記憶,是 Agent 基建|對話 Calvin@Vida
整理版優先睇
記憶正從產品功能變成 Agent 基建,OpenChronicle 開源方案讓記憶歸用戶所有
本文係筆者與 Calvin(Vida 團隊,清華 00 後,研究方向為 Proactive Agent)一個鐘頭嘅對話記錄。Calvin 認為,AI 模型能力越嚟越接近,真正影響用戶體驗嘅係模型擁有嘅關於用戶嘅記憶同 Context。佢哋團隊開源咗 OpenChronicle,一個本地優先、模型無關嘅記憶基礎設施,用嚟解決跨產品記憶唔連貫、上下文要靠手動維護嘅問題。
OpenAI 最近推出 Codex 嘅 Chronicle 記憶功能,但只限 Pro 用戶同 Mac 平台。Calvin 團隊隨即開源 OpenChronicle,不但提供相同功能,仲可以接入 Claude、Codex、OpenCode 等任何 Agent,而且記憶所有權歸用戶,唔係廠商。技術上採用 AX Tree 優先、截圖兜底嘅混合方案,成本低、準確度高、結構化。
整體結論係:記憶正在從「產品差異化功能」變成「Agent 時代嘅基礎設施」。OpenChronicle 想掀翻嘅,係大模型廠商靠記憶綁定用戶嘅商業模式,令記憶變成設備裏嘅一層開放基建,畀用戶自由選擇模型同 Agent。
- 記憶成為 Agent 基建:模型能力差距縮小後,記憶同 Context 係決定用戶體驗嘅關鍵
- OpenChronicle 開源方案:本地優先、模型無關,透過 MCP 協議畀任何 Agent 接入,記憶所有權歸用戶
- AX Tree 優先技術選型:比截圖 OCR 更平、更準、更結構化;Word/飛書呢類應用用截圖兜底
- 成本可控:輕度記錄每日約 50 美分 Token 費,重度使用 3-5 美金;可用本地模型進一步壓低成本
- 從被動到主動:記憶基礎設施之上,Vida 團隊正構建 Proactive Agent,根據 context 主動判斷、建議同行動
OpenChronicle GitHub 倉庫
開源嘅記憶基礎設施,支援 AX Tree 優先記錄、MCP 協議接入,與模型無關。
記憶:從產品功能變成 Agent 基建
Calvin 認為,以前模型能力差,記唔記住影響唔大;但而家 OpenAI、Claude 等模型能力接近,真正影響體驗嘅係記憶同 Context。佢哋團隊嘅 Proactive Agent 研究核心就係 Memory 同 Context,想搞清楚「怎樣記、記什麼」先可以令模型表現更好。
記憶嘅目標係令 AI 交互從無狀態變成有狀態,從有負擔變成無負擔。OpenAI Chronicle 綁定喺 Codex Pro 用戶,而 OpenChronicle 就係要打破呢種綁定,令記憶成為設備嘅基礎設施,同邊個模型協作都得。
AX Tree 優先:混合方案嘅取捨
技術實現上,OpenChronicle 唔係用常見嘅截圖 OCR+RAG,而係AX Tree 優先。AX Tree 係 macOS 系統層嘅輔助接口,將屏幕內容變成結構化文字樹,直接拎到應用名稱、焦點、編輯文字等資訊,唔使行視覺模型。
- 1 便宜:文本處理成本遠低於圖片
- 2 更準:對意圖信號嘅識別比 OCR 強好多
- 3 結構化且輕量化:存數據庫同檢索都更方便
不過 AX Tree 有短板——喺 Word、飛書呢類應用入面,內部渲染繞過系統輔助通道,只能讀到頂欄菜單同文檔標題。所以 OpenChronicle 係混合方案:AX Tree 優先,截圖兜底。截圖基於觸發器,只有光標運動、頁面滾動、應用切換先會觸發,避免睇電影等場景浪費 Token 同污染記憶。
Token 賬:50 美分 vs 3 美金嘅分界
對於 8 小時工作日、純靜默記錄嘅輕度使用,Token 消耗大約50 美分/日;高頻調用嘅重度場景就要 3-5 美金。如果用本地模型(例如筆記本部署 gpt-oss-120b),基本上只需要電費。
從「記住你說過什麼」到「記住你點樣做事」
市面上 AI 產品嘅 Memory 量唔缺,缺的是跨產品連貫。OpenChronicle 將 Mac 上所有應用操作放進同一個本地記憶池,按 7 個分類扁平存成 Markdown 文件。
- 你嘅個人資料(呢個人)
- 你嘅項目
- 你常用嘅工具
- 你關心嘅話題
- 你聯繫嘅人
- 你工作嘅組織
- 你經歷嘅事件
對外透過MCP 協議暴露成工具調用,Claude Code、Claude Desktop、Codex、OpenCode 都已有一鍵集成配置。咁樣,喺 Cursor 做嘅設計決策、飛書討論嘅架構方向、Slack 收到嘅需求反饋,都可以喺另一個對話窗口畀 Claude Desktop 直接承接。
Calvin 區分:「記住你說過什麼係 AI 嘅認知層;記住你點樣做事係 AI 嘅行動層,需要理解場景偏好、慣性同潛規則,難度大好多。」
開源掀桌:記憶應該歸邊個?
Calvin 團隊去年底就開始搞記憶,見到 OpenAI Chronicle 嘅時候第一反應係慌——怕 OpenAI 一口氣食曬所有場景。但仔細睇完發現 Codex 喺乾淨環境效果可以,日常凌亂 Workflow 就跟唔上。
呢啲唔係 Calvin 團隊第一次同 OpenAI 撞車。佢哋真正研究嘅係基於呢套基礎設施嘅Proactive Agent——唔係 reactive 等用戶問,而係根據 context 主動判斷、建議同行動。場景包括代碼中斷恢復、跨文檔協作、設計稿修改延續、長期個人知識沉澱。
最後 Calvin 話:希望記憶基礎設施成熟後,Proactive Agent 可以服務所有人,令已經依賴 Agent 做事嘅人更自然去創造。
PRODUCT
• 雖然 AI 越嚟越聰明,但每次對話,你都要補充好多嘢
• 讓 AI 記住你講過啲咩唔難,但要佢記住你做過啲嘢就好複雜
• 記憶呢樣嘢,已經由產品功能慢慢變成 Agent 基建
以上內容,嚟自我同 Calvin 嘅對話
北京時間 4 月 21 日,OpenAI 幫 Codex 加咗記憶功能,叫 Chronicle,等佢知道你啱先睇緊咩、兩星期前做緊咩項目Codex 凌晨更新,將屏幕內容「放入記憶」
但係呢...呢套嘢淨係俾 Pro 訂閲嘅用戶,亦只係俾 mac 用戶
一日之後,4 月 22 號夜晚,有個叫 OpenChronicle 嘅項目喺 GitHub 出現,提供咗相同嘅開源實現,仲喺嗰日衝到 X 嘅 today's news trending 第一
github.com/Einsia/OpenChronicle
Calvin 係呢個項目嘅負責人之一,清華嘅 00 後,主要方向係 Proactive Agent
尋日下午,我同佢傾咗一個鐘,本文係記錄
對了,Calvin 講嘢好快,雖然只係傾咗一個鐘,但我哋傾咗兩萬字
喺對話前,我問 Calvin:點解大家開始整記憶?
Calvin 話:以前模型能力太差,記唔記得住影響都唔大。但而家,隨住 OpenAI、Claude 新一代模型嘅發佈,甚至國內開源模型嘅追趕,模型之間嘅差距逐漸縮細,真正影響用戶使用體驗嘅將會係模型擁有嘅關於用戶嘅記憶同 Context 幾多
我哋而家喺做 Proactive Agent 嘅研究,核心要實現嘅,就係 Memory 同 Context。我哋想研究清楚,點樣記、記啲咩,先可以令模型表現更好。我哋關心嘅唔止係點樣令而家呢班擅長用 LLM、擅長寫 Prompt 嘅人用得更加「爽」;我哋仲關心點樣令嗰啲描述唔清需求、唔擅長用 LLM 嘅羣體用得更加「輕鬆」。
記憶,令人同 AI 嘅互動,由無狀態變成有狀態,由有負擔變成無負擔,本文由此開始
將記憶,放返你部電腦
Chronicle 係 OpenAI 俾 Codex 開發嘅記憶功能,為 Pro 訂閲用戶提供差異化服務,透過記憶綁定提高高價值用戶嘅遷移成本
OpenChronicle 係一個能夠獨立處理、保存用戶記憶嘅 AI Infra,由處理用戶上下文獲得並保存 Memory,到俾 Agent 使用都唔同任何一個模型同 harness 強綁定。用戶可以用本地部署嘅模型處理 Memory 嚟保護私隱安全,亦可以俾 Claude、Codex、OpenCode 等任何具備 tool-Using 能力嘅 LLM 同 Agent Harness 接入呢個系統發揮更大作用。
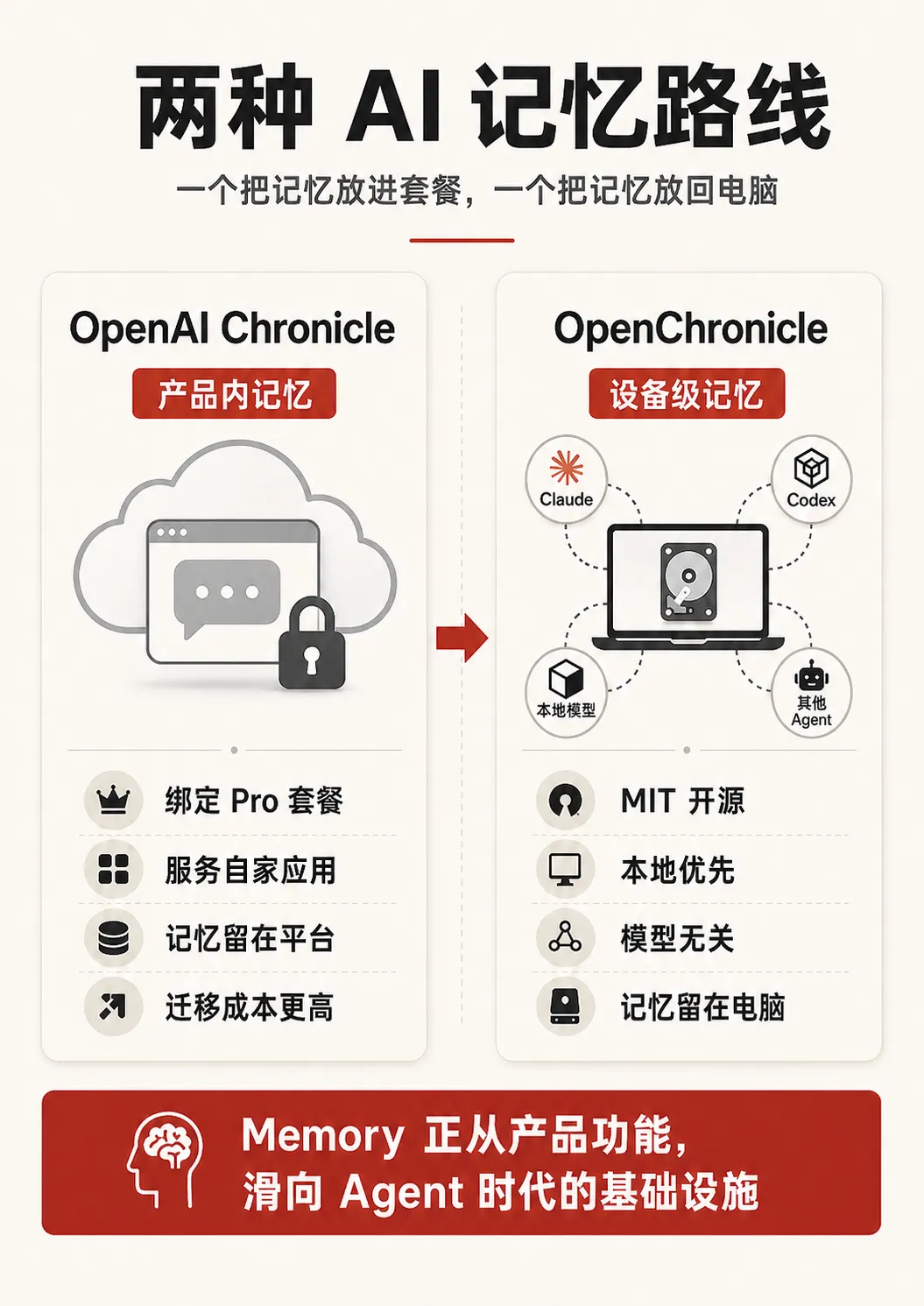
喺 Calvin 嘅設想入面,Agent 記憶嘅所有權,應該歸屬用戶,而唔係模型廠商
記憶應該係裝置裏面嘅一層基礎設施,同邊個模型合作都得
AX Tree 優先:Calvin 反覆計數之後揀嗰條路
講到「讓 AI 睇屏幕」嘅技術實現,我第一反應係「截圖保存 & OCR & RAG」,畢竟好多項目,包括 OpenAI 嘅,都係咁做
然後我去睇咗下 Open Chronicle 嘅程式碼,佢係 AX Tree 優先

AX Tree 呢樣嘢我未用過,就等 Calvin 解釋咗下:
AX Tree 係 macOS 系統層嘅一個老介面,本來俾殘障輔助技術讀屏用,將屏幕上面嘅內容,變成一棵結構化嘅樹狀描述
而家開緊邊個應用、焦點喺邊個輸入框、你喺度編輯緊咩文字、網頁 URL 係咩、掣上面寫緊咩字,AX Tree 直接俾文本,唔使經視覺
我哋都諗過純粹行視覺,但計完數之後都覺得 AX Tree 呢條路更紮實,至少喺 mac 上面係咁
同截圖相比,AX Tree 呢件事有三個好處:
一係平,文本嘅處理成本遠低過圖片
二係更準確,對意圖信號嘅識別比 OCR 強好多
三係結構化同輕量化,存入數據庫、做檢索都更方便
我追問話,AX Tree 有咩短板?
Calvin 話,AX Tree 喺 Word、飛書呢類應用入面,因為內部嘅渲染繞過咗系統輔助通道,所以通常只係讀到頂欄選單同文件標題,無辦法依賴 AX Tree正因為咁 OpenChronicle 係一個混合方案,AX Tree 優先,截圖兜底
仲有就係,OpenChronicle 嘅截圖係基於觸發器,遊標移動、頁面滾動、應用切換先會觸發處理。如果你打開 macOS 乜都唔做,記憶系統唔會每 5 秒影一張相返去餵模型。避免你喺睇電影呢類場景下,記憶頻繁觸發導致 Token 過量消耗同記憶污染
Token 數:50 美仙同 3 美金嘅分界
當意識到有咁多屏幕內容嘅時候,我就不得不好奇:Token 數點樣計?
具體啲講,對於 8 個鐘工作日,純粹靜默記錄、唔主動呼叫嘅輕度工作,要消耗幾多 Token?
“大概 50 美仙/日”,Calvin 咁講,然後補充話:如果係高頻呼叫、深度互動嘅重度場景,一日 3 到 5 美金
當然啦,OpenChronicle 允許用戶接入本地模型,所以如果你部電腦夠勁,其實...所需嘅就係電費:喺手提電腦上面,部署 gpt-oss-120b 模型
Calvin 順便講咗佢自己嘅使用習慣。佢係 ChatGPT Pro 200 美金套餐嘅長期用戶,平時將 Session Memory 全部關曬,因為 GPT 用用嚇成日跨話題亂咁搭
Chronicle 一出佢第一時間試咗,Codex 效果還可以,但日常 Workflow 嗰種混亂場景下就跟唔上
Claude 嘅記憶喺 General 層次上管理得最穩,基本上唔會互相撈亂,但 Claude 嘅 Memory 都只係喺 Claude 裏面有效
由「記住你講過咩」,到「記住你點樣做嘢」
我再問 Calvin:OpenChronicle 同而家市面上 AI 產品已經有嘅 Memory 功能,有咩分別?
Calvin 嘅判斷係,今日市面上 AI 產品嘅 Memory 量已經唔缺,缺嘅係跨產品嘅連貫性,上文下理全靠手動維護,換個項目就要重新同 AI 解釋一次你係邊個、你做緊咩、你之前嘅判斷係點形成
OpenChronicle 揀咗另一種結構,將 mac 上面所有嘅應用操作都放入同一個本地記憶池,按 7 個分類平坦儲存成 Markdown 文件,分別對應你呢個人、你嘅項目、你常用嘅工具、你關心嘅話題、你聯絡嘅人、你工作嘅組織、你經歷嘅事件。對外透過 MCP 呢個標準協議暴露成工具呼叫,Memory Layer 唔再綁死喺某個產品裏面
Claude Code、Claude Desktop、Codex、OpenCode 都已經有一鍵整合嘅配置範例。意思係,你喺 Cursor 做嘅設計決定、喺飛書同同事討論嘅架構方向、喺 Slack 收到嘅需求反饋,可以喺另一個對話視窗被 Claude Desktop 直接承接
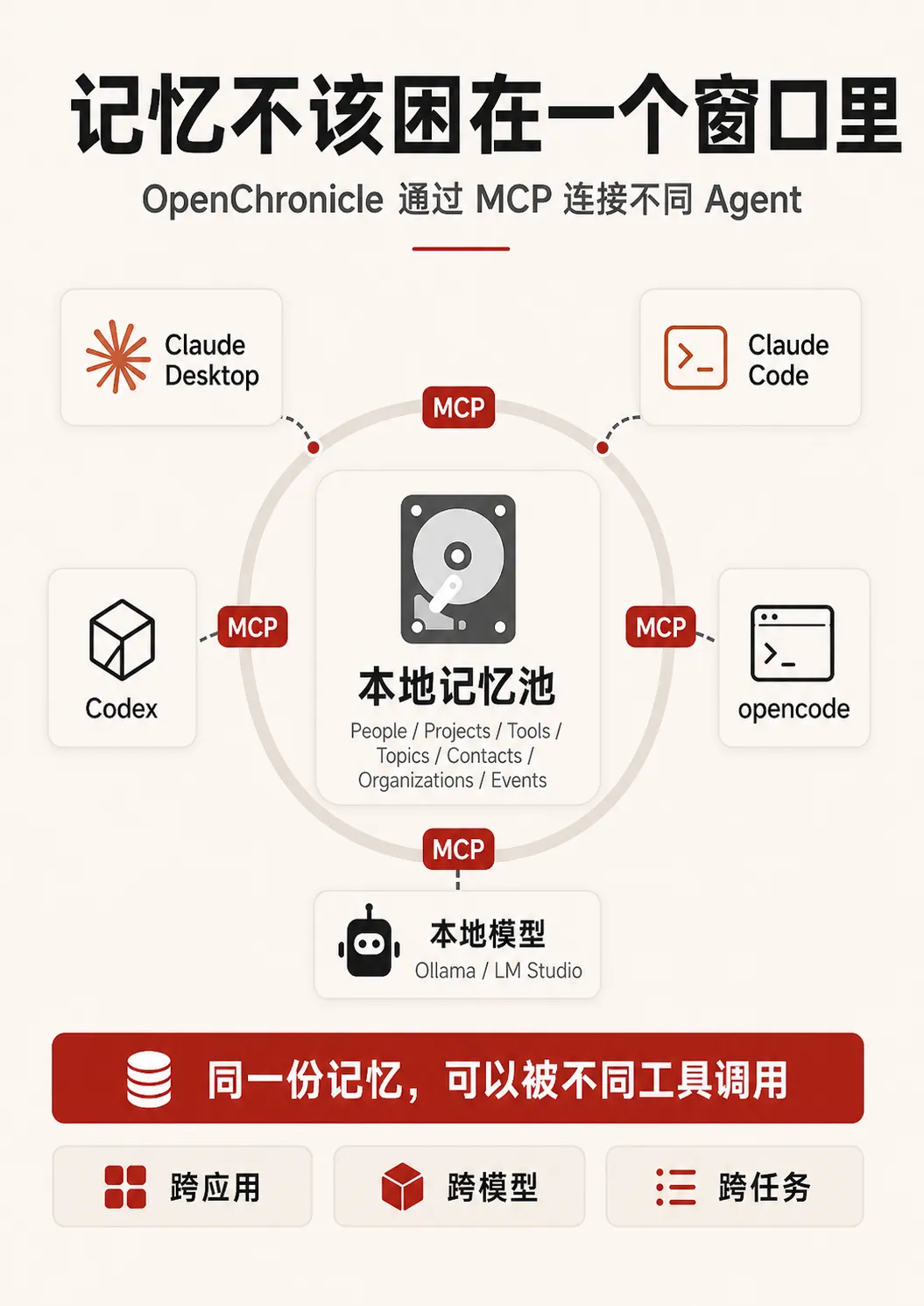
OpenChronicle 透過 MCP 協議同各類 Agent 協作
記住你講過咩,係 AI 嘅認知層,而記住你想點樣做嘢,係 AI 嘅行動層,需要理解你喺唔同場景下嘅偏好、慣性、潛規則,難好多:
例如,當你同 AI 講「加個日程」嘅時候,呢個日程係放喺飛書日程入面,定係放喺 Apple Calendar?
「我哋喺掀枱」
傾到一半,我問 Calvin:今年好多團隊,都喺度講記憶敍事,然後去融資,咁你哋點解選擇將呢個嘢開源?
Calvin 話:
掀枱...然後睇下邊個能夠喺場景裏面畀出 Best Practice
搞記憶呢件事,Calvin 佢哋由舊年底就開始做,然後我好奇,當見到 OpenAI 出 Chronicle 嗰一刻,佢第一反應係咩
Calvin話,第一秒的確有啲慌,怕 OpenAI 一次過食曬所有場景。但仔細睇完文件同實測之後,發現 Codex 呢種相對乾淨嘅環境入面效果可以,但去到日常 Workflow 嗰種混亂環境就仲有距離
與此同時,記憶正由「某個產品嘅差異化功能」逐漸變成「Agent 時代嘅基礎設施」,Cursor 嘅記憶、Claude 嘅記憶、ChatGPT 嘅記憶,都按各自產品視角組織。OpenAI Chronicle 將呢件事推前咗一大步,但礙於商業仍然將記憶圈喺自己嘅應用入面
插入個題外話,據我所知,今次唔係 Calvin 佢哋第一次同 OpenAI 撞車
哈哈哈哈哈哈哈
返到 Calvin 自己做緊嘅事
傾完工程細節同行業判斷,話題滑返去 Calvin 自己,佢帶領嘅 Vida 團隊真正喺度研究嘅,係基於呢套基礎設施之上嘅主動式 Agent
Calvin 亦同我解釋咗「主動式」:而家大部份 Agent 係 reactive 嘅,你唔問佢就唔鬱。主動式 Agent,可以根據你嘅 context 主動判斷、主動建議、主動行動
具體到場景,Calvin 同我講到佢哋做緊嘅事,係將呢套記憶能力同具體嘅 Workflow 縫合埋一齊。程式碼中斷後恢復、跨文件協作、設計稿修改延續、長期個人知識沉澱。Agent 真正進入你嘅日常作息,需要嘅就係「我知道你點樣做嘢」呢一層支撐
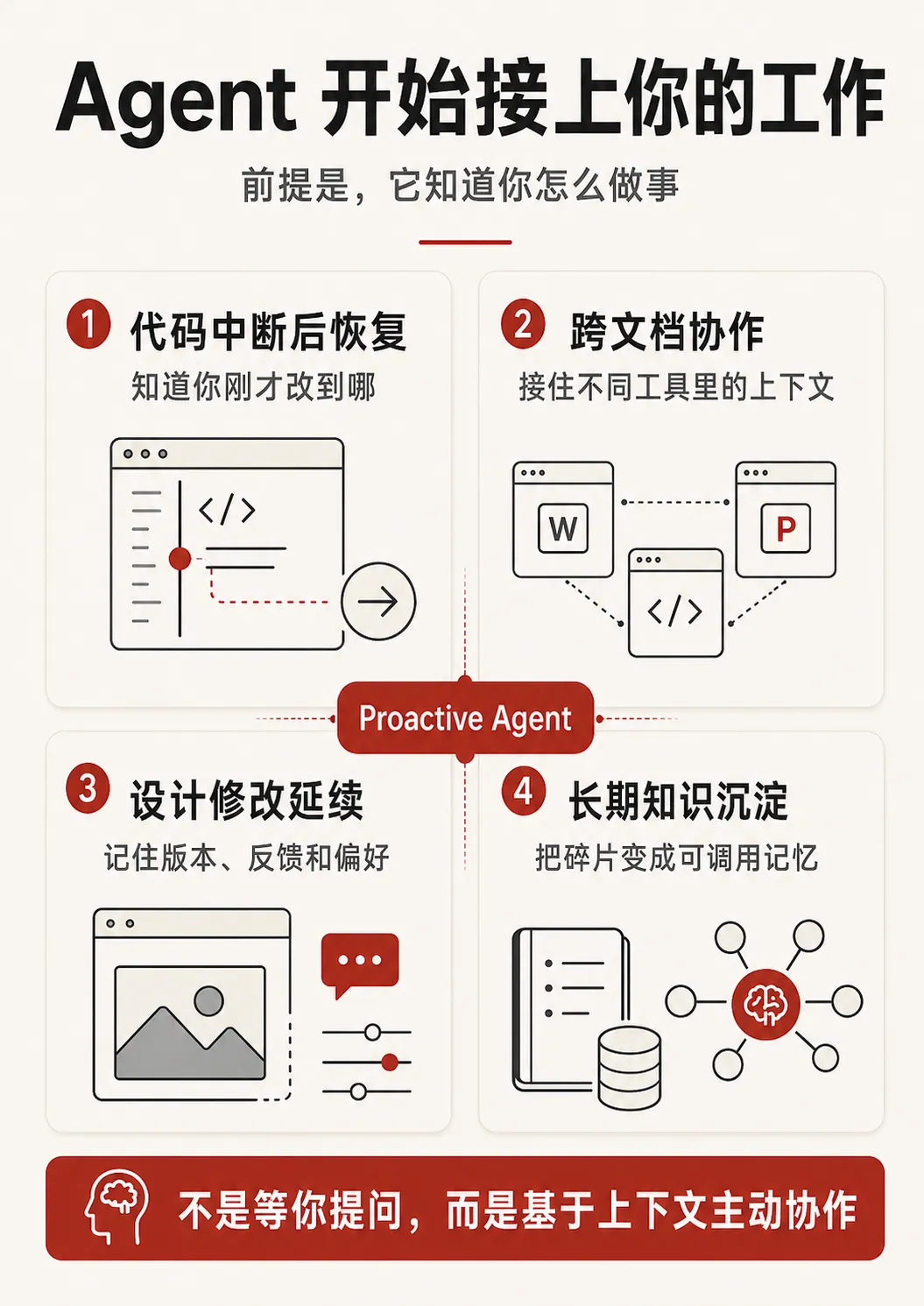
主動式 Agent 喺日常工作入面嘅幾個場景
Agent 應該服務於人,去放大嘅能力,唔可以令你變成各家廠商手上嘅資產,俾人爭奪上文下理,爭奪注意力
各家大模型廠商都喺度爭奪用戶嘅上文下理,畢竟用戶用得越多,Memory 越完整,搬去別家嘅成本越高
OpenChronicle 呢種本地優先、模型無關嘅開源路徑,係希望記憶屬於用戶、可以駁到任何 Agent 或者裝置上
最後我問 Calvin,如果未來建立咗一個 Proactive Agent,你希望佢能夠服務邊個?
Calvin 話:所有人
去建立成熟 Memory Infra 嘅 Proactive Agent,令已經依賴 Agent 做事嘅人更加自然咁去創造
如果你對佢哋呢個方向有興趣,可以喺 Github 上揾到更多嘅資訊,地址喺呢度:
github.com/Einsia/OpenChronicle
PRODUCT
• 雖然 AI 越來越聰明,但每次對話,你都得補充一堆東西
• 讓 AI 記住你說過什麼不難,但讓它記住你做過的事兒很複雜
• 記憶這個東西,已經從產品功能逐漸變成了 Agent 基建
以上內容,來自我和 Calvin 的對話
北京時間4 月 21 日,OpenAI 給 Codex 上線了記憶功能,叫做 Chronicle,讓它知道你剛才在看什麼、兩週前在做什麼項目Codex 凌晨更新,將屏幕內容「放進記憶」
但是呢...這套東西僅面向 Pro 訂閲的用戶,也只給 mac 用戶提供
一天後,4 月 22 日晚上,一個叫 OpenChronicle 的項目出現在 GitHub 上,提供了相同的開源實現,並在當天衝到了 X 的 today's news trending 第一
github.com/Einsia/OpenChronicle
Calvin 是這個項目的負責人之一,清華的 00 後,主要方向是 Proactive Agent
昨天下午,我和他聊了一個小時,本文為記錄
對了,Calvin 的語速很快,雖然只聊了一個小時,但我倆聊了兩萬字
在對話前,我問 Calvin:為啥大家開始弄記憶了?
Calvin 說:以前模型能力太差,記不記得住影響都不大。但現在,隨着 OpenAI、Claude 新一代模型的發佈,乃至國內開源模型的追趕,模型之間的差距逐步縮小,真正影響用戶使用體驗的將是模型擁有的關於用戶的記憶與 Context 多少
我們目前在做 Proactive Agent 的研究,核心要實現的,便是 Memory 和 Context。我們想要研究清楚,怎樣記,記什麼,才能讓模型表現更好。我們關心的不只是怎麼讓現在這些擅長使用 LLM,擅長寫 Prompt 人羣用的更"爽";我們還關心怎樣讓那些描述不清楚需求,不擅長使用 LLM 的羣體用的更"輕鬆"。
記憶,讓人與 AI 的交互,從無狀態變成有狀態,從有負擔變成無負擔,本文由此開始
把記憶,放回你的電腦
Chronicle 是 OpenAI 給 Codex 開發的記憶功能,為 Pro 訂閲用戶提供差異化的服務,通過記憶綁定提高高價值用戶的遷移成本
OpenChronicle 是能夠獨立處理、保存用戶記憶的 AI Infra,從處理用戶上下文獲得並保存 Memory,到給 Agent 使用都不與任何一個模型及 harness 強綁定。用戶可以使用本地部署的模型處理 Memory 來保護隱私安全,也可以讓 Claude、Codex、OpenCode 等任何具備 tool-Using 能力的 LLM 及 Agent Harness 接入這一系統發揮更大作用。
在 Calvin 的設想中,Agent 記憶的所有權,應該歸屬用戶,而不是模型廠商
記憶該是設備裏的一層基礎設施,跟誰的模型協作都行
AX Tree 優先:Calvin 反覆算賬後選的那條路
講到「讓 AI 看屏幕」的技術實現,我的第一反應是「截圖保存 & OCR & RAG」,畢竟很多項目,包括 OpenAI 的,都是這麼做的
然後我去翻閲了下 Open Chronicle 的代碼,他是 AX Tree 優先
AX Tree 這個東西我沒用過,就讓 Calvin 去解釋了下:
AX Tree 是 macOS 系統層的一個老接口,本來給殘障輔助技術讀屏用,把屏幕上的內容,做成一棵結構化的樹狀描述
當前打開的是哪個應用、焦點在哪個輸入框、你正在編輯什麼文字、網頁 URL 是什麼、按鈕上寫着什麼字,AX Tree 直接給文本,不用走視覺
我們也想過純走視覺,但算賬之後還是覺得 AX Tree 這條路更紮實,至少在 mac 上是這樣
跟截屏比,AX Tree 這件事有三個好處:
一是便宜,文本的處理成本遠低於圖片
二是更準,對意圖信號的識別比 OCR 強很多
三是結構化且輕量化,存進數據庫、做檢索都更方便
我追問說, AX Tree 有什麼短板?
Calvin 說,AX Tree 在 Word、⻜書這類應⽤⾥,由於內部的渲染繞開了系統輔助通道,所以通常只能讀到頂欄菜單和⽂檔標題,無法以來 AX Tree。正應為如此 OpenChronicle 是個混合方案,AX Tree 優先,截圖兜底
還有就是,OpenChronicle 的截圖基於觸發器,光標運動、頁面滾動、應用切換才會觸發處理。如果你打開 macOS 什麼都不動,記憶系統不會每 5 秒拍一張圖回去喂模型。避免你在看電影這種場景下,記憶頻繁觸發導致 Token 過量消耗與記憶污染
Token 賬:50 美分跟 3 美金的分界
當意識到有如此多屏幕內容的時候,我就不得不好奇了:Token 賬怎麼算?
具象一點來說,對於 8 小時工作日,純靜默記錄、不主動調用的輕度工作,要消耗多少 Token?
“差不多 50 美分/天”,Calvin 這麼說,然後又補充道:如果是高頻調用、深度交互的重度場景,一天 3 到 5 美金
當然了,OpenChronicle 允許用戶接入本地模型,所以如果你的電腦夠強,其實...所需要的就是電費:在筆記本上,部署 gpt-oss-120b 模型
Calvin 順嘴講了他自己的使用習慣。他是 ChatGPT Pro 200 美金套餐的常年用戶,平時把 Session Memory 全關了,因為 GPT 用着用着經常跨話題串台
Chronicle 出來他第一時間試了,Codex 效果還行,但日常 Workflow 那種凌亂場景裏就跟不上了
Claude 的記憶在 General 層次上管得最穩,基本不會互相串台,但 Claude 的 Memory 也就只在 Claude 裏有效
從「記住你說過什麼」,到「記住你怎麼做事」
我接着問 Calvin:OpenChronicle 跟現在市面上 AI 產品已有的 Memory 功能,差在哪?
Calvin 的判斷是,今天市面上 AI 產品的 Memory 量已經不缺,缺的是跨產品的連貫,上下文全靠手動維護,換個項目就要重新跟 AI 解釋一遍你是誰、你在做什麼、你之前的判斷是怎麼形成的
OpenChronicle 選的是另一種結構,把 mac 所有上的應用操作都進同一個本地記憶池,按 7 個分類扁平存成 Markdown 文件,分別對應你這個人、你的項目、你常用的工具、你關心的話題、你聯繫的人、你工作的組織、你經歷的事件。對外通過 MCP 這個標準協議暴露成工具調用,Memory Layer 不再綁在某個產品裏
Claude Code、Claude Desktop、Codex、OpenCode 都已經有一鍵集成的配置示例。意思是,你在 Cursor 裏做的設計決策、在飛書裏跟同事討論的架構方向、在 Slack 裏收到的需求反饋,可以在另一個對話窗口裏被 Claude Desktop 直接承接
OpenChronicle 通過 MCP 協議跟各類 Agent 協作
記住你說過什麼,是 AI 的認知層,而記住你想怎麼做事,是 AI 的行動層,需要理解你在不同場景下的偏好、慣性、潛規則,要難得多:
比如,當你跟 AI 說「加個日程」的時候,這個日程是被放在飛書日程裏,還是放在 Apple Calendar?
「我們在掀桌子」
聊到一半,我問 Calvin:今年許多團隊,都在講記憶敍事,然後去融資,那麼你們為啥選擇把這個東西開源?
Calvin 說:
掀桌子...然後看看誰能在場景裏給出 Best Practice
搞記憶這個事情,Calvin 他們從去年底就開始做了,然後我就好奇,當看到 OpenAI 發 Chronicle 的那一刻,他第一反應是什麼
Calvin說,第一秒確實有點慌,怕 OpenAI 一口氣把所有場景都吃下來。但仔細看完文檔和實測之後,發現 Codex 這種相對乾淨的環境裏效果可以,到日常 Workflow 那種凌亂環境就還有距離
與此同時,記憶正在從「某個產品的差異化功能」逐漸變成「Agent 時代的基礎設施」,Cursor 的記憶、Claude 的記憶、ChatGPT 的記憶,都按各自產品視角組織。OpenAI Chronicle 把這件事往前推了一大步,但是礙於商業卻仍將記憶圈在自己的應用裏
插入個題外話,據我所知,這次也不是 Calvin 他們第一次跟 OpenAI 撞車了
哈哈哈哈哈哈哈
回到 Calvin 自己在做的事
聊完工程細節和行業判斷,話題滑回到 Calvin 自己,他所帶領的 Vida 團隊真正在研究的,是基於這套基礎設施之上的主動式 Agent
Calvin 也給我解釋一下「主動式」:現在大部分 Agent 是 reactive 的,你不問它就不動。主動式 Agent,能根據你的 context 主動判斷、主動建議、主動行動
具體到場景,Calvin 跟我聊到他們在做的事,是把這套記憶能力跟具體的 Workflow 縫合起來。代碼中斷後恢復、跨文檔協作、設計稿修改延續、長期個人知識沉澱。Agent 真正進入你的日常作息,需要的就是「我知道你怎麼做事」這一層支撐
主動式 Agent 在日常工作裏的幾個場景
Agent 應該服務於人,去放大人的能力,不能讓你變成各家廠商手裏的資產,被爭奪上下文,被爭奪注意力
各家大模型廠商都在爭奪用戶的上下文,畢竟用戶用得越多,Memory 越完整,遷移到別家的成本越高
OpenChronicle 這種本地優先、模型無關的開源路徑,是希望記憶屬於用戶、可以接到任何 Agent 或者設備上
最後我問 Calvin,如果未來構建了一個 Proactive Agent,你希望它能服務誰?
Calvin 說:所有人
去構建成熟 Memory Infra 的 Proactive Agent,讓已經依賴 Agent 做事的人更自然的去創造
如果你對他們這個方向感興趣,可以在 Github 上找到更多的信息,地址在這裏:
github.com/Einsia/OpenChronicle