試玩PixVerse R1五分鐘,我意識到AI視頻不對勁了
整理版優先睇
PixVerse R1 係一個實時世界模型,改變AI視頻生成方式,變成可持續對話、幹預嘅視覺世界
作者冷逸係測評手替,深度體驗咗PixVerse R1呢個Real-time World Model。佢想講清楚呢個模型點樣唔同傳統AI視頻,整體結論係PixVerse R1唔係「生成得更快」嘅工具,而係一個全新媒介——Playable Reality。
用戶體驗上,傳統AI視頻係輸入Prompt → 等待 → 得到固定片段;PixVerse R1係邊想邊造世界,世界唔係預製,而係即時生成。用戶可以語音輸入指令,世界實時響應,好似同一個平行世界對話。呢種交互範式令用戶變成共創者,而唔係單純使用者。
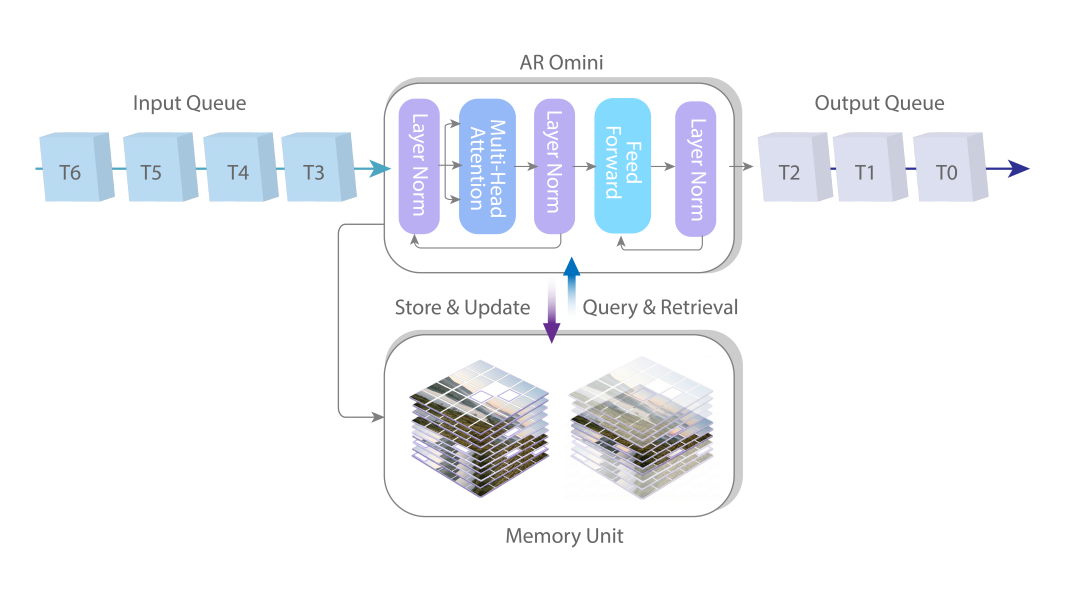
技術上,PixVerse R1由Omni基座模型、無限流式生成架構同實時生成引擎三部分構成。佢用自迴歸生成,唔係擴散模型,所以可以持續生成無限延展嘅視覺流。實時引擎將採樣步驟壓縮到1-4步,實現近乎實時嘅畫面變化。呢個模型令實時、長時序嘅AI生成世界第一次變得可行,意義在於從生成內容躍遷到生成世界。
- 傳統AI視頻係一次性生成結果;PixVerse R1係可實時幹預、持續演化嘅世界,用戶可以同世界對話
- 支援語音輸入,令幹預速度更自然,唔受打字速度限制
- 技術核心:Omni基座模型(多模態token流)+ 無限流式生成架構(自迴歸)+ 實時生成引擎(1-4步採樣)
- 自迴歸生成機制令視頻可以無限延展,而唔係固定長度片段,有長時間一致嘅世界感
- 呢個模型嘅意義係從「生成內容」走向「生成世界」,未來可被Agent接管,融合遊戲、仿真、訓練等場景
PixVerse R1 體驗地址
即時體驗實時世界模型
新交互範式:邊想邊造世界
PixVerse R1 嘅核心改變係視頻唔再係一次性生成嘅結果,而係一個可實時幹預、持續演化嘅視覺世界。作者用案例展示:一個冰雪世界嘅人物可以即時命令佢跑快啲,或者加入龍捲風,所有變化都係即刻反應。
創作界面同傳統AI視頻工具完全唔同:中央畫面長期實時生成、流式播放,下方支援語音輸入。用戶輸入嘅每句指令都會立刻作用喺當前世界上,唔似以前要等一段時間先見到結果。
- 1 傳統AI視頻:輸入Prompt → 等待 → 固定片段
- 2 3D模型:先生成靜態世界再進入
- 3 遊戲:玩預製好嘅世界
- 4 PixVerse R1:邊想邊造世界,現炒現食
語音輸入係關鍵,因為世界跑起嚟之後鍵盤打字速度跟唔上。目前單次創作最長5分鐘,但未來可能無限時長,限制嘅只係想象力。
技術拆解:三個核心組件
PixVerse公開咗技術論文,核心目標係將視頻生成從離線片段變成連續、可交互、實時響應嘅視覺流。實現方式由三部分構成:Omni基座模型、無限流式生成架構、實時生成引擎。
Omni基座模型係端到端嘅原生多模態模型,將文本、圖像、視頻、音頻統一成連續嘅token流,學咗大量真實世界數據,所以有長時間一致嘅世界感。實時引擎則將傳統幾十步採樣壓縮到1–4步,實現近乎實時嘅畫面變化。
論文demo展示:士兵用望遠鏡觀察、烏鴉飛過、巡邏隊發現、逃跑、跌喺坦克旁邊、飛機轟炸,鏡頭銜接自然,符合物理規律。
啟示:從生成內容到生成世界
作者認為PixVerse R1嘅意義係將世界模型從離線想像推進到實時生成、即時響應、長時一致嘅階段。每一次用戶輸入唔只係剪輯點,而係一次對世界狀態嘅幹預;每一幀畫面都係下一步推理嘅上下文。
呢個世界可以被反覆運行、被規模化調用、被Agent接管
一旦做到,遊戲、仿真、訓練、創作,甚至現實決策嘅預演,都會喺同一條技術線上融合。所以總結嚟講,呢次唔係「視頻生成更快了」,而係AI第一次開始擁有一個可以長期存在嘅世界。
- 從「生成內容」走向「生成世界」嘅躍遷
- 用戶變成世界嘅共創者,而唔係使用者
- 未來可被Agent接管,推動遊戲、仿真、訓練等領域融合
大家好,我係冷逸,你哋嘅測評手替又上線啦。
今日,我想同大家傾一款尋晚啱啱發佈嘅Real-time World Model——PixVerse R1。
我深度體驗咗一番,呢個模型真係有啲唔同。
佢唔係一款「生成得更快」嘅影片模型(雖然速度上PixVerse一早已經冇對手),而係從根本上改變咗影片嘅生成方式同交互邏輯。
俾大家睇個case,你就明啦。
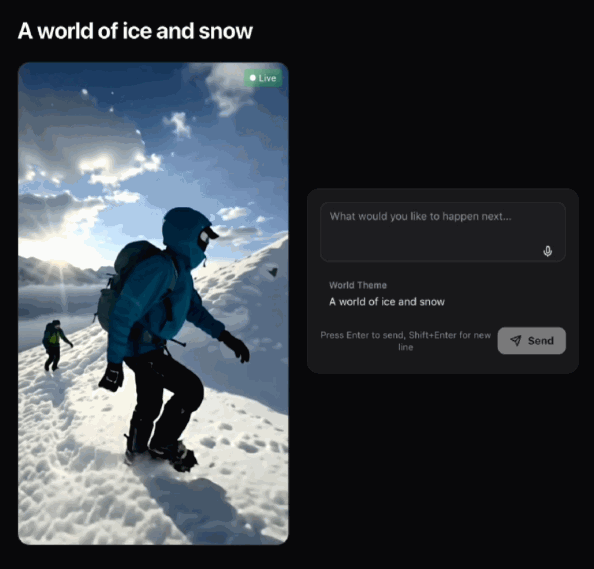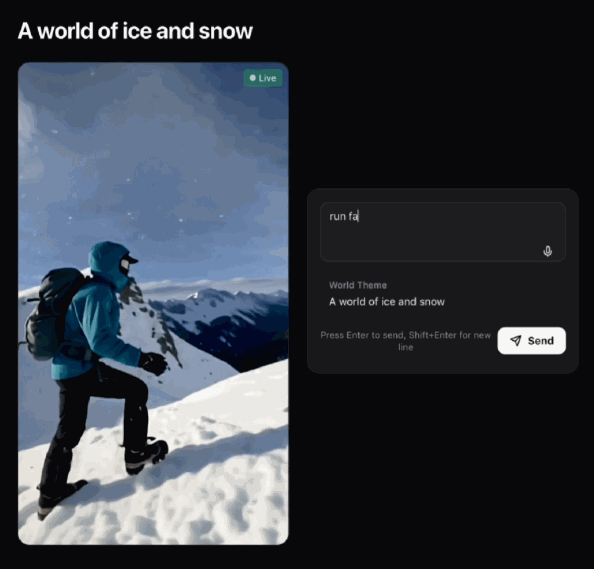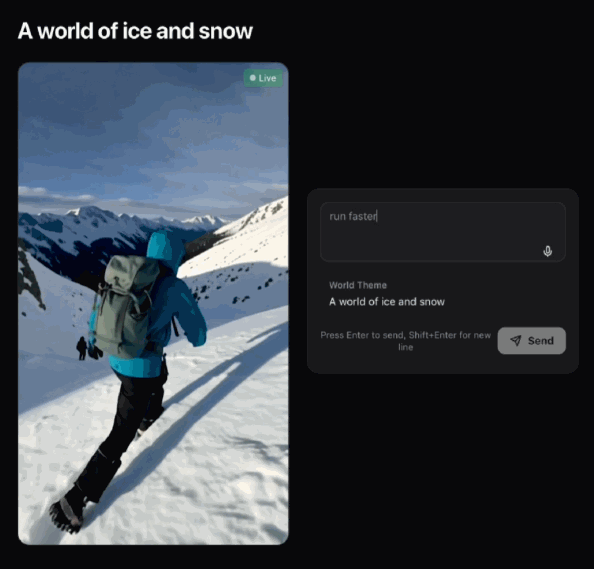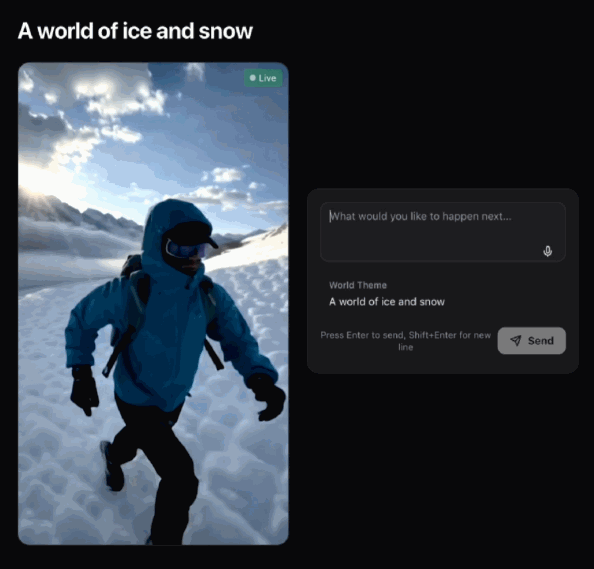
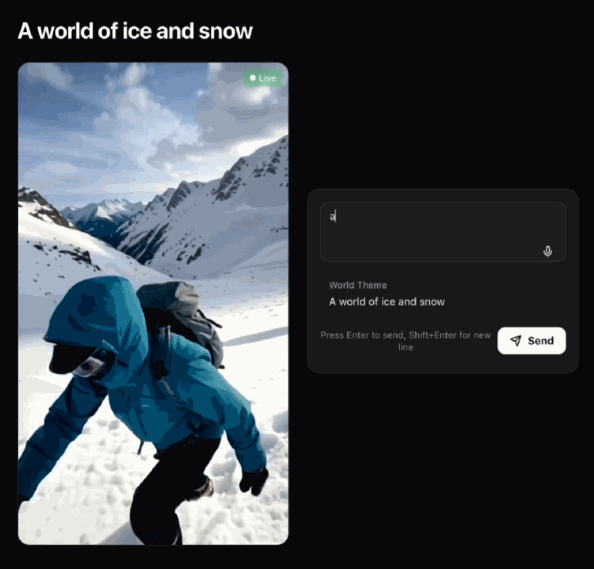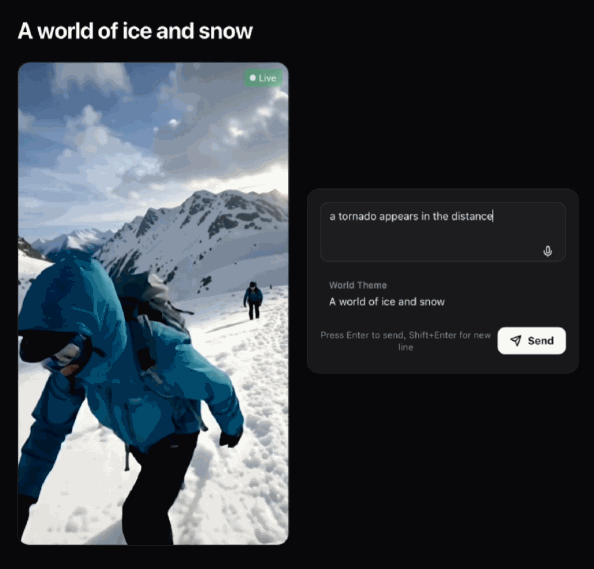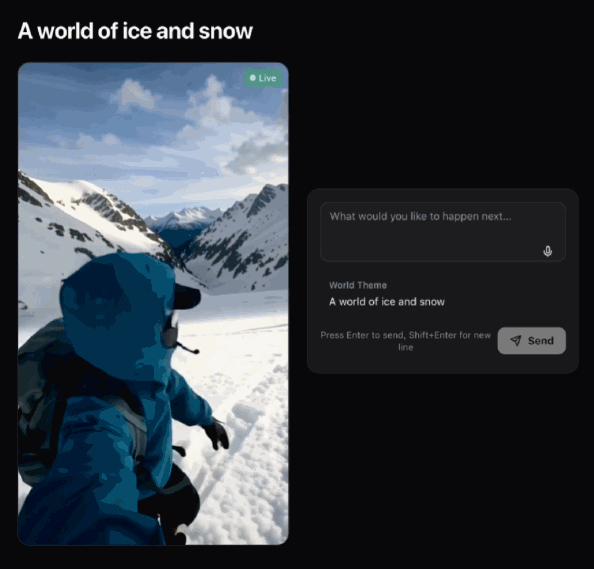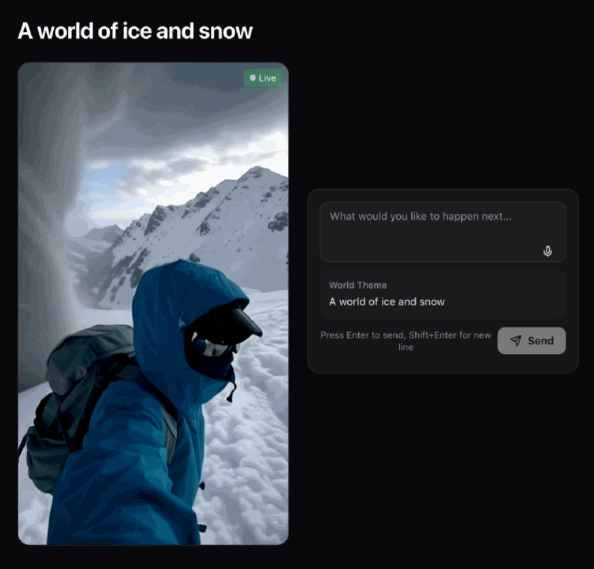
初始畫面:一個人在冰雪世界中行緊。
你可以即刻命令,叫佢跑得快啲。
亦可以令畫面中出現龍捲風(唔好問點解雪山上會見到龍捲風,冇AI辦唔到嘅事 )。
)。
成個過程非常順滑、連貫。你嘅Prompt會即刻作用喺畫面本身,即時改變影片狀態,生成一個持續演化嘅視覺世界。
完整演示錄屏我放咗喺度,一幀都冇剪。
呢個同以往嘅AI影片生成模式完全唔同:
以往嘅AI影片:輸入Prompt → 等待生成 → 得到一個固定嘅影片檔案。
而PixVerse R1令影片唔再係一次性生成嘅「結果」,而係一個可以即時幹預、持續演化嘅視覺世界。

一手體驗
尋晚模型上線之後,我深度玩咗下,同大家講下我嘅使用體驗。
體驗地址係realtime.pixverse.ai,首次打開你會見到咁樣嘅提示:
Visualize Your World in Real-time,Powered by PixVerse R1.
通過PixVerse R1,即時生成你嘅世界。

撳「Start」,進入創作頁面,可以自建主題或者揀推薦主題。
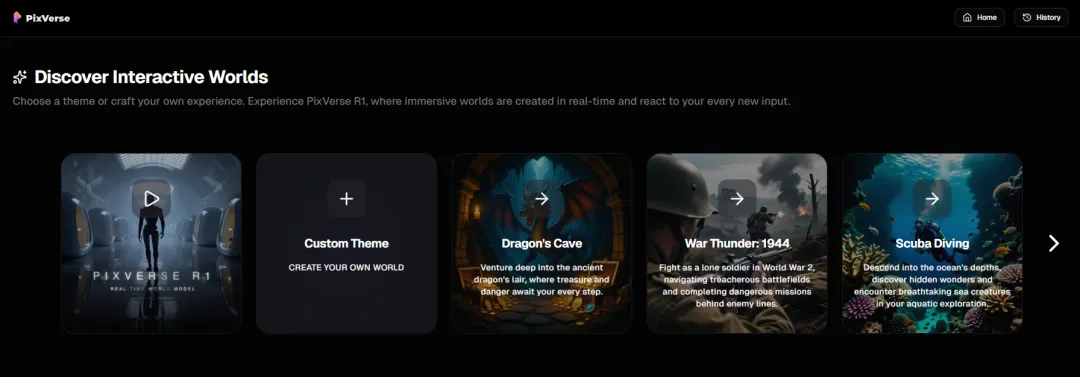
我哋揀一個「War Thunder」主題。
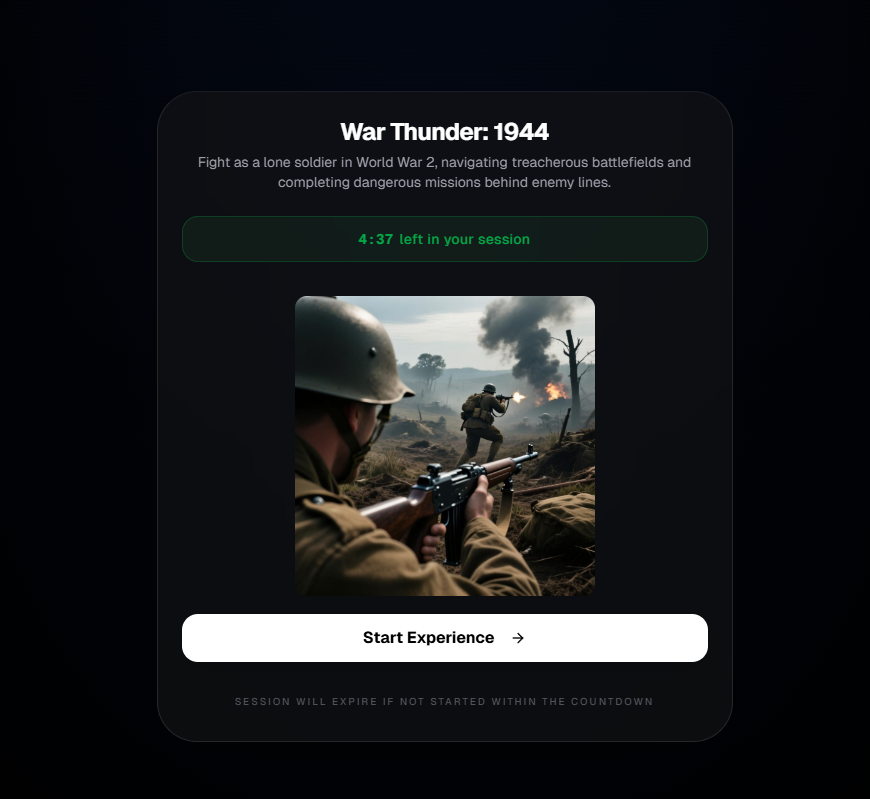
然後進入創作界面。
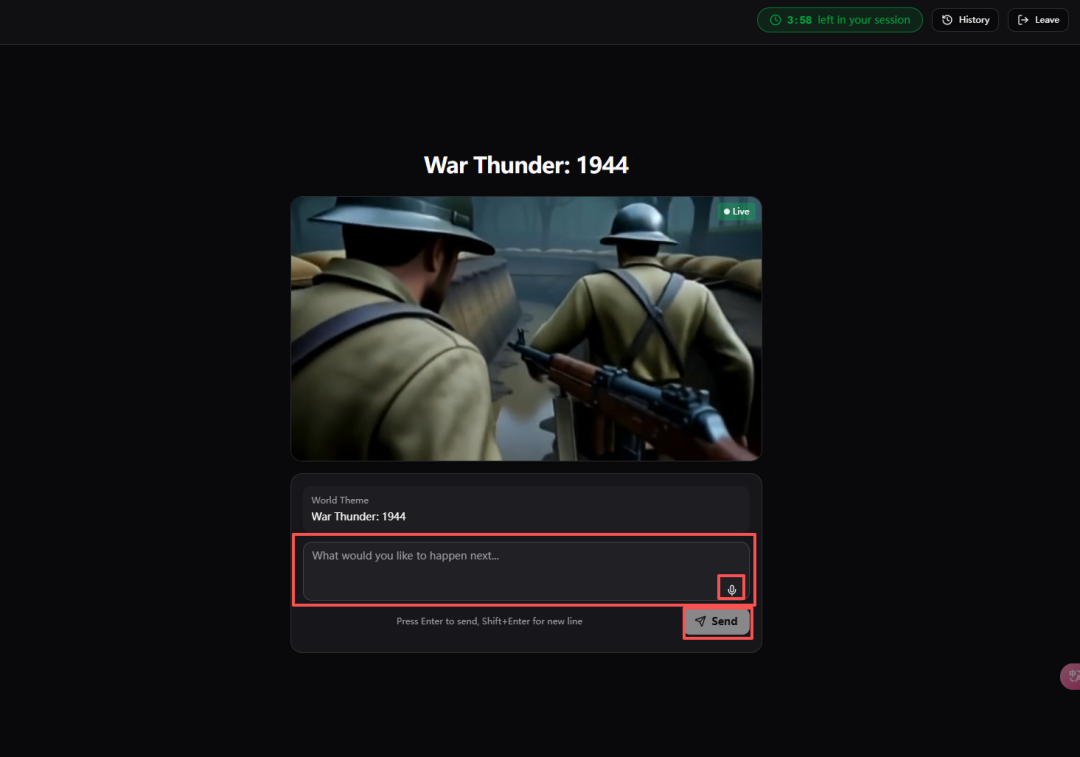
呢個時候你會發現,佢同所有傳統AI影片工具嘅界面都唔同:
中央畫面區域一直喺度即時生成、串流播放
右上角係倒數計時
下方係你嘅Prompt輸入區(支援語音)
你輸入嘅每一句指令,都會即刻作用喺當前世界上。
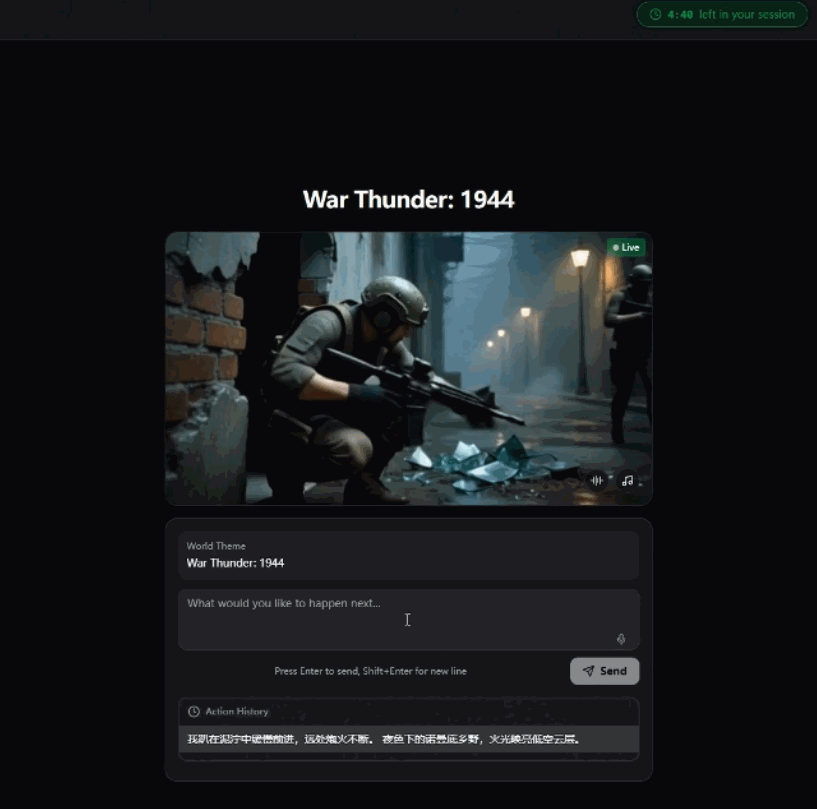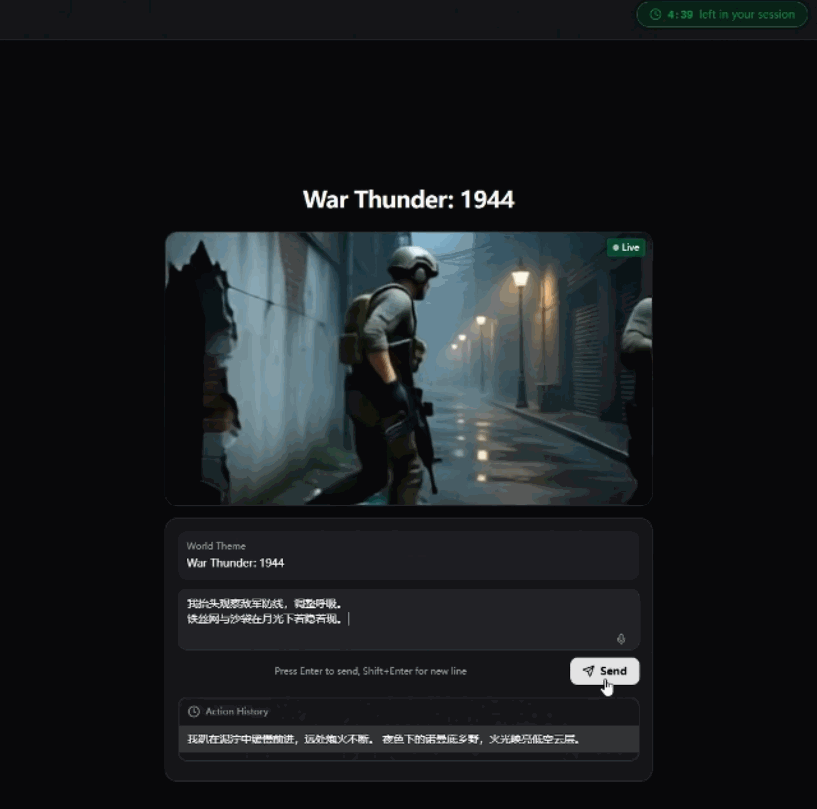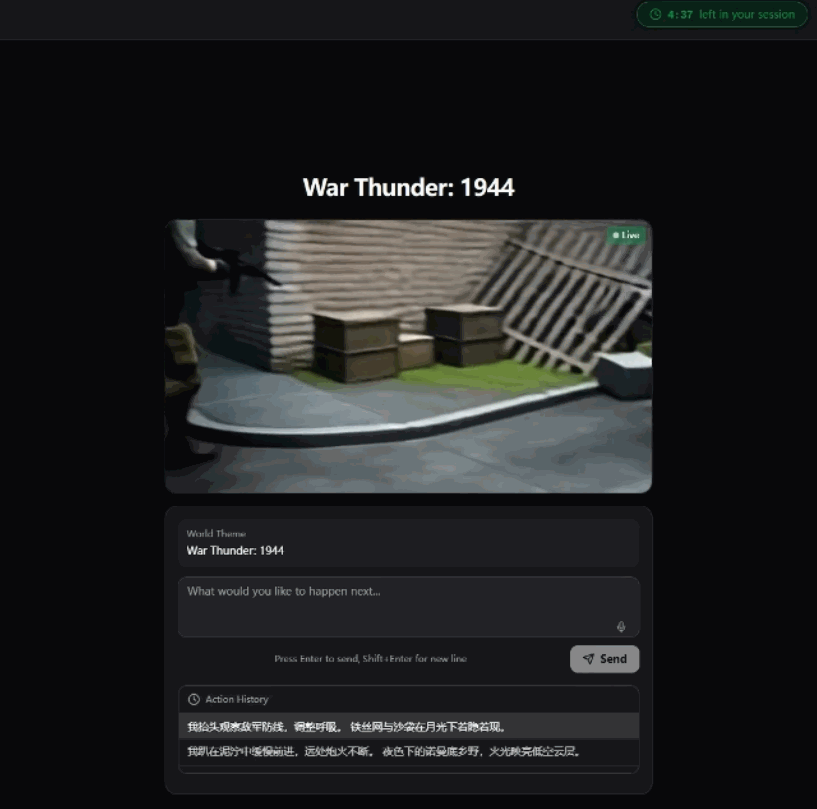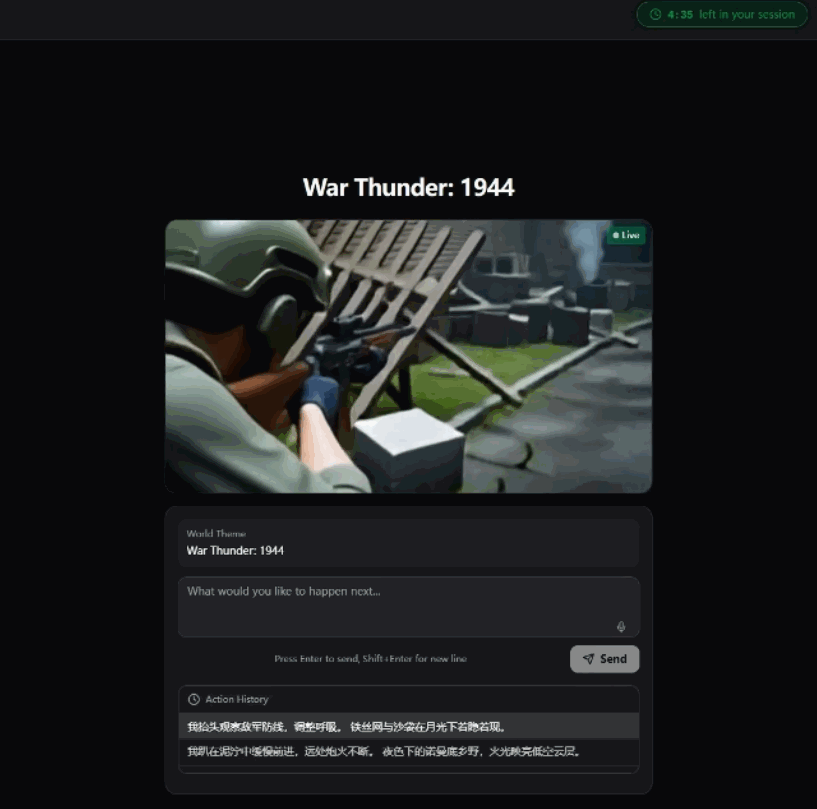
我錄咗一段操作過程,大家可以直觀感受下。
呢種體驗非常新鮮。
佢唔似傳統AI影片:俾一句Prompt,等一陣,拎到一個鏡頭;
亦唔似3D模型:先生成一個靜態世界,再俾你進入;
更加唔似遊戲:將一個「預先造好嘅世界」裝入盒子裏面俾你玩。
PixVerse-R1係「邊諗,邊造世界」。
世界唔係預製嘅,而係現炒嘅。一手,新鮮,而且充滿無限可能。
所以講真話,我啱啱開始體驗PixVerse R1,都冇辦法即刻俾到一個準確嘅定義。但有一點我好肯定,佢唔係現有任何一種媒體形態嘅簡單延伸。
佢更加似一個全新嘅物種。
一個可能會引領未來AI生成世界嘅全新媒介。
特別值得一提嘅係,佢都支援語音輸入。
大家都知道,鍵盤打字嘅速度,好難跟得上即時生成嘅影片世界。一旦世界開始「跑起」,語音輸入嘅優勢就好明顯。
你可以用PixVerse內置嘅語音工具,亦可以用第三方語音輸入。我都錄咗一個演示影片。
目前呢一版PixVerse R1,單次創作最長支援5分鐘。
但我覺得,呢一定唔係佢嘅終點。
未來或者會實現無限時長,到時限制佢嘅只會係我哋嘅想像力。
當然,如果淨係睇畫面質素,例如清晰度、物理細節、鏡頭精度等,佢仲未及PixVerse原始模型嘅效果,唔似大家熟悉嘅AI影片嘅質感。
但PixVerse R1開啟嘅,係一種全新嘅交互範式:
Real-time、Playable Reality
喺呢度,用戶唔再只係使用者,而更加似一個共創者,甚至係世界嘅一部分。
你唔係喺度「生成影片」,而係同一個平行世界持續對話。
佢唔係AI影片,唔係遊戲,唔係直播,亦唔係虛擬世界,而係一種可以被「玩」嘅影片現實(Playable Reality)。
從呢個角度睇,我覺得:PixVerse R1俾成個行業掟咗一枚唔係咁容易即刻理解嘅炸彈。
呢個都係點解,呢個Real-time World Model會被命名為PixVerse R1。

技術拆解
喺模型發佈嘅同時,PixVerse都公開咗佢哋嘅技術論文:
《PixVerse-R1: Next-Generation Real-Time World Model》。
核心目標得一個:將影片生成,從「離線片段」,變成「連續、可交互、即時響應嘅視覺流」。
點樣做到嘅呢?簡單嚟講由三部分構成:
Omni基座模型 + 無限串流生成架構 + 即時生成引擎
首先是Omni基座模型。
呢個係一個端到端嘅原生多模態模型,將文字、圖像、影片、音頻統一成連續嘅token流。
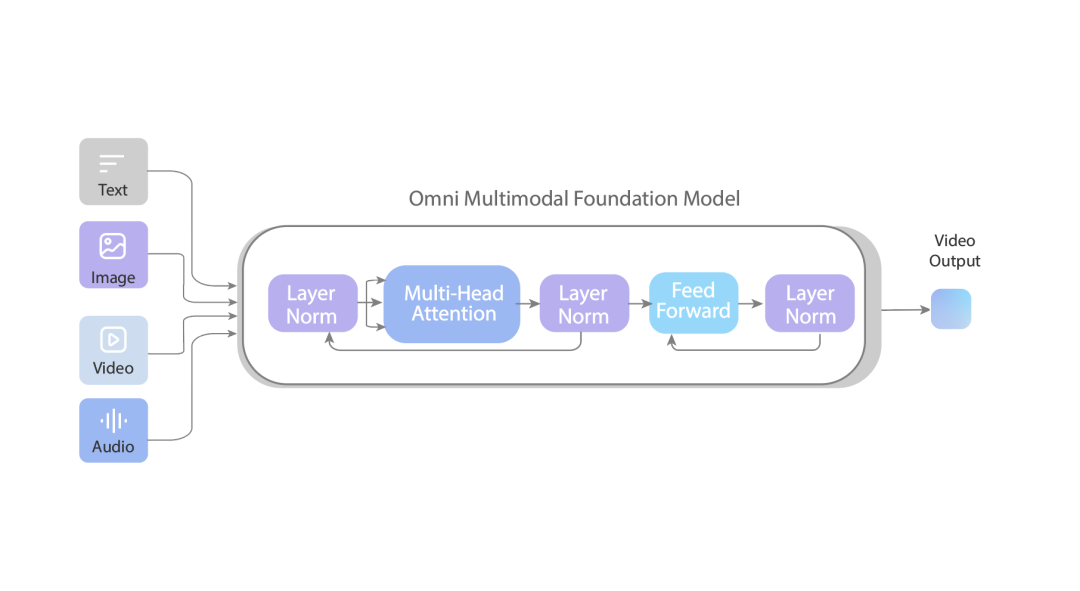
喺訓練階段,佢學習咗大量真實世界嘅影片數據,因此具備生成複雜、長時間一致場景嘅能力——即係我哋直觀感受到嘅「世界感」。
初始畫面:一個士兵趴喺雪地裏面,用望遠鏡觀察前方。
一隻烏鴉飛過。(綠色部分係提示詞)

巡邏隊發現咗士兵。佢開始拼命逃走。

佢跌低喺坦克旁邊。

飛機對坦克實施轟炸。
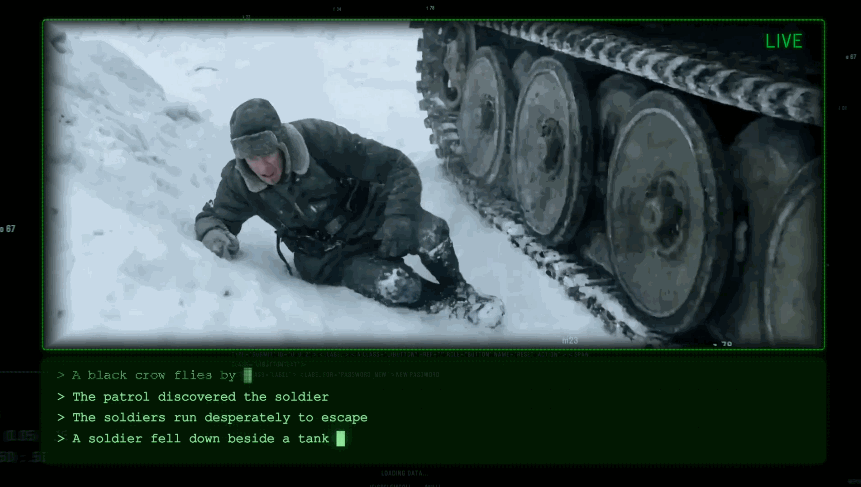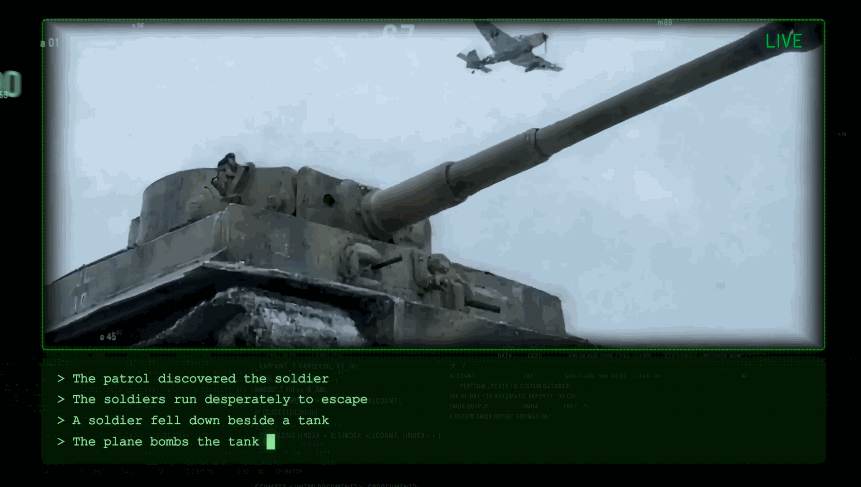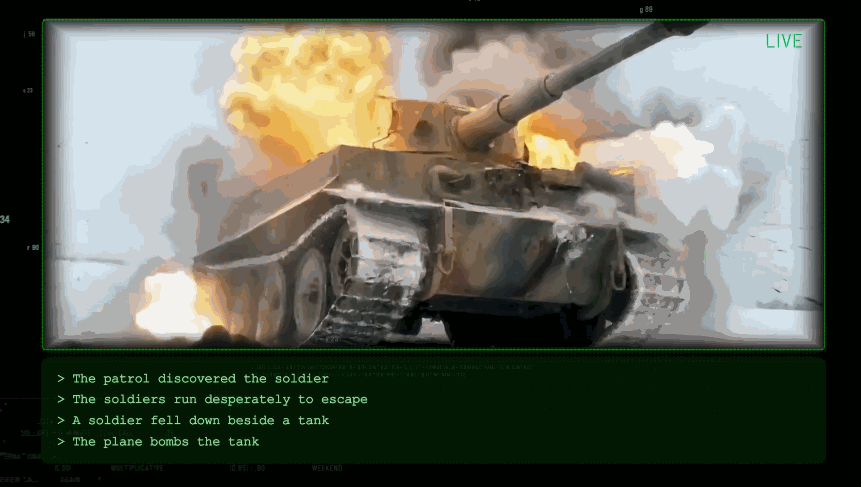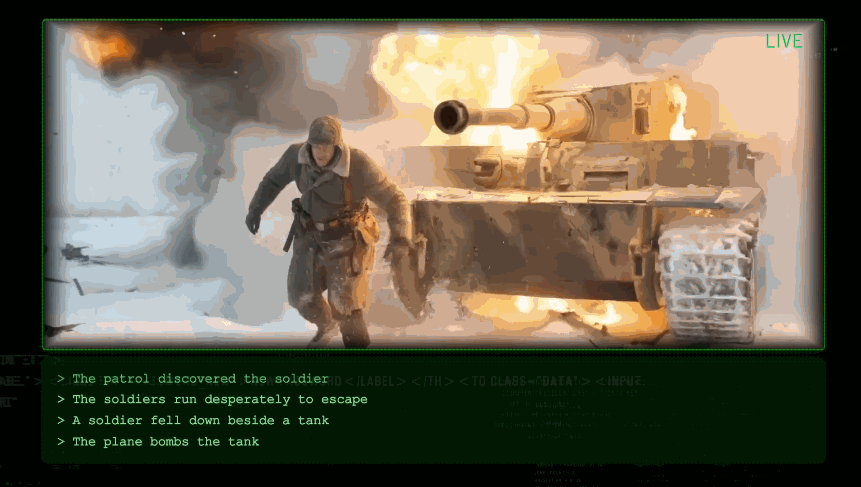
成個鏡頭銜接非常自然,而且跟從物理規律。完整嘅demo,我放咗喺度。
第二個關鍵點,係生成機制。
PixVerse R1採用嘅係自迴歸生成,而唔係傳統擴散模型嗰種「先計完整片段」嘅方式。
呢個意味住,佢可以持續生成、無限延展視覺流,而唔係淨係吐出一個固定長度嘅影片。
最後,亦係PixVerse嘅傳統強項——速度。
喺PixVerse R1中,佢哋重新設計咗即時生成引擎,將傳統影片生成中動輒幾十步嘅採樣過程,壓縮到1–4步。
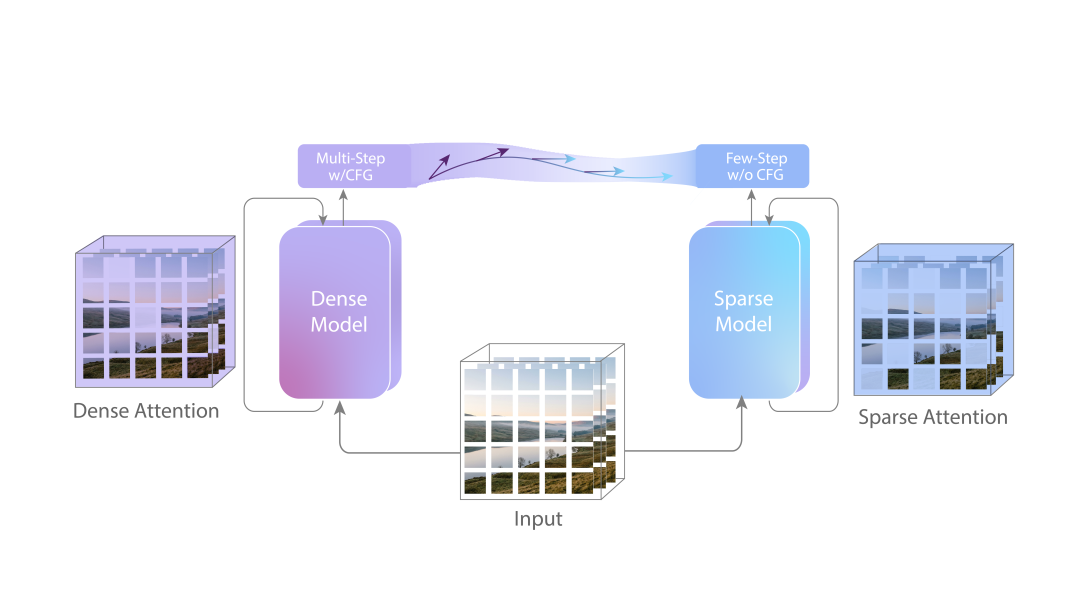
所以,我哋可以見到近乎即時響應嘅畫面變化。

寫在最後
成個體驗落嚟,我嘅感覺係:PixVerse R1令即時、長時序嘅AI生成世界第一次變得可行。
呢個唔止係影片媒介嘅一次演進,更加係一次從「生成內容」走向「生成世界」嘅躍遷。
佢嘅意義在於,將「世界模型」從離線想像,推進到即時生成、即時響應、長時一致嘅階段。
每一次用戶輸入,唔止係剪輯點,而係一次對世界狀態嘅幹預;每一幀畫面,都唔止係結果,而係下一步推理嘅上下文。
一旦咁樣嘅世界可以被反覆運行、被規模化調用、被Agent接管,遊戲、仿真、訓練、創作,甚至現實決策嘅預演,都會喺同一條技術線上融合。
所以,呢個唔係「影片生成更快咗」。
而是:AI,第一次開始擁有一個可以長期存在嘅世界。
大家好,我是冷逸,你們的測評手替又上線了。
今天,我想和大家聊一款昨晚剛剛發佈的Real-time World Model——PixVerse R1。
我深度體驗了一番,這個模型還真的有點不太一樣。
它不是一款“生成得更快”的視頻模型(儘管速度上PixVerse早已沒有對手),而是從根本上改變了視頻的生成方式和交互邏輯。
給大家看個case,你就明白了。
初始畫面:一個人在冰雪世界中行走。
你可以馬上命令,讓她跑得更快點。
也可以讓畫面中出現龍捲風(別問為什麼雪山上能見到龍捲風,就沒有AI辦不到的事情)。
整個過程非常絲滑、連貫。你的Prompt會立刻作用於畫面本身,實時改變視頻狀態,生成一個持續演化的視覺世界。
完整演示錄屏我放在這裏了,一幀未剪。
這和以往的AI視頻生成模式完全不同:
以往的AI視頻:輸入Prompt → 等待生成 → 得到一個固定的視頻文件。
而PixVerse R1讓視頻不再是一次性生成的“結果”,而是一個可實時干預、持續演化的視覺世界。
一手體驗
昨晚模型上線後,我深度玩了玩,給大家說下我的使用體驗。
體驗地址是realtime.pixverse.ai,首次打開你會看到這樣的提示:
Visualize Your World in Real-time,Powered by PixVerse R1.
通過PixVerse R1,實時生成你的世界。
點擊「Start」,進入創作頁面,可以自建主題或選擇推薦主題。
我們選擇一個「War Thunder」主題。
隨後進入創作界面。
這時候你會發現,它和所有傳統AI視頻工具的界面都不一樣:
中央畫面區域始終在實時生成、流式播放
右上角是倒計時
下方是你的Prompt輸入區(支持語音)
你輸入的每一句指令,都會立刻作用在當前世界上。
我錄製了一段操作過程,大家可以直觀感受下。
這種體驗非常新鮮。
它不像傳統AI視頻:發一句Prompt,等一會兒,拿到一個鏡頭;
也不像3D模型:先生成一個靜態世界,再讓你進入;
更不像遊戲:把一個“提前造好的世界”裝進盒子裏讓你遊玩。
PixVerse-R1是在“邊想,邊造世界”。
世界不是預製的,而是現炒的。一手,鮮活,且充滿無限可能。
所以說實話,我剛開始體驗PixVerse R1,也沒法立刻給它下一個準確的定義。但有一點我很確定,它不是現有任何一種媒體形態的簡單延伸。
它更像是一個全新的物種。
一個可能會引領未來AI生成世界的全新媒介。
特別值得一提的是,它也支持語音輸入。
大家都知道,鍵盤打字的速度,很難跟上實時生成的視頻世界。一旦世界開始“跑起來”,語音輸入的優勢就非常明顯。
你可以用PixVerse內置的語音工具,也可以用第三方語音輸入。我同樣錄了一個演示視頻。
目前這一版PixVerse R1,單次創作最長支持5分鐘。
但我覺得,這一定不是它的終點。
未來或許會實現無限時長,屆時限制它的只能是我們的想象力。
當然,如果單純看畫面質量,比如清晰度、物理細節、鏡頭精度等,它還不及PixVerse原始模型的效果,不像大家熟悉的AI視頻的質感。
但PixVerse R1開啓的,是一種全新的交互範式:
Real-time、Playable Reality
在這裏,用戶不再只是使用者,而更像是一個共創者,甚至是世界的一部分。
你不是在“生成視頻”,而是在和一個平行世界持續對話。
它不是AI視頻,不是遊戲,不是直播,也不是虛擬世界,而是一種可以被“玩”的視頻現實(Playable Reality)。
從這角度看,我感覺:PixVerse R1給整個行業扔下了一枚不太容易被立刻理解的炸彈。
這也是為什麼,這個Real-time World Model會被命名為PixVerse R1。
技術拆解
在模型發佈的同時,PixVerse也公開了他們的技術論文:
《PixVerse-R1: Next-Generation Real-Time World Model》。
核心目標只有一個:把視頻生成,從“離線片段”,變成“連續、可交互、實時響應的視覺流”。
怎麼做到的呢?簡單來說由三部分構成:
Omni基座模型 + 無限流式生成架構 + 實時生成引擎
首先是Omni基座模型。
這是一個端到端的原生多模態模型,把文本、圖像、視頻、音頻統一成連續的token流。
在訓練階段,它學習了大量真實世界的視頻數據,因此具備生成複雜、長時間一致場景的能力——也就是我們直觀感受到的“世界感”。
初始畫面:一位士兵趴在雪地裏,用望遠鏡觀察前方。
一隻烏鴉飛過。(綠色部分為提示詞)
巡邏隊發現了士兵。他開始拼命逃跑。
他跌倒在坦克旁邊。
飛機對坦克實施轟炸。
整個鏡頭銜接非常自然,且遵循物理規律。完整的demo,我放在這裏了。
第二個關鍵點,是生成機制。
PixVerse R1採用的是自迴歸生成,而非傳統擴散模型那種“先算完整片段”的方式。
這意味着,它可以持續生成、無限延展視覺流,而不是隻能吐出一個固定長度的視頻。
最後,也是PixVerse的傳統強項——速度。
在PixVerse R1中,他們重新設計了實時生成引擎,把傳統視頻生成中動輒幾十步的採樣過程,壓縮到了1–4步。
所以,我們能看到近乎實時響應的畫面變化。
寫在最後
整個體驗下來,我的感覺是:PixVerse R1讓實時、長時序的AI生成世界第一次變得可行。
這不僅是視頻媒介的一次演進,更是一次從「生成內容」走向「生成世界」的躍遷。
它的意義在於,把「世界模型」從離線想象,推進到了實時生成、即時響應、長時一致的階段。
每一次用戶輸入,不只是剪輯點,而是一次對世界狀態的干預;每一幀畫面,也不只是結果,而是下一步推理的上下文。
一旦這樣的世界可以被反覆運行、被規模化調用、被Agent接管,遊戲、仿真、訓練、創作,甚至現實決策的預演,都會在同一條技術線上融合。
所以,這並不是“視頻生成更快了”。
而是:AI,第一次開始擁有一個可以長期存在的世界。