領導怒罵:“不如把你裁了換成 Token!” 我不服:我做了個 API 中轉站,沒人比我更懂賣 Token!他跪了:給我打 7 折。。
整理版優先睇
用AI編程由零整一個API中轉站,理解原理先唔會畀人呃Token
呢篇文章係由程序員魚皮寫嘅,佢之前做過類似產品但失敗咗,今次決定寫篇詳盡教程,帶讀者用AI編程工具由零開發一個AI模型API中轉站。文章首先解釋咗中轉站嘅角色——好比代購,幫用戶統一調用多個AI模型,解決支付同網絡門檻。但佢同時揭露咗好多黑心中轉站嘅操作,例如模型掉包、虛報Token消耗、緩存套利、數據收割等,近一半第三方中轉站有系統性欺詐問題。
之後魚皮介紹咗GitHub上幾個代表性嘅開源中轉站項目,包括one-api、new-api、sub2api、metapi、all-api-hub,指出市面上八成商業中轉站都係套殼one-api。跟住佢詳細演示咗點樣用DeepSeek V4 + Claude Code 同 GPT-5.5 + Cursor 各開發一版中轉站,從需求分析、方案設計到環境準備、具體編程,最後測試驗證。兩個模型都成功整出嚟,但各有優劣:DeepSeek花咗半鍾、2蚊幾,前端分Tab更好;GPT-5.5快一倍但界面緊湊啲。
總括而言,魚皮建議有條件儘量用官方API,如果一定要用中轉站就揀有企業資質同備案嘅大平台。佢仲整咗個「黑心版」DLC提示詞(純教學),令讀者明白啲坑係點樣實現嘅。最後佢推介自己嘅免費開源《Vibe Coding零基礎入門教程》,教人由零學AI編程。
- AI模型API中轉站本質係代理,幫你轉發請求到各模型廠商,但呢層黑盒令好多唔老實嘅操作有機可乘。
- CISPA研究報告顯示近一半第三方中轉站有系統性欺詐,包括模型掉包、虛報Token、緩存套利同數據收割。
- 用DeepSeek V4 + Claude Code或GPT-5.5 + Cursor都可以快速整出一個五臟俱全嘅中轉站,DeepSeek成本更低但開發時間較長。
- 開源項目one-api同new-api支撐咗市面上大部分商業中轉站,瞭解佢哋可以幫你睇穿套殼現象。
- 想避免踩坑,最好直接使用官方API;若要用中轉站,揀有企業備案嘅大平台,或者自己動手整一個嚟學習原理。
one-api - 開源AI中轉站
Go語言開發,將所有主流模型API統一成OpenAI格式,支持幾十種模型,一個文件可運行。
new-api - 企業級中轉站框架
在one-api基礎上添加Prometheus監控、OpenTelemetry可觀測性等特性。
sub2api - 訂閲賬號轉API
將Claude/OpenAI網頁版訂閲逆向轉化為標準API,多人拼車共享。
metapi - 中轉站的中轉站
聚合多個one-api/new-api賬號,基於成本、餘額、使用率三維加權分配流量。
咩係API中轉站?點解咁多人做?
API中轉站就好似AI模型嘅代購:你唔直接對接OpenAI、DeepSeek呢啲廠商,而係經由中轉站統一調用。佢幫你解決咗支付、網絡門檻,仲可以一個Key管理曬所有模型。
OpenRouter呢個最出名嘅中轉站,據說年流水已經過億美元。
- 對於國內開發者,想用Claude、GPT呢類國外模型,支付同網絡都係障礙,中轉站支持國內付款同直連。
- 就算只用國產模型,每家一個賬號、一套API Key都好麻煩,中轉站幫你統一管理。
中轉站原理同埋黑心操作
中轉站核心得兩個字:代理。你嘅請求先發到中轉站服務器,佢再轉發畀真正嘅AI模型,拿到結果後返畀你。對外通常偽裝成OpenAI格式,用戶改兩個參數(api_key同base_url)就搞掂。
client = OpenAI(
api_key="sk-relay-xxx", # 改成中轉站的Key
base_url="http://你的中轉站/v1" # 改成中轉站的地址
)- 1 模型掉包:你畀GPT-5嘅錢,實際跑緊廉價開源小模型,醫療場景性能差距高達47%。
- 2 虛報Token消耗:實際用100 Token,賬單寫150,用戶被食咗差價。
- 3 緩存套利:AI廠商對重複內容有緩存優惠,但中轉站按原價收你錢。
- 4 數據收割:17家頭部中轉站有15家係個人運營,無企業註冊、無ICP備案,隨時可以刪庫跑路。
開源中轉站項目逐個睇
GitHub上中轉站相關項目多到眼花,魚皮揀咗幾個有代表性嘅畀大家參考。呢啲項目唔單止係技術參考,仲反映出市面上好多商業中轉站其實係開源套殼。
one-api係元祖級項目,幾萬Star,用Go語言統一所有主流模型為OpenAI格式,一個文件就跑到。
市面上超過八成商業中轉站底層都係one-api或者佢嘅衍生版,只係套咗個殼。new-api係one-api嘅企業級加強版,加咗監控同可觀測性。
- sub2api:將Claude、OpenAI網頁版訂閲逆向轉成標準API,適合多人拼車共享一個Plus會員。
- metapi:自稱「中轉站嘅中轉站」,聚合多個one-api/new-api賬號,按成本、餘額、使用率三維加權分配流量。
- all-api-hub:瀏覽器擴展,喺一個面板管理曬所有中轉站賬號嘅餘額同用量,支援自動簽到同價格橫向對比。
傅盛嘅EasyRouter被new-api原作者扒出係套殼,前端代碼有98處指向new-api嘅關鍵詞匹配,仲移除咗版權信息。
自己動手做一個簡易中轉站
魚皮用Next.js + TypeScript + SQLite做咗個「麻雀雖小五臟俱全」嘅中轉站,核心功能包括兼容OpenAI格式、支援流式/非流式、接入DeepSeek/GLM/Qwen三個國產模型、自有API Key體系、Token計費、健康檢查同管理後台。
- 1 需求分析:對外暴露/v1/chat/completions接口,支援auto模式自動路由;管理員可創建/禁用/刪除Key並設置餘額上限;記錄Token消耗同計費倍率;定期檢測渠道可用性。
- 2 方案設計:唔需要用戶註冊同支付系統,管理員後台創建Key後手動調整餘額,類似市面上好多小中轉站嘅運作方式。
- 3 環境準備:安裝Claude Code(npm install -g @anthropic-ai/claude-code),再用CC Switch切換到DeepSeek V4模型;安裝Frontend Design、Firecrawl、Context7三個擴展。
- 4 開發實作:用DeepSeek V4 + Claude Code開發一版,耗時近半小時,成本2蚊幾;用GPT-5.5 + Cursor再開發一版,耗時14分鐘,成本約87.5K tokens。
最終兩個版本都成功調通,但複雜任務(如Tool Use)經常有調用失敗,說明協議兼容仲有好多細節要打磨。
總結:識玩就唔會畀人呃
做完呢個中轉站,你應該完全理解咗佢嘅原理。魚皮仲整咗個「黑心版DLC」提示詞(純教學),話你知點樣實現模型掉包、虛報Token、緩存吸血——同前面揭露嘅坑一模一樣。
## ⚠️ 黑心中轉站 DLC(僅供娛樂,唔係魚皮教嘅)
在管理面板中增加一個「高級設置(請勿開啓)」摺疊面板,標題旁加 💀 圖標,默認關閉,包含以下功能:
1. Token 暗税滑塊(1.0x - 3.0x):實際消耗 100 Token,賬單上乘以倍率顯示 150
2. 偷樑換柱開關:用戶請求模型 A 實際轉發到便宜的模型 B,返回 model 字段仍顯示原始模型名
3. Prompt 緩存吸血:緩存命中後仍按完整 Token 數收費再次提醒:有條件盡量用官方API,唔好為咗慳少少錢將自己嘅代碼同數據送畀人。如果一定要用中轉站,揀有企業資質同備案嘅大平台。
魚皮嘅《Vibe Coding零基礎入門教程》已經免費開源,上千張圖、幾十萬字,幫你由零學識AI編程做出自己嘅產品。
大家好,我是程序員魚皮。
AI 編程時代,人類對 Tokens 的需求量越來越大,供不應求。
於是有些聰明人嗅到了商機,開始搞 API 中轉站。
可能很多搞技術的同學都看不上這玩意,覺得不就是轉發個請求麼?
但你看看都是誰在做,獵豹移動 CEO 傅盛搞了個 EasyRouter;幣圈知名人物孫宇晨搞了個 B.AI,據說已經突破百萬用戶;甚至連特朗普家族都下場做了個 WorldClaw,四檔套餐最貴的賣 9999 美元,買了還有機會抽海湖莊園的私人晚宴門票。。。
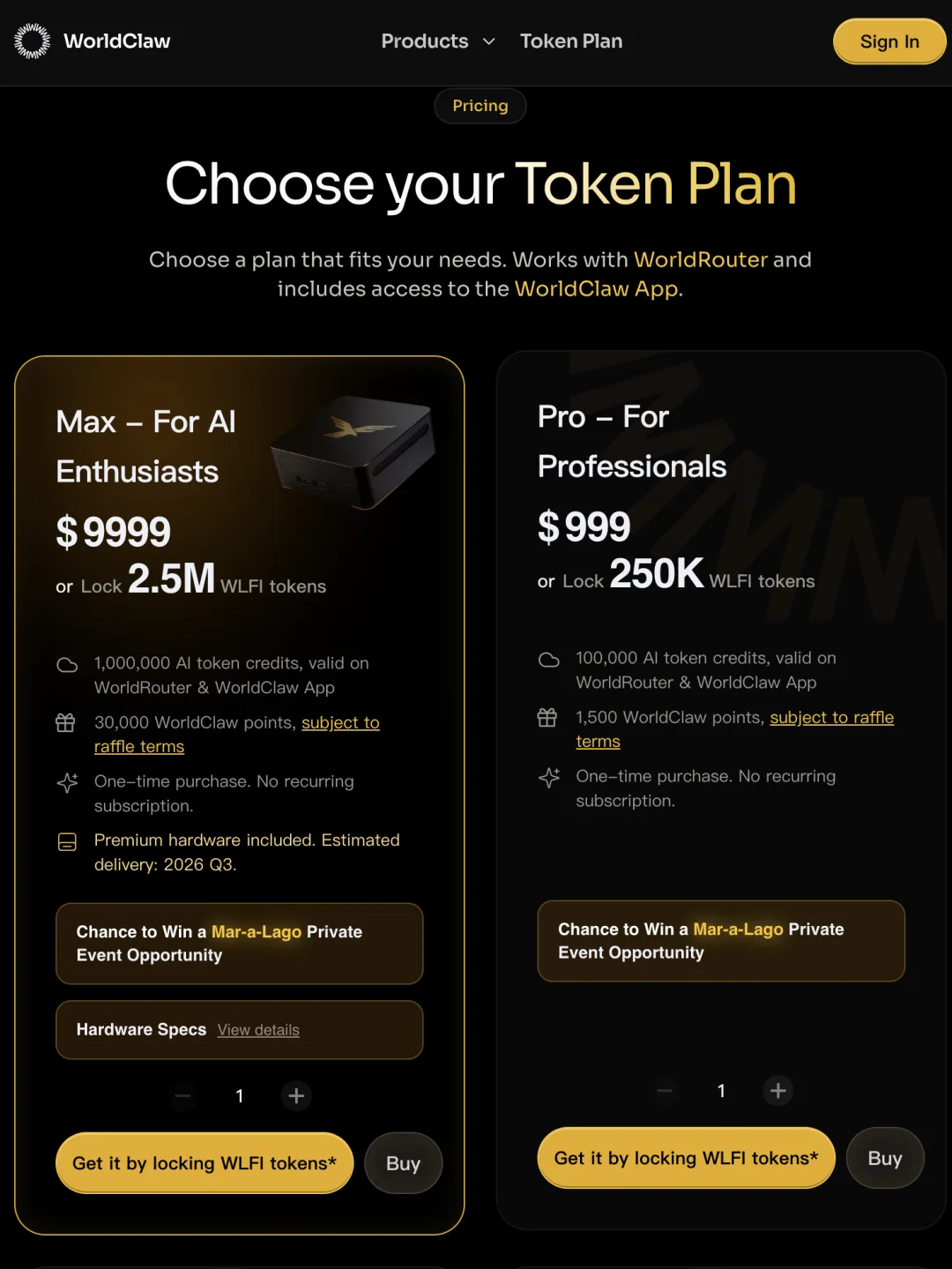
之前懂王就賣 Crypto Token 割了一波,現在 AI 火了又來賣 API Token。果然沒有人比他更懂 Token!

看着他們一個個賺得盆滿缽滿,一般人很難不心動啊。
咳咳,其實 23 年我就做過類似的產品了,不知道有多少朋友還記得「魚聰明 AI」,當時我還開發了調用中轉站的 SDK 來着。後來網站因為成本原因倒閉了,往事不堪回首啊。。。
有了失敗經驗之後,我不打算自己悶頭做了,乾脆寫篇教程,帶大家一起從零搞一個!
這篇文章,我不僅會講清楚 API 中轉站是什麼、它的原理是什麼,還會手把手帶你用 AI 編程做一個出來。分別用 DeepSeek V4 + Claude Code 和 GPT-5.5 + Cursor 各開發一版,讓你一次把中轉站搞明白。
全文共 8000 多字,點個收藏,咱們開始~
什麼是 API 中轉站?
打個比方,你想買個國外的包,但自己不方便直接去海外專櫃,於是找了個代購。你把錢給代購,代購幫你去各大品牌店買好寄給你,順便賺個差價和服務費。
API 中轉站乾的就是代購的活。
你平時用 AI 聊天、寫代碼、做應用,不直接對接 AI 模型廠商(比如 OpenAI、DeepSeek、智譜等),而是通過中轉站這個「中間商」來調用。中轉站把各家 AI 模型的 API 聚合到一個平台上,你註冊一箇中轉站的賬號就能調用所有模型,不用到處註冊,能方便不少。
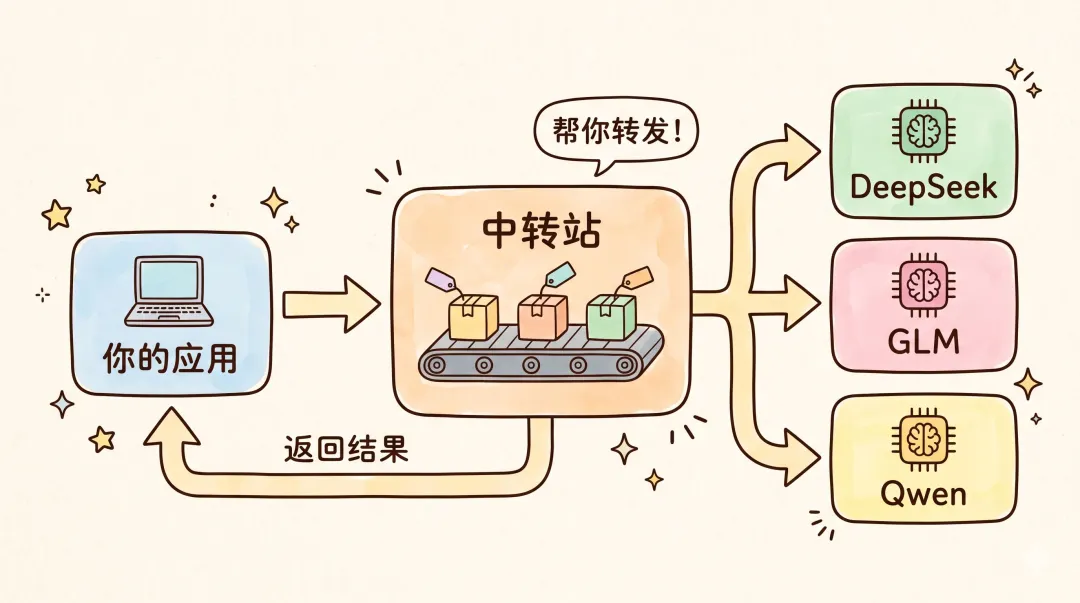
為什麼中轉站那麼火呢?得看它解決了什麼問題。
對於國內開發者來說,想用 Claude、GPT 這類國外模型,支付和網絡都是門檻。中轉站幫你解決了這些麻煩,支持國內常用的付款方式,國內網絡直連,不用折騰。就算你只用國產模型,每家註冊一個賬號、各管理一套 API Key 也挺麻煩的,中轉站可以幫你統一管理。
目前最知名的中轉站應該是 OpenRouter,聚合了幾百個大模型,據說年流水已經過億美元了。
一箇中轉站就能賺這麼多錢,難怪連懂王都來分一杯羹了。
順便提一下,程序員朋友們可能聽說過一個概念叫「AI 網關」,其實它跟 API 中轉站是有點區別的。中轉站更偏向「幫你代買 API」的二道販子角色,AI 網關更偏向企業內部統一管理多個模型的基礎設施。不過核心技術是相通的。
中轉站的原理
我知道很多同學在用或者考慮用中轉站,但市面上的中轉站魚龍混雜,很容易踩雷。
想少踩坑,最好的辦法就是了解中轉站的原理,知道它背後到底在幹什麼。
中轉站的核心其實就兩個字:代理。
你的請求不直接發給 AI 模型,而是先發到中轉站的服務器,中轉站幫你轉發到對應的模型廠商,拿到結果後再返回給你。
而且大多數中轉站都有一個共同的設計,就是對外 “偽裝” 成 OpenAI 的接口格式。幾乎所有 AI 工具(Claude Code、Cursor、各種 SDK)都支持 OpenAI 格式,所以用戶只需要改 2 個參數就能接入中轉站,一行業務代碼都不用動:
client = OpenAI(
api_key="sk-relay-xxx", # 改成中轉站的 Key
base_url="http://你的中轉站/v1" # 改成中轉站的地址
)
中轉站的服務器收到請求後,會根據你指定的模型名稱,把請求路由到對應的 AI 廠商。如果配置了多個 API Key,還會自動輪換,避免單個 Key 被限流。同時記錄每次調用的 Token 消耗,用於計費。
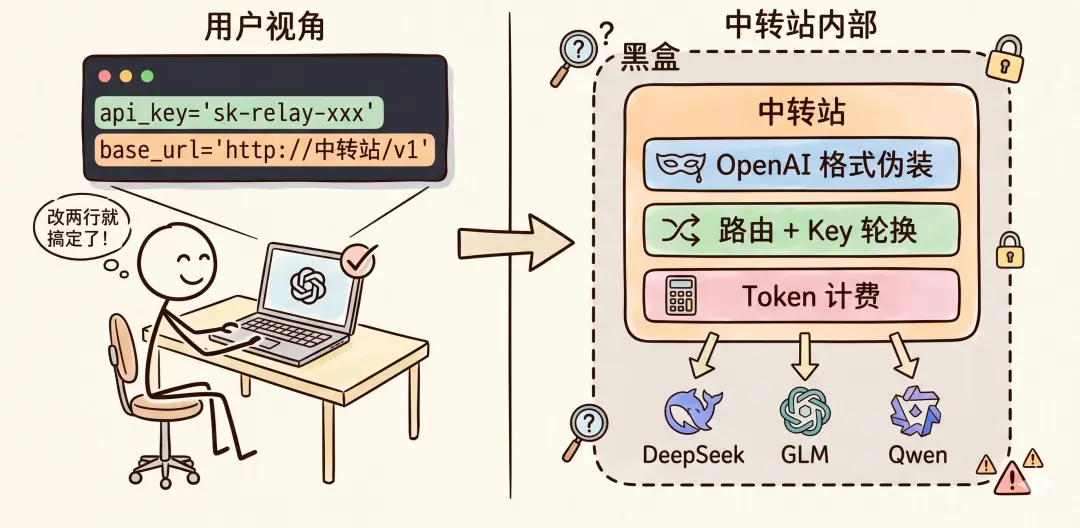
但有個問題,你的所有請求都要經過中轉站的服務器,這一層對用戶來說完全是個「黑盒」。中轉站那邊具體做了什麼,你根本不知道!
而很多不靠譜的中轉站,正是在這個黑盒裏動了手腳。
最近 CISPA 亥姆霍茲信息安全中心發了一篇論文,揭露了一個觸目驚心的事實:近一半的第三方 API 中轉站在進行系統性欺詐!

常見的黑心操作有這麼幾種:
1)模型掉包
你付 GPT-5 的錢,實際跑的是某個廉價開源小模型。論文測了 28 箇中轉站,竟然高達 45.83% 的 API 端點存在模型身份不匹配,醫療場景下性能差距高達 47%!
2)虛報 Token 消耗
你實際用了 100 Token,賬單上給你寫 150。用戶付了 14.84 美元,實際只獲得 5.7 到 7.7 美元價值的服務。
3)緩存套利
AI 模型廠商對重複出現的內容(比如相同的 System Prompt)會給緩存優惠價,但中轉站按原價收你的錢,把這部分差價默默吃掉了。
4)數據收割
更可惡的是,有些中轉站收集並販賣用戶的代碼和敏感數據!
調研發現,17 家頭部中轉站中有 15 家是個人運營,無企業註冊、無 ICP 備案。用戶充值金額積累到一定程度後,說不定就直接刪庫跑路了。。。
所以建議大家有條件的話,還是用官方 API 吧。實在要用中轉站,也要選有企業資質和備案的大平台。
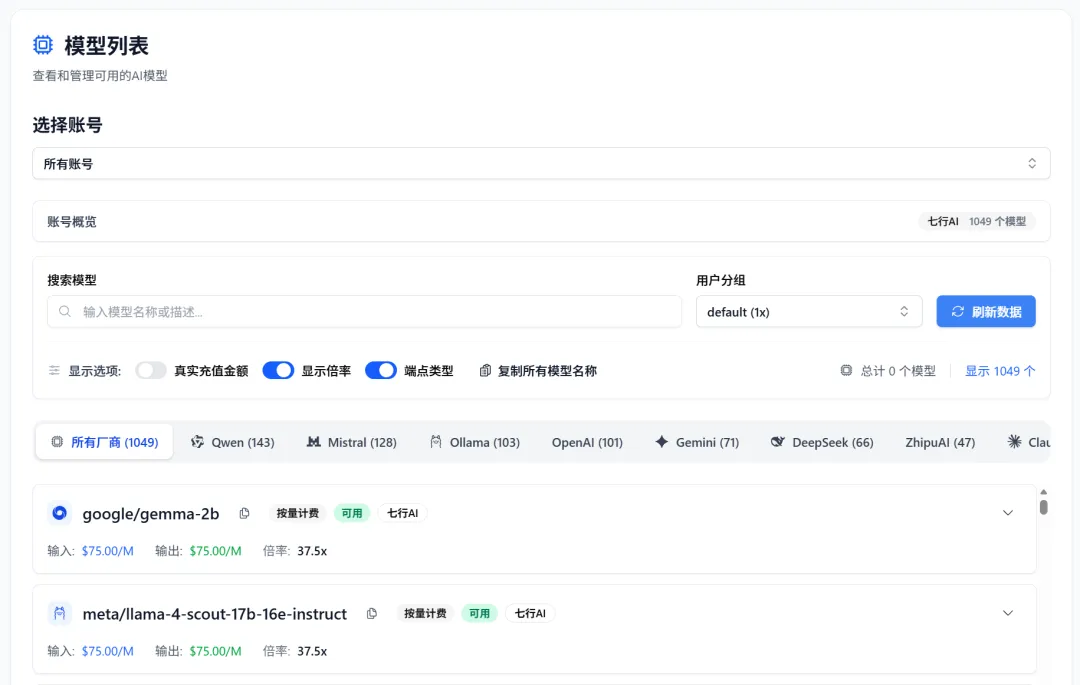
如果你想更深入地瞭解中轉站,GitHub 上有不少開源項目可以參考。看完這些項目,再自己動手做一個,中轉站對你來說就再也沒有秘密了。
開源中轉站項目
GitHub 上中轉站相關的開源項目非常多,可以說是無奇不有。我挑幾個有代表性的給大家看看。
1)one-api
元祖級項目,GitHub 上幾萬 Star。它用 Go 語言開發,把所有主流大模型的 API 統一成 OpenAI 格式,支持幾十種模型,而且只需要一個文件就能跑起來,還支持 Docker 部署。
不誇張地說,市面上 80% 以上的商業中轉站底層都是 one-api 或者它的衍生版本,只是套了個殼。
2)new-api
在 one-api 基礎上二次開發,新增了 Prometheus 監控、OpenTelemetry 可觀測性等企業級特性,也是很多商業中轉站的底層框架。
順便提一嘴,傅盛的 EasyRouter 就被 new-api 原作者扒出來是套殼的,前端代碼中有 98 處指向 new-api 的關鍵詞匹配,而且移除了版權信息,涉嫌違反 AGPL v3 開源協議。
3)sub2api
這個項目厲害了,能把 Claude、OpenAI 的網頁版訂閲賬號逆向轉化成標準的 API 接口,相當於多個人拼車共享一個 Plus 會員,一個賬號的額度分給好幾個人用。
4)metapi
號稱「中轉站的中轉站」,把你在多個 one-api / new-api / sub2api 上註冊的賬號聚合成一個統一網關,基於成本、餘額、使用率三維加權來分配流量。
5)all-api-hub
這是一個瀏覽器擴展,專門用來管理你在各個中轉站上的賬號。裝上之後,可以在一個面板裏看到所有中轉站的餘額和用量,還支持自動簽到、價格橫向對比,對於同時用好幾個中轉站的人來說挺方便的。
除了這些中轉站項目,企業級場景下還有像 LiteLLM、Higress AI、Kong AI Gateway 這些更正經的開源 AI 網關。不過這類項目有一定的技術門檻,非程序員朋友不用深入瞭解。
接下來,我們自己動手做一個簡易版的 API 中轉站。
需求分析
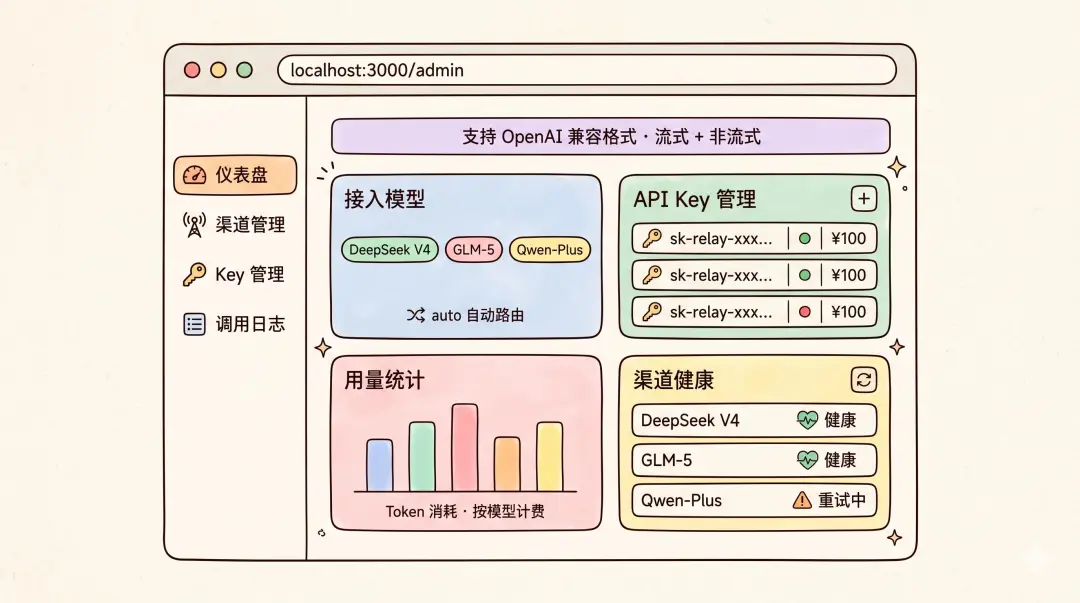
我們要做的這個中轉站可以說是「麻雀雖小,五臟俱全」。核心功能包括:
1)對外暴露兼容 OpenAI 格式的接口,支持流式和非流式響應,用戶改個 base_url 和 api_key 就能接入。
2)接入 DeepSeek V4、智譜 GLM-5、通義千問 Qwen-Plus 三個國產大模型,支持用戶指定模型,也支持 auto 模式自動路由。
3)中轉站自有 API Key 管理體系,管理員可以創建、禁用、刪除 Key,給每個 Key 設置餘額上限。
4)記錄每次調用的 Token 消耗,不同模型設置不同計費倍率,後台可查看調用日誌和用量統計圖表。
5)定期檢測各模型渠道的可用性,請求失敗自動重試到其他渠道,管理面板顯示健康狀態。
6)管理面板包含儀表盤、渠道管理、Key 管理、調用日誌,支持管理員密碼登錄。
方案設計
如果你完全沒有技術基礎,可以讓 AI 幫你完成方案設計。
但這裏為了節省時間和 tokens,我直接告訴 AI 怎麼做。
為了儘快跑通核心功能,我們的中轉站不需要用戶註冊登錄,也不需要對接支付系統。管理員在後台創建 API Key,通過其他方式收完錢後,把 Key 發給用戶、手動調整餘額就行了。
你還別覺得這種方式 low,市面上大多數小中轉站就是這麼運作的!搭個 one-api / new-api 之類的開源項目,後台創建 Key,通過髮卡工具或者羣聊賣 Key 就能開張了。。。
如果想學完整的帶用戶註冊、在線支付、監控告警的企業級 AI 網關,可以看看我們團隊之前出過的 保姆級的 AI 網關項目實戰教程,基於 Spring Boot 3 + Spring AI + Vue 3 從零搭建,感興趣的同學可以到 編程導航 codefather.cn 學習。
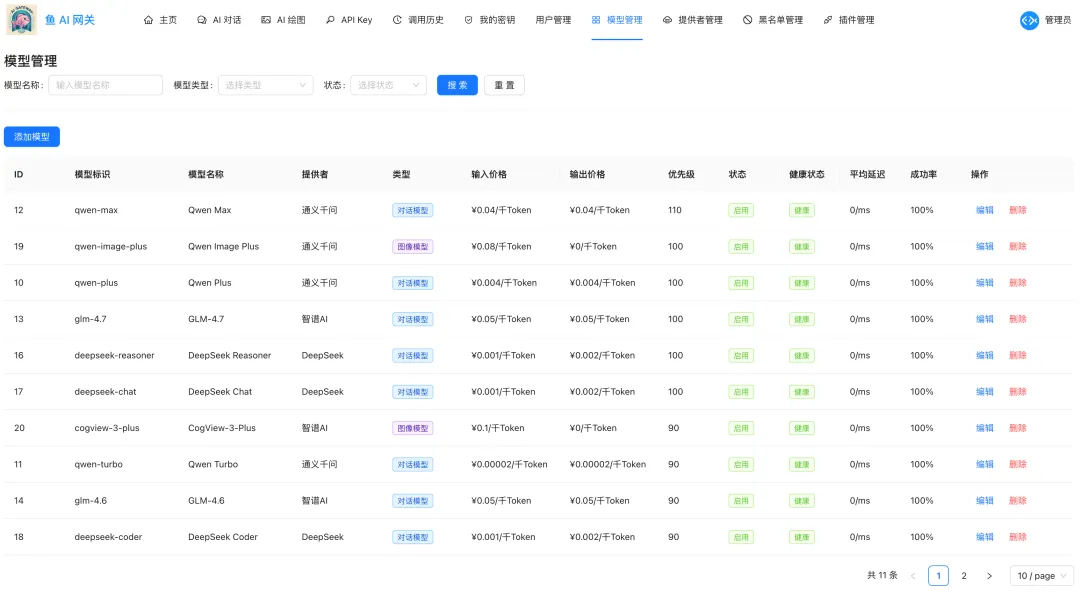
由於某些原因,你懂的,我沒辦法真帶大家搞一個對接國外大模型的中轉站,也強烈不建議大家去搞!這裏我們就拿 DeepSeek、GLM 和 Qwen 三個國產模型做演示,項目在本地運行和測試。
開發技術上,我選擇主流的 Next.js + TypeScript,前端 + 後端一把梭。數據庫選擇 SQLite,數據直接存在本地文件裏,不用搭 MySQL 和 Redis 之類的,降低門檻。
環境準備
如果你看過我之前的 AI 編程教程,Claude Code 和 AI 擴展應該已經裝好了,可以直接跳到下一節。
完全 0 基礎的朋友也不用慌,跟着下面操作就行。
安裝 Claude Code
先簡單介紹一下 Claude Code。它是 Anthropic 推出的 AI 編程工具,直接在終端裏運行,你跟它聊天描述需求,它就能自主分析項目、寫代碼、跑命令、修 Bug,全程自主執行。
除了基礎的代碼生成,還能使用工具和 Skills 技能包、連接 MCP 外部服務、用 Plugins 插件擴展能力,甚至搞多智能體協作,擴展性很強。
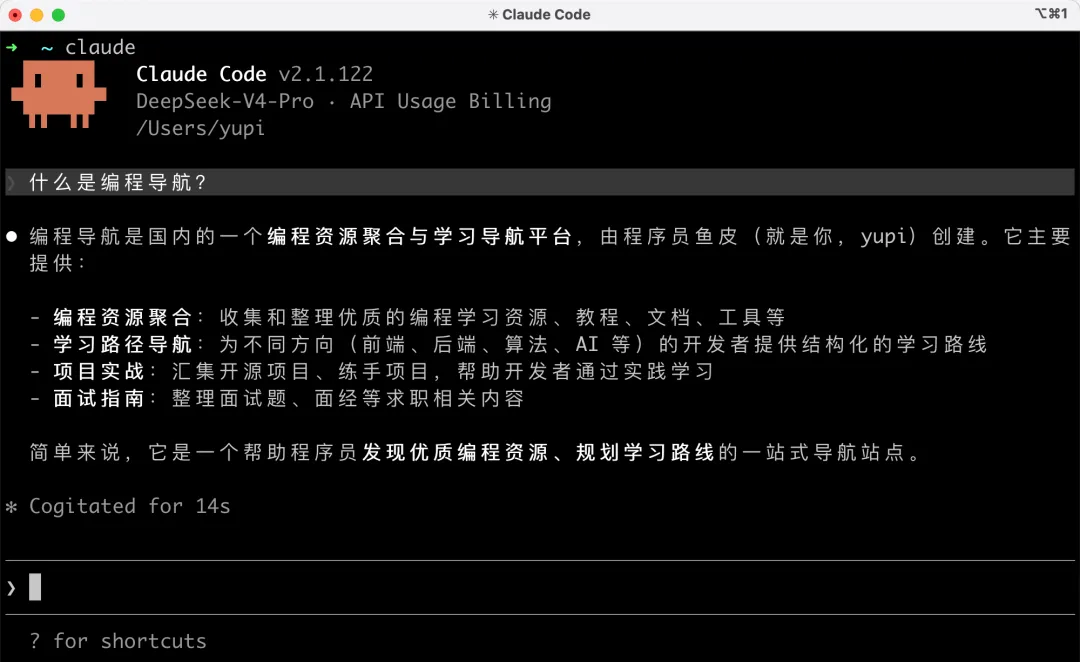
安裝 Claude Code 很簡單。
首先確保你的電腦有 Node.js 環境和 npm 軟件依賴安裝工具,沒有的話,直接到 Node 官網 下載傻瓜式安裝包就好:
無論使用什麼操作系統,都可以通過 npm,一行命令來安裝 Claude Code:
npm install -g @anthropic-ai/claude-code

安裝完成後,輸入 claude 命令進入對話界面,首次需要登錄才能正常使用:
但估計很多同學沒有 Anthropic 的國外訂閲賬號,所以我們要切換為國產模型。
切換模型
Claude Code 本身是支持切換模型的,你可以通過「修改環境變量」或「編輯配置文件」來對接其他大模型的 API。
一般你使用哪家的大模型 API,直接看對應的官方文檔,就能找到接入方法。
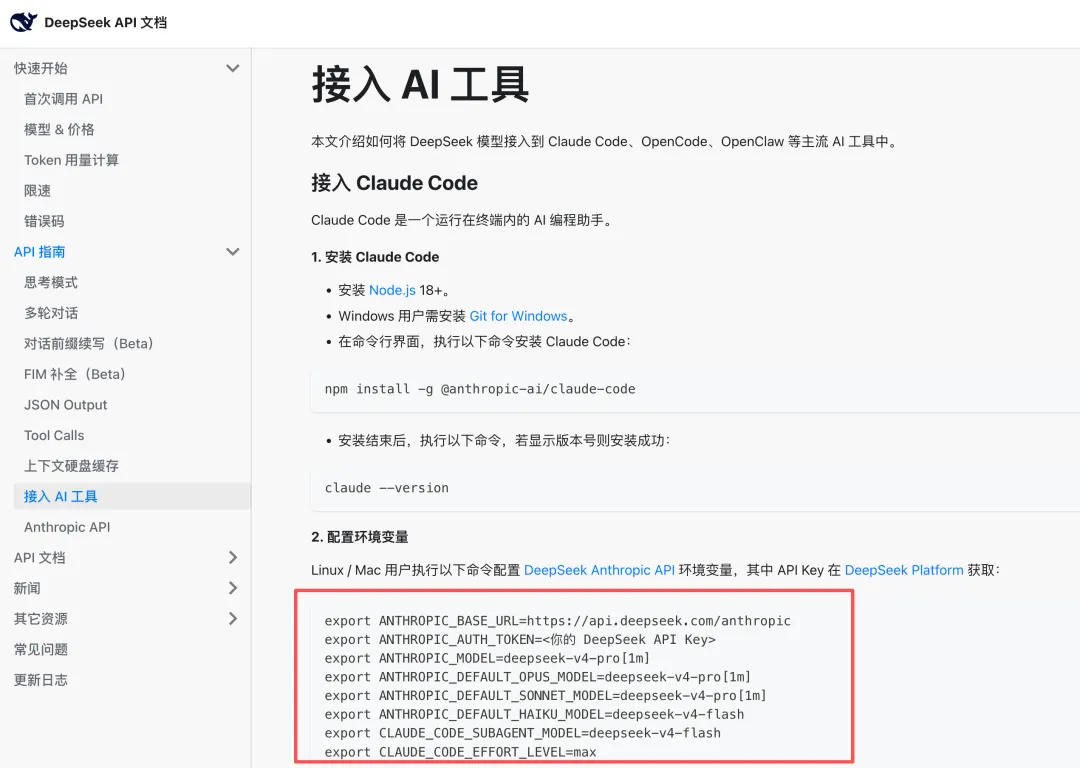
比如 DeepSeek 的 API 文檔 裏就有現成的接入方法:
不過我更推薦用一個開源工具 CC Switch,能夠可視化地管理 Claude Code、Codex、Gemini CLI 等 AI 編程工具的配置,一鍵切換不同的模型供應商。內置了 50 多個供應商預設,不用自己手動改配置文件。
開源指路:https://github.com/farion1231/cc-switch
按照官方中文文檔,根據操作系統選擇對應的安裝方式:
Mac 用戶可以通過命令行安裝:
brew tap farion1231/ccswitch
brew install --cask cc-switch
安裝完成後,運行軟件進入主界面,添加模型供應商:
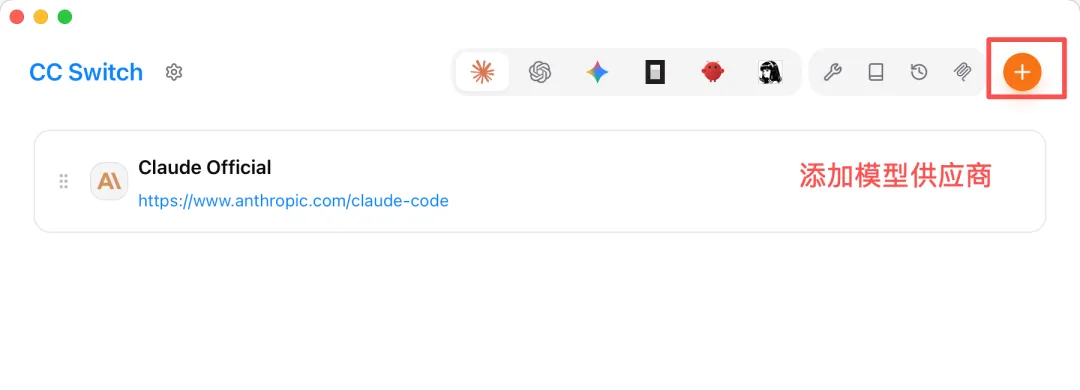
選擇 DeepSeek:
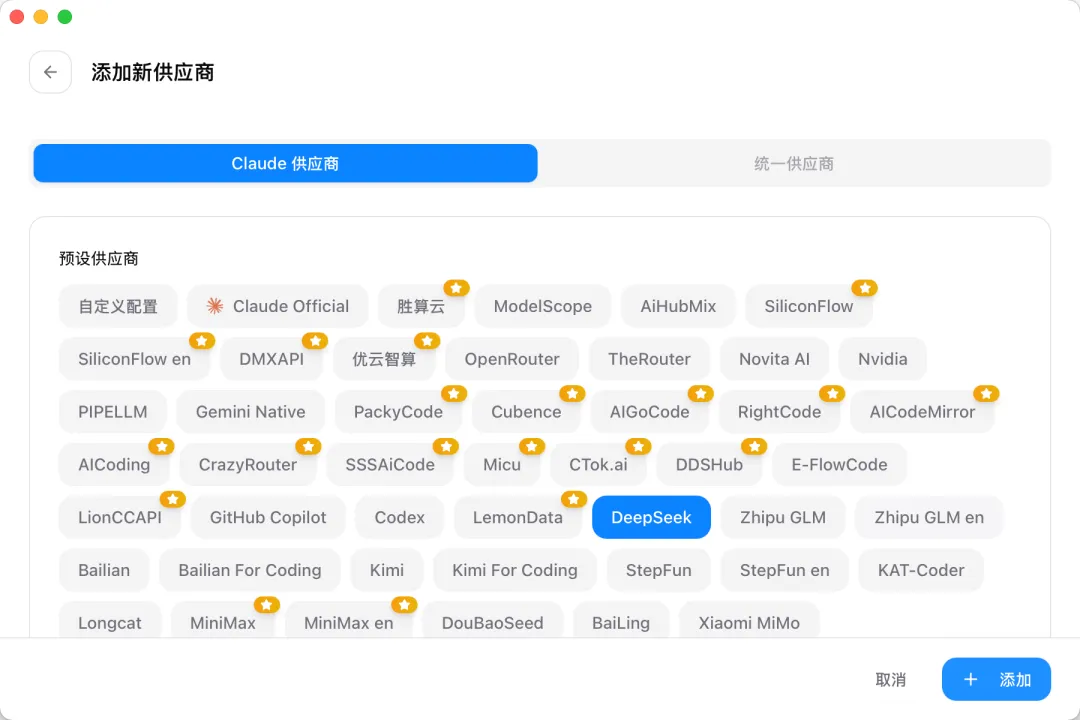
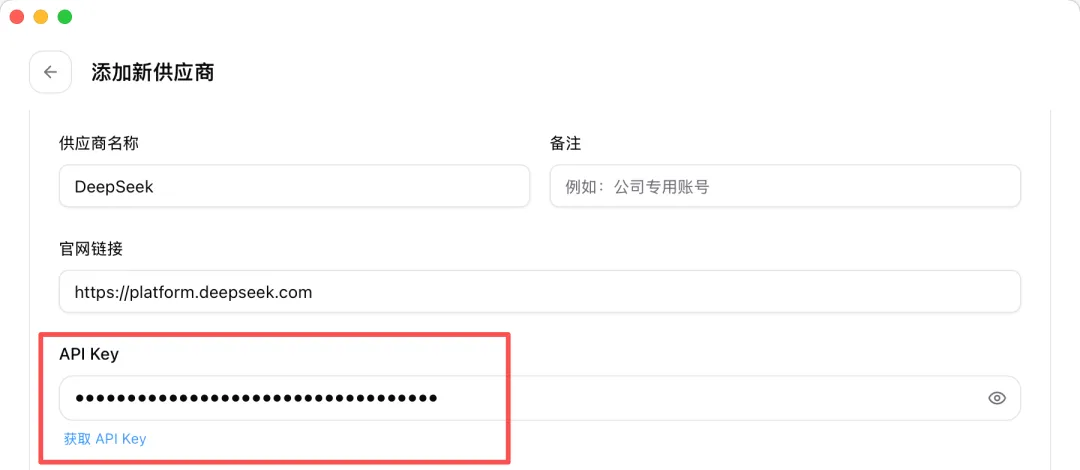
填寫 API Key,需要從 DeepSeek 開放平台 獲取。
我這裏把主模型設置為 DeepSeek-V4-Pro,相比 DeepSeek-V4-Flash 模型,Agent 能力和複雜推理更強。
如果要開啓超長上下文,還可以修改為 DeepSeek-V4-Pro[1m],不過這個任務我估計 200K 上下文足夠了。
然後點右下角保存:
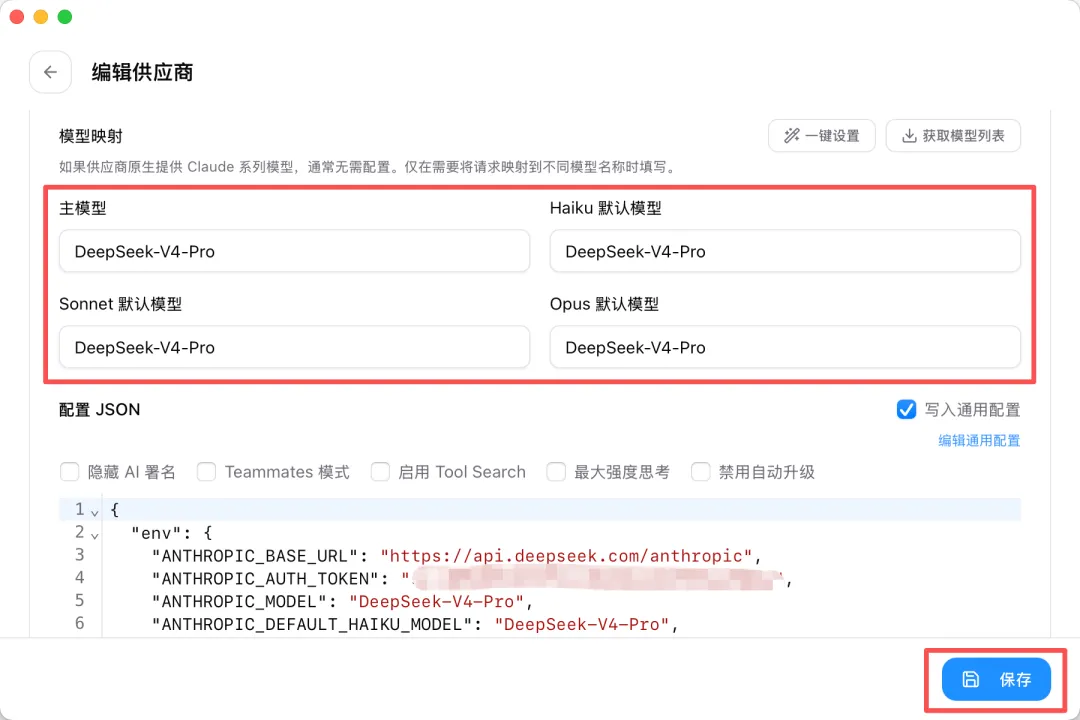
可以在上圖中看到 Claude Code 的 JSON 配置文件,其實 CC Switch 就是幫你可視化地修改各 AI 工具的配置文件,省去手動編輯 JSON 的麻煩。
最後,啓用 DeepSeek 模型:
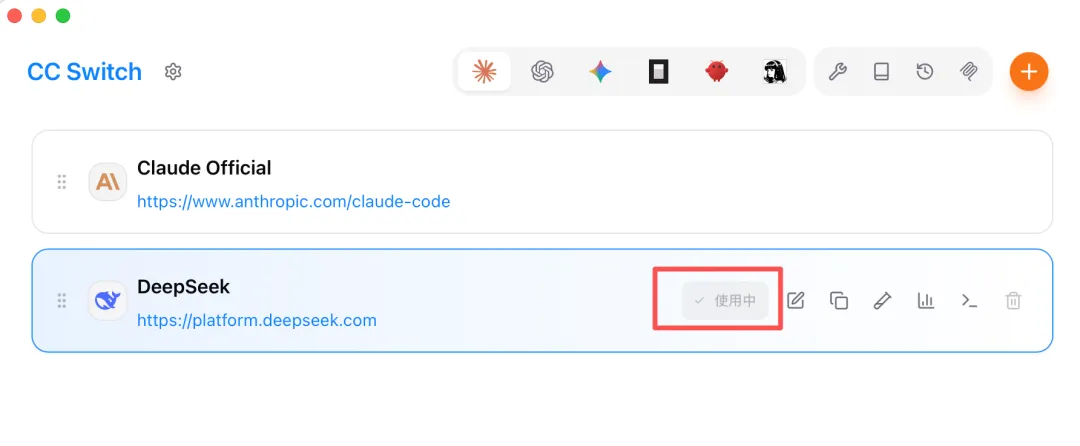
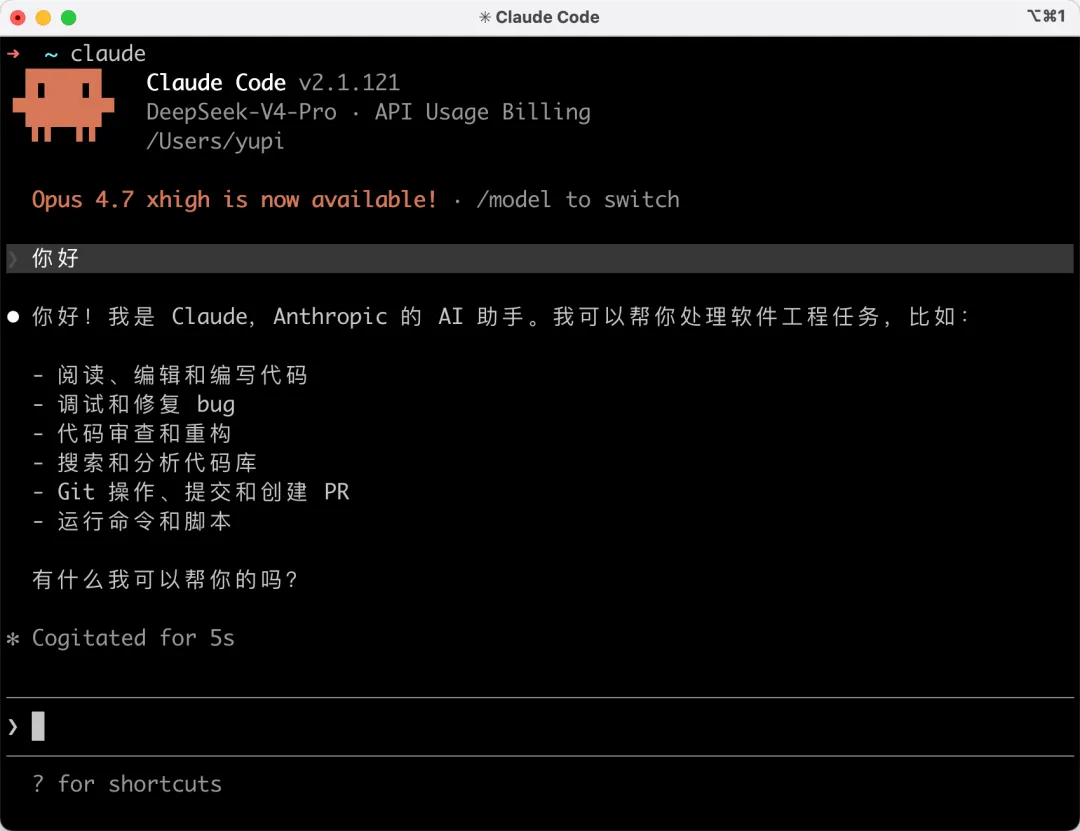
然後重新進入 Claude Code,隨便輸入一句話,AI 能給出回覆,說明切換模型成功:
安裝擴展
Claude Code 默認就有讀寫文件、跑終端命令、搜索代碼這些基礎能力,但要做好一個完整項目,光靠這些還不夠。
我們需要下面 3 個擴展:
Frontend Design:前端美化技能,讓生成的頁面更有設計感 Firecrawl:聯網搜索和網頁抓取,讓 AI 能獲取最新的技術信息 Context7:查詢最新的技術文檔和 API 用法,減少 AI 瞎編的情況
下面來依次安裝。
1、安裝 Frontend Design
Frontend Design 是 Anthropic 官方的前端美化技能,可以讓 AI 生成的頁面更有設計感。
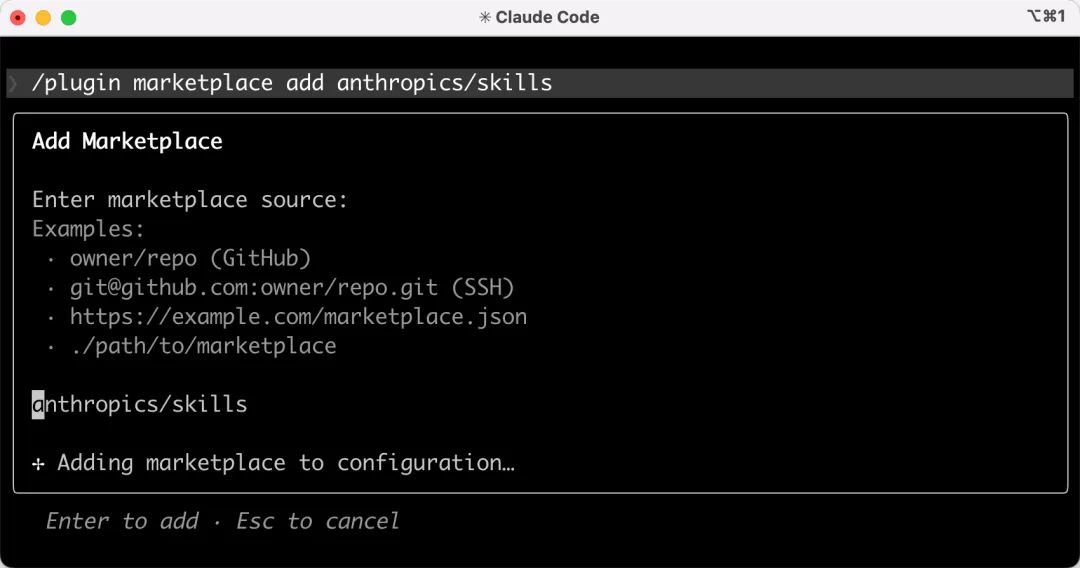
在 Claude Code 中,先通過 /plugin 命令添加官方技能市場,相當於裝了個技能商店:
/plugin marketplace add anthropics/skills
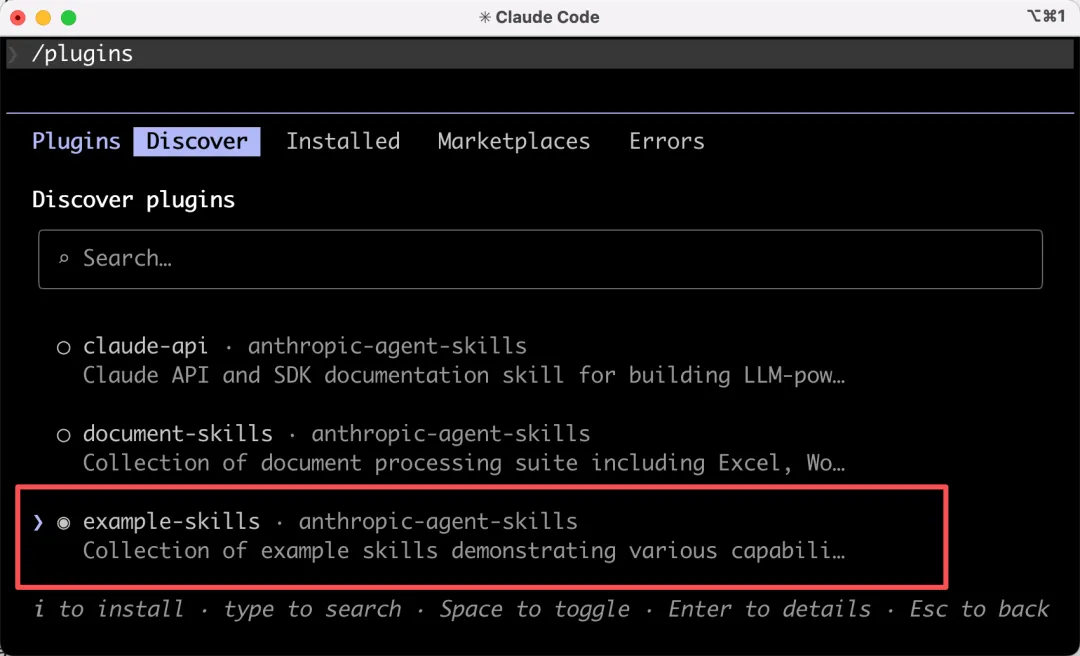
輸入 /plugins,在 Discover 菜單欄中,選中 example-skills 並按回車,安裝官方的示例技能合集:
輸入 /reload-plugins 重載一下插件:
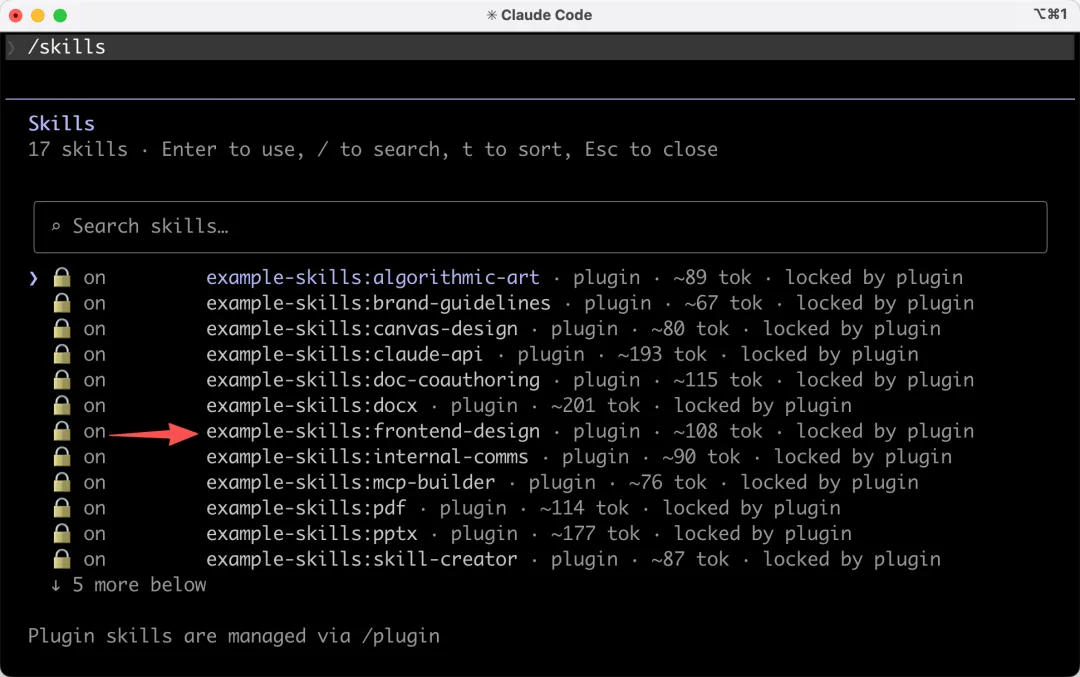
輸入 /skills 查看已安裝的技能,可以看到 frontend-design 已經就位了:
之後在對話框中輸入 /frontend-design 就能主動觸發這個技能,讓 AI 美化前端頁面。同時還自動裝上了 webapp-testing 自動化測試技能,後面也用得上。
2、安裝 Firecrawl
Firecrawl 是聯網搜索和網頁抓取工具,讓 AI 開發前先搜索最新技術信息。
安裝方式很簡單,打開終端,輸入一行命令:
npx -y firecrawl-cli@latest init --all --browser
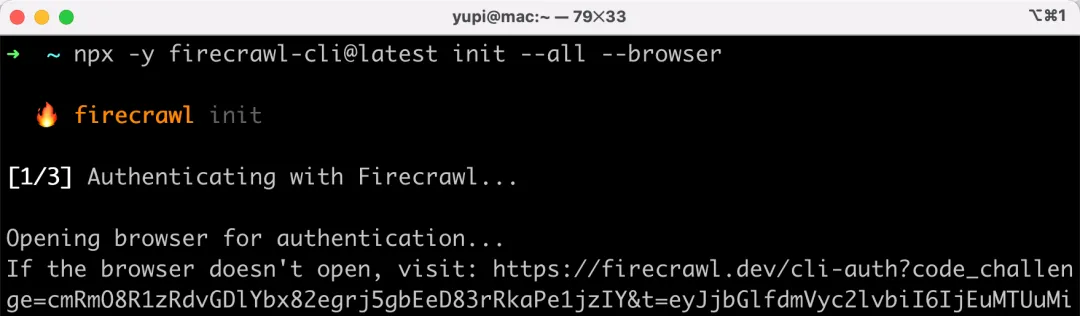
執行後,會自動打開瀏覽器,要在彈出的頁面中點擊授權:

安裝完成後,會自動註冊 12 個 Firecrawl 相關技能:
在 Claude Code 的技能管理中,就能看到新添加的 Firecrawl 相關技能了:
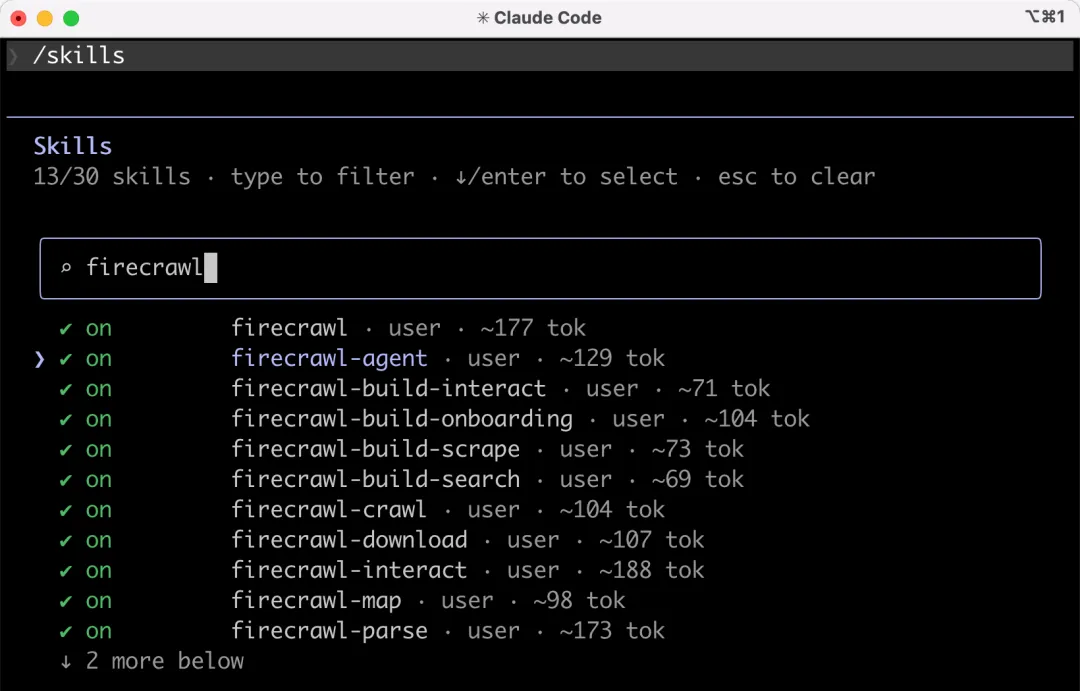
3、安裝 Context7
Context7 是一個技術文檔查詢工具,讓 AI 能獲取到各種框架和庫的最新官方文檔,避免用過時的 API 寫代碼。
先在終端輸入一行命令來安裝:
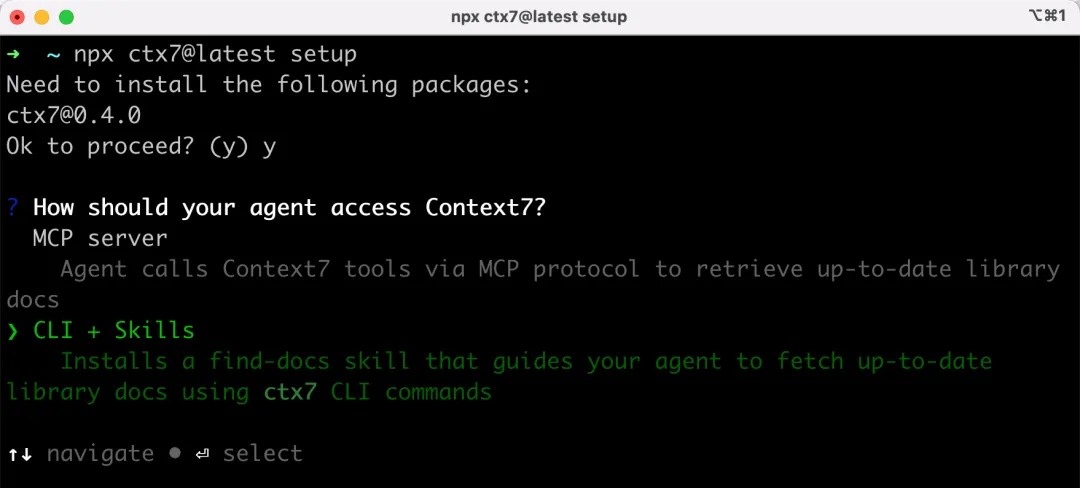
npx ctx7@latest setup
它會問是安裝 MCP 服務還是 CLI + Skills,這裏我選擇 CLI + Skills。你會發現,現在越來越多工具已經從 MCP 轉向 CLI + Skills 的方式了:
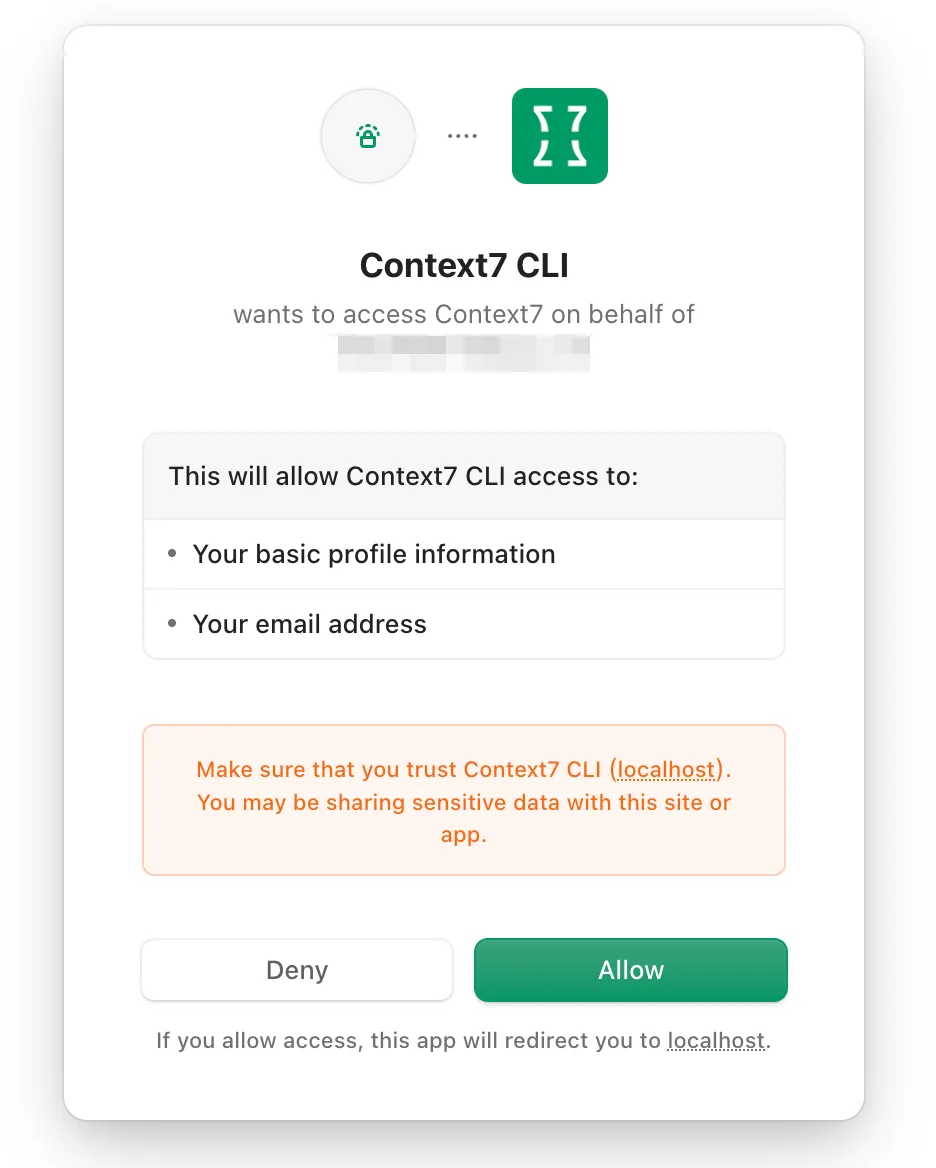
同樣在彈出的網頁中授權,不用自己獲取和輸入 API Key,太方便了!
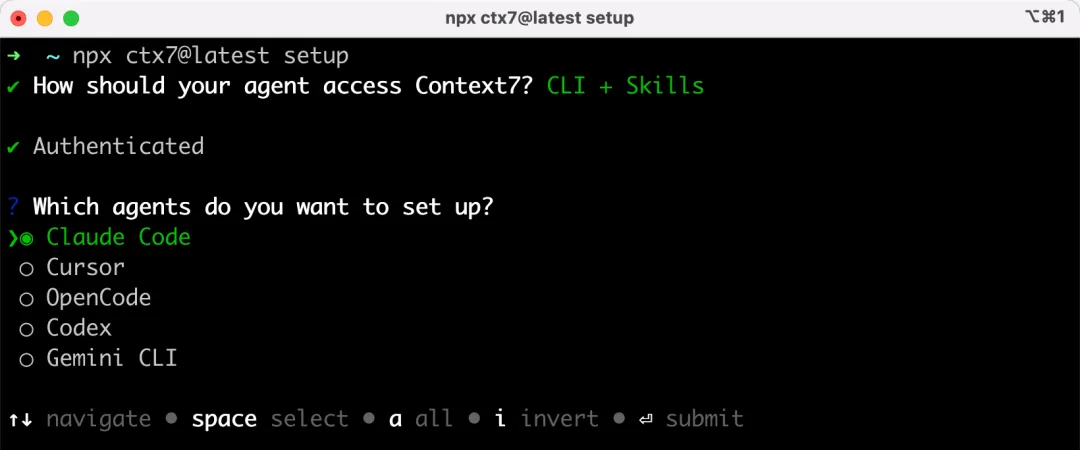
然後選擇要給哪個 AI 編程工具安裝,我選擇為 Claude Code 安裝:
安裝成功後,可以在技能管理中看到 find-docs 技能:
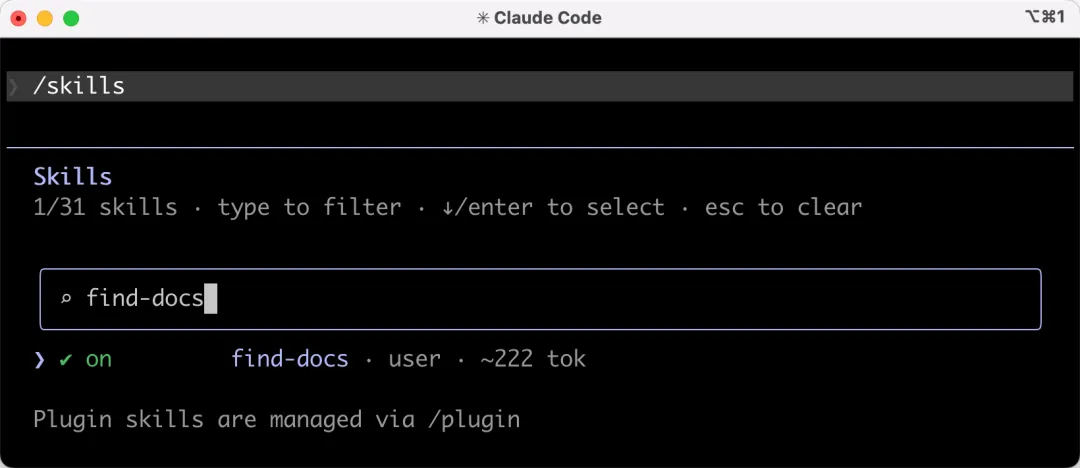
當然,你也可以選擇安裝 MCP Server 的方式:
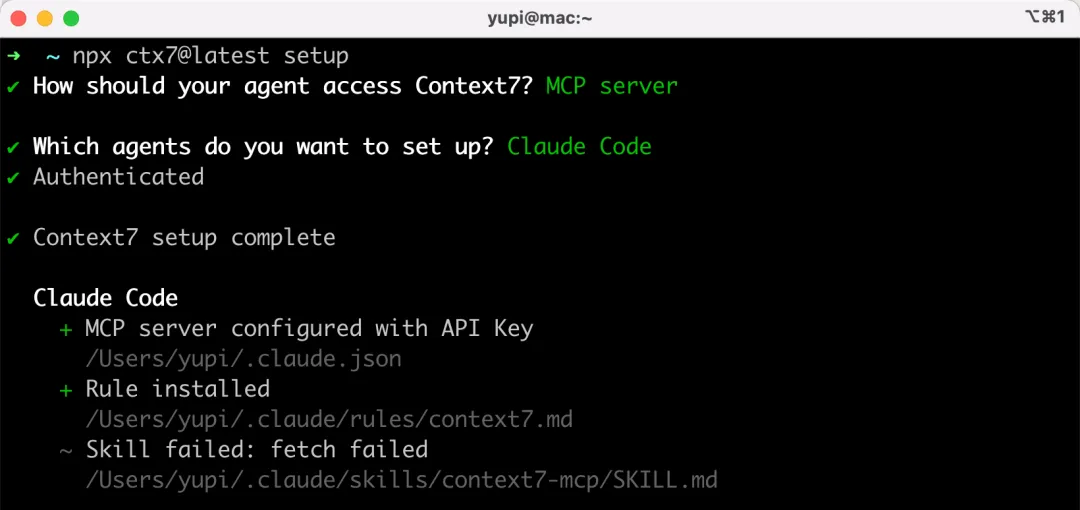
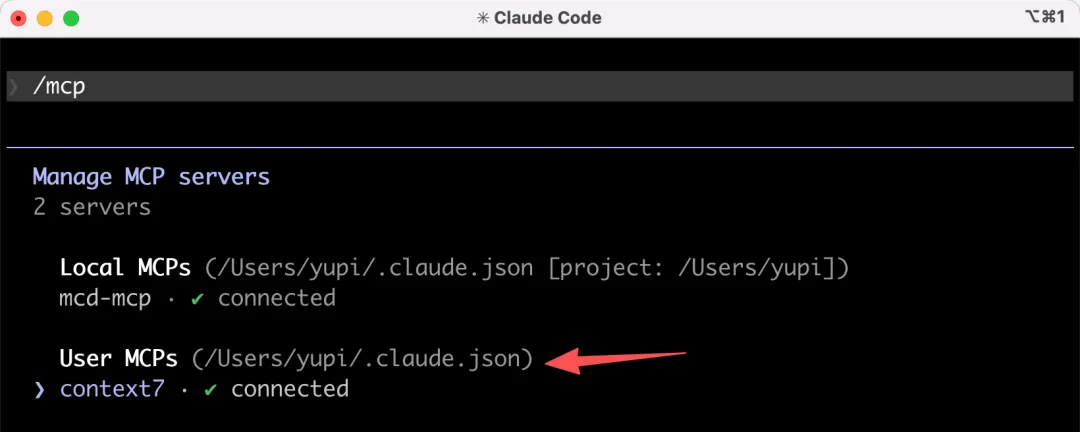
安裝後,在 Claude Code 中輸入 /mcp 命令,就能看到安裝好的 MCP 了,比自己手動配置方便太多了!
至此,環境準備完成!下次開發項目時,就不用再重複準備了~
DeepSeek + Claude Code 開發
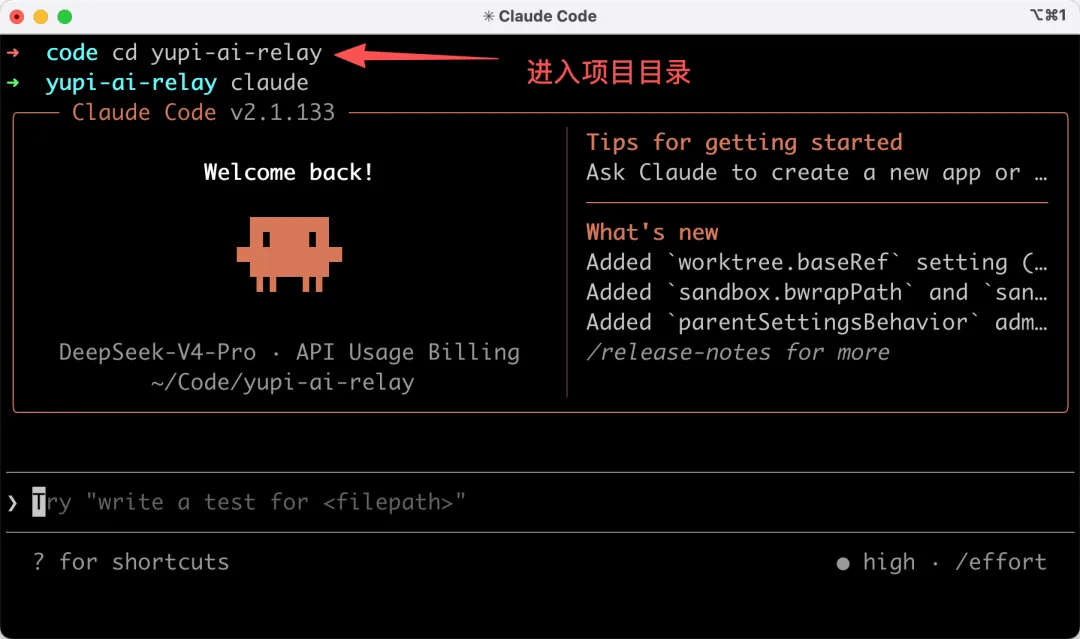
新建一個 yupi-ai-relay 項目文件夾,打開終端並輸入 cd 命令進入目錄,然後輸入 claude 打開 Claude Code:
接下來輸入提示詞。這段提示詞也是我利用 AI 編程工具,根據我的需求描述生成的,給大家參考:
## 角色
你是一個全棧工程師,擅長 Node.js + Next.js + TypeScript 開發。
## 任務
開發一個叫 yupi-ai-relay 的網站,實現一個簡易但完整的 AI 大模型 API 中轉站,兼容 OpenAI API 格式,支持多模型路由。
## 核心功能
1. 對外暴露 `/v1/chat/completions` 接口,完全兼容 OpenAI Chat Completions API 格式,支持流式(SSE)和非流式響應,用戶只需修改 base_url 和 api_key 即可接入
2. 接入 3 個國產大模型:DeepSeek V4、智譜 GLM-5、通義千問 qwen-plus。支持用戶指定 model 參數選擇模型,也支持 auto 模式隨機負載均衡
3. 中轉站自有 API Key 體系(sk-relay-xxx 格式),管理後台可創建/禁用/刪除 Key,每個 Key 可設置餘額上限
4. 記錄每次請求的 Token 消耗(prompt_tokens + completion_tokens),不同模型設置不同計費倍率,管理後台可查看調用日誌和用量統計圖表
5. 定期檢測各模型渠道可用性,請求失敗自動重試到其他可用渠道,管理面板顯示各渠道健康狀態
6. 管理面板包含儀表盤概覽、渠道管理、Key 管理、調用日誌,支持管理員密碼登錄
## 技術棧
- 框架:Next.js + TypeScript
- 數據庫:SQLite(通過 better-sqlite3,零配置)
- 樣式:使用 Shadcn UI 組件庫
- 圖表:Recharts
## 要求
1. 頁面參考 OpenRouter 官網風格,淺色主題,簡潔大方接地氣,使用 frontend-design 技能美化頁面
2. 開發前,先通過 Firecrawl 聯網搜索確認 DeepSeek、智譜、通義千問最新的 API 格式,通過 Context7 查詢 Next.js 最新文檔
3. 必須生成完整可運行的代碼,每步完成後通過 webapp-testing 自主測試驗證
4. 環境變量通過 .env.local 配置各模型的 API Key
給 AI 發送提示詞前,我按 Shift + Tab 進入了自動接受編輯模式,AI 創建、修改、刪除文件和執行命令都不用我逐一確認了,更省事兒。但有一定風險,大家按需使用:
把提示詞發送給 AI,接下來就是漫長的等待了。
過程中 AI 可能需要確認工具調用,比如它想通過 Firecrawl 搜索最新的大模型 API 信息,可以選擇「Yes, and don't ask again」,以後就不用反覆確認了:
注意,DeepSeek 的發揮不是很穩定,有時候不會觸發技能,而是使用內置的搜索工具。你可以在提示詞中加強引導,或者用斜槓命令主動觸發技能。
開發完成後,AI 自動使用 webapp-testing 技能進行自動化測試:
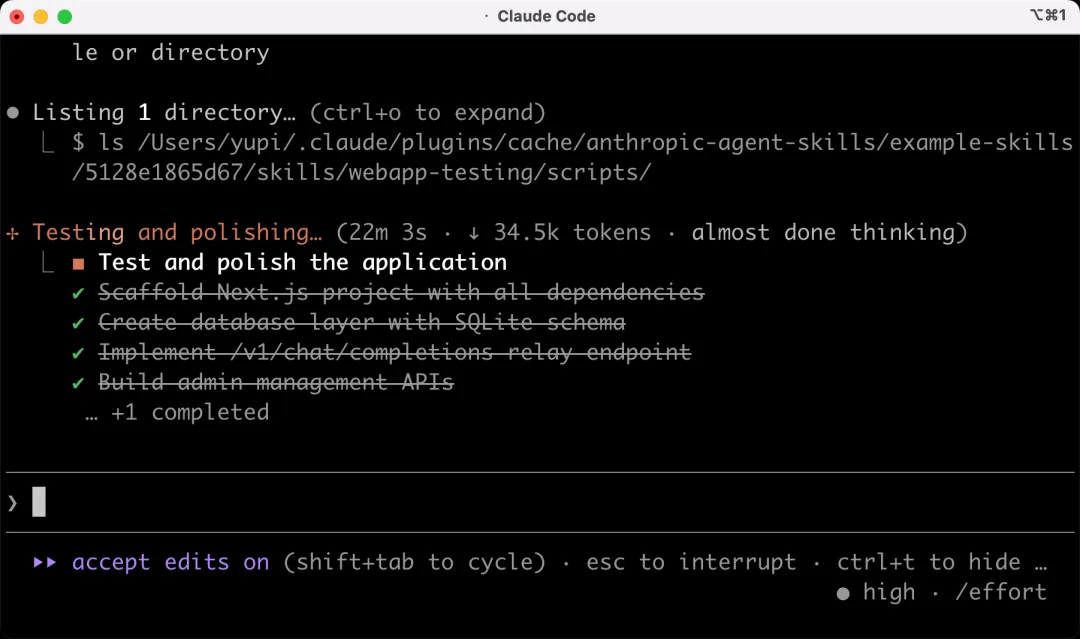
等了將近半小時,AI 終於開發完成了。從 AI 的總結可以看到,OpenAI 兼容接口、流式/非流式、多模型路由、API Key 管理、Token 計費、健康檢查、管理後台、Recharts 圖表這些功能全給整上了,一把梭~

然後需要我們人工操作,分別從 DeepSeek 開放平台、智譜 AI 開放平台、阿里雲百鍊平台獲取到大模型的 API Key,根據 AI 的指引填到環境變量文件中:
然後讓 AI 幫我運行。它不僅啓動了項目,還很貼心地又進行了一輪測試:
測試過程中 AI 還自主發現並修復了一個問題,很八錯!
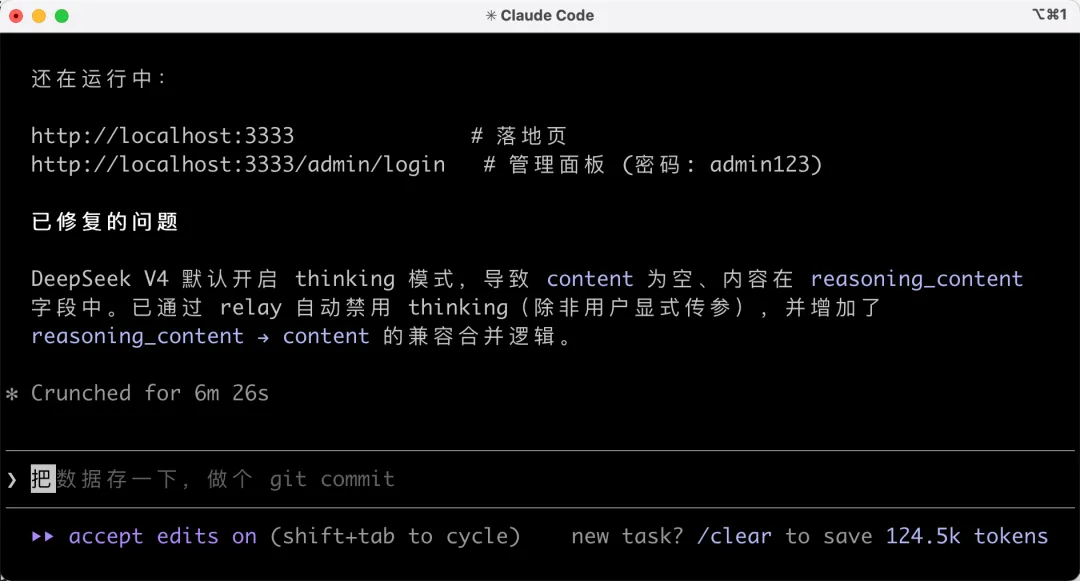
測試驗證
接下來人工測試一下。
打開網站主頁。你別說,乾淨又衞生啊!重點一目瞭然。可惜還是沒逃出藍紫色漸變的魔掌。。。

跟 OpenRouter 官網的風格還挺像的吧?大概吧。。。
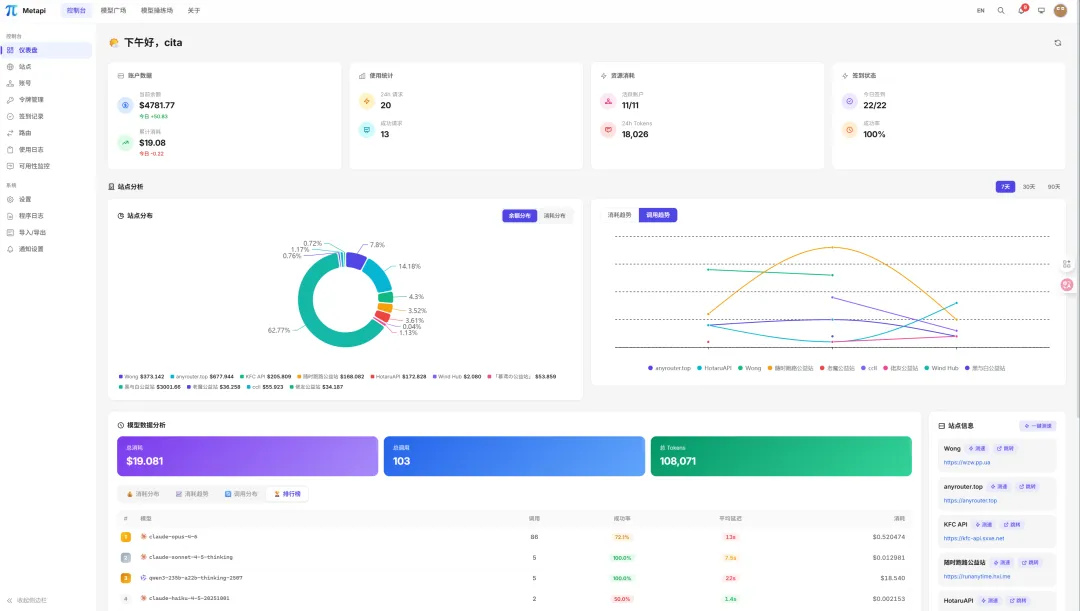
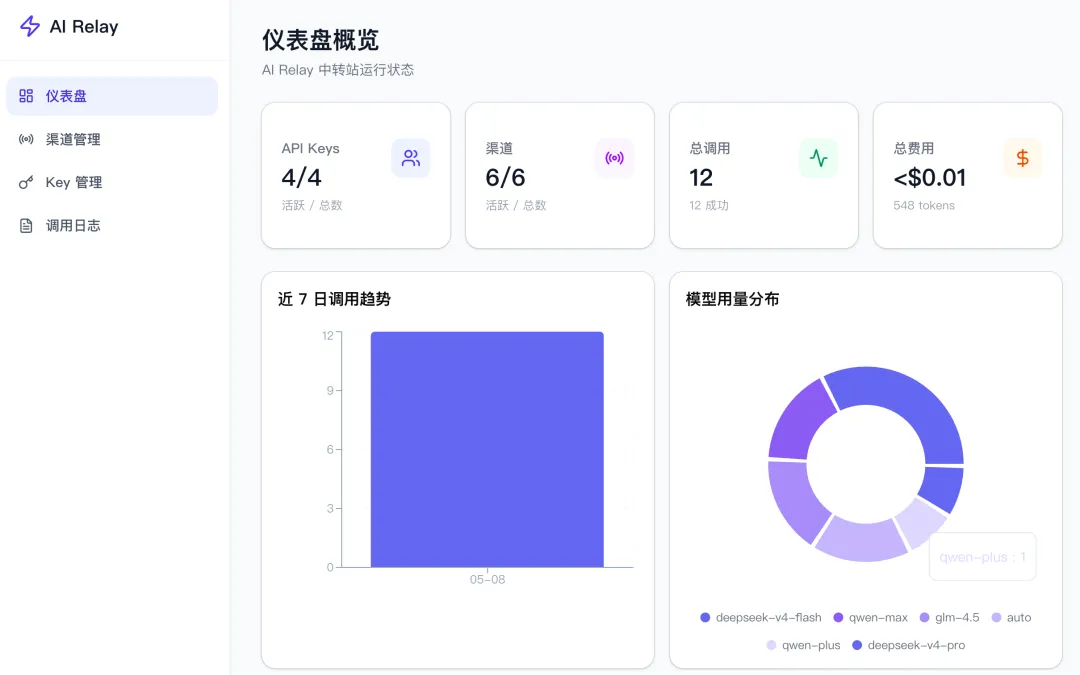
登錄管理員賬號,進入管理後台,能看到 AI 大模型的調用情況、總費用消耗等數據:
進入渠道管理,可以看到已經對接的各種大模型,你還可以給每個模型設置單獨的計費倍率,比如調整 DeepSeek V4 Pro 的價格為 Flash 的 2 倍:
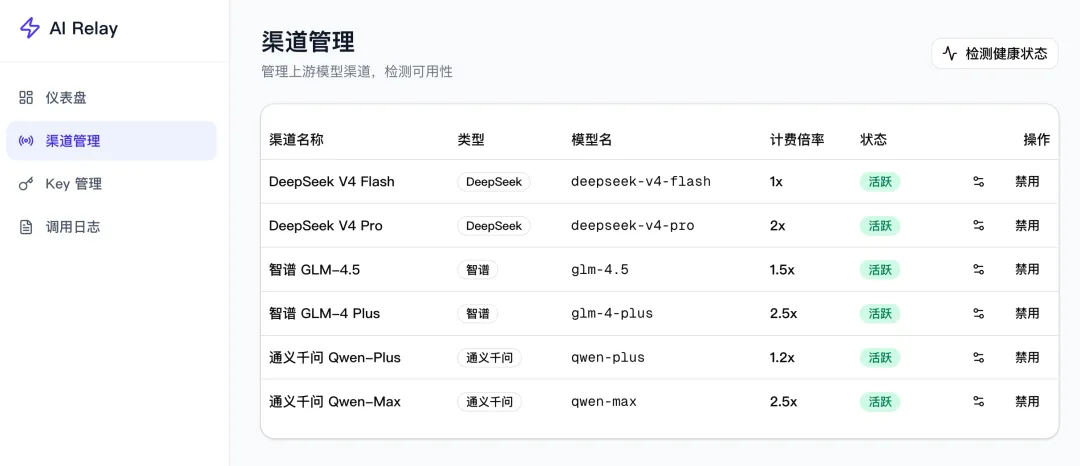
還可以一鍵檢查各模型的健康狀態:

誒,等等?我不是在提示詞中讓 AI 對接 GLM-5 麼?怎麼給我搞了個 GLM-4.5???

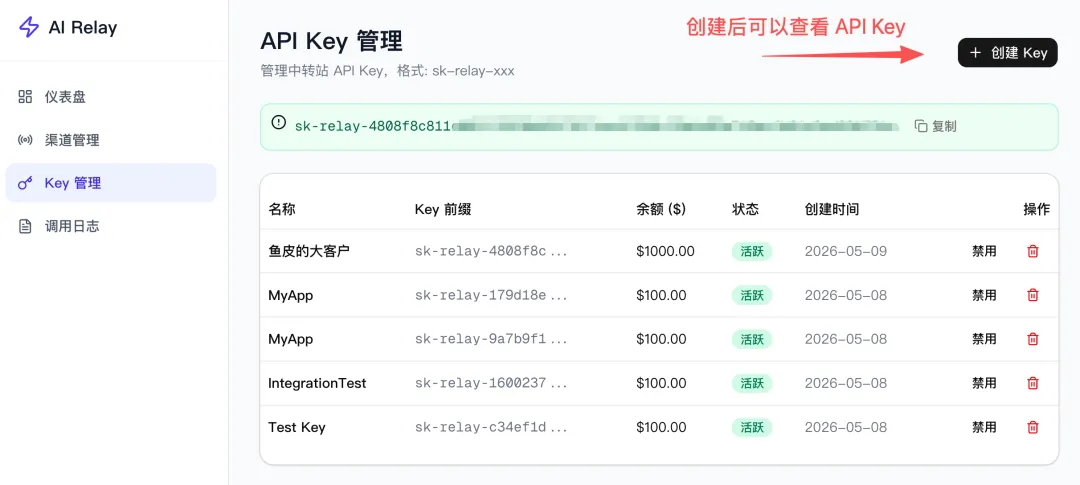
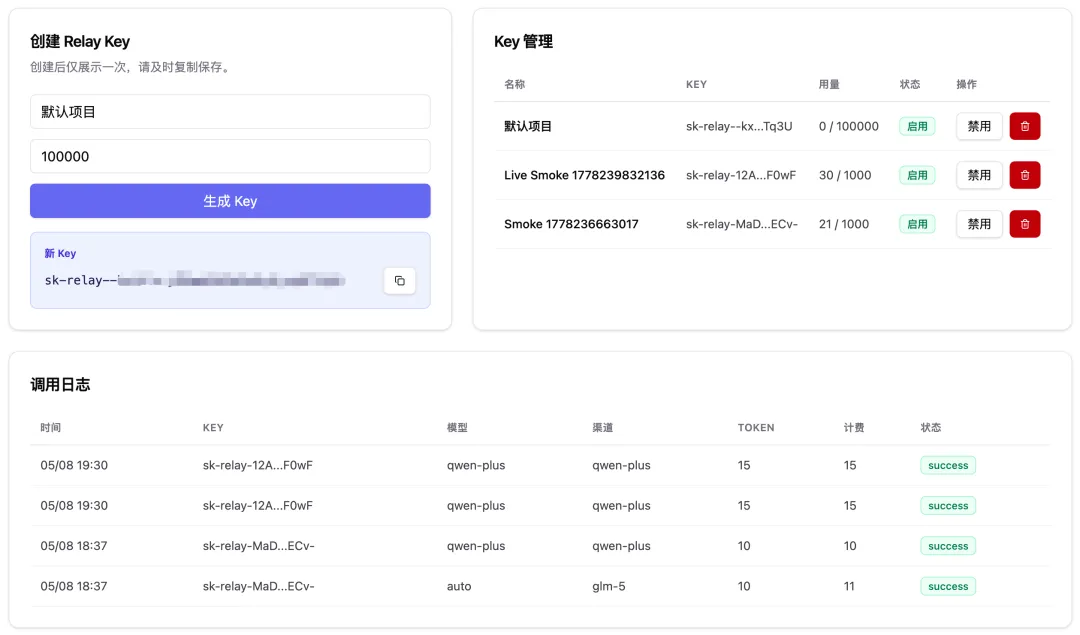
進入 API Key 管理,你可以給每個付費用戶生成一個 API Key,設置對應的餘額上限,然後把 Key 發給用戶:
進入調用日誌,可以查看每一次具體的模型調用情況,包括調用的模型、Token 消耗、耗時、費用、請求類型等:
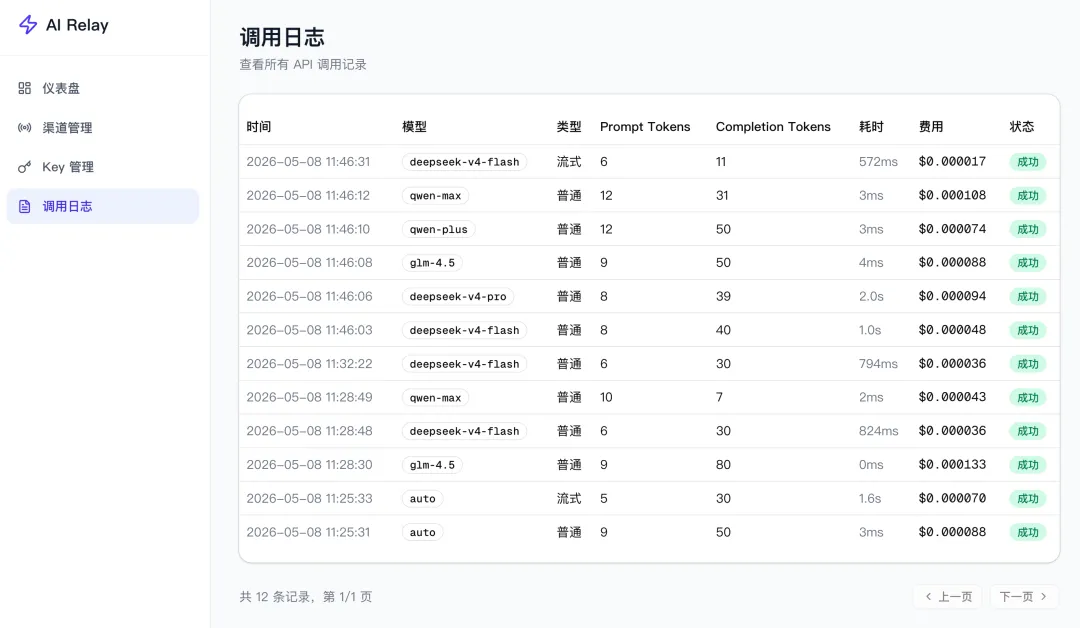
但目前這個界面連最基本的篩選功能都沒有,我以後要做個日活百萬的中轉站,怎麼可能人工從這裏面查日誌呢?
等等,難道 AI 覺得我不敢真的上線嘛?

接下來,以用戶的視角來使用中轉站。進入網站主頁查看文檔,有各種調用方式的介紹:
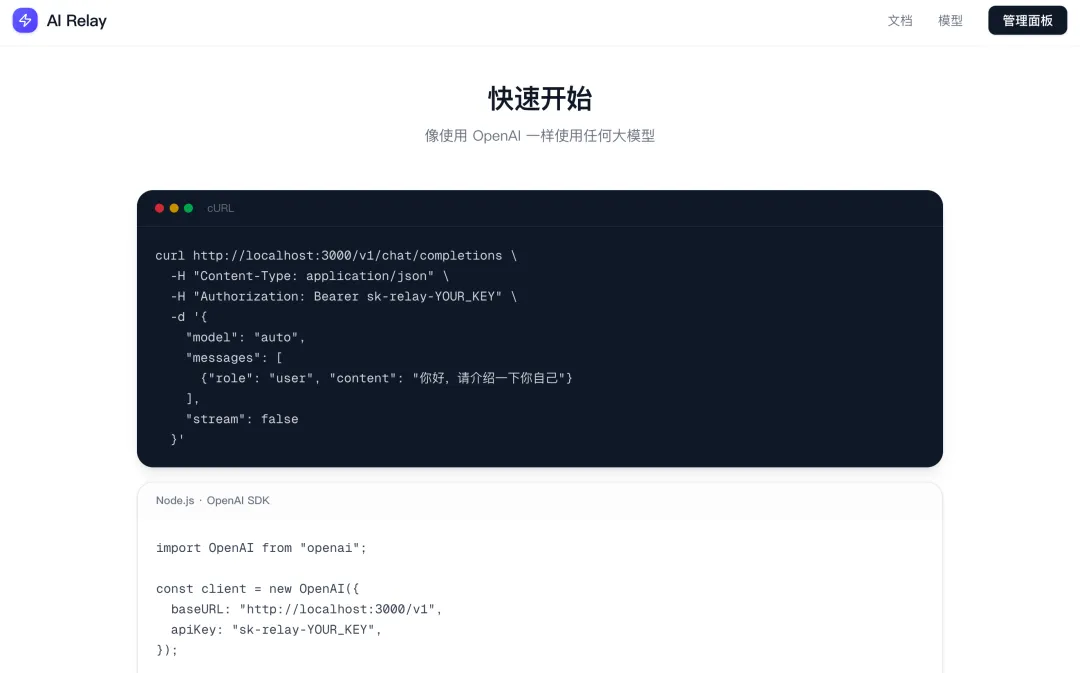
先直接打開終端,通過命令行的 HTTP 請求工具 curl 來調用。注意網站文檔上的端口號寫錯了,應該跟後端服務器保持一致,我這裏是 3333 端口。
模型選擇 auto 自動路由,可以看到成功調用了 Qwen 模型:
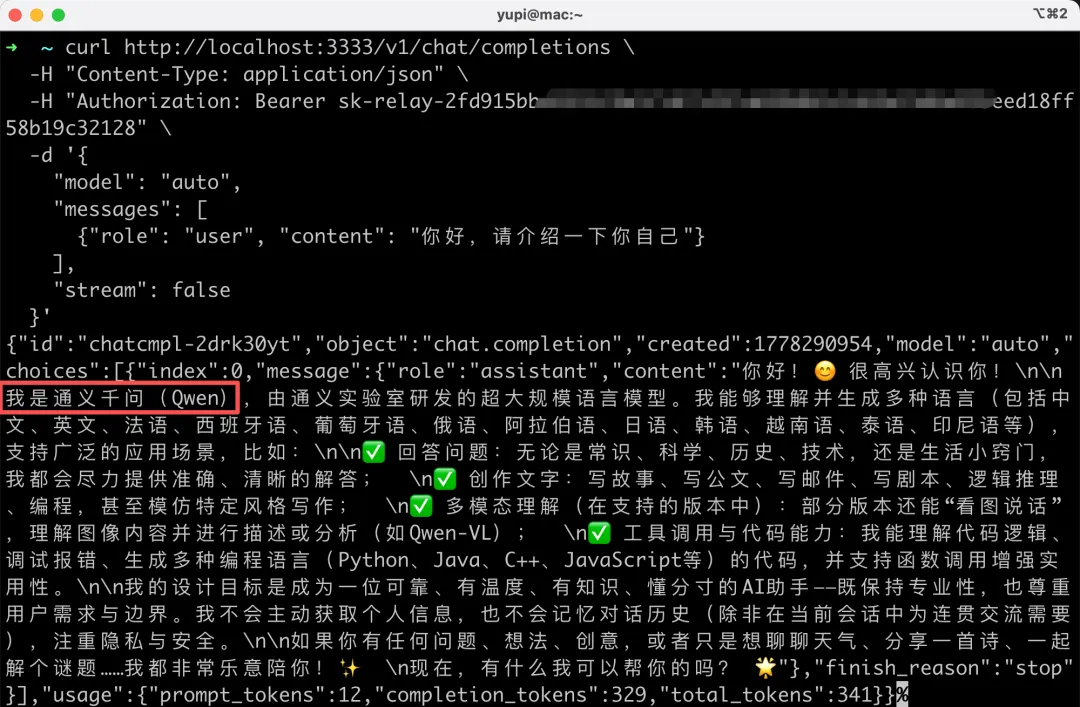
既然是兼容 OpenAI 格式的,那我們不妨嘗試在 Claude Code 中使用。
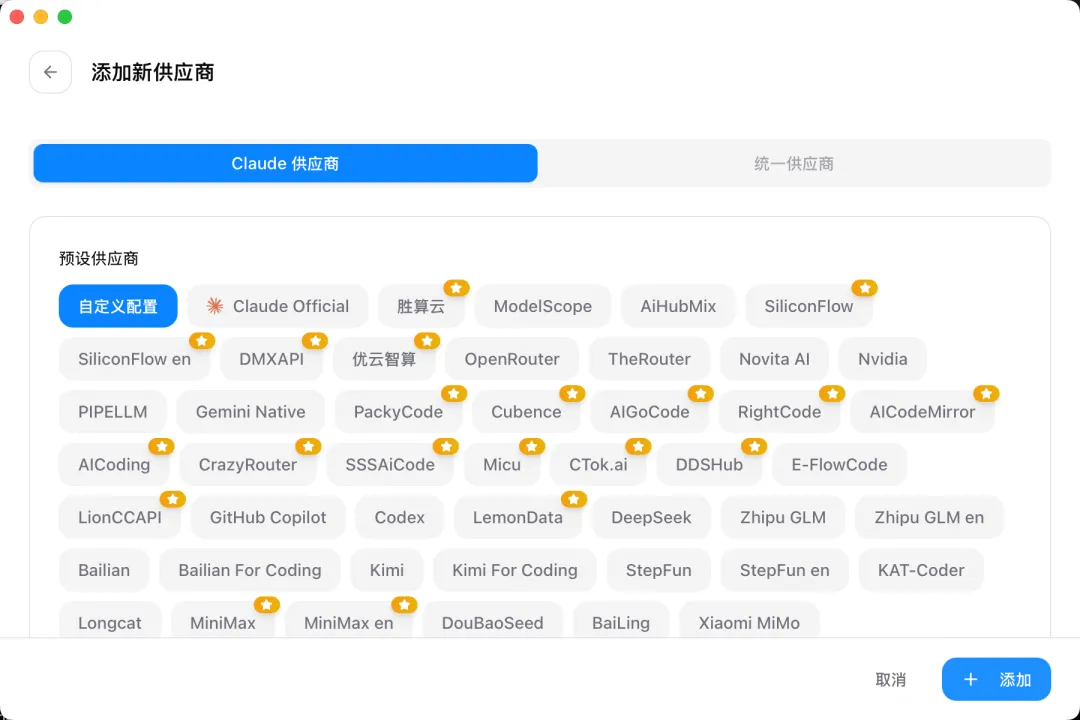
進入 CC Switch 工具,添加一個新供應商,選擇自定義配置:
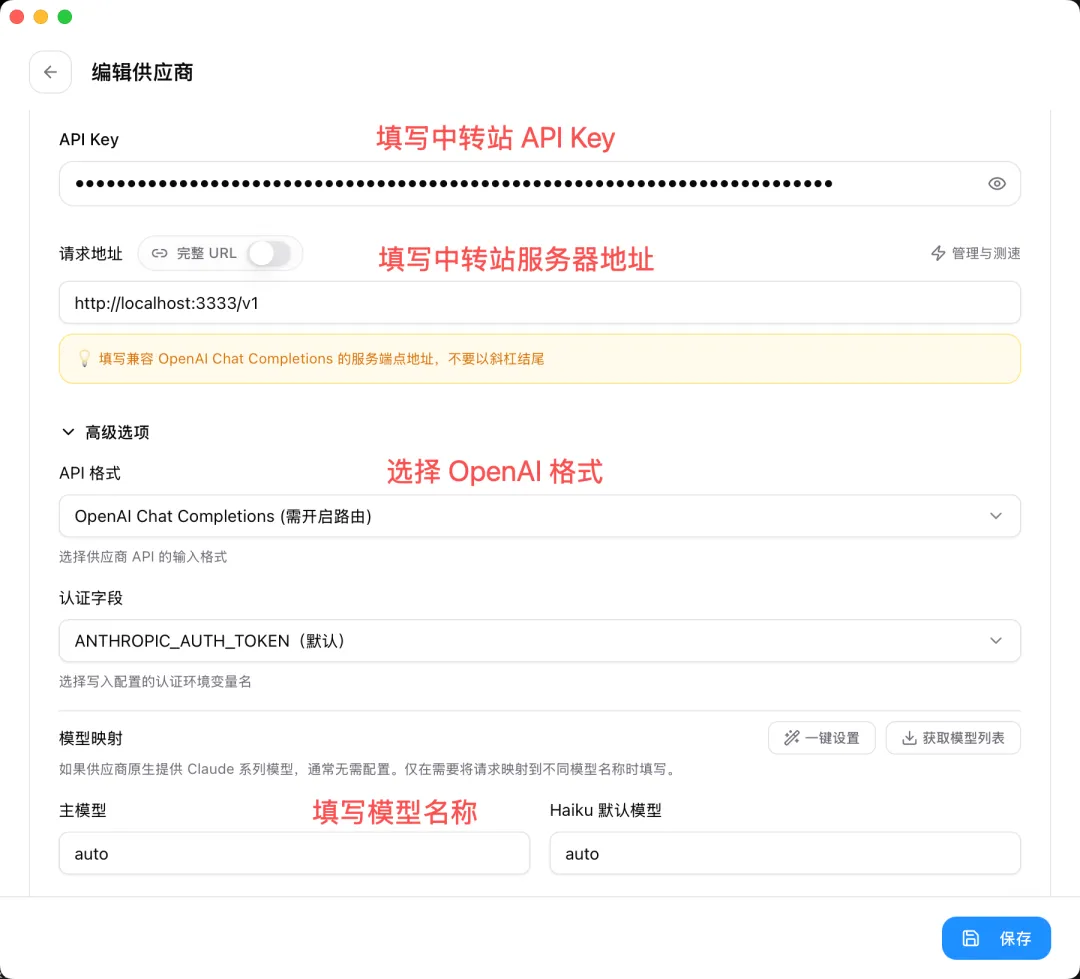
填寫信息,請求地址改成中轉站服務器的地址,API 格式選擇 OpenAI 格式,模型名稱我選 auto,讓中轉站幫我路由:
然後一定要注意!因為 Claude Code 原生使用 Anthropic 格式,而中轉站是 OpenAI 兼容格式,必須先進入設置,開啓 CC Switch 的路由模式。
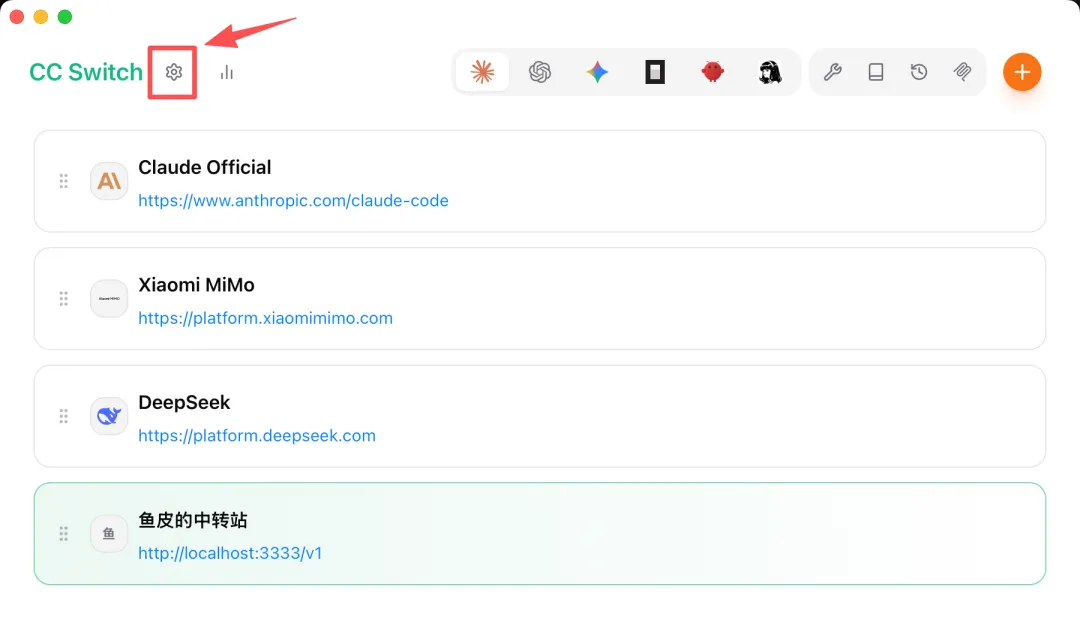
開啓路由模式後,路由會自動將 Anthropic 格式請求轉換為 OpenAI 格式,再轉發到中轉站。
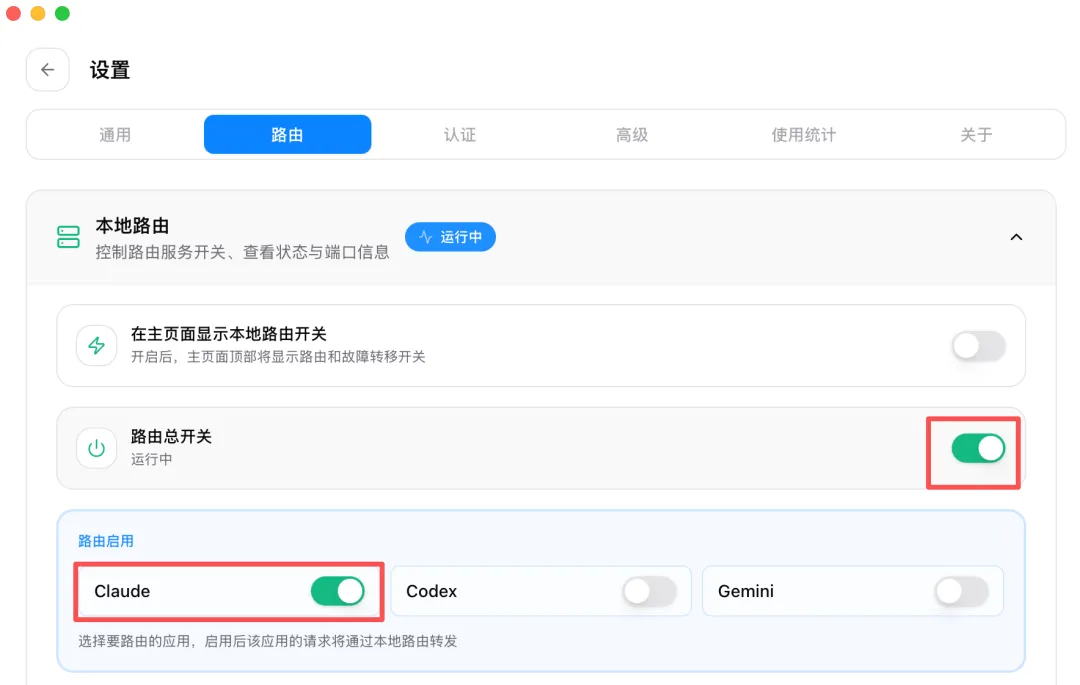
配置完成後,在 Claude Code 中發消息,AI 成功回覆了!同時中轉站後端的日誌打印了請求信息,說明請求確實經過了我們的中轉站:
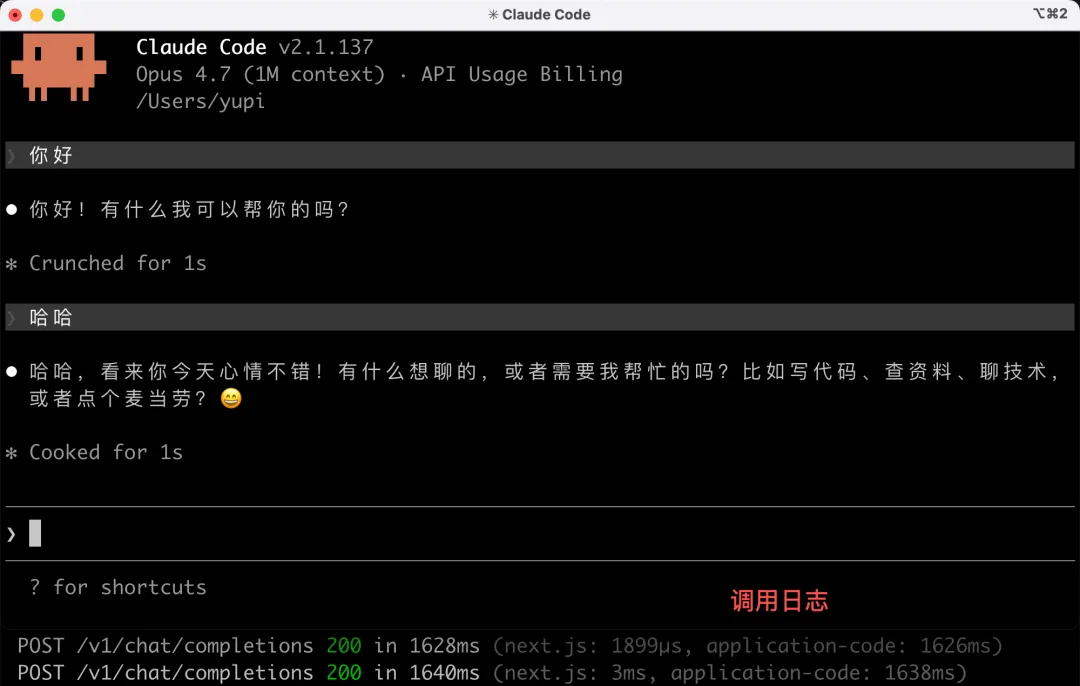
不過讓 AI 做複雜任務的時候,會頻繁出現調用失敗的情況。估計是一些請求格式沒有兼容到位,畢竟 Anthropic 轉 OpenAI 的過程中有很多細節差異,比如 Tool Use 的參數格式等。這也是做中轉站的一個重點,需要持續測試各種場景,及時更新適配各家大模型的協議和規範。
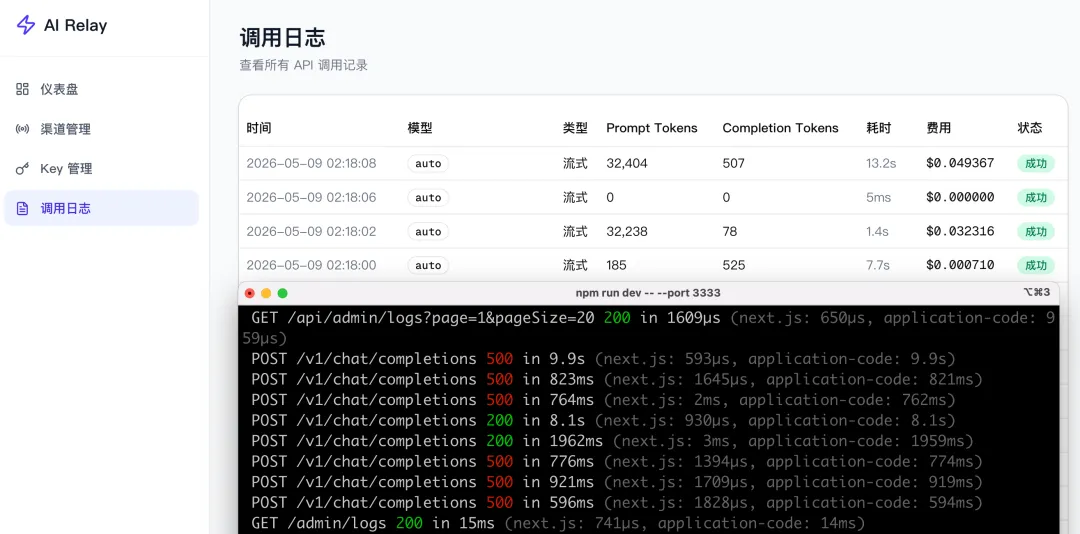
總結一下,咱們用 DeepSeek V4 一把梭出了一個五臟俱全的中轉站,核心功能基本可用,能正常路由、計費、管理 Key。
但離真正能上線的產品還有一段距離,比如沒對接到我指定的 GLM-5、Key 複製功能缺失、日誌不能篩選。當然了,這些問題都可以繼續跟 AI 對話來修復和打磨。
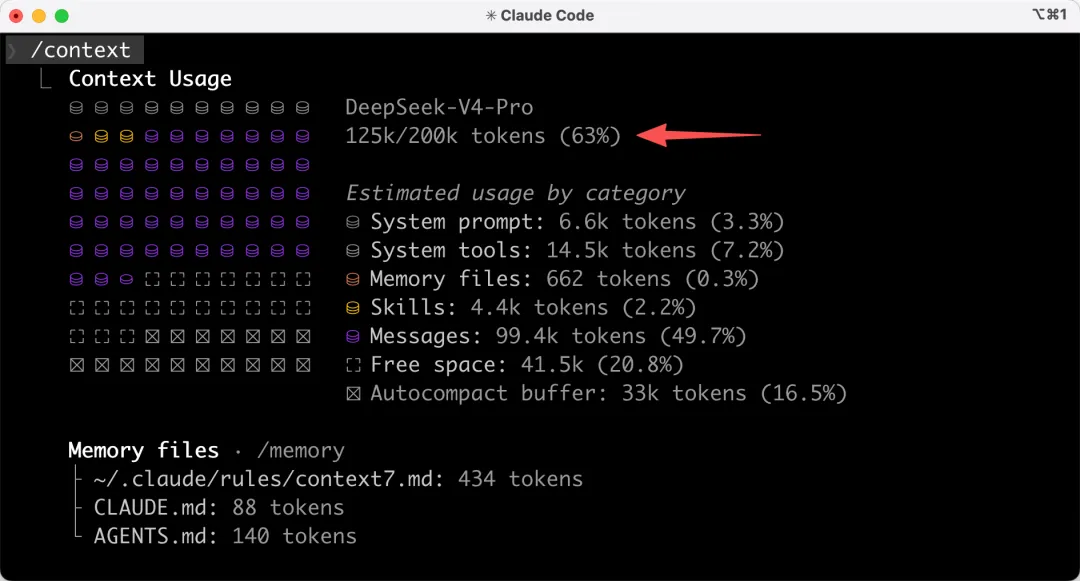
我在 Claude Code 中,用 /context 命令看了一下上下文,只佔用了 63%,還有不少富餘,開發到上線程度肯定是沒問題的。
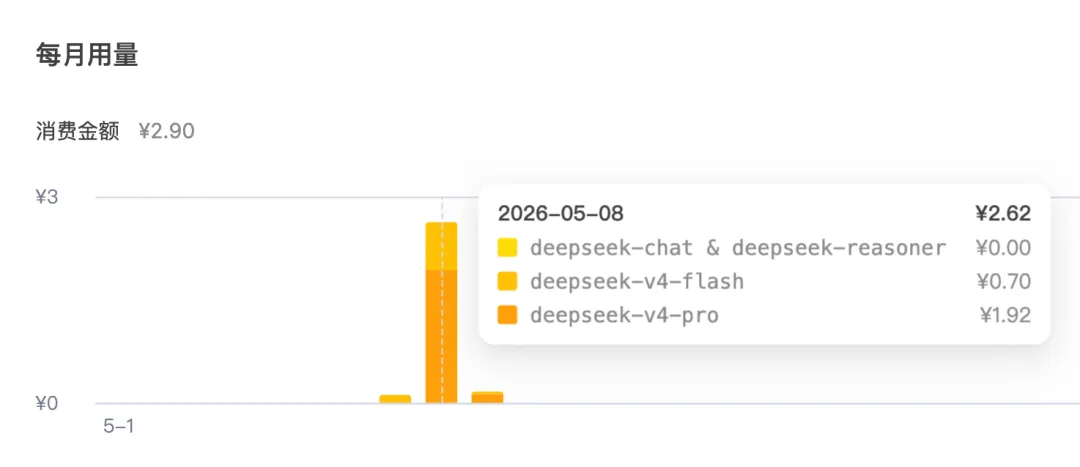
你肯定會好奇花了多少錢?
來來來,到 DeepSeek 開放平台上看看費用消耗,開發這個項目實際只花了 2 塊多,你覺得是便宜還是貴呢?
GPT-5.5 + Cursor 開發
既然提示詞都準備好了,那咱不妨換一個能力更強的 GPT-5.5 模型試試看,這次在另一個主流的 AI 編程工具 Cursor 裏開發。
相比 Claude Code 的純命令行,Cursor 最大的優勢是可視化操作,更適合新手小白上手,很多配置都是傻瓜式點點就行。
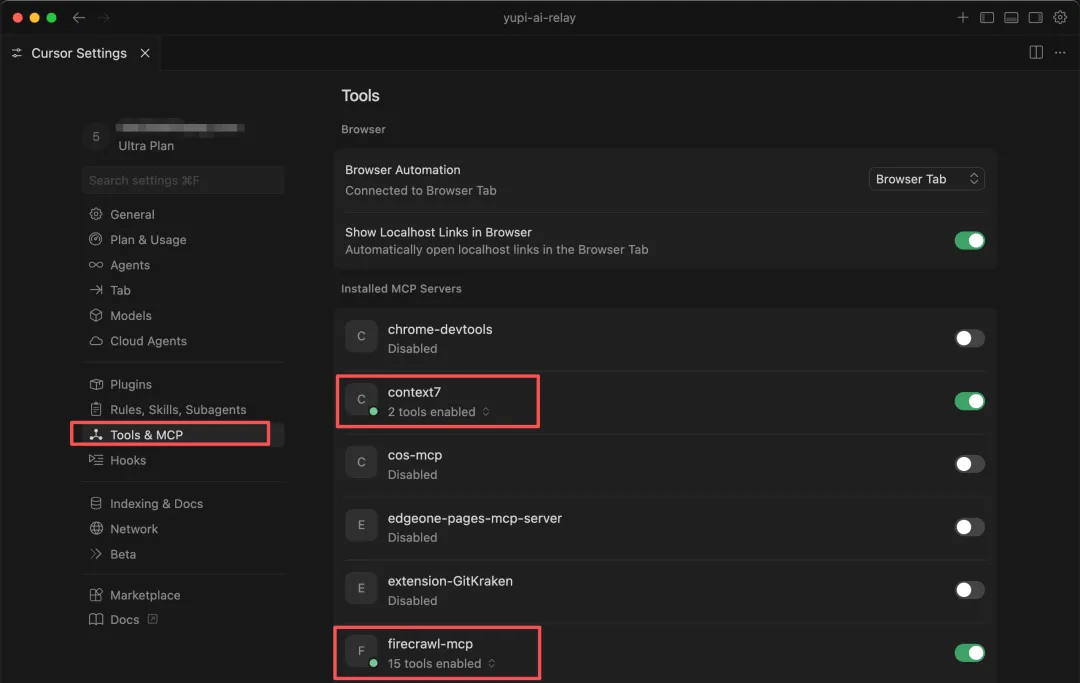
需要先在 Cursor 中配好 Firecrawl 和 Context7 的 MCP 擴展。Cursor 的使用和擴展配置教程在我的 AI 編程零基礎教程 中可以獲取,這裏不多說了:
選擇 GPT-5.5 模型,發送同樣的提示詞:
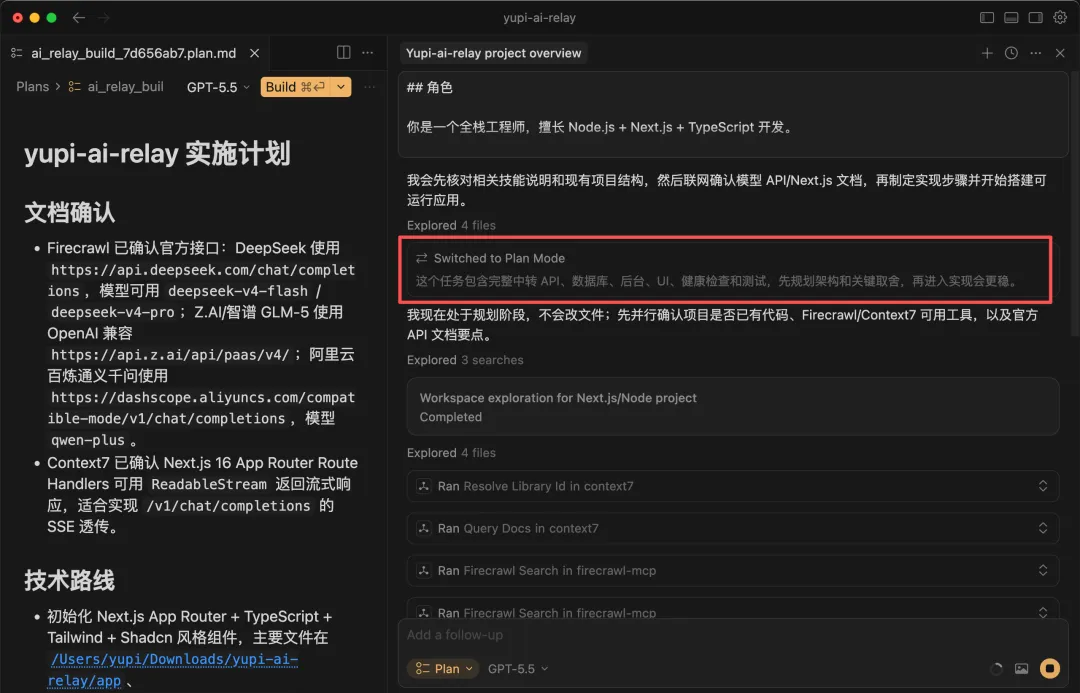
AI 自動切換到了計劃模式,先調用 MCP 獲取各家模型的最新 API 信息,然後生成了項目實施計劃:
簡單看一遍方案,沒啥問題,直接開始構建:
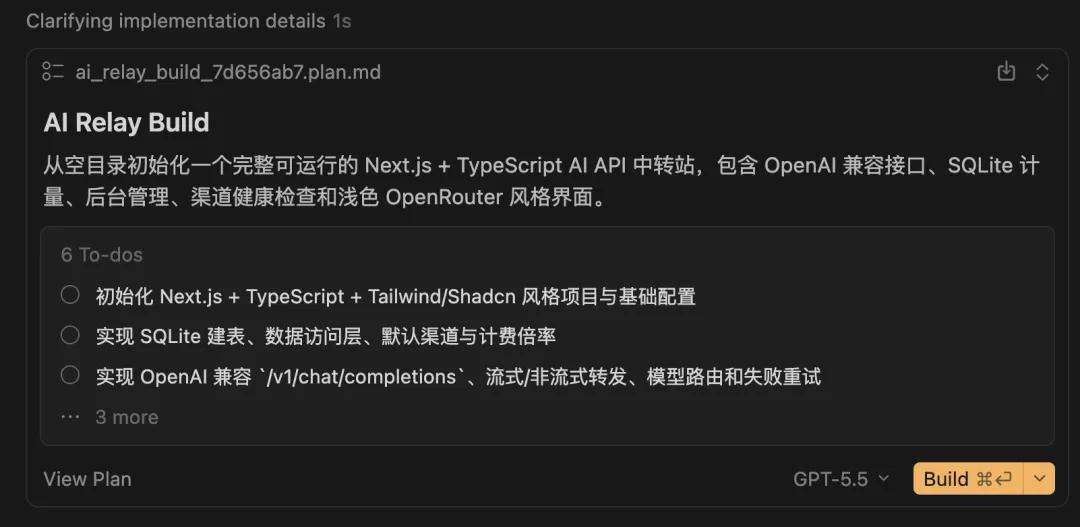
等代碼生成完成後,AI 還會自主打開瀏覽器進行測試,全程不需要我們人工操作,這期間我又做了 1 組提肛。
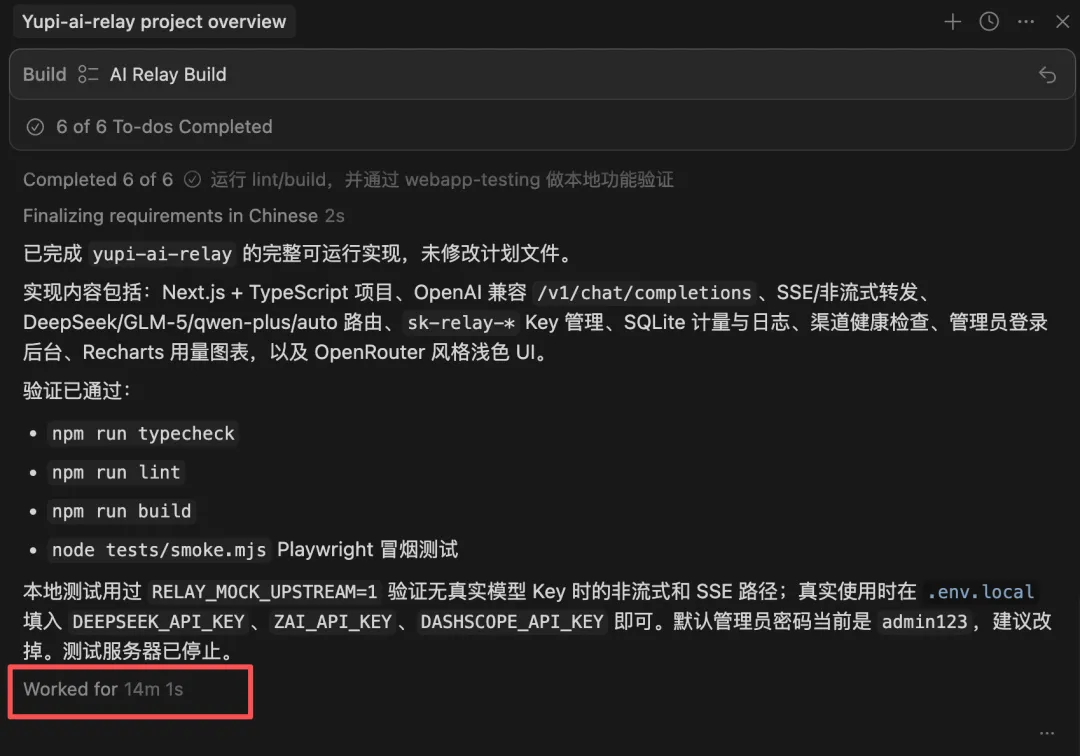
整體耗時 14 分鐘,比 DeepSeek 快了一倍多,消耗了 87.5K tokens:
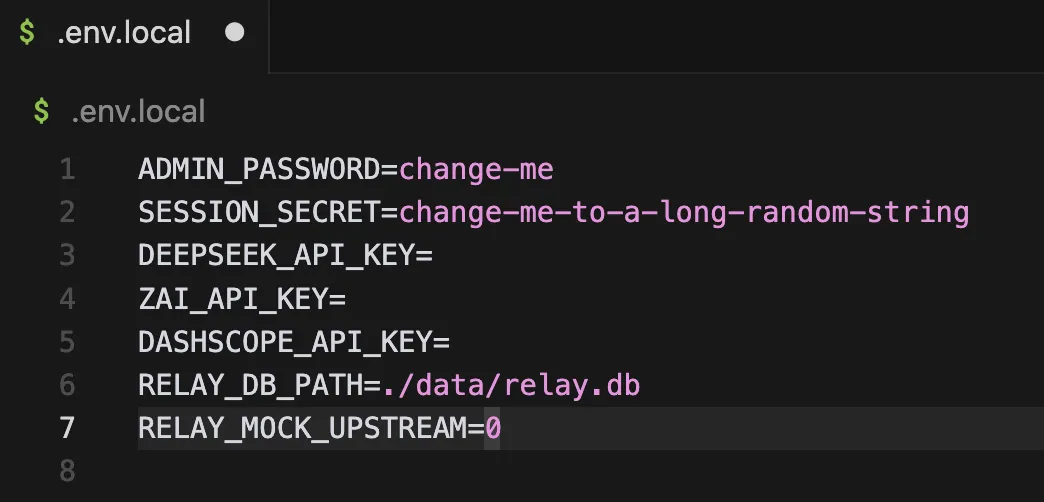
同樣根據 AI 的指引,分別獲取各平台的 API Key,填入環境變量文件:
最後,讓 AI 測試並運行,各種測試全部通過:
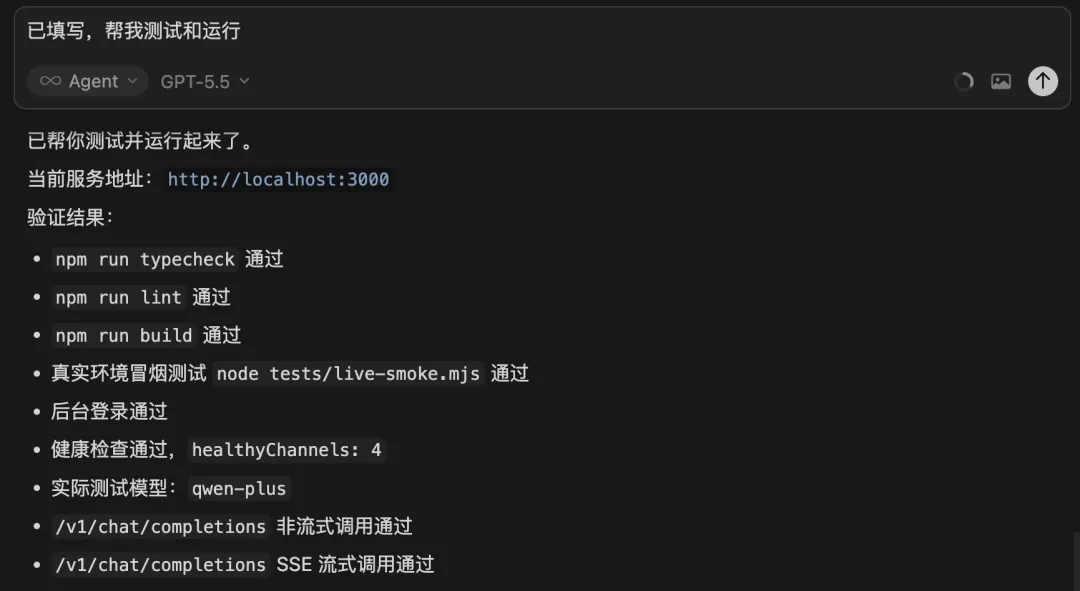
接下來讓我們人工測試一下。
打開網站,整體看着還不錯,除了有部分文字顏色不太合適。
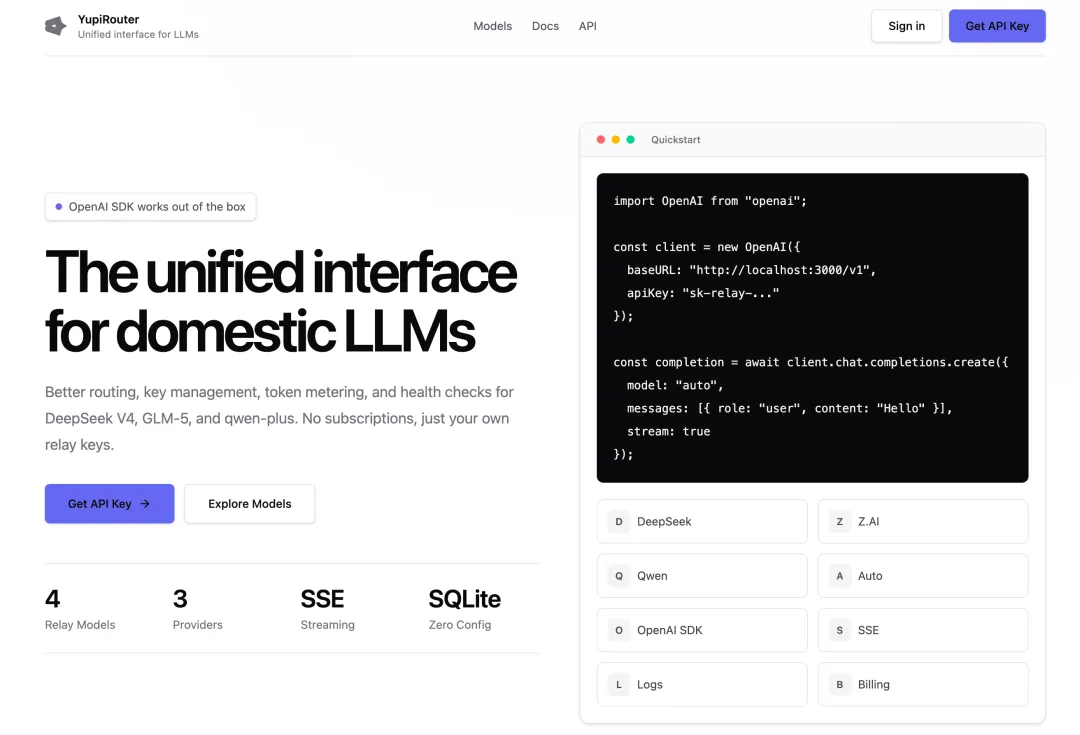
跟 DeepSeek 開發出來的一樣,沒有完全復刻 OpenRouter 主頁的風格。應該是我提示詞寫的不夠精確,下次應該說 100% 復刻。
進入到管理面板中,成功對接了 GLM-5 等大模型,其他功能和前面 DeepSeek 開發的中轉站類似:
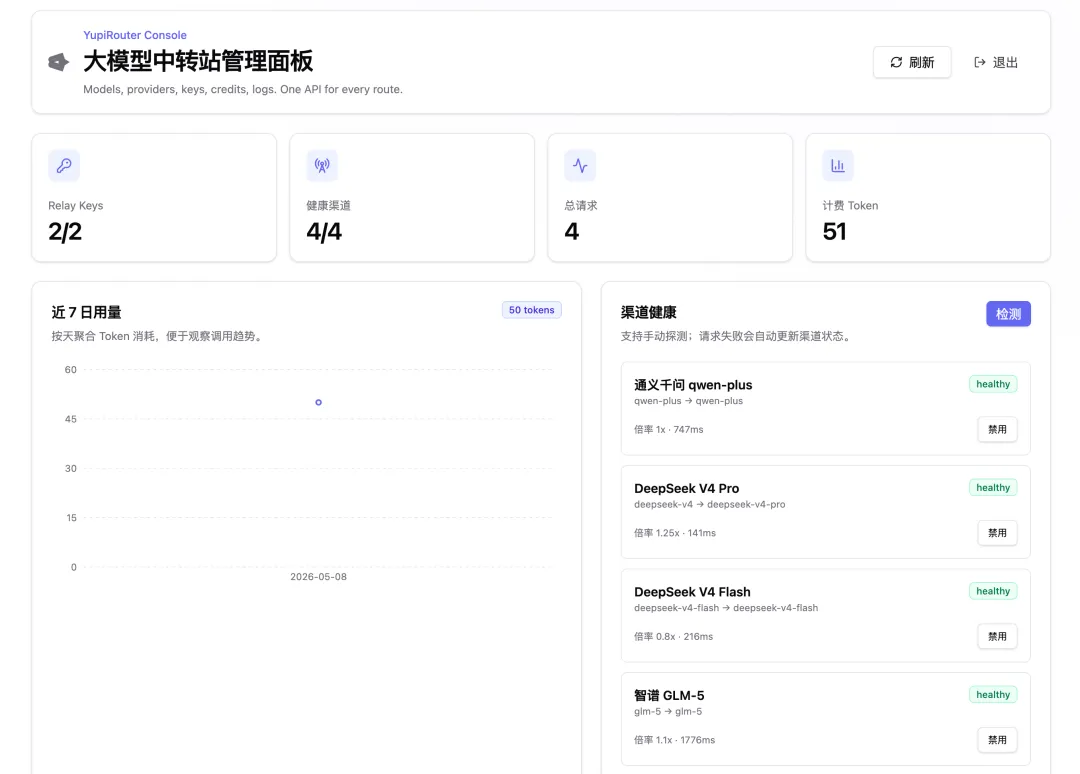
區別在於,GPT-5.5 選擇把所有管理功能全部塞到了一個頁面,而不是像 DeepSeek 那樣分成多個 Tab。佈局太緊湊了,我個人覺得 DeepSeek 的分 Tab 體驗更好。
創建一個 API Key,準備試試調用效果:
進入調用文檔,好傢伙這是啥玩意啊?感覺新用戶來了根本看不懂怎麼調用,也沒有 curl 調用示例。。。
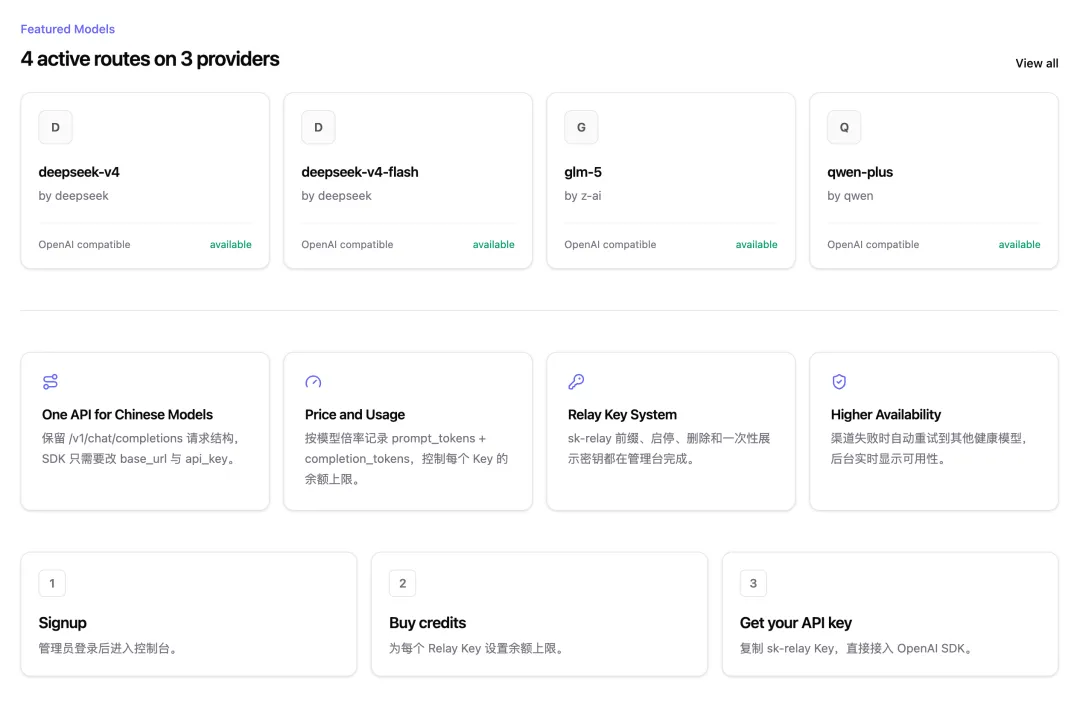
沒關係,咱們先用跟之前一樣的方式,通過 curl 測試,成功調用了 GLM-5 模型:
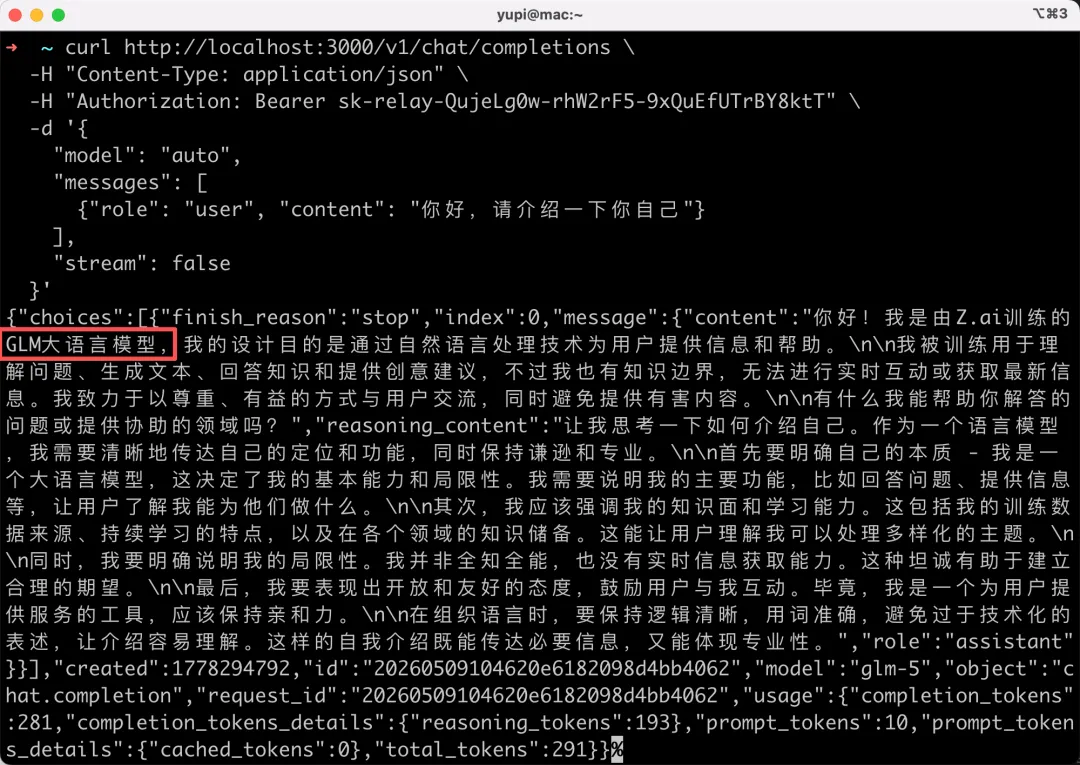
通過 Claude Code 測試也是一樣的結果,簡單對話能順利完成,複雜任務還是會報錯:
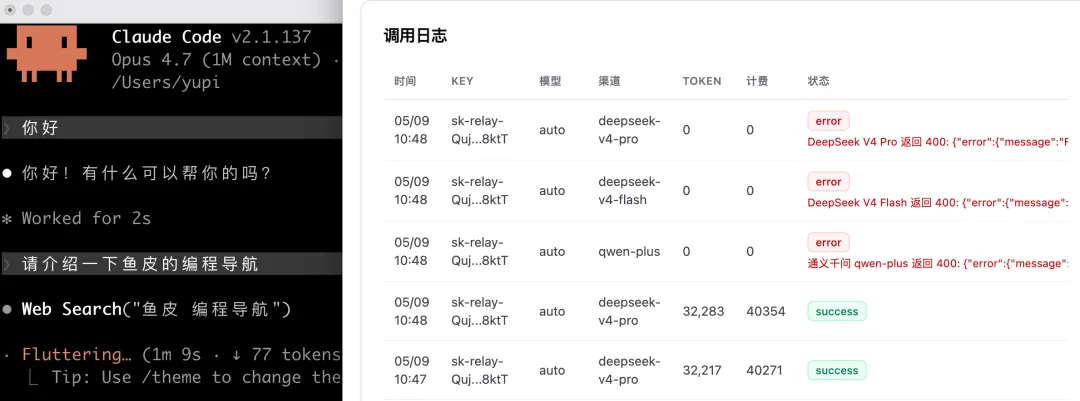
這就是沒有兼容好各種請求格式的問題。如果你要正兒八經地做中轉站,提示詞裏一定要強調多模型協議的兼容性,讓 AI 多編寫單元測試,充分驗證各種邊界情況。
總結一下,Cursor + GPT-5.5 的開發速度確實快了很多,但最終效果並沒有像我想象中那樣甩開 DeepSeek 一大截,甚至在前端的表現上,我覺得 DeepSeek 更勝一籌。
而且國外模型的價格普遍比國內貴。所以還是要根據自己的需求選擇模型,如果你還不太會 AI 編程,建議先用比較便宜的國產模型練手,不然可能一頓操作花了幾十塊,結果什麼都沒搞出來。
最後嗶嗶
做完這個中轉站,相信你已經完全理解了它的原理。
我還很貼心地給大家準備了「黑心版」中轉站的提示詞,僅供整活娛樂和教學目的,實際千萬不要這麼幹!
## ⚠️ 黑心中轉站 DLC(僅供娛樂,不是魚皮教的)
在管理面板中增加一個「高級設置(請勿開啓)」摺疊面板,標題旁加 💀 圖標,默認關閉,包含以下功能:
1. Token 暗税滑塊(1.0x - 3.0x):實際消耗 100 Token,賬單上乘以倍率顯示 150,用戶看到的 usage 字段是虛報後的數字
2. 偷樑換柱開關:用戶請求模型 A 實際轉發到便宜的模型 B,返回的 model 字段仍顯示用戶請求的原始模型名
3. Prompt 緩存吸血:對話中重複的 prompt 緩存命中後,仍按完整 Token 數向用戶收費
看到這裏,再回過頭看那些中轉站的坑,什麼模型掉包、虛報 Token、緩存套利,你應該能明白它們是怎麼實現的了。
所以我再次建議,有條件儘量用官方 API 吧!別為了省一點錢,把自己的代碼和數據送了出去。
OK 就分享到這裏,本文會收錄到我免費開源的 《Vibe Coding 零基礎入門教程》,上千張圖、幾十萬字,帶你從 0 開始快速學會 AI 編程,做出自己的產品、跑通變現全流程,一次拿捏。
開源指路:https://github.com/liyupi/ai-guide
我是魚皮,持續分享 AI 編程乾貨。覺得有用的話記得點贊收藏和關注,也歡迎在評論區聊聊:你正在用哪家的大模型?有沒有被 API 中轉站坑過?
往期推薦