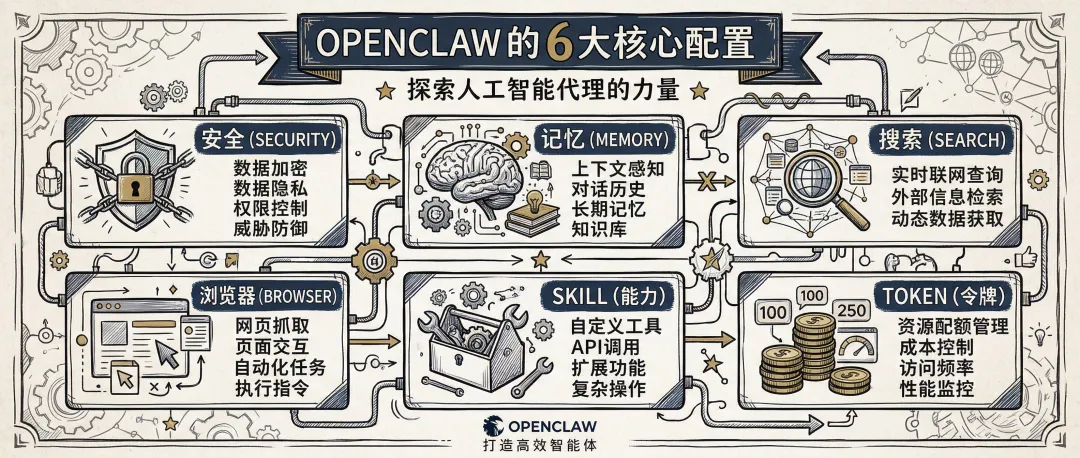
裝好OpenClaw先別急着聊天,配置好這6大模塊事半功倍!
整理版優先睇
OpenClaw 安裝只係起點,真正令佢變成可用系統嘅關鍵係六大模塊配置。本文提供具體安全、記憶、搜索、瀏覽器自動化、插件同成本管理建議,等 AI 由聊天機械人進化成穩定交付嘅數碼員工。
作者發現好多人將「安裝成功」當成「系統上線」,結果 OpenClaw 仍然似個聊天機械人。作者反問對方:你配安全未?你做記憶未?你管 token 未?對方沉默。呢個係 90% 用家卡住嘅地方。文章背景係作者自己嘅經驗,佢想解決嘅問題係點樣將 OpenClaw 從一個玩具變成真正可用嘅系統。整體結論係:你要當系統去經營配置,先可以得到穩定交付。
文章提出六大模塊:安全先行、記憶優化、搜索鏈路、瀏覽器自動化、插件策略同 Token 成本管理。每個模塊都有具體做法,例如改端口、收緊權限、增強記憶召回、按場景配搜索工具、用獨立瀏覽器環境、先裝穩態四件套插件、定期做 token 體檢等。作者強調呢啲配置唔係一次過,而係要持續經營。
最後作者提供一個 7 步清單俾新手今日就做,包括改端口、關公網聊天、文件白名單、skill 掃描、記憶增強、接搜索鏈路、心跳降配。做完呢啲,你就會感受到 OpenClaw 開始似「可交付嘅數碼員工」。
- 安全係首要,必須改默認端口、收緊聊天權限、文件採用白名單,安裝 skill 前先用 vetting 掃描風險。
- 記憶優化靠增強默認 memory、接入向量庫、或用 skill 沉澱做事方式,避免模型亂咁講。
- 搜索要按場景配置工具(browser、exec、web_fetch等),令 AI 接觸即時世界,唔好畀佢自閉。
- 瀏覽器自動化係由識講變成識做嘅分水嶺,建議用獨立瀏覽器環境,模擬人操作。
- Token 成本要主動管理:先用訂閲制控制開支,心跳任務用小模型降頻,每週做 token 體檢,先砍無效上下文。
記憶優化 Skill (Lancedb)
多智能體共享記憶,提升記憶召回質量,支援 token 下降同習慣適配。
官方技能庫
Awesome OpenClaw Skills 集合,包含大量社羣 skill。
小紅書運營 Skill
自動運營小紅書嘅 skill,可以直接安裝使用。
安裝同升級:用智能體一句搞掂
好多人俾繁瑣嘅安裝教程搞到頭暈,其實有個簡單方法:用 Cursor、Claude Code、Codex 呢啲智能體,直接喺對話框講一句「幫我安裝最近好 hit 嘅 OpenClaw」,等佢裝完再講「幫我啟動」就得。
安裝成功唔等於系統用得,真正嘅功夫喺後面嘅配置。
配置 API 同網關令牌都可以交畀智能體做,要換 API 直接同佢講就得。升級方面,OpenClaw 更新頻密但 bug 都多,建議非必要唔升級,真係要升級就繼續用智能體搞,遇到問題佢會直接解決。
安全先行:唔上鎖,後面全部都係白做
有同學無改默認端口同聊天權限,跑咗兩日就俾陌生人反覆探測。呢啲唔係方案好,只係好彩。
- 端口唔好用默認值:改端口唔係萬能防護,但可以擋住大多數低級掃描,5 分鐘就搞掂,性價比極高。
- 聊天權限一定要收口:配對機制唔好關,白名單唔好慳,重要操作加人工確認。你做嘅係數碼員工,唔係公眾聊天室。
- 文件權限行白名單:如果裝喺自己電腦,唔好開放全盤讀取,只開業務目錄,例如 workspace/content-factory 同 workspace/client-service。
- 裝 Skill 前先掃風險:ClawHub 上面好壞參半,一定要先掃描、再測試、先至放上生產線。
記憶優化:唔改記憶,佢越勤力就越亂講嘢
成日遇到噉嘅情況:昨日仲記得客戶 A,今日就將客戶 A 同客戶 B 搞亂。問題唔係提示詞唔夠長,而係底層記憶召回質量差。記憶係磁盤上嘅 Markdown 檔案,模型本身無持久記憶,要靠 memory 插件做檢索。
- 1 增強默認 memory:目標係召回更準、上下文更乾淨,通常呢步已經可以明顯減少記憶錯亂。
- 2 接入向量庫:將檢索交畀更專業嘅索引層,歷史記錄揾得更快更穩定,同上面一步唔衝突,可以同時裝。
- 3 用 skill:呢層最實用,例如 memory-lancedb-pro skill 支援多智能體共享記憶,token 下降,skills 會逐步適應你嘅習慣,變相將「你點樣做嘢」沉澱成系統能力。
記憶加 Skill 好似有 SOP 嘅團隊,記得你嘅偏好之餘仲按固定流程產出,穩定好多。
搜索鏈路同瀏覽器自動化:由識講到識做
淨係靠本地文檔,最多做個助理。要做業務,一定要令佢接觸即時世界。默認 web 抓取經常漏 JS 渲染同懶加載,所以你要按場景配置搜索工具:
- browser:主鏈路,直接開網頁做人類式檢索核對。
- exec + 第三方源:補充鏈路,用腳本拉公開 RSS 或頁面,例如用 nitter RSS 做時間戳核查。
- web_fetch:輕量抓取網頁正文,適合文章頁。
- web_search:理論可用,但需要配 API key(如 Tavily)。
瀏覽器自動化係從「識講」到「識做」嘅分水嶺。佢可以登錄、檢索、填表、回帖、跑流程。建議用獨立瀏覽器環境,避免同自己常用瀏覽器嘅密碼、cookie 搞亂。
# X賬號監控清單(AI日報)
## 01 公司 / 實驗室領袖 & 核心推動者
- @sama
- @elonmusk
- @ylecun
- @kaifuLee
- @AndrewYNg
- @demishassabis
- @gdb
- @AravSrinivas
- @OfficialLoganK
## 02 頂級研究員 & 思想家
- @geoffreyhinton
- @drfeifei
- @fchollet
- @ID_AA_Carmack
- @timnitgebru
- @GaryMarcus
- @karpathy
- @jeremyphoward
## 03 AI新聞 / 工具 / 趨勢觀察者
- @rowancheung
- @alliekmiller
- @Ronald_vanLoon
- @emollick
- @KirkDBorne
- @tunguz
- @antgrasso
## 04 新興 / 細分領域
- @mattshumer_
- @levelsio
- @EpochAIResearch
- @dwarkesh_sp
- @hardmaru
- @jimmyasoni
- @jxmnop
- @SonglinYang4
- @RulinShao
- @natolambert
- @rasbt
- @cwolferesearch
- @swyx
- @MelMitchell1
## 產出規則(固定)
- 先寫總覽(3-5行)
- 再按 01/02/03/04 分組輸出
- 僅保留過去24小時有動態的賬號(不做AI關鍵詞過濾)
- 每個賬號:100-200字總結 + 原文連結列表
- 採集策略:逐賬號主頁、逐條檢查時間戳是否在24小時內、順序低頻、模擬人工操作(避免高併發抓取)瀏覽器自動化係從識講到識做嘅分水嶺,建議優先配獨立瀏覽器環境。
插件策略同 Token 成本:貪多爛尾,管控先係王道
好多人一嚟就裝 20 個插件,第三日開始互相打架。建議先配「穩態四件套」:自我優化類、定時備份類、開發協作類、自己定製類。官方技能庫有好多選擇,但裝任何 skill 前一定要用 skill-vetting 掃安全威脅,再用 find-skills 幫手揾適合嘅。
Token 成本方面,最怕人未醒,賬單先醒。三招防範:
- 1 訂閲制代替裸用 API:訂閲唔一定平,但可控,可控比平更重要。中轉 API 一日唔使十蚊,但要揾穩定嘅。
- 2 心跳任務降配:心跳係隱形食 token 怪,建議用小模型、降低頻率、只保留關鍵檢查項。
- 3 每週做 Token 體檢:拉報告,找異常任務,請模型畀優化建議,或者交畀強推理模型覆盤。
成本優化順序:先砍無效上下文,再調任務頻率,最後先換模型。
呢個星期我俾人問到頭都大埋。
「我已經裝好啦,點解佢仲係好似一個聊天機械人咁?」
我反問一句:你set好安全未?你做咗記憶未?你搞掂token未?
對方沉默咗3秒。我都沉默咗3秒。
然後我哋一齊笑咗。
講白咗,好多人將「安裝成功」當成「系統上線」。
呢個就係而家90%嘅人卡住嘅地方。
今日講6個你今日就可以改、改完就會見到分別嘅配置。
安裝
喺講配置之前,先講嚇安裝。
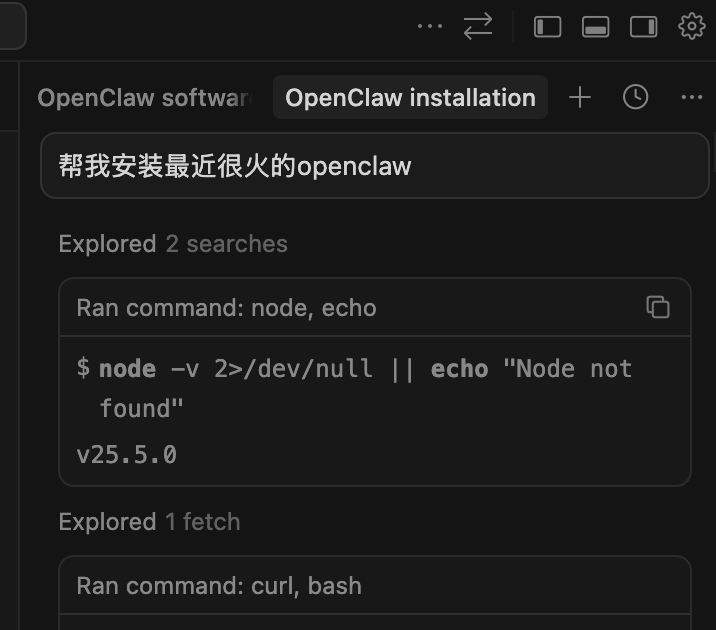
好多人俾繁瑣嘅安裝教程搞到頭都大,其實有個好簡單嘅安裝方法,用智能體安裝,cursor、cc、codex,都係智能體,直接喺對話框度講一句話:幫我安裝最近好興嘅openclaw。
然後等佢裝完你可以話幫我啟動。就係咁簡單。
跟住配置API同網關令牌。都可以交俾智能體做。
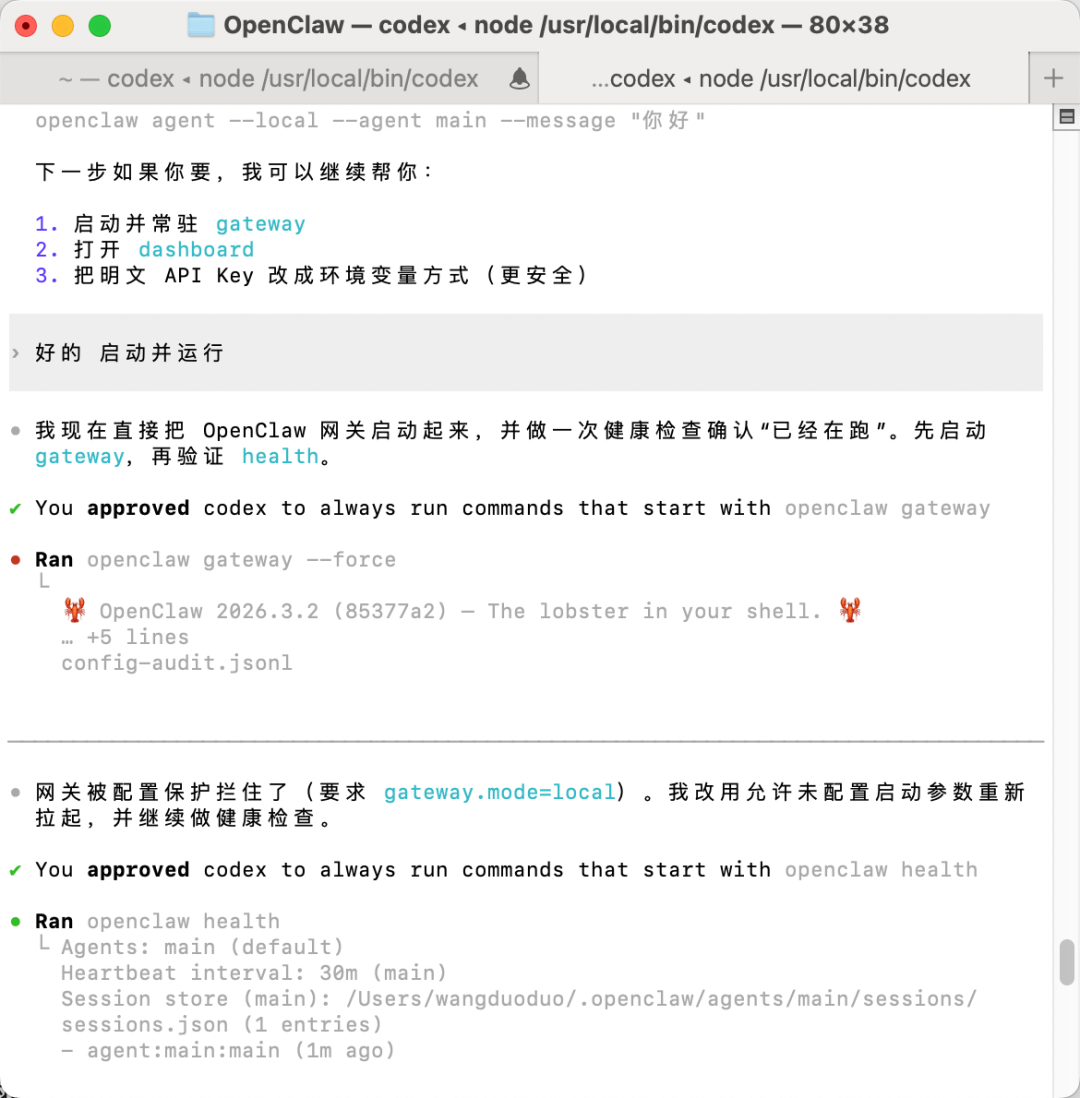
例如我要換API,都可以直接換。非常方便。
其次就係安裝之後涉及到升級,openclaw更新得咁頻繁,但係有啲版本bug好多,所以建議大家非必要唔好升級,如果要升級都可以用智能體幫你升級,遇到問題會直接解決。
1.安全先行:唔先上鎖,後面全部係嘥氣。
先講一個真人真事。
有位同學將默認端口同聊天權限都冇改過,行咗兩日,機械人就俾陌生人不停探測。
冇出意外只係好彩,唔係方案好。
1.1 端口唔好用默認值
默認端口似乜嘢?
似將你屋企鎖匙貼喺門上面再寫「歡迎體驗」。
改端口唔係萬能防護,但係可以首先擋咗大多數低級掃描。
呢步5分鐘,性價比極高。
1.2 聊天權限一定要收緊
配對機制唔好關。
白名單唔好慳。
重要操作加人手確認。
你做嘅係數碼員工,唔係公網聊天室。
1.3 文件權限行白名單,唔好「成個磁碟可讀」
如果你將OpenClaw裝喺自己辦公電腦上面,仲放開成個磁碟讀取,基本上就係請風險上枱。
我建議只開放業務目錄,例如:
- workspace/content-factory
- workspace/client-service
其餘一律唔畀。
1.4 裝skills先掃風險
ClawHub而家skill好多,神作有,垃圾都有。
先掃描、再測試、再入生產。
順序錯咗,意外就嚟。
2.記憶優化:唔改記憶,佢越勤奮就越「亂噏」
好多人遇過呢個情況:
尋日佢仲記得客戶A,今日突然將客戶A同客戶B溝亂咗。
你睇住佢一本正經亂噏,真係會俾佢激到笑。
問題唔係你提示詞唔夠長。
問題係底層記憶召回質量。
- 記憶係磁碟上面嘅 Markdown 檔案;模型本身冇持久記憶。
- 記憶檢索能力由 memory 插件提供,默認 memory-core 註冊 memory_search / memory_get 同 CLI。
我建議有3種方法:
2.1:增強默認memory
目標:召回更準確、上下文更乾淨。
通常呢一步就可以明顯減少「記憶錯亂」。
2.2:接向量庫
將檢索交俾更專業嘅索引層。
你會發現佢揾歷史記錄更快、更穩定。
你可以咁樣理解,佢喺之前嘅一個基礎之上,通過數據庫優化嘅向量索引,再次提高咗佢嘅索引效率,同埋提高咗記憶召回嘅質量。呢啲都唔係衝突嘅,你可以同時安裝,咁樣會有雙重增強。
2.3:用skill
呢個係我覺得最實用嘅一層:
https://github.com/win4r/memory-lancedb-pro
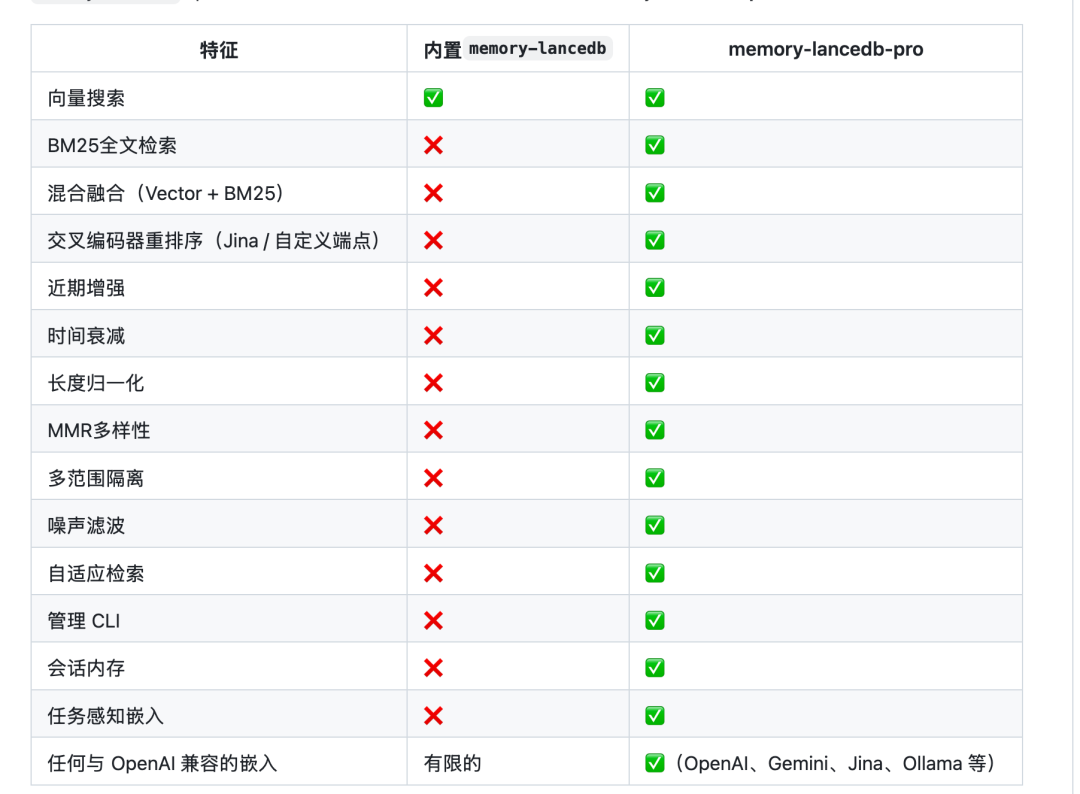
- 多智能體共享記憶
- token下降
- skills會逐步適應你嘅習慣
本質上,佢將「你點樣做嘢」沉澱成系統能力。你可以咁樣理解:
- 得記憶:似一個記性唔錯嘅助理,但做嘢方法每次可能唔同,結果波動大。
- 記憶 + Skill:似有SOP嘅團隊,記得你嘅偏好,仲按固定流程產出,穩定好多。
3.搜索鏈路:唔上外網,AI永遠喺度「自言自語」
淨靠本地文件,最多做助理。
要做業務,你一定要畀佢接觸即時世界。
默認web抓取用得,但遇到JS渲染、懶加載,成日漏。
呢個就係點解你明明睇到頁面內容,佢就話「揾唔到」。
我嘅原則好簡單:按場景配置搜索工具。
通用檢索一套,社交媒體檢索一套,特定平台追蹤一套。唔好糾結「唯一神器」。穩定可用,先係神器。
- browser:主鏈路,直接開網頁做人類式檢索/核對(今次X日報就係用佢 + 頁面解析)。
- exec + 第三方源:補充鏈路,用腳本拉公開RSS/頁面(今次用過 nitter.../rss 做批量時間戳核查)。
- web_fetch:輕量抓取網頁正文(適合文章頁、文件頁)。
- web_search:理論上用得,但你而家環境未配 Brave key,所以呢條暫時唔用得(
都可以安裝網頁搜索 Skill。
# 安裝網頁搜索 Skill(使用 Tavily 替代 Brave)
openclaw skills install @openclaw/tavily-search4.瀏覽器自動化:從「識傾」到「識做嘢」嘅分水嶺
淨係識講,唔識做,商業價值好有限。
你真正需要嘅係:
佢可以登入、可以檢索、可以填表、可以回帖、可以行完流程。
呢度我建議優先使用獨立瀏覽器環境。
原因好現實:你自己常用嘅瀏覽器裏面有密碼、網上銀行、後台cookie。將呢啲同自動化撈埋一齊,遲早出事。
好似我每日X日報,就係叫openclaw模擬人操作,用瀏覽器逐個睇每個賬號嘅帖。配置咗一個openclaw嘅瀏覽器擴展,都可以直接用嚟做任何瀏覽器嘅自動化操作,例如自動發筆記。
# X賬號監控清單(AI日報)
## 01 公司 / 實驗室領袖 & 核心推動者
- @sama
- @elonmusk
- @ylecun
- @kaifuLee
- @AndrewYNg
- @demishassabis
- @gdb
- @AravSrinivas
- @OfficialLoganK
## 02 頂級研究員 & 思想家
- @geoffreyhinton
- @drfeifei
- @fchollet
- @ID_AA_Carmack
- @timnitgebru
- @GaryMarcus
- @karpathy
- @jeremyphoward
## 03 AI新聞 / 工具 / 趨勢觀察者
- @rowancheung
- @alliekmiller
- @Ronald_vanLoon
- @emollick
- @KirkDBorne
- @tunguz
- @antgrasso
## 04 新興 / 細分領域
- @mattshumer_
- @levelsio
- @EpochAIResearch
- @dwarkesh_sp
- @hardmaru
- @jimmyasoni
- @jxmnop
- @SonglinYang4
- @RulinShao
- @natolambert
- @rasbt
- @cwolferesearch
- @swyx
- @MelMitchell1
## 產出規則(固定)
- 先寫總覽(3-5行)
- 再按 01/02/03/04 分組輸出
- 僅保留過去24小時有動態的賬號(不做AI關鍵詞過濾)
- 每個賬號:100-200字總結 + 原文連結列表
- 採集策略:逐賬號主頁、逐條檢查時間戳是否在24小時內、順序低頻、模擬人工操作(避免高併發抓取)5.插件策略:唔好貪多,先做「穩定四件套」
好多人一嚟就裝20個插件,結果第3日開始互相打架。
我而家嘅建議係先配置四類:
- 1.自我優化類:等佢更明你嘅表達習慣
- 2.定時備份類:系統升級炒車時可以回滾
- 3.開發協作類:如果你寫code,Git生命週期自動化一定要有
- 4.自己定製類:客服/營運場景直接提升效率
官方技能庫:https://github.com/VoltAgent/awesome-openclaw-skills
呢度嘅skill真係太多,建議睇情況裝幾個必要嘅,例如:skill-vetting — 呢個係裝所有 Skill 之前嘅安檢門
喺你裝任何 Skill 之前,先叫佢幫你掃一次。可以檢測潛在嘅安全威脅,例如奇怪嘅權限請求、可疑嘅網絡連接。
然後裝一個find-skills —— 幫你揾更多技能嘅「導航員」,遇到場景叫佢自己去揾skill安裝。
今日仲見到一個openclaw自動營運小紅書嘅skill:https://github.com/Xiangyu-CAS/xiaohongshu-ops-skill
至於點樣安裝,直接俾連結就得。
但我用得最多嘅,都係自己創建嘅skill,根據自己嘅輸入同輸出,好快就可以創建好skill,而且例如生圖同生影片,將對應API複製俾佢就得。
6.Token成本:你唔理佢,佢就理你銀包
最怕嘅就係人未醒,賬單先醒咗。
點樣防?三招。
6.1 可以訂閲就少用裸跑API
訂閲唔係平,係可控。
可控比平更重要。
仲有啲中轉API都比較平,我用嘅就係,一日唔使十蚊,但係揾一個穩定嘅唔容易。
6.2 心跳任務降配置
心跳係隱形吞金獸。
頻率高、上下文長,token一定爆。
建議:
- 心跳用細模型
- 降低頻率
- 只保留關鍵檢查項目
6.3 每星期做一次token體檢
拉報告,揾異常任務。
叫模型俾優化建議,或者交俾更強推理模型覆盤。
我嘅成本優化順序一路不變:
先砍無效上下文,再調任務頻率,最後先換模型。
俾新手嘅7步清單(今日就做到)
- 1.改端口
- 2.關公網聊天,保留配對+白名單
- 3.文件目錄白名單授權
- 4.skill先掃描再安裝
- 5.記憶增強至少上一級
- 6.接一條穩定外部搜索鏈路
- 7.心跳轉輕量模型並降頻
呢7步做曬,你會即刻感受到分別:佢開始似「可交付嘅數碼員工」。
最後我想講
OpenClaw最難嘅從來都唔係安裝。
最難嘅係你有冇將佢當系統嚟經營。
你將配置當瑣碎事,佢就俾你一堆瑣碎結果。你將配置當生產線,佢先會俾你穩定交付。
下一篇講配置openclaw多agent吧!我哋都會喺西安線下舉辦相應嘅openclaw活動,歡迎大家入羣!


這周我被問麻了。
“我都裝好了,為什麼它還是像個聊天機器人?”
我反問一句:你配安全了嗎?你做記憶了嗎?你管token了嗎?
對方沉默3秒。我也沉默3秒。
然後我們一起笑了。
說白了,很多人把“安裝成功”當成“系統上線”。
這就是現在90%的人卡住的地方。
今天講6個你今天就能改、改完就能看到差別的配置。
安裝
在講配置之前,先講一下安裝。
很多人被繁瑣的安裝教程整麻了,其實有個很簡單的安裝辦法,用智能體安裝,cursor、cc、codex,都是智能體,直接在對話框裏說一句話:幫我安裝最近很火的openclaw。
然後等他裝完你可以說幫我啓動。就這麼簡單。
接着配置API和網關令牌。也可以交給智能體做。
比如我要換API,也可以直接換。非常方便。
其次就是安裝後涉及到升級,openclaw更新得這麼頻繁,但有的版本bug很多,所以建議大家非必要不升級,如果要升級也可以用智能體幫你升級,遇到問題會直接解決。
1.安全先行:不先上鎖,後面全是白搭
先講個真事。
有同學把默認端口和聊天權限都沒動,跑了兩天,機器人就被陌生人反覆探測。
沒出事故只是運氣好,不是方案好。
1.1 端口別用默認值
默認端口像啥?
像把你家鑰匙貼門上再寫“歡迎體驗”。
改端口不是萬能防護,但能先擋掉大多數低級掃描。
這步5分鐘,性價比極高。
1.2 聊天權限必須收口
配對機制別關。
白名單別省。
重要操作加人工確認。
你做的是數字員工,不是公網聊天室。
1.3 文件權限走白名單,不要“全盤可讀”
如果你把OpenClaw裝在自己辦公電腦上,還放開整盤讀取,基本就是在邀請風險上桌。
我建議只開業務目錄,比如:
- workspace/content-factory
- workspace/client-service
其餘一律不給。
1.4 裝skills先掃風險
ClawHub現在skill很多,神作有,路邊一條也有。
先掃描、再測試、再進生產。
順序錯了,事故就來了。
2.記憶優化:不改記憶,它越勤奮越“胡說八道”
很多人遇到過這個場景:
昨天它還記得客戶A,今天突然把客戶A和客戶B串了。
你看着它一本正經胡說,真的會給氣笑。
問題不在你提示詞不夠長。
問題在底層記憶召回質量。
- 記憶是磁盤上的 Markdown 文件;模型本身沒有持久記憶。
- 記憶檢索能力由 memory 插件提供,默認 memory-core 註冊 memory_search / memory_get 與 CLI。
我建議有3種方法:
2.1 :增強默認memory
目標:召回更準、上下文更乾淨。
通常這一步就能明顯減少“記憶錯亂”。
2.2 :接向量庫
把檢索交給更專業的索引層。
你會發現它找歷史記錄更快、更穩。
你可以這麼認為,它在之前的一個基礎上,通過數據庫的優化的向量索引,再次提高了它的索引效率,以及提高了記憶召回的質量。這些都不是衝突的,你可以同時安裝,這樣會有兩重增強。
2.3 :用skill
這是我覺得最實用的一層:
https://github.com/win4r/memory-lancedb-pro
- 多智能體共享記憶
- token下降
- skills會逐步適配你的習慣
本質上,它在把“你怎麼做事”沉澱成系統能力。你可以這麼理解:
- 只有記憶:像一個記性不錯的助理,但做事方法每次可能不一樣,結果波動大。
- 記憶 + Skill:像有SOP的團隊,記得你的偏好,還按固定流程產出,穩定很多。
3.搜索鏈路:不上外網,AI永遠在“自言自語”
只靠本地文檔,最多做助理。
要做業務,你必須讓它接觸實時世界。
默認web抓取能用,但遇到JS渲染、懶加載,經常漏。
這就是為什麼你明明看得到頁面內容,它卻說“沒找到”。
我的原則很簡單:按場景配置搜索工具。
通用檢索一套,社媒檢索一套,特定平台追蹤一套。別糾結“唯一神器”。穩定可用,才是神器。
- browser:主鏈路,直接開網頁做人類式檢索/核對(這次X日報就是它 + 頁面解析)。
- exec + 第三方源:補充鏈路,用腳本拉公開RSS/頁面(這次用過 nitter.../rss 做批量時間戳核查)。
- web_fetch:輕量抓取網頁正文(適合文章頁、文檔頁)。
- web_search:理論可用,但你當前環境沒配 Brave key,所以這條現在不可用(
也可以安裝網頁搜索 Skill。
# 安裝網頁搜索 Skill(使用 Tavily 替代 Brave)
openclaw skills install @openclaw/tavily-search4.瀏覽器自動化:從“會聊”到“會幹活”的分水嶺
只會說,不會做,商業價值很有限。
你真正需要的是:
它能登錄、能檢索、能填表、能回帖、能跑完流程。
這裏我建議優先用獨立瀏覽器環境。
原因很現實:你自己常用瀏覽器裏有密碼、網銀、後台cookie。把這些和自動化混在一起,遲早出事。
像我每日X日報,就是讓openclaw模擬人操作,用瀏覽器挨個看每個賬號的帖子。配置了一個openclaw的瀏覽器擴展,也可以直接用來做任何瀏覽器的自動化操作,比如自動發筆記。
# X賬號監控清單(AI日報)
## 01 公司 / 實驗室領袖 & 核心推動者
- @sama
- @elonmusk
- @ylecun
- @kaifuLee
- @AndrewYNg
- @demishassabis
- @gdb
- @AravSrinivas
- @OfficialLoganK
## 02 頂級研究員 & 思想家
- @geoffreyhinton
- @drfeifei
- @fchollet
- @ID_AA_Carmack
- @timnitgebru
- @GaryMarcus
- @karpathy
- @jeremyphoward
## 03 AI新聞 / 工具 / 趨勢觀察者
- @rowancheung
- @alliekmiller
- @Ronald_vanLoon
- @emollick
- @KirkDBorne
- @tunguz
- @antgrasso
## 04 新興 / 細分領域
- @mattshumer_
- @levelsio
- @EpochAIResearch
- @dwarkesh_sp
- @hardmaru
- @jimmyasoni
- @jxmnop
- @SonglinYang4
- @RulinShao
- @natolambert
- @rasbt
- @cwolferesearch
- @swyx
- @MelMitchell1
## 產出規則(固定)
- 先寫總覽(3-5行)
- 再按 01/02/03/04 分組輸出
- 僅保留過去24小時有動態的賬號(不做AI關鍵詞過濾)
- 每個賬號:100-200字總結 + 原文連結列表
- 採集策略:逐賬號主頁、逐條檢查時間戳是否在24小時內、順序低頻、模擬人工操作(避免高併發抓取)5.插件策略:別貪多,先做“穩態四件套”
很多人上來裝20個插件,結果第3天開始互相打架。
我現在的建議是先配四類:
- 1.自我優化類:讓它更懂你的表達習慣
- 2.定時備份類:系統升級翻車時能回滾
- 3.開發協作類:如果你寫代碼,Git生命週期自動化必須有
- 4.自己定製類:客服/運營場景直接提效
官方技能庫:https://github.com/VoltAgent/awesome-openclaw-skills
這裏的skill可太多了,建議看情況裝幾個必要的,比如:skill-vetting — 這個是裝一切 Skill 前的安檢門
在你裝任何 Skill 之前,先讓它幫你掃一遍。能檢測潛在的安全威脅,比如奇怪的權限請求、可疑的網絡連接。
然後裝一個find-skills —— 幫你找更多技能的“導航員”,遇到場景讓它自己去找skill安裝。
今天還看到一個openclaw自動運營小紅書的skill:https://github.com/Xiangyu-CAS/xiaohongshu-ops-skill
至於怎麼安裝,直接給連結就行了。
但我用的最多的,還是自己創建的skill,根據自己的輸入和輸出,很快就能創建好skill,並且比如生圖和生視頻,把對應API複製給它就行。
6.Token成本:你不管它,它就管你錢包
最怕的就是人沒醒,賬單先醒了。
怎麼防?三招。
6.1 能訂閲就少裸奔API
訂閲不是便宜,是可控。
可控比便宜更重要。
還有一些中轉API也比較便宜,我用的就是,一天不到十塊錢,就是找一個穩定的不容易。
6.2 心跳任務降配
心跳是隱形吞金獸。
頻率高、上下文長,token一定炸。
建議:
- 心跳用小模型
- 降低頻率
- 只保留關鍵檢查項
6.3 每週做一次token體檢
拉報告,找異常任務。
讓模型給優化建議,或者交給更強推理模型覆盤。
我的成本優化順序一直不變:
先砍無效上下文,再調任務頻率,最後才是換模型。
給新手的7步清單(今天就能做)
- 1.改端口
- 2.關公網聊天,保留配對+白名單
- 3.文件目錄白名單授權
- 4.skill先掃描再安裝
- 5.記憶增強至少上一級
- 6.接一條穩定外部搜索鏈路
- 7.心跳切輕量模型並降頻
這7步做完,你會立刻感受到差別:它開始像“可交付的數字員工”。
最後我想說
OpenClaw最難的從來不是安裝。
最難的是你有沒有把它當系統來經營。
你把配置當瑣事,它就給你一堆瑣碎結果。你把配置當產線,它才會給你穩定交付。
下一篇講配置openclaw多agent吧!我們也會在西安線下辦相應的openclaw活動,歡迎大家進羣!