達爾文.skill 2.0正式開源發佈!讓你的所有skill左腳踩右腳實現自我進化
整理版優先睇
達爾文.skill 2.0 開源發佈:用微軟論文升級,讓 skill 自我進化,平均漲 15 分
呢篇文章係作者自身經驗分享,佢係一個活躍嘅 skill 開發者,寫咗大量業務同人物視角嘅 skill,但遇到人手審稿唔可行嘅問題。為咗令 skill 可以自我迭代,佢整咗達爾文 (darwin-skill) 呢個工具,核心係用多維度評分、逐維度改進、分數唔漲就回滾嘅工程流程,1.0 版本跑咗 40 次優化,平均提升 13.5 分,零回滾。
之後微軟研究院同日出咗兩篇論文(SkillLens 同 SkillOpt),揭示咗單一 AI 評委得 46.4% 準確率,同埋提出「驗證通過先接受」嘅原則。作者吸收呢兩篇論文精華,升級做達爾文 2.0:將評分標準由 8 維加到 9 維(包括失敗模式編碼、可執行具體性、高風險行動黑名單),強化驗證機制(多評委獨立審查、早停、幹跑告警),仲加入 human in the loop 嘅人工卡口,避免全自動失控。
整體結論係:達爾文 2.0 係面向個人開發者嘅輕量 skill 優化器,唔需要 benchmark,靠 rubric 打分,關鍵決策留畀人,仲有反例黑名單幫手避開常見地雷。作者用自己嘅 skill 生態做實測,優化近 30 個 skill,平均漲 15 分,其中一個 steve-jobs-perspective 更係單輪 +30 分。文章最後比較咗達爾文同 SkillOpt 嘅適用場景,並提供開源倉庫連結。
- 達爾文 1.0 用多維評分、逐維改進、分數唔漲自動回滾,跑 40 次平均提升 13.5 分,0 回滾;但單 AI 評委準確率得 46.4%,比掟銀仔仲差。
- 微軟 SkillLens 論文揭示三個關鍵評分維度(失敗模式編碼、可執行具體性、高風險行動黑名單)可將準確率由 46.4% 提升到 73.8%。
- 微軟 SkillOpt 論文提出「skill 文檔係外部可訓練狀態」嘅隱喻,並驗證「驗證通過才接受」機制喺 52 個組閤中都最強或並列最強。
- 達爾文 2.0 升級重點:評分標準 9 維(吸收 SkillLens 藥方)、多評委獨立審查、早停機制、human in the loop 人工卡口,避免全自動導致文檔失控。
- 實測近 30 個 skill,平均漲 15 分,最勁 steve-jobs-perspective 單輪 +30 分;自指評估達爾文自己都發現盲區,修復後從 86.05 升到 92.7。
達爾文.skill 2.0 GitHub 倉庫
MIT 協議開源嘅 darwin-skill 倉庫,包含完整嘅 skill 優化器實作,可以用嚟畀你嘅 agent 安裝然後優化任何 skill。
1.0 嘅成功同隱憂
作者寫咗大量 skill,公眾號、小紅書、視頻腳本、配圖、調研,仲有 21 個人物視角嘅 skill,形成一個小生態。但 skill 一多,人手審稿就搞唔掂,每條 skill 都要通讀、揾問題、改完再讀,根本唔可行。
核心思路係將 skill 迭代變成可重複嘅工程流程:多維度評分標準、每輪只改最低維度、分數冇漲自動回滾、寫 skill 嘅 AI 同評分嘅 AI 分開、低風險改動可以行幹跑模式。
跑咗一個月,平均漲 13.5 分,0 回滾。但作者心知呢個 0 回滾唔完全代表演算法神準,因為評分標準定得幾嚴,結果就有幾嚴。直到微軟兩篇論文出現,指明咗方向。
微軟兩篇論文嘅震撼
5 月 22 號微軟研究院同復旦、上交聯合掛咗兩篇姊妹論文:SkillLens 研究 skill 點樣評估,SkillOpt 研究 skill 點樣優化。一評一改,啱啱好封死「會進化嘅 skill」嘅兩端。
- 1 失敗模式編碼:skill 唔可以只寫「正確流程係咩」,要寫清楚「咩情況會出錯、出錯走邊條分支」。
- 2 可執行具體性:唔準用「建議」「可以考慮」「根據情況」「靈活把握」「視情況而定」呢啲軟化措辭。
- 3 高風險行動黑名單:skill 必須有個獨立章節話畀模型「絕對唔可以做啲咩」。
SkillOpt 更顛覆:直接話「skill 文檔應該被當成 frozen 模型嘅外部可訓練狀態,好似神經網絡嘅權重咁,透過反向傳播嚟優化」。
佢嘅優化循環有四階段:跑任務、覆盤、提議改動、驗證通過先接受。最後一步係關鍵:驗證唔過就拒絕寫入,呢個同達爾文 1.0 嘅「分數冇漲自動回滾」係同一個核心思想,只係數學嚴謹性上對方更紮實。
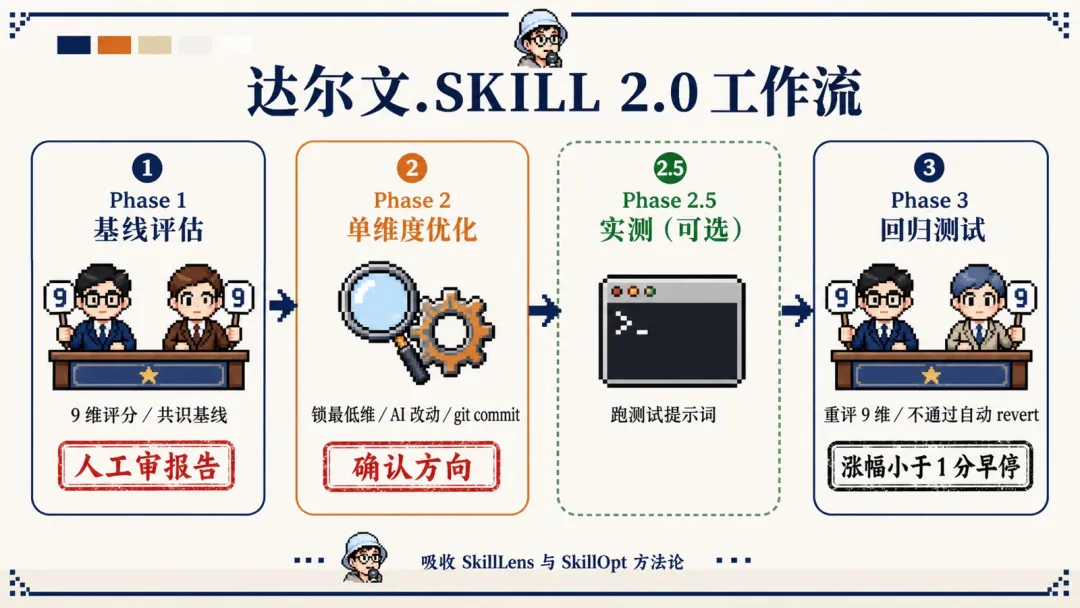
達爾文 2.0 嘅升級重點
吸收 SkillLens 嘅評分維度,將評分標準從 8 維升級到 9 維:失敗模式編碼、可執行具體性、高風險行動黑名單直接加入。
強化驗證機制:每輪啟動兩個獨立評委,共識分數先算數;下一輪啟用全新評委,避免錨定效應;分數入平台期自動停手;幹跑比例過 30% 強制告警,要行實測驗證。
加入 human in the loop,將流程切成階段,每個階段都有顯性人工卡口:基線評估要人工審報告,單維度優化有 CHECKPOINT 強制暫停等確認,迴歸測試有 STOP 強制停手。
實測驗證:真實 skill + 自指評估
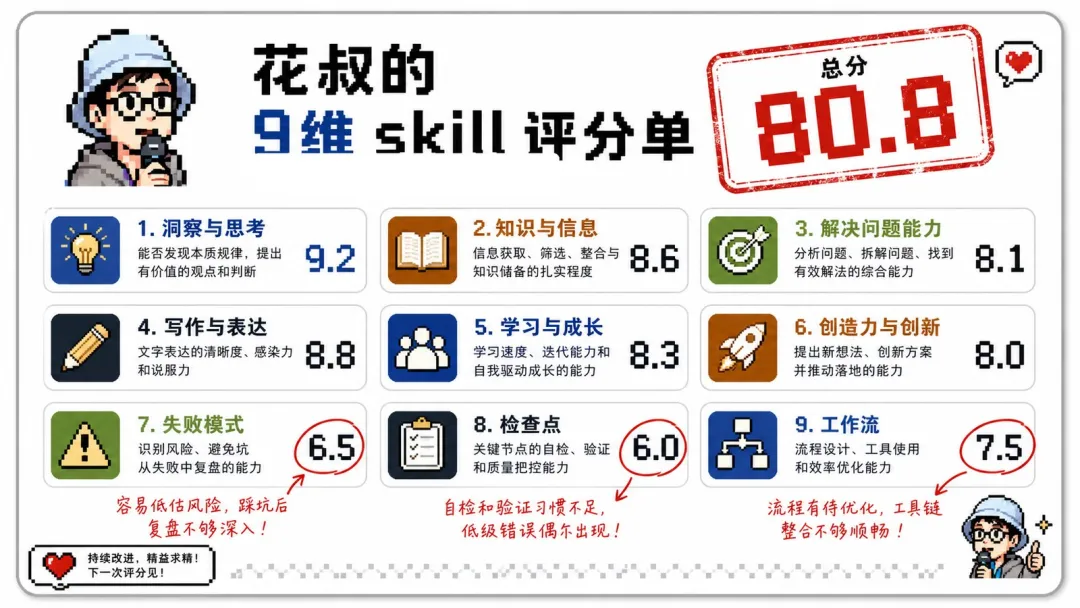
作者揀咗 huashu-gpt-image 做小白鼠,368 行嘅 skill。啟動兩個獨立評委,基線共識 80.8 分,最低維度係失敗模式。按規則只改失敗模式,新增「失敗模式與兜底樹」章節,文件從 368 行加到 449 行。
啟動兩個全新評委重評,共識 91.5 分,漲咗 10.7 分。失敗模式維度從 6.5 飆到 10 分滿分。有意發現「工作流」維度都自動從 7.5 跳到 9.0,反映維度相關簇嘅規律。
再攻第二低,加咗「單圖工作流」,新評委共識 91.65,只漲 0.15 分,早停機制觸發停手。然後作者做咗個有趣實驗:用 2.0 評估達爾文自己嘅 SKILL.md。兩個獨立評委俾出 86.05 分,並指出三處問題:版本描述未同步、檢查點冇顯性標記、軟化措辭超標。呢啲係寫規則嘅結構性盲區。
修復後再評:86.05 → 92.05。呢個遞歸案例證明工具唔單止優化提示詞,仲可以優化寫提示詞嘅方法論本身。
- 優化近 30 個 skill,平均漲幅 +15 分,最勁 steve-jobs-perspective 單輪 +30 分。
- 每個 skill 嘅優化都有完整 git commit 鏈可回溯,validation 冇過嘅改動自動 revert,human in the loop 檢查點全部行過。
- 作者直觀感受成個女媧生態嘅輸出質量有肉眼可見提升。
達爾文同 SkillOpt 嘅分工,同埋適用場景
達爾文同 SkillOpt 唔係替代關係,係分工。SkillOpt 係更系統、嚴格嘅工程方案,全自動、benchmark-driven,適合企業級、能定義清晰評估函數嘅場景。
達爾文 2.0 係面向個人開發者嘅輕量方案,rubric-driven,唔需要寫 benchmark,自動化策略加 human in the loop 雙引擎,適合主觀評估為主嘅場景,例如寫作、內容、風格類 skill。
- 1 唔需要 benchmark:用 rubric 打分,適合冇客觀 metric 嘅場景。
- 2 強制 human in the loop:每個 CHECKPOINT 等用戶確認,關鍵決策唔交畀 AI。
- 3 多評委獨立審查:每輪新評委避免錨定,對齊 SkillLens 嘅 73.8% 準確率藥方。
- 4 維度相關簇識別:發現「改一維帶動一簇」嘅結構規律,減少冗餘優化。
- 5 反例黑名單驅動:8 條來自真實踩坑,唔係空想。
作者總結:如果你做企業級、能定義 benchmark 嘅 skill 優化,用 SkillOpt。如果你做個人 skill 生態,需要快速迭代、可讀、可控、有人工卡口,用達爾文 2.0。
我前排喺GitHub上開源咗一個幾得意嘅skill,叫達爾文(darwin-skill)。
佢做嘅嘢好簡單:幫其他skill打分、提改進方案、改完再打分,分數冇升就回滾。成個流程好似生物進化,一代代變異、被揀選、淘汰,留下嚟嘅都係更強嘅版本。skill本身係靜態文件,加咗達爾文之後可以自己迭代自己。
上線一個月,跑咗40次優化,平均提升13.5分,0次回滾。
成績幾好。但係5月22號微軟研究院同一日掛咗兩篇論文,正面解決skill優化呢件事。呢兩篇論文令我意識到達爾文仲可以做得更嚴、更強。所以我吸收咗兩篇論文嘅精華做咗一次大升級,呢個就係達爾文2.0,可能係目前面向個人開發者最完整嘅skill優化器。
呢篇文章想講清楚三件事:微軟兩篇論文講咗啲乜、達爾文2.0吸收咗啲乜、佢喺咩情況下值得用。
1.0已經做啱嘅事
先簡單講下1.0點解有用。
我做skill大半年喇。公眾號、小紅書、視頻腳本、配圖、調研,各種業務流程都封裝成咗skill。加上21個人物視角嘅skill,已經係個小生態。
skill一多人工審稿就頂唔順。每個skill都要睇曬、揾問題、改完再睇,人力上唔可行。但你又唔可以唔理,一個寫規則嘅文件自己都冇人睇住,會慢慢漂移。
所以我整咗達爾文。核心思路係將skill迭代變成可重複嘅工程流程:多維度評分標準、每輪只改最低維度、分數冇升自動回滾、寫skill嘅AI同評分嘅AI分開、低風險改動容許幹跑模式。
跑咗一個月,平均升咗13.5分,0回滾。
但我心知呢個0回滾唔完全代表算法神準。評分標準定得有幾嚴,結果就有幾嚴。我嗰套8維標準已經算嚴格,但仲有改進空間。
直到5月22號嗰兩篇論文出現,將方向指咗俾我。
微軟同一日掛嘅兩篇論文
5月22號,微軟研究院同復旦、上交聯合喺arXiv掛咗兩篇論文,互為姊妹篇。
一篇是《From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills》(arXiv 2605.23899,項目代號SkillLens),研究skill應該點樣被評估。
另一篇係《SkillOpt: Executive Strategy for Self-Evolving Agent Skills》(arXiv 2605.23904),研究skill應該點樣被優化。
一前一後,一評一改,啱啱好將「會進化嘅skill」呢件事從兩邊封死。我先講SkillLens呢篇,再講SkillOpt。
SkillLens:等AI幫skill打分,準確率得46.4%

SkillLens入面有個數據令我背脊一涼:叫一個AI做評判,畀兩份skill打分揀邊份好啲,準確率得46.4%。
46.4%仲差過擲銀仔3.6個百分點。即係話喺鬆散嘅評分標準下,AI評判嘅判斷基本上唔可信。你跑出嚟嘅優化睇落好似升咗分,實際上可能只係評判喺度隨機搖骰仔。

但係論文畀咗藥方。研究團隊發現,只要喺評分標準度加三個關鍵維度,準確率可以從46.4%升到73.8%
失敗模式編碼:skill唔可以只寫「正確流程係乜」,一定要寫清楚「咩情況下會出錯、出錯咗行邊條分支」 可執行具體性:「建議」「可以考慮」「根據情況」「靈活把握」「視情況而定」呢啲說話全部唔可以寫。要咪明確,要咪唔寫 高風險行動黑名單:skill一定要有獨立嘅章節話俾個模型知「絕對唔可以做啲乜」
73.8%其實都唔算高,每4次決策仲係錯1次。但相比46.4%係27個百分點嘅飛躍。
SkillOpt:將skill當成神經網絡嘅可訓練參數
SkillOpt更狠。佢直接話:skill文件應該被當成frozen模型嘅「外部可訓練狀態」,好似神經網絡嘅權重咁,通過反向傳播嚟優化。
呢句話聽落好玄,翻成大白話就係:叫個模型跑一批真實任務、睇下邊啲skill版本表現好啲、保留好嘅版本、淘汰差嘅版本。分別在於被「訓練」嘅唔係模型權重,係skill文件本身嘅文字內容。
佢嘅優化循環有四個階段:
跑任務:叫目標模型用當前skill去跑一批真實任務,生成帶分數嘅軌跡 覆盤:另一個獨立嘅優化器模型分析成功同失敗嘅批次,識別可複用嘅規律 提議改動:喺「文本編輯預算」約束下(控制每輪改幾多字),提議skill文件嘅加/刪/改操作 驗證通過先接受:只有當留出嘅測試集分數嚴格提升,改動先會被接受;否則拒絕
最後一步係關鍵。驗證唔通過就拒絕寫入,呢個係將神經網絡訓練裏面「梯度方向必須降低loss」嘅原則,搬咗去文本空間。
論文測咗6個benchmark × 7個模型 × 3個執行環境(直接對話/Codex/Claude Code)總共52個組合。根據論文測試結果,SkillOpt喺全部52個組合入面都最強或並列最強。喺GPT-5.5上,SkillOpt生成嘅skill比「冇skill」提升咗23.5分(直接對話)、24.8分(Codex)、19.1分(Claude Code)。
佢擊敗嘅對手包括人手寫嘅skill、一次性LLM生成嘅skill,以及TextGrad、GEPA、EvoSkill等之前嘅prompt優化方法(以上均為論文測試基線)。
睇完呢篇論文我有兩個反應。
第一個反應係震撼。「skill好似神經網絡權重咁可訓練」係個好深刻嘅隱喻。佢將skill從「文件」重新定義成「外部狀態」,將skill優化從「人手調整」變成「可重複、有數學保障嘅工程流程」。
第二個反應係欣慰。SkillOpt嘅「驗證通過先接受」機制,同達爾文1.0嘅「分數冇升自動回滾」係同一個核心思想:驗證唔過就拒絕。呢件事我同微軟同時獨立做出嚟,只係數學嚴謹性上對方紮實啲。
達爾文2.0:吸收兩篇論文精華
明白咗兩篇論文之後,達爾文2.0嘅升級方向就好清楚:
吸收SkillLens嘅評分維度,令評估更嚴格。 對齊SkillOpt嘅「驗證通過先接受」設計,令優化更可靠。 加入SkillOpt冇嘅human in the loop,令流程喺個人開發者場景下可控。
評分標準從8維升級到9維(直接吸收SkillLens嘅73.8%藥方)
原本嘅「錯誤處理」維度改名做失敗模式編碼,要求寫出「如果X發生就做Y;否則做Z」嘅明確分支 原本嘅「明確性」維度改名做可執行具體性,明文禁止嗰五個軟化措辭,出現三處以上扣三分 新增第九維高風險行動黑名單,要求skill一定要有獨立嘅「唔好做啲乜」章節
權重做咗微調,讓位俾新維度。
強化驗證機制(對齊SkillOpt + 加多評委獨立設計)
之前1.0嘅回滾機制比較簡單:總分冇升就回滾。2.0細化成多層驗證:
多評委獨立審查:每輪啟動兩個獨立評委,共識分數先至算數(呢個係達爾文嘅獨立設計。SkillLens論文驗證嘅係單評委+新rubric嘅73.8%準確率,多評委係額外加固機制,唔係論文方法嘅複述) 評委員唔重用:下一輪啟動兩個全新評委,避免錨定效應 早停機制:分數進入平台期(單輪升幅<1分)自動停手,避免為湊分而堆冗餘 幹跑模式控制:幹跑比例超過30%自動告警,強制行實測驗證
加入human in the loop(達爾文區別於SkillOpt嘅核心)
呢個係達爾文同SkillOpt最大嘅分別,亦係個人開發者最需要嘅能力。
SkillOpt係benchmark-driven嘅全自動流程。你掉一堆任務同評分函數入去,佢跑一晚就吐出一個最佳skill出嚟。呢個範式適合企業級、能定義清晰評估函數嘅場景。
但對個人開發者,benchmark本身就難定義。一個公眾號寫作skill,你點寫benchmark?最終評估往往係「我自己讀落順唔順」「讀者反應好唔好」呢啲主觀維度,冇辦法塞入自動循環入面。
所以達爾文2.0將流程切成階段,每個階段都有明確嘅人工卡口:
第一階段基線評估:自動跑評委打分,人工審報告決定改啲乜 第二階段單維度優化:自動改最低維度,🔴 CHECKPOINT強制暫停等用戶確認改動方向 第二階段半測試提示詞跑(可選):自動跑實測,人工睇測試結果 第三階段迴歸測試:啟動新評委重評,🛑 STOP升幅低於閾值強制停手
每個🔴/🛑都係顯性嘅人工介入點。流程可以自動跑,但關鍵決策永遠交返俾人。呢個避免咗「跑咗一晚結果文件面目全非」嘅悲劇。
引入反例黑名單(論文要求 + 真實踩坑)
新增「反例黑名單」章節,八條嚟自我跑40次優化儲落嚟嘅實戰反模式:
同一個AI又改又評(SkillLens 46.4%印證) 用「git reset --hard」做回滾手段(應該用git revert) 為湊分而塞冗落入文件度 跳過測試提示詞直接評分 一輪內改多個維度 幹跑模式比例超過30% 靜默跳過異常 忽視維度相關簇
論文話你知反例黑名單好重要,但具體反例一定要嚟自實操。
呢個係論文畀唔到你嘅嘢。
拎真實skill嚟驗證2.0
升級完之後我要驗證佢真係更強,唔係從一個偏差換到另一個偏差。
我揀咗huashu-gpt-image做白老鼠。呢個係我自己寫嘅一個skill,用嚟調GPT-image-2生圖,368行,日常用得最多。
測試設計嘅關鍵係多評委獨立審查。啟動兩個獨立嘅AI評委,佢哋彼此唔知道對方存在,亦唔知道我之後會點改。
基線共識80.8分。兩個評委獨立指出咗相同嘅最低維度:失敗模式。
按規則每輪只改最低維度,改咗四處,新增「失敗模式與兜底樹」一整章。
文件從368行升到449行。
啟動兩個全新評委(唔重用之前兩個,避免錨定效應)重評。
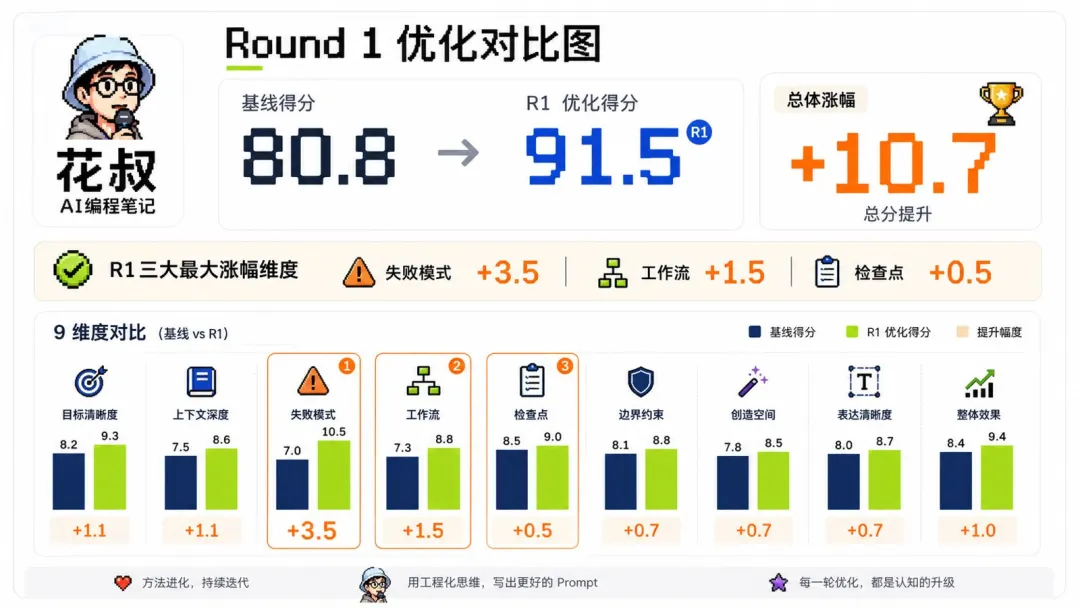
共識91.5,升咗10.7分。失敗模式嗰一維從6.5飆到10分滿分。
有件事我冇諗到。我只係改咗失敗模式,「工作流」嗰一維竟然從7.5跳到9.0。我冇掂過呢一維㗎?
諗清楚之後大概明咗。失敗模式要求寫出「如果X就做Y」嘅明確分支,寫咗出嚟之後流程自然變清楚。工作流、檢查點、失敗模式三維唔係獨立維度,佢哋係一簇,改一個會帶動隔籬嘅。
呢個係2.0新發現嘅規律:維度相關簇。
至於點解會有相關簇,我有幾個猜想:可能係評分維度本身設計有重疊;可能係改一處文件帶動咗周邊重構;重有可能係評委嘅心理錨定(見到一處變清楚會順手俾隔籬維度調高分)。我冇辦法分辨,只係測咗一個skill,數據唔夠。呢條經驗已經寫入反例黑名單第八條。
繼續攻第二低,加咗一段「單圖工作流」同原有嘅「批量工作流」對稱。再啟動兩個新評委,共識91.65。
只係升咗0.15。早停機制觸發,停手。
達爾文俾自己打分:理髮師悖論
到呢度2.0已經喺huashu-gpt-image呢個真實skill上證明咗+10.85提升,六個獨立評委共識。理論上可以收工。
但我有個唔係好正經嘅想法:用2.0俾達爾文自己打分會點。

寫規則嘅工具,俾自己寫嘅規則審判。呢個係另一個獨立實驗,對象唔再係huashu-gpt-image,而係達爾文自己嘅SKILL.md。
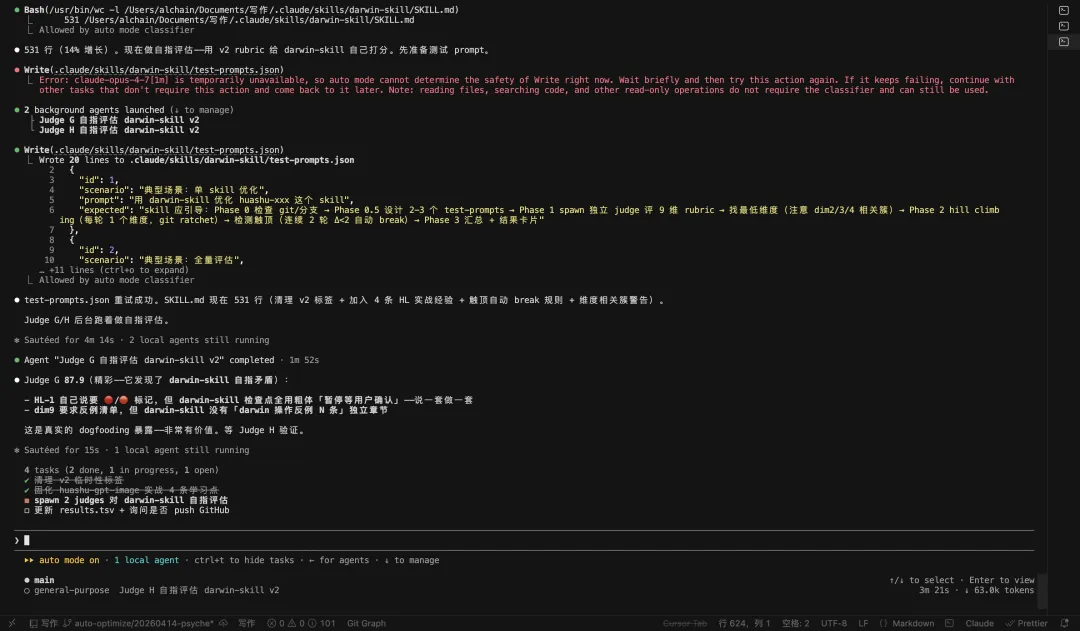
啟動兩個獨立評委,達爾文自己嘅基線俾出86.05(注意呢個係另一個文件嘅獨立基線,同前面huashu-gpt-image嘅80.8冇可比性)。佢哋不約而同指出三處可以更嚴:
第一處版本管理疏漏。文件描述仲寫住「8維評分標準」,正文已經9維。改完版本唔記得同步描述。
第二處檢查點未顯性標記。達爾文自己嘅第四維明文規定檢查點必須顯性標記(🔴/STOP/CHECKPOINT),但關鍵檢查點全部只用粗體強調,冇一個🔴/STOP。
第三處軟化措辭超標。達爾文第五維明文禁止「建議/可以考慮」等軟化措辭。評委喺我自己嘅文件度搜出四處違規。
我自己定嘅規則,我自己有幾處地方做得唔到位。
呢個唔係馬虎,係寫規則時嘅結構性盲區:作者嘅注意力自然喺「新加嘅規則有冇用」,唔喺「之前寫嘅內容係咪符合新規則」。呢種盲區冇辦法靠「小心啲」避免,因為你睇唔到自己睇唔到嘅嘢。
唯一解決辦法:叫獨立評委用你嘅規則審你。評委唔在意你寫嘅係「自己嘅工具」定係「人哋嘅工具」,佢只係按字面執行規則。
呢個其實係2.0嘅另一個隱性優勢:佢對作者一視同仁。
修完之後,以及一個遞歸發現
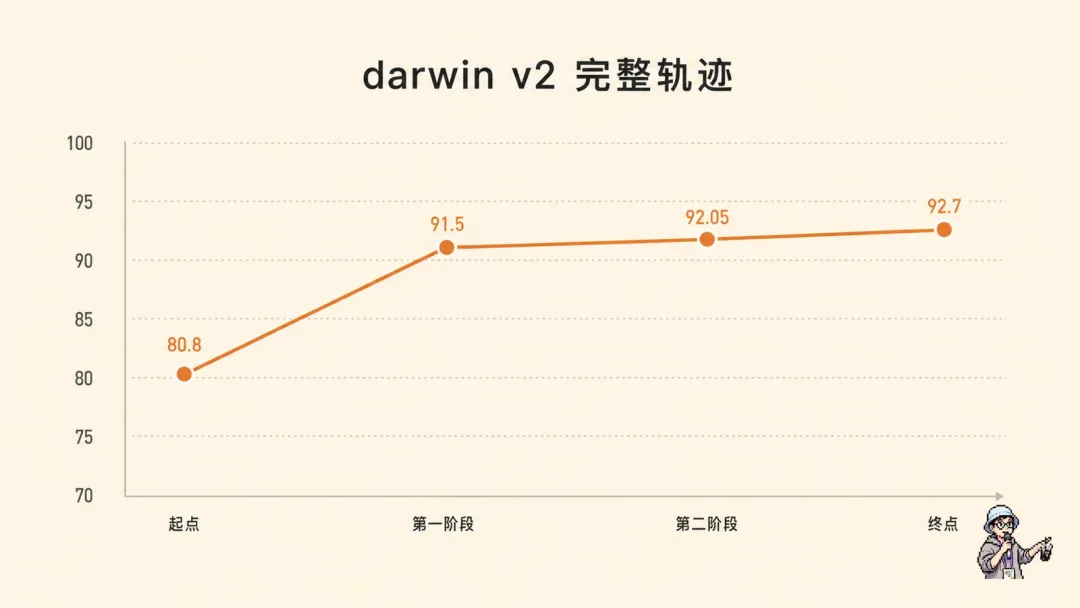
修呢三處之後,達爾文自己同步到9維,所有檢查點加上🔴/🛑視覺標記,軟化措辭硬化。再啟動兩個新評委重評:86.05→92.05。最後跟skill寫作最佳實踐將詳細論文證據下沉到子文件夾,主文件從550行精簡到484行,最終92.7。
但寫完上面呢啲之後,我做咗第三個獨立嘅小實驗:叫2.0跑一次huashu-gpt-image嘅skill文件本身(就係幫呢篇文章生成6張配圖嗰個)。
注意呢個同前面嘅「拎真實skill嚟驗證2.0」係兩件事。前面嗰次評嘅係skill入面寫嘅工作流同失敗模式;呢次評嘅係skill文件自身嘅寫作質量同結構(中咗SkillLens論文入面講嘅「文件可讀 ≠ 實際有用」)。兩次基線、目標、維度完全獨立。
理由好實際。寫呢篇文章時叫佢生成配圖,頭兩輪連續炒車。第一輪圖好醜冇風格;第二輪換具名錨定雜誌品牌名,模型直接將品牌名畫入圖度走偏。第三輪我明確話「用品牌資產做墊圖」先一次成功。
事後覆盤係skill文件自身嘅結構問題:冇將「品牌資產做墊圖」當默認操作,反而埋咗喺fallback樹最深處;另外「出版品牌名陷阱」完全冇顯式警告。
叫兩組獨立評委盲評修改前後:65→88(呢個係俾該skill文件自身寫作質量嘅獨立打分,同前面80.8/91.65係唔同維度嘅實驗設置)。

呢個遞歸案例本身就係2.0價值嘅最好證明。工具唔只可以優化生成嘅提示詞,仲可以優化寫提示詞嘅方法論本身。
一個會進化嘅skill,改進咗「如何寫出會進化嘅skill」呢件事。
唔只係個別案例:用2.0掃咗成個 skill 生態
證明2.0好用嘅最直接方式唔係講一兩個case,係叫佢去跑我成個skill庫。
過去幾日,我用2.0一口氣優化咗女媧蒸餾出嚟嘅所有 perspective skill,加上日常使用嘅業務 skill,總共近30個。每個都跑兩輪獨立評委、9維評分、validation-gated回滾。
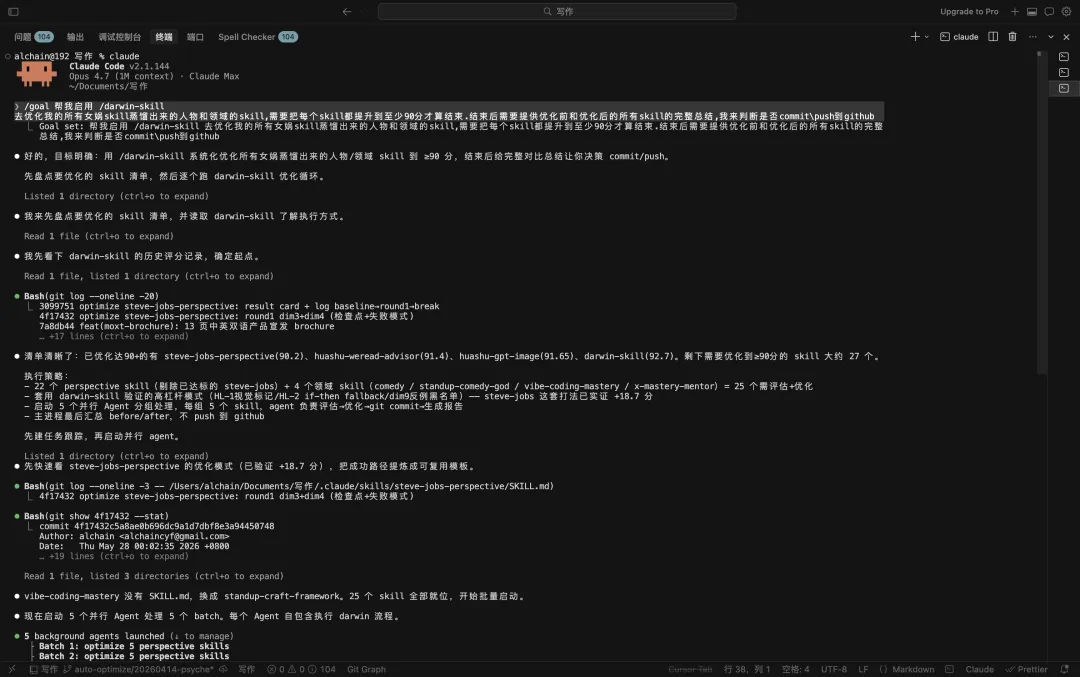
戰果係咁嘅(摘幾個有代表性嘅):
steve-jobs-perspective: 64 → 94(+30,單輪搞掂) huashu-weread-advisor: 80出頭 → 91.4 huashu-gpt-image: 80.8 → 91.65(前文實測) darwin-skill: 86.05 → 92.7(自指評估) vibe-coding-mastery / x-mastery-mentor / standup-comedy-god: 全部進入90+
平均升幅 +15分,最勁嘅steve-jobs-perspective單輪+30分。每個skill嘅優化都有完整git commit鏈可以回溯,validation冇過嘅改動全部自動revert,human in the loop檢查點都跑咗一遍。
呢件事最令我感慨嘅唔係分數,係規模感。
一個人維護30幾個skill,以前靠人審係nightmare,而家2.0跑一晚就全部掃一次,人只需要喺每個CHECKPOINT點頭或者搖頭。呢個就係將槓桿做出嚟嘅樣。
跑完之後我有一個直觀感受:成個女媧生態嘅輸出質量,可以用肉眼感知到提升。我自己用每一個skill嘅時候都覺得「啱,呢次佢真係更像嗰個人」,「啱,呢次佢真係將流程講清楚咗」。
呢個係達爾文 1.0 時代我冇辦法做到嘅事。
達爾文同SkillOpt嘅關係,以及佢喺咩情況下值得用
呢一章我想老實講清楚,達爾文同SkillOpt唔係替代關係,係分工。
SkillOpt係更系統、更嚴格嘅工程方案:全自動benchmark-driven,掉任務入去自己跑出最佳skill,數學嚴謹性高,52個測試組合52勝,適合企業級、能定義清晰評估函數嘅場景,適合規模化訓練skill、跨模型遷移。
達爾文2.0係面向個人開發者嘅輕量方案:rubric-driven,按可讀嘅評分標準俾文件打分(唔需要寫benchmark),自動化策略 + human in the loop雙引擎,適合主觀評估為主嘅場景(寫作、內容、風格類skill),適合獨立開發者快速迭代單個skill。
差異化優勢具體喺五處:
唔需要benchmark。SkillOpt依賴能跑分嘅validation set,達爾文用rubric打分,適合冇客觀metric嘅場景 強制human in the loop。每個CHECKPOINT等用戶確認,關鍵決策唔交俾AI 多評委獨立審查。每輪啟動新評委避免錨定,直接對齊SkillLens嘅73.8%準確率藥方 維度相關簇識別。識別「改一維帶動一簇」嘅結構規律,減少冗餘優化 反例黑名單驅動。8條嚟自真實踩坑,唔係空想
如果你做嘅係企業級、能定義benchmark嘅skill優化,用SkillOpt。
如果你做嘅係個人skill生態,需要快速迭代、可讀、可控、有人工卡口,用達爾文2.0。
倉庫喺邊
倉庫地址:https://github.com/alchaincyf/darwin-skill (MIT協議開源,提交編號5bfc6b4)
安裝好簡單:將倉庫連結掉俾你嘅agent,叫佢幫你安裝,然後喺agent度話「跑達爾文優化XX skill」就得。跑一輪基線評估+一輪優化大約15-30分鐘,主要時間喺等評委agent返回。
底層方法論參考:
arXiv 2605.23899《From Raw Experience to Skill Consumption》(項目代號SkillLens),評分標準升級來源 arXiv 2605.23904《SkillOpt: Executive Strategy for Self-Evolving Agent Skills》,驗證機制對齊來源
如果你都喺度維護一堆skill或者一套prompt,我推薦你試下達爾文2.0。

佢最大嘅價值唔係升嗰十幾分,而係將你嘅注意力從「自己審自己」轉移到「叫獨立評委審」,並將成個流程做成可重複、可回滾、有人工卡口嘅工程。
呢個轉移本身,就係槓桿。
我前陣子在GitHub上開源了一個有點意思的skill,叫達爾文(darwin-skill)。
它做的事情很單純:給別的skill打分、提改進方案、改完再打分,分數沒漲就回滾。整個流程像生物進化,一代代變異、被選擇、淘汰,留下來的都是更強的版本。skill本來是靜態文檔,加了達爾文之後能自己迭代自己。
上線一個月,跑了40次優化,平均提升13.5分,0次回滾。
成績不錯。但5月22號微軟研究院同一天掛了兩篇論文,正面解決skill優化這件事。這兩篇論文讓我意識到達爾文還能做得更嚴、更強。於是我吸收兩篇論文的精華做了一次大升級,這就是達爾文2.0,可能是目前面向個人開發者最完整的skill優化器。
這篇文章想講清楚三件事:微軟兩篇論文講了什麼、達爾文2.0吸收了什麼、它在什麼場景下值得用。
1.0已經做對的事
先簡單說說1.0為什麼管用。
我做skill大半年了。公眾號、小紅書、視頻腳本、配圖、調研,各種業務流程都封裝成了skill。加上21個人物視角的skill,已經是個小生態。
skill一多人工審稿就崩了。每個skill都通讀、找問題、改完再讀,人力上不可行。但你又不能放任不管,一個寫規則的文檔自己都沒人盯着,會慢慢漂移。
所以我做了達爾文。核心思路是把skill迭代變成可重複的工程流程:多維度評分標準、每輪只改最低維度、分數沒漲自動回滾、寫skill的AI和評分的AI分開、低風險改動允許幹跑模式。
跑了一個月,平均漲13.5分,0回滾。
但我心裏清楚這個0回滾不完全代表算法神準。評分標準定得多嚴,結果就有多嚴。我那套8維標準已經算嚴格了,但還有改進空間。
直到5月22號那兩篇論文出現,把方向給我指明瞭。
微軟同一天掛的兩篇論文
5月22號,微軟研究院和復旦、上交聯合在arXiv掛了兩篇論文,互為姊妹篇。
一篇是《From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills》(arXiv 2605.23899,項目代號SkillLens),研究skill應該怎麼被評估。
另一篇是《SkillOpt: Executive Strategy for Self-Evolving Agent Skills》(arXiv 2605.23904),研究skill應該怎麼被優化。
一前一後,一評一改,剛好把「會進化的skill」這件事從兩端封死。我先講SkillLens這篇,再講SkillOpt。
SkillLens:讓AI給skill打分,準確率只有46.4%
SkillLens裏有個數據讓我後背一涼:讓單個AI當評委,給兩份skill打分選哪份更好,準確率只有46.4%。
46.4%比扔硬幣還差3.6個百分點。這意味着在鬆散的評分標準下,AI評委的判斷基本不可信。你跑出來的優化看起來在漲分,實際上可能只是評委在隨機搖骰子。
但論文給了藥方。研究團隊發現,只要在評分標準里加三個關鍵維度,準確率能從46.4%升到73.8%
失敗模式編碼(Failure Mechanism Encoding):skill不能只寫「正確流程是什麼」,必須寫清楚「什麼情況下會出錯、出錯了走哪條分支」 可執行具體性(Actionable Specificity):「建議」「可以考慮」「根據情況」「靈活把握」「視情況而定」這些話全部不能寫。要麼明確要麼不寫 高風險行動黑名單(High-Risk Action Blacklist):skill必須有獨立的章節告訴模型「絕對不要做什麼」
73.8%其實也不算高,每4次決策還是錯1次。但相比46.4%是27個百分點的飛躍。
SkillOpt:把skill當成神經網絡的可訓練參數
SkillOpt更狠。它直接說:skill文檔應該被當成frozen模型的「外部可訓練狀態」,像神經網絡的權重一樣,通過反向傳播來優化。
這句話聽起來很玄,翻成大白話就是:讓模型跑一批真實任務、看哪些skill版本表現更好、保留好的版本、淘汰差的版本。區別在於被「訓練」的不是模型權重,是skill文檔本身的文字內容。
它的優化循環有四個階段:
跑任務(Rollout):讓目標模型用當前skill去跑一批真實任務,生成帶分數的軌跡 覆盤(Reflect):另一個獨立的優化器模型分析成功和失敗的批次,識別可複用的規律 提議改動(Edit):在「文本編輯預算」約束下(控制每輪改多少字),提議skill文檔的增/刪/改操作 驗證通過才接受(Validate):只有當留出的測試集分數嚴格提升,改動才被接受;否則拒絕
最後一步是關鍵。驗證不通過就拒絕寫入,這是把神經網絡訓練裏「梯度方向必須降低loss」的原則,搬到了文本空間。
論文測了6個benchmark × 7個模型 × 3個執行環境(直接對話/Codex/Claude Code)共52個組合。據論文測試結果,SkillOpt在所有52個組合裏都最強或並列最強。在GPT-5.5上,SkillOpt生成的skill比「沒skill」提升23.5分(直接對話)、24.8分(Codex)、19.1分(Claude Code)。
它擊敗的對手包括人工寫的skill、一次性LLM生成的skill,以及TextGrad、GEPA、EvoSkill等之前的prompt優化方法(以上均為論文測試基線)。
讀完這篇論文我有兩個反應。
第一反應是震撼。「skill像神經網絡權重一樣可訓練」是個深刻的隱喻。它把skill從「文檔」重新定義成「外部狀態」,把skill優化從「人工調整」變成「可重複、有數學保障的工程流程」。
第二反應是欣慰。SkillOpt的「驗證通過才接受」機制,和達爾文1.0的「分數沒漲自動回滾」是同一個核心思想:驗證不過就拒絕。這件事我和微軟同時獨立做出來了,只是數學嚴謹性上對方更紮實。
達爾文2.0:吸收兩篇論文精華
明白了兩篇論文之後,達爾文2.0的升級方向就很清楚:
吸收SkillLens的評分維度,讓評估更嚴格。 對齊SkillOpt的「驗證通過才接受」設計,讓優化更可靠。 加入SkillOpt沒有的human in the loop,讓流程在個人開發者場景下可控。
評分標準從8維升級到9維(直接吸收SkillLens的73.8%藥方)
原本的「錯誤處理」維度改名叫失敗模式編碼,要求寫出「如果X發生就做Y;否則做Z」的明確分支 原本的「明確性」維度改名叫可執行具體性,明文禁止那五個軟化措辭,出現三處以上扣三分 新增第九維高風險行動黑名單,要求skill必須有獨立的「不要做什麼」章節
權重做了微調,給新維度讓位。
強化驗證機制(對齊SkillOpt + 加多評委獨立設計)
之前1.0的回滾機制比較簡單:總分沒漲就回滾。2.0細化成多層驗證:
多評委獨立審查:每輪啓動兩個獨立評委,共識分數才算數(這是達爾文的獨立設計。SkillLens論文驗證的是單評委+新rubric的73.8%準確率,多評委是額外加固機制,不是論文方法的複述) 評委不復用:下一輪啓動兩個全新評委,避免錨定效應 早停機制:分數進入平台期(單輪漲幅<1分)自動停手,避免為湊分而堆冗餘 幹跑模式控制:幹跑比例超過30%自動告警,強制走實測驗證
加入human in the loop(達爾文區別於SkillOpt的核心)
這是達爾文跟SkillOpt最大的不同,也是個人開發者最需要的能力。
SkillOpt是benchmark-driven的全自動流程。你扔一堆任務和評分函數進去,它跑一晚上吐一個最佳skill出來。這個範式適合企業級、能定義清晰評估函數的場景。
但對個人開發者,benchmark本身就難定義。一個公眾號寫作skill,你怎麼寫benchmark?最終評估往往是「我自己讀着順不順」「讀者反應好不好」這種主觀維度,沒法塞進自動循環裏。
所以達爾文2.0把流程切成階段,每個階段都有明確的人工卡口:
第一階段基線評估:自動跑評委打分,人工審報告決定改什麼 第二階段單維度優化:自動改最低維度,🔴 CHECKPOINT強制暫停等用戶確認改動方向 第二階段半測試提示詞跑(可選):自動跑實測,人工看測試結果 第三階段迴歸測試:啓動新評委重評,🛑 STOP漲幅低於閾值強制停手
每個🔴/🛑都是顯性的人工介入點。流程能自動跑,但關鍵決策永遠交回給人。這避免了「跑了一晚上結果文檔面目全非」的悲劇。
引入反例黑名單(論文要求 + 真實踩坑)
新增「反例黑名單」章節,八條來自我跑40次優化攢下來的實戰反模式:
同一個AI又改又評(SkillLens 46.4%印證) 用「git reset --hard」當回滾手段(應該用git revert) 為湊分而往文檔裏塞冗餘 跳過測試提示詞直接評分 一輪內改多個維度 幹跑模式比例超過30% 靜默跳過異常 忽視維度相關簇
論文告訴你反例黑名單很重要,但具體反例必須來自實操。
這是論文給不了你的東西。
拿真實skill來驗證2.0
升級完之後我得驗證它真的更強,不是從一個偏差換到另一個偏差。
我挑了huashu-gpt-image做小白鼠。這是我自己寫的一個skill,用來調GPT-image-2生圖,368行,日常用得最多。
測試設計的關鍵是多評委獨立審查。啓動兩個獨立的AI評委,它們彼此不知道對方存在,也不知道我接下來要怎麼改。
基線共識80.8分。兩個評委獨立指出了相同的最低維度:失敗模式。
按規則每輪只改最低維度,改了四處,新增「失敗模式與兜底樹」一整章。
文件從368行漲到449行。
啓動兩個全新評委(不復用之前兩個,避免錨定效應)重評。
共識91.5,漲了10.7分。失敗模式那一維從6.5飆到10分滿分。
有件事我沒想到。我只改了失敗模式,「工作流」那一維居然從7.5跳到9.0。我沒碰這一維啊?
想清楚之後大概懂了。失敗模式要求寫出「如果X就做Y」的明確分支,寫出來之後流程自動變清晰。工作流、檢查點、失敗模式三維不是獨立維度,它們是一簇,改一個會帶動相鄰的。
這是2.0新發現的規律:維度相關簇。
至於為什麼會相關簇,我有幾個猜想:可能是評分維度本身設計有重疊;可能是改一處文檔帶動了周邊重構;還可能是評委的心理錨定(看到一處變清晰會順手給相鄰維度調高分)。我沒辦法分辨,只測了一個skill,數據不夠。這條經驗已經寫進反例黑名單第八條。
繼續攻第二低,加了一段「單圖工作流」與原有的「批量工作流」對稱。再啓動兩個新評委,共識91.65。
只漲了0.15。早停機制觸發,停手。
達爾文給自己打分:理髮師悖論
到這裏2.0已經在huashu-gpt-image這個真實skill上證明了+10.85提升,六個獨立評委共識。理論上可以收工。
但我有個不太正經的想法:用2.0給達爾文自己打分會怎樣。
寫規則的工具,被自己寫的規則審判。這是另一個獨立實驗,對象不再是huashu-gpt-image,而是達爾文自己的SKILL.md。
啓動兩個獨立評委,達爾文自己的基線給出86.05(注意這是另一個文件的獨立基線,跟前面huashu-gpt-image的80.8沒有可比性)。它們不約而同指出三處可以更嚴:
第一處版本管理疏漏。文檔描述還寫着「8維評分標準」,正文已經9維。改完版本忘記同步描述。
第二處檢查點未顯性標記。達爾文自己的第四維明文規定檢查點必須顯性標記(🔴/STOP/CHECKPOINT),但關鍵檢查點全部只用粗體強調,沒有一個🔴/STOP。
第三處軟化措辭超標。達爾文第五維明文禁止「建議/可以考慮」等軟化措辭。評委在我自己的文檔裏搜出四處違規。
我自己定的規則,我自己幾處地方做得不到位。
這不是馬虎,是寫規則時的結構性盲區:作者的注意力天然在「新加的規則有沒有用」,不在「之前寫的內容是否符合新規則」。這種盲區沒辦法靠「小心一點」避免,因為你看不見自己看不見的東西。
唯一解決辦法:讓獨立評委用你的規則審你。評委不在乎你寫的是「自己的工具」還是「別人的工具」,它只按字面執行規則。
這其實是2.0的另一個隱性優勢:它對作者一視同仁。
修完之後,以及一個遞歸發現
修這三處之後,達爾文自己同步到9維,所有檢查點加上🔴/🛑視覺標記,軟化措辭硬化。再啓動兩個新評委重評:86.05→92.05。最後按skill寫作最佳實踐把詳細論文證據下沉到子文件夾,主文檔從550行精簡到484行,最終92.7。
但寫完上面這些之後,我做了第三個獨立的小實驗:讓2.0跑一次huashu-gpt-image的skill文檔本身(就是給這篇文章生成6張配圖那個)。
注意這跟前面的「拿真實skill來驗證2.0」是兩件事。前面那次評的是skill裏寫的工作流和失敗模式;這次評的是skill文檔自身的寫作質量和結構(命中SkillLens論文裏說的「文檔可讀 ≠ 實際有用」)。兩次基線、目標、維度完全獨立。
理由很實際。寫這篇文章時讓它生成配圖,前兩輪連續翻車。第一輪圖很醜沒風格;第二輪換具名錨定雜誌品牌名,模型直接把品牌名畫進圖裏跑偏。第三輪我明確說「用品牌資產作墊圖」才一次成功。
事後覆盤是skill文檔自身的結構問題:沒把「品牌資產作墊圖」當默認操作,反而埋在fallback樹最深處;另外「出版品牌名陷阱」完全沒顯式警告。
讓兩組獨立評委盲評修改前後:65→88(這是給該skill文檔自身寫作質量的獨立打分,跟前面80.8/91.65是不同維度的實驗設置)。
這個遞歸案例本身就是2.0價值的最好證明。工具不只能優化生成的提示詞,還能優化寫提示詞的方法論本身。
一個會進化的skill,改進了「如何寫出會進化的skill」這件事。
不只是個例:用2.0掃了整個 skill 生態
證明2.0好用的最直接方式不是講一兩個case,是讓它去跑我整個skill庫。
過去幾天,我用2.0一口氣優化了女媧蒸餾出來的所有 perspective skill,加上日常使用的業務 skill,總共近30個。每個都跑兩輪獨立評委、9維評分、validation-gated回滾。
戰果是這樣的(摘幾個有代表性的):
steve-jobs-perspective: 64 → 94(+30,單輪搞定) huashu-weread-advisor: 80出頭 → 91.4 huashu-gpt-image: 80.8 → 91.65(前文實測) darwin-skill: 86.05 → 92.7(自指評估) vibe-coding-mastery / x-mastery-mentor / standup-comedy-god: 全部進入90+
平均漲幅 +15分,最猛的steve-jobs-perspective單輪+30分。每個skill的優化都有完整git commit鏈可回溯,validation沒過的改動全部自動revert,human in the loop檢查點都跑了一遍。
這件事最讓我感慨的不是分數,是規模感。
一個人維護30多個skill,過去靠人審是nightmare,現在2.0跑一晚上全掃一遍,人只需要在每個CHECKPOINT點頭或搖頭。這就是把槓桿做出來的樣子。
跑完之後我有一個直觀感受:整個女媧生態的輸出質量,可以肉眼感知到提升。我自己用每一個skill的時候都覺得"對,這次它真的更像那個人了""對,這次它真的把流程講清楚了"。
這是達爾文 1.0 時代我沒能做到的事。
達爾文跟SkillOpt的關係,以及它在什麼場景下值得用
這一章我想老實講清楚,達爾文跟SkillOpt不是替代關係,是分工。
SkillOpt是更系統、更嚴格的工程方案:全自動benchmark-driven,扔任務進去自己跑出最佳skill,數學嚴謹性高,52個測試組合52勝,適合企業級、能定義清晰評估函數的場景,適合規模化訓練skill、跨模型遷移。
達爾文2.0是面向個人開發者的輕量方案:rubric-driven,按可讀的評分標準給文檔打分(不需要寫benchmark),自動化策略 + human in the loop雙引擎,適合主觀評估為主的場景(寫作、內容、風格類skill),適合獨立開發者快速迭代單個skill。
差異化優勢具體在五處:
不需要benchmark。SkillOpt依賴能跑分的validation set,達爾文用rubric打分,適合沒有客觀metric的場景 強制human in the loop。每個CHECKPOINT等用戶確認,關鍵決策不交給AI 多評委獨立審查。每輪啓動新評委避免錨定,直接對齊SkillLens的73.8%準確率藥方 維度相關簇識別。識別「改一維帶動一簇」的結構規律,減少冗餘優化 反例黑名單驅動。8條來自真實踩坑,不是空想
如果你做的是企業級、能定義benchmark的skill優化,用SkillOpt。
如果你做的是個人skill生態,需要快速迭代、可讀、可控、有人工卡口,用達爾文2.0。
倉庫在哪
倉庫地址:https://github.com/alchaincyf/darwin-skill (MIT協議開源,提交編號5bfc6b4)
安裝很簡單:把倉庫連結丟給你的agent,讓它幫你安裝,然後在agent裏說「跑達爾文優化XX skill」即可。跑一輪基線評估+一輪優化大約15-30分鐘,主要時間在等評委agent返回。
底層方法論參考:
arXiv 2605.23899《From Raw Experience to Skill Consumption》(項目代號SkillLens),評分標準升級來源 arXiv 2605.23904《SkillOpt: Executive Strategy for Self-Evolving Agent Skills》,驗證機制對齊來源
如果你也在維護一堆skill或者一套prompt,我推薦試一下達爾文2.0。
它最大的價值不是漲那十幾分,而是把你的注意力從「自己審自己」轉移到「讓獨立評委審」,並把整個流程做成可重複、可回滾、有人工卡口的工程。
這個轉移本身,就是槓桿。