配好 Agent 後直接開幹?先了解如何省 token ,如何提升模型表現
整理版優先睇
掌握Claude Code嘅Token管理同模型調校,先慳token再提升表現,係高效用Agent嘅關鍵。
呢篇文章係由了山海分享佢用Claude Code配好Agent之後嘅實戰心得,重點講點樣慳token同提升模型表現。作者本身用過一段時間,發現token消耗係影響賬單同模型質素嘅主要原因,所以整理咗一套上下文管理同模型調校嘅方法。整體結論係:先做好上下文管理(用/clear、/compact、/focus等命令),再透過規劃(/plan)同調整思考深度(/effort)去提升表現,而唔係一味用更高階嘅模型。
具體嚟講,token係AI每次運算嘅計量單位,消耗太多會令模型「失憶」、輸出變差。作者提出五個必備習慣:任務切換時用/clear,對話變長用/compact壓縮,臨時問題用/btw隔離,出錯用/rewind回溯,新項目用/init建立記憶檔案。呢啲方法可以大幅減少無謂嘅token開支,同時保持關鍵資訊。提升表現方面,作者強調先規劃後執行,用/plan分析影響範圍同風險,再按複雜度用/effort調整思考深度(low到max),必要時切換/model。日常可以結合/fast加快速度,或者用/batch、/agents等高階功能。最後作者分享咗一個工作流:新項目用/init設定規範,日常用/plan→執行→/diff→/code-review,需要極致表現就用opus加high effort加ultraplan。佢認為AI工具會愈嚟愈強,但真正拉開差距嘅係點樣同佢相處。
- Token係AI消耗嘅計量單位,太大會令模型失憶同質素下降,慳token等於慳錢同延長對話壽命。
- 省token方法:用/clear斷開對話、/compact壓縮上下文、/btw臨時隔離、/rewind回溯、/init建立項目記憶。
- 提升表現先規劃:用/plan分析受影響檔案同風險,確認後再執行,降低返工率。
- 調校思考深度:/effort由low到max,簡單任務用low,複雜用high或xhigh,唔好長期max以免性價比低。
- 日常工作流:/init→/memory寫規範→/plan→執行→/diff→/code-review→/compact維護,高階可用/agents同/ultraplan。
Token:AI嘅「記憶幣」,用多用少影響深遠
簡單講,token就係Claude Code「睇嘢」同「思考」嘅計量單位。你每發一條訊息、AI每回一次答,佢都要將當前全部上下文重新讀一次。
token就係計量單位,直接影響賬單同模型輸出質素。
呢個機制帶嚟兩個問題:第一係賬單,token消耗愈多,錢燒得愈快;第二係模型質素,上下文愈長,模型愈容易「失憶」,回答變短、質素下降,甚至卡住。
五個必備習慣,慳token慳到盡
作者分享咗自己固定養成嘅習慣,可以有效控制token消耗,保持對話健康。
- 任務切換必/clear或/reset:寫完一個功能就清空對話歷史,只保留項目級記憶(CLAUDE.md同skills),避免AI串戲。
- 定期檢查加/compact壓一壓:用/context睇彩色網格圖,token佔用接近80%就用/compact,帶focus instructions可以定向壓縮關鍵資訊。
- 臨時問題用/btw做隔離:唔計入主上下文,唔會污染主線,問完就走。
- 出錯用/rewind時光倒流:AI改咗七八個文件崩曬?直接回到之前嘅檢查點,新手必備「後悔藥」。
- 新項目由/init開始:生成CLAUDE.md,寫明語言、框架、規範等,AI每次啟動自動加載,省掉重複解釋嘅token。
唔好盲目追算力,先規劃再調深度
省token只係保底,提升表現先係關鍵。作者提出核心組合:先規劃、再調強度、最後睇情況換模型。
/plan先想後做:大改動唔好直接掟需求,讓AI輸出受影響文件、改動順序同潛在風險。
確認後再執行,返工率直線下降。然後用/effort調整思考深度:簡單補全用low,複雜邏輯用high甚至xhigh,配合/fast可以再擠速度。
模型切換方面,日常開發sonnet夠用,難嘅重構或架構問題換/model opus。高階功能如/batch(拆並行子任務)、/agents(管子智能體)、/ultraplan(雲端深度規劃)可以讓AI自己組隊幹活,表現提升明顯。
- 1 先/plan規劃方案,確認後執行。
- 2 用/effort調思考深度,唔好長期max。
- 3 必要時/model切換到opus處理複雜問題。
- 4 高階用/batch、/agents、/ultraplan提升效率。
日常工作流:抄呢份功課就得
作者分享咗佢目前用緊嘅工作流,新手可以直接跟住做。新項目:/init → /memory寫規範 → /permissions配常用命令免密。
日常任務:/plan確認方案 → 執行 → /diff睇改動 → /code-review + /security-review把關。
對話維護:/context檢查 → /compact或/focus → 必要時/rewind。需要極致表現:/model opus + /effort high + /ultraplan。收尾用/recap總結進展,/memory加強記憶。

親愛嘅朋友們,夜晚好,我係了山海。
前兩日出咗個教學,點樣配置 Agent,有興趣嘅可以回顧嚇。
懶人包:有基礎嘅可以直接睇文末嘅一圖流,文字可以跳過。冇基礎嘅完整睇完就得。
配完之後,我哋正式進入下一環節,淨係講乾貨:
點樣慳 token
點樣提升模型表現效率
今次嘅實操以 Claude Code 為主,不過市面上主流嘅 Agent 思路基本上都一致,大部分命令都幾接近,幾有參考價值㗎。
畀啱啱嚟嘅觀眾科普一下:
Token 到底係個乜嘢?
點解咁重要?
簡單講,token 就係 Claude Code「睇嘢」同「思考」嘅計量單位。
你每次發一條訊息、AI 每次回一次覆,佢都要將當前全部上下文(歷史對話、項目文件、CLAUDE.md、加載咗嘅 skills 等)重新讀一次。
呢個嘢帶嚟兩個問題:
第一個就係你嘅賬單,賬單計費就係按照你消耗嘅 token 嚟計,用得越多,使嘅越多。如果模型每次都全部加載你嘅會話消息,啲錢消失嘅速度簡直……我當時嘅利是錢基本上都賠曬落去……唉心悒啊。
第二個問題係模型質量。上下文越長,token 消耗越大。燒到上限,模型就開始「失憶」、回答變短、質量下降,甚至直接卡死。
你以為佢喺度認真思考,其實佢可能已經俾歷史對話淹沒咗。
我自己啱啱配好 Agent 嘅時候,最常見嘅場景就係:寫寫嚇突然覺得「佢點解變蠢咗?」
其實係因為佢嘅上下文太長,注意力已經渙散咗。上下文本身嘅長度就會損害模型嘅輸出質量!
必備慳 token 妙招
由上下文管理開始
啱啱接觸 AI Agent 同 Vibe Coding 嘅朋友(好似新年嘅我),最容易犯嘅錯,就係由得啲對話一路堆住唔理。結果越堆越亂,token 好似雪球咁越滾越大。
我自己而家固定養成咗幾個習慣:
1. 任務切換必 /clear 或 /reset
寫完一個功能,準備開下一個?第一件事就係 /clear。佢會將當前對話歷史清除,只保留項目級別嘅記憶(CLAUDE.md 同 skills)。
唔好心悒,留低舊上下文只會令 AI 亂咗。
別名 /reset /new,記一個就得。
2. 定期檢查 + /compact 壓一壓
對話變長咗,先打 /context。
佢會畀你一張彩色網格圖,清楚話你知系統提示、skills、歷史對話各佔幾多,仲剩幾多空間。經驗法則:接近 80% 就應該鬱手㗎喇。
呢個時候用 /compact(可以帶 focus instructions),佢會將歷史提煉成精簡嘅技術摘要,關鍵信息保留,token 佔用直接打回原形。比直接 /clear 温和好多,適合唔想完全甩曬上下文嘅場景。
帶 focus instructions 就係更加具體嘅定向壓縮,例如:“/compact 將 API 嘅接口重點記憶整理。」
咁樣模型之後就唔會亂咁定義接口㗎喇。
3. /focus 同 /btw 做臨時隔離
需要臨時問啲小問題?用 /btw(by the way),佢唔會計入主上下文,唔會污染主線。想令模型只關注最近一輪對話?
/focus 好正,全屏模式下特別清爽。
呢個其實係我偷懶嘅時候,有時瀏覽器唔想開,但係又有啲問題,就突然問佢一下,問完就走,唔使負責,賽博渣男真爽。
4. /rewind 救命神器
AI 一連改咗七八個檔案,跑起嚟全部炒曬?你唔記得咗到底改咗乜嘢?
直接 /rewind 時光倒流,返番去之前嘅檢查點。別名 /checkpoint /undo,新手必備嘅「後悔藥」。
但我呢邊更推薦用 Git 做版本管理,git 肯定更清晰。不過未用過嘅可以先用呢個應急,學咗 git 再嚟,或者都可以用 Hermes 嘅 Worktree,嗰個都好方便,人哋幫你做咗版本管理。
5. 項目級別記憶由 /init 開始
每次新項目,第一件事係跑 /init,生成 CLAUDE.md。將語言、框架、編譯方式、代碼規範、唔好掂嘅目錄等全部寫清楚。
之後 AI 每次啟動都會自動加載,慳走大量重複解釋嘅 token。
我仲成日用 /memory 編輯呢個檔案,發現 AI 重複踩同一個坑,就即刻加規則入去,下次佢就會記住。
提升模型表現:
唔係堆算力,而係聰明咁用
慳 token 係保底,提升表現先係關鍵。唔好一開頭就不停轉 opus,咁樣 token 燒得仲快。
我嘅核心組合:先規劃,再調整強度,最後睇情況換模型
/plan 先諗後做:
大改動唔好直接掟需求。先 /plan,令佢輸出受影響檔案、改動順序、潛在風險。你確認之後再執行,返工率直線下降,質量高好多。
/effort 調整思考深度:
low / medium / high / xhigh / max。簡單補全用 low,複雜邏輯用 high 甚至 xhigh。配合 /fast 可以再榨速度。唔好長期 max,性價比會崩潰。
/model 靈活切換:
日常開發 sonnet 夠用,遇到難嘅重構或架構問題,轉 opus。/config 可以睇當前設定,仲可以改預設模型。
再高階少少,新手可以慢慢試 /batch(大任務拆做並行子任務)、/agents(管理智能體)、/ultraplan(雲端深度規劃)。呢啲可以令 AI 自己組隊做嘢,表現提升明顯。
我而家嘅日常工作流程
新手可以直接抄功課
新項目:/init → /memory 寫規範 → /permissions 配常用命令免密碼(唔使再每次彈視窗確認)
日常任務:/plan 確認方案 → 執行 → /diff 睇改動 → /code-review + /security-review 把關
對話維護:/context 檢查 → /compact 或 /focus → 有需要時 /rewind
需要極致表現:/model opus + /effort high + /ultraplan
收尾:/recap 總結進展,/memory 加強記憶
呢啲組合用熟咗,你會明顯覺得「Agent 越來越明我」。
當然,我都承認,目前仲有好多未完全行得通嘅地方。例如超大代碼庫之下點樣進一步優化,長週期項目記憶點樣維護得更好,呢啲我仲繼續試緊。我咁蠢,都仲摸索緊。
一圖流
其實係五張圖咋~



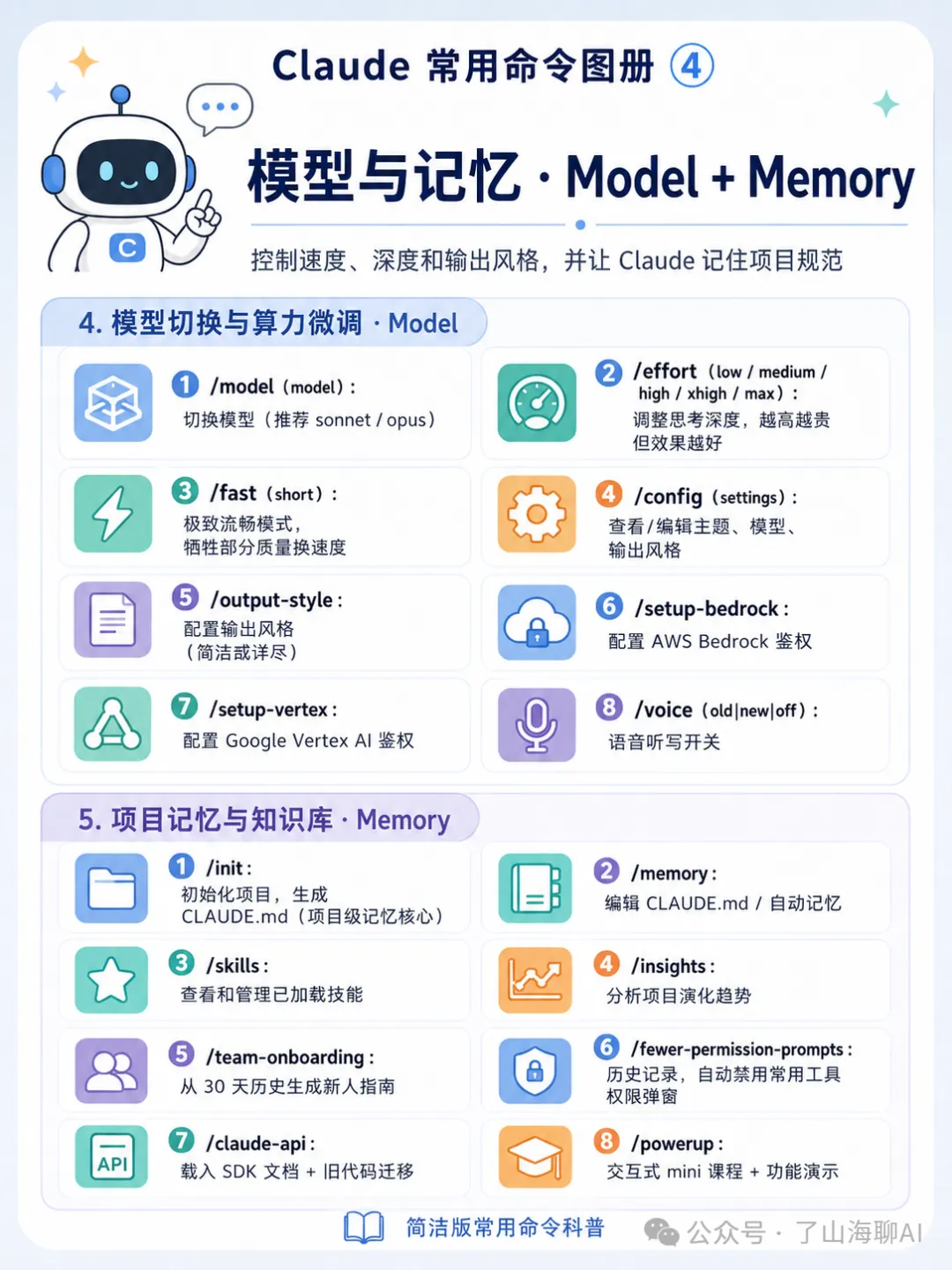

後記:
我嘅少少睇法
我一直堅持一個論調:AI 工具會越來越勁,但真正拉開差距嘅,永遠係你點樣同佢相處。
慳 token 唔係單純慳錢,而係延長對話嘅生命;提升模型表現,唔係盲目追算力,而係令佢真正成為你嘅聰明延伸。
你最近係咪用緊 Claude Code?配好 Agent 之後踩過邊啲 token 或表現相關嘅坑?有冇自己嘅打法?歡迎評論區一齊傾嚇,我都好想聽聽其他人嘅經驗。
我哋繼續保持好奇,一齊玩落去。
親愛的朋友們,晚上好,我是了山海。
前兩天發了教程,怎麼配置 Agent, 感興趣的可以回顧一下。
省流版:有基礎的直接文末一圖流,文字可以跳過。沒基礎的完整看完即可。
在配完以後,我們正式進入下一環節,只講乾貨:
怎麼省token
怎麼提升模型表現效率
這次的實操以Claude code 為主,不過市面上主流的Agent的思路基本都一致,大部分命令都比較接近,挺有參考意義的。
給剛來的觀眾科普一下:
Token 到底是個啥?
為啥這麼重要?
簡單說,token 就是 Claude code “看東西” 和 “思考” 的計量單位。
你每發一條消息、AI 每回一次答,它都要把當前全部上下文(歷史對話、項目文件、CLAUDE.md、加載的 skills 等)重新讀一遍。
這玩意帶來兩個問題:
第一個就是你的賬單,賬單計費就是按照你消耗的token來的,用的越多,花的越多。要是模型每次都全部加載你的會話消息,那錢的消失速度簡直。。。我當時的壓歲錢基本都賠進去了。。。哎心疼啊。
第二個問題是模型質量。上下文越長,token 消耗越大。燒到上限,模型就開始“失憶”、回答變短、質量下降,甚至直接卡住。
你以為它在認真思考,其實它可能已經被歷史對話淹沒了。
我自己剛配好 Agent 的時候,最常見的場景就是:寫着寫着突然覺得“它怎麼變笨了?”
其實是因為它的上下文太長,注意力已經渙散了。上下文本身的長度就會損害模型的輸出質量!
必備省 token 妙招
從上下文管理開始
剛接觸Ai Agent 和 Vibe Coding的朋友(比如春節的我),最容易犯的錯,就是讓對話一直堆着不管。結果越堆越亂,token 像雪球一樣滾大。
我自己現在固定養成的幾個習慣:
1. 任務切換必 /clear 或 /reset
寫完一個功能,準備開下一個?第一件事就是 /clear。它會把當前對話歷史幹掉,只保留項目級的記憶(CLAUDE.md 和 skills)。
別心疼,留着舊上下文只會讓 AI 串戲。
別名 /reset /new,記一個就行。
2. 定期檢查 + /compact 壓一壓
對話變長了,先敲 /context。
它會給你一張彩色網格圖,清楚告訴你係統提示、skills、歷史對話各佔多少,還剩多少空間。經驗法則:接近 80% 就該動手了。
這時候用 /compact(可以帶 focus instructions),它會把歷史提煉成精簡的技術摘要,關鍵信息保留,token 佔用直接打回原形。比直接 /clear 温和多了,適合不想完全丟掉上下文的場景。
帶focus instructions就是更加具體的定向壓縮,如:“/compact 把API的接口重點記憶整理。”
這樣模型後面不會亂定義接口了就。
3. /focus 和 /btw 做臨時隔離
需要臨時問點小問題?用 /btw(by the way),它不計入主上下文,不會污染主線。 想讓模型只關注最近一輪對話?
/focus 很香,全屏模式下特別清爽。
這個其實是我偷懶的時候,有時候瀏覽器不想打開,但是又有點問題,就突然問他一下,問完就走,不用負責,賽博渣男真爽。
4. /rewind 救命神器
AI 一連改了七八個文件,跑起來全崩?你忘了到底改了啥?
直接 /rewind 時光倒流,回到之前的檢查點。別名 /checkpoint /undo,新手必備的“後悔藥”。
但是我這邊更推薦Git進行版本管理嗷,git肯定更清晰。但是沒用過的可以先用這個應急一下,學了git再來,或者也可以用Hermes的Worktree,那個也很方便,人家幫你做好了版本管理。
5. 項目級記憶從 /init 開始
每次新項目,第一件事跑 /init,生成 CLAUDE.md。把語言、框架、編譯方式、代碼規範、不要碰的目錄等都寫清楚。
後面 AI 每次啓動都會自動加載,省掉大量重複解釋的 token。
我還經常用 /memory 編輯這個文件,發現 AI 反覆踩同一個坑,就立刻加規則進去,下次它就記住了。
提升模型表現:
不是堆算力,而是聰明地用
省 token 是保底,提升表現才是關鍵。別一上來就狂切 opus,那 token 燒得更快。
我的核心組合:先規劃,再調強度,最後看情況換模型
/plan 先想後做:
大改動別直接甩需求。先 /plan,讓它輸出受影響文件、改動順序、潛在風險。你確認後再執行,返工率直線下降,質量高很多。
/effort 調思考深度:
low / medium / high / xhigh / max。簡單補全用 low,複雜邏輯用 high 甚至 xhigh。配合 /fast 可以再擠速度。別一直 max,性價比會崩。
/model 靈活切換:
日常開發 sonnet 夠用,碰到難的重構或架構問題,切 opus。/config 可以看當前設置,還能改默認模型。
更高階一點,新手可以慢慢試 /batch(大任務拆並行子任務)、/agents(管子智能體)、/ultraplan(雲端深度規劃)。這些能讓 AI 自己組隊幹活,表現提升明顯。
我目前的日常工作流
新手可以直接抄作業
新項目:/init → /memory 寫規範 → /permissions 配常用命令免密(再也不用每次彈窗確認)
日常任務:/plan 確認方案 → 執行 → /diff 看改動 → /code-review + /security-review 把關
對話維護:/context 檢查 → /compact 或 /focus → 必要時 /rewind
需要極致表現:/model opus + /effort high + /ultraplan
收尾:/recap 總結進展,/memory 加強記憶
這些組合用熟了,你會明顯感覺到“Agent 越來越懂我”。
當然,我也得承認,目前還有很多沒完全跑通的地方。比如超大代碼庫下怎麼進一步優化,長週期項目記憶怎麼維護得更好,這些我還在繼續試。愚鈍如我,也還在摸索。
一圖流
其實是五張圖啦~
後記:
我的一點小看法
我始終堅持一個論調:AI 工具會越來越強,但真正拉開差距的,永遠是你怎麼和它相處。
省 token 不是單純省錢,是在延長對話的生命;提升模型表現,不是盲目追算力,而是讓它真正成為你的聰明延伸。
你最近在用 Claude Code 嗎?配好 Agent 後踩過哪些 token 或表現相關的坑?有什麼自己的打法?歡迎評論區一起聊聊,我也很想聽聽別人的經驗。
我們繼續保持好奇,一起玩兒下去。