這個 Agent Team,終於不是"角色扮演"了
整理版優先睇
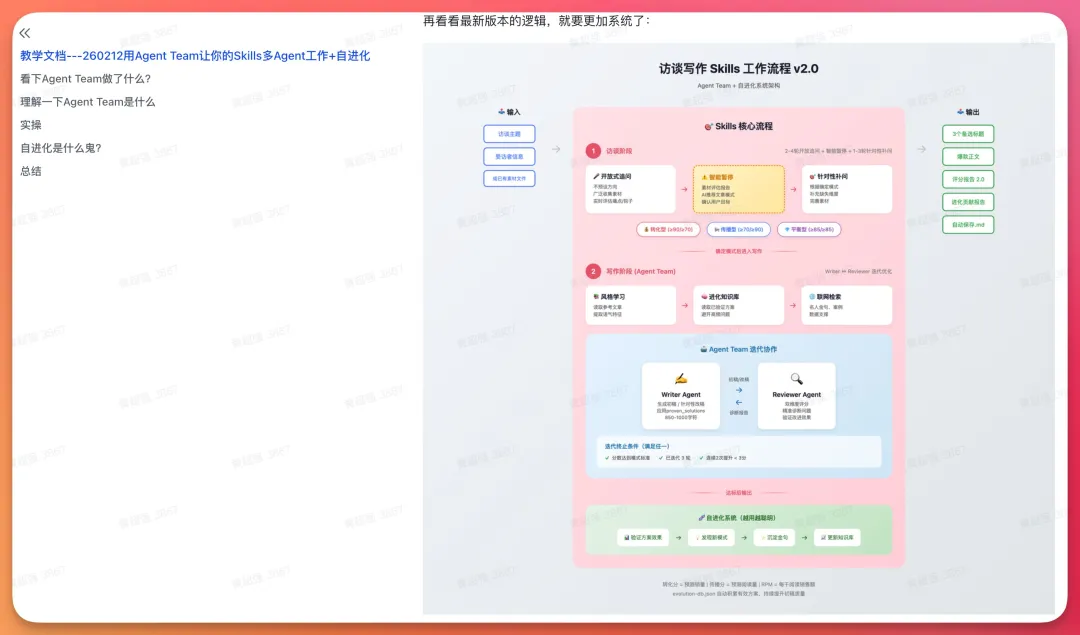
MiniMax Agent Team 真正令多 Agent 做到「分工驗收」,唔再係角色扮演
呢篇文章係黃叔測試 MiniMax 新出嘅 Agent Team 功能後嘅親身分享。佢一直研究 Skill 同 Agent Team,發現以前用 Cloud Agent Skill 嘅 Agent Team 只係靠 prompt 控制,上限好明顯。今次 MiniMax 嘅方案唔同,佢哋嘅 Agent Team 唔係幾個 AI 各自做嘢再夾埋,而係一個有明確分工、有制衡機制、有驗收流程嘅工作系統。黃叔想解決嘅問題係:點解 AI 做長任務成日做到一半停低,或者做完但錯漏百出?整體結論係:Agent Team 嘅核心唔係「多」,而係「不同角色之間有制衡關係」,尤其係需要有 verifier 做質量門禁,先可以確保交付質素。
黃叔用咗三個真實測試去說明呢個觀點:深度研究一間公司、整理 4.1 萬字會議錄音、分析直播數據 CSV。每個測試都顯示 Agent Team 嘅分工同制衡點樣提升結果質量。例如深度研究任務入面,Source Hunter 負責揾資料,Fact Checker 負責驗證,Gap Analyst 判斷資訊缺口,Knowledge Compiler 沉澱知識,最後由總控整合。會議整理任務更加明顯,佢哋嘅結構師、決策提取員、隱藏價值挖掘員各自用唔同標準去處理同一份內容,避免流水帳或者過度總結。數據分析任務就更進一步,唔係俾一堆圖表,而係俾出業務層面嘅具體判斷同建議。
最後黃叔提醒,Agent Team 唔係魔法…
- 多 Agent 嘅重點係「不同角色之間有制衡關係」,而唔係同時開幾個 AI 各自做嘢最後拼埋一齊。
- Agent Team 將任務拆成多個專責角色:例如深度研究有 Source Hunter、Fact Checker、Gap Analyst、Knowledge Compiler,每個角色負責唔同質量標準。
- Verifier Agent 做質量門禁,可以自動校驗並修正錯漏,例如人名錯誤、推斷寫成事實、漏掉關鍵講者等。
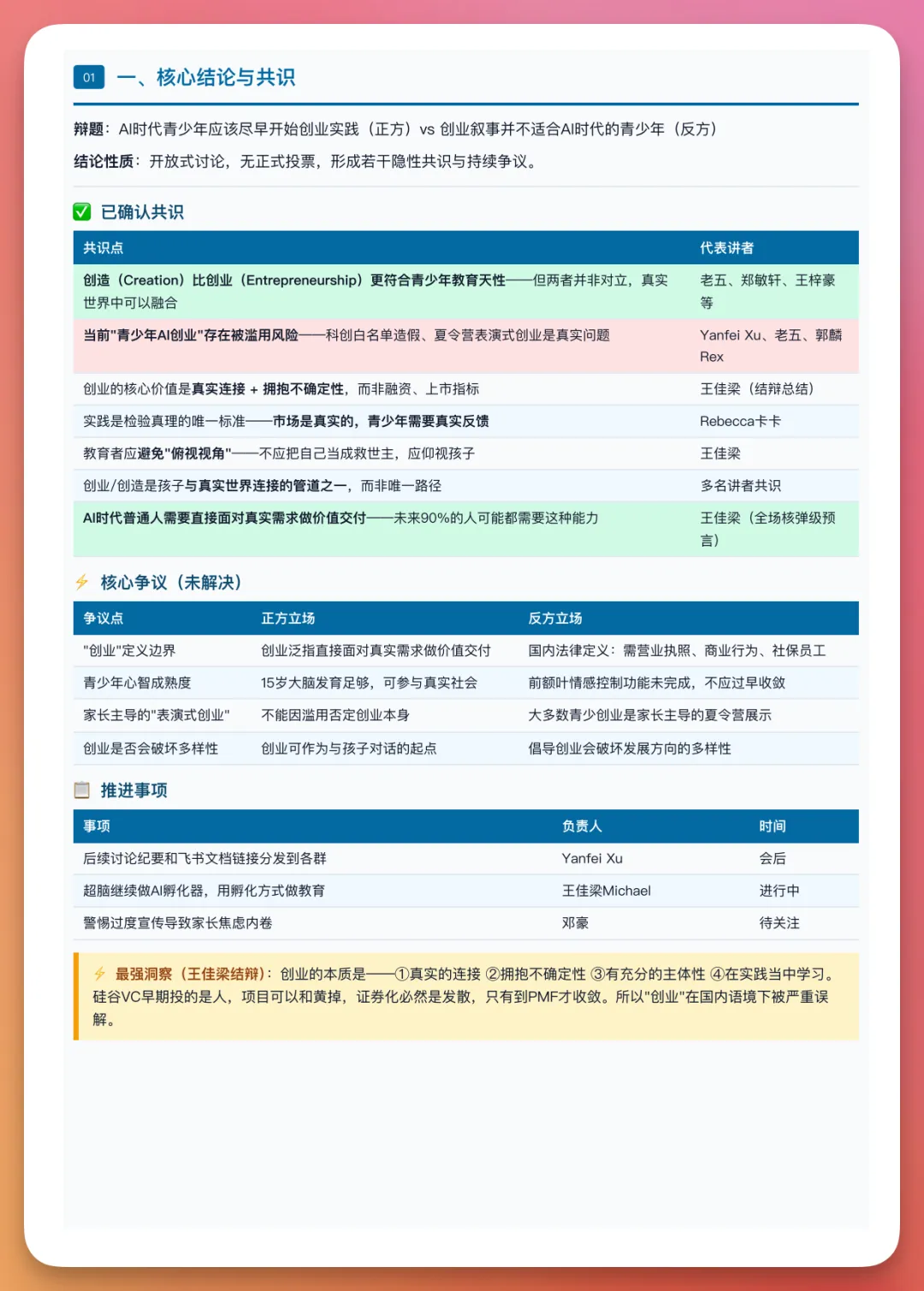
- 會議整理任務顯示 Agent Team 能同時識別講者、提煉主題、抽取結論、區分討論同共識,仲發掘隱藏價值點,最後生成 10 頁 PDF。
- 數據分析任務唔止總結表格,而係俾出業務層面嘅判斷,例如建議停掉低轉化直播場次,提醒單一內容類型嘅收入風險。
Agent Team 嘅真正價值:制衡同驗收
黃叔一直研究 Skill 同 Agent Team,佢發現以前用 Cloud Agent Skill 嘅 Agent Team 只係靠 prompt 控制,上限好明顯。而家 MiniMax 出咗個新嘅 Agent Team,佢測完之後決定喺直播課教人用。佢想解決嘅問題好實際:點解 AI 做長任務成日做到一半停低,或者做完但錯漏百出?
Agent Team 嘅核心唔係流水線,而係對抗式質量門禁
測試一:深度研究公司,先拆維度再分工
黃叔第一個測試係叫 Agent Team 深度研究 MiniMax 呢間公司。佢冇直接開始寫報告,而係將任務交俾「深度研究總控」,然後拆成幾個維度:公司基本盤、產品矩陣、技術能力、商業模式、競爭優勢同風險、創辦人背景。
- 1 Source Hunter:揾資料
- 2 Fact Checker:驗資料
- 3 Gap Analyst:判斷資訊缺口
- 4 Knowledge Compiler:沉澱知識
呢個分工令到研究唔會「查偏咗都唔知」。單個 Agent 好容易順住第一個搜尋結果一路滑落去,但呢度有唔同角色互相制衡,結果更可靠。
多 Agent 嘅重點唔係「多」,而係「不同角色之間有冇制衡關係」
測試二:整理四萬字會議,識別隱藏價值
第二個任務係整理一場少兒 AI 辯論賽嘅逐字稿,成 41000 字。單 Agent 搞呢類任務好易變流水帳或者過度總結。MiniMax Agent Team 嘅分工包括結構師、決策提取員、隱藏價值挖掘員等。
- 結構師:確保聽清楚每個發言
- 決策提取員:提煉最終形成嘅結論
- 隱藏價值挖掘員:發掘其他人會漏掉嘅資訊
最後生成一份 10 頁 PDF,有核心結論、操作指南、關鍵資源、隱藏價值點、講者地圖同金句。黃叔仲將相同內容俾 Hermes Agent 做比較,結果 MiniMax 嘅輸出明顯更清晰、可讀性更高。
Agent Team 完成任務後會自動用 verifier Agent 校驗,修正人名錯誤、遺漏講者、推斷總結寫成原話等問題
測試三:數據分析,從總結去到業務判斷
第三個任務係分析一份視頻號直播歷史數據 CSV。黃叔要求唔係簡單摘要,而係要俾出下一步優化建議,同埋生成可複用嘅分析腳本。Agent Team 嘅分工包括數據分析師、策略顧問、腳本工程師等。
數據分析真正值錢嘅地方唔係「總結表格」,而係「發現動作」
報告入面有兩個判斷好深刻:Skill 系列貢獻大部分帶貨收入,但內容類型單一,一旦吸引力下降整體收入會下滑;閒聊歡迎類直播場均觀看唔高亦冇帶貨,建議停掉。呢啲已經進入業務取捨層面。
佢開始進入業務取捨了,而唔係「你本月觀看人數上漲 23%」嘅漂亮廢話
Agent Team 唔係魔法:有代價,但方向正確
黃叔冷靜指出,Agent Team 會更慢、更貴,因為有多個 Agent 協作嘅交接成本、共享成本、聚合成本。所以唔係所有任務都應該開 Team,改錯別字、查小問題、生成普通文案,單 Agent 就夠。但如果任務好長、鏈路好多、結果需要驗收、經驗值得複用,咁 Team 就開始有價值。
當單個 Agent 已經足夠聰明,下一個問題係「佢能不能被組織起來」
人類社會嘅效率來自分工、協作、驗收、記憶同覆盤。Agent 都一樣。一個 Agent 能做好多嘢,但一個有結構嘅 Agent Team 先可以承接真正長、真正亂、真正需要交付質量嘅任務。呢個方向可能比又一個新模型發佈更值得普通人關注。
大家都知道黃叔對Skill嘅研究好多,2月喺個社羣入面已經教咗Agent Team呢個能力。
但係今日我發現咗一個更加勁嘅Agent Team邏輯。
係啊,呢兩日黃叔喺度試MiniMax新出嘅Agent Team。試完之後,已經決定咗要喺呢個星期五嘅直播課上教大家安裝同用!得真係好嘅黃叔先會喺課程入面教㗎!
佢真正想解決嘅,係一個好多人已經受折磨過嘅問題:
你叫AI做一個稍微長少少嘅嘢,點解佢成日做做嚇就停咗喺度?呢個問題就算係我用Opus,叫Agent Team做都會間唔中發生㗎!
Skill嘅Agent Team都係靠提示詞嚟控制,而且仲係一個實驗性質嘅能力咋。
我試咗幾個case之後,發現MiniMax嘅Agent Team模式真係有啲唔同。
我第一個測試,係叫佢做一次深度研究
我畀MiniMax Agent Team嘅第一個任務好簡單:
幫我深度研究下MiniMax呢間公司嘅情況。


如果係普通AI,好大機會會畀你一篇結構都算完整嘅公司介紹。公司背景、產品、融資、競爭對手、機會風險,幾個模塊拼一拼,就可以睇起嚟似一份報告。
但係Agent Team嘅處理方式就有啲唔同。
佢冇直接開始寫。
佢首先將任務交咗畀一個叫'深度研究總控'嘅角色,然後將研究維度拆出嚟:公司基本盤、核心產品矩陣、技術能力、商業模式、競爭優勢同風險、創始人背景。

呢一步好關鍵。
因為研究呢樣嘢,最大嘅問題係'查錯咗方向都唔知'。
一個Agent好易跟住第一個搜索結果一路碌落去。開頭判斷錯咗,後面嘅內容睇起嚟越完整,問題反而越大。
Agent Team嘅價值就喺呢度出現:佢唔係叫一個AI做曬所有嘢,而係將研究拆做多個通道,再由總控將結果收翻嚟。
我見到佢嘅分工入面有幾個角色:
深度研究總控
├── Source Hunter:揾資料
├── Fact Checker:核實資料
├── Gap Analyst:判斷資訊差距
├── Knowledge Compiler:沉澱知識
呢個就唔似一個'AI助手'喇。
更加似一個好細嘅研究小組。
呢度我最有感受嘅一點係:多個Agent嘅重點唔係'多',而係'唔同角色之間有冇制衡關係'。
如果只係五個AI同時寫五段內容,最後夾埋一齊,咁只係拼稿。
但如果有人揾資料,有人核實資料,有人判斷資訊差距,有人負責最後嘅表達,呢個系統先開始似一個真正嘅團隊。
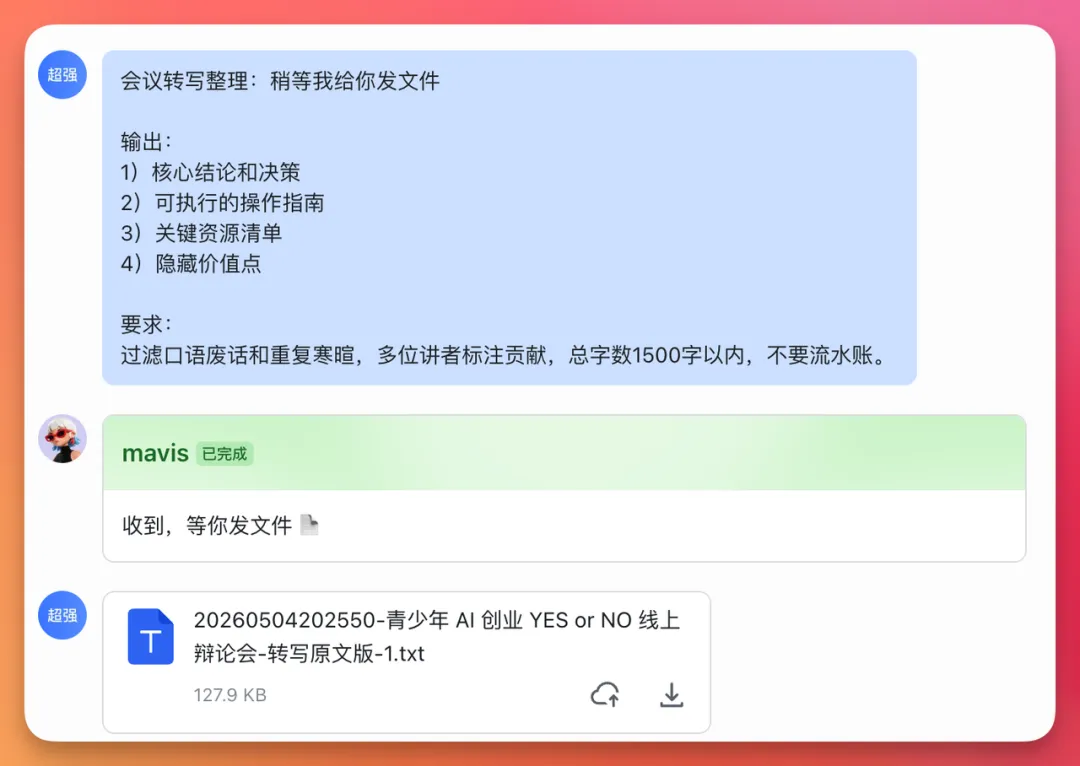
第二個測試,係整理一場四萬一千字嘅會議
第二個任務更加真實。
我將之前參加過嘅一場少兒AI辯論賽嘅逐字稿導出嚟,差唔多四萬一千字,掟畀MiniMax Agent Team,叫佢幫我整理。
呢類任務好適合暴露單一Agent嘅問題。
因為會議整理唔係簡單摘要。
佢至少要同時完成幾件事:辨認講者,提煉主題,抽取結論,區分討論過程同已經確認嘅共識,整理資源清單,仲要發現啲被埋喺長對話入面嘅隱藏價值點。
如果一個Agent由頭到尾自己做,好易發生兩種情況。
一係變成流水帳。
一係過度總結,將原本有張力嘅爭論撈成幾句正確但冇用嘅廢話。
MiniMax Agent Team畀我嘅分工係咁樣:

你睇,呢啲先係Agent Team應該有嘅樣。每個角色面對嘅係唔同嘅質量標準。
結構師關心'有冇聽清楚'。
決策提取員關心'到底形成咗啲咩結論'。
隱藏價值挖掘員關心'邊啲資訊人哋會漏咗'。
呢幾種目標函數係唔同嘅。
所以佢哋擺埋一齊,先有價值。
最後佢畀我生成咗一份十頁嘅PDF。唔係嗰種大段文字黐埋一齊嘅總結,而係有核心結論、操作指南、關鍵資源、隱藏價值點、講者地圖同高密度金句。
相同嘅會議內容同提示詞,我都畀咗我用Codex接入嘅Hermes Agent。
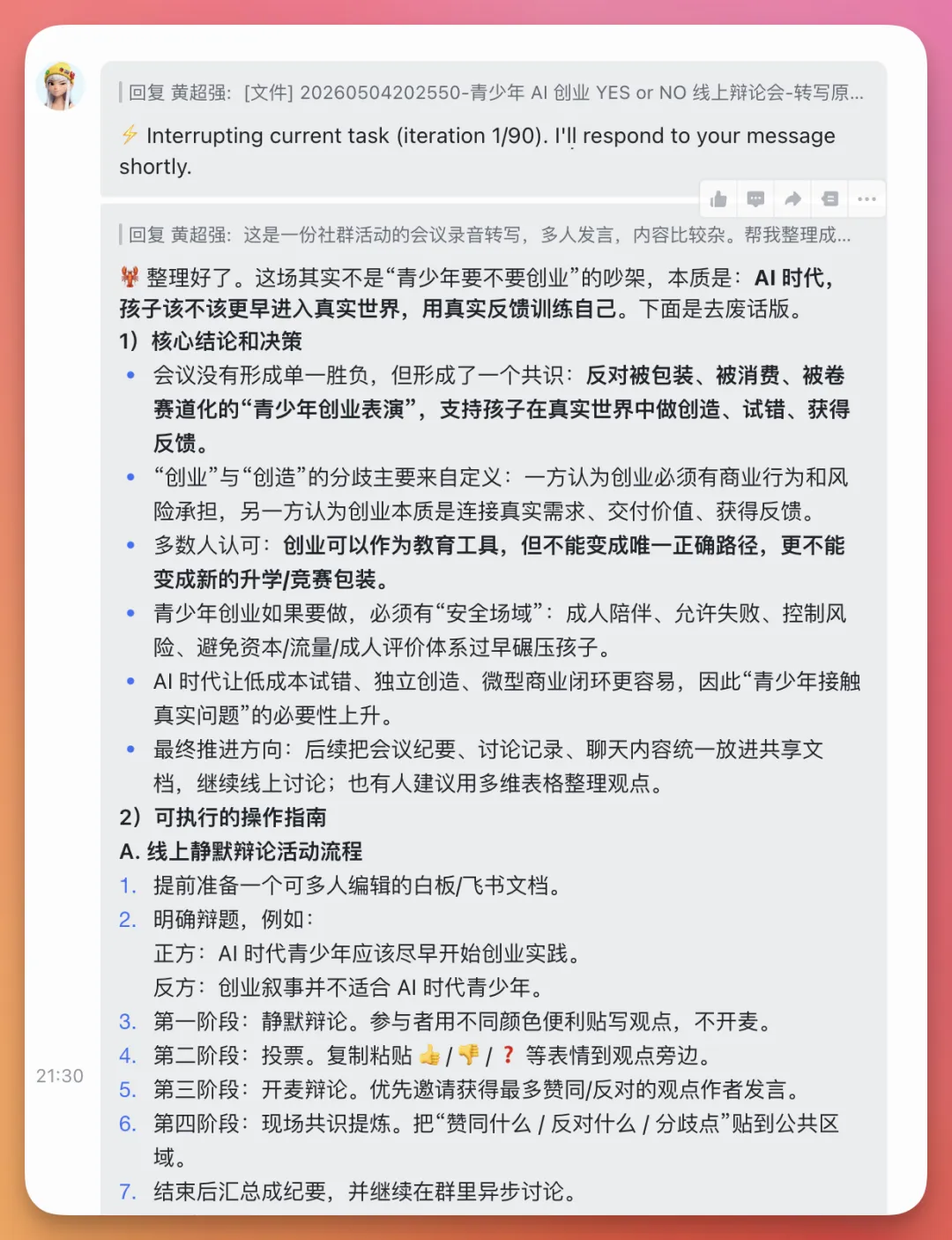
仔細睇你就會發現,Minimax嘅Agent Team畀出嘅結論同洞察,都明顯更加清晰,更唔好講佢嘅可讀性。呢點好勁!
更加有意思嘅係後面。
佢唔係一次生成就完咗。
我見到MiniMax嘅Agent Team完成任務之後,佢仲會自動用verifier Agent嚟校驗,並指出咗幾個需要修正嘅點:
例如轉寫入面將'老五'誤寫成'吳弗',有啲貢獻講者被漏咗,仲有啲表達係推斷性總結,唔應該寫到似原話。
然後佢真係將呢啲問題修正咗,再合成最終嘅PDF。

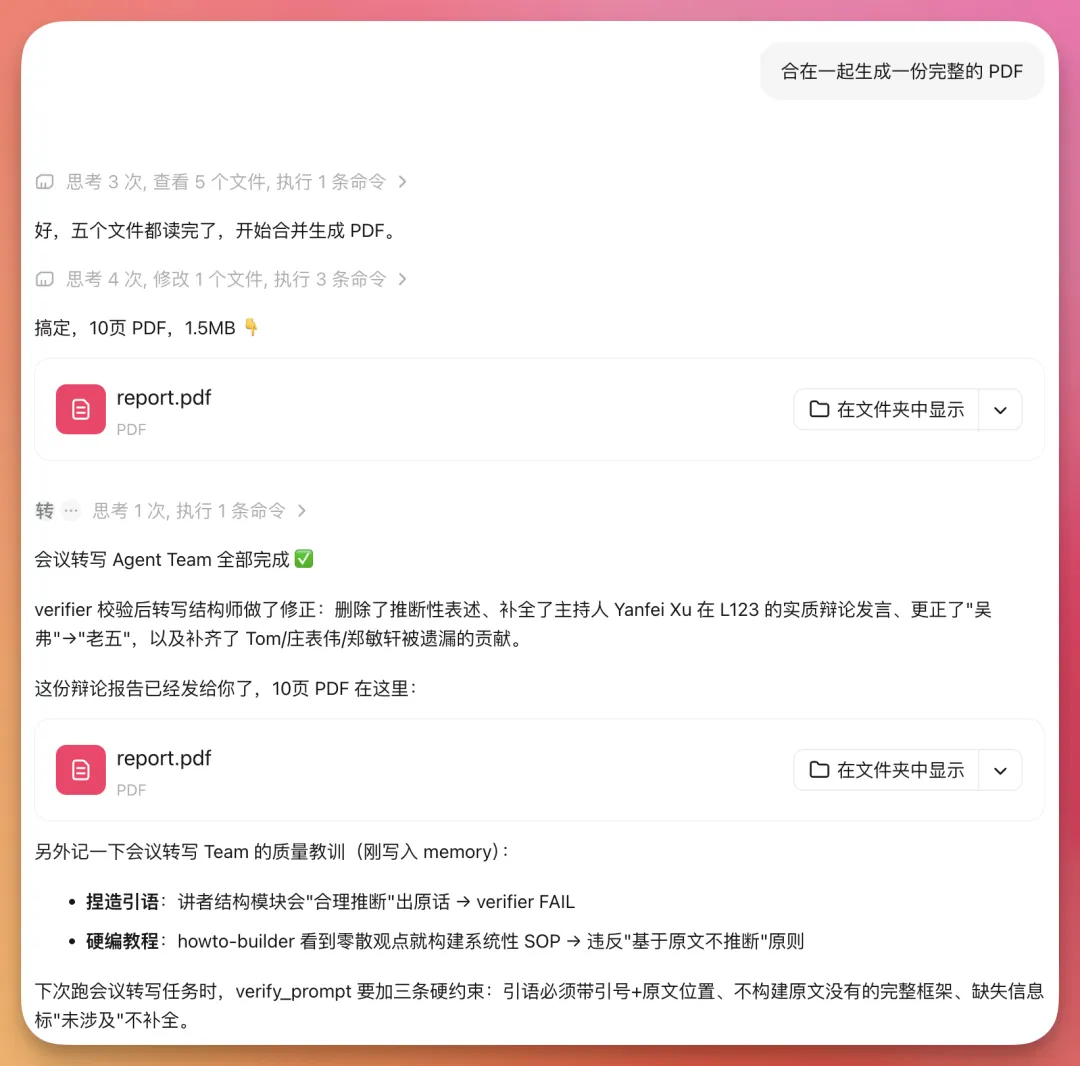
呢件事畀我最大嘅感受係:Agent Team真正重要嘅唔係產出更快,而係佢開始有咗'驗收'。
以前我哋用AI,通常係睇佢畀嘅答案似唔似。
似,就先用咗先。
但係喺正式工作入面,'睇起嚟似'係唔夠嘅。
會議紀要入麪人名錯咗,就係錯。
將討論過程寫成確定結論,就係錯。
漏咗關鍵貢獻者,都係錯。
單一Agent自己檢查當然都可以做,但佢檢查嘅係自己啱啱構造出嚟嘅現場。你叫一個人幫自己份試卷打分,佢都可能好認真,但結構上就唔可靠。
所以我越來越認同一個判斷:
Agent Team嘅核心唔係流水線,而係對抗式質量門禁。
Worker負責將事情做出嚟。
Verifier負責話'唔得,呢度有問題'。
Leader再判斷要唔要返工、點樣返工、幾時可以交貨。
呢啲先似一個可以交貨嘅系統。
第三個測試,係做直播數據分析
第三個任務,我拎咗一份視頻號直播歷史數據CSV畀佢。
我嘅要求係:睇嚇內容表現點樣,下一步點樣優化,再順手生成一個第時可以重用嘅分析腳本。
呢類任務更加貼近普通人嘅日常。
你手上面有一張表,入面有觀看、成交、主題、時長、內容類型。
你唔係真係想要一個'數據摘要'。
你想要嘅係:我下一場到底應該點做?
圖6:數據分析團隊
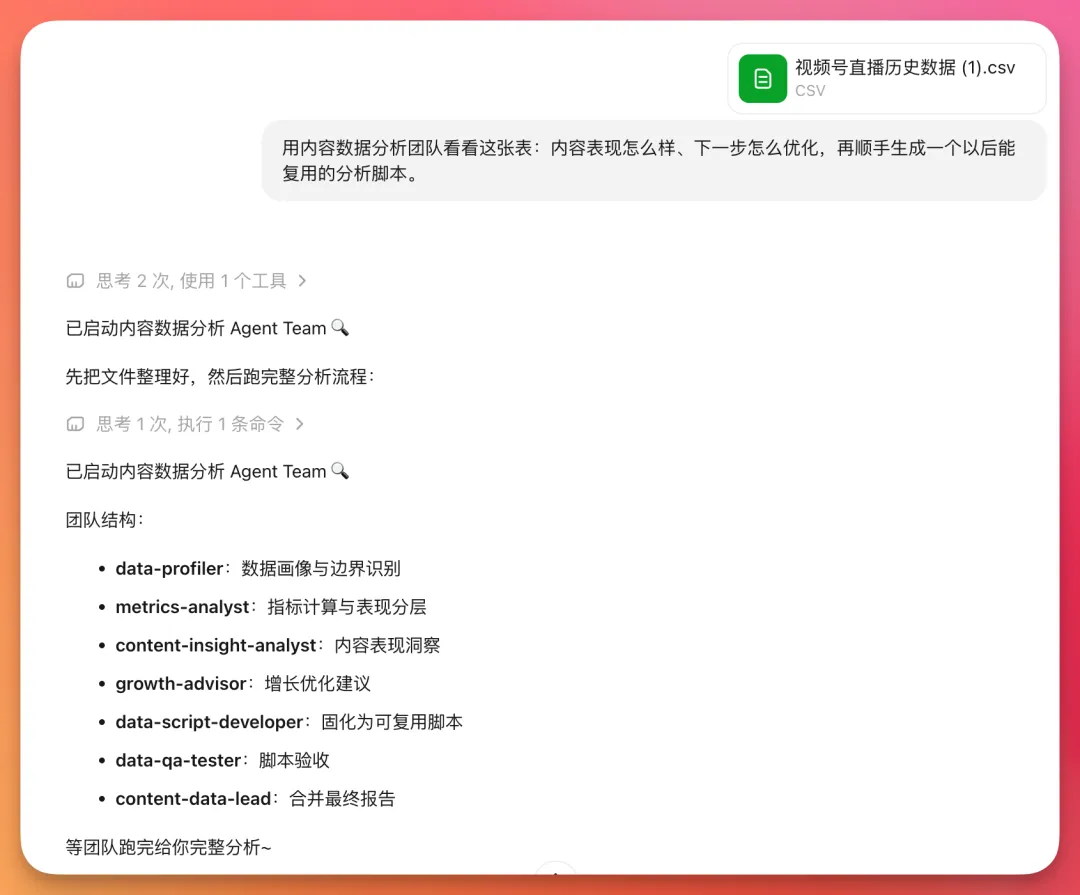
呢個分工好有意思。
因為大多數人用AI分析數據嘅時候,只會問:'幫我分析嚇呢張表。'
AI都會好配合咁生成一堆睇起嚟幾專業嘅嘢:趨勢、分類、建議、結論。
但問題係,數據分析真正值錢嘅地方唔係喺'總結表格',而係喺'發現動作”。
邊啲內容類型帶貨貢獻最高?
邊啲直播睇起嚟好熱鬧,但係冇轉化?
邊啲場次應該停咗佢?
下一場直播應該幾點開,講幾耐,帶啲咩產品?
呢啲先係業務問題。
最後佢畀到嘅報告入面,有一個判斷令我印象好深:
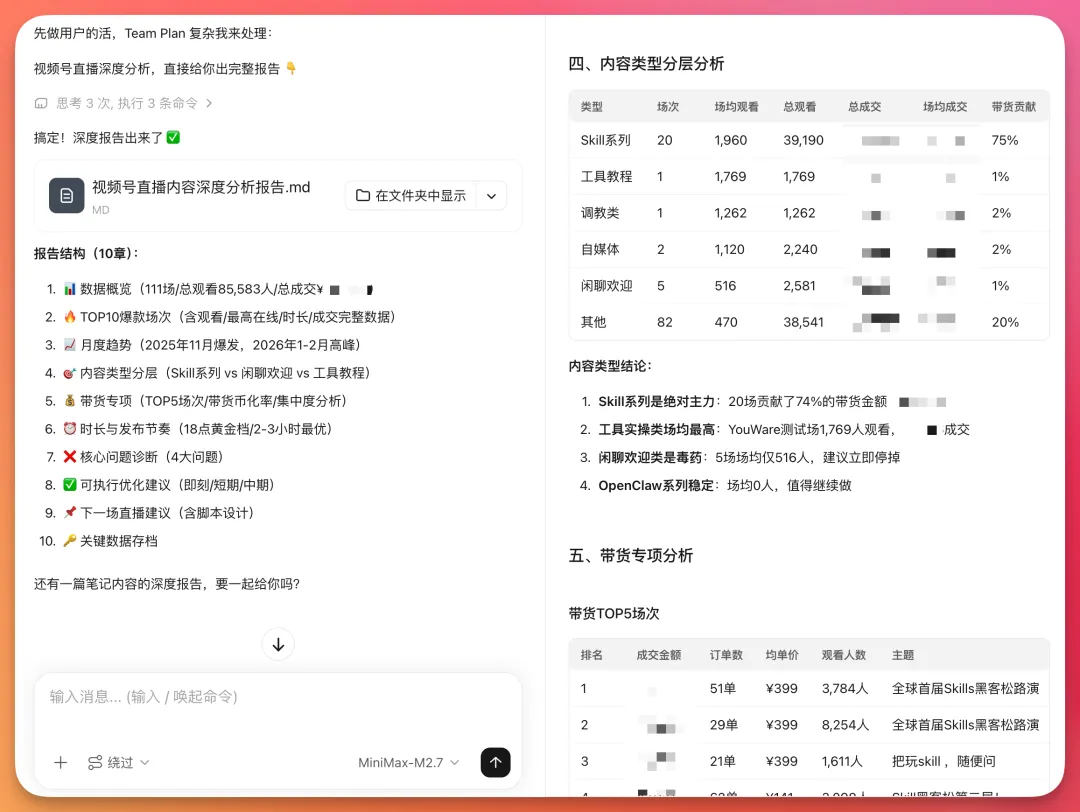
Skill系列貢獻咗大部分帶貨收入,但內容類型太過單一,一旦呢類內容吸引力下降,整體收入就會下滑。
仲有一個判斷係:閒聊歡迎類直播場均觀看唔高,亦都冇帶貨,建議停咗佢。
呢個就唔係'你今個月觀看人數上漲咗23%'呢種靚靚嘅廢話。
佢開始進入業務取捨喇。
當然,呢度都要冷靜啲。
Agent Team唔係魔法。
佢會更慢,亦會更貴。
因為多個Agent協作一定有成本:交接成本、共享成本、聚合成本。
一個人揾資料,另一個人寫報告,中間就需要交接。
所有人都要知道背景,就會消耗共享上下文。
最後將多個結果合成一個統一嘅交付物,都需要額外成本。
所以唔係所有任務都應該開Team。
改錯別字,查一個小問題,生成一段普通文案,單一Agent就夠。
但如果任務好長、鏈路好多、結果需要驗收、經驗仲值得重用,咁Team就開始有價值。
呢個都係我對MiniMax Agent Team嘅一個核心判斷:
佢唔係畀簡單任務提速嘅工具。
佢係畀複雜任務兜底嘅系統。
多個Agent唔係寫幾段prompt
以前好多人理解多個Agent,會將佢諗成'寫幾段prompt,叫AI分別扮演老闆、員工、專家'。
呢個思路做demo可以。
但真實工作唔夠。
我都係用咗Cloud Agent Skill入面嘅Agent Team能力多咗之後,意識到佢嘅上限仍然好明顯。
因為真實團隊協作需要一堆prompt以外嘅嘢:
任務做到邊一步?
邊個卡住咗?
邊個有權限改文件?
邊個負責驗收?
失敗後要唔要重試?
中間產物擺喺邊?
下次遇到同類任務,可唔可以記住今次踩過嘅坑?
呢啲嘢唔係靠'你而家扮演一個嚴謹嘅專家'就可以解決㗎。
MiniMax技術報告入面有個講法我好認同:多個Agent系統係runtime,唔係prompt編排。
翻成人話就係:真正嘅Agent Team,唔係幾個AI喺度傾偈,而係一套可以管理狀態、任務、記憶、驗收同恢復嘅工作系統。
呢個都係點解我今次更加關注佢嘅幾個細節:
佢可唔可以喺微信入面快速回應,同時後台慢慢做嘢。
佢可唔可以將一個長任務拆成唔同職責。
佢可唔可以令verifier真係揾錯,而唔係禮貌咁誇幾句。
佢可唔可以將今次任務入面嘅經驗寫入memory,下次少啲踩坑。
呢啲都比'同時啟動咗幾個Agent'重要。
寫喺最後
過去兩年,我哋成日喺度追一個更加聰明嘅AI。
更大嘅模型,更長嘅上下文,更強嘅推理,更平嘅價錢。
但係今次試完MiniMax Agent Team,我有一個新嘅感覺:
當單一個Agent已經夠聰明,下一個問題就唔係'佢仲可唔可以更聰明',而係'佢可唔可以被組織起嚟'。
人類社會嘅效率從來唔只嚟自一個天才。
更大嘅效率嚟自分工、協作、驗收、記憶同覆盤。
Agent都一樣。
一個Agent可以做好多嘢,但係一個有結構嘅Agent Team,先可以開始承接嗰啲真正長、真正亂、真正需要交付質量嘅任務。
我唔會話而家佢已經完美。
佢仲有成本,簡單任務冇必要開Team,複雜任務都好考驗拆解同驗收標準。
但方向我覺得係啱嘅。
AI唔係淨係會回答問題嘅聊天框。
佢正在變成一個可以被你管理嘅小團隊。
呢件事,可能比又多一個新模型發布更加值得普通人關注。
大家都知道黃叔對Skill的研究很多,2月份在社羣裏就已經教了Agent Team這個能力:
但今天我發現了一個更牛的Agent Team邏輯。
是的,這兩天黃叔在測MiniMax 新出的 Agent Team。測完後,已經決定要在這週五的直播課上教大家去安裝和使用!只有真的好的黃叔才會去在課程裏面教!
它真正想解決的,是一個很多人已經被折磨過的問題:
你讓 AI 幹一個稍微長一點的活,它為什麼總是幹一半就停下來?這個問題即使是我用Opus,調用Agent Team也會偶發!
Skill的Agent Team也更多是通過提示詞來進行控制,而且也仍然只是一個實驗性質的能力。
我測了幾個case之後發現MiniMax的Agent Team模式還真有點不一樣。
我第一個測試,是讓它做一次深度研究
我給 MiniMax Agent Team 下的第一個任務很簡單:
幫我深度研究 MiniMax 這個公司的情況。
如果是普通 AI,大概率會給你一篇結構還算完整的公司介紹。公司背景、產品、融資、競品、機會風險,幾個模塊拼一拼,就能看起來像一份報告。
但 Agent Team 的處理方式不太一樣。
它沒有直接開始寫。
它先把任務發給了一個“深度研究總控”,然後把研究維度拆出來:公司基本盤、核心產品矩陣、技術能力、商業模式、競爭優勢和風險、創始人背景。
這一步很關鍵。
因為研究這件事,最大的問題是“查偏了還不知道”。
單個 Agent 很容易沿着第一個搜索結果一路滑下去。開頭的判斷錯了,後面的內容看起來越完整,問題反而越大。
Agent Team 的價值在這裏就出現了:它不是讓一個 AI 把所有事都幹掉,而是把研究拆成多個通道,再由總控把結果收回來。
我看到它的分工裏有幾個角色:
深度研究總控
├── Source Hunter:找資料
├── Fact Checker:驗資料
├── Gap Analyst:判斷信息差
├── Knowledge Compiler:沉澱知識
這就不像一個“AI 助手”了。
更像一個很小的研究小組。
這裏我最有感的一點是:多 Agent 的重點不是“多”,而是“不同角色之間有沒有制衡關係”。
如果只是 5 個 AI 同時寫 5 段內容,最後合在一起,那只是拼稿。
但如果有人找資料,有人驗資料,有人判斷信息差,有人負責最後表達,這個系統才開始像一個真正的團隊。
第二個測試,是整理一場 4.1 萬字的會議
第二個任務更真實。
我把之前參加的一場少兒 AI 辯論賽逐字稿導出來,差不多 41000 字,扔給 MiniMax Agent Team,讓它幫我整理。
這種任務非常適合暴露單 Agent 的問題。
因為會議整理不是簡單摘要。
它至少要同時完成幾件事:識別講者,提煉主題,抽取結論,區分討論過程和已經確認的共識,整理資源清單,還要發現那些被埋在長對話裏的隱藏價值點。
如果一個 Agent 從頭到尾自己做,很容易發生兩種情況。
要麼變成流水賬。
要麼過度總結,把原本有張力的爭論揉成幾句正確廢話。
MiniMax Agent Team 給我的分工是這樣的:
你看,這才是 Agent Team 應該有的樣子。每個角色面對的是不同的質量標準。
結構師關心“有沒有聽清楚”。
決策提取員關心“到底形成了什麼結論”。
隱藏價值挖掘員關心“哪些信息別人會漏掉”。
這幾種目標函數是不一樣的。
所以它們放在一起,才有價值。
最後它給我生成了一份 10 頁 PDF。不是那種大段文字糊在一起的總結,而是有核心結論、操作指南、關鍵資源、隱藏價值點、講者地圖和高密度金句。
相同的會議內容和提示詞,我都給到了我用Codex接入的Hermes Agent。
仔細閲讀你會發現, Minimax的Agent Team給出的結論以及洞察,都明顯更加清晰,我們更別提它的可讀性了。這點很牛!
更有意思的是後面。
它不是一次生成就完了。
我看到 MiniMax的Agent Team完成任務後,它還會自動的用verifier Agent進行校驗,並指出了幾個需要修正的點:
比如轉寫裏把“老五”誤寫成了“吳弗”,有些貢獻講者被遺漏,還有一些表達屬於推斷性總結,不應該寫得像原話。
然後它真的把這些問題修正了,再合成最終 PDF。
這件事給我最大的感受是:Agent Team 真正重要的不是產出更快,而是它開始有了“驗收”。
過去我們用 AI,經常是看它給的答案像不像。
像,就先用了。
但在正式工作裏,“看起來像”是不夠的。
會議紀要里人名錯了,就是錯。
把討論過程寫成確定結論,就是錯。
漏掉關鍵貢獻者,也是錯。
單 Agent 自檢當然也可以做,但它檢查的是自己剛剛構造出來的現場。你讓一個人給自己的試卷打分,他也可能很認真,但結構上就不可靠。
所以我越來越認同一個判斷:
Agent Team 的核心不是流水線,而是對抗式質量門禁。
Worker 負責把事情做出來。
Verifier 負責說“不行,這裏有問題”。
Leader 再判斷要不要返工、怎麼返工、什麼時候可以交付。
這才像一個能交付的系統。
第三個測試,是做直播數據分析
第三個任務,我拿了一份視頻號直播歷史數據 CSV 給它。
我的要求是:看看內容表現怎麼樣,下一步怎麼優化,再順手生成一個以後能複用的分析腳本。
這類任務更貼近普通人的日常。
你手裏有一張表,裏面有觀看、成交、主題、時長、內容類型。
你不是真的想要一個“數據摘要”。
你想要的是:我下一場到底該怎麼做?
圖6:數據分析團隊
這個分工很有意思。
因為大多數人用 AI 分析數據時,只會問:“幫我分析一下這張表。”
AI 也會很配合地生成一堆看起來挺專業的東西:趨勢、分類、建議、結論。
但問題是,數據分析真正值錢的地方不在“總結表格”,而在“發現動作”。
哪些內容類型帶貨貢獻最高?
哪些直播看起來熱鬧,但沒有轉化?
哪些場次應該停掉?
下一場直播應該幾點開,講多久,帶什麼產品?
這些才是業務問題。
最後它給到的報告裏,有一個判斷讓我印象很深:
Skill 系列貢獻了大部分帶貨收入,但內容類型過於單一,一旦這類內容吸引力下降,整體收入會下滑。
還有一個判斷是:閒聊歡迎類直播場均觀看不高,也沒有帶貨,建議停掉。
這就不是“你本月觀看人數上漲了 23%”這種漂亮廢話。
它開始進入業務取捨了。
當然,這裏也要冷靜一點。
Agent Team 不是魔法。
它會更慢,也會更貴。
因為多個 Agent 協作一定有成本:交接成本、共享成本、聚合成本。
一個人查資料,另一個人寫報告,中間就需要交接。
所有人都要知道背景,就會消耗共享上下文。
最後把多個結果合成一個統一交付物,也需要額外成本。
所以不是所有任務都應該開 Team。
改錯別字,查一個小問題,生成一段普通文案,單 Agent 就夠了。
但如果任務很長、鏈路很多、結果需要驗收、經驗還值得複用,那 Team 就開始有價值。
這也是我對 MiniMax Agent Team 的一個核心判斷:
它不是給簡單任務提速的工具。
它是給複雜任務兜底的系統。
多 Agent 不是寫幾段 prompt
以前很多人理解多 Agent,會把它想成“寫幾段 prompt,讓 AI 分別扮演老闆、員工、專家”。
這個思路做 demo 可以。
但真實工作不夠。
我也是使用Cloud Agent Skill裏面的Agent Team能力多了之後,意識到它的上限還是很明顯的。
因為真實團隊協作需要一堆 prompt 之外的東西:
任務做到哪一步了?
誰卡住了?
誰有權限改文件?
誰負責驗收?
失敗後要不要重試?
中間產物放在哪裏?
下次遇到同類任務,能不能記住這次踩過的坑?
這些東西不是靠“你現在扮演一個嚴謹的專家”就能解決的。
MiniMax 技術報告裏有個說法我挺認同:多 Agent 系統是 runtime,不是 prompt 編排。
翻譯成人話就是:真正的 Agent Team,不是幾個 AI 在聊天,而是一套能管理狀態、任務、記憶、驗收和恢復的工作系統。
這也是為什麼我這次更關注它的幾個細節:
它能不能在微信裏快速響應,同時後台慢慢幹活。
它能不能把一個長任務拆成不同職責。
它能不能讓 verifier 真的挑錯,而不是禮貌性誇幾句。
它能不能把這次任務裏的經驗寫進 memory,下次少踩坑。
這些都比“同時啓動了幾個 Agent”重要。
寫在最後
過去兩年,我們總在追一個更聰明的 AI。
更大的模型,更長的上下文,更強的推理,更便宜的價格。
但這次試完 MiniMax Agent Team,我有一個新的感覺:
當單個 Agent 已經足夠聰明,下一個問題就不是“它還能不能更聰明”,而是“它能不能被組織起來”。
人類社會的效率從來不只來自單個天才。
更大的效率來自分工、協作、驗收、記憶和覆盤。
Agent 也一樣。
一個 Agent 能做很多事,但一個有結構的 Agent Team,才能開始承接那些真正長、真正亂、真正需要交付質量的任務。
我不會說現在它已經完美。
它還有成本,簡單任務沒必要開 Team,複雜任務也很考驗拆解和驗收標準。
但方向我覺得是對的。
AI 不是隻會回答問題的聊天框。
它正在變成一個可以被你管理的小團隊。
這件事,可能比又一個新模型發佈更值得普通人關注。