達爾文.skill 2.0上手實測:吸收微軟兩篇論文精華,讓AI skill自動進化
整理版優先睇
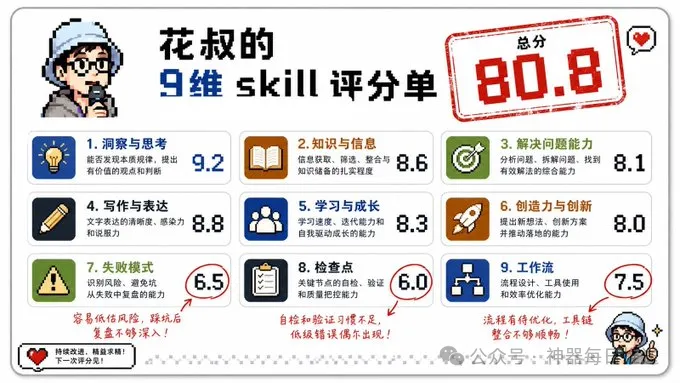
花叔實測 darwin-skill 2.0,吸收微軟兩篇論文精華,幫你自動優化 AI Skill
呢篇文章係花叔對 darwin-skill 2.0 嘅實測分享。花叔本身係 AI 工具愛好者,成日試用唔同工具。佢發現呢個新版直接吸收了微軟研究院兩篇論文(SkillLens 同 SkillOpt)嘅評分 rubric,用喺 opencode skill 上面,好少見。
整體嚟講,darwin-skill 做嘅係一件事:自動評估你啲 skill 嘅質量,揾出最弱嘅維度,自己改完再打分,分數升就保留,冇升就回滾。佢直接抄咗 Karpathy 嘅 autoresearch 邏輯,只係將訓練腳本換成 SKILL.md。花叔實測後覺得,如果你有十幾個 skill 又冇時間逐個執,呢個工具好適合;但如果 skill 已經高分(88以上),就推唔鬱,邊際收益好低。
結論係:呢個工具係一個「從60分提到80分」嘅好幫手,唔係萬能。佢嘅評分結構着重實測效果(40分入面25分睇真實 prompt 輸出),而且新增嘅三個維度(失敗模式編碼、可執行具體性、高風險行動黑名單)都係從論文度扒返嚟,好實用。
- darwin-skill 2.0 自動評估 skill 質量,識別最弱維度並改進,分數升就保留,冇升就回滾。
- 評分結構:滿分100,結構佔60分,效果佔40分;效果維度中25分直接睇真實 prompt 輸出,跑唔掂就零分。
- 新增三個維度:失敗模式編碼、可執行具體性、高風險行動黑名單,全部源自微軟論文。
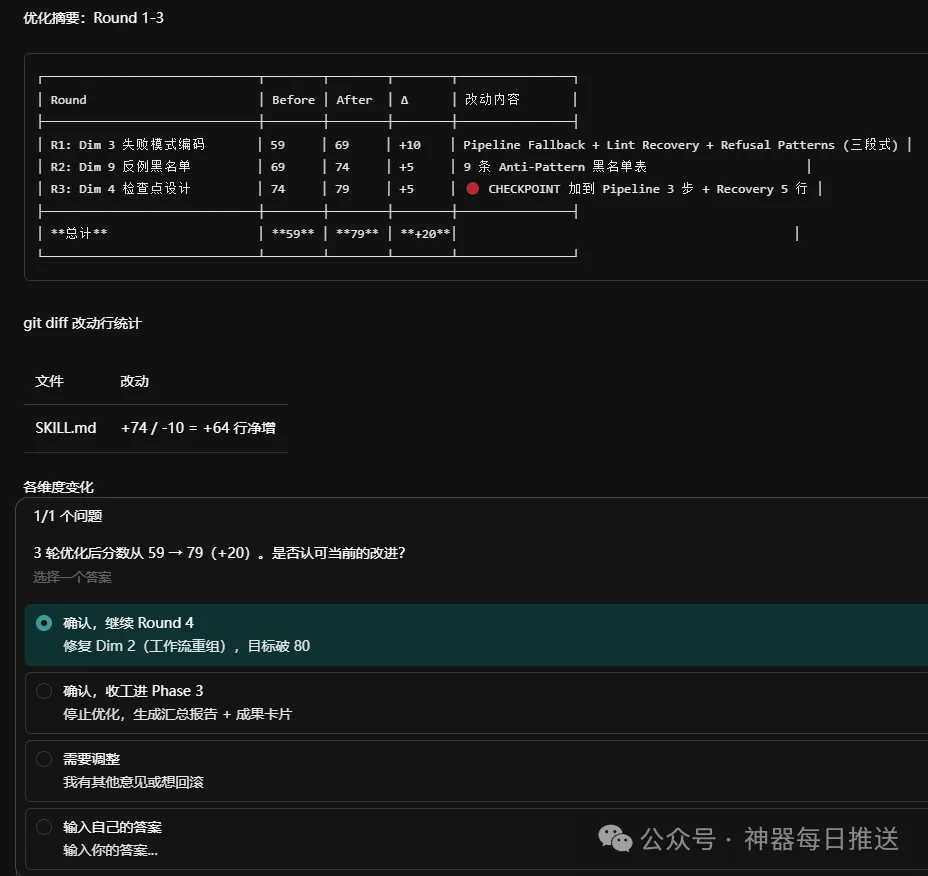
- 實測數據:低分 skill 有明顯提升(如 obsidian skill 從31.7升到51.2),但高分 skill(88+)推唔鬱。
- 適合 skill 超過10個、評分長期低過80嘅用家,一行命令安裝後自動迭代,唔使手動逐個精修。
darwin-skill 項目地址
GitHub 倉庫,包含源碼同使用說明
安裝命令
一鍵安裝 darwin-skill,然後用「優化所有 skills」指令執行
呢個工具解決咩問題?
手上有十幾個 skill 嘅人都知,維護唔到咁多。邊個寫得好、邊個跑起嚟翻車、差喺邊——靠人一個一個檢查唔現實。darwin-skill 做嘅嘢好窄:評估 skill 質量,揾出最差嗰個維度,自己改,改完重新打分。分數升就保留,冇升就回滾。
邏輯直接抄 Karpathy 嘅 autoresearch,只係將訓練腳本換成 SKILL.md
咁樣就慳返好多人工,尤其係對於一啲寫得粗糙嘅 skill,可以自動迭代改善。
評分結構:點樣先叫一個好 skill?
滿分100分,結構佔60分,效果佔40分。但實測嗰部分先係重點——40分裏面25分直接畀「拎真實 prompt 跑一次,輸出得唔得」。花叔話:一個結構滿分但跑起嚟一塌糊塗嘅 skill,遠不如寫得粗糙但好用嘅。所以效果維度跑得唔好就係零分。
v2.0 仲加咗三個維度,全部從微軟嗰兩篇論文度扒返嚟:
- 失敗模式編碼——唔係剩係話「小心出錯」,而係將已知嘅翻車路徑寫入 skill
- 可執行具體性——禁止「建議/可以考慮」呢啲字眼,一定要寫「執行以下命令」
- 高風險行動黑名單——rm、git reset --hard 呢啲操作必須顯式禁止
驗證都升級咗:每輪兩個獨立評委打分,下一輪換人,防止錨定效應。單輪漲唔到1分就停,唔會硬湊。不過高分 skill(88分以上)基本推唔鬱,邊際收益好低,改到咁上下再上就係吹毛求疵。
實測數據:幾分真係有進步?
GitHub 上公開跑出嚟嘅記錄,花叔自己都試過:
- huashu-gpt-image skill:80.8 → 91.5 → 91.65(+10.85,用咗6個評委)
- darwin-skill 自評:86.05 → 92.05 → 92.7
- obsidian skill(低分起步):31.7 → 51.2(+61.5%)
花叔自己實測審計咗 wewrite 技能,優化後評分提升咗大約10分,而且 skill 邏輯更清晰,大模型思考都更清晰。佢話效果係指數級提升。不過要注意:你想要嘅係一個由60分提到80分嘅工具,佢好合適;如果 skill 已經90分,佢幫唔到幾多。
低分 skill 提升明顯(+61.5%),高分 skill 邊際效益低
點樣用?一行命令搞掂
npx skills add alchaincyf/darwin-skill裝完之後,喺 opencode 或 openclaw 入面講「優化所有 skills」。如果淨係想優化某一個,直接講個 skill 名就得。darwin-skill 會自動掃描、揾出最低分維度、修改、commit、重新打分,每輪結束停一停畀你睇 diff。你確認就繼續,唔確認就回滾。大部分低分 skill 喺3-5輪內會見到明顯提升。
如果唔用 GitHub,直接 download zip 包,將 SKILL.md 放去 ~/.config/opencode/skills/darwin-skill/ 或 ~/.openclaw/skills/darwin-skill/ 就得。
幾時值得裝?
如果你有超過10個 skill,有啲寫得粗糙但冇時間逐個精修,評分又長期喺80分以下——裝一個畀佢自己迭代,半個月返嚟睇就得。
花叔今次吸收微軟兩篇論文精華,對 skill 優化係技術大躍遷
值得一提嘅係,花叔實測優化 wewrite 技能後,唔單止評分升咗,策劃選題嘅效果都明顯好咗。佢對另一個 skill 審計優化,未跑完就已經提升咗20分。所以如果你都想自己啲 skill 自動進化,不妨一試。
達爾文.skill 2.0
上手實測
花叔嘅 darwin-skill 新版最令我意外嘅係:佢直接吸收咗微軟研究院兩篇論文(SkillLens 同 SkillOpt)嘅實證 rubric。一個 opencode skill 同學界論文對齊,呢件事唔係好常見。

項目地址:
github.com/alchaincyf/darwin-skill
| / |
手上有幾十個 skill 嘅人都知,維護唔嚟。邊個寫得好、邊個 run 起嚟出事、差喺邊——靠人逐個檢查唔現實。darwin-skill 做嘅嘢好窄:評估 skill 質量,找到最差嗰個維度,自己改,改完重新打分。分數升咗保留,冇升就回滾。
邏輯直接抄嘅 Karpathy 嘅 autoresearch——只不過將訓練腳本換成咗 SKILL.md。
| / |
滿分100,結構佔60分,效果佔40分。但係實測嗰部分先係大頭——40分入面25分直接畀"拎真實 prompt 跑一次,輸出好唔好"。花叔嘅原話:一個結構滿分但 run 起嚟一塌糊塗嘅 skill,遠不如寫得粗糙但好用嘅。所以效果維度入面跑出嚟唔好就係零分。

v2.0 加咗三個維度,全部都係從微軟嗰兩篇論文抄返嚟嘅:
▪ 失敗模式編碼——唔淨係話"小心出錯",而係將已知嘅出事路徑寫入 skill。
▪ 可執行具體性——禁止"建議/可以考慮"呢啲詞,一定要寫"執行以下命令"。
▪ 高風險行為黑名單——rm、git reset --hard 呢啲操作一定要清楚禁止。
驗證都升級咗:每輪兩個獨立評委打分,下一輪換人,防止一個評委不斷評產生錨定。單輪升唔到1分就停,唔硬湊。
不過講真,佢都有侷限。高分 skill(88分以上)基本推唔鬱喇,邊際收益好低。呢個同預期一致——改到某個程度再上去就係吹毛求疵。
| / |
GitHub 上公開跑出嚟嘅記錄:
▪ huashu-gpt-image skill:80.8 → 91.5 → 91.65(+10.85,6個評委)
▪ darwin-skill 自評:86.05 → 92.05 → 92.7
▪ obsidian skill(低分起步):31.7 → 51.2(+61.5%)
你想要嘅係一個從60分提到80分嘅工具,佢好合適。如果 skill 已經90分咗,佢幫唔到太多。
我實測審計咗 wewrite 技能
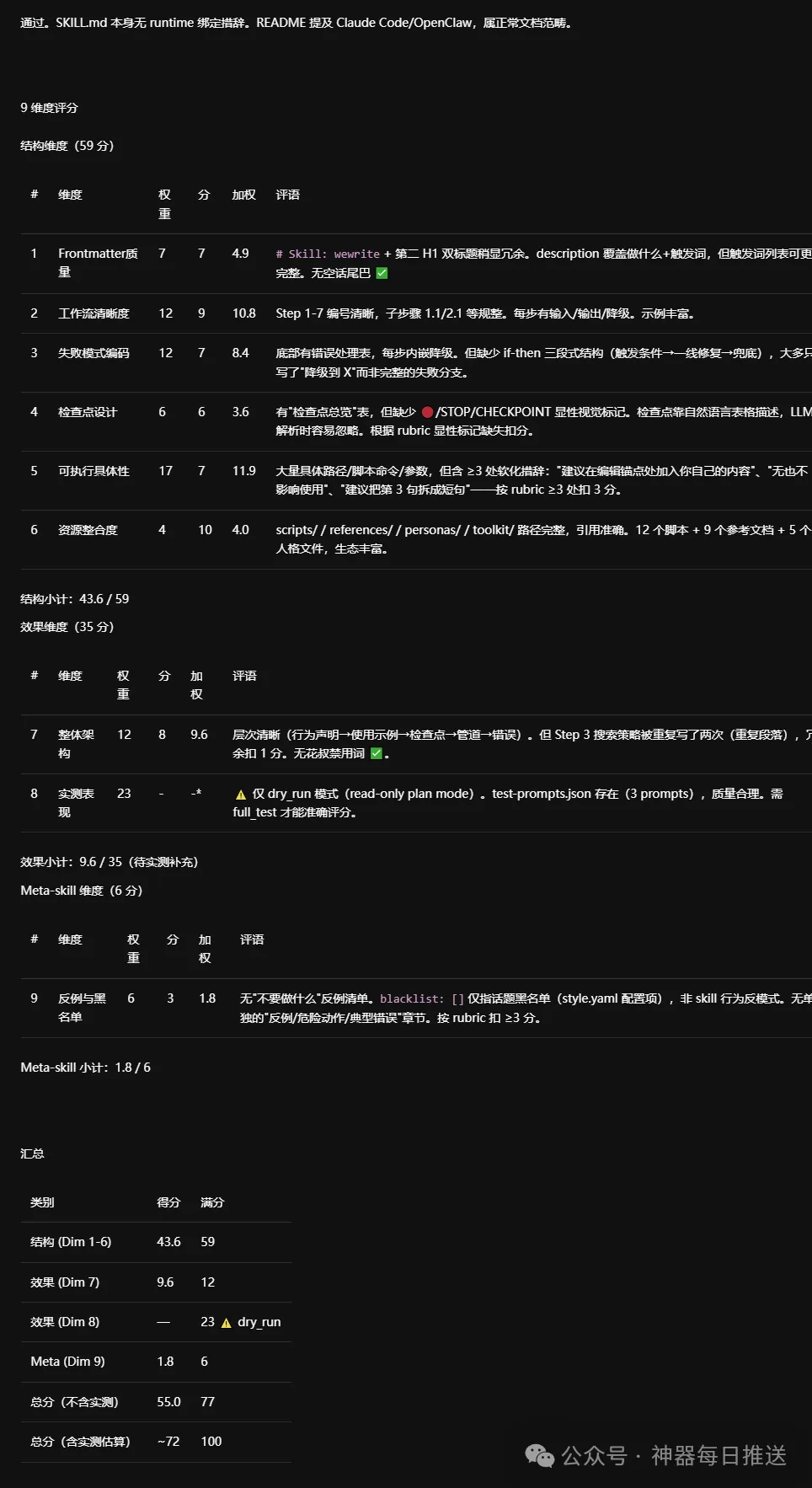
佢畀出嘅 skill 短板同優化意見

優化後嘅評分

| / |
一行命令:
01npx skills add alchaincyf/darwin-skill
裝完喺 opencode 或 openclaw 入面講"優化所有 skills"。淨係想 run 某一個,直接講 skill 名。
darwin-skill 會自動掃描、揾出最低分維度、修改、commit、重新打分,每輪結束停一停畀你睇 diff。你確認就繼續,唔確認就回滾。大部分低分 skill 3-5 輪內會見到明顯提升。
唔依賴 GitHub 嘅話直接下載 zip 包,將 SKILL.md 放到 ~/.config/opencode/skills/darwin-skill/ 或 ~/.openclaw/skills/darwin-skill/ 就行。
| / |
skill 超過10個、有啲寫得粗糙但冇時間逐個精修、評分又長期喺80以下——裝一個讓佢自己迭代去,半個月之後返嚟睇就得。
花叔今次吸收咗微軟研究院5月23發佈嘅兩篇論文(SkillLens 同 SkillOpt)之精華,對 skill 優化絕對係技術上嘅大躍進,以下係我優化 wewrite 技能後,實測令佢策劃選題嘅效果截圖。

實測評分升咗10分左右,更重要嘅係 skill 邏輯更清晰,大模型思考都更清晰咗,佢畀出嘅效果係指數級提升咗。
以下係對另一個 skill 嘅審計優化,未 run 完就已經升咗20分。
達爾文.skill 2.0
上手實測
花叔的 darwin-skill 新版最讓我意外的是:它直接吸收了微軟研究院兩篇論文(SkillLens 和 SkillOpt)的實證 rubric。一個 opencode skill 跟學界論文對齊,這事不太常見。
項目地址:
github.com/alchaincyf/darwin-skill
| / |
手上有幾十個 skill 的人都知道,維護不過來。哪個寫得好、哪個跑起來翻車、差在哪——靠人挨個檢查不現實。darwin-skill 做的事情很窄:評估 skill 質量,找到最拉胯的那個維度,自己改,改完重新打分。分數漲了保留,沒漲就回滾。
邏輯直接抄的 Karpathy 的 autoresearch——只不過把訓練腳本換成了 SKILL.md。
| / |
滿分 100,結構佔 60 分,效果佔 40 分。但實測那部分才是大頭——40 分裏 25 分直接給"拿真實 prompt 跑一遍,輸出好不好"。花叔的原話:一個結構滿分但跑起來一塌糊塗的 skill,遠不如寫得粗糙但好用的。所以效果維度裏跑出來不好就是零分。
v2.0 加了三個維度,全是從微軟那兩篇論文扒來的:
▪ 失敗模式編碼——不只是說"小心出錯",而是把已知的翻車路徑寫進 skill。
▪ 可執行具體性——禁止"建議/可以考慮"這種詞,必須寫"執行以下命令"。
▪ 高風險行動黑名單——rm、git reset --hard 這種操作必須顯式禁止。
驗證也升級了:每輪兩個獨立評委打分,下一輪換人,防止一個評委反覆評產生錨定。單輪漲不到 1 分就停,不硬湊。
不過說實話,它也有侷限。高分 skill(88 分以上)基本推不動了,邊際收益很低。這跟預期一致——改到一定程度再往上就是吹毛求疵。
| / |
GitHub 上公開跑出來的記錄:
▪ huashu-gpt-image skill:80.8 → 91.5 → 91.65(+10.85,6 個評委)
▪ darwin-skill 自評:86.05 → 92.05 → 92.7
▪ obsidian skill(低分起步):31.7 → 51.2(+61.5%)
你想要的是一個從 60 分提到 80 分的工具,它很合適。如果 skill 已經 90 分了,它幫不了太多。
我實測審計了wewrite技能
它給出的skill短板和優化意見
優化後的評分
| / |
一行命令:
01npx skills add alchaincyf/darwin-skill
裝完在 opencode 或 openclaw 中說"優化所有 skills"。只想跑某一個,直接說 skill 名字。
darwin-skill 會自動掃描、找出最低分維度、修改、commit、重新打分,每輪結束停一下讓你看 diff。你確認就繼續,不確認就回滾。大部分低分 skill 3-5 輪內能見到明顯提升。
不依賴 GitHub 的話直接下 zip 包,把 SKILL.md 放到 ~/.config/opencode/skills/darwin-skill/ 或 ~/.openclaw/skills/darwin-skill/ 就行。
| / |
skill 超過 10 個、有些寫得糙但沒時間逐一精修、評分又長期在 80 以下——裝一個讓它自己迭代去,半個月回頭看就行。
花叔這次吸收微軟研究院5月23發佈的兩篇論文(SkillLens 和 SkillOpt)之精華,對skill優化絕對是有技術上大躍遷,以下是我優化wewrite技能後,實測讓它策劃選題的效果截圖。
實測評分提升了10分左右,更重要的是skill邏輯更清晰,大模型思考也更清晰了,它給出的效果是指數級提升了。
以下是對另一個skill的審計優化,還沒跑完就提升了20分