讓 AI 測試助手“讀懂你的業務”:RAG 知識庫 + UI 截圖多模態解析
整理版優先睇
作者分享點樣用RAG知識庫同多模態UI解析,令AI測試助手真正「讀懂業務」,生成可落地嘅測試用例。
呢篇文章係《AI測試用例設計助手|LangGraph實戰系列》嘅第5篇。作者之前解決咗並行提速、質量閉環、多模型協同、結構化輸出等問題,但發現AI生成嘅測試用例仲係好「泛化」,成日漏咗權限規則、UI字段、歷史缺陷呢類業務細節。佢嘅結論係:要令AI測試助手「更似你嘅測試同事」,就要畀佢「你哋嘅資料」同「你哋嘅界面」。
作者提出兩條增強路線:RAG知識庫同多模態UI解析。RAG方面,佢拆成三個知識庫:產品知識庫(業務規則)、操作手冊庫(頁面細節)、歷史用例庫(經驗復用),並用Tool封裝成按需檢索,避免強制檢索增加成本同噪聲。多模態方面,佢設計咗parse_images節點,專門抽字段名、按鈕文案、提示語等「界面事實」,再注入到並行Worker入面,令生成嘅用例步驟更具體。兩者協同嘅效果最好:先用截圖補界面事實,再用RAG補業務規則。
不過作者都提到,呢兩條能力都係「可選」嘅——RAG有髒數據風險,多模態有解析成本同失敗風險,所以佢做咗開關控制同降級機制。最後佢總結:RAG+多模態係從「泛化生成器」變成「項目內可交付助手」嘅關鍵一步。
- RAG+多模態係令AI測試助手從「泛化生成器」變成「項目內可交付助手」嘅關鍵。
- RAG分為產品、操作手冊、歷史用例三個知識庫,用Tool封裝按需檢索,避免強制檢索。
- 多模態UI解析補界面事實(字段、按鈕、提示語),RAG補業務規則,兩者協同效果最好。
- RAG檢索結果應做摘要再注入,減少上下文長度;多模態應只提取測試相關結構化信息。
- 建議RAG做開關控制(ENABLE_KNOWLEDGE_BASE),多模態做降級處理,保證系統穩定。
內容片段
pythonfrom langchain.tools import tool@tooldef search_product_kb(query: str) -> str: """查詢產品知識庫:業務規則、流程、角色權限等。""" return bailian_client.search(index=KB_INDEX_PRODUCT, query=query)@tooldef search_manual_kb(query: str) -> str: """查詢操作手冊:頁面入口、字段、按鈕、提示語、交互步驟。""" return bailian_client.search(index=KB_INDEX_MANUAL, query=query)@tooldef search_history_case_kb(query: str) -> str: """查詢歷史用例庫:類似模塊的用例覆蓋模式、常見缺陷點。""" return bailian_client.search(index=KB_INDEX_HISTORY_CASE, query=query)為咩要「讀懂業務」?
LLM好擅長將話講得「似樣」,但佢天然唔知道你哋嘅權限模型、角色規則、歷史缺陷。剩係靠需求文檔一段文字,AI生成嘅用例往往會泛化、漏規則、難執行。
作者嘅做法係:喺生成階段畀模型兩類「外部能力」——RAG令佢可以查資料,多模態令佢可以讀懂截圖。呢兩條路線係為咗補足業務知識同界面細節。
RAG知識庫:拆成3類,按需檢索
作者將知識庫拆成產品知識庫(Product KB)、操作手冊庫(Manual KB)、歷史用例庫(History Case KB)。好處係檢索更精準、權限更清晰、可演進。
檢索方式係用Tool封裝,例如search_product_kb、search_manual_kb、search_history_case_kb。佢返回「可讀文本+結構化片段」,方便模型引用。
- 1 約束A:只有喺信息不足時先檢索,例如出現「權限/角色/審批/風控」等信號。
- 2 約束B:檢索結果一定要落到用例入面,例如檢索到「手機號校驗規則」,就要體現喺步驟同預期。
另外,作者建議將RAG結果做摘要再注入:先檢索,再壓縮成5-10條相關要點,最後用呢啲要點指導用例生成。咁樣可以降低上下文長度,減少無關信息幹擾。
UI截圖多模態解析:補界面事實
好多需求文檔寫得好空泛,但截圖入面先有關鍵細節:字段名、必填標識、placeholder、按鈕文案、禁用態、彈窗提示等。呢啲內容直接決定用例係唔係「跟得住步驟執行」。
parse_images節點嘅輸出唔係「描述圖片」,而係測試要用嘅結構化信息:頁面名稱、控件清單、字段規則、交互流程、文案、多端差異等。然後呢啲信息放入全局狀態嘅image_analysis,傳遞畀每個Worker使用。
作者仲考慮咗工程細節:支援file://、http/https、base64三種圖片來源,並做到失敗降級——圖片解析失敗唔影響純文本需求繼續跑。
RAG+多模態點樣協同?風險同取捨
實際效果最好嘅方式係:先用多模態補界面事實(字段、按鈕、提示語),再用RAG補業務規則(權限、風控、歷史缺陷)。最終Worker嘅上下文包含功能點描述、UI解析摘要、RAG檢索摘要等,咁樣先算「可落地」。
但作者都清楚風險:RAG可能有髒數據、檢索過長、成本不可控;多模態有截圖質素問題、解析耗時。所以佢將兩條能力都設計成可選:有開關控制(ENABLE_KNOWLEDGE_BASE),解析失敗可降級。
等 AI 測試助手「睇得明你盤生意」:RAG 知識庫接入 + UI 截圖多模態解析
前言:點解「識得業務」比「識得生成」更加重要
LLM 好叻講到似層層,但佢天生唔知:
- 你哋嘅權限模型、角色規則係乜
- 某個頁面字段有咩校驗/默認值/聯動邏輯
- 歷史上邊啲模組成日出問題,回歸要重點測啲乜
- 團隊測試規範同命名規則係點
所以淨靠「需求文檔一段文字」,AI 生成嘅用例往往會:
- 泛化:似範本,唔似你哋產品
- 漏規則:漏咗權限/風控/異常提示/邊界邏輯
- 難執行:步驟冇咗關鍵 UI 字段同按鈕名,落地時要人補返
我嘅做法係:喺生成階段畀模型兩類「外部能力」——
1)RAG:等佢可以查資料(產品知識/操作手冊/歷史用例)
2)多模態:等佢可以睇得明截圖(字段、按鈕、提示語、交互)
一、架構入面呢兩條增強能力放喺邊?
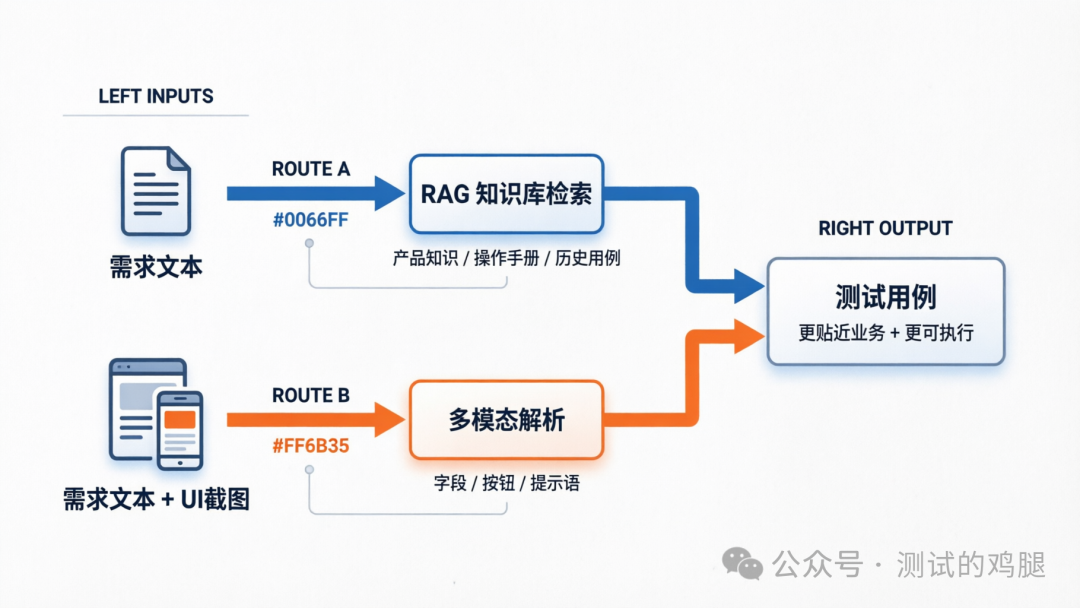
1.1 多模態嘅入口:條件路由「有圖先解析」
init_state 會識別輸入裏面有冇設計稿圖片:
- 純文字需求 → 行
parse_requirement - 文字 + 圖片 → 先行
parse_images,然後先入需求/生成流程 - 非需求 →
simple_chat
你可以理解成:截圖解析係用例生成嘅前置「補齊資訊」步驟。
1.2 RAG 嘅入口:喺 Worker 入面按需要調用 Tool
RAG 唔會放喺固定節點強制執行,而係:
- 將知識庫查詢封裝成
@tool - 在
generate_casesWorker 中以 Agent 方式按需要調用
原因好現實:唔係每個功能點都需要查庫。強制檢索會帶來:
- 成本上升(每個功能點都要查)
- 噪音變大(唔相關嘅內容混入上下文)
- 輸出更加唔穩定(上下文越長越容易偏)
我嘅目標係:識查、會查、應該查先查。
二、RAG 知識庫增強:3 類知識庫點拆,點用
2.1 我點解拆成 3 個知識庫
| 知識庫 | 主要內容 | 適合補啲乜 |
|---|---|---|
| 產品知識庫(Product KB) | 業務背景、流程、角色權限、規則說明 | 權限差異用例、核心業務規則、影響範圍 |
| 操作手冊(Manual KB) | 頁面入口、字段釋義、操作步驟、交互說明 | 可執行步驟、字段校驗、提示語、入口路徑 |
| 歷史用例庫(History Case KB) | 歷史覆蓋模式、回歸清單、常見缺陷點 | 回歸重點、異常場景範本、經驗重用 |
拆庫嘅好處:
- 檢索更精準(唔同問題去唔同庫)
- 權限更清晰(歷史用例可能更敏感)
- 可以進化(後期仲可以加「接口文檔庫/埋點規範庫」等)
2.2 用 Tool 封裝知識庫查詢(偽代碼示意)
pythonfrom langchain.tools import tool@tooldef search_product_kb(query: str) -> str: """查詢產品知識庫:業務規則、流程、角色權限等。""" return bailian_client.search(index=KB_INDEX_PRODUCT, query=query)@tooldef search_manual_kb(query: str) -> str: """查詢操作手冊:頁面入口、字段、按鈕、提示語、交互步驟。""" return bailian_client.search(index=KB_INDEX_MANUAL, query=query)@tooldef search_history_case_kb(query: str) -> str: """查詢歷史用例庫:類似模塊的用例覆蓋模式、常見缺陷點。""" return bailian_client.search(index=KB_INDEX_HISTORY_CASE, query=query)呢度我比較傾向返回「可讀文字 + 結構化片段」嘅混合結果(例如帶小標題/要點列表),方便模型引用。
2.3 Worker 裏面點樣「按需要檢索」?
在 generate_cases Worker 嘅 Prompt/策略入面,我會加兩個約束:
約束 A:淨係喺資訊唔夠先檢索
例如出現以下信號就建議檢索:
- 需求提到「權限/角色/審批/風控」等規則,但冇寫清楚
- 需求寫咗「按產品規範校驗」,但規範喺文檔入面
- 需求冇明確字段/提示語,但 UI/手冊有
約束 B:檢索結果一定要落喺用例入面
例如檢索到「手機號校驗規則」,就應該體現喺:
- 前置條件:帳號/手機號格式
- 步驟:輸入非法手機號
- 預期結果:提示語/禁用狀態/錯誤碼(如果有)
咁樣 RAG 先係「提升可執行性」,而唔係「堆上下文」。
2.4 一個好實用嘅落地建議:RAG 結果做「摘要再注入」
好多知識庫返回會好長。我嘅習慣係:
- 先檢索
- 再叫模型/規則將檢索結果壓縮成「同當前功能點相關嘅 5-10 條要點」
- 最後用呢啲要點指導用例生成
好處:
- 降低上下文長度
- 減少無關資訊幹擾
- 輸出更穩定
三、UI 截圖多模態解析:等用例真係行得鬱
好多需求文檔寫嘅係「支援編輯/刪除/篩選」,但截圖先有關鍵細節:
- 字段名、必填標記、placeholder
- 按鈕文字、禁用狀態、loading 狀態
- 彈窗標題、提示語、二次確認
- 表格列、篩選選項、分頁規則
- 錯誤提示、空狀態文字
呢啲內容直接決定用例係咪「可以跟住一步步執行」。
3.1 parse_images 節點輸出啲乜?
parse_images 嘅目標唔係「描述圖片」,而係抽取測試要用嘅資訊結構,例如:
- 頁面/模組名稱
- 關鍵控制項清單:輸入框、下拉選單、按鈕、分頁、表格列
- 字段規則:必填、長度、格式、範圍、聯動
- 交互流程:㩒掣後跳轉/彈窗/呼叫接口(如果可以推斷)
- 文字:錯誤提示、空狀態、成功提示
- 多端差異(如果截圖顯示)
最後將呢啲資訊放入全局狀態嘅 image_analysis,畀後續節點用。
3.2 點解我將 image_analysis 注入落 Worker?
因為用例生成發生喺 Worker(按功能點並行)入面。
最自然嘅做法係將 image_analysis 作為上下文傳遞畀每個 Worker:
- 功能點 A:引用截圖裏面嘅字段規則同按鈕文字
- 功能點 B:引用表格列同篩選選項
- 功能點 C:引用彈窗同提示語
咁樣每個功能點生成嘅用例都會更貼近 UI,步驟會更具體。
3.3 多種圖片來源格式兼容(工程上嘅「細節陷阱」)
喺真實場景入面,設計稿/截圖可能嚟自:
file://...本地路徑(LangGraph Studio 常見)http:///https://線上連結(協作最常見)base64(前端上傳或接口傳輸常見)
我嘅做法係:
- 在
init_state統一歸一化圖片輸入 parse_images淨係關心「我攞到嘅係一組可以解析嘅圖像引用」- 失敗時要可以降級:圖片解析失敗唔影響純文字需求繼續行(只係冇咁仔細)
四、RAG + 多模態點樣協同?(一個好關鍵嘅組合策略)
實際效果最好嘅方式係:
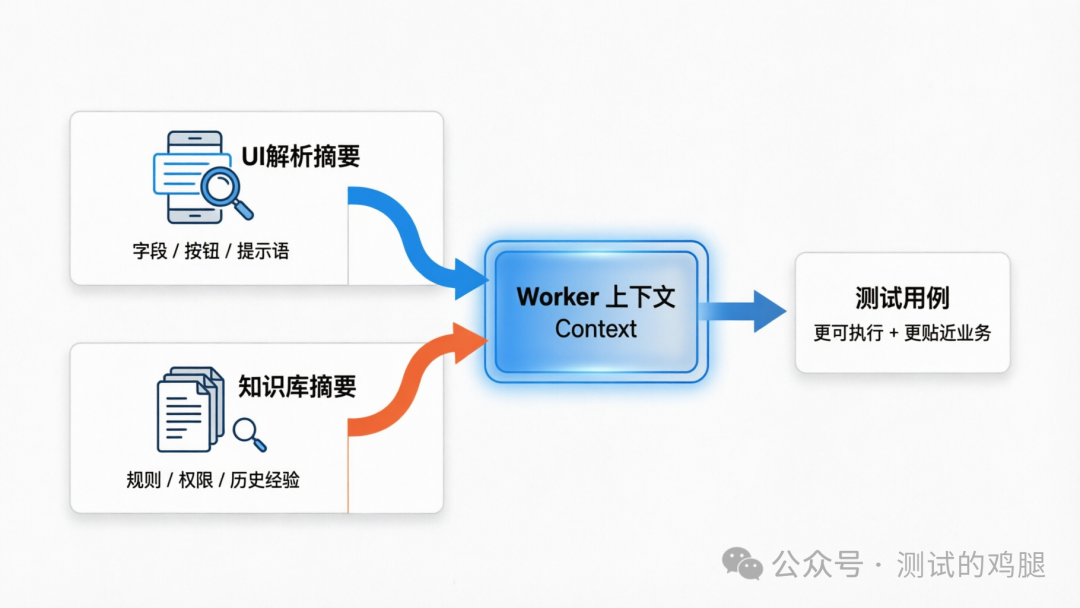
- 先用多模態補「界面事實」
例如:字段名、按鈕文字、提示語、必填標記、佈局資訊
呢類資訊嚟自截圖,可信度高、好具體。 - 再用 RAG 補「業務規則同歷史經驗」
例如:權限矩陣、風控規則、審批流程、常見缺陷點、團隊規範
呢類資訊嚟自知識庫,比較偏規則同經驗。
最後用例生成時,Worker 嘅上下文大約係:
- 功能點結構化描述(feature)
- UI 解析摘要(image_analysis)
- 業務知識檢索摘要(rag_summary,可選)
- 質量評審迴流建議(suggestions,可選)
- 現有用例參考(existing_cases,可選)
呢個就係「可以落地」嘅 AI 測試用例生成:有界面細節、有業務規則、有質量約束。
五、風險與 Trade-off:我點解將呢兩條能力都整成「可選」
5.1 RAG 嘅風險
- 知識庫污糟數據會「帶壞模型」
- 檢索結果太長會令輸出偏離
- 成本唔可控(尤其係功能點多嘅時候)
所以我整咗開關:
ENABLE_KNOWLEDGE_BASE=false時完全關閉- 開啓後都盡量按需要檢索,而唔係強制檢索
5.2 多模態嘅風險
- 截圖唔清晰/遮擋/多語言,會影響解析質量
- 解析時間同成本高過純文字
- 解析結果可能需要「摘要化」,否則上下文太長
所以我同樣將佢設計成:
- 有圖先行
parse_images - 解析失敗可以降級(純文字路徑繼續行)
六、總結:等 AI 「更加似你嘅測試同事」,關鍵係畀佢「你哋嘅資料」同「你哋嘅界面」
我認為,RAG 同多模態唔係「錦上添花」,而係將 AI 從「泛化生成器」變成「項目內可交付助手」嘅關鍵一步:
- RAG:等佢知道「你哋點做業務」
- 多模態:等佢知道「你哋頁面咩樣、點操作」
當兩者結合,再配合之前幾篇嘅:
- 並行 Worker 提速
- 質量評審閉環
- 多模型協同降低成本
- Pydantic 結構化輸出保持穩定
成個系統先真正具備「工程化可落地」嘅形態。
下一篇預告(第 6 篇)
《覆盤:做呢個 AI 測試助手,我踩過嘅坑同 8 個關鍵決策》
會將 LangGraph 選型、reducer、閾值策略、導出格式、配置體系等 trade-off 做一次完整覆盤。
讓 AI 測試助手“讀懂你的業務”:RAG 知識庫接入 + UI 截圖多模態解析
前言:為什麼“懂業務”比“會生成”更重要
LLM 很擅長把話說得“像樣”,但它天然不知道:
- 你們的權限模型、角色規則是什麼
- 某個頁面字段有哪些校驗/默認值/聯動邏輯
- 歷史上哪些模塊經常出問題,迴歸要重點測什麼
- 團隊測試規範與命名規則是什麼
所以只靠“需求文檔一段文字”,AI 生成的用例往往會:
- 泛化:像模板,不像你們產品
- 漏規則:漏掉權限/風控/異常提示/邊界邏輯
- 難執行:步驟缺關鍵 UI 字段與按鈕名,落地時得靠人補
我的做法是:在生成階段給模型兩類“外部能力”——
1)RAG:讓它能查資料(產品知識/操作手冊/歷史用例)
2)多模態:讓它能讀懂截圖(字段、按鈕、提示語、交互)
一、架構裏這兩條增強能力放在哪?
1.1 多模態的入口:條件路由“有圖先解析”
init_state 會識別輸入裏是否有設計稿圖片:
- 純文本需求 → 走
parse_requirement - 文本 + 圖片 → 先走
parse_images,再進入需求/生成流程 - 非需求 →
simple_chat
你可以理解為:截圖解析是用例生成的前置“補全信息”步驟。
1.2 RAG 的入口:在 Worker 內按需調用 Tool
RAG 不放在固定節點裏強制執行,而是:
- 把知識庫查詢封裝為
@tool - 在
generate_casesWorker 中以 Agent 方式按需調用
原因很現實:並不是每個功能點都需要查庫。強制檢索會帶來:
- 成本上升(每個功能點都要查)
- 噪聲變大(不相關內容混進上下文)
- 輸出更不穩定(上下文越長越容易漂)
我的目標是:能查、會查、該查才查。
二、RAG 知識庫增強:3 類知識庫怎麼拆,怎麼用
2.1 我為什麼拆成 3 個知識庫
| 知識庫 | 主要內容 | 適合補什麼 |
|---|---|---|
| 產品知識庫(Product KB) | 業務背景、流程、角色權限、規則說明 | 權限差異用例、核心業務規則、影響範圍 |
| 操作手冊(Manual KB) | 頁面入口、字段釋義、操作步驟、交互說明 | 可執行步驟、字段校驗、提示語、入口路徑 |
| 歷史用例庫(History Case KB) | 歷史覆蓋模式、迴歸清單、常見缺陷點 | 迴歸重點、異常場景模板、經驗複用 |
拆庫的好處:
- 檢索更精準(不同問題去不同庫)
- 權限更清晰(歷史用例可能更敏感)
- 可演進(後期還能加“接口文檔庫/埋點規範庫”等)
2.2 用 Tool 封裝知識庫查詢(偽代碼示意)
pythonfrom langchain.tools import tool@tooldef search_product_kb(query: str) -> str: """查詢產品知識庫:業務規則、流程、角色權限等。""" return bailian_client.search(index=KB_INDEX_PRODUCT, query=query)@tooldef search_manual_kb(query: str) -> str: """查詢操作手冊:頁面入口、字段、按鈕、提示語、交互步驟。""" return bailian_client.search(index=KB_INDEX_MANUAL, query=query)@tooldef search_history_case_kb(query: str) -> str: """查詢歷史用例庫:類似模塊的用例覆蓋模式、常見缺陷點。""" return bailian_client.search(index=KB_INDEX_HISTORY_CASE, query=query)這裏我更傾向於返回“可讀文本 + 結構化片段”的混合結果(例如帶小標題/要點列表),方便模型引用。
2.3 Worker 裏怎麼“按需檢索”?
在 generate_cases Worker 的 Prompt/策略裏,我會加兩個約束:
約束 A:只有在信息不足時才檢索
例如出現以下信號就建議檢索:
- 需求提到“權限/角色/審批/風控”等規則,但沒寫清楚
- 需求寫了“按產品規範校驗”,但規範在文檔裏
- 需求沒有明確字段/提示語,但 UI/手冊有
約束 B:檢索結果必須落到用例裏
比如檢索到“手機號校驗規則”,那就應該體現在:
- 前置條件:賬號/手機號格式
- 步驟:輸入非法手機號
- 預期:提示語/禁用態/錯誤碼(如果有)
這樣 RAG 才是“提升可執行性”,而不是“堆上下文”。
2.4 一個很實用的落地建議:RAG 結果做“摘要再注入”
很多知識庫返回會很長。我的習慣是:
- 先檢索
- 再讓模型/規則把檢索結果壓縮成“與當前功能點相關的 5-10 條要點”
- 最後用這些要點指導用例生成
好處:
- 降低上下文長度
- 減少無關信息干擾
- 輸出更穩定
三、UI 截圖多模態解析:讓用例真正��執行
很多需求文檔寫的是“支持編輯/刪除/篩選”,但截圖裏才有關鍵細節:
- 字段名、必填標識、placeholder
- 按鈕文案、禁用態、loading 態
- 彈窗標題、提示語、二次確認
- 表格列、篩選項、分頁規則
- 錯誤提示、空狀態文案
這些內容直接決定用例是否“能照着一步步執行”。
3.1 parse_images 節點輸出什麼?
parse_images 的目標不是“描述圖片”,而是抽取測試要用的信息結構,比如:
- 頁面/模塊名稱
- 關鍵控件清單:輸入框、下拉、按鈕、tab、表格列
- 字段規則:必填、長度、格式、範圍、聯動
- 交互流程:點擊後跳轉/彈窗/調用接口(如果能推斷)
- 文案:錯誤提示、空狀態、成功提示
- 多端差異(如果截圖顯示)
最後把這些信息放入全局狀態的 image_analysis,給後續節點使用。
3.2 為什麼我把 image_analysis 注入到 Worker?
因為用例生成發生在 Worker(按功能點並行)裏。
最自然的做法是把 image_analysis 作為上下文傳遞給每個 Worker:
- 功能點 A:引用截圖裏的字段規則與按鈕文案
- 功能點 B:引用表格列與篩選項
- 功能點 C:引用彈窗與提示語
這樣每個功能點生成的用例都更貼近 UI,步驟會更具體。
3.3 多種圖片來源格式兼容(工程上的“細節坑”)
在真實場景裏,設計稿/截圖可能來自:
file://...本地路徑(LangGraph Studio 常見)http:///https://在線連結(協作最常見)base64(前端上傳或接口傳輸常見)
我的做法是:
- 在
init_state統一歸一化圖片輸入 parse_images只關心“我拿到的是一組可解析的圖像引用”- 失敗時要能降級:圖片解析失敗不影響純文本需求繼續跑(只是不那麼細)
四、RAG + 多模態如何協同?(一個很關鍵的組合策略)
實際效果最好的方式是:
- 先用多模態補“界面事實”
比如:字段名、按鈕文案、提示語、必填標識、佈局信息
這類信息來自截圖,可信度高、非常具體。 - 再用 RAG 補“業務規則與歷史經驗”
比如:權限矩陣、風控規則、審批流、常見缺陷點、團隊規範
這類信息來自知識庫,更偏規則與經驗。
最終用例生成時,Worker 的上下文大概是:
- 功能點結構化描述(feature)
- UI 解析摘要(image_analysis)
- 業務知識檢索摘要(rag_summary,可選)
- 質量評審迴流建議(suggestions,可選)
- 既有用例參考(existing_cases,可選)
這就是“可落地”的 AI 測試用例生成:有界面細節、有業務規則、有質量約束。
五、風險與 Trade-off:我為什麼把這兩條能力都做成“可選”
5.1 RAG 的風險
- 知識庫髒數據會“帶壞模型”
- 檢索結果過長會讓輸出漂
- 成本不可控(尤其是功能點多時)
所以我做了開關:
ENABLE_KNOWLEDGE_BASE=false時完全關閉- 開啓後也儘量按需檢索,而不是強制檢索
5.2 多模態的風險
- 截圖不清晰/遮擋/多語言,會影響解析質量
- 解析耗時與成本高於純文本
- 解析結果可能需要“摘要化”,否則上下文過長
所以我同樣把它設計為:
- 有圖才走
parse_images - 解析失敗可降級(純文本路徑繼續跑)
六、總結:讓 AI “更像你的測試同事”,關鍵是給它“你們的資料”和“你們的界面”
在我看來,RAG 與多模態不是“錦上添花”,而是把 AI 從“泛化生成器”變成“項目內可交付助手”的關鍵一步:
- RAG:讓它知道“你們怎麼做業務”
- 多模態:讓它知道“你們頁面長什麼樣、怎麼操作”
當兩者結合,再配合前幾篇的:
- 並行 Worker 提速
- 質量評審閉環
- 多模型協同降本
- Pydantic 結構化輸出保穩定
整個系統才真正具備“工程化可落地”的形態。
下一篇預告(第 6 篇)
《覆盤:做這個 AI 測試助手,我踩過的坑和 8 個關鍵決策》
會把 LangGraph 選型、reducer、閾值策略、導出格式、配置體系等 trade-off 做一次完整覆盤。