讓 AI 自己寫自己的"員工手冊":關於 Agentic Context Engineering(ACE),一場正在醖釀的範式之爭
整理版優先睇
ACE框架讓AI自己寫員工手冊,用上下文演化取代模型重訓,開源模型+ACE可超越GPT-4.1 Agent
呢篇文章係作者對ACE論文(arXiv:2510.04618)嘅深度解讀。作者指出AI應用層長期分裂為fine-tuning同context adaptation兩條路,但自動prompt優化有兩個致命缺陷:Brevity Bias(簡潔偏見)同Context Collapse(上下文坍縮)。主流方法越自動化越傾向壓縮上下文,導致複雜任務效果反而變差。ACE就係從呢個死衚衕揾出嘅新路。
ACE將context當成活的員工手冊,由三個角色(Generator、Reflector、Curator)協作,通過Delta Updates只提交增量修改,避免壓縮。喺AppWorld基準上,ACE+DeepSeek-V3.1超越GPT-4.1驅動嘅生產級Agent,離線適配延遲降低82%,在線延遲降低91.5%。無監督場景下仍有+14.8%提升。
ACE唔係替代fine-tuning或RAG,而係分層架構中嘅一層。佢將上下文變成一種可持續積累嘅資產,為AI產品建立新護城河。作者判斷2025-2026將進入「上下文之爭」,建議從業者盡快實驗。
- 結論:ACE用三角色(Generator、Reflector、Curator)加Delta Updates,讓模型自動從執行經驗中提煉策略性知識,無需重訓即可持續提升Agent表現。
- 方法:核心創新喺增量更新(Delta Updates)同結構化playbook,禁止LLM整體重寫上下文,改用ADD/UPDATE/DELETE/MERGE操作,結合計數器實現生長與精煉。
- 差異:相比傳統prompt優化(GEPA、DSPy),ACE唔會陷入簡潔偏見同上下文坍縮,保留具體領域細節;相比Memory框架,ACE存任務級共享知識而唔係個人偏好。
- 啟發:ACE驗證咗「上下文可作為可進化資產」嘅理念,未來AI競爭會從模型同產品轉向運行時沉澱嘅context資產,playbook將成為公司嘅核心護城河。
- 可行動點:即刻喺ACE開源實現上實驗,先定義執行反饋信號(如API返回碼、用戶滿意度),再設計playbook section劃分,並準備用強底座模型扮演Reflector。
ACE論文 arXiv:2510.04618
Agentic Context Engineering 論文,提出ACE框架,由Stanford、SambaNova、UC Berkeley合著。
ACE官方開源倉庫
SambaNova開源嘅ACE完整實現,包含AppWorld同Finance benchmark腳本。
背景:自動 prompt 優化嘅兩個致命缺陷
AI應用層長期以嚟有兩條路令模型變聰明:動權重(Fine-tuning)同動輸入(Context Adaptation)。後者因為平、快、可解釋成為主力,但自動prompt優化有一條隱藏嘅死衚衕。
Brevity Bias(簡潔偏見)
所有自動優化方法都會不自覺咁將prompt越改越短,因為LLM天生識得「總結」,但複雜Agent任務需要嘅正正係嗰啲「瑣碎細節」。
Context Collapse(上下文坍縮)
論文Figure 2顯示,一個18,282 tokens嘅上下文被LLM壓縮成122 tokens,準確率由66.7%跌到57.1%。呢個過程睇落合理,但壓縮咗關鍵信息。
- 簡潔偏見(Brevity Bias):LLM自動優化時傾向壓縮,丟失關鍵細節,尤其係API時間格式、錯誤碼呢類具體知識。
- 上下文坍縮(Context Collapse):18,282 tokens被壓縮成122 tokens,準確率從66.7%跌到57.1%,比無適配仲差。
核心設計:三個角色加增量更新
ACE將組織知識積累嘅類比搬入LLM Agent,設立三個角色:Generator負責執行任務並產生軌跡,Reflector負責覆盤軌跡並提煉具體insight,Curator負責用確定性規則將insight合併入playbook。
{
"id": "b_00427",
"content": "查詢金融數據時,先按日期範圍過濾能顯著減小結果集,避免上下文爆炸",
"helpful_count": 12,
"harmful_count": 1,
"section": "task_guidance",
"created_at": "2025-10-15T10:30:00Z"
}- 1 Generator(生成器):照當前playbook執行任務,輸出執行軌跡。
- 2 Reflector(反思器):根因分析成敗,產出具體可操作嘅條目。
- 3 Curator(整理器):將insight轉為結構化bullet,通過規則合併入playbook。
實驗數據:開源模型打贏GPT-4.1
喺AppWorld基準上,ACE用DeepSeek-V3.1做底座,平均準確率59.5%,比ReAct baseline高+10.6個百分點。更震撼嘅係,喺最難嘅test-challenge分檔,ACE超越IBM-CUGA(GPT-4.1)8.4個百分點。
離線適配延遲降低82.3%
成本方面,離線適配ACE比GEPA延遲降低82.3%,rollout數量減少75.1%;在線比Dynamic Cheatsheet延遲降低91.5%,token成本降低83.6%。
- AppWorld平均準確率:ReAct 45.4% → ReAct+ACE 59.5%(+14.1pp)。
- 無監督設定下,ACE仍提升+14.8個百分點,對生產意義重大。
- 金融推理benchmark平均提升+8.6個百分點,適合垂直領域。
ACE喺技術棧嘅位置
ACE唔係取代任何現有技術,而係補齊一層:任務級共享知識。以下係佢同常見範式嘅關係。
ACE vs Fine-tuning:分層互補
- ACE vs Fine-tuning:ACE改輸入,成本低、可解釋、基座升級可複用;Fine-tuning改權重,適合改底層直覺。兩者分層:Fine-tuning管底層行為,ACE管上層知識。
- ACE vs RAG:RAG係問答時現查文檔,ACE係從經驗自動提煉策略。兩者互補,成熟Agent會兩者都用。
- ACE vs DSPy/GEPA:DSPy優化prompt文本,ACE優化context知識庫。可以共存:用DSPy優化三個角色各自嘅prompt。
- ACE vs Memory框架:Memory存用戶個人偏好(Letta/mem0),ACE存任務級共享策略。兩者並行,唔同層級。
侷限與未來影響
Reflector質量決定天花板
ACE嘅效果依賴強底座模型做Reflector,如果係7B模型,提煉唔到有用insight反而會入噪音。垂直領域若模型訓練數據冇覆蓋,Reflector會失靈。
Playbook中毒風險
如果Reflector喺某個時期持續產生錯誤insight,會污染playbook。生產環境需要canary playbook、版本控制同人在迴路審核。
作者認為我哋正見到AI適配棧嘅第一次嚴肅分層:底層權重(Fine-tuning)、中層記憶(Memory)、上層playbook(ACE)。Playbook會成為公司獨特嘅、不可複製嘅商業資產。
一篇 Stanford 的論文,正在質疑過去兩年 AI 行業最根本的那個假設:模型不行,就去調模型權重。 他們的答案是——別調權重,調上下文。上下文本身可以變成一個會學習的東西。
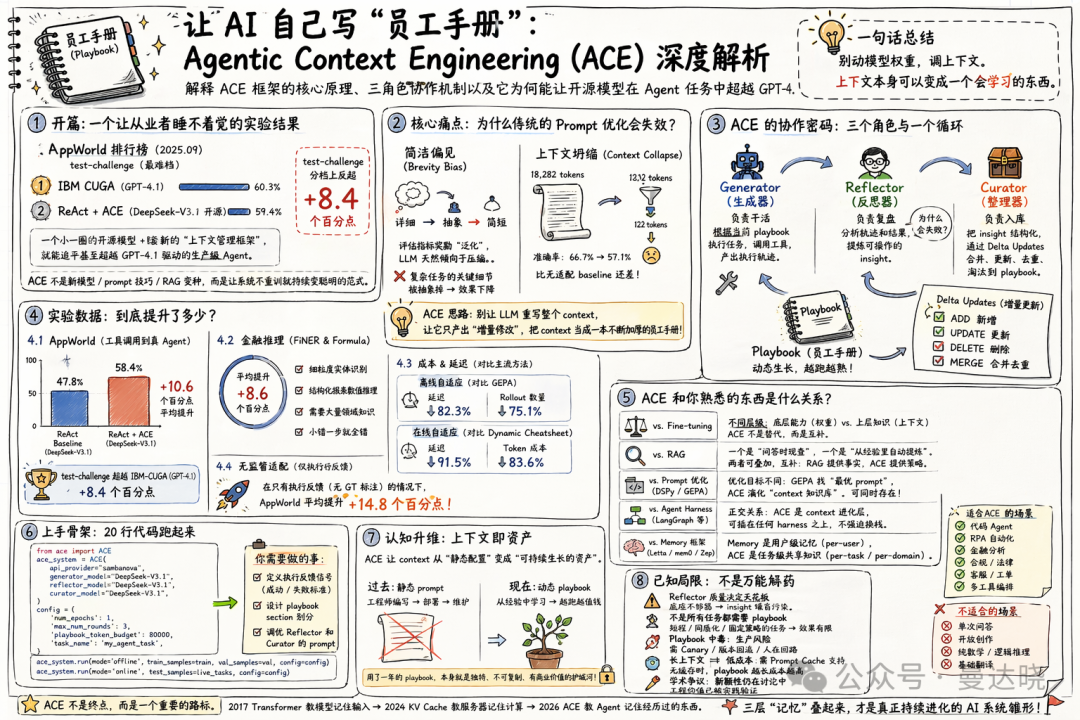
開篇:一個讓從業者睡不着覺的實驗結果
2025 年 9 月的某個週末,如果你去看 AppWorld 這個榜單——它是學術界公認最硬核的 Agent 能力評測,任務包括"把用戶 Phone 聯繫人列表裏的生日提醒同步到 Calendar"這類真實多工具協作——你會看到榜首掛着 IBM 的 CUGA,跑分 60.3%,底座是 GPT-4.1。
排第二的條目叫 "ReAct + ACE",跑分 59.4%。看起來平平無奇。直到你看到它的底座:DeepSeek-V3.1,一個開源模型。
在更難的 test-challenge 這一檔,這個"開源 + ACE"組合反超了 IBM-CUGA 8.4 個百分點。
就這一個數字,讓一羣 AI 圈的人在 Twitter 上熬了一夜:一個小一圈的開源模型,加上一套新的"上下文管理框架",就能追平甚至超越 GPT-4.1 驅動的生產級 Agent。
更戲劇性的是,這套框架幾乎不需要訓練。它沒有 fine-tune 任何一個參數。它做的事情是——讓模型自己寫一本關於這個任務的"員工手冊",做錯的地方自己改,做對的地方自己記,越跑越熟。
這篇論文叫 Agentic Context Engineering,簡稱 ACE,作者來自 Stanford、SambaNova 和 UC Berkeley。論文編號 arXiv:2510.04618,2025 年 10 月掛出來,目前已經投到 ICLR 2026,並在 12 月 SambaNova 開源了完整實現。
ACE 不是一個新的模型,不是一個新的 prompt trick,也不是"又一個 RAG 變種"。它試圖回答一個更大的問題:在 AI 應用層裏,有沒有一種方式,能讓系統不通過重訓就持續變聰明?
如果答案是有,那麼這篇論文就是這一波回答裏最值得認真讀的一份。
這篇文章不打算只做 paper 翻譯。我想做的,是把 ACE 背後那條"為什麼這件事現在重要"的完整邏輯鏈講清楚——從它解決的兩個隱蔽問題,到它的三角色設計,到它和 fine-tuning、RAG、DSPy、LangGraph 這些你熟悉的東西的關係,再到它在哪些場景真的能用、哪些場景純屬營銷噱頭。
讀完之後,你應該能清楚地判斷一件事:你們公司那個 Agent 產品,值不值得花三個工程師兩個月上一套 ACE。
第一章:先搞清楚背景——我們到底在爭論什麼?
在講 ACE 之前,必須先講清楚過去兩年 AI 應用層的一場隱形分裂。理解了這場分裂,你才能看懂 ACE 在其中站在哪一邊、以及它為什麼重要。
1.1 讓一個模型"變聰明"的兩條路
當你拿到一個基座模型,想讓它在你的具體業務上表現更好,歷史上只有兩條路:
路線 A:動權重(Fine-tuning)。收集一批標註數據,用 SFT、RLHF、DPO 或者 RL 的方式微調模型。這條路在 BERT 時代是主流,在 LLM 時代變得非常昂貴——你得有 GPU、有數據、有訓練 pipeline、有評估集,動輒幾萬到幾百萬美元。而且訓完之後,這個模型就和基座分叉了,基座升級你就得重新來一遍。
路線 B:動輸入(Context Adaptation)。不改模型,改 prompt。你往輸入裏塞更清晰的指令、塞 few-shot 示例、塞檢索回來的相關文檔、塞 tool 的描述。ChatGPT 時代以後所有人用的 prompt engineering、RAG、MCP、in-context learning——本質上都是這條路。
這兩條路各有信徒。過去兩年大致的共識是:路線 B 是主力,路線 A 是少數場景下的補充。理由也很直接——路線 B 便宜、快、可解釋、可迭代、不用擔心基座升級。你看現在幾乎所有火起來的 AI 產品,從 Perplexity 到 Cursor 到 Notion AI,都是在路線 B 上卷。
但路線 B 有一個被長期忽視的隱性成本:它的"知識"是靠人肉工程師一條一條寫進 prompt 的。當你的產品成熟、場景複雜、每次迭代都在改 system prompt 的時候,你會發現你僱了一個"prompt 維護工程師"團隊。這不是個笑話,這是 Anthropic、OpenAI、Scale AI 裏真實存在的崗位。
所以業界的下一個夢想是——能不能讓 prompt 也自動優化?
1.2 自動 prompt 優化的三代嘗試
第一代:黑盒搜索。2023 年前後出現的 APE(Automatic Prompt Engineer)、OPRO(Optimization by Prompting),思路是把 prompt 當成一個字符串去"搜索",用一些元 prompt 讓 LLM 生成候選、再用評估集打分挑最好的。效果有限,容易過擬合。
第二代:結構化優化。Stanford NLP 的 DSPy(Declarative Self-improving Python)是這條路的標杆。它把 prompt 當成代碼來管——你定義"簽名"(輸入輸出),它自動編譯 prompt 模板,再用 MIPROv2(Multi-Stage Instruction and Proposal Optimization Version 2) 這類優化器基於訓練數據調 prompt 裏的指令和 few-shot 示例。DSPy 還衍生出了 GEPA(Genetic-Pareto Reflective Prompt Evolution)——用遺傳算法 + 反思式進化,在 Pareto 前沿上維護多個高分 prompt 變體,效果據說能比 RL 訓練好 10-20 個點,rollout 數量少 35 倍。
第三代:帶記憶的自適應。2025 年出現的 Dynamic Cheatsheet(DC)更激進——它不只優化初始 prompt,而是讓 Agent 在運行過程中把"學到的經驗"寫進一個持久化的"小抄"裏,下次遇到類似問題就去查。這已經很接近 ACE 的思路了。
聽起來很美好對吧?問題是——這三代方法裏,每一代都藏着兩個致命缺陷。這兩個缺陷,就是 ACE 這篇論文的起點。
1.3 兩個沒人願意承認的坑:簡潔偏見 與 上下文坍縮
坑一:Brevity Bias(簡潔偏見)。
所有讓 LLM 自動優化 prompt 的方法,幾乎都會不可避免地把 prompt 越改越短。原因很微妙:評估指標往往獎勵"泛化"(通用的指令能在多個例子上都跑通),而 LLM 在被要求"改進這個 prompt"時,天然傾向於抽象、提煉、歸納——它是個被訓練來"總結"的東西啊。
在簡單任務上這沒毛病。但在複雜 Agent 任務上,致命的東西就藏在那些被它抽象掉的具體細節裏:某個 API 只接受特定時間格式,某個工具返回的 error code 含義,某類用戶輸入裏隱藏的歧義。這些"小破知識"不抽象才有用,一抽象就變成了廢話。
GEPA 論文甚至把"能把 prompt 做短"明確列為優勢。ACE 的作者針對這點給出了反例:對於 Agent 這種需要調工具、處理狀態、區分 edge case 的任務,長而詳細的上下文反而是剛需。
坑二:Context Collapse(上下文坍縮)。
這個更嚇人,而且有一個非常直白的實驗證據。
ACE 論文 Figure 2 裏展示了一個真實案例:一個 Agent 在 AppWorld 上累積了一個很豐富的上下文,長度是 18,282 tokens——裏面包含了大量的 API 細節、踩過的坑、成功路徑。研究者讓同一個 LLM "基於最近的經驗把這個 context 改寫一下"。
結果 LLM 幹了一件事:把 18,282 tokens 壓縮成了 122 tokens。是的,150 倍的壓縮。
準確率發生了什麼?從 66.7% 掉到 57.1%——比沒有任何適配的 baseline 還差。
這就是 Context Collapse。它的可怕之處在於,整個過程看起來非常"合理":模型在"優化"上下文,每一步都在"提煉精華"。但那些 18,000 token 裏的"瑣碎細節",恰恰是 Agent 在具體任務上能跑通的真正原因。壓縮掉了,能力就沒了。
把這兩個坑連起來看,你會發現自動 prompt 優化的主流路線走進了一個死衚衕:越想讓它自動化,它就越傾向於壓縮;越壓縮,複雜任務上的效果就越差。
ACE 就是從這個死衚衕裏找出來的一條新路。
第二章:ACE 的核心洞察——把 Context 當成"活的 Playbook"
講完背景,ACE 的基本思路其實一句話能說清:別讓 LLM 去重寫整個 context——讓它只產出"增量修改"。把 context 當成一本不斷加厚的員工手冊,而不是一篇不斷重寫的論文摘要。
這句話聽起來簡單,但實現得漂亮需要三個關鍵設計。我一個一個講。
2.1 設計一:三個角色,一個循環
ACE 的架構來自一個很聰明的類比——一個成熟的組織是怎麼積累知識的?
不是讓老闆一個人拍腦袋重寫員工手冊。而是:
執行的人(工程師)去做事、踩坑、成功、失敗
反思的人(項目經理)覆盤每一次行動,提煉經驗教訓
整理的人(知識庫管理員)把這些經驗教訓整合進手冊,更新、去重、分類
ACE 把這個結構原樣搬到了 LLM Agent 上,搞出了三個角色:
Generator(生成器):負責幹活。拿到一個任務,它照着當前的 playbook 去執行——推理、調工具、生成答案。它不學習,只做事。它的副產品是一條"執行軌跡"(trajectory)——包括每一步的推理、調用了什麼工具、工具返回了什麼、最終結果是成還是敗。
Reflector(反思器):負責覆盤。它拿到 Generator 的軌跡和執行結果(如果有標註答案就帶上標註;沒有也行,看代碼有沒有報錯、API 有沒有返 4xx、最終狀態對不對),然後做根因分析:這次對了是因為用了哪條策略?錯了是因為踩了哪個坑?有沒有什麼規律性的 insight 值得記下來?
關鍵是:Reflector 不是泛泛的"請總結一下"。ACE 的 prompt 設計要求它輸出具體的、可操作的條目。論文裏舉的例子很傳神:一個編程任務失敗了,Reflector 不會寫"Agent 犯了個錯",而是寫"Agent 用了不可靠的啓發式規則(關鍵詞匹配交易描述)而不是權威數據源(Phone 應用的聯繫人 API)"。這種顆粒度的 insight,才是下次不重蹈覆轍的抓手。
Curator(整理器):負責入庫。它把 Reflector 產出的 insight,轉換成一條條結構化的"bullet",然後通過一套確定性的規則(不是讓 LLM 重寫)把這些 bullet 合併進 playbook:增加、更新、去重、淘汰。
這裏有個很多人會問的問題:這三個角色是三個不同的模型嗎?
不是。在 ACE 論文的實驗裏,三個角色用的是同一個底座 LLM——DeepSeek-V3.1(非思考模式)。差別只在 prompt。作者特意這麼設計,就是為了證明:性能提升完全來自 context 構造本身,而不是某個更強的"老師模型"偷偷給了一個更弱的"學生模型"知識。
這個公平性設計值得記住,後面講侷限時還會用到。
2.2 設計二:Delta Updates——這才是真正的創新
如果 ACE 只是"三個角色輪流協作",那它和 Dynamic Cheatsheet 就沒什麼本質區別。真正讓 ACE 突破 Context Collapse 的,是它如何更新 playbook 的機制。
傳統做法(包括 DC)叫整體重寫(monolithic rewrite)——讓 LLM 讀完當前 context 和新經驗,然後寫一個"改進後的新 context"。問題我們上面講過了:LLM 會不受控地開始壓縮、抽象、丟細節。
ACE 的做法叫 Delta Updates——它禁止 LLM 去"重寫"整個 context。Curator 只能產出"增量操作":
ADD 一條新的 bullet
UPDATE 某條 bullet 的內容或計數
DELETE 某條不再適用的 bullet
MERGE 語義相似的 bullet 去重
然後這些增量操作被確定性地(不是讓 LLM 隨意合併)應用到 playbook 上。
這就像 Git 的 commit 和 diff——你不是每次都扔一個全新的代碼庫進去,而是隻提交變更。每一次變更可追溯、可審計、可回滾。
每條 bullet 是一個結構化對象,大致長這樣:
{
"id": "b_00427",
"content": "查詢金融數據時,先按日期範圍過濾能顯著減小結果集,避免上下文爆炸",
"helpful_count": 12,
"harmful_count": 1,
"section": "task_guidance",
"created_at": "2025-10-15T10:30:00Z"
}注意 helpful_count 和 harmful_count 這兩個計數器——Generator 在使用這條 bullet 的時候,會在 trajectory 裏標記"這條 bullet 幫到我了"或"這條 bullet 反而誤導我了"。Curator 根據這個反饋動態調整權重,長期被證明有害的 bullet 會被淘汰。
這就是 ACE 作者說的 grow-and-refine(生長與精煉)機制——既讓 playbook 能持續加厚,又不會無限膨脹。
2.3 設計三:分段管理,支持增量檢索
這一塊論文沒太高調,但其實非常重要。Playbook 不是一個扁平的 bullet 列表,它被分成多個 section(任務指引、API 備忘、常見陷阱、數據結構約定等)。每條 bullet 歸屬一個 section。
這樣做的好處有三個:
局部化更新:Curator 只需要改動相關 section,不影響別的。
精細化檢索:Generator 在執行任務時,可以只拉相關 section 的 bullet 進 prompt,而不是每次把整本手冊塞進去。ACE 默認使用 hybrid retrieval(關鍵詞 + 向量)按相關性挑選 top-k bullets。
可擴展:playbook 可以不斷長大,不用擔心把 context 撐爆。
這三個設計疊在一起,ACE 就從一個"又一個 memory 框架"變成了一個真正能在長週期運行裏不劣化的系統。
第三章:實驗數據——到底提升了多少?
光講設計不看數字,都是耍流氓。看數字。
3.1 AppWorld:從工具調用到真 Agent
AppWorld 是 ACE 最重頭的評測。這個 benchmark 設計得極其貼近真實——它模擬了一個有 9 個 app(Phone、Calendar、Amazon、Spotify 等)、457 個 API 的生態環境,任務要求 Agent 跨多個 app 完成複雜操作。
在相同底座(DeepSeek-V3.1)下,ACE 的表現是這樣的:
+10.6 個百分點的平均提升,對 Agent 評測來說是非常大的量級。
但更有分量的是那個前面講過的"打臉時刻":ReAct + ACE (DeepSeek-V3.1) 在 AppWorld 的 test-challenge 分檔上,超過了 IBM-CUGA (GPT-4.1) 8.4 個百分點。
把這句話翻譯成大多數人能懂的語言:用一個開源模型 + 一套上下文管理框架,在最難的測試集上擊敗了一個主流閉源大模型驅動的生產級 Agent。這對所有在"用 GPT-4/Claude 做 Agent 產品"的團隊來說,是一個值得嚴肅考慮的信號——底座不是唯一的變量。
3.2 金融推理:ACE 不只是為 Agent 設計的
ACE 還測了兩個金融分析 benchmark——FiNER(XBRL 財報裏的細粒度實體識別)和 Formula(結構化財報裏的數值推理)。這兩個任務的特點是:需要大量領域專用知識,小錯一步就全錯。
ACE 的平均提升是 +8.6 個百分點。這個數字不算誇張,但關鍵是提升的來源——ACE 的 Reflector 從錯誤裏識別出"某種實體類型的邊界條件"、"某種公式在特定披露格式下要調整單位"這類具體到令人髮指的領域 insight,然後積累進 playbook。
這暗示了一個商業價值很高的應用:垂直領域 Agent。法律、醫療、金融、合規這些領域,現在做 AI 產品的主要痛點之一就是"模型不懂我們行業的黑話和規矩"。傳統解法要麼是 fine-tune(貴),要麼是人工維護一個超長 system prompt(累)。ACE 給了第三條路。
3.3 成本和延遲——這才是我要重點講的
Agent 圈有個說法:accuracy 好看是文章,latency 好看是產品。ACE 在延遲和成本上的數字,才是真正讓工業界關注的部分。
離線自適應(類似做一次 prompt 優化):
對比 GEPA,ACE 的適配延遲降低 82.3%,rollout 數量減少 75.1%
翻譯成人話:做一次"讓 Agent 從訓練集學新東西",GEPA 跑一整晚,ACE 兩小時搞定
在線自適應(Agent 跑生產時持續學習):
對比 Dynamic Cheatsheet,ACE 的延遲降低 91.5%,token 成本降低 83.6%
這些數字為什麼能這麼誇張?因為 ACE 的核心優化——delta updates 不需要 LLM 去重寫整段 context。Curator 的合併、去重、淘汰操作是確定性的規則,不走 LLM。只有 Reflector 那一步(分析軌跡、提煉 insight)才需要 LLM 推理。
這裏有一個非常重要的工程直覺,正好是我上一篇講 prompt caching 一塊被忽視的算力金礦:關於 Prompt Caching,你需要知道的一切時埋下的伏筆:ACE 的 playbook 是"穩定前綴"。它在生產裏跑的時候,playbook 作為系統 prompt 的一部分,會被 KV Cache / Prompt Cache 命中。所以"playbook 越長 = 成本越高"這個直覺在有緩存的推理棧上是錯的。
ACE 作者自己在論文裏明確寫了這句話:"Long context ≠ higher serving cost"。這不是一句營銷話術,而是建立在 KV cache reuse、context offloading、long-context-aware serving 這些基礎設施已經成熟的前提上。
換句話說,ACE 和 prompt caching 是天然的搭檔。沒有 prompt caching,playbook 長到幾萬 token 就會把賬單燒穿。有了 prompt caching,playbook 越穩定、命中率越高、邊際成本趨近於零。
這是一個非常漂亮的基礎設施協同——ACE 用 token 換能力,prompt caching 讓 token 便宜到幾乎免費。兩件事疊在一起,才是完整的價值拼圖。
3.4 無監督適配:這是我覺得最震的一點
最後一組數據,也是我讀完整篇論文最受震動的點。
前面講的結果都是在"有 ground-truth 標註"的情況下跑的。但 ACE 做了一組額外實驗——把 GT 標註去掉,只讓 Reflector 看"執行反饋":代碼報沒報錯?API 返回是 2xx 還是 4xx?subgoal 有沒有達成?
在這種"無監督"設定下,ACE 依然拿到了顯著提升——論文報告 AppWorld 上 +14.8 個百分點的平均提升(相對無適配 baseline)。
這個數字對產品化的意義是核彈級的。因為在真實生產環境裏,你永遠拿不到那種乾淨標註的數據。用戶不會告訴你"剛才這個任務 Agent 做對了還是錯了"。你能拿到的只有執行信號——程序跑沒跑通、用戶下一條消息是不是"不對,我要的是 X"、訂單有沒有最終下單成功。
ACE 證明了:只要你能把這些執行信號結構化地餵給 Reflector,Agent 就能從這些"隱式反饋"裏持續改進。這意味着 ACE 可以直接部署到有閉環信號的生產環境裏——客服系統(用戶滿意度、會話結束方式)、代碼助手(編譯/測試通過率)、數據分析工具(查詢執行成功率)——自主地越跑越好。
第四章:ACE 和你熟悉的那些東西是什麼關係?
ACE 不是在真空裏誕生的。要理解它的真正位置,你必須把它放進現有的 AI 應用技術棧裏對比。下面我挨個把它和幾個最常見的範式做對比——哪些是正交的(可以疊加),哪些是競爭的(選一個就夠)。
4.1 ACE vs Fine-tuning:不是替代,是不同層級
"Stanford 宣佈 Fine-tuning 已死"——這是 ACE 論文出來後最聳動的標題。這話說得太滿了,但背後的邏輯值得認真拆。
真實的關係是分層的:
Fine-tuning 適合改動模型的"底層直覺"——比如讓模型習慣某種輸出風格、某種語氣、某種推理範式。這些東西寫在 prompt 裏要麼寫不完,要麼寫了也不穩定。
ACE 適合改動模型的"上層知識"——API 細節、領域術語、踩過的坑、最佳實踐。這些東西本質就是"可枚舉的規則",寫在 context 裏天然合適。
所以"Fine-tuning 已死"這個說法過於極端。更準確的說法是:過去我們因為"動權重"太貴,把一大堆本該用 context 解決的問題錯放到了 fine-tuning 上。ACE 把這部分工作還給了 context 層。未來的 AI 產品大概率是用強底座 + ACE 管知識 + 必要時再 fine-tune 行為的三層結構。
4.2 ACE vs RAG:一個是檢索,一個是提煉
這是最容易混淆的對比。兩者都在"往 context 裏塞東西"。差別在哪?
RAG 的本質是"問答時現查"。你有一個外部知識庫(文檔、數據庫、向量庫),每次用戶問問題,就去檢索相關片段塞進 prompt。知識庫本身是人手工構建和維護的——工程師寫清洗管道、切分文檔、生成 embedding。
ACE 的本質是"從經驗裏自動提煉"。它的 playbook 不是人工維護的,而是 Agent 在跑任務的過程中、從每一次成功和失敗裏、由 Reflector + Curator 自動生長出來的。playbook 裏不存"原文檔片段",存的是"經過推理提煉的策略性 bullet"。
舉個例子你就懂了:
RAG 方式:用戶問"我怎麼退訂閲"→ 去文檔庫檢索 → 找到"訂閲管理 FAQ 第 3 條"→ 塞進 prompt → 回答
ACE 方式:Agent 發現過去處理退訂請求時,10 次裏有 7 次用戶同時想改支付方式 → Reflector 提煉成一條 bullet:"處理退訂請求時主動詢問是否需要修改支付方式" → 寫進 playbook → 以後所有退訂對話都帶上這條先驗
兩者是互補的,不是替代的。一個成熟的 Agent 系統大概率兩者都用——RAG 提供事實和文檔,ACE 提供策略和經驗。論文作者自己也在討論部分明確說:ACE 不排除 RAG。
4.3 ACE vs Prompt 優化(DSPy / GEPA / MIPROv2)
這才是 ACE 真正的直接競爭者。它們都在做"讓 prompt 自動變好"這件事。
DSPy 是一個編程框架——它讓你用 Python 聲明式地定義 LLM pipeline(signatures → modules → optimizers),然後自動編譯 prompt。它的優化器(MIPROv2、BootstrapFewShot、GEPA)負責找最優的 prompt 指令和 demonstration。
GEPA 是 DSPy 生態裏最先進的 prompt 優化器——用遺傳 + Pareto 前沿搜索,通過反思來進化 prompt。它的目標是找到"一個最好的 prompt"。
ACE 的目標不一樣——它要演化的不是"prompt 文本",而是"context 裏的知識庫"。兩者在 ACE 的框架裏甚至可以同時存在:你可以用 DSPy/GEPA 去優化 Generator、Reflector、Curator 各自的 prompt(這就是 ACE 作者說的"prompt engineering as control layer"),然後 playbook 的內容由 ACE 循環自動生長。
有一個經典的比喻:GEPA 是在優化操作系統本身;ACE 是在優化操作系統裏運行的知識庫。兩者不衝突,共存共榮。
4.4 ACE vs Agent Harness
Agent Harness 是什麼?它是 Agent 的"執行骨架"——負責狀態管理、工具調度、多智能體編排、錯誤重試、流式輸出、消息路由。
ACE 不是 harness。ACE 是一個可以插在任何 harness 之上的 context 進化層。你在 LangGraph 裏寫的那個 Agent,用的底座依然是 LangGraph 的狀態機;只是它的 system prompt 裏多了一個"playbook"章節,這個章節背後有 ACE 循環在持續更新。
在開源的 ACE 實現裏,作者給的示例就是直接把 ACE 扣在 ReAct 這個最基礎的 harness 上。你完全可以把它扣在 LangGraph、LlamaIndex、Autogen 上,只要你能從 Agent 的執行過程中拿到"軌跡"和"執行反饋"兩個信號。
這種正交關係,是 ACE 最具產品化價值的一點——它不強迫你換技術棧。你現有的 Agent 基礎設施可以原封不動保留,在上面疊加一層 ACE 就行。
4.5 ACE vs Memory 框架(Letta / mem0 / Zep)
最後這個對比,藏着一個很重要的區別。
Memory 框架(比如 Letta、mem0、Zep)解決的是"讓 Agent 記住特定用戶的偏好和歷史對話"。它是per-user、per-session 的記憶。你告訴 Agent "我是素食主義者",下次對話它還記得。
ACE 的 playbook 是 per-task、per-domain 的。它不是記住"這個用戶是誰",而是記住"這類任務應該怎麼做"。它是整個 Agent 的"組織知識",不是某個用戶的"個人檔案"。
在真實的產品裏,這兩層是並行存在的:
Memory 層:存每個用戶的上下文、偏好、歷史(Letta/mem0)
Playbook 層:存整個產品的共享策略和 know-how(ACE)
忽略這個區別,會讓你在架構選型時搞混。很多團隊上來就說"我們要做 memory",其實他們想要的是"playbook"。
第五章:一個極簡的上手骨架(20 行以內)
給一個極簡骨架。下面這個是 ACE 官方開源倉庫 github.com/ace-agent/ace 的核心用法,刪到不能再刪:
from ace import ACE
# 三個角色共用同一個底座 LLM(ACE 論文的設置)
ace_system = ACE(
api_provider="sambanova",
generator_model="DeepSeek-V3.1",
reflector_model="DeepSeek-V3.1",
curator_model="DeepSeek-V3.1",
)config = {
'num_epochs': 1,
'max_num_rounds': 3, # Reflector 最多反思幾輪
'playbook_token_budget': 80000, # playbook 最大 token 數
'task_name': 'my_agent_task',
}
# 離線訓練:用一批歷史數據把 playbook 訓出來
ace_system.run(mode='offline', train_samples=train, val_samples=val, config=config)
# 上線後:持續在線演化
ace_system.run(mode='online', test_samples=live_tasks, config=config)就這。核心心智模型是:offline 階段用標註數據把初始 playbook 構造起來,online 階段讓它在生產中繼續長。你要改造的是自己的 DataProcessor——告訴 ACE 怎麼評判"這次任務是成是敗"。
如果你要上生產,真正需要花時間的不是這二十行代碼,是:
定義你的執行反饋信號(代碼有沒有報錯?用戶有沒有反悔?業務指標達到了嗎?)
設計你的 playbook section 劃分(哪些是 API 規則、哪些是 edge case、哪些是業務先驗?)
調 Reflector 和 Curator 的 prompt(這是新時代的 prompt engineering,你 prompt 寫得好不好,直接決定 playbook 長得好不好)
最後這一條 Reflector/Curator 的 prompt 本身就是核心資產——Medium 上已經有人把這層起了個名字叫 reflective prompting,意思是:靜態 prompt engineering 讓位給動態反思式 prompt engineering。
第六章:這條路不全是順風順水——ACE 的已知侷限
如果讀到這裏你覺得 ACE 是銀彈,那我前面白寫了。我既答應你讓你真正學到東西,那就得把這個框架的軟肋也講清楚。以下是我讀完論文、看完 GitHub 討論、刷完 Twitter 上各路從業者反應之後,整理的四類侷限。
6.1 Reflector 的質量決定天花板
ACE 的循環是個放大器——Reflector 提煉得好,playbook 越長越強;提煉得糟,playbook 就是一堆垃圾。
論文作者自己承認:ACE 依賴一個足夠強的底座模型來扮演 Reflector。在實驗裏他們用的是 DeepSeek-V3.1(671B 參數)。如果你換一個 7B 的小模型當 Reflector,它根本提煉不出有價值的 insight——ACE 反而會主動往 playbook 裏塞噪音。
這一點在垂直領域更致命。如果這個領域是模型訓練數據裏沒覆蓋到的(比如冷門的行業合規、區域性的法規、企業內部的 domain knowledge),Reflector 沒有能力從失敗中看出原因,ACE 會失靈。
實操上的啓示:上 ACE 之前,先做一個小實驗——手動挑 20 個失敗案例,問 Reflector "為什麼失敗了、應該怎麼改",看它能不能給出具體、可操作、不假大空的答案。如果答案都是"Agent 需要更仔細地理解用戶意圖"這種廢話,你的項目就不適合上 ACE,先換底座或者堆更多 domain context。
6.2 不是所有任務都需要 playbook
論文在討論部分坦誠寫了一段:HotPotQA 這樣的多跳問答任務、Game of 24 這種固定策略的數學推理,ACE 沒什麼用。
原因很直接:這些任務的解法是"短、規則化、可壓縮"的。Game of 24 只需要記住一個 meta 策略(枚舉所有運算順序),HotPotQA 只需要一句"檢索→篩選→合成"。往裏塞一本厚厚的 playbook 反而是干擾。
判斷標準:你的任務是不是長尾 + 有大量可枚舉的領域知識 + edge case 多?如果是,ACE 有用。如果是短程、同質化、靠單一推理模式解決的任務,ACE 是過度工程。
典型適合 ACE的場景:代碼 Agent、RPA 式自動化、金融分析、法律合規檢查、客服工單、多工具編排。
典型不適合 ACE的場景:單次問答、開放創作、純數學/邏輯推理、基礎翻譯。
6.3 Playbook 中毒:一個被低估的生產風險
這一條論文沒明說,但我在幾個生產討論裏看到從業者提到:如果 Reflector 在某個特定時期持續產生錯誤的 insight,這些錯誤 bullet 會污染 playbook。
舉個場景:你的 Agent 在某一週裏接到一批異常用戶(比如黑產賬號),Reflector 看這些"失敗"後提煉出了一條 bullet:"用戶請求看起來像自動化腳本時,要求額外驗證"。這條 bullet 寫進 playbook 之後,所有後續用戶都被影響——正常用戶也開始被額外驗證,體驗崩掉。
helpful_count / harmful_count 計數器能緩解這個問題,但不夠。生產實踐裏你還需要:
Canary playbook:新更新的 bullet 先只對 1% 流量生效,觀察指標
版本控制:playbook 必須像代碼一樣版本化,壞了能立刻回滾
人在迴路:對關鍵領域(支付、醫療、法律)的 bullet 新增,必須有人工審核
這個話題在 Medium 上被一位作者總結成 Staged Agent Optimization(分階段 Agent 優化)——先把系統做到可靠,再開自適應;而不是一上來就全自動。
6.4 "Long context ≠ higher serving cost" 是有前提的
我前面引用了 ACE 作者的這句話。現在要把前提講清楚。
這句話成立的前提是:你跑在支持 prompt caching 的推理棧上,而且命中率高。
如果你是在本地部署一個沒有 prompt cache 的 vLLM / TGI 服務,playbook 越長,prefill 成本線性上漲——一本 50K token 的 playbook 會讓每次請求的 TTFT 多出 1-2 秒,付費的話每百萬 token 實打實花錢。
ACE 的價值實現,需要配套的推理基礎設施:Anthropic 的 cache_control、OpenAI 的自動緩存、DeepSeek 的硬盤緩存、Google Gemini 的 implicit cache——有一個就夠。沒有的話,playbook 的長度就必須嚴格控制在 10K token 以內,否則成本會先於效果炸掉。
好消息是,今天主流的 API 都已經做到了這點。但如果你在自建推理棧,一定要先跑通 prefix caching。
6.5 學術爭議:這到底是 Dynamic Cheatsheet 的微創新嗎?
最後一個侷限是純學術層面。ACE 的架構基礎是 Dynamic Cheatsheet——Reflector 這個角色是 ACE 新加的,delta updates 是 ACE 的新做法,但整體 "Generator-Curator + 持久化記憶"的思路不是 ACE 獨創。
目前 ICLR 2026 審稿還在進行中,有部分審稿意見質疑 ACE 的新穎性:
Reflector 的"反思"本質上是 Reflexion (2023) 的思路
Delta updates 在 Mem0 這類 memory 框架裏早就有
總體貢獻更像"把已有技術打包 + 在 AppWorld 上做了強評測"
我對這個爭議的個人看法:即使 ACE 的每個零件都不是首創,它把這些零件組裝成一個能跑贏 SOTA 的生產級框架,本身就是有價值的工程貢獻。學術圈偏愛 "原創性",但工業界更關心"能不能跑通、能不能復現、能不能上生產"。從這個角度,ACE 的價值不會因為學術爭議被否定。
第七章:認知拔高——為什麼 ACE 這件事,比論文本身重要
7.1 AI 適配的"三層堆棧"正在形成
過去兩年,AI 應用層的適配技術沒有一個清晰的分層。大家把 fine-tuning、prompt engineering、RAG、agent memory、few-shot learning 混在一起討論,講的時候全是"哪個更好"。
ACE 出現之後,一個比較清晰的三層結構終於浮出水面:
┌────────────────────────────────────┐
│ 第 3 層:Playbook(ACE) │ ← 任務級共享知識,自動生長
│ "這類任務怎麼做" │ 中期(小時/天)演化
├────────────────────────────────────┤
│ 第 2 層:Memory(Letta/mem0) │ ← 用戶級個性化記憶
│ "這個用戶是誰、要什麼" │ 會話級(秒/分鐘)演化
├────────────────────────────────────┤
│ 第 1 層:Weights(Fine-tuning/RLHF) │ ← 模型級基礎能力
│ "怎麼推理、怎麼說話" │ 離線(天/周)演化
└────────────────────────────────────┘這三層各有自己的時間尺度、成本曲線、適用場景。未來成熟的 AI 產品團隊大概率會有三個崗位分別對應:Model Training Engineer(第 1 層)、Memory/Context Architect(第 2-3 層)、Reflective Prompt Engineer(第 3 層的 Reflector/Curator 優化)。
就像 2010 年前後 Web 應用棧分化出前端、後端、DBA 一樣。我們正在看着 AI 應用棧完成它的第一次嚴肅分層。
7.2 "上下文"正在變成一種可持續資產
這是我讀完 ACE 最深的一個想法。
過去我們對"prompt"的理解是:一個靜態的、每次部署時配置好的、屬於代碼的東西。它像 config 文件——工程師寫好、提交、部署、維護。
ACE 提出的 playbook 顛覆了這個認知:prompt 的一部分(知識部分)不再是代碼,而是數據資產。它會隨着 Agent 在真實世界裏運行而不斷增長,越跑越值錢。
換句話說:一個跑了半年的 ACE Agent,它的 playbook 本身就是一個獨特的、不可複製的、有商業價值的資產。你換個同樣的模型、同樣的代碼,但沒有這本 playbook,你就重新在原點開始。
這對 AI 產品的護城河邏輯是一個根本性的改變:
過去的護城河:模型、數據、用戶
ACE 帶來的新護城河:運行時積累的領域 playbook
想象一個場景:兩家同時做"AI 法律合同審查"的創業公司,A 家上了 ACE、跑了一年,playbook 裏積累了 40K token 的行業 edge case、過往踩坑、客戶反饋;B 家還在手寫 system prompt。即使兩家用的底座模型完全一樣,A 家的產品體驗會顯著更好。
這個 playbook 用不了三五年,就會出現在 AI 公司的資產負債表上。不是誇張——它是真實的生產要素。
7.3 競爭範式的第三次漂移
過去兩年,AI 產品的競爭焦點漂移了兩次:
2023 年:模型之爭。"誰有更強的 GPT/Claude"。那時候用 GPT-4 比 GPT-3.5 就是護城河。
2024 年:產品之爭。"誰把 LLM 包裝得最貼合場景"。Cursor、Perplexity、v0 這波公司靠的是產品形態和用戶體驗。
2025-2026 年:上下文之爭(我的判斷)。模型差距在縮小,開源和閉源的差距也在縮小(DeepSeek-V3.1 = GPT-4.1 on AppWorld 就是證據)。產品形態很容易被抄襲。真正難抄襲的,是這個產品在真實場景裏沉澱下來的 context 資產。
ACE 不是這場漂移的唯一驅動力——Prompt Caching、Memory 框架、RAG 的成熟、Long Context 能力的提升都在推這個方向。但 ACE 是其中第一個把"上下文作為可進化資產"這件事系統化、工程化的框架。
對投資人來說,這意味着評估一家 AI 公司的標準在變化。過去你問:
你用的什麼模型?
你的獨特數據是什麼?
你的用戶粘性怎麼樣?
以後你可能還要問:
你們有 context 進化機制嗎?
你們的 playbook 跑了多久?積累了什麼?
你們的 Reflector prompt 是怎麼調的?
如果基座模型下個月漲價 30%,你們怎麼辦?
這些問題的答案,將直接決定一個 AI 創業公司的長期壁壘。
7.4 一個留給你的問題
如果你在做 AI 產品,最後留給你一個具體問題:假如你的 Agent 明天開始運行 ACE,三個月後它的 playbook 會長什麼樣?
想象那本手冊的目錄。會有幾個 section?每個 section 裏會有多少條 bullet?它會記錄什麼樣的知識?這些知識和你現在在 system prompt 裏寫的那些東西,有什麼不同?
如果你想不出來,說明你的場景不適合 ACE——你的任務沒有足夠的"領域知識複雜性"可積累。
如果你能清晰地想象出三個月後那本手冊長什麼樣,甚至能提前寫下前 20 條 bullet——恭喜,你的場景非常適合 ACE,而且你應該今天就開始動手。
最後:從一個小 idea 到一場可能的範式之爭
ACE 這篇論文本身的技術貢獻其實不算革命性——Reflector 是改良自 Reflexion,Delta Updates 是 Git 的思路,Playbook 是 Dynamic Cheatsheet 的升級版。每一個零件都不新。
但把這些零件以這個結構組裝起來,再配上 AppWorld 上那個打臉 GPT-4.1 的實驗結果,它就變成了一個"可能改變 AI 適配範式"的工程範本。
歷史上真正重要的技術突破,很多時候不是單點的科學發現,而是已有零件的一次漂亮組裝。ACE 可能就是這樣一次組裝——在"prompt engineering vs fine-tuning"的二元對立裏,它撕開了一道新的縫:不動權重,也不手寫 prompt,讓上下文自己學。
這條路走不走得通?三年後就能看出來。但對一線從業者來說,不需要等三年——你可以下週開始實驗。SambaNova 已經把完整實現開源,論文的 GitHub 倉庫給了 AppWorld 和 Finance 兩個現成的 benchmark 腳本,你拿着自己的業務數據可以直接跑。
對產品經理來說,開始問自己那個問題:你的 Agent 三個月後的 playbook 會是什麼樣?
對創業者來說,把"上下文演化機制"放進你的產品架構圖。它現在還是一個 nice-to-have,但 12 個月內它會變成 must-have。
對投資人來說,把"context 資產"加進你的盡調清單。模型會貶值,產品會被抄襲,但跑了一年的 playbook 不會。
2017 年的 Transformer 教會了模型怎麼"記住"自己讀過的東西。2024 年的 KV Cache 教會了服務器怎麼"記住"算過的東西。2026 年的 ACE,也許在教 Agent 怎麼"記住"自己經歷過的東西。
這三層"記憶"疊起來,才是一個真正能在真實世界裏持續進化的 AI 系統的雛形。
ACE 不是終點。它是一個可能很重要的路標。