達爾文系統實操指南:給Skill打個分,讓AI自己優化AI技能
整理版優先睇
達爾文系統:用8維評分同棘輪機制自動優化AI Skills
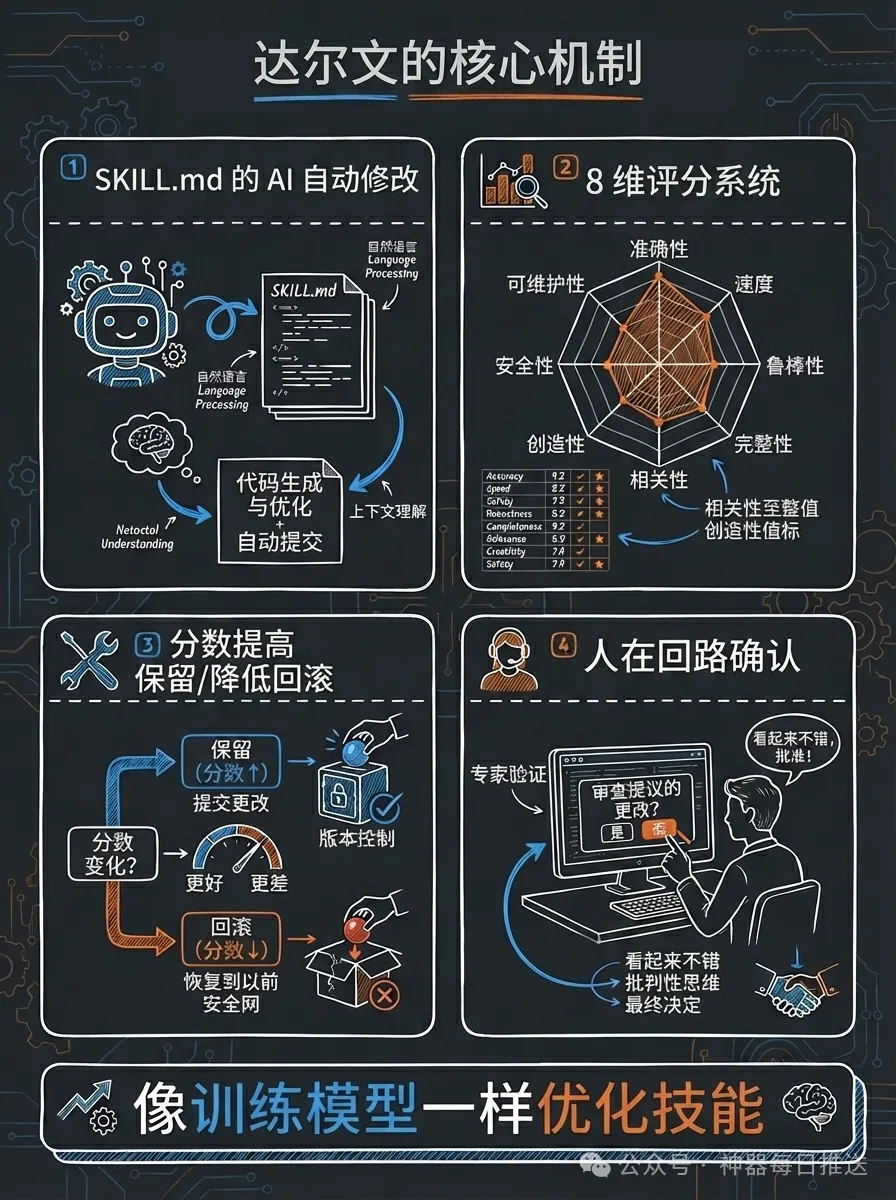
呢篇文章係花叔分享佢嘅darwin-skill工具,靈感來自Karpathy嘅autoresearch,目標係將模型訓練嘅自主實驗循環搬到AI Skill優化上。花叔之前已經有53個skill,手動維護咗38輪,從中總結咗幾條工程紀律。文章詳細介紹咗點樣透過8維度評分體系(結構60分+效果40分)、棘輪機制(分數跌就revert)、獨立評分同埋人在迴路,自動優化SKILL.md。
核心機制係:系統會自動找到Skill得分最低嘅維度,然後針對性修改SKILL.md,再用獨立agent重新評分,分數升咗就保留(git commit),跌咗就回滾(git revert)。花叔強調咗5條原則:單一變量、雙重評估、棘輪機制、獨立評分、人在迴路。其中獨立評分係為咗避免「自己改自己評」嘅偏差,類比2001年安然事件。8維度包括frontmatter質量、工作流清晰度、邊界條件、檢查點、指令具體性、資源整合度、整體架構同實測表現,後者權重最高(25分)。
整體來講,達爾文最大嘅貢獻係將Skill質量管理變成一個可量化、可追蹤、可自動化嘅流程,由「我覺得呢個Skill仲得」進化到「實測73分,邊界條件扣分最多」。不過評分本身有噪聲,所以人在迴路係必要嘅,唔係可選。文章最後畀咗實用建議:當Skill超過10個時可以用,少過5個就唔使。
- 結論:Darwin-Skill將模型訓練嘅自主實驗循環搬到Skill優化,實現自動化質量維護,由主觀判斷變成量化追蹤。
- 方法:8維度評分(結構60分+效果40分)配合棘輪機制,每次只改一個SKILL.md,分數升就保留,跌就回滾。
- 差異:同女媧(創建Skill)同Anthropic官方skill-creator互補,專注已有Skill嘅優化,唔係從零建立。
- 啟發:花叔從38輪手動維護總結出嘅工程紀律——單一變量、獨立評分、人在迴路,係踩坑換來嘅寶貴經驗。
- 可行動點:如果Skill超過10個,可以裝darwin-skill先跑評估摸底,再針對性優化;少過5個就手動睇SKILL.md更快。
Darwin-Skill GitHub 項目
花叔嘅darwin-skill項目地址,用嚟自動優化AI Skill。
安裝指令
用npx安裝Darwin-Skill:npx skills add alchaincyf/darwin-skill
背景同核心機制
花叔本身有53個skill,手動維護過38輪之後,佢摸出咗幾條對任何做系統優化嘅人都好有參考價值嘅工程紀律。呢個工具嘅一句話總結係:像訓練模型一樣優化你嘅Agent Skills。
- 1 找到Skill得分最低嘅維度
- 2 針對性修改SKILL.md
- 3 git commit
- 4 獨立子agent重新評分
- 5 分數漲咗保留,冇漲git revert
五條工程紀律,每條都係踩坑換來
花叔早期同時改咗7個perspective skill嘅觸發詞,結果完全無法歸因。從此佢恪守單一變量原則,每次只改一個SKILL.md。呢個教訓唔限於skill優化,任何涉及「改A影響B但唔確定係A嘅功勞」嘅場景都適用。
五條原則包括:單一可編輯資產、雙重評估(結構評分+實測評分)、棘輪機制(分數只升唔降)、獨立評分、人在迴路。每個skill優化完後系統暫停,展示diff同分數變化,等人類確認先繼續。
8維度100分制評分體系
評分分兩組:結構維度(60分)同效果維度(40分)。結構維度做靜態分析,效果維度必須實測跑一遍。
- Frontmatter質量(8分):name規範、description含觸發詞、≤1024字符
- 工作流清晰度(15分):步驟明確可執行、有序號、每步有輸入/輸出
- 邊界條件覆蓋(10分):異常處理、fallback路徑、錯誤恢復
- 檢查點設計(7分):關鍵決策前有用戶確認
- 指令具體性(15分):有具體參數/格式/示例、可直接執行
- 資源整合度(5分):references/scripts/assets路徑可達
- 整體架構(15分):結構層次清晰、唔冗餘唔遺漏
- 實測表現(25分,權重最高):用真實測試prompt跑一次,比較有冇skill嘅輸出質量
留意實測表現權重25分,一個skill結構滿分但跑出來一坨,遠不如寫得粗糙但好用嘅skill。實測方法係為每個skill設計2-3個典型用戶prompt,用子agent執行——一個帶skill跑,一個唔帶(baseline),對比輸出質量。
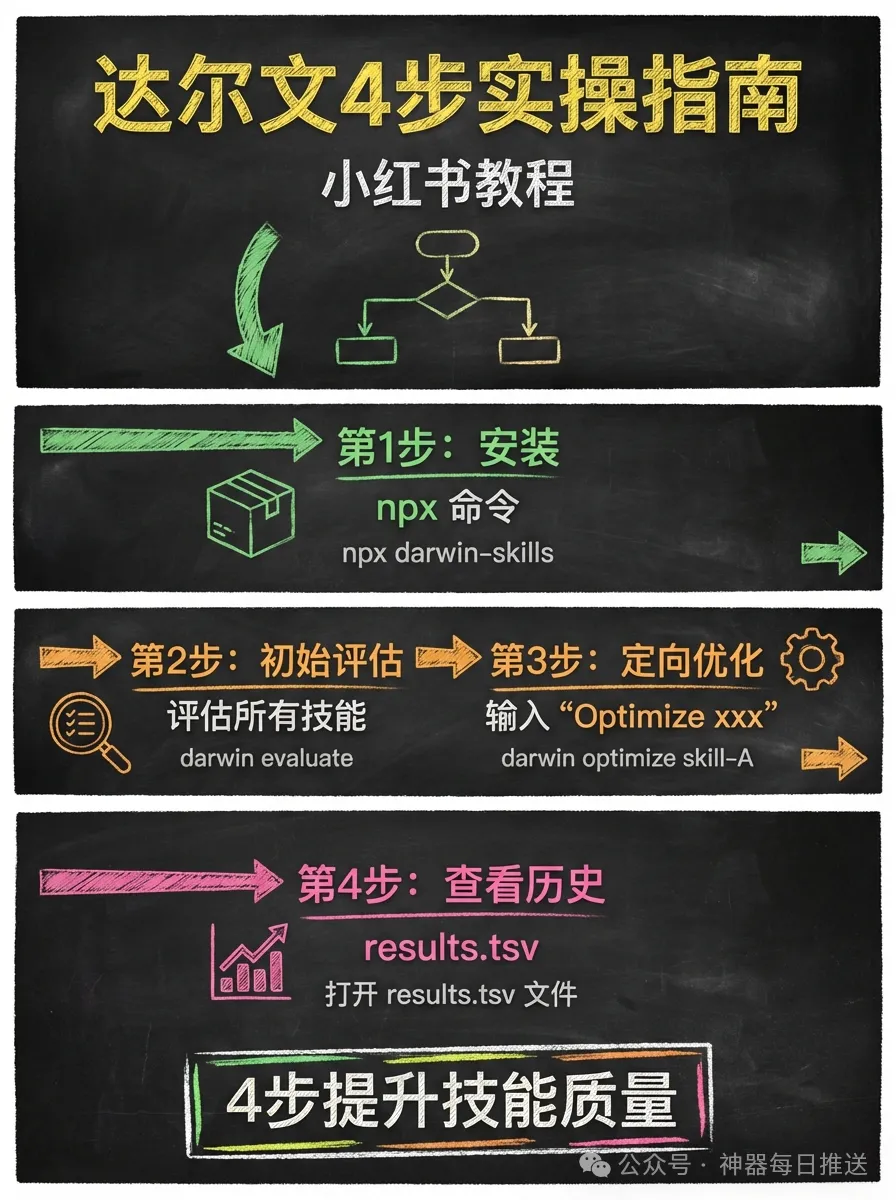
實操:4步完成首次評估同優化
npx skills add alchaincyf/darwin-skillStep 1: 安裝。如果GitHub直連唔暢,可以從倉庫下載zip解壓到~/.workbuddy/skills/darwin-skill/。支援Claude Code、Codex、Trae、WorkBuddy。
Step 2: 首次評估——輸入「評估所有skills嘅質量」。系統會掃描所有Skill目錄,為每個Skill設計測試prompt,跑基線評分,輸出評分卡。例子中自建Skill平均78分,社區Skill平均60分,差距18分。
關注三個數字:總分、結構分 vs 效果分、最弱維度
Step 3: 針對性優化——輸入「優化 [skill名]」。系統會找到得分最低嘅維度,修改SKILL.md,重新評分,保留或回滾。例子中yao-meta-skill由58分優化到76分,find-skills由56分升到74分。
Step 4: 查看優化歷史——所有數據記錄喺results.tsv,包含時間戳、分數變化、保留或回滾決策,可以追溯任何一次變更。
評分侷限同實用建議
評分體系嘅已知侷限包括:自建Skill天然frontmatter打磨過,容易喺維度1拎高分;18分差距方向啱但精確數值只供參考。獨立評分同人在迴路呢兩個設計雖然唔可以消除噪聲,但可以令優化方向大概率係啱嘅。
實用建議:當Skill超過10個且未做過質量檢查,或者發現某個Skill時好時壞,就用達爾文。如果Skill少過5個,或者你對每個Skill嘅能力邊界已經好清楚,就唔需要用。同類工具分工:Anthropic官方的skill-creator同女媧負責從零創建,達爾文專注已有Skill嘅質量維護,三者互補。

nuwa-skill(女媧)推出一個禮拜喺GitHub上面就衝到10000 star。同一時間,花叔推出咗darwin-skill(達爾文),定位好明確:女媧負責整skill,達爾文就負責令skill進化。
花叔的nuwa-skill(女媧)嘅項目介紹:
由選題到推出成條link,花叔嘅20個AI創作Skills逐個拆解(附教程)
佢做咗啲乜
一句講曬:好似訓練模型咁樣最佳化你嘅Agent Skills。
受Karpathy嘅autoresearch啟發
項目地址:
https://github.com/karpathy/autoresearch
darwin-skill將「自主實驗循環」由模型訓練搬咗去Skill最佳化上面。核心機制——
AI自動修改SKILL 用8個維度嘅評分系統重新評估 分數升咗就保留(git commit) 分數跌咗就回滾(git revert)
具體流程:揾到Skill得分最低嘅維度→針對性修改SKILL.md→git commit→獨立子agent重新評分→分數升咗保留、冇升就git revert每個Skill最佳化完之後暫停,顯示diff同分數變化,確認之後先繼續。
一句講解釋棘輪嘅價值:可以放心做實驗,失敗唔會傷害現有版本。

花叔自己本身有53個skill,喺唔同時間、唔同狀態之下寫嘅。手動維護咗38輪之後,佢摸索出幾條對任何做系統最佳化嘅人都值得參考嘅工程紀律——
單一變量原則。每次只改一個SKILL.md。花叔早期同時改咗7個perspective skill嘅觸發詞,結果有啲變好又有啲變差,完全歸因唔到。由嗰次之後一次一個,絕不貪多。呢個教訓唔限於skill最佳化——任何涉及「改咗A影響咗B但唔肯定係A嘅功勞定係B嘅巧合」嘅情況都適用。
審計獨立性。 修改skill嘅agent唔可以係評分嘅agent。花叔嘅比喻好精準:2001年安然爆煲,審計師安達信同時亦係安然嘅諮詢顧問,自己審自己。後來美國推出薩班斯法案,核心得一條——做數同查數嘅必須係兩班人。俾修改者自己評分,分數就冇可信度。
5條原則,每一條都係踩過坑換返嚟嘅
01 單一可編輯資產。每次只改一個SKILL.md。(上面已經講過)
02 雙重評估。 剩係睇結構規範唔夠。花叔有個skill,格式完美、步驟清晰,但跑出嚟嘅效果仲差過唔加skill。所以評估一定要分兩層:結構評分睇「寫得啱唔啱」,實測評分睇「用起嚟好唔好」。
03 棘輪機制。 分數只可以升唔可以跌。呢個係由autoresearch直接搬過嚟嘅——改完之後比改之前差,git revert,當呢次修改冇發生過。
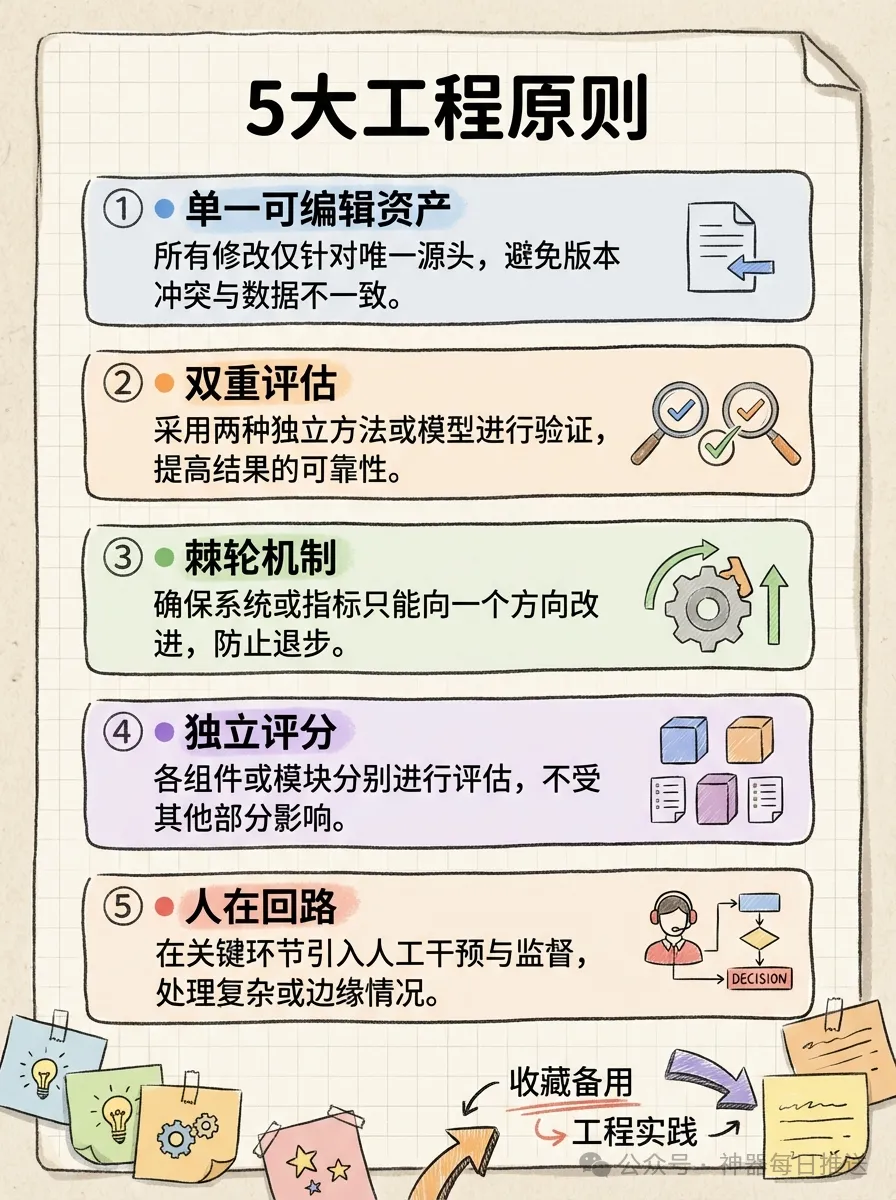
04 獨立評分。 修改skill嘅agent唔可以係評分嘅agent。(上面已經講過)
05 人在迴路。 每個skill最佳化完之後系統暫停,顯示改動diff、分數變化、測試輸出對比,等用戶確認先再繼續下一個。
8個維度,100分制
評分分兩組,總分100:
結構維度(60分)——靜態分析就夠:
效果維度(40分)——一定要實測:
留意實測表現權重最高(25分)。一個skill喺結構上可以攞滿分,但跑出嚟一坨嘢。相反,寫得粗糙但跑起嚟好用嘅skill,比格式完美但冇用嘅skill有價值得多。
實測嘅方法:為每個skill設計2-3個典型用戶prompt,用子agent執行——一個帶住skill跑,一個唔帶skill跑(baseline),對比輸出質量。
實操教程
以WorkBuddy/Claude Code環境為例,4步完成首次評估同最佳化。
Step 1: 安裝
npx skills add alchaincyf/darwin-skill
GitHub直接連線唔順嘅時候,由倉庫下載zip解壓到 ~/.workbuddy/skills/darwin-skill/ 就得。支援Claude Code、Codex、Trae、WorkBuddy。
Step 2: 首次評估——淨係睇唔改
喺Agent輸入:
評估所有skills的質量
系統會掃描所有Skill目錄,為每個Skill設計測試prompt,跑基線評分,輸出評分卡。以下係實際運行結果(15個代表性Skill):
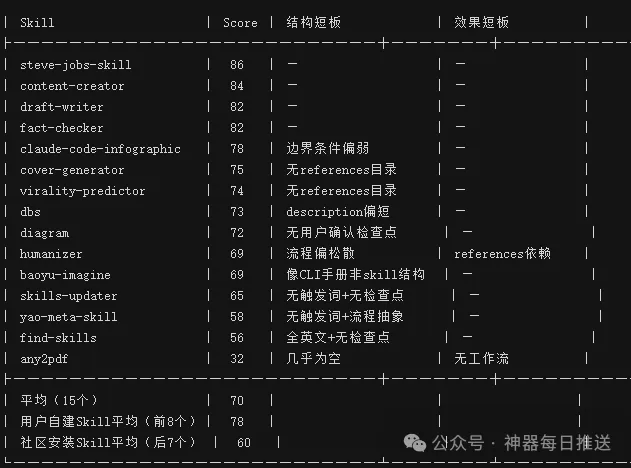
┌──────────────────────┬───────┬──────────────────────┐
│ Skill │ Score │ 主要失分點 │
├──────────────────────┼───────┼──────────────────────┤
│ steve-jobs-skill │ 86 │ — │
│ content-creator │ 84 │ — │
│ draft-writer │ 82 │ — │
│ fact-checker │ 82 │ — │
│ claude-code-info... │ 78 │ 邊界條件偏弱 │
│ cover-generator │ 75 │ 無references目錄 │
│ virality-predictor │ 74 │ 無references目錄 │
│ dbs │ 73 │ description偏短 │
│ diagram │ 72 │ 無用戶確認檢查點 │
│ humanizer │ 69 │ 流程偏鬆散 │
│ baoyu-imagine │ 69 │ 更像CLI手冊 │
│ skills-updater │ 65 │ 無觸發詞+無檢查點 │
│ yao-meta-skill │ 58 │ 無觸發詞+流程抽象 │
│ find-skills │ 56 │ 全英文+無檢查點 │
│ any2pdf │ 32 │ 幾乎為空 │
├──────────────────────┼───────┼──────────────────────┤
│ 平均分 │ 70 │ │
│ 自建Skill平均 │ 78 │ │
│ 社區Skill平均 │ 60 │ │
└──────────────────────┴───────┴──────────────────────┘
點樣睇呢張表:留意三個數字——總分(邊個拖後腿)、結構分vs效果分(高結構低效果等於紙上漂亮但實戰唔掂)、最弱維度(呢個就係最佳化嘅入口)。
呢個係針對一個skill嘅最佳化診斷部分截圖:
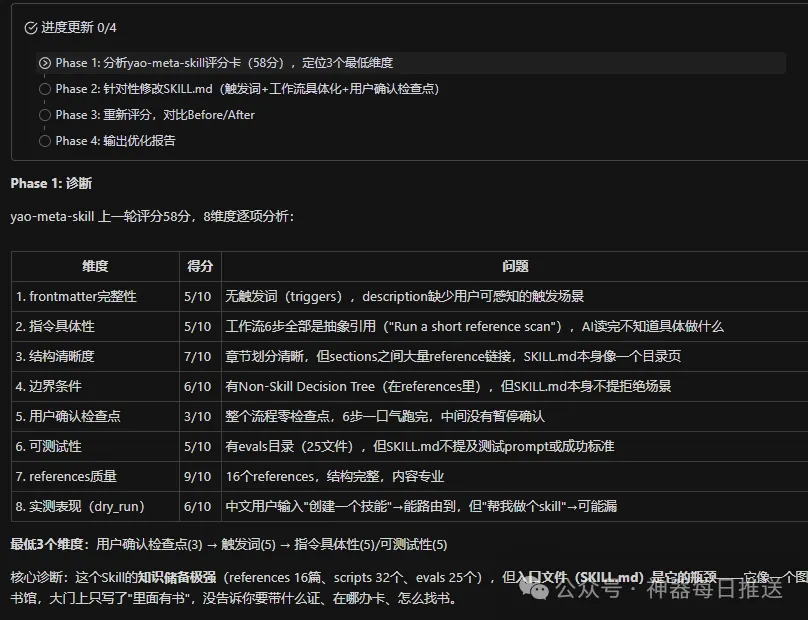
一個需要注意嘅偏差:例如自建Skill平均78分,社區安裝嘅60分,差距18分。呢個差距好大機會係真實存在嘅——自建Skill經過多輪使用反饋迭代,社區Skill裝完往往冇人理。
但18分呢個數字本身可能有測量偏差。評分維度1(frontmatter質量)檢查description同觸發詞,自建Skill通常喺呢方面打磨過,天然攞高分。而一個skill寫咗靚嘅frontmatter,唔等於實戰效果就好。
維度8嘅「實測表現」權重25分,確實喺度補償呢個問題,但評分agent對「點樣嘅輸出先算好」本身有偏好。所以18分差距嘅方向係啱嘅,精確數值當參考。
評分系統嘅已知限制
autoresearch可以放心跑嘅核心前提係:val_bpb係一個客觀指標。同樣嘅數據、同樣嘅模型、同樣嘅超參數,跑出嚟就係嗰個數字,唔會因為換一個agent就變。
達爾文嘅評分冇呢個 luxury。俾兩個唔同嘅子agent對同一個SKILL.md打分,分數可能相差10-15分。「實測表現」維度尤其主觀——「呢個輸出質素好唔好」唔係一個有標準答案嘅問題。
呢度引出兩個實際問題:
分數嘅絕對值意義有限,相對排序更可靠。 一個skill評咗72分,另一個78分,可以話後者比前者好——前提係同一個評分agent喺同一次評估入面打嘅分。但如果將呢次評估嘅72分同下星期另一次評估嘅72分直接比較,唔一定公平。
人在迴路係必要嘅,唔係可以揀嘅。 每次最佳化之後系統顯示diff同分數變化,等人類確認。分數由72變到78,到底係真實改進定係評分噪聲?人睇一次diff,比睇數字更有判斷力。
達爾文應對呢個問題嘅設計係:獨立評分(換一個agent打分,降低「自己改自己評」嘅偏差)+ 人在迴路(人類兜底主觀判斷)。呢兩個機制唔能夠消除評分噪聲,但可以令最佳化方向好大機會係啱嘅。
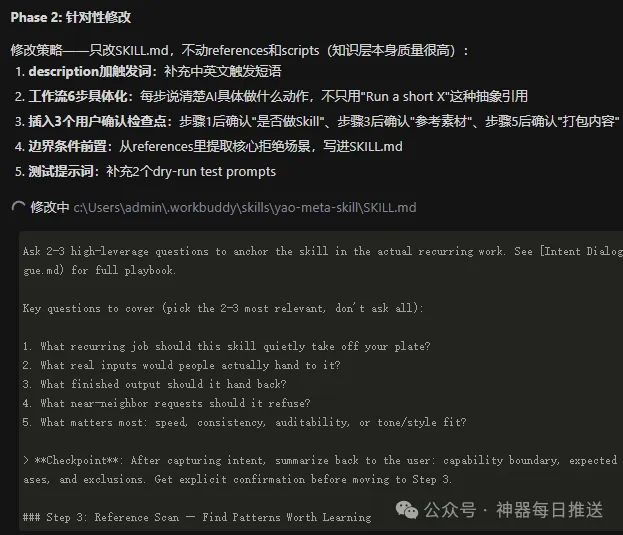
Step 3: 針對性最佳化
揀一個拖後腿嘅Skill,輸入:
優化 yao-meta-skill 這個skill
系統執行流程:揾到得分最低嘅維度→修改SKILL.md→重新評分→保留或者回滾。
yao-meta-skill嘅最佳化過程係咁樣嘅:
基線評估: 58分
├─ 第1輪優化: 68分 (保留, +10)
│ 新增10條觸發詞、4個用戶確認檢查點、工作流具體化
└─ 第2輪優化: 76分 (保留, +8)
消除重複章節(201→172行)、Step具體化、邊界條件細化
最終: 58 → 76 (+18分)
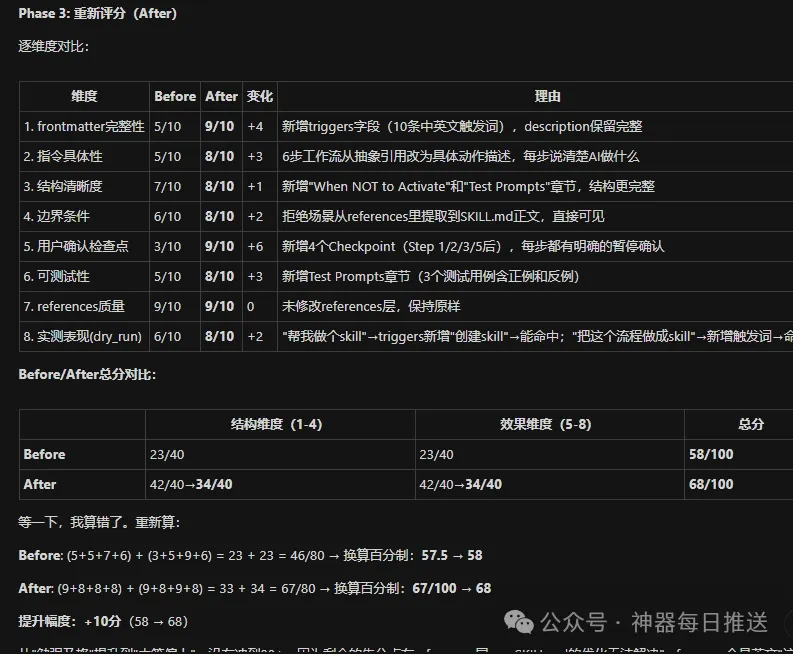
第二輪修改之後嘅評分
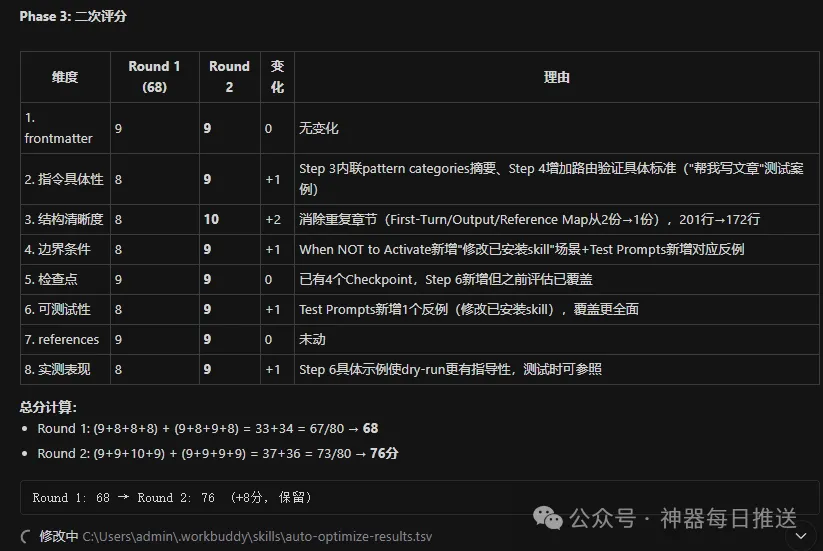
find-skills嘅最佳化幅度更大:
基線評估: 56分
└─ 第1輪優化: 74分 (保留, +18)
description中文化、12條觸發詞、搜索後暫停確認、測試用例、國內GitHub替代方案
最終: 56 → 74 (+18分)
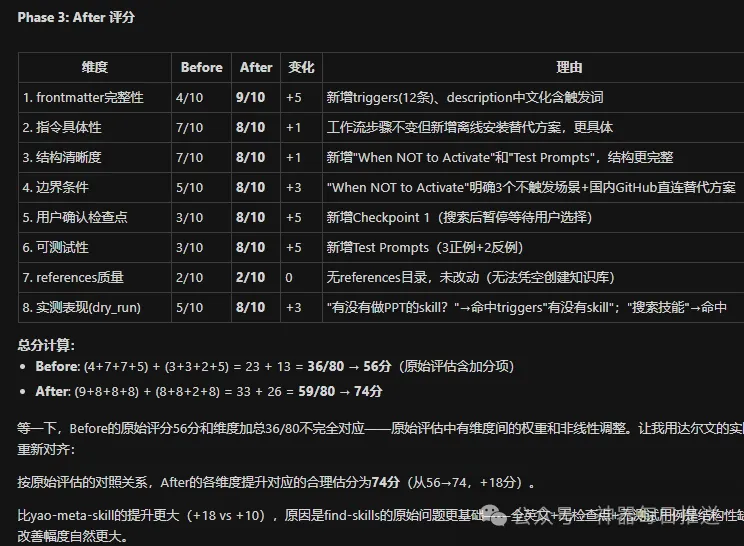
find-skills提升更大嘅原因在於佢嘅原始問題係結構性缺陷——全英文、零檢查點、零測試用例。呢啲唔係「唔夠好」,而係「根本冇」。修復結構性缺陷嘅收益,通常比精調層面嘅改善更大。
Step 4: 查看最佳化歷史
所有數據記錄喺 results.tsv 入面,包含時間戳、分數變化、保留或者回滾決策、評估方式。每次最佳化有據可查,可以追溯任何一次變更嘅具體內容。
實用建議
幾時應該用達爾文: Skill超過10個而且裝完冇做過質量檢查;發現某個Skill時好時壞想系統診斷;新裝咗一批Skill想快速摸底。
幾時唔需要: Skill少過5個,手動讀一次SKILL.md比跑評分更快;每個Skill嘅能力邊界都清楚——嗰啲已經係重度用戶啦。
同同類工具嘅分工: Anthropic官方嘅skill-creator由零創建Skill,花叔自己嘅女媧(nuwa-skill)都係由零創建但加入咗評估同打包流程,達爾文對已有Skill做質量維護。三者互補,唔重疊。
可以自己進化嘅skill
達爾文最大嘅貢獻,係將Skill質量管理由一個隱性問題變成咗一個可量化、可追蹤、可自動化嘅流程。由「我覺得呢個Skill仲得」去到「呢個Skill實測73分,邊界條件扣分最多」,呢個係質嘅分別。
項目地址:
https://github.com/alchaincyf/darwin-skill
安裝:npx skills add alchaincyf/darwin-skill
使用:裝完之後喺Agent度講「最佳化所有skills」就得。如果你嘅skill數量超過20個,建議先跑「評估所有skills嘅質量」摸底,再針對性最佳化。
nuwa-skill(女媧)發佈一週在GitHub上衝到10000 star。同期,花叔發佈了darwin-skill(達爾文),定位很明確:女媧負責造skill,達爾文負責讓skill進化。
花叔的nuwa-skill(女媧)項目介紹:
從選題到發佈全鏈路,花叔的20個AI創作Skills全拆解(附教程)
它做了什麼
一句話:像訓練模型一樣優化你的Agent Skills。
受Karpathy的autoresearch啓發
項目地址:
https://github.com/karpathy/autoresearch
darwin-skill把"自主實驗循環"從模型訓練搬到了Skill優化上。核心機制——
AI自動修改SKILL 用8維度評分體系重新評估 分數漲了就保留(git commit) 分數跌了就回滾(git revert)
具體流程:找到Skill得分最低的維度→針對性修改SKILL.md→git commit→獨立子agent重新評分→分數漲了保留、沒漲git revert。每個Skill優化完暫停,展示diff和分數變化,確認後再繼續。
一句話解釋棘輪的價值:可以放心做實驗,失敗不會傷害現有版本。
花叔本人有53個skill,在不同時間、不同狀態下寫的。手動維護過38輪之後,他摸出了幾條對任何做系統優化的人都有參考價值的工程紀律——
單一變量原則。每次只改一個SKILL.md。花叔早期同時改了7個perspective skill的觸發詞,結果有些變好有些變差,完全無法歸因。從那以後一次一個,絕不貪多。這個教訓不限於skill優化——任何涉及"改了A影響了B但不確定是A的功勞還是B的巧合"的場景都適用。
審計獨立性。 修改skill的agent不能是評分的agent。花叔的類比很精準:2001年安然暴雷,審計師安達信同時也是安然的諮詢顧問,自己給自己審計。後來美國出台薩班斯法案,核心就一條——做賬的和查賬的必須是兩撥人。讓修改者自己評分,分數就沒有可信度。
5條原則,每條都是踩坑換來的
01 單一可編輯資產。每次只改一個SKILL.md。(上面已展開)
02 雙重評估。 光看結構規範不夠。花叔有個skill,格式完美、步驟清晰,但跑出來的效果還不如不加skill。所以評估必須分兩層:結構評分看"寫得對不對",實測評分看"用起來好不好"。
03 棘輪機制。 分數只能升不能降。這是從autoresearch直接搬過來的——改完之後比改前差了,git revert,當這次修改沒發生過。
04 獨立評分。 修改skill的agent不能是評分的agent。(上面已展開)
05 人在迴路。 每個skill優化完後系統暫停,展示改動diff、分數變化、測試輸出對比,等用戶確認再繼續下一個。
8個維度,100分制
評分分兩組,總分100:
結構維度(60分)——靜態分析就夠了:
效果維度(40分)——必須實測:
注意實測表現權重最高(25分)。一個skill可以在結構上拿滿分,但跑出來一坨。反過來,寫得粗糙但跑起來好用的skill,比格式完美但沒用的skill有價值得多。
實測的方法:為每個skill設計2-3個典型用戶prompt,用子agent執行——一個帶skill跑,一個不帶skill跑(baseline),對比輸出質量。
實操教程
以WorkBuddy/Claude Code環境為例,4步完成首次評估和優化。
Step 1: 安裝
npx skills add alchaincyf/darwin-skill
GitHub直連不暢時,從倉庫下載zip解壓到 ~/.workbuddy/skills/darwin-skill/ 即可。支持Claude Code、Codex、Trae、WorkBuddy。
Step 2: 首次評估——只看不改
在Agent中輸入:
評估所有skills的質量
系統會掃描所有Skill目錄,為每個Skill設計測試prompt,跑基線評分,輸出評分卡。以下是實際運行結果(15個代表性Skill):
┌──────────────────────┬───────┬──────────────────────┐
│ Skill │ Score │ 主要失分點 │
├──────────────────────┼───────┼──────────────────────┤
│ steve-jobs-skill │ 86 │ — │
│ content-creator │ 84 │ — │
│ draft-writer │ 82 │ — │
│ fact-checker │ 82 │ — │
│ claude-code-info... │ 78 │ 邊界條件偏弱 │
│ cover-generator │ 75 │ 無references目錄 │
│ virality-predictor │ 74 │ 無references目錄 │
│ dbs │ 73 │ description偏短 │
│ diagram │ 72 │ 無用戶確認檢查點 │
│ humanizer │ 69 │ 流程偏鬆散 │
│ baoyu-imagine │ 69 │ 更像CLI手冊 │
│ skills-updater │ 65 │ 無觸發詞+無檢查點 │
│ yao-meta-skill │ 58 │ 無觸發詞+流程抽象 │
│ find-skills │ 56 │ 全英文+無檢查點 │
│ any2pdf │ 32 │ 幾乎為空 │
├──────────────────────┼───────┼──────────────────────┤
│ 平均分 │ 70 │ │
│ 自建Skill平均 │ 78 │ │
│ 社區Skill平均 │ 60 │ │
└──────────────────────┴───────┴──────────────────────┘
怎麼看這張表:關注三個數字——總分(誰拖後腿)、結構分vs效果分(高結構低效果等於紙面漂亮但實戰拉胯)、最弱維度(這就是優化的入口)。
這是針對一個skill的優化診斷部分截圖:
一個需要注意的偏差:比如自建Skill平均78分,社區安裝的60分,差距18分。這個差距大概率是真實存在的——自建Skill經過多輪使用反饋迭代,社區Skill裝完往往沒人管。
但18分這個數字本身可能有測量偏差。評分維度1(frontmatter質量)檢查description和觸發詞,自建Skill通常在這方面打磨過,天然拿高分。而一個skill寫了漂亮的frontmatter,不等於實戰效果就好。
維度8的"實測表現"權重25分,確實在補償這個問題,但評分agent對"什麼樣的輸出算好"本身有偏好。所以18分差距的方向是對的,精確數值當參考。
評分體系的已知侷限
autoresearch能放心跑的核心前提是:val_bpb是一個客觀指標。同樣的數據、同樣的模型、同樣的超參數,跑出來就是那個數字,不會因為換一個agent就變。
達爾文的評分沒有這個 luxury。讓兩個不同的子agent給同一個SKILL.md打分,分數可能差10-15分。"實測表現"維度尤其主觀——"這個輸出質量好不好"不是一個有標準答案的問題。
這引出兩個實際問題:
分數的絕對值意義有限,相對排序更可靠。 一個skill評了72分,另一個78分,能說後者比前者好——前提是同一個評分agent在同一次評估裏打的分。但把這次評估的72分和下週另一次評估的72分直接比較,不一定公平。
人在迴路是必要的,不是可選的。 每次優化後系統展示diff和分數變化,等人類確認。分數從72變到78,到底是真實改進還是評分噪聲?人讀一遍diff,比看數字更有判斷力。
達爾文應對這個問題的設計是:獨立評分(換一個agent打分,降低"自己改自己評"的偏差)+ 人在迴路(人類兜底主觀判斷)。這兩個機制不能消除評分噪聲,但能讓優化方向大概率是對的。
Step 3: 針對性優化
選一個拖後腿的Skill,輸入:
優化 yao-meta-skill 這個skill
系統執行流程:找到得分最低的維度→修改SKILL.md→重新評分→保留或回滾。
yao-meta-skill的優化過程是這樣的:
基線評估: 58分
├─ 第1輪優化: 68分 (保留, +10)
│ 新增10條觸發詞、4個用戶確認檢查點、工作流具體化
└─ 第2輪優化: 76分 (保留, +8)
消除重複章節(201→172行)、Step具體化、邊界條件細化
最終: 58 → 76 (+18分)
第二輪修改後的評分
find-skills的優化幅度更大:
基線評估: 56分
└─ 第1輪優化: 74分 (保留, +18)
description中文化、12條觸發詞、搜索後暫停確認、測試用例、國內GitHub替代方案
最終: 56 → 74 (+18分)
find-skills提升更大的原因在於它的原始問題是結構性缺陷——全英文、零檢查點、零測試用例。這些不是"不夠好",而是"根本沒有"。修復結構性缺陷的收益,通常比精調層面的改善更大。
Step 4: 查看優化歷史
所有數據記錄在 results.tsv 裏,包含時間戳、分數變化、保留或回滾決策、評估方式。每次優化有據可查,可以追溯任何一次變更的具體內容。
實用建議
什麼時候該用達爾文: Skill超過10個且裝完沒做過質量檢查;發現某個Skill時好時壞想系統診斷;新裝了一批Skill想快速摸底。
什麼時候不需要: Skill少於5個,手動讀一遍SKILL.md比跑評分更快;每個Skill的能力邊界都清楚——那已經是重度用戶了。
與同類工具的分工: Anthropic官方的skill-creator從零創建Skill,花叔自己的女媧(nuwa-skill)也從零創建但加入了評估和打包流程,達爾文對已有Skill做質量維護。三者互補,不重疊。
可自己進化的skill
達爾文最大的貢獻,是把Skill質量管理從一個隱性問題變成了一個可量化、可追蹤、可自動化的流程。從"我覺得這個Skill還行"到"這個Skill實測73分,邊界條件扣分最多",這是質的區別。
項目地址:
https://github.com/alchaincyf/darwin-skill
安裝:npx skills add alchaincyf/darwin-skill
使用:裝完後在Agent裏說"優化所有skills"即可。如果你的skill數量超過20個,建議先跑"評估所有skills的質量"摸底,再針對性優化。