翻完X上這位GPT Image 2大佬的50篇帖子,我拆出了他寫提示詞的底層方法論
整理版優先睇
拆解GPT Image 2高手提示詞嘅底層方法論:寫設計規範,唔係寫提示詞
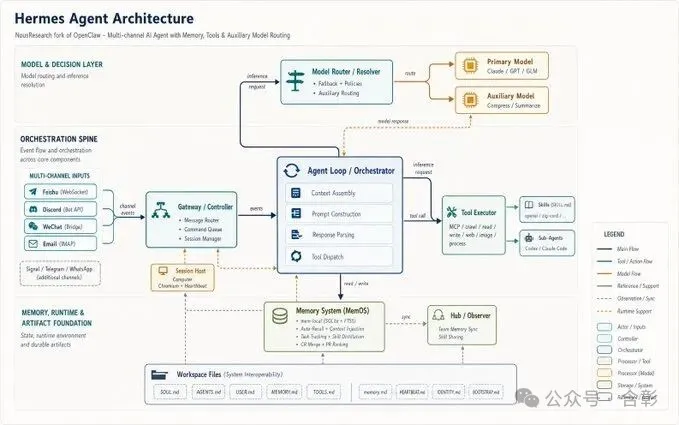
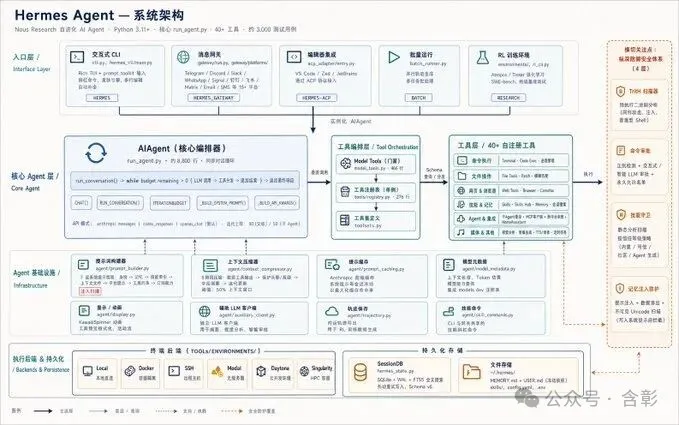
呢篇文章出自一位內容創作者,佢翻曬X博主@xiaoxiaodong01(自稱「國際,不知名,頂級圖片提示詞專家」)嘅大概50篇帖子,發現佢嘅提示詞之所以咁勁,唔係因為工藝複雜,而係因為本質上係畀AI寫「設計規範書」。作者想解決嘅問題係:點樣由「睇完覺得好勁但自己寫唔出」變成「掌握可複用嘅方法論」。整體結論係:只要套用一套固定流程(角色賦予、反定義、內部規劃、內容策劃、視覺系統構建、負面約束、輸出規格、變量區、自檢),任何人都可以寫出大師級提示詞。
作者先展示11個案例,涵蓋字體海報、紀實攝影、微縮模型、塗鴉海報、二維碼美化、情頭、文物海報、進化史信息圖、電商banner、Mermaid圖美化、漫畫日記,再歸納出6條鐵律。最後佢將呢套方法論封裝成一個叫「gpt-image2-prompt-director」嘅Skill,放咗上GitHub,等大家可以直接用。文章語氣似分享心得,帶住「授人以漁」嘅心態,提醒讀者門檻低咗但思維先係關鍵。
- 核心結論:咩提示詞高手本質係寫「設計規範」,唔係普通描述,要逼AI離開默認舒適區。
- 方法:用6條鐵律——定義角色、反定義(講清楚唔係咩)、先內部規劃、寫透負面約束、留變量區、加自檢環節。
- 差異專業提示詞同普通提示詞嘅分別在於有系統性流程,唔係靠靈感;每個約束都源於實際踩過嘅坑。
- 啟發:門檻降低後,好圖同普通圖嘅差距在於思維,要好似設計總監咁諗需求同約束。
- 可行動點:下載作者整嘅Skill(GitHub: hanzhangzzz/my-skill),一句指令就可以生成工程級提示詞,仲有Wow模式加強效果。
gpt-image2-prompt-director
互動式Skill!將6條鐵律自動化:幫你從模糊點子生成完整提示詞、診斷問題、基準測試,仲有Wow模式。
點解要拆呢位大佬嘅提示詞?
作者之前整理咗117條GPT Image 2提示詞,但覺得自己只係「睇同學」,未轉化到能力。於是佢去翻X博主@xiaoxiaodong01嘅全部帖子,差唔多50篇,每篇都帶完整工程級提示詞。
翻完之後佢冇停喺「好勁」呢個層面,而係拆開所有提示詞揾共性同骨架。
結論係:呢位大佬做嘅事,本質係畀AI寫「設計規範書」,唔係寫提示詞。只要套用佢套方法論,任何人都可以複用。
11個令作者停低嘅案例
博主嘅提示詞覆蓋極廣——字體設計、文物圖鑑、電商banner、表情包、二維碼美化、微縮模型、信息圖、Mermaid圖表、小紅書卡片、漫畫日記。以下係幾個精選:
- 任何一個詞直接變海報:分析詞義、情緒、文化聯想,字體同圖像互相咬合,配色兩到四色,有印刷品顆粒感。
- 一句話變紀實攝影:自動決定場景、構圖、光影,有路人遮擋、玻璃反光,擺拍感為零。提示詞仲自我約束「人物必須看得清面部輪廓」。
- 拍一張店鋪照片變微縮模型:45°俯視等距,韋斯安德森對稱構圖,紀念碑谷配色,好似精品品牌提案圖。佢話呢個提示詞係由失敗嘅學校地圖項目沉澱出來。
- 普通照片30秒變萌系塗鴉海報:自動識別場景人物,疊加塗鴉角色、手繪文字,連髒嘅洗碗液樽都會被貼紙蓋住。
- 上傳二維碼變成設計作品:二維碼融入卡片、標籤、招牌等自然圖形,可愛、高級、賽博、國風都得。
- 萬物皆情頭:用2:1橫向構圖,左右1:1裁開獨立,合埋有互動感;唔一定要固定套路,呼應可以來自構圖、材質、動作。
- 輸入文物名出博物館級知識海報:自動聯網搜索,配色從文物提煉,信息密度高但排版有呼吸感。直頭係一種策展思維。
- 任何主題一鍵生成進化史信息圖:自動梳理演進階段,台階式結構,每個節點帶時間標記,拒絕千篇一律暖棕米白。
呢11個案例跨度好大,但底層寫法係一樣嘅,正係作者要拆嘅方法論。
6條鐵律:佢係點樣寫提示詞?
作者從11個案例歸納出6條鐵律,每條都可以映射到至少3個具體案例。呢個就係佢提示詞嘅底層骨架。
- 1 先定義角色,再定義任務:幾乎每個提示詞第一句都係「你係邊個」,然後先話「你要做咩」。角色決定AI處理任務嘅姿態。
- 2 反定義先於正定義:先花篇幅講「呢個唔係咩」,再話係咩。GPT Image 2默認會出「好睇但普通嘅圖」,反定義逼佢離開舒適區。
- 3 要求AI先生成內部方案:先建立內部認知模型(分析含義、決定視覺語言),再出圖。多數人直接描述想要咩,精度差好遠。
- 4 將唔好咩寫透,寫成系統:負面約束係主體結構,唔係附註。例如Mermaid圖表有Hard bans清單,連「不要發光、不要3D」都列埋。
- 5 輸入契約——留一個乾淨嘅變量區:所有提示詞末尾都有清楚嘅用戶輸入區,例如「核心文字:___」「可選補充語境:___」。主體係引擎,變量區係燃料。
- 6 最後一道自檢:複雜任務末尾有自我檢查環節,例如Mermaid圖表有12條自檢清單:「語義是否守恆、主機制是否一眼可見…若不合格先重構。」
呢6條鐵律每一條背後都係博主實際踩過嘅坑,AI會反覆犯某啲錯誤,佢用約束一個個封死。
將方法論封裝成Skill,直接重用
作者將呢套方法論寫成一個互動式Skill——gpt-image2-prompt-director,放喺GitHub。四種用法:由模糊點子展開、由零生成創意、診斷修復現有提示詞、基準測試專家水平。
仲有一個Wow模式:覺得第一版太普通,就換更強嘅視覺容器、製造高概念碰撞、用網格分解增加變化。
「幫我將孤獨呢個詞變成一張概念海報」
「我有一張家門口小店嘅隨手拍,幫我做成電商banner」
「我今日寫咗一篇日記,幫我變成漫畫」作者希望讀者唔好只帶走幾個prompt,而係帶走思維——下次有諗法時,問自己:點樣將呢個點子變成一份AI能精準執行嘅設計規範?
人人做設計大師,但要先咁樣思考
GPT Image 2降低咗做圖門檻,但好圖同普通圖嘅差距喺思維——你要好似設計總監咁諗清楚需求、講明約束、逼退AI嘅默認惰性。
翻完X上這位GPT Image 2大佬的50篇帖子,我拆出了他寫提示詞的底層方法論
先交代一下背景。
上一篇寫了117條GPT Image 2提示詞的翻後感,感覺還停留在"看和學", 總覺得沒有轉換成自己的能力,也就是怎麼"創造"
看完那些案例,你大概率會覺得「太強了,但我自己寫不出來」, 我也是同感。
所以我又去翻別人的靈感,是一個X博主@xiaoxiaodong01的, 全部帖子翻完了,差不多50篇。每一篇都帶着一個完整的提示詞,每一個提示詞都是可以直接拿去用的工程級作品。
翻完之後我沒有停在「牛逼」這個層面。我把他所有的提示詞拆開看了一遍,找共性,找骨架,找那個「為什麼他寫的提示詞就是比別人強」的底層原因。
結論我覺得是: 他做的事,本質上是給AI寫設計規範書,不是寫提示詞。
你如果只看他的成品提示詞,你會覺得太長了、太複雜了、學不會。但如果你把他的方法論拆出來,你會發現這套東西是可以複用的。任何一個人,只要腦子裏有一個點子、一個詞、一張照片、一個主題,套上這套框架,出來的東西就不會差。
這篇文章要做的就是這件事。授人以漁, 文末我會附上我搞出來的skill, 讓每個想我一樣的設計小白、靈感匱乏的人,也能夠寫出很好的提示詞,出大師級作品。
先看案例,再拆方法論,最後給你一個可以直接用的skill。
先認識一下這位博主
@xiaoxiaodong01,X上的自我介紹是「國際,不知名,頂級圖片提示詞專家」。他第一個GPT Image 2提示詞帖子發在4月26號,到現在半個月不到,幾乎每天都有新東西。
他玩GPT真的溜
每一個提示詞都是一套完整的設計規範。有的提示詞長到你自己讀一遍需要五分鐘,但它生成的圖,你一眼就能看出和別人隨手寫的那種不一樣。
他覆蓋的品類極其廣。字體設計、文物圖鑑、電商banner、表情包、二維碼美化、微縮模型、信息圖、Mermaid圖表美化、小紅書卡片、漫畫日記...基本上你日常能想到的所有圖片需求,他都有對應的提示詞。
好,看案例。
11個讓我停了很久的案例
01 任何一個詞,直接變海報
你輸入一個詞、一句話、一組字母。它先理解這個詞的含義、情緒、文化聯想,再把這些理解轉譯成一張極簡概念海報。
字體像從畫面內部長出來的,文字和圖像互相咬合——人站在字前面,字被圖像切割,圖借字的留白構成動作。配色控制在兩到四個主色之內,有印刷品顆粒感。像一張展覽級海報。不像AI隨手出的圖。







02 一句話,變出一整套紀實攝影
你輸入拍攝主題和要求元素,它自動決定場景、構圖、光影、遮擋關係。
出來的東西像街拍攝影師站在合理距離內抓拍到的。前景可能有路人虛化的肩膀、經過的車輛邊緣、玻璃反光,主體清晰可辨認。擺拍感為零。光線是真實環境中自然存在的。畫面有一種「剛好看到這一幕」的偶然感,沒有廣告片那種精緻到假的質感。
這張提示詞最讓我意外的,是它的自我約束——明確要求人物不要太遠、必須看得清面部輪廓,不能為了氛圍犧牲辨識度。只有真正被AI坑過的人才會想到加這種限制。






03 拍一張店鋪照片,變成微縮模型
丟一張店鋪照片上去,或者直接輸入品牌名,它生成45°俯視等距的微縮3D建築模型。
韋斯安德森那種對稱構圖的精緻微縮場景。白色背景,建築放在小型抬升底座上,配色參考紀念碑谷那種低飽和柔和調子,有小人物、綠植、路牌、台階。像精品品牌的設計提案圖。不像AI隨手捏的玩具。
他說這個提示詞的緣起——「之前學校地圖項目想做這種效果,奈何建築位置難以正確,最後放棄,但沉澱下來了這種風格」。我看到這句的時候覺得特別真實。好的提示詞從哪來的?從失敗的項目里長出來的。憑空想不出來。










04 一張普通照片,30秒變萌系塗鴉海報
上傳任意照片,AI自動識別場景、人物、動作、情緒,然後智能修圖,再疊加上和人物互動的塗鴉角色、手繪文字、小貼紙。畫面裏雜亂不好看的區域——比如髒兮兮的洗碗液瓶子——會被自動識別出來,用小貼紙或色塊自然蓋掉。文字是場景識別後自動生成的,不是排版排出來的,風格跟着畫面走。
他演示了一張自己小孩在廚房擇豆子的照片。原圖是亂糟糟的廚房,30秒處理完,髒的洗碗液被識別後用塗鴉覆蓋了。他還說「甚至,和小孩子互動的插畫對象,都可以指定是奧特曼」。我看完立刻想到自己手機裏那堆拍廢了的照片。








05 上傳你的二維碼,讓它變成一個設計作品
把你那個黑白的、像膏藥一樣的二維碼丟上去,描述你想要的主題風格,它把二維碼融入到完整的視覺場景裏。
二維碼變成了卡片、標籤、票據、招牌、包裝、窗户、門牌——各種和主題相關的自然圖形對象。可愛治癒系、高級商務系、賽博科技系、國風水墨系,全都能跑。他演示的圖裏,每一種風格都立得住。





06 萬物皆情頭,墊一張圖就出
玩法比你想的還簡單。找一張你喜歡的圖墊上去,在提示詞結尾提一句畫面要求——或者乾脆不提。水靈靈的情頭就嘩啦啦湧出來了。
這套提示詞的核心是一個2:1橫向構圖,左右各1:1,裁開就是兩個獨立頭像。合在一起有互動感和默契——視線方向、身體朝向、動作暗示互相呼應。分開各自成立,合起來多一層意義。
他特別強調了一點:不要依賴固定套路。別一上來就粉色蝴蝶結配藍色領結。呼應可以來自構圖、材質、動作、氛圍,任何維度都行。這跟我翻完他全部帖子後的一個感受完全吻合——他的提示詞永遠在逼AI離開默認答案。
出來的幾張圖你們感受下。日系遠景文藝背影,左右氣質有明顯區分但又不割裂。裁開各自是一張好頭像,拼在一起是一張好照片。




07 輸入文物名,出來一張博物館級知識海報
輸入你想了解的文物名,它自動聯網搜索資料,花將近十分鐘整理內容,最後生成知識海報。
這已經不是「好看」能概括的了。主體文物清晰,超大字嵌入幾何圖形之中圍繞文物分佈,部分被遮擋但整體可讀。配色從文物本身提煉——青銅器走青銅綠、古銅褐,瓷器走月白、釉青。信息密度極高但排版有呼吸感。他說在排版上「費神3個小時,只為避免粗俗、匠氣」,看完成品我信了。
有一句話我特別在意:「觀者讀完後要有一種比聽講解更透、更準、更有收穫的感覺。」他把這句話當真了。後面所有約束都在為這個標準服務。



08 任何主題,一鍵生成進化史信息圖
你輸入一個主題——咖啡豆進化史、蘋果進化史、內褲進化史——它自動梳理完整演進階段、關鍵節點和代表性視覺對象。
成品是一條空間化的演進路徑。台階、平台、遞進結構,每個階段一個清晰節點,帶時間標記和代表性對象。配色因主題而異,拒絕千篇一律的暖棕米白。文字排版有編輯設計意識,不像PPT也不像教科書。
他測試了咖啡豆、蘋果、內褲、考古技術幾個完全不同的主題,每個都被認真對待。他說「GPT2的理解和調查太有誠意了,它會調查很多數據之後,大概花四五分鐘給出這些圖片」。





09 電商作圖邏輯,真的要變了
丟一張產品圖上去——哪怕是隨手拍的、光線很差的——再口述產品的賣點亮點。它生成一套完整的電商詳情頁圖片。
白底主圖乾淨專業,場景圖把商品放進真實使用環境,A+信息圖有分割拼貼和多場景展示。他說「親測最多一次10張,每次不同角度,交付都很驚喜」,還放了4次完整使用記錄的VCR連結。
有一句話我印象很深:「聰明的電商老闆們,早上就一句——小王,這個產品隨便拍幾張圖,我口述下亮點賣點,你讓ChatGPT綜合這些東西,生成一套詳情頁圖片,我們五分鐘後對一對。」他已經在演示這個未來。












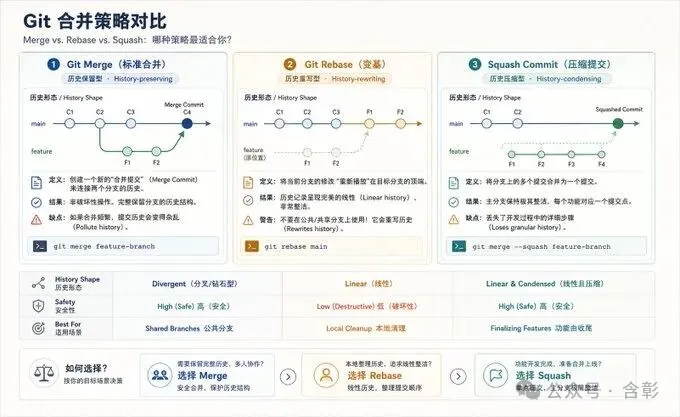
10 Mermaid圖太醜?丟給它,重畫
輸入Mermaid代碼或者截圖,它理解語義結構後重新編譯為高保真信息圖。
完全不是Mermaid換皮。它提取實體、角色、關係、分支,識別主機制類型,建立主路徑視覺軸。配色是暖灰白底加深藍結構色加低調強調色,字體是technical editorial風格,節點形態跟着角色走——事件用膠囊,決策用分叉,存儲用穩定低調的容器。
他說「我也是多年的碼農,我知道Mermaid畫圖很快很準,但美感就很一般了。程序員普遍缺乏美商。」這個提示詞就是來解決這事的。而且他還留了一個技巧——你可以跟ChatGPT說「我想改版成更扁平+治癒色系」,它就能幫你改出私人定製版。

11 你的日記,直接變漫畫
輸入文字日記或者口述內容,它自動提煉事件、行動、情緒,轉化為調格漫畫。
每一行一個面板,按時間或邏輯順序排列。默認線條手繪、柔和色彩、韓系插畫感,角色走治癒系,可根據輸入微調。他說「這個思路放大到一個高維度,基本上公眾號的漫畫矩陣玩法,你可以橫着走了」。


好,案例就看到這兒。
11個案例,跨越字體、攝影、模型、修圖、二維碼、情頭、文物、信息圖、電商、圖表、漫畫——品類完全不同。但你看完有沒有一個感覺?它們底層的「寫法」是一樣的。
這就是我這周拆出來的東西。
6條鐵律:他是怎麼寫提示詞的
下面這6條是我從上面11個案例裏直接歸納出來的。每條都能映射回至少3個具體案例。沒套什麼設計理論。
鐵律一:先定義角色,再定義任務
幾乎每一個提示詞的第一句話,說的都先是「你是誰」,然後才是「你要做什麼」。
字體海報開頭:「你要生成的不是普通插畫...而是一張基於詞語含義自動構建視覺隱喻的高級概念海報。你的核心任務是...」
文物圖鑑開頭:「你要生成的不是普通插畫,也不是標準化的信息板,而是一張經過聯網核實、知識準確、圖文一體的文物知識海報。」
電商banner開頭:「你是一位兼具頂級商業攝影審美與轉化意識的廣告設計師。」
Mermaid圖表開頭:「你是高級信息圖重構生成器,兼具信息架構師、視覺設計總監、技術機制圖設計師能力。」
角色定義決定了AI處理任務的姿態。一個「設計師」和一個「圖片生成器」處理同一個輸入,出來的東西完全不同。這條在11個案例裏出現了11次。
鐵律二:反定義先於正定義
他幾乎每個提示詞都先花大量篇幅說「這不是什麼」,再轉過來定義「這是什麼」。
字體海報開頭那一長串否定——不是普通插畫,不是字效海報,不是簡單把詞貼在畫面上。
文物圖鑑同理——不是普通插畫,不是標準化信息板。
信息圖——不是普通科普圖,不是純裝飾海報,不是機械排成一列的時間軸。
表情包這個案例更絕:「如果畫面開始好看,說明失敗。必須回到粗糙、混亂狀態。」一句話把整個風格方向鎖死。
GPT Image 2默認行為傾向於生成「好看但普通的圖」。你不告訴它不要什麼,它就滑向那個均值的、安全的、任何AI都能出的方向。反定義是逼它離開舒適區。
這條在11個案例裏出現了10次。
鐵律三:要求AI先生成「內部方案」,再出圖
他最好的那些提示詞,都有一個明確的「先想後做」段落。
字體海報:「在生成畫面之前,必須先對輸入文字進行多層分析...先理解整體含義、核心主題、主要情緒、潛在矛盾、精神氣質和最有力量的表達方向,再決定最適合的視覺語言。」
信息圖:「在開始生成前,你必須先智能判斷這個主題最適合被梳理成什麼樣的演進結構。」
文物圖鑑:「在正式生成之前,必須先執行聯網檢索與事實核驗。優先檢索博物館官網、文博機構官網。」
多數人寫提示詞是直接描述想要什麼。他的思路是先讓AI建立一個內部認知模型,再基於這個模型去生成。兩者的精度差距不是一點半點。
這條在11個案例裏出現了9次。
鐵律四:把「不要什麼」寫透,寫成系統
大多數提示詞會有個「注意事項」段落。他的提示詞裏,負面約束是主體結構的一部分,不是附註。
字體海報有一整節「執行限制」——不要機械套模板,不要堆元素,不要炫技,不要讓構圖失去秩序,不要做成普通文字+插圖的組合。
文物圖鑑更誇張。它禁掉的是一整套視覺系統:不要教科書式表格化排版、不要把最大文字放在畫面頂部、不要機械默認用燙金、不要所有主題都用同一款字體。
Mermaid圖表甚至列了Hard bans清單:不要漂亮版Mermaid、不要普通流程圖換皮、不要原樣保留subgraph大框、不要每個節點加圓形圖標、不要彩虹配色、不要發光、不要3D、不要玻璃擬態。
這些負面約束每一條背後,大概率都是他實際踩過的坑。AI會反覆犯某些特定類型的錯誤,他把這些錯誤一個個封死了。
這條在全部11個案例裏都能找到。
鐵律五:輸入契約——留一個乾淨的變量區
他所有提示詞的末尾,都有一個清晰的用戶輸入區。
字體海報:「用戶輸入內容:核心文字/單詞/詞組/字母: 文字語言: 可選補充語境:___」
文物圖鑑:「用戶輸入對象:馬踏飛燕 比例2:1」
信息圖:「現在請基於用戶輸入的主題:{{主題}},自動完成內容梳理...」
而且在技巧篇裏,他專門強調過:「所有提示詞,小小東出品的,都留足了自定義的口子,位置都很固定,在提示詞結尾。你除了和GPT-image2說出你要呈現的文字,還可以補充其他要求,尤其是畫面氣質的說明。哪怕是很口語的表達,你甚至可以幾百字小作文來表達。」
提示詞的主體是引擎,結尾的變量區是燃料。引擎不變,換燃料就能出不同的圖。你不用每次都重新設計整個提示詞。
這條在全部11個案例裏出現。
鐵律六:最後一道自檢
他最強的那些提示詞,末尾都有一個自我檢查環節。
Mermaid圖表最後有12條自檢清單:「語義是否守恆、是否沒有編造信息、主機制是否一眼可見、主路徑是否清楚、佈局是否明顯不同於原Mermaid/原圖...若任一項不合格,先重構畫面,再輸出最終信息圖。」
字體海報有明確的生成前判斷:「先智能分析用戶輸入內容,包括但不限於:這個詞語最核心的字面含義是什麼、情緒上偏向哪種傾向、是否具有雙關或悖論...」
這條比較複雜度的提示詞才有,簡單的不需要。但凡是複雜任務,自檢環節就會出現。
總結一下,6條串起來是一套完整的流程:
角色賦予 → 反定義 → 內部規劃 → 內容策劃 → 視覺系統構建 → 負面約束 → 輸出規格 → 變量區 → 自檢
這就是他寫提示詞的底層骨架。不管你輸入的是什麼——一個詞、一張照片、一個主題——這套流程都能把你從「我想要一張好看的圖」帶到「我要一份AI能精準執行的設計規範」。
我把這套方法論封裝成了一個Skill
拆完他全部帖子之後,我做了一件事。
我把這套方法論寫成了一套可複用的系統。交互式的Skill——你給它一個模糊的點子、一句話、一張圖、一個主題,它按這套方法論幫你生成完整的、工程級的GPT Image 2提示詞。
它叫 gpt-image2-prompt-director。
四種用法:
還有一個「Wow模式」。你覺得第一版太普通了,它會換更強的視覺容器、製造高概念碰撞、用網格分解增加變化。
底層就是上面那6條鐵律。做成了自動化,你不用背規則,告訴它你要什麼就行。
Skill傳到了GitHub,有興趣自己拿去玩:
https://github.com/hanzhangzzz/my-skill
裝好後跟它說一句話就能跑。「幫我把孤獨這個詞變成一張概念海報」。「我有一張家門口小店的隨手拍,幫我做成電商banner」。「我今天寫了一篇日記,幫我變成漫畫」。
最後
說回開頭那個點。
GPT Image 2把做圖的門檻降到了零。但門檻降得越低,做出好東西和做出普通東西的差距就越大。
這個差距不在技術。在思維。在你能不能像一個設計總監那樣,把需求想清楚、把約束說明白、把AI的默認惰性逼退。
翻完@xiaoxiaodong01的50篇帖子,我最大的感受其實不是GPT Image 2有多強。是他把提示詞當成了一門手藝在打磨。每個詞的取捨、每條約束的添加、每個變量區的位置,背後都有考量。
這門手藝,是可以學的。
這也是我寫這篇文章、做這個Skill的原因。我不希望你看完只帶走幾個prompt,我希望你帶走一套思維。下次你有一個點子的時候,先問自己一個問題:我怎麼把這個點子變成一份AI能精準執行的設計規範?
人人都是設計大師,前提是你得先像一個設計大師那樣思考。
對了,如果你想要@xiaoxiaodong01的全部提示詞原文合集,關注我後台私信「小小東」。我整理了一份完整的索引。
本文提到的 gpt-image2-prompt-director Skill 開源地址:https://github.com/hanzhangzzz/my-skill
下篇見。