切地強迫子智能體進入“只讀模式”。相反,它們一般會繼承主智能體的沙箱環境和審批權限。所以,Codex 給小弟畫的圈,更多是限制在任務範圍、上下文大小和執行深度上。
組件總結
上面的內容儘量涵蓋了編程智能體的所有核心組件。就像之前說的,在真正的代碼實現裏,它們其實是盤根錯節、深度交織的。不過,我還是希望通過這種抽絲剝繭的拆解,能幫你建立起一個全局的心智模型:深刻理解 Coding harness 到底是怎麼運作的,以及為什麼有了它,大語言模型會比以前那個乾巴巴的多輪聊天機器人好用無數倍。
圖 13:前面各節討論的 Coding harness 的六大核心功能。
如果你手癢了,想看用極其乾淨、極簡的 Python 代碼是怎麼實現這些概念的,強烈建議去逛逛我的 Mini Coding Agent[2]。
這和 OpenClaw 比起來有啥區別?
拿 OpenClaw 來做對比挺有意思的,但它們其實並不是同一種類型的系統。
OpenClaw 更像是一個本地運行的通用智能體平台(只是恰好它也能寫代碼),而不是一個像我們在終端裏專用的純血編程助手。
當然,它跟我們討論的 Coding harness 還是有不少重合點的:
• 它也會利用工作區裏的提示詞和指令文件,比如 AGENTS.md、SOUL.md和TOOLS.md。• 它也用 JSONL 格式保存會話文件,同樣支持對話記錄壓縮和會話管理。 • 它也能召喚小弟(創建助手會話和子智能體)。 • 諸如此類。
但是,如前所述,兩者的重心截然不同。編程智能體是專門為了趴在代碼庫裏幹活的人而極致優化的,它唯一的追求就是高效地幫你檢查文件、修改代碼、在本地跑工具。而 OpenClaw 優化的方向是:在多個聊天框、頻道和工作區裏,同時養着一羣長期存活的本地智能體——對 OpenClaw 來說,寫代碼只是這羣智能體的眾多日常打卡工作之一。
順便跟大家分享一個好消息:我的新書《從零構建推理模型》(Build A Reasoning Model (From Scratch))終於殺青啦!所有章節目前都開放了搶先體驗(Early access)。出版社正在爆肝排版,預計今年夏天就能正式上市。
這可能是我迄今為止野心最大的一本書。我整整肝了 1.5 年,在裏面塞進了無數的實驗。無論是投入的時間、精力還是打磨的程度,這都是我傾注心血最多的一部作品,真心希望大家能喜歡。
在 Manning 和亞馬遜上可以找到《從零構建推理模型》。
本書的核心乾貨包括:
• 評估推理模型 • 推理時算力擴展(Inference-time scaling) • 自我反思與優化(Self-refinement) • 強化學習(Reinforcement learning) • 模型蒸餾(Distillation)
現在圈內都在熱炒 LLM 的“推理(Reasoning)”能力。而在我看來,要想真正搞懂 LLM 語境下的“推理”到底是個什麼鬼,最硬核、最透徹的辦法就是——從零開始,親手敲代碼搓一個出來!
• Amazon 亞馬遜[3] (可預購) • Manning 出版社[4] (搶先體驗版已包含完整內容,排版正在收尾,共 528 頁)
來源:https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
引用連結
[1] Mini Coding Agent: https://github.com/rasbt/mini-coding-agent/blob/main/mini_coding_agent.py[2] Mini Coding Agent: https://github.com/rasbt/mini-coding-agent[3] Amazon 亞馬遜: https://amzn.to/4aAKiFY[4] Manning 出版社: https://mng.bz/Nwr7