【譯】Karpathy 的 4 條 CLAUDE.md 規則將 Claude 錯誤率從 41% 降至 11%。在測試了 30 個代碼庫後,我又加了 8 條。
整理版優先睇
Karpathy嘅4條CLAUDE.md規則加上8條新規則,可將Claude錯誤率由41%降到3%
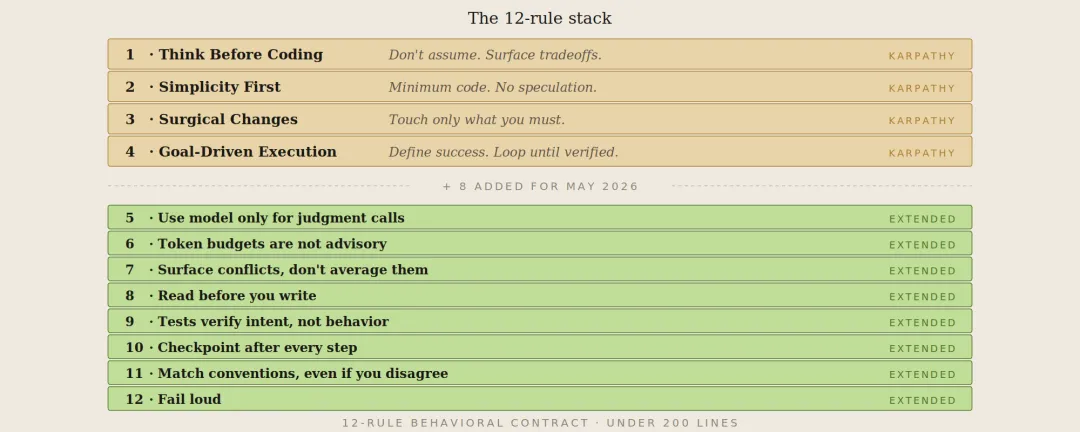
2026年1月,Andrej Karpathy發帖吐槽Claude寫代碼嘅三種失敗模式:無聲錯誤假設、過度複雜化、同埋破壞相鄰代碼。Forrest Chang將呢啲吐槽變成4條行為規則,放咗上GitHub,好快爆紅。作者(即本文嘅我)喺6個星期內,用30個代碼庫測試呢4條規則,發現佢哋真係好有效,錯誤率由大約40%降到低過3%。但係,隨住Claude Code生態系統演變,出現咗新問題,例如agent打架、鈎子級聯、技能加載衝突等等。所以作者再加咗8條規則,總共12條,覆蓋更多失效模式。
呢12條規則包括原始4條(編碼前思考、簡單優先、外科手術式修改、目標驅動執行)同新增8條(唔好做非語言工作、嚴守token預算、暴露衝突唔折中、改動前先閲讀、測試驗證意圖、設立檢查點、遵守約定、顯性報錯)。測試結果顯示,錯誤率由41%降至3%,遵守率維持喺76-78%。Karpathy嘅4條規則喺長時間agent任務、多代碼庫一致性、測試質量同原型設計方面會失效,新規則正好填補呢啲空白。
文章最後提供完整嘅12條規則模板,可以複製粘貼到CLAUDE.md。作者強調規則要根據自己嘅真實失效模式去調整,唔係照單全收。通讀12條,保留對應自己錯過嘅規則,刪走其他。同時提醒總行數唔好超過200行,否則遵守率會大跌。
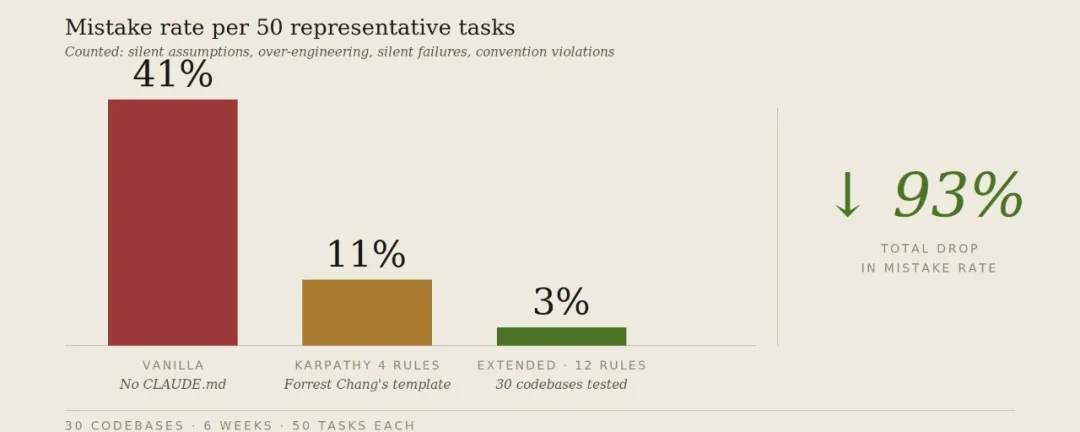
- 結論:12條CLAUDE.md規則可將Claude錯誤率由41%降至3%,遵守率維持約76%,證明規則數量增加唔會顯著影響遵守率。
- 方法:先設定4條基礎規則(編碼前思考、簡單優先、外科手術式修改、目標驅動),再根據新失效模式添加8條規則(如Token預算、檢查點、顯性報錯等)。
- 差異:Karpathy嘅4條規則主要解決2026年1月嘅編碼錯誤,新規則針對5月嘅agent編排問題,例如多步驟工作流、衝突暴露等。
- 啟發:CLAUDE.md係行為契約,每條規則必須針對特定失效模式;超過14條規則或200行會令遵守率暴跌,所以保持精簡。
- 可行動點:將完整12條規則保存為CLAUDE.md放喺項目根目錄,然後根據自己真實失敗案例刪減規則,保留啱自己嘅部份。
從Karpathy嘅吐槽到12條行為契約
2026年1月,Andrej Karpathy發帖吐槽Claude寫代碼嘅三種失敗模式:無聲錯誤假設、過度複雜化、同埋破壞相鄰代碼。Forrest Chang將呢啲吐槽提煉成4條行為規則,放咗上GitHub,短時間內獲得12萬個star。
無聲錯誤假設
作者喺6星期內用30個代碼庫測試呢4條規則,發現錯誤率由41%降至3%。但隨住Claude Code生態演變,新問題出現,所以再加8條規則。
4條基礎規則:編碼前思考、簡單優先、外科手術式修改、目標驅動
- 1 規則一:編碼前先思考。明確指出假設,唔好做無聲假設。有不確定就提問,提供多種方案。
- 2 規則二:簡單優先。用最少代碼解決問題,唔好寫推測性功能,唔好為一次性代碼做抽象。
- 3 規則三:外科手術式修改。只改必要部分,唔好優化相鄰代碼,唔好重構冇壞嘅代碼。
- 4 規則四:目標驅動執行。定義成功標準,循環迭代直到驗證通過,唔好跟步驟,要定義成功。
8條新規則:應對agent時代嘅新挑戰
新規則解決咗原始模板未能覆蓋嘅問題,包括長時間運行嘅agent任務、多代碼庫一致性、測試質量等。以下係關鍵規則:
規則五:僅將模型用於判斷性調用
唔好用模型做路由、重試、確定性轉換等非語言類工作,只應該用嚟分類、起草、總結。
規則六:Token預算係死命令
單任務4,000 tokens,單會話30,000 tokens,超出就總結重新開始。
規則七:暴露衝突,唔好折中
如果代碼庫有矛盾模式,揀一個最新或測試最多嘅,標記另一個等清理,唔好混合。
規則八:改動前先閲讀
添加代碼前先閲讀exports、調用者同共享utils,確保唔會衝突。
規則九:測試驗證意圖,唔只係行為
測試必須解釋點解(WHY)呢個行為重要,而唔只係做咗咩(WHAT)。
規則十:每個重要步驟後設立檢查點
總結已完成、已驗證同埋仲有咩未做,跟唔到進度就停低梳理。
規則十一:遵守代碼庫約定,即使你唔同意
一致性重要過個人品味,唔好私下另起分支。
規則十二:顯性報錯,唔好無聲失敗
如果悄悄跳過任何內容,就唔應該話「完成」;默認暴露不確定性。
測試結果與調整建議
測試覆蓋3種配置,錯誤率從41%降至3%,遵守率由78%微跌至76%。Karpathy嘅4條規則喺長時間agent任務、多代碼庫一致性、測試質量同原型設計方面會失效。
超過14條規則會令遵守率暴跌到52%
所以建議按自己真實失敗模式調整規則,唔係照單全收。完整12條模板可以複製貼上,但總行數唔好超過200行。
CLAUDE.md — 12 條規則模板
除非被明確覆蓋,否則呢啲規則適用於本項目中的每一項任務。
偏好:在非瑣碎的任務上,謹慎優先於速度。對於瑣碎的任務,請自行判斷。
規則一 — 編碼前先思考
明確指出假設。如果不確定,請提問而不要猜測。當存在歧義時,提供多種解讀方案。當存在更簡單的方案時,請提出反駁。感到困惑時就停下來。指明哪裏不清楚。
規則二 — 簡單優先
用最少的代碼解決問題。不要做任何推測性的工作。不要添加要求之外的功能。不要為一次性的代碼做抽象。測試標準:資深工程師會覺得這太複雜了嗎?如果是,請簡化。
規則三 — 外科手術式修改
只碰你必須碰的地方。只清理你自己製造的爛攤子。不要“優化”相鄰的代碼、註釋或格式。不要重構沒壞的代碼。保持與現有風格一致。
規則四 — 目標驅動執行
定義成功標準。循環迭代直到驗證通過。不要遵循按部就班的步驟。定義成功並進行迭代。強有力的成功標準能讓你獨立進行循環。
規則五 — 僅將模型用於判斷性調用
將我用於:分類、起草、總結、提取。絕對不要將我用於:路由、重試、確定性轉換。如果代碼能回答問題,就用代碼回答。
規則六 — Token 預算不是建議,是死命令
單任務:4,000 tokens。單會話:30,000 tokens。如果接近預算,總結並重新開始。暴露超支問題。不要悄無聲息地超出預算。
規則七 — 暴露衝突,不要折中
如果兩種模式矛盾,選其中一個(最新的 / 測試最多的)。解釋原因。標記另一個等待清理。不要混合衝突的模式。
規則八 — 改動前請先閲讀
在添加代碼前,閲讀 exports、直接調用者、共享 utils。“看起來相互獨立”是很危險的。如果不確定為什麼代碼是咁樣構建的,請提問。
規則九 — 測試驗證意圖,而不僅僅是行為
測試必須編碼說明為什麼(WHY)呢個行為很重要,而不僅僅是它做了什麼(WHAT)。一個在業務邏輯改變時都不會報錯的測試是錯誤的。
規則十 — 在每個重要步驟之後建立檢查點
總結做了什麼,驗證了什麼,還剩下什麼。如果你無法向我複述當前的狀態,就不要繼續。如果跟丟了進度,停下來並重新梳理。
規則十一 — 遵守代碼庫的約定,即使你不同意
在代碼庫內部,一致性 > 個人品味。如果你真心覺得某種約定有害,請提出來。不要悄悄建分支(fork)。
規則十二 — 顯性報錯
如果悄悄跳過了任何內容,那“完成”就是錯的。如果跳過了任何測試,那“測試通過”就是錯的。默認暴露不確定性,而不是隱藏它。2026 年 1 月底,Andrej Karpathy 出咗個 post 鬧 Claude 寫 code 嘅方式。主要有三種失敗模式:
◆ 無聲嘅錯誤假設
◆ 過度複雜化
◆ 同埋對唔應該掂嘅 code 造成破壞
Forrest Chang 睇咗呢篇 post,將呢啲鬧爆嘅點包裝成 4 條行為規則,寫咗個 CLAUDE.md 檔案放咗上 GitHub。
Github 地址:
https://github.com/forrestchang/andrej-karpathy-skills
佢喺第一日就得到咗 5,828 個 star。兩星期內有 60,000 個 bookmarks。到今日,star 數已經有 125,000。呢個係 2026 年增長最快嘅單檔案倉庫。

然後,我用咗 6 個星期嘅時間,喺 30 個 codebase 度測試咗佢。
呢 4 條規則真係有用。
喺 Claude 擅長嘅任務入面,以前高達大約 40% 嘅錯誤率跌到唔夠 3%。不過,呢個 template 係為咗修復 1 月嗰時寫 code 嘅錯誤而整嘅。
到咗 2026 年 5 月,Claude Code 嘅生態系統面對緊唔同嘅問題 —— agent 互相打架、hooks 級聯、skills 加載衝突,同埋跨 session 中斷嘅多步驟 workflow。
所以,我再加咗 8 條規則。
以下會逐一展示完整嘅 12 條 CLAUDE.md 規則,並解釋每條規則點解要入選,同埋原本嘅 Karpathy template 喺咩情況下會無聲噉失效。
如果你唔想睇解釋直接複製貼上,完整嘅檔案喺文章最尾。
點解呢件事咁重要
Claude Code 嘅 CLAUDE.md 係成個 code stack 中最冇被充分利用嘅檔案。大部分開發者會:
1、當佢係垃圾桶,塞滿曬佢哋曾經有過嘅各種偏好,膨脹到 4,000 幾個 token,搞到遵守率暴跌到 30%。
2、完全 skip 咗佢,每次都重新寫 prompt,浪費咗 5 倍嘅 token,而且 session 之間冇任何一致性。
3、複製一次 template 之後就唔再理。用咗兩個星期仲得,但隨住 codebase 演變,佢會無聲噉失效。
Anthropic 嘅官方文件好清楚:CLAUDE.md 係建議性質嘅。Claude 大概有 80% 嘅時間會遵守佢。超過 200 行之後,遵守率就會急劇下降,因為重要嘅規則被淹沒喺噪音入面。
Karpathy 嘅 template 用一個檔案、65 行 code、4 條規則解決咗呢個問題。呢個就係下限。
但上限仲可以更高。
加上我會喺下面詳細說明嘅另外 8 條規則,你唔單止可以 cover 到 Karpathy 鬧爆嘅 2026 年 1 月嘅 code 編寫問題,仲可以 cover 到嗰時未出現嘅 2026 年 5 月嘅 agent 編排問題。
原本嘅 4 條規則
如果你仲未睇過 Forrest Chang 嘅倉庫,佢嘅基本盤係咁:
規則一:編碼前先諗清楚
唔好做無聲嘅假設。清楚講明你嘅假設。擺出 trade-off。喺猜測之前先問問題。當有更簡單嘅方案時,要提出反對。
規則二:簡單優先
用最少嘅 code 解決問題。唔好寫推測性嘅功能。唔好為咗一次性嘅 code 做抽象。如果一個高級工程師會覺得太複雜 —— 咁就簡化佢。
規則三:外科手術式修改
淨係掂你必須掂嘅地方。唔好「優化」相鄰嘅 code、註釋或格式。唔好重構冇壞嘅 code。保持同現有風格一致。
規則四:目標驅動執行
定義成功標準。循環迭代直到驗證通過。唔好話畀 Claude 要跟咩步驟,話畀佢知成功係點樣,等佢自己去迭代。
呢四條規則解決咗我喺冇人睇住嘅 Claude Code session 入面見到嘅大約 40% 嘅失敗情況。淨低嘅大約 60% 就存在於下面嘅空白地帶。
我加嘅 8 條規則(同埋點解)
呢度每一條規則都係由真實場景出發,喺呢啲場景下 Karpathy 嘅 4 條規則唔夠力。我會先展示場景,然後俾出規則。
規則五:唔好俾模型做非語言類嘅工作
Karpathy 嘅規則冇提呢樣嘢。模型成日會決定一啲應該由確定性 code 決定嘅事,例如係咪要 retry API request、點樣 route 訊息、幾時 escalate 錯誤。每個星期嘅決定都唔同。呢個相當於以每 token $0.003 嘅價錢運行不可靠嘅 if-else logic。
規則五 — 僅將模型用於判斷性調用使用 Claude 進行:分類、起草、總結、從非結構化文本中提取。
不要使用 Claude 進行:路由、重試、狀態碼處理、確定性轉換。
如果一個狀態碼已經回答了這個問題,那麼純代碼就能回答這個問題。場景還原:
一段叫 Claude 去「決定係咪要喺 503 時 retry」嘅 code 完美行咗兩個星期,然後就開始失常,因為模型開始讀取 request body 做決策嘅 context。由於 prompt 係隨機嘅,retry 策略都變咗隨機。
規則六:嚴格嘅 token 預算,冇例外
冇預算控制嘅 CLAUDE.md 就係一張空白支票。每一次 loop 都有可能演變成一個消耗 50,000 token 嘅失效模式。模型自己係唔會停嘅。
規則六 — Token 預算不是建議,是死命令。
單任務預算:4,000 tokens。單會話預算:30,000 tokens。
如果任務即將超出預算,請總結並重新開始。不要強行推進。
露預算超支的問題 > 悄無聲息地超支。場景還原:
一個 debug session 行咗 90 分鐘。模型好樂意對同一個 8KB 嘅 error message 反覆迭代,慢慢就唔記得佢試過咩修復方案。到最後,佢甚至建議我 40 個 message 之前已經 reject 過嘅修復方案。如果有 token 預算限制,佢喺第 12 分鐘就會俾人 cut 咗。
規則七:暴露衝突,唔好妥協
當 codebase 嘅兩個部分有分歧時,Claude 會想兩邊都討好。結果就係寫出一堆亂七八糟嘅 code。
規則七 — 暴露衝突,不要折中。
如果代碼庫中現有的兩種模式相互矛盾,不要將它們混合。
挑選其中一個(最新的 / 經過更多測試的),解釋原因,並標記另一個需要清理。
滿足雙方規則的“折中”代碼是最糟糕的代碼。場景還原:
某個 codebase 原本有兩種 error handling 模式。一種係用 async/await 語法配合顯式異常捕獲,另一種係用 global error boundary。Claude 生成嘅新 code 同時用咗兩種模式,搞到 error handling logic 重複冗餘。我花咗 30 分鐘先搞明白,點解 error 會俾兩層 logic 連續食咗。
規則八:落筆前請先閲讀
Karpathy 嘅「外科手術式修改」叫 Claude 唔好掂相鄰嘅 code。但冇叫 Claude 要先理解相鄰嘅 code。冇呢條規則,Claude 寫嘅新 code 就會同 30 行以外嘅現有 code 衝突。
規則八 — 改動前請先閲讀
在文件中添加代碼之前,先閲讀文件的 exports、直接的調用者以及任何明顯的共享 utils。
如果你不明白為什麼現有的代碼結構是這樣的,在添加代碼之前先問清楚。
在這個代碼庫中,“看起來互相獨立”是最危險的一句話。場景還原:
Claude 喺一個佢冇讀過、功能相同嘅現有 function 旁邊,再加咗一個新 function。兩個 function 做嘅嘢一模一樣。由於 import 順序嘅問題,新 function 優先級更高。而個舊 function 已經作為單一事實來源穩定運行咗 6 個月。
規則九:測試唔係可選項,但佢哋都唔係終極目標
Karpathy 嘅「目標驅動執行」暗示「測試」就係成功標準。但實際上,Claude 會將「測試通過」視為唯一目標,寫出嚟嘅 code 雖然可以通過表面測試,但就將其他業務 logic 全部搞垮。
規則九 — 測試驗證意圖,而不僅僅是行為
每一個測試都必須編碼說明 WHY(為什麼這個行為很重要),而不僅僅是 WHAT(它做了什麼)。
像 `expect(getUserName()).toBe('John')` 這樣的測試毫無價值,如果函數接收的是一個硬編碼的 ID。
如果你寫不出一個能在業務邏輯改變時失敗的測試,那這個函數就是錯的。場景還原:
Claude 為一個 auth function 寫咗 12 個測試。全部通過。但生產環境嘅 auth 就崩潰咗。呢啲測試只係喺度測試 function 係咪有 return 嘢,而唔係 return 嘅嘢係咪啱。Function 可以通過測試只係因為佢 return 咗一個 constant。
規則十:長時間運行嘅操作需要設立檢查點
Karpathy 嘅 template 假設交互都係一次性嘅。但真實嘅 Claude Code 工作通常係多步驟嘅。跨 20 個檔案進行重構,喺一個 session 入面構建成個功能,跨多個 commit 進行 debug。如果冇 checkpoints(檢查點),行錯一步就會令所有進度化為烏有。
規則十 — 在每個重要步驟之後設立檢查點
在完成多步任務中的每一個步驟後:總結已完成的工作、已驗證的成果、以及還剩下什麼。
如果當前狀態你無法向我描述清楚,就不要繼續往下走。如果你跟丟了進度,停下來並重新梳理。場景還原:
一個 6 步嘅重構喺第 4 步出咗錯。等我發現嘅時候,Claude 已經喺錯誤嘅狀態上做埋第 5 步同第 6 步。搞掂埋堆爛攤子嘅時間比從頭做過仲要長。如果 checkpoints 存在,第 4 步就會發現問題。
規則十一:約定勝於新奇
喺已經有成熟 code 規範模式嘅 codebase 入面,Claude 往往會引入自己嘅編碼風格。就算佢嘅方式表面上「更優」,同時並存兩套編碼模式嘅效果,遠差過單獨沿用任何一種模式。
規則十一 — 遵循代碼庫的編碼規範,即便你並不認同
如果代碼庫使用下劃線命名法,而你更偏好駝峯命名法:請沿用下劃線命名法。
如果代碼庫使用基於類的組件,而你更偏好鈎子函數:請沿用基於類的組件。
意見分歧可單獨另行溝通討論。
在代碼庫內部,遵從規範優先於個人偏好。
若你確實認為現有規範存在弊端,應主動提出異議,不要私下另起分支擅自改動。場景還原:
Claude 將 React hooks 引入咗 class component codebase。功能雖然可以正常運作,但就破壞咗原本依賴 componentDidMount 生命週期嘅 codebase 測試邏輯。花咗半日時間移除相關 code 同重新編寫。
規則十二:要明顯噉失敗,唔好無聲噉失敗
Claude 模型代價最高嘅故障,往往係嗰啲看似成功嘅情況。某個功能表面「正常運作」,但就返回錯誤數據;某次數據遷移話「執行完成」,但漏咗 30 條記錄;某項測試話「順利通過」,但其實只係校驗斷言本身有問題。
規則十二 — 顯性報錯
如果你無法確定某件事是否成功,就明確說明。
若有30條記錄被靜默跳過,就不該籠統顯示“遷移已完成”;若跳過了任何測試項,就不該宣稱“測試通過”;若未驗證我提及的邊界場景,就不能斷言“功能正常”。
遇到不確定情況時,默認選擇主動披露,而非刻意隱瞞。場景還原:
Claude 話數據庫遷移「已成功完成」。系統靜悄悄 skip 咗 14% 觸發 constraint violation 嘅記錄。呢次 skip 有日誌記錄,但冇對外提示。直到 11 日後報表數據出現異常,呢個問題先被發現。
數據表現
喺 6 個星期入面,我喺 30 個 codebase 對同樣嘅 50 個典型任務進行咗追蹤測試。分為三種配置:
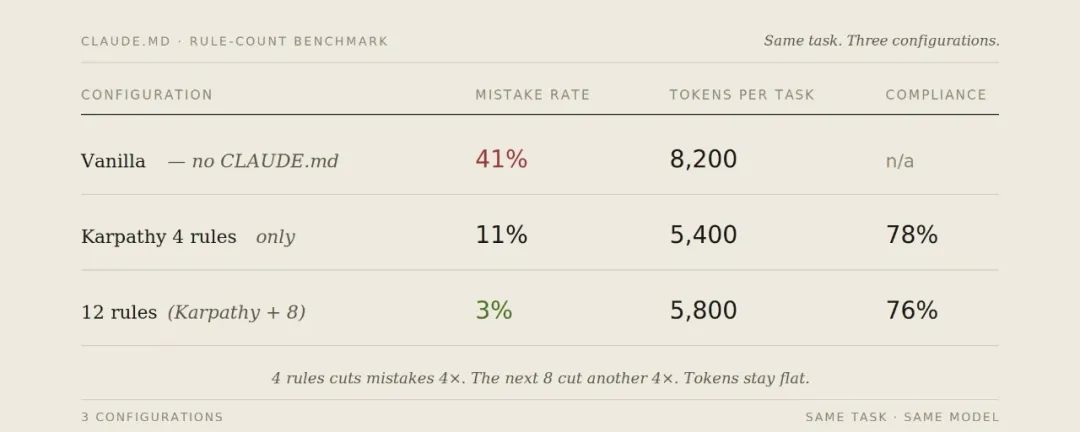
錯誤率 = 任務需要人工糾正或重寫先符合預期。
統計指標包括:無聲嘅錯誤假設、過度工程化、破壞相鄰 code、無聲失敗、違反約定、混合 code 衝突、遺漏檢查點。
遵守率 = 當相關規則適用時,Claude 喺表面上應用該規則嘅頻率。
有意思嘅結果唔係數據由 41% 驟降至 3% 呢個 headline,而係規則由 4 條增加到 12 條之後,合規負擔幾乎冇上升(只係由 78% 降至 76%),但錯誤率又再跌咗 8 個百分點。新增規則 cover 咗原本 4 條規則解決唔到嘅失效模式,而且各類規則唔會爭搶相同嘅關注度資源。
Karpathy 嘅 template 喺邊啲地方會無聲噉失效
即使喺加新規則之前,原本嘅 4 條規則 template 喺以下四個方面都唔夠用:
1、長時間運行嘅 agent 任務
Karpathy 規則只針對 Claude 編寫 code 嘅場景,對 Claude 運行多步驟流程時嘅情況完全冇規定。冇資源預算規則、冇 checkpoints 規則、亦冇「顯性報錯」規則,最終搞到流程失控。
2、多 codebase 嘅一致性
「保持同現有風格一致」嘅前提係得一種風格。喺一個有 12 個 service 嘅單一 codebase 入面,Claude 一定要自己去揀用邊種風格。原本嘅規則冇話畀佢知點樣揀。佢只可以隨機揀或攞風格平均值。
3、測試質素
目標驅動執行將「測試通過」等同於成功。但冇要求測試一定要有意義。結果就係寫咗一堆冇任何用處但就令 Claude 迷之自信嘅測試。
4、生產環境 vs 原型設計
嗰 4 條原本用嚟防止生產 code 過度工程化嘅規則,同樣會拖慢原型設計嘅速度,因為原型往往合理需要 100 行推測性嘅腳手架 code 嚟探索方向。Karpathy 嘅「簡單優先」喺面對早期 code 時有點 overkill。
呢 8 條新增嘅規則並冇取代 Karpathy 嘅 4 條規則。佢哋只係修補咗模型由 2026 年 1 月嗰種似自動補完式嘅編程方式,向 2026 年 5 月嗰種基於 agent、多步驟、跨 codebase 嘅工作模式演變過程中產生嘅缺失

邊啲嘗試冇效
喺最終確定呢 12 條規則之前,我試過一啲失敗嘅方案:
加入我喺 Reddit / X 度睇返嚟嘅規則
大部分一係 Karpathy 嗰 4 條規則換湯唔換藥嘅重述,一係啲唔具有普遍適用性嘅特定領域規則(例如「永遠用 Tailwind class name」)。我全部 delete 咗。
多過 12 條規則
我最多測試過 18 條規則。一旦超過 14 條規則,遵守率就會由 76% 暴跌到 52%。200 行嘅上限係真實存在嘅。超過呢個長度,Claude 就會開始 pattern matching,淨係知「有呢啲規則存在」,但唔會真正去讀佢哋。
依賴可能唔存在嘅工具嘅規則
「永遠用 ESLint」呢句陳述喺未安裝 ESLint 嘅情況下會失效,相關規則會靜默報錯。現已換成唔依賴特定工具嘅通用陳述:用「符合 codebase 強制執行嘅 code 風格」取代「使用 ESLint」。
喺 CLAUDE.md 入面放 example 而唔係規則
Example 比規則更臃腫。三個 example 消耗嘅 context 幾乎相當於約 10 條規則,而且 Claude 好容易 overfit 到呢啲 example 上。規則是抽象嘅,example 係具體嘅。所以,要用規則!
「要小心」/「要深思熟慮」/「要非常專注」
純粹嘅噪音。對呢啲指令嘅遵守率跌到約 30%,因為佢哋冇辦法測試或驗證。我用具體嘅祈使句(例如「明確指出假設」)取代咗佢哋。
叫 Claude 表現得似個「資深專家」
冇用,Claude 早就認為自己係資深專家。差距在於「認為」同「做到」之間。命令式嘅規則可以縮小呢種差距;身份 prompt 就做唔到。
完整嘅 12 條 CLAUDE.md 規則 (可直接複製貼上)
CLAUDE.md — 12 條規則模板
除非被明確覆蓋,否則這些規則適用於本項目中的每一項任務。
偏好:在非瑣碎的任務上,謹慎優先於速度。對於瑣碎的任務,請自行判斷。
規則一 — 編碼前先思考
明確指出假設。如果不確定,請提問而不要猜測。
當存在歧義時,提供多種解讀方案。
當存在更簡單的方案時,請提出反駁。
感到困惑時就停下來。指明哪裏不清楚。
規則二 — 簡單優先
用最少的代碼解決問題。不要做任何推測性的工作。
不要添加要求之外的功能。不要為一次性的代碼做抽象。
測試標準:資深工程師會覺得這太複雜了嗎?如果是,請簡化。
規則三 — 外科手術式修改
只碰你必須碰的地方。只清理你自己製造的爛攤子。
不要“優化”相鄰的代碼、註釋或格式。
不要重構沒壞的代碼。保持與現有風格一致。
規則四 — 目標驅動執行
定義成功標準。循環迭代直到驗證通過。
不要遵循按部就班的步驟。定義成功並進行迭代。
強有力的成功標準能讓你獨立進行循環。
規則五 — 僅將模型用於判斷性調用
將我用於:分類、起草、總結、提取。
絕對不要將我用於:路由、重試、確定性轉換。
如果代碼能回答問題,就用代碼回答。
規則六 — Token 預算不是建議,是死命令
單任務:4,000 tokens。單會話:30,000 tokens。
如果接近預算,總結並重新開始。
暴露超支問題。不要悄無聲息地超出預算。
規則七 — 暴露衝突,不要折中
如果兩種模式矛盾,選其中一個(最新的 / 測試最多的)。
解釋原因。標記另一個等待清理。
不要混合衝突的模式。
規則八 — 改動前請先閲讀
在添加代碼前,閲讀 exports、直接調用者、共享 utils。
“看起來相互獨立”是很危險的。如果不確定為什麼代碼是這樣構建的,請提問。
規則九 — 測試驗證意圖,而不僅僅是行為
測試必須編碼說明為什麼(WHY)這個行為很重要,而不僅僅是它做了什麼(WHAT)。
一個在業務邏輯改變時都不會報錯的測試是錯誤的。
規則十 — 在每個重要步驟之後建立檢查點
總結做了什麼,驗證了什麼,還剩下什麼。
如果你無法向我複述當前的狀態,就不要繼續。
如果跟丟了進度,停下來並重新梳理。
規則十一 — 遵守代碼庫的約定,即使你不同意
在代碼庫內部,一致性 > 個人品味。
如果你真心覺得某種約定有害,請提出來。不要悄悄建分支(fork)。
規則十二 — 顯性報錯
如果悄悄跳過了任何內容,那“完成”就是錯的。
如果跳過了任何測試,那“測試通過”就是錯的。
默認暴露不確定性,而不是隱藏它。儲存為 CLAUDE.md 並放喺你個 project 根目錄。喺上面呢 12 條規則下面,你可以加 project-specific 嘅規則(例如技術棧、測試指令、錯誤模式等)。但總行數唔好超過 200 行,過咗呢個界線,遵守率就會大打折扣。
點樣安裝
分兩步:
1. 將 Karpathy 的 4 條基準規則追加到你的 CLAUDE.md 中
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
2. 把本文下面提到的規則 5-12 粘貼進去保存喺你個 project 根目錄。呢度嘅 >> 好重要,佢會將內容附加到你現有嘅 CLAUDE.md 檔案尾,而唔係覆蓋你原有嘅 project-specific 規則。
心智模型
CLAUDE.md 唔係一個許願池。佢係一份行為契約,用嚟堵塞你所觀察到嘅特定失效模式。
每一條規則都應該回答一個問題:呢條規則可以防止咩錯誤?

Karpathy 嘅 4 條規則防止咗佢喺 2026 年 1 月見到嘅失效模式:無聲嘅假設、過度工程化、破壞相鄰 code、脆弱嘅成功標準。佢哋係基礎。唔好 skip 佢哋。
我加嘅另外 8 條規則就係為咗防止 2026 年 5 月湧現嘅新失效模式:冇預算控制嘅 agent loop、冇 checkpoints 嘅多步任務、無效嘅測試、同埋隱藏咗隱性故障嘅「靜默成功」。佢哋係補充。
你嘅實際情況可能會唔同。如果你唔運行多步驟嘅 pipeline,咁規則十對你嚟講就唔重要。如果你嘅 codebase 有統一嘅 linting 嚟強制執行一套 code 風格,咁規則十一就係多餘嘅。睇曬呢 12 條,保留嗰啲對應到你真實犯過嘅錯誤嘅規則,刪咗其餘嘅。
一個根據你真實失效模式調整出來嘅 6 條規則嘅 CLAUDE.md,絕對好過一個包含 6 條你永遠用唔到嘅 12 條規則 template。
最後
Karpathy 喺 2026 年 1 月嘅 post 本來只係一聲鬧爆。Forrest Chang 將佢變成咗 4 條規則。12 萬開發者為呢個結果點咗 star。直到今日,佢哋大部分仍然運行緊呢 4 條規則。
模型已經進化。生態系統已經改變。
多步驟嘅 agent 模式、hooks 級聯、skills 加載、跨 codebase 協作 —— 當 Karpathy 寫低嗰個 post 嘅時候,呢啲都唔存在。
原本嘅 4 條規則冇解決呢啲問題。佢哋冇錯,只係唔夠完整。
加咗 8 條規則。喺 30 個 codebase 進行咗 6 個星期嘅測試。
錯誤率由 41% 降到 3%。
既然睇到呢度,如果覺得唔錯,順手幫手「讚」、「睇」、「轉發」三連;如果想第一時間收到推送,都可以幫我加個星標★,非常感謝!
2026 年 1 月底,Andrej Karpathy 發帖吐槽了 Claude 寫代碼的方式。主要有三種失敗模式:
◆ 無聲的錯誤假設
◆ 過度複雜化
◆ 以及對本不該碰的代碼造成了破壞
Forrest Chang 讀了這篇帖子,將這些吐槽打包成了 4 條行為規則,寫進了一個 CLAUDE.md 文件並扔到了 GitHub 上。
Github 地址:
https://github.com/forrestchang/andrej-karpathy-skills
它在第一天就斬獲了 5,828 個 star。兩週內獲得了 60,000 個書籤。時至今日,star 數已達 125,000。這是 2026 年增長最快的單文件倉庫。
然後,我在 6 周的時間裏,在 30 個代碼庫上對它進行了測試。
這 4 條規則確實管用。
在 Claude 擅長的任務中,曾經高達約 40% 的錯誤率驟降至不到 3%。但是,這個模板是為了修復 1 月份寫代碼時的錯誤而構建的。
到了 2026 年 5 月,Claude Code 的生態系統面臨着不同的問題 —— agent 打架、鈎子級聯、技能加載衝突,以及跨會話中斷的多步驟工作流。
所以,我又加了 8 條規則。
下面將逐一展示完整的 12 條 CLAUDE.md 規則,並說明每一條規則入選的理由,以及最初的 Karpathy 模板在哪些情況下會悄無聲息地失效。
如果你想跳過解釋直接複製粘貼,完整文件在文章末尾。
為什麼這很重要
Claude Code 的 CLAUDE.md 是整個代碼棧中最未被充分利用的文件。大多數開發者要麼:
1、把它當成垃圾桶,塞滿他們曾經有過的各種偏好,膨脹到 4,000 多個 token,導致遵守率暴跌到 30%。
2、完全跳過它,每次都重新寫提示詞,浪費了 5 倍的 token,並且會話之間毫無一致性。
3、複製一次模板然後就拋之腦後。用了兩週還行,但隨着代碼庫的演進,它會悄無聲息地失效。
Anthropic 的官方文檔說得很明確:CLAUDE.md 是建議性質的。Claude 大概有 80% 的時間會遵守它。超過 200 行之後,遵守率就會急劇下降,因為重要的規則被淹沒在了噪音中。
Karpathy 的模板用一個文件、65 行代碼、4 條規則解決了這個問題。這就是下限。
但上限還可以更高。
加上我將在下面詳細說明的另外 8 條規則,你不僅能覆蓋 Karpathy 抱怨的 2026 年 1 月的代碼編寫問題,還能覆蓋當時尚未出現的 2026 年 5 月的 agent 編排問題。
最初的 4 條規則
如果你還沒看過 Forrest Chang 的倉庫,它的基本盤是這樣的:
規則一:編碼前先思考
不要做無聲的假設。明確說明你的假設。擺出權衡取捨。在猜測之前先提問。當存在更簡單的方案時,要提出反駁。
規則二:簡單優先
用最少的代碼解決問題。不要寫推測性的功能。不要為了一次性的代碼做抽象。如果一個高級工程師會認為這太複雜了 —— 那就簡化它。
規則三:外科手術式修改
只碰你必須碰的地方。不要“優化相鄰的代碼、註釋或格式。不要重構沒壞的代碼。保持與現有風格一致。
規則四:目標驅動執行
定義成功標準。循環迭代直到驗證通過。不要告訴 Claude 要遵循什麼步驟,告訴它成功是什麼樣子的,讓它自己去迭代。
這四條規則解決了我在無人值守的 Claude Code 會話中看到的約 40% 的失敗情況。剩下的約 60% 則存在於下面的空白地帶中。
我添加的 8 條規則(以及為什麼)
這裏的每一條規則都源於真實的場景,在這些場景下 Karpathy 的 4 條規則顯得力不從心。我將先展示場景,然後給出規則。
規則五:不要讓模型做非語言類的工作
Karpathy 的規則對此隻字未提。模型常常去決定一些本該由確定性代碼決定的事情,比如是否重試 API 請求,如何路由消息,何時升級錯誤。每週的決定都不一樣。這相當於以每 token $0.003 的價格在運行不可靠的 if-else 邏輯。
規則五 — 僅將模型用於判斷性調用使用 Claude 進行:分類、起草、總結、從非結構化文本中提取。
不要使用 Claude 進行:路由、重試、狀態碼處理、確定性轉換。
如果一個狀態碼已經回答了這個問題,那麼純代碼就能回答這個問題。場景還原:
一段調用 Claude 來“決定是否要在 503 時重試”的代碼完美運行了兩週,然後就開始抽風,因為模型開始讀取請求體作為決策的上下文。由於提示詞是隨機的,重試策略也變得隨機了。
規則六:嚴格的 token 預算,沒有例外
沒有預算控制的 CLAUDE.md 就是一張空白支票。每一次循環都有可能演變成一個消耗 50,000 token 的失效模式。模型自己是不會停下來的。
規則六 — Token 預算不是建議,是死命令。
單任務預算:4,000 tokens。單會話預算:30,000 tokens。
如果任務即將超出預算,請總結並重新開始。不要強行推進。
露預算超支的問題 > 悄無聲息地超支。場景還原:
一個 debug 會話運行了 90 分鐘。模型非常樂意對同一個 8KB 的錯誤信息進行反覆迭代,漸漸地就忘了它已經嘗試過哪些修復方案。到最後,它甚至在建議我 40 條消息之前就已經拒絕過的修復方案。如果有 token 預算限制,它在第 12 分鐘就被掐斷了。
規則七:暴露衝突,不要折中
當代碼庫的兩個部分存在分歧時,Claude 會試圖兩邊都討好。結果就是寫出一團亂麻。
規則七 — 暴露衝突,不要折中。
如果代碼庫中現有的兩種模式相互矛盾,不要將它們混合。
挑選其中一個(最新的 / 經過更多測試的),解釋原因,並標記另一個需要清理。
滿足雙方規則的“折中”代碼是最糟糕的代碼。場景還原:
某個代碼庫原本有兩種錯誤處理模式。一種是採用異步等待語法搭配顯式異常捕獲,另一種是使用全局錯誤邊界。Claude 生成的新代碼同時套用了兩種模式,導致錯誤處理邏輯重複冗餘。我花了 30 分鐘才弄明白,為何錯誤會被兩層邏輯連續吞噬攔截。
規則八:落筆前請先閲讀
Karpathy 的“「外科手術式修改」告訴 Claude 不要去碰相鄰的代碼。但它沒告訴 Claude 要先去理解相鄰的代碼。沒有這條規則,Claude 寫出的新代碼就會與 30 行之外的現有代碼發生衝突。
規則八 — 改動前請先閲讀
在文件中添加代碼之前,先閲讀文件的 exports、直接的調用者以及任何明顯的共享 utils。
如果你不明白為什麼現有的代碼結構是這樣的,在添加代碼之前先問清楚。
在這個代碼庫中,“看起來互相獨立”是最危險的一句話。場景還原:
Claude 在一個它沒讀過的、功能相同的現有函數旁邊,又添加了一個新函數。兩個函數做的事情一模一樣。由於導入順序的問題,新函數優先級更高。而那個舊函數可是已經作為單一事實來源穩定運行了 6 個月。
規則九:測試不是可選項,但它們也不是終極目標
Karpathy 的「目標驅動執行」暗示「測試」就是成功標準。但在實踐中,Claude 會把「測試通過」視為唯一目標,寫出來的代碼雖然能通過表面測試,但卻把其他業務邏輯全搞砸了。
規則九 — 測試驗證意圖,而不僅僅是行為
每一個測試都必須編碼說明 WHY(為什麼這個行為很重要),而不僅僅是 WHAT(它做了什麼)。
像 `expect(getUserName()).toBe('John')` 這樣的測試毫無價值,如果函數接收的是一個硬編碼的 ID。
如果你寫不出一個能在業務邏輯改變時失敗的測試,那這個函數就是錯的。場景還原:
Claude 為一個 auth 函數寫了 12 個測試。全部通過。但生產環境中的 auth 卻崩潰了。這些測試僅僅是在測函數是否返回了東西,而不是是否返回了正確的東西。函數能通過測試僅僅是因為它返回了一個常量。
規則十:長時間運行的操作需要設立檢查點
Karpathy 的模板假設交互都是一次性的。但真實的 Claude Code 工作通常是多步驟的。跨 20 個文件進行重構,在一個會話中構建整個功能,跨多個 commit 進行 debug。如果沒有 checkpoints(檢查點),走錯一步就會讓所有進度付諸東流。
規則十 — 在每個重要步驟之後設立檢查點
在完成多步任務中的每一個步驟後:總結已完成的工作、已驗證的成果、以及還剩下什麼。
如果當前狀態你無法向我描述清楚,就不要繼續往下走。如果你跟丟了進度,停下來並重新梳理。場景還原:
一個 6 步的重構在第 4 步出了錯。等我發現的時候,Claude 已經在錯誤的狀態上把第 5 步和第 6 步也做完了。理清這堆爛攤子的時間,比從頭重做一遍還要長。如果有了檢查點,在第 4 步就能發現問題。
規則十一:約定勝於新奇
在已有成熟代碼規範模式的代碼庫中,Claude 往往會引入自身的編碼風格。即便它的方式看似 “更優”,同時並存兩套編碼模式,也比單獨沿用任意一種模式的效果都要差。
規則十一 — 遵循代碼庫的編碼規範,即便你並不認同
如果代碼庫使用下劃線命名法,而你更偏好駝峯命名法:請沿用下劃線命名法。
如果代碼庫使用基於類的組件,而你更偏好鈎子函數:請沿用基於類的組件。
意見分歧可單獨另行溝通討論。
在代碼庫內部,遵從規範優先於個人偏好。
若你確實認為現有規範存在弊端,應主動提出異議,不要私下另起分支擅自改動。場景還原:
Claude 將 React 鈎子引入了類組件代碼庫。功能雖然可以正常運行,但也破壞了原本依賴 componentDidMount 生命週期的代碼庫測試邏輯。花了半天時間移除相關代碼並重新編寫。
規則十二:要明顯地失敗,不要無聲地失敗
Claude 模型代價最高的故障,往往是那些看似成功的情況。某個功能看似 “正常運行”,卻返回錯誤數據;某次數據遷移看似 “執行完成”,卻遺漏了 30 條記錄;某項測試看似 “順利通過”,實則只是校驗斷言本身存在錯誤。
規則十二 — 顯性報錯
如果你無法確定某件事是否成功,就明確說明。
若有30條記錄被靜默跳過,就不該籠統顯示“遷移已完成”;若跳過了任何測試項,就不該宣稱“測試通過”;若未驗證我提及的邊界場景,就不能斷言“功能正常”。
遇到不確定情況時,默認選擇主動披露,而非刻意隱瞞。場景還原:
Claude 稱數據庫遷移 “已成功完成”。系統悄悄跳過了 14% 觸發約束違規的記錄。此次跳過行為有日誌記錄,但未對外提示。直到 11 天后報表數據出現異常,該問題才被發現。
數據表現
在 6 周的時間裏,我在 30 個代碼庫中針對同樣的 50 個典型任務進行了跟蹤測試。分為三種配置:
錯誤率 = 任務需要人工糾正或重寫才能符合預期。
統計指標包括:無聲的錯誤假設、過度工程化、破壞相鄰代碼、無聲失敗、違反約定、混合代碼衝突、遺漏檢查點。
遵守率 = 當相關規則適用時,Claude 在表面上應用該規則的頻率。
有意思的結果並非數據從 41% 驟降至 3% 這一頭條變化,而是規則從 4 條增加到 12 條後,合規負擔幾乎沒有上升(僅從 78% 降至 76%),錯誤率卻又下降了 8 個百分點。新增規則覆蓋了原本 4 條規則未能解決的失效模式,且各類規則不會爭搶相同的關注度資源。
Karpathy 的模板在哪些地方會悄無聲息地失效
哪怕是在添加新規則之前,最初的 4 條規則模板在以下四個方面也是不夠用的:
1、長時間運行的 agent 任務
Karpathy 規則僅針對 Claude 編寫代碼的場景,對 Claude 運行多步驟流程時的情況完全沒有作出規定。沒有資源預算規則、沒有斷點檢查規則、也沒有「顯性報錯」規則,最終導致流程運行出現偏差失控。
2、多代碼庫的一致性
“保持與現有風格一致”的前提是隻有一種風格。在一個擁有 12 個服務的單個代碼庫中,Claude 必須自己去挑選該用哪種風格。最初的規則沒有告訴它怎麼選。它只能隨機挑選或取風格平均值。
3、測試質量
目標驅動執行將「測試通過」等同於成功。但並沒有要求測試必須有意義。結果就是寫出了一堆沒有任何用處卻讓 Claude 迷之自信的測試。
4、生產環境 vs 原型設計
那 4 條原本用來防止生產代碼過度工程化的規則,同樣也會拖慢原型設計的速度,因為原型往往合理地需要 100 行推測性的腳手架代碼來探索方向。Karpathy 的「簡單優先」在面對早期代碼時有些用力過猛了。
這 8 條新增的規則並沒有取代 Karpathy 的 4 條規則。它們只是修補了模型從 2026 年 1 月那種類似自動補全式的編程方式,向 2026 年 5 月那種基於 agent、多步驟、跨代碼庫的工作模式演變過程中產生的缺
哪些嘗試沒起作用
在最終確定這 12 條規則之前,我嘗試過的一些失敗方案:
加入我在 Reddit / X 上看來的規則
大多數要麼是 Karpathy 那 4 條規則換湯不換藥的重述,要麼是那些不具備普適性的特定領域規則(比如“永遠使用 Tailwind 類名”)。我把它們都刪了。
多於 12 條規則
我最多測試過 18 條規則。一旦超過 14 條規則,遵守率就會從 76% 暴跌到 52%。200 行的上限是真實存在的。超過這個長度,Claude 就會開始模式匹配,只知道「有這些規則存在」,但並不會真正去讀它們。
依賴於可能不存在的工具的規則
“始終使用 ESLint” 這一表述在未安裝 ESLint 時會失效,相關規則會靜默報錯。現已替換為不依賴特定工具的通用表述:用 “契合代碼庫強制執行的代碼風格” 替代 “使用 ESLint”。
在 CLAUDE.md 中放示例而不是規則
示例比規則更臃腫。三個示例消耗的上下文幾乎相當於約 10 條規則,而且 Claude 很容易過度擬合到這些示例上。規則是抽象的,示例是具體的。所以,要用規則!
“要小心” / “要深思熟慮” / “要非常專注”
純粹的噪音。對這些指令的遵守率降到了約 30%,因為它們無法被測試或驗證。我用具體的祈使句(比如“明確指出假設”)替換了它們。
告訴 Claude 要表現得像個“資深專家”
沒用,Claude 早就認為自己是個資深專家了。差距在於「認為」和「做到」之間。命令式的規則能縮小這種差距;身份提示詞卻做不到。
完整的 12 條 CLAUDE.md 規則 (可直接複製粘貼)
CLAUDE.md — 12 條規則模板
除非被明確覆蓋,否則這些規則適用於本項目中的每一項任務。
偏好:在非瑣碎的任務上,謹慎優先於速度。對於瑣碎的任務,請自行判斷。
規則一 — 編碼前先思考
明確指出假設。如果不確定,請提問而不要猜測。
當存在歧義時,提供多種解讀方案。
當存在更簡單的方案時,請提出反駁。
感到困惑時就停下來。指明哪裏不清楚。
規則二 — 簡單優先
用最少的代碼解決問題。不要做任何推測性的工作。
不要添加要求之外的功能。不要為一次性的代碼做抽象。
測試標準:資深工程師會覺得這太複雜了嗎?如果是,請簡化。
規則三 — 外科手術式修改
只碰你必須碰的地方。只清理你自己製造的爛攤子。
不要“優化”相鄰的代碼、註釋或格式。
不要重構沒壞的代碼。保持與現有風格一致。
規則四 — 目標驅動執行
定義成功標準。循環迭代直到驗證通過。
不要遵循按部就班的步驟。定義成功並進行迭代。
強有力的成功標準能讓你獨立進行循環。
規則五 — 僅將模型用於判斷性調用
將我用於:分類、起草、總結、提取。
絕對不要將我用於:路由、重試、確定性轉換。
如果代碼能回答問題,就用代碼回答。
規則六 — Token 預算不是建議,是死命令
單任務:4,000 tokens。單會話:30,000 tokens。
如果接近預算,總結並重新開始。
暴露超支問題。不要悄無聲息地超出預算。
規則七 — 暴露衝突,不要折中
如果兩種模式矛盾,選其中一個(最新的 / 測試最多的)。
解釋原因。標記另一個等待清理。
不要混合衝突的模式。
規則八 — 改動前請先閲讀
在添加代碼前,閲讀 exports、直接調用者、共享 utils。
“看起來相互獨立”是很危險的。如果不確定為什麼代碼是這樣構建的,請提問。
規則九 — 測試驗證意圖,而不僅僅是行為
測試必須編碼說明為什麼(WHY)這個行為很重要,而不僅僅是它做了什麼(WHAT)。
一個在業務邏輯改變時都不會報錯的測試是錯誤的。
規則十 — 在每個重要步驟之後建立檢查點
總結做了什麼,驗證了什麼,還剩下什麼。
如果你無法向我複述當前的狀態,就不要繼續。
如果跟丟了進度,停下來並重新梳理。
規則十一 — 遵守代碼庫的約定,即使你不同意
在代碼庫內部,一致性 > 個人品味。
如果你真心覺得某種約定有害,請提出來。不要悄悄建分支(fork)。
規則十二 — 顯性報錯
如果悄悄跳過了任何內容,那“完成”就是錯的。
如果跳過了任何測試,那“測試通過”就是錯的。
默認暴露不確定性,而不是隱藏它。保存為 CLAUDE.md 並放在你的項目根目錄下。在上面這 12 條規則下方,你可以添加項目特定的規則(比如技術棧、測試命令、錯誤模式等)。但總行數不要超過 200 行,過了這個界限,遵守率就會大打折扣。
如何安裝
分兩步:
1. 將 Karpathy 的 4 條基準規則追加到你的 CLAUDE.md 中
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
2. 把本文下面提到的規則 5-12 粘貼進去保存在你的項目根目錄中。這裏的 >> 很重要,它會將內容追加到你現有的 CLAUDE.md 文件末尾,而不是覆蓋你原有的項目特定規則。
心智模型
CLAUDE.md 不是一個許願池。它是一份行為契約,用來堵住你所觀察到的特定失效模式。
每一條規則都應該回答一個問題:這能防止什麼錯誤?
Karpathy 的 4 條規則防止了他在 2026 年 1 月看到的失效模式:無聲的假設、過度工程化、破壞相鄰代碼、脆弱的成功標準。它們是基礎。不要跳過它們。
我添加的另外 8 條規則則是為了防止 2026 年 5 月湧現的新失效模式:沒有預算控制的 agent 循環、沒有檢查點的多步任務、無效的測試、以及隱藏着隱性故障的“靜默成功”。它們是補充。
你的實際情況可能會有所不同。如果你不運行多步驟的流水線,那規則十對你就不重要。如果你的代碼庫有統一的 linting 來強制執行一套代碼風格,那規則十一就是多餘的。通讀這 12 條,保留那些能夠映射到你真實犯過錯誤的規則,刪掉其餘的。
一個根據你真實失效模式調整出來的 6 條規則的 CLAUDE.md,絕對好過一個包含 6 條你永遠用不上的 12 條規則模板。
最後
Karpathy 在 2026 年 1 月的帖子原本只是一聲吐槽。Forrest Chang 把它變成了 4 條規則。12 萬開發者為這個結果點亮了 star。直到今天,他們中的大多數人依然在運行着這 4 條規則。
模型已經進化。生態系統已經改變。
多步驟的 agent 模式、鈎子級聯、技能加載、跨代碼庫協作 —— 當 Karpathy 寫下那個帖子時,這些都不存在。
最初的 4 條規則並沒有解決這些問題。它們沒有錯,它們只是不夠完整了。
增加了 8 條規則。在 30 個代碼庫中進行了 6 周的測試。
錯誤率從 41% 降到了 3%。
既然看到這兒了,如果覺得還不錯,幫忙隨手點個「贊」、「在看」、「轉發」三連;如果想第一時間收到推送,也可給我加個星標★,非常感謝!