駕馭 Claude 的智能 | 構建應用的 3 個關鍵模式【譯】
整理版優先睇
善用 Claude 已知工具、放手畀佢自主管理、謹慎設定邊界——三個關鍵模式,令應用跟得上 Claude 嘅進化步伐。
呢篇文章由 Anthropic 團隊嘅 Lance Martin 撰寫,原文標題係 'Harnessing Claude's Intelligence | 3 Key Patterns for Building Apps'。文章指出,Claude 呢類生成式 AI 系統係被「培育」出嚟而唔係「製造」出嚟,所以開發者用嘅智能體框架往往基於過時嘅假設。為咗令應用跟得上 Claude 嘅進化,同時兼顧延遲同成本,作者提出三個核心模式。
第一個模式係善用 Claude 已知嘅技能,例如 bash 工具同文本編輯器工具,呢啲係 Claude 最擅長嘅工具,可以組合成豐富模式。Claude 喺 SWE-bench Verified 上用呢兩個工具就達到 49% 得分。第二個模式係思考「我可以放手唔管啲乜?」,即係畀 Claude 自主管理上下文同記憶,例如透過技能庫漸進式展開上下文、用壓縮技術濃縮歷史、用記憶文件夾持久化重要資訊,而唔係外層框架硬塞所有內容。喺 BrowseComp 測試中,畀 Claude 過濾自己輸出同埋用記憶文件夾,準確率大幅提升。
第三個模式係謹慎設定邊界,包括巧妙設計上下文工程嚟最大化緩存命中率,同埋用聲明式工具處理高風險動作。文章強調,隨住 Claude 能力躍遷,要唔厭其煩咁審視舊假設,砍掉無謂嘅框架包袱。總括嚟講,呢啲模式嘅核心係信任 Claude 嘅能力,不斷問自己「我又可以放手唔管啲乜?」。
- 結論:善用 Claude 已知嘅 bash 同 text editor 工具,比自訂複雜框架更有效,佢哋可以組合成極豐富嘅模式。
- 方法:讓 Claude 自主編排行動,用代碼執行工具過濾工具結果,避免強制所有結果入上下文,只有精簡結果先進入模型。
- 差異:舊假設以為要詳細 system prompt,實際上應該用技能庫漸進式展開;Claude 越嚟越擅長管理自己嘅上下文同記憶,例如用壓縮同記憶文件夾。
- 啟發:Claude 能力持續進化,要定期審視框架假設,砍掉不必要嘅限制,避免「苦澀嘅教訓」。
- 可行動點:設定邊界時,要識別高風險動作並用聲明式工具處理;利用緩存斷點將靜態內容放前面,最大化緩存命中率,節省成本。
Bash 工具
Claude 最擅長嘅工具之一,用於執行命令行指令,係 SWE-bench 基準測試嘅基礎工具。
文字編輯器工具
Claude 擅長嘅另一個通用工具,用於查看、創建同修改檔案,常與 bash 工具搭配使用。
智能體技能 (Agent Skills)
技能庫允許 Claude 按需讀取完整技能內容,實現漸進式上下文展開,避免系統提示詞過長。
記憶工具 (Memory Tool)
Claude 可以將重要上下文寫入記憶文件夾,需要時讀取,實現持久化記憶,提升長週期任務表現。
模式一:善用 Claude 已知嘅技能
文章開頭引用咗 Anthropic 聯合創辦人 Chris Olah 嘅講法:生成式 AI 系統與其話係被「製造」出嚟,不如話係被「培育」出嚟。呢個比喻帶出咗用 Claude 開發應用嘅挑戰:開發者成日用智能體框架去彌補 Claude 自身做唔到嘅嘢,但呢啲框架往往基於過時嘅假設。
Claude 3.5 Sonnet 喺 SWE-bench Verified 上只用咗一個 bash 工具同一個文本編輯器工具就達到 49% 得分,創下當時行業最高水平。
Anthropic 官方編程助手 Claude Code 都係基於呢啲工具構建。智能體技能、編程式工具調用、記憶工具,本質上都係由基礎嘅 bash 同 text editor 工具組合衍生出嚟。
模式二:思考「我可以放手唔管啲乜?」
智能體框架裏面寫滿咗我哋對 Claude 能力邊界嘅偏見,認為呢樣唔得嗰樣唔得。隨住 Claude 越嚟越強大,係時候重新檢驗呢啲陳舊假設。最常犯嘅錯誤假設係:每次工具調用嘅結果都必須塞返入上下文窗口,等 Claude 決定下一步。
將所有工具結果轉化成 token 畀模型處理,唔單止慢同貴,而且往往毫無必要。
呢個模式喺非編程測試中都大放異彩:喺 BrowseComp 測試中,當 Opus 4.6 獲準過濾自身工具輸出後,準確率直接從 45.3% 飆升到 61.6%。
- 1 管理上下文:用技能庫(Skills)代替詳細 system prompt,只預先加載 YAML 頭部資訊,等 Claude 按需讀取完整技能內容,避免浪費 token。
- 2 上下文編輯(Context Editing):Claude 可以選擇性刪掉過時或唔相關嘅內容,例如舊工具結果或自己早期嘅思考草稿,保持上下文精簡。
- 3 子智能體(Subagents):開一個全新嘅上下文窗口專注處理特定任務,Opus 4.6 用呢招令 BrowseComp 準確率再提升 2.8%。
- 持久化上下文:壓縮(Compaction)技術讓 Claude 自己濃縮總結過去嘅上下文,喺馬拉松式任務中唔會「斷片」。Opus 4.6 喺 BrowseComp 用壓縮達到 84% 準確率。
- 記憶文件夾(Memory Folder):Claude 好似記筆記咁將重要上下文寫成文件存起,需要時讀取。Sonnet 4.5 用記憶文件夾後,BrowseComp-Plus 準確率由 60.4% 提升到 67.2%。
- 長線遊戲例子:早期 Sonnet 3.5 玩 Pokémon 只會亂記 NPC 廢話,Opus 4.6 則整理出結構化戰術筆記,仲提煉埋「經驗教訓」,輕鬆攞到 3 個道館徽章。
/gameplay/learnings.md (- 遊戲/經驗教訓.md):
- 喇叭芽嘅催眠粉+緊束連招:必須喺佢催眠粉命中前,用「咬住」快速擊倒佢。絕對唔可以讓佢佈置戰術!
- 第一世代揹包限制:最多隻能放 20 個道具。入迷宮前一定要掉咗冇用嘅技能機器 (TMs)。
- 旋轉地磚迷宮:唔同嘅入口 y 座標會導致完全唔同嘅終點。嘗試所有入口,並喺多個口袋空間中穿梭。
- B1F y=16 牆壁確認係實體嘅,範圍覆蓋所有 x=9-28(第 14557 步記錄)模式三:謹慎設定邊界
外層智能體框架相當於畀 Claude 著咗件約束衣,目的係保障用戶體驗、控制花銷或者守住安全底線。巧妙設計上下文工程可以令緩存命中率拉滿,因為 Messages API 係無狀態嘅,每輪都要重新打包上下文。
命中緩存嘅 token 價格只係基礎輸入 token 價格嘅 10%,所以最大化緩存命中率對省錢同提速好重要。
- 靜態內容放前,動態內容放後:將穩定嘅系統提示詞、工具列表排喺前面,呢啲係緩存嘅頭部。
- 用消息更新提醒:如果需要提醒模型,喺消息末尾追加 <system-reminder>,唔好修改原始提示詞(會令成個緩存失效)。
- 唔好中途換模型:緩存係跟特定模型走,切換模型會令緩存全盤作廢。需要更平模型時請用子智能體。
- 謹慎管理工具:工具列表位於緩存頭部,增加或刪除任何一個工具都會令緩存失效。動態發現新工具時請用工具搜尋功能。
- 及時更新斷點:對於多輪對話應用,應將斷點移至最新消息,推薦使用自動緩存。
另一方面,Claude 唔天然知道你應用嘅安全底線,只會發出「調用工具」嘅指令。雖然 bash 工具超強,但佢拋出嘅只係一串命令行字符,框架好難管控。
Claude Code 嘅自動模式(auto-mode)係一個特別例子:佢用第二個 Claude 去審查第一個 Claude 嘅 bash 指令是否安全,用魔法打敗魔法,減少對傳統專屬工具嘅依賴。但對於一着不慎滿盤皆輸嘅操作,老老實實寫一個專屬工具依然不可撼動。
隨住 Claude 能力躍遷,要唔厭其煩咁審視應用中嘅結構同邊界,反覆問自己:「呢次我又可以放手唔管啲乜?」
駕馭 Claude 的智能 | 構建應用的三大核心模式【譯】
原文:Harnessing Claude's Intelligence | 3 Key Patterns for Building Apps | Claude[1]
作者:Lance Martin
Anthropic 的聯合創始人 Chris Olah 曾說過[2],像 Claude 這樣的生成式 AI 系統,與其說是被“製造”出來的,不如說是被“培育”出來的。研究人員設定好引導它們生長的條件,但最終會演化出怎樣的確切結構或能力,往往是無法準確預測的。
這給使用 Claude 開發應用帶來了挑戰:開發者通常會使用 AI 套殼或智能體框架 (agent harnesses)(指用來包裹、控制和輔助 AI 模型運行的外部代碼結構)來彌補 Claude 自身做不到的事情。這些框架基於各種“假設”構建,但隨着 Claude 能力的不斷進化,這些假設很快就會過時。因此,即使是本文分享的經驗之談,也需要你時常温故而知新。
在這篇文章中,我們將分享團隊在構建應用時應該採用的三個核心模式。這些模式能幫助你的應用跟上 Claude 智能進化的步伐,同時兼顧延遲和系統成本。這三大模式分別是:善用它已知的技能、思考“我可以放手不管什麼”,以及謹慎設定智能體框架的邊界。
1. 善用 Claude 已知的技能 (Use what Claude knows)
我們強烈建議,使用 Claude 已經非常熟悉的工具來構建你的應用。
時間拉回 2024 年底,Claude 3.5 Sonnet 在 SWE-bench Verified(一個用於評估 AI 解決真實軟件工程問題能力的權威基準測試)上達到了 49% 的得分,創下了當時的行業最高水平[3]。令人驚訝的是,它僅僅使用了一個 bash 工具[4](一種允許 AI 在計算機命令行中執行指令的工具)和一個用於查看、創建和修改文件的文本編輯器工具[5]。Anthropic 的官方編程助手 Claude Code 也是基於這些同樣的工具構建的。Bash[4] 最初並非為構建 AI 智能體 (AI Agent) 而設計,但它卻是 Claude 深諳此道的工具,並且隨着時間的推移,Claude 駕馭它的技巧會越來越純熟。
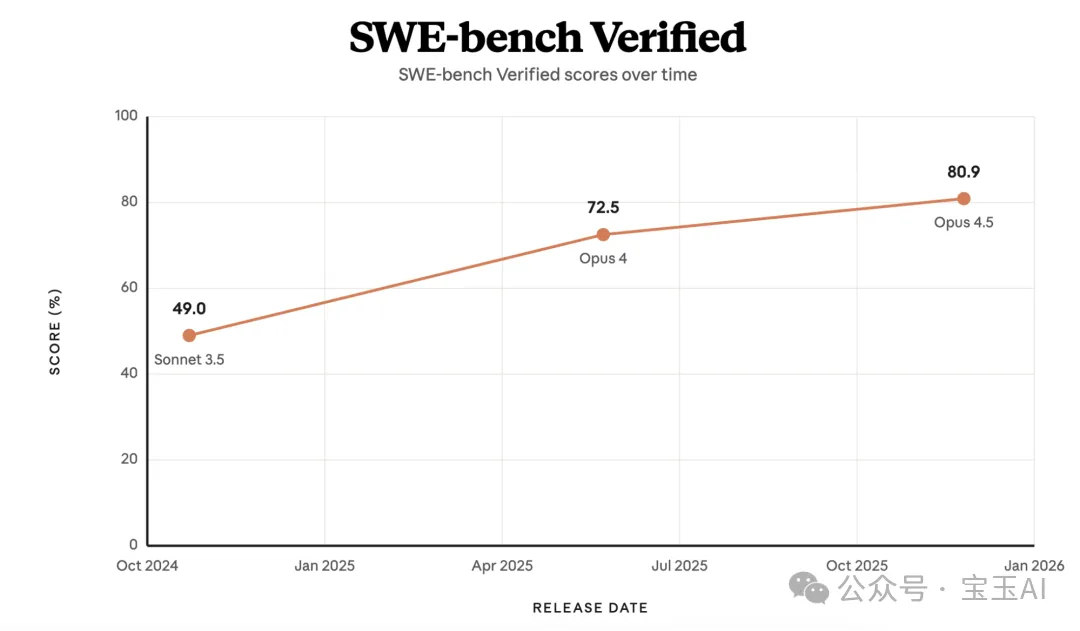
各個版本 Claude 模型在 SWE-bench Verified 基準測試中的得分,直觀地展現了它的進化之路。
我們發現,Claude 能夠將這些通用工具組合成極其豐富的模式,以此來解決各種複雜問題。例如,智能體技能 (Agent Skills)[6]、編程式工具調用 (programmatic tool calling)[7] 以及記憶工具 (memory tool)[8],本質上都是由基礎的 bash 和文本編輯器工具組合衍生而來的。
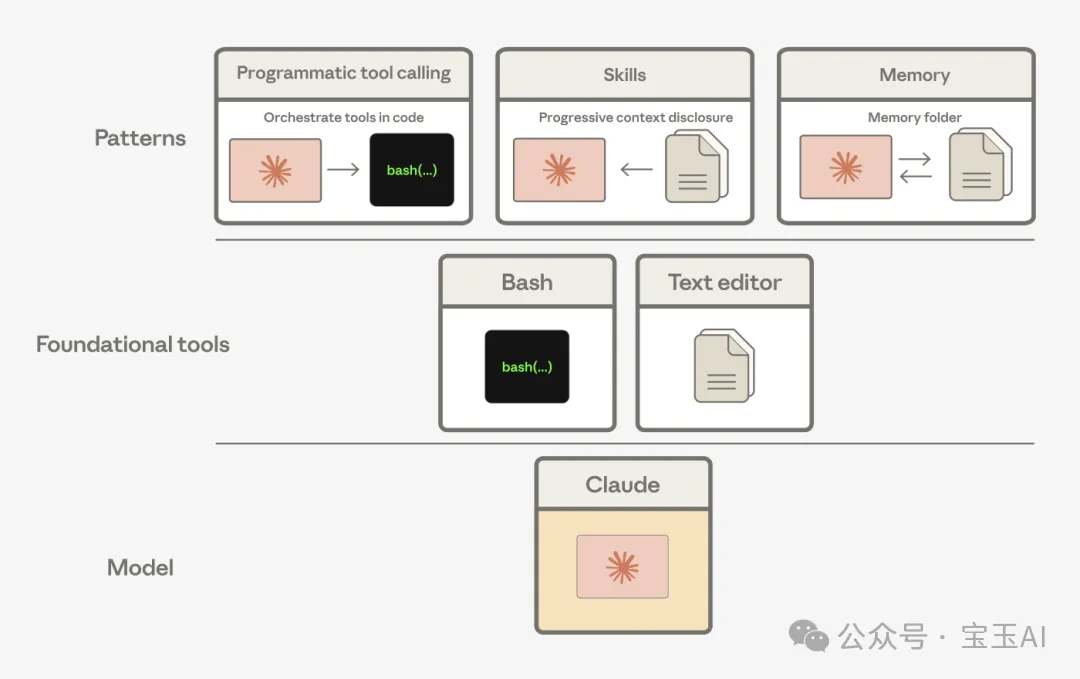
編程式工具調用、技能和記憶工具,其實都是我們 bash 和文本編輯器工具的精妙組合。
2. 思考:“我可以放手不管什麼?” (Ask‘what can I stop doing?’)
如前所述,智能體框架裏寫滿了我們對 Claude 能力邊界的偏見[9](認為它這也不行,那也不行)。隨着 Claude 變得越來越強大,是時候去重新檢驗這些陳舊的假設了。
讓 Claude 自主編排行動
大家常犯的一個錯誤假設是:認為每次調用工具返回的結果,都必須立刻塞回 Claude 的上下文窗口 (context window)[10] 中,好讓它決定下一步幹嘛。但實際上,把所有的工具結果都轉化成詞元 (tokens) 給模型處理,不僅速度慢、成本高,而且往往毫無必要——尤其是當這個結果僅僅是為了傳遞給下一個工具,或者 Claude 只需要結果中極小的一部分數據時。
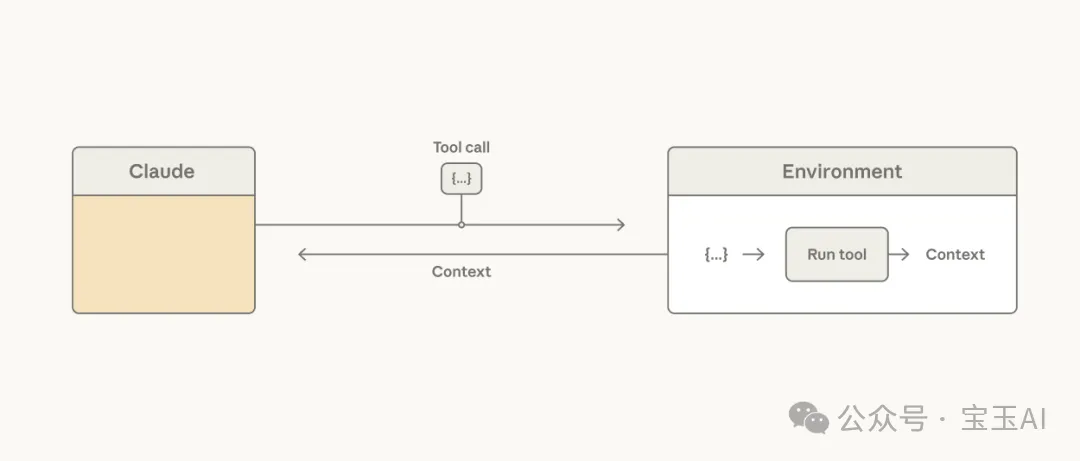
Claude 調用工具,隨後這些工具在特定的環境中執行。
想象一個場景:為了分析一個龐大數據表中的某一列,你把整個表格都扔給了模型。結果是整個表格塞滿了上下文,而你要為 Claude 根本不需要的那些行支付高昂的 token 費用。雖然你可以在工具開發時加入硬編碼過濾 (hard-coded filters)[11] 來解決這個問題,但這治標不治本。問題的核心在於:外層的智能體框架正在替模型做編排決策 (orchestration decision),而現實是,Claude 自己才是做這個決定的最佳人選。
只要給 Claude 開放一個代碼執行 (code execution)[12] 工具(比如 bash 工具[4] 或特定編程語言的交互環境 REPL[12]),難題就迎刃而解:它允許 Claude 自己寫代碼來執行工具調用,並親自處理這些工具之間的數據流轉邏輯。與其讓框架強制把所有結果都餵給上下文,不如讓 Claude 決定哪些結果直接略過、哪些進行過濾,或者哪些直接像流水線一樣輸入給下一次調用。全程無需弄髒寶貴的上下文窗口,只有最終代碼執行得出的精簡結果,才會真正進入 Claude 的視野。
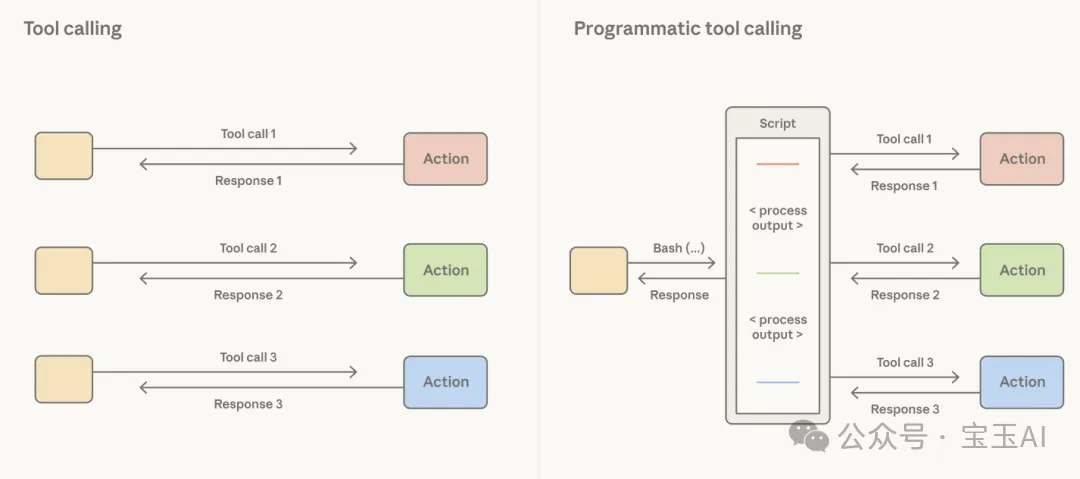
Claude 能夠親自編寫代碼,來控制工具的調用並串聯它們之間的邏輯。
在這個過程中,流程編排的指揮棒從外層框架交還給了大語言模型 (LLM) 本身。因為寫代碼是 Claude 編排動作的一種極其通用的方式,所以一個強大的編程模型,自然也就是一個強大的通用 AI 智能體。Claude 巧妙運用這一模式,在非編程類的評估測試中[13]也大放異彩:在 BrowseComp(一個測試智能體瀏覽網頁能力的基準測試[14])中,當我們賦予 Opus 4.6 過濾自身工具輸出的能力後,它的準確率直接從 45.3% 狂飆到了 61.6%。
讓 Claude 管理自己的上下文
針對特定任務的上下文提示,能指引 Claude 更好地使用 bash 和文本編輯器等通用工具。過去我們總以為,必須針對每個任務,手工雕琢極其詳細的系統提示詞 (system prompts)[15]。然而,這種提前把指令“填鴨式”塞進提示詞的做法,在面對海量任務時根本行不通:你增加的每一個 token,都在無情消耗 Claude 的注意力預算[16](相當於模型的腦力,塞入太多無用信息會導致模型抓不住重點),提前加載那些百年不用一次的指令,純粹是浪費資源。
賦予 Claude 訪問技能 (skills)[17] 庫的能力,完美破解了這個僵局:現在,只需把每個技能簡短的 YAML 頭部信息(類似目錄摘要)預先加載到上下文窗口中,讓 Claude 知道有哪些技能可用即可。如果當前任務需要,Claude 會主動調用讀取文件的工具,將完整的技能內容進行“漸進式展開”(按需加載)。
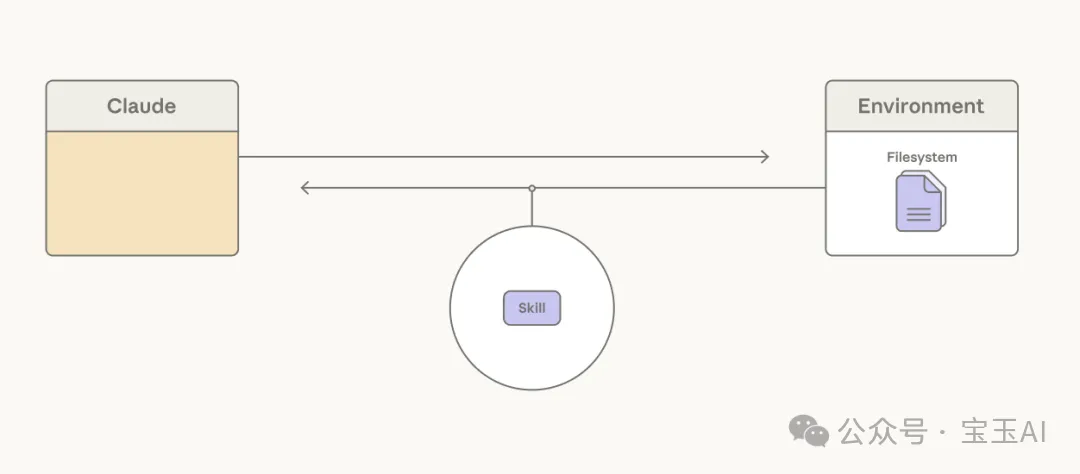
Claude 會藉助技能庫,根據任務需求逐步展開相關的上下文。
如果說技能讓 Claude 擁有了自由拼裝上下文的能力,那麼上下文編輯 (context editing)[18] 則是相反的藝術:它提供了一種機制,允許模型選擇性地刪掉那些過時或不再相關的廢話,比如陳舊的工具執行結果,或者自己早期的思考草稿。
不僅如此,有了子智能體 (subagents)[19] 的協助,Claude 越來越懂得何時應該“另起爐灶”——開啓一個乾乾淨淨的全新上下文窗口,來隔離並專注處理某項特定任務。在 Opus 4.6 中[20],這種召喚子智能體的神技,讓其在 BrowseComp 測試上的成績,比表現最好的單智能體方案還提升了 2.8%。
讓 Claude 持久化自己的上下文
對於需要長時間運行的智能體,很容易耗盡單一上下文窗口 (context window)[10] 的容量。業界普遍以為,這時候必須在模型外部搭建一套複雜的檢索架構(例如 RAG)來充當記憶系統。但我們的大量研究表明:更聰明的做法是給 Claude 提供簡便的工具,讓它自己決定哪些內容值得保存下來。
例如,壓縮 (compaction)[21] 技術允許 Claude 自己對過去的上下文進行濃縮總結,從而在馬拉松式的長週期任務中不至於“斷片”。經歷了幾輪模型迭代,Claude 挑選記憶內容的眼光越來越準。以 BrowseComp 為例[22](這是一個自主探索型的搜索任務),以前無論我們給 Sonnet 4.5 多少壓縮預算,它的準確率死活卡在 43%。但在同樣的配置下,Opus 4.5 躍升到了 68%,而最新的 Opus 4.6 更是飆升至了 84%。
引入記憶文件夾 (memory folder)[8] 則是另一種妙招。它允許 Claude 像記筆記一樣,把重要的上下文寫成文件存起來,需要的時候再去讀取翻看。我們在智能體搜索任務中見證了它的威力:在 BrowseComp-Plus 測試中,僅僅是給了 Sonnet 4.5 一個記憶文件夾,就讓它的準確率從 60.4% 穩穩提升到了 67.2%[23]。
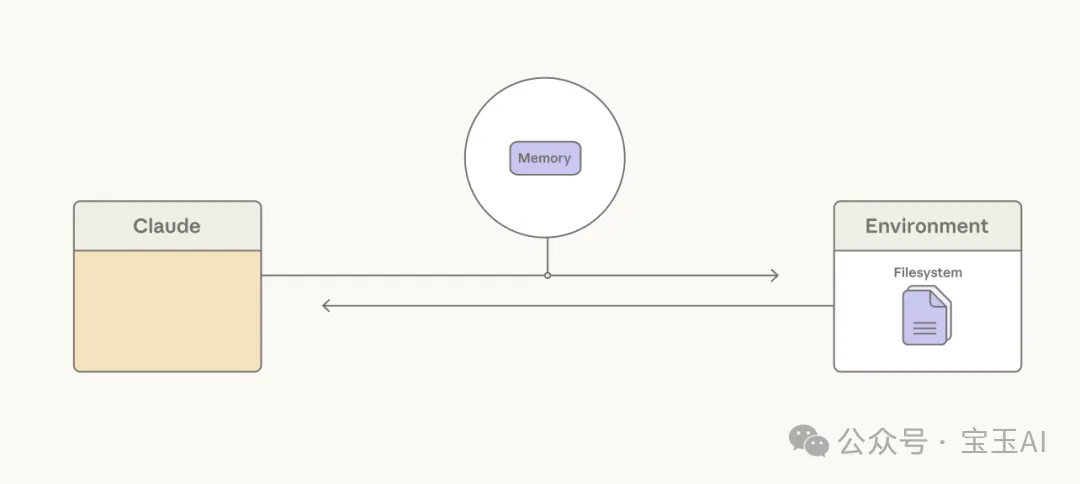
Claude 可以將重要的上下文持久化保存到記憶文件夾中。
讓 AI 玩《寶可夢》(Pokémon) 這樣的長線遊戲[24],是展示 Claude 記憶文件夾利用能力飛躍的絕佳案例。早期的 Sonnet 3.5 簡直把記憶當成了會議速記,只會傻乎乎地記錄遊戲裏 NPC(非玩家角色)說了什麼廢話,根本抓不住重點。玩了 14,000 步之後,它生成了 31 個凌亂的文件——甚至包括兩份幾乎一模一樣的關於毛毛蟲寶可夢的無聊筆記——而且遊戲進度悲催地卡在第二個城鎮:
caterpie_weedle_info (綠毛蟲和獨角蟲信息):
- 綠毛蟲 (Caterpie) 和獨角蟲 (Weedle) 都是毛毛蟲形態的寶可夢。
- 綠毛蟲是沒有毒性的。
- 獨角蟲是有毒性的。
- 這些信息對未來的相遇和戰鬥至關重要。
- 如果我們的寶可夢中毒了,我們需要儘快去寶可夢中心治療。而當我們派上後期的強大模型時,畫風突變,它開始記起“硬核戰術筆記”。同樣的 14,000 步,Opus 4.6 只生成了 10 個井井有條、按目錄分類的文件。它不僅橫掃拿下了 3 枚道館徽章,甚至還從自己踩過的坑裏,提煉出了一份專門的“經驗教訓”文檔:
/gameplay/learnings.md (遊戲/經驗教訓.md):
- 喇叭芽的催眠粉+緊束連招:必須在它催眠粉命中前,用“咬住”快速擊倒它。絕對不能讓它佈置戰術!
- 第一世代揹包限制:最多隻能放 20 個道具。進迷宮前一定要把沒用的技能機器 (TMs) 扔掉。
- 旋轉地磚迷宮:不同的入口 y 座標會導致完全不同的終點。嘗試所有入口,並在多個口袋空間中穿梭。
- B1F y=16 牆壁確認是實體的,範圍覆蓋所有 x=9-28(第 14557 步記錄)3. 謹慎設定邊界 (Set boundaries carefully)
外層的智能體框架相當於給 Claude 穿上了一層約束衣,目的通常是為了保障用戶體驗 (UX)、控制花銷,或者是守住安全底線。
巧妙設計上下文工程 (Context Engineering),讓緩存命中率拉滿
Messages API[25] 是無狀態的。這意味着 Claude 本身就像擁有“金魚的記憶”,它看不到之前的對話歷史。因此,在每一輪對話中,外層框架都必須像個盡職的快遞員,把新的上下文連同之前所有的動作記錄、工具說明以及給 Claude 的指令,一併打包重新發送過去。
為了避免重複勞動,我們可以通過設置斷點 (breakpoints)[26] 來緩存提示詞。換句話說,Claude API 會把斷點之前的所有上下文內容寫進緩存裏,並在下一次請求來的時候,檢查當前內容是否與之前的緩存相匹配。
要知道,命中緩存的 token 價格僅僅是基礎輸入 token 價格的 10%[27]!為了幫你的應用既省錢又提速,以下是在智能體框架中最大化緩存命中率的幾條黃金原則:
<system-reminder>,而不是去修改原始的提示詞(修改前面會導致整個緩存失效)。 | |
利用聲明式工具打造 UX、可觀測性與安全邊界
Claude 並不天然懂得你應用的“安全底線”在哪,也不知道你的產品界面長啥樣。它只會悶頭髮出“調用工具”的指令,剩下的髒活累活全由外層框架接手。雖然 bash 工具給了 Claude 在代碼世界裏翻江倒海的超能力,但對於外層框架而言,bash 工具拋出來的只是一串乾巴巴的命令行字符——不管 Claude 執行什麼危險動作,格式全是一樣的,這讓框架很難做管控。
此時,將某些關鍵動作晉升為專屬的聲明式工具 (dedicated tools) 就顯得尤為重要。這給了外層框架一個特定的、帶有明確參數類型的“抓手”,讓它能遊刃有餘地進行攔截審查、設置權限閘門、渲染前端界面,或者進行安全審計。
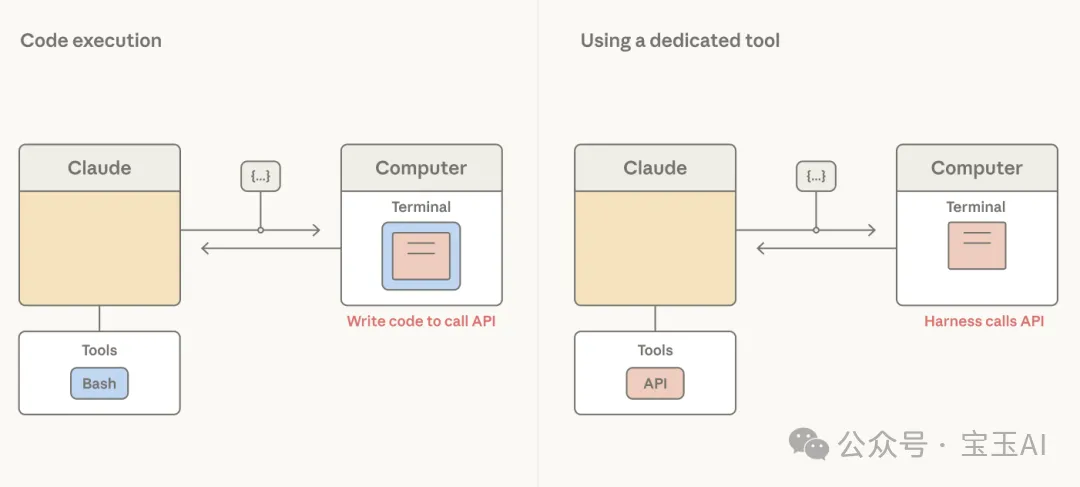
那些容易觸碰安全紅線的動作,天生就該被做成專屬工具。“是否可逆”是一個極佳的判斷標準。對於像調用外部 API 這種潑水難收的操作,你可以設置一道門檻,強制要求“用戶確認”後才能放行。對於像 edit(編輯)這樣的寫入工具,你可以內置一個“文件陳舊度檢查”,防止 Claude 稀裏糊塗地覆蓋掉別人剛剛修改過的文件。
基於安全性、用戶體驗或可觀測性的考量,我們應當為特定的高危/關鍵操作配備專屬工具。
當某個動作需要直觀地展示給終端用戶時,專屬工具也大有可為。例如,它可以被渲染成一個前端彈窗 (modal),清晰地向用戶提問、拋出多個選項,或者乾脆暫停智能體的運行循環,乖乖等待用戶給出反饋再繼續。
最後,專屬工具對於系統的可觀測性(排查問題)大有裨益。當動作是一個格式嚴謹的工具時,外層框架就能拿到結構化的參數數據,隨後的日誌記錄、鏈路追蹤和場景回放都會變得輕而易舉。
當然,“要不要把這個動作做成專屬工具”絕不是一錘子買賣,需要你持續重新評估。以 Claude Code 的自動模式 (auto-mode)[28](本文發佈時正處於研究階段)為例,它為 bash 工具套上了一層極其硬核的安全邊界:它會召喚“第二個 Claude”來閲讀這串命令行字符,讓 AI 來審查 AI 的操作是否安全。這種“用魔法打敗魔法”的模式,實際上減少了對傳統專屬工具的依賴。不過,這種做法只適用於用戶對大方向足夠信任的任務。對於那些一着不慎滿盤皆輸的高危操作,老老實實寫一個專屬工具依然擁有不可撼動的地位。
展望未來 (Looking forward)
Claude 智能的邊界一直在狂奔拓荒。每當它完成一次能力上的躍遷,我們過去對它“做不到什麼”的成見,都必須重新推翻再驗證。
我們一次次見證了歷史的重演。在我們為長週期任務搭建的一個智能體[9]中,Sonnet 4.5 一旦察覺到上下文快要塞滿了,就會出現“恐慌”,然後草草結束任務。為了緩解它的“上下文焦慮症”,我們在代碼裏硬加了強行清理上下文窗口的“重置”邏輯。結果到了 Opus 4.5,這個毛病竟然自己不治而愈了!於是,我們當年煞費苦心寫出來的“上下文重置”代碼,瞬間變成了智能體框架裏毫無用處的歷史包袱(dead weight)。
痛快地砍掉這些包袱極其重要,因為它們往往會反過來成為束縛 Claude 發揮實力的瓶頸(這也印證了 AI 界著名的“苦澀的教訓 (the Bitter Lesson)”:過度依賴人類經驗的手工規則,最終往往會拖累模型自身依靠算力進化出的能力)。在未來漫長的歲月裏,我們應當不厭其煩地審視應用中的結構和邊界,並反覆拷問自己那個靈魂問題:“這一次,我又可以放手不管什麼了?”
如果你想親手把玩本文討論的所有工具和開發模式,歡迎訪問。
致謝 (Acknowledgements)
本文由 Claude 平台團隊技術人員 Lance Martin 撰寫。特別感謝 Thariq Shihipar、Barry Zhang、Mike Lambert、David Hershey 以及 Daliang Li 對本文涵蓋主題提供的深度探討。同時,感謝 Lydia Hallie、Lexi Ross、Katelyn Lesse、Andy Schumeister、Rebecca Hiscott、Jake Eaton、Pedram Navid 以及 Molly Vorwerck 提供的編輯審閲與寶貴反饋。
來源:https://claude.com/blog/harnessing-claudes-intelligence
引用連結
[1] Harnessing Claude's Intelligence | 3 Key Patterns for Building Apps | Claude: https://claude.com/blog/harnessing-claudes-intelligence[2] 說過: https://www.darioamodei.com/post/the-urgency-of-interpretability[3] 行業最高水平: https://www.anthropic.com/engineering/swe-bench-sonnet[4] bash 工具: https://platform.claude.com/docs/en/agents-and-tools/tool-use/bash-tool[5] 文本編輯器工具: https://platform.claude.com/docs/en/agents-and-tools/tool-use/text-editor-tool[6] 智能體技能 (Agent Skills): https://agentskills.io/home[7] 編程式工具調用 (programmatic tool calling): https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling[8] 記憶工具 (memory tool): https://platform.claude.com/docs/en/agents-and-tools/tool-use/memory-tool[9] 智能體框架裏寫滿了我們對 Claude 能力邊界的偏見: https://www.anthropic.com/engineering/harness-design-long-running-apps[10] 上下文窗口 (context window): https://platform.claude.com/docs/en/build-with-claude/context-windows[11] 硬編碼過濾 (hard-coded filters): https://platform.claude.com/docs/en/about-claude/models/migration-guide#additional-recommended-changes[12] 代碼執行 (code execution): https://platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool[13] 非編程類的評估測試中: https://claude.com/blog/improved-web-search-with-dynamic-filtering[14] 基準測試: https://arxiv.org/abs/2504.12516[15] 系統提示詞 (system prompts): https://platform.claude.com/docs/en/release-notes/system-prompts[16] Claude 的注意力預算: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents[17] 技能 (skills): https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview[18] 上下文編輯 (context editing): https://platform.claude.com/docs/en/build-with-claude/context-editing[19] 子智能體 (subagents): https://code.claude.com/docs/en/sub-agents[20] 在 Opus 4.6 中: https://www-cdn.anthropic.com/0dd865075ad3132672ee0ab40b05a53f14cf5288.pdf[21] 壓縮 (compaction): https://platform.claude.com/docs/en/build-with-claude/compaction[22] 以 BrowseComp 為例: https://www-cdn.anthropic.com/14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf[23] 從 60.4% 穩穩提升到了 67.2%: https://www-cdn.anthropic.com/bf10f64990cfda0ba858290be7b8cc6317685f47.pdf[24] 長線遊戲: https://www.youtube.com/watch?v=CXhYDOvgpuU[25] Messages API: https://platform.claude.com/docs/en/build-with-claude/working-with-messages[26] 斷點 (breakpoints): https://platform.claude.com/docs/en/build-with-claude/prompt-caching[27] 基礎輸入 token 價格的 10%: https://platform.claude.com/docs/en/about-claude/pricing[28] 自動模式 (auto-mode): https://www.anthropic.com/engineering/claude-code-auto-mode