這款神級 Skill 徹底殺瘋,公眾號/飛書/推文通殺!任何 URL 都能轉成 Markdown
整理版優先睇
markdown-proxy:一個Claude Code Skill,自動將任何URL轉為乾淨Markdown,解決反爬、噪音同降級問題
大家好,我係小智,專注AI工具、AI智能體同編程提效痛點分析。對於搞內容矩陣嘅朋友嚟講,有一個高頻痛點:每日都需要透過URL抓取大量文章、推文或文檔作為參考資料。但係直接將連結掉畀AI,結果往往唔多理想——要麼因為防爬蟲機制提取唔出內容,要麼只係拎到一堆充滿噪音嘅HTML代碼。要知道,餵畀大模型嘅數據,質量越高、結構越清晰(尤其係Markdown格式),佢輸出嘅結果先至越精準。
markdown-proxy就係專門為解決呢個痛點而生嘅方案。佢係一個極其強大嘅Claude Code Skill,安裝之後,你只需要將任何URL掉畀Claude,佢就會自動判斷連結類型,選擇最合適嘅抓取通道,為你輸出乾淨、結構化嘅Markdown內容。無論係反爬嚴格嘅微信公眾號、需要認證嘅飛書文檔,定係X/Twitter嘅推文,佢都能輕鬆搞定。
整體結論:markdown-proxy以不足400行Python代碼,結合免費代理服務,實現咗一個零API Key依賴(除飛書外)、能應對多種平台限制嘅URL轉Markdown方案。佢嘅Skill化設計令用戶無需記命令,喺對話中直接發連結即可,大大降低使用門檻。無論係開發者定係內容創作者,都能從中獲益。
- markdown-proxy係一個Claude Code Skill,能夠將任何URL自動轉換為乾淨Markdown,顯著提升AI對網頁內容嘅理解同處理效果。
- 採用路由分發 + 四層降級架構:微信公眾號用Playwright無頭瀏覽器繞過反爬;飛書文檔直接調用開放API轉換Block;YouTube用專用skill;其他URL經r.jina.ai、defuddle.md、agent-fetch、defuddle CLI四級降級,確保高可用。
- 相比Claude Code內置WebFetch,解決咗三大硬傷:過唔到登錄牆、輸出充滿噪音、無自動降級策略。
- Skill化設計示範咗點樣將複雜工具整合到AI對話中,用戶唔需要學習新指令,直接發連結就搞掂,係AI工具整合嘅最佳實踐。
- 可以立即用`npx skills add joeseesun/markdown-proxy`安裝,基礎功能開箱即用;如需抓取公眾號,額外安裝Playwright;如需飛書文檔,設定環境變量FEISHU_APP_ID同FEISHU_APP_SECRET。
markdown-proxy GitHub 項目
Claude Code Skill,將任意URL轉為Markdown,支援微信公眾號、飛書文檔、Twitter等平台。
URL轉Markdown嘅痛點與一次過解決方案
對於需要經常將網頁內容餵畀AI分析嘅開發者或內容創作者嚟講,直接將URL丟畀Claude Code往往唔work,因為內置WebFetch有三個硬傷:登錄牆過唔到、輸出噪音多、無自動降級策略。
直接將URL丟畀AI,往往只拎到噪音HTML或空白頁面,數據質量大打折扣。
為咗解決呢個高頻痛點,小智推薦咗一個Claude Code Skill——markdown-proxy,佢可以自動判斷連結類型,選擇最合適嘅抓取通道,輸出乾淨嘅Markdown內容。無論係反爬嚴格嘅微信公眾號、需要認證嘅飛書文檔,定係X/Twitter推文,都搞得掂。
內置WebFetch有三個硬傷:登錄牆、噪音、無降級,呢啲都係日常使用嘅主要障礙。
- 登錄牆過唔去:微信公眾號有反爬機制,飛書文檔需要API認證,X/Twitter內容難直接獲取。
- 輸出噪音太多:HTML混雜導航欄、側邊欄、廣告、JS代碼,提取後需大量清理。
- 無降級策略:一個代理服務跪低就徹底抓唔到,冇自動切換能力。
路由分發 + 四層降級:點樣保證可用性
markdown-proxy嘅核心設計係路由分發加多層降級。收到一個URL後,先判斷連結類型,再選擇對應嘅抓取通道:微信公眾號用Playwright無頭瀏覽器,飛書文檔用開放API,YouTube用專用Skill,其他所有URL就用代理級聯。
四層降級確保任何URL都有備用方案,唔會一個服務跪低就全軍覆沒。
通用URL嘅代理級聯從第一層到第四層分別係:r.jina.ai(內容最全)、defuddle.md(輸出最乾淨)、agent-fetch(本地工具,用npx執行)、defuddle CLI(本地CLI)。每一層掛咗都會自動跳到下一層。
專有平台走專用通道,保證抓取成功率;通用URL有四層降級,任何一層掛了自動跳到下一層。
呢個設計令markdown-proxy喺任何情況下都有備案,可用性極高。
四大抓取通道詳解:微信、飛書、通用、Twitter
markdown-proxy針對唔同平台設計咗專屬抓取通道,以下係詳細運作方式:
- 1 微信公眾號:用Playwright無頭Chromium瀏覽器繞過反爬,成功加載後用BeautifulSoup解析出標題、作者、時間同正文,輸出帶YAML frontmatter嘅Markdown。腳本約120行Python。
- 2 飛書文檔:直接調用飛書開放API拉取Blocks,然後逐個轉換為Markdown。支援docx、docs同wiki三種文檔類型,Blocks映射覆蓋標題、列表、代碼塊、引用等十幾種,代碼塊支援70種語言。腳本約280行Python,需配置FEISHU_APP_ID同FEISHU_APP_SECRET。
- 3 通用URL:唔需要自己搭建服務,巧妙組合兩個免費在線代理(r.jina.ai、defuddle.md)同兩個本地工具(agent-fetch、defuddle CLI)形成四級降級。r.jina.ai內容最完整,defuddle.md輸出更乾淨,agent-fetch用npx執行,defuddle CLI係最終防線。
- 4 Twitter推文:將呢部分委託畀專用嘅Twitter Skill處理,支援文字同多媒體信息,輸出排版良好嘅Markdown。
通用URL抓取零API Key依賴,r.jina.ai同defuddle.md都係免費服務,唔需要註冊賬號。
飛書Block解析覆蓋全面,對於未知類型亦有兜底邏輯,嘗試提取文本元素。
Twitter推文委託專用Skill,確保多媒體內容完整保留。
lang_map = {
7: "bash", 8: "c", 10: "cpp", 25: "go",
31: "java", 32: "javascript", 50: "python",
53: "rust", 62: "typescript", ...
}一行指令安裝,零API Key依賴嘅技術亮點
安裝markdown-proxy非常簡單,只需一條命令:
npx skills add joeseesun/markdown-proxy 一鍵安裝,立即可用。
基礎功能(通用URL抓取)只需要curl,macOS同Linux都自帶,開箱即用。如果需要抓取公眾號,額外安裝Playwright同相關Python套件;如需飛書文檔,設定環境變量就得。
零API Key依賴係通用URL抓取嘅最大亮點,只有飛書文檔需要額外認證(因為權限模型限制)。
使用體驗非常順暢:裝好之後,直接喺Claude對話中發URL就得,唔需要任何特殊指令。Claude會自動識別URL類型,選擇對應嘅抓取通道,輸出格式化嘅Markdown內容。
直接喺對話中發連結,Claude自動搞掂,唔使記任何命令或切換工具。
大家好,我係小智,專注 AI 工具、AI 智能體同編程提效
痛點分析
對於搞內容矩陣嘅朋友嚟講,有一個高頻痛點:每日都需要經 URL 去抓大量文章、推文或者文檔做參考資料。但直接掉個連結俾 AI,結果通常都唔太理想——一係因為防爬蟲機制提取唔到內容,一係只係拎到一堆充滿噪音嘅 HTML code。要知道,餵俾大模型嘅數據,質量越高、結構越清晰(尤其係 Markdown 格式),佢輸出嘅結果先至越精準。
markdown-proxy 就係專為解決呢個痛點而設計嘅。佢係一個極之強大嘅 Claude Code Skill,安裝之後,你只需要將任何 URL 掉俾 Claude,佢就會自動判斷連結類型,揀最啱嘅抓取通道,為你輸出乾淨、結構化嘅 Markdown 內容。無論係反爬嚴格嘅微信公眾號、需要認證嘅飛書文檔,定係 X/Twitter 嘅推文,佢都可以輕鬆搞掂。
項目地址:https://github.com/joeseesun/markdown-proxy
點解需要佢?
Claude Code 本身有 WebFetch 工具,但佢有幾個致命傷:
第一,登錄牆過唔到。 微信公眾號文章有反爬機制,直接請求會拎到空白頁面。飛書文檔需要 API 認證,裸抓乜都拎唔到。X/Twitter 嘅內容亦都越來越難直接獲取。
第二,輸出噪音太多。 就算頁面開得到,HTML 裏面混咗導航欄、側邊欄、廣告、JavaScript code,提取出嚟嘅內容需要大量清理。
第三,冇降級策略。 一個代理服務死咗就徹底抓唔到,冇自動切換嘅能力。
markdown-proxy 針對呢三個問題分別俾咗方案:用專用腳本搞掂登錄牆,代理服務輸出乾淨 Markdown,四層級聯保證可用性。
工作原理
markdown-proxy 嘅核心設計係路由分發 + 多層降級。收到一個 URL 之後,佢會先判斷連結類型,再揀對應嘅抓取通道:
URL 進來
│
├─ mp.weixin.qq.com → Playwright 無頭瀏覽器抓取
├─ feishu.cn / larksuite.com → 飛書開放 API 抓取
├─ youtube.com / youtu.be → 專用 YouTube skill
└─ 其他所有 URL → 代理級聯
├─ 1. r.jina.ai(內容最全)
├─ 2. defuddle.md(輸出最乾淨)
├─ 3. agent-fetch(本地工具)
└─ 4. defuddle CLI(本地 CLI)呢個設計有兩個好處:一來專有平台行專用通道,保證抓取成功率;二來通用 URL 有四層降級,任何一層死咗會自動跳到下一層。
四大抓取通道詳解
1. 微信公眾號:Playwright 無頭瀏覽器
公眾號文章嘅反爬係出名嘅嚴格,普通 HTTP request 拎到嘅一係空頁面,一係驗證碼。markdown-proxy 用 Playwright 開一個無頭 Chromium 瀏覽器嚟繞過呢個限制。好似下面咁,系統會喺後台自動打開並成功加載公眾號頁面:
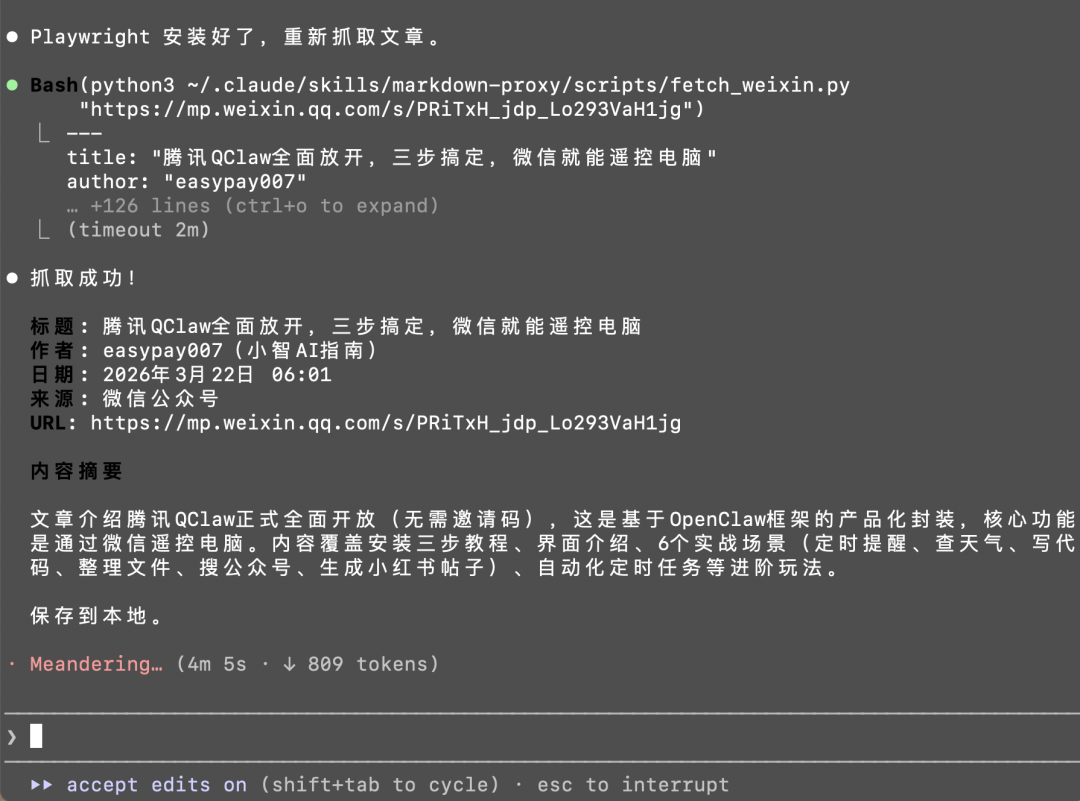
核心邏輯喺 scripts/fetch_weixin.py,大約 120 行 Python code:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) ..."
)
await page.goto(url, wait_until="domcontentloaded", timeout=30000)
await page.wait_for_selector("#js_content", timeout=15000)
html = await page.content()拎到完整 HTML 之後,用 BeautifulSoup 解析出標題、作者、發佈時間同正文內容,圖片連結都會保留。最終輸出帶 YAML frontmatter 嘅乾淨 Markdown 文件,提取效果非常之好:
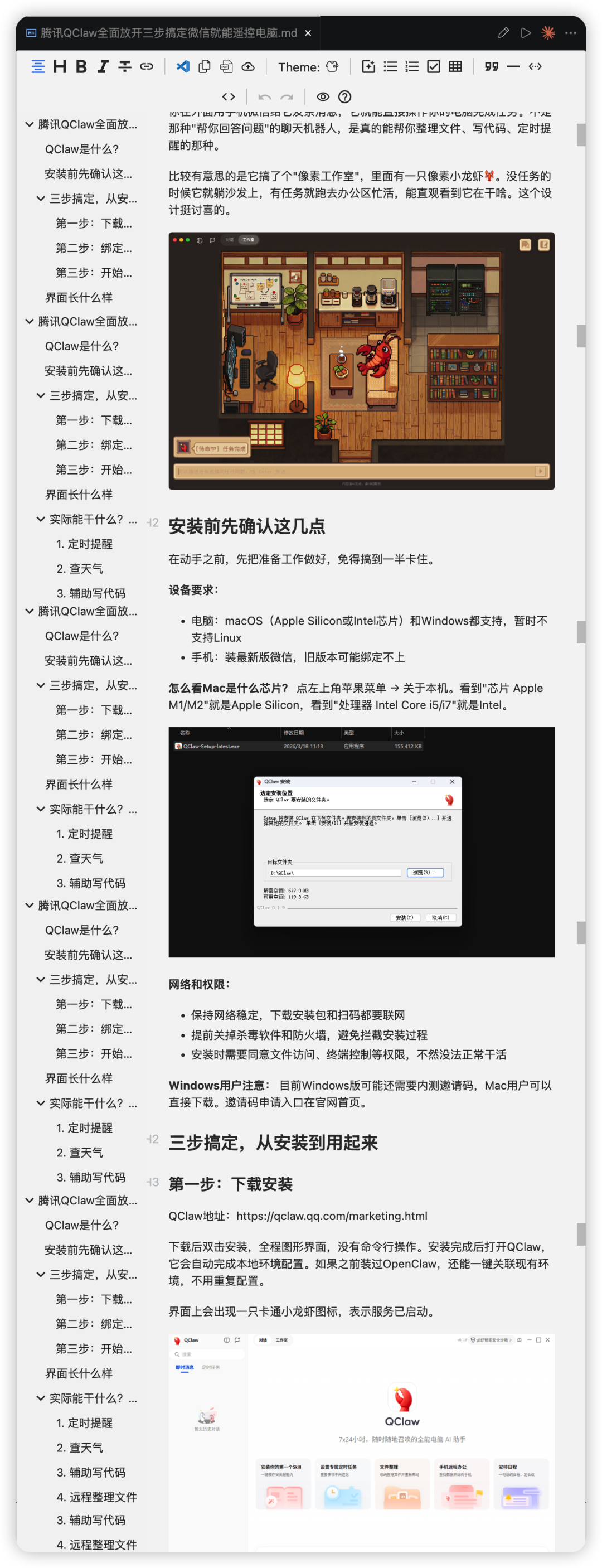
2. 飛書文檔:開放 API 直連
飛書文檔唔係普通網頁,佢嘅內容係經 API 以 Block 結構化數據嘅形式儲存。markdown-proxy 內置咗 scripts/fetch_feishu.py(約 280 行),直接調用飛書開放 API 拉取文檔 blocks,然後逐個轉換做 Markdown。你可以見到,就算係複雜嘅飛書文檔結構都可以被精準還原:
支援三種飛書文檔類型:
Block 轉 Markdown 嘅映射非常全面,覆蓋咗標題、列表、code block、引用、待辦事項、公式、圖片等十幾種類型。code block 仲支援 70 種編程語言嘅語法標識映射:
# 飛書的語言代碼到字符串的映射(節選)
lang_map = {
7: "bash", 8: "c", 10: "cpp", 25: "go",
31: "java", 32: "javascript", 50: "python",
53: "rust", 62: "typescript", ...
}使用前需要配置飛書應用嘅 FEISHU_APP_ID 和 FEISHU_APP_SECRET 環境變數,並俾應用授予 docx:document:readonly 權限。
3. 通用 URL:代理服務級聯
對於普通網頁,markdown-proxy 唔需要任何自建基礎設施,佢巧妙地組合咗兩個免費嘅在線代理服務同兩個本地工具:
r.jina.ai(首選)—— Jina AI 提供嘅免費 URL 轉 Markdown 服務。用法極之簡單,喺原始 URL 前面加上 https://r.jina.ai/ 就行:
curl -sL "https://r.jina.ai/https://example.com/article"內容最完整,圖片連結都會保留。
defuddle.md(備選)—— 另一個免費嘅文章提取服務,輸出更乾淨,仲帶 YAML frontmatter 元信息。用法類似,URL 前面加 https://defuddle.md/。
agent-fetch(本地降級)—— 當兩個在線代理都唔得嘅時候,回退到本地工具。經 npx 直接運行,唔需要預裝。
defuddle CLI(最終降級)—— 最後一道防線,本地 CLI 工具,適合普通網頁。
4. Twitter 推文
Twitter 推文有專門嘅工具鏈(元信息解析等),markdown-proxy 將呢部分委託俾專用嘅 Twitter skill 處理。無論係簡單嘅文字推文定係帶有多媒體信息嘅推文:
透過 markdown-proxy,都可以被完整提取並轉換為排版良好嘅 Markdown 格式:
安裝與使用
安裝
一行命令搞掂:
npx skills add joeseesun/markdown-proxy安裝過程非常簡單,控制枱會顯示安裝進度同相關依賴嘅配置情況:
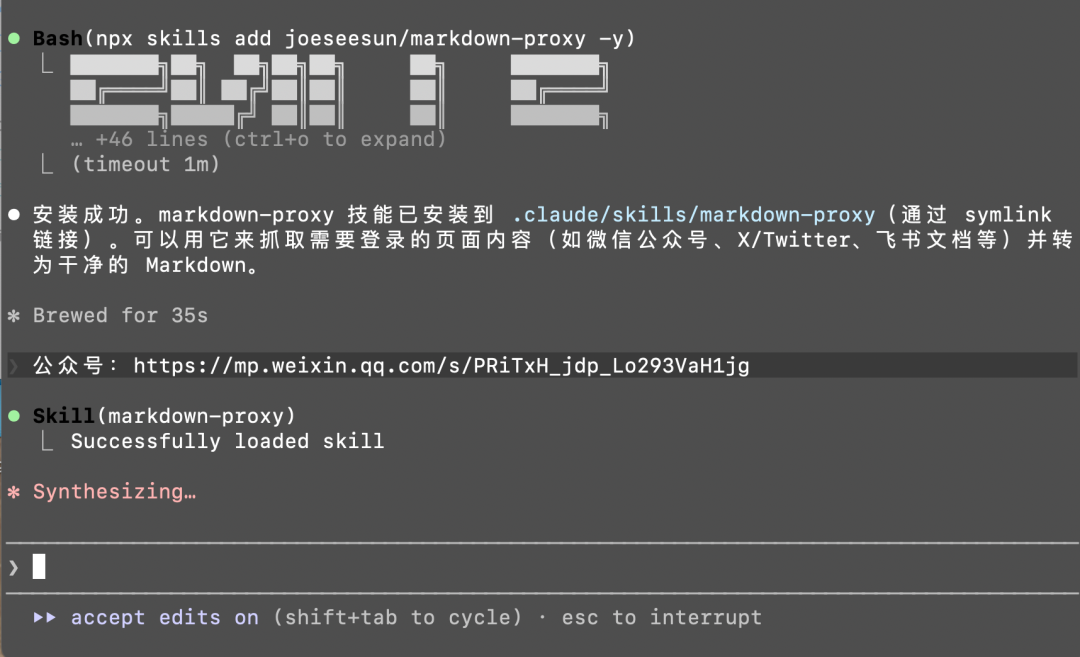
驗證安裝成功:
ls ~/.claude/skills/markdown-proxy/SKILL.md前置依賴
基礎功能(通用 URL 抓取)只需要 curl,macOS 同 Linux 都自帶,開箱即用。
如果需要抓取公眾號文章,額外安裝 Playwright:
pip install playwright beautifulsoup4 lxml
playwright install chromium如果需要抓取飛書文檔,配置環境變數:
export FEISHU_APP_ID="your_app_id"
export FEISHU_APP_SECRET="your_app_secret"使用
安裝好之後,直接掉個 URL 俾 Claude 就得,唔需要任何特殊指令:
幫我讀一下這篇文章:https://example.com/post
抓取這條推文:https://x.com/user/status/123456
讀一下這篇公眾號:https://mp.weixin.qq.com/s/abc123
把這個飛書文檔轉成 Markdown:https://xxx.feishu.cn/docx/xxxxxxxxClaude 會自動識別 URL 類型,揀對應嘅抓取通道,輸出格式化後嘅 Markdown 內容。
技術實現亮點
代碼量極細。 成個項目得兩個 Python script 加一個 SKILL.md 配置文件。公眾號抓取約 120 行,飛書 API 約 280 行。通用 URL 抓取甚至唔需要 code,直接用 curl 調用外部代理。
零 API Key 依賴。 通用 URL 抓取用嘅 r.jina.ai 同 defuddle.md 都係免費服務,唔使註冊賬號或配置 API Key。只有飛書文檔先需要額外認證——因為飛書嘅文檔權限模型決定咗一定要行 API。
Skill 化設計。 作為 Claude Code Skill 而唔係獨立工具,佢嘅使用體驗係無縫嘅。用戶唔需要記命令、唔需要切換工具,直接喺對話中掉連結就得。SKILL.md 裏面定義咗完整嘅路由邏輯同降級策略,Claude 會自動執行。
飛書 Block 解析覆蓋全面。 飛書文檔嘅 Block 類型有二十幾種,markdown-proxy 覆蓋咗最常用嘅十幾種,包括標題(1-7 級)、有序/無序列表、code block(70 種語言)、引用、公式、待辦、分割線、圖片等。對於未知類型都有兜底邏輯,嘗試提取裏面嘅文本元素。
常見問題速查
適合邊個用?
markdown-proxy 適合所有 Claude Code 用戶,尤其係:
• 日常需要俾 Claude 閲讀和分析網頁文章嘅開發者 • 需要抓取微信公眾號內容做研究或整理嘅人 • 團隊協作中需要將飛書文檔內容導出做 Markdown 嘅人 • 經常需要從 X/Twitter 等社交平台提取信息嘅人
入羣交流 & 領取福利
關於點樣使用 Claude Code 和 OpenClaw 嘅各種玩法,小智開咗一個學習交流羣,歡迎大家一齊交流玩法心得。

如果本文對你有幫助,都請幫手點個 讚👍 + 在看 啦!❤️關注小智AI指南公眾號,AI 路上唔迷路
大家好,我是小智,專注 AI 工具,AI 智能體和編程提效
痛點分析
對於搞內容矩陣的朋友們來說,有一個高頻痛點:每天都需要通過 URL 抓取大量文章、推文或文檔作為參考資料。但直接把連結丟給 AI,結果往往不盡如人意——要麼因為防爬蟲機制提取不出內容,要麼只拿到一堆充滿噪音的 HTML 代碼。要知道,餵給大模型的數據,質量越高、結構越清晰(尤其是 Markdown 格式),它輸出的結果才越精準。
markdown-proxy 就是專門為解決這個痛點而生的。它是一個極其強大的 Claude Code Skill,安裝之後,你只需要把任何 URL 丟給 Claude,它就能自動判斷連結類型,選擇最合適的抓取通道,為你輸出乾淨、結構化的 Markdown 內容。不管是反爬嚴格的微信公眾號、需要認證的飛書文檔,還是 X/Twitter 的推文,它都能輕鬆搞定。
項目地址:https://github.com/joeseesun/markdown-proxy
為什麼需要它?
Claude Code 本身有 WebFetch 工具,但它有幾個硬傷:
第一,登錄牆過不去。 微信公眾號文章有反爬機制,直接請求拿到的是空白頁面。飛書文檔需要 API 認證,裸抓什麼也拿不到。X/Twitter 的內容也越來越難直接獲取。
第二,輸出噪音太多。 即使頁面能打開,HTML 裏混着導航欄、側邊欄、廣告、JavaScript 代碼,提取出的內容需要大量清理。
第三,沒有降級策略。 一個代理服務掛了就徹底抓不到了,沒有自動切換的能力。
markdown-proxy 針對這三個問題分別給出了方案:專用腳本搞定登錄牆,代理服務輸出乾淨 Markdown,四層級聯保證可用性。
工作原理
markdown-proxy 的核心設計是路由分發 + 多層降級。收到一個 URL 後,它先判斷連結類型,再選擇對應的抓取通道:
URL 進來
│
├─ mp.weixin.qq.com → Playwright 無頭瀏覽器抓取
├─ feishu.cn / larksuite.com → 飛書開放 API 抓取
├─ youtube.com / youtu.be → 專用 YouTube skill
└─ 其他所有 URL → 代理級聯
├─ 1. r.jina.ai(內容最全)
├─ 2. defuddle.md(輸出最乾淨)
├─ 3. agent-fetch(本地工具)
└─ 4. defuddle CLI(本地 CLI)這個設計有兩個好處:一是專有平台走專用通道,保證抓取成功率;二是通用 URL 有四層降級,任何一層掛了自動跳到下一層。
四大抓取通道詳解
1. 微信公眾號:Playwright 無頭瀏覽器
公眾號文章的反爬是出了名的嚴格,普通 HTTP 請求拿到的要麼是空頁面,要麼是驗證碼。markdown-proxy 用 Playwright 啓動一個無頭 Chromium 瀏覽器來繞過這個限制。就像下面這樣,系統會在後台自動打開併成功加載公眾號頁面:
核心邏輯在 scripts/fetch_weixin.py,大約 120 行 Python 代碼:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) ..."
)
await page.goto(url, wait_until="domcontentloaded", timeout=30000)
await page.wait_for_selector("#js_content", timeout=15000)
html = await page.content()拿到完整 HTML 後,用 BeautifulSoup 解析出標題、作者、發佈時間和正文內容,圖片連結也會保留。最終輸出帶 YAML frontmatter 的乾淨 Markdown 文件,提取效果非常出色:
2. 飛書文檔:開放 API 直連
飛書文檔不是普通網頁,它的內容是通過 API 以 Block 結構化數據的形式存儲的。markdown-proxy 內置了 scripts/fetch_feishu.py(約 280 行),直接調用飛書開放 API 拉取文檔 blocks,然後逐個轉換為 Markdown。你可以看到,即便是複雜的飛書文檔結構也能被精準還原:
支持三種飛書文檔類型:
Block 轉 Markdown 的映射非常全面,覆蓋了標題、列表、代碼塊、引用、待辦事項、公式、圖片等十幾種類型。代碼塊還支持 70 種編程語言的語法標識映射:
# 飛書的語言代碼到字符串的映射(節選)
lang_map = {
7: "bash", 8: "c", 10: "cpp", 25: "go",
31: "java", 32: "javascript", 50: "python",
53: "rust", 62: "typescript", ...
}使用前需要配置飛書應用的 FEISHU_APP_ID 和 FEISHU_APP_SECRET 環境變量,並給應用授予 docx:document:readonly 權限。
3. 通用 URL:代理服務級聯
對於普通網頁,markdown-proxy 不需要任何自建基礎設施,它巧妙地組合了兩個免費的在線代理服務和兩個本地工具:
r.jina.ai(首選)—— Jina AI 提供的免費 URL 轉 Markdown 服務。用法極其簡單,在原始 URL 前面加上 https://r.jina.ai/ 就行:
curl -sL "https://r.jina.ai/https://example.com/article"內容最完整,圖片連結也會保留。
defuddle.md(備選)—— 另一個免費的文章提取服務,輸出更乾淨,還帶 YAML frontmatter 元信息。用法類似,URL 前面加 https://defuddle.md/。
agent-fetch(本地降級)—— 當兩個在線代理都不可用時,回退到本地工具。通過 npx 直接運行,不需要預裝。
defuddle CLI(最終降級)—— 最後一道防線,本地 CLI 工具,適合普通網頁。
4. Twitter 推文
Twitter 推文有專門的工具鏈(元信息解析等),markdown-proxy 把這部分委託給專用的 Twitter skill 來處理。不管是簡單的文本推文還是帶有多媒體信息的推文:
通過 markdown-proxy,都能被完整地提取並轉換為排版良好的 Markdown 格式:
安裝與使用
安裝
一行命令搞定:
npx skills add joeseesun/markdown-proxy安裝過程非常簡單,控制枱會顯示安裝進度和相關依賴的配置情況:
驗證安裝成功:
ls ~/.claude/skills/markdown-proxy/SKILL.md前置依賴
基礎功能(通用 URL 抓取)只需要 curl,macOS 和 Linux 都自帶,開箱即用。
如果需要抓取公眾號文章,額外安裝 Playwright:
pip install playwright beautifulsoup4 lxml
playwright install chromium如果需要抓取飛書文檔,配置環境變量:
export FEISHU_APP_ID="your_app_id"
export FEISHU_APP_SECRET="your_app_secret"使用
安裝好之後,直接給 Claude 發 URL 就行,不需要任何特殊指令:
幫我讀一下這篇文章:https://example.com/post
抓取這條推文:https://x.com/user/status/123456
讀一下這篇公眾號:https://mp.weixin.qq.com/s/abc123
把這個飛書文檔轉成 Markdown:https://xxx.feishu.cn/docx/xxxxxxxxClaude 會自動識別 URL 類型,選擇對應的抓取通道,輸出格式化後的 Markdown 內容。
技術實現亮點
代碼量極小。 整個項目只有兩個 Python 腳本加一個 SKILL.md 配置文件。公眾號抓取約 120 行,飛書 API 約 280 行。通用 URL 抓取甚至不需要代碼,直接用 curl 調用外部代理。
零 API Key 依賴。 通用 URL 抓取用的 r.jina.ai 和 defuddle.md 都是免費服務,不需要註冊賬號或配置 API Key。只有飛書文檔需要額外認證——因為飛書的文檔權限模型決定了必須走 API。
Skill 化設計。 作為 Claude Code Skill 而不是獨立工具,它的使用體驗是無縫的。用戶不需要記命令、不需要切換工具,直接在對話中發連結就行。SKILL.md 裏定義了完整的路由邏輯和降級策略,Claude 會自動執行。
飛書 Block 解析覆蓋全面。 飛書文檔的 Block 類型有二十多種,markdown-proxy 覆蓋了最常用的十幾種,包括標題(1-7 級)、有序/無序列表、代碼塊(70 種語言)、引用、公式、待辦、分割線、圖片等。對於未知類型也有兜底邏輯,嘗試提取其中的文本元素。
常見問題速查
適合誰用?
markdown-proxy 適合所有 Claude Code 用戶,特別是:
• 日常需要讓 Claude 閲讀和分析網頁文章的開發者 • 需要抓取微信公眾號內容做研究或整理的人 • 團隊協作中需要把飛書文檔內容導出為 Markdown 的人 • 經常需要從 X/Twitter 等社交平台提取信息的人
進羣交流 & 領取福利
關於如何使用 Claude Code 和 OpenClaw 的各種玩法,小智建了一個學習交流羣,歡迎大家一起溝通玩法心得。
如果本文對您有幫助,也請幫忙點個 贊👍 + 在看 哈!❤️關注小智AI指南公眾號,AI 路上不迷路