谷歌 Gemini CLI 墊底!首個 AI 編程 Agent 最新榜單出爐
整理版優先睇
AI 編程 Agent 最新榜單:工具比模型更重要,Cursor CLI 搭配 Claude Opus 4.7 奪冠,DeepSeek 成本最抵
呢篇文章由「AI信息Gap」嘅木易(Top2 + 美國 Top10 CS 碩,AI 產品經理)整理,主要講 Artificial Analysis 首個「編程 Agent 全棧測評」。以往嘅榜單分開測模型同工具,但今次終於將「模型+工具」捆綁測試,包含 358 道題,涵蓋修 bug、終端操作同讀代碼三類能力。整體結論係:工具選擇對效能影響好大,同一模型放喺唔同工具分數可以差成 1 分,所以以後揀編程 Agent 唔好剩係睇模型排行榜。
排名方面,Cursor CLI 搭配 Claude Opus 4.7 以 61 分奪冠,Codex + GPT-5.5 同 Claude Code + Claude Opus 4.7 並列第二(60 分)。開源陣營都有驚喜,智譜 GLM-5.1 + Claude Code 拎 53 分(開源第一),Kimi K2.6 同 DeepSeek V4 Pro 各 50 分,同閉源差距已縮窄到個位數。但谷歌 Gemini CLI 搭 Gemini 3.1 Pro 只得 43 分,全場墊底,反映工具層面有大問題,GitHub issue 區亦有唔少投訴。
速度同成本方面,Claude Code + Claude Opus 4.7 平均每個任務最快(5.8 分鐘),最慢組合係最快嘅 7 倍。Token 消耗差異亦大,Claude Opus 4.7 平均 170 萬 token,GLM-5.1 要 …
- 工具選擇對 AI 編程 Agent 效能影響重大:同一模型喺 Cursor CLI 同 Claude Code 分數差 1 分,選 Agent 不能只看模型榜單。
- 評測方法:三個基準(SWE-Bench-Pro-Hard-AA、Terminal-Bench v2、SWE-Atlas-QnA)共 358 題,捆綁模型同工具測試。
- 排名差異:Cursor CLI + Claude Opus 4.7 以 61 分奪冠;開源陣營 GLM-5.1、Kimi K2.6、DeepSeek V4 Pro 全部入前七,與閉源差距只有個位數;谷歌 Gemini CLI 43 分墊底,反映工具缺陷。
- 啟發:編程 Agent 嘅效能取決於「模型+工具」組合,開源模型性價比高,DeepSeek 成本僅 0.35 美元/任務。
- 可行動點:實際體驗為準,可優先試用 Cursor CLI + Claude Opus 4.7 或 DeepSeek V4 Pro + Claude Code,同時關注速度同成本指標。
首個捆綁測評:模型+工具一齊測
同一個 Claude Opus 4.7,放進 Cursor CLI 能拎 61 分,放進 Claude Code 拎 60 分——模型一樣,工具唔同,結果就唔同。第三方評測機構 Artificial Analysis 最近發佈咗首個「編程 Agent 全棧測評」,一次過測「模型+工具」組合,包含三個基準共 358 道題,涵蓋修 bug、終端操作同讀代碼答題三類能力。
排名結果:Cursor CLI 奪冠,Google 墊底
Cursor CLI 搭配 Claude Opus 4.7,綜合得分 61,全場第一。Codex + GPT-5.5 同 Claude Code + Claude Opus 4.7 並列第二,60 分。開源陣營三位選手全部擠進前七:智譜 GLM-5.1 + Claude Code 拎 53 分(開源第一),Kimi K2.6 同 DeepSeek V4 Pro 各得 50 分,與閉源差距已係個位數。
但谷歌 Gemini CLI 搭配 Gemini 3.1 Pro 只得 43 分,全場墊底。Gemini 3.1 Pro 喺模型綜合榜單排名唔低,但放進自家 CLI 就拉胯,問題可能喺工具度。GitHub 開發者反映 Gemini CLI 改個島嶼名要搜 15 分鐘、簡單問題等 13 分鐘,工具體驗明顯不足。
速度與成本:差異懸殊,DeepSeek 性價比王
速度方面,Claude Code + Claude Opus 4.7 平均每個任務 5.8 分鐘,全場最快;最慢組合係最快嘅 7 倍。Token 消耗差異更大:Claude Opus 4.7 平均 170 萬 token,GLM-5.1 消耗 480 萬,部分原因係模型陷入循環。
- 1 成本之王:DeepSeek V4 Pro 配 Claude Code,每個任務 0.35 美元,又強又平。
- 2 最平組合:Cursor CLI + Composer 2(基於 Kimi K2.5),每個任務僅 0.07 美元(約 5 毫人民幣)。
- 3 最貴組合:Codex + GPT-5.5 要 2.21 美元,GLM-5.1 + Claude Code 要 2.26 美元,相差約 30 倍。
Composer 2 嘅秘密:Kimi K2.5 做底
Cursor 今年 3 月發佈 Composer 2,唔夠 24 小時就俾開發者喺 API 響應度扒出模型 ID,寫住 kimi-k2p5-rl-0317。月之暗面隨後喺 X 上發帖祝賀,話「好榮幸 Kimi K2.5 成為 Composer 2 嘅基礎」。Cursor 承認咗,仲話喺 Kimi K2.5 上做咗大量持續預訓練同強化學習。呢件事反映開源模型嘅潛力——可以透過微調變身頂級工具嘅底層引擎。
三個基準點解構成
呢份榜單由三個基準測試構成:SWE-Bench-Pro-Hard-AA(Scale AI 出品,150 道真實代碼修復題)、Terminal-Bench v2(Laude 研究院出品,84 道終端操作題,涵蓋系統管理、密碼學、機器學習)、SWE-Atlas-QnA(Scale AI 出品,124 道代碼理解題)。綜合指數係每個基準各運行 3 遍取 pass@1 平均分。358 道題入面,修 bug 佔 42%,讀代碼佔 35%,終端操作佔 23%。
最後提提大家:榜單只能作為參考,一切以真實體驗為準。編程唔係模型單打獨鬥,模型係發動機,工具係底盤,兩者夾唔夾好緊要。
同一個 Claude Opus 4.7,放入 Cursor CLI 可以拎 61 分,放入 Claude Code 就拎 60 分。
模型一樣,工具唔同,結果就唔同。
第三方 AI 評測機構 Artificial Analysis 最近發布咗首個「編程 Agent 全棧測評」。唔止測模型,仲連 Agent 工具一齊測試。三個基準,包含 358 道題,修 bug、終端操作、讀代碼答題,三類能力。
以前嘅 AI 榜單都係分開嘅。模型還模型,工具還工具。
今次終於有人將「模型 + 工具」捆綁埋一齊測啦。
結果有啲意思。
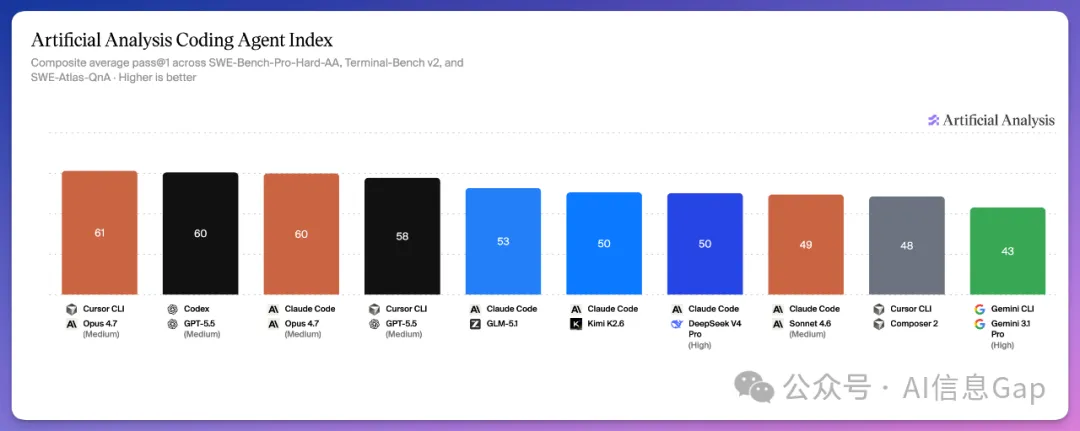
Cursor CLI 搭配 Claude Opus 4.7,綜合得分 61,全場第一。
Codex + GPT-5.5 同 Claude Code + Claude Opus 4.7,並列第二,60 分。 GPT-5.5,攞咗 58 分。
差距其實唔大,但都符合邏輯。同一個模型,換一套工具,分數就有差別。
以後揀編程 Agent,唔好淨係睇模型排行榜啦。
開源陣營三個選手全部躋身前七。
智譜 GLM-5.1 + Claude Code 攞咗 53 分,開源第一。Kimi K2.6 和 DeepSeek V4 Pro 緊隨其後,各得 50 分。
相比閉源模型,雖然仲未追到,但差距已經係個位數啦。
而且,呢三個國產開源模型都強過中等推理強度嘅 Claude Sonnet 4.6(49 分)。
谷歌今次嘅成績唔係幾好睇。
Gemini CLI 搭配 Gemini 3.1 Pro,43 分。全場墊底。
Gemini 3.1 Pro 喺模型綜合榜單上排名唔低。但放入自家 Gemini CLI,編程實戰成績直接仆街。
模型係一方面,但更大嘅問題,可能係在於工具。
GitHub 上 Gemini CLI 嘅 issue 區最近都唔係幾太平。有開發者反饋,叫 Gemini CLI 喺遊戲文件入面改一個島嶼名,搜咗 15 分鐘,改咗 3 分鐘。仲有人簡單問一句「你用緊咩模型」,等咗 13 分鐘先答。
只能夠話開發者工具呢方面,谷歌仲差啲火候。無論係反重力 Antigravity,定係 Gemini CLI。
除咗性能,速度都好重要。
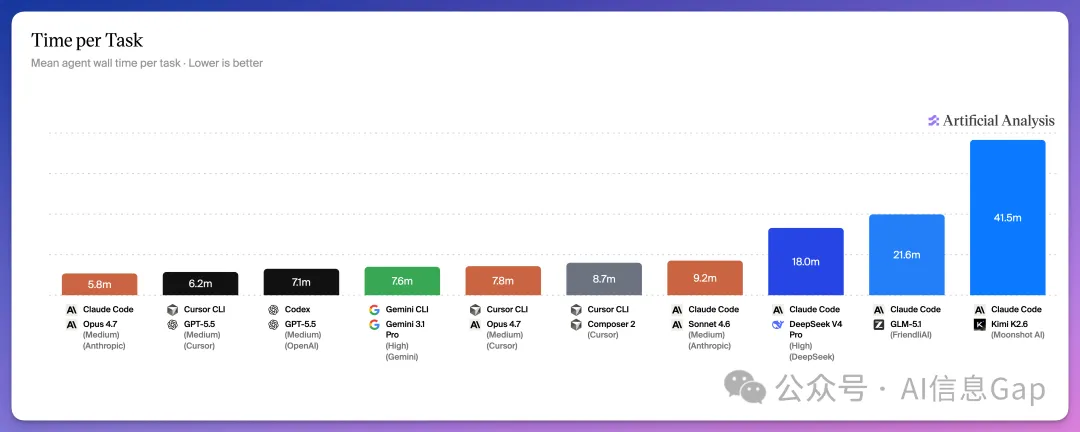
Claude Code 搭配 Claude Opus 4.7,平均每個任務 5.8 分鐘,全場最快。
Cursor CLI + GPT-5.5 第二名,6.2 分鐘。Codex + GPT-5.5 第三,7.1 分鐘。
最慢嘅組合,係最快組合嘅 7 倍。
任務時長 7 倍嘅背後,係 token 用量嘅巨大差異。Claude Opus 4.7 平均每個任務消耗 170 萬 token,Kimi K2.6 消耗 370 萬,GLM-5.1 消耗 480 萬。
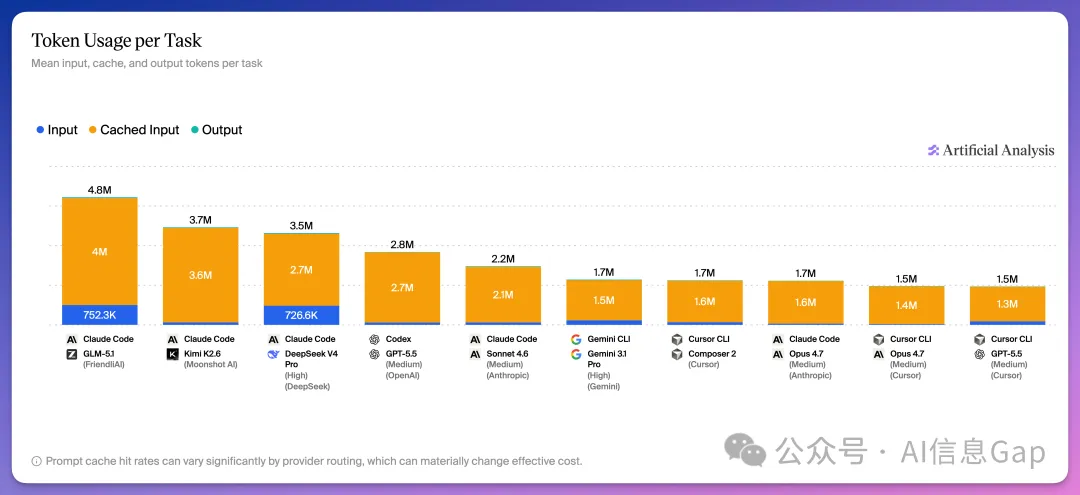
Artificial Analysis 喺報告入面提到,GLM-5.1 token 消耗量大嘅部分原因,係模型喺某啲任務上陷入咗循環。
如果考慮 token 成本,DeepSeek 係絕對嘅王者。
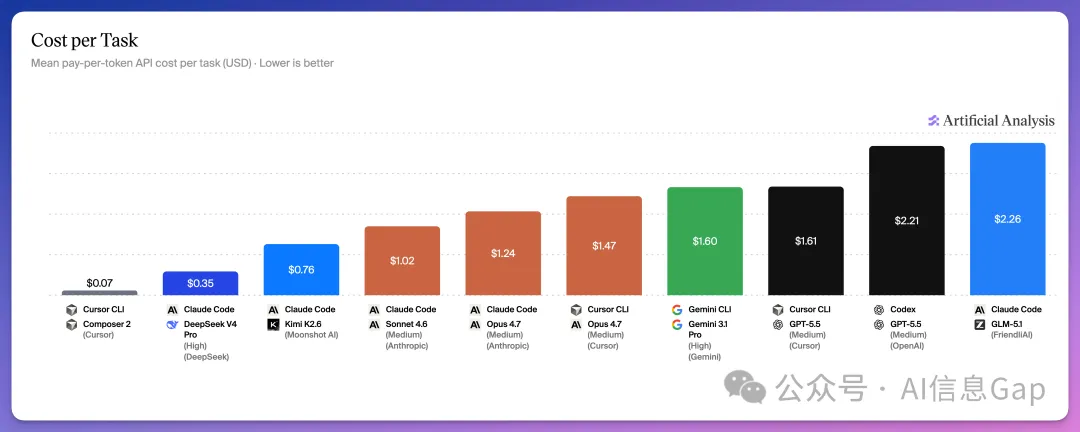
Cursor CLI + Composer 2(一個 Cursor 自研嘅模型),每個任務 0.07 美元。摺合人民幣大約 5 毫子。
DeepSeek V4 Pro 搭配 Claude Code,0.35 美元。又勁又平。
最貴嘅兩個組合,Codex + GPT-5.5 要 2.21 美元,GLM-5.1 + Claude Code 要 2.26 美元。
最平同最貴嘅,相差大約 30 倍。
Composer 2 係一個有故事嘅模型。今年 3 月 Cursor 發布 Composer 2,唔夠 24 小時,就有開發者喺 API 響應入面扒出咗模型 ID,寫住 kimi-k2p5-rl-0317。
月之暗面官方隨後喺 X 上發帖祝賀,話「我哋好自豪 Kimi K2.5 能成為 Composer 2 嘅基礎。」Cursor 承認咗,話喺 Kimi K2.5 上做咗大量持續預訓練同強化學習。
呢份榜單由三個基準測試構成。
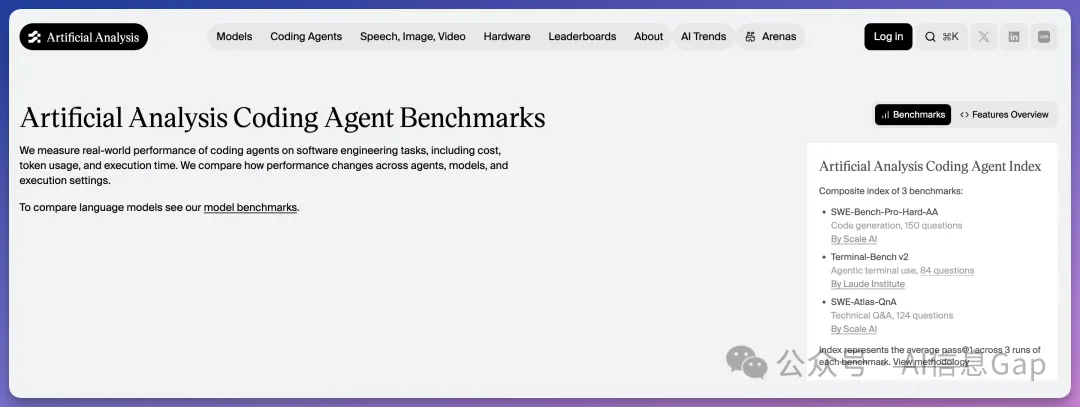
SWE-Bench-Pro-Hard-AA,Scale AI 出品,150 道真實代碼修復題,難度好大。
Terminal-Bench v2,Laude 研究院出品,84 道終端操作題,涵蓋系統管理、密碼學、機器學習。
SWE-Atlas-QnA,都係 Scale AI 出品,124 道代碼理解題,問代碼點樣運行、bug 嘅根本原因係咩。
綜合指數係三個基準各運行 3 次取 pass@1 平均分。358 道題入面,修 bug 佔 42%,讀代碼佔 35%,終端操作佔 23%。
編程唔係 AI 模型單打獨鬥。
同樣嘅模型,放喺唔同嘅工具入面體感可能截然不同。模型係引擎,工具係底盤,都會影響最終效果。
最後,榜單只能夠作為參考,一切以真實體驗為準。
我係木易,Top2 + 美國 Top10 CS 碩,而家係 AI 產品經理。
關注「AI信息Gap」,令 AI 成為你嘅外掛。
同一個 Claude Opus 4.7,放進 Cursor CLI 裏能拿 61 分,放進 Claude Code 拿 60 分。
模型一樣,工具不一樣,結果就不一樣。
第三方 AI 評測機構 Artificial Analysis 最近發佈了首個「編程 Agent 全棧測評」。不只測模型,帶着 Agent 工具一起測試。三個基準,包含 358 道題,修 bug、終端操作、讀代碼答題,三類能力。
以前的 AI 榜單都是分開的。模型是模型,工具是工具。
這次終於有人把「模型 + 工具」捆綁在一起測了。
結果有點意思。
Cursor CLI 搭配 Claude Opus 4.7,綜合得分 61,全場第一。
Codex + GPT-5.5 和 Claude Code + Claude Opus 4.7,並列第二,60 分。接下來是 Cursor CLI 搭配 GPT-5.5,拿了 58 分。
差距其實不大,但也符合邏輯。同一個模型,換一套工具,分數就有差別。
以後選編程 Agent,別隻看模型排行榜了。
開源陣營三個選手全部擠進前七。
智譜 GLM-5.1 + Claude Code 拿了 53 分,開源第一。Kimi K2.6 和 DeepSeek V4 Pro 緊隨其後,各得 50 分。
相比於閉源模型,雖然還沒追上,但差距已經是個位數了。
而且,這三個國產開源模型都要強於中等推理強度的 Claude Sonnet 4.6(49 分)。
谷歌這次的成績不太好看。
Gemini CLI 搭配 Gemini 3.1 Pro,43 分。全場墊底。
Gemini 3.1 Pro 在模型綜合榜單上排名不低。但放進自家的 Gemini CLI,編程實戰成績直接拉胯。
模型是一方面,但更大的問題,可能在於工具。
GitHub 上 Gemini CLI 的 issue 區最近也不太平。有開發者反饋,讓 Gemini CLI 在遊戲文件裏改一個島嶼名字,搜了 15 分鐘,改了 3 分鐘。還有人簡單問一句「你用的什麼模型」,等了 13 分鐘才回答。
只能說開發者工具這塊,谷歌還差點火候。不論是反重力 Antigravity,還是 Gemini CLI。
除了性能,速度也很重要。
Claude Code 搭配 Claude Opus 4.7,平均每個任務 5.8 分鐘,全場最快。
Cursor CLI + GPT-5.5 第二名,6.2 分鐘。Codex + GPT-5.5 第三,7.1 分鐘。
最慢的組合,是最快組合的 7 倍。
任務時長 7 倍的背後,是 token 用量的巨大差異。Claude Opus 4.7 平均每個任務消耗 170 萬 token,Kimi K2.6 消耗 370 萬,GLM-5.1 消耗 480 萬。
Artificial Analysis 在報告裏提到,GLM-5.1 token 消耗量大的部分原因,是模型在某些任務上陷入了循環。
如果考慮 token 成本,DeepSeek 是絕對的王者。
Cursor CLI + Composer 2(一個 Cursor 自研的模型),每個任務 0.07 美元。摺合人民幣大約 5 毛錢。
DeepSeek V4 Pro 搭配 Claude Code,0.35 美元。又強又便宜。
最貴的兩個組合,Codex + GPT-5.5 要 2.21 美元,GLM-5.1 + Claude Code 要 2.26 美元。
最便宜和最貴的,相差大約 30 倍。
Composer 2 是一個有故事的模型。今年 3 月 Cursor 發佈 Composer 2,不到 24 小時,就有開發者在 API 響應裏扒出了模型 ID,寫着 kimi-k2p5-rl-0317。
月之暗面官方隨後在 X 上發帖祝賀,說「我們很自豪 Kimi K2.5 能成為 Composer 2 的基礎。」Cursor 承認了,說在 Kimi K2.5 上做了大量持續預訓練和強化學習。
這份榜單由三個基準測試構成。
SWE-Bench-Pro-Hard-AA,Scale AI 出品,150 道真實代碼修復題,難度很大。
Terminal-Bench v2,Laude 研究院出品,84 道終端操作題,涵蓋系統管理、密碼學、機器學習。
SWE-Atlas-QnA,也是 Scale AI 出品,124 道代碼理解題,問代碼怎麼運行的、bug 的根本原因是什麼。
綜合指數是三個基準各運行 3 遍取 pass@1 平均分。358 道題裏,修 bug 佔 42%,讀代碼佔 35%,終端操作佔 23%。
編程不是 AI 模型單打獨鬥。
同樣的模型,放在不同的工具裏體感可能截然不同。模型是發動機,工具是底盤,都會影響最終效果。
最後,榜單隻能作為參考,一切以真實體驗為準。
我是木易,Top2 + 美國 Top10 CS 碩,現在是 AI 產品經理。
關注「AI信息Gap」,讓 AI 成為你的外掛。