視頻分鏡提示詞Skill,詳細製作過程分享!
整理版優先睇
將劇本自動化轉化為 AI 影片分鏡提示詞的 Skill 製作全攻略,教你點樣用結構化思維拆解複雜任務。
呢篇文章係由作者阿真分享,針對 AI 影片創作中「劇本轉分鏡」呢個痛點,提供咗一套完整嘅 Coze Skill 製作思路同埋技術架構。作者想解決嘅係點樣將一段文字劇本,穩定噉轉化成包含角色、場景、運鏡等細節嘅專業提示詞,避免 AI 生成內容時風格走樣或者邏輯混亂。
整體結論係:要做出高質量嘅 AI 工具,唔可以只靠一條簡單嘅 Prompt,而係要將任務拆解成「SKILL.md(定義)、scripts(執行)、references(規範)、assets(模板)」四個層次。透過將劇本解析、角色提取、分鏡生成等步驟腳本化,可以大幅提升產出嘅一致性同埋可重用性。
- 核心架構:採用四層結構,包括 SKILL.md 定位入口、scripts 自動化腳本、references 知識規範同埋 assets 交付模板。
- 標準化流程:將製作過程拆解成「劇本解析、角色提取、場景分析、分鏡生成、提示詞優化、一致性檢查、格式導出」七大步驟。
- 模組化腳本:建議將唔同功能寫成獨立 Python 腳本(如 parse_script.py),方便單獨測試同埋節省 Token 消耗。
- 一致性控制:透過 references 文件夾存放術語表同埋風格指南,確保 AI 喺生成唔同鏡頭時,角色外貌同場景氛圍唔會跳戲。
- 實戰建議:開發 Skill 時應先制定標準(輸入輸出格式),中期優化功能模組,後期再進行多劇本測試同埋封裝。
劇本轉影片分鏡 Skill 完整文件
包含 SKILL.md、自動化腳本、參考規範同模板嘅完整 Skill 包,可直接喺 Coze 或相關工具使用。
Coze Skill 在線體驗
作者分享喺 Coze 平台嘅劇本生成分鏡工具,可以直接上手試用。
高質量 Skill 嘅四層文件結構
要做一個專業嘅 Skill,唔係寫一段 Prompt 就搞掂,而係要好似寫程式咁有組織。作者建議將文件分成四個部分,各司其職:
由劇本到分鏡:七步自動化流程
作者將整個轉換過程拆細,確保 AI 唔會因為資訊量太大而「斷片」。呢個流程可以確保由文字到畫面嘅轉換係有跡可循嘅:
劇本解析 -> 角色提取 -> 場景分析 -> 分鏡生成 -> 提示詞優化 -> 一致性檢查 -> 多格式導出
其中「一致性檢查」係關鍵,佢會交叉比對角色同場景喺唔同鏡頭之間有無偏差,輸出修復建議。
核心定義文件:SKILL.md 範例
呢份係 Skill 嘅靈魂,定義咗 AI 應該點樣處理用戶上傳嘅劇本文件。
# 短劇劇本轉視頻提示詞生成器
## 工作流程
1. 劇本智能解析 (scripts/parse_script.py)
2. 角色設定提取 (scripts/character_extractor.py)
3. 場景設定分析 (scripts/scene_analyzer.py)
4. 分鏡提示詞生成 (scripts/storyboard_generator.py)
5. 一致性校驗 (scripts/consistency_checker.py)
6. 導出 (scripts/export_utils.py)
## 輸出結構
- 項目元數據
- 風格總設定
- 角色/場景設定庫
- 完整分鏡提示詞 (中文)開發心得:點樣同 AI 溝通最有效?
作者分享咗幾個開發技巧,等你可以更慳 Token 兼且提高準確率:

喂大家好!我係阿真!新年快樂!
好耐冇見喇,放假放得好爽,返嚟要搏命做嘢喇。今日呢篇比較輕鬆,我先熱吓身,寫個簡單啲關於影片提示詞 Skill 製作嘅內容。
上次寫 Coze Skill 嘅時候,我曾經分享過一個劇本生成分鏡嘅 Skill,大家可以直接喺 Coze 用,連結喺:
https://www.coze.cn/?skill_share_pid=7596234767713173538
亦都可以直接下載 Skill 檔案,附件連結我放咗喺文章最後嘅飛書雲端文檔連結度。原版 Skill 做得比較通用,大家可以喺我嘅基礎上面再改。

關於佢點樣用,我喺 Coze Skill 都寫過,就唔再多講喇,喺上面呢個 Coze 技能度亦都可以睇到使用案例:

或者下載最後嘅 Skill 檔案,上傳去支援 Skill 嘅工具度用都得:
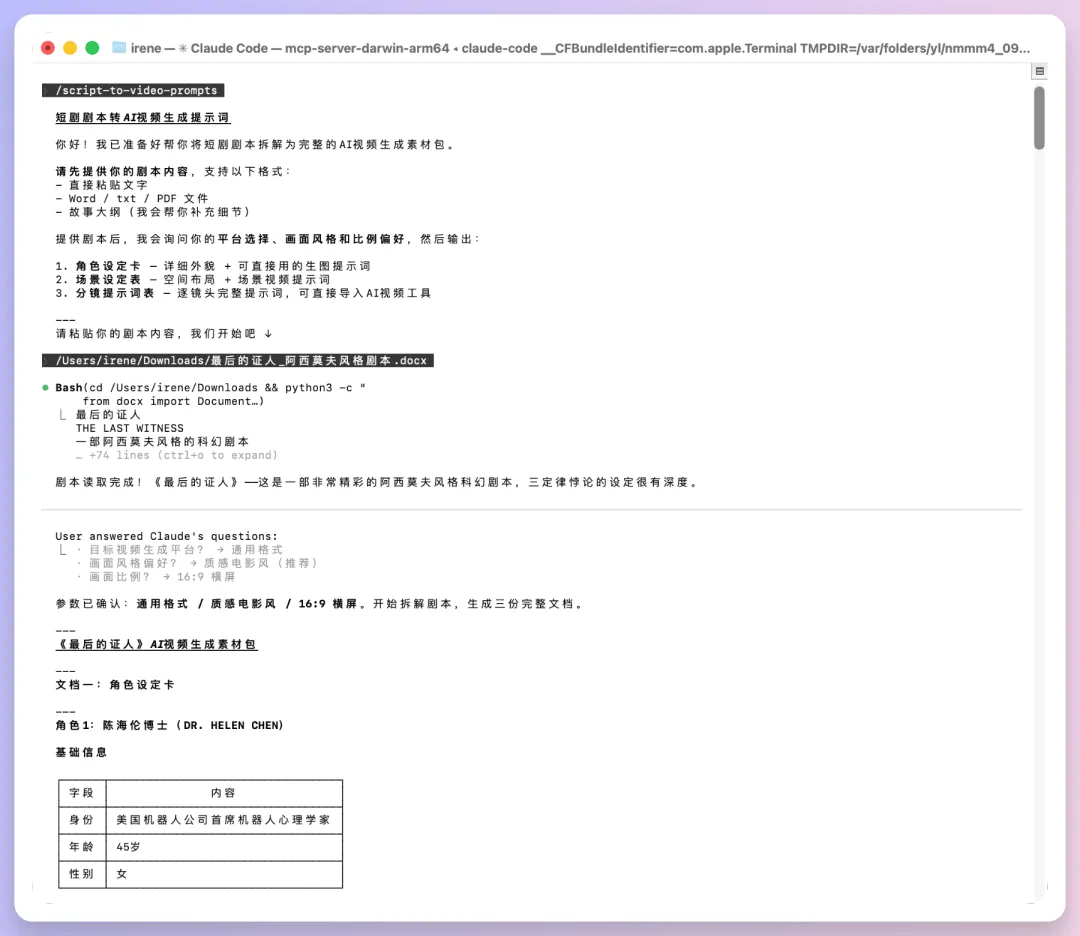
今日分享呢類 Skill 係點樣整嘅。
簡單嚟講思路就係,首先諗清楚要做啲咩,然後將任務一步步拆細,先整好整體結構,再填充內容。
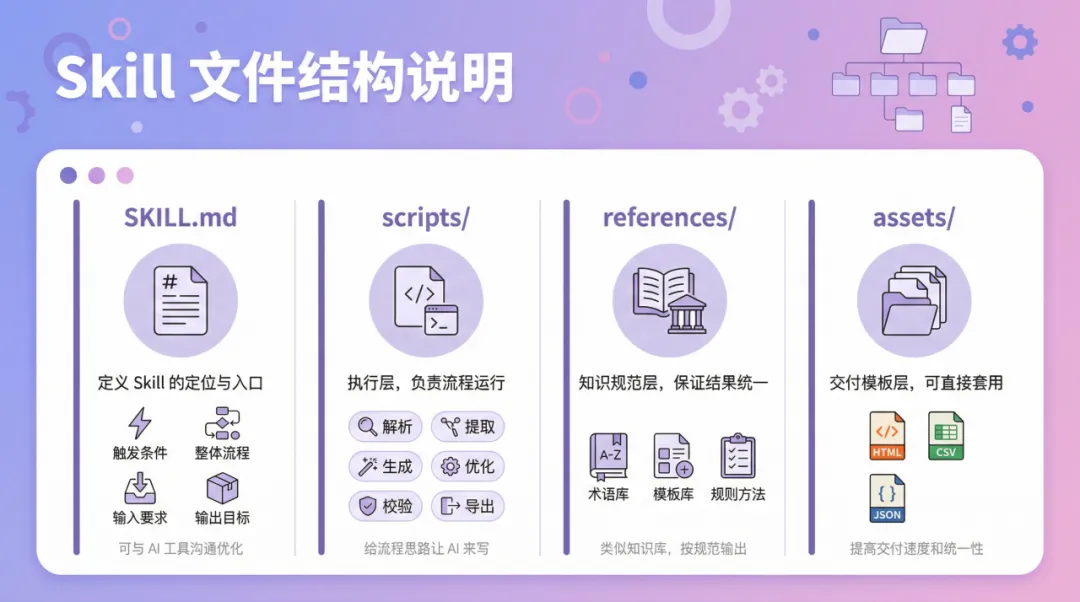
完整嘅 Skill 結構係咁樣嘅:

上面幾個結構嘅說明👇
SKILL.md:定義呢個 Skill 嘅定位同入口,說明點樣觸發、整體流程、輸入要求、輸出目標。呢個可以自己寫個雛形,然後同 AI 工具溝通再優化。
scripts/:執行層,呢度放嘅係 Python 自動化腳本,負責將流程真正行起嚟(解析、提取、生成、優化、匯出等)。呢部分可以俾個流程思路等 AI 嚟寫。
references/:知識規範層,提供術語、模板、規則同方法,保證結果統一、可解釋、可複用。類似知識庫,可以將平時用開嘅格式規範擺入去,並且喺需要生成具體某部分內容嘅時候,要求佢跟住呢個規範輸出。
assets/:交付模板層,提供可以直接套用嘅資源檔案(例如 HTML/CSV/JSON 模板同速查表)。佢可以提高交付速度同統一性,避免每次都要由零開始整格式同排版。
下面係 SKILL.md 檔案,完整嘅 Skill 內容大家可以喺文章最後嘅分享連結去下載睇返:
---
name: script-to-video-prompts
description: 短劇劇本轉視頻提示詞生成器。將用戶上傳的短劇劇本文檔智能拆解為可直接用於AI視頻生成的完整中文提示詞體系。輸出包括:角色設定提示詞、場景設定提示詞、逐鏡頭分鏡提示詞。支持批量處理、多格式導出、一致性校驗。當用戶說"劇本轉視頻提示詞"、"拆解劇本生成分鏡"、"短劇轉視頻"、"批量生成分鏡提示詞"、"劇本可視化"時觸發。
---
# 短劇劇本轉視頻提示詞生成器
將短劇劇本文檔智能拆解為可直接用於AI視頻生成的完整中文提示詞體系,支持自動化批量處理。
## 用戶輸入
- 短劇劇本文檔(Word/PDF/TXT/Markdown/Final Draft .fdx)
- 可選:風格參考圖片、角色參考圖片、已有角色設定表
## 工作流程
### 1. 劇本智能解析
使用 `scripts/parse_script.py` 解析劇本:
- 自動識別劇本格式(標準編劇格式/自由格式)
- 提取場次(Scene)、場景描述(Action)、角色對白(Dialogue)、動作指示(Parenthetical)
- NLP分析:情緒曲線、節奏變化、畫面密度
- 自動生成場次時長估算
### 2. 角色設定提取
使用 `scripts/character_extractor.py` 提取角色信息:
- 基礎外貌(年齡、性別、體型、五官特徵)
- 髮型髮色、膚色
- 服裝造型(支持多場次服裝變化追蹤)
- 角色氣質/性格的視覺化表達
- 標誌性道具/配飾
輸出格式參考 [references/character_template.md](references/character_template.md)
### 3. 場景設定分析
使用 `scripts/scene_analyzer.py` 分析場景:
- 場景類型(室內/室外、具體地點)
- 空間結構、關鍵道具佈置
- 光線設計(光源類型、方向、強度、色温)
- 色彩基調、視覺氛圍
- 天氣/時間/季節
輸出格式參考 [references/scene_template.md](references/scene_template.md)
### 4. 分鏡提示詞生成
使用 `scripts/storyboard_generator.py` 生成分鏡:
- 鏡頭編號(場次-鏡號)
- 景別(大特寫/特寫/中近景/中景/中遠景/遠景/大遠景),詳見 [references/shot_terminology.md](references/shot_terminology.md)
- 畫面構圖(三分法位置、視線引導)
- 角色動作、表情、站位
- 運鏡方式(固定/推/拉/搖/移/跟等),詳見 [references/shot_terminology.md](references/shot_terminology.md)
- 情緒氛圍關鍵詞,詳見 [references/mood_keywords_library.md](references/mood_keywords_library.md)
- 建議時長(秒)
- 轉場方式
### 5. 一致性校驗
使用 `scripts/consistency_checker.py` 校驗:
- 角色跨鏡頭一致性控制
- 場景連續性檢查
- 光影風格統一性校驗
- 詳見 [references/consistency_control.md](references/consistency_control.md)
### 6. 導出
使用 `scripts/export_utils.py` 導出:
- 支持格式:Markdown/JSON/CSV/Excel
- 支持按場次/角色/場景分類導出
- 可生成可視化分鏡腳本
## 輸出結構
```
一、項目元數據
- 片名、集數、總時長、場次數
二、風格總設定
- 畫面風格、色彩體系、光影風格
三、角色設定庫
- JSON結構化數據 + 自然語言描述
四、場景設定庫
- JSON結構化數據 + 自然語言描述
五、完整分鏡提示詞
- 按場次順序排列,提示詞全部使用中文
六、一致性參考表
- 角色/場景一致性種子詞
```
## 參考文件
### scripts/(自動化腳本)
- `parse_script.py` - 劇本解析器
- `character_extractor.py` - 角色信息提取
- `scene_analyzer.py` - 場景分析
- `storyboard_generator.py` - 分鏡生成
- `consistency_checker.py` - 一致性校驗
- `export_utils.py` - 多格式導出
- `prompt_optimizer.py` - 提示詞優化
### references/(規範文檔)
- `screenplay_format_spec.md` - 劇本格式規範
- `character_template.md` - 角色設定模板
- `scene_template.md` - 場景設定模板
- `shot_terminology.md` - 景別/運鏡術語詞典
- `mood_keywords_library.md` - 情緒氛圍關鍵詞庫
- `video_style_guide.md` 視頻風格指南
- `consistency_control.md` - 一致性控制指南
- `prompt_patterns.md` - 高效提示詞模式庫
### assets/(模板資源)
- `storyboard_template.csv` - 分鏡腳本CSV模板
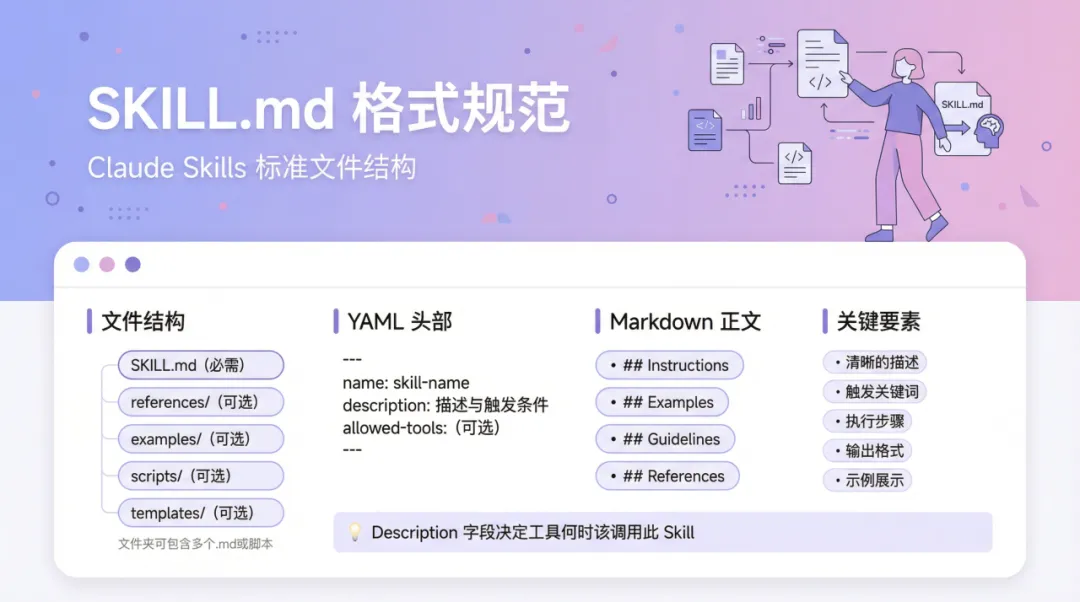
- `export_template.html` - 可視化導出HTML模板下方【文件結構】係 Skill 嘅檔案結構,佢嘅檔案結構入面一定要有 SKILL.md 檔案。YAML 頭部、Markdown 正文同關鍵要素係SKILL.md 嘅格式規範。(可選)嘅部分係唔固定嘅,可以係檔案亦可以係資料夾,資料夾嘅命名亦都可以跟返自己嘅要求嚟👇
製作 Skill 嘅時候,可以前期制定標準,中期優化功能模組,後期測試優化同封裝。下面係完整嘅執行思路,注意下方雖然分咗步驟,但實際生成 Skill 嘅時候,佢亦都可以一次過執行晒所有要求,再根據效果繼續優化調整。
前期:制定標準
我希望呢個 Skill 嘅工作流程係咁樣嘅:
劇本解析 → 角色提取 → 場景分析 → 分鏡生成 → 提示詞優化 → 一致性檢查 → 匯出。

如果冇具體明確嘅工作流程要求,後面所有實現都會預設跟住呢個規範。
確定支援邊啲輸入:例如 txt/md/docx/pdf/fdx。同時定義預設輸入係一個劇本文檔,亦都可以係一段話甚至一句話,但係咁樣嘅話效果同內容走向可能會比較難控制;「推薦輸入」可以加角色圖參考、風格圖參考、畫幅要求、時長限制。
先寫清楚最終要產出邊啲檔案:角色設定、場景設定、分鏡提示詞、一致性報告、匯出檔案格式等,呢一步嘅作用係防止中途愈做愈偏。
確定每一步輸入輸出係點樣。我希望佢輸出嘅分鏡表係點樣,希望佢輸出角色設計提示詞格式係點樣等等。呢一步好關鍵,每個輸出項嘅欄位(field)先定好,再叫 AI 按要求輸出,後面就唔會亂。
例如我希望完整嘅分鏡提示詞表係跟住第 X 幕第 X 場景,每個場景嘅提示詞表包含鏡頭編號、景別、畫面描述、構圖、運鏡、光線、色調、氛圍、時長、鏡頭角度、提示詞等。咁我可以自己整或者叫 AI 嚟生成一個咁樣統一嘅表格模板,如果本身有呢類模板,亦都可以直接擺入去。後面嘅每個腳本都讀寫呢個模板,並且跟住呢個格式輸出,咁就唔會唔同幕同場景之間格式對唔上。
可以整定啲 Template(模板)擺喺 assets 入面,等 AI 生成腳本嗰陣可以參考呢啲規範嚟整。
中期:優化功能模組
references 入面係擺術語同埋模板。
成個 Prompt(提示詞)嘅規則可以輸出做獨立文件,例如劇本格式規範、鏡頭術語、情緒詞庫、Prompt 模板、一致性指南等等。咁樣會更加方便修改同埋規範指定方向嘅內容。其他人睇嗰陣,亦都會知點解要咁做。
assets 入面係擺啲可以重複使用嘅模板內容。
例如:分鏡 CSV 模板、角色 Prompt 模板、HTML 模板、Cheat Sheet(速查表)等等。咁樣每次開新 Project 都可以直接 reuse(複用),唔使重新做過排版同埋啲 Field(字段)。
建議 references 同 assets 入面嘅內容分開生成同優化,輸出咗檔案之後先擺入去,再俾個指定路徑等之後嘅腳本去 call(調用)。
跟住落嚟 7-12 呢幾個模組都係腳本,呢啲全部可以交俾 AI 寫。例如第 7 點嘅 Prompt 參考如下:
幫我生成腳本,用於把原始劇本內容(支持 `txt/md/docx/pdf/fdx`)解析成結構化 JSON,要求自動識別並分類:場景標題(INT/EXT 或“第X場/場景X”)、角色名、對白、動作、轉場,並輸出中文字段:`標題`、`場景列表`、`全角色`、`全地點`、`總時長秒數`、`元數據`(含`場景數`、`角色數`、`地點數`),其中每個場景至少包含`場景編號`、`場景標題`、`地點`、`時間段`、`內外景`、`角色`;規則是“上一行是角色名則下一行優先判定為對白,否則判定為動作”,沒有場景標題時自動創建默認場景,空行跳過;重點先保證穩健性和通用性,不追求複雜算法,優先做到“任何劇本或任意文本內容都能讀入並形成場景列表”;支持通過命令行傳入文件路徑並輸出格式化 JSON,代碼儘量清晰、註釋簡單、依賴缺失時提示安裝。簡單啲(自己直接寫)都得,如果寫完唔滿意,可以喺呢個基礎上叫 AI 優化個 Prompt:
生成一個通用劇本解析腳本,能讀取常見文本格式並智能分析內容,自動識別場景、角色、對白、動作和轉場,輸出清晰的結構化 JSON;要求優先保證穩定可用,即使輸入不規範也能自動補默認場景並正常返回結果。而家啲 AI 工具都好醒目,我哋只要要求佢生成 Skill 嗰陣整埋獨立腳本,佢就會自己搞掂。大多數情況都唔使另外再入 Prompt。
7. 實現【劇本解析】模組
將原始劇本變做結構化數據。識別並生成場景標題、角色名、對白、動作同埋轉場。
8. 實現【角色提取】模組
喺【7】嘅解析結果入面提取角色檔案:性別、年齡層、體型、髮型、關鍵詞。要求輸出嗰陣俾埋每個角色一段 Prompt 描述,之後整分鏡可以直接用,call 嗰陣都方便啲。
9. 實現【場景分析】模組
喺【7】嘅每個場景入面提取地點、室內定室外、時間段、光線、氛圍,幫每個場景生成一條基礎視覺 Prompt。呢一層係全條片嘅視覺基礎,之後嘅鏡頭都會疊加喺上面。
10. 實現【分鏡生成】模組
跟住【7】嘅場景自動拆開做鏡頭,起碼要包括:建立鏡頭(Establishing Shot)、角色出場、對話鏡頭。每個鏡頭都要有編號、景別、運鏡、動作、時長、轉場同埋 Prompt。首先要保證「有鏡頭可以用」,之後再慢慢優化鏡頭嘅藝術感。
11. 實現【提示詞優化】模組
將鏡頭 Prompt 做統一處理:術語標準化、刪除重複嘅 Prompt、補返啲質量詞(提升畫面質素同穩定性嘅萬能詞,例如高質量、電影感、清晰對焦呢類)。咁樣可以令輸出更加夾啲片嘅 Model,唔會每段風格都散晒。有時間嘅話,仲可以針對唔同風格、唔同影片 Model 嚟整唔同嘅 Prompt 規範表。
12. 實現【一致性檢查】模組
檢查角色跨鏡頭嘅 Prompt、場景有無突然跳咗去第度、光線轉變會唔會好突兀等等,最後輸出「問題 + 修復建議 + 複用規範 Prompt」。
後期:測試優化同埋封裝
確認預設嘅導出格式,呢度我希望起碼支援 JSON + CSV + Markdown。目標係等唔同崗位嘅人都可以直接睇同埋直接用。
用 2-3 份唔同嘅劇本行一次全流程。呢啲劇本可以用 AI 生成,或者自己提供都得。
重點檢查:啲 Field(字段)有無漏、鏡頭啱唔啱、Prompt 係咪符合自己要求。
重要嘅部分可以單獨拎出嚟,補充返獨立文件同腳本。例如我對影片 Prompt 有特定要求,咁就可以整一個獨立嘅 Prompt 參考文件(擺喺 references)或者 Prompt 格式參考模板(擺喺 assets),並要求腳本喺指定場景 call 佢。
發現有問題就叫 AI 針對返對應嘅模組嚟改。
最後整理做一個清晰嘅目錄,最簡單可以只係一個 SKILL.md,複雜啲就可以加埋 scripts/、references/、assets/ 呢啲資料夾。我呢度嘅格式係:
SKILL.md + scripts/ + references/ + assets/。
呢部分直接叫 AI 封裝 Skill 然後自己 confirm 就得。去到呢一步,我哋就擁有一個比較完整嘅 Skill 喇。
梳理晒全部步驟之後,就可以輸出一個完整嘅 Prompt,叫 AI 生成 Skill。需要詳細輸出嘅地方,可以單獨生成 Prompt 或者模板之後擺入去,要求腳本去 call。
下面我放咗最初我嘅提示詞要求,後期對呢組提示詞進行咗分步嘅詳細優化,但係我個 Claude 賬號被封咗,所以優化提示詞嘅過程冇咗😅,但大致嘅邏輯思路係上面咁樣嘅,供大家參考。另外,references/ 同埋 assets/ 入面嘅內容都建議通過多輪對話優化到自己滿意為止。
你是一個 Skill 開發助手,幫我從零構建一個「劇本轉視頻分鏡提示詞」Skill。請按以下規格和順序執行,不可跳步,不可合併步驟。
---
【第一步:工作流程定義】
這個 Skill 的工作流程是:先解析劇本結構,識別出幕、場景、對白和動作描述;然後提取所有角色,為每個角色生成設定;接着分析所有場景,為每個場景生成設定;再把每個場景拆解成具體鏡頭,生成分鏡提示詞表;之後對每條提示詞做優化,確保它足夠具體、包含必要的視覺參數、並且與角色和場景設定一致;然後做一致性檢查,交叉比對角色、場景與分鏡之間的偏差;最後按用戶要求的格式導出。不可以跳步,不可以合併步驟。如果用戶沒有特別要求改變流程,永遠執行完整的七步。
【第二步:輸入規格定義】
支持接收 txt、md、docx、pdf 和 fdx 格式的劇本文件。最低可運行的輸入是一個劇本文檔,哪怕只是一段話甚至一句核心概念也能啓動流程,但必須在開始前告訴用戶:當前輸入信息有限,後續生成內容的風格一致性和走向可能不完全可控,建議補充更多信息。推薦的輸入是劇本加上角色參考圖、風格參考圖、目標畫幅比例、目標時長、以及希望的視覺風格關鍵詞。用戶提供的參考圖永遠優先於自己的推斷。
【第三步:最終產出定義】
最終產出:一份角色設定文檔,包含每個角色的外貌、服裝、氣質關鍵詞和可用於 AI 生圖的完整提示詞;一份場景設定文檔,包含每個場景的空間描述、光線類型與方向、主色調和氛圍詞;一份完整的分鏡提示詞表,按照幕、場景、鏡頭三級結構組織;一份一致性檢查報告,標註角色和場景在不同鏡頭之間的視覺偏差;最後是以上所有內容的導出文件,支持 CSV、Markdown、Excel 和 HTML 格式。這五樣東西是這個 Skill 存在的全部目的,任何中間步驟都是為了最終產出它們。
【第四步:統一結構規範】
分鏡提示詞表按第 X 幕第 X 場景組織,每個場景的提示詞表包含以下字段:鏡頭編號、景別、畫面描述、構圖、運鏡、光線、色調、氛圍、時長、鏡頭角度、提示詞。先生成這個統一的表格模板,後面所有腳本都讀寫這個模板並按此格式輸出。
【第五步:references 內容】
生成以下規範文檔:劇本格式規範、鏡頭術語表、情緒詞庫、提示詞模板、一致性檢查指南。每個文檔獨立成文件,方便後期單獨修改。
【第六步:assets 內容】
基於第四步的結構規範,生成以下可複用模板文件:分鏡 CSV 模板、角色提示詞模板、HTML 導出模板、速查表。
【第七步:劇本解析腳本】
寫一個腳本,能讀劇本文件,分出場景、角色、對白和動作,最後輸出為 JSON 格式。代碼清晰精煉、註釋清楚。
【第八步:角色提取腳本】
從解析結果裏提取角色檔案,包含性別、年齡段、體型、髮型、關鍵詞。為每個角色輸出一段可直接用於 AI 生圖的提示詞描述。
【第九步:場景分析腳本】
從每個場景裏提取地點、室內外、時間段、光線、氛圍,為每個場景生成一條基礎視覺提示詞。
【第十步:分鏡生成腳本】
按場景自動拆成鏡頭,至少包含建立鏡頭、角色出場、對話鏡頭,每個鏡頭嚴格按照第四步定義的字段輸出。
【第十一步:提示詞優化腳本】
對所有鏡頭提示詞做統一處理:術語標準化、去重複、補質量詞、輸出質量打分。參考 references/ 中的提示詞模板和鏡頭術語表。
【第十二步:一致性檢查腳本】
檢查角色跨鏡頭是否漂移、場景是否跳變、光線是否變化突兀,輸出「問題 + 修復建議 + 複用規範提示詞」報告。
【第十三步:導出腳本】
將所有產出內容導出為 JSON、CSV、Markdown 三種格式,HTML 格式基於 assets/ 中的 HTML 模板生成。
【第十四步:測試】
用 2-3 份不同類型的劇本跑全流程,重點檢查:字段是否缺失、鏡頭是否正確生成、提示詞是否符合 references/ 中的規範。發現問題後定位到對應腳本,只修改該腳本,不動其他文件。告訴我每份劇本的測試結果和發現的問題。
【第十五步:封裝 SKILL.md】
基於以上所有內容,生成完整的 SKILL.md 文件,包含:定位說明、觸發方式、完整七步流程說明、輸入要求、輸出目標、文件目錄結構。
---
所有文件生成完畢後,輸出完整目錄結構,以及如何用一份測試劇本跑通全流程的指南。幾個問題
最開始點樣理清製作一個 Skill 嘅思路?
首先抓一條主線:諗清楚「用嚟做乜、輸入啲乜、交付輸出啲乜」,再將中間嘅步驟進行拆分(例如解析、生成、檢查、導出),然後要求統一格式,再叫 AI 輸出。
輕鬆慵懶版嘅順序可以係:提示詞直接要求佢可以通過輸入啲乜,獲得啲乜嘢輸出,中間嘅流程係點樣嘅,有邊啲模板可以調用,最後叫 AI 寫腳本。等呢個搞掂咗,需要啲乜再補充。咁樣做唔會一開始就陷入技術細節,亦都唔容易做做下走咗樣。
有任何唔清楚嘅地方都可以問 AI,由大方向到細化都可以問。例如:


AI 可能會寫得好詳細,我哋提取關鍵要素就得。
喺叫 AI 按要求生成 Skill 之前,將要求盡可能梳理得全面啲,覺得邏輯唔夠清晰或者仲有優化空間,都可以叫 AI 繼續去優化提示詞。
點解自動化腳本要單獨抽出來?
自動化腳本要單獨抽出來,係因為佢同說明文檔、模板資源嘅職責完全唔同:喺呢度,腳本負責執行流程並產出結果,參考文檔負責解釋規則同標準,模板就負責規範格式同交付嘅外觀。
點解要分咁多個子腳本?
喺複雜嘅 Skill 入面,將腳本單獨擺喺 scripts/,可以等我哋直接調用、測試、替換同部署,唔會被文檔內容干擾;同時當規則有變嗰陣,我哋可以只係改 references/,當邏輯有變嗰陣就只係改 scripts/,維護成本同排錯成本都會明顯降低。
後期如果要修改內容,點樣要求 AI 去排查同修改會比較慳 token,而且準確高效率?
最簡單嘅方法係:每次只係叫 AI 做一件小事,並話畀佢知「只係改邊度、唔好亂改、改完點樣驗收」。你可以直接講:只係檢查並修改 scripts/scene_analyzer.py(複製文件路徑)入面嘅光線規則,唔好郁其他文件;先搵出問題點,再做最小變動;最後只係話我知改咗邊幾行、會影響啲乜、點樣驗證。咁樣 AI 唔會周圍讀文件、唔會大改 code,token 花得少,結果亦都更穩陣。
至於要唔要改 SKILL.md,取決於你改嘅係規則說明定係代碼細節。
小白判斷法:如果用戶使用方式變咗,就改 SKILL.md;如果只係內部實現變咗,可以唔改。
Skill 下載
下載呢個 Skill,可以查看內部所有文件,安裝咗就可以直接用:
https://my.feishu.cn/docx/PsPfdVFD9oZ3nZxcvBFcGxdgnje
如果對 Skill 唔夠了解,推薦閱讀我好友 @一澤Eze 呢篇:Agent Skills 終極指南:入門、精通、預測
小結
好啦今日嘅分享就先到呢度,啱啱恢復開工感覺腦袋唔係幾靈光咁,等有時間單獨整理 Seedance 2.0 嘅多種提示詞模板同埋寫法。幾時先可以爽快咁用啊,真係好慢!
題外話,大家最近有冇用 OpenClaw?對佢有乜新睇法?我有幾個問題,歡迎朋友們喺評論區一齊討論,用佢賺到錢未定係純粹使錢?用佢完成嘅任務其他工具有冇得替代,定係得佢先做到?用佢使咗幾多錢,攞到啲乜嘢階段性成果未?
期待大家猛猛三連(點讚、訂閱、分享),下期見!
嗨大家好!我是阿真!新年快樂!
好久不見了,放假給我放爽了,回來猛猛幹活了。今天這篇比較輕鬆,我先復健一下,寫個簡單一點的關於視頻提示詞 Skill 製作的。
上次寫Coze Skill的時候,我曾經分享過一個劇本生成分鏡的Skill,大家可以直接在 Coze 使用,連結在:
https://www.coze.cn/?skill_share_pid=7596234767713173538
也可以直接下載 Skill 文件,文件附件連結我放文章最後的飛書雲文檔連結了。原 Skill 做得比較通用,大家可以在我的基礎上修改。
關於它怎麼使用,我在 Coze Skill 也寫過,就不再贅述,在上面這個 Coze 技能這裏也可以看到使用案例:
或者下載最後的 Skill 文件,上傳到支持 Skill 使用的工具使用也可以:
今天分享這樣的 Skill 怎麼做。
簡單來說思路就是,首先想明白要做什麼,然後將任務一步步拆細,先有整體結構,然後填充枝葉。
完整的 Skill 結構是這樣的:
上面幾個結構的說明👇
SKILL.md:定義這個 Skill 的定位與入口,說明怎麼觸發、整體流程、輸入要求、輸出目標。 這個可以自己寫一個雛形,然後和 AI 工具溝通並優化。
scripts/:執行層,這裏放的 Python 自動化腳本,它負責把流程真正跑起來(解析、提取、生成、優化、導出等)。這個可以給到流程思路讓AI來寫。
references/:知識規範層,提供術語、模板、規則和方法,保證結果統一、可解釋、可複用。類似知識庫,可以把往常使用的格式規範放進來,並且在需要生成具體某個部分的內容的時候,要求它按照這個規範輸出。
assets/:交付模板層,提供可直接套用的資源文件(如 HTML/CSV/JSON 模板與速查表)。它可以提高交付速度和統一性,避免每次從零做格式與排版。
下面是SKILL.md文件,完整 Skill 內容大家可以在文章最後的分享連結去下載查看:
---
name: script-to-video-prompts
description: 短劇劇本轉視頻提示詞生成器。將用戶上傳的短劇劇本文檔智能拆解為可直接用於AI視頻生成的完整中文提示詞體系。輸出包括:角色設定提示詞、場景設定提示詞、逐鏡頭分鏡提示詞。支持批量處理、多格式導出、一致性校驗。當用戶說"劇本轉視頻提示詞"、"拆解劇本生成分鏡"、"短劇轉視頻"、"批量生成分鏡提示詞"、"劇本可視化"時觸發。
---
# 短劇劇本轉視頻提示詞生成器
將短劇劇本文檔智能拆解為可直接用於AI視頻生成的完整中文提示詞體系,支持自動化批量處理。
## 用戶輸入
- 短劇劇本文檔(Word/PDF/TXT/Markdown/Final Draft .fdx)
- 可選:風格參考圖片、角色參考圖片、已有角色設定表
## 工作流程
### 1. 劇本智能解析
使用 `scripts/parse_script.py` 解析劇本:
- 自動識別劇本格式(標準編劇格式/自由格式)
- 提取場次(Scene)、場景描述(Action)、角色對白(Dialogue)、動作指示(Parenthetical)
- NLP分析:情緒曲線、節奏變化、畫面密度
- 自動生成場次時長估算
### 2. 角色設定提取
使用 `scripts/character_extractor.py` 提取角色信息:
- 基礎外貌(年齡、性別、體型、五官特徵)
- 髮型髮色、膚色
- 服裝造型(支持多場次服裝變化追蹤)
- 角色氣質/性格的視覺化表達
- 標誌性道具/配飾
輸出格式參考 [references/character_template.md](references/character_template.md)
### 3. 場景設定分析
使用 `scripts/scene_analyzer.py` 分析場景:
- 場景類型(室內/室外、具體地點)
- 空間結構、關鍵道具佈置
- 光線設計(光源類型、方向、強度、色温)
- 色彩基調、視覺氛圍
- 天氣/時間/季節
輸出格式參考 [references/scene_template.md](references/scene_template.md)
### 4. 分鏡提示詞生成
使用 `scripts/storyboard_generator.py` 生成分鏡:
- 鏡頭編號(場次-鏡號)
- 景別(大特寫/特寫/中近景/中景/中遠景/遠景/大遠景),詳見 [references/shot_terminology.md](references/shot_terminology.md)
- 畫面構圖(三分法位置、視線引導)
- 角色動作、表情、站位
- 運鏡方式(固定/推/拉/搖/移/跟等),詳見 [references/shot_terminology.md](references/shot_terminology.md)
- 情緒氛圍關鍵詞,詳見 [references/mood_keywords_library.md](references/mood_keywords_library.md)
- 建議時長(秒)
- 轉場方式
### 5. 一致性校驗
使用 `scripts/consistency_checker.py` 校驗:
- 角色跨鏡頭一致性控制
- 場景連續性檢查
- 光影風格統一性校驗
- 詳見 [references/consistency_control.md](references/consistency_control.md)
### 6. 導出
使用 `scripts/export_utils.py` 導出:
- 支持格式:Markdown/JSON/CSV/Excel
- 支持按場次/角色/場景分類導出
- 可生成可視化分鏡腳本
## 輸出結構
```
一、項目元數據
- 片名、集數、總時長、場次數
二、風格總設定
- 畫面風格、色彩體系、光影風格
三、角色設定庫
- JSON結構化數據 + 自然語言描述
四、場景設定庫
- JSON結構化數據 + 自然語言描述
五、完整分鏡提示詞
- 按場次順序排列,提示詞全部使用中文
六、一致性參考表
- 角色/場景一致性種子詞
```
## 參考文件
### scripts/(自動化腳本)
- `parse_script.py` - 劇本解析器
- `character_extractor.py` - 角色信息提取
- `scene_analyzer.py` - 場景分析
- `storyboard_generator.py` - 分鏡生成
- `consistency_checker.py` - 一致性校驗
- `export_utils.py` - 多格式導出
- `prompt_optimizer.py` - 提示詞優化
### references/(規範文檔)
- `screenplay_format_spec.md` - 劇本格式規範
- `character_template.md` - 角色設定模板
- `scene_template.md` - 場景設定模板
- `shot_terminology.md` - 景別/運鏡術語詞典
- `mood_keywords_library.md` - 情緒氛圍關鍵詞庫
- `video_style_guide.md` 視頻風格指南
- `consistency_control.md` - 一致性控制指南
- `prompt_patterns.md` - 高效提示詞模式庫
### assets/(模板資源)
- `storyboard_template.csv` - 分鏡腳本CSV模板
- `export_template.html` - 可視化導出HTML模板下方【文件結構】是 Skill 的文件結構,它的文件結構中必須有 SKILL.md 文件。YAML頭部、Markdown正文和關鍵要素是SKILL.md 格式規範。(可選)的部分是不固定的,可以是文件也可以是文件夾,文件夾的命名也可以按照自己的要求來👇
製作 Skill 的時候,可以前期制定標準,中期優化功能模塊,後期測試優化與封裝。下面是完整的執行思路,注意下方雖然分了步驟,但是實際生成 Skill 的時候它也可以一次執行所有要求,再根據效果繼續優化調整的。
前期:制定標準
我希望這個 Skill 的工作流程是這樣的:
劇本解析 → 角色提取 → 場景分析 → 分鏡生成 → 提示詞優化 → 一致性檢查 → 導出。
如果沒有具體明確的工作流程要求,後面所有實現都會默認按照這個規範。
確定支持哪些輸入:比如txt/md/docx/pdf/fdx。 同時定義默認輸入是一個劇本文檔,也可以是一段話甚至一句話,但是這樣的話效果和內容走向可能會不太可控;“推薦輸入”可加角色圖參考、風格圖參考、畫幅要求、時長限制。
先寫清楚最終要產出哪些文件:角色設定、場景設定、分鏡提示詞、一致性報告、導出文件格式等,這一步的作用是防止中途越做越偏。
確定每一步輸入輸出長什麼樣。我希望它輸出分鏡表是什麼樣的,希望它輸出角色設計提示詞格式是什麼樣的等等。這一步很關鍵,每個輸出項的字段先定好,再讓 AI 按要求輸出,後面就不會亂。
比如我希望完整的分鏡提示詞表是按照第 X 幕第 X 場景,每個場景的提示詞表包含鏡頭編號、景別、畫面描述、構圖、運鏡、光線、色調、氛圍、時長、鏡頭角度、提示詞等。那麼我可以自己做或者讓AI來生成這樣一個統一的表格模板,如果本身有這樣的模板,也可以直接放進去。後面的每個腳本都讀寫這個模板,並且按照這個格式輸出,這樣就不會不同幕和場景之間格式互相對不上。
可以製作模板放在 assets 裏,讓 AI 生成的腳本參考這些模板規範進行生成。
中期:優化功能模塊
references 中存放術語與模板。
整個提示詞的規則可以輸出為單獨的文檔,比如劇本格式規範、鏡頭術語、情緒詞庫、提示詞模板、一致性指南等。這樣會更方便修改和規範指定方向的文檔內容。其他人查看時,也能知道為什麼這麼做。
assets 中存放可複用模板內容。
比如:分鏡 CSV 模板、角色提示詞模板、HTML 模板、速查表等等。這樣每次新項目也能直接複用,不用重做排版和字段。
references 和 assets 中的內容建議單獨生成、優化,輸出文件後放進去,再給到指定路徑給後續腳本調用。
接下來的 7-12 幾個模塊都是腳本,這些都可以讓 AI 來寫。比如 7 的提示詞參考如下:
幫我生成腳本,用於把原始劇本內容(支持 `txt/md/docx/pdf/fdx`)解析成結構化 JSON,要求自動識別並分類:場景標題(INT/EXT 或“第X場/場景X”)、角色名、對白、動作、轉場,並輸出中文字段:`標題`、`場景列表`、`全角色`、`全地點`、`總時長秒數`、`元數據`(含`場景數`、`角色數`、`地點數`),其中每個場景至少包含`場景編號`、`場景標題`、`地點`、`時間段`、`內外景`、`角色`;規則是“上一行是角色名則下一行優先判定為對白,否則判定為動作”,沒有場景標題時自動創建默認場景,空行跳過;重點先保證穩健性和通用性,不追求複雜算法,優先做到“任何劇本或任意文本內容都能讀入並形成場景列表”;支持通過命令行傳入文件路徑並輸出格式化 JSON,代碼儘量清晰、註釋簡單、依賴缺失時提示安裝。更簡單點(自己直接寫),這樣寫不滿意的話可以在這個基礎上讓 AI 優化提示詞:
生成一個通用劇本解析腳本,能讀取常見文本格式並智能分析內容,自動識別場景、角色、對白、動作和轉場,輸出清晰的結構化 JSON;要求優先保證穩定可用,即使輸入不規範也能自動補默認場景並正常返回結果。現在的 AI 工具都很機靈了,我們只要要求它生成 Skill 的時候生成單獨的腳本,它就會自己生成。大多數時候都不需要單獨輸入提示詞。
7. 實現【劇本解析】模塊
把原始劇本變成結構化數據。識別生成場景標題、角色名、對白、動作、轉場。
8. 實現【角色提取】模塊
從【7】的解析結果裏提角色檔案:性別、年齡段、體型、髮型、關鍵詞。要求輸出時給每個角色一段提示詞描述,後面分鏡直接可用,調用也方便。
9. 實現【場景分析】模塊
從【7】的每個場景裏提地點、室內外、時間段、光線、氛圍,給每個場景生成一條基礎視覺提示詞。這一層是全片視覺基礎,後面鏡頭都在它上面疊加。
10. 實現【分鏡生成】模塊
按【7】的場景自動拆成鏡頭,至少包含:建立鏡頭、角色出場、對話鏡頭。每個鏡頭都要有編號、景別、運鏡、動作、時長、轉場、提示詞。先保證“有鏡頭可用”,再逐步優化鏡頭藝術性。
11. 實現【提示詞優化】模塊
把鏡頭提示詞做統一處理:術語標準化、去重複提示詞、補質量詞(提升畫面質量和穩定性的萬能詞,比如高質量、電影感、清晰對焦這類)。這樣能讓輸出更適配視頻模型,不會每條風格都散。有時間的話還可以針對不同風格單獨製作不同風格、不同視頻模型的提示詞規範表。
12. 實現【一致性檢查】模塊
檢查角色跨鏡頭提示詞、場景是否跳變、光線是否變化突兀等,輸出“問題 + 修復建議 + 複用規範提示詞”。
後期:測試優化與封裝
確認默認導出格式,這裏我希望至少支持 JSON + CSV + Markdown。目標是讓不同職能都能直接看和用。
用 2-3 份不同的劇本跑全流程。這個劇本可以 AI 生成也可以自己提供。
重點檢查:字段是否缺失、鏡頭是否正確、提示詞是不是符合自己的要求。
重要的部分可以單獨拎出來補充單獨文檔和腳本,比如我對視頻提示詞有指定的要求,那麼可以單獨一個提示詞參考文檔(放在 references )或提示詞格式參考模板(放在 assets )並要求腳本在指定場景調用。
發現問題就讓 AI 針對對應模塊修改。
最後整理為清晰目錄,最簡單的可以就一個SKILL.md,複雜一些就可以加上腳本、參考、模板等文件夾了,我這裏的格式是:
SKILL.md + scripts/ + references/ + assets/。
這個直接讓 AI 封裝Skill然後自己確認就可以。到這一步,我們就擁有一個比較完整的 Skill 了。
梳理完全部步驟後,就可以輸出一個完整的提示詞,讓 AI 生成 Skill 了。需要詳細輸出的地方,可以單獨生成提示詞或模板後放進去,要求腳本調用。
下面我放了最初我的提示詞要求,後期對這組提示詞進行了分佈的詳細優化,但是我的 Claude 賬號被封了所以優化提示詞的過程沒有了😅,但大致的邏輯思路是上面這樣的,供大家參考。另外,references/ 和 assets/ 中的內容也建議通過對話多輪優化到自己滿意的效果。
你是一個 Skill 開發助手,幫我從零構建一個「劇本轉視頻分鏡提示詞」Skill。請按以下規格和順序執行,不可跳步,不可合併步驟。
---
【第一步:工作流程定義】
這個 Skill 的工作流程是:先解析劇本結構,識別出幕、場景、對白和動作描述;然後提取所有角色,為每個角色生成設定;接着分析所有場景,為每個場景生成設定;再把每個場景拆解成具體鏡頭,生成分鏡提示詞表;之後對每條提示詞做優化,確保它足夠具體、包含必要的視覺參數、並且與角色和場景設定一致;然後做一致性檢查,交叉比對角色、場景與分鏡之間的偏差;最後按用戶要求的格式導出。不可以跳步,不可以合併步驟。如果用戶沒有特別要求改變流程,永遠執行完整的七步。
【第二步:輸入規格定義】
支持接收 txt、md、docx、pdf 和 fdx 格式的劇本文件。最低可運行的輸入是一個劇本文檔,哪怕只是一段話甚至一句核心概念也能啓動流程,但必須在開始前告訴用戶:當前輸入信息有限,後續生成內容的風格一致性和走向可能不完全可控,建議補充更多信息。推薦的輸入是劇本加上角色參考圖、風格參考圖、目標畫幅比例、目標時長、以及希望的視覺風格關鍵詞。用戶提供的參考圖永遠優先於自己的推斷。
【第三步:最終產出定義】
最終產出:一份角色設定文檔,包含每個角色的外貌、服裝、氣質關鍵詞和可用於 AI 生圖的完整提示詞;一份場景設定文檔,包含每個場景的空間描述、光線類型與方向、主色調和氛圍詞;一份完整的分鏡提示詞表,按照幕、場景、鏡頭三級結構組織;一份一致性檢查報告,標註角色和場景在不同鏡頭之間的視覺偏差;最後是以上所有內容的導出文件,支持 CSV、Markdown、Excel 和 HTML 格式。這五樣東西是這個 Skill 存在的全部目的,任何中間步驟都是為了最終產出它們。
【第四步:統一結構規範】
分鏡提示詞表按第 X 幕第 X 場景組織,每個場景的提示詞表包含以下字段:鏡頭編號、景別、畫面描述、構圖、運鏡、光線、色調、氛圍、時長、鏡頭角度、提示詞。先生成這個統一的表格模板,後面所有腳本都讀寫這個模板並按此格式輸出。
【第五步:references 內容】
生成以下規範文檔:劇本格式規範、鏡頭術語表、情緒詞庫、提示詞模板、一致性檢查指南。每個文檔獨立成文件,方便後期單獨修改。
【第六步:assets 內容】
基於第四步的結構規範,生成以下可複用模板文件:分鏡 CSV 模板、角色提示詞模板、HTML 導出模板、速查表。
【第七步:劇本解析腳本】
寫一個腳本,能讀劇本文件,分出場景、角色、對白和動作,最後輸出為 JSON 格式。代碼清晰精煉、註釋清楚。
【第八步:角色提取腳本】
從解析結果裏提取角色檔案,包含性別、年齡段、體型、髮型、關鍵詞。為每個角色輸出一段可直接用於 AI 生圖的提示詞描述。
【第九步:場景分析腳本】
從每個場景裏提取地點、室內外、時間段、光線、氛圍,為每個場景生成一條基礎視覺提示詞。
【第十步:分鏡生成腳本】
按場景自動拆成鏡頭,至少包含建立鏡頭、角色出場、對話鏡頭,每個鏡頭嚴格按照第四步定義的字段輸出。
【第十一步:提示詞優化腳本】
對所有鏡頭提示詞做統一處理:術語標準化、去重複、補質量詞、輸出質量打分。參考 references/ 中的提示詞模板和鏡頭術語表。
【第十二步:一致性檢查腳本】
檢查角色跨鏡頭是否漂移、場景是否跳變、光線是否變化突兀,輸出「問題 + 修復建議 + 複用規範提示詞」報告。
【第十三步:導出腳本】
將所有產出內容導出為 JSON、CSV、Markdown 三種格式,HTML 格式基於 assets/ 中的 HTML 模板生成。
【第十四步:測試】
用 2-3 份不同類型的劇本跑全流程,重點檢查:字段是否缺失、鏡頭是否正確生成、提示詞是否符合 references/ 中的規範。發現問題後定位到對應腳本,只修改該腳本,不動其他文件。告訴我每份劇本的測試結果和發現的問題。
【第十五步:封裝 SKILL.md】
基於以上所有內容,生成完整的 SKILL.md 文件,包含:定位說明、觸發方式、完整七步流程說明、輸入要求、輸出目標、文件目錄結構。
---
所有文件生成完畢後,輸出完整目錄結構,以及如何用一份測試劇本跑通全流程的指南。幾個問題
最開始怎麼理清製作一個 Skill 的思路?
先抓一條主線:先想清楚“用來做什麼、輸入什麼、交付輸出什麼”,再把中間步驟進行拆分(比如解析、生成、檢查、導出),然後要求統一格式,再讓 AI 輸出。
輕鬆慵懶版順序可以是:提示詞直接要求它可以通過輸入什麼,獲得什麼輸出,中間的流程是怎樣的,有哪些模板可以調用,最後讓 AI 寫腳本。等這個完成了,需要什麼再補充。這樣做不會一開始就陷入技術細節,也不容易做着做着跑偏。
有任何不清楚的地方都可以問 AI,從大方向到細化都可以問。比如:
AI可能會寫得很詳細,我們提取關鍵要素就可以。
再讓 AI 按要求生成 Skill 之前把要求儘可能梳理全面,感覺邏輯不夠清晰或者還有優化空間,都可以讓 AI 去繼續優化提示詞。
為什麼自動化腳本要單獨出來?
自動化腳本要單獨出來,是因為它和說明文檔、模板資源的職責完全不同:在這裏,腳本負責執行流程併產出結果,參考文檔負責解釋規則和標準,模板負責規範格式和交付外觀。
為什麼要分很多個子腳本?
複雜的 Skill 中,把腳本單獨放在 scripts/,可以讓我們直接調用、測試、替換和部署,不會被文檔內容干擾;同時當規則變化時,我們可以只改 references/,當邏輯變化時只改 scripts/,維護成本和排錯成本都會明顯降低。
後期如果要修改內容,怎麼要去要求 AI 去排查和修改比較節省 token ,並且準確高效率?
最簡單的方法是:每次只讓 AI 幹一件小事,並告訴它“只改哪裏、不要亂改、改完怎麼驗收”。你可以直接說:只檢查並修改 scripts/scene_analyzer.py(複製文件路徑) 裏的光線規則,別動其他文件;先找問題點,再最小改動;最後只告訴我改了哪幾行、會影響什麼、怎麼驗證。這樣 AI 不會到處讀文件、不會大改代碼,token 花得少,結果也更穩。
至於要不要改 SKILL.md,取決於改的是規則說明還是代碼細節。
小白判斷法:如果用戶使用方式變了,就改 SKILL.md;如果只是內部實現變了,可以不改。
Skill下載
下載這個 Skill ,可以查看內部所有文件,安裝即可直接使用:
https://my.feishu.cn/docx/PsPfdVFD9oZ3nZxcvBFcGxdgnje
如果對 Skill 不夠了解,推薦閲讀我好友@一澤Eze的這篇:Agent Skills 終極指南:入門、精通、預測
小結
好啦今天的分享就先到這裏,剛恢復開工感覺腦子不是很靈光的樣子,等有時間單獨整理 Seedance 2.0 的多種提示詞模板及其寫法。幾時才能爽用啊真的好慢!
題外話,大家最近使用 OpenClaw 了嗎?對它有什麼新的看法嗎?我有幾個問題,歡迎朋友們評論區一起討論,用它賺到錢了嗎還是純花錢?用它完成的任務其他工具可以替代完成,還是隻有它可以做到?用它花了多少錢了,取得了什麼階段性成果了嗎?
期待大家的猛猛三連,下期見!