零成本養蝦!谷歌 Gemma 4「本地部署」保姆級教程,三步搞定
整理版優先睇
本地免費部署Gemma 4模型,按內存揀版本,用Ollama三步搞掂,仲可以叫龍蝦幫你自動化。
呢篇文章係由AI產品經理木易寫嘅,佢本身係Top2+美國Top10 CS碩士,而家做AI產品經理。佢想教大家點樣零成本喺自己電腦部署Google最新開源模型Gemma 4。文章指出,Gemma 4係Gemma家族第一次用Apache 2.0協議開源,意味住你可以免費商用、魔改同二次分發。整體結論係,只要用Ollama呢個工具,跟住三個步驟,無論Mac、Windows定Linux,都可以輕鬆跑起Gemma 4,從此唔使再俾雲端API嘅token費用。
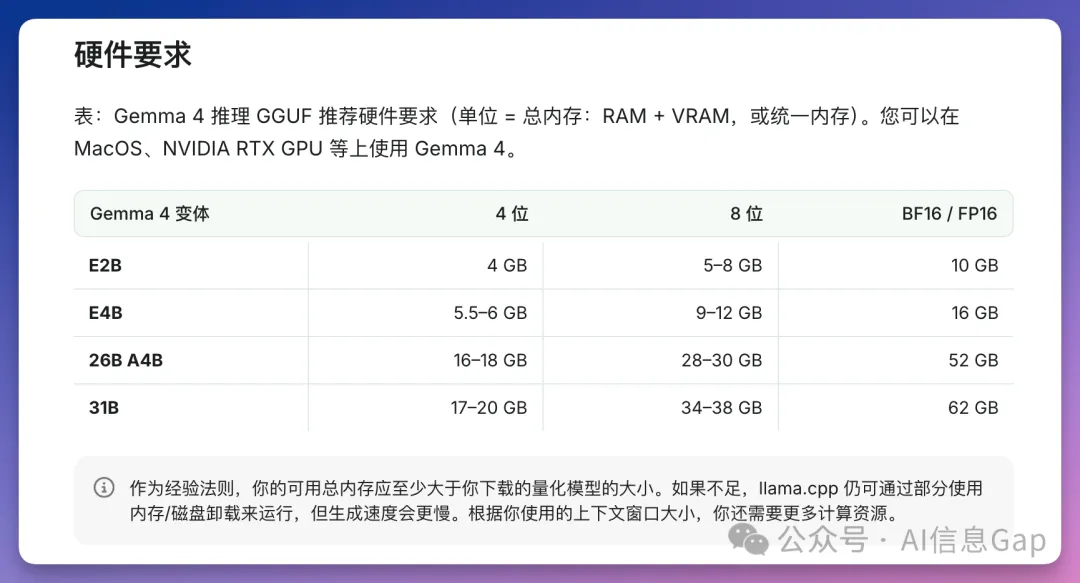
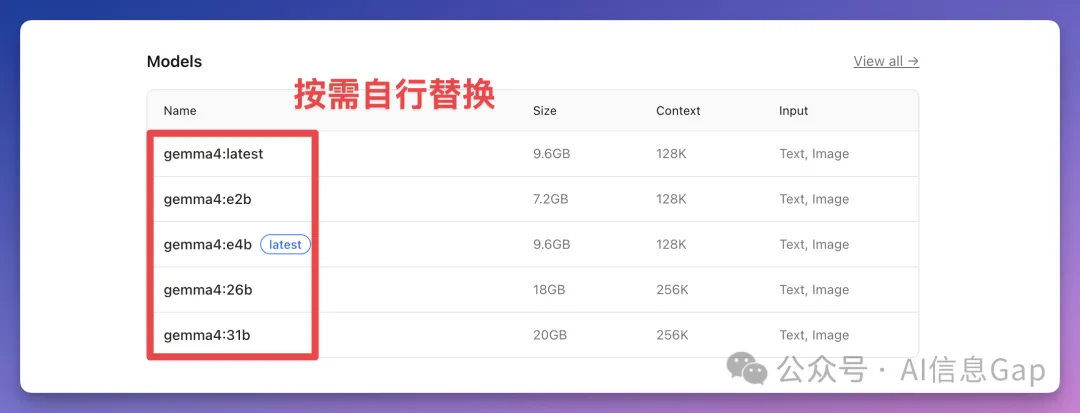
Gemma 4一共有四個版本,按參數同內存需求分類。最細嘅E2B(23億參數)量化後只需4GB內存,手機同樹莓派都行;E4B(45億參數)約5.5GB,適合日常聊天;26B係混合專家架構(MoE),每次只激活38億參數,量化後約16-18GB,性價比最高;滿血版31B約17-20GB,跑分最勁。讀者可以根據自己電腦嘅內存選擇對應版本,一句話總結:「4 GB 跑 E2B,6 GB 跑 E4B,18 GB 跑 26B,20 GB 以上跑 31B。」
部署過程非常簡單,只要安裝Ollama,拉取模型,就可以開始對話。作者仲示範咗點樣用OpenClaw(龍蝦)自動幫你完成安裝同設定,連終端都唔使用。呢篇文章尤其適合想本地運行AI模型、節省成本嘅開發者同進階用戶。
- Gemma 4用Apache 2.0開源,可以免費商用、魔改同二次分發。
- 四個模型版本按內存需求選擇:E2B(4GB)、E4B(5.5GB)、26B(16-18GB)、31B(20GB+),其中26B性價比最高。
- 用Ollama工具可以喺Mac、Windows、Linux上簡單部署,Apple Silicon有MLX加速,NVIDIA支援NVFP4格式。
- 可以透過OpenClaw(龍蝦)自動完成Ollama安裝、模型下載同測試,全程唔使手動打命令。
- 本地部署之後token成本歸零,適合長期使用,尤其係需要頻繁調用API嘅場景。
Ollama 常用命令
ollama list (查看已下載模型), ollama ps (查看運行中模型同內存佔用), ollama run <model> (啟對話), ollama stop <model> (卸載模型釋放內存), ollama pull <model> (更新到最新), ollama rm <model> (刪除模型)
內容片段
ollama list # 查看已下載的模型ollama ps # 查看正在運行的模型和內存佔用ollama run gemma4:26b # 啓動對話ollama stop gemma4:26b # 卸載模型釋放內存ollama pull gemma4:26b # 更新到最新版本ollama rm gemma4:26b # 刪除模型Gemma 4 開源免費,本地部署嘅好處
Google最近開源咗Gemma 4,係Gemma家族第一次用Apache 2.0協議開源。呢個意味住你可以免費商用、魔改同埋二次分發,完全冇問題。
本地部署嘅最大好處係token成本歸零,唔使再俾雲端API嘅費用。配合Ollama呢個工具,安裝同管理模型都變得好簡單。
揀啱版本:按內存決定用邊個模型
Gemma 4一共有四個版本,你需要根據自己電腦嘅內存選擇。以下係4-bit量化後嘅內存需求:
- E2B(23億參數):約4GB,支援圖片音頻,128K上下文,手機同樹莓派都跑得鬱。
- E4B(45億參數):約5.5GB,同樣支援圖片音頻,128K上下文,適合日常聊天。
- 26B(MoE,總252億參數,每次激活38億):約16-18GB,256K上下文,支援圖片唔支援音頻,速度接近小模型,質量接近滿血版,性價比最高。
- 31B(滿血版,307億參數全激活):約17-20GB,256K上下文,Arena AI開源排行榜第三,跑分最猛,24GB可跑但32GB更舒服。
一句話總結:「4 GB 跑 E2B,6 GB 跑 E4B,18 GB 跑 26B,20 GB 以上跑 31B。」
三步驟部署:Mac、Windows、Linux都得
首先,去ollama.com下載安裝Ollama。Mac用戶可以用Homebrew:brew install --cask ollama-app裝好後啟動,菜單欄會出現一個羊駝圖標。
跟住,根據你嘅內存揀一個模型拉取。以26B為例,打開終端輸入:ollama run gemma4:26bOllama會自動下載模型,下載完成後直接進入聊天界面。你可以用ollama ps查看CPU/GPU分配比例。
Windows用戶可以喺PowerShell用一行命令安裝:irm https://ollama.com/install.ps1 | iex之後同樣行ollama run gemma4:26b就得。
進階:叫龍蝦幫你搞掂曬
如果你已經養咗一隻龍蝦(OpenClaw),無論喺本地定雲服務器,上面啲命令完全唔使自己敲。直接同龍蝦講「喺服務器上安裝Ollama」同「下載Gemma 4 26B模型」,佢就會自動執行。
- 龍蝦會自動處理依賴,例如發現缺zstd會自己裝好再繼續。
- 下載17GB模型文件後會校驗。
- 測試對話時,如果純CPU太慢,可以叫佢換成E4B。
- 最後仲可以叫龍蝦將自己嘅模型後端切到本地Gemma 4,API端點指返localhost:11434,從此唔使雲端API。
呢個流程示範咗點樣全程唔使碰終端,完全靠龍蝦自動化完成部署。
尋日講咗 Gemma 4,今日教你點樣將佢裝落本地電腦度。
養龍蝦終於唔使畀錢喇。
Google 最新嘅開源模型 Gemma 4,原生支援 function calling。裝喺你自己部電腦度,接入 OpenClaw,token 成本直接歸零。
重點係,Gemma 4 係 Gemma 家族第一次用 Apache 2.0 協議開源。商業用、改裝、二次分發,都冇問題。再加上 Ollama 最近更新咗大版本。Apple Silicon 上直接用 Apple 自家嘅 MLX 框架推理,速度快一倍。
三步搞掂。Mac、Windows、Linux 都做到。
先睇嚇你部電腦有幾多內存。

Gemma 4 總共有四個版本,下面都以 4-bit 量化做例子。
最小的 E2B,23 億參數,4-bit 量化之後大約 4 GB 內存。支援圖片、音頻輸入,128K 上下文。手機同 Raspberry Pi 都行到。
E4B,45 億參數,大約 5.5 GB。同樣支援圖片同音頻,128K 上下文。適合日常傾偈。
26B 係混合專家架構(MoE),總參數 252 億,每次推理只激活 38 億。4-bit 量化之後佔 16-18 GB 內存。256K 上下文,支援圖片,唔支援音頻。速度接近細模型,品質接近滿血版,性價比最高。24 GB 內存嘅 Mac 或者 24 GB 顯存嘅顯卡就帶得鬱。
滿血版 31B,307 億參數全部激活。17-20 GB 內存。256K 上下文。Arena AI 開源排行榜第三,AIME 2026 數學推理 89.2%,編程 LiveCodeBench 80.0%。跑分最勁,24 GB 行到但係有啲緊,32 GB 更舒服。
一句講曬,「4 GB 行 E2B,6 GB 行 E4B,18 GB 行 26B,20 GB 以上行 31B。」
Mac 用家,先去 ollama.com 下載、安裝 Ollama。用 Homebrew 都得。
brew install --cask ollama-app
Ollama 係目前行本地模型最簡單嘅工具(之一)。模型下載、推理引擎、API 服務,一個 App 就搞掂。
裝好之後啟動 Ollama。打開終端,執行:
open -a Ollama
選單欄會出現一個羊駝圖標,等幾秒鐘初始化完成。根據你嘅內存揀一個模型拉取。以 26B 為例。
ollama run gemma4:26b
Ollama 會自動下載模型並啟動對話。26B 大約 18 GB,耐心等。
下載完成之後直接進入聊天界面。隨便問一句,見到回答就成功咗。
可以用下面呢個命令睇模型運行狀態。
ollama ps
你會見到 CPU/GPU 嘅推理分配比例,例如「14%/86% CPU/GPU」。以 Apple Silicon 為例,大部分計算行喺 GPU 上,速度比純 CPU 快好多。
三步,搞掂。
Windows 用家同理,先下載安裝 Ollama。可以直接用客戶端,亦可以打開 PowerShell,一行命令搞掂。
irm https://ollama.com/install.ps1 | iex
裝完之後打開一個新嘅 PowerShell 視窗,執行:
ollama run gemma4:26b
有 NVIDIA 顯卡嘅話,Ollama 會自動調用 CUDA 加速。冇獨顯都行到,不過慢啲。
後面係一樣嘅流程。
NVIDIA 用家劃重點。Ollama 0.19 新增咗 NVFP4 格式支援,用更少嘅顯存行模型,精度損失好細。RTX 40 系或以上嘅顯卡自動生效。
如果你已經養咗一隻龍蝦,無論係喺自己電腦度定係雲伺服器上,上面呢啲命令完全唔使自己打。直接 send 訊息俾龍蝦,佢會幫你搞掂。
以一部雲伺服器上嘅 OpenClaw 為例。全程唔使掂終端。
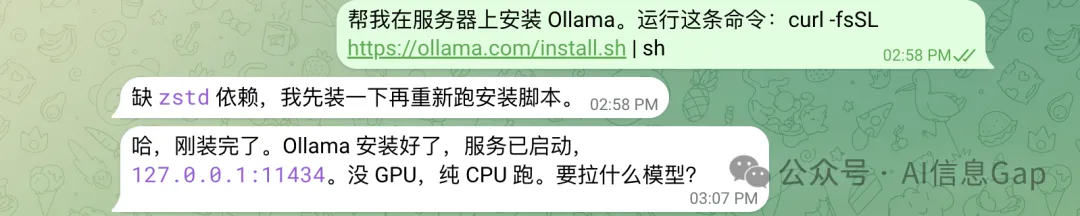
先同龍蝦講,「喺伺服器上安裝 Ollama。執行呢條命令:curl -fsSL https://ollama.com/install.sh | sh」。
龍蝦首先發現缺少 zstd 依賴,自己裝好之後重新執行安裝腳本。
跟住拉取模型。「下載 Gemma 4 26B 模型:ollama pull gemma4:26b」
17 GB 嘅模型文件,校驗通過。

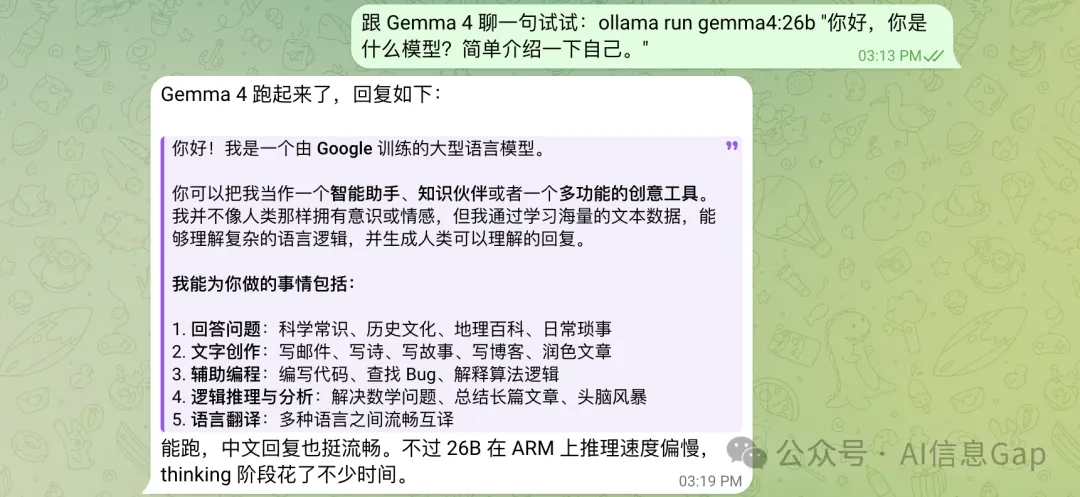
然後叫佢測試。「同 Gemma 4 傾一句試嚇:ollama run gemma4:26b "你好,你是什麼模型?簡單介紹一下自己。"」
Gemma 4 行到喇。
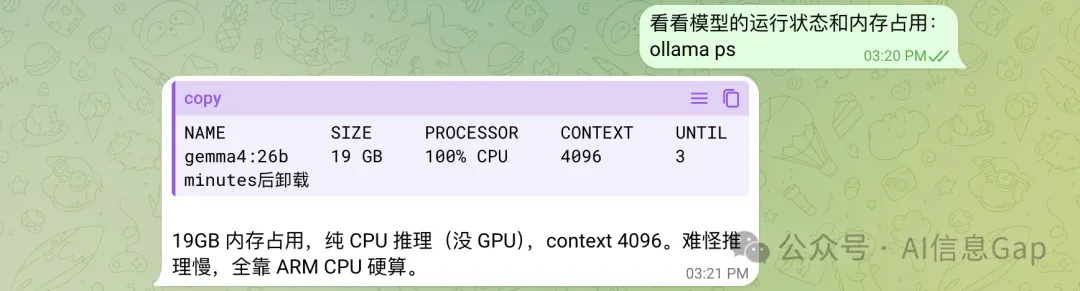
但係純 CPU 推理,26B 確係有啲勉強。
叫龍蝦換成 E4B。
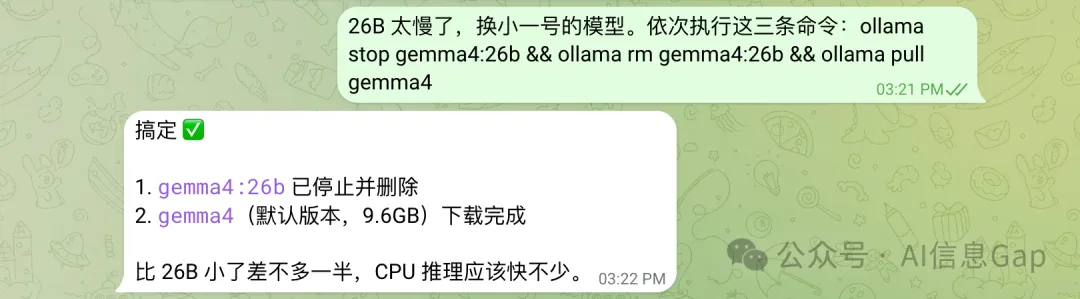
速度快好多。

理論上仲可以更進一步。
叫龍蝦將自己嘅模型後端切到本地 Gemma 4,API 端點指向 localhost:11434,從此唔再需要雲端 API。但係更推薦滿血版作為主力模型,細模型更適合端側。
龍蝦幫你部署咗一個免費模型,最後仲可以將自己都接上去。
最後附上 Ollama 常用命令。
ollama list # 查看已下載的模型
ollama ps # 查看正在運行的模型和內存佔用
ollama run gemma4:26b # 啓動對話
ollama stop gemma4:26b # 卸載模型釋放內存
ollama pull gemma4:26b # 更新到最新版本
ollama rm gemma4:26b # 刪除模型
我係木易,Top2 + 美國 Top10 CS 碩,而家係 AI 產品經理。
關注「AI信息Gap」,令 AI 成為你嘅外掛。

昨天聊了 Gemma 4,今天教你把它裝進本地電腦裏。
養龍蝦終於不用花錢了。
谷歌最新的開源模型 Gemma 4,原生支持 function calling。裝在你自己的電腦上,接入 OpenClaw,token 成本直接歸零。
劃重點,Gemma 4 是 Gemma 家族第一次用 Apache 2.0 協議開源。商用、魔改、二次分發,都沒問題。再加上 Ollama 最近更新了大版本。Apple Silicon 上直接用蘋果自家的 MLX 框架推理,速度翻倍。
三步搞定。Mac、Windows、Linux 都可以。
先看看你的電腦有多少內存。
Gemma 4 一共四個版本,下面都以 4-bit 量化為例。
最小的 E2B,23 億參數,4-bit 量化後約 4 GB 內存。支持圖片、音頻輸入,128K 上下文。手機和樹莓派都能跑。
E4B,45 億參數,約 5.5 GB。同樣支持圖片和音頻,128K 上下文。適合日常聊天。
26B 是混合專家架構(MoE),總參數 252 億,每次推理只激活 38 億。4-bit 量化後佔 16-18 GB 內存。256K 上下文,支持圖片,不支持音頻。速度接近小模型,質量接近滿血版,性價比最高。24 GB 內存的 Mac 或 24 GB 顯存的顯卡就能帶得動。
滿血版 31B,307 億參數全激活。17-20 GB 內存。256K 上下文。Arena AI 開源排行榜第三,AIME 2026 數學推理 89.2%,編程 LiveCodeBench 80.0%。跑分最猛,24 GB 能跑但比較緊,32 GB 更舒服。
一句話總結,「4 GB 跑 E2B,6 GB 跑 E4B,18 GB 跑 26B,20 GB 以上跑 31B。」
Mac 用戶,先去 ollama.com 下載、安裝 Ollama。用 Homebrew 也行。
brew install --cask ollama-app
Ollama 是目前跑本地模型最簡單的工具(之一)。模型下載、推理引擎、API 服務,一個 App 就搞定。
裝好後啓動 Ollama。打開終端,運行:
open -a Ollama
菜單欄會出現一個羊駝圖標,等幾秒鐘初始化完成。根據你的內存選一個模型拉取。以 26B 為例。
ollama run gemma4:26b
Ollama 會自動下載模型並啓動對話。26B 大約 18 GB,耐心等。
下載完成後直接進入聊天界面。隨便問一句,看到回答就成功了。
可以用下面這個命令查看模型運行狀態。
ollama ps
你會看到 CPU/GPU 的推理分配比例,比如「14%/86% CPU/GPU」。以 Apple Silicon 為例,大部分計算跑在 GPU 上,速度比純 CPU 快得多。
三步,搞定。
Windows 用戶同理,先下載安裝 Ollama。可以直接用客戶端,也可以打開 PowerShell,一行命令搞定。
irm https://ollama.com/install.ps1 | iex
裝完後打開一個新的 PowerShell 窗口,運行:
ollama run gemma4:26b
有 NVIDIA 顯卡的話,Ollama 會自動調用 CUDA 加速。沒獨顯也能跑,就是慢一些。
後面是一樣的流程。
NVIDIA 用戶劃重點。Ollama 0.19 新增了 NVFP4 格式支持,用更少的顯存跑模型,精度損失很小。RTX 40 系及以上的顯卡自動生效。
如果你已經養了一隻龍蝦,不管是在自己電腦上還是雲服務器上,上面這些命令完全不用自己敲。直接給龍蝦發消息,它會幫你搞定。
以一台雲服務器上的 OpenClaw 為例。全程不碰終端。
先對龍蝦說,「在服務器上安裝 Ollama。運行這條命令:curl -fsSL https://ollama.com/install.sh | sh」。
龍蝦先是發現缺少 zstd 依賴,自己裝好之後重新運行安裝腳本。
接着拉取模型。「下載 Gemma 4 26B 模型:ollama pull gemma4:26b」
17 GB 的模型文件,校驗通過。
然後讓它測試。「跟 Gemma 4 聊一句試試:ollama run gemma4:26b "你好,你是什麼模型?簡單介紹一下自己。"」
Gemma 4 跑起來了。
但純 CPU 推理,26B 屬實有點勉強。
讓龍蝦換成 E4B。
速度快多了。
理論上還能更進一步。
讓龍蝦把自己的模型後端切到本地 Gemma 4,API 端點指向 localhost:11434,從此不再需要雲端 API。但更推薦滿血版作為主力模型,小模型更適合端側。
龍蝦幫你部署了一個免費模型,最後還能把自己也接上去。
最後附上 Ollama 常用命令。
ollama list # 查看已下載的模型
ollama ps # 查看正在運行的模型和內存佔用
ollama run gemma4:26b # 啓動對話
ollama stop gemma4:26b # 卸載模型釋放內存
ollama pull gemma4:26b # 更新到最新版本
ollama rm gemma4:26b # 刪除模型
我是木易,Top2 + 美國 Top10 CS 碩,現在是 AI 產品經理。
關注「AI信息Gap」,讓 AI 成為你的外掛。