那些Agent神文沒告訴你的事:一股腦照着做只會讓系統更爛
整理版優先睇
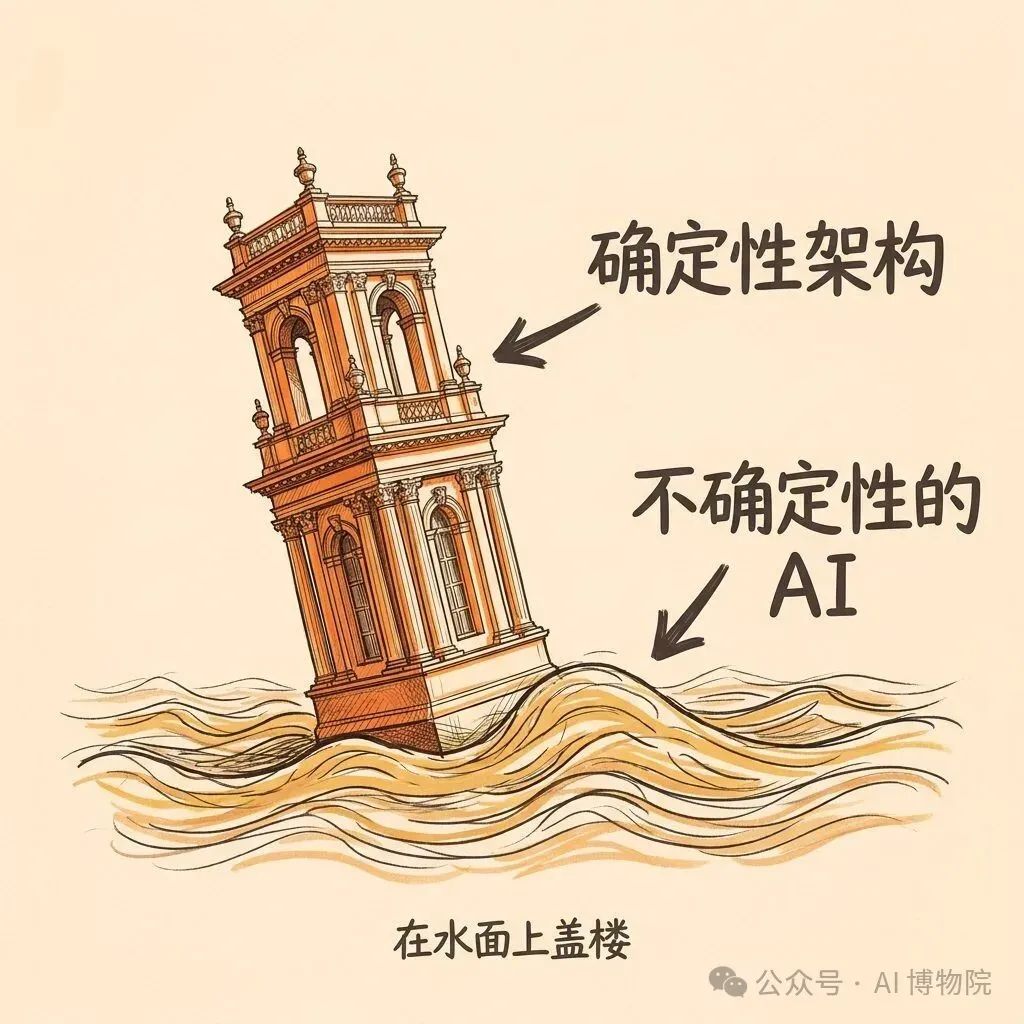
Agent 神文係畢業圖紙,唔係新手說明書;先跑起最簡單方案,再逐步加複雜度
呢篇文章係由一位踩坑博主嘅真實經驗改編。佢做緊一個視頻 AI agent,讀咗兩篇 agent 神文之後,照抄高階架構,結果 token 用多咗、效果冇變好、失敗率反而上升。最後佢拆曬所有架構,回到最簡單寫法,先明白 AI 設計同傳統軟件係兩回事。
作者想解決嘅問題係:點解跟住網上成熟 agent 文章照做,系統反而仲衰?整體結論係,神文展示嘅係終極方案,但唔係學習路徑。你應該先用最簡單嘅方法跑通 baseline,再按需要逐步加入工具、上下文隔離、記憶等功能。唔好一嚟就用複雜架構,否則只會增加成本同 debug 難度。
文章強調一個反直覺嘅原則:AI agent 本身係非確定性系統,疊加精緻架構等於在不確定性上疊加確定性,好容易出事。正確做法係先確認任務係咪真係需要 agent,再從最簡單 prompt 同 workflow 開始,逐步進化。
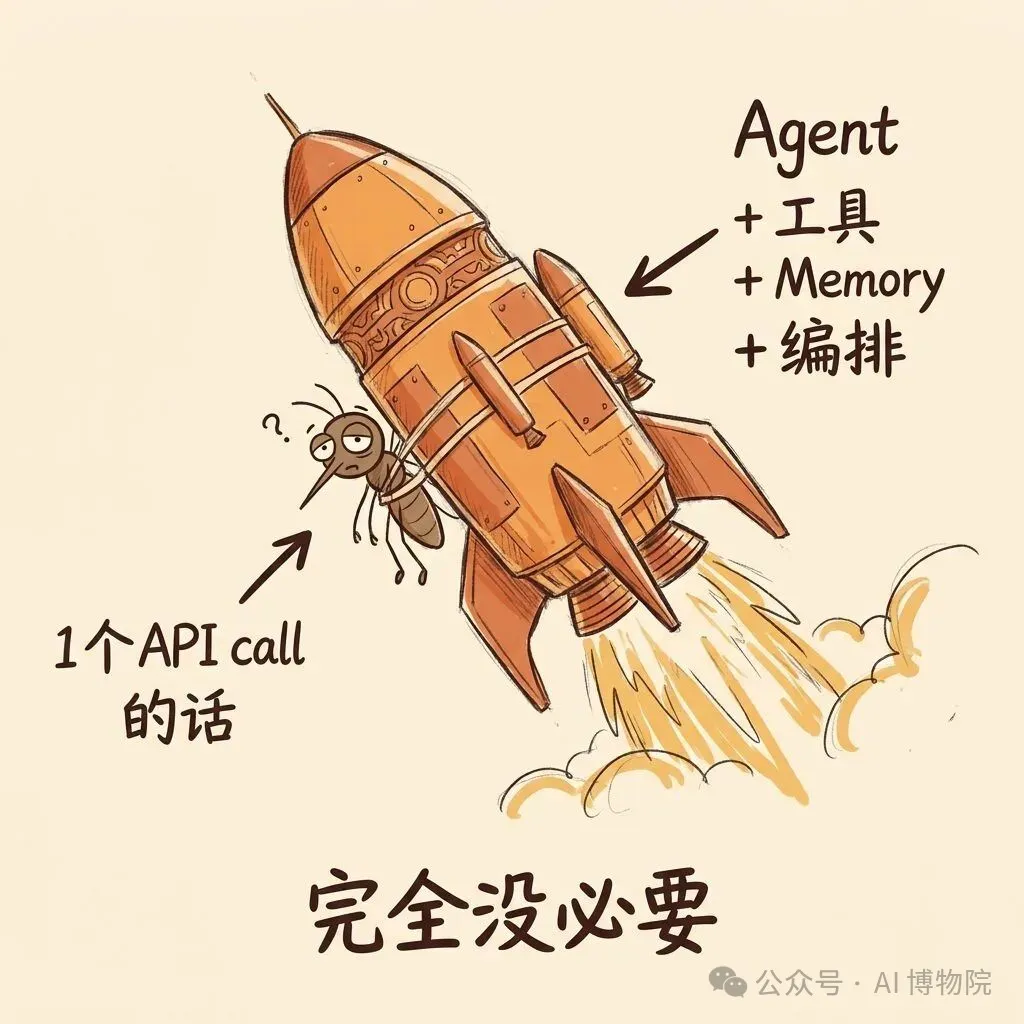
- 1 個 API call 搞得掂嘅事,唔好用 agent;多步驟唔等於 agent,確定性流程用 workflow 就得
- 真正需要對話 agent 嘅信號:流程必須人介入,或者功能選項多到前端會爆炸
- 選框架時先用最簡單用法跑 baseline,唔好俾複雜框架引導你閉門造車
- Prompt 第一版要簡單,先睇模型點做,再逐步加限制,唔好一嚟就抄成熟 prompt
- 上下文隔離同 memory 係後期先需要嘅嘢,唔好一開始就加;當需要傳遞不能改嘅內容時,memory 先係必需品
唔好將神文當說明書
呢篇嘢係由一位博主嘅踩坑回顧改編。佢做緊視頻 AI agent,讀咗兩篇神文之後,即時照抄高階架構——上下文隔離、記憶、規劃者-執行者,乜都齊。結果 token 用多咗,效果冇好過,失敗率仲要升,仲有啲 fail 根本 debug 唔到。
神文係畢業設計圖紙,唔係新手施工指南
佢最後拆曬所有架構,返去最簡單寫法,一路寫一路醒覺:AI 設計同傳統軟件係兩個世界。我睇完佢篇文,覺得佢踩嘅每個坑都指向同一件事:網上 agent 文章只 show 最終架構,但冇講點樣一步步演化出嚟。
由最簡單開始,唔好一嚟就上複雜
AI agent 係非確定性系統,疊架構等於疊加不確定性
博主有個好反直覺嘅總結:AI agent 本身已經唔確定,你再喺上面疊一層精緻架構,等於喺不確定性上疊確定性,好易出事。佢舉例:一開始只想將一段話總結成一句,一個 API call 搞掂,佢竟然用咗 plan-and-execute,規劃完再執行,鏈路複雜曬。
- 1 個 API call 搞得掂 → 直接 call,唔好加 agent
- 多步驟但中間唔使人介入 → 用 workflow(如 N8N、Dify),唔需要對話 agent
咁幾時先真係要用對話 agent?兩個 signal:第一,流程必須人介入(例如模型做唔到,要人教);第二,功能選項多到前端會指數增長,你唔想每種功能都整一個按鍵。呢兩個 signal 未到之前,對話 agent 冇必要存在。
選框架,唔好俾「硬核」氹到
鏈長唔等於要用複雜調度
佢又踩咗個典型坑:一嚟就想揀最強、最完整嘅框架。佢話自己搞錯咗兩種「長鏈」:workflow 嘅長鏈係由頭跑到尾,要考慮排程、重試、併發;但對話式 agent 嘅長鏈係可以俾人切開嘅,行幾步停一停,同 user 確認再繼續。
先跑起最基本版本,知道 baseline 先再加複雜嘢
佢最後揀咗個平平無奇嘅 SDK,可以即刻 run。佢話:複雜架構有個隱藏坑——佢會引誘你乜都未跑就開始畫節點,閉門造車。你連個 task 模型搞唔搞得掂都未知,就諗節點點 flow。建議係,就算你揀咗複雜框架,都要先用最簡單用法跑一次 baseline,睇下任務嘅底線,再決定使唔使加節點。
Prompt 同工具都要逐步加
Prompt 第一版唔好寫成說明書,先俾好少限制,睇模型點做
佢又試過抄成熟項目嘅 system prompt,結果 token 爆炸、效果冇好過。佢舉例:想叫模型做視覺設計,唔俾複雜 prompt 反而出到可用結果;塞啲專業 prompt 落去,佢就開始拆步驟規劃,慢咗仲要冇好啲。正確做法係先寫好簡單,睇佢點做,然後逐少加限制,俾一兩個例子,模型跟到就得。
之後先加工具。模型做唔好好多時係能力問題,唔係 prompt 問題。例如想 AI 參考網上流行設計,但模型拎唔到數據,咁就要加搜索工具。加三四個工具之後,模型就會自己諗用邊個工具,甚至自己串埋一齊用——呢啲就係湧現。
加工具後模型會變聰明,但要小心上下文稀釋
但加得多工具之後,會出現一個詭異階段:模型持續性變差,成功率下降。原因係工具說明、歷史對話、圖片等資訊太多,模型注意力俾平均稀釋咗。呢個時候先需要用上下文隔離——將唔同任務分開,每個子 agent 只睇自己需要嘅資訊。
Memory 同評估:最後先諗嘅嘢
當要傳遞唔可以改嘅長內容時,memory 先係必需品
入咗規劃者-執行者結構後,佢撞到一個問題:規劃者要將一段代碼原封不動交俾執行者。直接 copy-paste 會浪費 output token,而且模型好難保證一字不差——佢可能會順手改咗你想修嘅 bug。所以必須引入 memory:規劃者將代碼寫入文件,傳文件名俾執行者。咁樣 token 成本下降、錯誤率低咗。
最後點評估系統?答案係:每次都存低完整嘅執行過程,唔係結果。睇下用咗邊啲工具、調用順序、token 消耗、有冇資訊冇用到。到呢步,先會發現開頭嗰兩篇神文同你手上嘅 system 對得上。
神文係圖紙,唔係說明書;等自己長到嗰個階段先再翻
字數 4774,大約要睇 24 分鐘
上個禮拜刷到一篇博主嘅踩坑回顧,寫得幾好。
佢喺做一個視頻 AI agent。某日讀到兩篇關於 agent 嘅神級文章,醍醐灌頂——抄完,佢嘅 agent 就完美曬。
然後佢就開始咗。架構升級、系統提示詞重寫、上下文隔離、加 memory,一輪操作落嚟,成個嘢睇落精緻到不得了。
做完之後佢呆咗。
同樣嘅任務,token 用得更多,效果冇好到,失敗率反而升咗,關鍵係有啲失敗例子根本冇得 debug。佢問自己:唔係呀嘛,我唔會真係咁渣呀?
後來佢將嗰版架構全部拆咗,返到幾乎最簡單嘅寫法,一邊重寫一邊諗通一件事——AI 嘅設計同傳統軟件嘅設計,係兩個世界嚟嘅。
我將佢呢篇踩坑回顧讀咗三次。
唔係因為佢寫得幾靚,而係因為佢踩嘅每一個坑都指向同一件事:我哋今時今日喺網上讀到嘅 agent 文章,見到嘅都係某個成熟系統嘅最終架構。但好少人講,呢套架構係點樣生出來嘅、佢喺路上踩過咩坑、點解一定要長成而家呢個樣。
呢篇博主嘅踩坑路線圖,正好將呢條暗線攤開咗。
我將佢跟花叔嘅方式重新講一次。例子係佢嘅,判斷係我從呢條路見到嘅。
好多人寫 code 嘅時候會自動切到系統設計模式——將模組、依賴、部署都規劃清楚,最多前期慢啲,但係穩陣。
放喺傳統後端嚟講,呢個思路冇問題。
但 AI 唔係呢樣嘢。
呢位博主有一個好反直覺嘅總結:AI agent 本身係一個非確定性嘅系統。你喺佢上面再疊一層精緻嘅架構,等於喺不確定性上面疊加確定性。
佢舉咗一個自己做過嘅蠢事:一開始只想將一段話總結成一句話——一個完全可以 1 個 API call 搞掂嘅事。結果直接畀佢上咗 plan-and-execute。先叫佢規劃點樣總結,再叫佢執行總結。
任務冇變複雜,鏈路先變複雜咗。
唔係 AI 唔得。係條路被行複雜咗。
1 個 API call 搞得掂嘅事,唔好用 Agent
佢用自己嘅頻道做例子。佢嘅頻道好早就用 AI 㗎喇,但用得好樸素。
寫標題,將稿丟入去叫佢生成 10 個,揀一個。做封面,叫佢生成一個視覺主體,文字自己填。
呢啲事講到底係一次 call 嘅功夫。
如果為咗呢啲嘢專登搭一個 agent、加工具、做記憶、搞編排——嗱就係幫蚊裝火箭助推器。睇落好型,完全冇必要。
所以第一條原則好殘酷:1 個 API call 搞得掂嘅問題,唔好用 agent。 唔好為咗用 agent 而用 agent。
多步驟 ≠ Agent
後來佢有新需求。
剪片嘅時候成日發現自己講嘢有大量語氣詞、重複段落、卡頓位——剪片本質上係幫自己擦屎。佢自然諗,可唔可以叫 AI 幫手將呢啲廢話剪走。
呢一步問題升級咗。
已經唔係一個 call 搞得掂㗎喇:首先要將視頻轉成帶時間戳嘅字幕、判斷邊啲片段要剪、生成剪輯方案、再控制音頻同視頻。呢個係多步驟問題。
但留意——多步驟 ≠ agent。
呢個係第二個特別容易踩嘅坑。好多人一見多步驟就直接上 agent。唔一定㗎。
呢條鏈路有一個好重要嘅特徵:中間過程唔需要用戶介入。
佢嘅自然使用方式係:上載視頻、㩒一下、拎到結果。輸入確定、步驟固定、輸出一次性俾曬。
呢種情況下,agent 係多餘嘅。
佢本質上係一個確定性流程,就算步驟再多、中間夾咗再多 AI,佢都仲係一個流程。呢個階段,workflow 嗰種鏈式結構就夠用㗎喇,N8N、dify 都得。唔需要對話,唔需要多輪交互,亦都唔需要叫用戶中途插嘴。
一個好重要嘅判斷指標:如果用戶唔需要中途反覆參與,你大概都唔需要對話 agent。
幾時先真係需要對話 Agent
咁佢用自己另一個坑嚟答呢個問題。
佢曾經做過一個功能,叫一鍵生成特效。當時天真咁以為,㩒一下掣就可以拎到一套鍾意嘅動畫。
現實兜巴星佢。
佢大概唔會一次就生成到滿意。有時風格唔啱,有時節奏唔啱,有時淨係想鬱一個小細節。
呢個唔係啱錯題,有時甚至是審美題。
或者直接啲講,模型當前能力做唔到,需要人嚟指導、去教、反覆試反覆改。
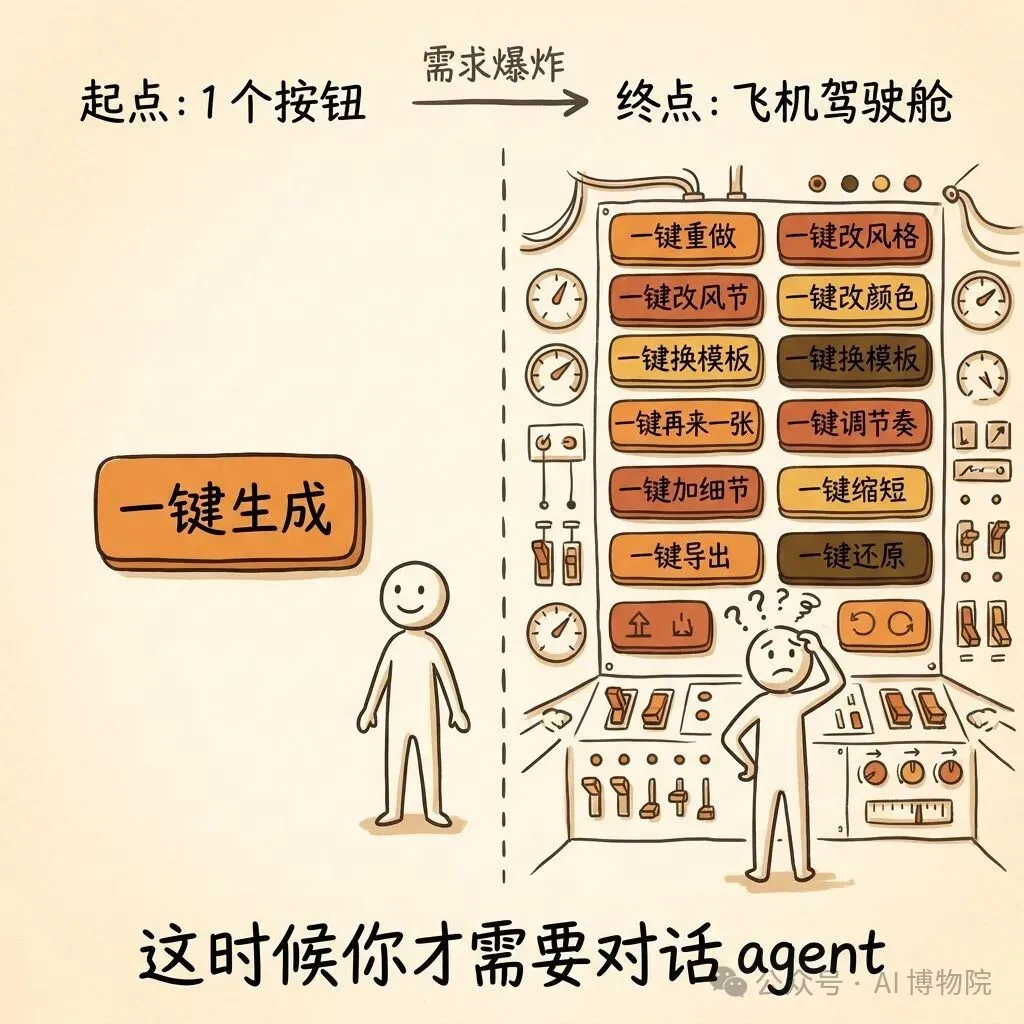
如果呢個時候你仲堅持用按鈕,會發生咩事?你要加好多好多按鈕去控制佢。一鍵重做、一鍵改風格、一鍵改顏色、一鍵換模板、一鍵再來一張……每出一種需求就加一個掣。
最後呢個產品會變成飛機駕駛艙。
呢個時候你先自然需要一種通用入口。
所以你真正需要狹義上嘅對話式 AI agent,通常只有兩個信號:
第一,流程一定要人介入。一係被動——模型能力唔夠;一係主動——決定依賴人嘅偏好。
第二,功能選項多到前端會指數增長,你唔想為每一種功能都整一個獨立嘅界面。
呢兩個信號到之前,對話 agent 其實冇必要存在。
揀框架,唔好俾「硬核」呃到
決定要做 agent 之後,佢即刻又踩咗一個好典型嘅坑。
一嚟就想揀最勁、最完整、可以覆蓋一切嘅框架。簡單嘅 SDK 睇唔上眼——個腦入面有個幻覺:我個問題咁複雜,一定要用最硬核嘅後端。
後來佢先意識到呢個係概念錯誤。鏈長,唔等於一定要用複雜嘅調度。
佢當時係將兩種「長鏈」搞亂咗。
workflow 嘅長鏈係另一種。㩒一下掣,由頭跑到尾,十步二十步連續執行。呢個時候你確實要考慮任務分發、重試、隊列調度、併發恢復——因為佢真係要喺後端橫著跑到底。
但對話式 agent 唔係咁跑嘅。佢嘅長鏈係可以俾人切開嘅長鏈。每跑一步停一陣,或者跑幾步停一陣,同用戶確認,再繼續。整體係一條長流程,但每次真正執行嘅片段其實好短。
呢個意味住,你根本唔需要一嚟就搭一個可以連跑 20 步、仲頂得住各種異常嘅重型調度系統。
佢最後揀咗一個睇落平平無奇嘅方案——某個集成度高、上手快嘅 SDK。好多人覺得佢冇咁萬能,但佢有一個巨大嘅優點:可以即刻跑得起。
先將嘢跑得起,比一步到位優雅更加重要。
複雜架構仲有一個隱藏嘅坑——佢會引導你亂咁設計。
你揀咗 LangGraph 呢啲好勁嘅後端,佢自然會引導你做一件事:仲乜都未跑,就開始畫節點。你忍唔住諗呢件事應該拆成邊啲步驟、每個節點負責咩、數據點樣喺節點之間流轉。聽落好專業。
但你連最簡單嘅問題解唔解得掂都未知。
呢個就係閉門造車。你車輪畫得幾圓,路有幾闊你都唔知。呢度其實有兩重不確定性:
一係呢個問題個模型到底解唔解得掂;二係你嘅架構會唔會反過來幹擾佢。
我嘅建議好簡單:就算你揀咗複雜架構,都唔係錯嘅,但你至少要用佢最簡單嘅用法跑一次,先將呢個問題嘅 baseline 跑出嚟。知到任務嘅底線喺邊,先決定使唔使加節點、使唔使加重編排。
Prompt 都唔好由複雜開始
跑通之後,下一步要寫系統提示詞。佢又踩咗一個超級典型嘅坑。
佢當時揾各種成熟項目嘅 prompt,即係啲被傳來傳去、號稱效果炸裂嗰啲。仲唔夠。專登去翻某啲知名項目洩露出嚟嘅系統提示詞,心諗:人哋寫得咁好,照抄總唔會差掛。
兩秒鐘就出事。
第一,效果冇好到;第二,token 消耗直接爆炸。
佢舉咗一個例子。原本淨係想叫模型幫手做一個視覺設計。唔俾複雜 prompt,直接話「你係一個視覺設計師,俾個方案我」——佢可以俾你一個幾有用嘅結果。
將啲專業提示詞一嘢塞曬入去,佢就開始拆步驟、規劃流程、一步一步執行,最後係更慢,並冇更好。
Prompt 嘅第一版唔好寫成嗰種好複雜嘅說明書。
先寫到幾乎冇乜限制條件,睇佢會點做,然後再不斷加約束上去。希望輸出更格式化、希望某部分諗多啲,俾佢一兩個例子。只要模型跟到你嘅指令,叫佢一步一步加上去,佢會照做。
講真,到呢度系統提示詞呢件事基本就過咗。
佢唔係寫得唔好,係冇工具
接下來你會遇到一個好現實嘅問題。
好多時模型做得唔好,唔係提示詞寫得唔夠好,係任務本身需要嘅能力,佢根本冇。
嗰位博主舉嘅例子係動效設計——佢希望 AI 可以參考網上啲流行設計。但個模型根本拎唔到呢啲數據。
呢個時候你再點改提示詞都冇用。唔係寫法問題,係能力缺失。
呢一步正確嘅動作唔係改提示詞,係加工具。
希望佢參考網上資訊,佢一定要識得搜索。希望佢寫嘅 code 可以執行,佢一定要驗證到。
呢個時候先係真正引入工具嘅時機。
加咗三四個工具之後,佢話,嗰種感覺好明確——模型開始似一個 agent 喇。佢自己諗清楚應該用邊個工具,甚至自己將工具串埋用。
呢個就係所謂嘅「湧現」——工具之間出現一加一大過二嘅效果。
留意,呢個階段佢其實冇做咩複雜架構,仲未引入規劃。系統仲係最基本嘅版本。
詭異嘅衰退——上下文稀釋
啱啱開始加工具嗰段時間,佢話,做 AI 嘅體驗係爽到爆。每加一個工具就明顯叻咗啲。之前做唔到嘅事而家做到喇。你會忍唔住繼續加。
但好快就進入一個好詭異嘅階段。
唔係間中失敗,係呢個 agent 嘅性能持續變差。成功率開始跌,準確率時高時低,有時佢開始聽唔明人話。明顯感覺到——佢唔係唔識做,係越做越亂。
呢度其實唔係模型唔得,係上下文開始失控。
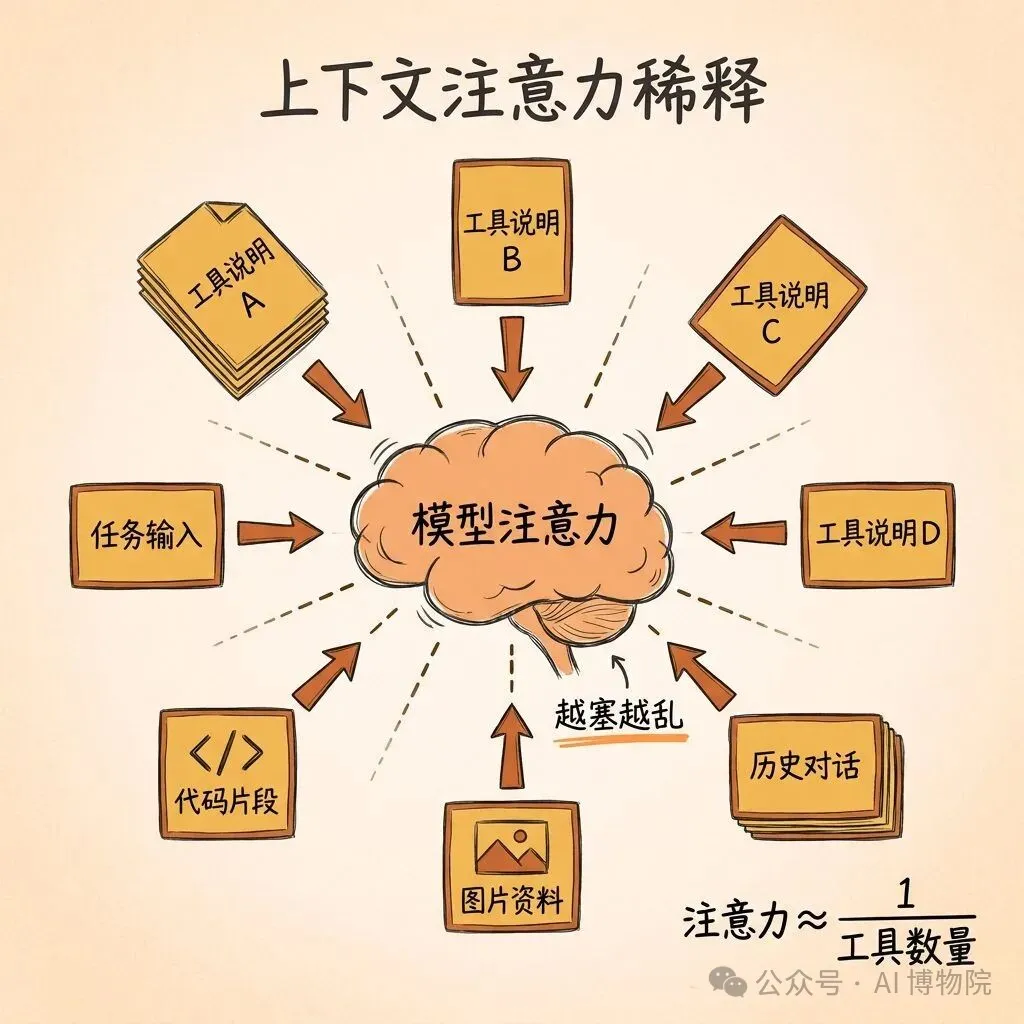
工具一多,每個工具背後都帶一大段說明。任務複雜,輸入本身亦都越來越長。再加上歷史對話、code、圖片呢啲唔同嘅資訊一嘢塞入個模型,太多、太散,模型嘅注意力被平均稀釋咗。
呢個係一個好典型嘅現象——上下文注意力稀釋。
到呢一步你先真正需要文章開頭提到嘅第一篇神文。
佢本質上淨係做一件事:喺做某一類任務嘅時候,叫個模型淨係睇佢需要睇嘅嘢。
嗰位博主用視頻 agent 做例子。設計某種視頻效果其實係兩類完全唔同嘅任務:
第一類係設計。佢關心嘅係意圖、風格、版式元素、氛圍,需要大量開放、可以發散嘅資訊,然後做分析同總結。
第二類係寫 code,將設計好嘅資訊實現出嚟。佢關心嘅係明確嘅指令、接口結構、輸出格式、正確性。需要嘅資訊越少越精確越好。
如果將呢兩件事撈埋一齊會發生咩事?
任務細嘅時候仲可以行得鬱。任務一複雜,設計嘅資訊開始擾亂 code 生成嘅準確性,code 嘅資訊開始拖慢設計嘅判斷。兩個任務互相污染上下文,系統要用好多時間去理清楚。
當不同任務明顯需要唔同嘅上下文時,上下文隔離先有意義。
呢個時候你先會開始考慮——係咪需要一個頂層規劃者,佢知道全局資訊,去調度下面嘅執行者。每個執行者淨係負責專項任務:設計 agent 淨係負責設計,code agent 淨係負責 code。佢哋透過規劃者嘅控制,淨係睇到自己需要嗰一小撮資訊。
你諗下——如果一個所謂嘅「子 agent」睇到嘅上下文同頂層規劃者完全一樣,咁呢個子 agent 就完全冇意義。
傳遞唔改得嘅內容時——Memory 唔係優化項
進入呢種規劃者 - 執行者結構之後,佢即刻撞上一個繞唔開嘅問題。
假設用戶而家俾咗一段 code,希望幫佢改。
頂層規劃者會見到呢段 code,但佢唔負責寫 code,需要將呢個任務交俾下面嘅 code 執行者。
問題嚟喇:規劃者點樣將呢段 code 百分百原封不動咁交俾執行者?
最直接嘅方案係,輸入入嚟嘅嘢再原樣輸出一次,俾個執行者。
呢一步好唔合理,因為呢度同時發生兩件衰嘢。
第一,你係為咗複製貼上而俾錢。輸入一段 code、輸出一段 code,本質上係 copy-paste,但消耗咗大量 output token。output token 好貴㗎。
第二,你冇辦法保證一字不差。模型唔擅長機械複製,就算你明講「一行都唔準改」,佢都好可能順手將佢見到嘅明顯 bug 改埋。或者你輸入嘅 code 入面有一個錯嘅標點,佢幫你「改返啱」——而你本來就係要去修呢個 bug 嘅,佢喺你見到之前就將個症狀冚咗。
呢種情況喺好多場景下係災難性嘅。
到呢一刻你先意識到:有啲資訊我只係想儲起佢,而唔係叫個模型反覆讀寫。
呢個時候,一定要引入 memory。
記憶系統都好簡單。佢唔係喺傳遞內容,係喺傳遞內容嘅指針。
頂層規劃者見到呢段 code 之後,將佢寫到一個檔案系統度,檔案名叫 X。規劃者通知下面嘅執行者:「你要改一段 code,存在 X。」執行者根據檔案名將內容讀出來,然後去改。
咁樣一來,規劃者唔輸出完整嘅 code,執行者唔依賴規劃者嘅輸出。output token 成本直接下降,錯誤率明顯降低。
所以當你開始做上下文隔離、而且需要傳遞「唔改得嘅長內容」時,memory 就唔再係優化項,係必需品。
內存 vs 外存:決定一件事放邊度、放幾耐
引入記憶系統之後,你會聽到另一個好常見嘅講法——內存、外存。
呢兩個詞其實冇咁玄。分別就一句話:
呢輪對話完咗就消失嘅,係內存。多輪之間都拎得到嘅,係外存。
佢哋唔係兩種神秘能力,本質上係一個決定——呢樣嘢,放喺邊、放幾耐。
點解有分別?因為有啲資訊淨係對呢一輪有用。如果你寫到出面繼續帶住,反而會變成噪音,污染下一輪嘅行為。呢啲嘢就應該留喺內存。
但有啲資訊一定要跨輪次保存。最典型就係 Claude 呢啲系統入面嘅任務列表——步驟多,中間要用戶確認。呢個時候你引入一個外部狀態:而家行到第幾步、用戶畀咗咩輸入、下一步應該執行咩。
唔好一嚟就諗住內存外存全部要用曬。
順序永遠係:行到呢個階段,發現唔用唔得,先用。
點樣知佢邊度好、邊度差
行到呢一步,系統已經變得相當複雜。隔離、記憶、規劃者 - 執行者全部有齊。
隨之而嚟嘅就係:好難除錯,好難排查。
咁要點樣評價呢個系統邊度做得好、邊度差?
答案只有一個——將每一次運行嘅全過程儲起嚟。
唔係儲結果,係儲過程。佢用咗邊啲工具、調用順序係點、每一步消耗咗幾多 token、有邊啲上下文根本冇用到、有邊啲資訊根本就唔應該俾到執行者。
當你回頭讀咁樣一整條流程時,你先會知點樣可以將任務規劃得更快、token 用得更加慳、成功率更加高。
到呢一步,你會突然發現——開頭嗰兩篇神文,同你手上呢個系統終於對得上。
Long run task 點解一定要 memory?Context engineering 到底喺度做緊啲咩?
嗰位博主寫咗一句令我印象好深嘅話:佢最初失敗嘅原因,唔係呢兩篇文章唔啱,係佢當時所處嘅階段根本仲未需要佢哋。
神文係畢業設計圖紙,唔係新手施工指南
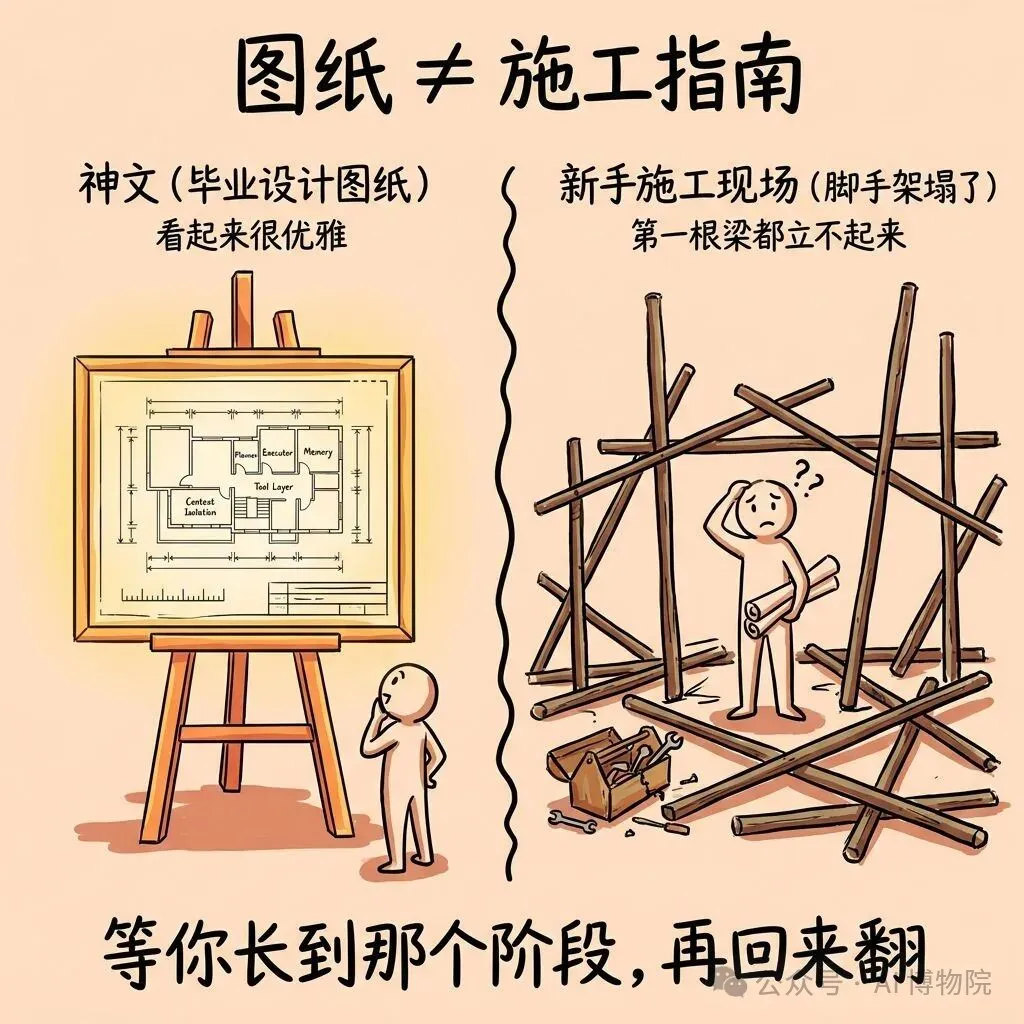
嗰啲比較成型嘅 agent 文章,更加似係一份畢業設計嘅完整圖紙。
當你已經做過中間所有實驗、踩過所有坑,返轉頭睇嗰張圖,會覺得佢設計得好精巧。但如果你第一日開始學畫圖,直接跟呢張畢業設計去施工,你大概連第一條樑都起唔到。
問題唔係呢啲架構唔夠優雅,亦唔係你唔可以揀優雅嘅架構。
係你唔需要一嚟就優雅。
我將呢位博主踩坑路線圖讀完之後,同自己定咗一個小小嘅規矩——遇到任何架構師味濃嘅 AI 神文,先問一句:呢個係圖紙,定係說明書?
係圖紙,就收埋。等自己大個到嗰個階段,再返嚟翻。
千祈唔好讓「優雅」,成為你 AI 系統設計路上嘅絆腳石。
字數 4774,閲讀大約需 24 分鐘
上週末刷到一篇博主的踩坑回顧,寫得挺好。
他在做一個視頻 AI agent。某天讀到兩篇關於 agent 的神文,醍醐灌頂——抄完,他的 agent 就完美了。
然後他就開始了。架構升級、系統提示詞重寫、上下文隔離、加 memory,一通操作下來,整個東西看起來精緻得不行。
做完之後他傻了。
同樣的任務,token 花得更多,效果沒變好,失敗率反而上去了,關鍵是有些失敗例子根本沒法 debug。他自問:不應該啊,難道我真的這麼菜?
後來他把那一版架構全拆了,回到幾乎最簡單的寫法,一邊重寫一邊想清楚一件事——AI 的設計和傳統軟件的設計,是兩套世界。
我把他這篇踩坑回顧讀了三遍。
不是因為他寫得有多漂亮,是因為他踩的每一個坑都在指向同一件事:我們今天在網上讀到的 agent 文章,看到的都是某個成熟系統的最終架構。但很少有人講,這套架構是怎麼長出來的、它在路上踩過哪些坑、為什麼必須長成現在這個樣子。
這篇博主的踩坑路線圖,正好把這條暗線展開了。
我把它按花叔的方式重講一遍。例子是他的,判斷是我從這一路看到的。
很多人寫代碼的時候會自動切到系統設計模式——把模塊、依賴、部署都規劃清楚,最多前期慢一點,但穩。
放在傳統後端裏,這個思路沒問題。
但 AI 不是這個東西。
這位博主有一個非常反直覺的總結:AI agent 本身就是一個非確定性的系統。你在它上面再疊一層精緻的架構,等於在不確定性上疊加確定性。
他舉了一個自己幹過的蠢事:一開始只想把一段話總結成一句話——一個完全可以 1 個 API call 搞定的事。結果直接給它上了 plan-and-execute。先讓它規劃怎麼總結,再讓它執行總結。
任務沒變複雜,鏈路先變複雜了。
不是 AI 不行。是路被走複雜了。
1 個 API call 能解決的事,不要用 Agent
他拿自己的頻道舉例。他的頻道很早就在用 AI 了,但用得非常樸素。
寫標題,把稿子丟進去讓它生成 10 個,挑一個。做封面,讓它生成一個視覺主體,文字自己填。
這種事說白了就是一次 call 的活。
如果為了這點事專門搭一個 agent、加工具、做記憶、搞編排——那就是給蚊子裝火箭助推器。看起來很酷,完全沒必要。
所以第一條原則非常殘酷:1 個 API call 能解決的問題,不要用 agent。 不要為了用 agent 而用 agent。
多步驟 ≠ Agent
後來他有了新需求。
剪視頻的時候經常發現自己說話有大量語氣詞、重複段、卡頓處——剪視頻本質上是在幫自己擦屁股。他自然想,能不能讓 AI 幫把這些廢話剪掉。
這一步問題升級了。
它已經不是一個 call 能搞定的了:先把視頻轉成帶時間戳的字幕、判斷哪些片段要剪、生成剪輯方案、再控制音頻和視頻。這是一個多步驟問題。
但注意——多步驟 ≠ agent。
這是第二個特別容易踩的坑。很多人一看到多步驟就直接上 agent。不一定。
這條鏈路有個非常重要的特徵:中間過程不需要用戶介入。
它的自然使用方式是:上傳視頻、點一下、拿到結果。輸入確定、步驟固定、輸出一次性給到。
這種情況下,agent 是多餘的。
它本質是一個確定性流程,哪怕步驟再多、中間夾了再多 AI,它也還是一個流程。這種階段,workflow 那種鏈式結構就夠了,N8N、dify 都行。不需要對話,不需要多輪交互,也不需要讓用戶中途插嘴。
一個非常重要的判斷指標:如果用戶不需要中途反覆參與,你大概率不需要對話 agent。
什麼時候才真的需要對話 Agent
那他用自己另一個坑來回答這個問題。
他曾經做過一個功能,叫一鍵生成特效。當時天真地以為,點一下按鈕就能拿到一套喜歡的動畫。
現實給了他一巴掌。
它大概率不會一次就生成到滿意。有時候風格不對,有時候節奏不對,有時候只想動一個小細節。
這不是對錯題,有時候甚至是審美題。
或者更直接地說,模型當前能力達不到,需要人去指導、去教、反覆試反覆改。
如果這個時候你還堅持用按鈕,會發生什麼?你需要加非常多的按鈕去控制它。一鍵重做、一鍵改風格、一鍵改顏色、一鍵換模板、一鍵再來一張……每出一種需求就加一個按鍵。
最後這個產品會變成飛機駕駛艙。
這時候你才天然需要一種通用入口。
所以你真正需要狹義上的對話式 AI agent,通常只有兩個信號:
第一,流程必須讓人介入。要麼被動——模型能力不夠;要麼主動——決策依賴人的偏好。
第二,功能選項多到前端會指數增長,你不想為每一種功能都做一個獨立的界面。
這兩個信號到來之前,對話 agent 其實沒必要存在。
選框架,別被"硬核"騙了
確定要做 agent 之後,他馬上又踩了一個特別典型的坑。
一上來就想選最強、最完整、能覆蓋一切的框架。簡單的 SDK 看不上——腦子裏有個幻覺:我這個問題這麼複雜,必須用最硬核的後端。
後來他才意識到這是個概念錯誤。鏈長,不等於必須用複雜的調度。
他當時是把兩種"長鏈"搞混了。
workflow 的長鏈是另一種。點一下按鈕,從頭跑到尾,十步二十步連續執行。這種時候你確實要考慮任務分發、重試、隊列調度、併發恢復——因為它真的要在後端橫着跑到底。
但對話式 agent 不是這麼跑的。它的長鏈是可以被人切開的長鏈。每跑一步停一下,或者跑幾步停一下,跟用戶確認,再繼續。整體是一條長流程,但每次真正執行的片段其實很短。
這意味着,你根本不需要一上來就搭一個能連跑 20 步、還能扛住各種異常的重型調度系統。
他最後選了一個看起來平平無奇的方案——某個集成度高、上手快的 SDK。很多人覺得它沒那麼萬能,但它有個巨大的優點:能馬上跑起來。
先把東西跑起來,比一步到位優雅更重要。
複雜架構還有一個隱藏的坑——它會誘導你瞎設計。
你選了 LangGraph 這種很厲害的後端,它會自然引導你做一件事:還什麼都沒跑,就開始畫節點。你忍不住想這件事該拆成哪些步驟、每個節點負責什麼、數據怎麼在節點之間流轉。聽起來非常專業。
但你連最簡單的問題能不能解決都不知道。
這就是閉門造車。你車輪畫得再圓,路有多寬你都不知道。這裏其實有兩重不確定性:
一是這個問題模型到底能不能解決;二是你的架構會不會反過來干擾它。
我的建議很簡單:哪怕你選了複雜架構,也不是錯的,但你至少要用它最簡單的用法跑一遍,先把這個問題的 baseline 跑出來。知道任務的底線在哪,再決定要不要加節點、要不要加更重的編排。
Prompt 也別從複雜開始
跑通之後,接下來要寫系統提示詞。他又踩了一個超級典型的坑。
他當時找各種成熟項目的 prompt,那種被傳來傳去、號稱效果炸裂的。還不夠。專門去翻某些知名項目泄露出來的系統提示詞,心想:別人寫得這麼好,照抄總不會差吧。
兩秒鐘就翻車。
第一,效果沒有更好;第二,token 消耗直接爆炸。
他舉了一個例子。原本只是想讓模型幫做一個視覺設計。不給複雜 prompt,直接說"你是一個視覺設計師,給我一個方案"——它能給你一個挺能用的結果。
把那些專業的提示詞一股腦塞進去,它開始拆步驟、規劃流程、一步一步執行,最後是更慢,並不更好。
Prompt 的第一版不要寫成那種很複雜的說明書。
先寫得幾乎沒什麼限制條件,看它會怎麼做,然後再不斷往上加約束。希望輸出更格式化、希望某部分多想一點,給它一兩個例子。只要模型能 follow 你的指令,讓它一步一步往上加東西,它能照着做。
說實話,到這裏系統提示詞這件事就基本過了。
他不是寫不好,是沒工具
接下來你會遇到一個非常現實的問題。
很多時候模型做不好,不是提示詞寫得不夠好,是任務本身需要的能力,他根本沒有。
那位博主舉的例子是動效設計——他希望 AI 能參考網上一些流行的設計。但模型根本拿不到這些數據。
這種時候你再怎麼改提示詞都沒用。不是寫法的問題,是能力的缺失。
這一步正確動作不是改提示詞,是加工具。
希望它參考網上信息,它必須會搜索。希望它寫出來的代碼能跑,它必須能驗證。
這種時候才是真正引入工具的時機。
加上三四個工具之後,他說,那種感覺非常明確——模型開始像一個 agent 了。它自己想清楚該用哪個工具,甚至自己把工具串起來用。
這就是所謂的"湧現"——工具之間出現一加一大於二的效果。
注意,這個階段他其實沒做什麼複雜架構,還沒引入規劃。系統還是最基礎的版本。
詭異的衰退——上下文稀釋
剛開始加工具那段時間,他說,做 AI 的體驗是爽爆的。每加一個工具就明顯變聰明一點。之前做不了的事現在能做了。你會忍不住繼續加。
但很快就進入一個非常詭異的階段。
不是偶爾失敗,是這個 agent 的性能持續性變差。成功率開始下降,準確率忽高忽低,有時候它開始聽不懂人話。能明顯感覺到——它不是不會做,是越做越亂。
這地方其實不是模型不行了,是上下文開始失控。
工具一多,每個工具背後都帶一大段說明。任務複雜,輸入本身也越來越長。再加上歷史對話、代碼、圖片這種各種各樣的信息一股腦塞進模型,太多、太散,模型的注意力被平均稀釋掉。
這是一個非常典型的現象——上下文注意力稀釋。
到這一步你才真正需要文章開頭提到的第一篇神文。
它本質上只幹一件事:在做某一類任務的時候,讓模型只看到他需要看到的東西。
那位博主拿視頻 agent 舉例。設計某種視頻效果其實是兩類完全不同的任務:
第一類是設計。它關心意圖、風格、版式元素、氛圍,需要大量開放的、可發散的信息,然後做分析和總結。
第二類是寫代碼,把設計好的信息實現出來。它關心明確的口令、接口結構、輸出格式、正確性。需要的信息越少越精確越好。
如果把這兩件事混在一起會發生什麼?
任務小的時候還能跑一跑。任務一旦複雜,設計的信息開始擾亂代碼生成的準確性,代碼的信息開始拖慢設計的判斷。兩個任務相互污染上下文,系統需要花大量時間去把它理清楚。
當不同任務明顯需要不一樣的上下文時,上下文隔離才有意義。
這時候你才會開始考慮——是不是需要一個頂層規劃者,他知道全局信息,去調度下面的執行者。每個執行者只負責專項任務:設計 agent 只負責設計,代碼 agent 只負責代碼。它們通過規劃者的控制,只看到自己需要的那一小撮信息。
你品一下——如果一個所謂的"子 agent"看到的上下文跟頂層規劃者完全一樣,那這個子 agent 就完全沒有意義。
傳遞不能改的內容時——Memory 不是優化項
進入這種規劃者 - 執行者結構之後,他立刻撞上一個繞不開的問題。
假設用戶現在給了一段代碼,希望幫他改。
頂層規劃者會看到這段代碼,但它不負責寫代碼,需要把這個任務交給下面的代碼執行者。
問題來了:規劃者怎麼把這段代碼百分之百原封不動地交給執行者?
最直接的方案是,輸入進來的東西再原樣輸出一遍,給到執行者。
這一步非常不合理,因為這裏同時發生兩件糟糕的事。
第一,你在為複製粘貼付費。輸入一段代碼、輸出一段代碼,本質上是 copy-paste,但消耗了大量 output token。output token 是很貴的。
第二,你沒法保證一字不差。模型並不擅長機械複製,哪怕你明說"一行都不要改",它也很可能順手把它看到的明顯 bug 給改了。或者你輸入的代碼裏有一個錯誤的標點,它給你"改正確了"——而你本來就是要去修這個 bug 的,它在你看到之前就把症狀給掩蓋了。
這種情況在很多場景下是災難性的。
到這一刻你才意識到:有些信息我只想存着,而不是讓模型反覆讀寫。
這個時候,必須引入 memory。
記憶系統也很簡單。它不是在傳遞內容,是在傳遞內容的指針。
頂層規劃者看到這段代碼之後,把它寫到一個文件系統裏,文件名是 X。規劃者告訴下面的執行者:"你要改一段代碼,存在 X。"執行者根據文件名把內容讀出來,再去改。
這一來,規劃者不輸出完整的代碼,執行者不依賴規劃者的輸出。output token 成本直接下降,錯誤率明顯降低。
所以當你開始做上下文隔離、並且需要傳遞"不能改動的長內容"時,memory 就不再是優化項,是必需品。
內存 vs 外存:決定一件事存哪、存多久
引入記憶系統之後,你會聽到另一個很常見的說法——內存、外存。
這兩個詞其實沒那麼玄。區別就一句話:
這輪對話結束就消失的,是內存。多輪之間都能拿到的,是外存。
它們不是兩種神秘能力,本質上是一個決定——這個東西,存在哪、存多久。
為什麼有差別?因為有些信息只對這一輪有用。如果你寫到外面繼續帶着,反而會變成噪音,污染下一輪的行為。這種東西就該留在內存裏。
但有些信息必須跨輪次保存。最典型的就是 Claude 這種系統裏的任務列表——步驟多,中間需要用戶確認。這時候你引入一個外部狀態:現在走到第幾步了,用戶給了什麼輸入,下一步該執行什麼。
不要一上來就想着內存外存全都要用。
順序永遠是:走到這個階段,發現不用不行了,才用。
怎麼知道它哪裏好、哪裏差
走到這一步,系統已經變得相當複雜。隔離、記憶、規劃者 - 執行者全有了。
隨之而來的就是:很難調試,很難排查。
那要怎麼評價這個系統哪裏做得好、哪裏差?
答案只有一個——把每一次運行的全過程存下來。
不是存結果,是存過程。它用了哪些工具、調用順序是什麼、每一步消耗了多少 token、有哪些上下文根本沒被用到、有哪些信息根本不該給到執行者。
當你回頭讀這樣一整條流程時,你才知道怎樣能把任務規劃得更快、token 用得更省、成功率更高。
到這一步,你會突然發現——開頭那兩篇神文,跟你手裏的這個系統終於對上了。
Long run task 為什麼一定要 memory?Context engineering 到底在做什麼?
那位博主寫下了一句讓我印象很深的話:他最初失敗的原因,不是這兩篇文章不對,是他當時所處的階段根本還不需要它們。
神文是畢業設計圖紙,不是新手施工指南
那種比較成型的 agent 文章,更像是一份畢業設計的完整圖紙。
當你已經做過中間所有實驗、踩過所有坑,回頭看那張圖,會覺得它設計得非常精巧。但如果你第一天開始學畫圖,直接照着這張畢業設計去施工,你大概率連第一根梁都立不起來。
問題不是這些架構不夠優雅,也不是你不能選擇優雅的架構。
是你不需要一上來就優雅。
我把這位博主踩坑路線圖讀完後,給自己提了一個小小的規矩——遇到任何架構師味濃的 AI 神文,先問一句:這是圖紙,還是說明書?
是圖紙,就收着。等自己長到那個階段了,再回來翻。
千萬不要讓"優雅",成為你 AI 系統設計路上的絆腳石。