誰說谷歌Antigravity不好用?我用Skill-Creator構建百萬字知識庫Skill
整理版優先睇
用Skill-Creator配合Antigravity IDE,成功構建一個能處理百萬字文檔嘅本地知識庫Skill,全程由AI自動完成
呢篇文章嘅作者係一位開發者,佢分享咗點樣用Antigravity IDE同Anthropic官方嘅Skill-Creator嚟建立一個可以處理百萬字文檔嘅本地知識庫Skill。佢嘅目標係要整一個能夠處理txt、pdf、docx格式嘅知識庫,用DeepSeek API做向量化同問答,並且確保可以安全處理超大文件,避免一次性載入內存。
作者揀咗Antigravity嘅Manager模式,輸入初始指令後,AI自動生成技能框架,並喺過程中遇到ChromaDB衝突時自行改用自研嘅TinyVectorStore,展現出強大嘅問題解決能力。最終嘅SKILL.md包含ingest_file同ask_kb兩個動作,指定要用分批方式處理文件。作者用近50萬字嘅長篇小說做測試,將中文字符換算成tokens後接近100萬tokens,成功入庫之後,問咗一個原作冇但衍生作品有嘅問題,系統順利檢索到正確答案,證明佢唔係單純背書。
作者總結咗幾點經驗:Antigravity中Claude Opus 4.6額度少,用幾次就冇;Gemini 3 Pro表現不如Flash,後者反應更快更聰明;要建立「流」意識分批處理大數據,唔好一口氣讀曬;數據庫分片可提升效率,將不同書籍分開存儲;同埋Vibe Coding時注意版本控制。總體而言,呢個方法證明AI可以自主完成大部分技術工作,大幅度降低構建專業知識庫嘅門檻,值得一試。
- 結論:用Antigravity IDE配合Skill-Creator可以自動化構建處理百萬字文檔嘅本地知識庫,AI能自主解決大部分技術障礙。
- 方法:使用Manager模式輸入指令,讓AI按計劃執行;遇到依賴問題時,AI可以自行改寫向量庫(如將ChromaDB換成自研TinyVectorStore)。
- 差異:Antigravity中的Gemini 3 Pro(High)表現不如Gemini 3 Flash,後者更聰明反應更快;Claude Opus 4.6雖然好用但額度少。
- 啟發:處理大規模數據必須建立「流」意識,所有環節都要分段分批處理;數據庫分片(Sharding)可以有效擴展查詢效能。
- 可行動點:進行Vibe Coding時要做好版本控制;硬件環境受限時可以自建輕量級向量索引,避免依賴第三方庫。
Claude Skills官方倉庫
下載Anthropic官方嘅skills倉庫,包含skill-creator,係建立技能嘅起點。
準備工作同初始設定
開始之前,作者先確保有正常運行嘅Antigravity IDE、硅基流動嘅API Key,同埋準備好長文本測試文檔。
作者揀咗Manager模式,因為佢更擅長規劃同執行任務,後續有問題可以叫agent自行調整。
首先下載Anthropic官方嘅Claude Skills倉庫,再將skill-creator放入工作區嘅.agent目錄下。具體步驟如下:
- 下載Claude Skills:https://github.com/anthropics/skills
- 喺指定工作區新建.agent目錄
- 將Claude嘅skills文件夾copy到.agent目錄下
- 喺對話框輸入初始指令
構建長文本知識庫Skill嘅過程
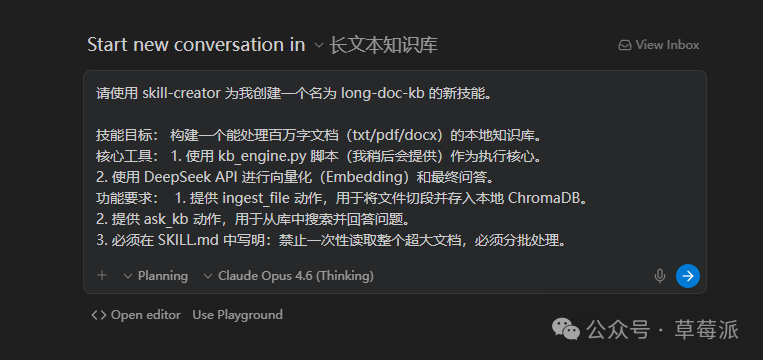
作者喺Antigravity對話框輸入指令,要求skill-creator創建一個名為long-doc-kb嘅新技能,目標係處理百萬字文檔。指令中指定咗核心工具同功能要求。
AI喺執行過程中遇到ChromaDB嘅DLL衝突,自行改用Python同NumPy自建TinyVectorStore,展現咗自主解決問題嘅能力。
經過幾輪優化,最終嘅SKILL.md包含ingest_file同ask_kb兩個動作,用DeepSeek API進行向量化同問答。
測試入庫同檢索
作者用近50萬字嘅長篇小說做測試,將中文字符換算成tokens後接近100萬tokens。成功將文件切段存入TinyVectorStore,完成入庫。
為咗避免背書式回答,作者問咗一個原作冇但衍生作品有嘅問題,成功驗證RAG檢索嘅效果。
整體測試結果理想,證明呢個Skill可以處理大規模文檔嘅知識查詢,而且唔會單純背書。
經驗總結
作者總結咗幾點重要經驗:
處理百萬Token時必須建立起「流」嘅意識,分段分批處理係關鍵。
- Antigravity中Claude Opus 4.6額度太少,用幾次就冇;Gemini 3 Pro(High)表現不如Gemini 3 Flash。
- 整個過程讓agent自行執行命令,遇到問題自行解決,幾乎唔需要人工幹預。
- 如果硬件環境受限或依賴環境受阻,可以勇敢地自己寫向量索引。
- 數據量大時,數據庫分片(Sharding)係高效嘅擴展方案,可以實現查詢時局部喚醒。
一、準備功夫
可以正常運行嘅Antigravity IDE
硅基流動嘅 API Key
準備好長文本嘅測試文檔
二、構建長文本知識庫 Skill 嘅過程
先下載 Claude Skills,地址:https://github.com/anthropics/skills
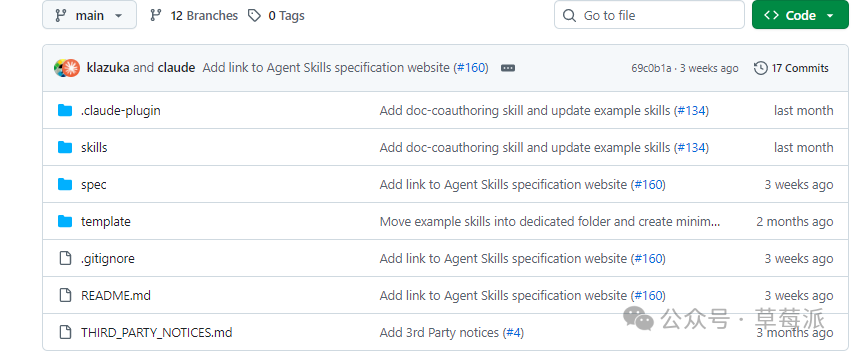
呢個係 Anthropic 官方推出嘅skills 倉庫,其中 skill-creator 可以指導你創建新嘅 Skill。跟住用 skill-creator 嚟生成長文本知識庫 skill
Antigravity 支援全局 Skills 同工作區 Skills

我哋將 Claude Skills 放喺工作區下面,喺指定嘅工作區入面新建 .agent 目錄,再將 Claude 嘅 skills 文件夾 copy 到 .agent 目錄底下。
喺 Antigravity 嘅對話框入面,輸入初始指令(建議用 Manager 模式,因為佢更擅長規劃同執行任務),之後有問題就畀 agent 自己調整
「請使用 skill-creator 為我創建一個名為 long-doc-kb 嘅新技能。
技能目標: 構建一個可以處理百萬字文檔(txt/pdf/docx)嘅本地知識庫。
核心工具:
1. 使用 kb_engine.py 腳本(我等陣會提供)作為執行核心。
2. 使用 DeepSeek API 進行向量化(Embedding)同最終問答。
功能要求:
1. 提供 ingest_file 動作,用嚟將文件切段同存入本地 ChromaDB。
2. 提供 ask_kb 動作,用嚟從庫入面搜索同回答問題。
3. 必須喺 SKILL.md 入面寫明:禁止一次過讀取整個超大文檔,必須分批處理。」
ChromaDB 因為環境入面 DLL 衝突,最後換咗做 python 同 numpy 庫自主研發嘅 TinyVectorStore 輕量級數據庫——呢啲都係 Agent 喺執行嘅過程中發現問題自行解決嘅。
Note:Claude Opus 4.6(Thinking)喺 Antigravity 裏面已經可以用得,但Claude Opus 4.5 已經用唔到。
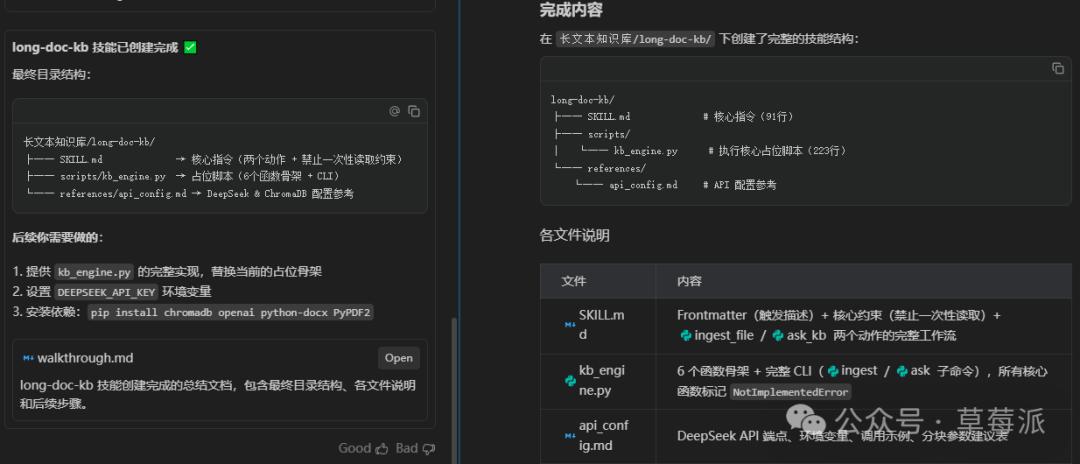
兩分鐘之後,初始框架搭建好咗,跟住 agent 會自行優化
喺 Antigravity Terminal裏面手動安裝依賴包,或者直接俾 Agent 嚟安裝
pip install chromadb openai python-docx PyPDF2
agent 已經將 kb_engine.py 嘅佔位腳本寫好,叫佢直接實現腳本
幾輪優化之後,可以直接用嘅 SKILL.md 如下:

ingest 入庫測試
揾一篇近 50 萬字嘅長篇小說,將中文字元換算成 tokens 之後,總共嘅 tokens 接近 100 萬 tokens
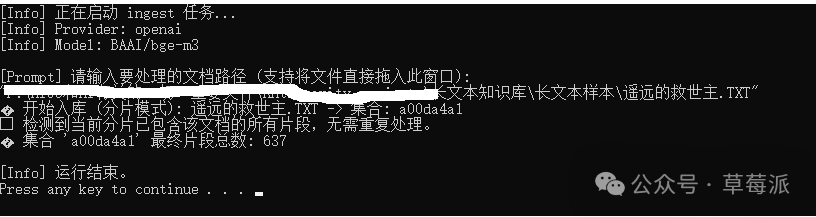
RAG 檢索測試
為咗避免背書式回答問題,問佢一個原作入面冇但係衍生作品入面有嘅問題

三、幾點總結
Antigravity 裏面嘅 Claude Opus 4.6 額度太少,用幾次就冇曬
Antigravity 裏面嘅 Gemini 3 Pro(High)冇 Gemini 3 flash 咁好用,後者用起上嚟更聰明同反應快,Pro 似乎降智比較多
成個過程中,叫 agent 自行執行命令,遇到問題就自己解決問題——佢會自己解決所有問題,幾乎唔需要人工幹預
如果硬件環境受限或者依賴環境受阻,請勇敢啲自己寫向量索引
喺處理百萬 Token 嗰陣,必須建立「流」嘅意識。由文件讀取到處理,再到 API 調用,凡是涉及大規模數據嘅環節,都必須可控咁進行「分段分批」
數據量大嗰陣,數據庫分片 Sharding 係高效嘅擴展方案。將唔同書籍、唔同時段嘅知識存做獨立文件,可以實現「查詢時局部喚醒」
Vibe Coding 嗰陣請注意版本控制
一、準備工作
可以正常運行的Antigravity IDE
硅基流動的API Key
準備好長文本的測試文檔
二、構建長文本知識庫Skill的過程
先下載Claude Skills,地址:https://github.com/anthropics/skills
這是Anthropic 官方推出的skills 倉庫,其中skill-creator能指導你創建新的技Skill。接下來用skill-creator來生成長文本知識庫skill
Antigravity支持全局Skills和工作區Skills
我們將Claude Skills放在工作區下,在指定的工作區中新建.agent目錄,再將Claude的skills文件夾copy到.agent目錄下。
在 Antigravity 的對話框中,輸入初始指令(建議使用 Manager 模式,因為它更擅長規劃和執行任務),後續有問題讓agent自行調整
“請使用 skill-creator 為我創建一個名為 long-doc-kb 的新技能。
技能目標: 構建一個能處理百萬字文檔(txt/pdf/docx)的本地知識庫。
核心工具:
1. 使用 kb_engine.py 腳本(我稍後會提供)作為執行核心。
2. 使用 DeepSeek API 進行向量化(Embedding)和最終問答。
功能要求:
1. 提供 ingest_file 動作,用於將文件切段並存入本地 ChromaDB。
2. 提供 ask_kb 動作,用於從庫中搜索並回答問題。
3. 必須在 SKILL.md 中寫明:禁止一次性讀取整個超大文檔,必須分批處理。”
ChromaDB因為環境中DLL衝突最後換成了python和numpy庫自主研發的TinyVectorStore輕量級數據庫----這些都是Agent在執行的過程中發現了問題自行解決的。
Note: Claude Opus 4.6(Thinking)在Antigravity裏已經可以用了,但Claude Opus 4.5無法再用。
兩分鐘後,初始框架搭建好了,後續agent會自行優化
在Antigravity Terminal裏手動安裝依賴包或直接讓Agent來安裝
pip install chromadb openai python-docx PyPDF2
agent已經將kb_engine.py的佔位腳本寫好,讓它直接實現腳本
幾輪優化後,可以直接使用的SKILL.md如下:
ingest入庫測試
找一篇近50萬字的長篇小說,將中文字符換算成tokens之後,總的tokens接近100萬tokens
RAG檢索測試
為了避免背書式回答問題,問它一個原作中沒有但衍生作品中有的問題
三、幾點總結
Antigravity中的Claude Opus4.6額度太少,用幾次就沒了
Antigravity中的Gemini 3 Pro(High)沒有Gemini 3 flash好用,後者用起來更聰明並且反應快,Pro似乎降智比較多
整個過程中,讓agent自行執行執行命令,遇到問題自行解決問題---它會自己解決所有問題,幾乎不需要人工干預
如果硬件環境受限或依賴環境受阻,請勇敢地自己寫向量索引
在處理百萬 Token 時,必須建立起“流”的意識。從文件讀取到處理,再到 API 調用,凡是涉及大規模數據的環節,都必須可控地進行“分段分批”
數據量大時,數據庫分片Sharding 是高效的擴展方案。將不同書籍、不同時段的知識存為獨立文件,可以實現“查詢時局部喚醒”
Vibe Coding時請注意版本控制