豆包 Seed 2.0 Lite升級:給 Agent 裝上眼睛和耳朵
整理版優先睇
豆包 Seed 2.0 Lite 升級,用低價全模態畀 Agent 睇片聽嘢,解決字幕痛點
作者係一個成日拍 B 站視頻嘅 AI 內容創作者,最怕剪字幕,因為語音識別成日將專有名詞(例如 Claude Opus 4.7、huashu-design)認錯,搞到要逐個改。佢一直諗:如果錄之前可以話畀模型聽「我等陣會講呢啲字」,係咪就可以避免?
最近字節跳動嘅火山引擎推出咗豆包 Seed 2.0 Lite(0428版),呢個模型本來已經可以睇圖、讀視頻,今次仲補埋聽覺——真正「聽」音頻,連情緒、環境聲、多個說話人都捕捉到。更重要係,佢可以直接成段視頻分析,唔係淨係睇一幀靜態圖。作者實測用佢做字幕:畀埋背景同46個易錯術語清單,結果全部正確,成本仲低過唔畀上下文。
作者認為,呢次升級嘅核心唔係「模型識聽」,而係「模型可以喺你畀嘅上下文入面聽」。真正價值係畀 Claude Code、Cursor 呢啲 coding agent 補返對眼同對耳——將視頻、音頻直接變成結構化文本,然後再畀主 agent 處理。成個工作流唔使換工具,只係加一層前置感官。價錢方面,比 Gemini 3 Flash 平六倍,一條 4 分半鐘嘅片轉字幕唔使一分錢,真係用得落 production。
- 結論:豆包 Seed 2.0 Lite 用超低價提供全模態感知,補齊 coding agent 嘅「視聽缺口」
- 方法:將視頻或音頻連同背景 prompt 直接餵畀模型,佢會喺畀嘅上下文入面識別,減少錯字
- 差異:同普通語音識別唔同,佢識得睇成段視頻,分析畫面節奏、字體、動效,甚至寫分鏡表
- 啟發:帶上下文嘅 prompt 反而更平,因為模型唔使亂估,輸出 token 少咗,成本低 20%
- 可行動點:日常用 Claude Code 嘅人可以將豆包當成前置感官,接一層 API 就即刻有齊眼耳
剪字幕之痛:模型冇上下文,專有名詞亂譯
作者習慣自由講嘢錄視頻,之後先上字幕。但自動字幕成日將「Claude Opus 4.7」聽成「Claude 四點七」、「Codex」變「Code X」、「huashu-design」變「花書 Diffusion」。呢啲錯誤源於語音識別模型喺錄音時冇上下文,只能揀最熟悉嘅同音組合。
自動字幕嘅通病:佢唔知我喺度錄乜,所以喺所有同音組合入面揀一個最熟嘅
作者喺 Claude Code 呢類 coding agent 入面做嘢,但呢啲工具冇原生音視頻通道,搞到每次都要跳出去用其他工具做字幕,再貼返嚟。呢個「跳出跳入」嘅過程就係「花書 Diffusion」翻車嘅原因。
豆包 Seed 2.0 Lite:畀 Agent 裝返對眼同耳
字節跳動推出咗豆包 Seed 2.0 Lite(0428版),喺原本已經可以睇圖、讀視頻嘅基礎上,補返聽覺。佢真係「聽」音頻,連情緒、環境聲、多個說話人都捕捉到。最關鍵係佢可以直接處理成段視頻,唔係淨係靜態圖。
御三家入面暫時只有 Gemini 做到呢項能力,但佢哋實在太貴,冇咁實用
而且豆包 Seed 2.0 Lite 嘅調用方式同任何大模型 API 一樣,你可以喺 prompt 入面話畀佢知你講緊乜。作者用一段音頻做測試:畀埋1900字嘅 prompt(錄製背景、說話人風格、46個易錯術語),結果13個專有名詞全部正確;唔畀 prompt 嘅話命中率係0%。
實戰一:帶上下文嘅字幕,成本仲要低兩成
作者將同一段音頻分別掟畀剪輯軟件自動字幕同豆包 Seed 2.0 Lite。剪輯軟件嗰邊將 GitHub 聽成 GitLab、Claude Opus 4.7 變 COS4.7、huashu-design 變花書design。豆包嗰邊全部正確。
豆包唔寫 prompt 直接跑,效果只比剪輯軟件好少少;真正嘅能力係「喺你畀嘅上下文入面聽」
成本數據好反直覺:帶上下文嘅 prompt 雖然多咗1208個 prompt token,但模型唔使亂估,輸出 token 少咗763個,總成本反而平咗20%,單次唔夠一分錢。
- 1 唔畀上下文:關鍵術語命中率0/13,字幕72條(太碎),總成本0.0101元
- 2 畀術語清單+背景:13/13全中,字幕41條(適合閲讀),總成本0.0081元(平20%)
實戰二:直接睇競品片寫分鏡,唔使再寫千字 brief
作者將 OpenAI 發佈 GPT-5.5 嘅55秒英雄動畫直接掟畀豆包 Seed 2.0 Lite,叫佢按8個維度(節奏、視覺系統、動效轉場、文案策略等)輸出結構化分析,再寫一份豆包自家發佈動畫嘅分鏡表。
佢真係畀到:5段時間碼、字體 Inter、強調色 #A855F7 紫、BPM 80-90、平均切換頻率3.5秒
作者跟住將豆包預設嘅紫色換成火山方舟品牌色(#006EFF / #00E5E5),優化咗一段全模態感官可視化嘅動畫描述,再交畀自己另一個 skill(huashu-design)寫 code 出動畫。成個流程從睇片到出 MP4,中間完全冇人寫過一份 brief。
豆包做唔到 video generation,佢只係「睇得明視頻」;但係將「睇得明」呢件事變成 API call,已經夠消滅大量 manual 工序
佢喺工作台嘅位置:前置感官層,唔係取代主模型
作者強調,豆包 Seed 2.0 Lite 唔係用嚟取代你而家嘅主力 LLM,佢嘅輸出能力(寫 code、複雜推理)比不上 Claude Opus、GPT-5.5。但係輸入呢邊,佢提供咗一整代 coding agent 都冇嘅能力:將視頻、音頻、圖片同文本同等地位塞入同一個 API 調用。
前置感官層:視頻/音頻/截圖 → 豆包 Seed 2.0 Lite → 結構化文本 → Claude Code / Codex / OpenClaw / Trae → 代碼/文章
你唔使換工作台,繼續用 Claude Code、OpenClaw、Trae 都得,只要喺前面加一層豆包,你原來嘅工作流即刻有齊完整嘅眼同耳。價錢方面:同 Gemini 3 Flash 比,文本輸入平6倍,輸出平6倍。一條4分38秒嘅片轉字幕一次唔到一分錢。
最近一個月模型發佈實在太捲喇。Claude Opus 4.7、GPT-5.5、DeepSeek V4 一個接一個,我每日打開 X 都覺得自己就快俾新模型淹沒。淨係我自己,前幾個禮拜就趕住做咗三期 B 站視頻去解讀呢堆發佈。
拍過視頻嘅人應該體會到,做視頻最痛苦嘅環節之一就係剪字幕。
我錄視頻從來唔跟劇本讀。
相比對住劇本讀稿,我通常都係鍾意自由隨性咁講,會顯得更自然。然後遇到嘅情況就係:專業術語講到一半改口、數字換咗講法、諗到一個例子塞入去,呢啲就係我錄視頻嘅常態。之後剪輯嘅第一步永遠係上字幕,丟入剪輯軟件自動識別,再花一個鐘頭改返啱。
我超級討厭呢個環節。唔係麻煩。每次見到字幕入面嗰堆識別錯位嘅術語,我都會有啲恍惚,總覺得有種話我普通話、英文發音唔標準嘅彈幕喺度嘲諷咁飄過。
需要改啲咩呢?「Claude Opus 4.7」俾人聽成「Claude 四點七」,「Codex」俾人斬成「Code X」,「GPT-5.5」變咗「GBT 5.5」。
呢啲都仲算好,最離譜一次:上個禮拜我錄咗一段介紹我自己開源嘅 huashu-design skill,自動字幕竟然俾我轉出一行字「花書 Diffusion」。
佢完全將 Huashu Design 重新解析成一個根本唔存在嘅 AI 模型。以下呢種錯誤都算客氣架喇。
我研究咗一下原因。呢個係語音識別工具通用嘅工作方式:佢聽音頻嘅時候唔知我錄緊乜,冇上下文,於是在所有可能嘅同音組合入面揀一個佢最熟嘅。「huashu-design」呢種組合從來冇喺佢訓練數據出現過。
呢件事困擾我至少三年。每次寫完劇本我都會諗:如果錄之前可以同模型講一聲「我陣間會講 Codex、Claude Opus 4.7、Hermes Agent,huashu-design 係我自己嘅開源項目」,佢會唔會就唔會犯呢種錯?
我講嚇我嘅工作枱。我大部分時間喺 Claude Code 等 Coding Agent 入面做嘢,寫文章、改代碼、做調研、整理素材都喺佢入面。佢對我嘅意義係:絕大多數任務都應該喺呢個工作枱入面自動化完成,少跳出去用其他工具,少切換上下文。
但係 Claude Code 呢個工作枱入面冇原生嘅音視頻通道。我錄嘅 B 站視頻丟唔入去(就算丟入去都只可以截圖分析),會議錄音根本冇得直接處理,人哋嘅產品發佈動畫都要手動轉寫。佢喺文字呢一層好強,但喺「眼睛+耳朵」呢一層基本係空嘅。我每次想將視頻或者音頻變成可以處理嘅文本,都要跳出工作枱,用其他工具,再將結果貼返入去。而呢個跳出去嘅環節,就係「花書 Diffusion」出事嘅地方。
呢件事其實唔係字幕工具一間嘅問題。你睇嚇國內大模型公司最近呢半年嘅發佈節奏就明,幾乎間間都跟住 Anthropic 將 coding 同 agentic 打到最盡,多模態放咗喺相對靠後嘅位置。
我明呢個選擇。coding 同 agentic 的確係模型最高價值嘅方向,亦係模型公司之間分勝負嘅地方。但係做內容呢一行,成日會卡住嘅反而係多模態:要睇競品視頻係點樣剪嘅、要將會議錄音整理成紀要、要幫自己嘅 video 做精準字幕、要從一段長視頻入面抽出 3 個關鍵片段。呢啲嘢 LLM 本身解決唔到,每次都要跳出工作枱,揾一個語音識別工具、一個抽幀腳本、一個膠水流程拼埋一齊。
最近喺火山引擎見到字節方舟發咗豆包 Seed 2.0 Lite(0428版)。見到個價錢咁低有啲心動,跟住就啟發咗幾種新嘅工作流靈感~
佢喺原本 02 月 Lite 版嘅基礎上做咗一件事:今次 Lite 都可以聽嘢喇。原本嘅 Lite 已經可以睇圖、可以讀視頻、可以處理文字,今次將聽覺補返上嚟。係真係「聽」,唔單止係將聲音轉成文字,連情緒、環境聲、多個說話人都可以一齊捕捉。
仲有一個特別值得強調嘅點係,唔好一睇「全模態」就以為佢同普通圖像理解模型差唔多。佢係可以直接讀視頻㗎,唔係淨係睇一幀靜態圖。你掟一段 60 秒嘅視頻入去,佢可以話俾你知畫面節奏、字體風格、動效轉場、音視頻係咪一致,呢啲嘢 GPT-5.5、Claude Opus 4.7 都做唔到。御三家入面暫時得 Gemini 做咗呢項能力,但佢哋實在係有啲貴,冇咁實用。
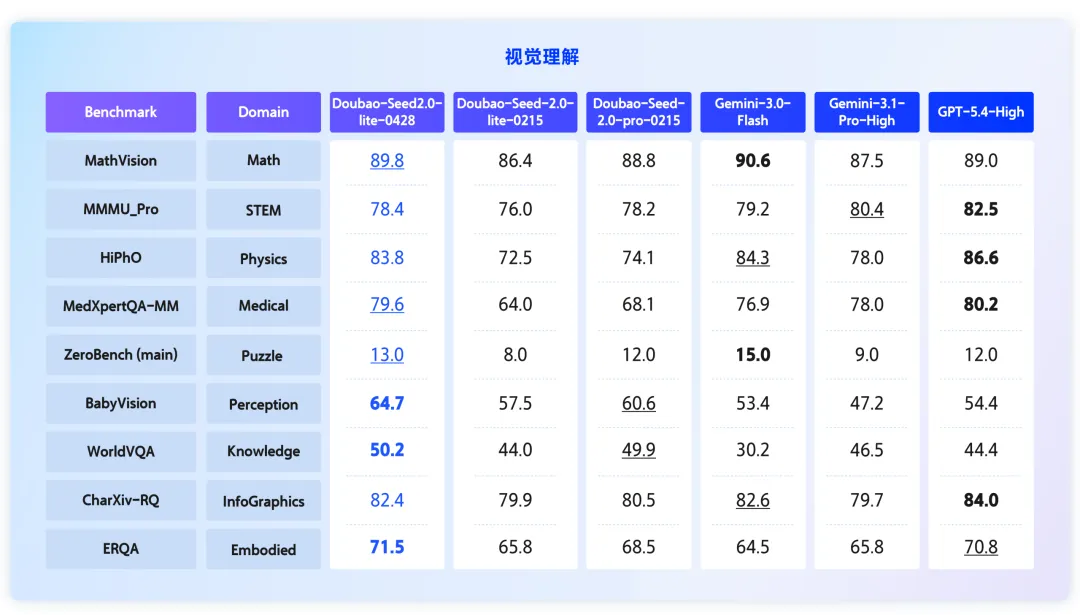
同埋,甚至以性能表現嚟講,最新嘅 Seed 2.0 Lite 唔止超過咗前一代 Seed 2.0 Pro 嘅視覺理解能力,仲喺多個維度都達到咗 SOTA 級別👇
所以嚴格嚟講,佢幫 Agent 裝上嘅唔只係耳朵,仲係一對可以讀視頻嘅眼睛。我陣間會用兩個 demo 將呢兩件事都行一次。
而且關鍵喺呢度:豆包 Seed 2.0 Lite 嘅調用方式同你調任何一個大模型 API 冇分別。即係你可以喺 prompt 入面話俾佢知你陣間會聽啲乜。
我將嗰段錄有「huashu-design」嘅音頻丟俾佢,再加一個 1900 字嘅 prompt:錄製背景、說話人風格、46 個易錯術語清單(GPT-5.5、Claude Opus 4.7、Codex、Anthropic、Apollo Research……)。叫佢輸出標準 SRT 字幕。
然後我將同一段音頻都丟入剪輯軟件自動字幕——剪輯軟件係大多數人做視頻嘅默認選擇,同佢對比最直接。結果:
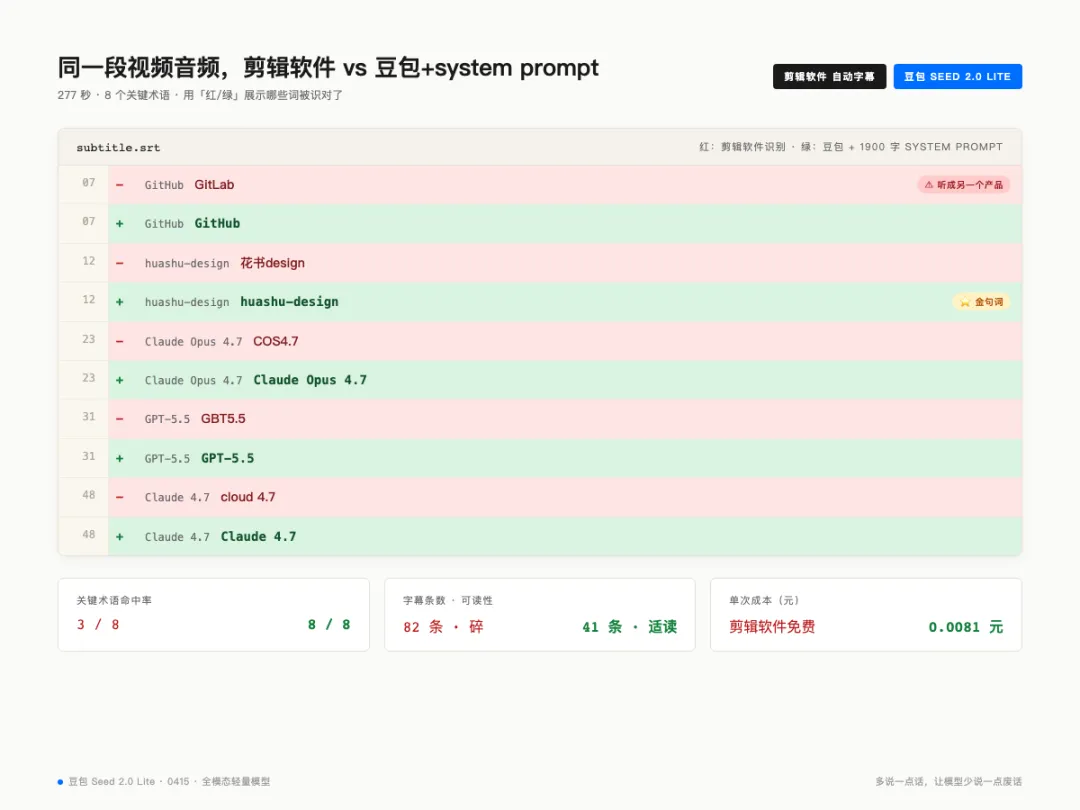
剪輯軟件將 GitHub 聽成 GitLab、Claude Opus 4.7 變 COS4.7、GPT-5.5 變 GBT5.5、Claude 4.7 變 cloud 4.7、huashu-design 變花書design——呢個唔係剪輯軟件差,係所有自動字幕工具嘅通病:冇上下文,模型只能喺同音組合入面揀佢最熟嗰個。平時會拍 video 嘅同學應該明我講乜。
咁豆包呢邊呢?全對huashu-design、Claude Opus 4.7、GPT-5.5、GitHub、Claude 4.7,一個都冇錯。
但呢度要補一個 best practice,如果唔係你跟住試可能會失望:豆包唔寫 prompt 直接行,效果只係比剪輯軟件好少少——仍然會將一部分專有名詞認歪。佢真正嘅能力,係你將背景、術語清單、說話人風格都寫入 prompt 之後先至解鎖。今次升級真正解鎖嘅唔係「模型可以聽」,係「模型可以喺你俾嘅上下文入面聽」。
所以如果你想將佢塞入生產鏈路,prompt 上下文係必須要做嘅功課。少咗呢一步,全模態嘅能力就發揮唔出嚟。
更加出乎意料嘅係成本。一段 277 秒嘅音頻,加咗 1900 字 prompt 反而比冇加更平——prompt token 多咗 1208 個,但模型唔使亂估,輸出 token 少咗 763 個。總成本下降 20% ,單次唔夠一分錢。
事情到呢度其實未完,因為「帶上下文做字幕」只係今次 0428 升級最淺嘅一層。我之後連續做咗兩個 demo,一個係用佢去睇另一間 AI 嘅產品發佈動畫,一個係驗證佢喺真實工作流入面嘅位置。亦即係呢篇文章真正想講嗰件事:
呢一代 Agent 工具,無論係 Claude Code、Cursor 定 OpenClaw,一直缺一對可以聽音頻、可以睇視頻嘅耳朵同眼睛。豆包 Seed 2.0 Lite 0428 好難得咁補返上嚟,價錢仲好抵。
叫 AI 睇另一間 AI 嘅產品視頻
字幕呢條線我行通之後,做咗第二個實驗,更加狠啲。因為我發現 Seed 2.0 Lite 模型喺視頻理解能力上有啲勁,機會係全方位碾壓 Gemini-3-Pro 嘅水平👇

OpenAI 上個禮拜喺 X 發 GPT-5.5 嘅時候配咗一條 55 秒嘅 hero 動畫:白色底、Inter 字體、打字機標題、4 段產品演示(扭計骰、跨 Slack 改 bug、生成財務 PPT、blossom logo 收尾)。
呢種動畫係產品發佈嘅標準品,我自己做過幾次,次次都要拉競品視頻反覆睇,寫一份俾前端嘅 brief,再過一次設計稿。成個鏈路最少三日。
先睇嚇 OpenAI 嗰段原視頻係點樣:
我將呢條 55 秒視頻直接餵俾豆包 Seed 2.0 Lite,寫咗一份 prompt:你睇完呢條片,按 8 個維度(節奏、視覺系統、動效轉場、文案策略、品牌資產、音頻、鏡頭、遷移建議)俾一份結構化輸出我,最後俾一份「豆包 Seed 2.0 Lite 發佈動畫」嘅分鏡表,要具體到顏色 hex、字號、動效時序,令前端可以直接開工。
佢真係俾咗。
視頻入面幾乎所有可以觀察到嘅細節佢都認到:5 段時間碼(0-4s 標題、5-13s 扭計骰、14-34s Slack 改 bug、35-50s 生成 PPT、51-55s logo 收尾)、字體氣質(Inter 類無襯線、字重 700/400/500 三層)、強調色 #A855F7 紫色、blossom 花形符號喺扭計骰表面同結尾出現兩次、BPM 大約 80-90、平均切換頻率 3.5 秒。佢仲順便指出開場頭 3 秒嘅鈎子結構同結尾 3 秒嘅品牌定格邏輯。
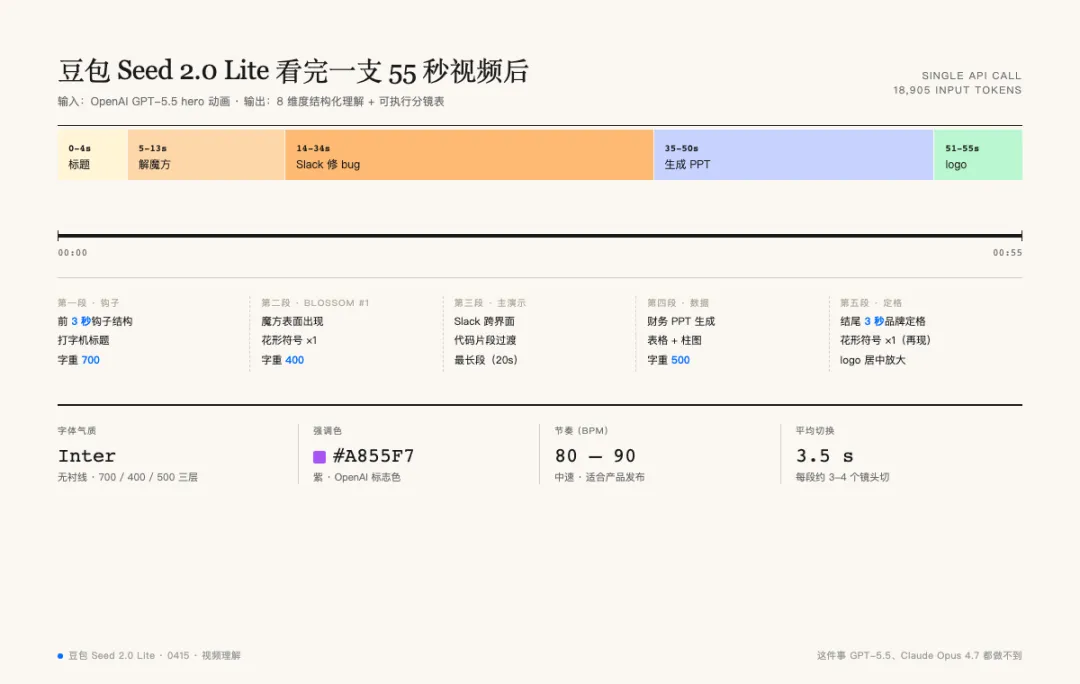
更加有用嘅係 H 部分。佢俾我寫咗一份可執行嘅分鏡表:7 段、每段時間碼、畫面元素、文案、動效、要用嘅數據點。我將呢份表再過咗一次,將佢默認套用 OpenAI 紫色嗰部分換成火山方舟自己嘅品牌色(#006EFF / #00E5E5),將 5-13s 嗰段「全模態感官可視化」具體化(左邊波形圖、中間豆包 logo 脈衝、右邊抽幀縮略圖三欄匯聚),加咗 SFX 節拍同字體規範,整成一份最終藍本。
然後呢份藍本交俾我自己另一個 skill huashu-design(專門做 HTML 動畫嘅),叫佢根據藍本寫代碼、Playwright 錄屏、ffmpeg 出 MP4。最後產出係咁樣:
成個鏈路由睇片到拎到 MP4,冇人寫過一份 brief。
我以前做產品視頻係咁樣:睇 5 個競品 → 寫 8 千字 brief → 揾設計師 → 改 3 輪。而家變成:將 1 個競品丟入 LLM → LLM 寫 brief → 另一個 LLM 寫代碼出動畫。中間嗰 8 千字嘅 brief,係今次升級入面第一個被消滅嘅環節。
呢個 demo 唔係想證明豆包可以做到 video,佢做唔到,佢只係睇得明 video。叫 AI 睇 video 呢件事嘅價值,係將「拆解參考」呢道工序由手動變成 API 調用。
數據對比:同一段音頻,兩個 prompt
返去字幕嗰條線,我將對比數據完整列一列,方便你睇清楚 prompt 上下文到底改變咗啲乜。
最反直覺嘅係最後一行。帶上下文嘅 prompt 多咗 1208 個 prompt token,你直覺以為會更貴,但 completion 嗰邊模型唔使亂估,反而少咗 763 個 token。講多啲嘢,等模型講少啲廢話。呢個係今次升級入面第二個被消滅嘅環節:模型亂估嘅成本。
佢喺工作枱入面嘅位置
將呢兩個 demo 連埋一齊睇,論點其實好簡單。
豆包 Seed 2.0 Lite 0428 唔係嚟取代你而家用緊嘅 LLM 嘅。佢嘅輸出能力,寫代碼、複雜推理、長鏈路 Agent,一定唔及 Claude Opus、GPT-5.5 呢啲旗艦。我唔會用佢去寫 1 萬行代碼。
但輸入呢一邊,佢提供嘅係 Claude Code、Cursor、Codex、OpenClaw 呢一整代 coding agent 都冇嘅能力:令你可以直接將 video、音頻、圖片同文本以同等地位塞入同一個 API 調用,令 prompt 入面嘅上下文直接作用喺感知層。
呢個係「前置感官層」嘅意思,係佢喺你工作流入面嘅位置:

重點喺呢度:你唔使換工作枱。 日常用 Claude Code、Codex、龍蝦 OpenClaw、Hermes Agent,或者字節自家嘅 Trae 都得——將豆包 Seed 2.0 Lite 當成前置感官接一層入去,你原本嘅工作流即刻就有齊全嘅眼睛同耳朵。唔使遷移、唔使學新工具,只係幫現有嘅 coding agent 補返佢原本冇嗰部分感知。
呢個月頭我出咗一本 Hermes Agent 嘅橙皮書,講長鏈路 Agent 點樣將多步驟任務串埋。當時書入面有一節專門講 Agent 工作流嘅「輸入側瓶頸」:絕大多數任務卡喺「點樣將現實世界嘅 video/音頻/會議錄屏餵俾 Agent」呢一步。
呢本書寫完之後我自己喺工作流入面都未真正解決呢個問題,繞路用 Whisper + 手動改字幕、用 Gemini 處理 video、用一堆膠水腳本拼埋。豆包 Seed 2.0 Lite 0428 係我見到嘅第一個用一次 API 調用就將呢兩件事都解決嘅全模態輕量模型。
價錢都係呢個論點嘅支撐。我只係同同檔嘅全模態輕量模型對比,旗艦模型唔係同一個檔次,冇必要拉入嚟。
同同尺寸嘅 Gemini 3 Flash 比,文本輸入平 6 倍,輸出平 6 倍。呢個價錢意味住你可以真係將佢塞入生產鏈路,唔係淨係做 demo。我嗰段 4 分 38 秒 video 轉字幕一次唔夠一分錢,即係我每日錄嘅幾個 video 片段全部行一次語音識別都係幾毫子。當成本低到「唔使考慮成本」嘅時候,調用頻率就會升一個量級,工作流嘅形態都會跟住變。
下次開 Claude Code 嘅時候,你可以試嚇將嗰段唔想手動轉錄嘅會議錄屏丟俾佢喇。
你都係時候幫你嘅龍蝦裝返對真嘅耳朵同眼睛喇。
最近一個月模型發佈太捲了。Claude Opus 4.7、GPT-5.5、DeepSeek V4 一個接一個,我每天打開 X 都覺得自己快被新模型淹沒。光是我自己,前幾周就趕着做了三期 B 站視頻去解讀這些發佈。
錄過視頻的人應該有體會,做視頻最痛苦的環節之一,是剪字幕。
我錄視頻從來不按腳本念。
相比看着腳本讀稿,我通常還是更喜歡自由隨性點講,會顯得更有認為。然後遇到的情況就是:專業術語念一半改口、數字換種說法、想到一個例子塞進去,這是我錄視頻的常態。然後剪輯的第一步永遠是上字幕,丟進剪輯軟件自動識別,再花一個鐘頭改回來。
我特別討厭這個環節。倒不是麻煩。每次看到字幕裏那一堆識別錯位的術語,我都會有點恍惚,總覺得有種說我普通話、英語發音不標準的彈幕在壞壞的飄過。
需要改寫什麼呢?「Claude Opus 4.7」被聽成「Claude 四點七」,「Codex」被切成「Code X」,「GPT-5.5」變成「GBT 5.5」。
這些都還好,最離譜的一次:上週我錄了一段介紹我自己開源的 huashu-design skill,自動字幕給我轉出來一行字「花書 Diffusion」。
它完全把 Huashu Design 重新解析成了一個根本不存在的 AI 模型。下面這種錯誤都算客氣了。
我研究了一下原因。這是語音識別工具通用的工作方式:它在聽音頻的時候不知道我在錄什麼,沒有上下文,於是在所有可能的同音組合裏挑一個它最熟悉的。「huashu-design」這種組合從來沒在它訓練數據裏出現過。
這件事困擾我至少三年。每次寫完腳本我都會想:要是錄之前能跟模型說一聲「我接下來要講 Codex、Claude Opus 4.7、Hermes Agent,huashu-design 是我自己的開源項目」,它會不會就不犯這種錯?
我說一下我的工作台。我大部分時間在 Claude Code 等Coding Agent裏幹活,寫文章、改代碼、做調研、整理素材都在它裏面。它對我的意義是:絕大多數任務都應該在這個工作台內自動化完成,少跳出去用別的工具,少切換上下文。
但 Claude Code 這個工作台裏沒有原生的音視頻通道。我錄的 B 站視頻丟不進去(即便丟進去也只能截圖分析),會議錄音根本沒法直接處理,別人家的產品發佈動畫也得手動轉寫。它在文字這一層非常強,在「眼睛+耳朵」這一層基本是空的。我每次想把視頻或者音頻變成可以處理的文本,都得跳出工作台,去用別的工具,再把結果粘回來。而這個跳出去的環節,就是「花書 Diffusion」翻車的地方。
這事兒其實不是字幕工具一家的問題。你看國內大模型公司最近這半年的發佈節奏就明白了,幾乎所有家都跟着 Anthropic 把 coding 和 agentic 捲到極致,多模態放在了相對靠後的位置。
我能理解這個選擇。coding 和 agentic 確實是模型最高價值的方向,也是模型公司之間分勝負的地方。但做內容這一行,經常會卡住的反而是多模態:要看競品視頻是怎麼剪的、要把會議錄音整理成紀要、要給自己的視頻做精準字幕、要從一段長視頻裏撈出 3 個關鍵片段。這些事 LLM 本身解決不了,每次都要跳出工作台,找一個語音識別工具、一個抽幀腳本、一個膠水流程拼起來。
最近在火山引擎看到字節方舟發了豆包 Seed 2.0 Lite(0428版)。看到價格這超低的價格有點心動,然後,正好啓發了幾種新的工作流靈感~
它在原來 02 月 Lite 版的基礎上做了一件事:這次 Lite 也能聽了。原來的 Lite 已經能看圖、能讀視頻、能處理文字,這次把聽覺補上了。是真的「聽」,不只是把聲音轉成文字,連情緒、環境聲、多說話人都能一起捕捉。
以及有個特別值得強調的點是,別一看「全模態」就以為它跟普通圖像理解模型差不多。它是能直接讀視頻的,不是隻能看一幀靜態圖。你扔一段 60 秒的視頻進去,它能告訴你畫面節奏、字體風格、動效轉場、音視頻是否一致,這件事 GPT-5.5、Claude Opus 4.7 都做不到。御三家裏暫時只有Gemini做了這項能力,但是他們實在是特麼有點貴了,沒那麼實用。
以及,甚至從性能表現來說,最新的Seed 2.0 Lite不止超過了前一代的Seed 2.0 Pro的視覺理解能力,甚至在多個維度上都達到了SOTA級別👇
所以嚴格來說,它給 Agent 裝上的不只是耳朵,還是一雙能讀視頻的眼睛。我接下來會用兩個 demo 把這兩件事都跑一遍。
而且關鍵點在這裏:豆包 Seed 2.0 Lite 的調用方式跟你調任何一個大模型 API 沒區別。這意味着你可以在 prompt 裏告訴它你接下來要聽的是什麼。
我把那段錄有「huashu-design」的音頻丟給它,附上一個 1900 字的 prompt:錄製背景、說話人風格、46 個易錯術語清單(GPT-5.5、Claude Opus 4.7、Codex、Anthropic、Apollo Research……)。讓它輸出標準 SRT 字幕。
然後我把同一段音頻也丟進剪輯軟件自動字幕——剪輯軟件是大多數人做視頻的默認選擇,對比它最直觀。結果:
剪輯軟件這邊把 GitHub 聽成了 GitLab、Claude Opus 4.7 變 COS4.7、GPT-5.5 變 GBT5.5、Claude 4.7 變 cloud 4.7、huashu-design 變花書design——這不是剪輯軟件爛,是所有自動字幕工具的通病:沒有上下文,模型只能在同音組合裏挑它最熟的那個。平時會拍視頻的同學應該懂我在說什麼。
豆包這邊呢?全對。huashu-design、Claude Opus 4.7、GPT-5.5、GitHub、Claude 4.7,一個不錯。
但這裏要補一個 best practice,不然你照着去試可能會失望:豆包不寫 prompt 直接跑,效果只比剪輯軟件好一點——還是會把一部分專有名詞識別歪。它真正的能力,是你把背景、術語清單、說話人風格都寫進 prompt 之後才解鎖的。這次升級真正解鎖的不是「模型能聽」,是「模型能在你給的上下文裏聽」。
所以如果你要把它塞進生產鏈路,prompt 上下文是必須做的功課。少了這一步,全模態的能力就發揮不出來。
更出乎意料的是成本。一段 277 秒的音頻,加了 1900 字 prompt 反而比不加便宜——prompt token 多了 1208 個,但模型不用瞎猜了,輸出 token 少了 763 個。總成本下降 20% ,單次不到一分錢。
事情到這裏其實沒完,因為「帶上下文做字幕」只是這次0428升級最淺的一層。我接下來連做了兩個 demo,一個是用它去看另一支 AI 的產品發佈動畫,一個是驗證它在真實工作流裏的位置。也就是這篇文章真正想說的那件事:
這一代 Agent 工具,不管是 Claude Code、Cursor 還是 OpenClaw,一直缺一雙能聽音頻、能看視頻的耳朵和眼睛。豆包 Seed 2.0 Lite 0428 非常難得給補上了,價格還很實惠。
讓 AI 看另一支 AI 的產品視頻
字幕這條線我跑通之後,做了第二個實驗,更狠一點。因為我發現Seed 2.0 Lite模型在視頻理解能力上有點猛,機會是全方面碾壓Gemini-3-Pro的水平👇
OpenAI 上週在 X 上發 GPT-5.5 的時候配了一支 55 秒的 hero 動畫:白底、Inter 字體、打字機標題、4 段產品演示(解魔方、跨 Slack 修 bug、生成財務 PPT、blossom logo 收尾)。
這種動畫是產品發佈的標準品,我自己做過幾次,每次都得拉競品視頻反覆看,寫一份給前端的 brief,再過一遍設計稿。整個鏈路三天起步。
先看看 OpenAI 那段原視頻長什麼樣:
我把這支 55 秒視頻直接餵給豆包 Seed 2.0 Lite,寫了一份 prompt:你看完這個視頻,按 8 個維度(節奏、視覺系統、動效轉場、文案策略、品牌資產、音頻、鏡頭、遷移建議)給我一份結構化輸出,最後給我一份「豆包 Seed 2.0 Lite 發佈動畫」的分鏡表,要具體到顏色 hex、字號、動效時序,讓前端能直接動手。
它真給了。
視頻裏幾乎所有可觀測的細節它都識別到了:5 段時間碼(0-4s 標題、5-13s 解魔方、14-34s Slack 修 bug、35-50s 生成 PPT、51-55s logo 收尾)、字體氣質(Inter 類無襯線、字重 700/400/500 三層)、強調色 #A855F7 紫、blossom 花形符號在魔方表面和結尾出現兩次、BPM 估值 80-90、平均切換頻率 3.5 秒。它還順手指出了開場前 3 秒的鈎子結構和結尾 3 秒的品牌定格邏輯。
更有用的是 H 部分。它給我寫了一份可執行的分鏡表:7 段、每段時間碼、畫面元素、文案、動效、要用的數據點。我把這份表又過了一遍,把它默認套用 OpenAI 紫色那部分換成火山方舟自己的品牌色(#006EFF / #00E5E5),把 5-13s 那段「全模態感官可視化」具象化(左側波形圖、中間豆包 logo 脈衝、右側抽幀縮略圖三欄匯聚),加了 SFX 節拍和字體規範,整成一份最終藍本。
然後這份藍本交給我自己另一個 skill huashu-design(專門做 HTML 動畫的),讓它按藍本寫代碼、Playwright 錄屏、ffmpeg 出 MP4。最後產出長這樣:
整個鏈路從看視頻到拿到 MP4,沒有人寫一份 brief。
我以前做產品視頻是這樣的:看 5 個競品 → 寫 8 千字 brief → 找設計師 → 改 3 輪。現在變成:把 1 個競品丟進 LLM → LLM 寫 brief → 另一個 LLM 寫代碼出動畫。中間那 8 千字的 brief,是這次升級裏第一個被吃掉的環節。
這個 demo 不是為了證明豆包能做視頻,它做不了,它只是看懂了視頻。讓 AI 看視頻這件事的價值,是把「拆解參考」這道工序從手動變成 API 調用。
數據對比:同一段音頻,兩個 prompt
回到字幕那條線,我把對比數據完整列一下,方便你看清楚 prompt 上下文到底改變了什麼。
最反直覺的是最後一行。帶上下文的 prompt 多 1208 個 prompt token,你直覺以為更貴,但 completion 那一邊模型不用瞎猜了,反而少 763 個 token。多說一點話,讓模型少說一點廢話。這是這次升級裏第二個被吃掉的環節:模型瞎猜的成本。
它在工作台裏的位置
把這兩個 demo 串起來看,論點其實很簡單。
豆包 Seed 2.0 Lite 0428 不是來替換你正在用的 LLM 的。它的輸出能力,寫代碼、複雜推理、長鏈路 Agent,肯定比不過 Claude Opus、GPT-5.5 這種旗艦。我也不會用它去寫 1 萬行代碼。
但輸入這一側,它提供的是 Claude Code、Cursor、Codex、OpenClaw 這一整代 coding agent 都沒有的能力:讓你直接把視頻、音頻、圖片以和文本同等地位塞進同一個 API 調用,讓 prompt 裏的上下文直接作用在感知層。
這是「前置感官層」的意思,是它在你工作流裏的位置:
重點在這裏:你不用換工作台。 日常用 Claude Code、Codex、龍蝦 OpenClaw、Hermes Agent,或者字節自家的 Trae 都行——把豆包 Seed 2.0 Lite 當成前置感官接一層進去,你原來的工作流立刻就有了完整的眼睛和耳朵。不用遷移、不用學新工具,只是給現有的 coding agent 補上它原來缺的那部分感知。
這個月初我發了一本 Hermes Agent 的橙皮書,講長鏈路 Agent 怎麼把多步驟任務串起來。當時書裏有一節專門講 Agent 工作流的「輸入側瓶頸」:絕大多數任務卡在「怎麼把現實世界的視頻/音頻/會議錄屏餵給 Agent」這一步。
這本書寫完之後我自己在工作流裏也沒真正解決這個問題,繞過去用 Whisper + 手動改字幕、用 Gemini 處理視頻、用一堆膠水腳本拼。豆包 Seed 2.0 Lite 0428 是我看到的第一個用一次 API 調用就把這兩件事都解決的全模態輕量模型。
價格也是這個論點的支撐。我只跟同檔的全模態輕量模型對比,旗艦模型不是同一個段位,沒必要拉進來。
跟同尺寸的 Gemini 3 Flash 比,文本輸入便宜 6 倍,輸出便宜 6 倍。這個價格意味着你可以把它真的塞進生產鏈路,不只是做 demo。我那段 4 分 38 秒視頻轉字幕一次不到一分錢,意味着我每天錄的幾個視頻片段全跑一遍語音識別也只要幾毛錢。當成本低到「不用考慮成本」的時候,調用頻率就會漲一個量級,工作流的形態會跟着變。
下一次開 Claude Code 的時候,你可以試着把那段不願意手動轉錄的會議錄屏丟給它了。
你也是時候給你的龍蝦裝上真正的耳朵和眼睛了。